
Modeling and Prediction of Environmental Factors and Chlorophyll a Abundance by Machine Learning Based on Tara Oceans Data


Abstract
1. Introduction
2. Materials and Methods
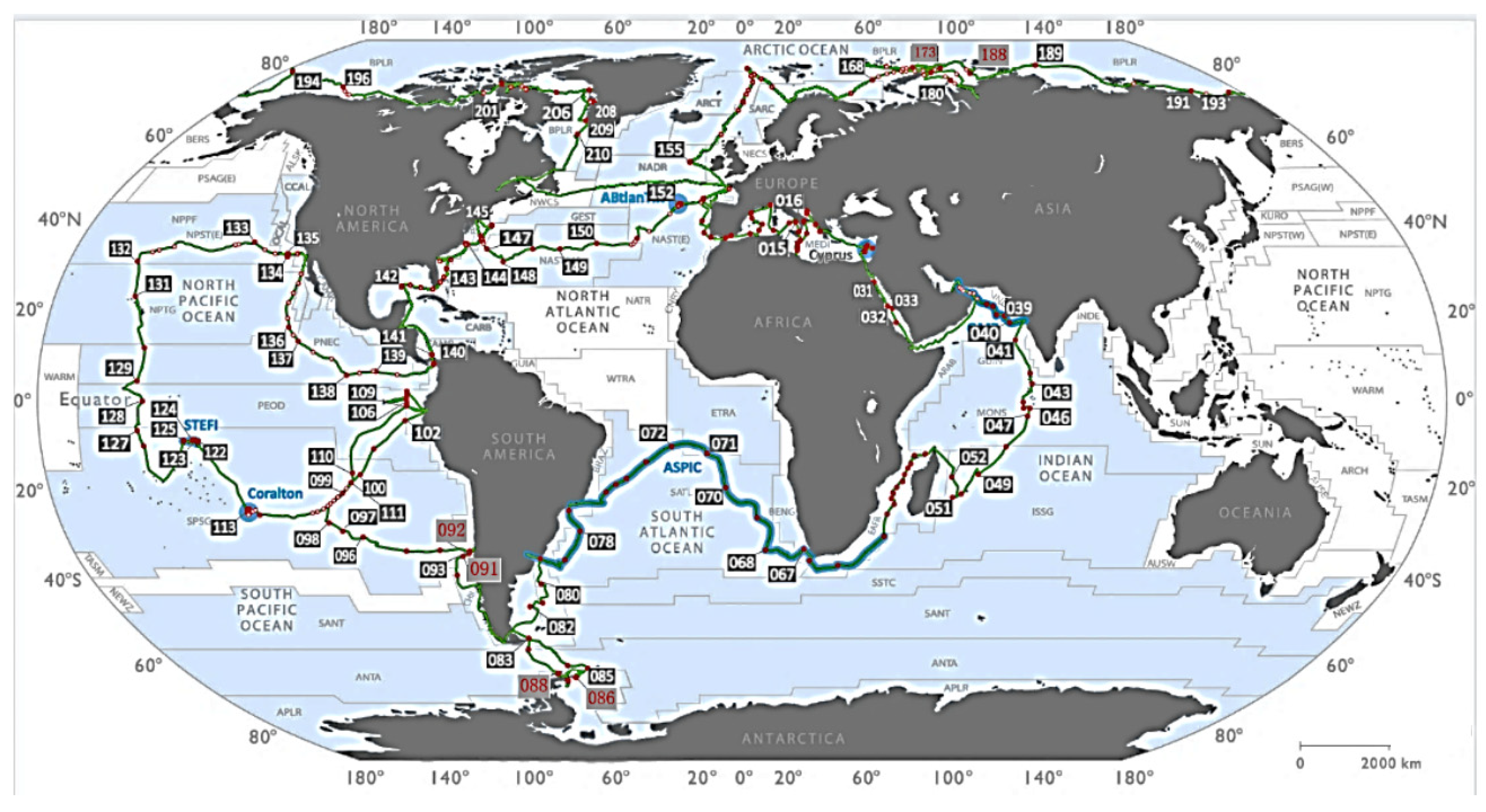
2.1. Data Sources
2.2. Data Cleaning
3. Comprehensive Correlation Model
3.1. Character Importance
3.2. Pearson Correlation
3.3. Comprehensive Correlation Evaluation Model
4. Integrated Prediction Model
4.1. Extreme Gradient Boosting Regression
4.2. LOOCV Validation
4.3. Objective for Prediction
5. Results and Discussion
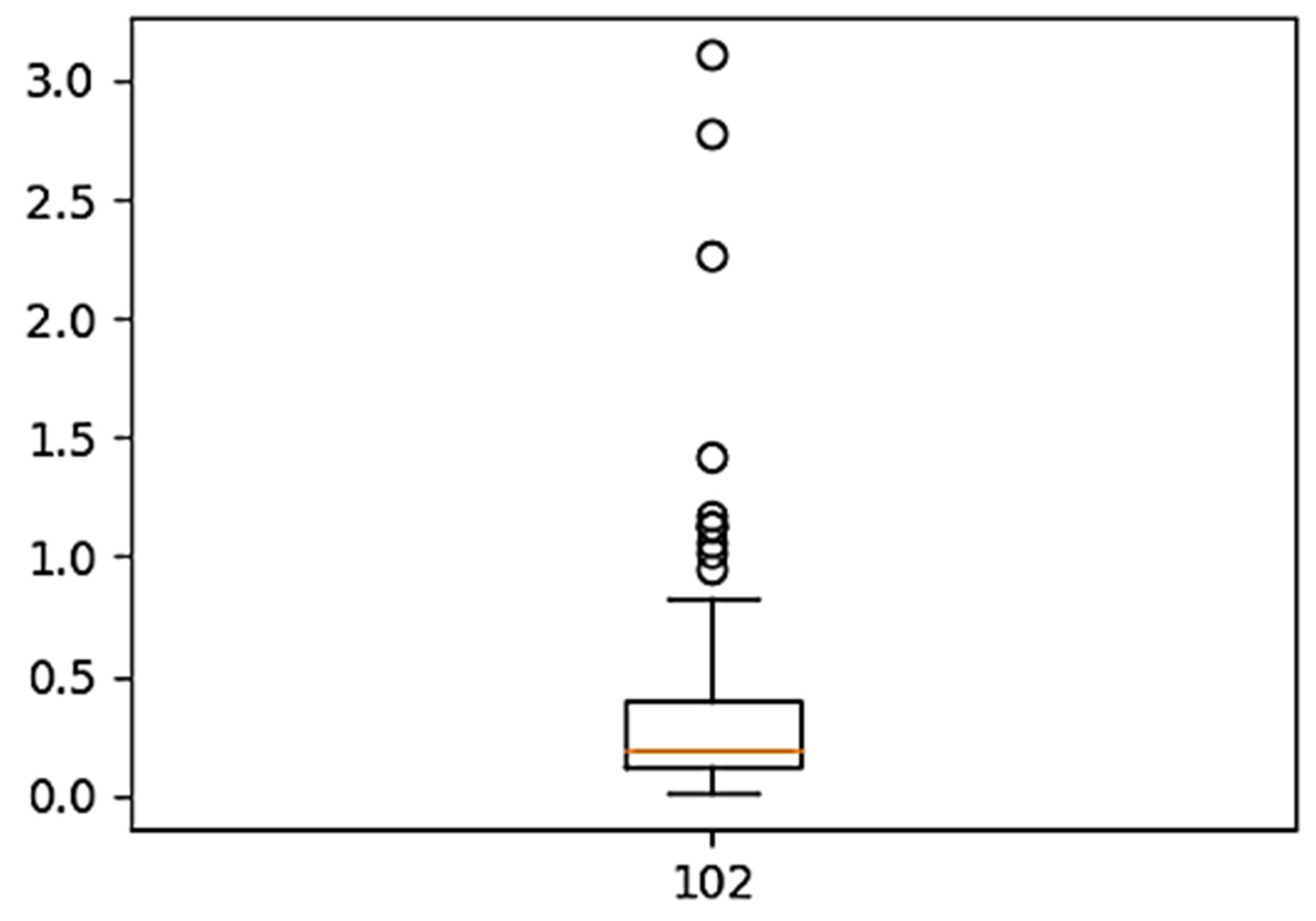
5.1. Raw Data Processing
5.2. Evaluation of Characteristic Importance of Environmental Factors
5.3. Environmental Factors Modeling
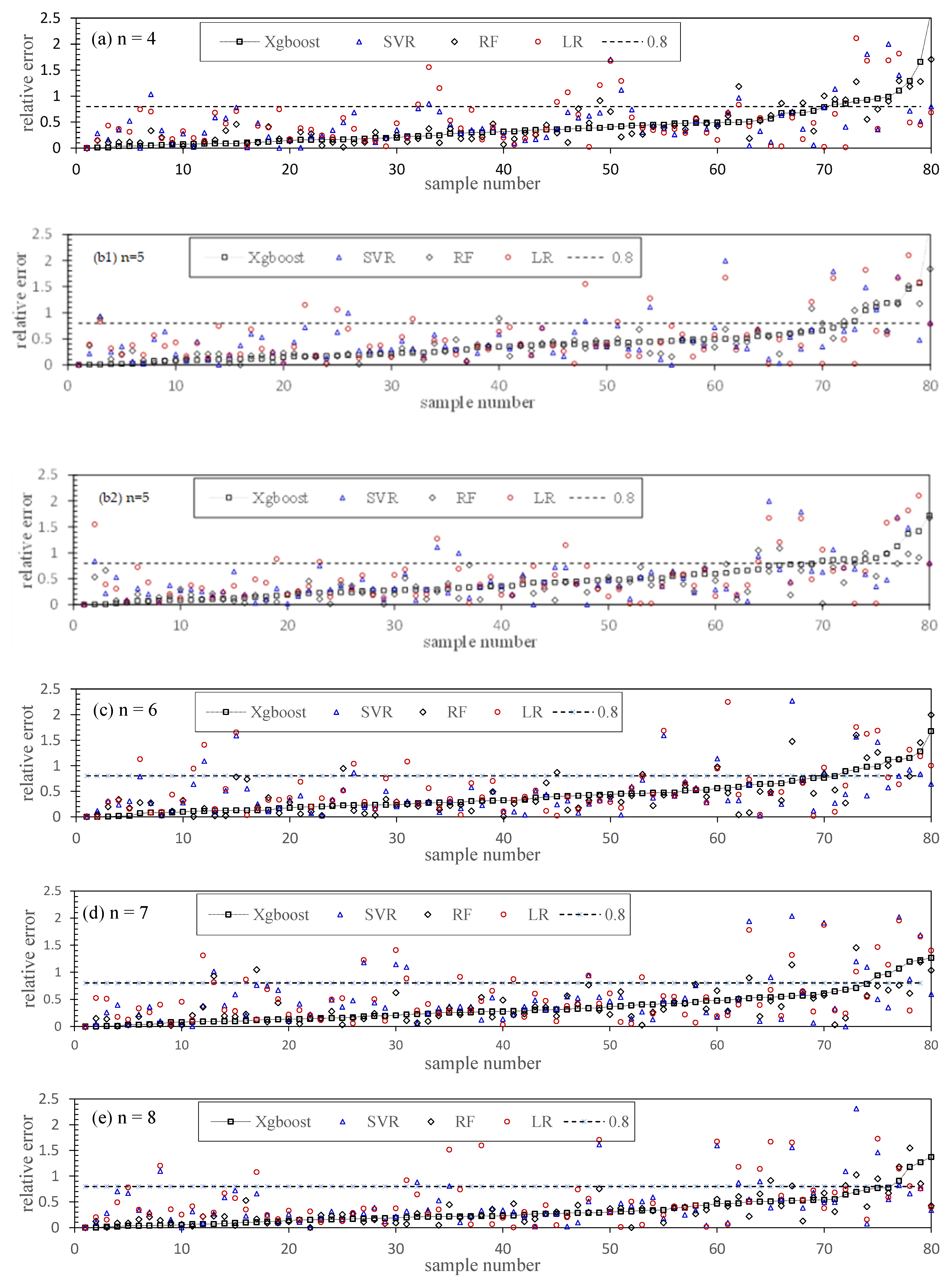
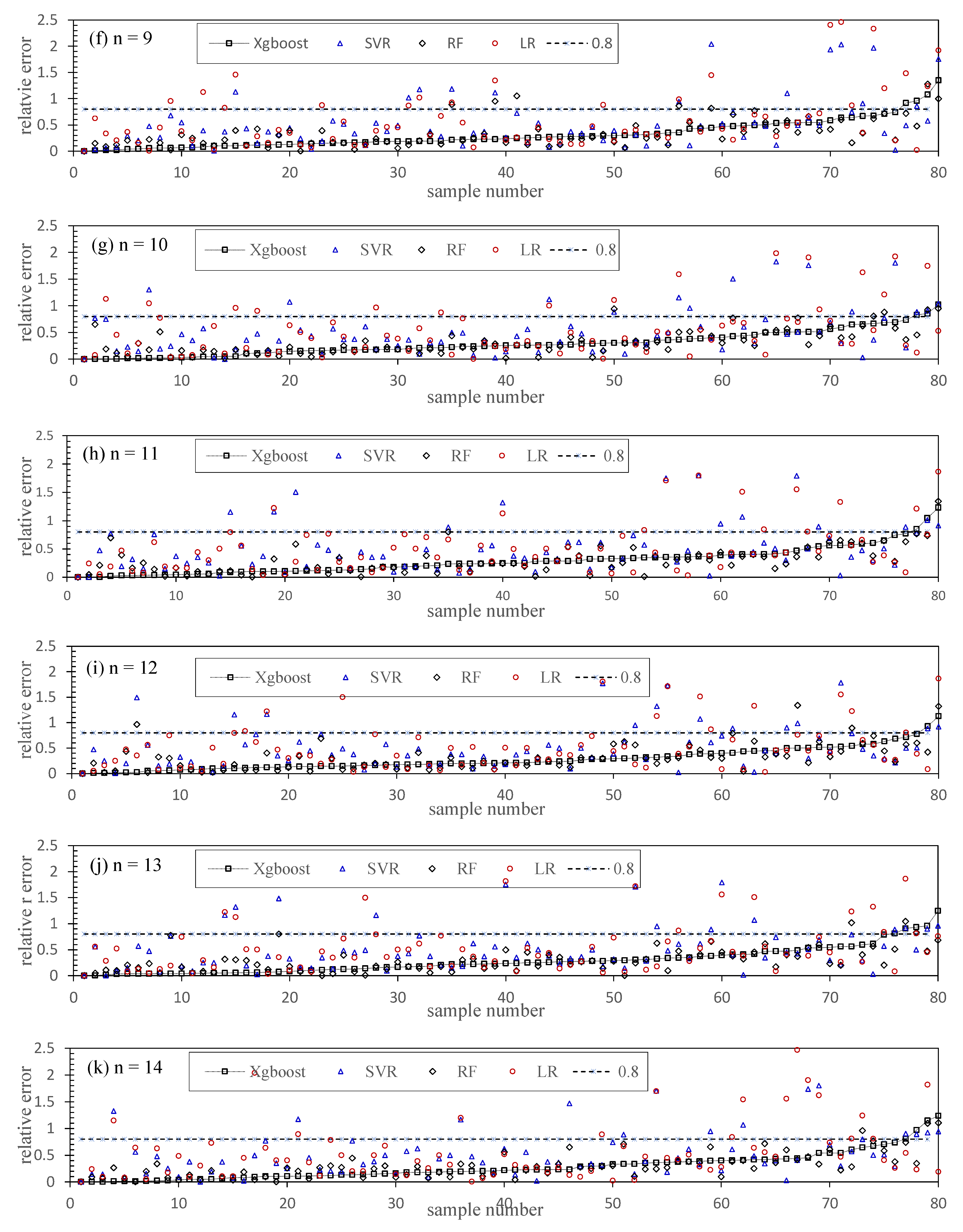
5.4. Chl-a Abundance Prediction
5.5. Modeling Optimization and Comparison
6. Conclusions
- (1)
- The comprehensive correlation model of marine environmental factors considers both the direct correlation between any two environmental factors and the potential correlation among multiple factors. It is helpful for the selection of factors for Chl-a modeling and prediction.
- (2)
- A multi-environmental factor prediction model can accurately predict the amount of Chl-a, which can help to determine Chl-a abundance on other indicators of the marine environment.
- (3)
- The more environmental factors used for Chl-a predicting, the more accurate the results will be. With increasing amounts of marine environmental data included, the machine learning technologies will be used for additional relevant studies. Revealing small-scale, refined and systematic laws of the marine environment requires additional marine observation, monitoring and measurement data. This approach will help to develop a deeper understanding of the underlying mechanisms behind the dynamic changes in the marine environment, and thus develop more efficient ways to protect the marine environment.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Madin, E.M.; Dill, L.M.; Ridlon, A.D.; Heithaus, M.R.; Warner, R.R. Human activities change marine ecosystems by altering predation risk. Glob. Chang. Biol. 2016, 22, 44–60. [Google Scholar] [CrossRef]
