Maintenance Strategy Optimization of a Coal-Fired Power Plant Cooling Tower through Generalized Stochastic Petri Nets

 ,
,  and
and
Abstract
1. Introduction
2. Generalized Stochastic Petri Nets (GSPN)
- P = {P1, P2, … Pm} is a finite set of places;
- T = {t1, t2, …, tm} is a finite set of transitions;
- Pre: P × T is the place application;
- Post: P × T is the following place application
- M0 = {0, 1, 2, 3, …, ith} is the initial marking of the PN, represents the number of tokens in the ith place.
3. The Proposed Method
- Corrective maintenance: carried out only after a failure has occurred, aims only to correct faults and return the equipment to its full operation;
- Preventive maintenance: it is intended to prevent breakages and the appearance of failures in machines and components. The preventive tasks are carried out periodically, being fulfilled as planned and before failures occur, ensuring that the machines maintain their functioning effectively and reliably;
- Predictive maintenance: relies on monitoring and inspection of the equipment for the determination of its operational condition, maintenance interventions will only be carried out if a deviation on the equipment’s normal behavior is detected.
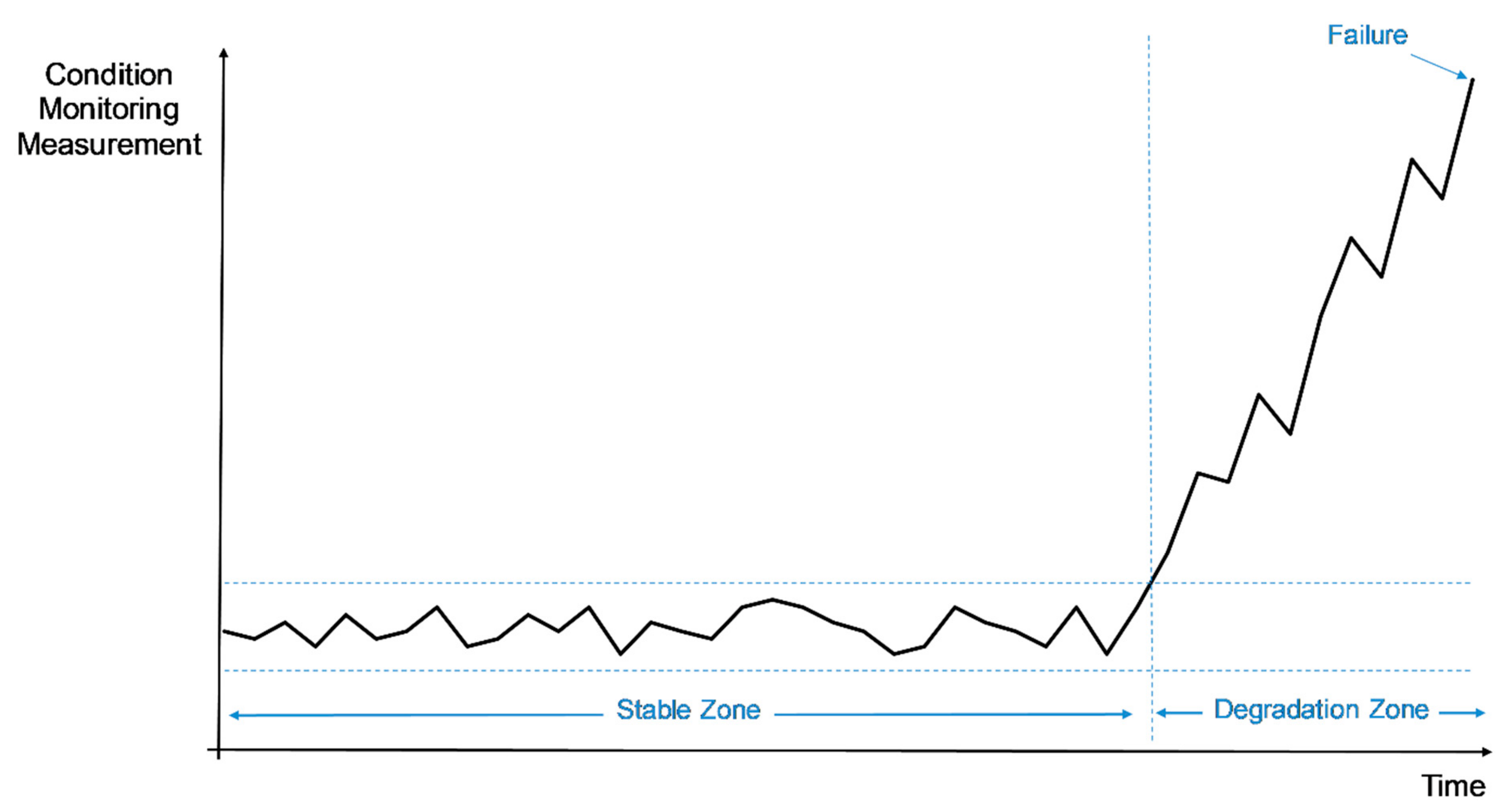
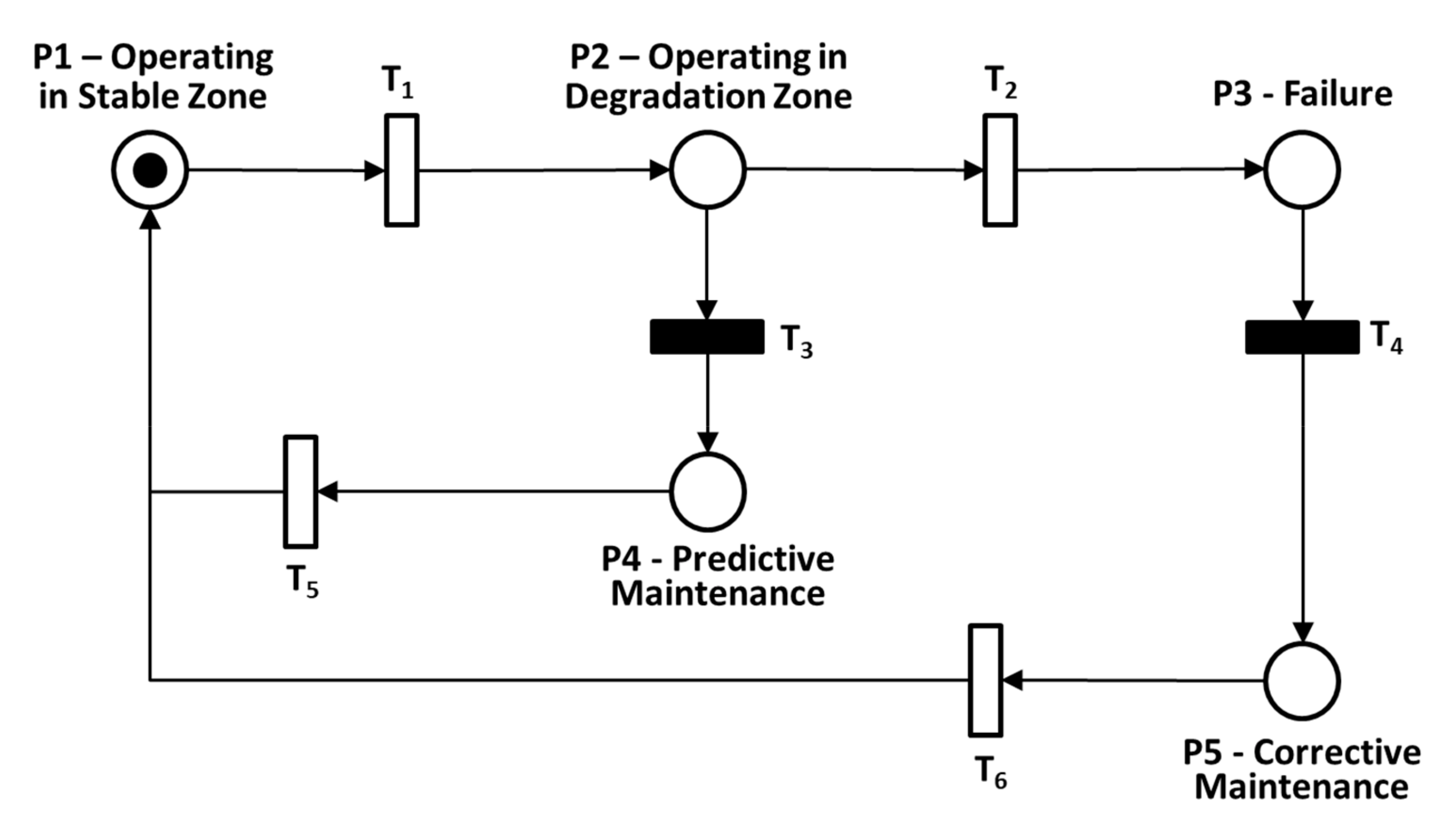
- P1: The machine is operating in the stable zone;
- P2: The machine is operating in the degradation zone and will soon fail;
- P3: The machine has failed and is no longer operable;
- P4: The machine is going through repair before it fails, because it has previously entered in the degradation zone;
- P5: The machine is going through repair after it has failed.
- T1: it is a timed transition that, if fired, makes the token go from P1 to P2, i. e., represents the machine going from the stable zone to the degradation zone. The firing delay is random and based on a probabilistic distribution that represents the time that the machine usually operates in the stable zone;
