
MC-NILM: A Multi-Chain Disaggregation Method for NILM


Abstract
:
1. Introduction
- (1)
- We proposed a multi-chain energy disaggregation method that considers the relationship between appliances for energy disaggregation and constructs a separate energy disaggregation chain for each appliance;
- (2)
- We proposed two methods to reduce the complexity of the search for MC-NILM structure;
- (3)
- Our experimental results demonstrated that the MC-NILM method is a general framework to leverage the existing NILM algorithms as sub-models and improve the overall performance of the original algorithms.
2. NILM Problem Statement
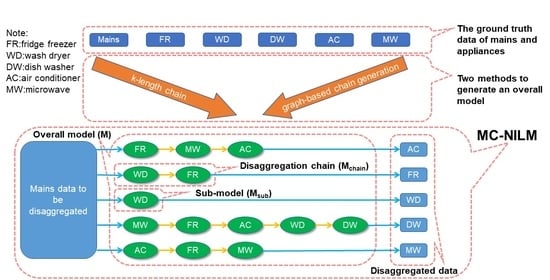
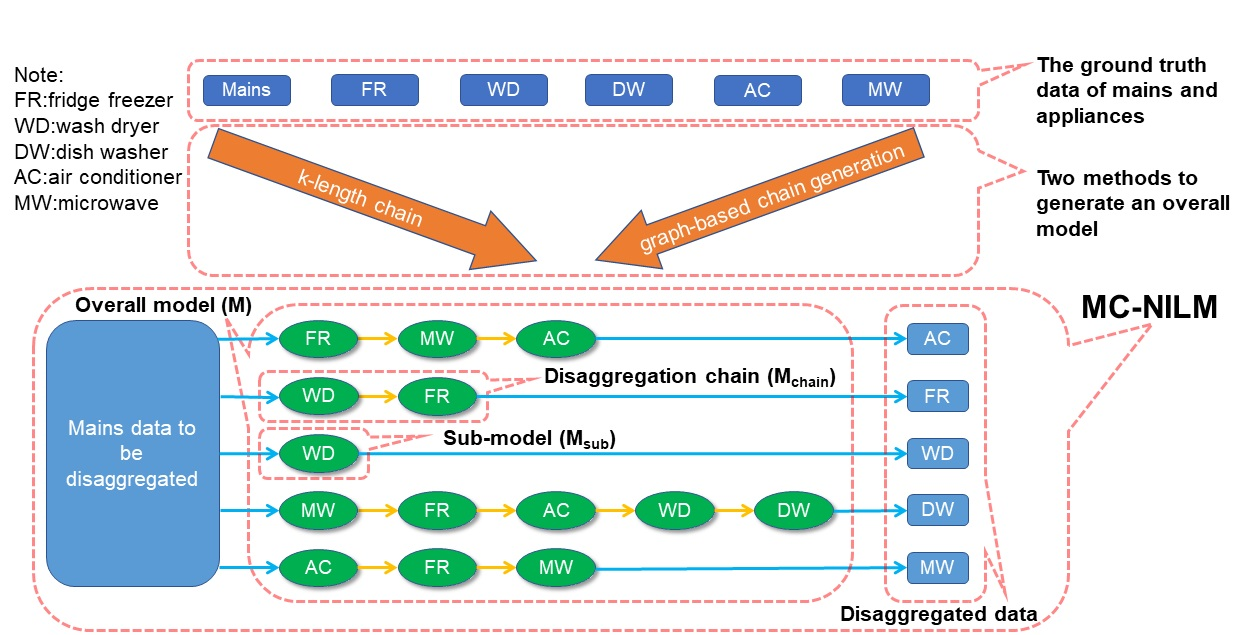
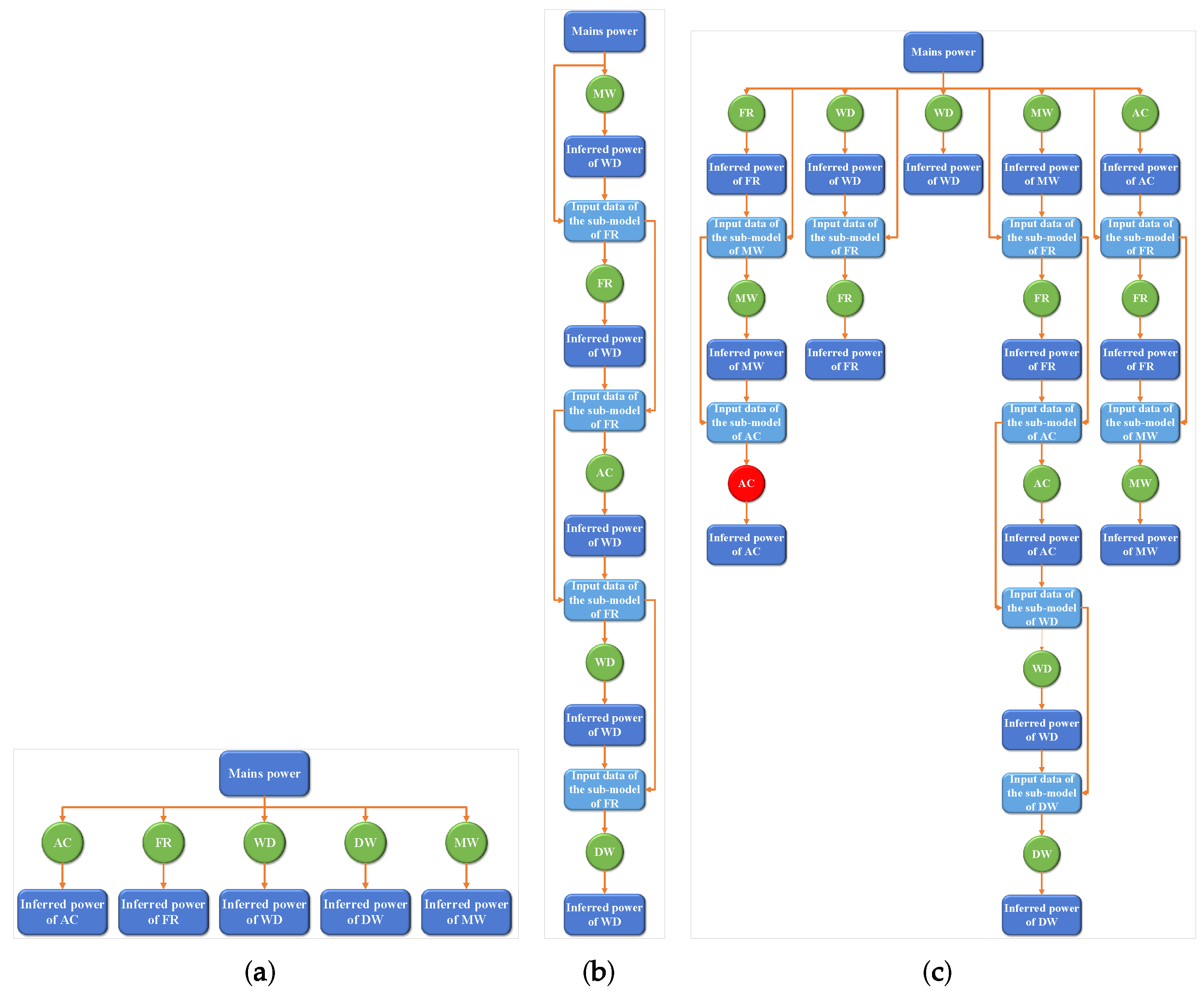
3. MC-NILM
3.1. Overview
- We divide the whole dataset into three parts: sub-model training dataset , multi-chain structure search dataset , and performance testing dataset ;
- We use to train multiple sub-models, which can be used to form disaggregation chains;
- We use to search for the optimal multi-chain model for the target appliances, which is denoted by as a whole;
- We evaluate the performance of on .