- Biard, T.; Bigeard, E.; Audic, S.; Poulain, J.; Gutierrez-Rodriguez, A.; Pesant, S.; Stemmann, L.; Not, F. Biogeography and diversity of Collodaria (Radiolaria) in the global ocean. ISME J. 2017, 11, 1331–1344. [Google Scholar] [CrossRef] [PubMed]
- Pesant, S.; Tara Oceans Consortium Coordinators; Not, F.; Picheral, M.; Kandels-Lewis, S.; Le Bescot, N.; Gorsky, G.; Iudicone, D.; Karsenti, E.; Speich, S.; et al. Open science resources for the discovery and analysis of Tara Oceans data. Sci. Data 2015, 2, 150023. [Google Scholar] [CrossRef]
- Sunagawa, S.; Coelho, L.P.; Chaffron, S.; Kultima, J.R.; Labadie, K.; Salazar, G.; Djahanschiri, B.; Zeller, G.; Mende, D.R.; Alberti, A.; et al. Structure and function of the global ocean microbiome. Science 2015, 348, 6237. [Google Scholar] [CrossRef]
- Karlusich, J.; Ibarbalz, F.M.; Bowler, C. Phytoplankton in the Tara Ocean. Annu. Rev. Mar. Sci. 2020, 12, 233–265. [Google Scholar] [CrossRef]
- Zhang, X.L.; Yang, X.; Wang, S.J.; Jiang, Z.W.; Xie, Z.X.; Zhang, L. Draft Genome Sequences of Nine Cultivable Heterotrophic Proteobacteria Isolated from Phycosphere Microbiota of Toxic Alexandrium catenella LZT09. Microbiol. Resour. Announc. 2020, 9, e00281-20. [Google Scholar] [CrossRef]
- Zhang, X.L.; Tian, X.Q.; Ma, L.Y.; Feng, B.; Liu, Q.H.; Yuan, L.D. Biodiversity of the symbiotic bacteria associated with toxic marine dinoflagellate Alexandrium tamarense. J. Biosci. Med. 2015, 3, 23–28. [Google Scholar] [CrossRef]
- Zhang, X.L.; Ma, L.Y.; Tian, X.Q.; Huang, H.L.; Yang, Q. Biodiversity study of intracellular bacteria closely associated with paralytic shellfish poisoning dinoflagellates Alexandrium tamarense and A. minutum. Int. J. Environ. Resour. 2015, 4, 23–27. [Google Scholar] [CrossRef]
- Xu, G.; Shi, Y.; Sun, X.; Shen, W. Internet of Things in Marine Environment Monitoring: A Review. Sensors 2019, 19, 1711. [Google Scholar] [CrossRef]
- Bonnefon, J.F.; Rahwan, I. Machine Thinking, Fast and Slow. Trends Cogn. Sci. 2020, 24, 1019–1027. [Google Scholar] [CrossRef] [PubMed]
- Sunagawa, S.; Karsenti, E.; Bowler, C.; Bork, P. Computational eco-systems biology in Tara Oceans: Translating data into knowledge. Mol. Syst. Biol. 2015, 11, 809. [Google Scholar] [CrossRef] [PubMed]
