Hybrid PV Power Forecasting Methods: A Comparison of Different Approaches




Abstract
1. Introduction
2. Methods
2.1. Physical Models
2.1.1. Maximum Power Point Calculation
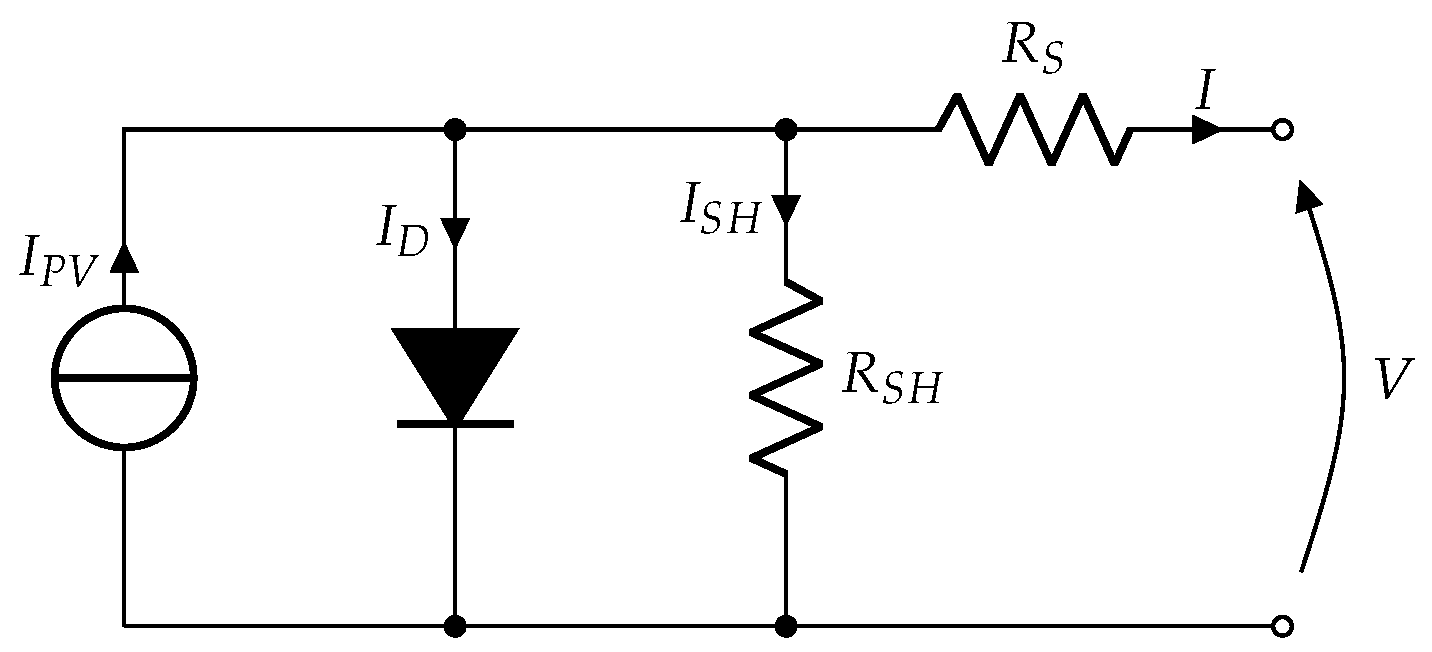
2.1.2. Five-Parameter PV Model
2.1.3. Parameter Identification from Datasheet
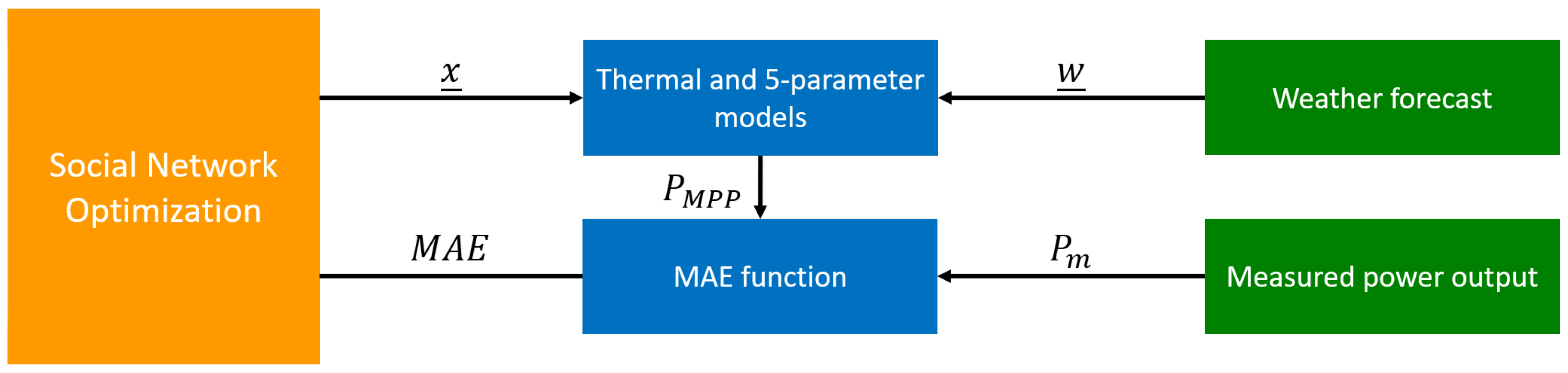
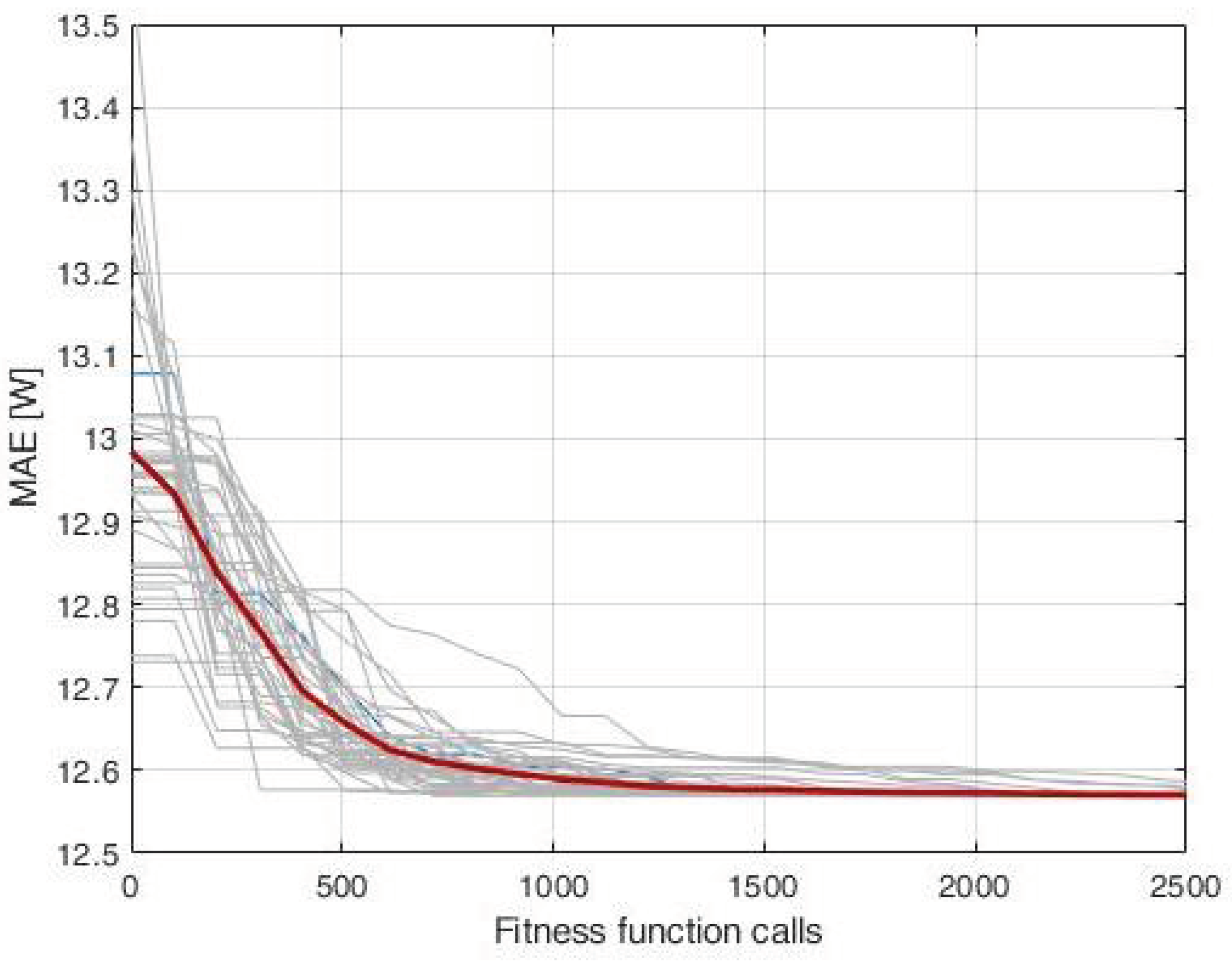
2.1.4. Parameter Identification with EAs
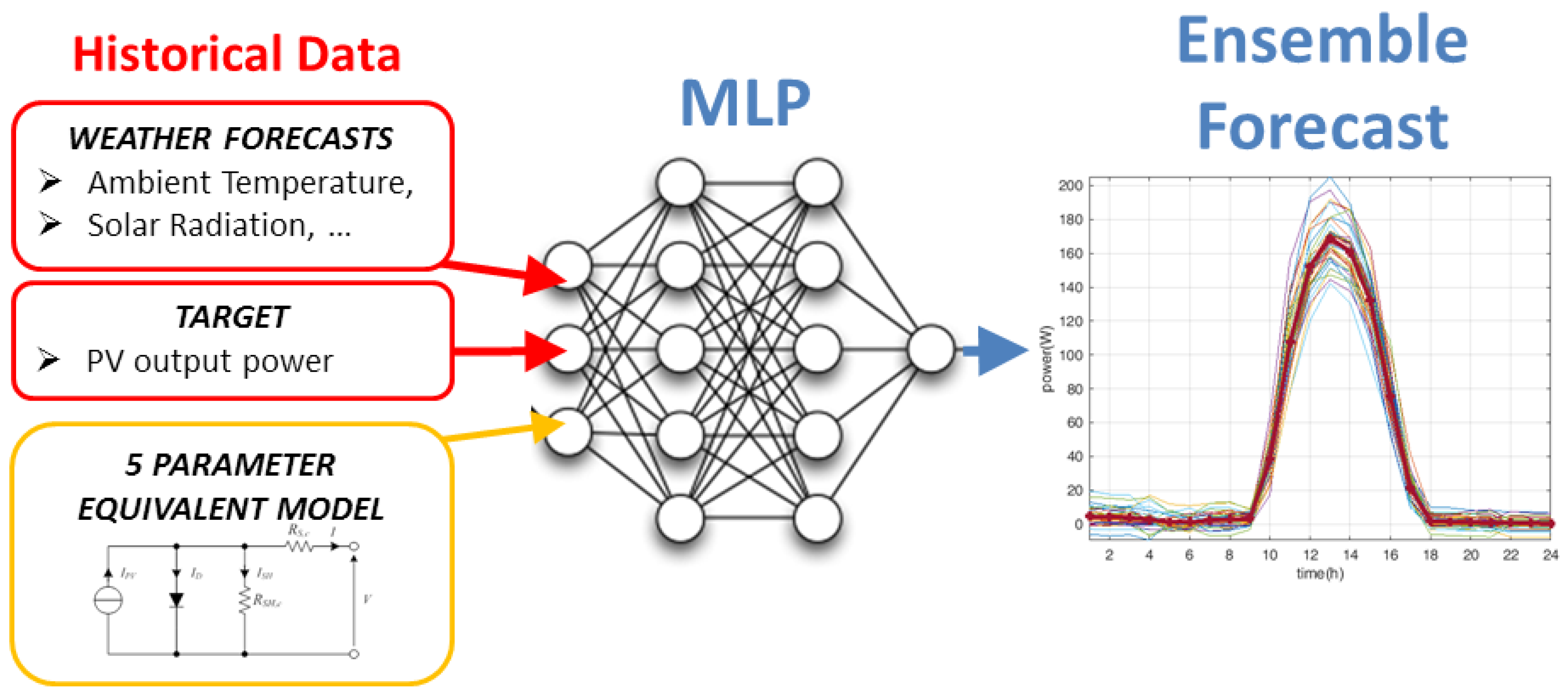
2.2. Hybrid Models
3. Results and Discussion
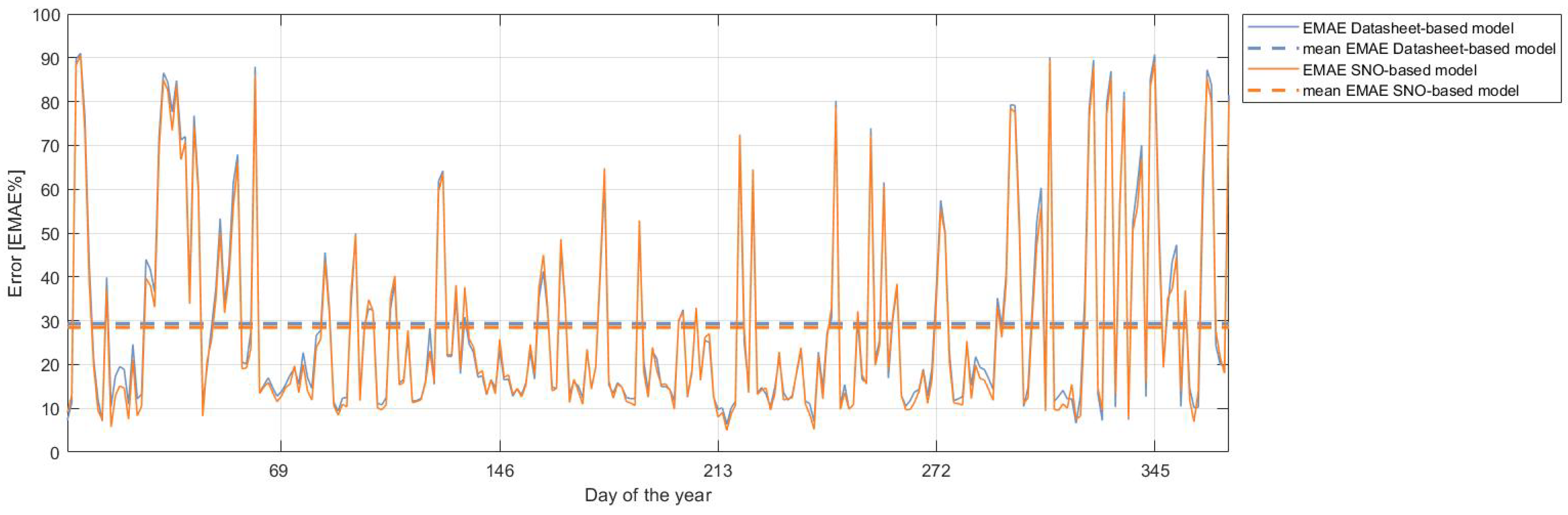
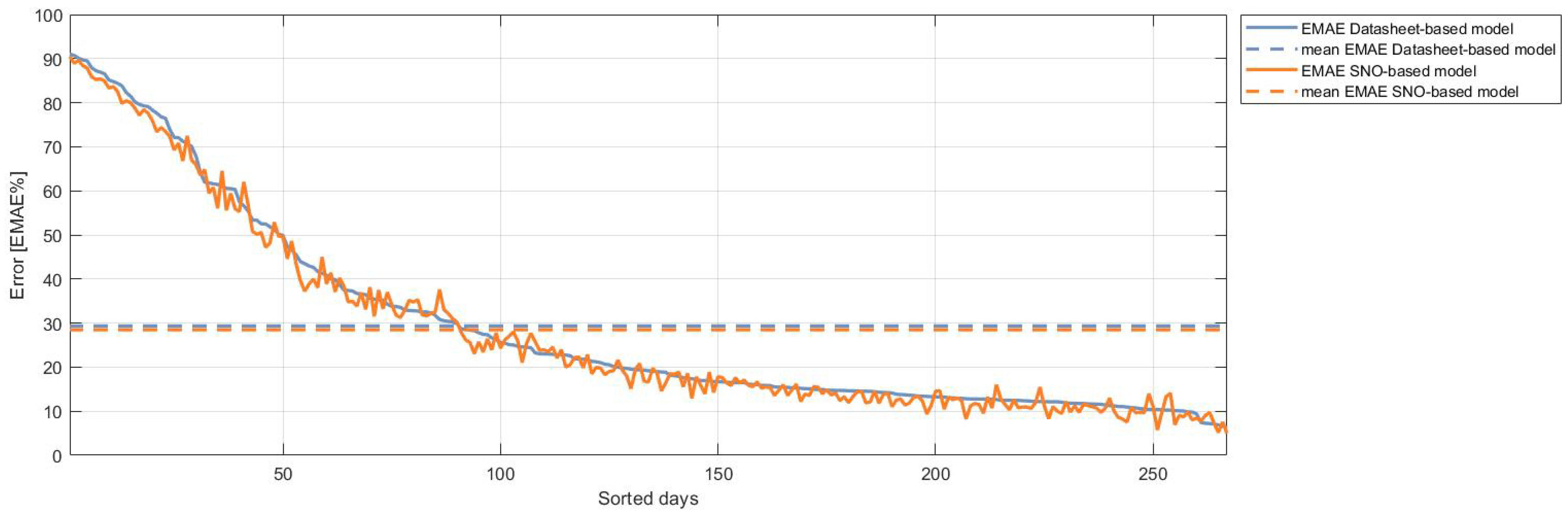
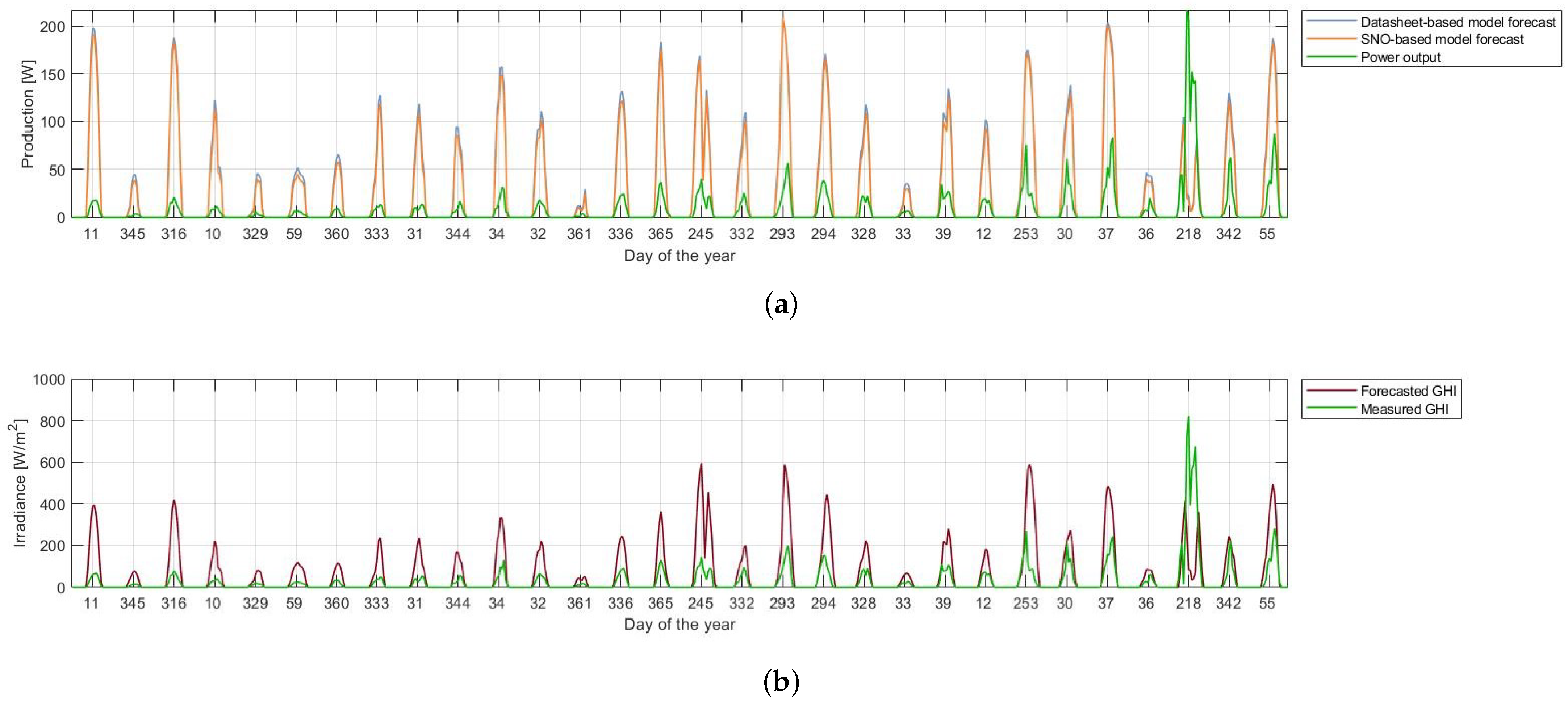
3.1. Forecasting with Physical Models
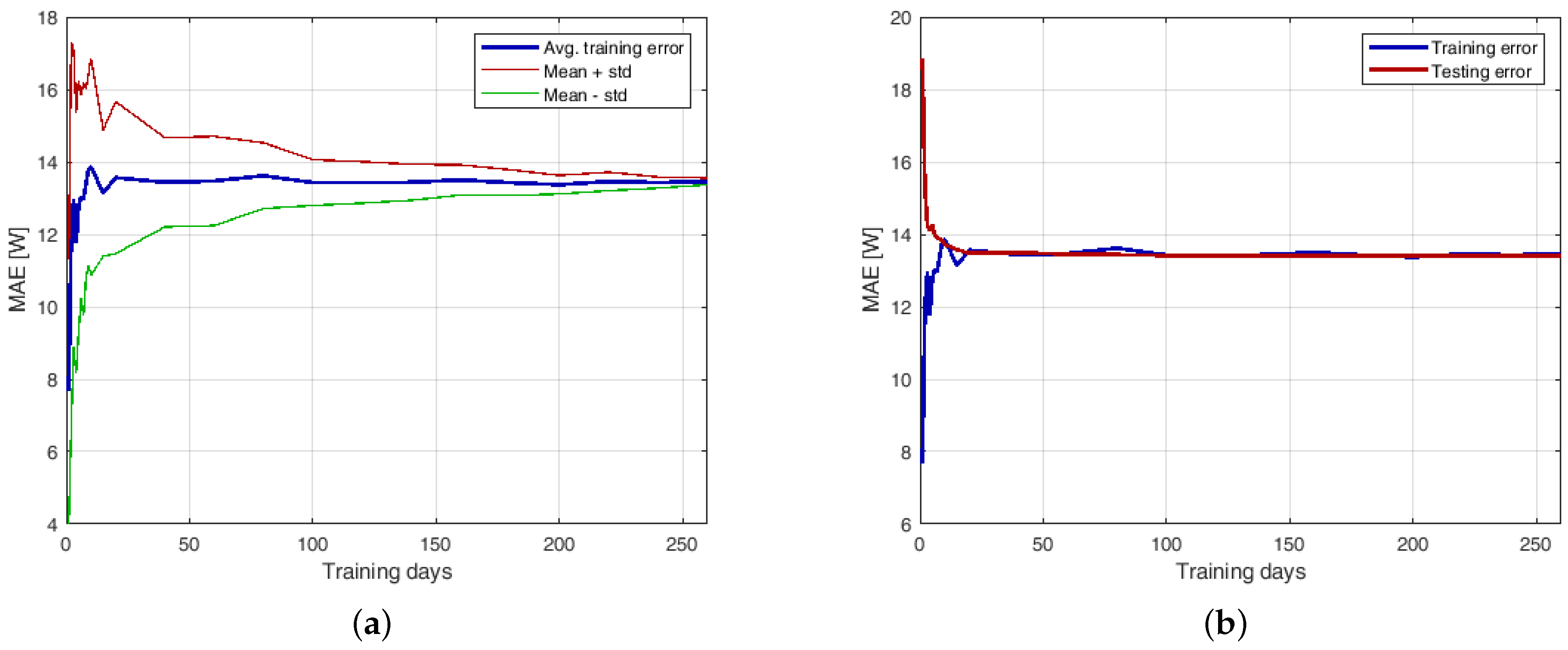
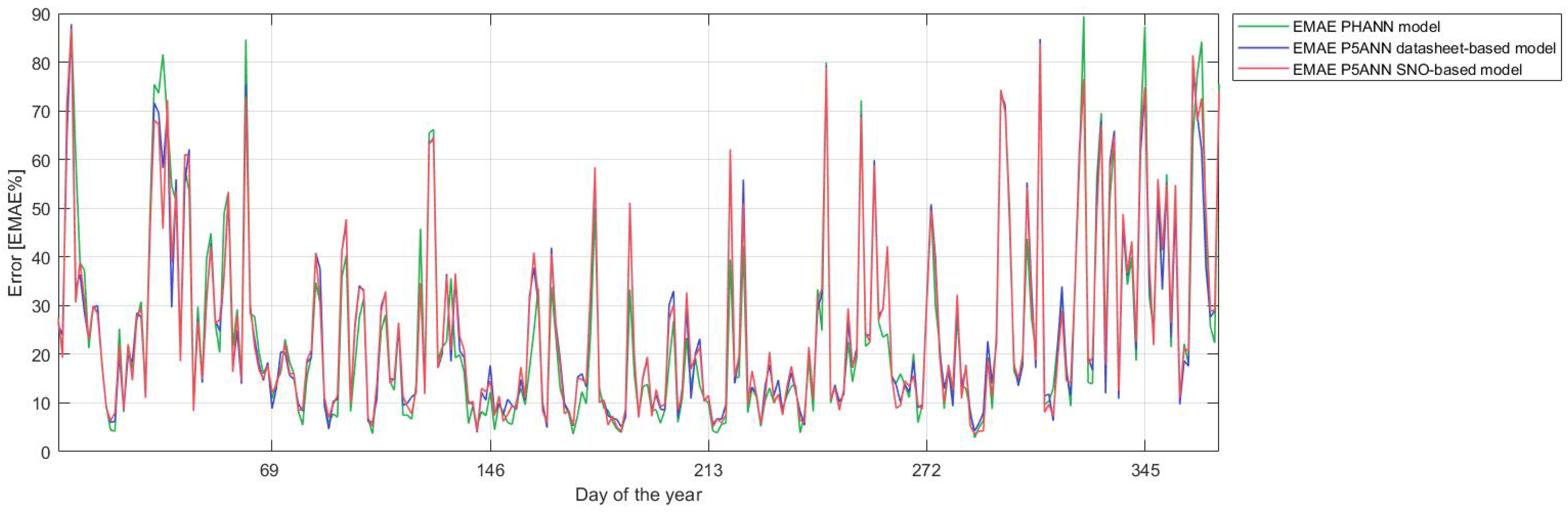
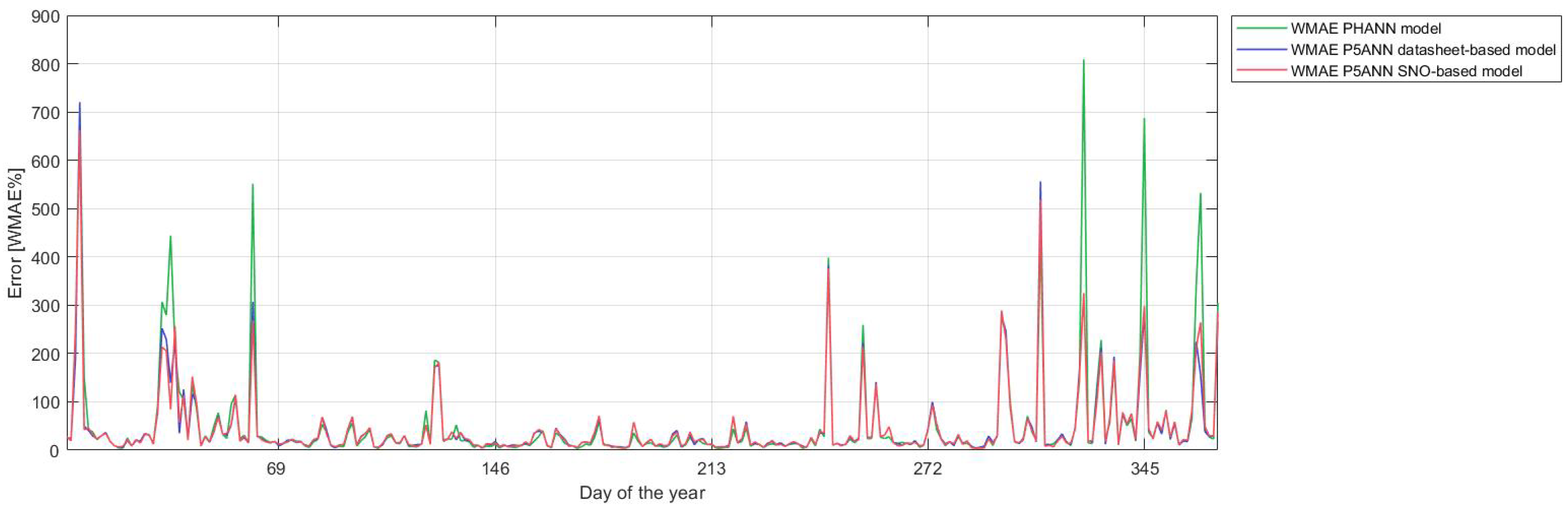
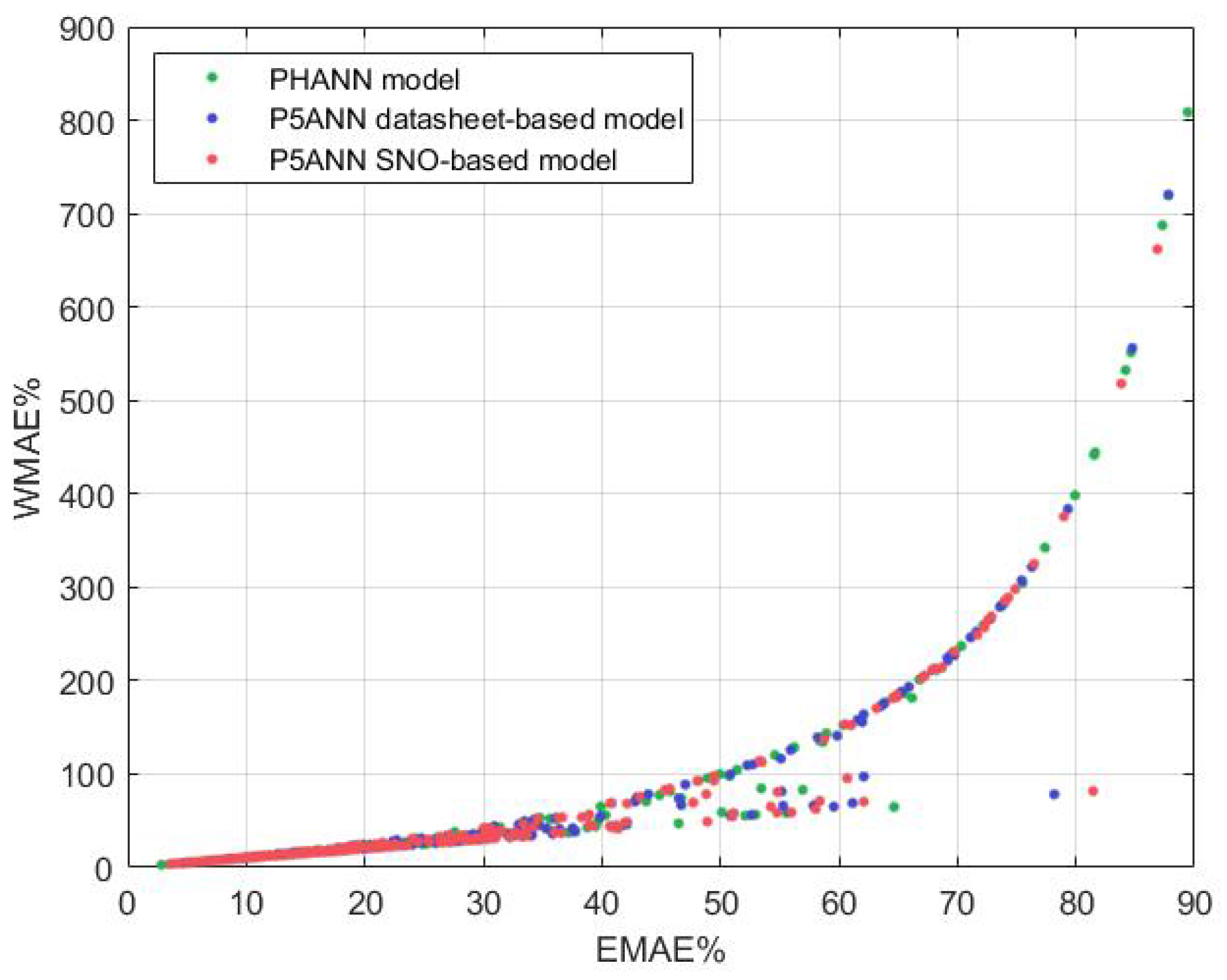
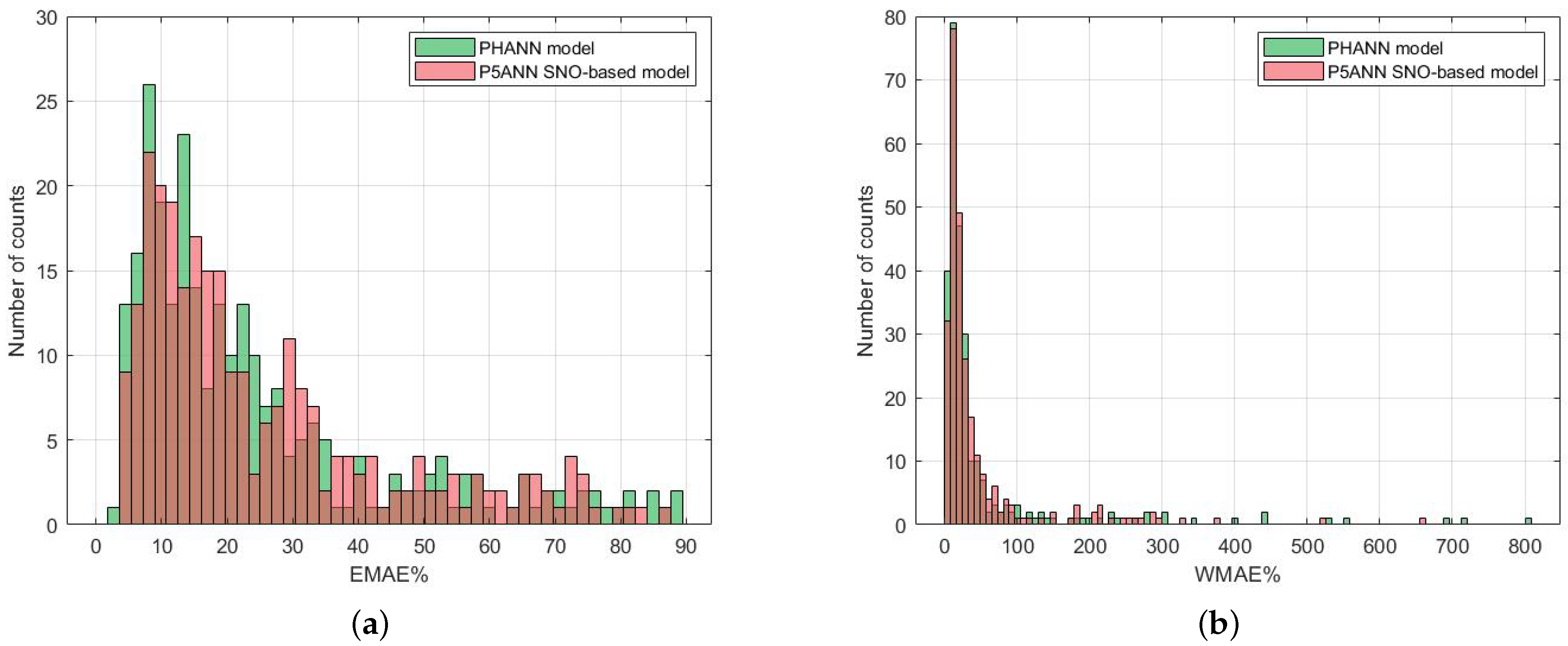
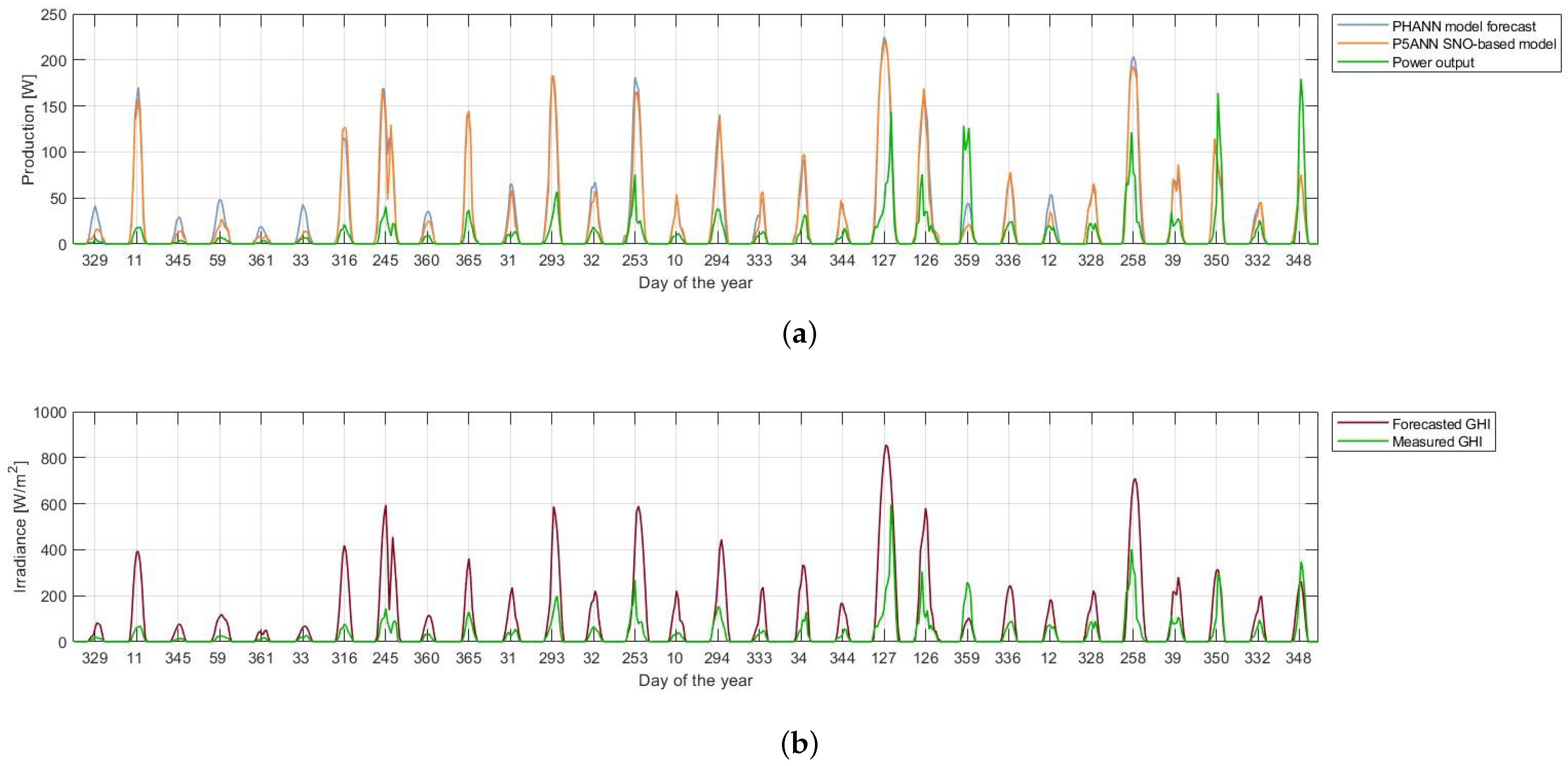
3.2. Forecasting with ANN and Hybrid Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A. Cost Indexes
- Normalized mean square error () is widely used as a primary error metric because it underline large errors:
- The normalized mean absolute error () is the mean absolute error divided by the module rated power (C):
- The envelope-weighted mean absolute error () increases the importance of the error in the morning or evening:
