
Multi-State Reliability Assessment Model of Base-Load Cyber-Physical Energy Systems (CPES) during Flexible Operation Considering the Aging of Cyber Components



Abstract
1. Introduction
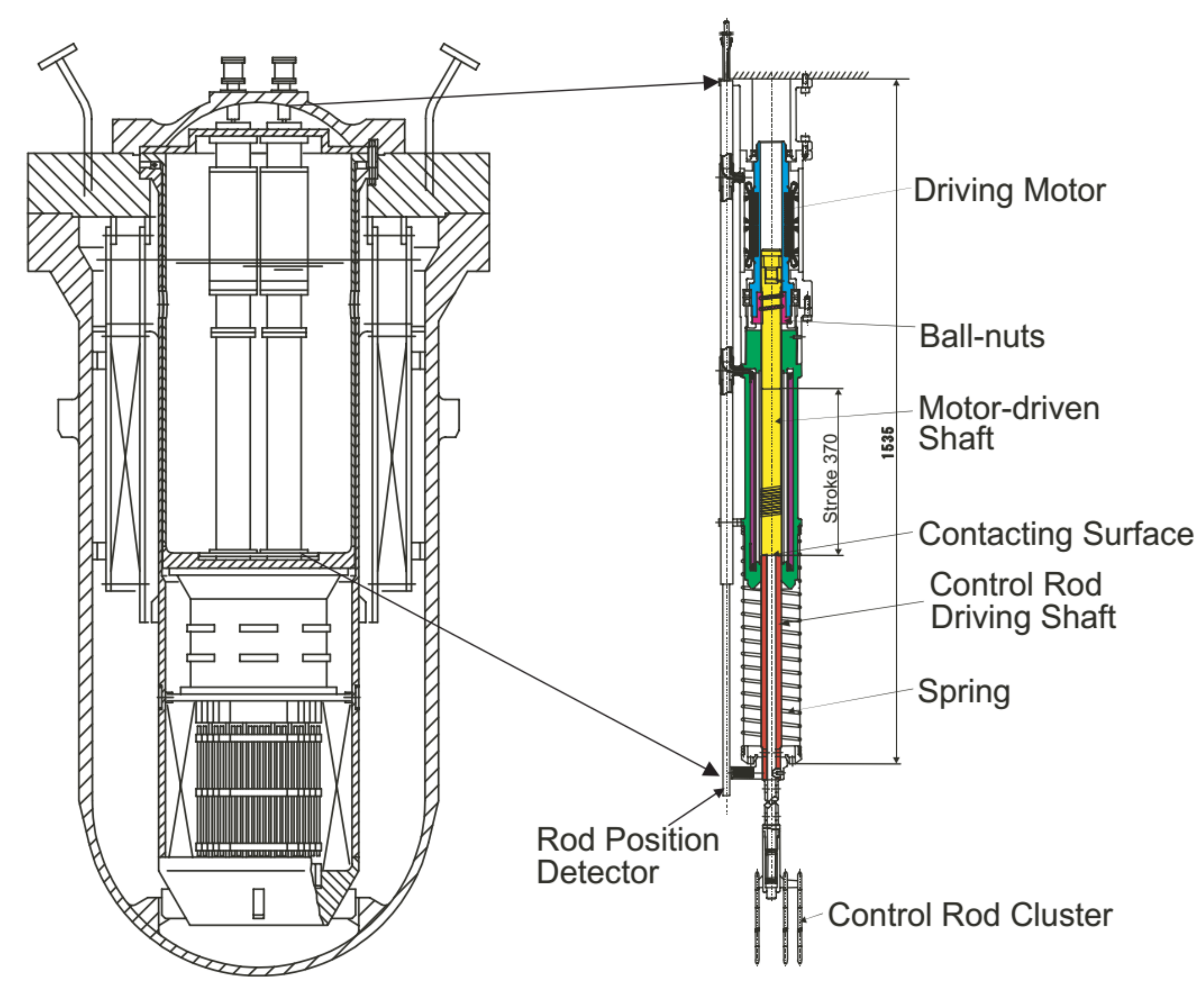
2. The Control Rod System
2.1. Control Rod System Description
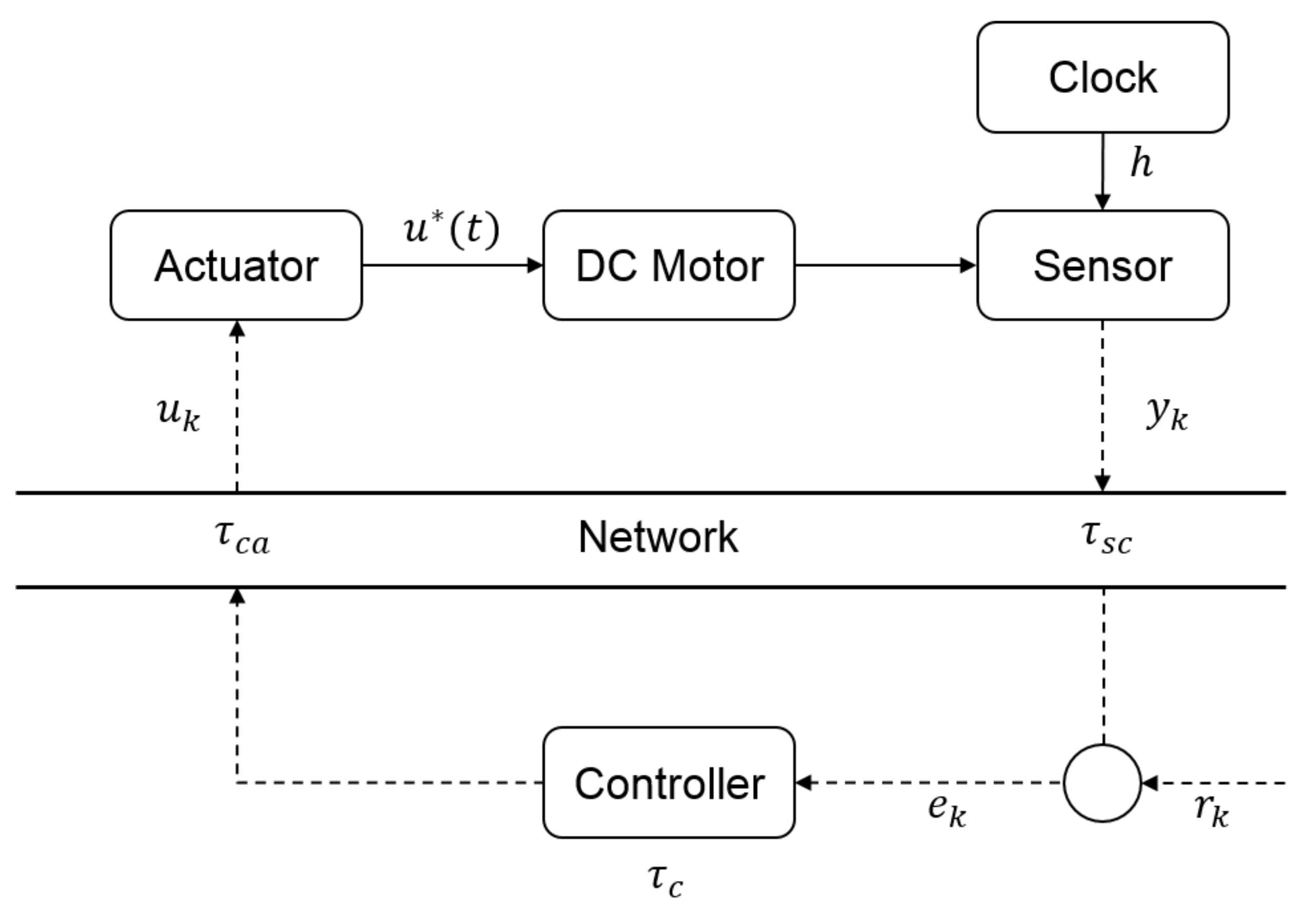
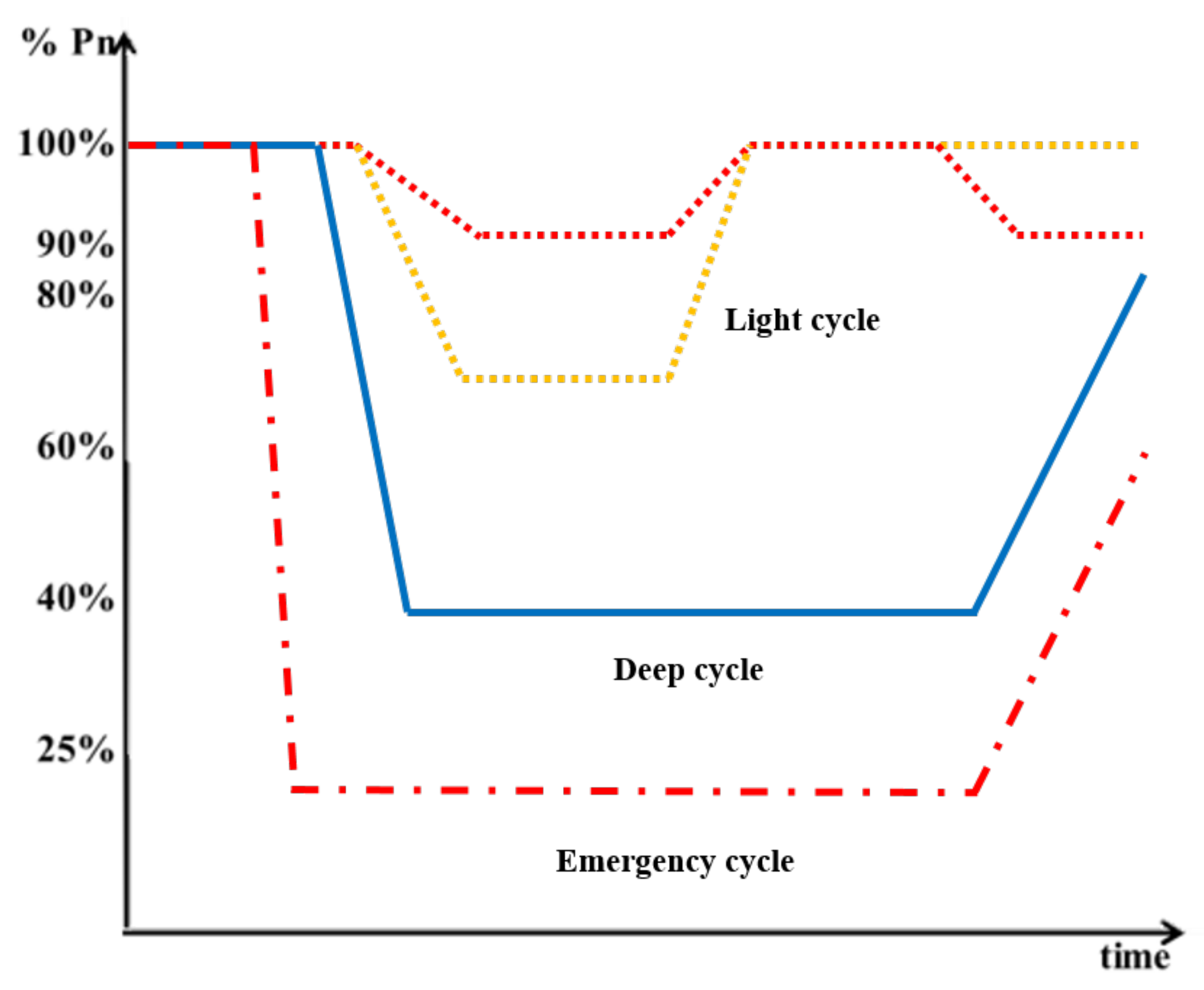
2.2. Load-Following Operation of the CRS
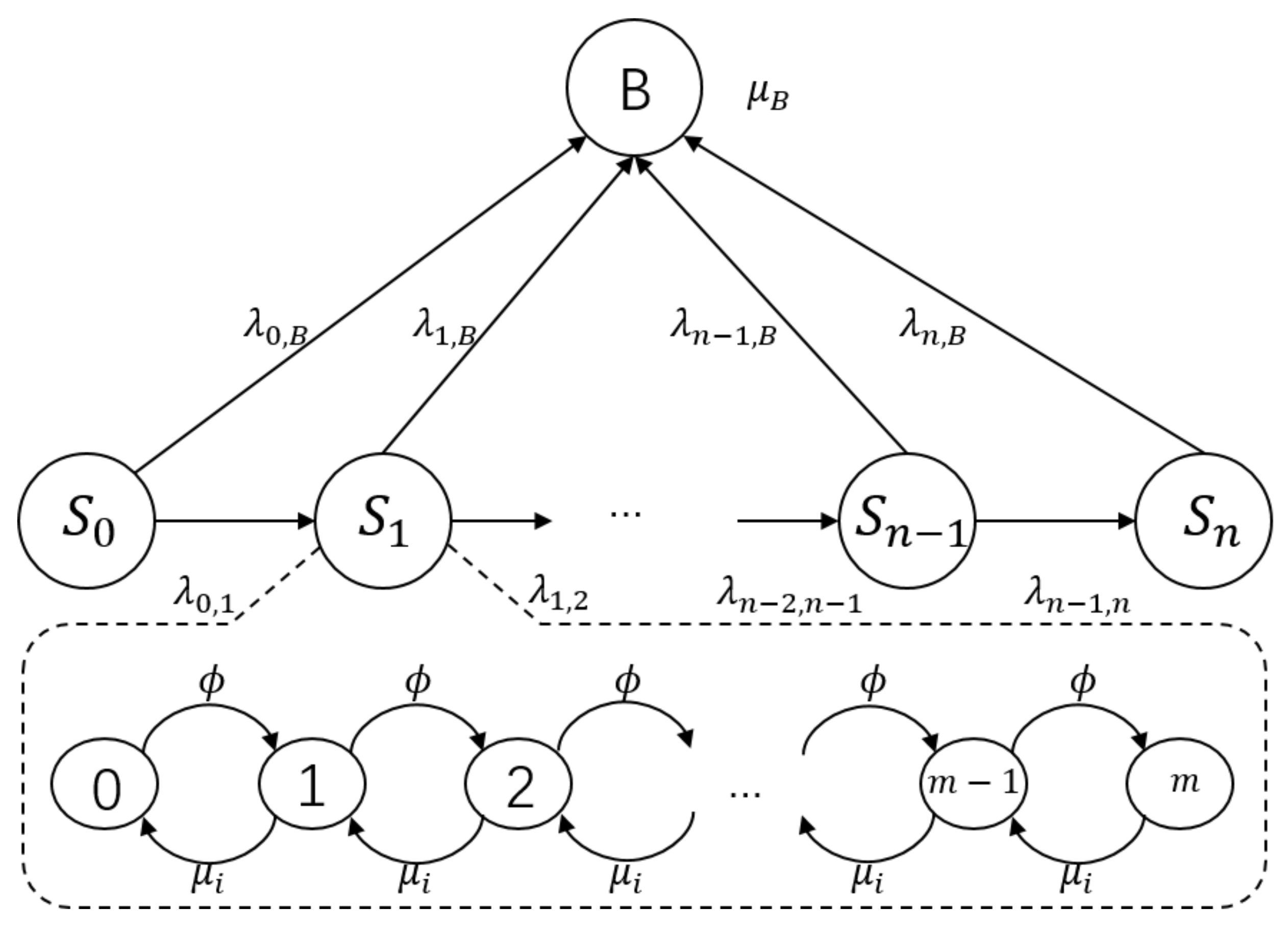
3. Modelling of Cyber Systems Aging
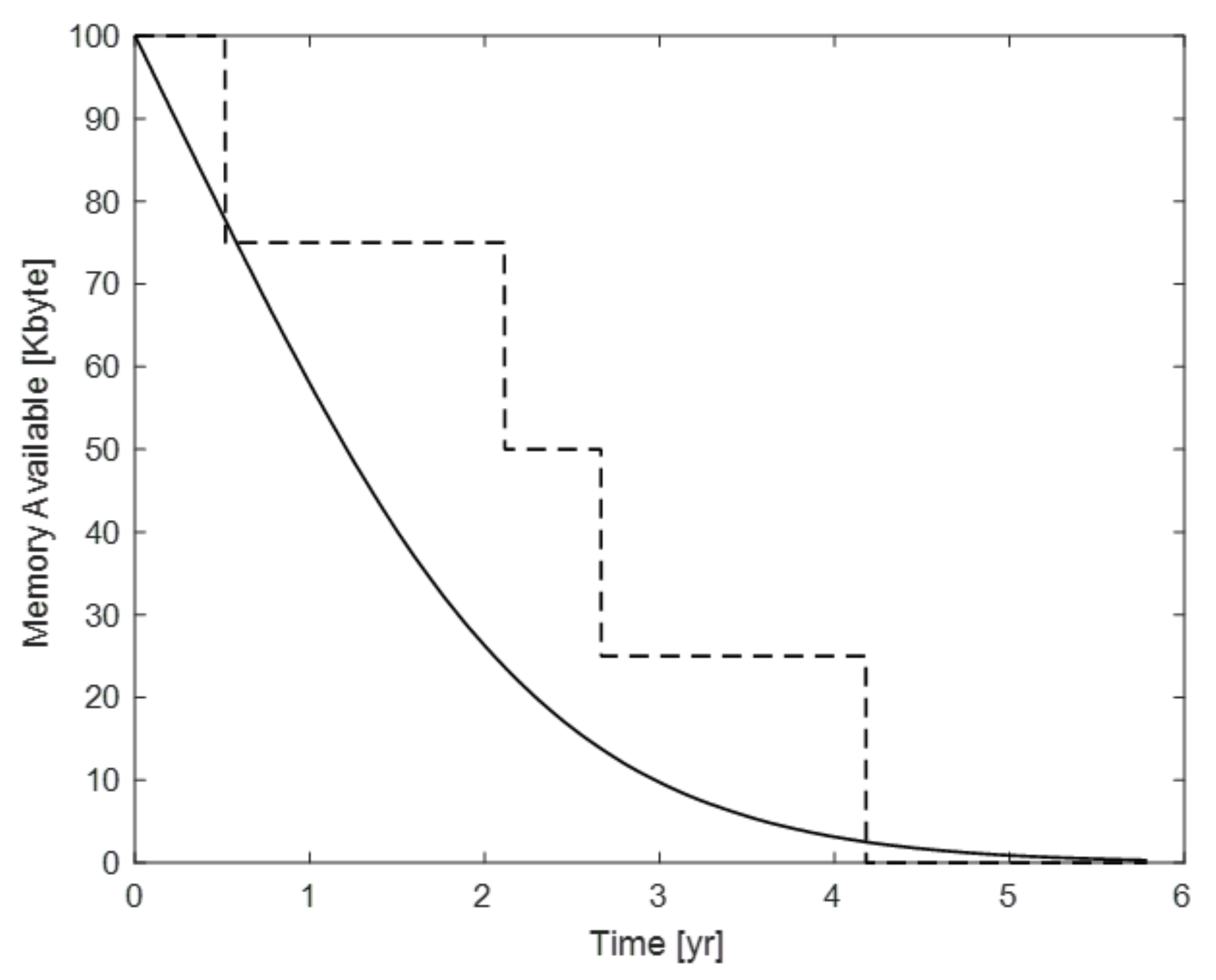
3.1. Memory Leakage
3.2. Data-Jamming
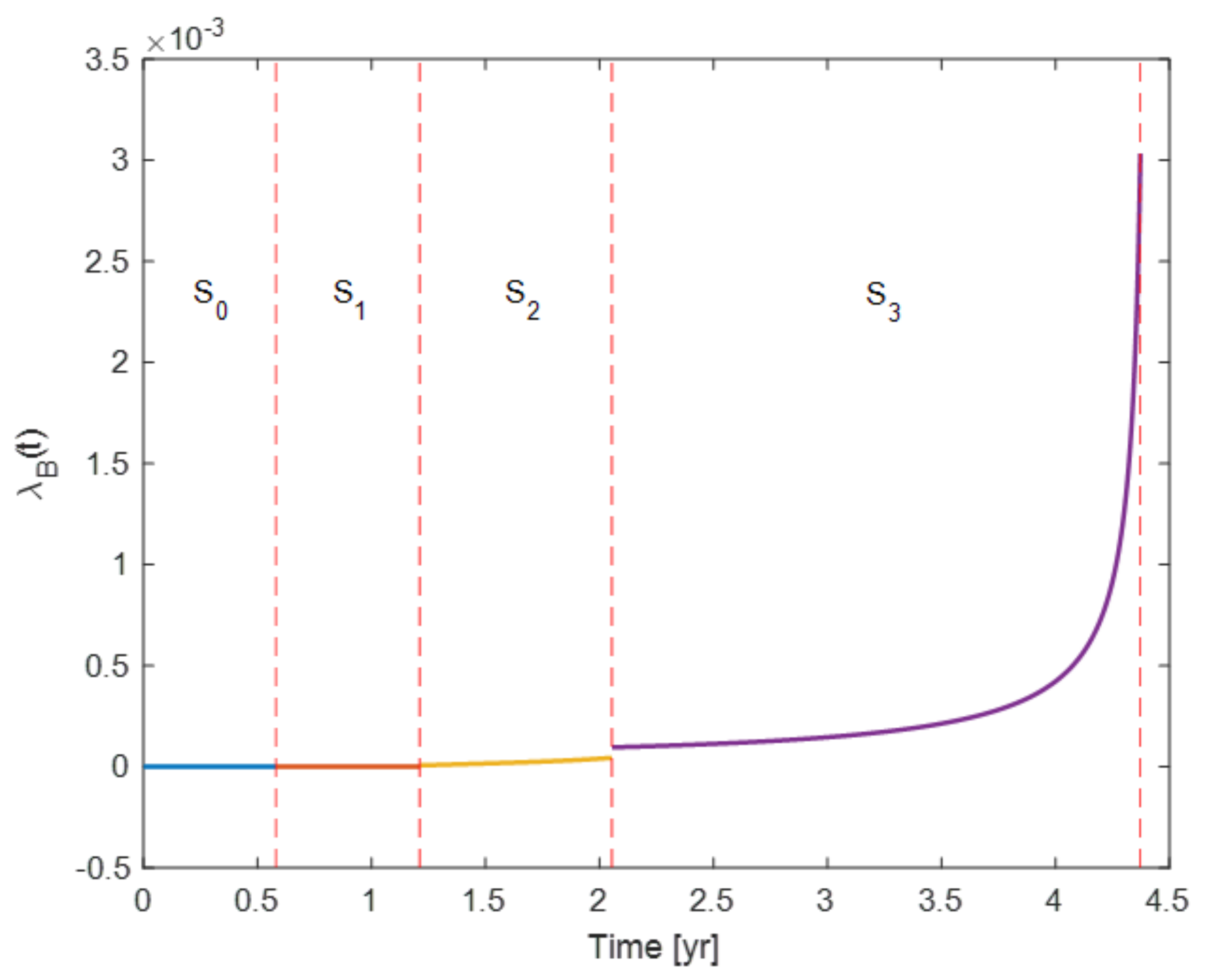
3.3. Calculation of the System-Blocking Transition Rate
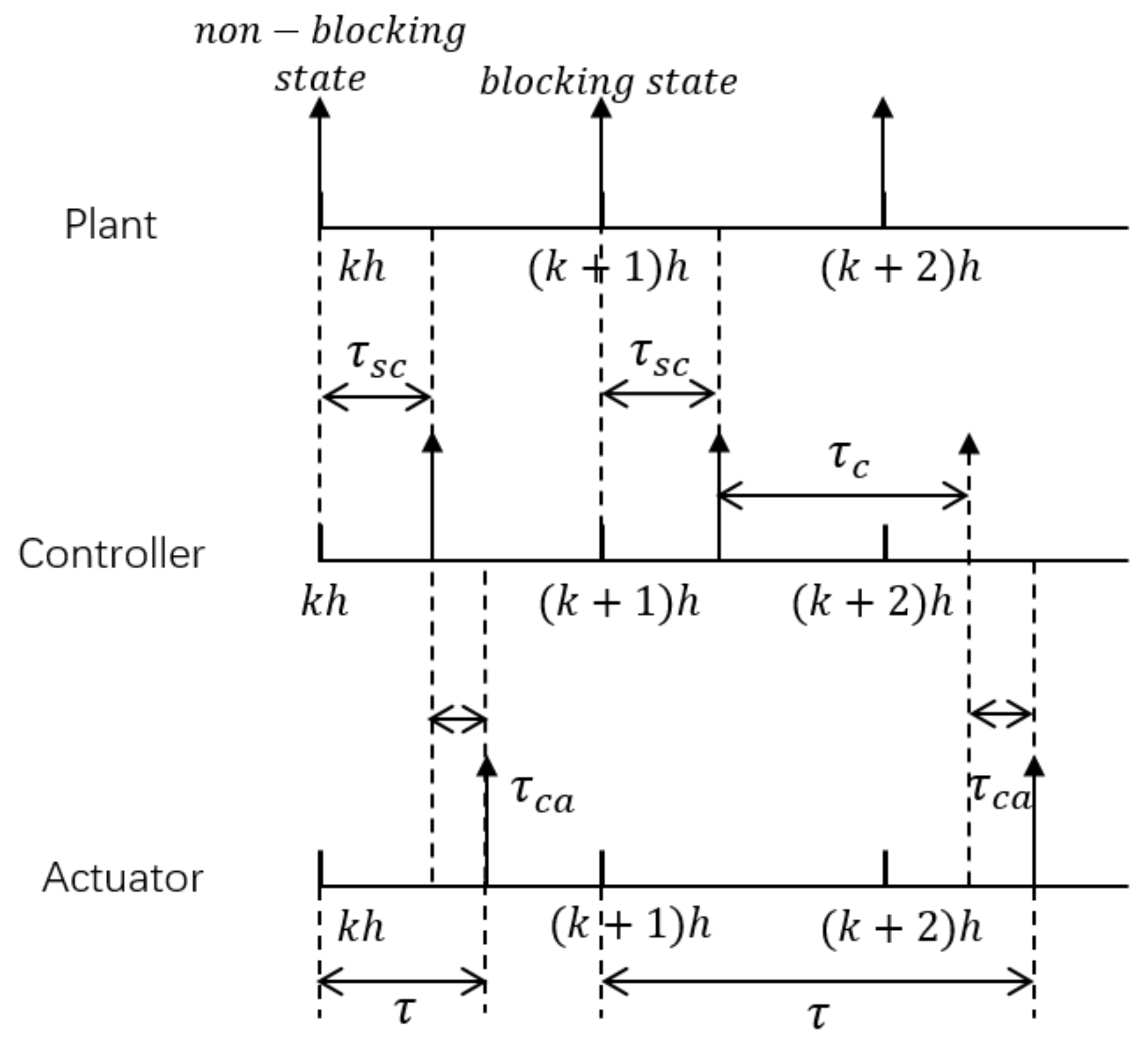
3.4. Calculation of the Control Delay
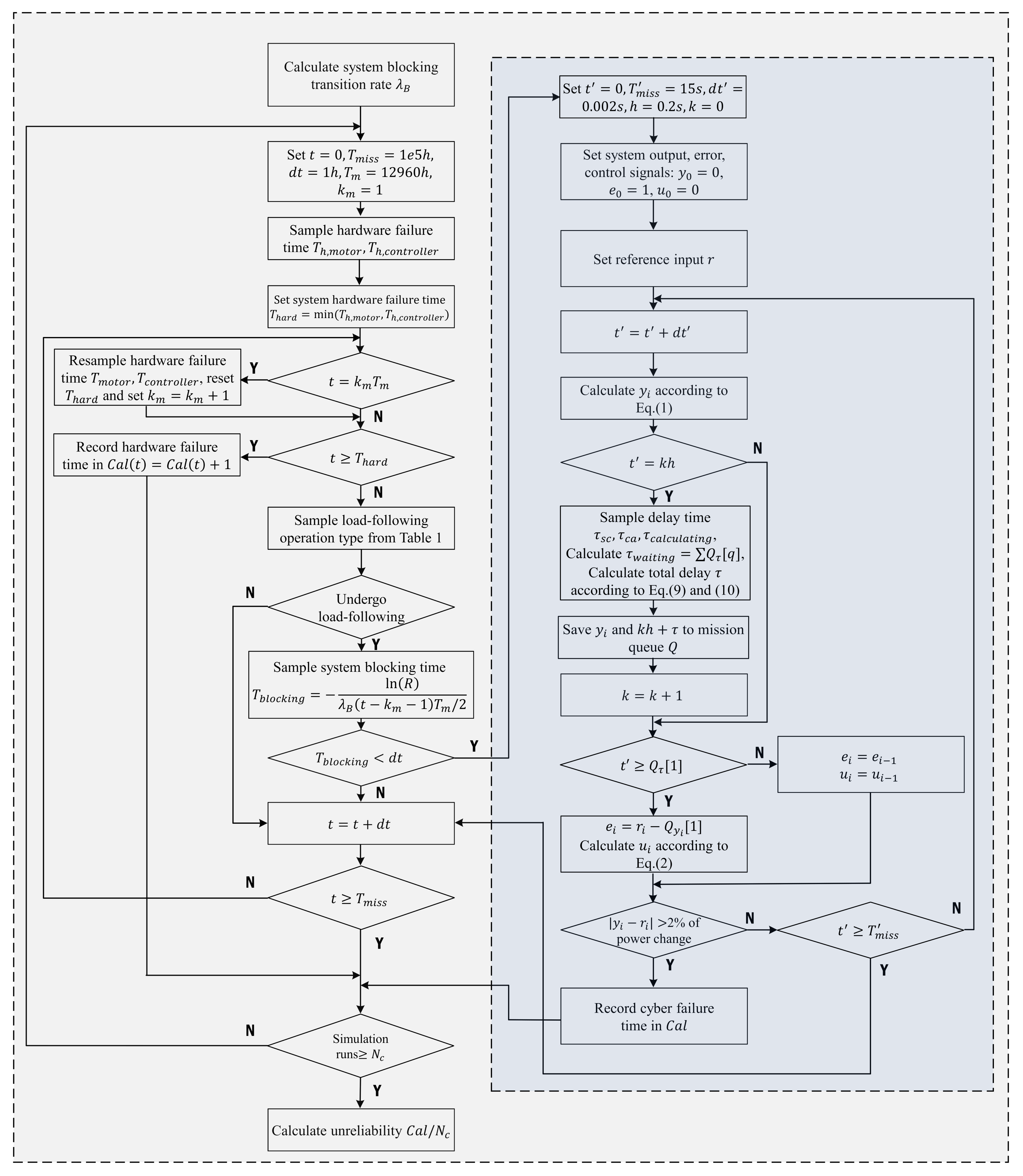
4. Reliability Analysis of the CRS
- Calculate system-blocking transition rate with the model described in [15] and the procedure summarized in Section 3.3;
- Set: initial time , mission time h, simulation time step h, maintenance period h (18 months) and index of maintenance cycle ;
- Sample the DC motor and controller hardware failure times and , respectively, from the exponential distributions whose rates are reported in Table 3;
- Set the system failure time due to hardware stochastic failures: ;
- Check whether the system must undergo maintenance:
- If :(i) alternately maintain the DC motor and controller (AGAN policy), and resample the corresponding hardware failure time, or ;(ii) reset the system hardware failure time as step 4;(iii) set ;
- Check if the hardware stochastic failure time t exceeds :
- If , record system failure time due to hardware stochastic failure in the failure time counter: , and jump to step 9;
- If :(i) sample load-following operation type L from the 3rd column in Table 1: if L is the index for which , where , is the load-following occurred probability and R is a random value sampled from the uniform distribution in ; the load-following operation type L is obtained;(ii) sample the system-blocking time , where R is another random value sampled from the uniform distribution in ;(iii) if (system transits to blocking state B), start to run the load-following simulation with the type sampled in i) as following steps (a) to (h):
- (a)
- Set: load-following simulation initial time , mission time s, time step s, sample interval s and sample iteration number , mission queue array Q with “first in first out” processing principle;
