Robust Building Energy Load Forecasting Using Physically-Based Kernel Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
3. Building Energy Load Forecasting Algorithm Using Gaussian Process
3.1. Gaussian Process Regression
3.2. Covariance Function Modeling
3.2.1. Kernel Types
- 1.
- Periodic Function:
- 2.
- Squared Exponential:
- 3.
- Matern Kernel:
- 4.
- Linear Kernel:
- 5.
- Random Noise Kernel
3.2.2. Long-Term Forecasting
3.2.3. Short-Term Forecasting
4. Evaluation
4.1. Experimental Setup
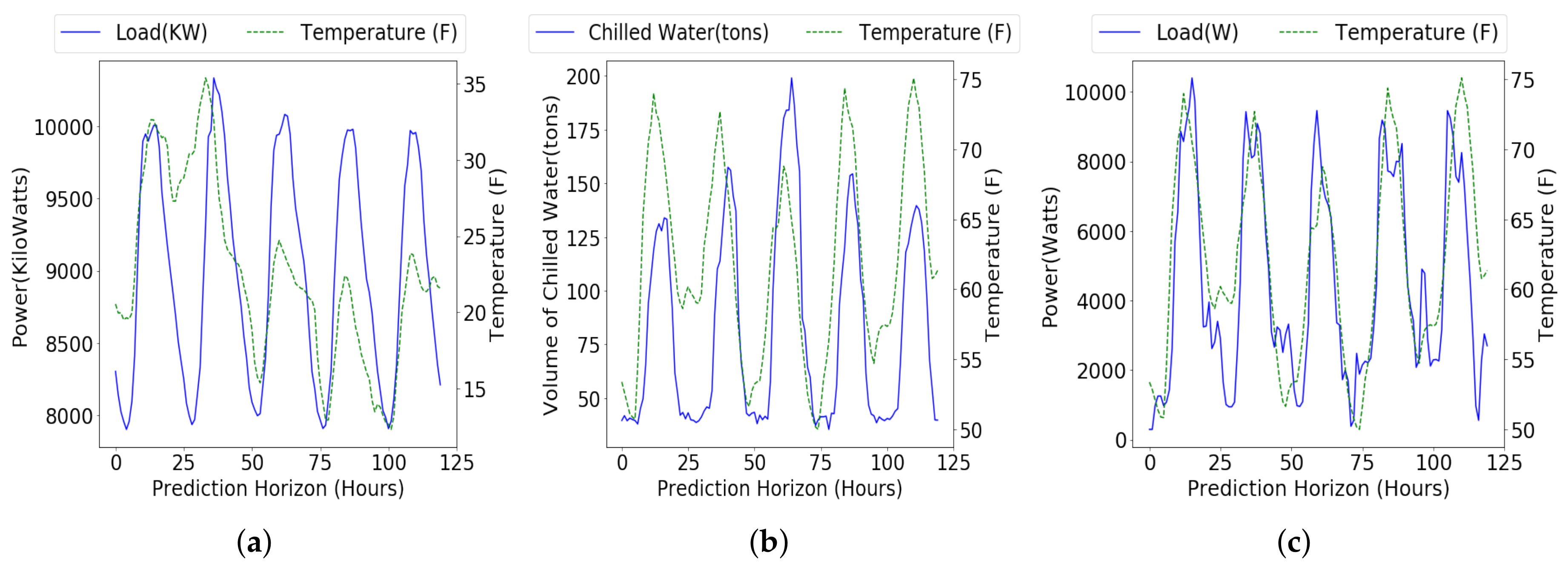
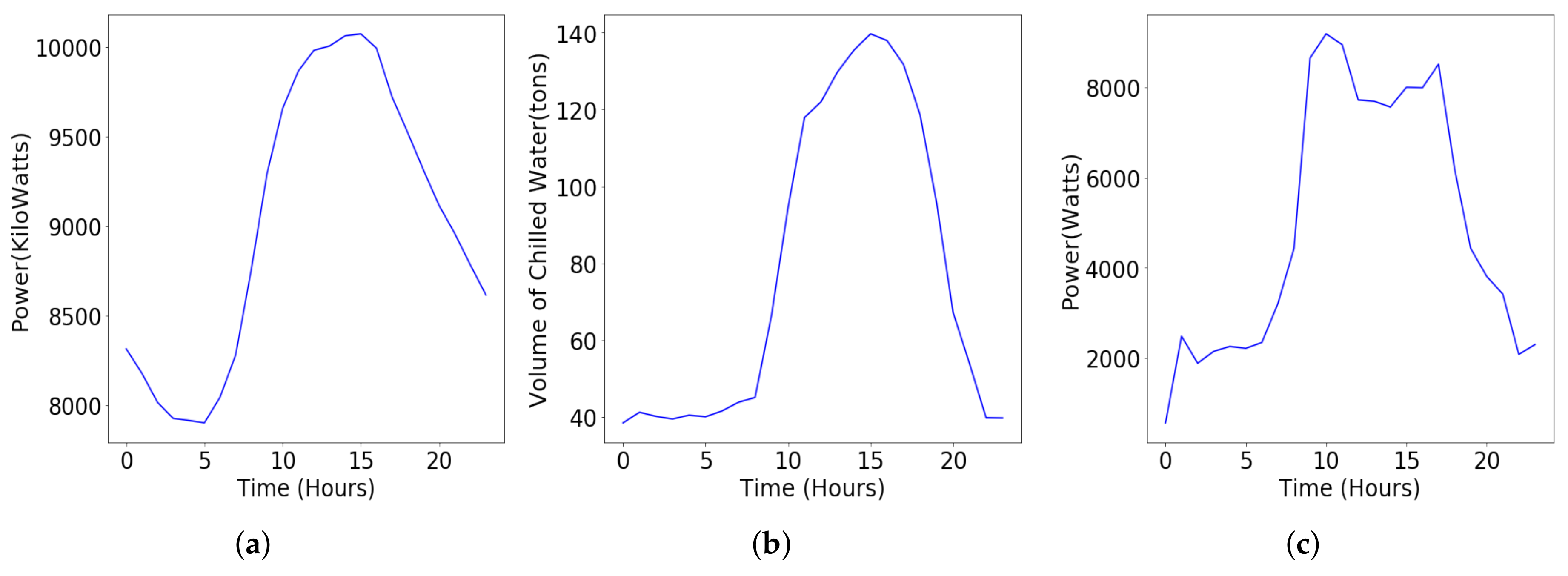
