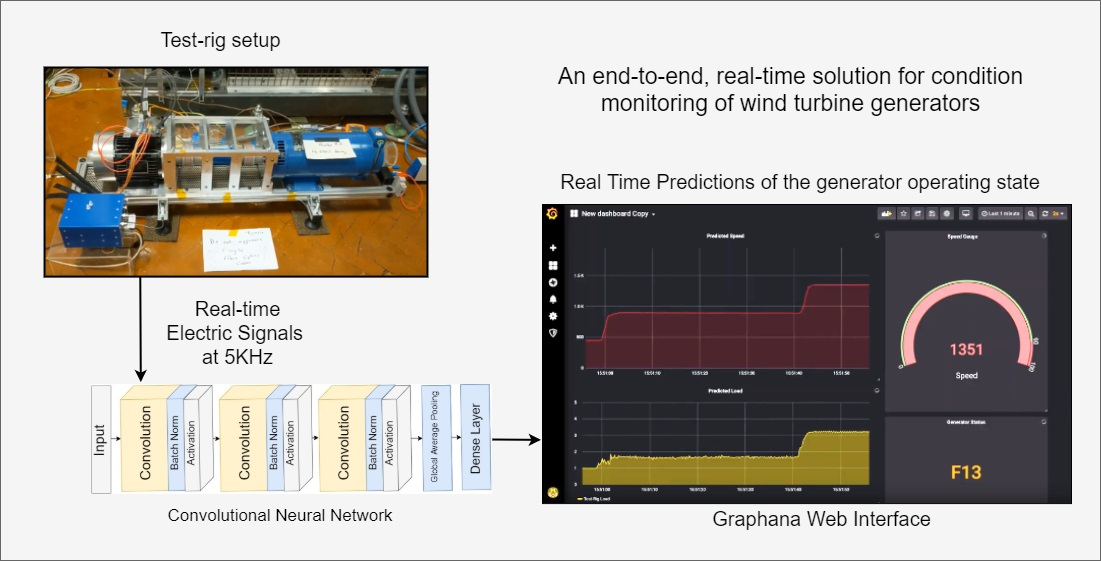
An End-to-End, Real-Time Solution for Condition Monitoring of Wind Turbine Generators

 ,
,  ,
,
Abstract

1. Introduction
2. Materials and Methods
2.1. System Description
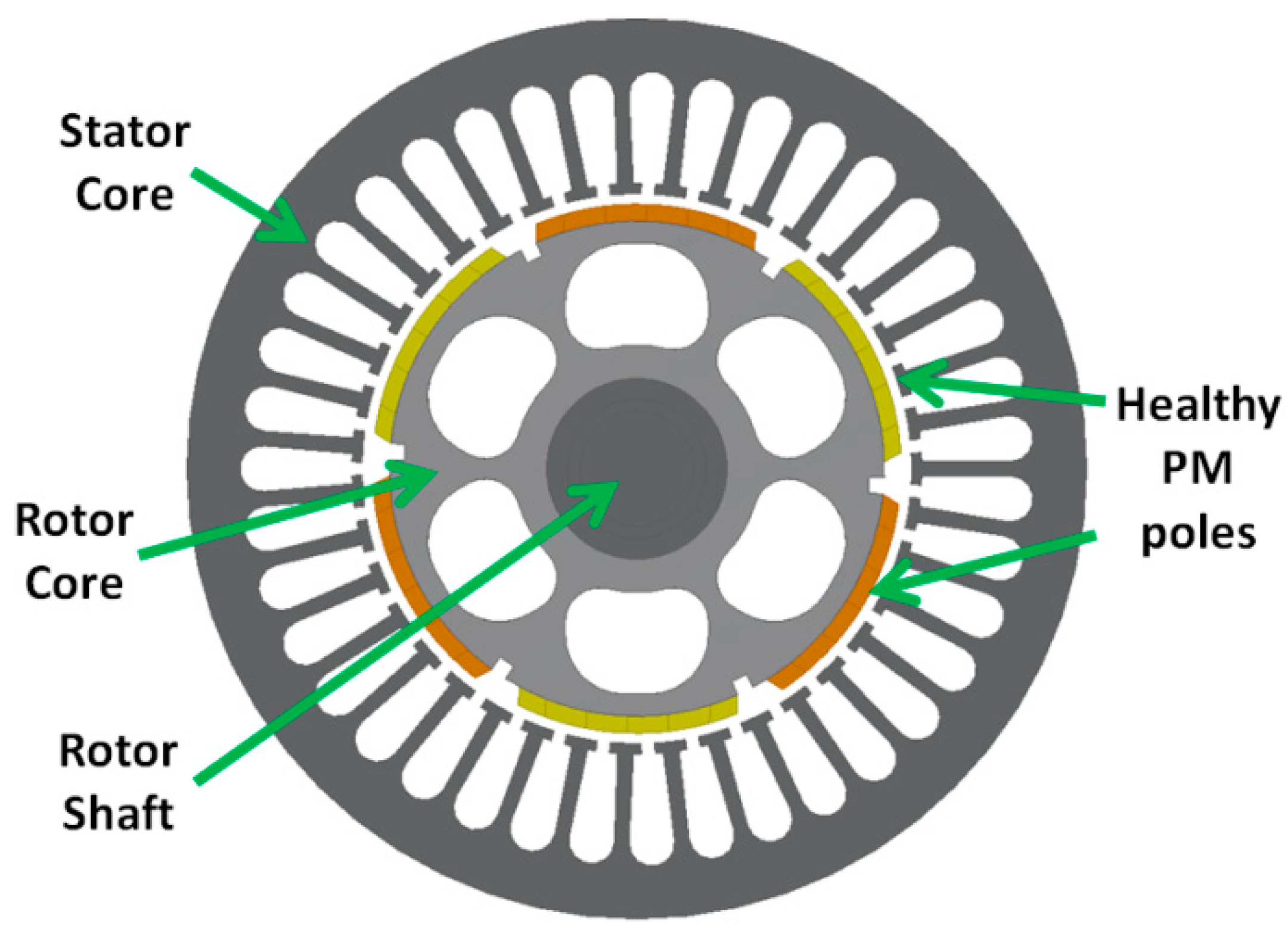