- (b)
- Set: initial system output , error and control signals ;
- (c)
- Set: system reference input r according to different types of load-following operations (for example: for load-following operations from to );
- (d)
- Set ;
- (e)
- Calculate according to Equation (1)
- (f)
- Check whether new data are collected from the sensors.If :
- –
- Sample the calculation delay from the exponential distribution with parameter in Table 2;
- –
- Sample the transmission delay and from the Gaussian distributions with the parameters in Table 2;
- –
- Calculate the data waiting time , where q is the index of data waiting in the mission queue;
- –
- –
- Save and into mission queue Q as the k-th sample data and its processing end time;
- –
- Set
- (g)
- Check whether the actuator time for getting the new control signal [1] (i.e., the first data in mission queue Q) exceeds the delay time :
- –
- If , set , calculate according to Equation (2) and take the first data out of the mission queue;
- –
- If , set and
- (h)
- Check whether the system output , which refers to the system power output, exceed of the power change above and below the reference values (i.e., the safety bounds):
- –
- If , record the cyber failure time in the failure time counter: , and jump to step 9;
- –
- If , repeat to until time exceeds , and finish the simulation of load-following
- ;
- Repeat steps 4 to 7 until time t exceeds for one simulation run;
- Run (e.g., times) steps 2 to 8 and calculate the system unreliability simply as .
5. Results
5.1. Normal Condition
- Only hardware stochastic failures (i.e., by neglecting step 6 (i) to (iii) of the reliability assessment procedure described in Section 4);
- Only cyber aging (i.e., by neglecting steps and 5 (ii) of the reliability assessment procedure described in Section 4);
- Both hardware stochastic failures and cyber aging.
- Hardware stochastic failures remain the principle cause of system failure;
- Each periodic maintenance (each 18 months) efficiently reduces the system unreliability;
- As CRS ages, longer delays are to be accommodated by the control loop, increasing the contribution of cyber aging to system failure, two years after the controller has undergone maintenance each time (with AGAN policy that clears all the aging-related errors);
- The largest contribution of cyber aging to system failure is recorded three years after maintenance.
