1. Introduction
Brazil faces chronic energy shortages, particularly in remote riverside communities in the Amazonas State where a lack of infrastructure, expertise and financial input [
1] reduces the abilities of communities to meet their energy needs. According to Trindade and Cordeiro [
2], using 2018 data, around 5% of the Amazonas State population in Brazil, distributed in 2261 communities and 41,167 households, do not have electricity. The Federal government’s rural electrification programme, known as
Luz Para Todos (Light for All) [
3] created in 2003 by decree 4873 and extended to 2018 by decree 8387 aims to provide energy access to all through mini-grids and standalone systems. According to Cabre et al. [
1], energy is to be supplied by renewable, diesel and/or hybrid systems for remote communities in which grid connection is not a viable option. Among other benefits, these interventions promise to economically empower disadvantaged and unelectrified communities.
The Amazonas State is a peculiar area of Brazil, representing 18% of the whole country’s geographical area, surrounded and flooded by the Amazon river basin, with few roads and with extensive use of the rivers as the means of transport to its rural area. The State has an area equivalent to that of five countries in Europe combined (Portugal, Spain, France, and Germany), however the population is just 1.8% of those countries. Three Amazonas State policies are of particular importance:
In 2007, the Amazonas State implemented the
Programa Bolsa Floresta (Forest Assistance Programme), which pays families from 16 conservation areas to protect the forest. The focus of the programme is on introducing alternative economic efforts and ensuring regular visits to the communities in order to avoid deforestation [
4]. However, there is no provision within the programme to provide additional electrification or regular educational activities.
The adoption of protected forest areas with little oversight to check if the forest has been kept standing. This policy is not linked either with the need for electrification or education. According to the Amazonas State Environment Secretary [
5] 57.3% of protected forest is divided among indigenous areas, State protected areas, municipality protected areas, and Federal protected areas. Partially due to this policy, Amazonas State has 97% of the original forest coverage intact.
The
Luz para Todos programme [
3] aims to provide electricity to all parts of the state but has had limited reach in Amazonas State due to the difficulties in extending the grid to remote regions of the Amazon Rainforest. Considerable financial investment will be required to provide electricity to these remote regions and to ensure that this infrastructure is maintained.
The 17 Sustainable Development Goals (SDGs) [
6] are divided into economic, social, and environmental goals and form a coherent part of the United Nation’s global development agenda. Goal 7 calls for universal access to affordable, reliable, and sustainable energy. Goal 7 is also related to the 2015 Paris Agreement to reduce greenhouse gas (GHG) emissions. Schunder and Bagchi-Sen [
7] have shown that in developing countries, household energy consumption contributes substantially to GHG emissions.
In this paper, we investigate which societal factors contribute to the cooking fuel choices in the surveyed communities. Based on our results we evaluate whether the existing government policies applicable to the Amazonas State address the SDGs. We aim to identify whether there is significant progress towards the SDGs for this region. Investigations into the household fuel choices can indicate which socio-economic factors could contribute to communities reaching their SDG goals: by improving education; by increasing the income of residents; or by promoting and favouring the use of electricity from renewable sources.
As the economic status of households in these communities is expected to improve, He et al. [
8] have shown that aspects of their daily life, such as the choice of cooking fuels, are expected to improve. In particular, the energy ladder hypothesis formulated based on data from Zimbabwe [
9], Botswana [
10], and Ghana [
11] stipulates that the households would switch from using traditional fuels, such as
Firewood, towards more sophisticated fuels, such as Liquefied Petroleum Gas (LPG) or electricity. (For simplicity, the term
Gas is used to denote LPG for the rest of the paper.) The meta-analysis in [
12] argues that this switching is needed as it brings benefits in terms of health and environmental sustainability. As seen in [
12,
13] these fuels are often categorised under solid and non-solid fuel types, or as primitive, transition, and advanced fuel types. Along these lines,
Firewood is considered as a solid and primitive fuel, while
Gas is considered an advanced and non-solid fuel.
Charcoal, on the other hand, is considered a transition fuel by [
12]. For reasons of health and environmental conservation, the move towards the more sophisticated fuel types like electricity is largely thought to be desirable. However, the energy ladder hypothesis has been disproved in many surveys and alternate models, such as the approach by Alem et al. [
14] have been proposed. Recent studies, such as that by Mekonnen and Köhlin [
15] in Ethiopia, have shown that instead of fuel switching, households rather tend to stack different kinds of fuels together, such as
Firewood and Charcoal, or
Charcoal and Gas or Electricity, or
Firewood, Charcoal and Gas or Electricity in what is known as
fuel stacking. Fuel stacking therefore represents a slower transition toward the exclusive use of advanced fuel types.
