Feature Reduction for Power System Transient Stability Assessment Based on Neighborhood Rough Set and Discernibility Matrix


Abstract
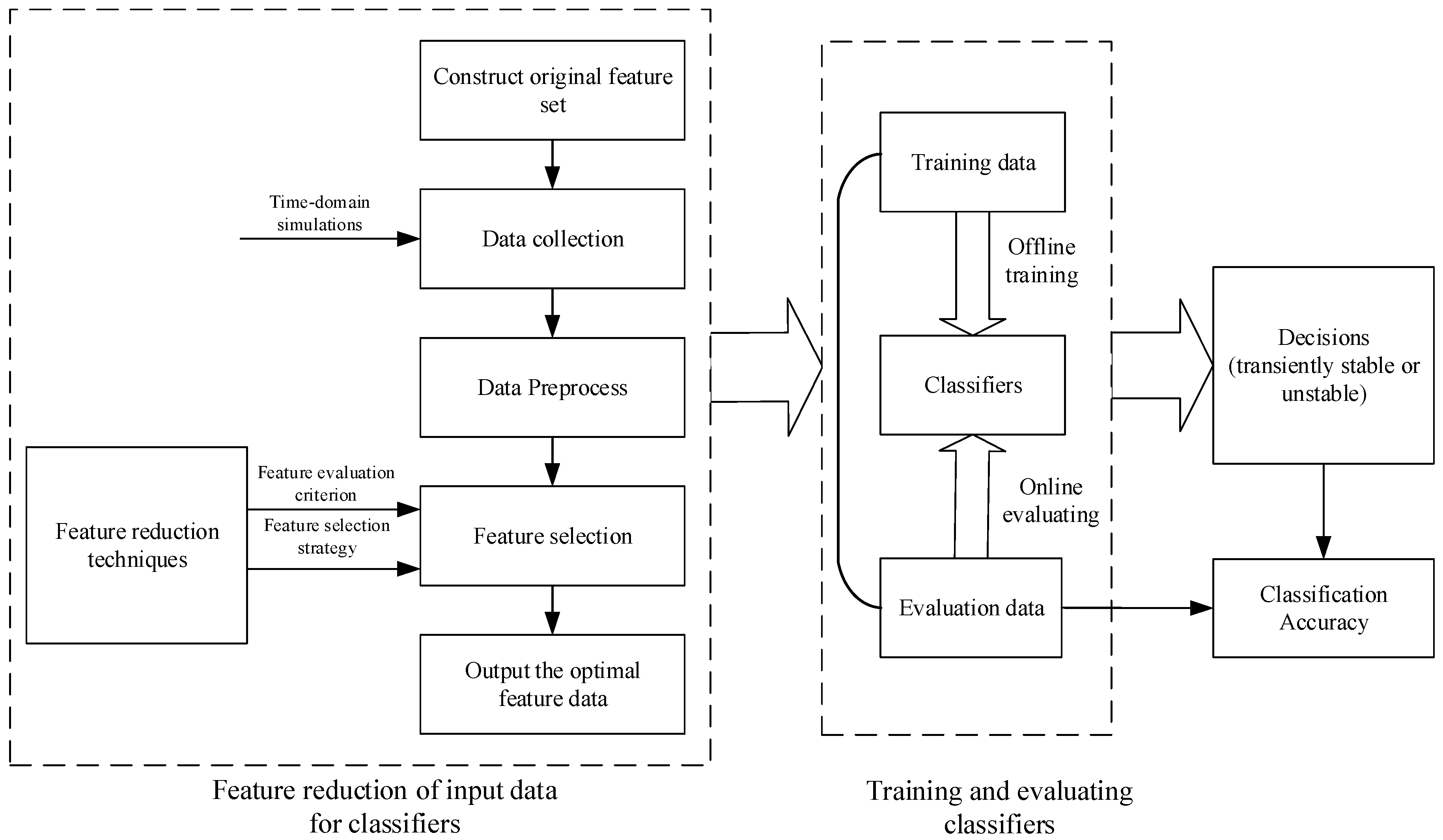
:1. Introduction
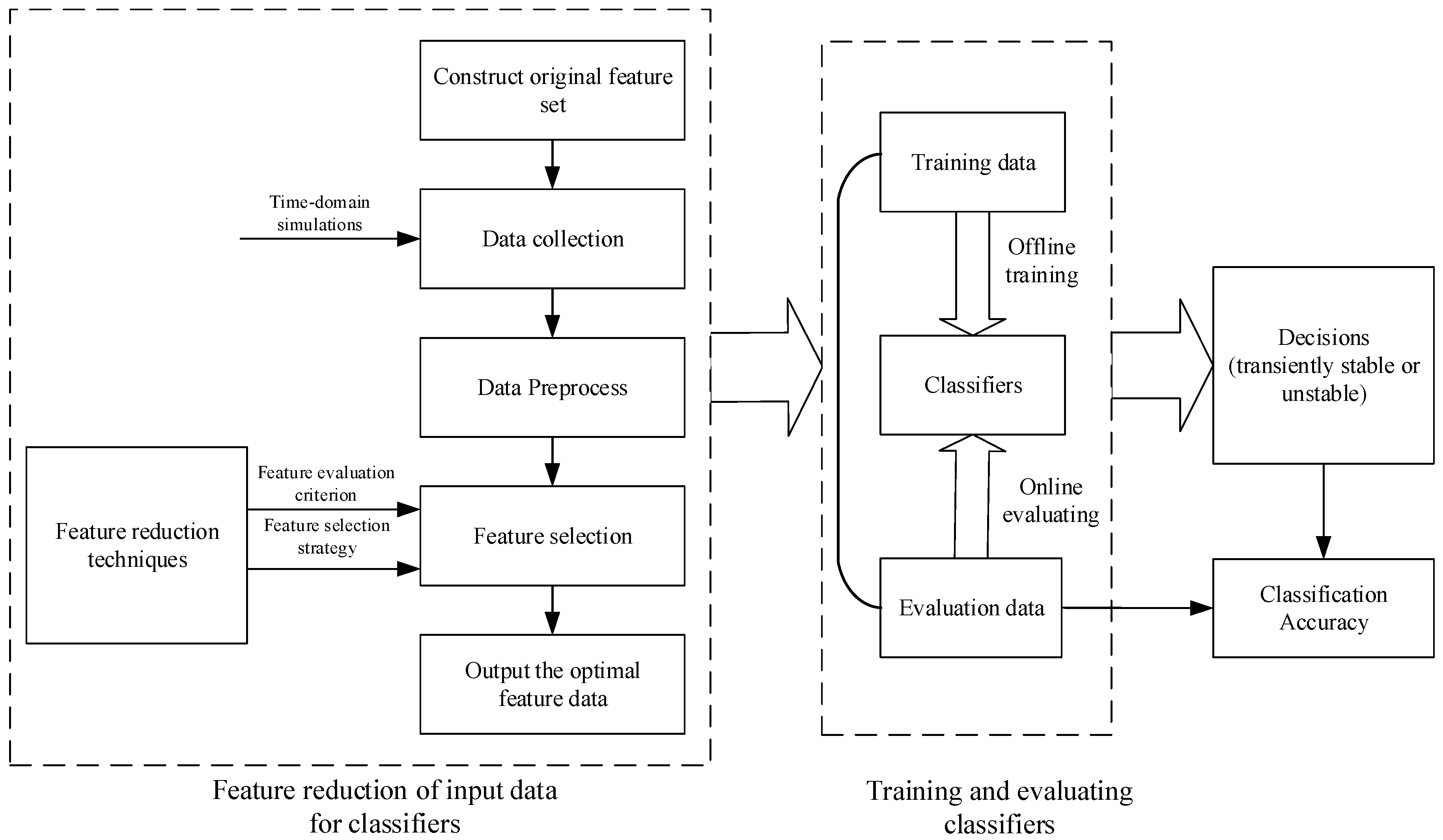
2. Construction Principles of the Initial Input Features for Transient Stability Assessment
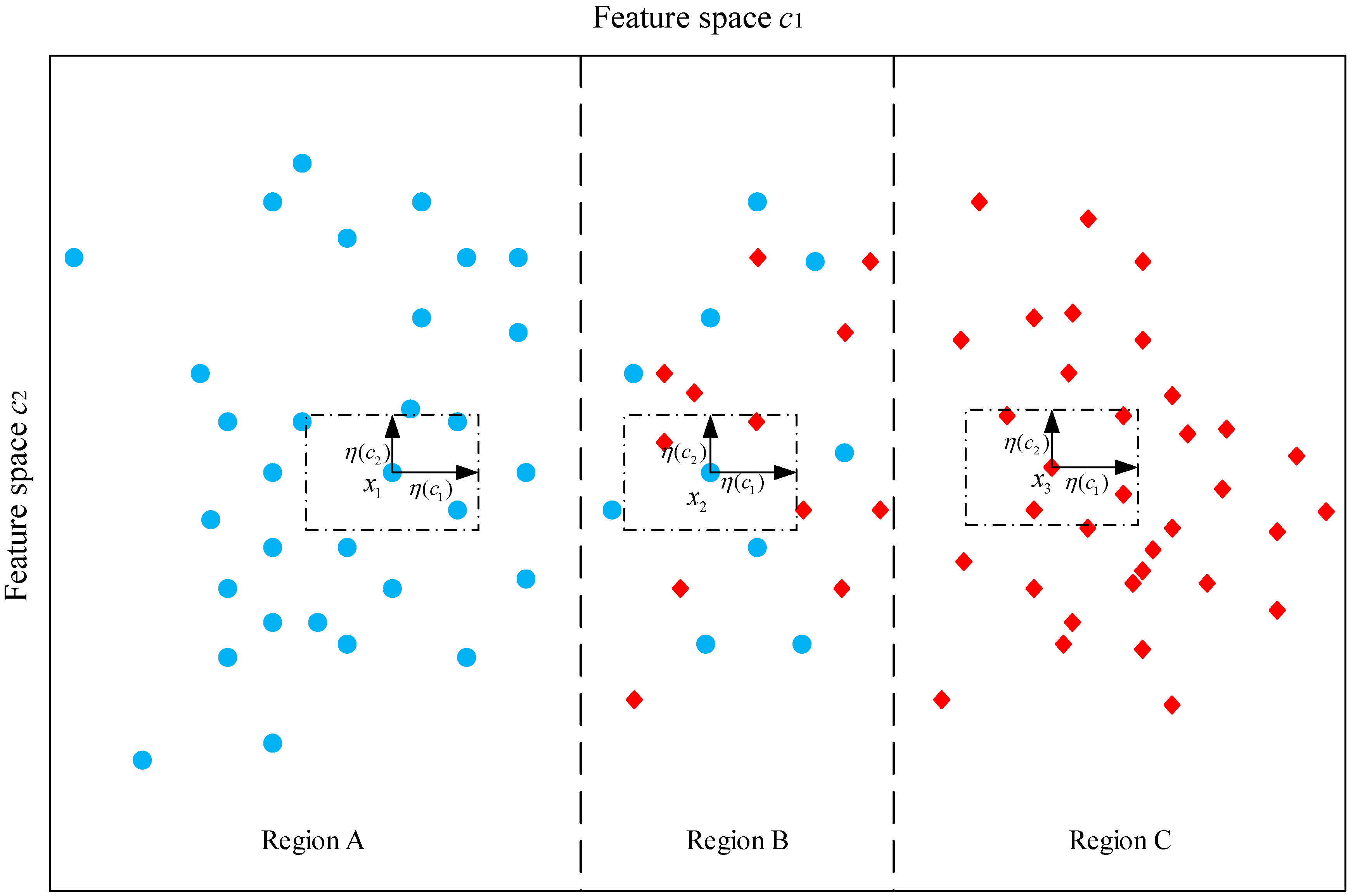
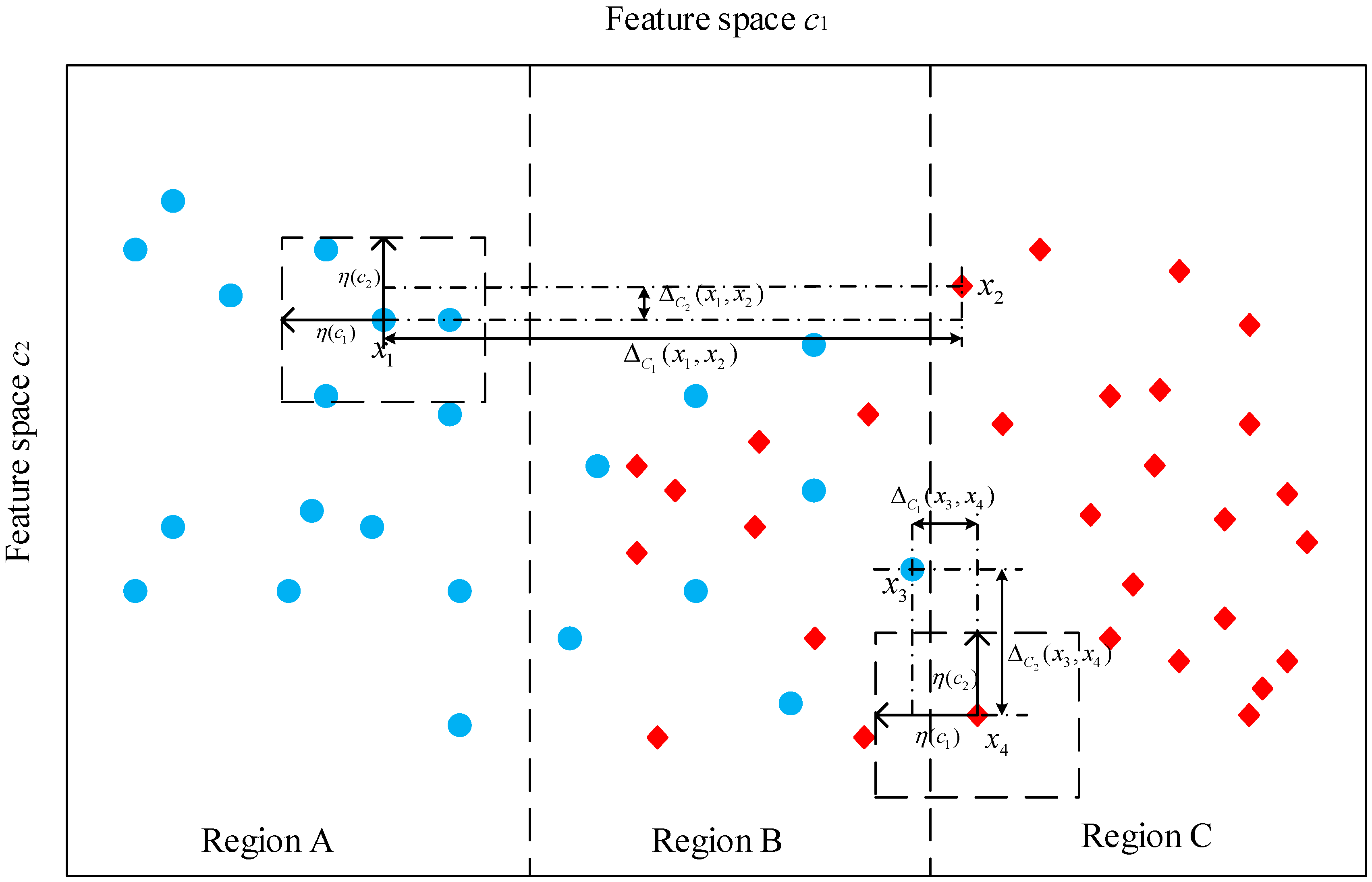
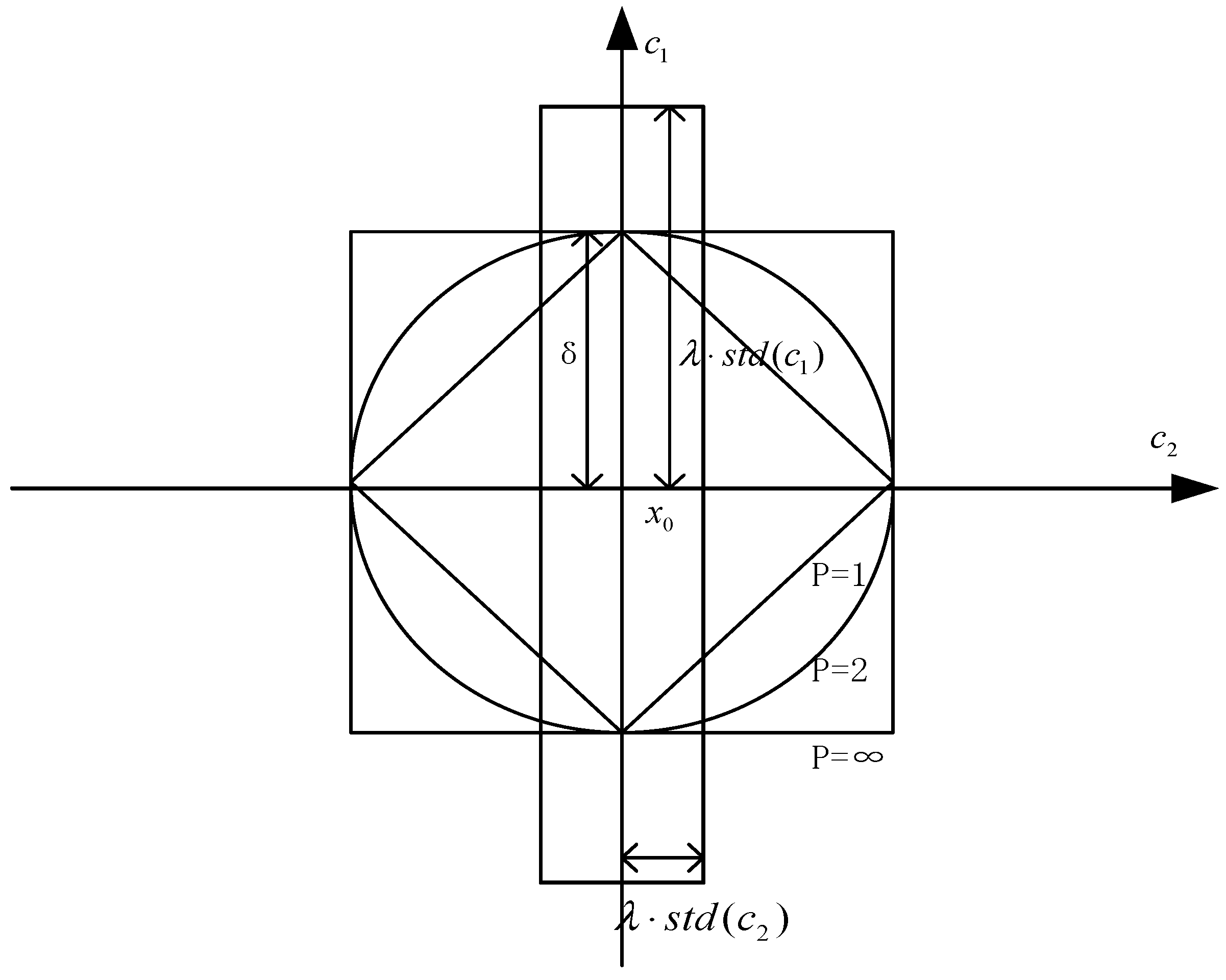
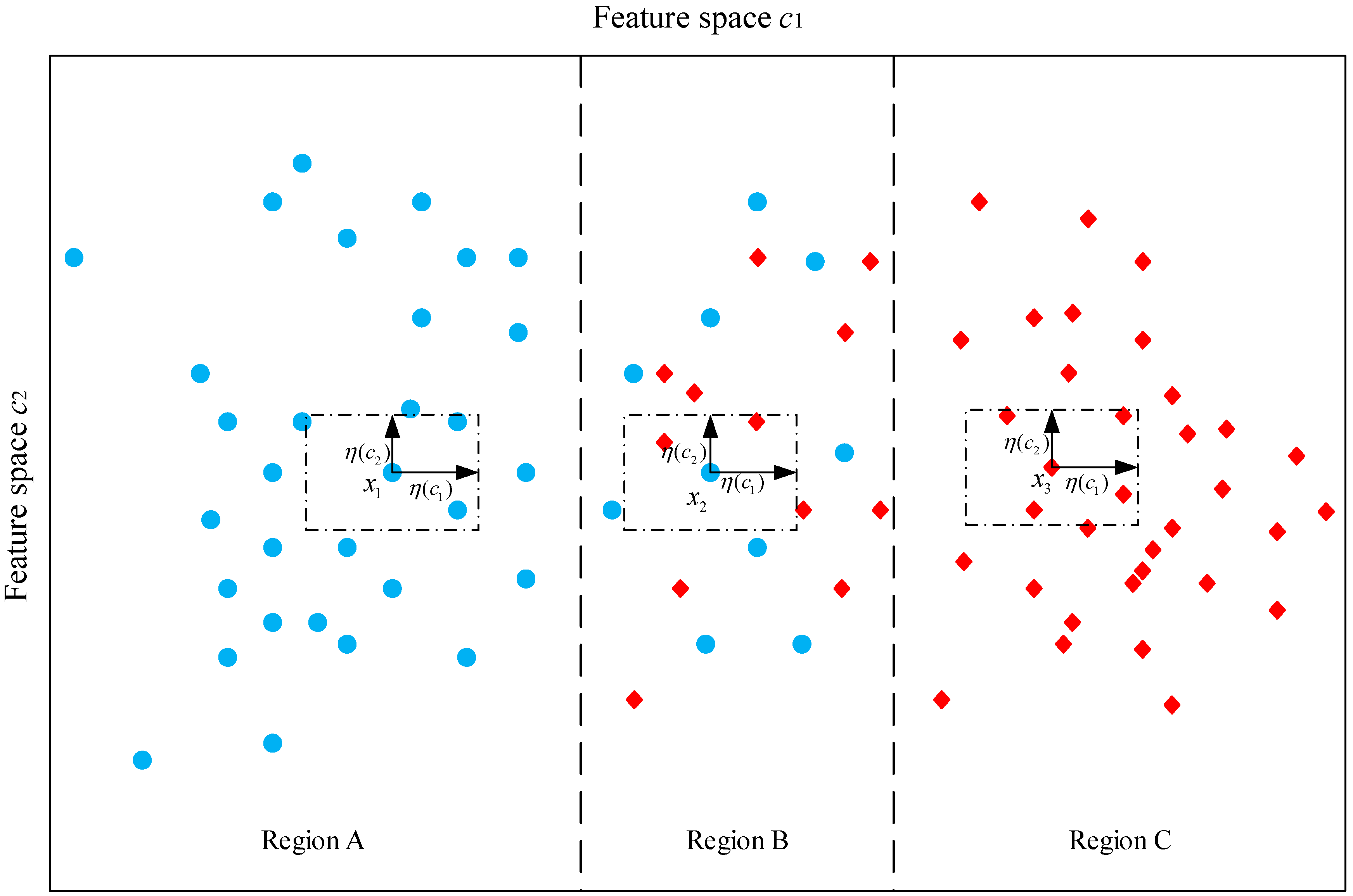