5.2. Emergency Condition
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| Controller failure rate | |
| Transition rate from state to blocking state B | |
| Transition rate between state and state | |
| DC motor stochastic failure rate | |
| Blocking service rate | |
| Non-blocking service rate | |
| Data arrival rate | |
| Total delay time | |
| Controller processing delay time | |
| Calculation time of data in mission queue | |
| Transmission delay between controller and actuator | |
| Transmission delay between sensor and controller | |
| Waitting time of data to be processed in mission queue | |
| Conditional probability of system-blocking with j data in the queue and M memory available | |
| B | system-blocking state |
| Counter of system failure times | |
| Simulation time step | |
| e | System error signal |
| g | Probability density function of memory requested by a data sample |
| G | Cumulative distribution function of memory requested by a data sample |
| h | Sensor sampling interval |
| i | Index of simulation steps |
| k | Data sampling sequence number |
| Index of maintenance action | |
| M | Total memory available |
| m | Maximum number of tasks |
| n | Number of degradation states |
| Number of simulation runs to calculate system unreliability | |
| Number of simulation runs to calculate memory curve | |
| Normal power rate | |
| Probability of system-blocking from state | |
| Probability of data-jamming | |
| q | Index of data waiting in the mission queue |
| Q | Mission queue array |
| Delay time of the data waiting in mission queue Q | |
| Value of the data waiting in mission queue Q | |
| r | System reference input |
| R | Random value sampled from uniform distribution in |
| System normal or degradation state | |
| Maintenance period | |
| system-blocking time | |
| Controller stochastic failure time | |
| DC motor stochastic failure time | |
| System failure time due to hardware stochastic failure | |
| Mission time | |
| u | Control signal output |
| x | Memory request of each task |
| y | System power output |
| Cyber-Physical Energy System | |
| Cyber-Physical System | |
| Control Rod System | |
| Instrumental & Control | |
| Nuclear Power Plant | |
| Pressurized Wawter Reactor | |
| Renewable Energy Source |
References
- Baheti, R.; Gill, H. Cyber-physical systems. Impact Control Technol. 2011, 12, 161–166. [Google Scholar]