4.1.1. Electricity Consumption Data of Carnegie Mellon University
4.1.2. Cooling and Lighting Load Data of Y2E2 Building in Stanford University
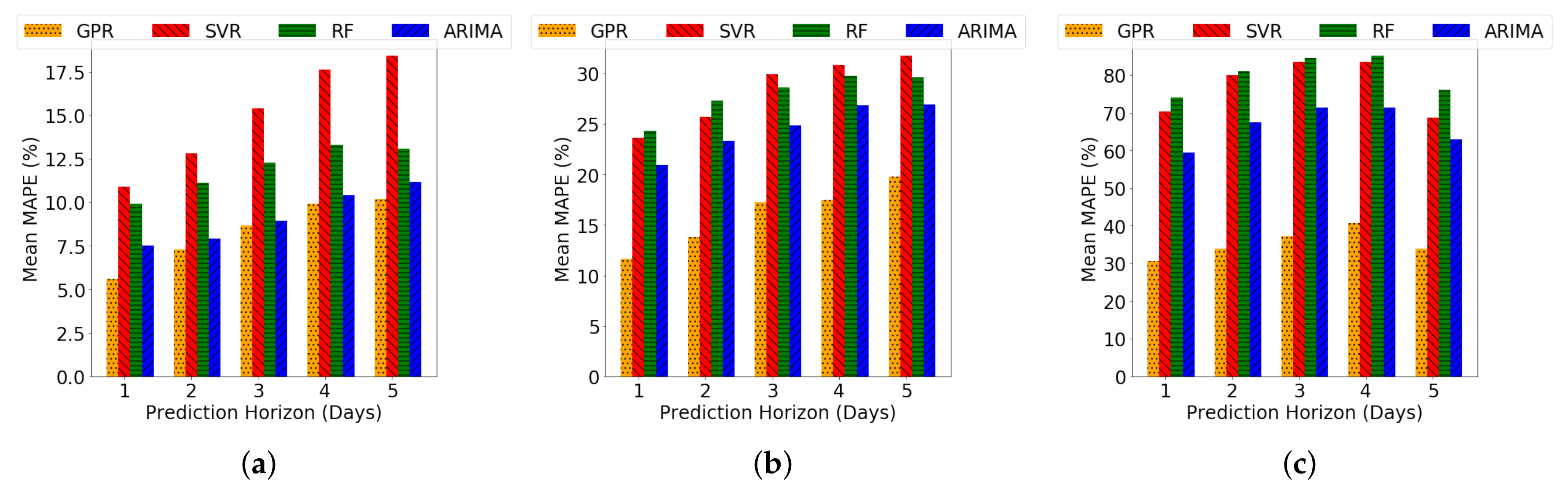
4.1.3. Benchmark Methods
4.2. Results and Discussion
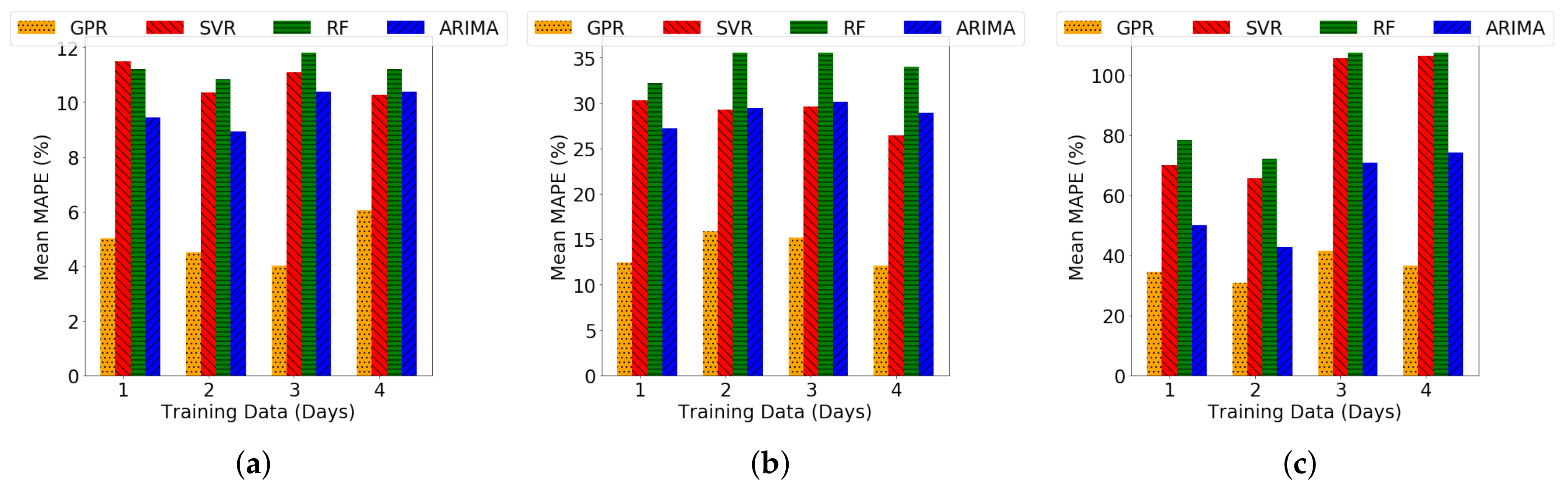
4.2.1. Long-Term Forecasting under Varying Duration of Training Data
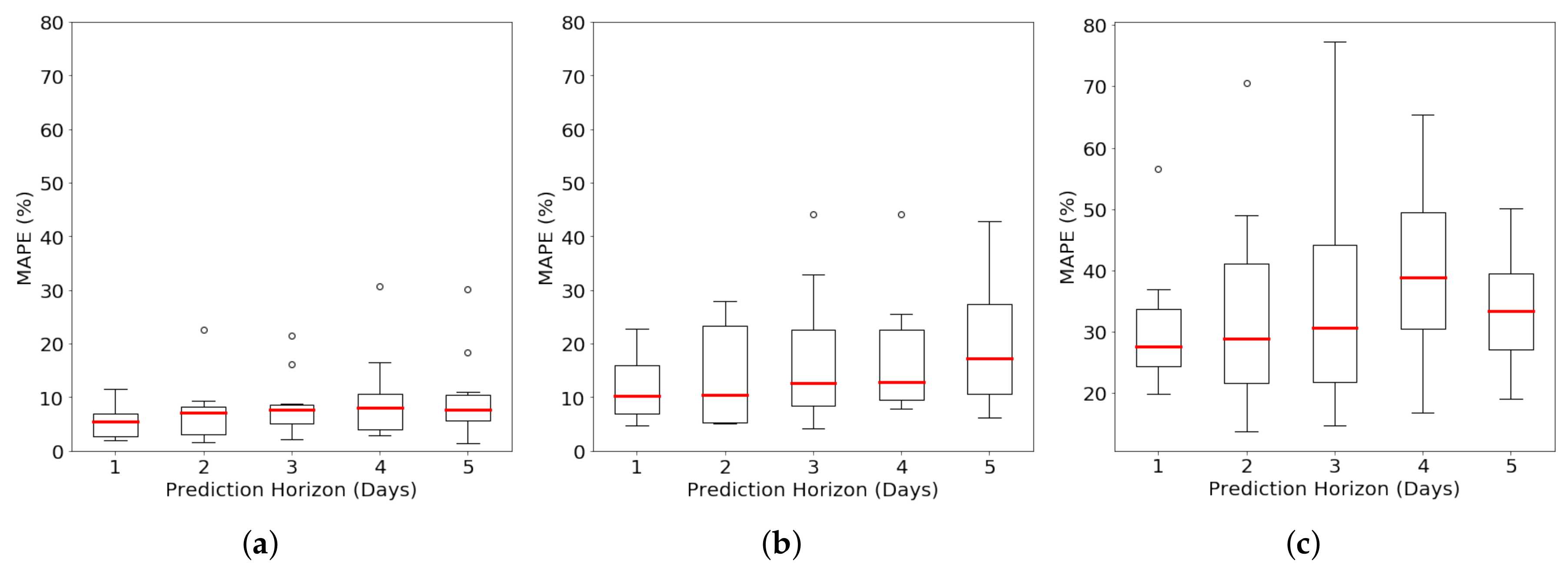
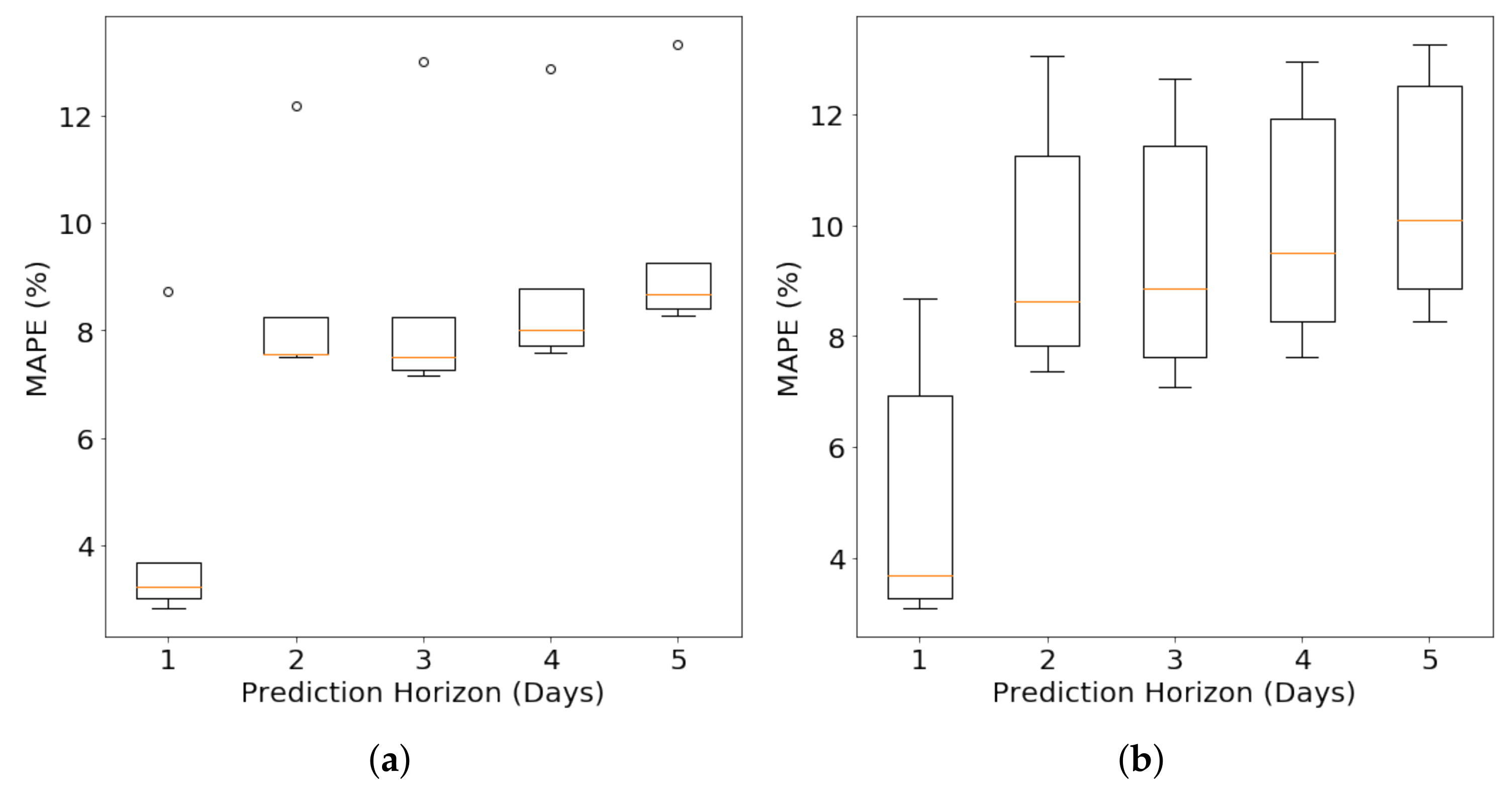
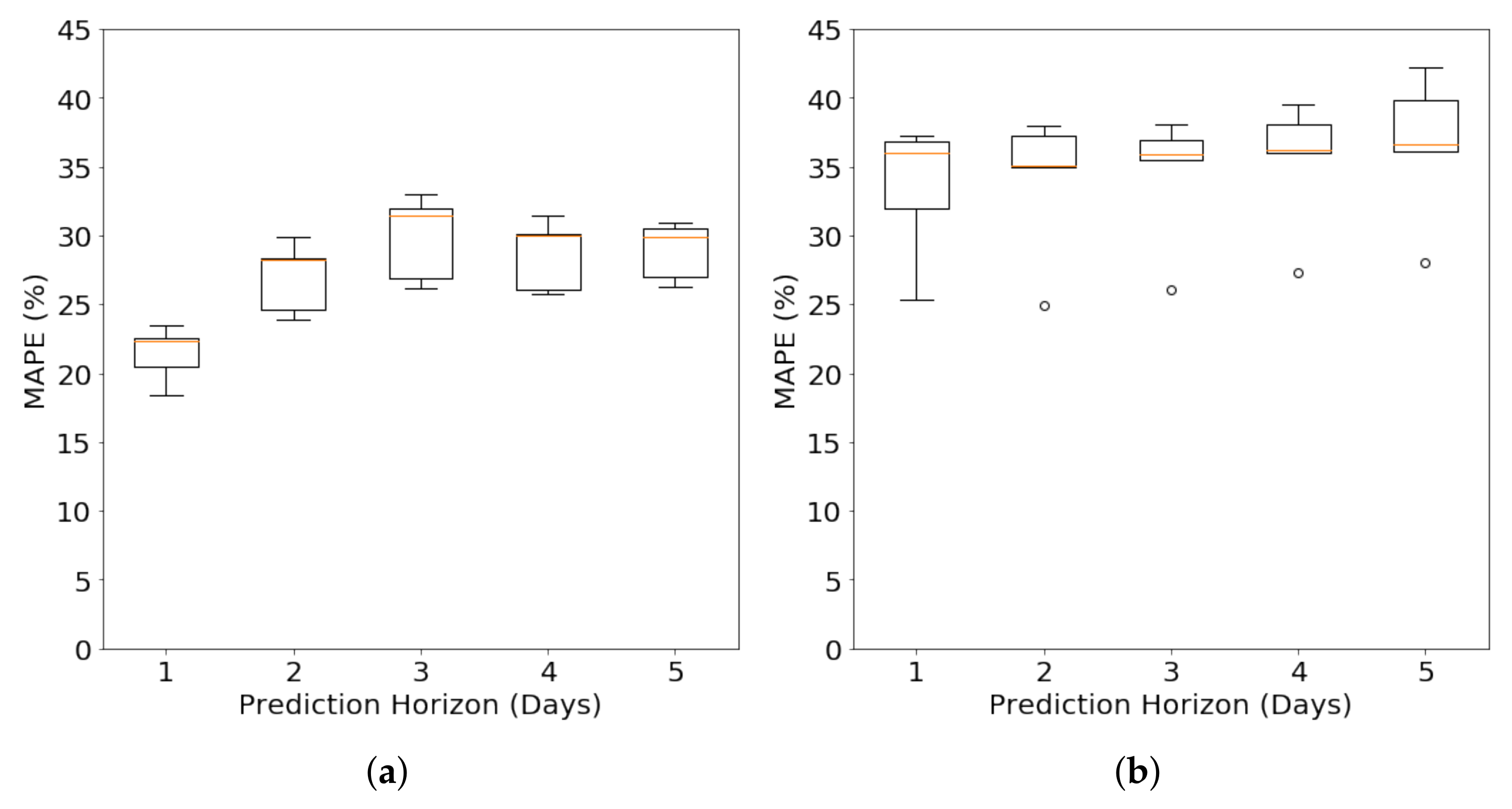
4.2.2. Long-Term Forecasting under Varying Prediction Horizon
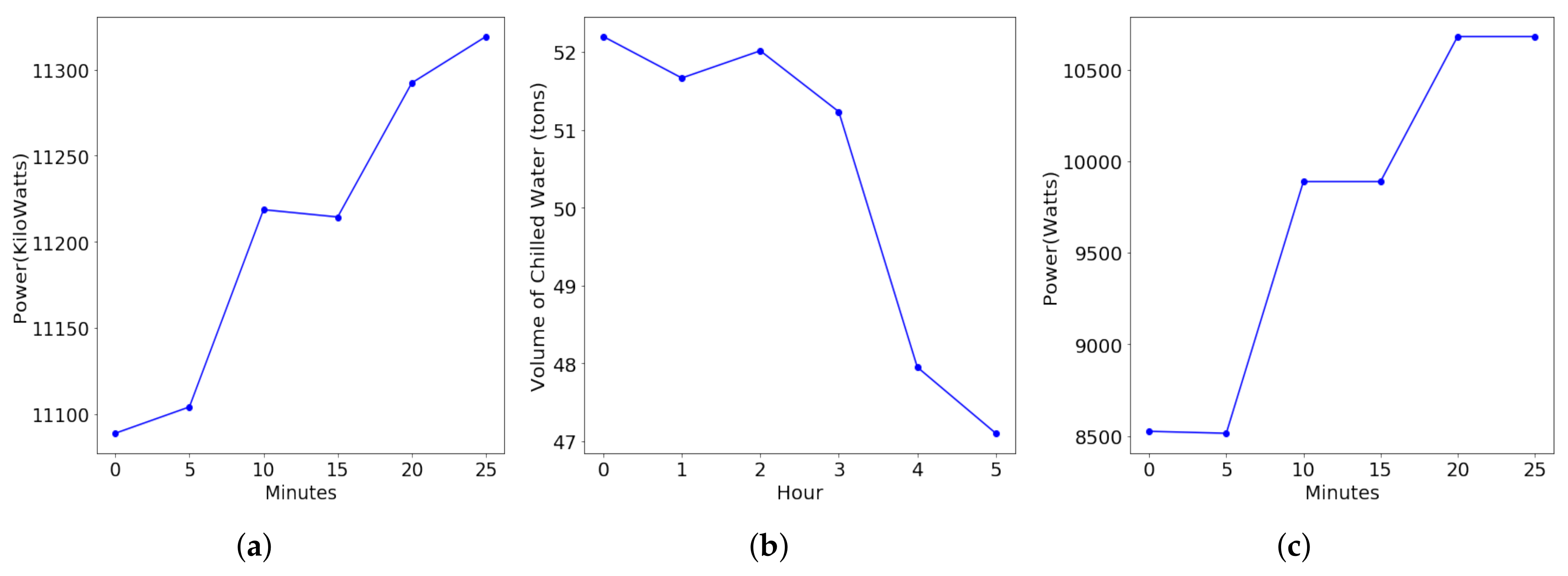
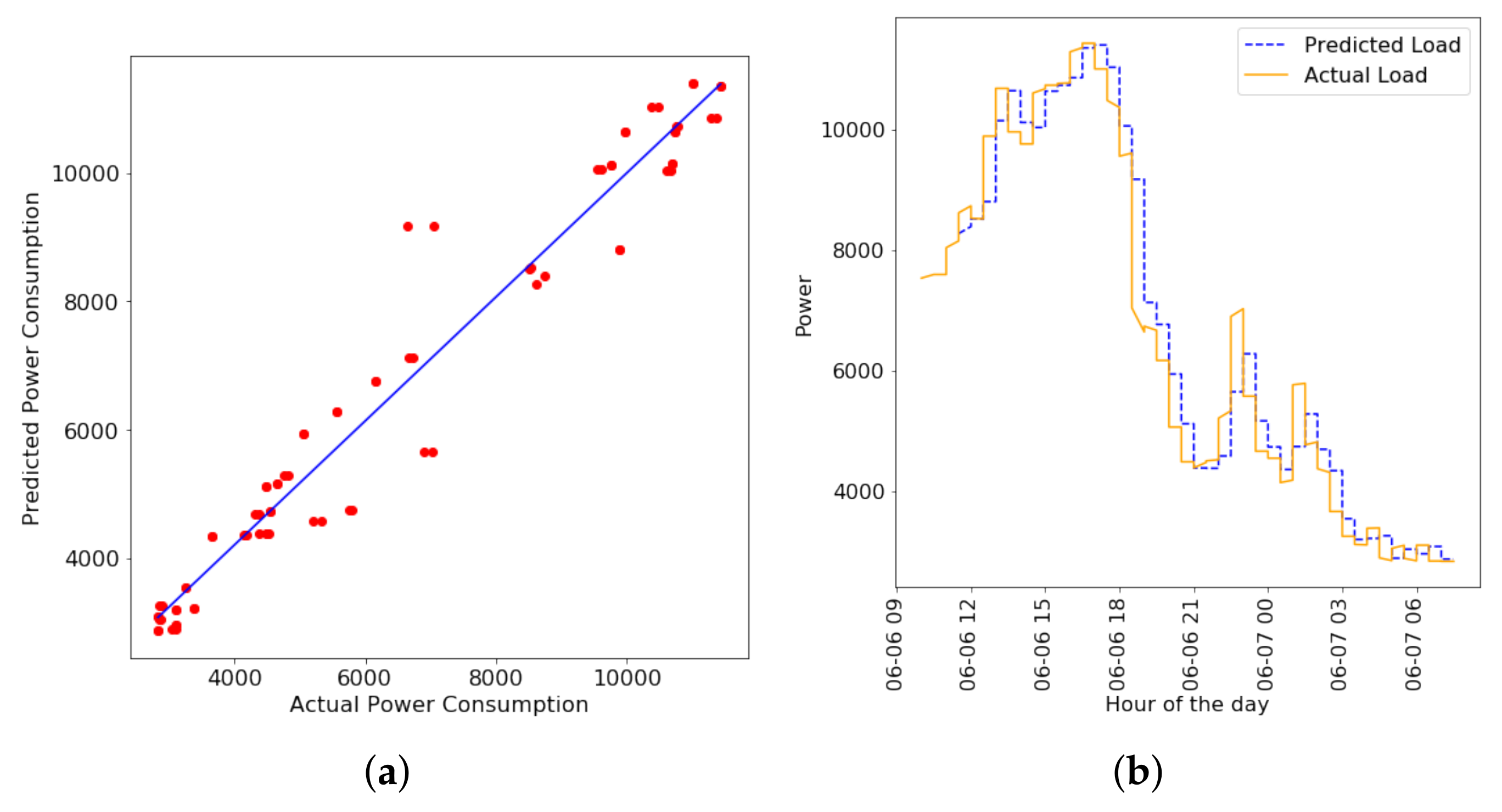
4.2.3. Short-Term Forecasting
