An Ensemble Stochastic Forecasting Framework for Variable Distributed Demand Loads


Abstract
1. Introduction
- Define an online stochastic predictive framework with a computation time of less than a minute.
- Define a prediction model capable of training a robust forecast model with a single or limited historical dataset.
- Define a prediction framework scalable and adaptable to different distributed demand load types.
- Define an error correction model capable of compensating forecast error.
2. Challenges in Load Forecasting
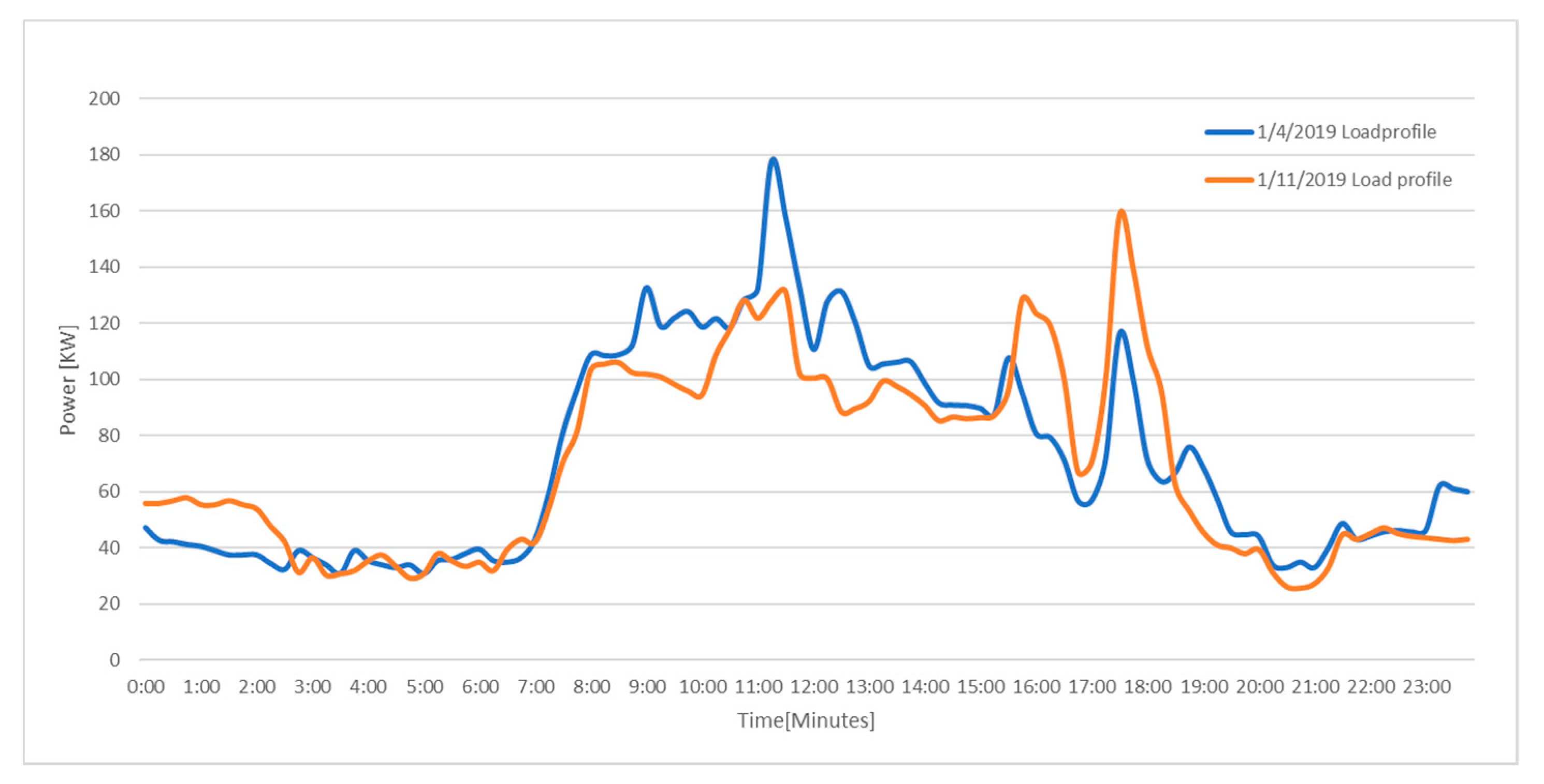
2.1. Unreliable Data Acquisition
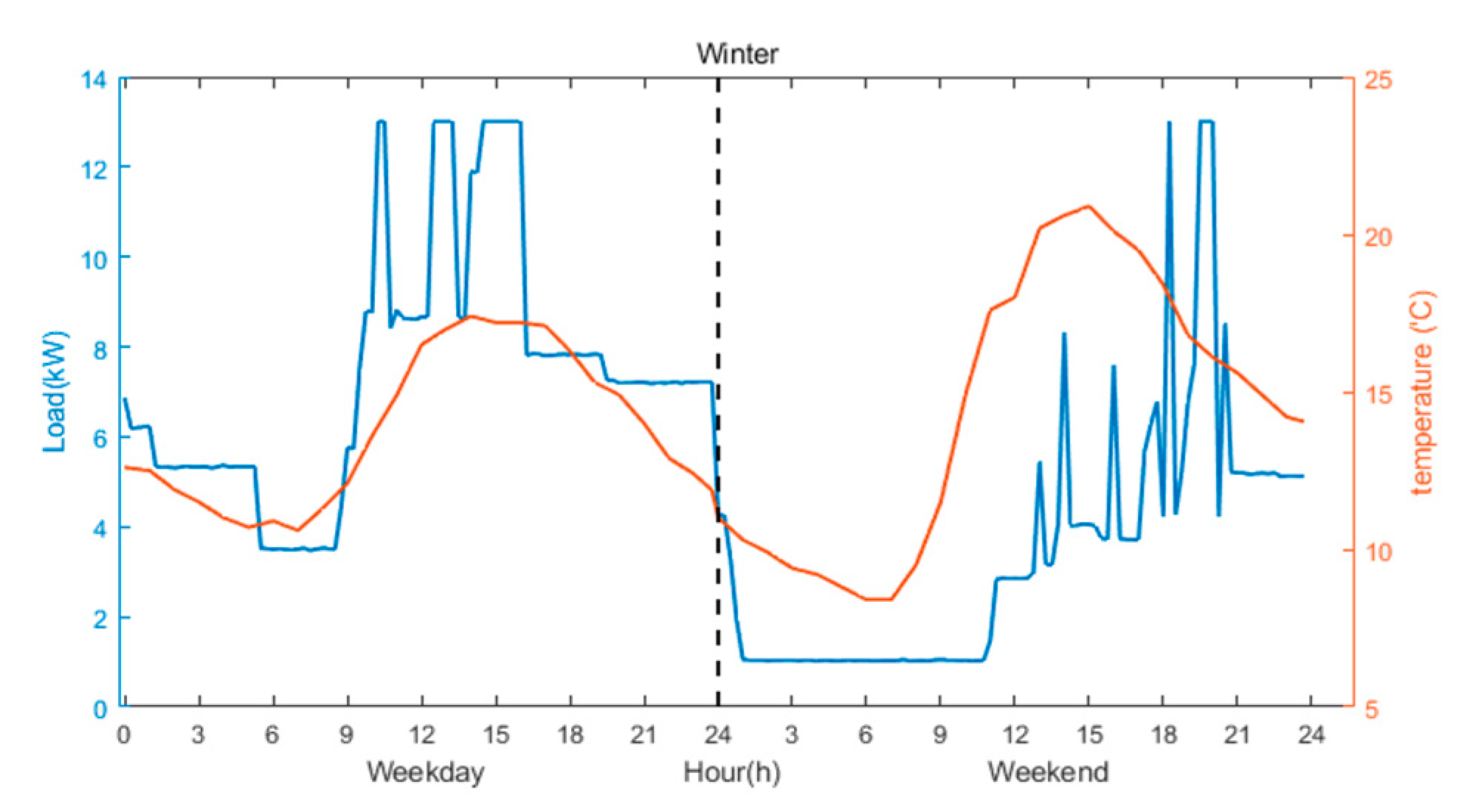
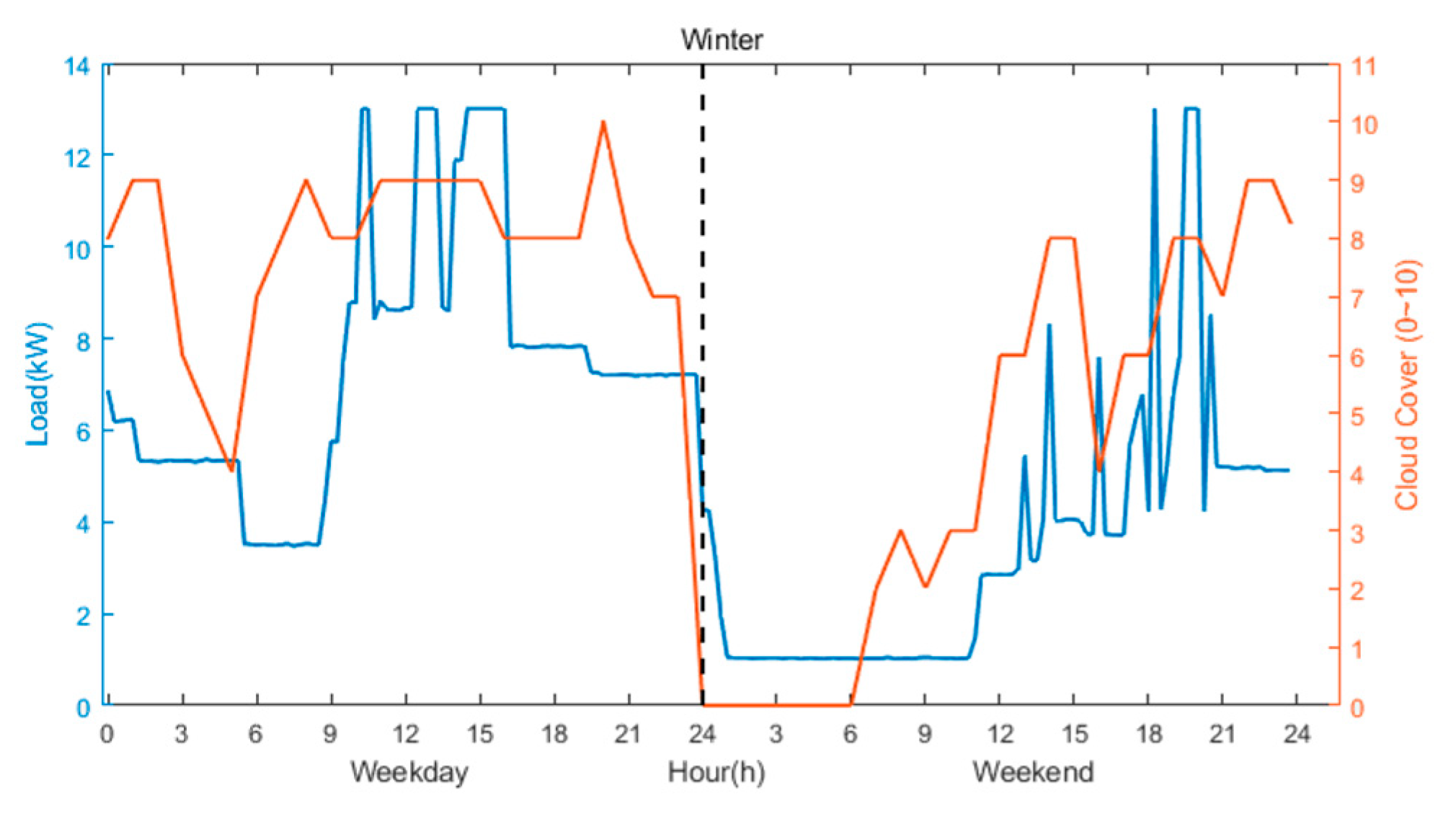
2.2. Adaptive Predictive Modeling
