Day Ahead Hourly Global Horizontal Irradiance Forecasting—Application to South African Data



Abstract
1. Introduction
1.1. Background
1.2. An Overview of the Literature on Solar Irradiance Forecasting
1.3. Highlights of The Study
2. Models
2.1. Additive Quantile Regression Models
2.1.1. Partially Linear Additive Models
2.1.2. Partially Linear Additive Quantile Regression Models
2.2. Variable and Model Selection
2.2.1. Lasso via Hierarchical Pairwise Interactions
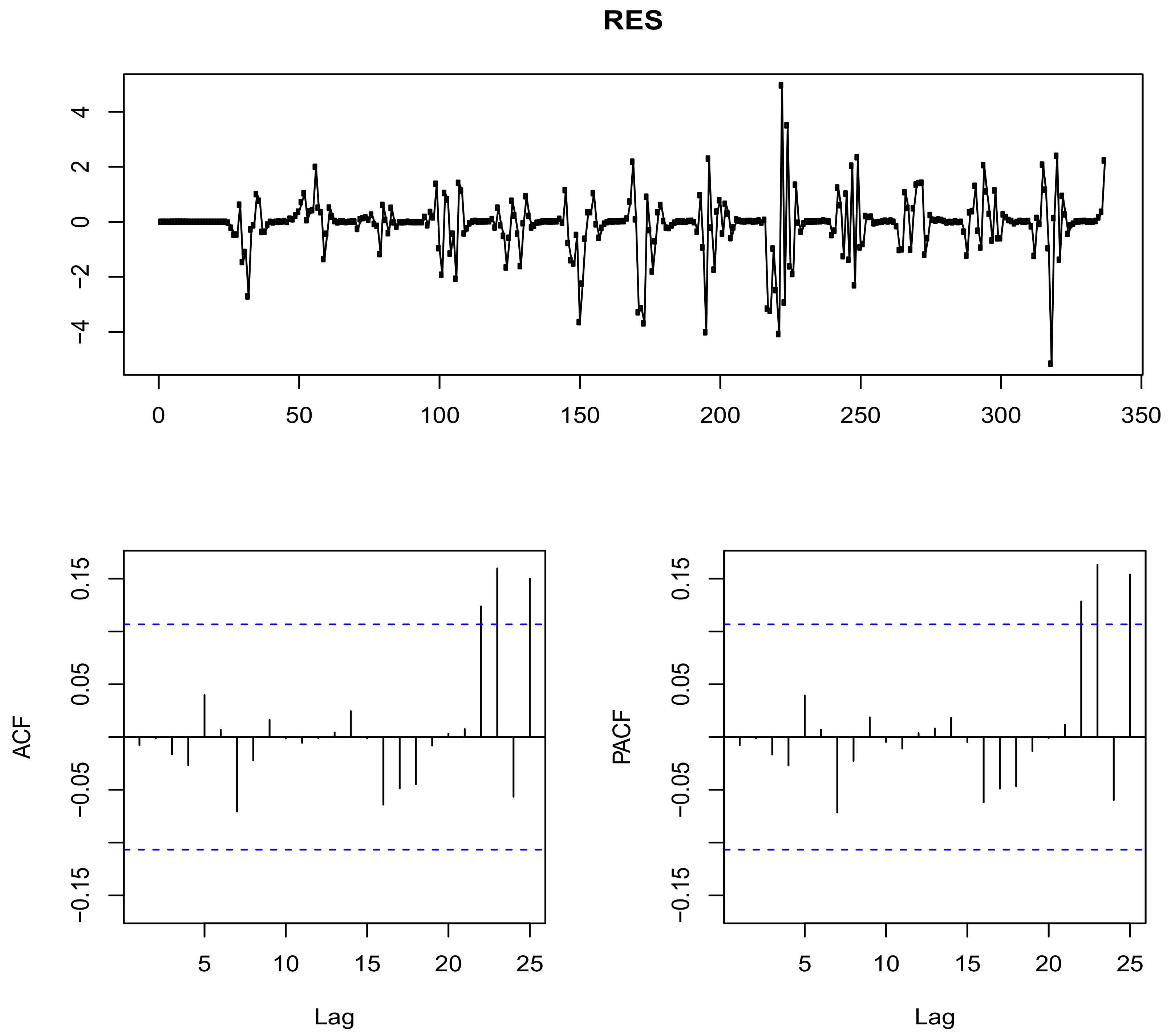
2.2.2. Residual Analysis
- Estimate the parameters;
- Check if the response variables and predictors are stationary using the Kwiatkowski-Phillips-Schmidt-Shin (KPSS) unit root test;
- If not apply differencing until all variables become stationary;
- Extract residuals and use the Ljung Box-test to test for autocorrelation and if still autocorrelated, identify an appropriate SARIMA model by repeating the process until the desired results are achieved. The residuals are also tested for normality using the Shapiro-Wilk test.
2.3. Forecast Combination
2.3.1. Convex Combination
2.3.2. Quantile Regression Averaging
2.4. Error Measures for Probabilistic Forecasting and Evaluation of Methods
2.4.1. Continuous Rank Probability Score
