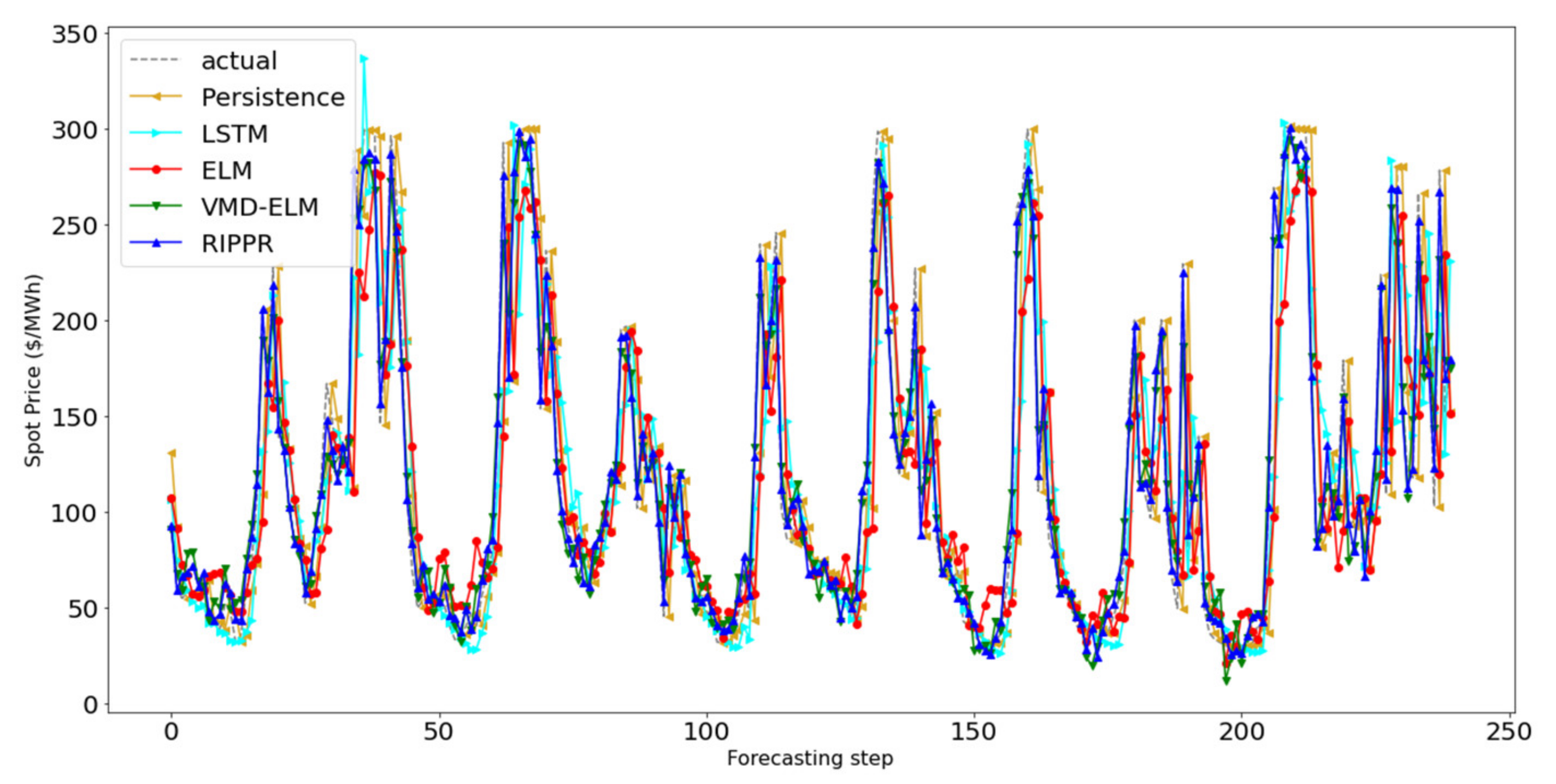
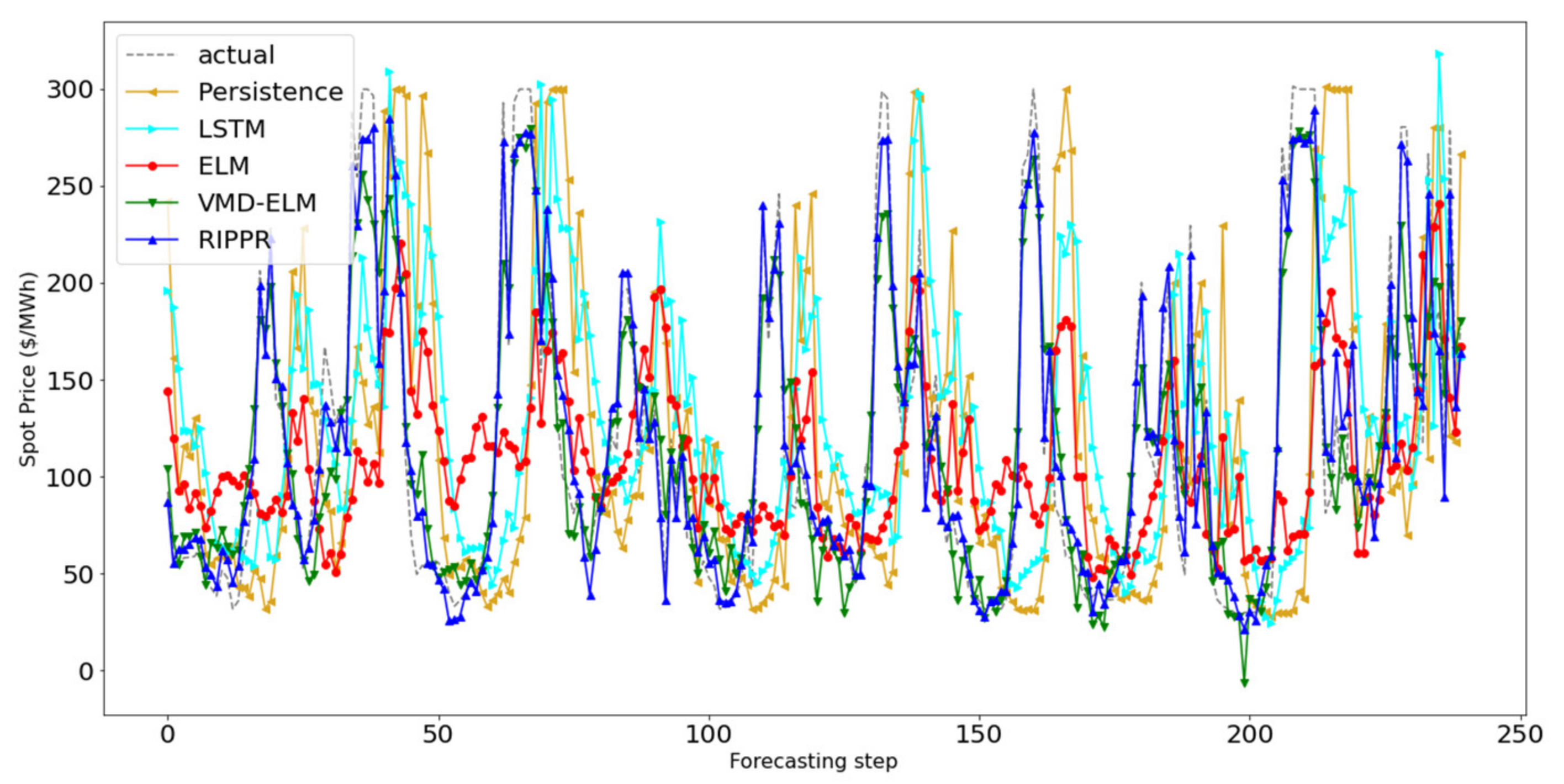
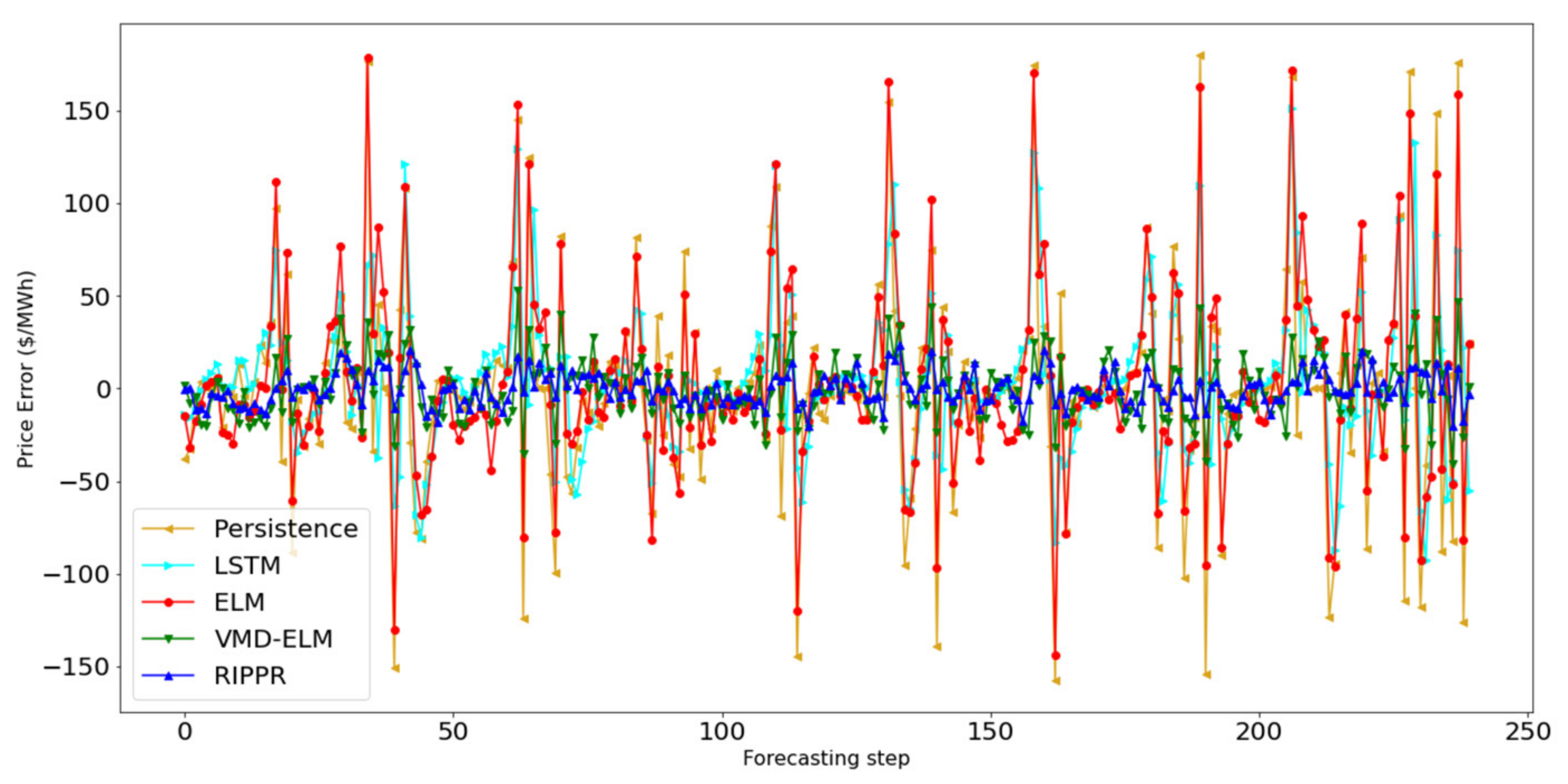
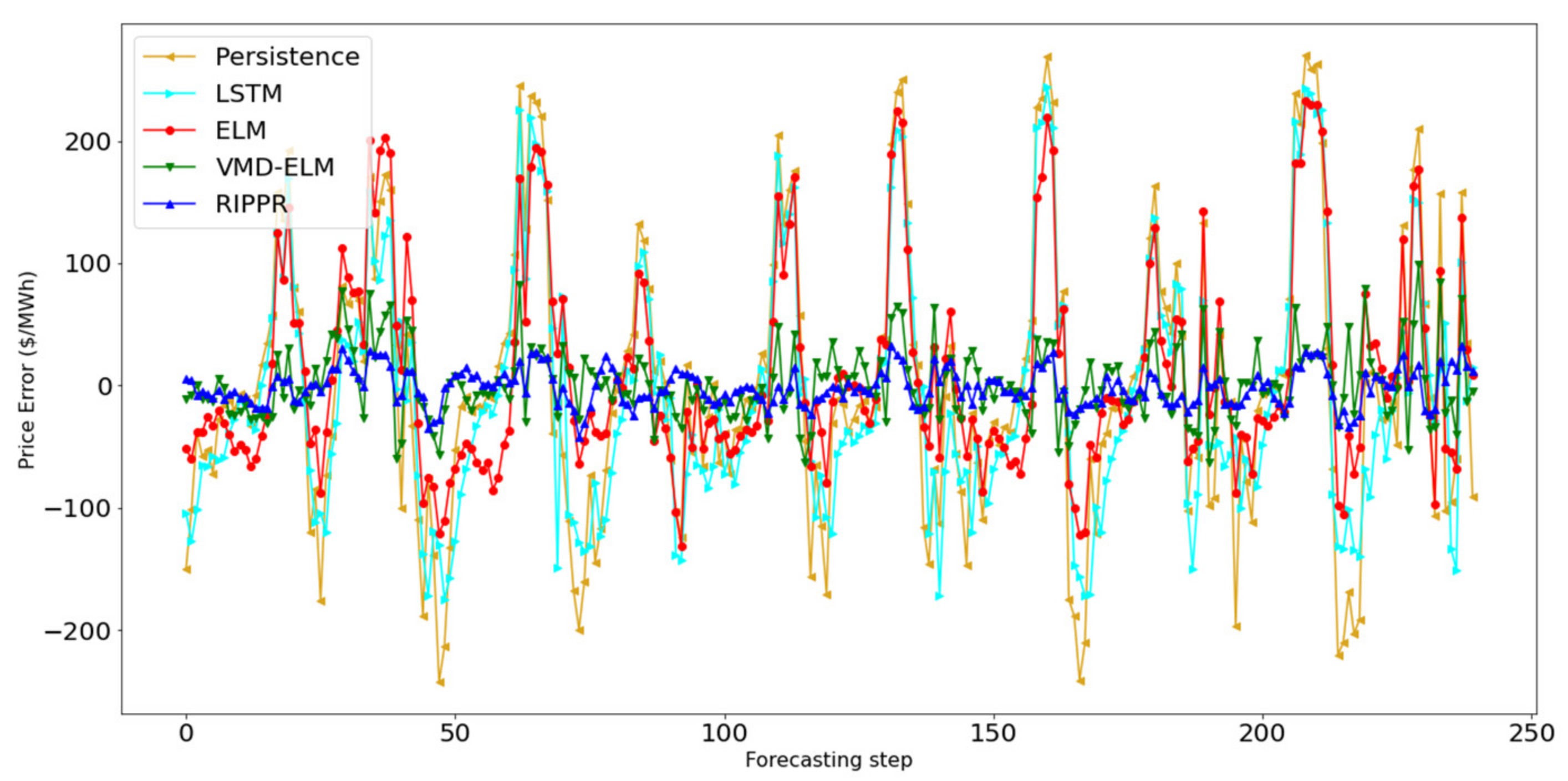
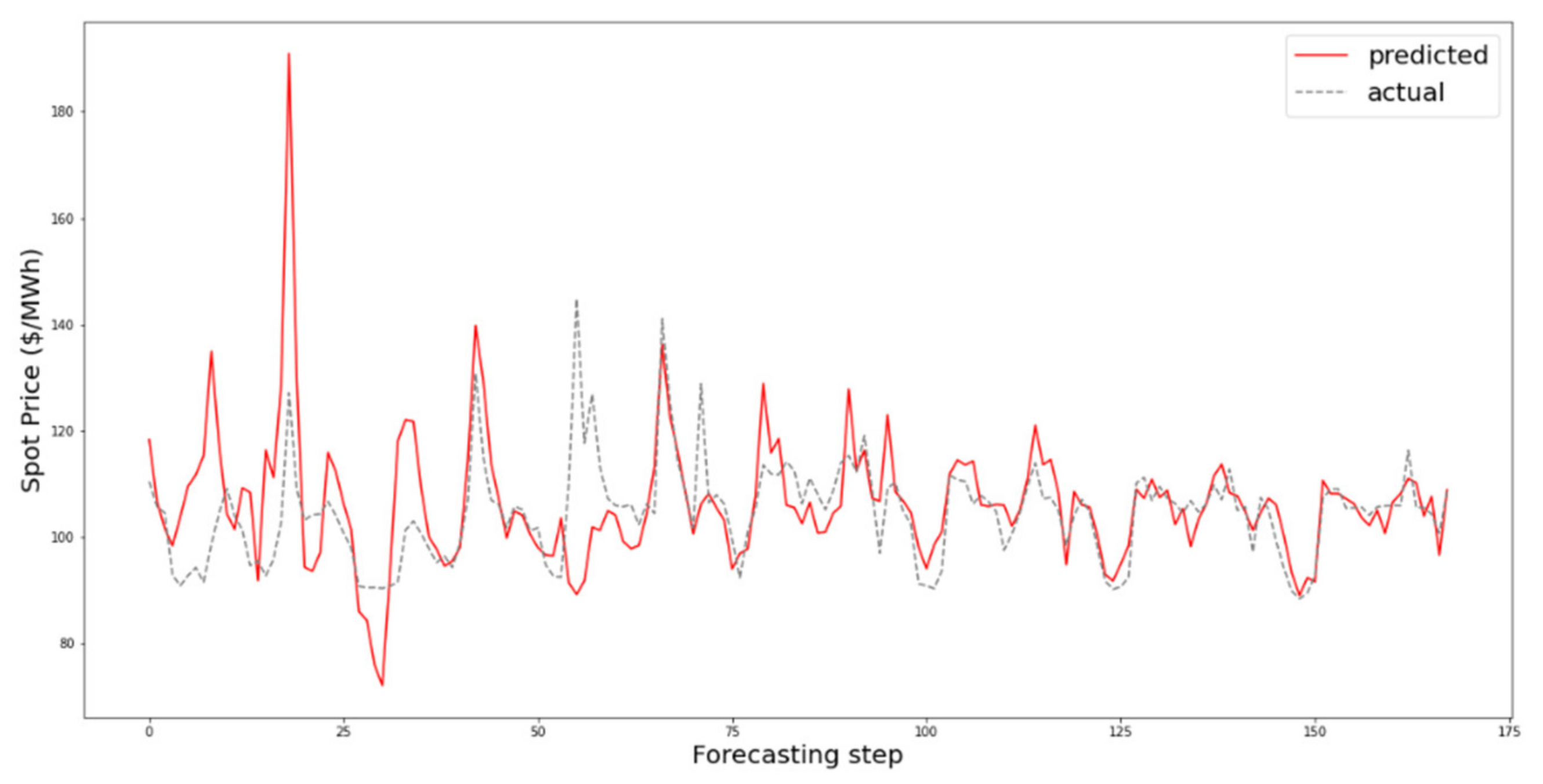
The proposed method, RIPPR, is a machine learning ensemble-based decomposition method that addresses these limitations. In brief, the proposed approach consists of five main components. The pre-processing module includes a normalization as well as an extreme outlier removal process, which is then processed by the data decomposition module. The data decomposition module decomposes a given data stream into K sub-series where the optimal parameters for the decomposition are chosen by the optimization module, including the value K. It is followed up by the Forecasting module where each sub-series is modeled with RVLF for h-step ahead point forecast, which then aggregated for each subseries in the post-processing module to produce the h-step ahead point forecast. The RIPPR process is illustrated in
Figure 1. It comprises of five modules, data pre-processing, data decomposition, optimization, time series forecasting and post-processing. Each module is delineated in the following subsections.