- Lee, J.; Bagheri, B.; Kao, H.A. A cyber-physical systems architecture for industry 4.0-based manufacturing systems. Manuf. Lett. 2015, 3, 18–23. [Google Scholar] [CrossRef]
- Pierobon, L.; Casati, E.; Casella, F.; Haglind, F.; Colonna, P. Design methodology for flexible energy conversion systems accounting for dynamic performance. Energy 2014, 68, 667–679. [Google Scholar] [CrossRef]
- Lokhov, A. Technical and Economic Aspects of Load Following with Nuclear Power Plants; NEA OECD: Paris, France, 2011. [Google Scholar]
- Koutras, V.P.; Platis, A.N.; Gravvanis, G.A. On the optimization of free resources using non-homogeneous Markov chain software rejuvenation model. Reliab. Eng. Syst. Saf. 2007, 92, 1724–1732. [Google Scholar] [CrossRef]
- Trivedi, K.S.; Vaidyanathan, K.; Goseva-Popstojanova, K. Modeling and analysis of software aging and rejuvenation. In Proceedings of the 33rd Annual Simulation Symposium (SS 2000), Washington, DC, USA, 16–20 April 2000; pp. 270–279. [Google Scholar]
- Tipsuwan, Y.; Chow, M.Y. Network-based controller adaptation based on QoS negotiation and deterioration. In Proceedings of the IECON’01. 27th Annual Conference of the IEEE Industrial Electronics Society (Cat. No. 37243), Denver, CO, USA, 29 November–2 December 2001; Volume 3, pp. 1794–1799. [Google Scholar]
- Rajkumar, S.M.; Chakraborty, S.; Dey, R.; Deb, D. Online delay estimation and adaptive compensation in wireless networked system: An embedded control design. Int. J. Control Autom. Syst. 2020, 18, 856–866. [Google Scholar] [CrossRef]
- Di Maio, F.; Colli, D.; Zio, E.; Tao, L.; Tong, J. A multi-state physics modeling for estimating the size-and location-dependent loss of coolant accident initiating event probability. In 2017 International Topical Meeting on Probabilistic Safety Assessment and Analysis, PSA 2017; American Nuclear Society: La Grange Park, IL, USA, 2017; Volume 2, pp. 1185–1192. [Google Scholar]
- Lee, D.Y.; Choi, J.G.; Lyou, J. A safety assessment methodology for a digital reactor protection system. Int. J. Control. Autom. Syst. 2006, 4, 105–112. [Google Scholar]
- Boudali, H.; Dugan, J.B. A continuous-time Bayesian network reliability modeling, and analysis framework. IEEE Trans. Reliab. 2006, 55, 86–97. [Google Scholar] [CrossRef]
- Wang, W.; Di Maio, F.; Zio, E. Three-loop Monte Carlo simulation approach to Multi-State Physics Modeling for system reliability assessment. Reliab. Eng. Syst. Saf. 2017, 167, 276–289. [Google Scholar] [CrossRef]