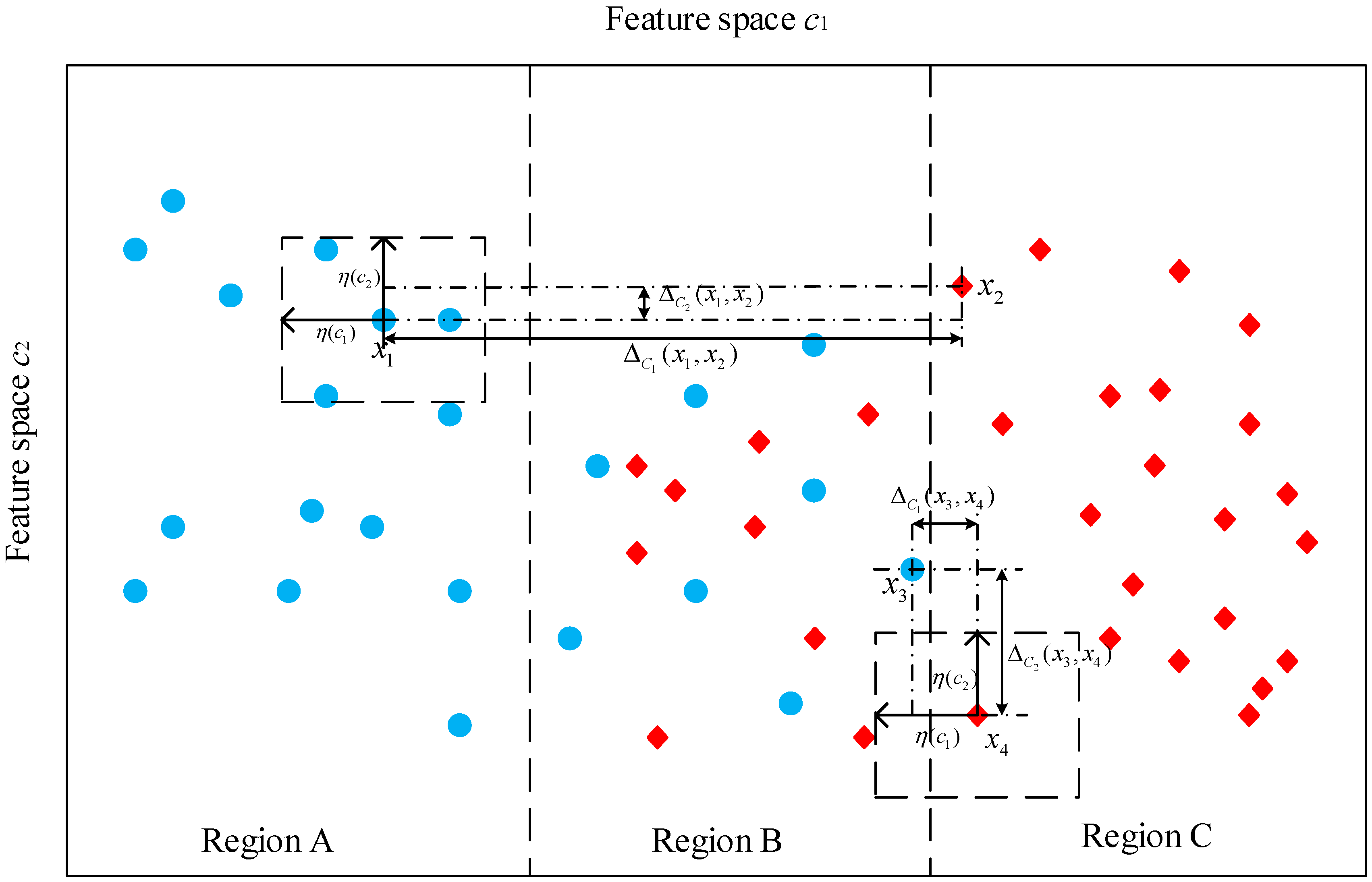
3. Fundamentals on Neighborhood Rough Set
4. Feature Reduction Using Neighborhood Rough Set and Discernibility Matrix
| Algorithm 1: Feature Selection Strategy Based on NRS and Discernibility Matrix |
| Input: Neighborhood information system , where is the set of samples, is the set of features, is the decision attribute which divides samples into several equivalence classes . , . |
| Output: reduction set |