Moreover, the current consensus is that the choice of which fuels are stacked does not solely depend on household income, and as noted by Heltberg [
16], does not significantly depend on income at all. Heltberg [
17] has also hinted at other factors—such as the household occupancy, civil status and education level of the household head, the availability and access to fuel, and whether the household is a permanent or temporary residence—as influential in the choice of cooking fuel in different geographical regions. Muller and Yan’s review [
18] shows that an abundance of these factors and their variability in different geographical regions underscore the importance of identifying which particular factors, among all such factors collected in a given survey, most significantly affect the household fuel choice. Identifying these significant factors, as done for rural Kenya [
19] or rural China [
20], yields information that directly influences energy policy, especially in many developing countries where the use of traditional fuels is more common.
Since not all factors collected in a given survey impact the fuel choice behaviour significantly, several works [
21,
22,
23] have focused on identifying the
significant factors (referred to as
determinants) of household fuel choice in different countries and geographical regions, such as Ethiopia [
14,
15], Ghana [
23], China [
22], and Guatemala [
16]. Heltberg [
17] observed that determinants as identified in these studies tend to vary significantly between geographical regions due to differences in factors, such as education level and availability and access to fuel. For example, for a community with easy access to
Gas, the fuel switching or stacking behaviour may be impacted by some other factor, such as income, to a different degree from a community with no easy access to
Gas. The existing variations in these determinants and the extent of their unique influence in different geographical regions motivate our main contribution in this paper: the identification of fuel choice determinants in riverside communities in the Amazonas State of Brazil, using a multinomial logistic regression model [
24]. The model is given in
Section 2.1. To the best of our knowledge, very few works have been conducted to investigate the determinants of household fuel choice in this region. The work by Heltberg [
17], which considers other parts of rural Brazil, achieves a coefficient of determination (
) for the model of fuel choice behaviour that leaves room for improvement (much of the variation is unexplained).
Furthermore, to identify the fuel choice determinants in riverside communities in the Amazonas State, we address the issues of model validation and feature selection and how they can potentially lead to drawing inaccurate conclusions about the determinants of household fuel choice in
Section 2.1 and
Section 4.4. In our context, model validation consists of reserving an independent dataset to test the correctness or accuracy of the trained multinomial logistic regression model in terms of predicting the fuel choice, while feature selection refers to identifying the optimal set of fuel choice factors to be used to develop the model.
The rest of the paper is organised as follows:
Section 2 reviews relevant literature in the area of household fuel choice behaviour, as well as the statistical method often employed in the identification of the determinants of household fuel choice. In
Section 3, we describe the materials and methods used in the collection of the dataset on which the analysis in this paper is based. We provide a detailed discussion of our results in
Section 6 and conclude with recommendations on energy policy in riverside communities in the Amazonas State of Brazil in
Section 7.
2. Literature Review
While clean and energy-efficient methods of cooking provide benefits in terms of health, environment, and sustainable development, their adoption has not been widespread in many developing countries [
18], with Santillan et al. [
25] finding a correlation (
) between the Human Development Index (HDI) of a country and its Multidimensional Energy Poverty Index (MEPI). For example, Olang et al. [
26] notes that, while there is a general desire towards the adoption of advanced fuel types in Kenya, they have been hindered to some extent by poverty and other factors, such as availability and access to fuel. This has led to intense research for various regions, such as Afghanistan [
27], Bhutan [
28], Kenya [
29], Turkey [
30], and India [
31], on which factors determine the transition from a primitive cooking fuel, such as
Firewood to that of an advanced fuel, such as
Gas or Electricity. Reviews, such as Kowsari and Zerriffi’s three dimensional energy profile proposition [
32] and Heltberg’s multi-country study [
33], show that the increasing body of evidence is enabling a better understanding of the phenomenon and factors surrounding energy use. Beyond the adoption of an advanced fuel type, the work by Tigabu [
34] has also investigated what factors account for the sustained use of such advanced fuel types.