2.2.1. Data Pre-Processing Module
The pre-processing module receives the raw time series data as input. In the context of energy markets, short-term EPF is a core capability of an energy market that drives the market’s operational activities. The short-term EPF is also called spot or day-ahead price forecasting. Here we consider raw time series data to be the spot prices that the National Electricity Market Operators use to match the supply of electricity from power stations with real-time consumption by households and businesses. All electricity in the spot market is bought and sold at the spot price.
In general, to obtain an accurate forecast, the input time series data that are used to model the forecasting model should be normalized in consideration of the new data that the model will account for in the future. Due to the high fluctuation and varying nature of the energy market, each dataset and data sample is unique, posing unique challenges for EPF. In the context of spot prices, the primary challenge is the presence of noise, including duplicated values, missing data points, and extreme outliers that will make the forecasting model weak. In RIPPR, we adopt two techniques to suppress the noise in input data streams. First, we remove the extreme values to discard extreme outliers in the input data, and second, we normalize the input data prior to feeding it to the prediction model.
Extreme values (or outliers) are data points that significantly differ from other observations, and the removal of such extreme values is considered as one of the significant steps in data pre-processing. This is because machine learning algorithms and corresponding predictions/forecasts are sensitive to the range and distribution of the input data points; therefore, outliers can mislead the training process resulting in longer training times and less accurate models. Extreme values can be of two types, (1) outliers that are introduced due to human or mechanical errors, and (2) extreme values that are caused by natural variations of a given distribution. In the context of smart grid/spot prices, the first type is rarely attested. However, a common case is the presence of extreme outliers. For instance, wholesale energy prices are influenced by a range of factors, including weather, local economic activities, international oil prices and resource availability. The availability of such factors could lead spot prices to be extremely volatile and unpredictable. Thereby, we intend to address these extreme values using extreme value analysis that use the statistical tails of the underlying distribution of the variable and find the values at the extreme end of the tails. Followed by the extreme value removal, we perform min–max normalization on the time series data to scale the time series data in the range 0 and 1. In general, the min–max normalization technique does not handle outliers and extreme values, and this is why normalization is preceded by extreme value removal.
A limitation of the min-max normalization technique is that the values used in the train-test phases can be very different from a real-world scenario, where the minimum and maximum values of a time series is not prior. It is necessary to make a realistic assumption of the min–max values based on expert knowledge of the energy market.
2.2.2. Data Decomposition Module
Time series data can exhibit a variety of patterns; therefore, splitting such time series data into several distinct components, each representing an underlying pattern category, could lead to better analysis and pattern identification. The complex characteristics of the electricity spot price market make it even harder to capture the underlying patterns in order to forecast spot prices, which makes decomposition an essential component of the proposed approach. In recent work, a number of signal decomposition algorithms that can be utilized for time series forecasting were proposed. For example, Empirical Mode Decomposition (EMD) [
37], Ensemble EMD [
38], Complete Ensemble EMD with adaptive noise [
39], Empirical Wavelet Transform (EWT) [
40] and Variational Mode Decomposition [
41] are several recent signal decomposition techniques.
As stated by Wang et al. [
42], Variational Mode Decomposition (VMD) is the state-of-the-art data decomposition method in signal modeling. VMD decomposes a signal into an ensemble of band-limited Intrinsic Mode Functions (IMF). It is more effective than other signal decomposition methods as it is able to generate IMF components concurrently using the ADMM optimization method [
43], it can avoid the error caused during the recursive calculating and ending effect, which is a significant issue of EMD [
30] and it is significantly robust to noise as well [
41].
In VMD, a real-valued input signal
s is decomposed into a discrete number of modes
uk that have specific sparsity properties while reproducing the input. Each mode of
χk is assumed to be most compact around a center pulsation
ωk, which is determined along with the decomposition. Based on the original algorithm, the resulting constrained variational problem is expressed as follows.
where {
uk}:= {
u1,….,uk} and {
ωk}:= {
ω1,…., ωk} are shorthand notations for the set of all modes and their center frequencies, respectively, and
f is the input signal. Equally,
is understood as the summation over all modes. Here,
K is the total number of the decomposed modes. Since the decomposition is mainly based on the parameter
K, a significant effort should be placed to select the optimal value.
To address the constrained variational problem, VMD uses an optimization methodology called ADMM [
41] to select the central frequencies and intrinsic mode functions centered on those frequencies concurrently. First, minimization with respect to u
k (modes) is considered, and the following is obtained for û
kn+1:
Secondly, minimization with respect to
ωk (center frequencies) is considered and following is obtained for
ωkn+1:Here
ukn+1,
ωkn+1 and
λn+1 are updated continuously until convergence. When the following convergence condition is met, the algorithm terminates, producing the K modes.