- Bork, P.; Bowler, C.; Vargas, C.D.; Gorsky, G. Tara oceans-studies plankton at planetary scale. Science 2015, 384, 873. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Jiang, Z.; Zhou, X.; Zhang, R.; Xie, Z.; Zhang, S.; Wu, Y.; Ge, Y.; Zhang, X. Haliea alexandrii sp. nov., isolated from phycosphere microbiota of the toxin-producing dinoflagellate Alexandrium catenella. Int. J. Syst. Evol. Microbiol. 2020, 70, 1133–1138. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Jiang, Z.W.; Zhang, J.; Zhou, X.; Zhang, X.L.; Wang, L.; Yu, T.; Wang, Z.; Bei, J.; Dong, B. Mesorhizobium alexandrii sp. nov., isolated from phycosphere microbiota of PSTs-producing marine dinoflagellate Alexandrium minutum amtk4. Antonie Van Leeuwenhoek 2020, 113, 907–917. [Google Scholar] [CrossRef] [PubMed]
- Duan, Y.; Jiang, Z.; Wu, Z.; Sheng, Z.; Yang, X.; Sun, J.; Zhang, X.; Yang, Q.; Yu, X.; Yan, J. Limnobacter alexandrii sp. nov., a thiosulfate-oxidizing, heterotrophic and EPS-bearing Burkholderiaceae isolated from cultivable phycosphere microbiota of toxic Alexandrium catenella LZT09. Antonie Van Leeuwenhoek 2020, 13, 1689–1698. [Google Scholar] [CrossRef]
- Brivio, P.A.; Giardino, C.; Zilioli, E. Determination of chlorophyll concentration changes in lake garda using an image-based radiative transfer code for landsat TM images. Int. J. Remote Sens. 2010, 22, 487–502. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Deng, T.; Chau, K.W.; Duan, H.F. Machine learning based marine water quality prediction for coastal hydro-environment management. J. Environ. Manag. 2021, 284, 112051. [Google Scholar] [CrossRef] [PubMed]
- Ding, W.; Zhang, C.; Shang, S.; Li, X. Optimization of deep learning model for coastal chlorophyll a dynamic forecast. Ecol. Model. 2022, 467, 109913. [Google Scholar]
- Villar, E.; Farrant, G.K.; Follows, M.; Garczarek, L.; Speich, S.; Audic, S.; Bittner, L.; Blanke, B.; Brum, J.R.; Brunet, C.; et al. Environmental characteristics of Agulhas rings affect interocean plankton transport. Science 2015, 348, 1261447. [Google Scholar] [CrossRef] [PubMed]
- Kisi, O.; Parmar, K.S. Application of least square support vector machine and multivariate adaptive regression spline models in long term prediction of river water pollution. J. Hydrol. 2016, 534, 104–112. [Google Scholar] [CrossRef]