3.2. Sub-Model Training
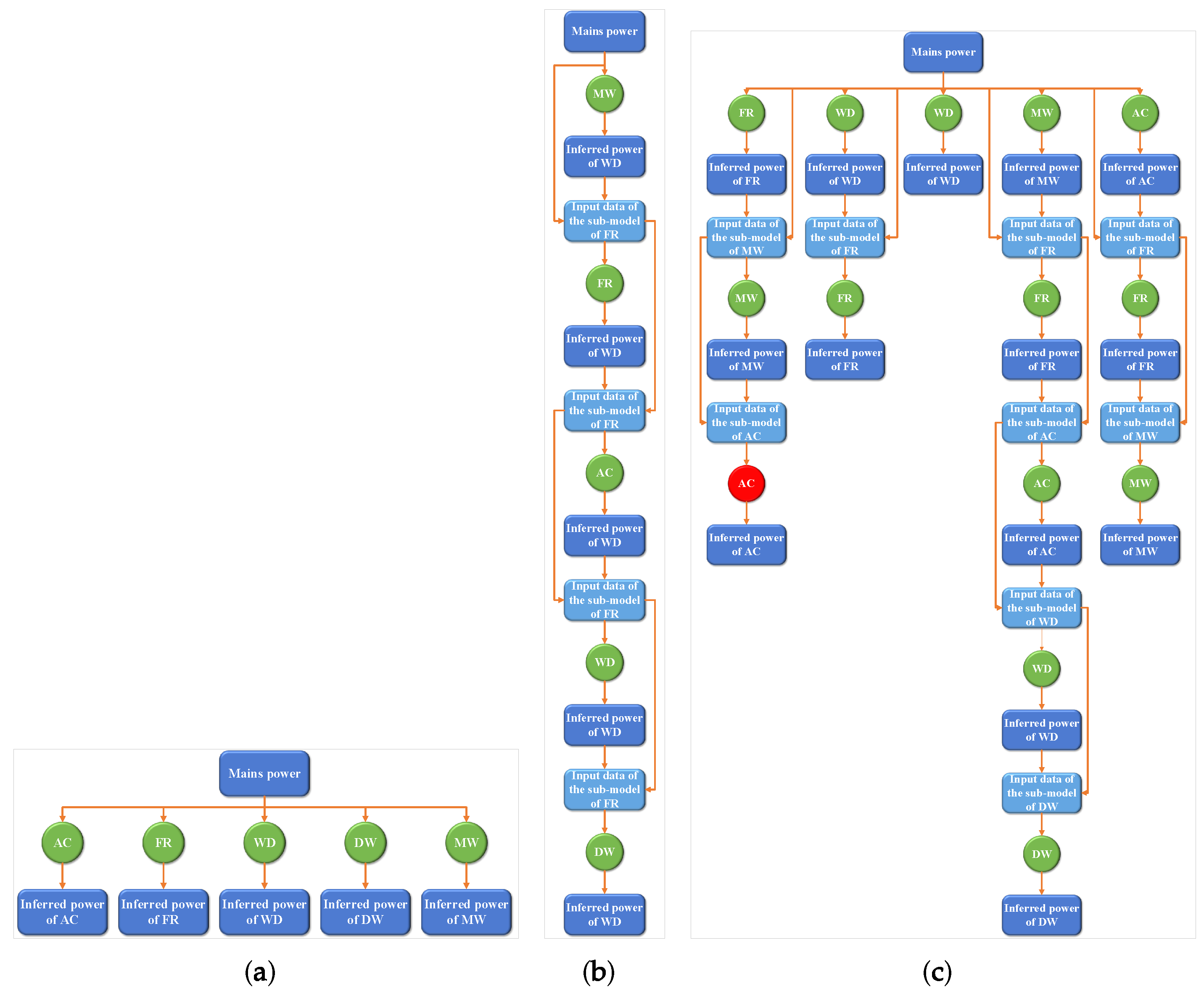
3.3. Energy Disaggregation in a Chain
| Algorithm 1: Process of inferring power of appliance by MC-NILM |
 |
3.4. Complexity Analysis
3.5. Complexity Reduction
3.5.1. K-Length Chain
3.5.2. Graph-Based Chain Generation
- (1)
- Because an appliance cannot exist more than once in a chain, these paths should be simple paths with non-cyclic.