2.4.2. Dawid-Sebastiani Score
2.4.3. Pinball Loss Function
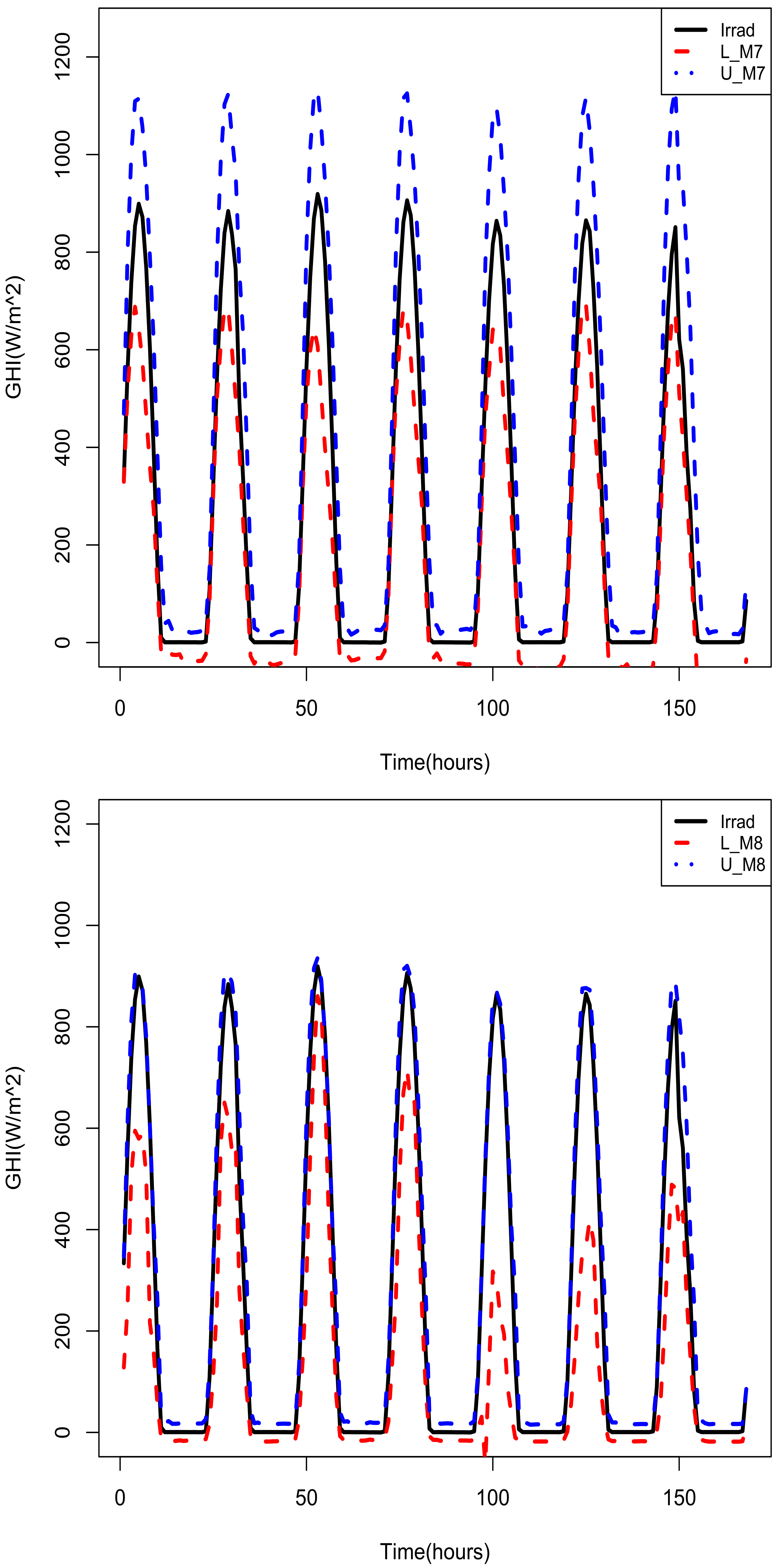
2.5. Prediction Intervals
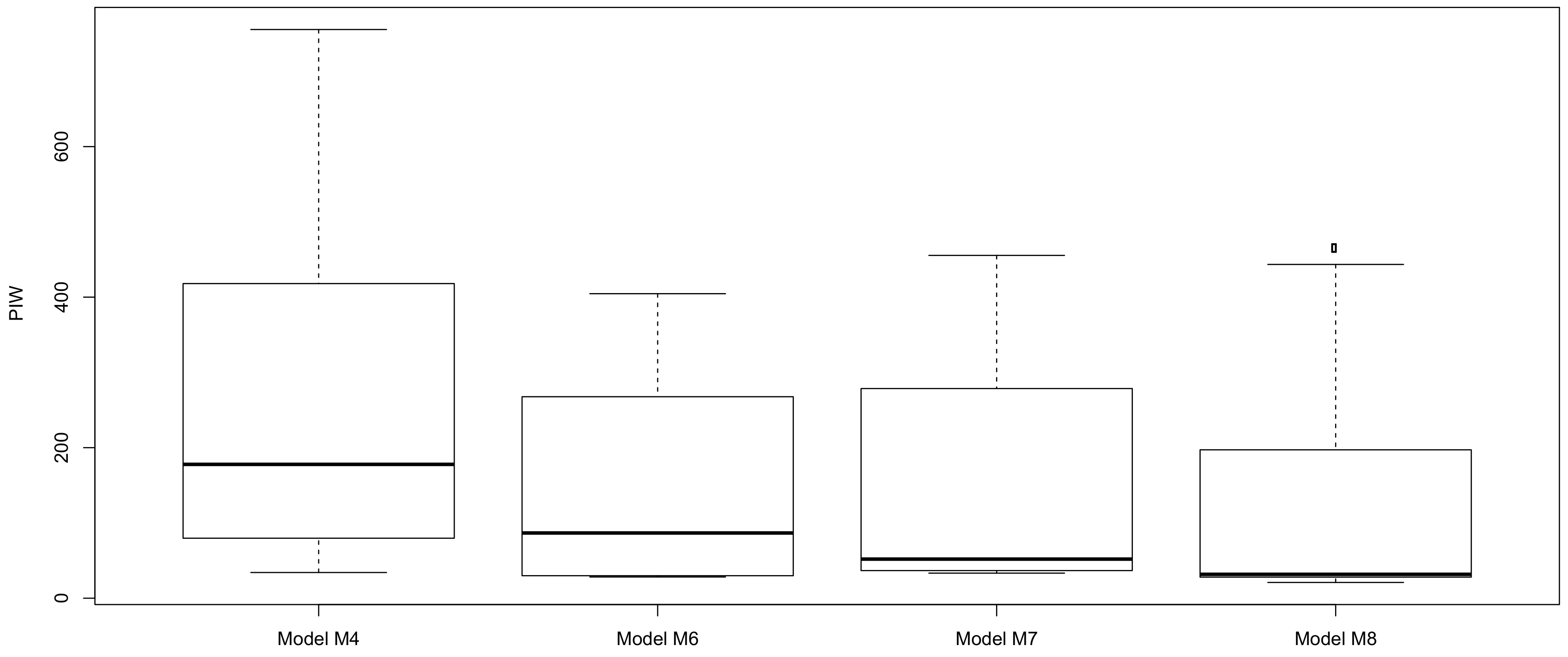
2.5.1. Prediction Intervals Widths
2.5.2. Performance of Estimated Prediction Intervals
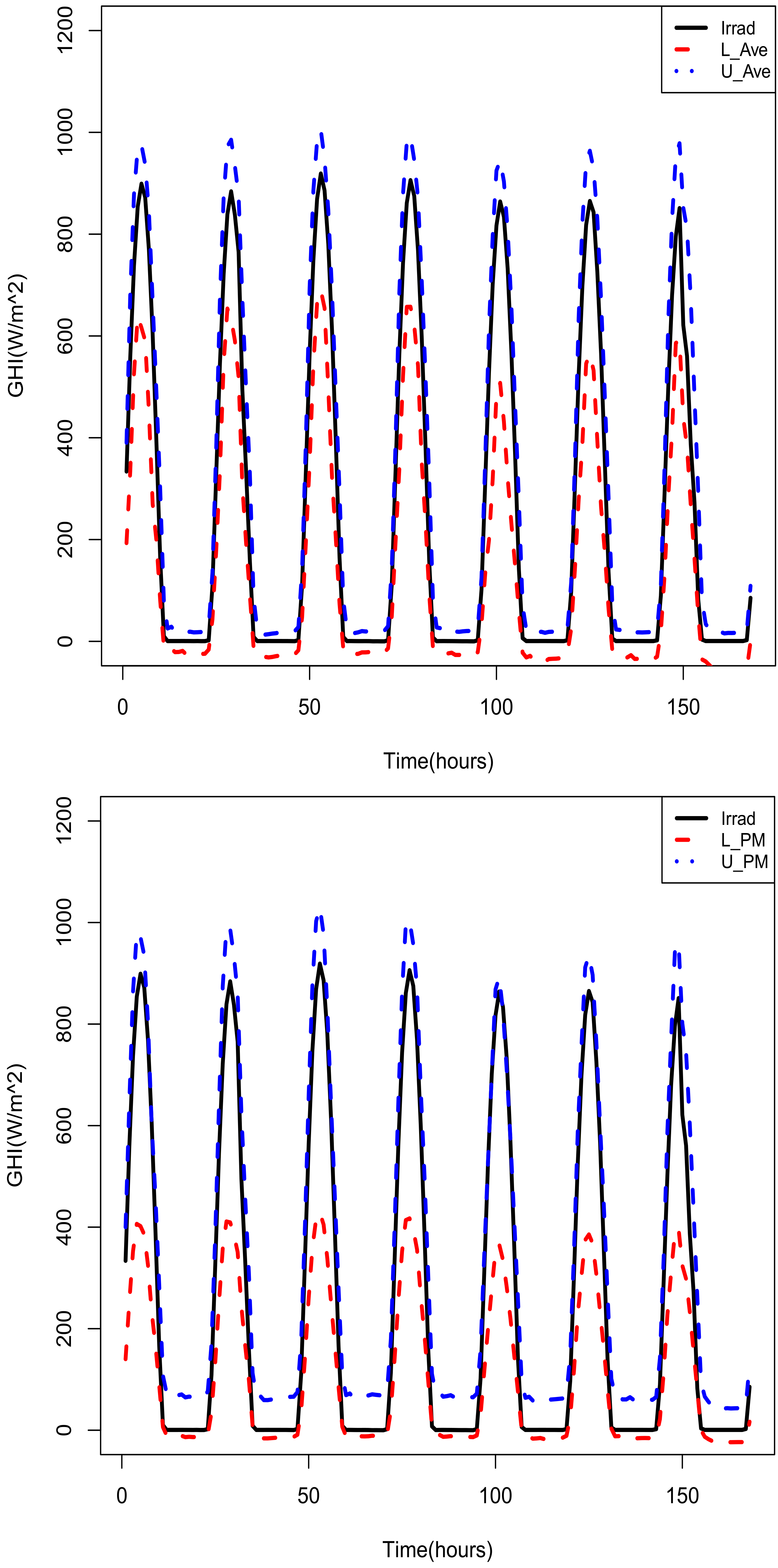
Simple Average
Median Method
Probability Averaging of Endpoints and Simple Averaging of Midpoints
2.6. Benchmark Models
2.6.1. Stochastic Gradient Boosting
2.6.2. Support Vector Regression
3. Empirical Results and Discussion
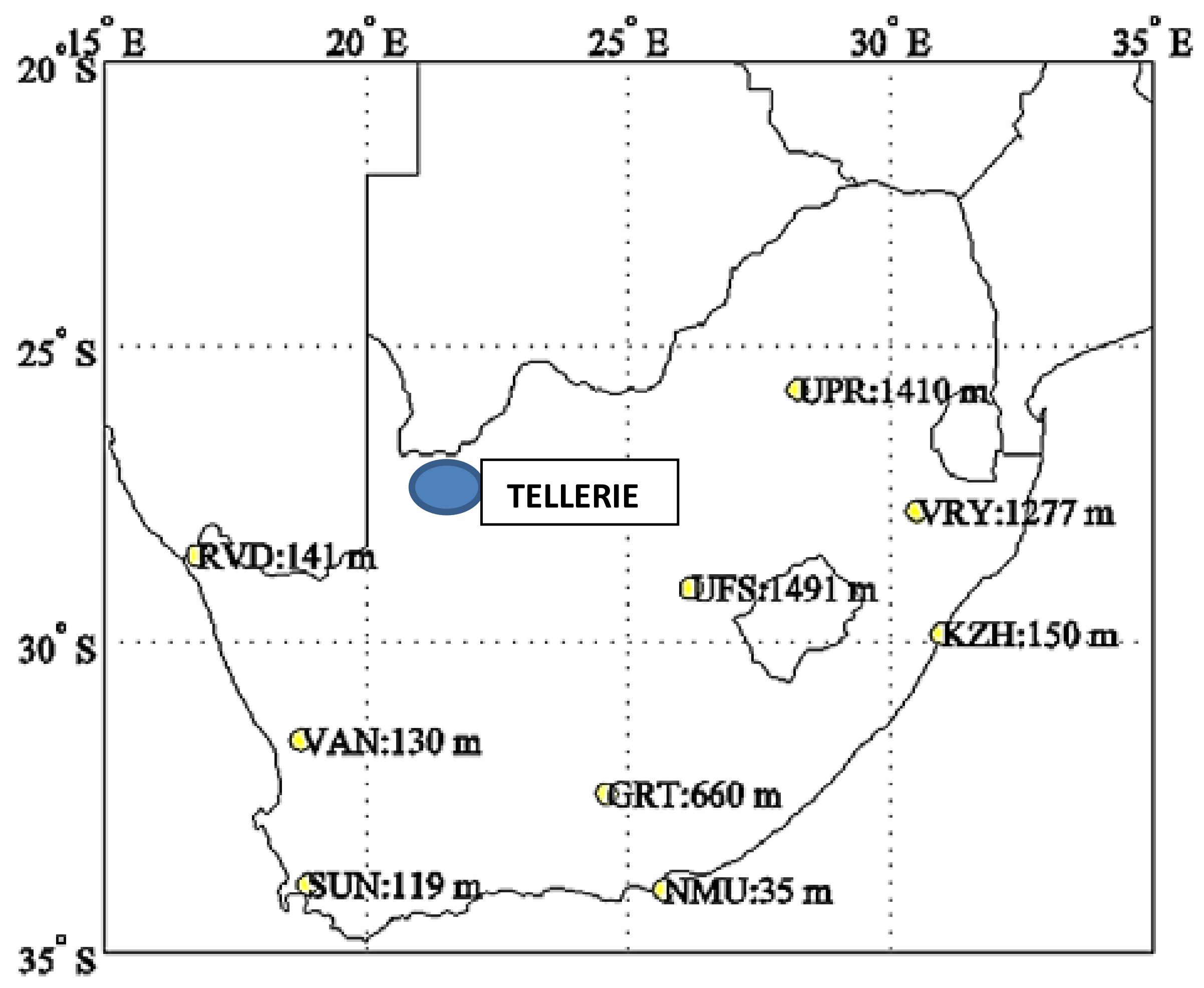
3.1. Data Source
- Latitude: S
- Longitude: E
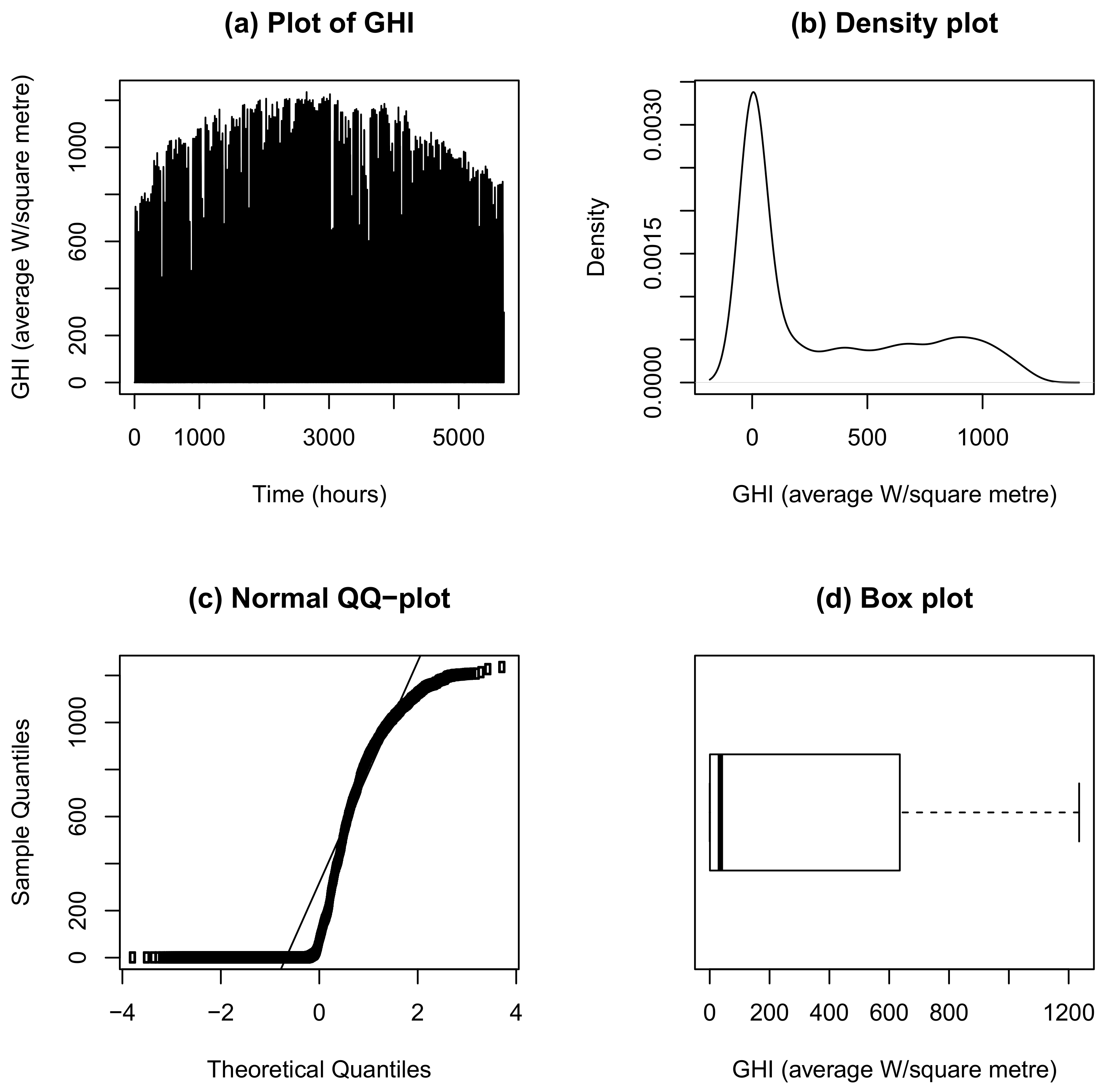
3.2. Exploratory Data Analysis
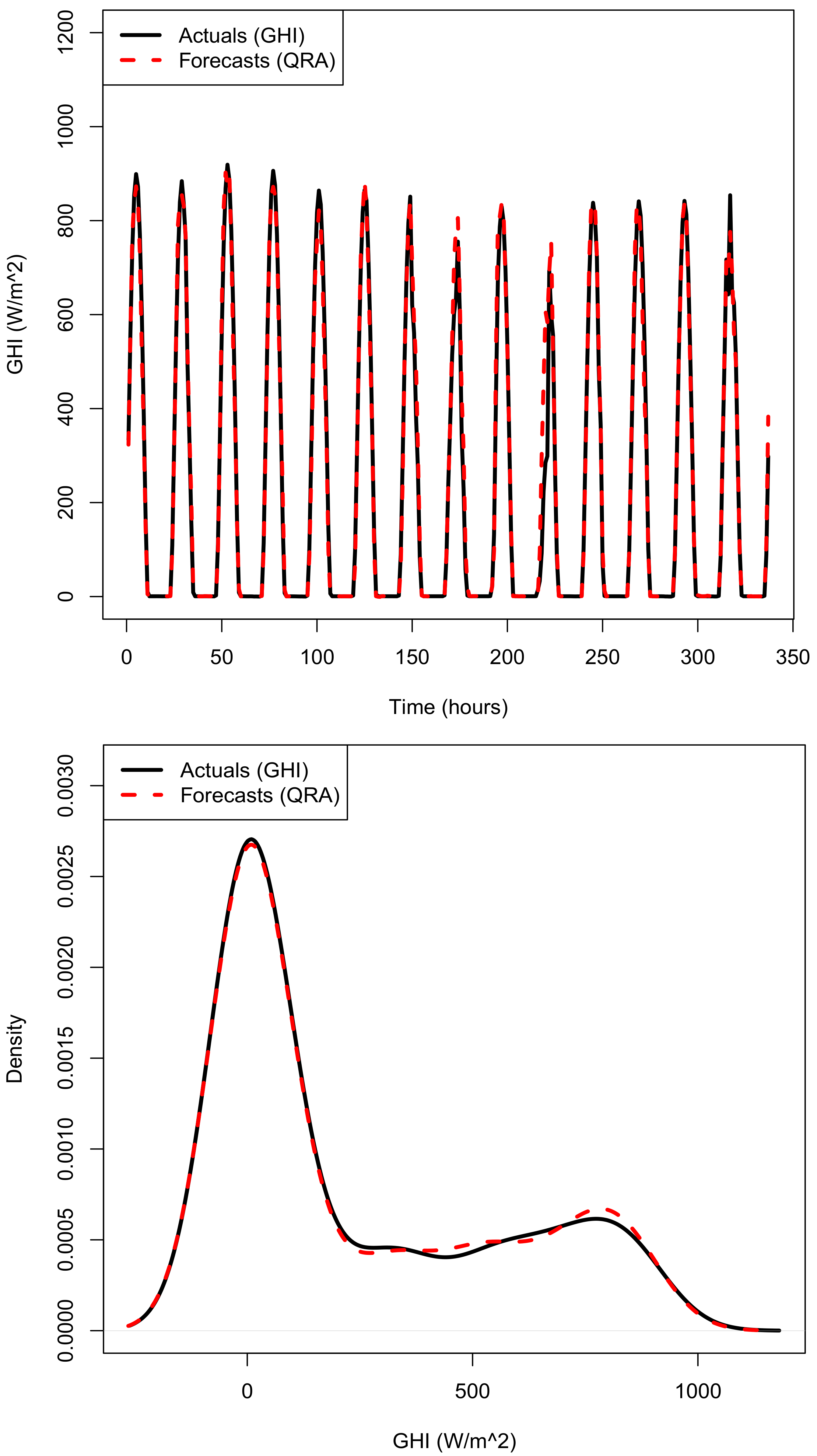
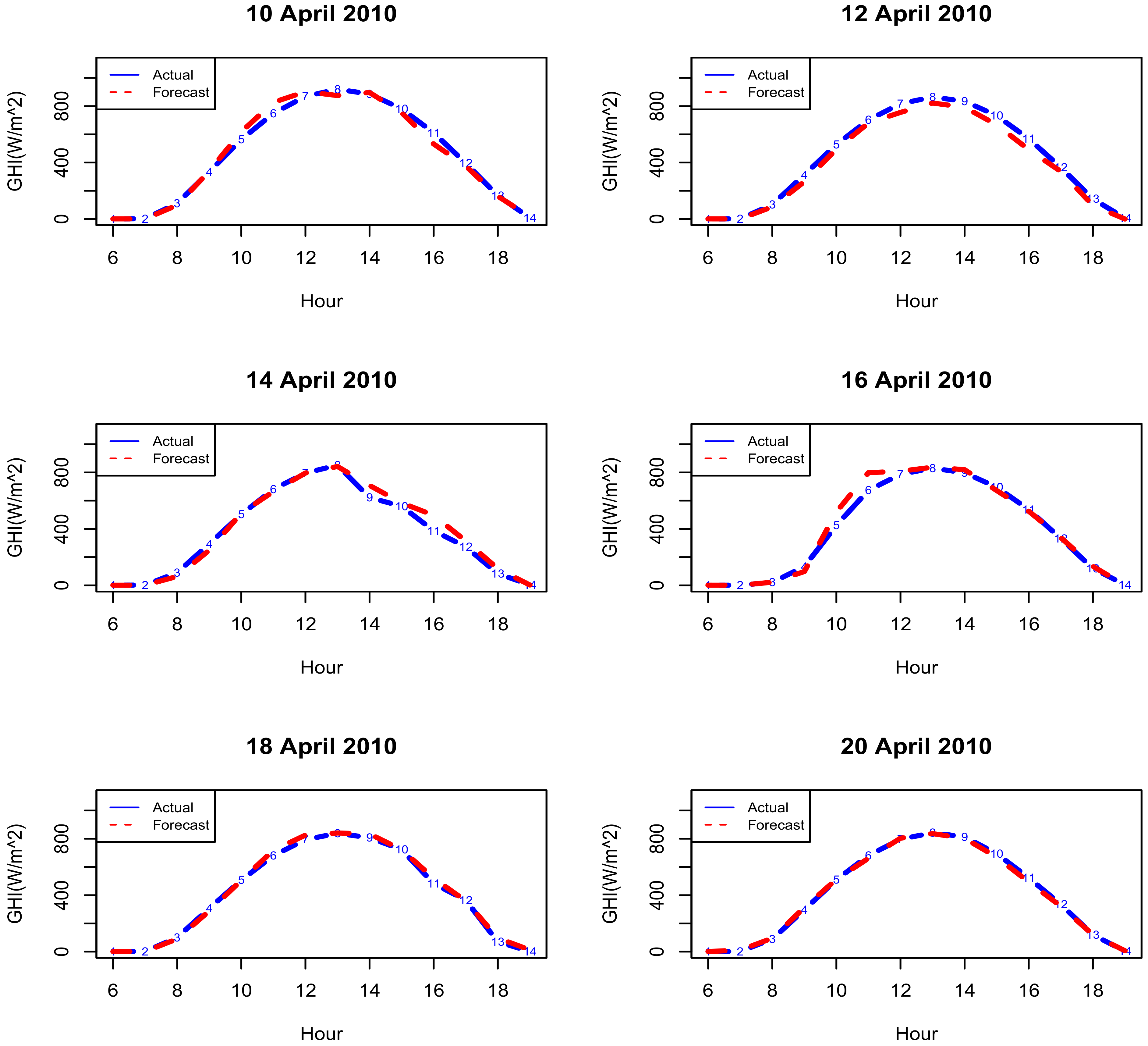
3.3. Forecasting Results
3.3.1. Variable Selection Using Lasso Via Hierarchical Interactions
3.3.2. Variable Importance
3.3.3. Partially Linear Additive Quantile Regression Models with and Without Interactions
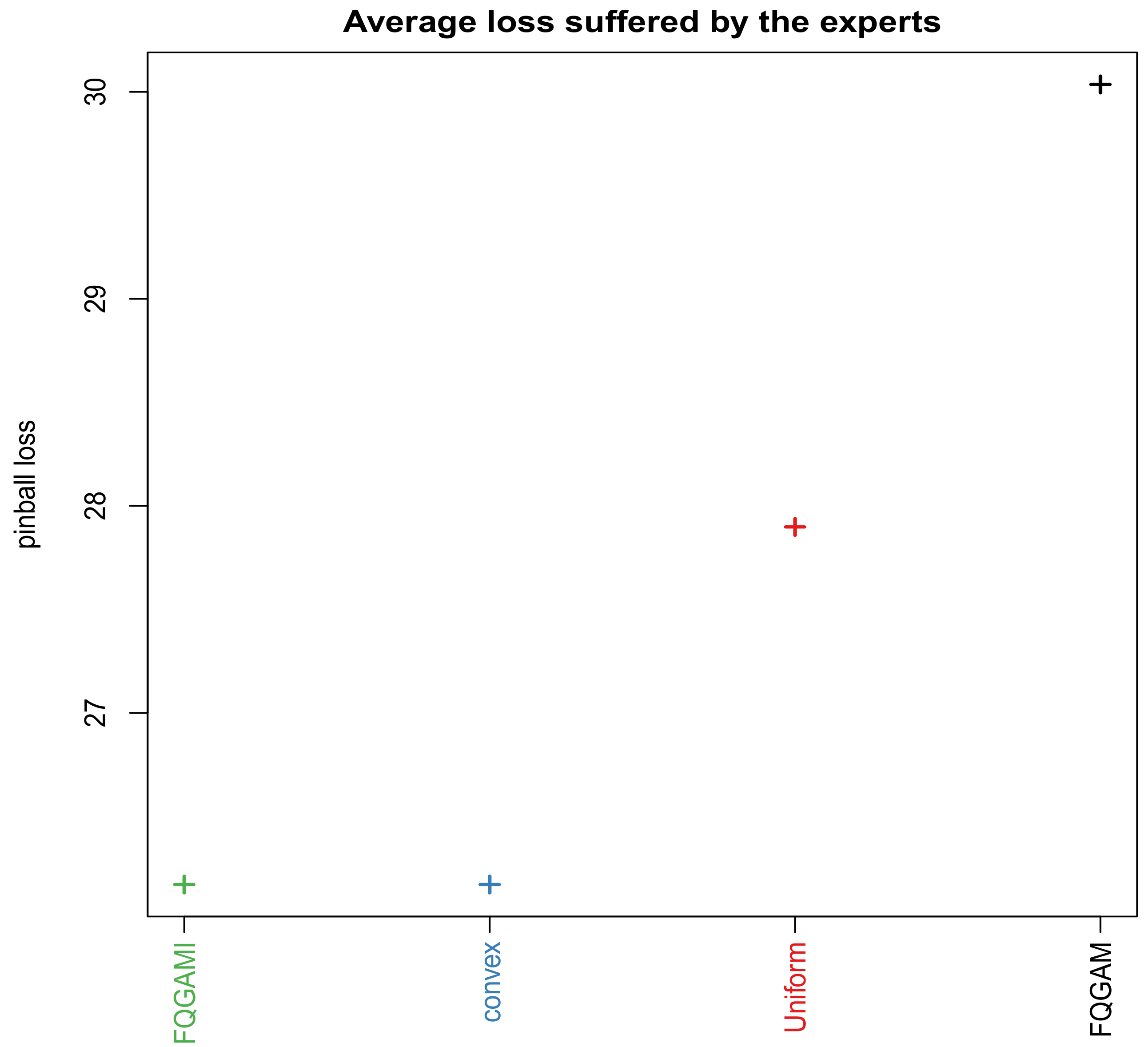
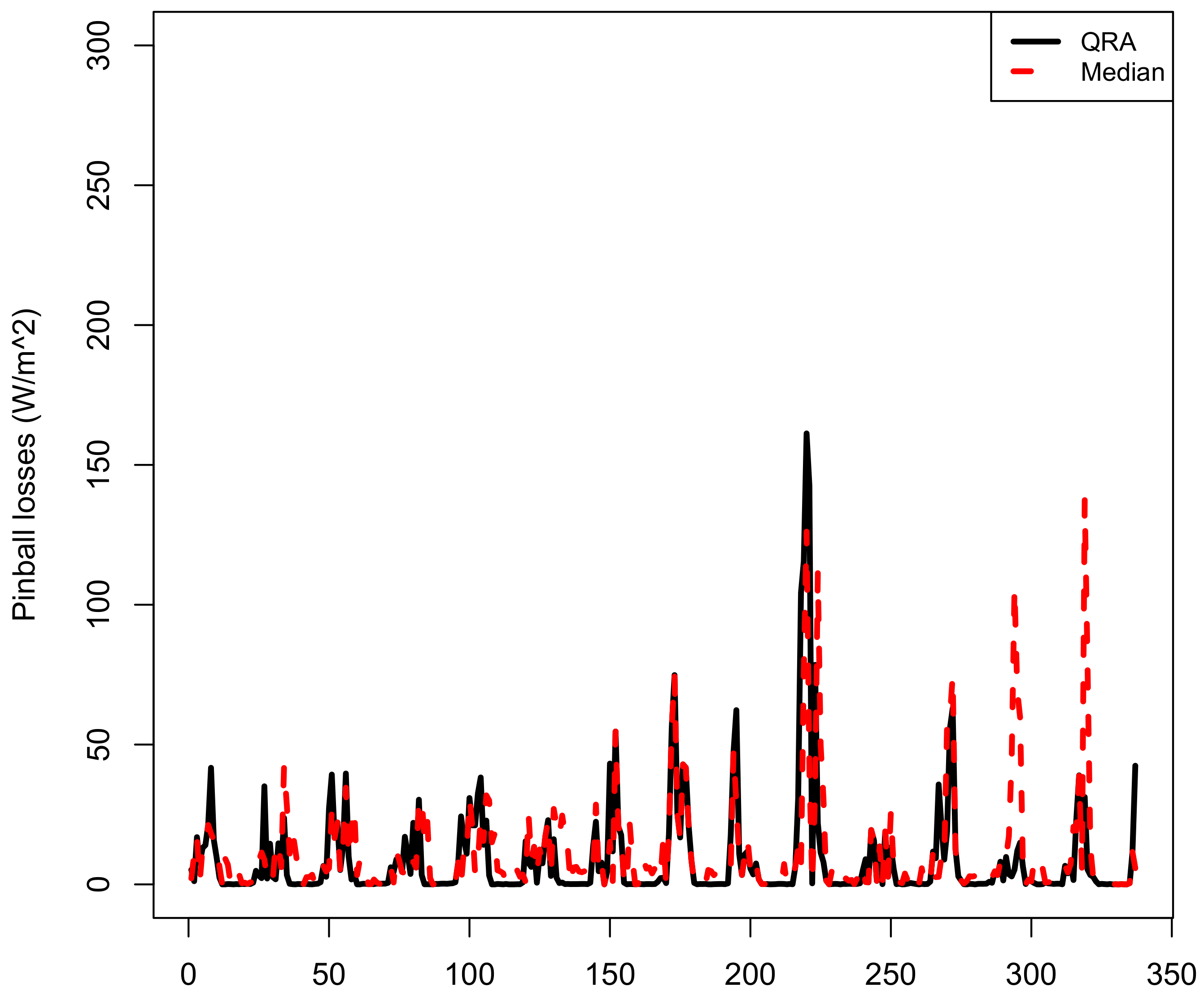
3.4. Quantile Regression Averaging and Comparative Analysis of the Models
3.4.1. Quantile Regression Averaging
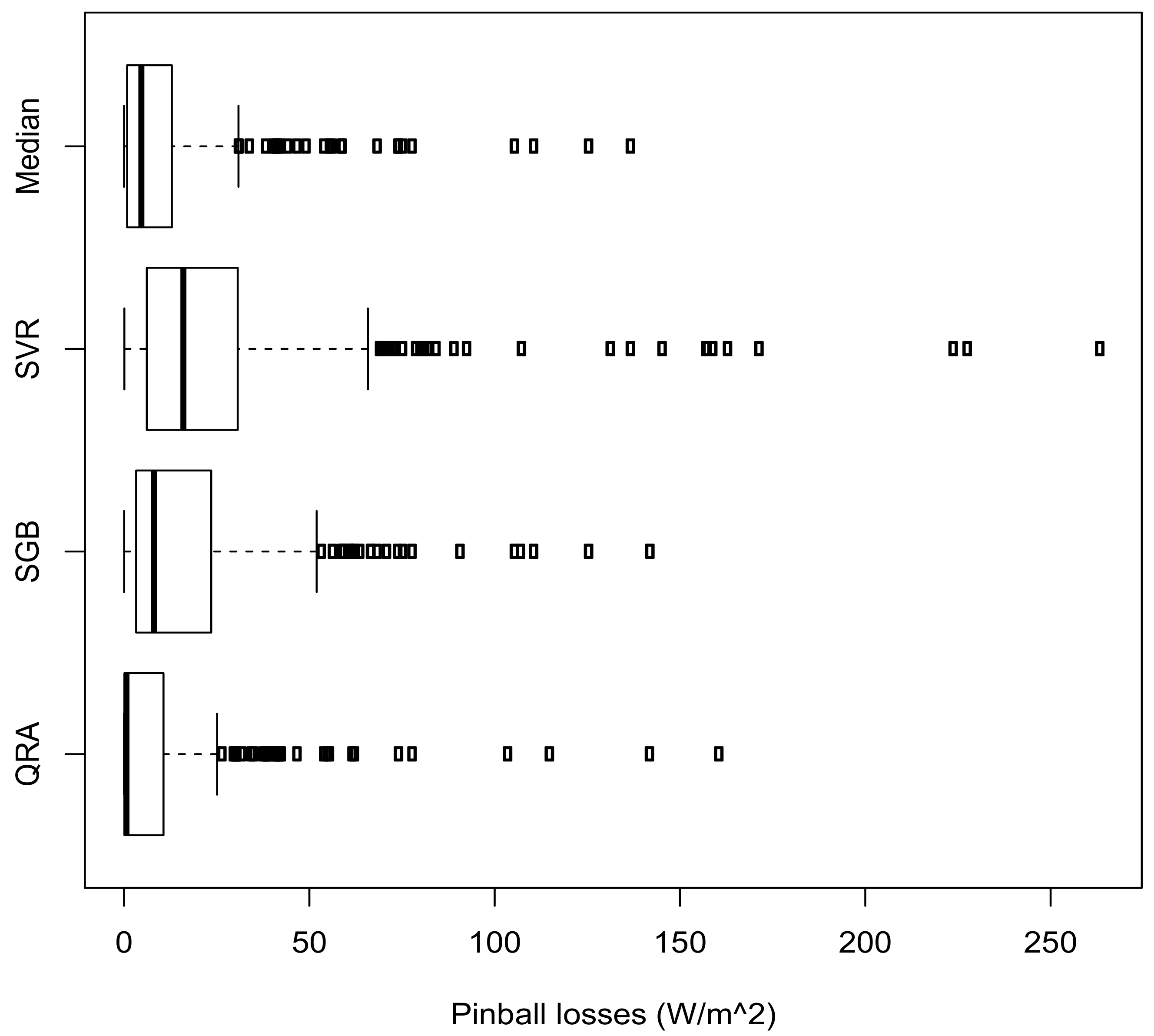
3.4.2. Comparative Analysis of the Models