- T2: it is a timed transition that, if fired, makes the token go from P2 to P3, i. e., represents the machine going from the degradation zone to a failed state. The firing delay is random and based on a probabilistic distribution that represents the time that the machine usually operates in the degradation zone;
- T3: it is an immediate transition that, if fired, makes the token go from P2 to P4, i. e., represents the machine going from the degradation zone to repair before it fails. Since it is an immediate transition, this means that as soon as the token arrives at P2, it would immediately go to P4, but in the model proposed here, this will only happen if the maintenance team is available to repair the machine;
- T4: it is an immediate transition that, if fired, makes the token go from P3 to P5, i. e., represents the machine going from the failed state to repair. Since it is an immediate transition, this means that as soon as the token arrives at P3, it would immediately go to P5, but in the model proposed here, this will only happen if the maintenance team is available to repair the machine;
- T5: it is a timed transition that, if fired, makes the token go from P4 back to P1, i. e., represents the machine going from repair back to operating in the stable zone. The firing delay is random and based on a probabilistic distribution that represents the time that the machine usually stays in repair;
- T6: it is a timed transition that, if fired, makes the token go from P4 back to P1, i. e., represents the machine going from repair back to operating in the stable zone. The firing delay is random and based on a probabilistic distribution that represents the time that the machine usually stays in repair.
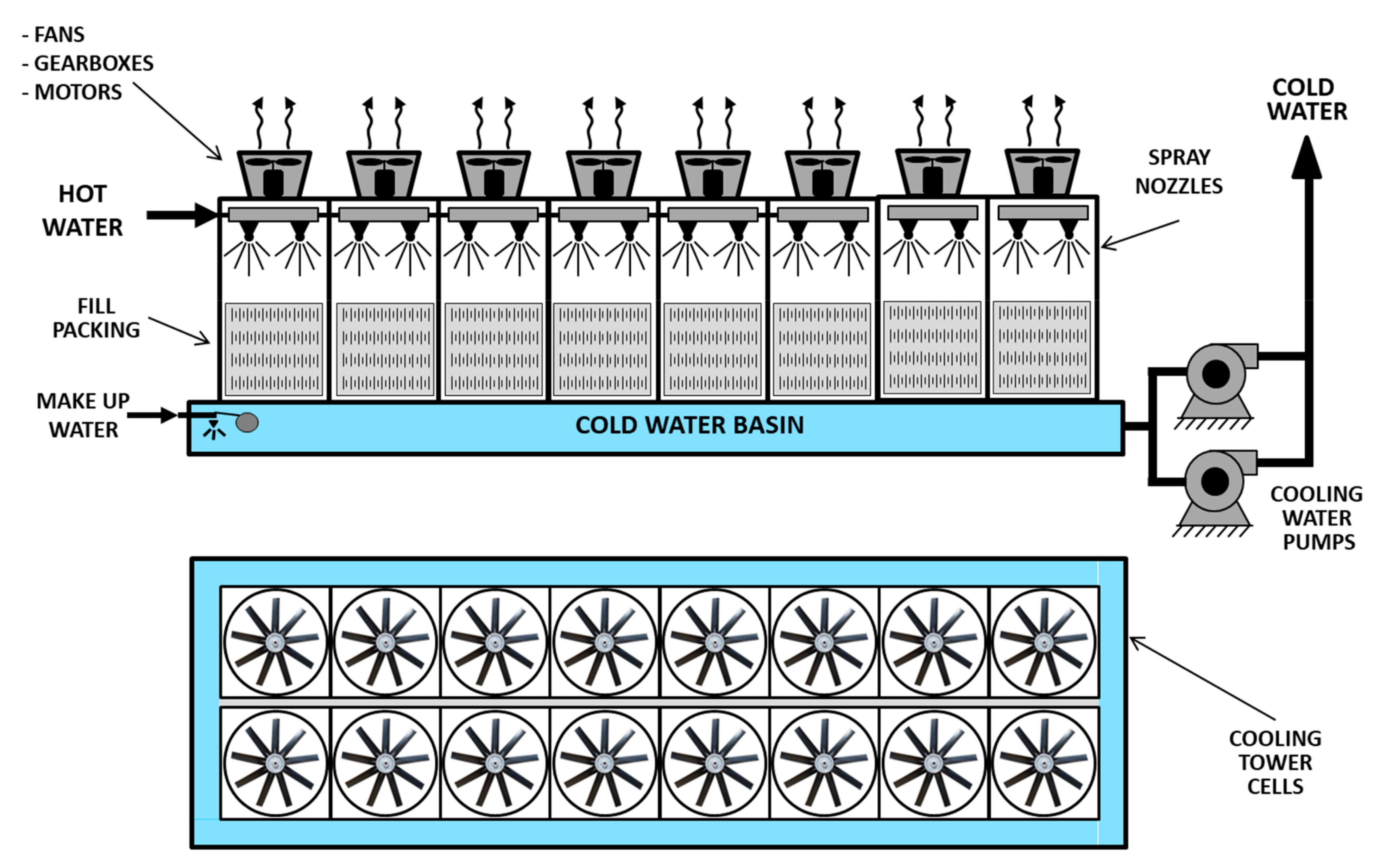
4. Maintenance Strategy Optimization of a Cooling Tower