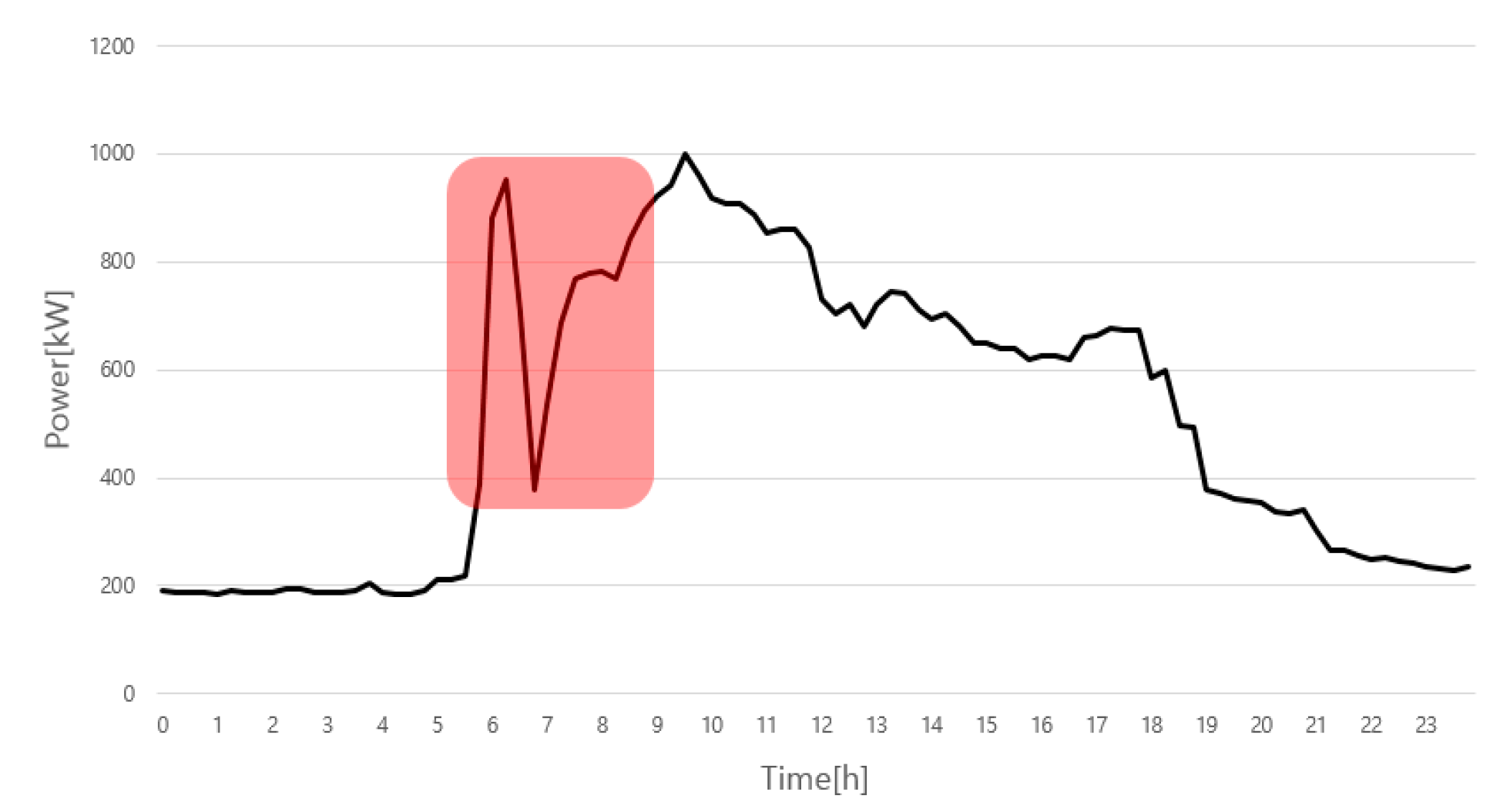
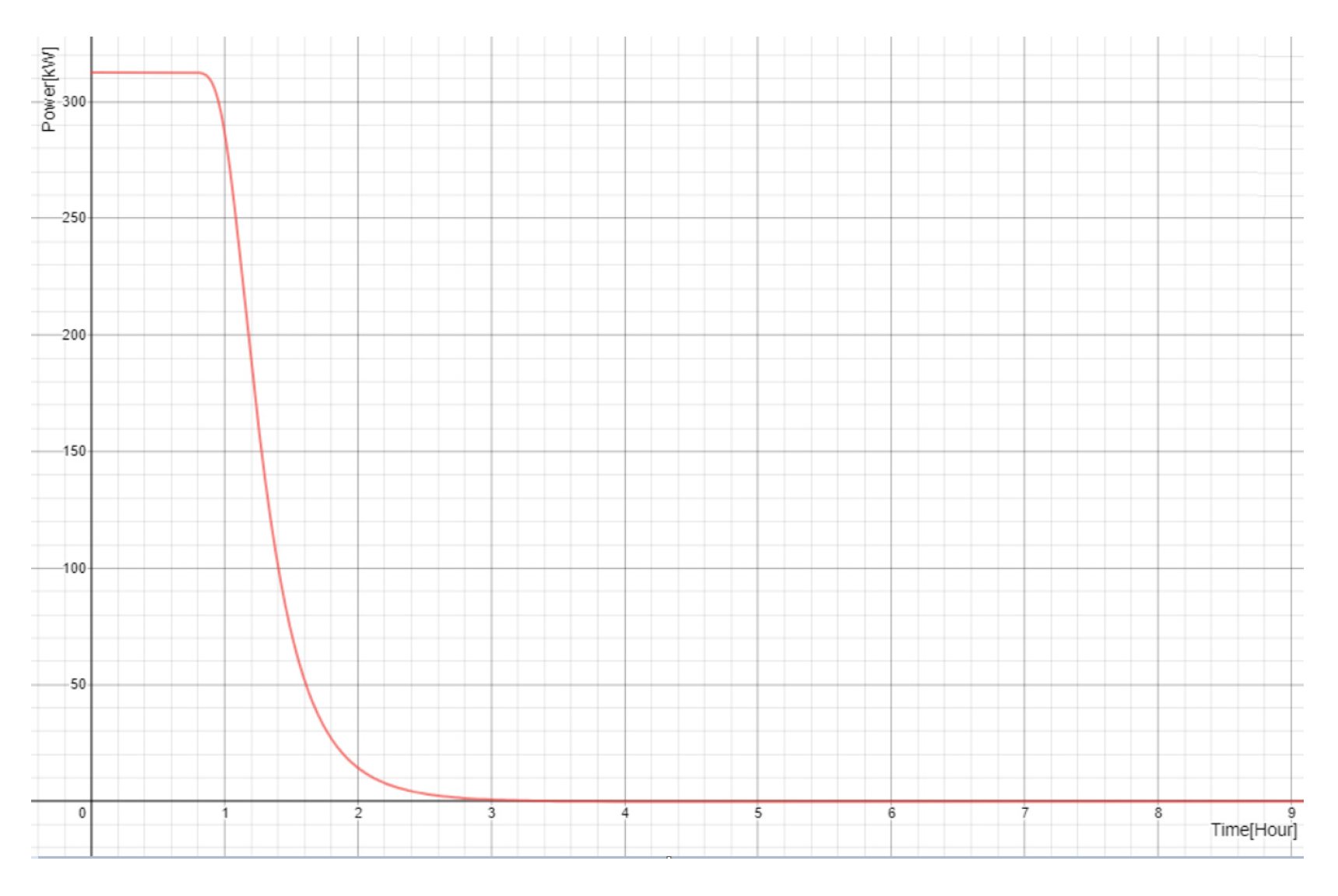
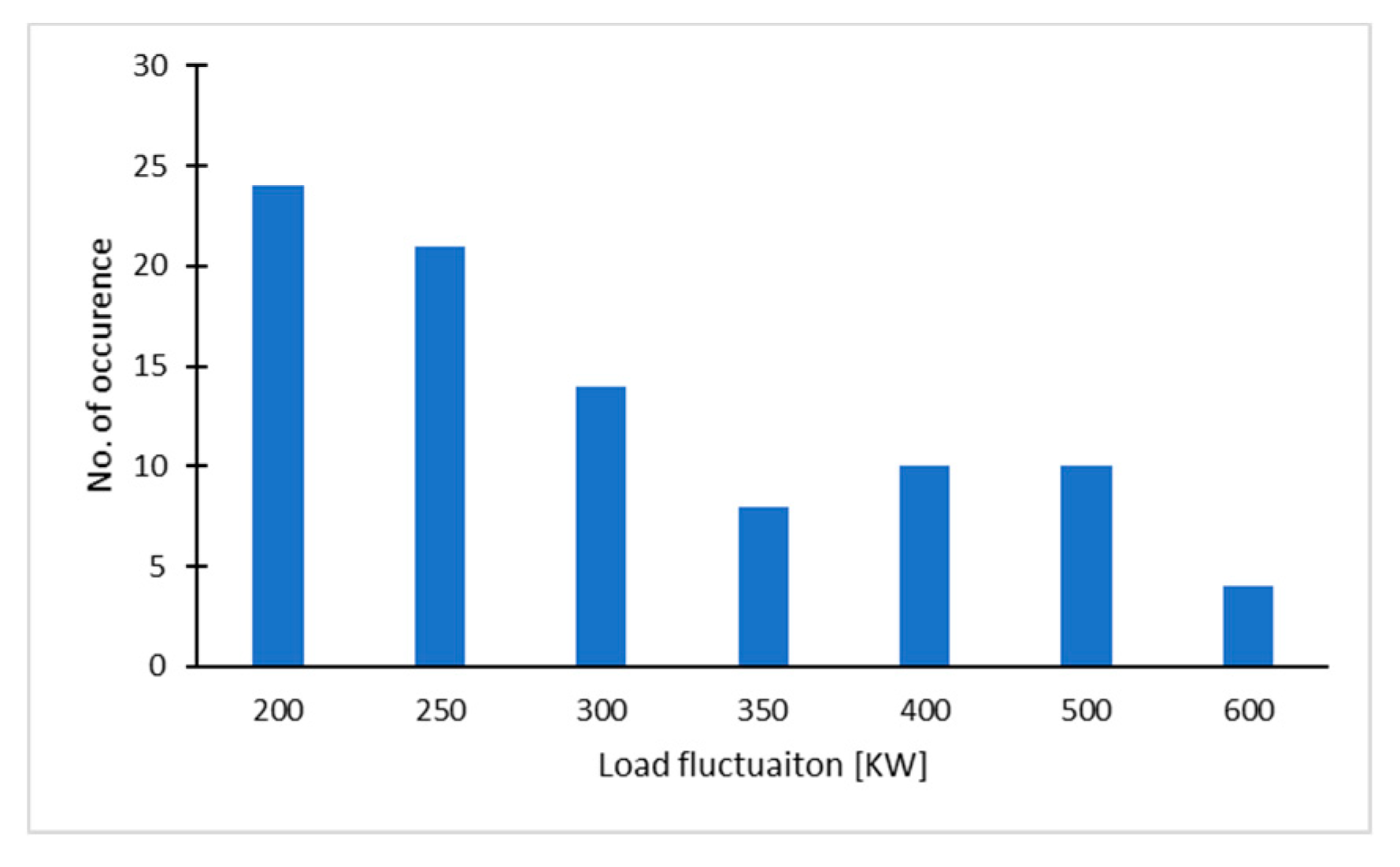
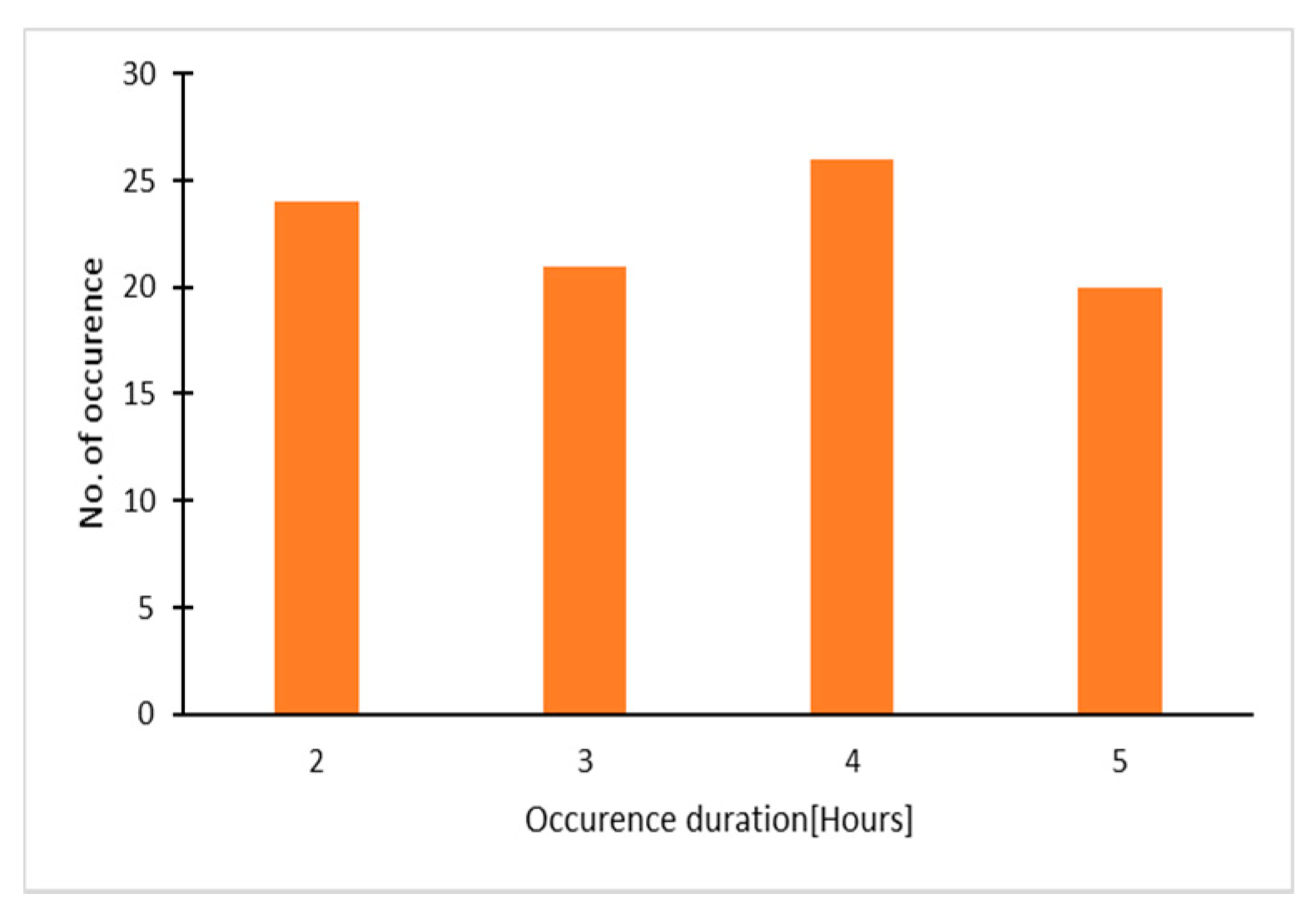
2.3. Transient-State Forecast Error
2.4. Model Selection Criteria
3. Probabilistic Load Forecasting Model Generation
3.1. Data Integrity Risk Reduction
3.2. Feature Variable Selection
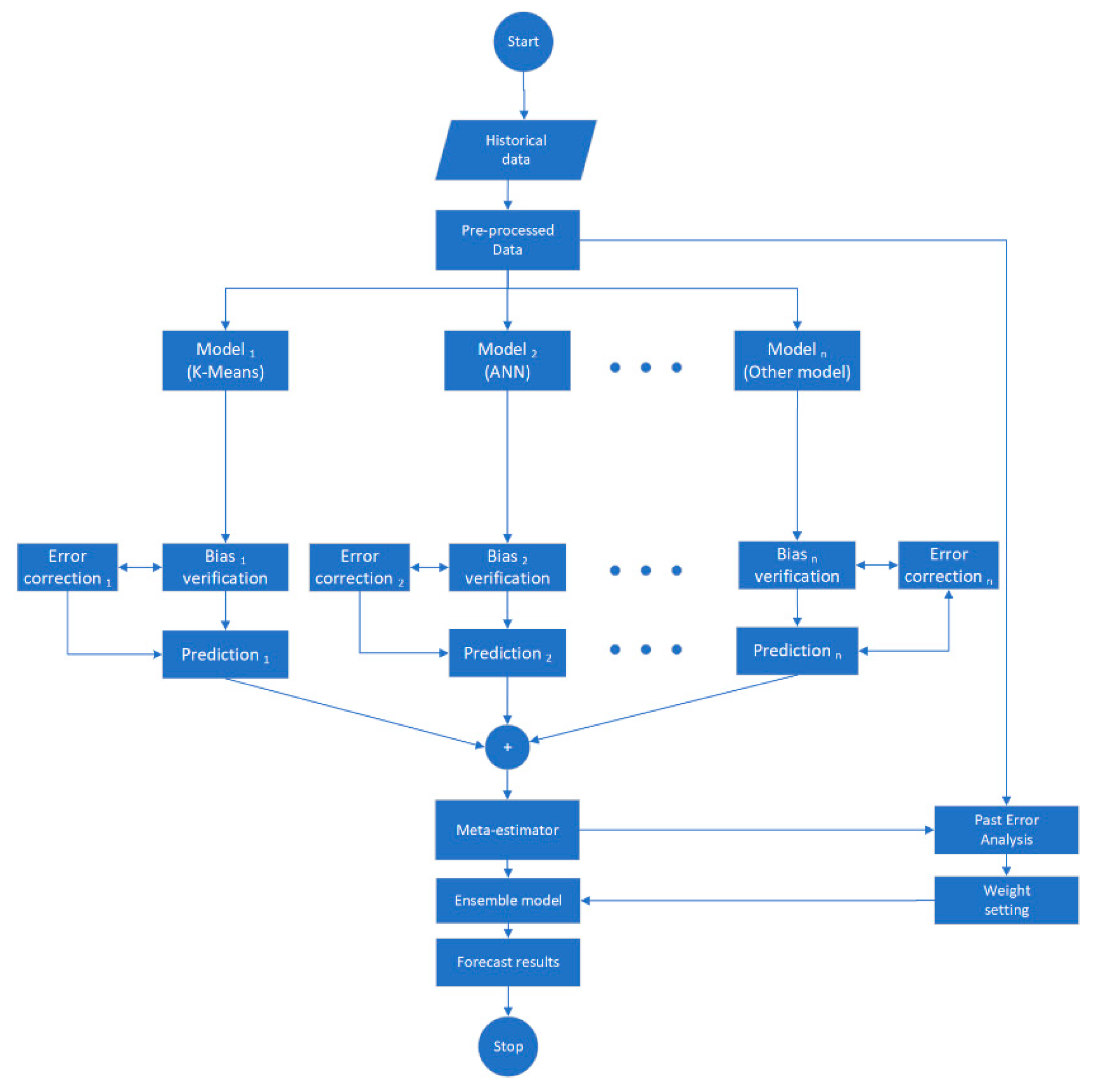
3.3. The Ensemble Strategy of Multiple Models
| Algorithm 1: Algorithm for Stochastic Demand Load Forecast. | |
| Input: | Recent past actual load data |
| Forecast period feature parameters | |
| Estimated ensemble hyperparameters | |
| Trained prediction models | |
| Output: | Time-series stochastic load forecast |
| 1: | Select the input parameters, from the set of n forecast features variables at time t. |
