1. Introduction
Oil and gas wells are drilled from the surface of the Earth to underlying hydrocarbon reservoirs. The whole drilling operation is carried out through a mechanical drill string which contains a drill bit installed at its lower tip for crushing the rock layers. These drill bits are normally worn out due to wear and tear over time as they move forward inside the formation. Drill bits are changed regularly through tripping operations in the oil and gas industry. These drill bits are costly in nature and needed to be properly selected as they may represent up to 10–40% of the dryhole cost of the wellbore [
1]. The average cost of drilling a well varies from 4.9 million to 650 million U.S. dollars depending upon the type of wells. However, overall expenditures for drilling an oil well are needed to be minimized for achieving cost-effective drilling operations. The cost of drilling operation for a hydrocarbon well is mainly dependent on various factors namely, the operating cost of the drill rig, the time required for drilling target formations, the number of tripping operations, life of the drill bit, and drill bit cost [
1]. Still, drilling costs can be significantly minimized through the selection of appropriate drill bit designs which in turn reduces the operating time of the rig with less tripping events and more life expectancy of the drill bit. Moreover, the selection of suitable drill bit types for drilling geological formations is a problematic task due to complex interactions between reservoir properties, drill string hardware design, and various operational parameters [
2]. Thus, the selection of appropriate drill bit type is an important task for drilling engineers while planning for new oil and gas wells.
With the advancement of sensor-based measurements, a large amount of well data are being generated during field operations such as measurement-while-drilling, logging-while-drilling, etc. [
3]. However, the automated selection of drill bit type is possible using earlier drilled offset wells’ data. These data are highly complex with the problem of nonlinearity, high dimensionality, noise, and imbalance in nature [
3,
4]. Therefore, the interpretation of wells data has become difficult for conventional techniques that are unable to process the bulk amount of data and make fast decisions for drill bit type selection. Various researchers have proposed empirical and data-driven models to correlate complex drilling variables for drill bit selection as described briefly in the next section. The remaining paper is organized as follows:
Section 2, presents a literature review.
Section 3, briefly describes the various data-driven models utilized in this work.
Section 4, explains the research methodology adopted in the paper, whereas
Section 5, contains results and discussion. Finally, the
Section 6, concludes the major findings of the research work along with future scope.
2. Literature Review
Several researchers have suggested various empirical correlations for the selection of appropriate drill bit types. One of the most popular conventional methods for the selection of drill bits is cost per foot (
CPF) [
5].
CPF can be calculated as given below:
where
CBIT is the cost of bit in dollars,
CRIG is the cost of operating drill rig per hour,
Tbr is run time of the drill bit,
Tco is the connection time,
Tt is tripping time in hours, and
LD is the length of the drilled interval. The main drawback of
CPF is that it does consider the drilling variables and formation type which directly and indirectly affects drill bit life. This method can’t be utilized for drilling the directional and horizontal wells [
5]. The second method for bit selection is based on the calculation of specific energy (
SE) which is required to remove the unit volume of rock during drilling operations [
6].
SE can be determined as given below.
where
RPM is rounds per minute (rpm), BD is the diameter of bit (ft),
WOB is the weight on bit (lb), and
ROP is the penetration rate (ft/h). This Equation (2) has considered only three important drilling parameters but ignored the rock mechanics and vibrational impacts on the dullness grading of the drill bit. Further, the International Association of Drilling Contractors (IADC, Houston, TX, USA) suggested the use of bit dullness for selecting the roller cone as well as fixed cutter bits. Eight diverse parameters were utilized to describe the dull bit conditions. Diverse conditions were assigned from one to eight codes symbolizing the degree of dullness existing in a drill bit [
7]. However, this technique has a major drawback that requires human visual expertise for the evaluation of drill bit conditions. Thus, the chances of human error are high in this dill bit selection technique.
In 1964, Hightower attempted to select drill bits based on the geological information and drilling data obtained from previously drilled offset wells [
8]. He utilized sonic logs to define formation drillability to select suitable drill bit types for drilling new geological formations [
8]. However, he did not determine the rock strength directly but indirectly estimated it through the theory of elasticity. Mason [
9] utilized sonic logs, offset wells data, and lithological information for the selection drill bit type. Perrin et al. [
10] proposed a drilling index to evaluate the performance drill bit that was also applicable for horizontal and directional drilling operations. Mensa-Wilmot et al. [
11] suggested a new formation drillability parameter for drill bit evaluation and integrated several rock mechanics parameters in it. Xu et al. [
12] modified the equation of
CPF using mud logging data which was found to be more efficient than the conventional
CPF equation for the selection of drill bit [
12]. Uboldi et al. [
13] conducted micro indentation tests on the cuttings of subsurface rock layers to determine the mechanical characteristics of subsurface rock layers. Further, they estimated the compressive index of rock formations along with lithological data which were then utilized by a Drill Bit Optimization System to help the driller for drill bit selection [
13]. Sherbeny et al. [
14] used wellbore images and mineralogy logs for the selection and design of drill bits. Mardiana and Noviasta [
15] combined rock strength analysis and finite element modeling for the selection of drill bits. Cornel and Vazquez [
16] utilized bit dullness data for the selection of optimum drill bit types for different geological formations. They also optimized the PDC bit design and drilling hydraulics to identify optimum operational parameters.