- The weighted mean absolute error (), in which the normalization has been performed according to the measured power:
- The objective mean absolute error (), in which the error is corrected using the irradiation level in clear sky conditions ():
References
- Choudhary, P.; Srivastava, R.K. Sustainability perspectives-a review for solar photovoltaic trends and growth opportunities. J. Clean. Prod. 2019, 227, 589–612. [Google Scholar] [CrossRef]
- Dolara, A.; Grimaccia, F.; Magistrati, G.; Marchegiani, G. Optimization Models for Islanded Micro-grids: A Comparative analysis between linear programming and mixed integer programming. Energies 2017, 10, 241. [Google Scholar] [CrossRef]
- Aziz, N.I.A.; Sulaiman, S.I.; Shaari, S.; Musirin, I.; Sopian, K. Optimal sizing of stand-alone photovoltaic system by minimizing the loss of power supply probability. Sol. Energy 2017, 150, 220–228. [Google Scholar] [CrossRef]
- Muhsen, D.H.; Nabil, M.; Haider, H.T.; Khatib, T. A novel method for sizing of standalone photovoltaic system using multi-objective differential evolution algorithm and hybrid multi-criteria decision making methods. Energy 2019, 174, 1158–1175. [Google Scholar] [CrossRef]
- Hashemi, B.; Cretu, A.M.; Taheri, S. Snow Loss Prediction for Photovoltaic Farms Using Computational Intelligence Techniques. IEEE J. Photovolt. 2020, 10, 1044–1052. [Google Scholar] [CrossRef]