| 2: | For each point-forecast model, estimate the load , at time t with ensemble hyperparameter as shown: |
| 3: | For each measured load, from a set of recently measured load data, forecast the demand load, and estimate the error, as follows: |
| ; | |
| 4: | Shift the load forecast, with the error as follows: |
| = ; | |
| 5: | Fit a histogram to . From the histogram, we estimate the mean, minimum and maximum value at a 95% confidence interval |
3.4. Error Correction Model
3.4.1. Variance Error Correction
| Algorithm 2: Variance Error Correction Model. | |
| Input: | Recent past 7-days(N) actual load data |
| Output: | Deterministic load forecast values |
| 1: | Select the input parameters, from the set of features variables at time t of load profile, |
| 2: | Estimate the load , at time t of each daily load profile, with K-means forecast model, |
| ; , | |
| Repeat process; | |
| 3: | For each actual load, from a set of recent 7-days, measured load data, estimate the error, as follows: |
| ; , | |
| 4: | For the forecast period, t, estimate average error: |
| 5: | Shift load forecast, with mean error to form shifted load as follows: |
| =; | |
3.4.2. Permanent Bias Error Correction
| Algorithm 3: Permanent Bias Error Correction Model. | |
| Input: | Recent past 7-days(N) actual load data |
| Output: | Deterministic load forecast values |
| 1: | Select the input parameters, from the set of features variables at time t of load profile, . |