- Yajima, H.; Derot, J. Application of the Random Forest model for chlorophyll-a forecasts in fresh and brackish water bodies in Japan, using multivariate long-term databases. J. Hydroinform. 2018, 20, 206–220. [Google Scholar] [CrossRef]
- Sun, Q.; Zhang, J.; Xu, X. Research and application of rule updating mining algorithm for marine water quality monitoring data. Pol. Marit. Res. 2018, 25, 136–140. [Google Scholar] [CrossRef]
- Zeng, J.; Tang, Z. Evaluate machine learning models used for upscaling surface ocean CO2 measurements. Ocean Sci. 2017, 13, 303–313. [Google Scholar] [CrossRef]
- Misra, A.; Vojinovic, Z.; Ramakrishnan, B.; Luijendijk, A.; Ranasinghe, R. Shallow water bathymetry mapping using support vector machine technique and multispectral imagery. Int. J. Remote Sens. 2018, 39, 4431–4450. [Google Scholar] [CrossRef]
- Ling, H.; Qian, C.X.; Kang, W.C.; Liang, C.Y.; Chen, H.C. Combination of support vector machine and k-fold cross validation to predict compressive strength of concrete in marine environment. Constr. Build. Mater. 2019, 206, 355–363. [Google Scholar] [CrossRef]
- Franklin, J.B.; Sathish, T.; Vinithkumar, N.; Kirubagaran, R. A novel approach to predict chlorophyll-a in coastal-marine ecosystems using multiple linear regression and principal component scores. Mar. Pollut. Bull. 2020, 152, 110902. [Google Scholar] [CrossRef] [PubMed]
- Bi, S.; Li, Y.; Liu, G.; Song, K.; Xu, J.; Dong, X.; Cai, X.; Mu, M.; Miao, S.; Lyu, H. Assessment of Algorithms for Estimating Chlorophyll-a Concentration in Inland Waters: A Round-Robin Scoring Method Based on the Optically Fuzzy Clustering. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4200717. [Google Scholar] [CrossRef]
- Li, J.; An, X.; Li, Q. Application of XGBoost algorithm in the optimization of pollutant concentration. Atmos. Res. 2022, 276, 106238. [Google Scholar] [CrossRef]
- Hu, H.; Westhuysen, A.; Chu, C.; Fujisaki-Manome, A. Predicting Lake Erie wave heights and periods using XGBoost and LSTM. Ocean Model. 2021, 164, 101832. [Google Scholar] [CrossRef]
- Wang, J.; Du, X.; Qi, X. Strain prediction for historical timber buildings with a hybrid Prophet-XGBoost model. Mech. Syst. Signal Process. 2022, 179, 109316. [Google Scholar] [CrossRef]
