Risk Measures and Portfolio Optimization



{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The m-dimensional column vectors with each component equal to 1 is denoted by .
- The Euclidean norm of a matrix or vector is denoted by . The denotes the set of -valued, square-integrable functions defined on , with its natural inner product Here is the corresponding norm.
- denotes the area of a circle with radius 1.
2. The Model
- One asset is invested in the money market. The money market is represented by ,The interest rate denoted by is deterministic.
- Assets are traded continuously over a finite time horizon in a frictionless market.
- m assets are traded in the stock which follow a geometric Brownian motion, i.e.,is deterministic and denotes an invertible volatility matrix; is deterministic and denotes the drift of the stock, . is a m-dimensional Brownian motion and . Drift and volatility functions are square-integrable.
- Number of shares of asset i held in the portfolio is denoted by . The fraction of wealth invested in the risky stock i is denoted by is deterministic.
- , denotes the confidence level.
3. Portfolio Optimization with Risk Constraints
3.1. Risk Measures
3.1.1. Value at Risk (VaR)
3.1.2. Average Value at Risk-(AVaR)
3.1.3. Limited expected loss measure
3.2. Portfolio Optimization by Minimizing Risk Measures
3.3. Portfolio Optimization by Minimizing Risk subject to Expected Return Constraint
3.4. Portfolio Optimization by Maximizing Expected Wealth with Risk Constraints
4. Numerical Analysis
4.1. Optimal Strategy with Risk Constraints
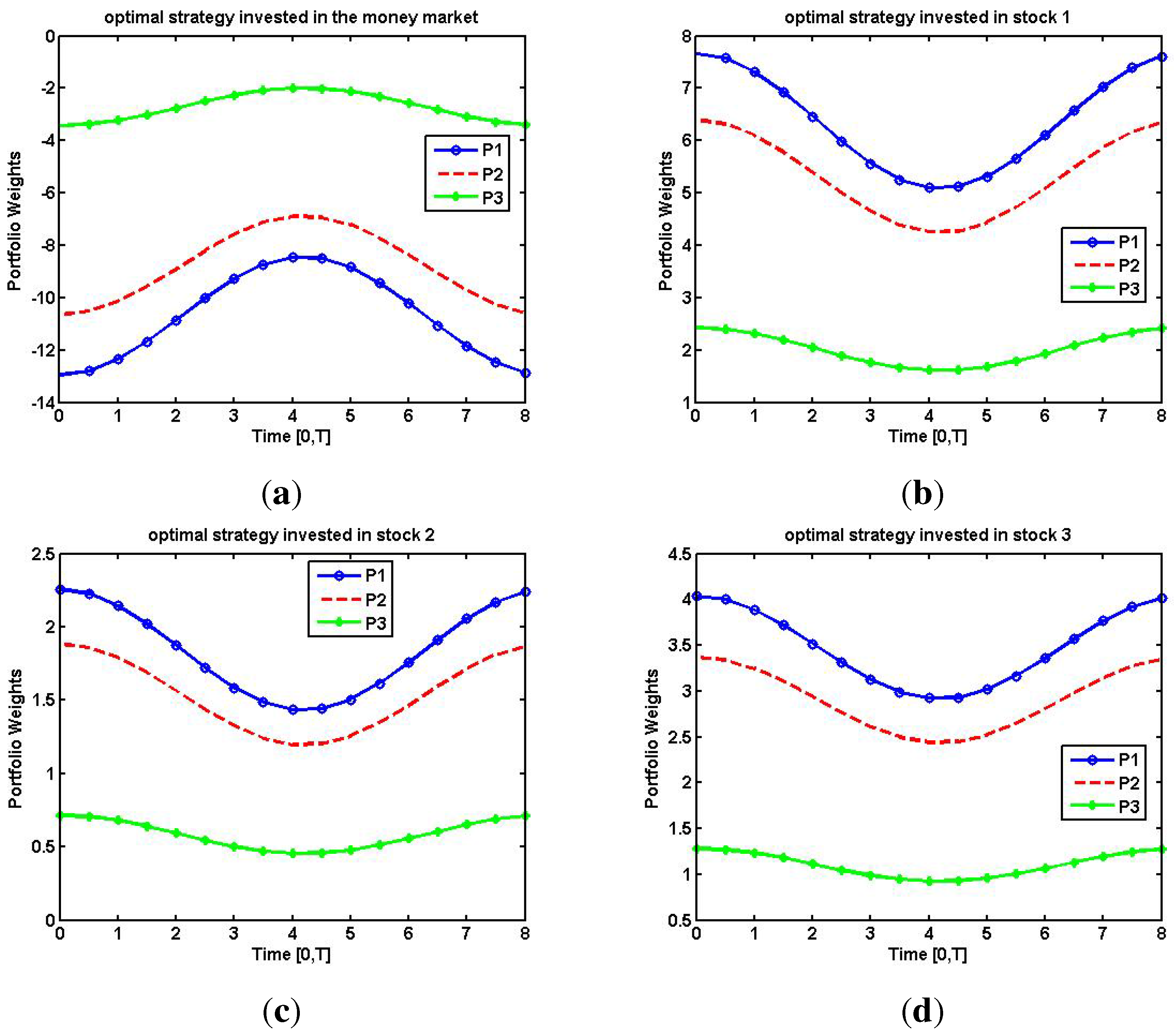
4.2. Expected Return with Risk Constraints
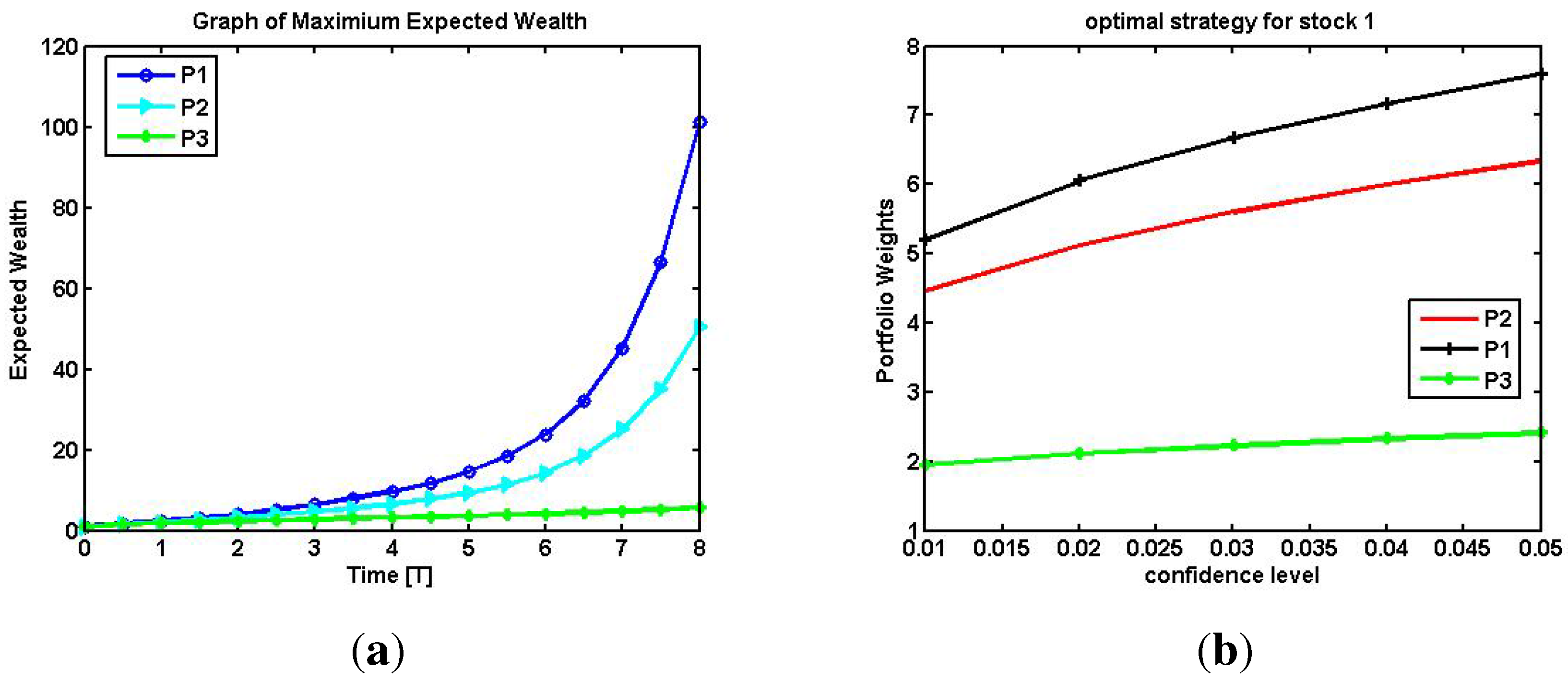
4.3. Optimal Strategy with Different Confidence Interval
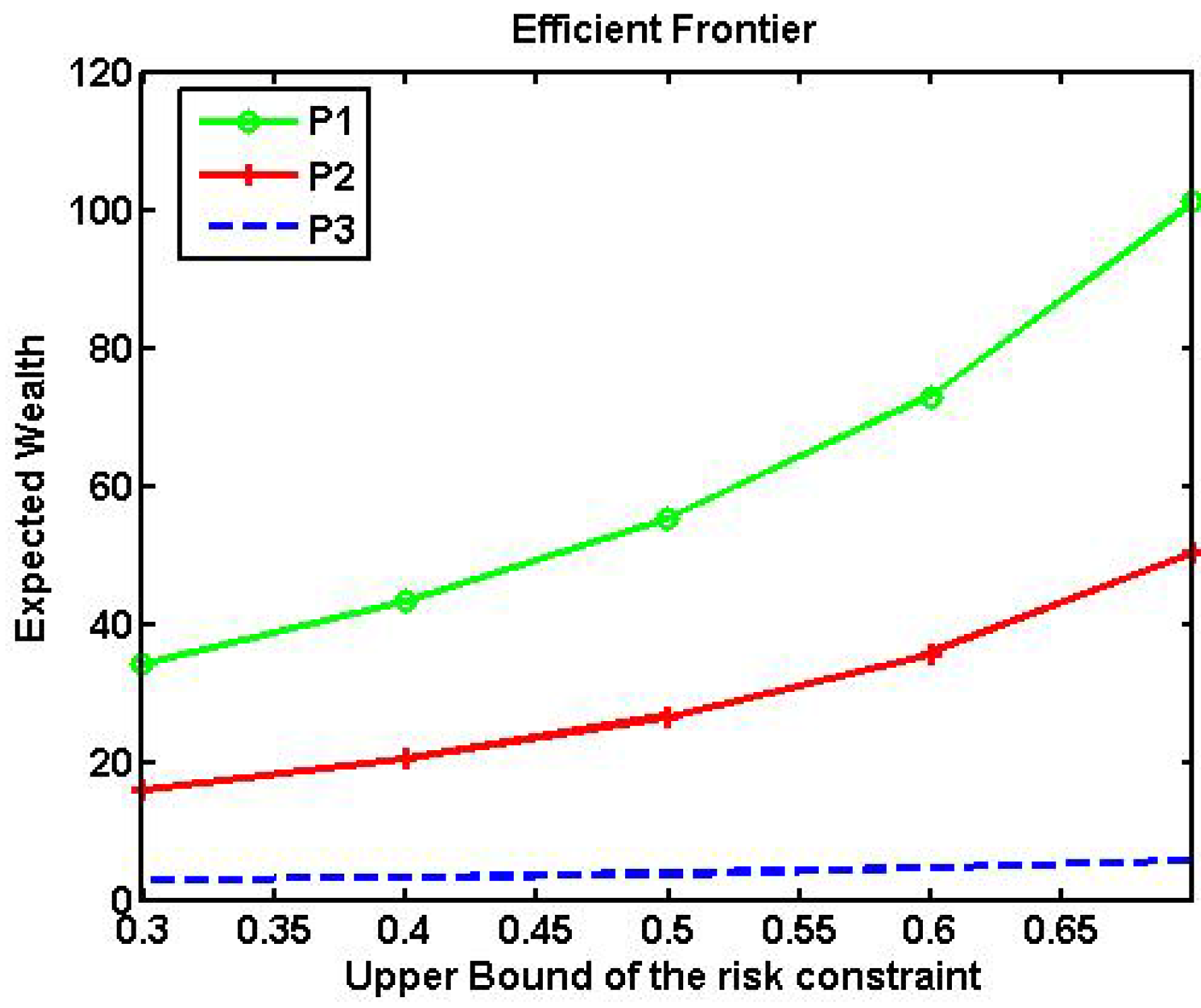
4.4. Efficient Frontier
5. Conclusions
Author Contributions
Conflicts of Interest
A. Appendix
A.1. Proof of Proposition 3.1.1.1
A.2. Proof of Proposition 3.1.2.1
A.3. Proof of Proposition 3.1.3.1 Using the same approach as in the proof of section 3.1.1.1 and 3.1.2.1
A.4. Proof of the theorem 3.2.1
A.5. Proof of Theorem 3.3.1
A.6. Proof of Theorem 3.4.1
References
- H. Markowitz. “Foundation of Portfolio Theory.” J. Financ. 46 (1991): 469–477. [Google Scholar] [CrossRef]
- D.N. Nawrocki. “A brief history of downside risk measure.” J. Invest. 8 (1999): 9–25. [Google Scholar] [CrossRef]