- Guo, M.; Zang, H.; Gao, S.; Chen, T.; Xiao, J.; Cheng, L.; Wei, Z.; Sun, G. Optimal tilt angle and orientation of photovoltaic modules using HS algorithm in different climates of China. Appl. Sci. 2017, 7, 1028. [Google Scholar] [CrossRef]
- Liu, C.; Xu, W.; Li, A.; Sun, D.; Huo, H. Analysis and optimization of load matching in photovoltaic systems for zero energy buildings in different climate zones of China. J. Clean. Prod. 2019, 238, 117914. [Google Scholar] [CrossRef]
- Titri, S.; Larbes, C.; Toumi, K.Y.; Benatchba, K. A new MPPT controller based on the Ant colony optimization algorithm for Photovoltaic systems under partial shading conditions. Appl. Soft Comput. 2017, 58, 465–479. [Google Scholar] [CrossRef]
- Li, H.; Yang, D.; Su, W.; Lü, J.; Yu, X. An overall distribution particle swarm optimization MPPT algorithm for photovoltaic system under partial shading. IEEE Transact. Ind. Electron. 2018, 66, 265–275. [Google Scholar] [CrossRef]
- Mao, M.; Zhou, L.; Yang, Z.; Zhang, Q.; Zheng, C.; Xie, B.; Wan, Y. A hybrid intelligent GMPPT algorithm for partial shading PV system. Control Eng. Pract. 2019, 83, 108–115. [Google Scholar] [CrossRef]
- Hayder, W.; Ogliari, E.; Dolara, A.; Abid, A.; Ben Hamed, M.; Sbita, L. Improved PSO: A Comparative Study in MPPT Algorithm for PV System Control under Partial Shading Conditions. Energies 2020, 13, 2035. [Google Scholar] [CrossRef]