| 2: | Estimate the load , at time t of each daily load profile, with K-means forecast model, |
| ; , | |
| Repeat process; | |
| 3: | For each actual load, from a set of recent 7-days, measured load data, estimate the error, as follows: |
| ; , | |
| 4: | For the forecast period, t, estimate average error: |
| , | |
| 5: | For all if or , then estimate error rate, |
| , | |
| 6: | Shift load forecast, with error rate to form shifted load as follows: |
| , | |
3.4.3. Temporary Bias Error Correction
4. Case Study and Scenario Analysis
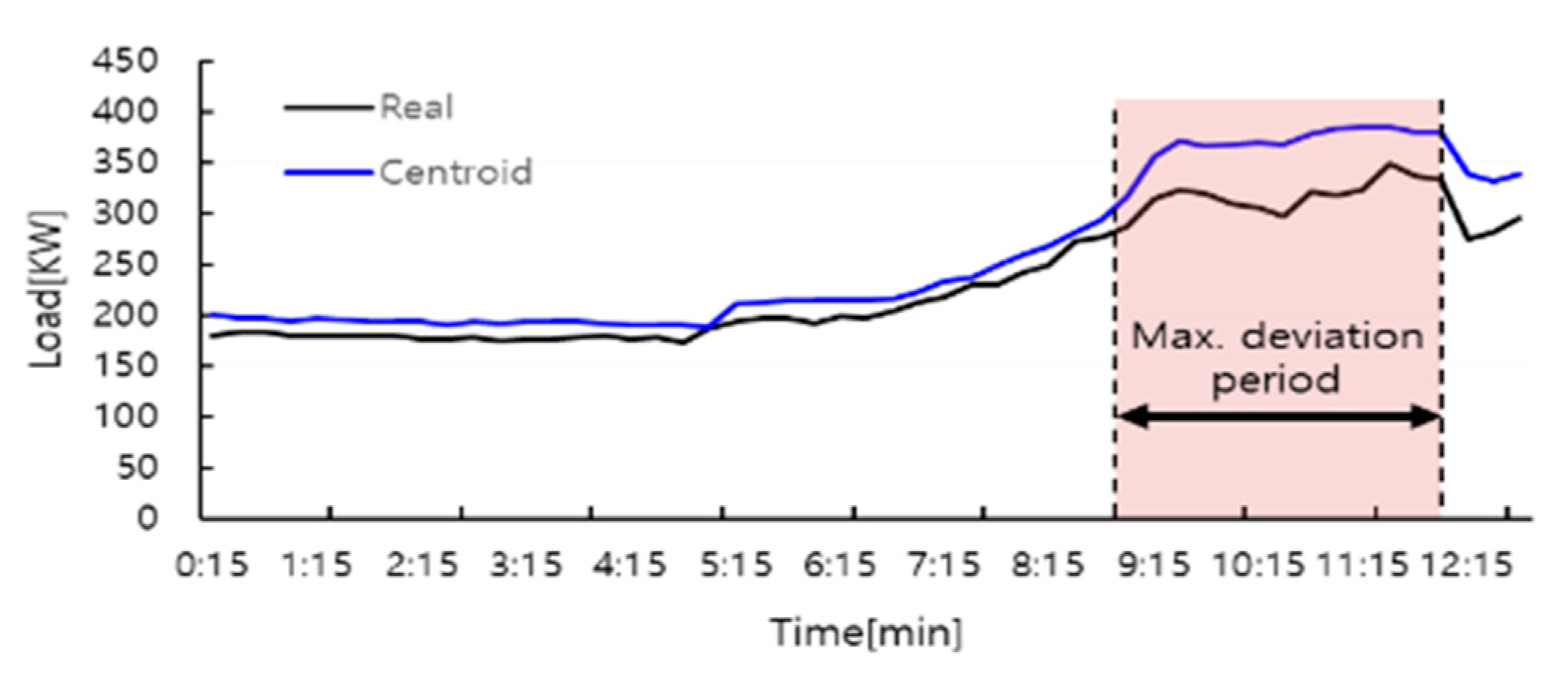
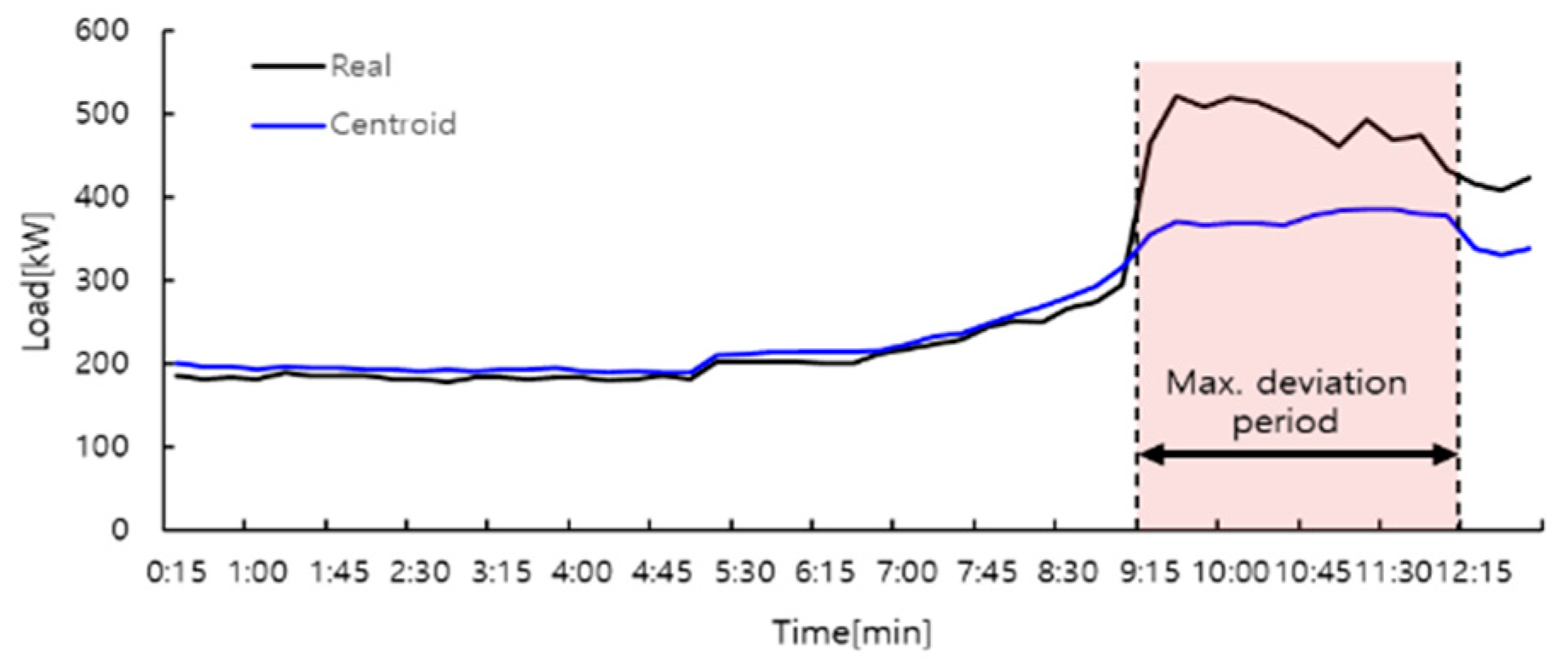
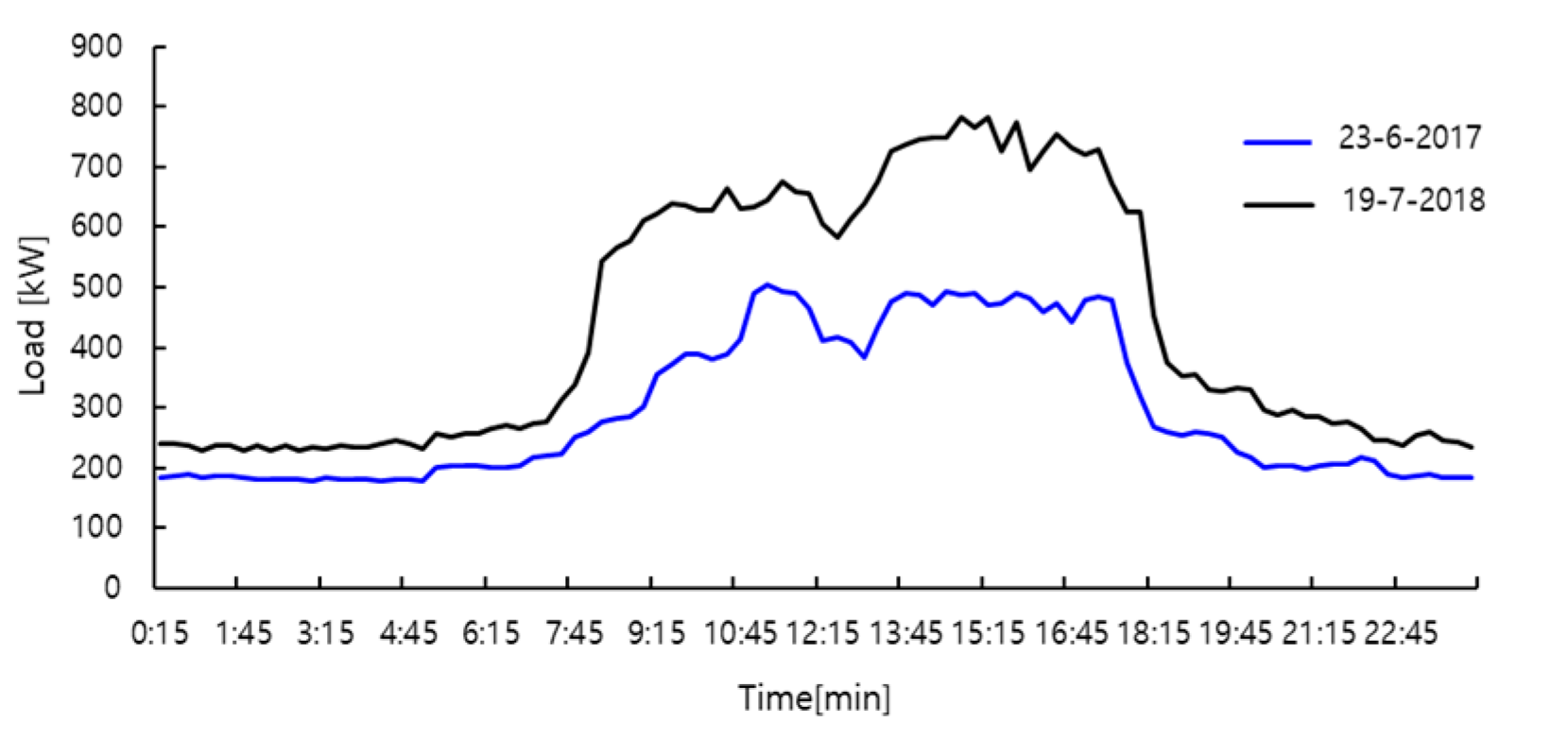
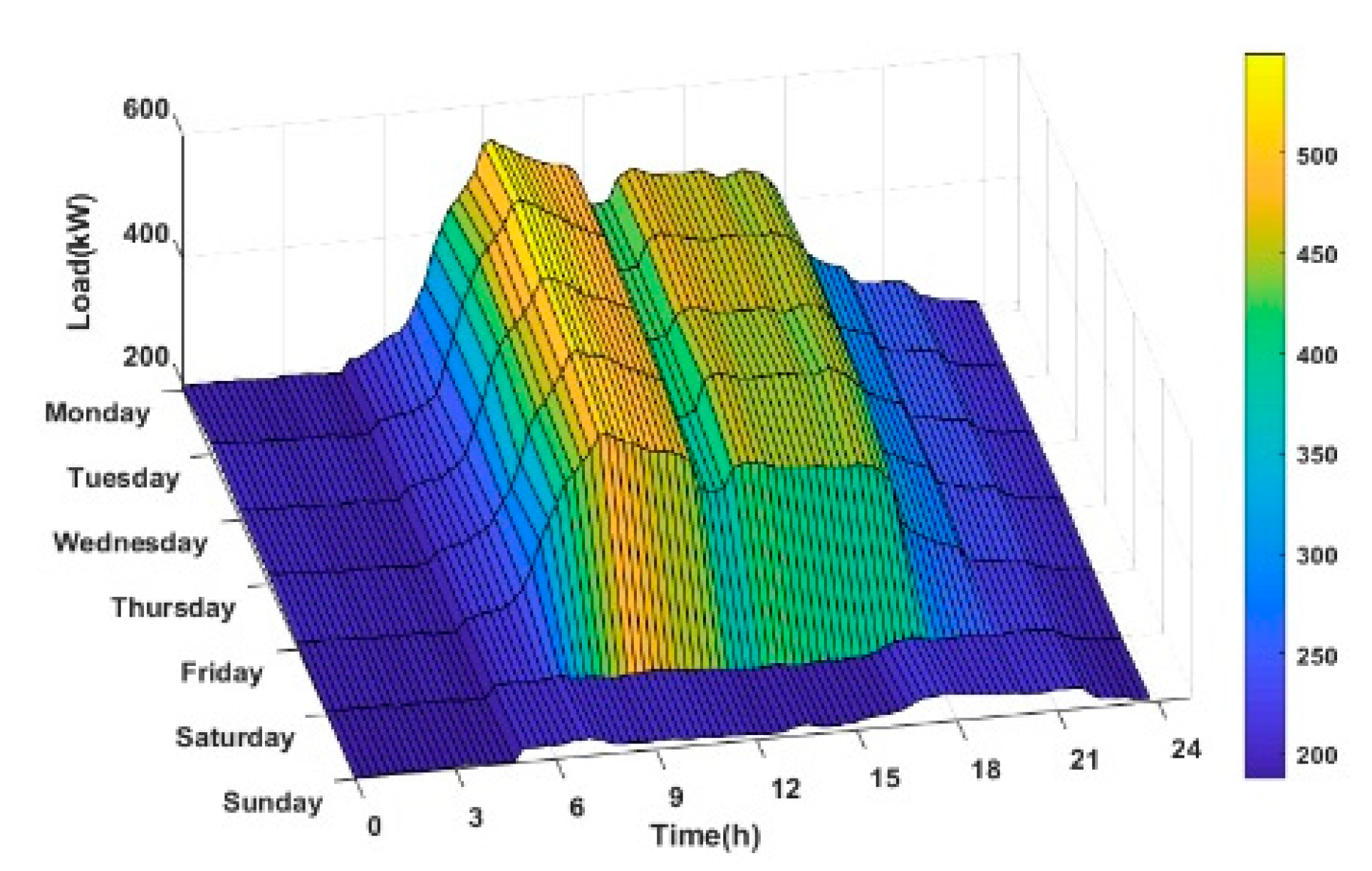