- Wang, W.; Di Maio, F.; Zio, E. Adversarial Risk Analysis to Allocate Optimal Defense Resources for Protecting Cyber–Physical Systems from Cyber Attacks. Risk Anal. 2019, 39, 2766–2785. [Google Scholar] [CrossRef]
- Wang, W.; Cammi, A.; Di Maio, F.; Lorenzi, S.; Zio, E. A Monte Carlo-based exploration framework for identifying components vulnerable to cyber threats in nuclear power plants. Reliab. Eng. Syst. Saf. 2018, 175, 24–37. [Google Scholar] [CrossRef]
- Hao, Z.; Di Maio, F.; Zio, E. A Multi-State Model of the Aging Process of Cyber-Physical Systems. In Proceedings of the 30th European Safety and Reliability Conference, ESREL 2020, Venice, Italy, 1–5 November 2020. [Google Scholar]
- Du, X.; Qi, Y.; Hou, D.; Chen, Y.; Zhong, X. Modeling and performance analysis of software rejuvenation policies for multiple degradation systems. In Proceedings of the 2009 33rd Annual IEEE International Computer Software and Applications Conference, Seattle, WA, USA, 20–24 July 2009; Volume 1, pp. 240–245. [Google Scholar]
- Huang, Y.; Kintala, C.; Kolettis, N.; Fulton, N.D. Software rejuvenation: Analysis, module and applications. In Proceedings of the Twenty-Fifth International Symposium on Fault-Tolerant Computing, Pasadena, CA, USA, 27–30 June 1995; pp. 381–390. [Google Scholar]
- Grottke, M.; Matias, R.; Trivedi, K.S. The fundamentals of software aging. In Proceedings of the 2008 IEEE International Conference on Software Reliability Engineering Workshops (ISSRE Wksp), Seattle, WA, USA, 11–14 November 2008; pp. 1–6. [Google Scholar]
- Garg, S.; Puliafito, A.; Telek, M.; Trivedi, K. Analysis of preventive maintenance in transactions based software systems. IEEE Trans. Comput. 1998, 47, 96–107. [Google Scholar] [CrossRef]
- Cloosterman, M.B.; Van de Wouw, N.; Heemels, W.; Nijmeijer, H. Stability of networked control systems with uncertain time-varying delays. IEEE Trans. Autom. Control. 2009, 54, 1575–1580. [Google Scholar] [CrossRef]
- Åström, K.J.; Wittenmark, B. Computer-Controlled Systems: Theory and Design; Courier Corporation: North Chelmsford, MA, USA, 2013. [Google Scholar]
- Divandari, M.; Hashemi-Tilehnoee, M.; Khaleghi, M.; Hosseinkhah, M. A novel control-rod drive mechanism via electromagnetic levitation in MNSR. Nukleonika 2014, 59, 73–79. [Google Scholar] [CrossRef]