3.4.3. Comparative Analysis with the Benchmark Models
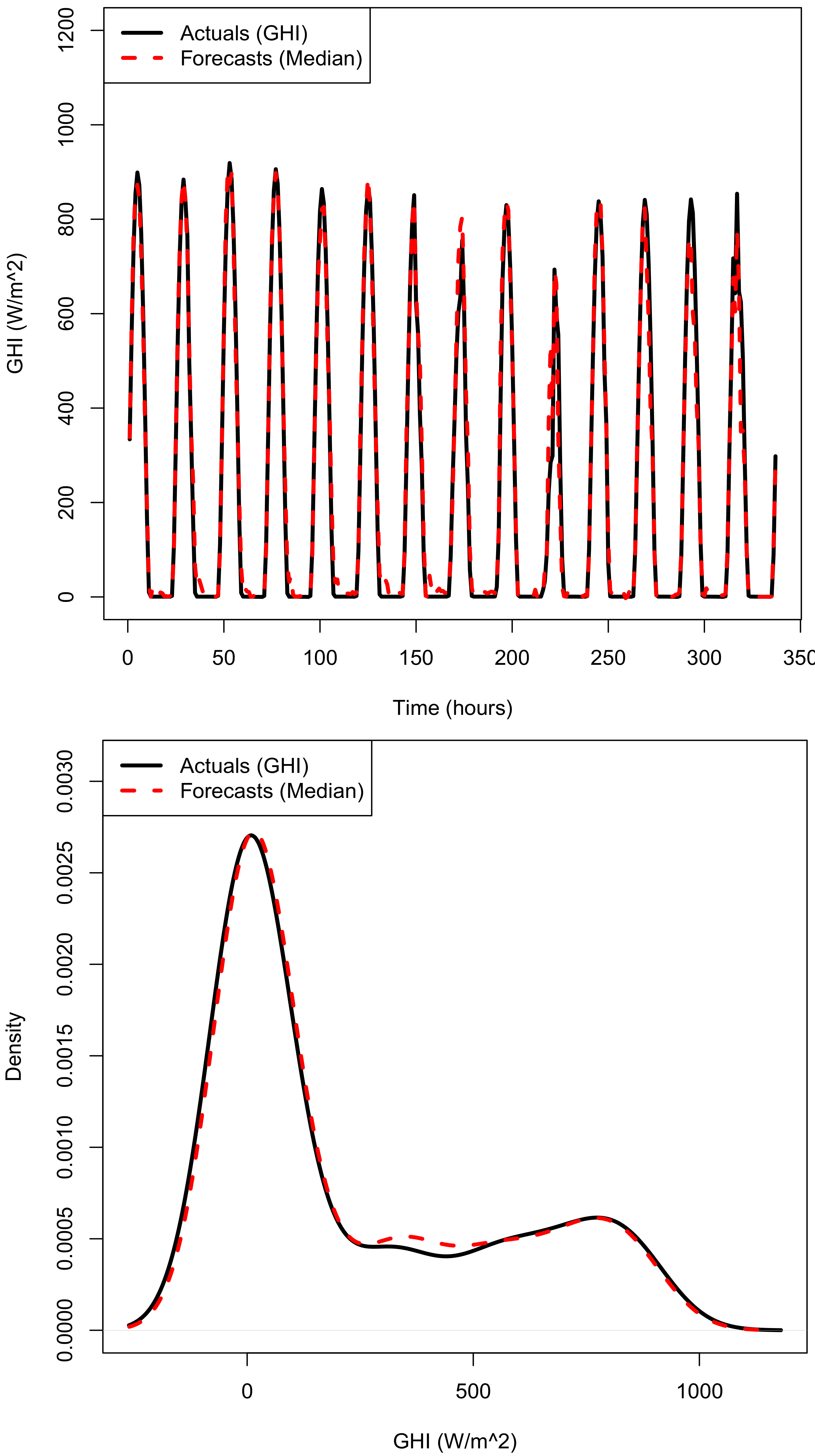
3.4.4. Combining Prediction Intervals and Out of Sample Forecasts
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AIC | Akakike Information Criterion |
| BIC | Bayesian Information Criterion |
| CRPS | Continuous Rank Probability Score |
| CV | Cross Validation |
| DSS | Dawid-Sebastini Score |
| GAM | Generalised Additive Model |
| GHI | Global Horizontal Irradiance |
| GLM | Generalised Linear Model |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| OLSR | Ordinary Least Squares Regression |
| PLAM | Partial Linear Additive Model |
| PLAQR | Partial Linear Additive Quantile Regression |
| PLF | Pinball Loss Function |
| PICP | Prediction Interval Coverage Probability |
| PINAD | Prediction Interval Normalised Average Deviation |
| PINAW | Prediction Interval Normalised Average Width |
| PM | Probability averaging of endpoints and simple averaging of Midpoints |
| QR | Quantile Regression |
| QRA | Quantile Regression Averaging |
Appendix A. Combined Median Forecasts

References