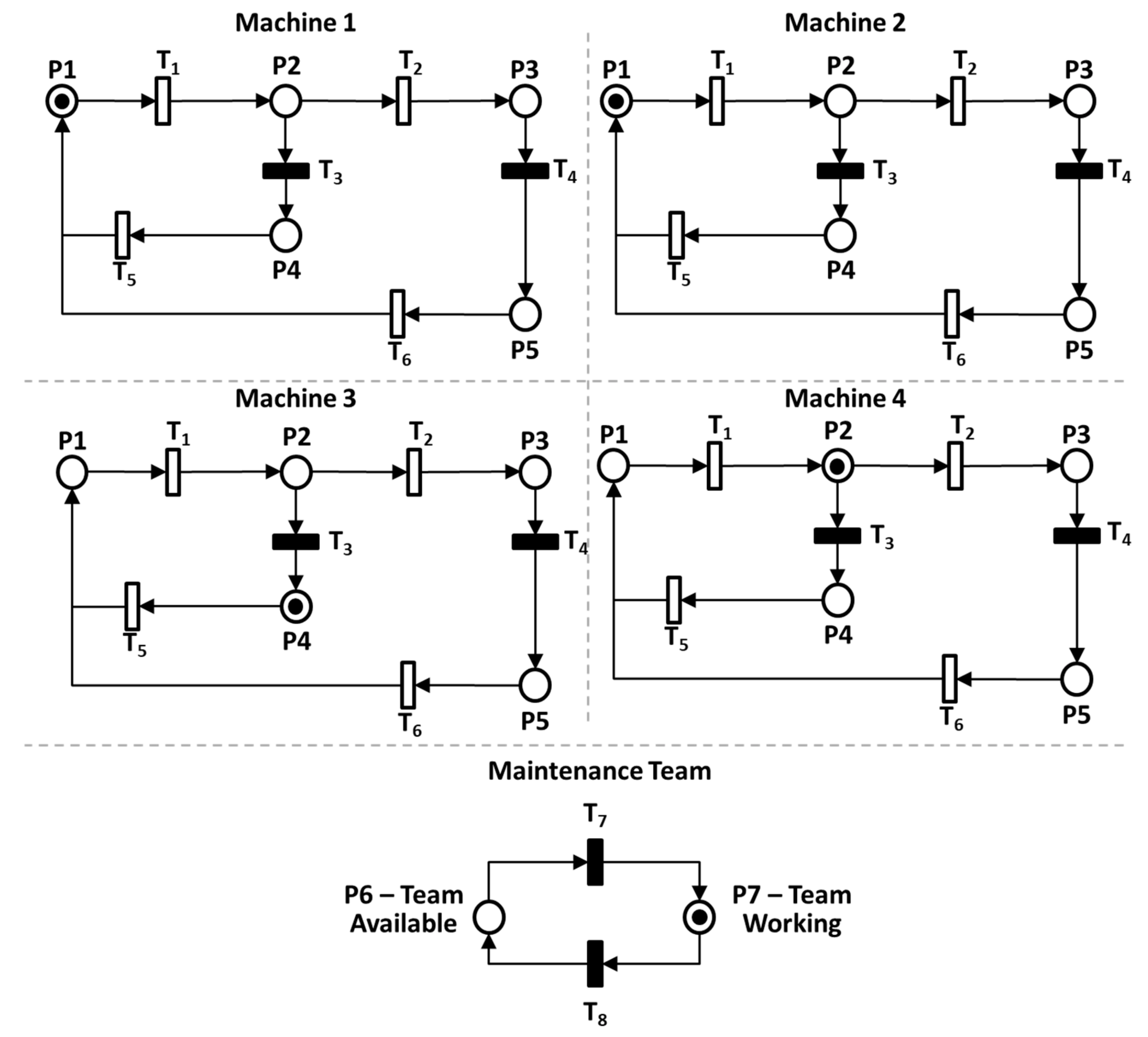
4.1. GSPN Model for the Cooling Tower
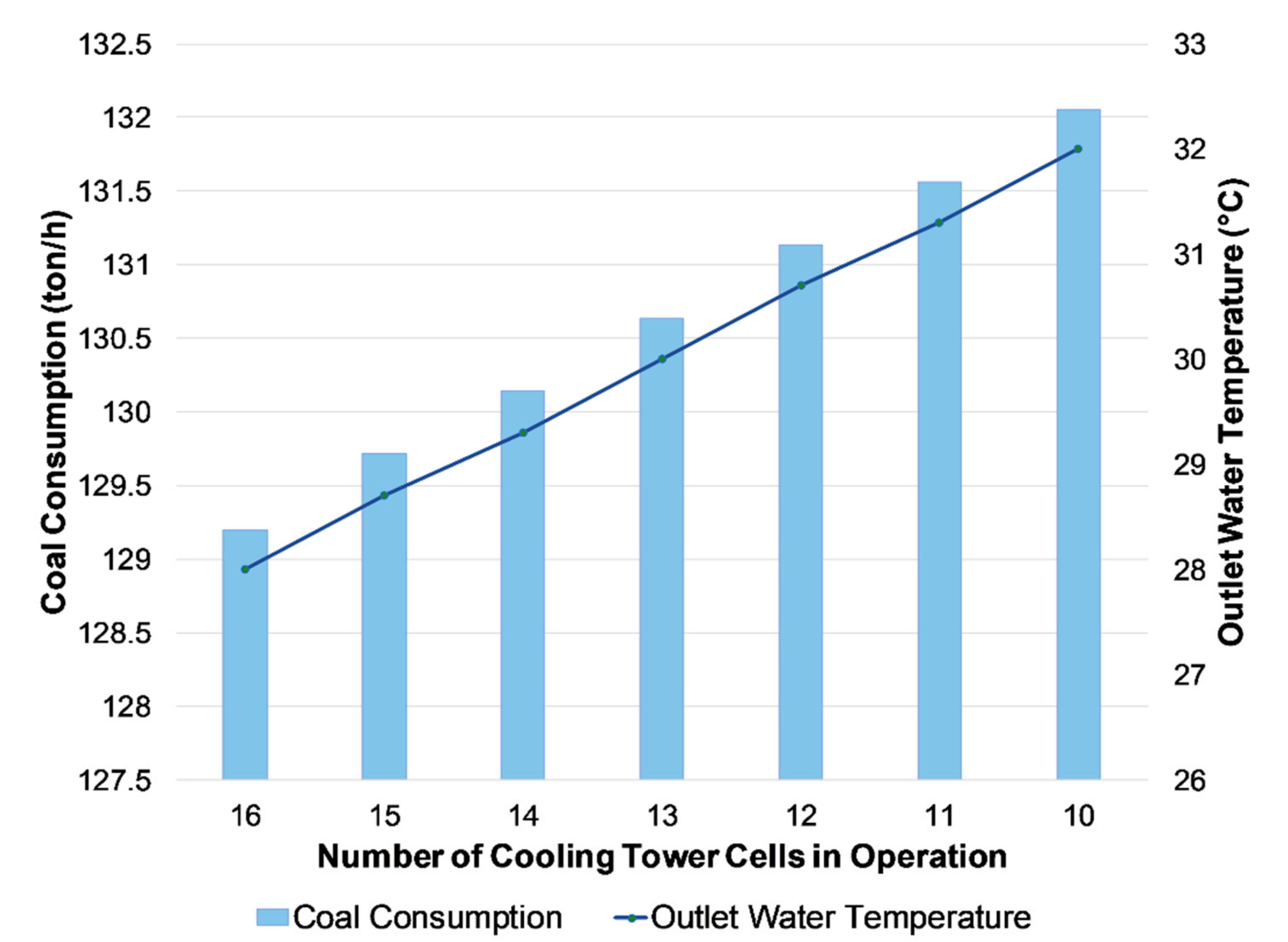
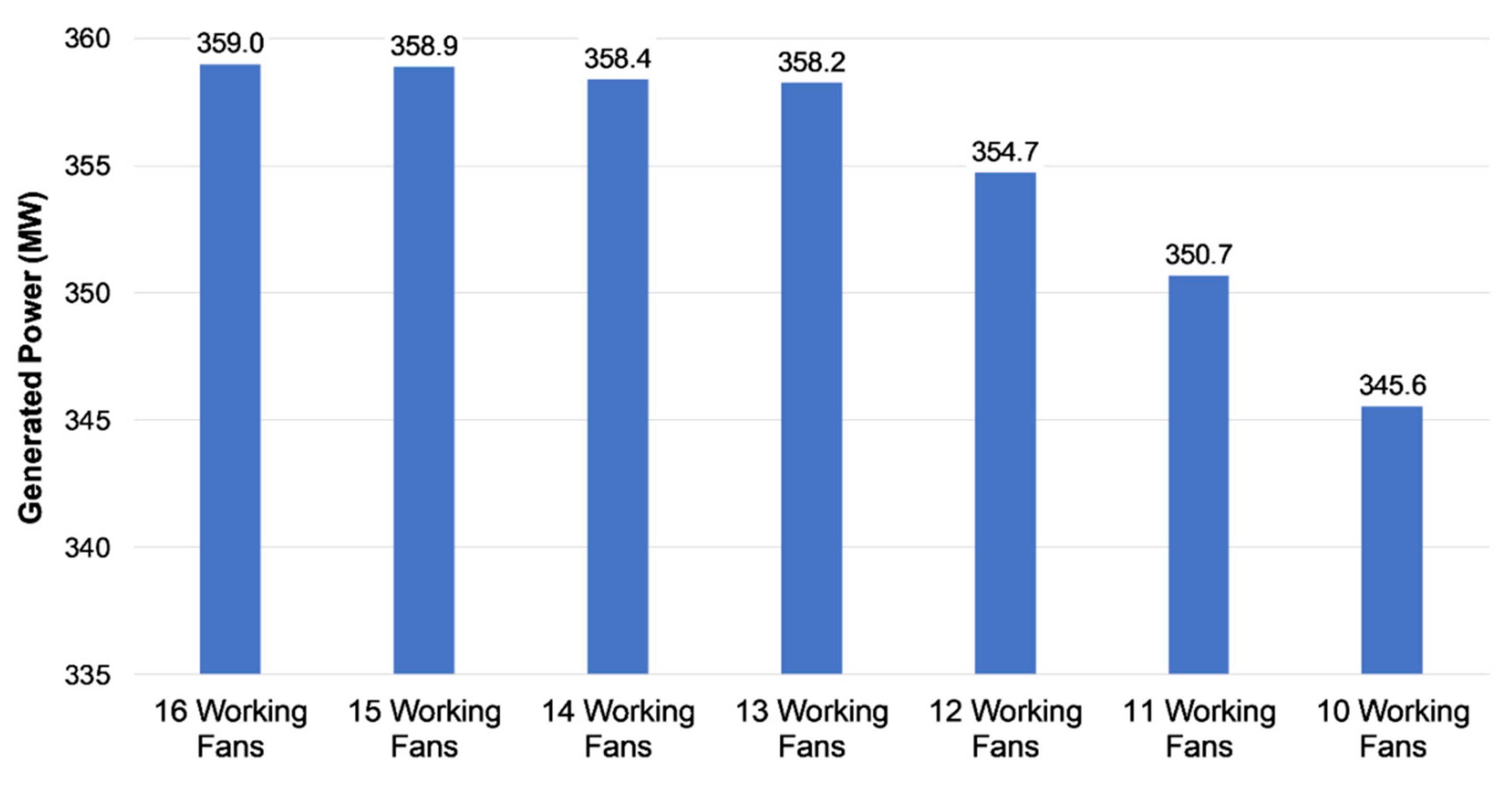
4.2. Thermodynamic Analysis
4.3. Cost–Benefit Analysis
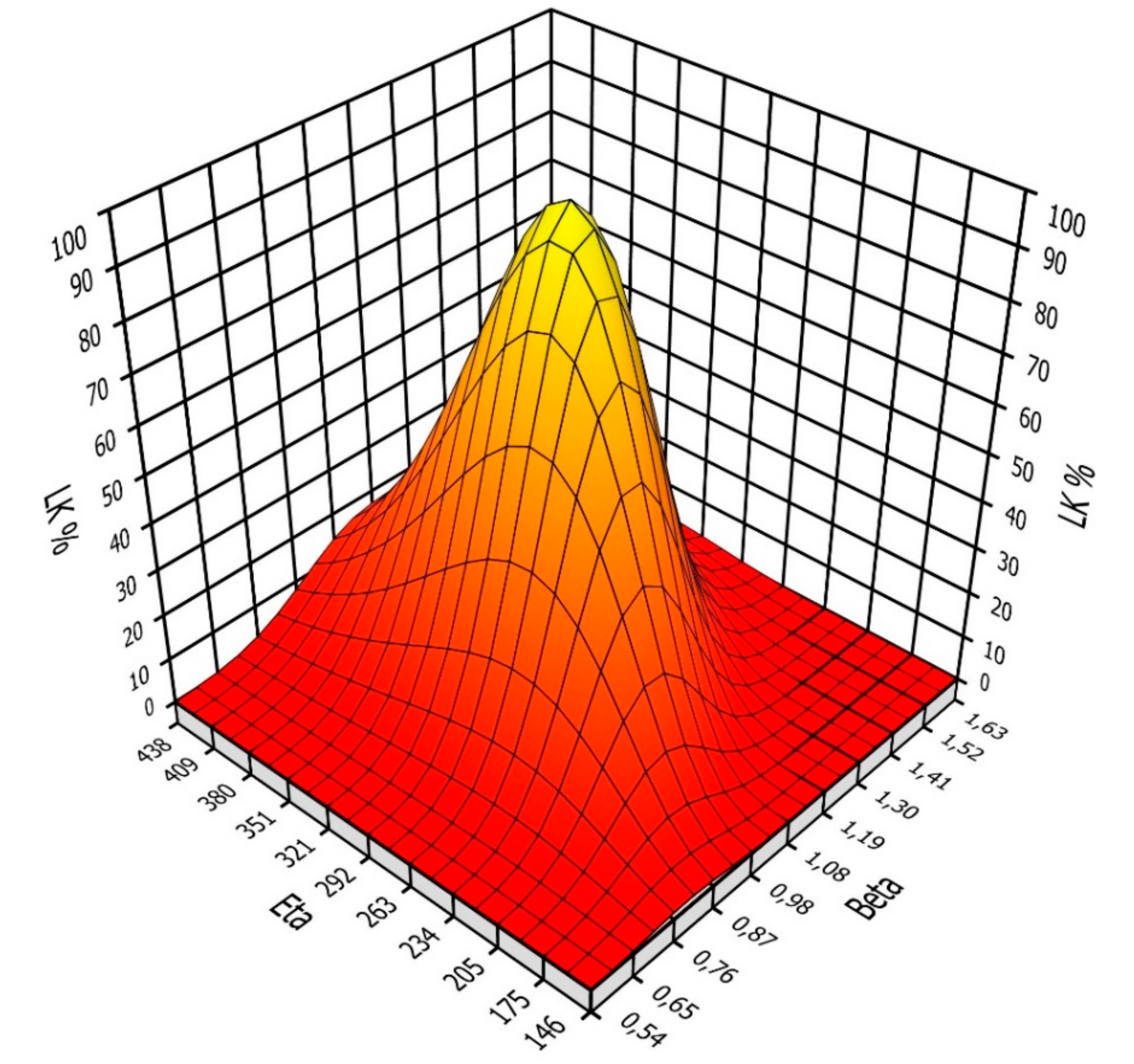
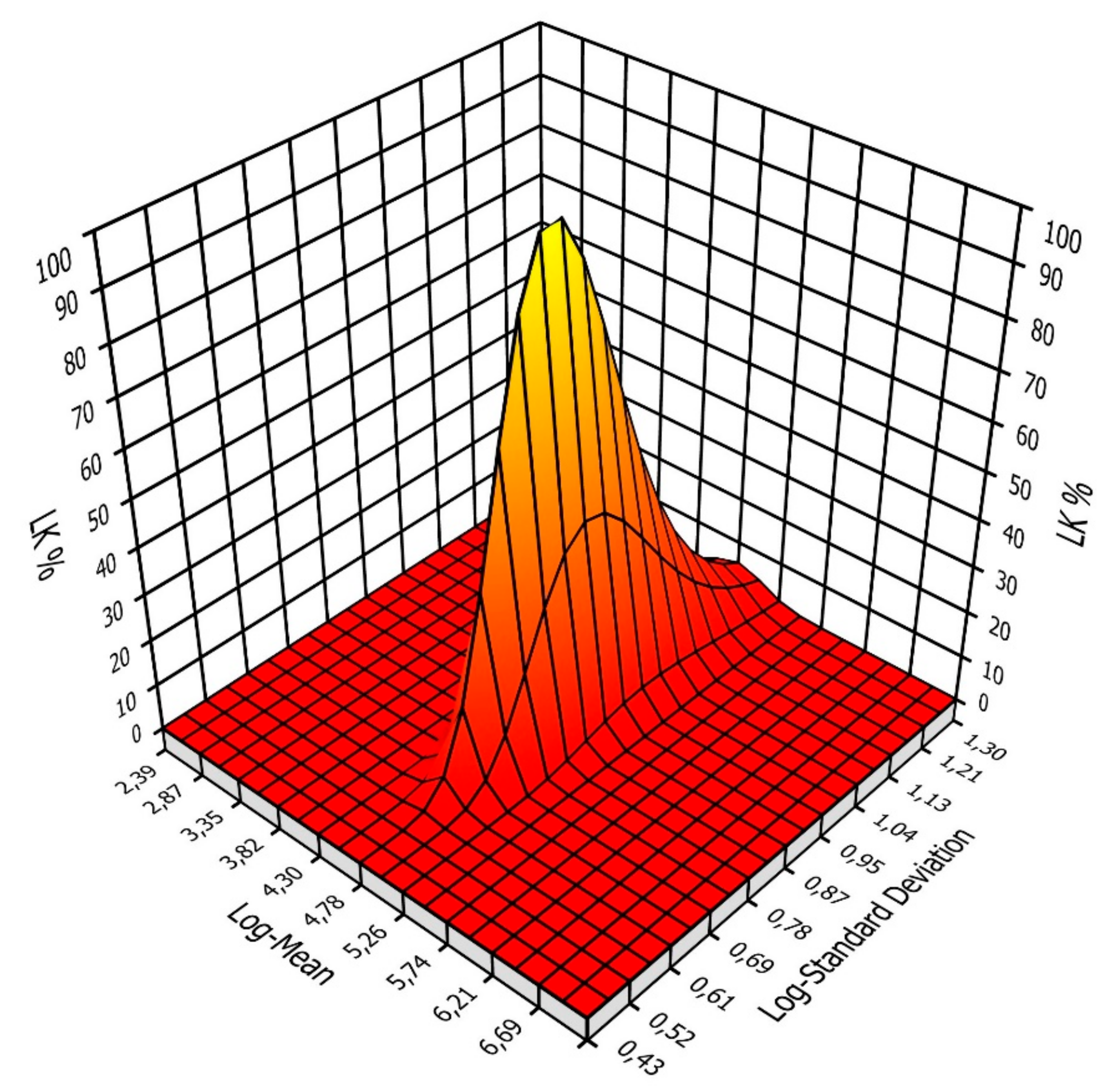
4.4. Sensitivity Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- IEA. Electricity Information: Overview; IEA: Paris, France, 2018. [Google Scholar]
- Wróblewski, W.; Dykas, S.; Rulik, S. Selection of the cooling system configuration for an ultra-critical coal-fired power plant. Energy Convers. Manag. 2013, 76, 554–560. [Google Scholar] [CrossRef]
- Fu, C.; Anantharaman, R.; Jordal, K.; Gundersen, T. Thermal efficiency of coal-fired power plants: From theoretical to practical assessments. Energy Convers. Manag. 2015, 105, 530–544. [Google Scholar] [CrossRef]
- Carazas, F.G.; Souza, G.F.M. Risk-based decision making method for maintenance policy selection of thermal power plant equipment. Energy 2010, 35, 964–975. [Google Scholar] [CrossRef]
- Modarresi, M.S.; Xie, L.; Campi, M.; Garatti, S.; Care, A.; Thatte, A.; Kumar, P.R. Scenario-based Economic Dispatch with Tunable Risk Levels in High-renewable Power Systems. IEEE Trans. Power Syst. 2018. [Google Scholar] [CrossRef]
- Tang, C.; Xu, J.; Sun, Y.; Liu, J.; Li, X.; Ke, D.; Yang, J.; Peng, X. Look-Ahead Economic Dispatch With Adjustable Confidence Interval Based on a Truncated Versatile Distribution Model for Wind Power. IEEE Trans. Power Syst. 2018, 33, 1755–1767. [Google Scholar] [CrossRef]
- Carazas, F.J.G.; de Souza, G.F.M. Availability analysis of gas turbines used in power plants. Int. J. Thermodyn. 2009, 12, 28–37. [Google Scholar]
- Carazas, F.J.G.; Salazar, C.H.; Souza, G.F.M. Availability analysis of heat recovery steam generators used in thermal power plants. Energy 2011, 36, 3855–3870. [Google Scholar] [CrossRef]
