Energy-Efficient Thread Mapping for Heterogeneous Many-Core Systems via Dynamically Adjusting the Thread Count


Abstract
:1. Introduction
2. Related Work
3. Impact Factors on Computing Performance
- Program characteristics. Some programs are computation intensive. The increase in thread count can help achieve better performance. Some programs are memory intensive, that is, spawning more threads does not improve the performance due to the shared storage capacity and storage bandwidth limitations. Some programs are communication intensive, that is, frequent information interaction between threads; thus, setting too many threads incurs considerable lock synchronization overhead and significantly decreases performance. Moreover, the different portions of some applications have different characteristics. We should dynamically set thread count according to program characteristics to achieve optimal performance.
- Hardware architecture and OS level impact factors. These factors mainly include the thread count, cache miss rate, bandwidth utilization, thread context switch rate, and thread migration rate.
4. Optimum Thread Count Prediction Model (TCPM)
4.1. Notations of Performance Metrics
- Turnaround time (TT) refers to the total time consumed in executing the program.
- TTn refers to the turnaround time of the program that runs n processing threads.
- TT1 refers to the turnaround time of the program that runs a single processing thread.
- SIP refers to the sum of instructions of a program.
- IPS1 refers to the number of executing instructions per second when running the single thread.
- IPSN refers to the number of executing instructions per second when running n threads.
4.2. Theoretical Basis of TCPM
4.3. TCPM Establishment
- The values of IPS1 and IPSN can be collected by sampling and testing the program that runs at different numbers of processing cores and threads, for which Equation (2) can be used to calculate the value of f. After obtaining the multiple pairs values of (f, n), the coefficients α, β, and γ can be calculated using the least squares. The process is detailed as follows.