- Mohammed, A.A.; Yaqub, W.; Aung, Z. Probabilistic forecasting of solar power: An ensemble learning approach. In Intelligent Decision Technologies. IDT 2017. Smart Innovation, Systems and Technologies; Neves-Silva, R., Jain, L., Howlett, R., Eds.; Springer: Cham, Switzerland, 2015; Volume 39, pp. 449–458. [Google Scholar]
- Chatfield, C. Calculating interval forecasts. J. Bus. Econ. Stat. 1993, 11, 121–135. [Google Scholar]
- Gaba, A.; Tsetlin, I.; Winkler, R.L. Combining interval forecasts. Decis. Anal. 2017, 14, 1–20. [Google Scholar] [CrossRef]
- Warner, G.A. Solar Energy in South Africa: Challenges and Opportunities. 2014. Available online: http://www.ee.co.za/article/solar-energy-south-africa-challenges-opportunities.html (accessed on 5 November 2018).
- Jozi, A.; Pinto, T.; Praca, I.; Vale, Z. Decision support application for energy consumption forecasting. Appl. Sci. 2019, 9, 699. [Google Scholar] [CrossRef]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Martinez-de-Pison, F.J.; Antonanzas-Torres, F. Review of photovoltaic power forecasting. Sol. Energy 2016, 136, 78–111. [Google Scholar] [CrossRef]
- Massidda, L.; Marrocu, M. Quantile regression post-processing of weather forecast for short-term solar power probabilistic forecasting. Energies 2018, 11, 1763. [Google Scholar] [CrossRef]