| Step 1: Normalize the data by 0-1 normalization method to decrease the influence caused by difference of units of measures. |
| Step 2: Compute the discernibility matrix of NIS and the discernibility set of to . Choose the nonempty units in with single feature, and put them into core set . |
| Step 3: For each unit in , if the intersection of and is not empty, delete the unit from . |
| Step 4: Put the features in core set into reduction set, namely, . |
| Step 5: If , then go to Step 7, otherwise, go to Step 6. |
| Step 6: For each feature , compute the discernibility set and importance of to . Find the maximum and the corresponding feature . Put into reduction set and delete units which includes from . Then go to Step 5. |
| Step 7: Output the reduction set . |
5. Illustrative Example
5.1. New England 10 Generator 39 Bus System
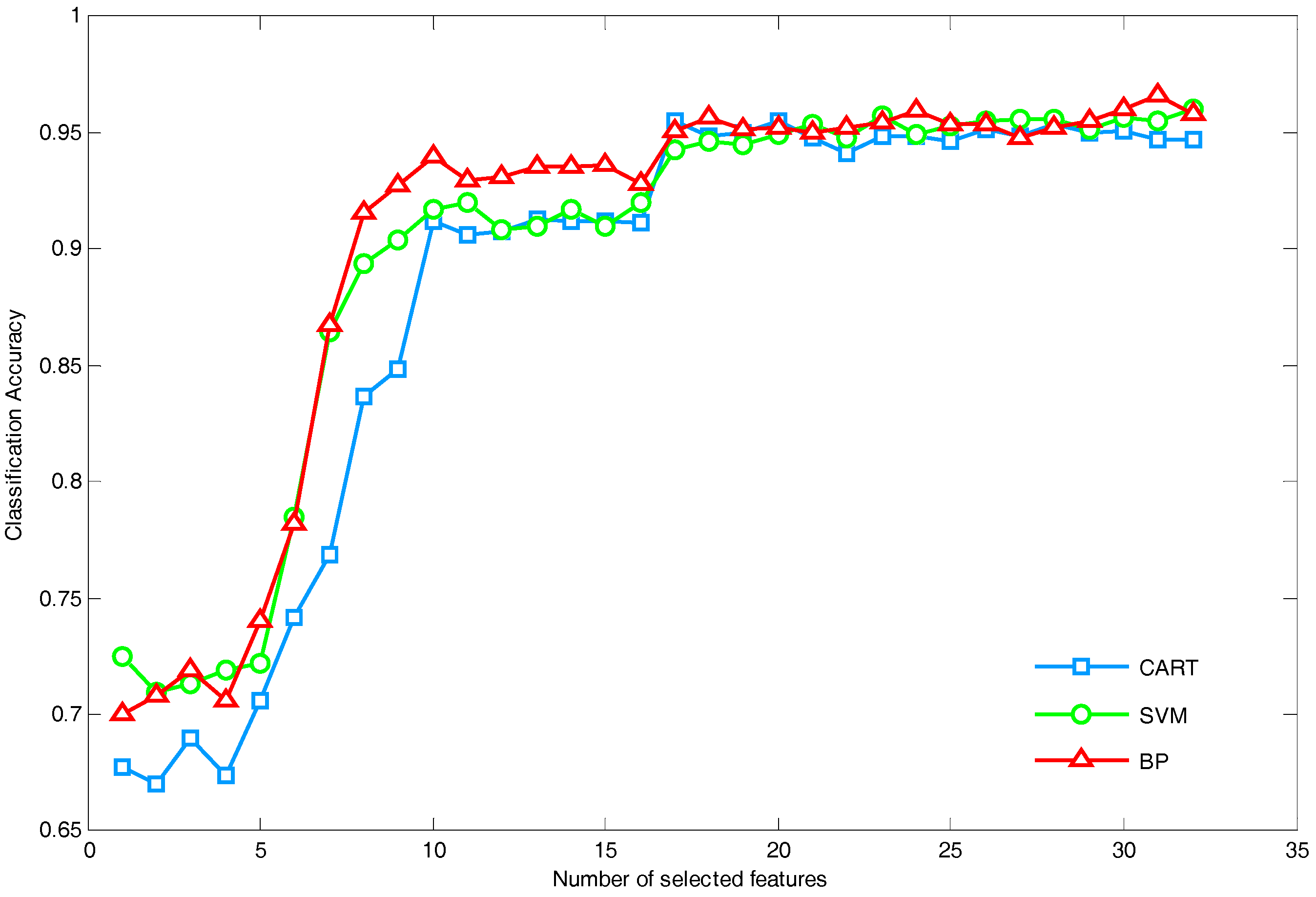
5.1.1. Performance Analysis of Feature Selection Strategy