With the advancement of sensor-based measurements, a large amount of wells data are being generated during field operations such as measurement-while-drilling, logging-while-drilling, etc. The interpretation of wells data has become difficult for conventional techniques that are unable to process the bulk amount of wells data and make fast decisions for drill bit type selection. Thus, smart computational models are applied for the processing of big wells data to select suitable drill bit types. Several researchers have suggested the utilization of machine learning models as an alternative approach for the automatic selection of drill bit types based on previously drilled offset wells data. In 2000, Bilgesu et al. [
1] applied artificial neural networks (ANN) for the selection of drill bit types to drill various formations but they failed to include the reservoir properties in their training data. Further, Yilmaz et al. [
17] employed the ANN model for the selection of drill bit type. They selected bit type based on the desired values of the rate of penetration (ROP) and other drilling variables. They also showed that ANN based models were good only for providing initial suggestions regarding the drill bit type when tested for diverse field conditions [
17]. Edalatkhah, Rasoul, and Hashemi [
18] applied ANN and Genetic algorithm (GA) for the choice of bit types based on desired and optimum values of drilling ROP. Hou, Chien, and Yuan, [
19] applied ANN for the screening of polycrystalline diamond compact (PDC) drill bits trained on offset wells data, drillability and lithofacies information. Nabilou [
20] studied the impact of drill bit selection parameters especially geo-mechanical factors in a case study of an oil and gas reservoir existing in the southwest part of Iran. Efendiyev et al. [
21] selected run speed and cost of the drill bit as significant criteria for the selection drill bits. Momeni et al. [
22] applied ANN for the prediction of drill bit types based on the offset wells drilling data and predicted ROP values by adding predicted drill bit types in the training dataset. Abbas et al. [
23] selected drill bit types based on the optimum values of ROP using ANN and GA. Manuel et al. [
24] selected drill bits types for different geological depths using image processing techniques, principal component analysis (PCA), and ANN. Most of the abovementioned research works are trained on the balanced datasets with less number of drill bit types. The successful applications of ANN have shown that data-driven models have the potential for the automation of the bit selection process. However, none of them have considered the problem of imbalanced data that will naturally occur due to the varying thickness of subsurface lithofacies. The actual field data contain the uneven distribution of data samples that result in a complex imbalance multiclass classification problem during drill bit selection. This uneven distribution of training data samples affects the generalization capability of supervised machine models for unseen data and also make them unreliable. Here, the generalization of machine learning models means that the trained models provide their best possible performance results for unseen testing data also. Therefore, proper investigation of machine learning models is required to evaluate their effectiveness for the screening of drill bit types with complex offset wells data to provide more pragmatic solutions.
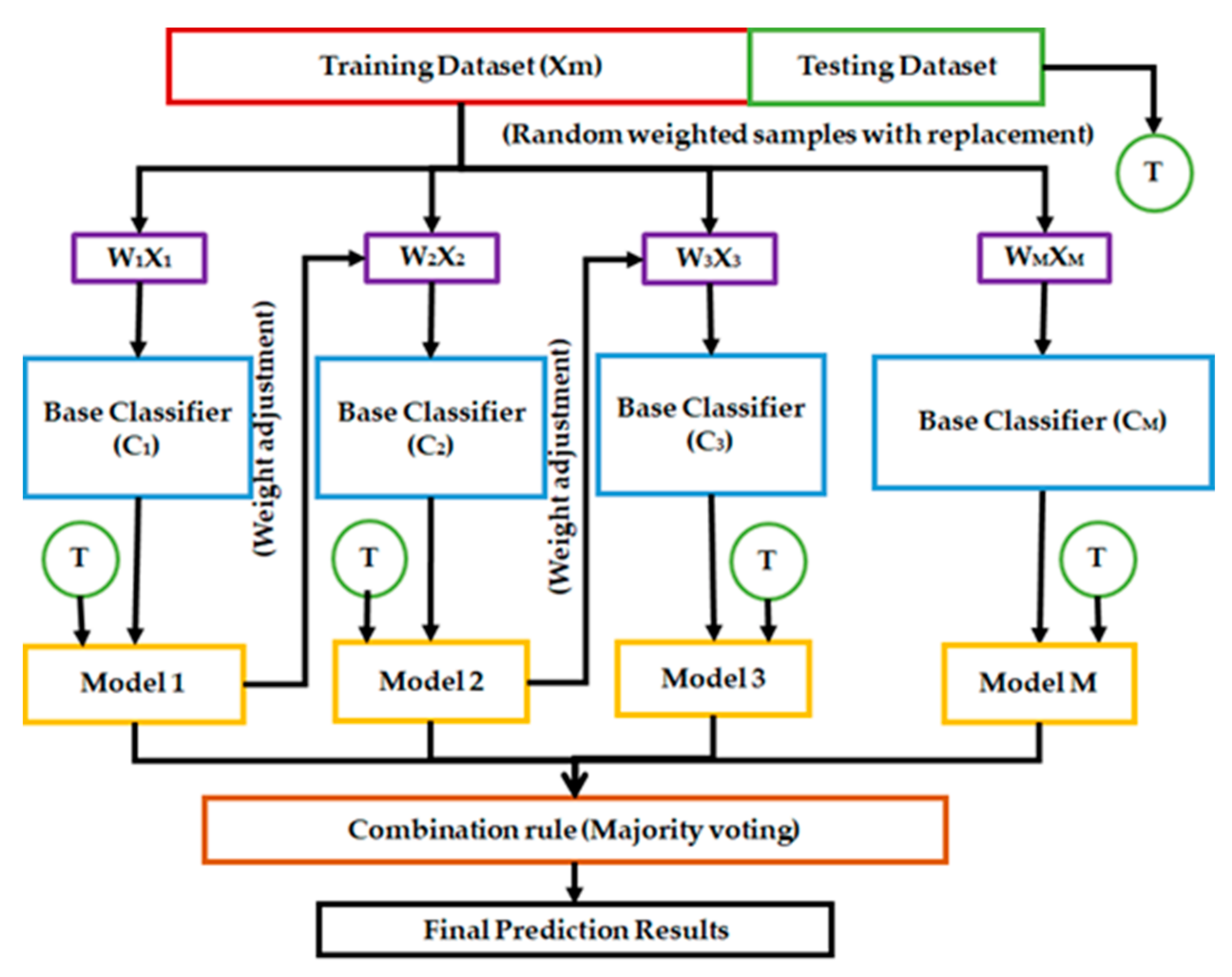
Here, the drill bit selection process has been formulated as a multiclass classification problem where diverse drill bit types have acted as class labels. In this paper, two ensemble methods namely, AdaBoost and random forest (RF) have been investigated for handling the complex multiclass imbalanced data problem associated with intelligent drill bit selection. These ensemble paradigms contain boosting techniques in its internal architecture which has been reported useful for solving the imbalanced data issues. They also reduce the bias and variance error associated with training data that provide a better generalization to the prediction results. These ensemble methods are combined with data resampling techniques to enhance their capability of dealing with imbalanced data. Additionally, the behavior of four popular classifiers namely, K-nearest neighbors classifier (KNC), naïve Bayes classifier (NBC), multilayer perceptron (MLP), and support vector classifier (SVC), have also been studied to select diverse bit types for drilling critically unstable geological formations. The abovementioned popular classifiers have also been tested to study the impact of imbalance and establish the supremacy of the proposed approach. The primary motivation of this research work is to explore popular machine learning algorithms in quest of higher drill bit selection accuracy and better generalization. The primary objectives of this study are given below:
- (1)
The applicability of intelligent models for drill bit selection has been reviewed.