- Albaradei, S.; Thafar, M.; Alsaedi, A.; Van Neste, C.; Gojobori, T.; Essack, M.; Gao, X. Machine learning and deep learning methods that use omics data for metastasis prediction. Comput. Struct. Biotechnol. J. 2021, 19, 5008–5018. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Feng, Q.; Zhang, B.P.; Gao, J.J.; Sheng, Z.; Xue, Q.P.; Zhang, X.L. Marinobacter alexandrii sp. nov., a novel yellow-pigmented and algae growth-promoting bacterium isolated from marine phycosphere microbiota. Antonie Van Leeuwenhoek 2021, 114, 709–718. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Z.; Duan, Y.; Yang, X.; Yao, B.; Zeng, T.; Wang, X.; Feng, Q.; Qi, M.; Yang, Q.; Zhang, X.L. Nitratireductor alexandrii sp. nov., from phycosphere microbiota of toxic marine dinoflagellate Alexandrium tamarense. Int. J. Syst. Evol. Microbiol. 2020, 70, 4390–4397. [Google Scholar] [CrossRef]
- Yang, Q.; Jiang, Z.W.; Huang, C.H.; Zhang, R.N.; Li, L.Z.; Yang, G.; Feng, L.J.; Yang, G.F.; Zhang, H.; Zhang, X.L. Hoeflea prorocentri sp. nov., isolated from a culture of the marine dinoflagellate Prorocentrum mexicanum PM01. Antonie Van Leeuwenhoek 2018, 111, 1845–1853. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.L.; Li, G.X.; Ge, Y.M.; Iqbal, N.M.; Yang, X.; Cui, Z.D.; Yang, Q. Sphingopyxis microcysteis sp. nov., a novel bioactive exopolysaccharides-bearing Sphingomonadaceae isolated from the Microcystis phycosphere. Antonie Van Leeuwenhoek 2021, 114, 845–857. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Ge, Y.M.; Iqbal, N.M.; Yang, X.; Zhang, X.L. Sulfitobacter alexandrii sp. nov., a new microalgae growth-promoting bacterium with exopolysaccharides bioflocculanting potential isolated from marine phycosphere. Antonie Van Leeuwenhoek 2021, 114, 1091–1106. [Google Scholar] [CrossRef]
- Zhang, X.L.; Qi, M.; Li, Q.H.; Cui, Z.D.; Yang, Q. Maricaulis alexandrii sp. nov., a novel active bioflocculants-bearing and dimorphic prosthecate bacterium isolated from marine phycosphere. Antonie Van Leeuwenhoek 2021, 114, 1195–1203. [Google Scholar] [CrossRef]
- Yang, Q.; Jiang, Z.; Zhou, X.; Zhang, R.; Wu, Y.; Lou, L.; Ma, Z.; Wang, D.; Ge, Y.; Zhang, X.; et al. Nioella ostreopsis sp. nov., isolated from toxic dinoflagellate, Ostreopsis lenticularis. Int. J. Syst. Evol. Microbiol. 2020, 70, 759–765. [Google Scholar] [CrossRef]