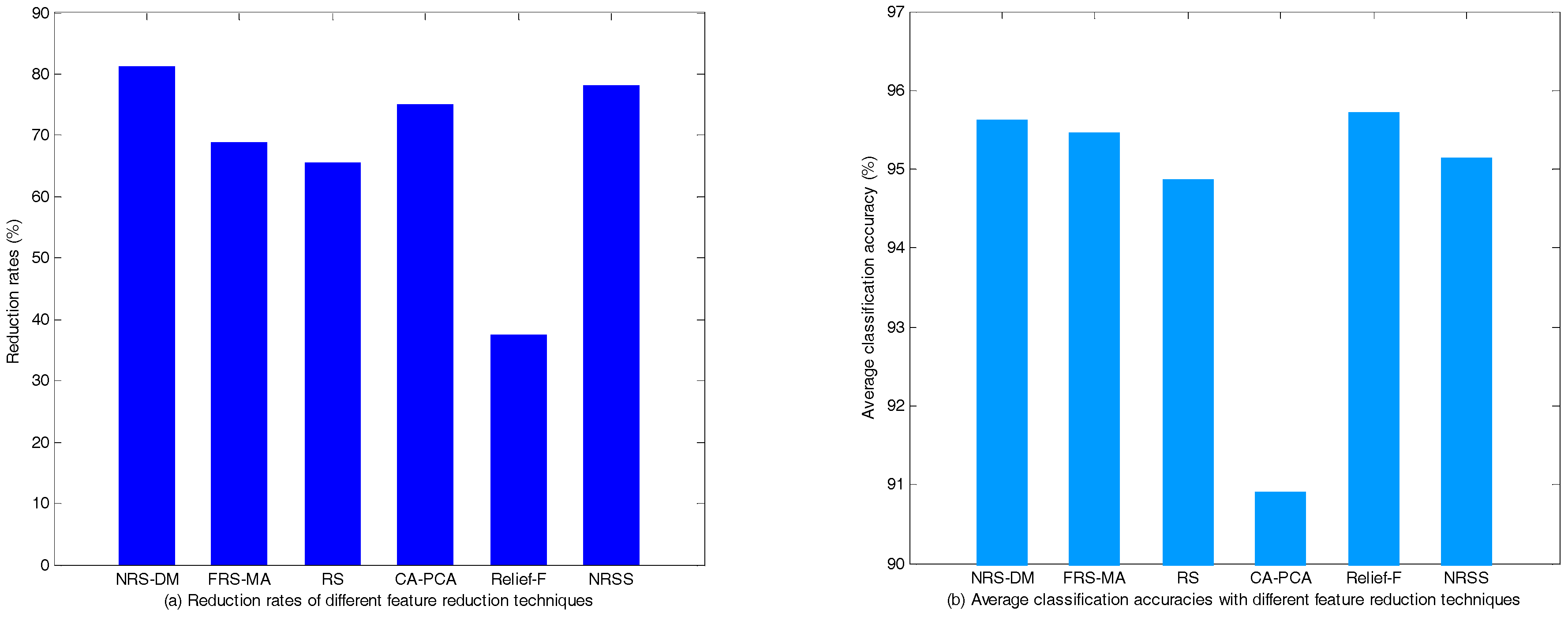
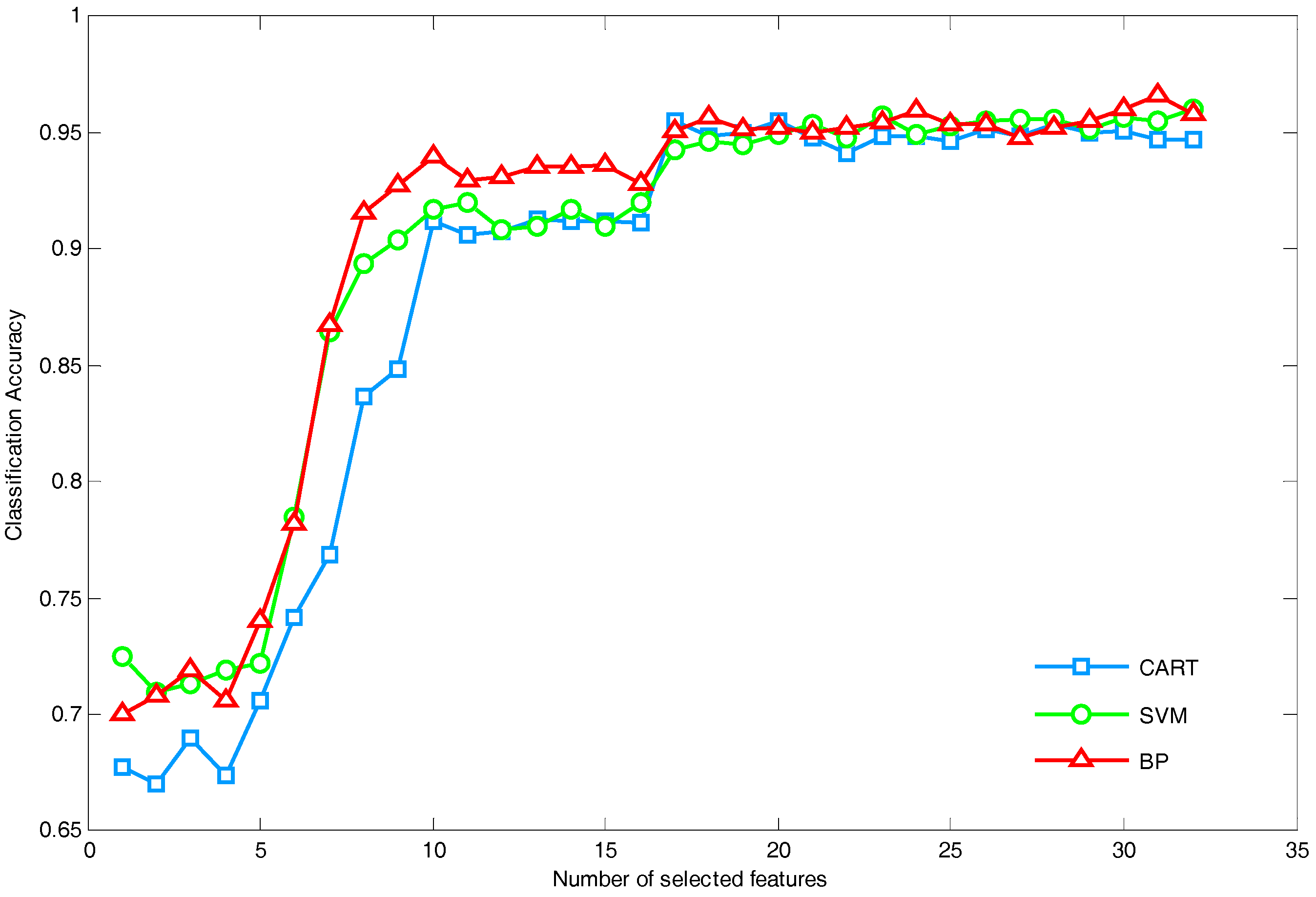
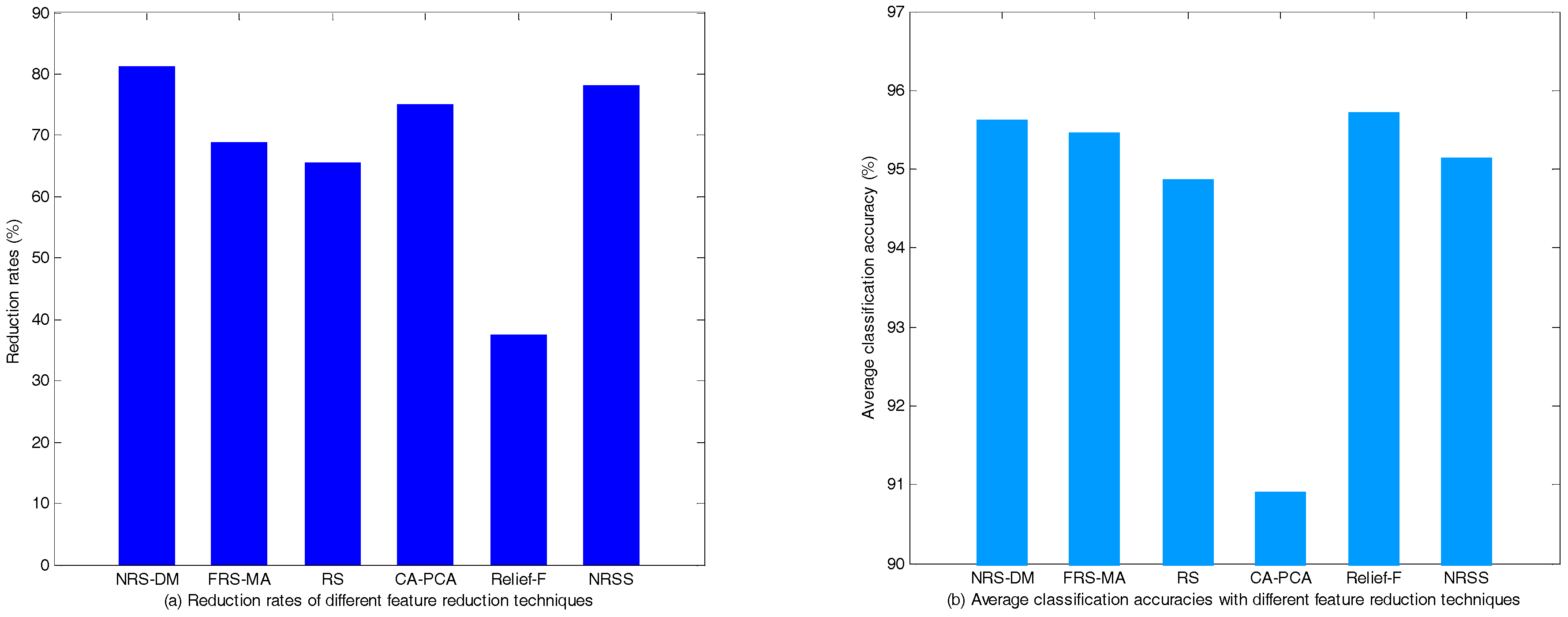
5.1.2. Performance Comparison of Different Feature Reduction Methods
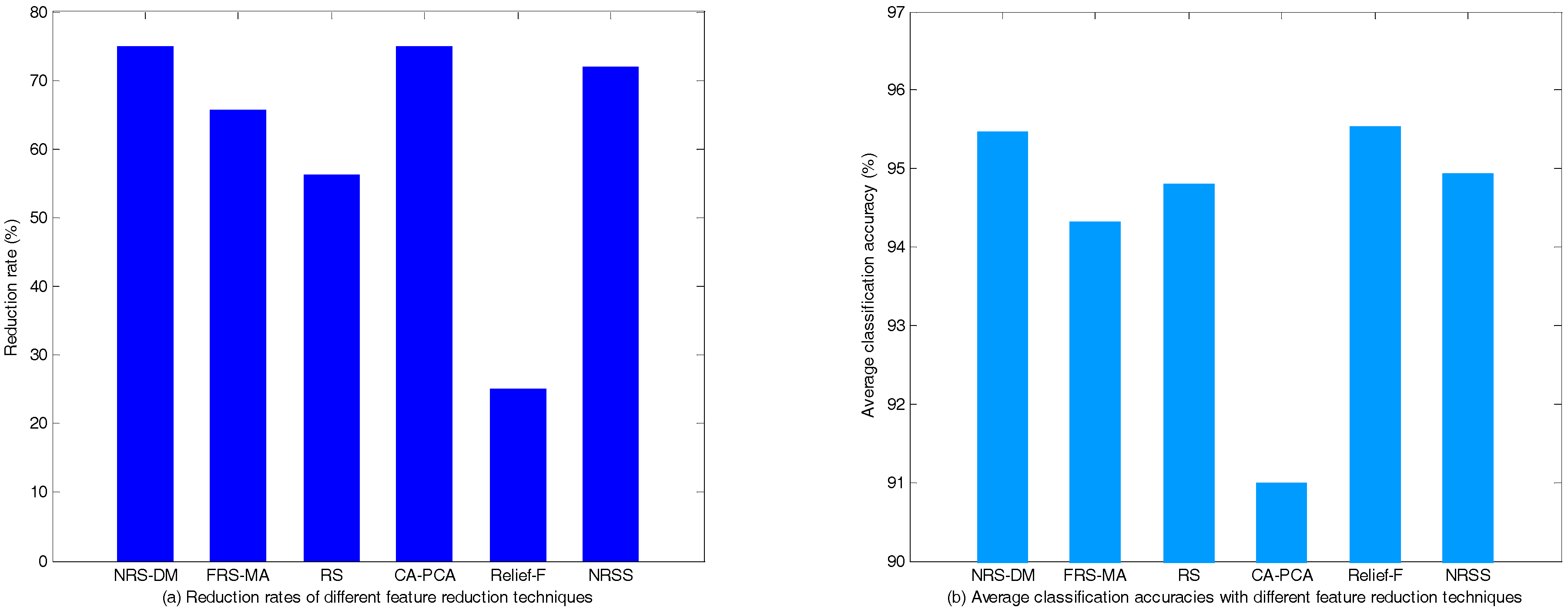
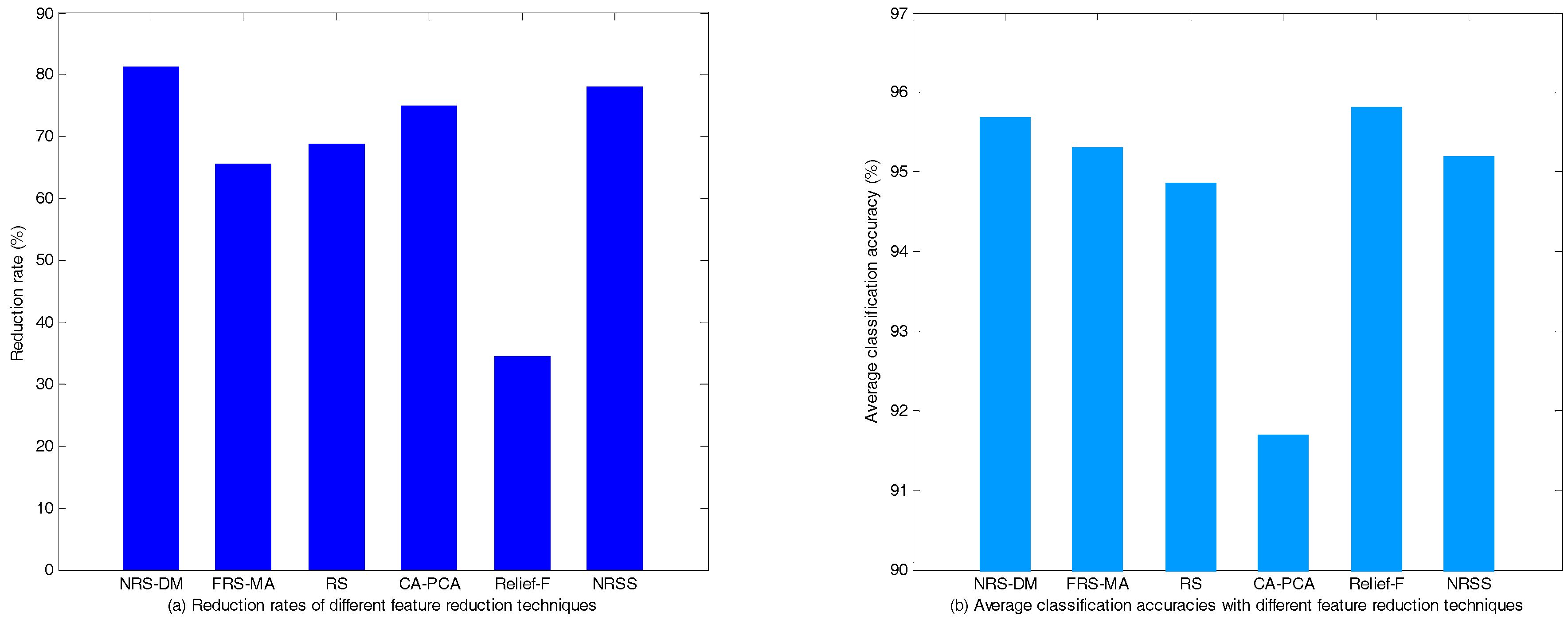
5.1.3. Performance Test in the Condition of N-1 Contingencies
5.2. Australian Simplified 14 Generators System
5.2.1. Performance Analysis of Feature Selection Strategy
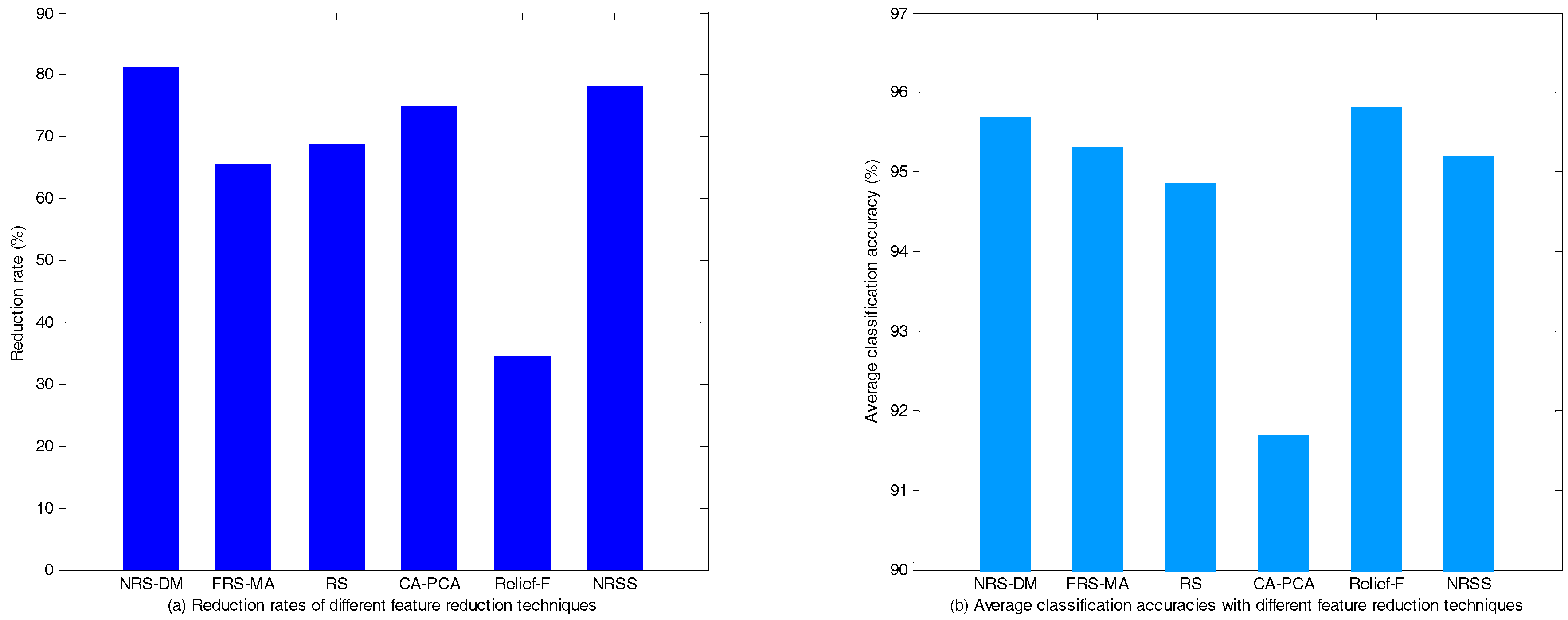