- (2)
- These paths should be the shortest paths from the to the of the target appliances to ensure that the performance obtained by inferring the power of the target appliance through the paths is the best.
| Algorithm 2: Graph-based algorithm (GBA) for chain generation. |
 |
4. Experiment
- CPU: Intel(R) Xeon(R) Silver 4210 CPU @ 2.20 GHz (8 cores);
- GPU: GeForce RTX 2080 Ti ();
- RAM: 16 GB;
- OS: Ubuntu 16.04.7 LTS;
- TenserFlow: 1.14.0;
- PyTorch 1.3.1.
4.1. Datasets
- Dataport: Dataport is the largest public residential home energy dataset. It contains power readings logged at minute intervals from hundreds of homes in the United States. We used 112 days of data from 68 homes from mid-June onwards in the year 2015. We divided the data of 68 families into , and datasets, with dataset size ratio of 60%, 20% and 20%, respectively.
- UK-DALE (UK Domestic Appliance-Level Electricity): This dataset contains power readings logged at 6 seconds intervals of more than ten types of appliances in five households in the UK. We chose 5 appliances: kettle, microwave, dishwasher, fridge freeze, and washer dryer as our target appliance. These 5 appliances have different energy consumption modes, which can verify the performance of the models in almost all aspects. In the experiment, we used the data from April 2013 to October 2013 as , the data from October 2013 to April 2014 as , and the data from April 2014 to October 2014 as .
4.2. Experimental Settings
4.2.1. Baseline
4.2.2. Metric
4.3. Experiment Results
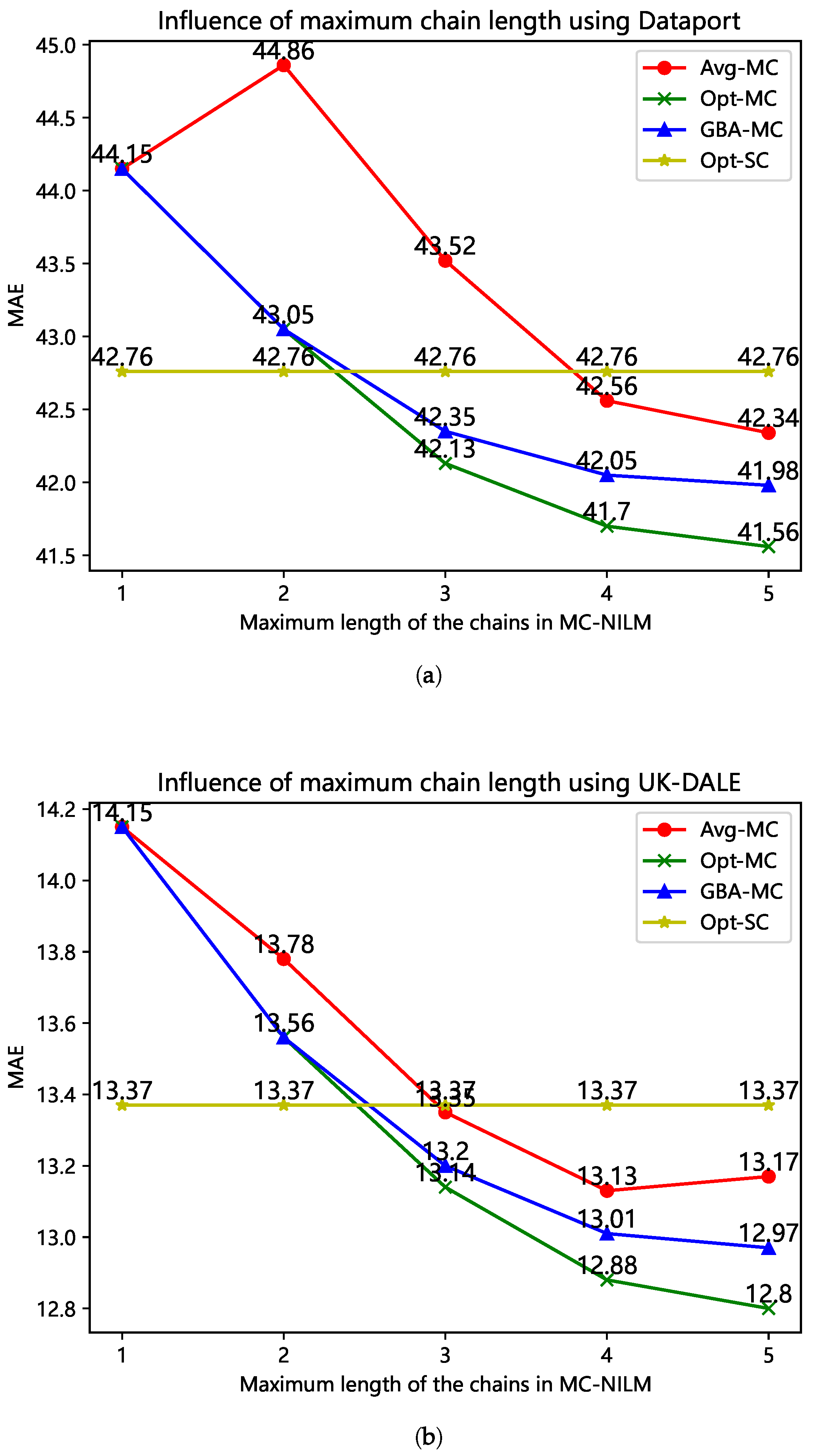
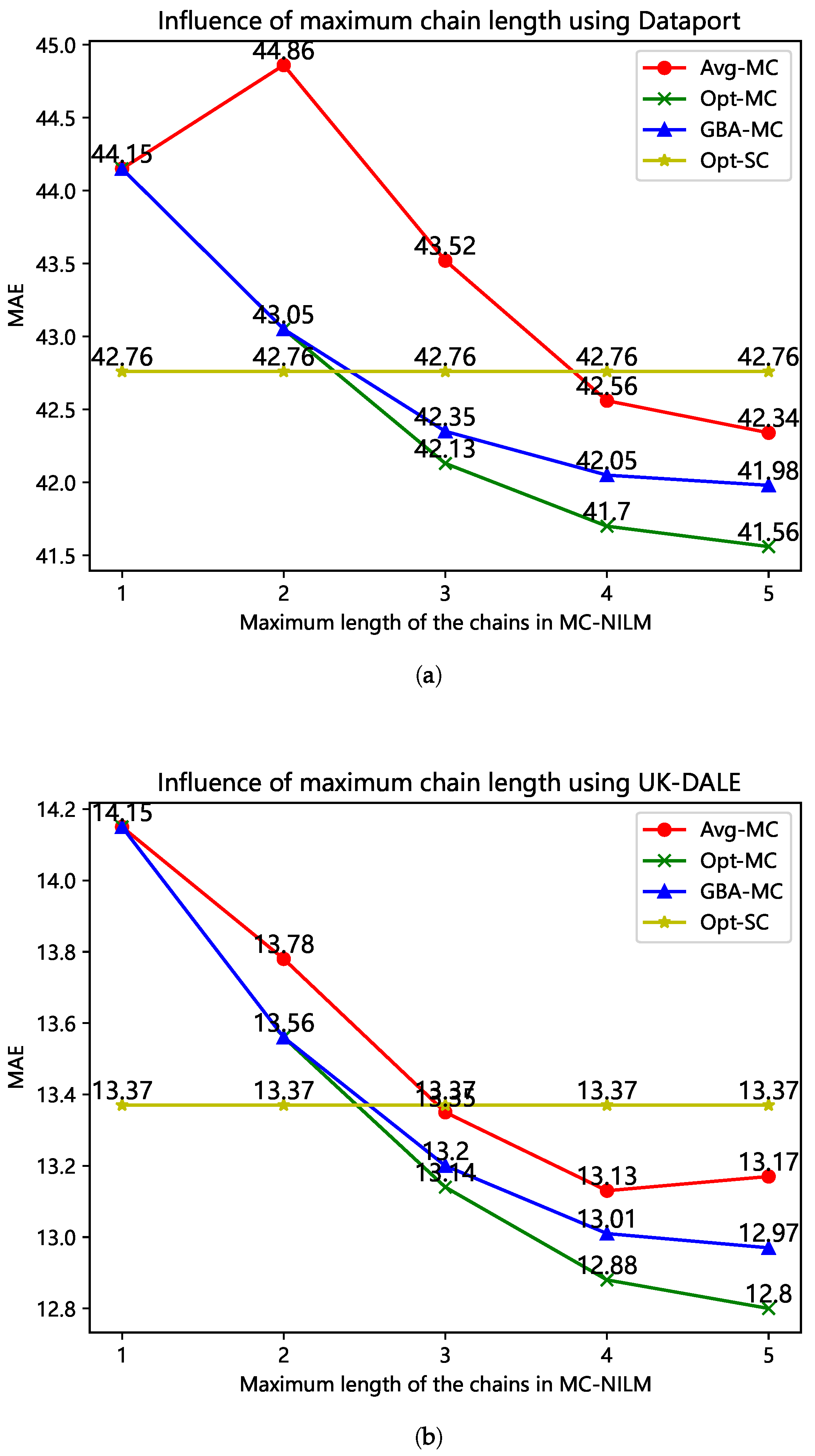
4.3.1. Evaluation of Complexity Reduction Algorithms
4.3.2. MC-NILM vs. SC-NILM
- (1)
- The brute-force method to obtain the optimal SC-NILM (Opt-SC).
- (2)
- The greedy method to obtain the SC-NILM (Gre-SC) [26].
- (3)
- The brute-force method to obtain the optimal MC-NILM (Opt-MC).
- (4)
- Calculate the average performance of all MC-NILM (Ave-MC).
- (5)
- GBA to obtain the MC-NILM (GBA-MC).
4.3.3. Generality of MC-NILM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Armel, K.C.; Gupta, A.; Shrimali, G.; Albert, A. Is disaggregation the holy grail of energy efficiency? The case of electricity. Energy Policy 2013, 52, 213–234. [Google Scholar] [CrossRef] [Green Version]