- (a)
- Using Equation (3), we obtain the following:where n is the thread count.
- (b)
- Using the least squares, we obtain the following:
- (c)
- The following equation is solved to calculate the coefficients α, β, and γ to minimize the deviation value of S:Transforming Equation (6), we obtain the following:
- (d)
- Considering the obtained different pairs values of the (f, n) into Equation (6), we can construct the equation that includes the unknown coefficients α, β, and γ, then solve the equation to calculate the unknown coefficients α, β, and γ.
- The extreme value theorem is used to calculate the value n that minimizes the relative turnaround time f in Equation (3). The calculating process is as follows:Equation (8) denotes the final thread count prediction model.
- By sampling real-time values of IPS1 and IPSn with different thread numbers, we can calculate the relative turnaround time f according to Equation (2) combined with Equation (6) for obtaining the coefficients α, β, and γ. Finally, the thread count n can be calculated according to Equation (8), which is the optimum thread count.
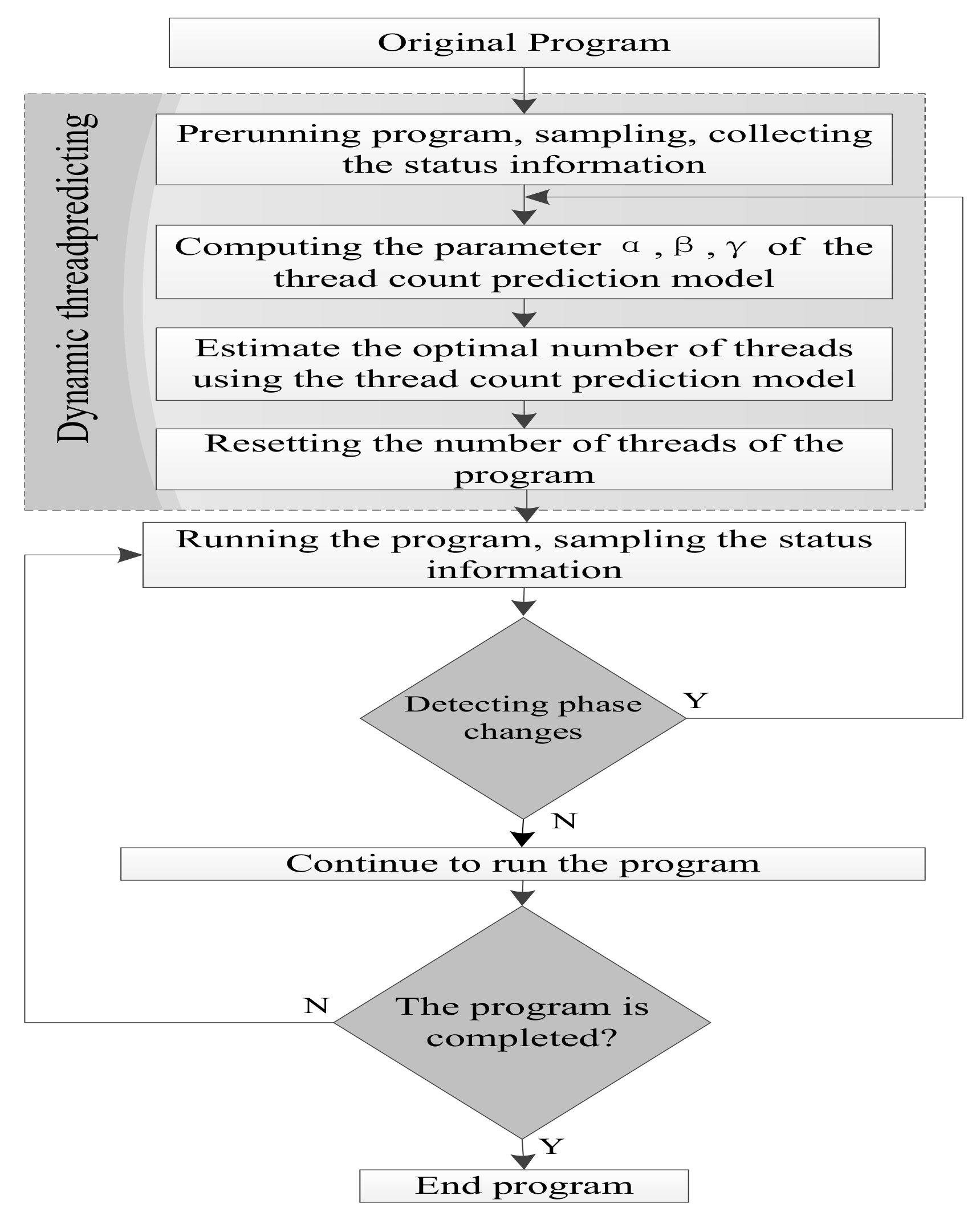
5. DPTM Mechanism
6. DPTM Framework and Implementation
6.1. DPTM Framework
6.2. Sampling the Status Information
6.3. Detecting the Phase Changes of the Running Program
6.3.1. Threshold Values of the Performance Metric
6.3.2. Detection Algorithm of the Program Phase Changes
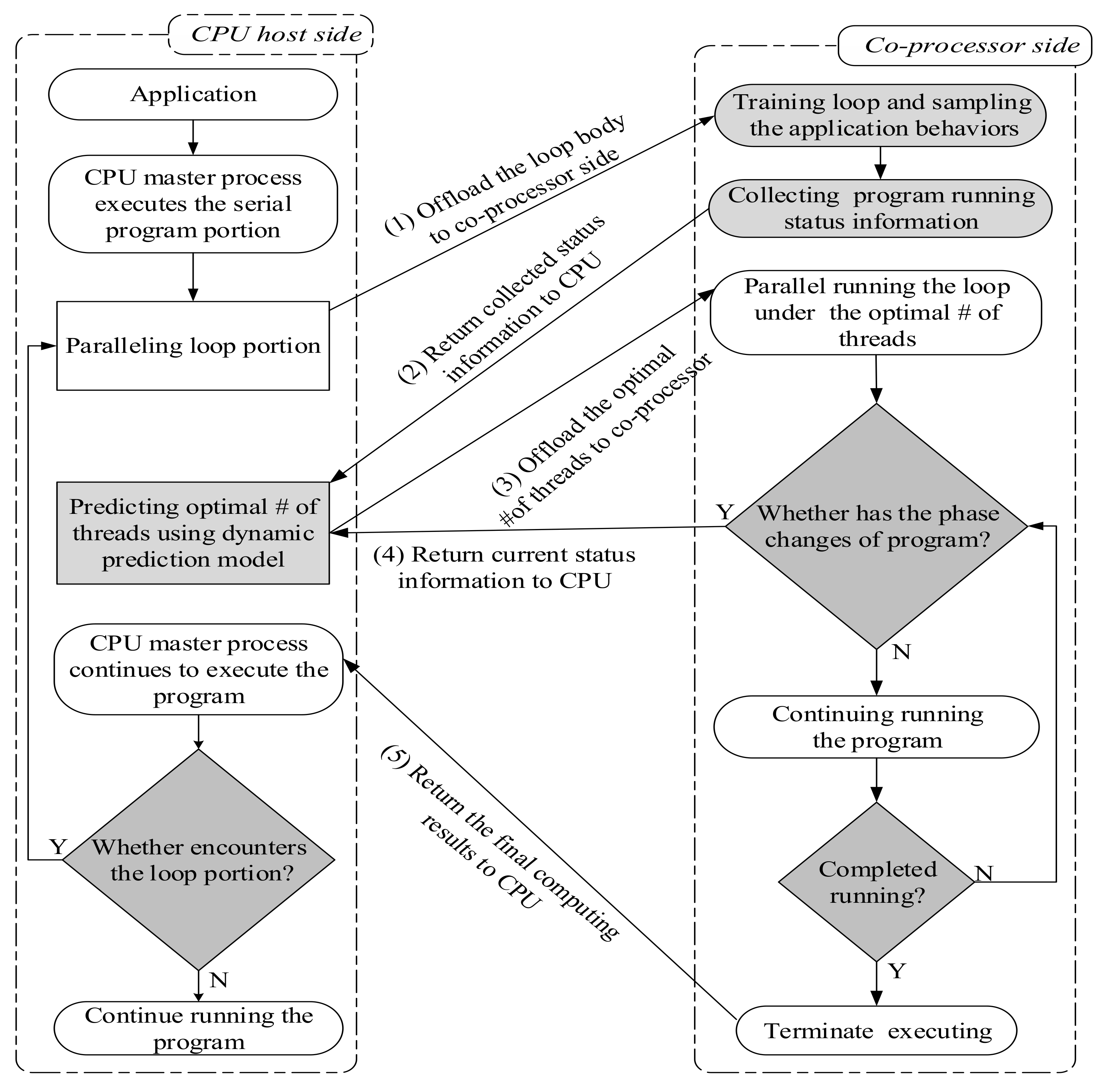
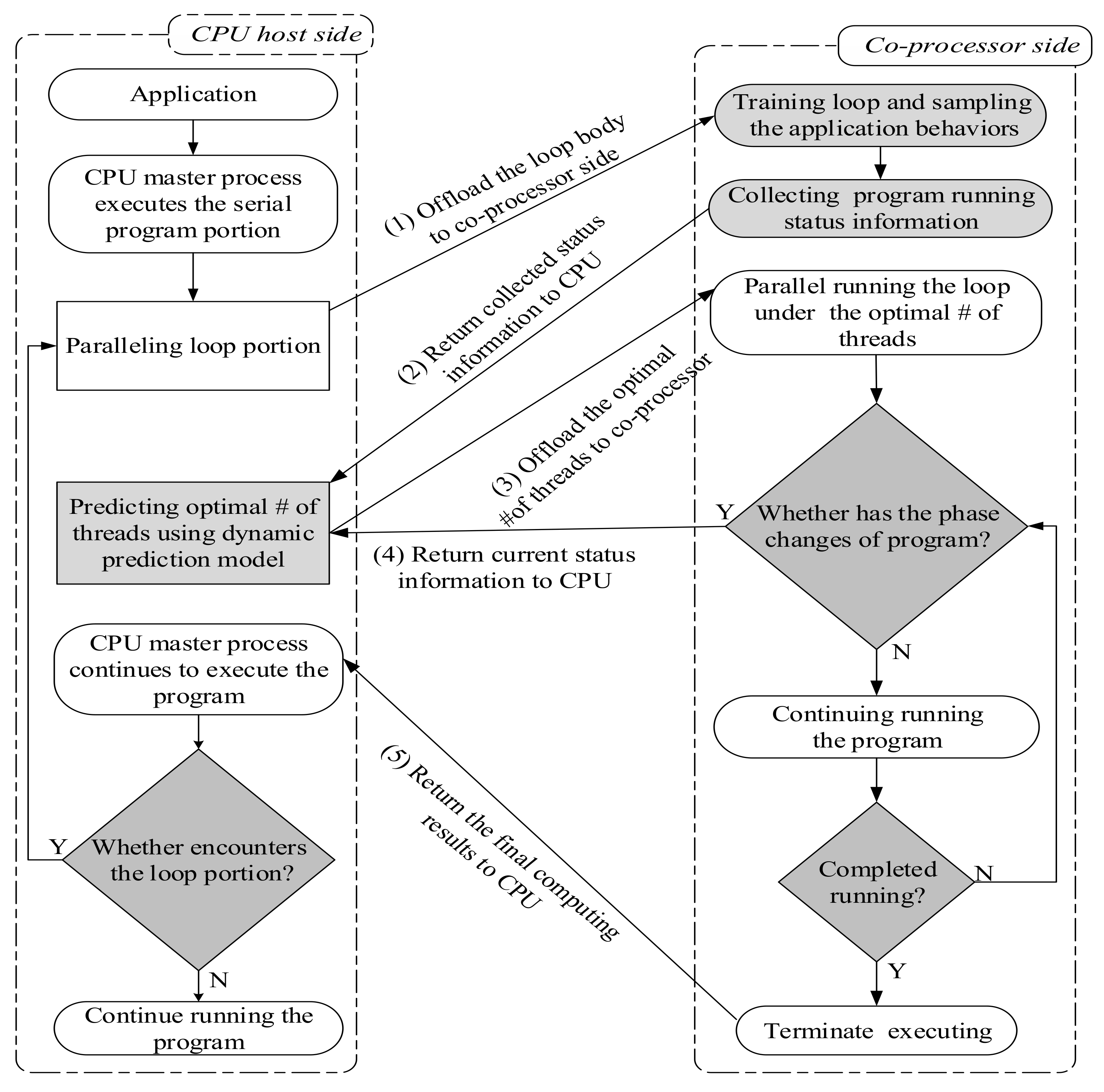
6.4. DPTM Framework Implementation
- HOST SIDE 1 code: The CPU master process first executes the program. When encountering the loop part, it uses the #pragma offload target (MIC SIDE 1) to offload the loop code to the MIC co-processor to execute. It then performs the #pragma offload_wait target (mic) to wait for the execution results of MIC.