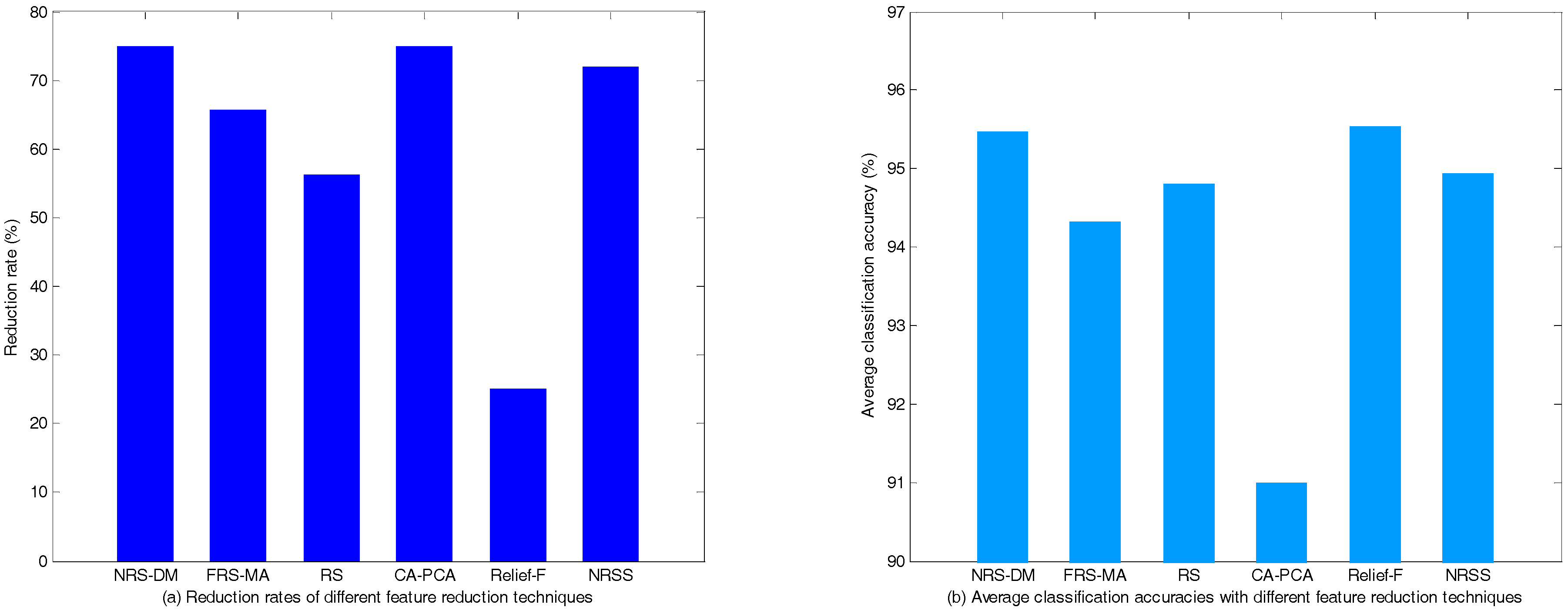
5.2.2. Performance Comparison of Different Feature Reduction Methods
6. Conclusions
- By using neighborhood rough set theory, the input space is divided into positive region and boundary region, which can intuitively describe the effective classification information contained in the feature space. Compared with some existing evaluation index, such as CA, Relief-F and Pawlak rough set, the NRS is more comprehensive to characterize features.