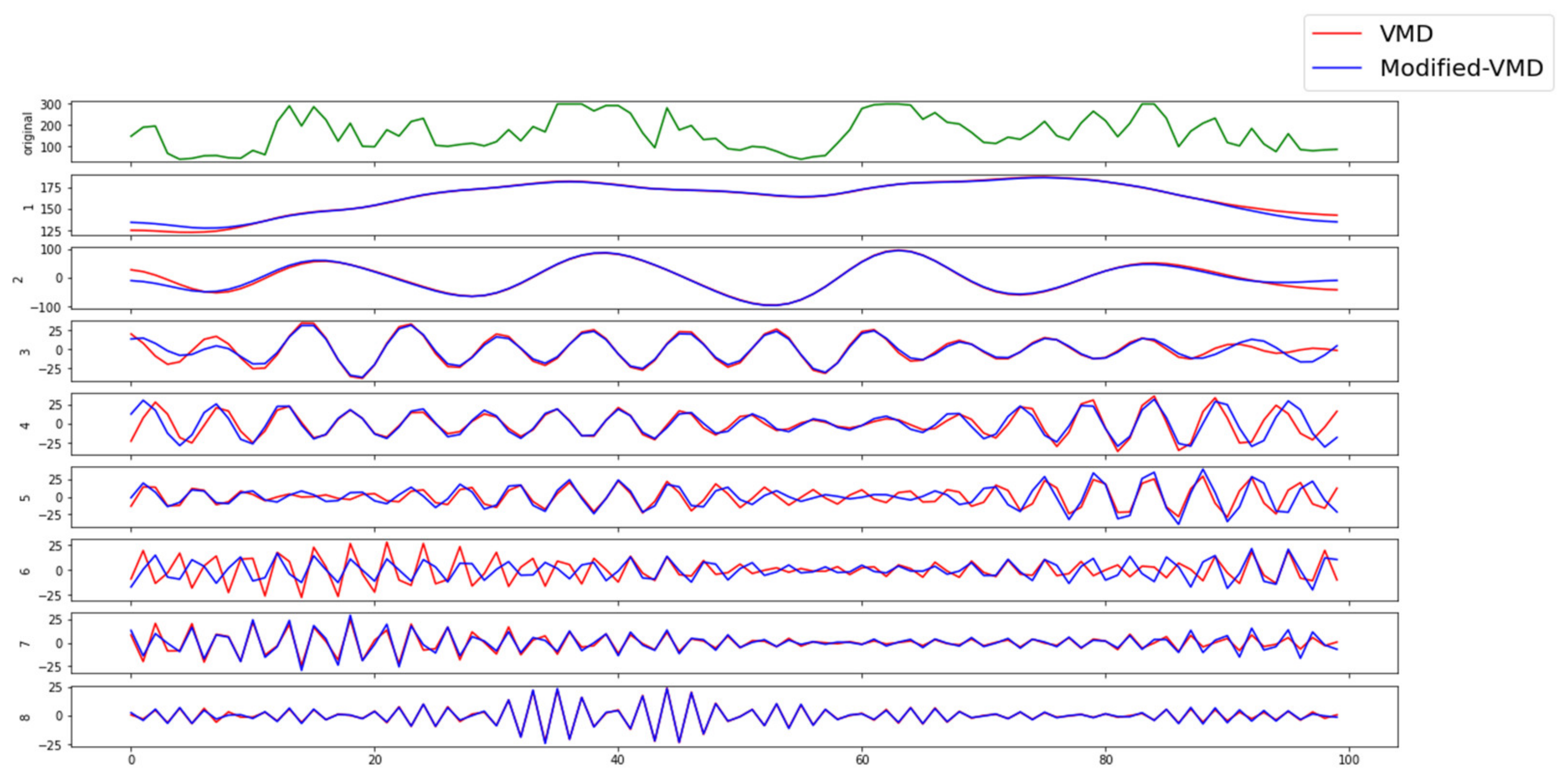
The generic VMD algorithm is effective for discrete, finite time signals; however, the boundaries of the signal are a key technical challenge due to the vanishing derivatives in the time domain boundary [
41]. To address this challenge, VMD introduces a mirror extension of the signal by half its length on each side. However, this means the prediction is based on using previously seen values as future point forecasts. This is because decomposed sub-signals assume that the original signal will continue in the form of a mirror extension. Therefore, generic VMD cannot be used directly in a real-world time series forecasting setting. In RIPPR, we modified the VMD algorithm by removing this mirror extension.
In
Figure 2, we compared the generic VMD algorithm and the modified version (that has the mirror extension removed) on a benchmark dataset. The results indicate that the two versions obviously differ, which will lead to different forecasting performances. However, the effectiveness of the modified-VMD algorithm is necessary for practical use.
Returning to the core capability of the VMD method, the decomposition of a signal depends on the settings of its input parameters. The VMD method consists of five parameters, namely, mode number (
K-the number of modes to be recovered), balancing parameter (α-the bandwidth of extracted modes (low value of α yields higher bandwidth)), time-step of dual ascent (
τ), initial omega (
ω) and tolerance (
ε). As experimentally proven by Dragomiretskiy and Zosso [
41], ε, τ and ω has standard values across any given signal distribution. The standard values are;
ε = 1 × 10
−6,
ω = 0,
τ = 0. However,
k and
α depends on the signal, and this means for each new signal distribution, these two parameters needed to be adjusted. We address this in the next module using particle swarm optimization (PSO).
