This section describes the characteristics of the data used for the analysis. The data include information about wind speed and direction as well as prices of electricity for a hypothetical wind farm located in Central Italy with coordinates of 42 N and 13.75 E. The data frequency is hourly for 5 years, from 1 July 2015 to 30 June 2020, amounting to a total of 43,848 observations.
2.2. Wind Energy Production
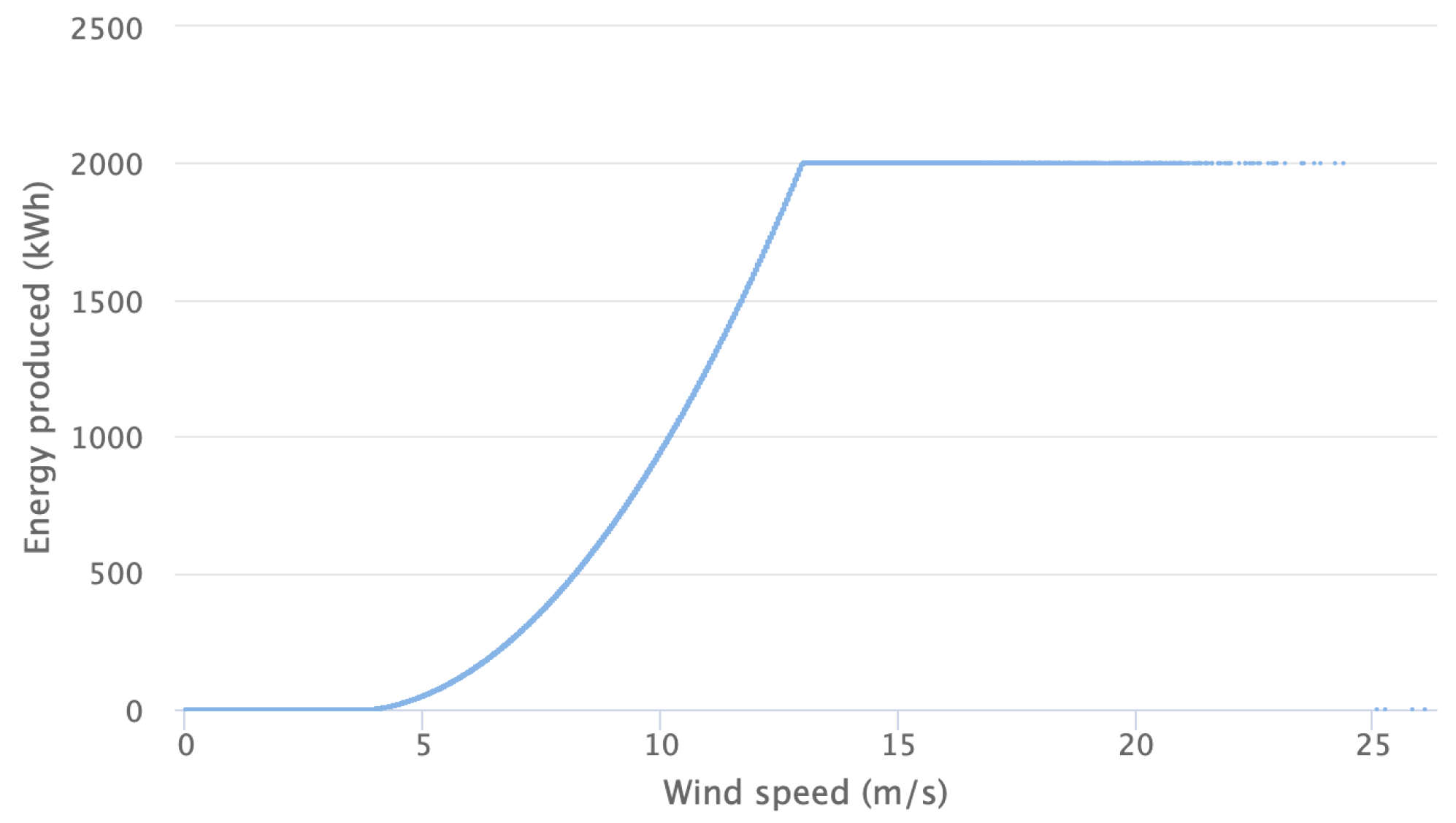
To obtain an estimation of the wind turbine income, we needed to convert the wind speed to energy production. Wind turbines transform the kinetic energy of wind into electrical power through the rotational movement of the blades. The amount of energy produced depends on the wind intensity, as well as on the characteristics of the blades. For this purpose, the turbine is characterised by its power curve, which is generally given by the turbine producer. In our application, we considered a generic wind turbine with the following characteristics:
Hub height of the turbine: 95 m;
Rated power of the turbine: 2 MW;
Cut-in wind speed: 4 m/s;
Rated wind speed: 13 m/s;
Cut-out wind speed: 25 m/s.