- Dolara, A.; Grimaccia, F.; Mussetta, M.; Ogliari, E.; Leva, S. An Evolutionary-Based MPPT Algorithm for Photovoltaic Systems under Dynamic Partial Shading. Appl. Sci. 2018, 8, 558. [Google Scholar] [CrossRef]
- Shareef, H.; Mutlag, A.H.; Mohamed, A. Random Forest-Based Approach for Maximum Power Point Tracking of Photovoltaic Systems Operating under Actual Environmental Conditions. Comput. Intell. Neurosci. 2017, 2017, 1673864. [Google Scholar] [CrossRef] [PubMed]
- Petrone, G.; Luna, M.; La Tona, G.; Di Piazza, M.C.; Spagnuolo, G. Online Identification of Photovoltaic Source Parameters by Using a Genetic Algorithm. Appl. Sci. 2018, 8, 9. [Google Scholar] [CrossRef]
- Xiong, G.; Zhang, J.; Yuan, X.; Shi, D.; He, Y. Application of symbiotic organisms search algorithm for parameter extraction of solar cell models. Appl. Sci. 2018, 8, 2155. [Google Scholar] [CrossRef]
- Niccolai, A.; Dolara, A.; Grimaccia, F. Analysis of Photovoltaic Five-Parameter Model. In Proceedings of the 2018 International Conference on Smart Systems and Technologies (SST), Osijek, Croatia, 10–12 October 2018; pp. 205–210. [Google Scholar]
- Louzazni, M.; Khouya, A.; Amechnoue, K.; Gandelli, A.; Mussetta, M.; Crăciunescu, A. Metaheuristic algorithm for photovoltaic parameters: Comparative study and prediction with a firefly algorithm. Appl. Sci. 2018, 8, 339. [Google Scholar] [CrossRef]