In early publications [
9,
10,
11], the economic status of a household was originally thought to be the sole determinant of this transition, in what became known as the energy ladder hypothesis. However, several works have since disputed [
9,
11,
16] this theory. For example, Malakar [
35] showed that, in rural India, income had little influence on the choice of advanced cooking fuel. Additionally, increasing research has pointed to the phenomenon of fuel stacking [
11,
12,
14,
15], and have hinted at several other factors influencing this transition [
9,
11,
16,
36,
37,
38]. The review in Fredriks et al. [
39] shows that there can be a wide range of socio-demographic factors that influence household energy behaviours and patterns. For example, Heltberg [
16] identified the following factors as significantly influencing the energy choice behaviour in Brazil, Ghana, Vietnam, Guatemala, India, Nepal, Nicaragua, and South Africa: education level of the household, household size, percentage of females in the household, number of rooms in the household, household expenditure, access to electricity, and others. Rao and Reddy [
31] identified further factors, such as the age of the household head and their religion as influencing the fuel choice behaviour in India, while Olang et al. [
26] identified the cooking location as another key determinant of fuel choice in Kenya. On the whole, Saksena [
40] classifies these fuel choice factors under household demand-side factors (such as household income) and community-wide supply-side factors (such as access to fuel), arguing from an economic perspective that supply-side factors may prevent a wealthy household from transitioning towards an advanced fuel type, even though there might be demand for the advanced fuel.
However, the factors identified in the above works do not apply to all geographical regions. For example, Pundo [
41] found in rural Kenya no significant effect of age of the household or household size on the fuel choice in rural Kenya, while the study in [
42] has found that in Pakistan, an increase in the age of the household resulted in an increase in energy consumption. Ouedraogo [
43] found no significant influence of household ownership or gender on the fuel choice in Burkina Faso. Baral [
44] has found that energy consumption and resource dependence varies over time with high-income households relying on more sophisticated fuels, such as
Gas, while lower-income household continue to use traditional fuels such as fuel-wood. Mekonnen and Köhlin [
15] found no influence on the percentage of females in a household on the fuel choice in Ethiopia.
The differences in the degree of influence of these factors across different geographical regions [
17] have stirred up recent work [
11,
14,
18,
21] in understanding what the determinants of household fuel choice are in the different regions. Some existing work [
14,
15,
16,
17,
21] regarding the determinants of household fuel choice behaviours in terms of fuel stacking have often been accompanied by rigorous statistical modelling of survey data, the most common technique being multinomial logistic regression.
Multinomial logistic regression is often employed to relate the various fuel choice factors, such as age or income of household head, to whether or not the household is likely to stack one or more fuel types. Because multinomial logistic regression is fundamentally a statistical classification technique, employing logistic analysis to identify the determinants of household fuel choice is essentially a statistical classification problem. In the general sense of the concept, statistical classification involves classifying objects into one of several distinct groups or categories, based on the features of the objects. In the context of household fuel choice, classification refers to the task of identifying which category of cooking fuels a household employs—such as Firewood and Charcoal, Charcoal and Gas, or Firewood, Charcoal and Gas—based on factors, such as those mentioned above, including income, household occupancy, occupation and civil status of the household head. The subset of the factors which contribute most significantly to identifying the cooking fuels a household employs is then identified as the set of determinants of household fuel choice.
This paper follows the same methodology to identify the determinants of fuel choice behaviour in riverside communities in the Amazonas State of Brazil. Furthermore, we validate the multinomial logit model and investigate the influence of feature selection on its performance.
2.1. Multinomial Logistic Regression
Multinomial logistic regression, more commonly referred to as multinomial logit, is a multi-class classification technique that is used in multiclass scenarios, i.e., in scenarios where the dependent variable to be predicted has more than two categories. Multinomial logit is a multi-class extension of logistic regression and, in the following, we provide a brief background for the method.
Suppose that the choice of cooking fuel (denoted by
y) in a household is suspected to depend on the following variables:
: household income;
: occupation of the household head;
: civil status of household head;
: number of household occupants; and,
: availability and access to different fuel types. In general, there will be up to
d different variables considered. Let
represent the set of these
d variables, as:
Because the dependent variable y denotes the choice of cooking fuel, it is a class label or a categorical variable. For the moment, we suppose there are only two categories for y, namely: Gas (G) and Charcoal (C); in other words, we assume that a household uses either Gas (G) only or Charcoal (C) only. We may assign numerical attributes to y, as follows: Gas (G) and Charcoal (C) .
Logistic regression finds a linear combination of
, parameterised by
and
b, and passes the results through a logistic function that is bounded between 0 and 1 to obtain a probabilistic score for the dependent variable
y. More specifically, logistic regression seeks to find parameters
and
b that relate the independent variables
to the dependent variable
y, as follows [
45]:
where
The parameters
and
b are normally found by maximising the log-likelihood of the dataset or by minimising the cross-entropy error [
45]. The function that is given in (
3) is the logistic function, which ensures that the output
z remains within the range
, which can be interpreted as the probability that a household uses gas or
Charcoal.