- (2)
Ensemble models are investigated in quest of higher bit selection accuracy.
- (3)
A comparative study of popular machine learning models has been performed for drill bit selection.
- (4)
The problem of imbalanced data is addressed in this work that adversely affects the performance of machine learning models for the selection of the drill bit.
- (5)
The impact of softer and unstable geological formations that produce critical training data for machine learning models have been discussed to select diverse drill bit types.
- (6)
The behavior of machine learning models has also been studied for drill bit selection in critical formations.
- (7)
The future implications of this work are elaborated for automatic drill bit selection.
The comparison of results has been performed to identify the best performing classifier among all the above-mentioned models. All the applied machine learning models have been trained and tested using Norwegian oil and gas field data. The data related challenges associated with the drill bit selection process have also been discussed. This paper discusses issues related to intelligent classifiers and imbalanced petroleum data such as applicability issues, performance difficulties, performance evaluation parameters, and possible data-driven solutions. Overall, a comprehensive study of machine learning models has been performed to assess the challenges associated with the automatic drill bit selection process with practical field datasets.
5. Results and Discussion
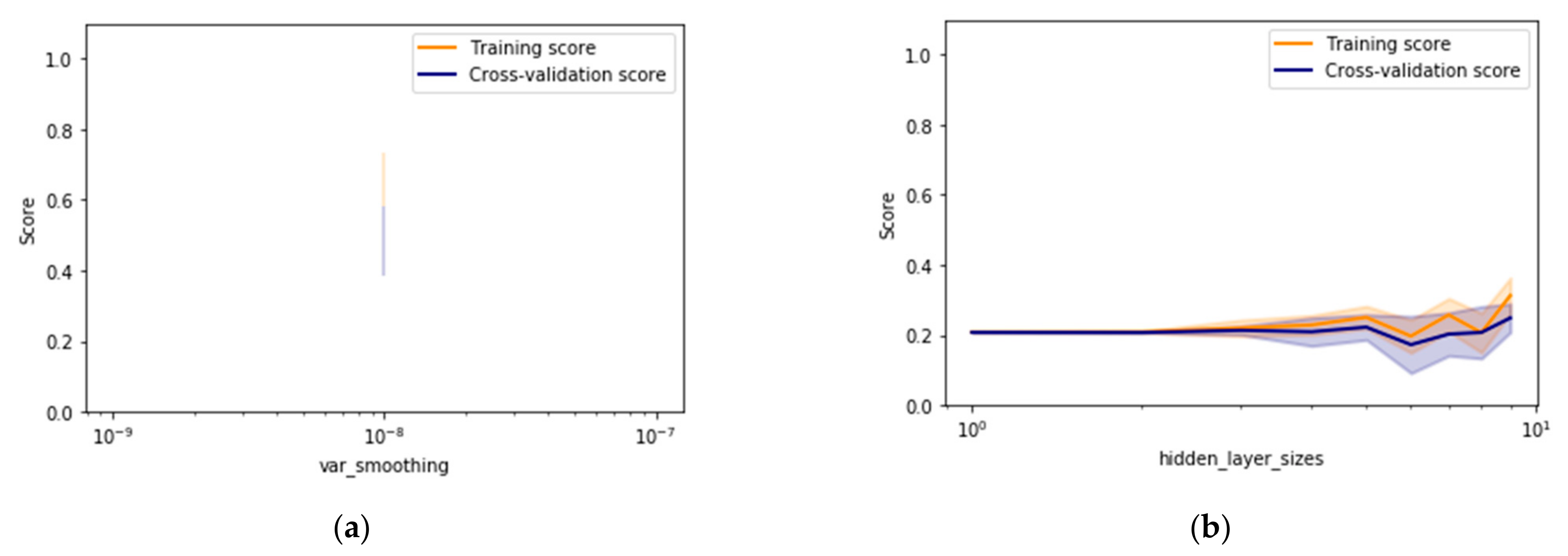
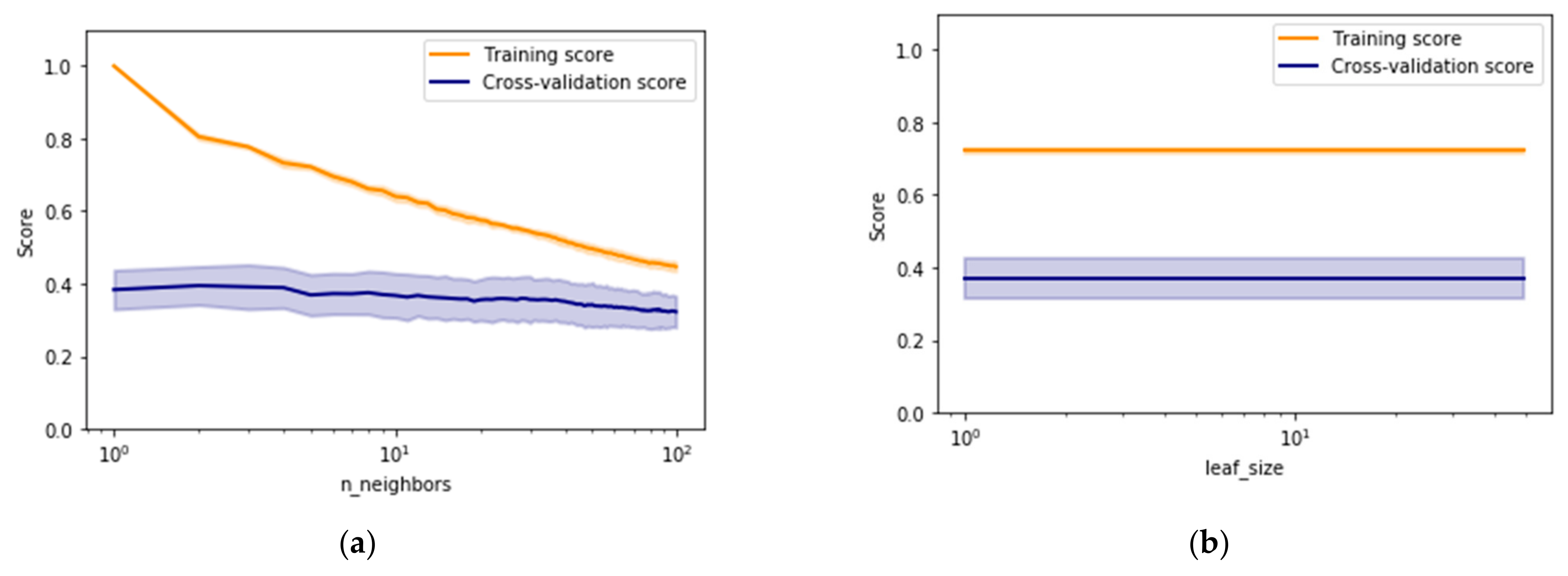
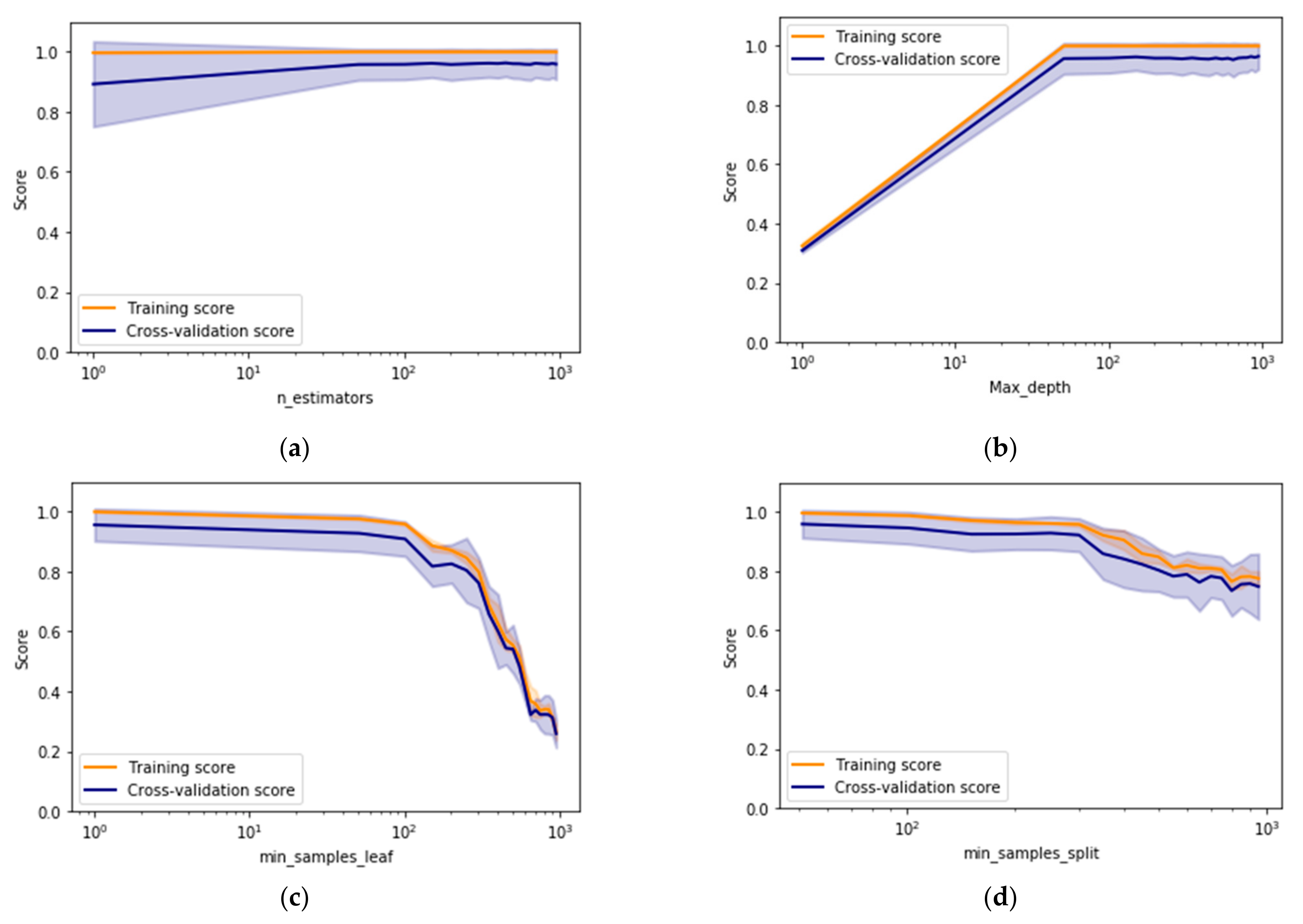
This section discusses the results obtained while selecting different types of drill bit through machine learning models. Two ensemble methods namely, AdaBoost and random forest (RF), have been investigated for handling the complex multiclass imbalanced data problem associated with the intelligent drill bit selection process. Validation curves have been generated to identify the stable regions existing in ranges of various models’ parameters as shown in