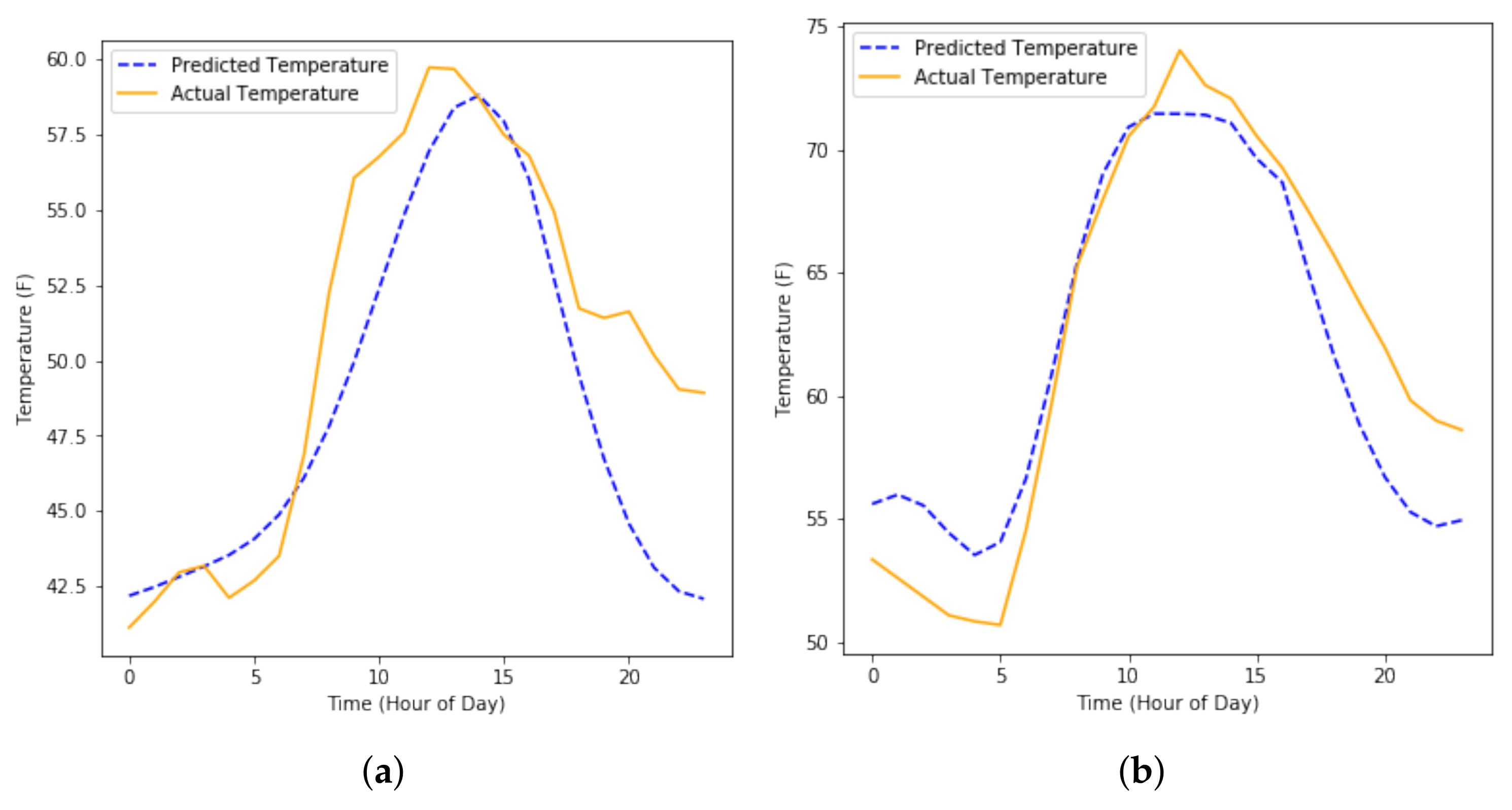
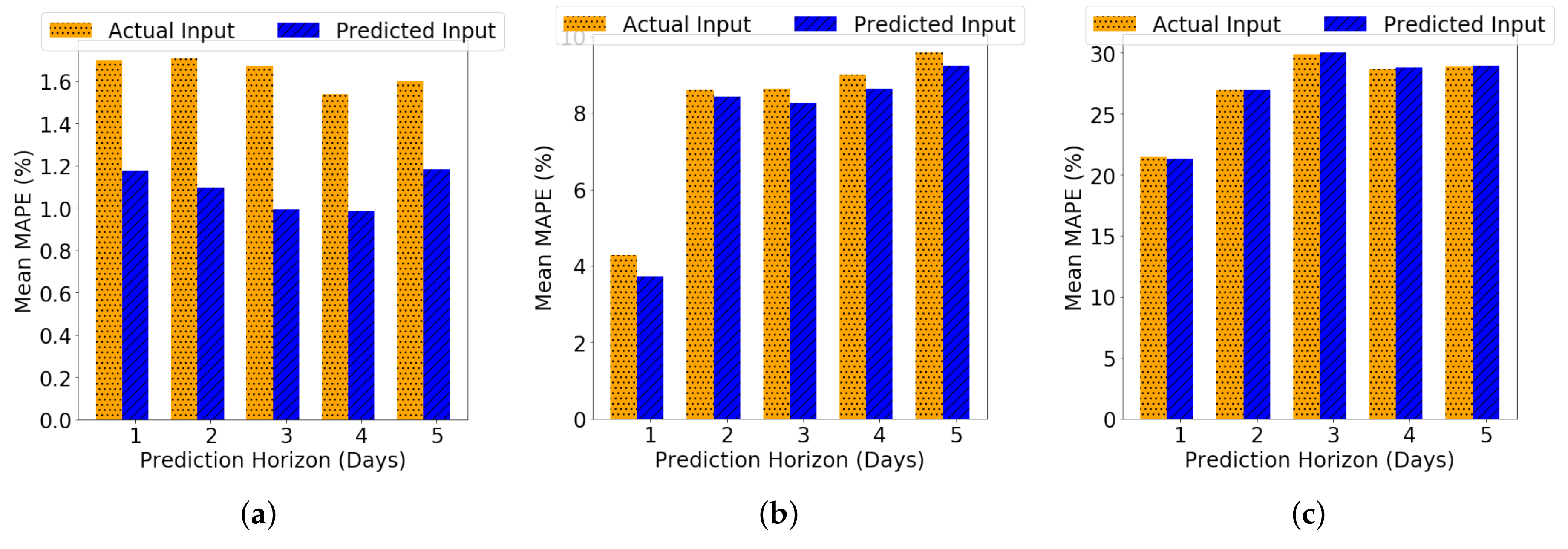
4.2.4. Long-Term Forecasting with Predicted Inputs
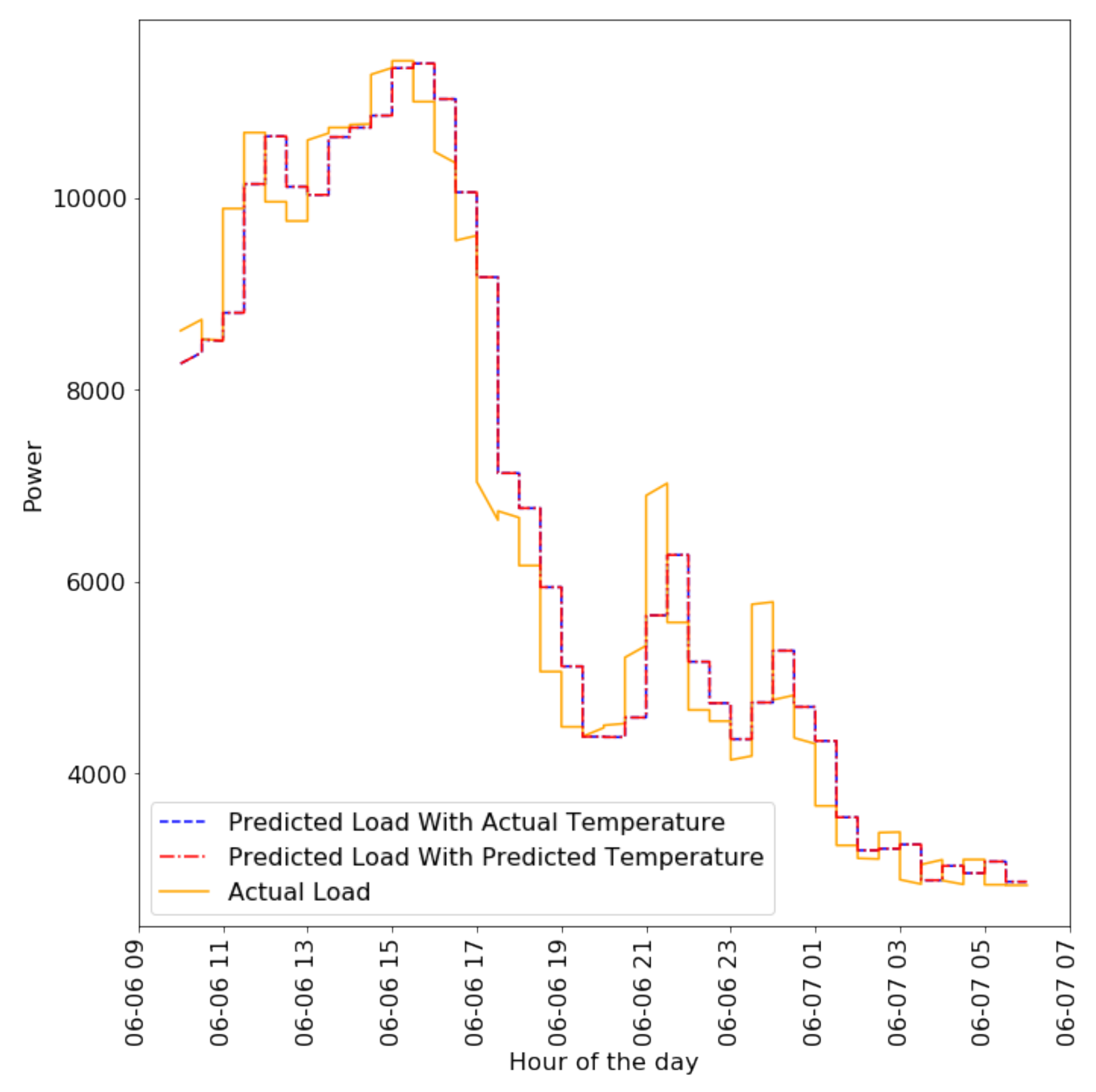
4.2.5. Short-Term Forecasting with Predicted Inputs
4.2.6. Impacts of Different Kernels
- 1.
- Matern kernel for Y2E2 Building’s Cooling Load Forecasting
- 2.
- A combination of Matern and Linear Kernel for Y2E2 Building’s lighting load forecasting
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Congressional Budget Office. How Much Does the Federal Government Support the Development and Production of Fuels and