- MIC SIDE 1 code: The MIC first regulates the control register CR4.PCE status by calling the init_module() to directly access the rdmpc from the user-space to obtain the performance status information. It then pre-runs the program by calling the function pre_running_program(). The status information is then read, collected, and returned to the CPU master process by calling the functions read_pmc(), collect_status_information(), and return_status_information (HOST SIDE 2) individually.
- HOST SIDE 2 code: The CPU master process predicts the optimal thread count by calling predicting_optimal_number_threads (status_info, opt_number_thread) and then uses the pragma clause #pragma offload_transfer target (MIC SIDE 2) in (opt_number_threads) to send the optimum thread count to the MIC co-processor side to control the parallelism of the loop code running on the MIC co-processor.
- MIC SIDE 2 code: The MIC co-processor re-executes the loop code according to the optimum thread count while continuously detecting the phase changes by calling detecting_running_exception.
- HOST SIDE 3 code: The CPU master process continues to execute the subsequent portion code of the program after receiving the computing results from the MIC side. If the loop execution part is encountered, it will be offloaded to the MIC co-processor for execution according to the previous running mechanism. The program continuously iterates until the application is finished.
7. Experimental Evaluation
7.1. Experimental Environment
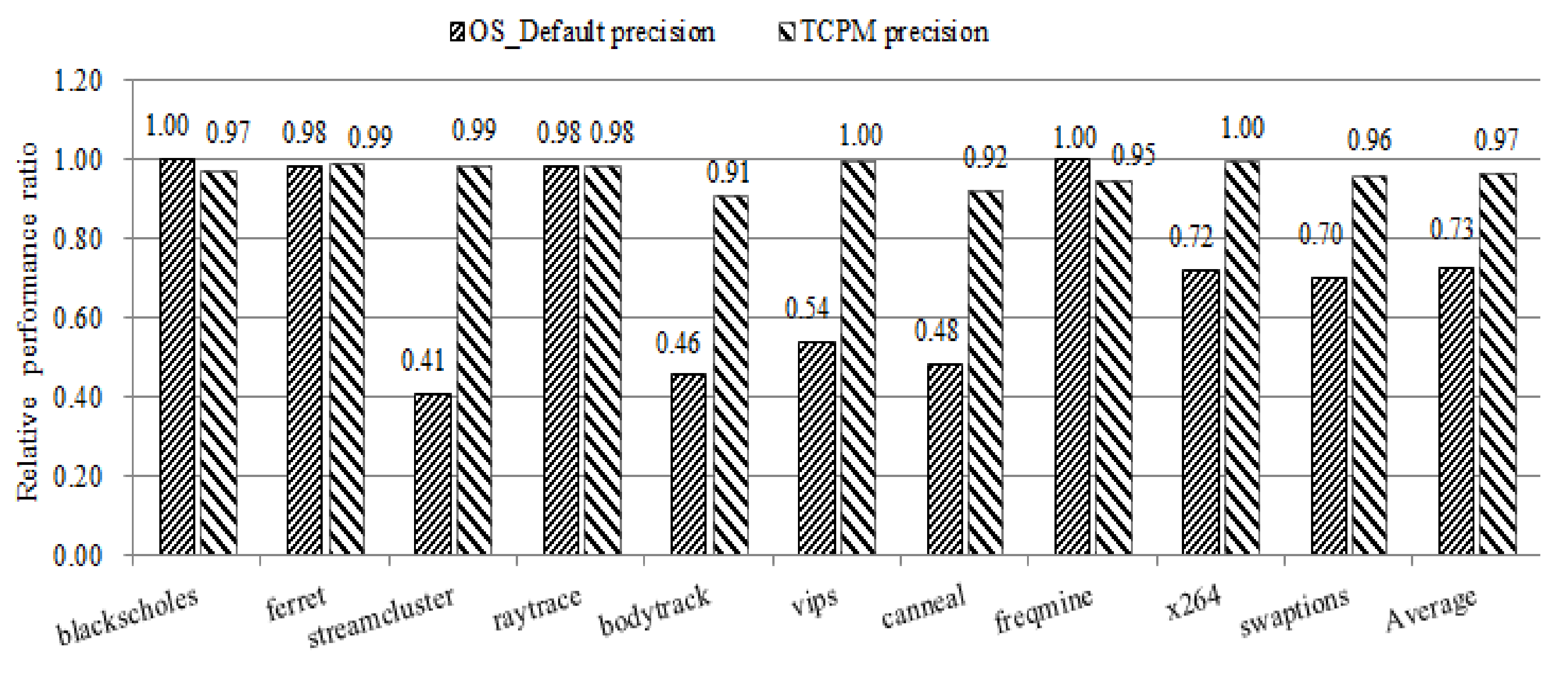
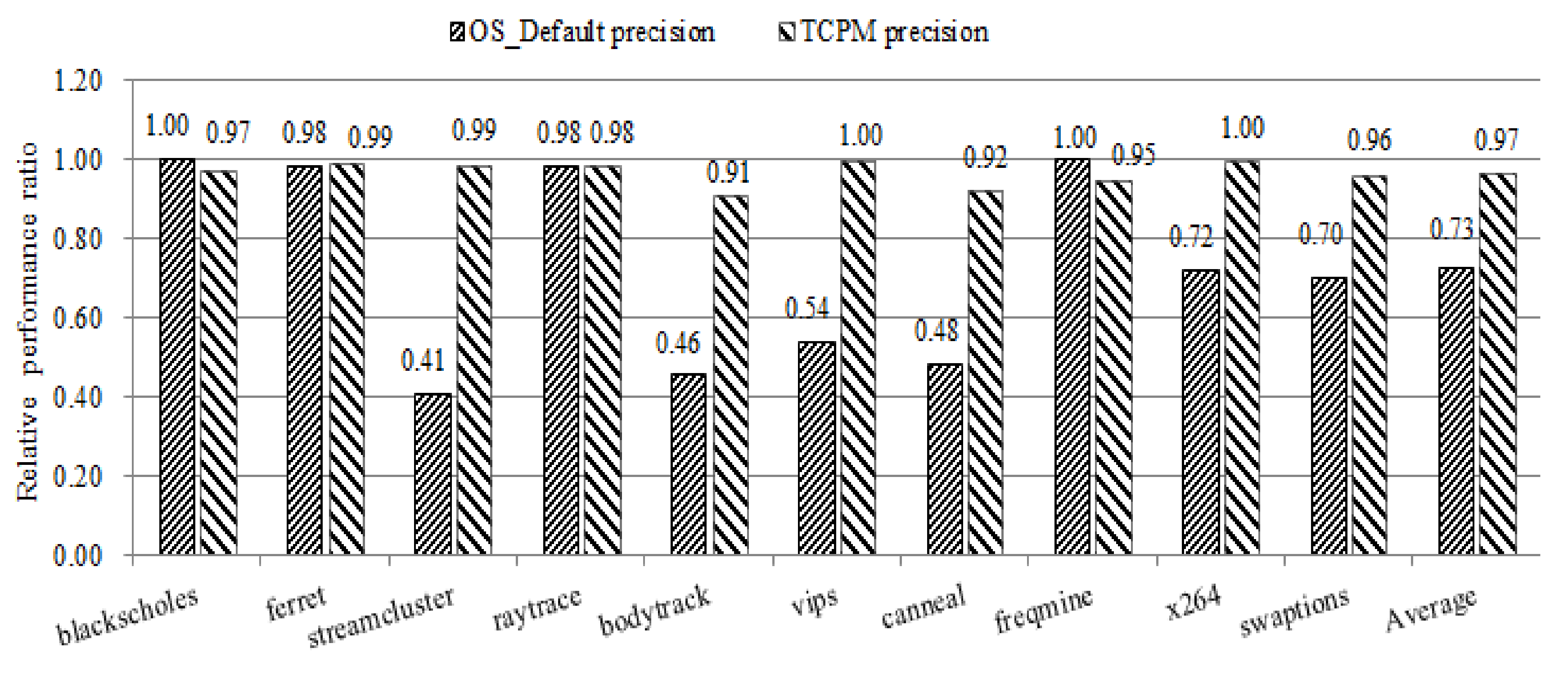
7.2. TCPM Prediction Accuracy Evaluation
7.3. DPTM Evaluation
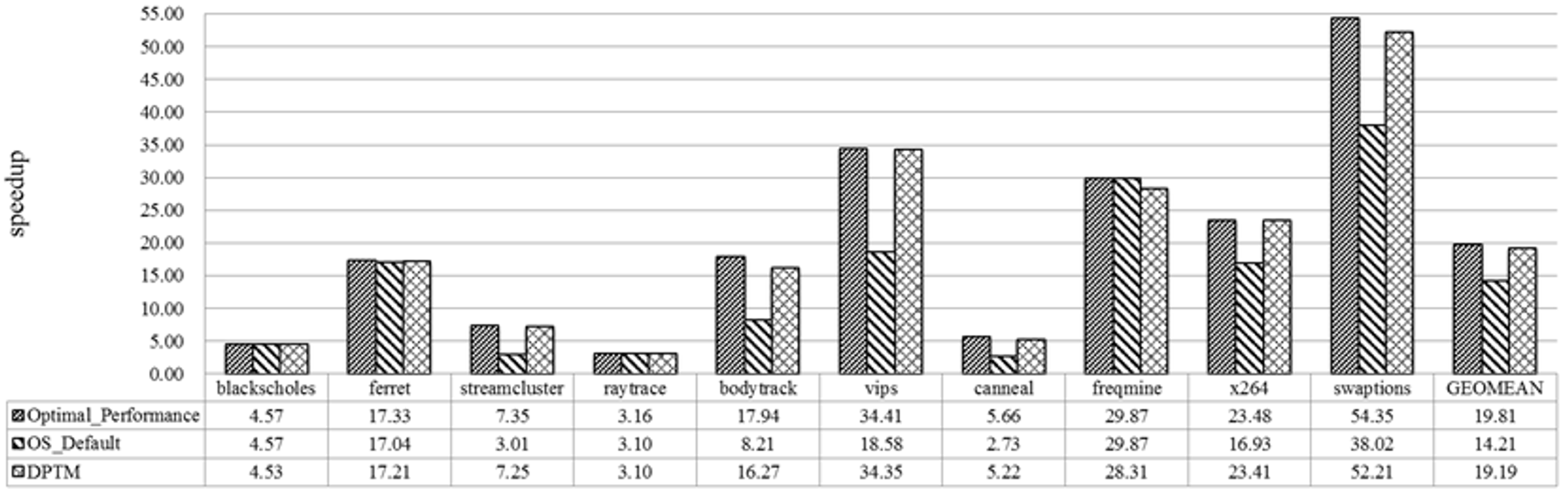
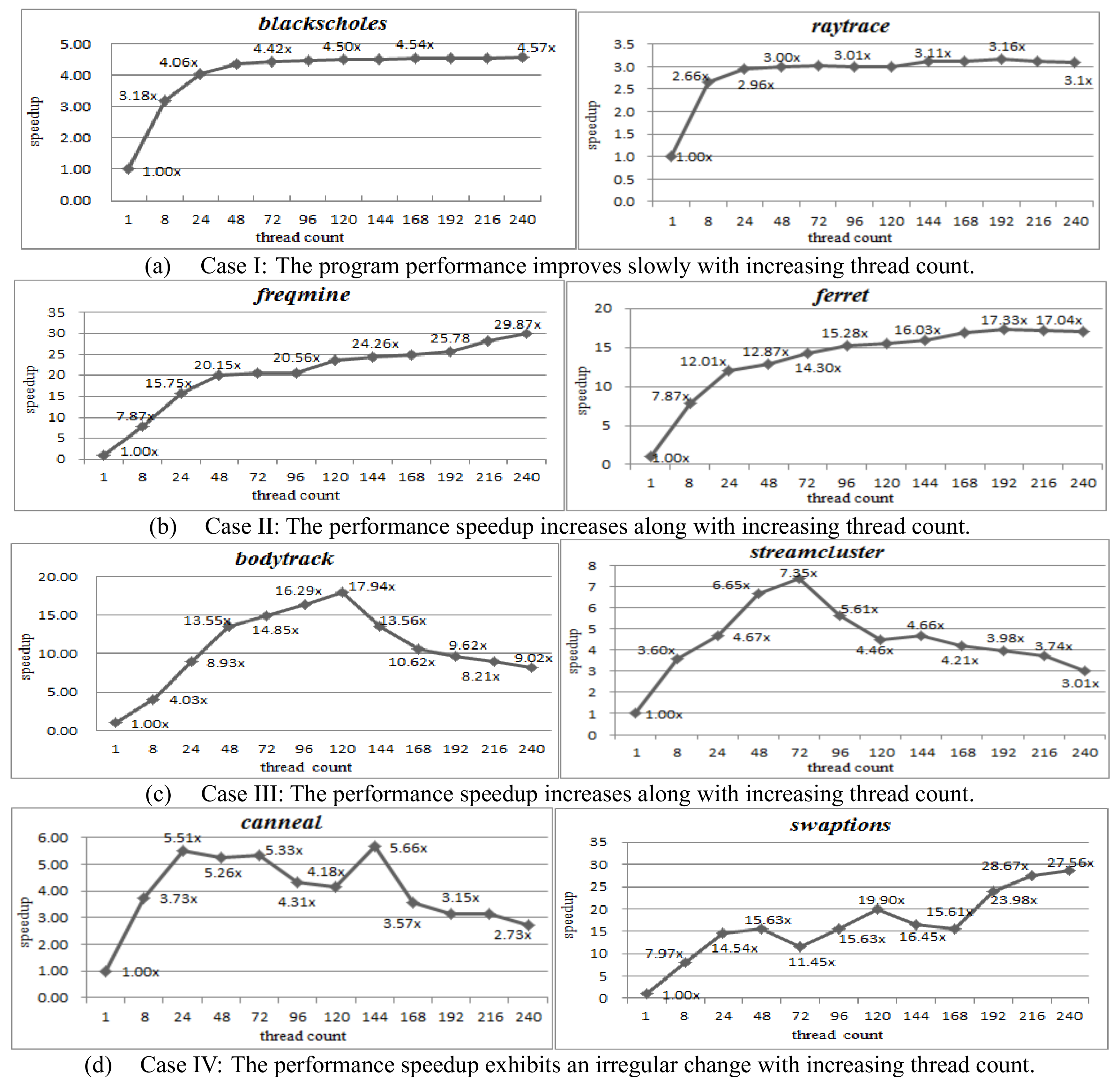
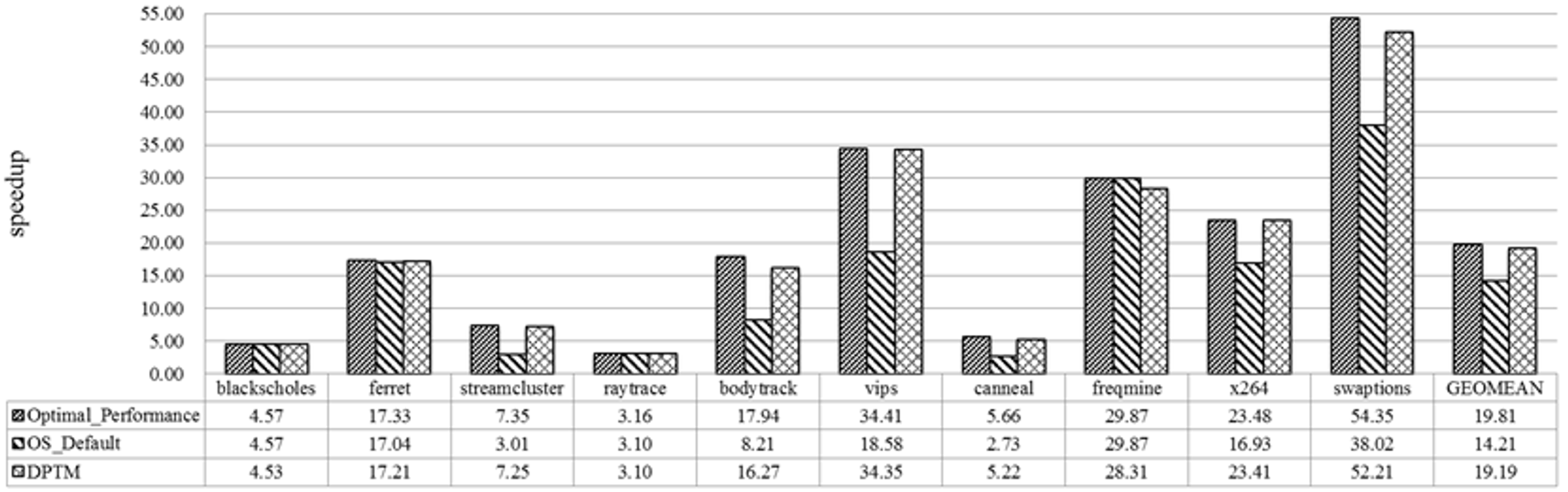
7.3.1. Performance Speedup Evaluation
7.3.2. Cache Miss Evaluation
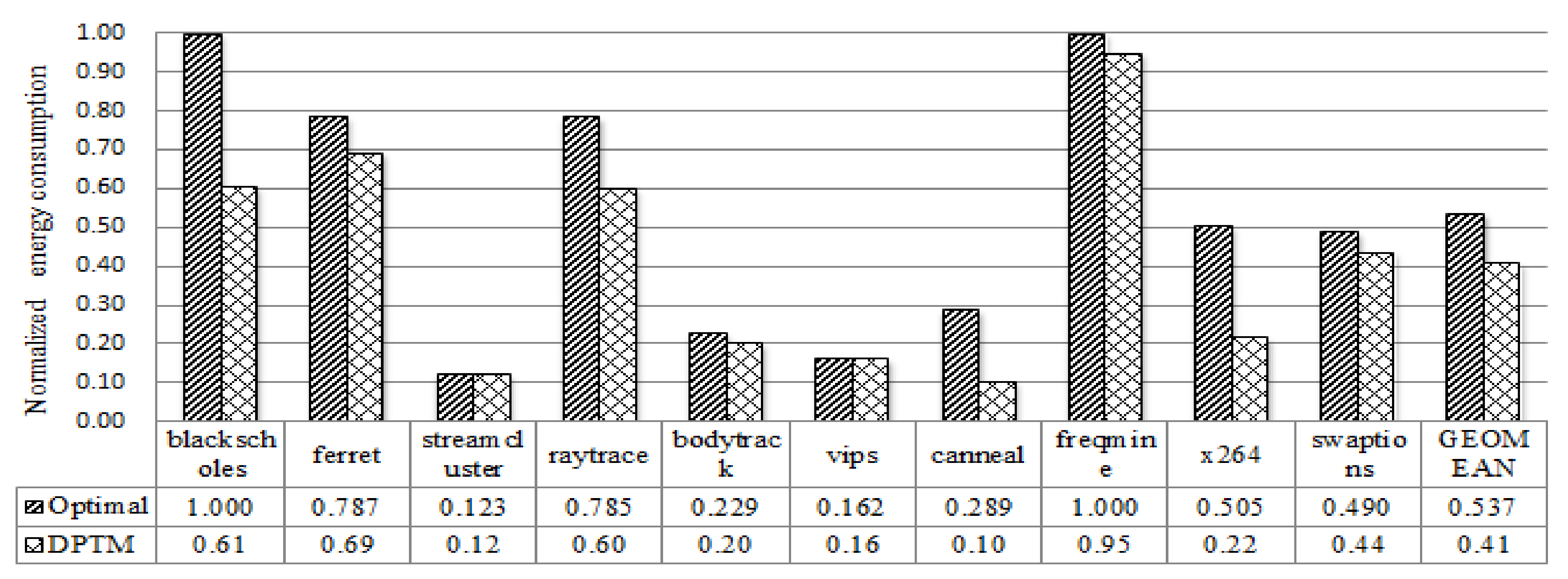
7.3.3. Energy Consumption Evaluation
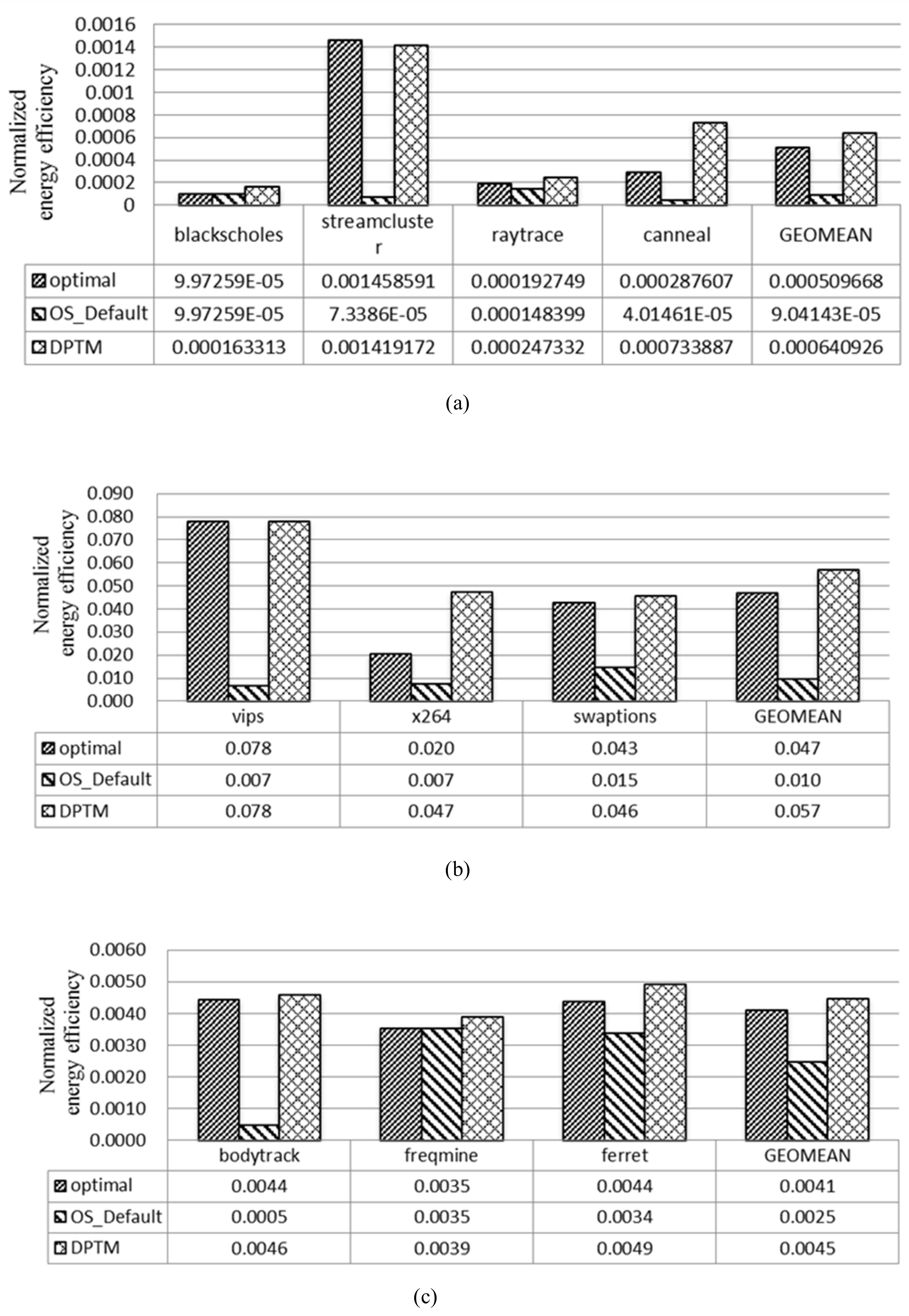
7.3.4. Energy–Performance Efficiency Evaluation
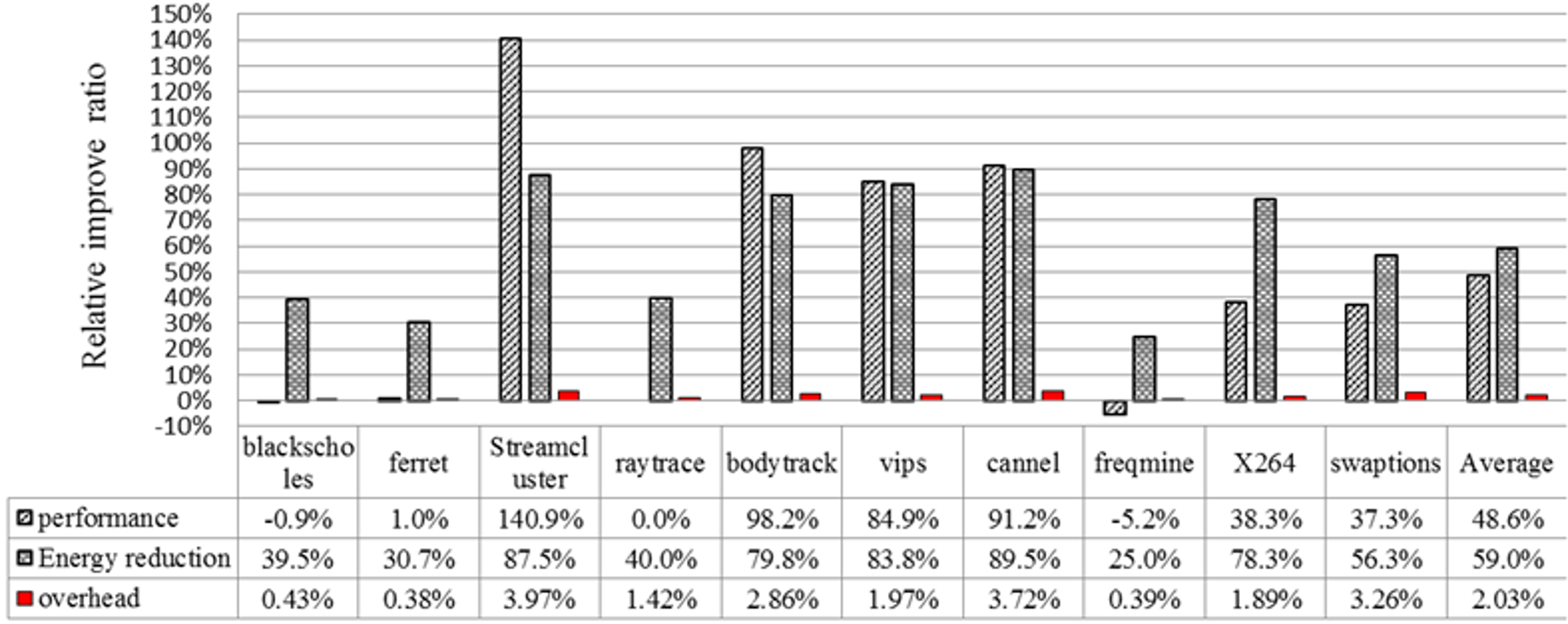
7.3.5. Overhead Evaluation