2.2.3. Optimization Module
The number of modes to be recovered (
K) and the balancing parameter (
α) determine the accuracy of the VMD decomposition. In this module, we utilize particle swarm optimization [
44] (PSO) to select the most suitable values for these two values
K,
α, for a given forecasting horizon. We consider the prediction time for a given time-step as the objective function of the optimization technique.
PSO is a metaheuristic parallel search technique used for the optimization of continuous non-linear problems, inspired by the social behavior of bird flocking and fish schooling [
45]. PSO is a global optimization algorithm for addressing optimization problems on which a point or surface in an n-dimensional space represents the best solution. In this algorithm, several cooperative agents are used, and each agent exchanges information obtained in its respective search process. Each agent, referred to as a particle, follows two rules, (1) follow the best performing particle and (2) move toward the best conditions found by the particle itself. Thereby, each particle ultimately evolves to an optimal or a near-optimal solution. PSO requires only primitive mathematical operators and is computationally inexpensive in terms of both memory requirements and speed when compared with other existing evolutionary algorithms [
46].
The standard PSO (Algorithm 1) algorithm can be defined using the following equations,
| Algorithm 1 Standard particle swarm optimization |
| Input: Objective function to be minimized (or maximized) |
| Parameters: swarm size, c1,c2,ω, itermax,error |
| Output: gbest |
| 1: Initialize population (Number of particles = swarm size) with random position and velocity; |
| 2: Evaluate the fitness value of each particle. Fitness evaluation is conducted by supplying the candidate solution to the objective function; |
| 3: Update individual and global best fitness values (pbest,i and gbest). Positions are updated by comparing the newly calculated fitness values against the previous ones and replacing the pbest,i and gbest, as well as their corresponding positions, as necessary; |
| 4: Update velocity and position of each particle in the swarm, using Equations (5) and (6); |
| 5: Evaluate the convergence criterion. If the convergence criterion is met, terminate the process; if the iteration number equals itermax, terminate the process; otherwise, the iteration number will increase by 1 and go to step 2. |
where
xi is the position of particle
i;
vi is the velocity of particle
i;
k denotes the iteration number;
ω is the inertia weight;
r1 and
r2 are random variables uniformly distributed within (0, 1); and
c1, c2 are the cognitive and social coefficient, respectively. The variable p
best,i is used to store the best position that the
ith particle has found so far, and g
best is used to store the best position of all the particles. The basic PSO is influenced by a number of control parameters, namely the dimension of the problem, number of particles, step size (
α), inertia weight (
ω), neighborhood size, acceleration coefficients, number of iterations (iter
max), and the random values that scale the contribution of the cognitive and social components. Additionally, if velocity clamping or constriction is used, the maximum velocity and constriction coefficient also influence the performance of the PSO.
A novel contribution of this module is that we have extended the basic PSO algorithm to take both continuous space (ℝ+-space) and discrete space (ℤ+-space) for optimization. In the given context, two variables exist for the optimization purpose, namely K and α. The variable α is a continuous variable, while K is a discrete variable. Therefore, we modify the basic PSO to consider both ℝ+ and ℤ+ spaces in optimization.
At the start of the algorithm, we place particles randomly such that particle position for each particle with respect to
K is discrete. Then, we round off the
vi(
k+1)
α to the nearest integer before adding it to
xi (
k) (Equation (6)). As such, we change Equation (6) for variable
K as follows:
where ‘[ ]’ operation represents rounding to the nearest integer.
The following section describes the fitness function that is used in the RIPPR approach. This fitness function is selected to cover both prediction accuracy as well as time taken to the prediction. The more obvious fitness function will be to use the testRMSE directly so that PSO will find an optimal (K, α) combination so that the forecasting accuracy will be higher. However, our experiments show that by doing so, it will result in a higher K value which is not desirable when considering the time taken for the prediction (K separate models will be created for each sub-series).
To overcome the aforementioned issue, we have included a penalty term to penalize having a higher
K value while having good accuracy. The final fitness function is as follows:
where
β is constant, we can control the penalizing term by adjusting the
β value. From our experiments on energy price forecasting, we see that having
β = 1 leads to better accuracy as well as manages to penalize having a higher
K value precisely. Depending on the application, the value for
K should be chosen accordingly. The calculation of the fitness function is given in Algorithm 2.