- Bhangu, N.S.; Singh, R.; Pahuja, G.L. Reliability centred maintenance in a thermal power plant: A case study. Int. J. Product. Qual. Manag. 2011, 7, 209–228. [Google Scholar] [CrossRef]
- Krishnasamy, L.; Khan, F.; Haddara, M. Development of a risk-based maintenance (RBM) strategy for a power-generating plant. J. Loss Prev. Process Ind. 2005, 18, 69–81. [Google Scholar] [CrossRef]
- Khan, F.; Haddara, M.; Khalifa, M. Risk-Based Inspection and Maintenance (RBIM) of Power Plants. In Thermal Power Plant Performance Analysis; Springer Series in Reliability Engineering; Springer: London, UK, 2012; pp. 249–279. [Google Scholar]
- Ignat, S. Power Plants Maintenance Optimization Based on CBM Techniques. IFAC Proc. Vol. 2013, 46, 64–68. [Google Scholar] [CrossRef]
- Li, Y.G.; Nilkitsaranont, P. Gas turbine performance prognostic for condition-based maintenance. Appl. Energy 2009, 86, 2152–2161. [Google Scholar] [CrossRef]
- Melani, A.H.A.; Murad, C.A.; Caminada Netto, A.; de Souza, G.F.M.; Nabeta, S.I. Criticality-based maintenance of a coal-fired power plant. Energy 2018, 147, 767–781. [Google Scholar] [CrossRef]
- Selvik, J.T.; Aven, T. A framework for reliability and risk centered maintenance. Reliab. Eng. Syst. Saf. 2011, 96, 324–331. [Google Scholar] [CrossRef]
- Niu, G.; Yang, B.S.; Pecht, M. Development of an optimized condition-based maintenance system by data fusion and reliability-centered maintenance. Reliab. Eng. Syst. Saf. 2010, 95, 786–796. [Google Scholar] [CrossRef]
- Haghifam, M.R.; Manbachi, M. Reliability and availability modelling of combined heat and power (CHP) systems. Int. J. Electr. Power Energy Syst. 2011, 33, 385–393. [Google Scholar] [CrossRef]
- Sabouhi, H.; Abbaspour, A.; Fotuhi-Firuzabad, M.; Dehghanian, P. Reliability modeling and availability analysis of combined cycle power plants. Int. J. Electr. Power Energy Syst. 2016, 79, 108–119. [Google Scholar] [CrossRef]