2.1.1. Examined PM Motor
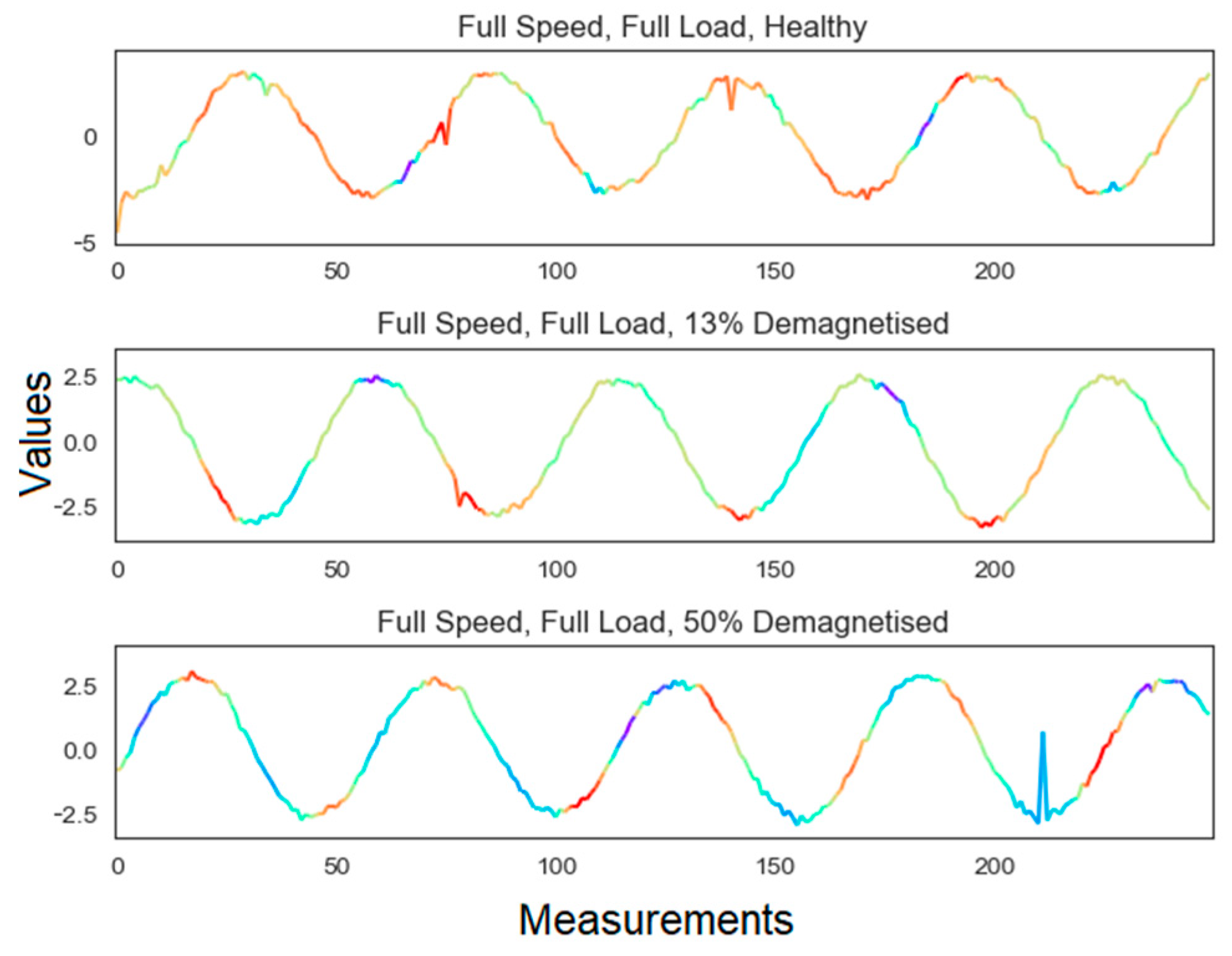
2.1.2. The Examined Demagnetized Rotor Conditions
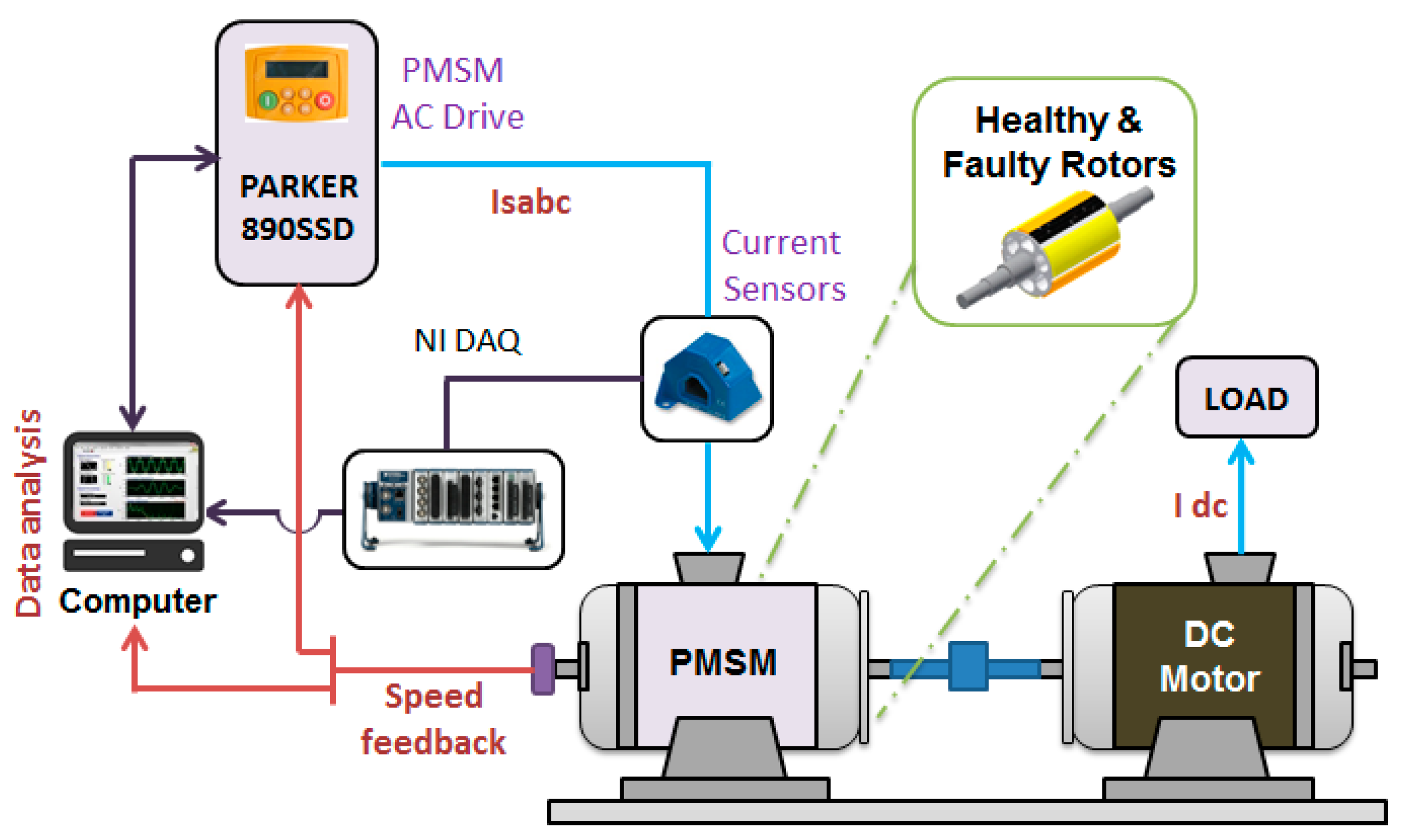
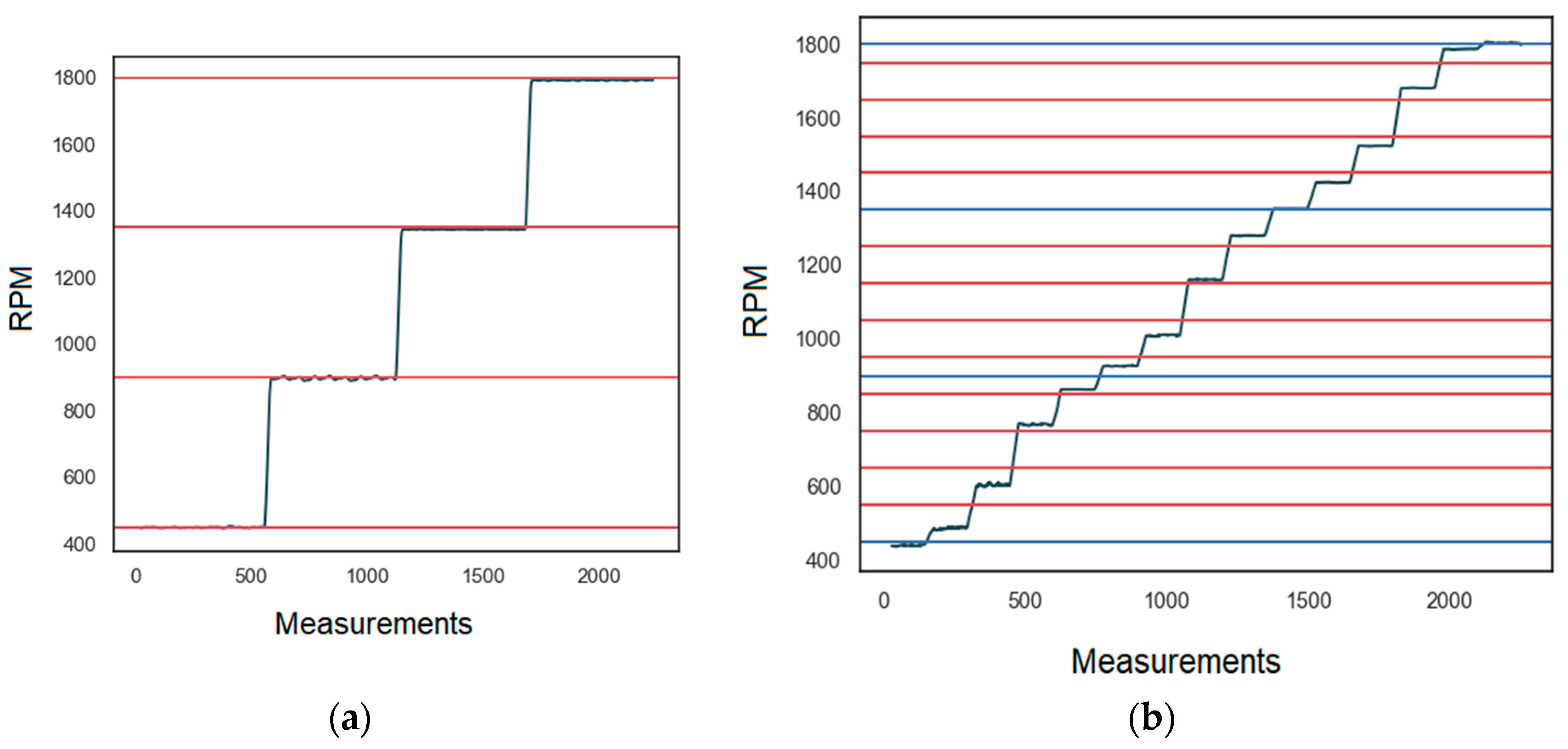
2.1.3. Test-Rig Description