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Brodtkorb, A.R.; Dyken, C.; Hagen, T.R.; Hjelmervik, J.M.; Storaasli, O.O. State-of-the-art in heterogeneous computing. Sci. Programm. 2010, 18, 1–33. [Google Scholar] [CrossRef]
- Ju, T.; Dong, X.; Chen, H.; Zhang, X. DagTM: An Energy-Efficient Threads Grouping Mapping for Many-Core Systems Based on Data Affinity. Energies 2016, 9, 754. [Google Scholar] [CrossRef]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The PARSEC benchmark suite: Characterization and architectural implications. In Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques (PACT), Toronto, ON, Canada, 25–29 August 2008; pp. 72–81. [Google Scholar] [CrossRef]
- Ju, T.; Weiguo, W.W.; Chen, H.; Zhu, Z.; Dong, X. Thread Count Prediction Model: Dynamically Adjusting Threads for Heterogeneous Many-Core Systems. In Proceedings of the 21st IEEE International Conference on Parallel and Distributed Systems, Melbourne, Australia, 14–17 December 2015; pp. 459–464. [Google Scholar] [CrossRef]
- Pusukuri, K.K.; Gupta, R.; Bhuyan, L.N. Thread reinforcer: Dynamically determining number of threads via os level monitoring. In Proceedings of the IEEE International Symposium on Workload Characterization (IISWC), Austin, TX, USA, 6–8 November 2011; pp. 116–125. [Google Scholar] [CrossRef]
- Sasaki, H.; Tanimoto, T.; Inoue, K.; Nakamura, H. Scalability-based manycore partitioning. In Proceedings of the 21st ACM International Conference on Parallel Architectures and Compilation Techniques (PACT), Minneapolis, MN, USA, 19–23 September 2012; pp. 107–116. [Google Scholar] [CrossRef]
- Suleman, M.A.; Qureshi, M.K.; Patt, Y.N. Feedback-driven threading: Power-efficient and high-performance execution of multi-threaded workloads on CMPs. In Proceedings of the 13th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Seattle, WA, USA, 1–5 March 2008; pp. 227–286. [Google Scholar] [CrossRef]