- Khoshgoftar Manesh, M.H.; Pouyan Rad, M.; Rosen, M.A. New procedure for determination of availability and reliability of complex cogeneration systems by improving the approximated Markov method. Appl. Therm. Eng. 2018, 138, 62–71. [Google Scholar] [CrossRef]
- Billinton, R.; Allan, R.N. Reliability Evaluation of Engineering Systems; Springer: Boston, MA, USA, 1992; ISBN 978-1-4899-0687-8. [Google Scholar]
- Melani, A.H.A.; Martha de Souza, G.F.; Murad, C.A.; Caminada Netto, A.; Nabeta, S.I. Petri Net based reliability analysis of thermoelectric plant cooling tower. In Proceedings of the 24th ABCM International Congress of Mechanical Engineering, Curitiba, Brazil, 3–8 December 2017. [Google Scholar]
- Melani, A.H.A.; Caminada Netto, A.; Murad, C.A.; de Souza, G.F.M.; Nabeta, S.I. Petri Net Based Reliability Analysis of Thermoelectric Plant Cooling Tower System: Effects of Operational Strategies on System Reliability and Availability. In Proceedings of the Joint ICVRAM ISUMA Uncertainties Conference, Florianópolis, Brazil, 8–11 April 2018. [Google Scholar]
- Reddy, G.B.; Murty, S.S.N.; Ghosh, K. Timed Petri net: An expeditious tool for modelling and analysis of manufacturing systems. Math. Comput. Model. 1993, 18, 17–30. [Google Scholar] [CrossRef]
- He, X.; Murata, T. High-Level Petri Nets-Extensions, Analysis, and Applications; Elsevier Inc.: Amsterdam, The Netherlands, 2005; ISBN 9780121709600. [Google Scholar]
- Schruben, L.; Yucesan, E. Transforming Petri Nets into Event Graph Models. In Proceedings of the Proceedings of the 1994 Winter Simulation Conference, Orlando, FL, USA, 11–14 December 1994; pp. 560–565. [Google Scholar]
- Murata, T. Petri nets: Properties, analysis and applications. Proc. IEEE 1989, 77, 541–580. [Google Scholar] [CrossRef]