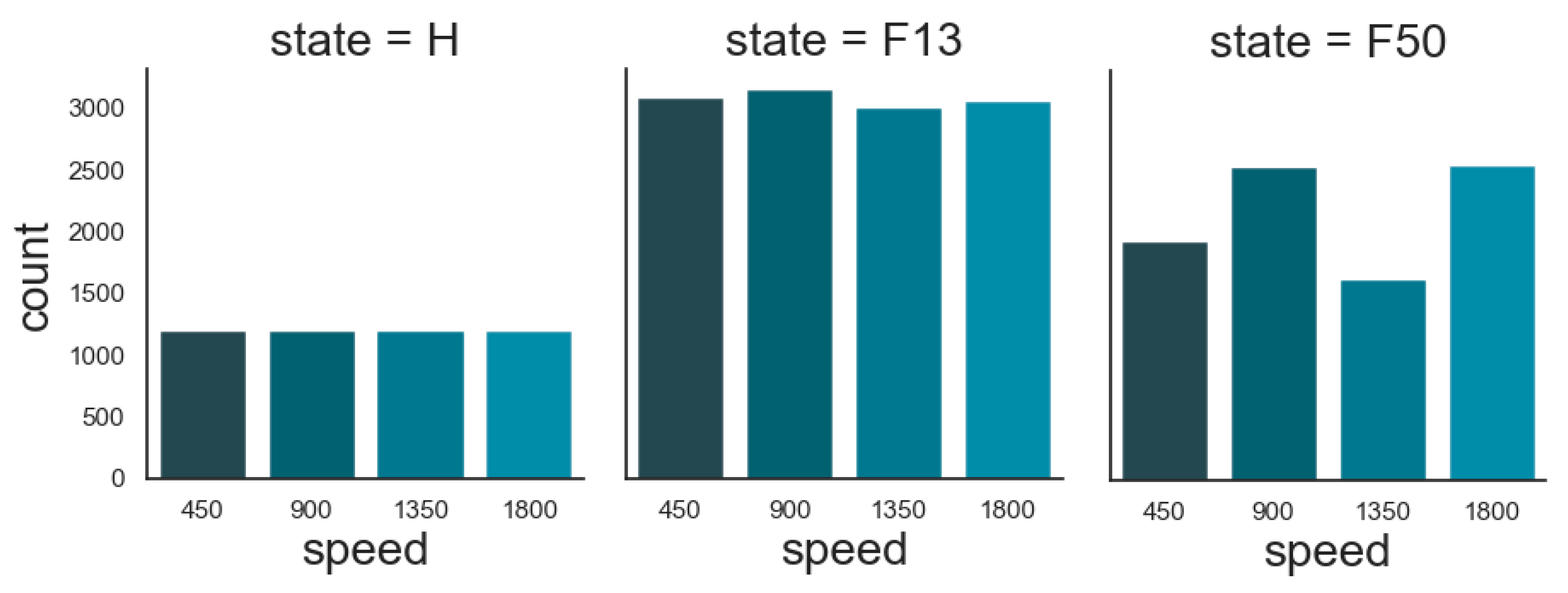
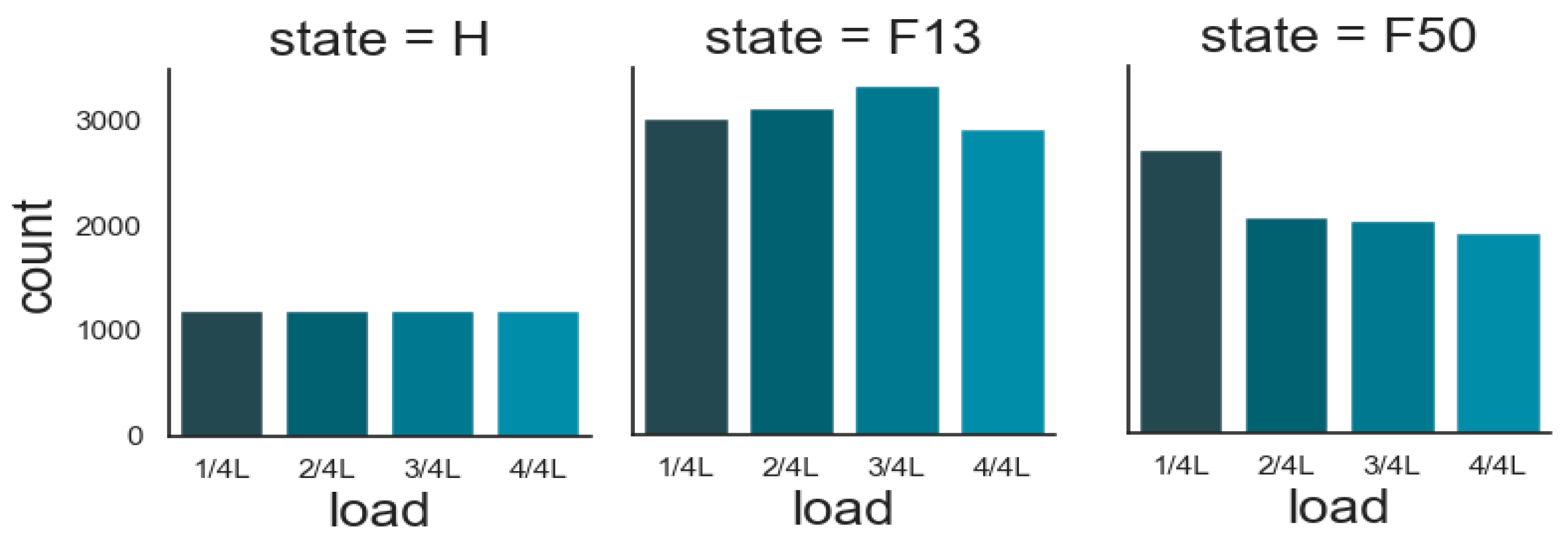
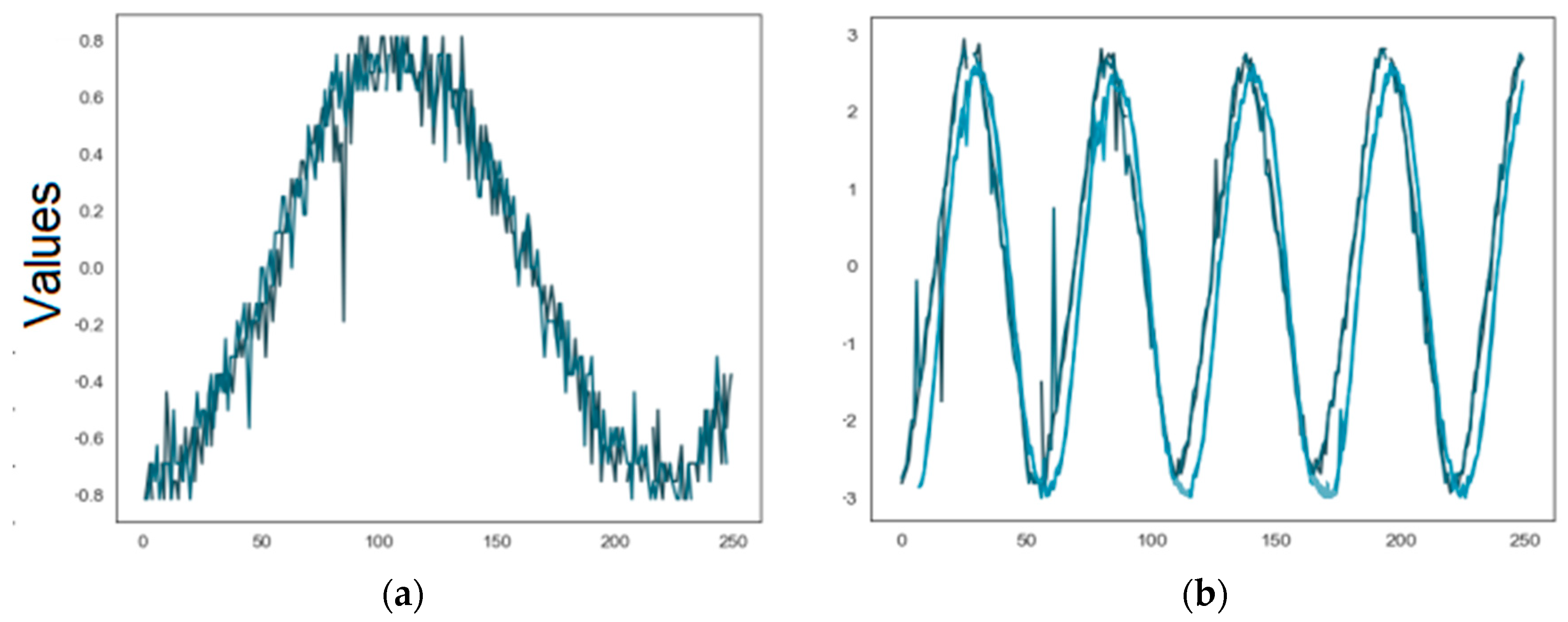
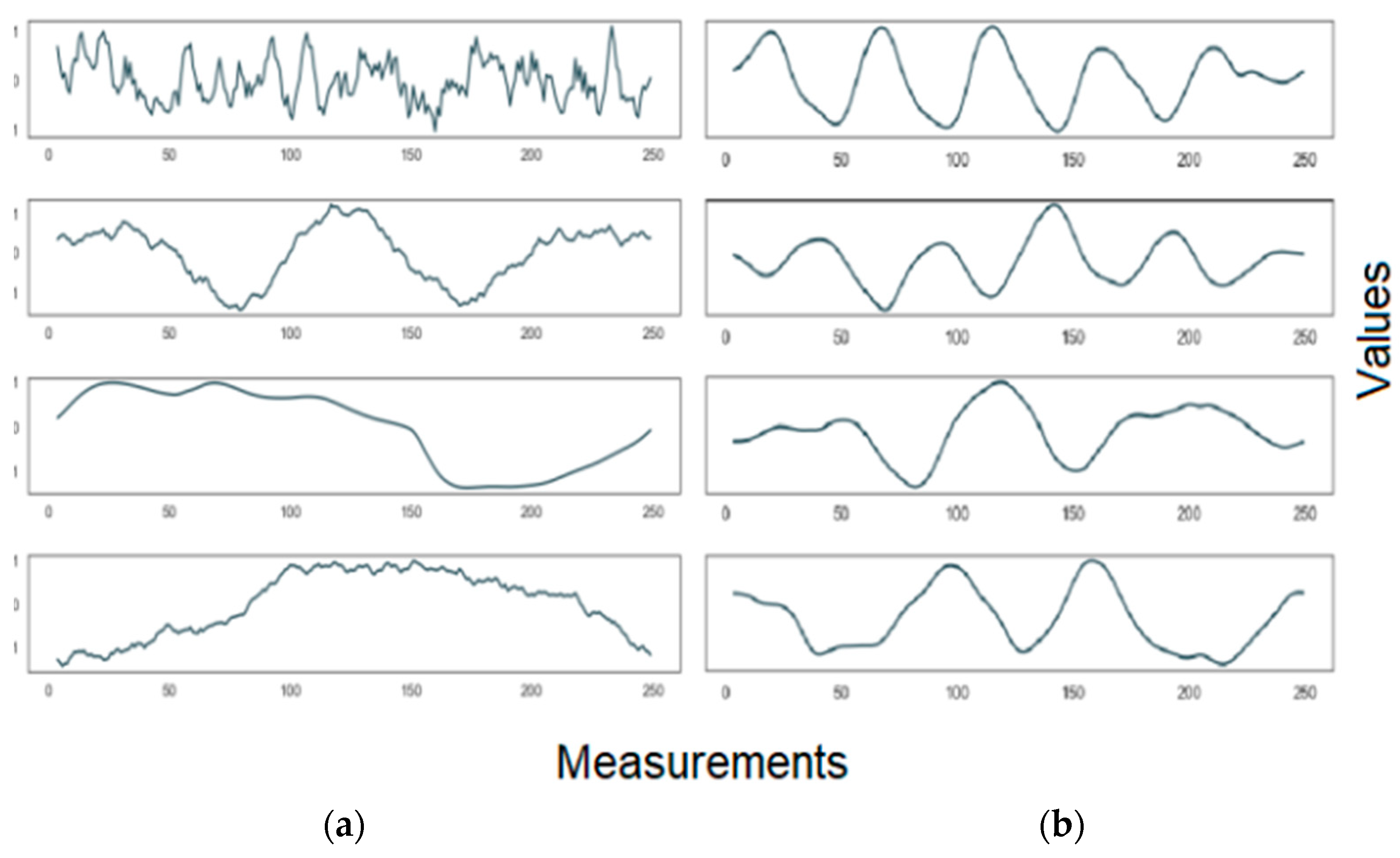
2.2. Descriptive Statistics of the Data
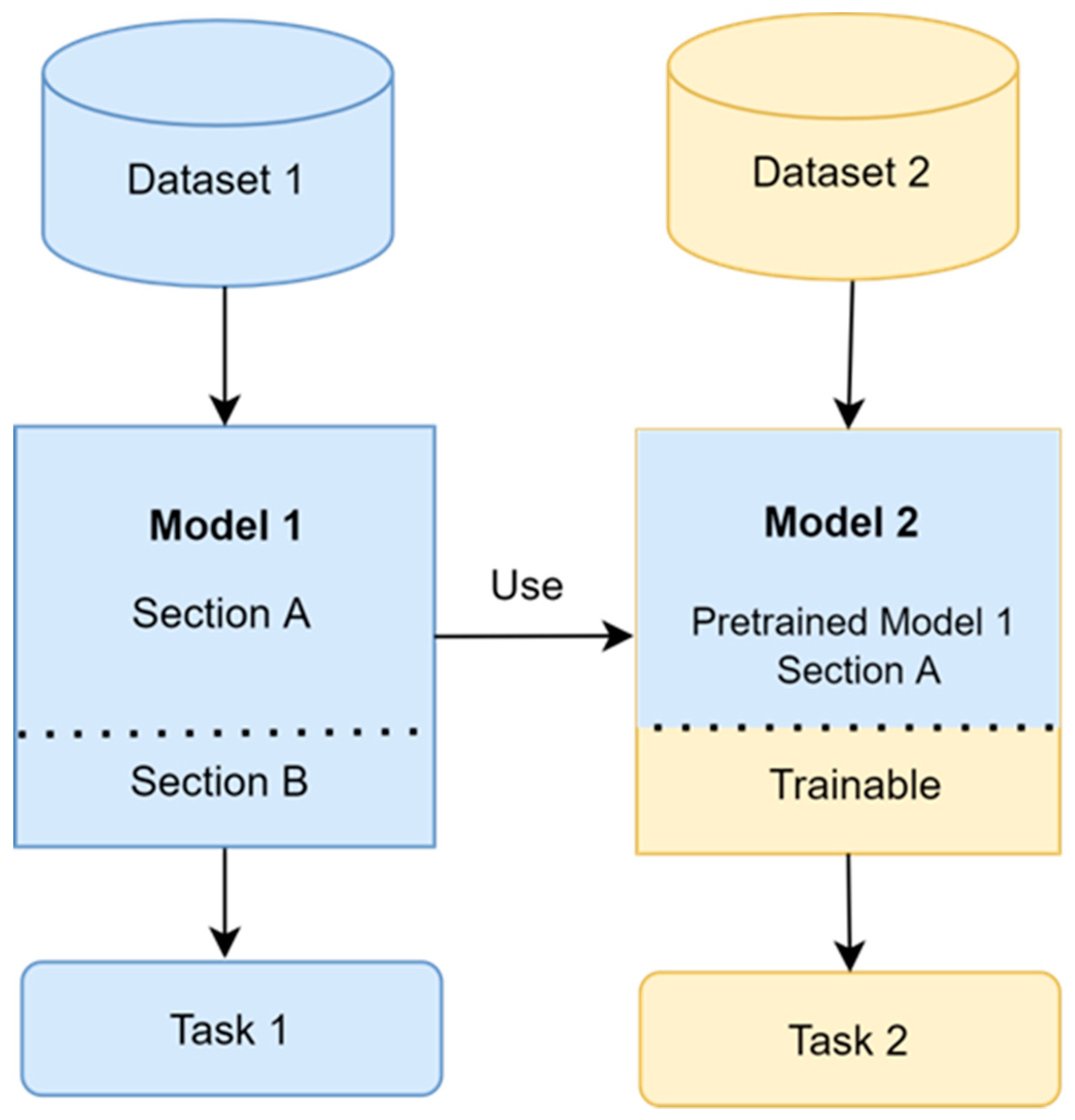