- Ahmed, A.; Khalid, M. A review on the selected applications of forecasting models in renewable power systems. Renew. Sustain. Energy Rev. 2019, 100, 9–21. [Google Scholar] [CrossRef]
- Abuella, M.; Chowdhury, B. Solar Irradiance Probabilistic Forecasting by Using Multiple Linear Regression Analysis. In Proceedings of the SoutheastCon 2015, Fort Lauderdale, FL, USA, 9–12 April 2015. [Google Scholar]
- Sobrina Sobri, S.; Koohi-Kamali, S.; Rahima, N.A. Solar photovoltaic generation forecasting methods: A review. Energy Convers. Manag. 2018, 156, 459–497. [Google Scholar] [CrossRef]
- Xie, T.; Zhang, G.; Liu, H.; Liu, F.; Du, P. A hybrid forecasting method for solar output power based on variational mode decomposition, deep belief networks and auto-regressive moving average. Appl. Sci. 2018, 8, 1901. [Google Scholar] [CrossRef]
- Huang, J.; Perry, M. A semi-empirical approach using gradient boosting and k-nearest neighbors regression for gefcom2014 probabilistic solar irradiance forecasting. Int. J. Forecast. 2016, 32, 1081–1086. [Google Scholar] [CrossRef]
- Grantham, A.; Gel, R.Y.; Boland, J.W. Non-parametric short-term probabilistic forecasting for solar radiation. Sol. Energy 2016, 133, 465–475. [Google Scholar] [CrossRef]