The relationship in (
3) can be rewritten as:
Because
z is a probability value, (
4) explicitly captures the influence of the independent variables
on the log-likelihood of a household using a particular fuel type and not the other. In our particular scenario where we have only considered two categories for the dependent variable
y, namely
Gas (
G) and
Charcoal (
C), an increase in
z corresponds to an increase in the probability of
Gas use according to (
2). Thus, the relation in (
4) is equivalent to:
Now, suppose that we have more than two class labels or categories for
y, for example: (1)
Gas (
G); (2)
Firewood (
F); and, (3)
Charcoal (
C). In order to generalise logistic regression to these 3 categories, one of the categories is arbitrarily selected as the reference category, against which logistic regression models are trained for all other categories. For example, with category
C (
Charcoal) arbitrarily selected as the reference, the following logistic regression models are required:
Thus, from (
6) and (
7), the probability of each of the non-reference categories of
y—can be obtained in terms of the probability of the reference category
C, as follows:
Because the sum of the probabilities of all 3 categories must equal 1, the probability of the reference category can be solved for from the following:
from which the probability of any other category, i.e.,
Gas (
G) and
Charcoal (
C) can be derived according to (
10). In general, for a dependent variable
y with
k distinct categories,
logistic regression equations are necessary and sufficient for multinomial logistic regression.
However, like many other statistical classification methods, the statistical analysis that has accompanied the identification of the determinants of household fuel choice while using multinomial logistic regression have several pitfalls that can lead to overestimating or underestimating the importance of some variables. In particular,
The statistical models employed in the literature are not often validated [
11,
14,
17,
18,
21]. Model validation involves testing the model of fuel choice behaviour on a test dataset (that was not used for training the model) in order to evaluate the correctness of the model. Given that multinomial logit is a classification technique, the validation that is required is in terms of how accurately the multinomial logit model predicts the cooking fuel categories for all households based on the factors or variables considered. This measure of accuracy is known as the classification accuracy. A satisfactory classification accuracy is necessary in order to draw robust conclusions regarding the statistically significant factors. Without model validation, any conclusions drawn regarding the determinants of household fuel choice, despite their being statistically significant, may be unreliable, since the logit models may have poor classification accuracy.
Achieving poor classification accuracy from validation using the multinomial logit model may suggest one of two things: first, more sophisticated machine learning algorithms for classification, such as artificial neural networks [
46], may be used in place of multinomial logit to achieve superior classification accuracy; with these machine learning approaches, different conclusions may be drawn regarding the determinants of household fuel choice. Secondly, the relationship between fuel choice behaviour and the variables considered may be inconsequential, despite some variables being statistically significant.
Several surveys collect much information about a given household; some parameters tend to be irrelevant to the understanding of their fuel choice behaviour. For example, Pundo [
41] collected information, such as the household labour activities and found that they have no significant influence on the energy choice behaviour. Understandably, such information is collected because it is safer to make no prior assumptions as to the factors that determine the fuel choice. However, these nuisance factors, when considered in the statistical model, often cause over-fitting and often lead to identifying the wrong factors as the predominant ones. Specifically, the inclusion of these nuisance factors in the statistical models tend to account for noisy samples, so that the model fails to correctly predict new samples. This problem makes feature selection an indispensable aspect of statistical modelling. Feature selection involves finding an optimal subset of the fuel choice factors to be used to develop the multinomial logit model in order to reduce the effect of overfitting that may result from including nuisance factors.
In our efforts to identify the determinants of fuel choice behaviour in riverside communities in the Amazonas, we simultaneously address the above issues of model validation and feature selection in order to obtain robust conclusions that can positively and consequentially influence energy policy.
5. Effects of Feature Selection
Often, not all of the response variables gathered in a survey are relevant in determining the fuel choice behaviour of households; examples include the type of plantations or the number of pets in the household. Other response variables may be redundant in the presence of others; for example, in a community where there is a fairly equal number of household occupants, the number of males in the household may be redundant, if the number of females is already considered. The inclusion of these redundant and irrelevant response variables in the multinomial logit model can lead to overfitting of the model, and may highlight the wrong determinants.