2.3. Convolutional Neural Network (CNN) Model
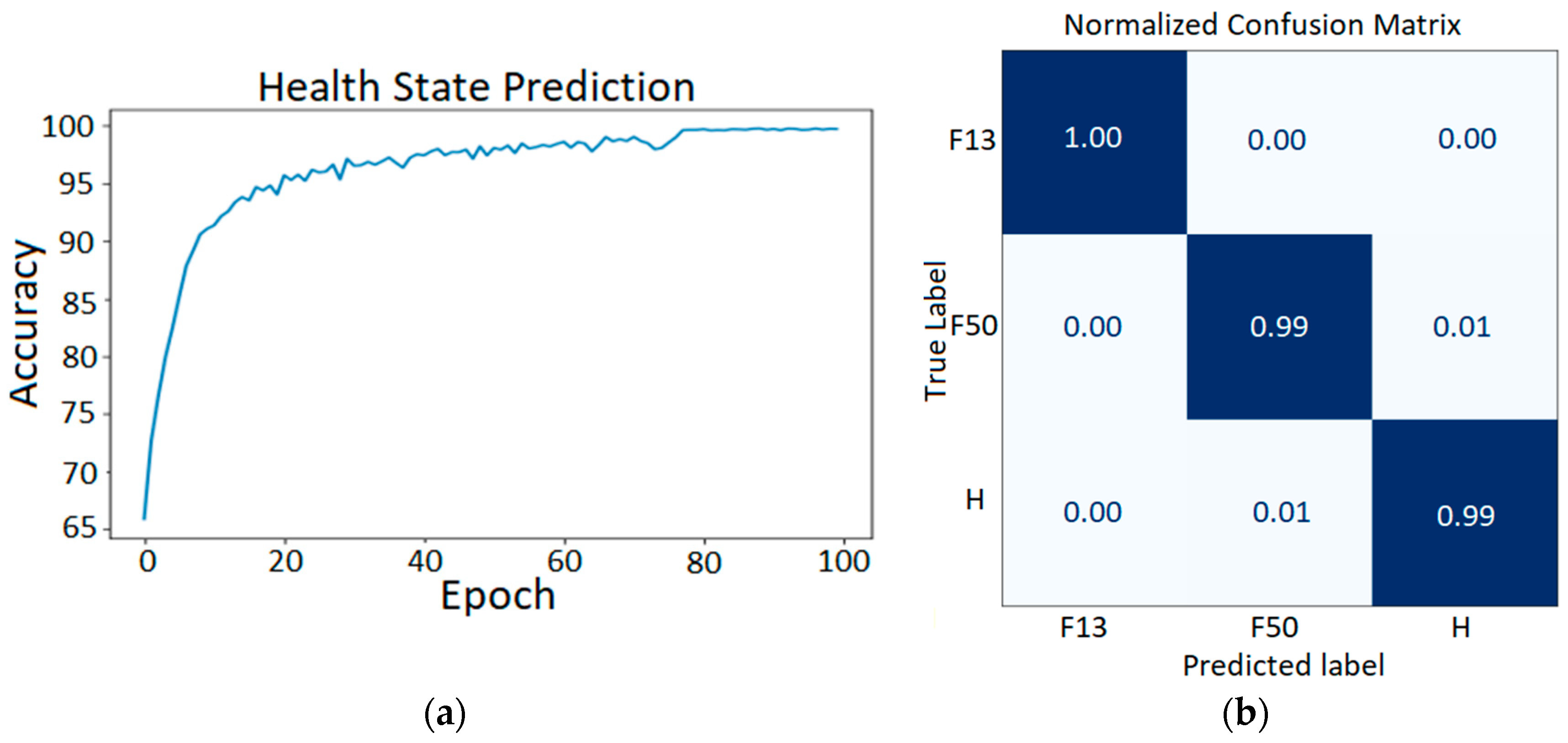
3. Results
Model Performance
4. Discussion
4.1. Related Work
- Traditional physics-based models: these models assume a mathematical understanding behind failures and are rigid in updating with new data;
- Conventional data-driven models: bottom-up approaches that offer more flexibility but are unable to model large scale data; such models require expert knowledge and hand-crafted features;
- Deep-learning models: a bottom-up approach based on Artificial Neural Networks (ANNs), which find discriminating features in data without the need for an expert and represent a stepping stone towards end-to-end learning.