Energy Technologies? Available online: https://www.cbo.gov/publication/43040 (accessed on 31 January 2018).
- gov.uk. Environmental Taxes, Reliefs and Schemes for Businesses. Available online: https://www.gov.uk/green-taxes-and-reliefs (accessed on 31 January 2018).
- Kallakuri, C.; Vaidyanathan, S.; Kelly, M.; Cluett, R. The 2016 International Energy Efficiency Scorecard. 2016. Available online: http://habitatx.com/wp-content/uploads/2016/07/2016_ACEEE_country_report.pdf (accessed on 31 January 2018).
- United States Energy Information Administration. How Much Energy Is Consumed in U.S. Residential and Commercial Buildings? Available online: https://www.eia.gov/tools/faqs/faq.php?id=86&t=1 (accessed on 31 January 2018).
- United States Energy Information Administration. International Energy Outlook 2016. Available online: https://www.eia.gov/outlooks/ieo/pdf/0484(2016).pdf (accessed on 31 January 2018).
- Chen, D.; Irwin, D. SunDance: Black-box Behind-the-Meter Solar Disaggregation. In Proceedings of the Eighth International Conference on Future Energy Systems (e-Energy ’17), Shatin, Hong Kong, 16–19 May 2017; ACM: New York, NY, USA, 2017; pp. 45–55. [Google Scholar]
- Mohan, R.; Cheng, T.; Gupta, A.; Garud, V.; He, Y. Solar Energy Disaggregation using Whole-House Consumption Signals. In Proceedings of the 4th International Workshop on Non-Intrusive Load Monitoring (NILM), Austin, TX, USA, 7–8 March 2014. [Google Scholar]
- Li, X.; Wen, J. Review of building energy modeling for control and operation. Renew. Sustain. Energy Rev. 2014, 37, 517–537. [Google Scholar] [CrossRef]
- eQUEST: The QUick Energy Simulation Tool. 2016. Available online: http://www.doe2.com/equest/ (accessed on 31 January 2018).
- EnergyPlus. 2017. Available online: https://energyplus.net/ (accessed on 31 January 2018).