- Ridi, A.; Gisler, C.; Hennebert, J. A survey on intrusive load monitoring for appliance recognition. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 3702–3707. [Google Scholar]
- Ruano, A.; Hernandez, A.; Ureña, J.; Ruano, M.; Garcia, J. NILM techniques for intelligent home energy management and ambient assisted living: A review. Energies 2019, 12, 2203. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Li, W.; Chan, K.W.; Cao, Y.; Kuang, Y.; Liu, X.; Wang, X. Smart home energy management systems: Concept, configurations, and scheduling strategies. Renew. Sustain. Energy Rev. 2016, 61, 30–40. [Google Scholar] [CrossRef]
- Belley, C.; Gaboury, S.; Bouchard, B.; Bouzouane, A. An efficient and inexpensive method for activity recognition within a smart home based on load signatures of appliances. Pervasive Mob. Comput. 2014, 12, 58–78. [Google Scholar] [CrossRef] [Green Version]
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Huber, P.; Calatroni, A.; Rumsch, A.; Paice, A. Review on Deep Neural Networks Applied to Low-Frequency NILM. Energies 2021, 14, 2390. [Google Scholar] [CrossRef]
- Gupta, S.; Reynolds, M.S.; Patel, S.N. ElectriSense: Single-point sensing using EMI for electrical event detection and classification in the home. In Proceedings of the 12th ACM international conference on Ubiquitous Computing, Copenhagen, Denmark, 26–29 September 2010; pp. 139–148. [Google Scholar]
- Tabatabaei, S.M.; Dick, S.; Xu, W. Toward non-intrusive load monitoring via multi-label classification. IEEE Trans. Smart Grid 2016, 8, 26–40. [Google Scholar] [CrossRef]
- Ruzzelli, A.G.; Nicolas, C.; Schoofs, A.; O’Hare, G.M. Real-time recognition and profiling of appliances through a single electricity sensor. In Proceedings of the 2010 7th Annual IEEE Communications Society Conference on Sensor, Mesh and Ad Hoc Communications and Networks (SECON), Boston, MA, USA, 21–25 June 2010; pp. 1–9. [Google Scholar]
- Hassan, T.; Javed, F.; Arshad, N. An empirical investigation of VI trajectory based load signatures for non-intrusive load monitoring. IEEE Trans. Smart Grid 2013, 5, 870–878. [Google Scholar] [CrossRef] [Green Version]