- Yoritsune, T.; Ishida, T.; Imayoshi, S. In-vessel type control rod drive mechanism using magnetic force latching for a very small reactor. J. Nucl. Sci. Technol. 2002, 39, 913–922. [Google Scholar] [CrossRef][Green Version]
- Yuanqiang, W.; Xingzhong, D.; Huizhong, Z.; Zhiyong, H. Design and tests for the HTR-10 control rod system. Nucl. Eng. Des. 2002, 218, 147–154. [Google Scholar] [CrossRef]
- Bakhri, S. Investigation of Rod Control System Reliability of Pwr Reactors. KnE Energy 2016, 1, 94–105. [Google Scholar] [CrossRef]
- Tipsuwan, Y.; Chow, M.Y. Control methodologies in networked control systems. Control Eng. Pract. 2003, 11, 1099–1111. [Google Scholar] [CrossRef]
- Divandari, M.; Hashemi-Tilehnoee, M.; Asgari-Ziarati, B.; Hosseinkhah, M.; Sabagh, K. Minimizing torque ripple in a brushless DC motor with fuzzy logic: Applied to control rod driving mechanism of MNSR. Nucl. Sci. Tech. 2015, 26, 10601-010601. [Google Scholar]
- Lazarev, G.; Hrustalyov, V.; Garievskij, M. 1. Non-baseload Operation in Nuclear Power Plants: Load Following and Frequency Control Modes of Flexible Operation. Nucl. Energy Ser. 2018, 1, 173. [Google Scholar]
- Bruynooghe, C.; Eriksson, A.; Fulli, G. Load-following operating mode at Nuclear Power Plants (NPPs) and incidence on Operation and Maintenance (O&M) costs. JRC Rep. 2010, 5, JRC60700. [Google Scholar]
- Ludwig, H.; Salnikova, T.; Stockman, A.; Waas, U. Load cycling capabilities of german nuclear power plants (NPP). VGB Powertech 2011, 91, 38–44. [Google Scholar]
- Yue, D.; Han, Q.L.; Peng, C. State feedback controller design of networked control systems. In Proceedings of the 2004 IEEE International Conference on Control Applications, Taipei, Taiwan, 2–4 September 2004; Volume 1, pp. 242–247. [Google Scholar]
- Peng, C.; Tian, Y.C.; Tade, M.O. State feedback controller design of networked control systems with interval time-varying delay and nonlinearity. Int. J. Robust Nonlinear Control IFAC-Affil. J. 2008, 18, 1285–1301. [Google Scholar] [CrossRef]
- Bovenzi, A.; Cotroneo, D.; Pietrantuono, R.; Russo, S. Workload characterization for software aging analysis. In Proceedings of the 2011 IEEE 22nd International Symposium on Software Reliability Engineering, Hiroshima, Japan, 29 November–2 December 2011; pp. 240–249. [Google Scholar]
- Li, L.; Vaidyanathan, K.; Trivedi, K.S. An approach for estimation of software aging in a web server. In Proceedings of the International Symposium on Empirical Software Engineering, Nara, Japan, 3–4 October 2002; pp. 91–100. [Google Scholar]