- Grimaccia, F.; Leva, S.; Mussetta, M.; Ogliari, E. ANN sizing procedure for the day-ahead output power forecast of a PV plant. Appl. Sci. 2017, 7, 622. [Google Scholar] [CrossRef]
- Dolara, A.; Grimaccia, F.; Leva, S.; Mussetta, M.; Ogliari, E. Comparison of Training Approaches for Photovoltaic Forecasts by Means of Machine Learning. Appl. Sci. 2018, 8, 228. [Google Scholar] [CrossRef]
- Ogliari, E.; Niccolai, A.; Leva, S.; Zich, R.E. Computational intelligence techniques applied to the day ahead PV output power forecast: PHANN, SNO and mixed. Energies 2018, 11, 1487. [Google Scholar] [CrossRef]
- Thong, P.H. Some novel hybrid forecast methods based on picture fuzzy clustering for weather nowcasting from satellite image sequences. Appl. Intell. 2017, 46, 1–15. [Google Scholar]
- Socaci, I.A.; Czibula, G.; Ionescu, V.S.; Mihai, A. XNow: A deep learning technique for nowcasting based on radar products’ values prediction. In Proceedings of the 2020 IEEE 14th International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 21–23 May 2020; pp. 117–122. [Google Scholar]
- Niccolai, A.; Nespoli, A. Sun Position Identification in Sky Images for Nowcasting Application. Forecasting 2020, 2, 488–504. [Google Scholar] [CrossRef]
- Dolara, A.; Grimaccia, F.; Leva, S.; Mussetta, M.; Ogliari, E. A physical hybrid artificial neural network for short term forecasting of PV plant power output. Energies 2015, 8, 1138–1153. [Google Scholar] [CrossRef]