4.2. Interpreting CNN Results
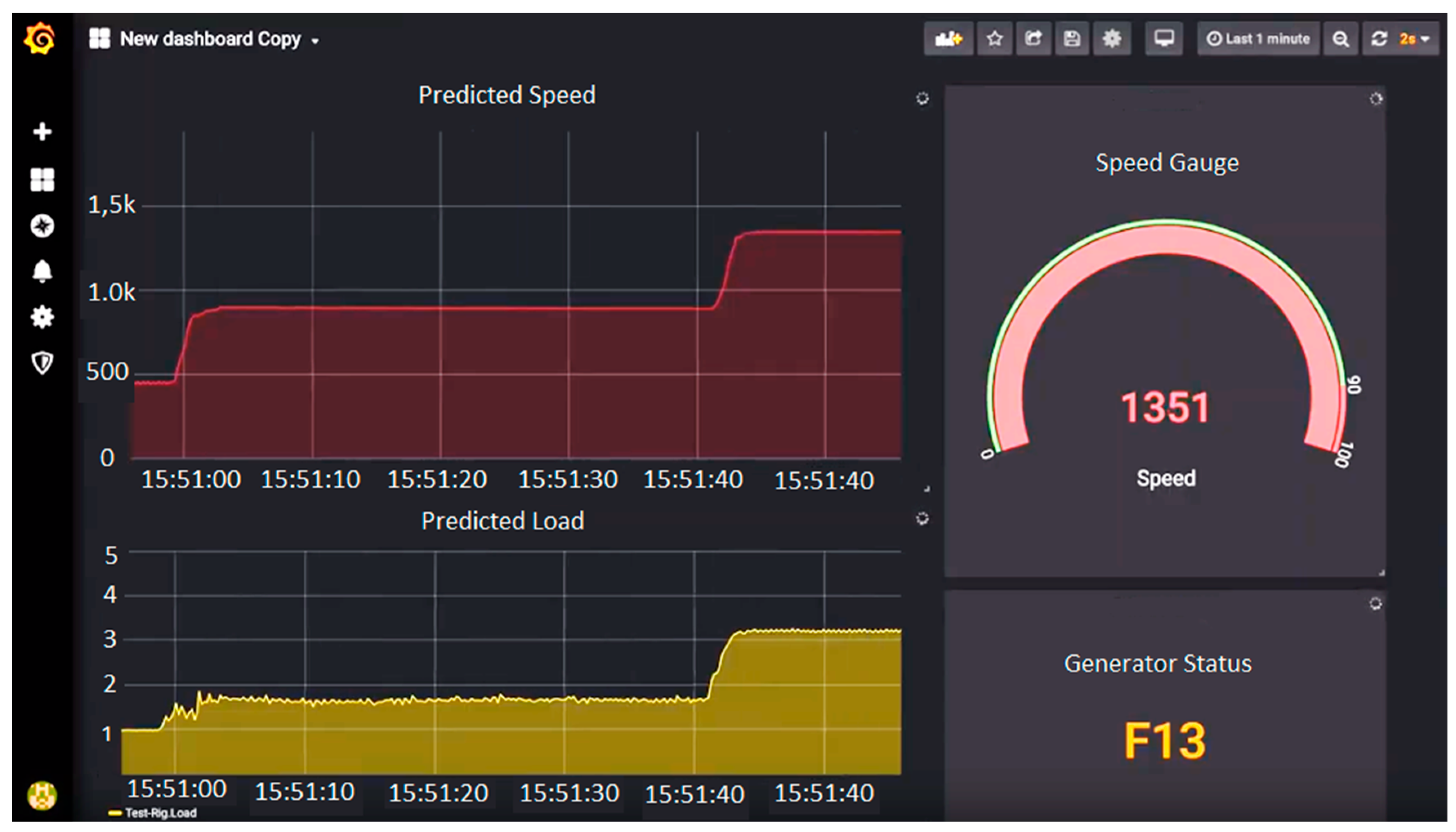
4.3. Storage and Visualization
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Barnes, M.; Brown, K.; Carmona, J.; Cevasco, D.; Collu, M.; Crabtree, C.; Crowther, W.; Djurovic, S.; Flynn, D.; Green, P.R.; et al. Technology Drivers in Windfarm Asset Management Position Paper. 14 June 2018. Available online: https://www.windpoweroffshore.com/article/1448667/uk-offshore-facing- (accessed on 31 August 2020).
- Orsted. Making Green Energy Affordable How the Offshore Wind Energy Industry Matured-and What We Can Learn from it. Available online: orsted.com/en/about-us/whitepapers/making-green-energy-affordable (accessed on 1 September 2020).
- Rolnick, D.; Donti, P.L.; Kaack, L.H.; Kochanski, K.; Lacoste, A.; Sankaran, K.; Ross, A.S.; Milojevic-Dupont, N.; Jaques, N.; Waldman-Brown, A.; et al. Tackling Climate Change with Machine Learning. 2019. Available online: http://arxiv.org/abs/1906.05433 (accessed on 1 September 2020).
- Yang, W.; Tavner, P.J.; Crabtree, C.J.; Feng, Y.; Qiu, Y. Wind turbine condition monitoring: Technical and commercial challenges. Wind Energy 2014, 17, 657–669. [Google Scholar] [CrossRef]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep Learning and Its Applications to Machine Health Monitoring: A Survey. Mech. Syst. Signal Process. 2015, 14, 1–14. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Melecio, J.I.; Djurović, S.; Schofield, N. FEA model study of spectral signature patterns of PM demagnetisation faults in synchronous PM machines. J. Eng. 2019, 2019, 4127–4132. [Google Scholar] [CrossRef]
- Mohammed, A.; Melecio, J.I.; Djurović, S. Electrical Machine Permanent Magnets Health Monitoring and Diagnosis Using an Air-Gap Magnetic Sensor. IEEE Sens. J. 2020, 20, 5251–5259. [Google Scholar] [CrossRef]
- Melecio, J.I.; Mohammed, A.; Djurovic, S.; Schofield, N. 3D-printed rapid prototype rigs for surface mounted PM rotor controlled segment magnetisation and assembly. In Proceedings of the 2019 IEEE International Electric Machines and Drives Conference (IEMDC 2019), San Diego, CA, USA, 11–15 May 2019. [Google Scholar]
- Stetco, A.; Mohammed, A.; Djurovic, S.; Nenadic, G.; Keane, J. Wind Turbine operational state prediction: Towards featureless, end-to-end predictive maintenance. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 4422–4430. [Google Scholar]
- De Prado, M.L. Advances in Financial Machine Learning, 1st ed.; Wiley Publishing: Hoboken, NJ, USA, 2018. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 1 September 2020).
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. arXiv 2017, arXiv:1611.06455v4. [Google Scholar]
- Chen, Y.; Keogh, E.; Hu, B.; Begum, N.; Bagnall, A.; Mueen, A.; Batista, G. The UCR Time Series Classification Archive. 2015. Available online: https://www.cs.ucr.edu/~eamonn/time_series_data/ (accessed on 31 October 2018).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Wang, J.; Li, S.; An, Z.; Jiang, X.; Qian, W.; Ji, S. Batch-normalized deep neural networks for achieving fast intelligent fault diagnosis of machines. Neurocomputing 2019, 329, 53–65. [Google Scholar] [CrossRef]
- Géron, A. Hands-on Machine Learning with Scikit-Learn and Tensor Flow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Ai, G.; Dodge, J.; Smith, N.A.; Etzioni, O.; Ai, R. Green AI. 2019. Available online: https://arxiv.org/abs/1907.10597 (accessed on 31 August 2020).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, US, 2016. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Ince, T.; Kiranyaz, S.; Member, S.; Eren, L. Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Cui, Z.; Chen, W.; Chen, Y. Multi-Scale Convolutional Neural Networks for Time Series Classification General Terms. Available online: https://arxiv.org/pdf/1603.06995.pdf (accessed on 16 July 2019).