- Grottke, M.; Li, L.; Vaidyanathan, K.; Trivedi, K.S. Analysis of software aging in a web server. IEEE Trans. Reliab. 2006, 55, 411–420. [Google Scholar] [CrossRef]
- Magalhães, J.P.; Silva, L.M. Prediction of performance anomalies in web-applications based-on software aging scenarios. In Proceedings of the 2010 IEEE Second International Workshop on Software Aging and Rejuvenation, San Jose, CA, USA, 2 November 2010; pp. 1–7. [Google Scholar]
- Cassidy, K.J.; Gross, K.C.; Malekpour, A. Advanced pattern recognition for detection of complex software aging phenomena in online transaction processing servers. In Proceedings of the International Conference on Dependable Systems and Networks, Washington, DC, USA, 23–26 June 2002; pp. 478–482. [Google Scholar]
- Alonso, J.; Belanche, L.; Avresky, D.R. Predicting software anomalies using machine learning techniques. In Proceedings of the 2011 IEEE 10th International Symposium on Network Computing and Applications, Cambridge, MA, USA, 25–27 August 2011; pp. 163–170. [Google Scholar]
- Cotroneo, D.; Natella, R.; Pietrantuono, R.; Russo, S. A survey of software aging and rejuvenation studies. ACM J. Emerg. Technol. Comput. Syst. (JETC) 2014, 10, 1–34. [Google Scholar] [CrossRef]
- Bao, Y.; Sun, X.; Trivedi, K.S. A workload-based analysis of software aging, and rejuvenation. IEEE Trans. Reliab. 2005, 54, 541–548. [Google Scholar] [CrossRef]
- Bolch, G.; Greiner, S.; De Meer, H.; Trivedi, K.S. Queueing Networks and Markov Chains: Modeling and Performance Evaluation with Computer Science Applications; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Trivedi, K. Probability and Statistics with Reliability, Queuing and Computer Science Applications; John Wiley & Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Long, M.; Wu, C.H.; Hung, J.Y. Denial of service attacks on network-based control systems: Impact and mitigation. IEEE Trans. Ind. Inform. 2005, 1, 85–96. [Google Scholar] [CrossRef]
- Chyou, Y.P.; Yu, D.D.; Cheng, Y.N. Performance validation on the prototype of control rod driving mechanism for the TRR-II project. Nucl. Eng. Des. 2004, 227, 195–207. [Google Scholar] [CrossRef]
- Iida, H.; Imayoshi, S.; Morimoto, K.; Watanabe, M.; Komada, N.; Takeshita, T. Long-term stability of Sm2Co17-type magnets for control rod drive mechanism (CRDM) in a nuclear reactor. IEEE Trans. Magn. 1995, 31, 3653–3655. [Google Scholar] [CrossRef]