- Ren, C.Z.; Gao, H.M.; Dai, J.; Zhu, W.Z.; Xu, F.F.; Ye, Y.; Zhang, X.L.; Yang, Q. Taxonomic and Bioactivity Characterizations of Mameliella alba Strain LZ-28 Isolated from Highly Toxic Marine Dinoflagellate Alexandrium catenella LZT09. Mar. Drugs 2022, 20, 321. [Google Scholar] [CrossRef]
- Zhang, G.; Yang, Y.; Wang, S.; Sun, Z.; Jiao, K. Alkalimicrobium pacificum gen. nov., sp. nov., a marine bacterium in the family Rhodobacteraceae. Int. J. Syst. Evol. Microbiol. 2015, 65, 2453–2458. [Google Scholar] [CrossRef]
- Yang, Q.; Jiang, Z.; Zhou, X.; Xie, Z.; Wang, Y.; Wang, D.; Feng, L.; Yang, G.; Ge, Y.; Zhang, X. Saccharospirillum alexandrii sp. nov., isolated from the toxigenic marine dinoflagellate Alexandrium catenella LZT09. Int. J. Syst. Evol. Microbiol. 2020, 70, 820–826. [Google Scholar] [CrossRef]
- Wang, X.; Ye, Y.; Xu, F.F.; Duan, Y.H.; Xie, P.F.; Yang, Q.; Zhang, X. Maritimibacter alexandrii sp. nov.; a New Member of Rhodobacteraceae Isolated from Marine Phycosphere. Curr. Microbiol. 2021, 78, 3996–4003. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Zhang, X.; Jiang, Z.; Yang, X.; Zhang, X.; Yang, Q. Combined characterization of a new member of Marivita cryptomonadis, strain LZ-15-2 isolated from cultivable phycosphere microbiota of toxic HAB dinoflagellate Alexandrium catenella LZT09. Braz. J. Microbiol. 2021, 52, 739–748. [Google Scholar] [CrossRef] [PubMed]
- Landry, Z.C.; Vergin, K.; Mannenbach, C.; Block, S.; Yang, Q.; Blainey, P.; Carlson, C.; Giovannoni, S. Optofluidic Single-Cell Genome Amplification of Sub-micron Bacteria in the Ocean Subsurface. Front. Microbiol. 2018, 9, 1152. [Google Scholar] [CrossRef] [PubMed]
- Sommeria-Klein, G.; Watteaux, R.; Ibarbalz, F.M.; Pierella Karlusich, J.J.; Iudicone, D.; Bowler, C.; Morlon, H. Global drivers of eukaryotic plankton biogeography in the sunlit ocean. Science 2021, 374, 594–599. [Google Scholar] [CrossRef]
- Sunagawa, S.; Acinas, S.G.; Bork, P.; Bowler, C.; Tara Oceans Coordinators; Eveillard, D.; Gorsky, G.; Guidi, L.; Iudicone, D.; Karsenti, E.; et al. Tara Oceans: Towards global ocean ecosystems biology. Nat. Rev. Microbiol. 2020, 18, 428–445. [Google Scholar] [CrossRef]