Figure 7,
Figure 8,
Figure 9 and
Figure 10. A detailed description of drill bit types has been provided in
Table A1 of
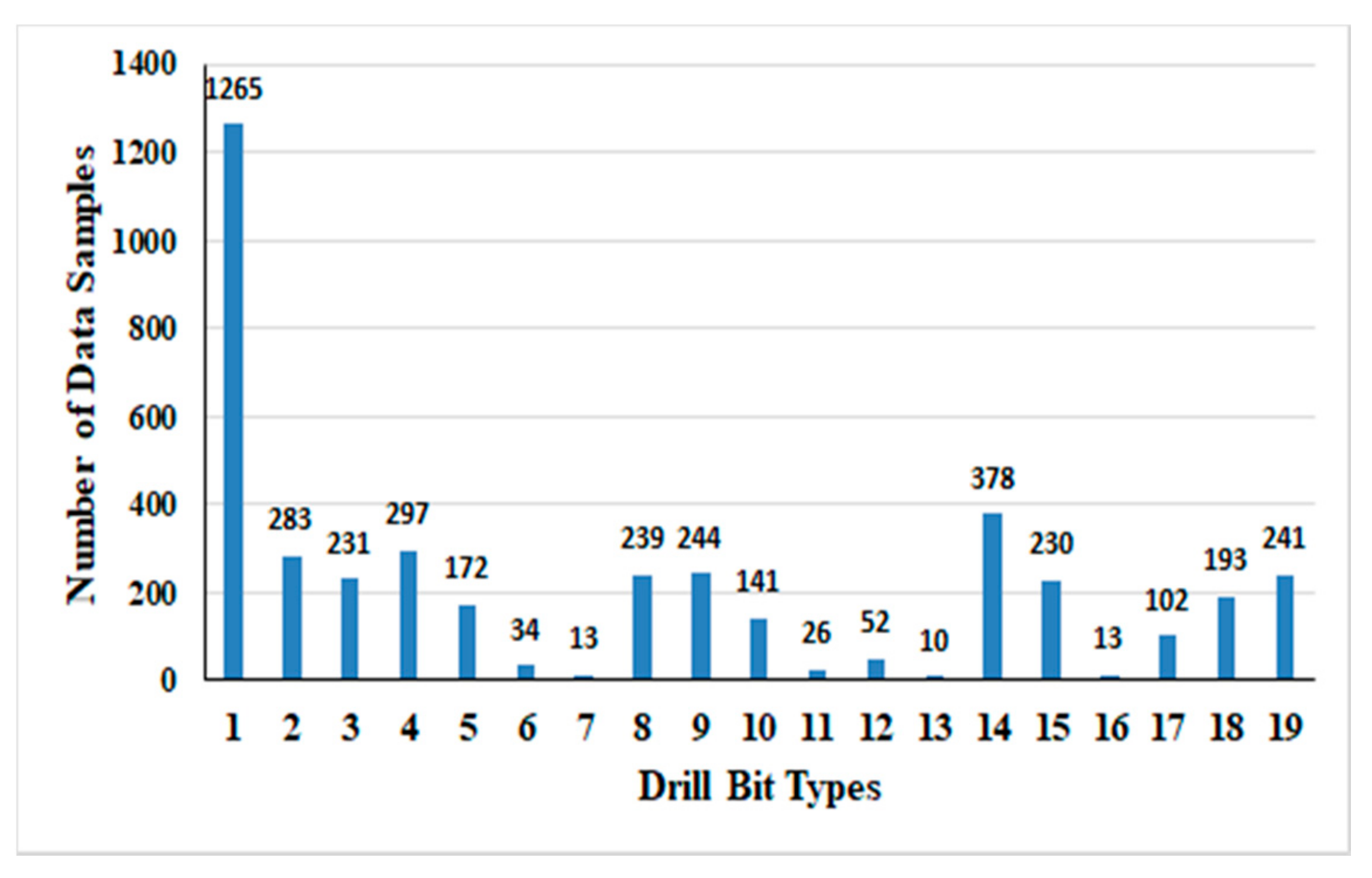
Appendix A. Two data-driven experimental scenarios have been simulated to test the intelligent bit selection approach. In the first experimental scenario, machine learning models were trained and tested on the combined dataset obtained from eight wells using 10-FCV. The input data utilized for training and testing of various machine learning models contain uneven training samples belonging to various classes as shown in
Figure 4. In the case of imbalanced data, classification accuracy becomes unreliable and unfit for the performance evaluation of machine learning models. Thus, average values of recall, precision, F1 score,
G-mean, and MCC, have been determined to examine the overall performance of various machine learning models.