- Lee, J.; Wu, H.; Ravichandran, M.; Clark, N. Thread tailor: Dynamically weaving threads together for efficient, adaptive parallel applications. In Proceedings of the 37th ACM Annual International Symposium on Computer architecture (ISCA), Saint-Malo, France, 19–23 June 2010; pp. 270–279. [Google Scholar] [CrossRef]
- Heirman, W.; Carlson, T.E.; Van Craeynest, K.; Eeckhout, L.; Hur, I.; Jaleel, A. Undersubscribed threading on clustered cache architectures. In Proceedings of the 20th IEEE International Symposium on High Performance Computer Architecture (HPCA), Orlando, FL, USA, 15–19 February 2014; pp. 678–689. [Google Scholar] [CrossRef]
- Heirman, W.; Carlson, T.E.; Craeynest, K.V.; Hur, I.; Jaleel, A.; Eeckhout, L. Automatic SMT threading for OpenMP applications on the Intel Xeon Phi co-processor. In Proceedings of the 4th ACM International Workshop on Runtime and Operating Systems for Supercomputers, Munich, Germany, 10 June 2014. [Google Scholar] [CrossRef]
- Kanemitsu, H.; Hanada, M.; Nakazato, H. Clustering-Based Task Scheduling in a Large Number of Heterogeneous Processors. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 3144–3157. [Google Scholar] [CrossRef]
- Singh, A.K.; Basireddy, K.R.; Merrett, G.V.; Al-Hashimi, B.M.; Prakash, A. Energy-Efficient Run-Time Mapping and Thread Partitioning of Concurrent OpenCL Applications on CPU-GPU MPSoCs. ACM Trans. Embed. Comput. Syst. 2017, 16. [Google Scholar] [CrossRef]
- Birhanu, T.M.; Choi, Y.J.; Li, Z.; Sekiya, H.; Komuro, N. Efficient Thread Mapping for Heterogeneous Multicore IoT Systems. Mobile Inf. Syst. 2017, 1–8. [Google Scholar] [CrossRef]
- Liu, C.; Thanarungroj, P.; Gaudiot, J.L. How many cores do we need to run a parallel workload: A test drive of the Intel SCC platform? J. Parallel Distrib. Comput. 2014, 74, 2582–2595. [Google Scholar] [CrossRef]
- Donyanavard, B.; Mück, T.; Sarma, S.; Dutt, N. SPARTA: Runtime task allocation for energy efficient heterogeneous many-cores. In Proceedings of the Eleventh IEEE/ACM/IFIP International Conference on Hardware/Software Codesign and System Synthesis, Pittsburgh, PA, USA, 2–7 October 2016. [Google Scholar] [CrossRef]