- Patrick, P.; O’Connor, A.K. Practical Reliability Engineering, 5th ed.; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Nývlt, O.; Rausand, M. Dependencies in event trees analyzed by Petri nets. Reliab. Eng. Syst. Saf. 2012, 104, 45–57. [Google Scholar] [CrossRef]
- Mansour, M.M.; Wahab, M.A.A.; Soliman, W.M. Petri nets for fault diagnosis of large power generation station. Ain Shams Eng. J. 2013, 4, 831–842. [Google Scholar] [CrossRef]
- Lefebvre, D.; Leclercq, E.; El Medhi, S.O. Petri Net Models for Detection, Isolation and Identification of Faults in DES; IFAC: New York, NY, USA, 2009; Volume 42, ISBN 9783902661463. [Google Scholar]
- Melani, A.H.A.; Silva, J.M.; Silva, J.R.; Souza, G.F.M. de Fault diagnosis based on Petri Nets: The case study of a hydropower plant. IFAC-PapersOnLine 2016, 49, 1–6. [Google Scholar] [CrossRef]
- Beirong, Z.; Xiaowen, X.; Wei, X. Availability Modeling and Analysis of Equipment Based on Generalized Stochastic Petri Nets. Res. J. Appl. Sci. Eng. Technol. 2012, 4, 4362–4366. [Google Scholar]
- Thangamani, G. Generalized Stochastic Petri Nets for Reliability Analysis of Lube Oil System with Common-Cause Failures. Am. J. Comput. Appl. Math. 2012, 2, 152–158. [Google Scholar] [CrossRef]
- Talebberrouane, M.; Khan, F.; Lounis, Z. Availability analysis of safety critical systems using advanced fault tree and stochastic Petri net formalisms. J. Loss Prev. Process Ind. 2016, 44, 193–203. [Google Scholar] [CrossRef]
- Leigh, J.M.; Dunnett, S.J. Use of Petri Nets to Model the Maintenance of Wind Turbines. Qual. Reliab. Eng. Int. 2016, 32, 167–180. [Google Scholar] [CrossRef]
- Long, F.; Zeiler, P.; Bertsche, B. Modelling the flexibility of production systems in Industry 4.0 for analysing their productivity and availability with high-level Petri nets. IFAC-PapersOnLine 2017, 50, 5680–5687. [Google Scholar] [CrossRef]