- Alessandrini, S.; Monachel, D.; Sperati, S.; Cervone, G. An analog ensemble for short-term probabilistic solar irradiance forecast. Appl. Energy 2015, 157, 95–110. [Google Scholar] [CrossRef]
- Juban, R.; Ohlsson, H.; Maasoumya, M.; Poirier, L.; Kolter, J.Z. A multiple quantile regression approach to the wind, solar, and price tracks of gefcom2014. Int. J. Forecast. 2016, 32, 1094–1102. [Google Scholar] [CrossRef]
- Yang, D.; Ye, Z.; Lim, L.H.I.; Dong, Z. Very short term irradiance forecasting using the lasso. Sol. Energy 2015, 114, 314–326. [Google Scholar] [CrossRef]
- Bien, J.; Taylor, J.; Tibshirani, R. A lasso for hierarchical interactions. Ann. Stat. 2013, 41, 1111–1141. [Google Scholar] [CrossRef] [PubMed]
- Lim, M.; Hastie, T. Learning interactions via hierarchical group-lasso regularization. J. Comput. Graph. Stat. 2015, 24, 627–654. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Zho, K.; Lian, H. Bayesian quantile regression for partially linear additive models. Stat. Comput. 2015, 25, 651–668. [Google Scholar] [CrossRef]
- Wang, F.; Zhen, Z.; Wang, B.; Mi, Z. Comparative study on KNN and SVM based weather classification models for day ahead short term solar PV power forecasting. Appl. Sci. 2018, 8, 28. [Google Scholar] [CrossRef]