| Algorithm 2 Fitness value calculation for PSO |
| Input: K, α, Data (X), forecasting horizon |
| Output: Fitness value |
| 1: Decompose the data (X) using VMD for the given (K, α) combination; |
| 2: Divide each sequence (sub-series) into multiple input/output patterns called samples for the given forecasting horizon; |
| 3: Split the samples set into train and test split at a ratio of 6:4; |
| 4: Train on the train data using the time series forecasting module for each sub-series; |
| 5: Predict for the test data using trained models for each sub-series; |
| 6: Aggregate the predicted values for each sub-series to obtain the final prediction for the test data; |
| 7: Calculate the RMSE value between actual values and predicted values for the test data (testRMSE); |
| 8: Calculate fitness value as follows: . |
In
Figure 3, we illustrate the learning process of PSO to find the optimal components for VMD. This experiment is conducted using dataset A (
Table 1). We used the following parameters in the PSO algorithm, swarm_size = 10, inertia = 0.7, local_weight =2 and global weight = 2. We can see that the learning process follows the discrete–continuous search space as expected. It keeps the variable K in a discrete space while handling the alpha variable in a continuous search space. The best position for each iteration is circled in the plot with the iteration number. The spectrum of colors is used to distinguish between particles of each iteration.
Further visualization of the PSO learning process with respect to the fitness value is shown in
Figure 4. On the left is the contour plot for the scattered data and on the right is the surface plot of the contour plot. The convergence of the PSO to a global optimum mainly depends on its parameters. The β × K term in the fitness function prevents looking at higher K values in the search space. Thus above-mentioned parameter configuration manages to find near-optimal components for VMD in 10–15 min of time.
2.2.4. Time Series Forecasting Module
The forecasting module generates predictions for each sub-series of the input time-series data that are decomposed by the VMD algorithm. In the context of predicting sub-series of decomposed input data, each time-step is remodeled; thus, it is not possible to use the previously trained predictive model to predict future values. Therefore, for each new time-step, the predictive model needs to be remodeled, and the re-training process should be efficient and effective to provide an accurate predictive model in a limited amount of time. This duration should ideally be less than the time between two time-steps in the time-series function.
In general, most recent approaches utilize feedforward neural networks; however, such feedforward connectionist networks are comparatively slow in training. This slow learning of feedforward neural networks continues to be a major shortcoming for EPF. The key reasons for this latency are the utilization of slow gradient-based learning algorithms and iterative tuning of all parameters of the network during the learning process. In general, randomly connected neural networks and Random Vector Functional Link (RVFL) [
47] in particular are popular alternative methods for overcoming this limitation. These networks are characterized by the simplicity of RVFL’s design and training process. It makes them a very attractive alternative for solving practical machine learning problems in edge computing. Further, our recent result on the efficient FPGA implementation of RVFL [
48] makes this type of network particularly suitable for the target real-time prediction scenario. Here we use a variant of RVFL known as Extreme Learning Machines (ELM) [
49]. ELM is a single hidden layer feedforward neural network (SLFN) that randomly chooses input weights and analytically determines the output weights. The technical details of the ELM algorithm used for the RIPPR approach are described below.
For
N arbitrary distinct input samples (
xi,
ti), where
xi = [
xi1,
xi2, …,
xin]
T Rn and
ti = [
ti1,
ti2, …,
tim]
T Rm standard SLFNs with
N hidden nodes and activation function
g(
x) are mathematically modelled as:
where
wi = [
wi1,
wi2, …,
win]
T is the weight connecting the
ith hidden node and the input nodes,
βi = [
βi1,
βi2, …,
βin]
T is the weight connecting the
ith hidden node and the output nodes,
Ñ is the number of hidden layer nodes, and
bi is the threshold of the
ith hidden nodes.
wi⋅
xi denotes the inner product of
wi and
xi. The above
N equations can be written compactly as:
where
H denotes the hidden layer’s output matrix. ELM tends to reach not only the smallest training error but also the smallest norm of output weights. According to Bartlett’s theory for feedforward neural networks reaching smaller training error, the smaller the norms of weights are, the better generalization performance of the network.
In the following formulations, 11–15, we deliberate the workings of the learning and generalization of the ELM model. Firstly, output weight optimization is solved as a minimization problem using the generalized inverse matrix of the hidden layer, followed by fine-tuning of the ELM generalization across two cases for N >> L and N > L.
The output weight can be obtained by solving the following minimization problem:
where
H,
and
T are defined in (10). The reason to minimize the norm of the output weights
is to maximize the distance of the separating margins of the two different classes in the RVLF feature space.
The optimal solution is given by:
where
H† denotes the Moore–Penrose generalized inverse matrix of the hidden layer’s output matrix, which can be calculated by the following mathematical transformation. This eliminates the lengthy training phase where network parameters will be adjusted with some hyperparameters in most learning algorithms:
Input weights of the SLFN are randomly chosen, then the output weights (linking the hidden layer to the output layer) of an SLFN are analytically determined by the minimum norm least-squares solutions of a general system of linear equations. The running speed of ELM can be a thousand times faster than traditional iterative implementations of SLFNs. To further extend the generalizability of ELM, regularized extreme learning machine algorithm is introduced [
50]. The original algorithm is extended by adding a regularization parameter (C) to control the generalization. This is divided into two cases as follows;
Case 1:
If the number of training data is very large, for example, it is much larger than the dimensionality of the feature space,
Case 2:
N > L:
where
I is the identity matrix.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}