- Figueiredo, M.; Ribeiro, B.; de Almeida, A. Electrical signal source separation via nonnegative tensor factorization using on site measurements in a smart home. IEEE Trans. Instrum. Meas. 2013, 63, 364–373. [Google Scholar] [CrossRef]
- Batra, N.; Dutta, H.; Singh, A. Indic: Improved non-intrusive load monitoring using load division and calibration. In Proceedings of the 2013 12th International Conference on Machine Learning and Applications, Miami, FL, USA, 4–7 December 2013; Volume 1, pp. 79–84. [Google Scholar]
- Kolter, J.Z.; Jaakkola, T. Approximate inference in additive factorial hmms with application to energy disaggregation. In Proceedings of the Machine Learning Research, Volume 22: Artificial Intelligence and Statistics, La Palma, Canary Islands, 21–23 April 2012; pp. 1472–1482. [Google Scholar]
- Lange, H.; Bergés, M. Efficient inference in dual-emission FHMM for energy disaggregation. In Proceedings of the Workshops at the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–13 February 2016. [Google Scholar]
- Altrabalsi, H.; Liao, J.; Stankovic, L.; Stankovic, V. A low-complexity energy disaggregation method: Performance and robustness. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence Applications in Smart Grid (CIASG), Orlando, FL, USA, 9–12 December 2014; pp. 1–8. [Google Scholar]
- Zhao, B.; Stankovic, L.; Stankovic, V. On a training-less solution for non-intrusive appliance load monitoring using graph signal processing. IEEE Access 2016, 4, 1784–1799. [Google Scholar] [CrossRef] [Green Version]
- Kelly, J.; Knottenbelt, W. Neural nilm: Deep neural networks applied to energy disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Korea, 4–5 November 2015; pp. 55–64. [Google Scholar]
- do Nascimento, P.P.M. Applications of Deep Learning Techniques on NILM. Master’s Dissertation, Universidade Federal do Rio de Janeiro, Rio de Janeiro, Brazil, 2016. [Google Scholar]
- Kim, J.; Kim, H.; Le, T.-T.-H. Classification performance using gated recurrent unit recurrent neural network on energy disaggregation. In Proceedings of the 2016 international conference on machine learning and cybernetics (ICMLC), Jeju, Korea, 10–13 July 2016; Volume 1, pp. 105–110. [Google Scholar]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.H.; Sutton, C.A. Sequence-to-Point Learning with Neural Networks for Non-Intrusive Load Monitoring; AAAI: Menlo Park, CA, USA, 2018. [Google Scholar]