- Chaibia, Y.; Allouhib, A.; Malvonic, M.; Salhia, M.; Saadanid, R. Solar irradiance and temperature influence on the photovoltaic cell equivalent-circuit models. Sol. Energy 2019, 188, 1102–1110. [Google Scholar] [CrossRef]
- De Soto, W.; Klein, S.; Beckman, W. Improvement and validation of a model for photovoltaic array performance. Sol. Energy 2006, 80, 78–88. [Google Scholar] [CrossRef]
- Dolara, A.; Leva, S.; Manzolini, G. Comparison of different physical models for PV power output prediction. Sol. Energy 2015, 119, 83–99. [Google Scholar] [CrossRef]
- Laudani, A.; Mancilla-David, F.; Riganti-Fulginei, F.; Salvini, A. Reduced-form of the photovoltaic five-parameter model for efficient computation of parameters. Sol. Energy 2013, 97, 122–127. [Google Scholar] [CrossRef]
- Jain, A.; Kapoor, A. Exact analytical solutions of the parameters of real solar cells using Lambert W-function. Sol. Energy Mater. Sol. Cells 2004, 81, 269–277. [Google Scholar] [CrossRef]
- IEC. EN 60891:2010-Photovoltaic Devices—Procedures for Temperature and Irradiance Corrections to Measured I-V Characteristics; IEC: Londin, UK, 2010. [Google Scholar]
- Dainese, C.; Faranda, R.; Leva, S. Thermal Analysis for Different Types of PV Panels. In Proceedings of the Power and Energy Systems, EuroPES 2009, Palma de Mallorca, Spain, 7–9 September 2009. [Google Scholar]