- Pusukuri, K.K.; Vengerov, D.; Fedorova, A.; Kalogeraki, V. FACT: A framework for adaptive contention-aware thread migrations. In Proceedings of the 8th ACM International Conference on computing frontiers, Ischia, Italy, 3–5 May 2011; pp. 1–10. [Google Scholar] [CrossRef]
- Tillenius, M.; Larsson, E.; Badia, R.M.; Martorell, X. Resource-Aware Task Scheduling. ACM Trans. Embed. Comput. Syst. 2014, 14, 1–25. [Google Scholar] [CrossRef]
- Eyerman, S.; Eeckhout, L. System-level performance metrics for multiprogram workloads. IEEE Micro 2008, 28, 42–53. [Google Scholar] [CrossRef]
- Sun, X.; Chen, Y. Reevaluating Amdahl’s law in the multicore era. J. Parallel Distribut. Comput. 2010, 70, 183–188. [Google Scholar] [CrossRef]
- Huang, T.; Zhu, Y.; Yin, X.; Wang, X.; Qiu, M. Extending Amdahl’s law and Gustafson’s law by evaluating interconnections on multi-core processors. J. Supercomput. 2013, 66, 305–319. [Google Scholar] [CrossRef]
- Rafiev, A.; Al-Hayanni, M.A.N.; Xia, F.; Shafik, R.; Romanovsky, A.; Yakovlev, A. Speedup and Power Scaling Models for Heterogeneous Many-Core Systems. IEEE Trans. Multi-Scale Comput. Syst. 2018, 99, 1–14. [Google Scholar] [CrossRef]
- Etinski, M.; Corbalan, J.; Labarta, J.; Valero, M. Understanding the future of energy-performance trade-off via DVFS in HPC environments. J. Parallel Distrib. Comput. 2012, 72, 579–590. [Google Scholar] [CrossRef]
- Rodrigues, R.; Koren, I.; Kundu, S. Does the Sharing of Execution Units Improve performance/Power of Multicores? ACM Trans. Embed. Comput. Syst. 2015, 14, 1–24. [Google Scholar] [CrossRef]
- Ma, J.; Yan, G.; Han, Y.; Li, X. An analytical framework for estimating scale-out and scale-up power efficiency of heterogeneous many-cores. IEEE Trans. Comput. 2016, 65, 367–381. [Google Scholar] [CrossRef]
- Newburn, C.J.; Dmitriev, S.; Narayanaswamy, R.; Wiegert, J.; Murty, R.; Chinchilla, F. Offload Compiler Runtime for the Intel® Xeon Phi Coprocessor. In Proceeding of the 27th IEEE Parallel and Distributed Processing Symposium Workshops & PhD Forum, Cambridge, MA, USA, 20–24 May 2013; pp. 1213–1225. [Google Scholar] [CrossRef]