- Yang, Z.; Becerik-Gerber, B. A model calibration framework for simultaneous multi-level building energy simulation. Appl. Energy 2015, 149, 415–431. [Google Scholar] [CrossRef]
- Zhao, J.; Lasternas, B.; Lam, K.P.; Yun, R.; Loftness, V. Occupant behavior and schedule modeling for building energy simulation through office appliance power consumption data mining. Energy Build. 2014, 82, 341–355. [Google Scholar] [CrossRef]
- Fumo, N.; Mago, P.; Luck, R. Methodology to estimate building energy consumption using EnergyPlus Benchmark Models. Energy Build. 2010, 42, 2331–2337. [Google Scholar] [CrossRef]
- Azar, E.; Menassa, C. A conceptual framework to energy estimation in buildings using agent based modeling. In Proceedings of the 2010 Winter Simulation Conference, Baltimore, MD, USA, 5–8 December 2010; pp. 3145–3156. [Google Scholar]
- Yu, D. A two-step approach to forecasting city-wide building energy demand. Energy Build. 2018, 160, 1–9. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N.M. A review of data-driven building energy consumption prediction studies. Renew. Sustain. Energy Rev. 2018, 81, 1192–1205. [Google Scholar] [CrossRef]
- Zhao, H.-X.; Magoulès, F. A review on the prediction of building energy consumption. Renew. Sustain. Energy Rev. 2012, 16, 3586–3592. [Google Scholar] [CrossRef]
- Ahmad, A.; Hassan, M.; Abdullah, M.; Rahman, H.; Hussin, F.; Abdullah, H.; Saidur, R. A review on applications of ANN and SVM for building electrical energy consumption forecasting. Renew. Sustain. Energy Rev. 2014, 33, 102–109. [Google Scholar] [CrossRef]
- Yildiz, B.; Bilbao, J.; Sproul, A. A review and analysis of regression and machine learning models on commercial building electricity load forecasting. Renew. Sustain. Energy Rev. 2017, 73, 1104–1122. [Google Scholar] [CrossRef]
- Daut, M.A.M.; Hassan, M.Y.; Abdullah, H.; Rahman, H.A.; Abdullah, M.P.; Hussin, F. Building electrical energy consumption forecasting analysis using conventional and artificial intelligence methods: A review. Renew. Sustaina. Energy Rev. 2017, 70, 1108–1118. [Google Scholar] [CrossRef]
- Zhou, K.; Fu, C.; Yang, S. Big data driven smart energy management: From big data to big insights. Renew. Sustain. Energy Rev. 2016, 56, 215–225. [Google Scholar] [CrossRef]
- United States Energy Information Administration. Nearly Half of All U.S. Electricity Customers Have Smart Meters. Available online: https://www.eia.gov/todayinenergy/detail.php?id=34012 (accessed on 31 January 2018).
- United States Energy Information Administration. How Many Smart Meters Are Installed in the United States, and Who Has Them? Available online: https://www.eia.gov/tools/faqs/faq.php?id=108&t=3 (accessed on 31 January 2018).
- American Council for an Energy-Efficient Economy. Improving Access to Energy Usage Data. Available online: https://aceee.org/sector/local-policy/toolkit/utility-data-access (accessed on 31 January 2018).
- Noh, H.Y.; Rajagopal, R. Data-driven forecasting algorithms for building energy consumption. Proc. SPIE 2013, 8692, 86920T. [Google Scholar]
- Yang, Y.; Li, S.; Li, W.; Qu, M. Power load probability density forecasting using Gaussian process quantile regression. Appl. Energy 2017, 213, 499–509. [Google Scholar] [CrossRef]
- Lloyd, J.R. GEFCom2012 hierarchical load forecasting: Gradient boosting machines and Gaussian processes. Int. J. Forecast. 2014, 30, 369–374. [Google Scholar] [CrossRef]
- Atsawathawichok, P.; Teekaput, P.; Ploysuwan, T. Long term peak load forecasting in Thailand using multiple kernel Gaussian Process. In Proceedings of the 2014 11th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Nakhon Ratchasima, Thailand, 14–17 May 2014; pp. 1–4. [Google Scholar]
- Lauret, P.; David, M.; Calogine, D. Nonlinear Models for Short-time Load Forecasting. Energy Procedia 2012, 14, 1404–1409. [Google Scholar] [CrossRef]
- Neto, A.H.; Fiorelli, F.A.S. Comparison between detailed model simulation and artificial neural network for forecasting building energy consumption. Energy Build. 2008, 40, 2169–2176. [Google Scholar] [CrossRef]
- Yezioro, A.; Dong, B.; Leite, F. An applied artificial intelligence approach towards assessing building performance simulation tools. Energy Build. 2008, 40, 612–620. [Google Scholar] [CrossRef]
- Balcomb, J.D.; Crowder, R.S. ENERGY-10, A Design Tool Computer Program for Buildings. In Proceedings of the American Solar Energy Society’s 20th Passive Solar Conference (Solar ’95), Minneapolis, MN, USA, 15–20 July 1995. [Google Scholar]
- Wang, S.; Xu, X. Parameter estimation of internal thermal mass of building dynamic models using genetic algorithm. Energy Convers. Manag. 2006, 47, 1927–1941. [Google Scholar] [CrossRef]
- Mena, R.; Rodríguez, F.; Castilla, M.; Arahal, M. A prediction model based on neural networks for the energy consumption of a bioclimatic building. Energy Build. 2014, 82, 142–155. [Google Scholar] [CrossRef]
- Agarwal, A.; Munigala, V.; Ramamritham, K. Observability: A Principled Approach to Provisioning Sensors in Buildings. In Proceedings of the 3rd ACM International Conference on Systems for Energy-Efficient Built Environments (BuildSys ’16), Stanford, CA, USA, 15–17 November 2016; ACM: New York, NY, USA, 2016; pp. 197–206. [Google Scholar]
- Jetcheva, J.G.; Majidpour, M.; Chen, W.P. Neural network model ensembles for building-level electricity load forecasts. Energy Build. 2014, 84, 214–223. [Google Scholar] [CrossRef]
- Kwok, S.S.; Lee, E.W. A study of the importance of occupancy to building cooling load in prediction by intelligent approach. Energy Convers. Manag. 2011, 52, 2555–2564. [Google Scholar] [CrossRef]
- Xuemei, L.; Yuyan, D.; Lixing, D.; Liangzhong, J. Building cooling load forecasting using fuzzy support vector machine and fuzzy C-mean clustering. In Proceedings of the 2010 International Conference on Computer and Communication Technologies in Agriculture Engineering, Chengdu, China, 12–13 June 2010; Volume 1, pp. 438–441. [Google Scholar]
- Dagnely, P.; Ruette, T.; Tourwé, T.; Tsiporkova, E.; Verhelst, C. Predicting Hourly Energy Consumption. Can Regression Modeling Improve on an Autoregressive Baseline? In Proceedings of the Third ECML PKDD Workshop on Data Analytics for Renewable Energy Integration, Porto, Portugal, 11 September 2015; Springer-Verlag: New York, NY, USA, 2015; Volume 9518, pp. 105–122. [Google Scholar]
- Huang, S.; Zuo, W.; Sohn, M.D. A Bayesian Network model for predicting cooling load of commercial buildings. Build. Simul. 2017, 11, 87–101. [Google Scholar] [CrossRef]