- Pierella Karlusich, J.J.; Bowler, C.; Biswas, H. Carbon Dioxide Concentration Mechanisms in Natural Populations of Marine Diatoms: Insights From Tara Oceans. Front. Plant Sci. 2021, 12, 657821. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Chl-a | Long | Lat | Temp | Den | Oxygen | CO3 | Amm |
|---|---|---|---|---|---|---|---|---|
| TARA_091 | 0.828 | −73.100 | −34.161 | 17.609 | 24.893 | 229.394 | 0.013 | 0.048 |
| TARA_092 | 2.258 | −71.998 | −33.690 | 15.912 | 25.302 | 245.324 | 0.013 | 0.073 |
| TARA_086 | 0.220 | −53.006 | −64.360 | −0.494 | 26.718 | 398.312 | 0.000 | 0.007 |
| TARA_088 | 1.129 | −56.794 | −63.402 | −0.763 | 27.684 | 335.243 | 0.013 | 0.118 |
| TARA_173 | 0.417 | 79.420 | 78.956 | −0.160 | 26.994 | 385.281 | 0.001 | 0.004 |
| TARA_188 | 1.417 | 91.856 | 78.252 | −1.650 | 26.511 | 388.304 | 0.000 | 0.002 |
| Parameters | N_Estimators | Min_Samples _Split | Min_Samples _Leaf | Min_Weight _Fraction_Leaf | Max_Depth |
|---|---|---|---|---|---|
| Values | 100 | 2 | 1 | 0 | 2 |
| Parameter | Character Importance Index | Pearson Correlation Coefficient | Normalized Pearson Correlation Coefficient | Comprehensive Correlation Index |
|---|---|---|---|---|
| Density | 0.151 | 0.339 | 0.091 | 0.129 |
| Temperature | 0.103 | −0.575 | 0.154 | 0.121 |
| Latitude | 0.098 | 0.106 | 0.028 | 0.121 |
| Beta470 | 0.089 | 0.050 | 0.013 | 0.089 |
| Oxygen | 0.080 | 0.600 | 0.161 | 0.079 |
| Ammonium | 0.080 | 0.290 | 0.078 | 0.070 |
| CO3 | 0.070 | 0.397 | 0.107 | 0.063 |
| Bru | 0.067 | −0.270 | 0.073 | 0.055 |
| Okubo | 0.054 | 0.068 | 0.018 | 0.051 |
| PO4 | 0.041 | 0.226 | 0.061 | 0.051 |
| Salinity | 0.040 | −0.264 | 0.071 | 0.040 |
| NO2 | 0.037 | 0.158 | 0.042 | 0.039 |
| Gra | 0.037 | 0.120 | 0.032 | 0.036 |
| Iron | 0.027 | −0.187 | 0.050 | 0.035 |
| Longitude | 0.027 | 0.072 | 0.019 | 0.023 |
| XGBoost | RF | SVR | Linear Regression | |
|---|---|---|---|---|
| MRE | 0.398 | 0.413 | 0.461 | 0.532 |
| MAE | 0.096 | 0.104 | 0.110 | 0.118 |
| RMSE | 0.144 | 0.152 | 0.155 | 0.166 |
| R2 | 0.550 | 0.496 | 0.470 | 0.390 |
| XGBoost | RF | SVR | Linear Regression | |
|---|---|---|---|---|
| MRE | 0.408 | 0.421 | 0.459 | 0.549 |
| MAE | 0.096 | 0.103 | 0.109 | 0.114 |
| RMSE | 0.142 | 0.148 | 0.154 | 0.157 |
| R2 | 0.56 | 0.522 | 0.488 | 0.462 |
| XGBoost | RF | SVR | Linear Regression | |