- Through analyzing the mechanism and principle of positive region of input space based on NRS theory, the discernibility matrix is constructed and a feature selection strategy based on that is designed to search the optimal feature set. The comparative experiments show that our proposed search strategy expends lower computation time, which has higher search efficiency.
- Both the normal power network topology and the condition in N-1 configuration are considered; it shows that our method is applicable to different circumstances. Moreover, the features selected by the proposed method are applicable to different classifiers such as CART, RBF-SVM and BP-Neural Network. Compared with several existing feature reduction methods of TSA, the proposed method owns the maximum reduction rate and relatively the best classification performance, which is more favorable to find the optimal feature subset.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Morison, K.; Wang, L.; Kundur, P. Power system security assessment. Power Energy Mag. IEEE 2004, 2, 30–39. [Google Scholar] [CrossRef]
- Kundur, P.; Paserba, J.; Ajjarapu, V.; Anderson, G.; Bose, A.; Canizares, C.; Hatziargyriou, N.; Hill, D.; Stankovic, A.; Taylor, C.; et al. Definition and classification of power system stability. IEEE Trans. Power Syst. 2004, 19, 1397–1401. [Google Scholar]
- Pavella, M. Power system transient stability assessment—Traditional vs. modern methods. Control Eng. Pract. 1998, 6, 1233–1246. [Google Scholar] [CrossRef]
- Pavella, M. From the Lyapunov general theory to a practical direct method for power system transient stability. Electr. Technol. Russ. 2000, 2, 112–131. [Google Scholar]
- Ernst, D.; Ruizvega, D.; Pavella, M.; Hirsch, P.M.; Sobajic, D. A unified approach to transient stability contingency filtering, ranking and assessment. IEEE Trans. Power Syst. 2001, 16, 435–443. [Google Scholar] [CrossRef]
- Capitanescu, F.; Ramos, J.L.M.; Panciatici, P. State-of-the-art, challenges, and future trends in security constrained optimal power flow. Electr. Power Syst. Res. 2011, 81, 1731–1741. [Google Scholar] [CrossRef]
- Ruiz-Vega, D.; Messina, A.R.; Pavella, M. Online assessment and control of transient oscillations damping. IEEE Trans. Power Syst. 2004, 19, 1038–1047. [Google Scholar] [CrossRef]
- Zhang, Y.; Markham, P.; Xia, T.; Chen, L.; Ye, Y.; Wu, Z.; Yuan, Z.; Wang, L.; Bank, J.; Burgett, J.; et al. Wide-area frequency monitoring network (FNET) architecture and applications. IEEE Trans. Smart Grid 2010, 1, 159–167. [Google Scholar] [CrossRef]
- Li, Q.; Cui, T.; Weng, Y.; Negi, R.; Franchetti, F.; Ilic, M.D. An information-theoretic approach to PMU placement in electric power system. IEEE Trans. Smart Grid 2013, 4, 446–456. [Google Scholar] [CrossRef]
- Terzija, V.; Valverds, G.; Cai, D.Y.; Regulski, P.; Madani, V.; Fitch, J.; Skok, S.; Begovic, M.M.; Phadke, A. Wide-area monitoring, protection, and control of future electric power networks. Proc. IEEE 2011, 99, 80–93. [Google Scholar] [CrossRef]
- Wahab, N.I.A.; Mohamed, A.; Hussain, A. Fast transient stability assessment of large power system using probabilistic neural network with feature reduction techniques. Expert Syst. Appl. 2011, 38, 11112–11119. [Google Scholar] [CrossRef]
- Wang, B.; Fang, B.; Wang, Y.; Liu, H.; Liu, Y. Power system transient stability assessment based on big data and the core vector machine. IEEE Trans. Smart Grid 2016, 7, 2561–2570. [Google Scholar] [CrossRef]
- Rahmatian, M.; Chen, Y.C.; Palizban, A.; Moshref, A.; Dunford, W.G. Transient stability assessment via decision trees and multivariate adaptive regression splines. Electr. Power Syst. Res. 2017, 142, 320–328. [Google Scholar] [CrossRef]
- Sulistiawati, I.B.; Priyadi, A.; Qudsi, O.A.; Soeprijanto, A.; Yorino, N. Critical clearing time prediction within various loads for transient stability assessment by means of the extreme learning machine method. Int. J. Electr. Power Energy Syst. 2016, 77, 345–352. [Google Scholar] [CrossRef]
- Sharifian, A.; Sharifian, S. A new power system transient stability assessment method based on Type-2 fuzzy neural network estimation. Int. J. Electr. Power Energy Syst. 2015, 64, 71–87. [Google Scholar] [CrossRef]
- Sawhney, H.; Jeyasurya, B. A feed-forward artificial neural network with enhanced feature selection for power system transient stability assessment. Electr. Power Syst. Res. 2006, 76, 1047–1054. [Google Scholar] [CrossRef]
- Tso, T.K.; Gu, X.P. Feature selection by separability assessment of input spaces for transient stability classification based on neural networks. Int. J. Electr. Power Energy Syst. 2004, 26, 153–162. [Google Scholar] [CrossRef]
- Wahab, N.I.A.; Mohamed, A.; Hussain, A. Feature selection and extraction methods for power systems transient stability assessment employing computational intelligence techniques. Neural Process. Lett. 2012, 35, 81–102. [Google Scholar] [CrossRef]
- Ye, S.; Wang, X.; Liu, Z. Dual-stage feature selection for transient stability assessment based on support vector machine. Proc. CSEE 2010, 30, 28–34. [Google Scholar]
- Pawlak, Z. Rough sets. Int. J. Parallel Program. 1982, 38, 88–95. [Google Scholar] [CrossRef]
- Chen, D.G.; Yang, Y.Y. Attribute reduction for heterogeneous data based on the combination of classical and fuzzy rough set models. IEEE Trans. Fuzzy Syst. 2014, 22, 1325–1334. [Google Scholar] [CrossRef]
- Tsang, E.C.C.; Chen, D.G.; Yeung, D.S.; Wang, X.; Lee, J.W.T. Attributes Reduction using fuzzy rough sets. IEEE Trans. Fuzzy Syst. 2008, 16, 1130–1141. [Google Scholar] [CrossRef]
- Li, F.; Miao, D.Q.; Pedrycz, W. Granular multi-label feature selection based on mutual information. Pattern Recognit. 2017, 67, 410–423. [Google Scholar] [CrossRef]
- Hu, Q.H.; Zhang, L.; Chen, D.G.; Pedrycz, W.; Yu, D. Gaussian Kernel Based Fuzzy Rough Sets: Model, Uncertainty Measures and Applications. Int. J. Approx. Reason. 2010, 51, 453–471. [Google Scholar] [CrossRef]
- Gu, X.P.; Tso, S.K.; Zhang, Q. Combination of rough set theory and artificial neural networks for transient stability assessment. Int. Conf. Power Technol. 2000, 1, 19–24. [Google Scholar]
- Liu, Y.; Gu, X.P.; Li, J. Discretization in artificial neural networks used for transient stability assessment. Proc. CSEE 2005, 25, 56–61. [Google Scholar]
- Gu, X.P.; Li, Y.; Jia, J.H. Feature selection for transient stability assessment based on kernelized fuzzy rough sets and memetic algorithm. Int. J. Electr. Power Energy Syst. 2015, 64, 664–670. [Google Scholar] [CrossRef]
- Hu, Q.H.; Yu, D.R.; Xie, Z.X. Neighborhood classifiers. Expert Syst. Appl. 2008, 34, 866–876. [Google Scholar] [CrossRef]
- Hu, Q.H.; Liu, F.J.; Yu, D.R. Mixed feature selection based on granulation and approximation. Knowl. Based Syst. 2008, 21, 294–304. [Google Scholar] [CrossRef]
- Hu, Q.H.; Yu, D.R.; Liu, J.F.; Wu, C. Neighborhood rough set based heterogeneous feature subset selection. Inf. Sci. Int. J. 2008, 178, 3577–3594. [Google Scholar] [CrossRef]
- Qian, J.; Miao, D.Q.; Zhang, Z.H.; Li, W. Hybrid approaches to attribute reduction based on indiscernibility and discernibility relation. Int. J. Approx. Reason. 2011, 52, 212–230. [Google Scholar] [CrossRef]
- Yao, Y.Y.; Zhao, Y. Discernibility matrix simplification for constructing attribute reducts. Inf. Sci. 2009, 179, 867–882. [Google Scholar] [CrossRef]