- Song, K.; Shi, J.; Yi, X.; Xie, Y.; Liu, G.; Lu, M. Accelerated Life Data Analysis for Control Rod Drive Mechanism Coil. In Proceedings of the 2019 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), Beijing, China, 15–17 August 2019; pp. 940–943. [Google Scholar]
- Greene, R. Aging assessment of BWR control rod drive systems. Nucl. Saf. 1992, 33, 87–99. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Load Cycle | Number of Load Cycles | Probability |
|---|---|---|
| 100-90-100 | 100,000 | |
| 100-80-100 | 100,000 | |
| 100-60-100 | 15,000 | |
| 100-40-100 | 12,000 | |
| 100-20-100 (emergency) | 100 | |
| No load-following | – |
| Parameter | Description | Value |
|---|---|---|
| n | Number of degradation states | 3 |
| Transition rate between states and | [h | |
| m | Maximum number of tasks | 10 |
| Data coming rate | 50 [s | |
| Service rate in state | 100 [s | |
| Service rate in state | 85 [s | |
| Service rate in state | 70 [s | |
| Service rate in state | 55 [s | |
| Service rate in state Blocking | 30 [s | |
| M | Total memory available | 100 [Kb] |
| x | Memory request of each task | U(2,7) [Kb] |
| Transmission delay | N(13.1,5.7) [ms] |
| Parameter | Description | Value |
|---|---|---|
| Controller failure rate | [h | |
| DC motor failure rate | [h |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Z.; Di Maio, F.; Zio, E. Multi-State Reliability Assessment Model of Base-Load Cyber-Physical Energy Systems (CPES) during Flexible Operation Considering the Aging of Cyber Components. Energies 2021, 14, 3241. https://doi.org/10.3390/en14113241
Hao Z, Di Maio F, Zio E. Multi-State Reliability Assessment Model of Base-Load Cyber-Physical Energy Systems (CPES) during Flexible Operation Considering the Aging of Cyber Components. Energies. 2021; 14(11):3241. https://doi.org/10.3390/en14113241
Chicago/Turabian StyleHao, Zhaojun, Francesco Di Maio, and Enrico Zio. 2021. "Multi-State Reliability Assessment Model of Base-Load Cyber-Physical Energy Systems (CPES) during Flexible Operation Considering the Aging of Cyber Components" Energies 14, no. 11: 3241. https://doi.org/10.3390/en14113241
APA StyleHao, Z., Di Maio, F., & Zio, E. (2021). Multi-State Reliability Assessment Model of Base-Load Cyber-Physical Energy Systems (CPES) during Flexible Operation Considering the Aging of Cyber Components. Energies, 14(11), 3241. https://doi.org/10.3390/en14113241