- Wang, F.; Yu, Y.; Zhang, Z.; Li, J.; Zhen, Z.; Li, K. Wavelet decomposition and convolutional LSTM networks based improved deep learning model for solar irradiance forecasting. Appl. Sci. 2018, 8, 1286. [Google Scholar] [CrossRef]
- Koenker, R. Quantile Regression; Cambridge University Press: New York, NY, USA, 2005. [Google Scholar]
- Hastie, T.; Tibshirani, R. Generalized Additive Models; Chapman & Hall: London, UK, 1990. [Google Scholar]
- Hardle, W.; Hlavka, Z.; Klinke, S. XploRe: Application Guide; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Koenker, R.; Bassett, G. Regression quantiles. Econom. J. Econom. Soc. 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Davino, C.; Furno, M.; Vistocco, D. Quantile Regression: Theory and Applications; John Wiley & Sons: Chichester, UK, 2013. [Google Scholar]
- Hoshino, T. Quantile regression estimation of partially linear additive models. J. Non-Parametr. Stat. 2014, 26, 509–536. [Google Scholar] [CrossRef]
- Wood, S.N. Generalized Additive Models: An Introduction with R, 2nd ed.; Taylor and Francis: New York, NY, USA, 2017. [Google Scholar]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice. Second Edition, 2017. Available online: https://www.otexts.org/fpp (accessed on 15 September 2018).