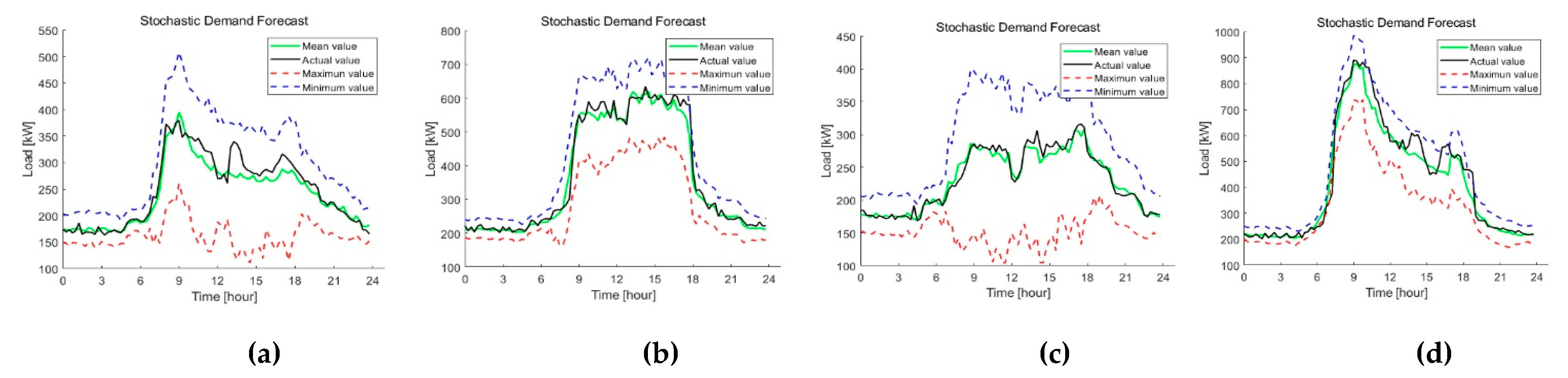
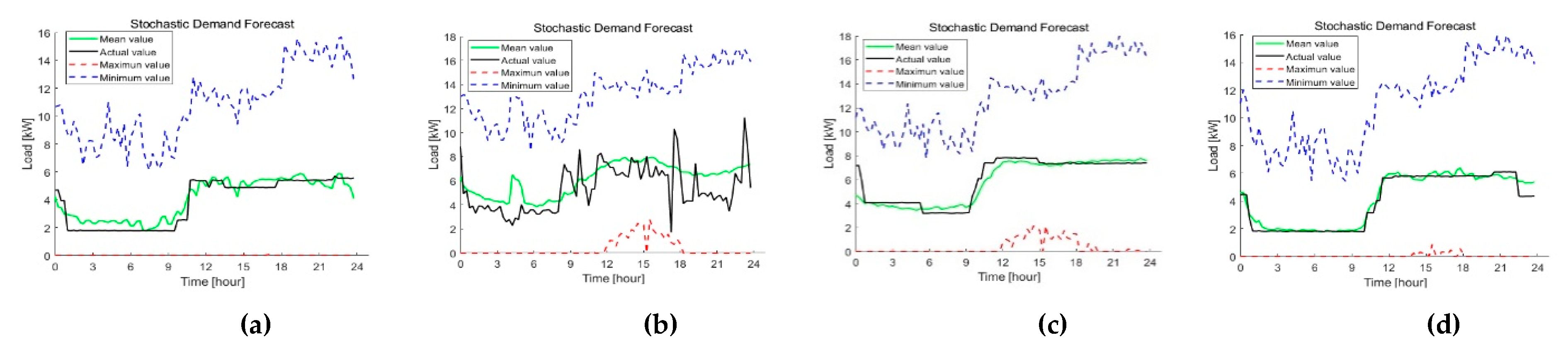
4.1. Case I: Performance of the Proposed Model on Korea Power Company Buildings Dataset
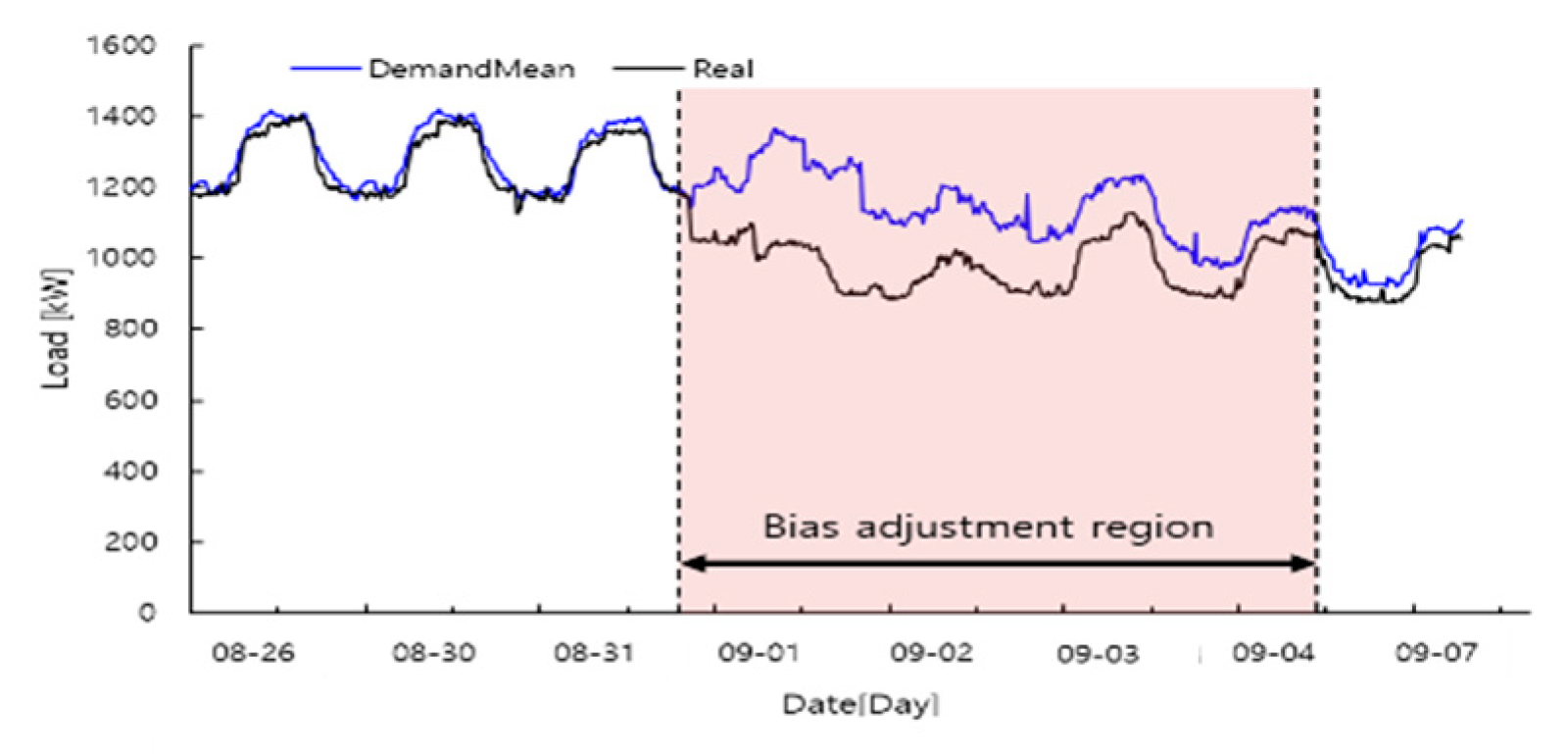
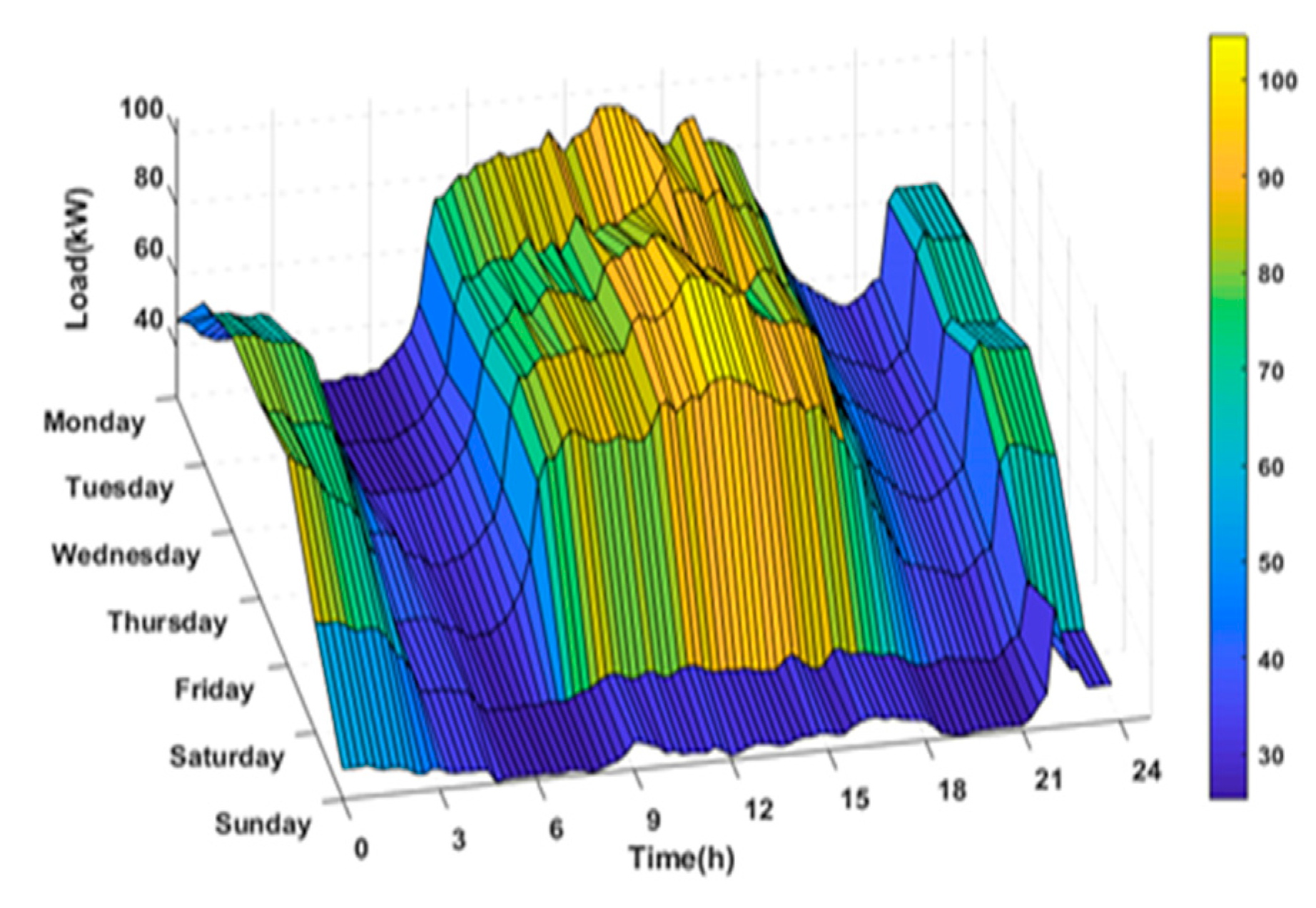
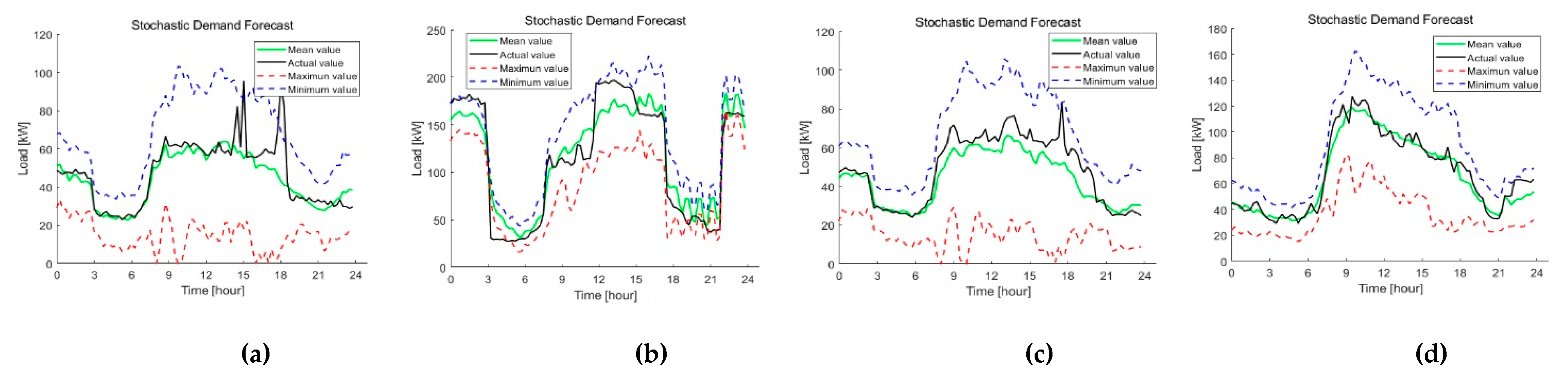
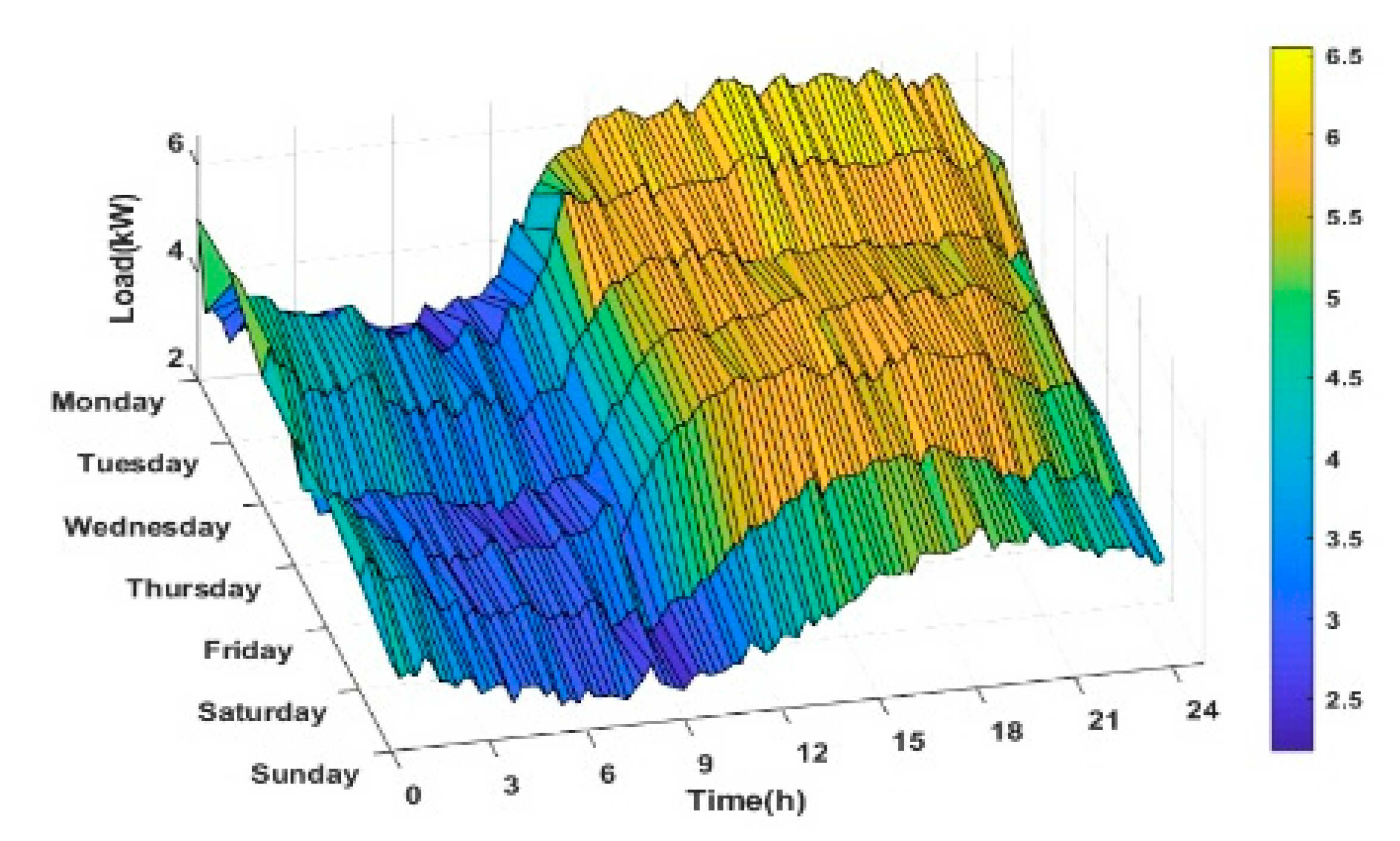
4.2. Case II: Performance of the Proposed Model on Testbed Dataset
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Spiliotis, K.; Ramos Gutierrez, A.I.; Belmans, R. Demand flexibility versus physical network expansions in distribution grids. Appl. Energy 2016, 182, 613–624. [Google Scholar] [CrossRef]
- Fitariffs. Feed-in Tariffs. Available online: https://www.fitariffs.co.uk/fits/ (accessed on 14 January 2019).