- Sera, D.; Teodorescu, R.; Rodriguez, P. PV panel model based on datasheet values. In Proceedings of the 2007 IEEE International Symposium on Industrial Electronics, Seoul, Korea, 5–8 July 2013; pp. 2392–2396. [Google Scholar]
- Zhu, X.; Fu, Z.; Long, X.; Xin-Li. Sensitivity analysis and more accurate solution of photovoltaic solar cell parameters. Sol. Energy 2011, 85, 393–403. [Google Scholar] [CrossRef]
- Niccolai, A.; Grimaccia, F.; Mussetta, M.; Zich, R. Optimal task allocation in wireless sensor networks by means of social network optimization. Mathematics 2019, 7, 315. [Google Scholar] [CrossRef]
- Ogliari, E.; Nespoli, A. Photovoltaic Plant Output Power Forecast by Means of Hybrid Artificial Neural Networks. Adv. Struct. Mater. 2020, 128, 203–222. [Google Scholar] [CrossRef]
- SolarTechLAB at Politecnico di Milano. Available online: http://www.solartech.polimi.it/ (accessed on 2 December 2020).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasheet Electrical Data | STC | NOCT | |
|---|---|---|---|
| Rated Power | (W) | 285 | 208 |
| Rated Voltage | (V) | 31.3 | 28.4 |
| Rated Current | (A) | 9.10 | 7.33 |
| Open-Circuit Voltage | (V) | 39.2 | 36.1 |
| Short-Circuit Current | (A) | 9.73 | 7.87 |
| Parameter | Datasheet Estimation | SNO-Based Estimation |
|---|---|---|