- Marasinghe, D. Quantile Regression for Climate Data. Master’s Thesis, Clemson University, Clemson, SC, USA, 2014. [Google Scholar]
- Bates, J.M.; Granger, C.W.J. The combination of forecasts. J. Oper. Res. Soc. 1969, 20, 451–468. [Google Scholar] [CrossRef]
- Gaillard, P.; Goude, Y. Forecasting Electricity Consumption by Aggregating Experts; How to Design a Good Set of Experts. In Modeling and Stochastic Learning for Forecasting in High Dimensions; Lecture Notes in Statistics; Antoniadis, A., Poggi, J.M., Brossat, X., Eds.; Springer: Cham, Switzerland, 2015; Volume 217, pp. 95–115. [Google Scholar]
- Sigauke, C. Forecasting medium-term electricity demand in a South African electric power supply system. J. Energy South. Afr. 2017, 28, 54–67. [Google Scholar] [CrossRef]
- Nowotarski, J.; Weron, R. Computing electricity spot price prediction intervals using quantile regression and forecast averaging. Comput. Stat. 2015, 30, 791–803. [Google Scholar] [CrossRef]
- Gneiting, T.; Katzfuss, M. Probabilistic forecasting. Annu. Rev. Stat. Its Appl. 2014, 1, 125–151. [Google Scholar] [CrossRef]
- Dawid, A.P.; Sebastiani, P. Coherent dispersion criteria for optimal experimental design. Ann. Stat. 1999, 27, 65–81. [Google Scholar]
- Sun, X.; Wang, Z.; Hu, J. Prediction interval construction for byproduct gas flow using optimizing twin extreme learning machine. Math. Probl. Eng. 2017, 2017, 1–12. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 2000. [Google Scholar]
- Zhandire, E. Predicting clear-sky global horizontal irradiance at eight locations in South Africa using four models. J. Energy South. Afr. 2017, 28, 77–86. [Google Scholar] [CrossRef]
- Maidman, A. Partially Linear Additive Quantile Regression: “PLAQR” R Package. 2017. Available online: https://cran.r-project.org/web/packages/plaqr/plaqr.pdf (accessed on 5 September 2018).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Min | 1st Qu | Median | Mean | 3rd Qu | Max | Skewness | Kurtosis | Jarque-Bera |
|---|---|---|---|---|---|---|---|---|
| 0.000 | 0.64 | 34.84 | 305.91 | 635.20 | 1235.00 | 0.86 | −0.79 | 854.21 (0.000) |
| Main Effect | RN | WS | WindDir | AirTC | RH | BP | HOUR | noltrend | Lag1 | Lag2 | Tight? | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RN | −6.29 | −4.62 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | −1.67 | |
| WS | 4.04 | 0 | 0 | 0 | 0 | 0 | 4.04 | 0 | 0 | 0 | 0 | |
| WindDir | 8.87 | 0 | 0 | −1.14 | 0 | 0 | 4.29 | −3.007 | 0.43 | 0 | 0 | * |
| AirTC | 169.62 | 0 | 0 | 0 | 43.81 | −15.83 | 0.61 | −106.10 | 0 | 0 | 0 | |
| RH | −49.30 | 0 | 0 | 0 | −15.83 | 0.49 | −4.21 | 28.77 | 0 | 0 | 0 | * |
| BP | 38.28 | 0 | 4.04 | 4.29 | 0.61 | −4.21 | 0 | 0 | 0 | 0 | 8.26 | |
| HOUR | −97.36 | 0 | 0 | −3.00 | −106.10 | 28.77 | 0 | −196.79 | 0 | 0 | 0 | * |
| noltrend | 0.43 | 0 | 0 | 0.43 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| Lag1 | 2.845 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | −2.85 | 0 | * |
| Lag2 | 14.19 | −1.67 | 0 | 0 | 0 | 0 | 8.26 | 0 | 0 | 0 | 0 |
| Variable | Relative Influence |
|---|---|
| hour | 40.458 |
| AirTC | 30.769 |
| Lag2 | 11.019 |
| RN*Lag2 | 10.884 |
| noltrend | 2.535 |
| BP*Lag2 | 1.867 |
| Lag1 | 0.594 |
| AirTC*hour | 0.430 |
| WindDir*hour | 0.359 |
| RH | 0.285 |
| RH*AirTC | 0.224 |
| RN | 0.164 |
| WS*BP | 0.146 |
| WindDir*BP | 0.127 |
| WindDir*noltrend | 0.071 |
| WindDir | 0.036 |
| BP | 0.021 |
| WS | 0.010 |
| Models | AdjR | AIC | BIC |
|---|---|---|---|
| PLAQR (M3) | 0.947 | 61,191.64 | 60,748.55 |
| PLAQR (M4) | 0.954 | 60,744.76 | 60,056.53 |
| Summary Statistics of Residuals | ||||
|---|---|---|---|---|
| Model M4 | Model M6 | Model M7 | Model M8 | |
| Standard deviation | 79.53 | 0.67 | 48.85 | 41.14 |
| Mean | −25.12 | −0.56 | −6.56 | −4.50 |
| Median | 4.49 | −0.13 | −0.10 | −0.11 |
| 1st Quartile | −66.21 | −1.04 | −0.70 | −0.94 |
| 3rd Quartile | 26.23 | −0.05 | 1.69 | 1.57 |
| Skewness | −2.34 | −1.34 | −4.04 | −3.45 |
| Kurtosis | 7.89 | 1.61 | 24.46 | 21.25 |
| Under and over Predictions | ||||
| Mean under predicted | 0.53 | 0.43 | 0.43 | 0.42 |
| Mean Over predicted | 0.47 | 0.57 | 0.57 | 0.58 |
| Under prediction | 179 | 144 | 145 | 141 |
| Over prediction | 158 | 193 | 192 | 196 |
| Models | PICP | PINAW | PINAD | Mean PI |
|---|---|---|---|---|
| Model M6 | 98.52% | 27.01% | 0.08% | 155.66 |
| Model M7 | 98.81% | 27.92% | 0.09% | 153.99 |
| Model M8 | 98.82% | 15.27% | 0.05% | 140.36 |
| Accuracy Measures | M8 (QRA) | SVR (Benchmark) | SGB (Benchmark) | MEdian Forecasts |
|---|---|---|---|---|
| CRPS | 151.57 | 160.4182 | 167.55 | 158.83 |
| Pinball loss | 8.82 | 26.31 | 17.18 | 10.89 |
| DSS | 12.25 | 12.49 | 12.53 | 12.45 |
| PICP | 98.82% | 84.57% | 82.50% | 89.91% |
| Mean PI | 140.36 | 170.83 | 135.32 | 129.50 |
| Individual Models | Below Lower Limit | Above Upper Limit | Hit Rate |
|---|---|---|---|
| Model M6 | 4 | 3 | 0.979 |
| Model M7 | 5 | 0 | 0.985 |
| Model M8 | 3 | 1 | 0.988 |
| Combinations | |||
| Simple average | 3 | 0 | 0.991 |
| Median | 4 | 0 | 0.988 |
| PM | 7 | 8 | 0.955 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mpfumali, P.; Sigauke, C.; Bere, A.; Mulaudzi, S. Day Ahead Hourly Global Horizontal Irradiance Forecasting—Application to South African Data. Energies 2019, 12, 3569. https://doi.org/10.3390/en12183569
Mpfumali P, Sigauke C, Bere A, Mulaudzi S. Day Ahead Hourly Global Horizontal Irradiance Forecasting—Application to South African Data. Energies. 2019; 12(18):3569. https://doi.org/10.3390/en12183569
Chicago/Turabian StyleMpfumali, Phathutshedzo, Caston Sigauke, Alphonce Bere, and Sophie Mulaudzi. 2019. "Day Ahead Hourly Global Horizontal Irradiance Forecasting—Application to South African Data" Energies 12, no. 18: 3569. https://doi.org/10.3390/en12183569
APA StyleMpfumali, P., Sigauke, C., Bere, A., & Mulaudzi, S. (2019). Day Ahead Hourly Global Horizontal Irradiance Forecasting—Application to South African Data. Energies, 12(18), 3569. https://doi.org/10.3390/en12183569