In general, the power curve is linked to two critical values for wind speed. Below the first threshold—i.e., the cut-in value—the turbine does not produce energy at all, meaning that the kinetic energy of the wind is too weak to move the blades. In addition, above the second threshold—i.e., the cut-off value—the turbine is blocked to avoid structural damage. Between these two limits, there is a cubic relation, known as the Betz law, which links the wind speed with the energy produced. This typical behaviour of the wind turbine production is clearly evident in
Figure 4, which shows the power curve given by the producer of the turbine considered in our application. Besides, taking into account that the wind data were generated for a height of 50 m and the wind turbine height was at 95 m, we used an exponential scaling factor, as in [
15], using the following dependence from the altitude:
where
is the wind speed at the height of the wind turbine,
is the value of the wind speed at 50 m—in our application
m and
m—and
is a factor that takes into account the morphology of the area near the wind turbine. This parameter depends on the region in which the turbine is located. Its value ranges from 0.01 and 0.001 depending on buildings or trees in the area; for offshore application, it is equal to 0.0001. For our analysis, we considered a mean value for an onshore application; thus, we choe
= 0.005.
2.5. Model
The analysis of wind speed and price data clearly shows that there are cross-correlations between the series and the lagged series, suggesting the use of a multivariate model that considers some history of the process. A good candidate could be the multivariate Markov model with the inclusion of the dependencies from a certain level of past values. However, a Markov chain model would require the estimation of the probabilities of all possible combination of the transitions from one state to another for each series and each lag. In such a model, the number of parameters to estimate is liable to drastically increase with the number of states, series and time lags.
To overcome the estimation issue in the high-order Markov chains, in [
19], the authors proposed the Mixture Transition Distribution model (MTD) to reduce the number of parameters in the estimation. Moreover, in [
22], the authors applied the same approach to the multivariate Markov chains. In this paper, we propose a combination of the two approaches to deal simultaneously with high-order Markov chains and multivariate Markov chains.
In general, for a given Markov process
, taking values in the set
, the Markov property for its high-order chain can be written as
where
and
l is the order of the chain; i.e., the number of time lags.
Equation (
2) states that the probability of being in state
at time
t does not depend on the full historical path of the process but only on the states occupied by it during the last
l transitions. Therefore, the present case depends on the last
l observations only.
According to [
19], the high-order Markov property can be rewritten, on the basis of the MTD model, by the following relation:
This property declares that the probability of being in state
at time
t still depends on the
l states occupied by the process at previous time lags, but this dependency is represented by a linear combination of the probabilities of transitioning from state
at time
to state
at time
t. Therefore, based on the MTD model, we need to estimate
l transition probability matrices whose entries represent the probability of transitioning from state
to state
. Let
be the transition probability from state
at time
to state
at time
t; the property in (
3) can be written as
However, if we consider a homogeneous Markov chain with states taking values in the set
, the process can be fully described by a probability vector
and a time-independent transition probability matrix
whose entries
are the probabilities of transitioning from state
i, independent of the lag, to state
. Thus, the probability distribution at time
t can be expressed in terms of the one-step transition as
or, given an initial probability distribution vector,
, as
With the homogeneity condition, the relation in (
4) can be updated as
with
being an element of the matrix
that represents the probability of transitioning from state
i to state
.
To ensure that we deal with probabilities in Equation (
7), we need to ensure that
implying the following conditions:
Considering the convex linear combination presented in Equation (
7), we have to estimate fewer parameters compared to the full high-order Markov chain. Specifically, we have
parameters for the transition probability matrix with
m states plus
values for the
coefficients, compared to a total of
parameters for a full high-order Markov chain.
For a comprehensive review of the MTD model and its applications, we refer the reader to [
25].
The same MTD model approach can be applied to the multivariate Markov process. We now consider
series without including the time lags. In this case, the property in (
3) becomes
with
.
This property states that the probability of being in a determined state at time
t depends on the states occupied by all series at time
, according to a linear combination of the transition probability matrices
. Each element of these matrices represents the probability of transitioning from state
i in series
at time
to state
in series
at time
t, as indicated in the following matrix:
Therefore, we need to estimate matrices with parameters, plus values for the coefficients. The total number of parameters to estimate for a multivariate Markov chain is .
As for the high-order Markov model, the multivariate Markov model is subject to the same conditions in (
8):
For our purpose, we combine the previously described models and propose a high-order multivariate Markov model. The properties in Equations (
7) and (
9) can be jointly written as
subject to
For clarity, of the conditioning vectors of the probability in Equation (
12), where the probability of being in series
in state
depends on the states
occupied by the
series in the
l lags, we can write the equation with the help of the following matrix representation:
If we have only one series, the matrix reduces to the column vector and the model is a high-order Markov chain. On the contrary, if we have only one lag, the matrix reduces to the row vector and the model is the multivariate Markov chain.
Considering the homogeneous case, as in (
7), the total number of parameters to estimate becomes
.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}