- Nosratabadi, S.M.; Hooshmand, R.-A.; Gholipour, E. A comprehensive review on microgrid and virtual power plant concepts employed for distributed energy resources scheduling in power systems. Renew. Sustain. Energy Rev. 2017, 67, 341–363. [Google Scholar] [CrossRef]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- Xenos, D.P.; Mohd Noor, I.; Matloubi, M.; Cicciotti, M.; Haugen, T.; Thornhill, N.F. Demand-side management and optimal operation of industrial electricity consumers: An example of an energy-intensive chemical plant. Appl. Energy 2016, 182, 418–433. [Google Scholar] [CrossRef]
- Sepehr, M.; Eghtedaei, R.; Toolabimoghadam, A.; Noorollahi, Y.; Mohammadi, M. Modeling the electrical energy consumption profile for residential buildings in Iran. Sustain. Cities Soc. 2018, 41, 481–489. [Google Scholar] [CrossRef]
- Tucci, M.; Crisostomi, E.; Giunta, G.; Raugi, M. A Multi-Objective Method for Short-Term Load Forecasting in European Countries. IEEE Trans. Power Syst. 2016, 31, 3537–3547. [Google Scholar] [CrossRef]
- Wang, C.-h.; Grozev, G.; Seo, S. Decomposition and statistical analysis for regional electricity demand forecasting. Energy 2012, 41, 313–325. [Google Scholar] [CrossRef]
- Calderón, C.; James, P.; Urquizo, J.; McLoughlin, A. A GIS domestic building framework to estimate energy end-use demand in UK sub-city areas. Energy Build. 2015, 96, 236–250. [Google Scholar] [CrossRef]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Wang, Q.; Zhou, B.; Li, Z.; Ren, J. Forecasting of short-term load based on fuzzy clustering and improved BP algorithm. In Proceedings of the 2011 International Conference on Electrical and Control Engineering, Yichang, China, 16–18 September 2011; pp. 4519–4522. [Google Scholar]
- Hernandez, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J.; Chinarro, D.; Gomez-Sanz, J.J.; Cook, D. A multi-agent system architecture for smart grid management and forecasting of energy demand in virtual power plants. IEEE Commun. Mag. 2013, 51, 106–113. [Google Scholar] [CrossRef]
- Hippert, H.S.; Pedreira, C.E.; Souza, R.C. Neural networks for short-term load forecasting: A review and evaluation. IEEE Trans. Power Syst. 2001, 16, 44–55. [Google Scholar] [CrossRef]
- Kaytez, F.; Taplamacioglu, M.C.; Cam, E.; Hardalac, F. Forecasting electricity consumption: A comparison of regression analysis, neural networks and least squares support vector machines. Int. J. Electr. Power Energy Syst. 2015, 67, 431–438. [Google Scholar] [CrossRef]
- Jain, R.K.; Smith, K.M.; Culligan, P.J.; Taylor, J.E. Forecasting energy consumption of multi-family residential buildings using support vector regression: Investigating the impact of temporal and spatial monitoring granularity on performance accuracy. Appl. Energy 2014, 123, 168–178. [Google Scholar] [CrossRef]
- Kuo, R.J.; Li, P.S. Taiwanese export trade forecasting using firefly algorithm based K-means algorithm and SVR with wavelet transform. Comput. Ind. Eng. 2016, 99, 153–161. [Google Scholar] [CrossRef]
- Zhang, F.; Deb, C.; Lee, S.E.; Yang, J.; Shah, K.W. Time series forecasting for building energy consumption using weighted Support Vector Regression with differential evolution optimization technique. Energy Build. 2016, 126, 94–103. [Google Scholar] [CrossRef]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Short-term load forecasting for non-residential buildings contrasting artificial occupancy attributes. Energy Build. 2016, 130, 519–531. [Google Scholar] [CrossRef]
- Sandels, C.; Widén, J.; Nordström, L.; Andersson, E. Day-ahead predictions of electricity consumption in a Swedish office building from weather, occupancy, and temporal data. Energy Build. 2015, 108, 279–290. [Google Scholar] [CrossRef]
- Wang, X.; Lee, W.; Huang, H.; Szabados, R.L.; Wang, D.Y.; Olinda, P.V. Factors that Impact the Accuracy of Clustering-Based Load Forecasting. IEEE Trans. Ind. Appl. 2016, 52, 3625–3630. [Google Scholar] [CrossRef]
- Deihimi, A.; Orang, O.; Showkati, H. Short-term electric load and temperature forecasting using wavelet echo state networks with neural reconstruction. Energy 2013, 57, 382–401. [Google Scholar] [CrossRef]
- Mena, R.; Rodrguez, F.; Castilla, M.; Arahal, M. A prediction model based onneural networks for the energy consumption of a bioclimatic building. Energy Build. 2014, 82, 142–155. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, Q.; Sun, M.; Kang, C.; Xia, Q. An Ensemble Forecasting Method for the Aggregated Load With Subprofiles. IEEE Trans. Smart Grid 2018, 9, 3906–3908. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, N.; Tan, Y.; Hong, T.; Kirschen, D.S.; Kang, C. Combining Probabilistic Load Forecasts. IEEE Trans. Smart Grid 2019, 10, 3664–3674. [Google Scholar] [CrossRef]
- Chen, Y.; Tan, H.; Berardi, U. Day-ahead prediction of hourly electric demand in non-stationary operated commercial buildings: A clustering-based hybrid approach. Energy Build. 2017, 148, 228–237. [Google Scholar] [CrossRef]
- Fumo, N.; Mago, P.; Luck, R. Methodology to estimate building energy consumption using EnergyPlus Benchmark Models. Energy Build. 2010, 42, 2331–2337. [Google Scholar] [CrossRef]
- Ji, Y.; Xu, P.; Ye, Y. HVAC terminal hourly end-use disaggregation in commercial buildings with Fourier series model. Energy Build. 2015, 97, 33–46. [Google Scholar] [CrossRef]
- Bracale, A.; Caramia, P.; Carpinelli, G.; Fazio, A.R.D.; Varilone, P. A Bayesian-Based Approach for a Short-Term Steady-State Forecast of a Smart Grid. IEEE Trans. Smart Grid 2013, 4, 1760–1771. [Google Scholar] [CrossRef]
- Collotta, M.; Pau, G. An Innovative Approach for Forecasting of Energy Requirements to Improve a Smart Home Management System Based on BLE. IEEE Trans. Green Commun. Netw. 2017, 1, 112–120. [Google Scholar] [CrossRef]
- Deng, Z.; Wang, B.; Xu, Y.; Xu, T.; Liu, C.; Zhu, Z. Multi-Scale Convolutional Neural Network With Time-Cognition for Multi-Step Short-Term Load Forecasting. IEEE Access 2019, 7, 88058–88071. [Google Scholar] [CrossRef]
- Ding, N.; Benoit, C.; Foggia, G.; Bésanger, Y.; Wurtz, F. Neural Network-Based Model Design for Short-Term Load Forecast in Distribution Systems. IEEE Trans. Power Syst. 2016, 31, 72–81. [Google Scholar] [CrossRef]
- Han, L.; Peng, Y.; Li, Y.; Yong, B.; Zhou, Q.; Shu, L. Enhanced Deep Networks for Short-Term and Medium-Term Load Forecasting. IEEE Access 2019, 7, 4045–4055. [Google Scholar] [CrossRef]
- Li, R.; Li, F.; Smith, N.D. Multi-Resolution Load Profile Clustering for Smart Metering Data. IEEE Trans. Power Syst. 2016, 31, 4473–4482. [Google Scholar] [CrossRef]
- Motepe, S.; Hasan, A.N.; Stopforth, R. Improving Load Forecasting Process for a Power Distribution Network Using Hybrid AI and Deep Learning Algorithms. IEEE Access 2019, 7, 82584–82598. [Google Scholar] [CrossRef]
- Ouyang, T.; He, Y.; Li, H.; Sun, Z.; Baek, S. Modeling and Forecasting Short-Term Power Load With Copula Model and Deep Belief Network. IEEE Trans. Emerg. Top. Comput. Intell. 2019, 3, 127–136. [Google Scholar] [CrossRef]
- Tang, X.; Dai, Y.; Wang, T.; Chen, Y. Short-term power load forecasting based on multi-layer bidirectional recurrent neural network. IET Gener. Transm. Distrib. 2019, 13, 3847–3854. [Google Scholar] [CrossRef]
- Teixeira, J.; Macedo, S.; Gonçalves, S.; Soares, A.; Inoue, M.; Cañete, P. Hybrid model approach for forecasting electricity demand. CIRED Open Access Proc. J. 2017, 2017, 2316–2319. [Google Scholar] [CrossRef][Green Version]
- Xu, T.; Chiang, H.; Liu, G.; Tan, C. Hierarchical K-means Method for Clustering Large-Scale Advanced Metering Infrastructure Data. IEEE Trans. Power Deliv. 2017, 32, 609–616. [Google Scholar] [CrossRef]
- Zhang, W.; Quan, H.; Srinivasan, D. An Improved Quantile Regression Neural Network for Probabilistic Load Forecasting. IEEE Trans. Smart Grid 2019, 10, 4425–4434. [Google Scholar] [CrossRef]
- Khan, I.; Capozzoli, A.; Corgnati, S.P.; Cerquitelli, T. Fault Detection Analysis of Building Energy Consumption Using Data Mining Techniques. Energy Procedia 2013, 42, 557–566. [Google Scholar] [CrossRef]
- Carsey, V.J.; Wagner, C.G.; Walters, E.E.; Rosner, B.A. Resistant and test based outlier rejection: Effects on Gaussian one- and two-sample inference. Technometrics 1997, 39, 320–330. [Google Scholar] [CrossRef]
- Jovanovic, R.Z.; Sretenovic, A.A.; Zivkovic, B.D. Ensemble of various neural networks for prediction of heating energy consumption. Energy Build. 2015, 94, 189–199. [Google Scholar] [CrossRef]
- Zhang, Y.N.; O’Neill, Z.; Dong, B.; Augenbroe, G. Comparisons of inverse modeling approaches for predicting building energy performance. Build. Environ. 2015, 86, 177–190. [Google Scholar] [CrossRef]
- KEPCO. iSmart-Smart Power Management. Available online: https://pccs.kepco.co.kr/iSmart/ (accessed on 4 August 2017).