Feature selection involves selecting the optimal subset out of a set of response variables (features), which does not contain redundant or irrelevant response variables, so that the trained model suffers a reduced effect of overfitting. For a dataset with n response variables, there are subsets that may be formed from the set of n features. The simplest way to choose the best performing subset is to perform cross-validation on each one of the subsets, i.e., for each one of the subsets, a multinomial logit model is trained and tested on a test fold. The subset that yields the best classification or predictive accuracy is chosen as the optimal subset. This approach to feature selection is known as a wrapper. Because wrappers involve exhaustively evaluating the cross-validation predictive accuracy for each of the subsets, they can be computationally expensive for large number of response variables n. Thus, other approaches, known as filters, in a bid to reduce the computation required, evaluate such metrics as the mutual information or correlation coefficient instead of the cross-validation predictive accuracy of the model. Alternatively, rather than an exhaustive searching through all possible subsets, other feature selection approaches employ local search procedures, such as variable neighbourhood search, so that they evaluate the performance for only a few probable subsets.
More practically, an L1-regularisation can be used to automatically select features during the training of the multinomial logit model. This does not present any computational burden, since there is no exhaustive search of the optimal features, but rather the regularisation penalty essentially forces the irrelevant features to zero.
In this paper, we employ the L1-penalty with the regularisation coefficient set at , which was optimised via cross-validation. This regularisation setting zeroed out four communities, which were thus excluded from the multinomial logit model.
Our results show that the set of all 14 response variables (that are expanded to 26, once nominal response variables are one-hot encoded) in
Table 1 give a classification accuracy of
, while the optimal subset of features (16 including one-hot encoded variables) obtained via the L1-regularisation, gives a classification accuracy of
; the difference between these two classification accuracies has a
p-value of
, and it is statistically significant at the
confidence level.
Therefore, we proceed to train a multinomial logit model with only the optimal subset of features in order to identify the determinants of household fuel choice, after redundant and irrelevant features, such as the number of men and women in the household and the place of cooking, have been removed. We believe the number of men and women were found to be irrelevant features, because they likely contain no more information over the number of people at meals daily.
Table 7 shows the results.
5.1. Interpretation of Results
The following conclusions are drawn from the results presented in
Table 7:
5.1.1. Charcoal and Gas vs. Firewood, Charcoal and Gas
The determinant of this fuel stacking behaviour is the income level of the household. Specifically, as their income level increases, a household that uses Charcoal and Gas as their cooking fuels becomes less likely to add Firewood to their fuel mix.
5.1.2. Firewood and Gas vs. Charcoal and Gas
The determinant of this fuel switching behaviour is the number of people at meals each day. In particular, as the number of people at meals increases, a household that uses Charcoal and Gas as cooking fuels becomes more likely to switch the Charcoal component to Firewood.
5.1.3. Gas vs. Charcoal and Gas
For this fuel stacking behaviour, none of the determinants is significant, even at the
confidence level. This contrasts with the counter-intuitive conclusions presented in
Section 4.3.3, where the number of meals and the number of people at meals were identified as significant.
7. Conclusions
The Sustainable Development Goals (SDGs) are a call for action by all countries to promote prosperity while protecting the planet. Goal 7 calls for universal access to affordable, reliable, and sustainable energy. It also encourages the adoption of renewable energy sources.