| (A) | 1.64 | 2.95 |
| (A) | 9.731 | 8.01 |
| n | 1.259 | 2.0 |
| () | 0.279 | |
| () | 2856.9 | 101.25 |
| Model | NMAE | WMAE | nRMSE | EMAE | OMAE |
|---|---|---|---|---|---|
| Datasheet-based | 5.25 | 83.32 | 32.61 | 29.34 | 19.80 |
| SNO-based | 4.90 | 74.22 | 29.60 | 28.47 | 18.32 |
| Model | NMAE | WMAE | nRMSE | EMAE | OMAE |
|---|---|---|---|---|---|
| ANN-based | 4.05 | 48.6 | 19.78 | 25.81 | 15.04 |
| P5ANN datasheet-based | 4.03 | 46.28 | 19.08 | 25.5 | 14.95 |
| P5ANN SNO-based | 4.03 | 46.29 | 18.9 | 25.61 | 15 |
| PHANN | 3.75 | 53.47 | 21.4 | 24.72 | 14.23 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niccolai, A.; Dolara, A.; Ogliari, E. Hybrid PV Power Forecasting Methods: A Comparison of Different Approaches. Energies 2021, 14, 451. https://doi.org/10.3390/en14020451
Niccolai A, Dolara A, Ogliari E. Hybrid PV Power Forecasting Methods: A Comparison of Different Approaches. Energies. 2021; 14(2):451. https://doi.org/10.3390/en14020451
Chicago/Turabian StyleNiccolai, Alessandro, Alberto Dolara, and Emanuele Ogliari. 2021. "Hybrid PV Power Forecasting Methods: A Comparison of Different Approaches" Energies 14, no. 2: 451. https://doi.org/10.3390/en14020451
APA StyleNiccolai, A., Dolara, A., & Ogliari, E. (2021). Hybrid PV Power Forecasting Methods: A Comparison of Different Approaches. Energies, 14(2), 451. https://doi.org/10.3390/en14020451