- Goode, K.B.; Moore, J.; Roylance, B.J. Plant machinery working life prediction method utilizing reliability and condition-monitoring data. Proc. Inst. Mech. Eng. Part E J. Process Mech. Eng. 2000, 214, 109–122. [Google Scholar] [CrossRef]
- Wang, W. A two-stage prognosis model in condition based maintenance. Eur. J. Oper. Res. 2007, 182, 1177–1187. [Google Scholar] [CrossRef]
- You, M.-Y.; Li, L.; Meng, G.; Ni, J. Two-Zone Proportional Hazard Model for Equipment Remaining Useful Life Prediction. J. Manuf. Sci. Eng. 2010, 132, 041008. [Google Scholar] [CrossRef]
- Mba, C.U.; Makis, V.; Marchesiello, S.; Fasana, A.; Garibaldi, L. Condition monitoring and state classification of gearboxes using stochastic resonance and hidden Markov models. Measurement 2018, 126, 76–95. [Google Scholar] [CrossRef]
- Salameh, J.P.; Cauet, S.; Etien, E.; Sakout, A.; Rambault, L. Gearbox condition monitoring in wind turbines: A review. Mech. Syst. Signal Process. 2018, 111, 251–264. [Google Scholar] [CrossRef]
- García Márquez, F.P.; Tobias, A.M.; Pinar Pérez, J.M.; Papaelias, M. Condition monitoring of wind turbines: Techniques and methods. Renew. Energy 2012, 46, 169–178. [Google Scholar] [CrossRef]
- Sheldon, J.; Mott, G.; Lee, H.; Watson, M. Robust wind turbine gearbox fault detection. Wind Energy 2014, 17, 745–755. [Google Scholar] [CrossRef]
- Ayang, A.; Wamkeue, R.; Ouhrouche, M.; Djongyang, N.; Essiane Salomé, N.; Pombe, J.K.; Ekemb, G. Maximum likelihood parameters estimation of single-diode model of photovoltaic generator. Renew. Energy 2019, 130, 111–121. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Kateri, M. On the maximum likelihood estimation of parameters of Weibull distribution based on complete and censored data. Stat. Probab. Lett. 2008, 78, 2971–2975. [Google Scholar] [CrossRef]
- ReliaSoft Corporation Maximum Likelihood Function. Available online: https://www.weibull.com/hotwire/issue33/relbasics33.htm (accessed on 16 January 2019).