- Yasin, A. A top-down method for performance analysis and counters architecture. In Proceeding of the IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Monterey, CA, USA, 23–25 March 2013; pp. 35–44. [Google Scholar] [CrossRef]
- Knauerhase, R.; Brett, P.; Hohlt, B.; Li, T.; Hahn, S. Using OS observations to improve performance in multicore systems. IEEE Micro. 2008, 28, 54–66. [Google Scholar] [CrossRef]
- Tallent, N.R.; Mellor-Crummey, J.M. Effective performance measurement and analysis of multithreaded applications. In Proceeding of the 14th ACM SIGPLAN symposium on principles and practice of parallel programming, Raleigh, NC, USA, 14–18 April 2009; pp. 229–240. [Google Scholar] [CrossRef]
- Zhang, W.; Li, J.; Yi, L.; Chen, H. Multilevel Phase Analysis. ACM Trans. Embed. Comput. Syst. 2015, 14, 1–29. [Google Scholar] [CrossRef]
- Intel OpenMP Runtime Library. Available online: http://www.openmprtl.org/ (accessed on 20 November 2017).
- Weaver, V.M.; Johnson, M.; Kasichayanula, K.; Ralph, J.; Luszczek, P.; Terpstra, D. Measuring Energy and Power with PAPI. In Proceedings of the IEEE International conference on Parallel Processing Workshops, Pittsburgh, PA, USA, 10–13 September 2012; pp. 262–268. [Google Scholar] [CrossRef]
- Terpstra, D.; Jagode, H.; You, H.; Dongarra, J. Collecting performance data with PAPI-C. Tools High Perform. Comput. 2010, 157–173. [Google Scholar] [CrossRef]
- Ge, R.; Feng, X.; Song, S.; Chang, H.-C.; Li, D.; Cameron, K.W. Powerpack: Energy profiling and analysis of high-performance systems and applications. IEEE Trans. Parallel Distrib. Syst. 2009, 21, 658–671. [Google Scholar] [CrossRef]
- Reddy, B.K.; Singh, A.K.; Biswas, D.; Merrett, G.V.; Al-Hashimi, B.M. Inter-cluster Thread-to-core Mapping and DVFS on Heterogeneous Multi-cores. IEEE Trans. Multi-Scale Comput. Syst. 2018, 4, 369–382. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark | Optimal | OS_Default | TCPM | |||
|---|---|---|---|---|---|---|
| # of Threads | Speedup | # of Threads | Speedup | # of Threads | Speedup | |