- Zhao, Y.; Yao, Y.Y.; Luo, F. Data analysis based on discernibility and indiscernibility. Inf. Sci. 2007, 177, 4959–4976. [Google Scholar] [CrossRef]
- Pai, A. Energy Function Analysis for Power System Stability; Springer: Berlin, Germany, 1989. [Google Scholar]
- Robnik-Sikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef]
- Moeini, A.; Kamwa, I.; Brunelle, P.; Sybille, G. Open data IEEE test systems implemented in simpowersystems for education and research in power grid dynamics and control. In Proceedings of the 2015 50th International Universities Power Engineering Conference (UPEC), Stoke on Trent, UK, 1–4 September 2015; pp. 1–6. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Feature Description |
|---|---|
| 1 | Mean value of all the mechanical power at t0 |
| 2 | Total energy adjustment of system |
| 3 | Maximum value of active power impact on generator at t1 |
| 4 | Minimum value of active power impact on generator at t1 |
| 5 | Mean value of generator accelerating power at t1 |
| 6 | Rotor angle relative to center of inertia of generator with the maximum acceleration at t1 |
| 7 | Generator rotor angle with the maximum difference relative to center of inertia at t1 |
| 8 | Mean value of all generator angular acceleration at t1 |
| 9 | Generator angular acceleration with the maximum difference relative to center of inertia at t1 |
| 10 | Variance of all generator angular acceleration at t1 |
| 11 | Variance of all generator accelerating power at t1 |
| 12 | Mean value of all generator accelerating power at t2 |
| 13 | Maximum generator rotor kinetic energy at t2 |
| 14 | Mean value of generator rotor kinetic energy at t2 |
| 15 | Rotor kinetic energy of generator with the maximum angular acceleration at t2 |
| 16 | Active power impact on system at t2 |
| 17 | Rotor angle relative to center of inertia of generator with the maximum rotor kinetic energy at t2 |
| 18 | Difference of generator rotor angle relative to center of inertia at t1 and t2 |
| 19 | Generator rotor angle with the maximum difference relative to center of inertia at t2 |
| 20 | Difference of generator rotor angular velocity relative to center of inertia at t1 and t2 |
| 21 | Generator rotor angular velocity with the maximum difference relative to center of inertia at t2 |
| 22 | Difference of maximum and minimum generator rotor angular velocity at t2 |
| 23 | Difference of generator rotor acceleration relative to center of inertia at t1 and t2 |
| 24 | Generator rotor acceleration with the maximum difference relative to center of inertia at t2 |
| 25 | Difference of maximum and minimum generator rotor acceleration at t2 |
| 26 | Difference of maximum and minimum generator rotor kinetic energy at t2 |
| 27 | Difference of maximum and minimum variation of generator rotor kinetic energy at t2 |
| 28 | Sum of generator active power at t2 |
| 29 | Difference of maximum and minimum generator rotor angle at t2 |
| 30 | Variance of all generator accelerating power at t2 |
| 31 | Mean value of all generator rotor angular velocity at t2 |
| 32 | Mean value of all the mechanical power at t2 |
| Feature Selection Strategy | Selected Features in Reduction | Accuracy (%) CART | Accuracy (%) RBF-SVM | Accuracy (%) BP | Computation Time |
|---|---|---|---|---|---|
| DM | 17,1,10,7,3,2 | 95.33 ± 1.84 | 95.80 ± 1.76 | 95.75 ± 1.69 | 162.37 s |
| Forward | 17,5,1,24,3,6 | 94.10 ± 2.03 | 95.23 ± 2.03 | 94.29 ± 1.63 | 224.55 s |
| Backward | 9,22,26,29,31,32 | 96.03 ± 2.17 | 95.60 ± 1.92 | 95.07 ± 1.86 | 340.28 s |
| Feature Reduction Method | Selected Optimal Feature Set | Dimension | Accuracy (%) CART | Accuracy (%) RBF-SVM | Accuracy (%) BP |
|---|---|---|---|---|---|
| NRS-DM | 17,1,10,7,3,2 | 6 | 95.33 ± 1.84 | 95.80 ± 1.76 | 95.75 ± 1.69 |
| FRS-MA | 1,2,4,7,8,14, 17,23,26,31 | 10 | 95.08 ± 2.02 | 95.28 ± 1.71 | 96.02 ± 1.88 |
| RS | 17,2,13,12,21,7, 3,27,25,4,9 | 11 | 95.12 ± 1.87 | 94.25 ± 2.08 | 95.29 ± 2.08 |
| CA-PCA | * 1,2,3,4,5,6,7,8,9,12,13,17, 19,20,21,24,25,26,27,29,30 | 8 | 88.30 ± 2.43 | 92.12 ± 2.35 | 92.28 ± 1.95 |
| Relief-F | 2,7,8,9,10,13,14,16,17,18, 19,21,22,23,24,25,28,30,31,32 | 20 | 95.12 ± 1.78 | 96.08 ± 1.34 | 95.96 ± 1.80 |
| NRSS | 17,5,32,1,7,6,3 | 7 | 95.92 ± 1.78 | 94.45 ± 1.87 | 95.04 ± 2.38 |
| The original feature set | -- | 32 | 94.75 ± 2.06 | 95.67 ± 1.63 | 96.46 ± 1.69 |
| Feature Reduction Method | Selected Optimal Feature Set | Dimension | Accuracy (%) CART | Accuracy (%) RBF-SVM | Accuracy (%) BP |
|---|---|---|---|---|---|
| NRS-DM | 6,17,29,10,7,2 | 6 | 95.44 ± 1.55 | 95.51 ± 1.31 | 96.07 ± 1.12 |
| FRS-MA | 1,2,3,14,16,17, 19,20,26,31,32 | 11 | 95.15 ± 1.46 | 94.87 ± 1.47 | 95.87 ± 1.32 |
| RS | 13,21,12,9,4,7, 26,8,3,19 | 10 | 95.08 ± 1.39 | 94.93 ± 1.48 | 94.58 ± 1.45 |
| CA-PCA | * 1,2,3,4,5,6,7,8,9,12,13, 17,19,20,21,25,26,27,29,30 | 8 | 89.44 ± 2.06 | 93.07 ± 1.67 | 92.58 ± 1.79 |
| Relief-F | 2,7,8,9,10,11,13,14,16,17,18, 19,21,22,23,25,28,29,30,31,32 | 21 | 95.53 ± 1.37 | 96.18 ± 1.11 | 95.73 ± 1.00 |
| NRSS | 17,7,1,2,3,6,11 | 7 | 95.28 ± 1.22 | 94.63 ± 1.45 | 95.69 ± 1.13 |
| The original feature set | -- | 32 | 95.43 ± 1.26 | 95.30 ± 1.19 | 96.28 ± 1.20 |
| Feature Selection Strategy | Selected Features in Reduction | Accuracy (%) CART | Accuracy (%) RBF-SVM | Accuracy (%) BP | Computation Time |
|---|---|---|---|---|---|
| DM | 5,30,13,2,4,8,19,7 | 96.38 ± 1.45 | 96.03 ± 1.22 | 94.02 ± 1.32 | 209.96 s |
| Forward | 31,32,6,2,29,8,5,13,30 | 95.25 ± 1.46 | 95.13 ± 1.43 | 94.27 ± 1.49 | 1335.06 s |
| Backward | 5,8,17,22,25,26,29,30,31,32 | 95.90 ± 1.79 | 95.94 ± 1.61 | 94.23 ± 1.48 | 1447.29 s |
| Feature Reduction Method | Selected Optimal Feature Set | Dimension | Accuracy (%) CART | Accuracy (%) RBF-SVM | Accuracy (%) BP |
|---|---|---|---|---|---|
| NRS-DM | 5,30,13,2,4,8,19,7 | 8 | 96.38 ± 1.45 | 96.03 ± 1.22 | 94.02 ± 1.32 |
| FRS-MA | 2,4,7,13,14,18, 20,21,22,26,31 | 11 | 93.79 ± 2.15 | 95.19 ± 1.66 | 94.02 ± 1.55 |
| RS | 21,16,7,29,2,4,14, 30,10,5,8,17,28,19 | 14 | 94.95 ± 1.66 | 95.04 ± 1.27 | 94.44 ± 1.10 |
| CA-PCA | * 1,2,3,4,5,6,7,8,9,11,12,13,15, 16,19,20,21,26,27,28,29,30,32 | 8 | 90.14 ± 2.15 | 92.48 ± 1.64 | 90.38 ± 2.09 |
| Relief-F | 2,5,7,8,9,10,11,12,13,14,18,19,20, 21,22,23,24,25,27,28,29,30,31,32 | 24 | 95.13 ± 1.50 | 96.33 ± 1.21 | 95.15 ± 1.28 |
| NRSS | 31,32,1,2,11,5,13,8,30 | 9 | 94.90 ± 1.82 | 95.94 ± 1.24 | 93.98 ± 1.15 |
| The original feature set | -- | 32 | 94.55 ± 1.81 | 95.63 ± 1.22 | 94.41 ± 1.62 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Xiao, J.; Wang, X. Feature Reduction for Power System Transient Stability Assessment Based on Neighborhood Rough Set and Discernibility Matrix. Energies 2018, 11, 185. https://doi.org/10.3390/en11010185
Li B, Xiao J, Wang X. Feature Reduction for Power System Transient Stability Assessment Based on Neighborhood Rough Set and Discernibility Matrix. Energies. 2018; 11(1):185. https://doi.org/10.3390/en11010185
Chicago/Turabian StyleLi, Bingyang, Jianmei Xiao, and Xihuai Wang. 2018. "Feature Reduction for Power System Transient Stability Assessment Based on Neighborhood Rough Set and Discernibility Matrix" Energies 11, no. 1: 185. https://doi.org/10.3390/en11010185
APA StyleLi, B., Xiao, J., & Wang, X. (2018). Feature Reduction for Power System Transient Stability Assessment Based on Neighborhood Rough Set and Discernibility Matrix. Energies, 11(1), 185. https://doi.org/10.3390/en11010185