- Pan, T.; Chen, J.; Zhou, Z.; Wang, C.; He, S. A Novel Deep Learning Network via Multi-Scale Inner Product with Locally Connected Feature Extraction for Intelligent Fault Detection. IEEE Trans. Ind. Inform. 2019, 15, 5119–5128. [Google Scholar] [CrossRef]
- Sun, W.; Zhao, R.; Yan, R.; Shao, S.; Chen, X. Convolutional Discriminative Feature Learning for Induction Motor Fault Diagnosis. IEEE Trans. Ind. Inform. 2017, 13, 1350–1359. [Google Scholar] [CrossRef]
- Kao, I.-H.; Wang, W.-J.; Lai, Y.-H.; Perng, J.-W. Analysis of Permanent Magnet Synchronous Motor Fault Diagnosis Based on Learning. IEEE Trans. Instrum. Meas. 2019, 68, 310–324. [Google Scholar] [CrossRef]
- Jeong, H.; Lee, H.; Kim, S.W. Classification and Detection of Demagnetization and Inter-Turn Short Circuit Faults in IPMSMs by Using Convolutional Neural Networks. In Proceedings of the 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, 23–27 September 2018; pp. 3249–3254. [Google Scholar]
- Kong, Z.; Tang, B.; Deng, L.; Liu, W.; Han, Y. Condition monitoring of wind turbines based on spatio-temporal fusion of SCADA data by convolutional neural networks and gated recurrent units. Renew. Energy 2020, 146, 760–768. [Google Scholar] [CrossRef]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- De Mulder, W.; Bethard, S.; Moens, M.F. A survey on the application of recurrent neural networks to statistical language modeling. Comput. Speech Lang. 2015, 30, 61–98. [Google Scholar] [CrossRef]
- Srinivasan, P.A.; Guastoni, L.; Azizpour, H.; Schlatter, P.; Vinuesa, R. Predictions of turbulent shear flows using deep neural networks. Phys. Rev. Fluids 2019, 4, 1–15. [Google Scholar] [CrossRef]
- Sak, H.; Senior, A.; Rao, K.; Beaufays, F. Fast and accurate recurrent neural network acoustic models for speech recognition. arXiv 2015, arXiv:1507.06947. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Available online: http://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf (accessed on 27 August 2020).
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the Locality and Breaking the Memory Bottleneck of Transformer on Time Series Forecasting. 2019. Available online: http://arxiv.org/abs/1907.00235 (accessed on 1 September 2020).
- Guastoni, L.; Encinar, M.P.; Schlatter, P.; Azizpour, H.; Vinuesa, R. Prediction of wall-bounded turbulence from wall quantities using convolutional neural networks. J. Phys. Conf. Ser. 2020, 1522, 012022. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2019. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 31 July 2019).
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California: Berkeley, CA, USA, 1967; Volume 233, pp. 281–297. [Google Scholar]
- Instruments, N. GitHub-ni/nidaqmx-python: A Python API for interacting with NI-DAQmx. Available online: https://github.com/ni/nidaqmx-python (accessed on 19 July 2019).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. 2016. Available online: https://ai.google/research/pubs/pub45381 (accessed on 19 July 2019).
- Open Source Time Series Platform|InfluxData. Available online: https://www.influxdata.com/time-series-platform/ (accessed on 30 April 2019).
- Noor, S.; Naqvi, Z.; Yfantidou, S.; Zimányi, E.; Zimányi, Z. Time Series Databases and InfluxDB. Universite Libre de Bruxelles. Available online: http://cs.ulb.ac.be/public/_media/teaching/influxdb_2017.pdf (accessed on 6 May 2019).
- DB-Engines. DB-Engines Ranking—Popularity Ranking of Time Series DBMS. Available online: https://db-engines.com/en/ranking/time+series+dbms (accessed on 19 July 2019).
- Grafana. Grafana—The Open Platform for Analytics and Monitoring. Available online: https://grafana.com/ (accessed on 16 July 2019).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 1/4 Load | 2/4 Load | 3/4 Load | 4/4 Load | |
|---|---|---|---|---|
| 450 rpm | 300 H (0.567) 742 F13 (0.723) 600 F50 (0.726) | 300 H (1.021) 825 F13 (1.280) 524 F50 (1.196) | 300 H (1.438) 742 F13 (1.622) 600 F50 (1.687) | 300 H (1.824) 641 F13 (2.100) 600 F50 (2.094) |
| 900 rpm | 300 H (0.604) 895 F13 (0.893) 581 F50 (0.956) | 300 H (1.065) 762 F13 (1.235) 592 F50 (1.235) | 300 H (1.405) 960 F13 (1.452) 674 F50 (1.538) | 300 H (1.941) 540 F13 (2.178) 700 F50 (2.003) |
| 1350 rpm | 300H (0.517) 737 F13 (0.738) 326 F50 (0.807) | 300 H (1.043) 785 F13 (1.223) 494 F50 (1.278) | 300 H (1.331) 658 F13 (1.507) 389 F50 (1.537) | 300 H (1.826) 835 F13 (1.826) 422 F50 (2.000) |
| 1800 rpm | 300H (0.642) 628 F13 (0.705) 1191F50 (0.485) | 300 H (1.215) 731 F13 (1.244) 444 F50 (1.281) | 300 H (1.611) 818 F13 (1.517) 443 F50 (1.601) | 300 H (2.021) 893 F13 (1.951) 479 F50 (1.960) |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stetco, A.; Ramirez, J.M.; Mohammed, A.; Djurović, S.; Nenadic, G.; Keane, J. An End-to-End, Real-Time Solution for Condition Monitoring of Wind Turbine Generators. Energies 2020, 13, 4817. https://doi.org/10.3390/en13184817
Stetco A, Ramirez JM, Mohammed A, Djurović S, Nenadic G, Keane J. An End-to-End, Real-Time Solution for Condition Monitoring of Wind Turbine Generators. Energies. 2020; 13(18):4817. https://doi.org/10.3390/en13184817
Chicago/Turabian StyleStetco, Adrian, Juan Melecio Ramirez, Anees Mohammed, Siniša Djurović, Goran Nenadic, and John Keane. 2020. "An End-to-End, Real-Time Solution for Condition Monitoring of Wind Turbine Generators" Energies 13, no. 18: 4817. https://doi.org/10.3390/en13184817
APA StyleStetco, A., Ramirez, J. M., Mohammed, A., Djurović, S., Nenadic, G., & Keane, J. (2020). An End-to-End, Real-Time Solution for Condition Monitoring of Wind Turbine Generators. Energies, 13(18), 4817. https://doi.org/10.3390/en13184817