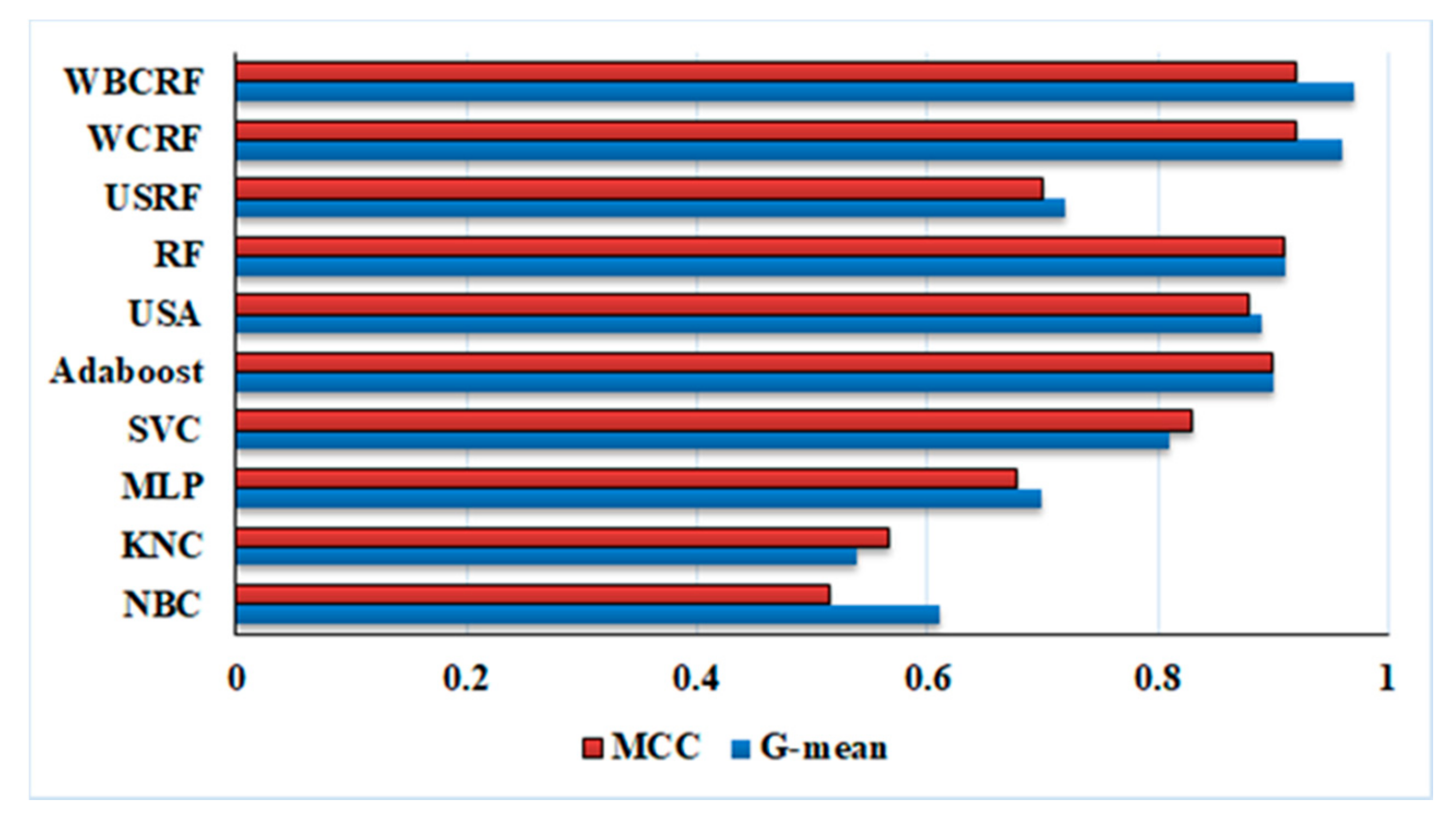
Table 5 shows the classification performance of standard classifiers for bit selection. It can be observed from
Table 5 that the performance of NBC and KNC are the lowest among all the other classifiers. NBC has failed to learn about hidden dependencies or patterns among diverse variables present inside the training data samples related to smaller classes. Smaller classes have existed sparsely in the training data space due to data scarcity which also harms the performance of KNC with testing data.
MLP model has been trained on 70% of input data along with 15% for validation and 15% as testing data. The optimum number of the hidden layer’s neurons of MLP was estimated based on minimum training error after several iterations as shown in
Table A2 provided in
Appendix A. MLP is three layers of a popular neural network with a backpropagation (BP) paradigm in its internal architecture for the training phase. BP trains the MLP network iteratively by adjusting the weights associated with each variable present inside training data. The weights adaptation is dependent on the length of the gradient vector calculated for error minimization in the training phase. The expected length of the gradient vector is dependent on the number of samples present for each class. During imbalanced data conditions, majority classes dominate the whole error minimization process during the training phase and produce larger errors for minority classes. Thus, the performance of MLP is adversely affected by the imbalance condition. MLP, NBC, and KNC classifiers are prone to become biased for majority classes in imbalanced data conditions. However, MLP has emerged as the second-best performing single supervise classifier for drill bit selection followed by SVC in the first place as shown in
Table 5. SVC is known to have some level of immunity for imbalanced data condition but become biased to majority classes in critically high imbalance condition. All of the above said supervised models fail to provide proper generalization and become unreliable for selection of drill bit type. Therefore, ensemble methods have been investigated for drill bit selection to achieve better model generalization.
AdaBoost and RF are the two ensemble methods that have been utilized for handling the imbalanced offset wells data for drill bit selection. RF has achieved higher testing accuracy than AdaBoost for bit selection as shown in
Table 5. Although, ensemble methods have given much better results as compared to single supervised classifiers which are affected by the imbalance conditions. Thus, both of these techniques were modified to enhance their capability of imbalanced data classification. AdaBoost and RF have been combined with an undersampling technique that reduced the data samples from majority classes to make the whole dataset balance. Here, the class having the lowest number of data samples was taken standard (class BT 13 with 10 samples) and other classes were undersampled accordingly. However, this approach has degraded the performance of both ensemble methods as their training and testing accuracies are heavily dependent upon the majority class samples as shown in
Table 6. In imbalanced data conditions, classifiers normally ignore smaller classes as fewer data samples are available during the training phase. It increases difficulties for intelligent paradigms to learn and identify any hidden pattern. This technique may produce satisfactory results when a reasonable amount of data samples are present in the smaller classes. Further, oversampling was performed to tackle this critical imbalance condition through SMOTE techniques. In SMOTE, the class having the largest number of data samples (BT 1 with 1265 data samples) was taken as a standard for the generation of synthetic data. SMOTE utilizes k-nearest neighbors samples (k = 5) to acquire the data distribution of subsets for each class. The results are shown in
Table 6. Which demonstrate enhancement in training and testing accuracies of ensemble classifiers, along with other performance metrics for oversampling.