|---|---|---|---|---|
| MRE | 0.419 | 0.425 | 0.446 | 0.572 |
| MAE | 0.107 | 0.104 | 0.112 | 0.12 |
| RMSE | 0.152 | 0.151 | 0.155 | 0.160 |
| R2 | 0.501 | 0.508 | 0.470 | 0.430 |
| XGBoost | RF | SVR | Linear Regression | |
|---|---|---|---|---|
| MRE | 0.344 | 0.378 | 0.447 | 0.562 |
| MAE | 0.083 | 0.086 | 0.112 | 0.125 |
| RMSE | 0.125 | 0.127 | 0.158 | 0.169 |
| R2 | 0.660 | 0.649 | 0.460 | 0.370 |
| Factor Numbers | Max Depth | N_Estimators | Reg_Alpha | Gamma | Learning Rate | Sub-Sample | Min_Child Weight | Colsample _Bytree |
|---|---|---|---|---|---|---|---|---|
| 4 | 1 | 70 | 0 | 0 | 1 | 0.8 | 1 | 1 |
| 5 | 1 | 70 | 0 | 0 | 1 | 0.8 | 1 | 1 |
| 6 | 3 | 70 | 0.01 | 0 | 0.1 | 0.75 | 4 | 0.8 |
| 7 | 3 | 70 | 0.01 | 0 | 0.1 | 0.75 | 6 | 0.8 |
| 8 | 4 | 70 | 0.01 | 0 | 0.1 | −0.75 | 7 | 0.8 |
| 9 | 3 | 70 | 0.001 | 0.1 | 0.1 | 0.8 | 5 | 0.8 |
| 10 | 3 | 70 | 0.1 | 0 | 0.1 | 0.75 | 7 | 0.8 |
| 11 | 3 | 70 | 0.1 | 0 | 0.1 | 0.85 | 5 | 0.75 |
| 12 | 3 | 70 | 0.001 | 0 | 0.1 | 0.85 | 7 | 0.85 |
| 13 | 3 | 70 | 0.1 | 0 | 0.1 | 0.8 | 3 | 0.75 |
| 14 | 3 | 70 | 0.01 | 0 | 0.1 | 0.85 | 3 | 0.75 |
| 15 | 3 | 70 | 0.1 | 0 | 0.1 | 0.85 | 3 | 0.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Z.; Du, D.; Zhang, X.; Yang, Q. Modeling and Prediction of Environmental Factors and Chlorophyll a Abundance by Machine Learning Based on Tara Oceans Data. J. Mar. Sci. Eng. 2022, 10, 1749. https://doi.org/10.3390/jmse10111749
Cui Z, Du D, Zhang X, Yang Q. Modeling and Prediction of Environmental Factors and Chlorophyll a Abundance by Machine Learning Based on Tara Oceans Data. Journal of Marine Science and Engineering. 2022; 10(11):1749. https://doi.org/10.3390/jmse10111749
Chicago/Turabian StyleCui, Zhendong, Depeng Du, Xiaoling Zhang, and Qiao Yang. 2022. "Modeling and Prediction of Environmental Factors and Chlorophyll a Abundance by Machine Learning Based on Tara Oceans Data" Journal of Marine Science and Engineering 10, no. 11: 1749. https://doi.org/10.3390/jmse10111749
APA StyleCui, Z., Du, D., Zhang, X., & Yang, Q. (2022). Modeling and Prediction of Environmental Factors and Chlorophyll a Abundance by Machine Learning Based on Tara Oceans Data. Journal of Marine Science and Engineering, 10(11), 1749. https://doi.org/10.3390/jmse10111749