| blackscholes | 240 | 4.57 | 240 | 4.57 | 144 | 4.53 |
| ferret | 192 | 17.33 | 240 | 17.04 | 168 | 17.21 |
| streamcluster | 72 | 7.35 | 240 | 3.01 | 72 | 7.25 |
| raytrace | 192 | 3.16 | 240 | 3.1 | 144 | 3.1 |
| bodytrack | 120 | 17.94 | 240 | 8.21 | 96 | 16.27 |
| vips | 72 | 34.41 | 240 | 18.58 | 72 | 34.35 |
| cannel | 144 | 5.66 | 240 | 2.73 | 48 | 5.22 |
| freqmine | 240 | 29.87 | 240 | 29.87 | 216 | 28.31 |
| X264 | 168 | 23.48 | 240 | 16.93 | 72 | 23.41 |
| swaptions | 168 | 54.35 | 240 | 38.02 | 144 | 52.21 |
| blackscholes | 240 | 4.57 | 240 | 4.57 | 144 | 4.53 |
| Average | 161 | 18.43 | 240 | 13.33 | 118 | 17.85 |
| Benchmark Program | Total Time | DPTM Adjusting Time | Additional Overhead |
|---|---|---|---|
| blackscholes | 192.63 | 0.83 | 0.43% |
| ferret | 20.80 | 0.08 | 0.38% |
| streamcluster | 70.95 | 2.82 | 3.97% |
| raytrace | 87.04 | 0.37 | 0.43% |
| bodytrack | 37.05 | 1.06 | 2.86% |
| vips | 6.13 | 0.12 | 1.96% |
| canneal | 148.18 | 5.51 | 3.72% |
| freqmine | 37.23 | 0.15 | 0.40% |
| x264 | 6.90 | 0.13 | 1.88% |
| swaptions | 7.92 | 0.34 | 4.29% |
| Average | – | – | 2.03% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, T.; Zhang, Y.; Zhang, X.; Du, X.; Dong, X. Energy-Efficient Thread Mapping for Heterogeneous Many-Core Systems via Dynamically Adjusting the Thread Count. Energies 2019, 12, 1346. https://doi.org/10.3390/en12071346
Ju T, Zhang Y, Zhang X, Du X, Dong X. Energy-Efficient Thread Mapping for Heterogeneous Many-Core Systems via Dynamically Adjusting the Thread Count. Energies. 2019; 12(7):1346. https://doi.org/10.3390/en12071346
Chicago/Turabian StyleJu, Tao, Yan Zhang, Xuejun Zhang, Xiaogang Du, and Xiaoshe Dong. 2019. "Energy-Efficient Thread Mapping for Heterogeneous Many-Core Systems via Dynamically Adjusting the Thread Count" Energies 12, no. 7: 1346. https://doi.org/10.3390/en12071346
APA StyleJu, T., Zhang, Y., Zhang, X., Du, X., & Dong, X. (2019). Energy-Efficient Thread Mapping for Heterogeneous Many-Core Systems via Dynamically Adjusting the Thread Count. Energies, 12(7), 1346. https://doi.org/10.3390/en12071346