- Yianni, P.C.; Neves, L.C.; Rama, D.; Andrews, J.D. Accelerating Petri-Net simulations using NVIDIA Graphics Processing Units. Eur. J. Oper. Res. 2018, 265, 361–371. [Google Scholar] [CrossRef]
- Andrews, J.; Prescott, D.; de Rozières, F. A stochastic model for railway track asset management. Reliab. Eng. Syst. Saf. 2014, 130, 76–84. [Google Scholar] [CrossRef]
- Ferreira, C.; Canhoto Neves, L.; Silva, A.; de Brito, J. Stochastic Petri net-based modelling of the durability of renderings. Autom. Constr. 2018, 87, 96–105. [Google Scholar] [CrossRef]
- Reliasoft Weibull++. Available online: https://www.reliasoft.com/products/reliability-analysis/weibull (accessed on 1 February 2018).
- SATODEV GRIF Software. Available online: https://www.satodev.com/ (accessed on 1 February 2018).
- CCEE Preço Médio da Câmara de Comercialização de Energia Elétrica (R$/MWh). Available online: https://www.ccee.org.br/portal/faces/pages_publico/o-que-fazemos/como_ccee_atua/precos/precos_medios (accessed on 1 January 2019).
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item Number | Time to Alarm (h) | Time between Alarm and Failure (h) | Time to Repair (h) |
|---|---|---|---|
| 1 | 3288 | 39 | 139 |
| 2 | 2496 | 266 | 82 |
| 3 | 5688 | 377 | 189 |
| 4 | 168 | 1140 | 230 |
| 5 | 648 | 331 | 23 |
| 6 | 1752 | 341 | 78 |
| 7 | 3792 | 65 | 156 |
| 8 | 816 | 28 | 240 |
| 9 | 360 | 584 | 201 |
| 10 | 960 | 161 | 303 |
| 11 | 3384 | 142 | 48 |
| 12 | 1200 | 118 | 72 |
| 13 | 792 | 68 | 8 |
| 14 | 1152 | 641 | 122 |
| 15 | 912 | 72 | 187 |
| 16 | 2904 | 761 | 144 |
| 17 | 624 | 322 | 194 |
| 18 | 552 | 125 | 170 |
| 19 | 696 | 79 | 198 |
| 20 | 3192 | 147 | 205 |
| 21 | 504 | 123 | 157 |
| Number of Operating Cells | 1 Repair Team | 2 Repair Teams | 3 Repair Teams | |||
|---|---|---|---|---|---|---|
| Working Time (h) | Coal Consumption (tons) | Working Time (h) | Coal Consumption (tons) | Working Time (h) | Coal Consumption (tons) | |
| 16 Cells in Operation | 738 | 95,410 | 2190 | 282,948 | 2453 | 316,902 |
| 15 Cells in Operation | 3122 | 404,973 | 2716 | 352,250 | 3154 | 409,064 |
| 14 Cells in Operation | 1509 | 196,426 | 2803 | 364,807 | 2015 | 262,205 |
| 13 Cells in Operation | 1053 | 137,410 | 701 | 91,454 | 1051 | 137,182 |
| 12 Cells in Operation | 782 | 102,086 | 175 | 22,864 | 88 | 11,432 |
| 11 Cells in Operation | 569 | 74,307 | 88 | 11,432 | 0 | 0 |
| 10 Cells in Operation | 986 | 128,608 | 88 | 11,432 | 0 | 0 |
| Total | 8760 | 1,139,220 | 8760 | 1,137,187 | 8760 | 1,136,785 |
| Costs Description | 1 Repair Team | 2 Repair Teams | 3 Repair Teams | |
|---|---|---|---|---|
| Total costs with coal | Cost per ton (US$/ton) | 83.44 | 83.44 | 83.44 |
| Tons of coal consumed (ton/year) | 1,139,220 | 1,137,187 | 1,136,785 | |
| Total costs with (US$/year) | 95,056,527 | 94,886,853 | 94,853,303 | |
| Costs for buying energy on free market | Average price of MWh on the Brazilian free market (US$) | 73.83 | 73.83 | 73.83 |
| MWh bought on the free market | 18,960.7 | 2311.1 | 290.4 | |
| Total costs with MWh bought (US$/year) | 1,399,868 | 170,629 | 21,440 | |
| Expenses with maintenance teams | Cost of man hour (US$/h) | 16 | 16 | 16 |
| Working hours per year of one maintenance technician (h/year) | 2080 | 2080 | 2080 | |
| Number of maintenance technicians | 3 | 6 | 9 | |
| Total of Expenses (US$/year) | 99,840 | 199,680 | 299,520 | |
| Total Costs (US$/year) | 96,556,236 | 95,257,162 | 95,174,263 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melani, A.H.A.; Murad, C.A.; Caminada Netto, A.; Souza, G.F.M.; Nabeta, S.I. Maintenance Strategy Optimization of a Coal-Fired Power Plant Cooling Tower through Generalized Stochastic Petri Nets. Energies 2019, 12, 1951. https://doi.org/10.3390/en12101951
Melani AHA, Murad CA, Caminada Netto A, Souza GFM, Nabeta SI. Maintenance Strategy Optimization of a Coal-Fired Power Plant Cooling Tower through Generalized Stochastic Petri Nets. Energies. 2019; 12(10):1951. https://doi.org/10.3390/en12101951
Chicago/Turabian StyleMelani, Arthur H.A., Carlos A. Murad, Adherbal Caminada Netto, Gilberto F.M. Souza, and Silvio I. Nabeta. 2019. "Maintenance Strategy Optimization of a Coal-Fired Power Plant Cooling Tower through Generalized Stochastic Petri Nets" Energies 12, no. 10: 1951. https://doi.org/10.3390/en12101951
APA StyleMelani, A. H. A., Murad, C. A., Caminada Netto, A., Souza, G. F. M., & Nabeta, S. I. (2019). Maintenance Strategy Optimization of a Coal-Fired Power Plant Cooling Tower through Generalized Stochastic Petri Nets. Energies, 12(10), 1951. https://doi.org/10.3390/en12101951