- Dudek, G. Short-Term Load Forecasting Using Random Forests. In Proceedings of the Intelligent Systems’2014, Warsaw, Poland, 24–26 September 2014; Springer International Publishing: Cham, Switzerland, 2015; pp. 821–828. [Google Scholar]
- Lahouar, A.; Slama, J.B.H. Random forests model for one day ahead load forecasting. In Proceedings of the IREC2015 The Sixth International Renewable Energy Congress, Sousse, Tunisia, 24–26 March 2015; pp. 1–6. [Google Scholar]
- Massana, J.; Pous, C.; Burgas, L.; Melendez, J.; Colomer, J. Short-term load forecasting for non-residential buildings contrasting artificial occupancy attributes. Energy Build. 2016, 130, 519–531. [Google Scholar] [CrossRef]
- Fernández, I.; Borges, C.E.; Penya, Y.K. Efficient building load forecasting. In Proceedings of the 2011 IEEE 16th Conference on Emerging Technologies & Factory Automation (ETFA 2011), Toulouse, France, 5–9 September 2011; pp. 1–8. [Google Scholar]
- Xuemei, L.; Lixing, D.; Jinhu, L.; Gang, X.; Jibin, L. A Novel Hybrid Approach of KPCA and SVM for Building Cooling Load Prediction. In Proceedings of the 2010 Third International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand, 9–10 January 2010. [Google Scholar]
- Fan, C.; Xiao, F.; Wang, S. Development of prediction models for next-day building energy consumption and peak power demand using data mining techniques. Appl. Energy 2014, 127, 1–10. [Google Scholar] [CrossRef]
- Hagan, M.T.; Behr, S.M. The Time Series Approach to Short Term Load Forecasting. IEEE Trans. Power Syst. 1987, 2, 785–791. [Google Scholar] [CrossRef]
- Pai, P.F.; Hong, W.C. Support vector machines with simulated annealing algorithms in electricity load forecasting. Energy Convers. Manag. 2005, 46, 2669–2688. [Google Scholar] [CrossRef]
- Soares, L.J.; Medeiros, M.C. Modeling and forecasting short-term electricity load: A comparison of methods with an application to Brazilian data. Int. J. Forecast. 2008, 24, 630–644. [Google Scholar] [CrossRef]
- O’Neill, Z. Development of a Probabilistic Graphical Energy Performance Model for an Office Building. ASHRAE Trans. 2014, 120. [Google Scholar]
- O’Neill, Z.; O’Neill, C. Development of a probabilistic graphical model for predicting building energy performance. Appl. Energy 2016, 164, 650–658. [Google Scholar] [CrossRef]
- Jensen, K.L.; Toftum, J.; Friis-Hansen, P. A Bayesian Network approach to the evaluation of building design and its consequences for employee performance and operational costs. Build. Environ. 2009, 44, 456–462. [Google Scholar] [CrossRef]
- Sheng, H.; Xiao, J.; Cheng, Y.; Ni, Q.; Wang, S. Short-Term Solar Power Forecasting Based on Weighted Gaussian Process Regression. IEEE Trans. Ind. Electron. 2018, 65, 300–308. [Google Scholar] [CrossRef]
- Cheng, F.; Yu, J.; Xiong, H. Facial Expression Recognition in JAFFE Dataset Based on Gaussian Process Classification. IEEE Trans. Neural Netw. 2010, 21, 1685–1690. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yeung, D.Y. Multi-task warped Gaussian process for personalized age estimation. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2622–2629. [Google Scholar]
- Deisenroth, M.P.; Fox, D.; Rasmussen, C.E. Gaussian Processes for Data-Efficient Learning in Robotics and Control. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 408–423. [Google Scholar] [CrossRef] [PubMed]
- Ko, J.; Klein, D.J.; Fox, D.; Haehnel, D. Gaussian Processes and Reinforcement Learning for Identification and Control of an Autonomous Blimp. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 Apirl 2007; pp. 742–747. [Google Scholar]
- Nguyen-Tuong, D.; Peters, J. Local Gaussian process regression for real-time model-based robot control. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 380–385. [Google Scholar]
- Urtasun, R.; Fleet, D.J.; Fua, P. 3D People Tracking with Gaussian Process Dynamical Models. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; Volume 1, pp. 238–245. [Google Scholar]
- Marquand, A.; Howard, M.; Brammer, M.; Chu, C.; Coen, S.; Mourão-Miranda, J. Quantitative prediction of subjective pain intensity from whole-brain fMRI data using Gaussian processes. NeuroImage 2010, 49, 2178–2189. [Google Scholar] [CrossRef] [PubMed]
- Challis, E.; Hurley, P.; Serra, L.; Bozzali, M.; Oliver, S.; Cercignani, M. Gaussian process classification of Alzheimer’s disease and mild cognitive impairment from resting-state fMRI. NeuroImage 2015, 112, 232–243. [Google Scholar] [CrossRef] [PubMed]
- Ziegler, G.; Ridgway, G.; Dahnke, R.; Gaser, C. Individualized Gaussian process-based prediction and detection of local and global gray matter abnormalities in elderly subjects. NeuroImage 2014, 97, 333–348. [Google Scholar] [CrossRef] [PubMed]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 1. [Google Scholar]
- Bhinge, R.; Park, J.; Law, K.H.; Dornfeld, D.A.; Helu, M.; Rachuri, S. Toward a Generalized Energy Prediction Model for Machine Tools. J. Manuf. Sci. Eng. 2016, 139, 041013. [Google Scholar] [CrossRef] [PubMed]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer-Verlag: Secaucus, NJ, USA, 1996. [Google Scholar]
- Duvenaud, D. The Kernel Cookbook: Advice on Covariance Functions. Available online: http://www.cs.toronto.edu/~duvenaud/cookbook/index.html (accessed on 31 January 2018).
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions; Dover Publications, Inc.: New York, NY, USA, 1972. [Google Scholar]
- Eric, W.; Weisstein. Kronecker Delta. From MathWorld—A Wolfram Web Resource. 2016. Available online: http://mathworld.wolfram.com/KroneckerDelta.html (accessed on 31 January 2018).
- Klessig, R.; Polak, E. Efficient implementations of the Polak-Ribiere conjugate gradient algorithm. SIAM J. Control 1972, 10, 524–549. [Google Scholar] [CrossRef]
- matplotlib, 2018. Available online: https://matplotlib.org/api/_as_gen/matplotlib.pyplot.boxplot.html (accessed on 31 March 2018).













© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prakash, A.K.; Xu, S.; Rajagopal, R.; Noh, H.Y. Robust Building Energy Load Forecasting Using Physically-Based Kernel Models. Energies 2018, 11, 862. https://doi.org/10.3390/en11040862
Prakash AK, Xu S, Rajagopal R, Noh HY. Robust Building Energy Load Forecasting Using Physically-Based Kernel Models. Energies. 2018; 11(4):862. https://doi.org/10.3390/en11040862
Chicago/Turabian StylePrakash, Anand Krishnan, Susu Xu, Ram Rajagopal, and Hae Young Noh. 2018. "Robust Building Energy Load Forecasting Using Physically-Based Kernel Models" Energies 11, no. 4: 862. https://doi.org/10.3390/en11040862
APA StylePrakash, A. K., Xu, S., Rajagopal, R., & Noh, H. Y. (2018). Robust Building Energy Load Forecasting Using Physically-Based Kernel Models. Energies, 11(4), 862. https://doi.org/10.3390/en11040862