MCC and
G-mean values have also shown enhancement as compared to the earlier undersampling case. In oversampling combinations, the ensemble classifiers are found to be more reliable and stable due to the higher values of
MCC and
G-mean.
In the second approach, classes are assigned weights to focus the classification operation on the samples of minority classes at the algorithm level. The weights will be adjusted according to the inverse relationship with class frequencies in the training data. This will result in the formation of a weighted class RF classifier (WCRF) for the classification of imbalanced data. It can be observed from
Table 6 that the WCRF has given a better performance than standard RF for drill bit selection in terms of precision, recall,
MCC, and
G-mean. This indicates that WCRF has a greater generalization ability than standard RF due to enhancement in testing results. The generalization of supervised models such as ANN, AdaBoost, RF, etc. depends upon their classification performance with unseen data samples that are available in testing datasets. The higher performance of the classifier with the test dataset indicates better generalization of the trained classifier model which is always desirable.
In the third approach, separate weight adjustment of classes has been performed based on its distribution in every bootstrap sample in place of the whole training dataset. Such a configuration of RF is known as RF with a bootstrap class weighting (WBCRF) classifier. This classifier contains the benefits of both data sampling and weighting techniques that are quite useful for compensating for the impact of imbalance conditions. Training and testing results of WBCRF have shown a slight performance improvement when compared with WCRF. Both these approaches have provided higher
MCC and
G-mean values than the standard RF paradigm as shown in
Table 6 and
Figure 13. The WBCRF technique has given the best classification results as compared to other classifiers considered in this study.
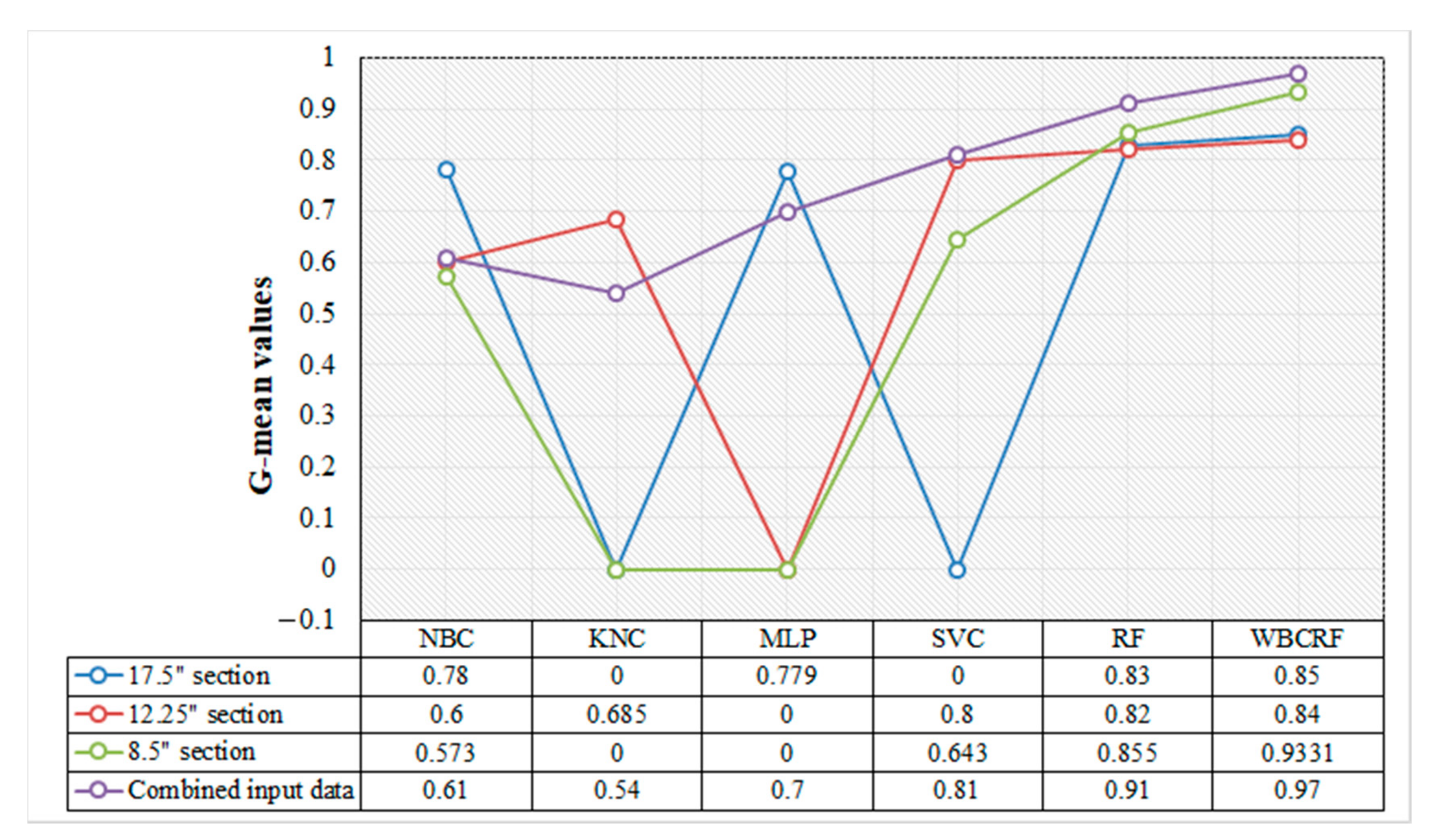
In the second experimental scenario, three subsets have been created from eight wells data containing data samples belonging to 17.5”, 12.25”, and 8.5” individual wellbore sections. All the earlier applied classifiers have been trained and tested on these subsets. The performance of conventional classifiers has been assessed in terms of recall,
G-mean, precision, and F1 score for every BT to understand the effect of imbalanced data.