- Pan, Y.; Liu, K.; Shen, Z.; Cai, X.; Jia, Z. Sequence-to-subsequence learning with conditional gan for power disaggregation. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3202–3206. [Google Scholar]
- Puente, C.; Palacios, R.; González-Arechavala, Y.; Sánchez-Úbeda, E.F. Non-Intrusive Load Monitoring (NILM) for Energy Disaggregation Using Soft Computing Techniques. Energies 2020, 13, 3117. [Google Scholar] [CrossRef]
- Piccialli, V.; Sudoso, A.M. Improving Non-Intrusive Load Disaggregation through an Attention-Based Deep Neural Network. Energies 2021, 14, 847. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, S.; Hwang, E. Frequency Selective Auto-Encoder for Smart Meter Data Compression. Sensors 2021, 21, 1521. [Google Scholar] [CrossRef]
- Jia, Y.; Batra, N.; Wang, H.; Whitehouse, K. A tree-structured neural network model for household energy breakdown. World Wide Web Conf. 2019, 2872–2878. [Google Scholar] [CrossRef]
- Batra, N.; Kelly, J.; Parson, O.; Dutta, H.; Knottenbelt, W.; Rogers, A.; Singh, A.; Srivastava, M. NILMTK: An open source toolkit for non-intrusive load monitoring. In Proceedings of the 5th International Conference on Future Energy Systems, Cambridge, UK, 11–13 June 2014; pp. 265–276. [Google Scholar]
- Sadeghianpourhamami, N.; Ruyssinck, J.; Deschrijver, D.; Dhaene, T.; Develder, C. Comprehensive feature selection for appliance classification in NILM. Energy Build. 2017, 151, 98–106. [Google Scholar] [CrossRef] [Green Version]
- Parson, O.; Fisher, G.; Hersey, A.; Batra, N.; Kelly, J.; Singh, A.; Knottenbelt, W.; Rogers, A. Dataport and NILMTK: A building data set designed for non-intrusive load monitoring. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (Globalsip), Orlando, FL, USA, 14–16 December 2015; pp. 210–214. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 1–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hart, G.W. Prototype Nonintrusive Appliance Load Monitor: Progress Report 2; MIT Energy Laboratory: Cambridge, MA, USA, 1985. [Google Scholar]
- Batra, N.; Singh, A.; Whitehouse, K. If you measure it, can you improve it? exploring the value of energy disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Korea, 4–5 November 2015; pp. 191–200. [Google Scholar]