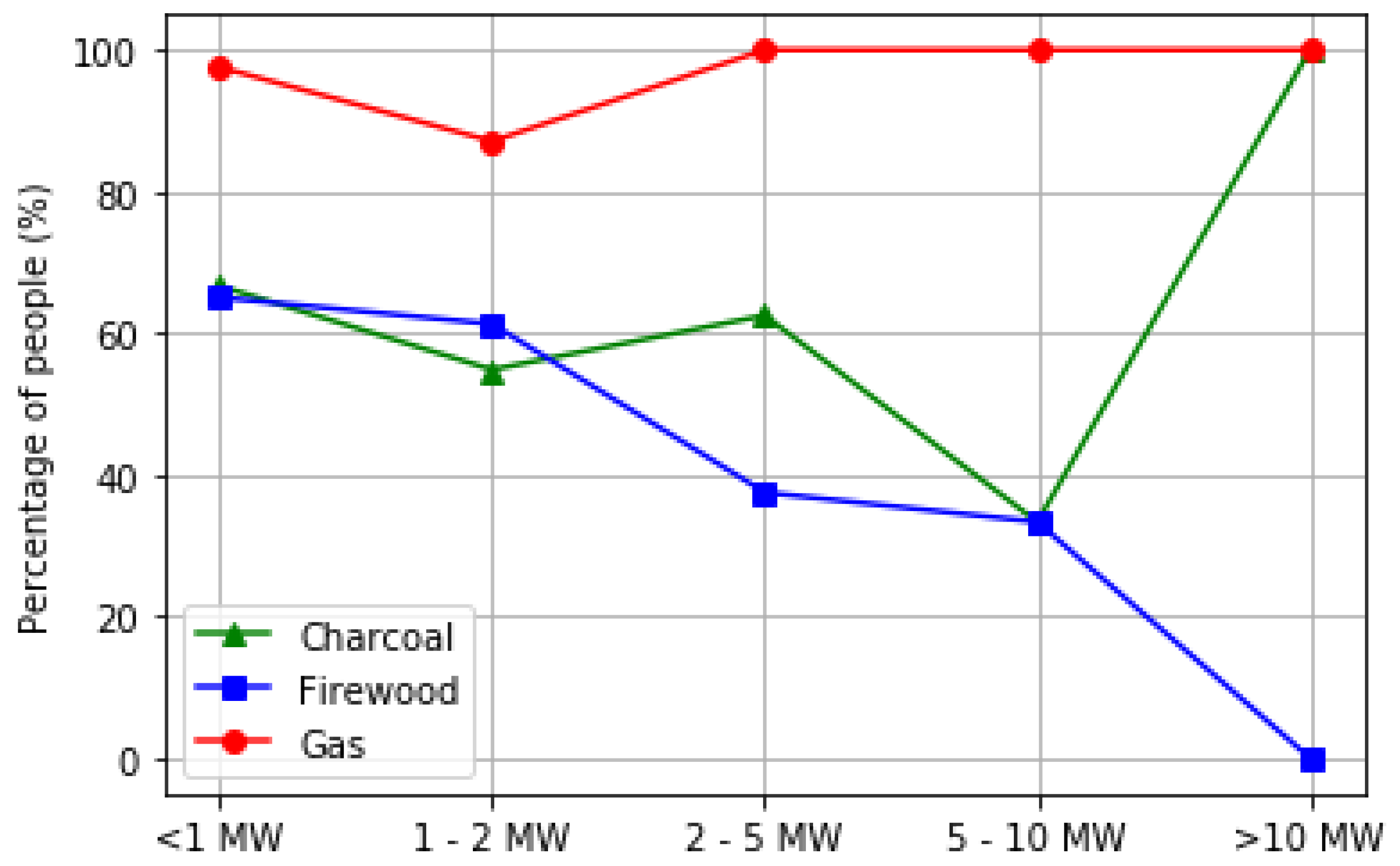
In this paper, we studied a total of 14 isolated riverside communities from the largest State of Brazil, in the heart of the Amazon Rainforest, none of them electrified until 2018. We were able to show, with statistical significance, that the fuel choice, fuel switching, and fuel stacking are dependent on several key factors, including: age of household, the number of people at meals each day, the number of meals daily, the community, education of the household head, and the income level of the household.
A key finding is that a model using feature selection produces a more statistically accurate model than one produced without this. Furthermore, this change alters which key factors are identified as significant.
It follows that an understanding of fuels use and stacking in communities can drive choice for energy empowerment that will form strong positive feedback loops towards several SDGs. Regarding the education determinant, we note that there are schools in 12 of the 14 communities, but those communities are mainly house elementary age pupils. If a dweller is to be educated further, they will migrate to the city. The funding for city education is not usually funded by government programs. However, some families receive a monthly stipend from the State governments income distribution program, Bolsa Flor This stipend is less than the minimum wage. Policies that lack an awareness of the local context may unintentionally reinforce inequalities. During the interviews, it became obvious that most resident community leaders are aware of the actual status quo of the three dimensions of sustainable development—economic, social, and environmental. Improvements can be made through an effective universal electrification program; by providing comprehensive opportunities for teachers of all levels, and through better income programs that are focused on regional potentials and local supply chains.
Furthermore, when considering that the 14 communities surveyed use diesel generators for electricity a few hours a day, we can conclude that, so far, the ‘Goal 7: Affordable and Clean Energy’ and ‘Goal 13: Climate Action’ are far from being reached in the Amazonas State. The communities in the Amazonas State in Brazil do not have highways or telecommunication infrastructure, only the rivers. The challenge is huge in terms of logistics and investment.
Extrapolating the results to the rest of the 2261 communities and 41,167 families that are without electricity in the Amazonas State, the SDGs will not be met until 2030. Moreover, the green house gas emissions will continue to rise.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}