Table 7,
Table 8 and
Table 9 contain drill bit selection test results for the 17.5” section subset. It can be observed from the abovementioned tables that bit type 16 (minority class) is hard to predict due to a smaller quantity of data points available during the training phase. KNC, SVC, and MLP have also failed to identify BT 16 due to scarcity of data samples as shown in
Table 7,
Table 8 and
Table 9. Thus,
G-mean values are recorded to be zero for SVC, KNC, and MLP as it is clear identification of the development of unreliable biased majority class classifiers.
The drill bit 16 is intentionally discussed for understanding the effects of data imbalance arise while drilling through the thin lithofacies layer. The subsurface formations have varied thickness patterns in their natural state which result in random unequal data samples for the training phase. Therefore, the uneven distribution of training data has been particularly considered to evaluate the worst to the best performance of each classifier. Uneven data samples for various bit types (class labels) in training data make classification difficult for machine learning models. Drill bit selection has been formulated as a multiclass classification problem with 19 diverse bit types as class labels as shown in
Table A1. However, large fluctuation in the values of precision, recall, F1 score can be observed from
Table 8 and
Table 9. Standard RF has shown good classification performance even for bit type 16 due to the presence of random bootstrap resampling technique in its internal architecture. RF has given the best prediction performance for the 17.5” section subset with good immunity to data imbalance conditions. Further, WBCRF has also been evaluated for 17.5” datasets that have given more accurate results with stable values for precision, recall, and F1 score.
In the data subset of the 12.25” section, performance for every classifier has been recorded as shown in
Table 10,
Table 11 and
Table 12. Higher fluctuations in the values of precision, recall, and F1 score has been recorded in classification results. This indicates that these sections are physically challenging drilling zones. RF and WBCRF have given impressive results for the classification of these critical geological zones as shown in
Table 10,
Table 11 and
Table 12. In this section, BTs 6 and 11 are minority classes that are hard to classify. However, only MLP becomes a bias classifier as it fails to classify any samples for BT 11 as shown in
Figure 13.
The geological lithofacies existing in section 8.5” are found to be the most challenging formations for drilling operations due to several faults and unstable zones existing along its depths. The 8.5” section formations have been reported to be unstable because they are made up of softer rocks such as claystone, sandstone, siltstone, tuff, marl, limestone, and argillaceous clay contents. Certain incidents of gas leaks and drill string stuck ups were also recorded while drilling 8.5” section of the wells with high stick slips conditions in its upper formations. Polycrystalline diamond compact bits (PDC) were primarily utilized for drilling softer 8.5” section because of their higher ROP values and stable drilling operation (
Table A1). However, it becomes difficult for the driller to choose the right PDC bit type as varieties of bit models are available while planning for drilling operations. The pattern recognition has become difficult in the 8.5” section as the performance of all the classifiers has shown more fluctuations in their precision and recall values due to heterogeneity of lithofacies as shown in
Table 13,
Table 14 and
Table 15. Here, BT 12 and 13 are the minority classes for which KNC and MLP failed to identify any samples while SVC and NBC have shown poor prediction performance as shown in
Figure 13. Finally, worst-to-best accuracy of various classifiers in second data-driven scenario can be given as: WBCRF (0.92–0.99), RF (0.91–0.98), SVC (0.88–0.94), MLP (0.74–0.89), KNC (0.61–0.81), and NBC (0.53–0.75). RF and WBCRF have shown great immunity for data imbalance condition and successfully maintained their performance even in the critical 8.5” section. Recently, hybrid drill bits (e.g., Kymera) have been developed that combined the properties of conventional PDC bit and roller cone bit types [
56]. These hybrid bits seem to be a good solution for drilling problematic 8.5” section while maintaining the stability of drilling operations.
Figure 14 provides a summary of
G-mean scores achieved by intelligent models for both experimental scenarios. A comparative table of significant research publications has been provided in
Appendix A as
Table A3.
The present study shows that the ensemble methods have great potential for automatic drill bit selection. With data resampling and boosting approaches, reliability, stability, and performances of ensemble methods have improved as discussed in earlier parts of this section. The proposed models do not have any known specific limitation. However, these models are needed to be tested on the field with real-time streaming well data to achieve more insight about their performance in practical scenarios. With the rapid advancement in sensor based data acquisition new measurements may be available in future oil and gas wells. This will require retraining of the proposed models with newer training data sets. More research work is required for understanding the drill bit selection process with real-time streaming data. It is highly recommended that driller (field engineers) should understand the problems associated with drilling data before applying any data driven models for drill bit selection. During data acquisition, data samples must be carefully captured in such a way that equal number of data samples will be available for each geological formations. The proposed models is advancement in the existing technology that will enhance the efficiency of drilling operations for better extraction and utilization of hydrocarbon resources for long sustainable time period. This will promote global economic development that have huge impact on human sustainability. This will also satisfy the goals of sustainable development described by United Nation Development Programme (UNDP). To meet the global energy demands, more unconventional wells are being drilled that requires industrial innovation to face the technological challenges. This study provides an approach to automate the drill bit selection process over any field, which will minimize human error, time, and drilling operational costs.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