- Parson, O.; Ghosh, S.; Weal, M.; Rogers, A. Non-intrusive load monitoring using prior models of general appliance types. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 356–362. [Google Scholar]
- Krystalakos, O.; Nalmpantis, C.; Vrakas, D. Sliding window approach for online energy disaggregation using artificial neural networks. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; pp. 1–6. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Appliance | Kettle | Microwave | Dish Washer | Fridge Freezer | Wash Dryer | Air Conditioner |
|---|---|---|---|---|---|---|
| Threshold | 2000 | 200 | 10 | 50 | 20 | 1000 |
| Max Length | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Opt-MC | 5 | 25 | 55 | 75 | 80 |
| GBA-MC | 5 | 25 | 30 | 34 | 37 |
| Dataset | Metrics | Opt-SC | Gre-SC | Ave-MC | Opt-MC | GBA-MC |
|---|---|---|---|---|---|---|
| Dataport | MAE | 42.763 | 43.819 | 42.359 | 41.561 | 41.982 |
| SAE | 0.402 | 0.426 | 0.356 | 0.310 | 0.326 | |
| F1 | 0.424 | 0.402 | 0.459 | 0.497 | 0.462 | |
| UK-DALE | MAE | 13.372 | 13.938 | 13.171 | 12.801 | 12.972 |
| SAE | 0.112 | 0.125 | 0.114 | 0.090 | 0.099 | |
| F1 | 0.563 | 0.538 | 0.581 | 0.633 | 0.620 |
| Method | Edge Detection | CO | Exact FHMM | DAE | Online GRU |
|---|---|---|---|---|---|
| Original method | 68.673 | 61.379 | 53.744 | 18.423 | 11.469 |
| GBA-NILM | 65.903 | 57.800 | 49.909 | 16.902 | 10.389 |
| Improvement (%) | 4.034 | 5.831 | 7.136 | 8.256 | 9.417 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, H.; Jia, J.; Yang, X.; Zhu, W.; Zhang, H. MC-NILM: A Multi-Chain Disaggregation Method for NILM. Energies 2021, 14, 4331. https://doi.org/10.3390/en14144331
Ma H, Jia J, Yang X, Zhu W, Zhang H. MC-NILM: A Multi-Chain Disaggregation Method for NILM. Energies. 2021; 14(14):4331. https://doi.org/10.3390/en14144331
Chicago/Turabian StyleMa, Hao, Juncheng Jia, Xinhao Yang, Weipeng Zhu, and Hong Zhang. 2021. "MC-NILM: A Multi-Chain Disaggregation Method for NILM" Energies 14, no. 14: 4331. https://doi.org/10.3390/en14144331
APA StyleMa, H., Jia, J., Yang, X., Zhu, W., & Zhang, H. (2021). MC-NILM: A Multi-Chain Disaggregation Method for NILM. Energies, 14(14), 4331. https://doi.org/10.3390/en14144331