- Kweather. Kweather-Total Weather Service Provider. Available online: http://www.kweather.co.kr/main/main.html (accessed on 6 March 2016).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Type | Variable Name | Value |
|---|---|---|
| Predictors | Year | 4-digit number year. E.g., 2017 |
| Month | 2-digit number month. E.g., 01 | |
| Day | 2-digit number day. E.g., 06 | |
| Hour | 2-digits number hour. E.g., 23 | |
| Quarter index | One digit for minutes. E.g., 1(15 min), 2(30 min) | |
| P1 | Day of the week: 1(Mon), 2(Tues), …7(Sun) | |
| P2 | Day type: E.g., 1(Holidays), 2(weekdays), 3(Weekends) | |
| P3 | The highest temperature in °C | |
| P4 | Cloud cover: E.g. 1: sunny (cloud 0–5 mm) 2: cloudy (cloud 6–10 mm) | |
| Respond | Demand | Energy consumption in kW |
| Date | P1 | P2 | P3 | P4 |
|---|---|---|---|---|
| 23 June 2017 | 5 | 4 | 34.8 | 1 |
| 19 July 2018 | 4 | 4 | 34.7 | 1 |
| Process | Model Training [s] | Forecast [s] |
|---|---|---|
| K-means | 50.86 | 1.44 |
| ANN | 61.70 | 20.58 |
| Ensemble | 592.75 | 0.002 |
| Dataset | Ensemble | K-Means with Bayesian | ANN | ||
|---|---|---|---|---|---|
| KEPCO dataset | MAPE | Spring | 17.0928 | 17.06893 | 20.04814 |
| Summer | 16.45506 | 16.33028 | 17.51668 | ||
| Fall | 22.02287 | 34.34863 | 21.94459 | ||
| Winter | 17.57218 | 21.73072 | 19.42727 | ||
| RMSE | Spring | 11.19016 | 10.59841 | 12.52269 | |
| Summer | 10.55273 | 10.79871 | 10.73513 | ||
| Fall | 22.00363 | 33.5403 | 22.5707 | ||
| Winter | 14.8416 | 17.97763 | 15.57768 | ||
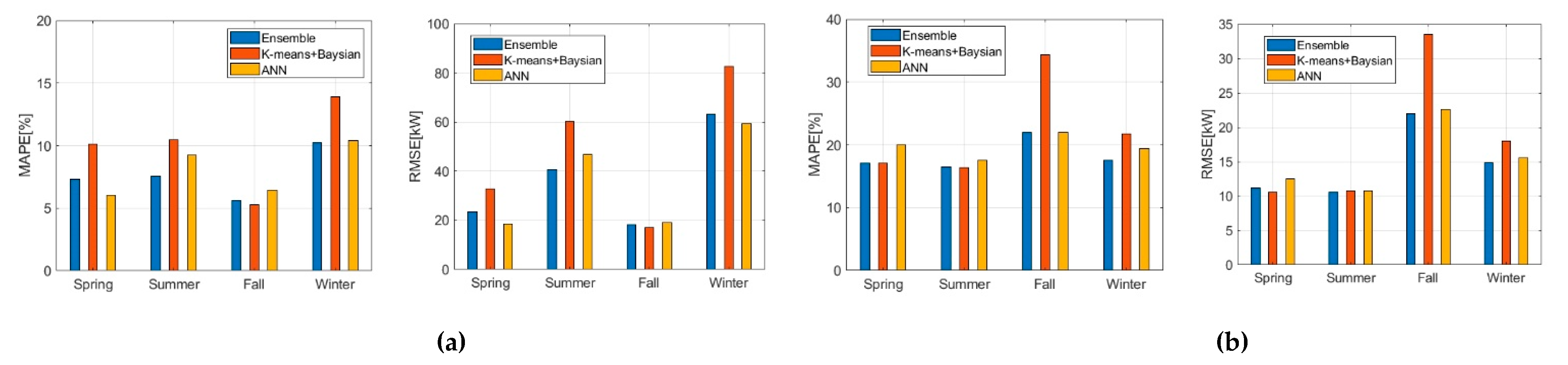
| KEPRI dataset | MAPE | Spring | 7.3435 | 10.1011 | 6.013 |
| Summer | 7.52238 | 10.4581 | 9.22479 | ||
| Fall | 5.62856 | 5.27346 | 6.41714 | ||
| Winter | 10.2523 | 13.90402 | 10.38853 | ||
| RMSE | Spring | 23.41024 | 32.69604 | 18.52118 | |
| Summer | 40.75116 | 60.16406 | 46.72084 | ||
| Fall | 18.07842 | 17.08345 | 19.13558 | ||
| Winter | 63.23432 | 82.75472 | 59.46993 |
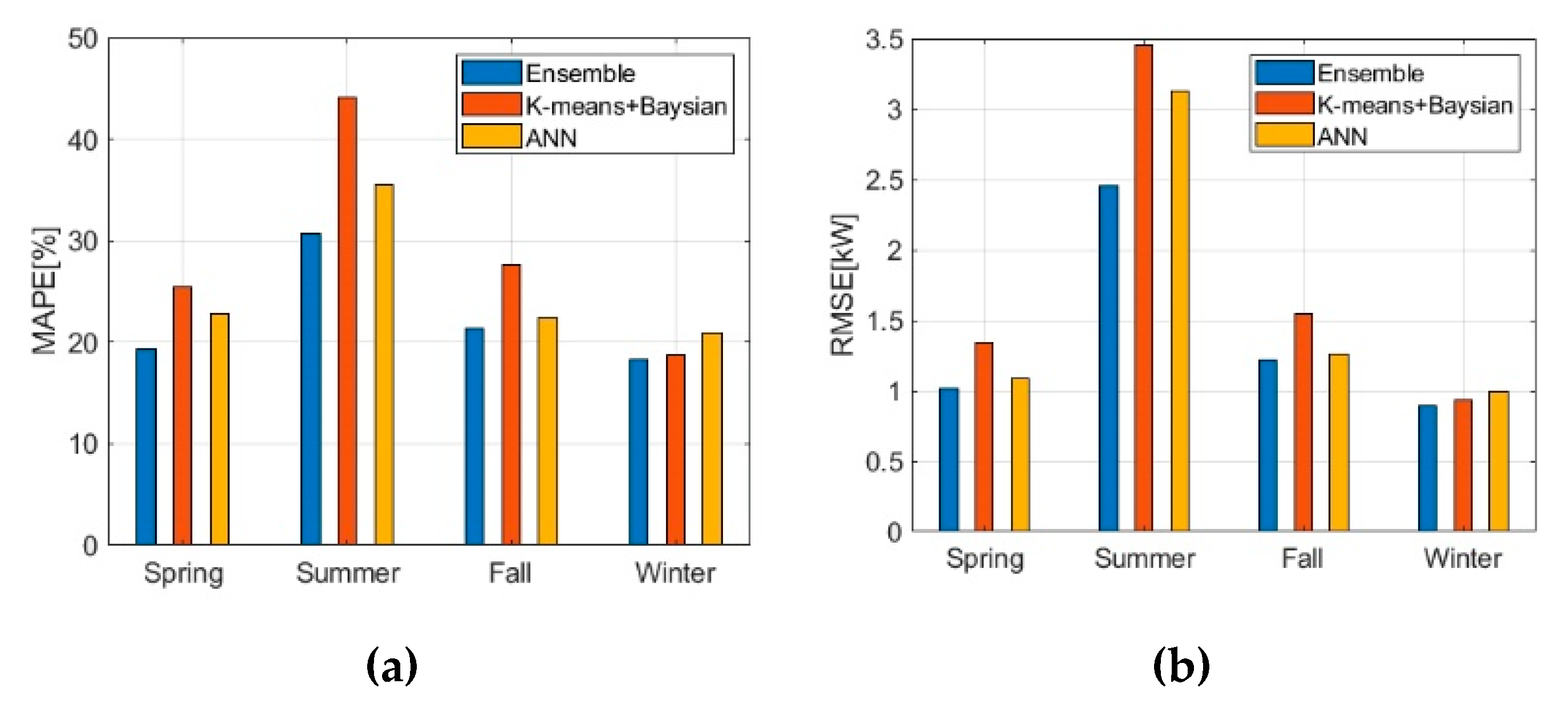
| Performance Index | Ensemble | K-Means with Bayesian | ANN | |
|---|---|---|---|---|
| MAPE | Spring | 19.27277 | 25.50984 | 22.78469 |
| Summer | 30.74737 | 44.09545 | 35.52047 | |
| Fall | 21.35013 | 27.61316 | 22.40761 | |
| Winter | 18.30707 | 18.67867 | 20.87263 | |
| RMSE | Spring | 1.01556 | 1.34224 | 1.085257 |
| Summer | 2.455532 | 3.452222 | 3.130337 | |
| Fall | 1.21539 | 1.541551 | 1.264588 | |
| Winter | 0.892299 | 0.938574 | 0.999332 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agyeman, K.A.; Kim, G.; Jo, H.; Park, S.; Han, S. An Ensemble Stochastic Forecasting Framework for Variable Distributed Demand Loads. Energies 2020, 13, 2658. https://doi.org/10.3390/en13102658
Agyeman KA, Kim G, Jo H, Park S, Han S. An Ensemble Stochastic Forecasting Framework for Variable Distributed Demand Loads. Energies. 2020; 13(10):2658. https://doi.org/10.3390/en13102658
Chicago/Turabian StyleAgyeman, Kofi Afrifa, Gyeonggak Kim, Hoonyeon Jo, Seunghyeon Park, and Sekyung Han. 2020. "An Ensemble Stochastic Forecasting Framework for Variable Distributed Demand Loads" Energies 13, no. 10: 2658. https://doi.org/10.3390/en13102658
APA StyleAgyeman, K. A., Kim, G., Jo, H., Park, S., & Han, S. (2020). An Ensemble Stochastic Forecasting Framework for Variable Distributed Demand Loads. Energies, 13(10), 2658. https://doi.org/10.3390/en13102658