- H. Markowitz. “Portfolio Selection.” J. Financ. 7 (1952): 77–91. [Google Scholar]
- W. Sharpe. “Mutual Fund Performance.” J. Bus. 9 (1966): 119–138. [Google Scholar] [CrossRef]
- D. Duffie, and H.R. Richardson. “Mean-Variance Hedging in Continuous Time.” Ann. Appl. Probab. 1 (1991): 1–15. [Google Scholar] [CrossRef]
- X.Y. Zhou, and G. Yin. “Markowitz Mean-Variance Portfolio Selection with Regime Switching: A continuous-time model.” SIAM J. Control Optim. 42 (2003): 1466–1482. [Google Scholar] [CrossRef]
- S. Xie, Z. Li, and S. Wang. “Continuous-time Portfolio Selection with Liability: Mean-Variance model and Stochastic LQ approach.” Insur.: Math. Econ. 42 (2008): 943–953. [Google Scholar] [CrossRef]
- S.W. Jewell, Y. Li, and T.A. Pirvu. “Non-linear equity portfolio variance reduction under a mean-variance framework–A delta-gamma approach.” Oper. Res. Lett. 41 (2013): 694–700. [Google Scholar] [CrossRef]
- S. Emmer, C. Klu¨ppelberg, and R. Korn. “Optimal portfolios with bounded capital at risk.” Math. Financ. 11 (2001): 365–384. [Google Scholar] [CrossRef]
- S. Basak, and A. Shapiro. “Value-at-risk based management: Optimal policies and Asset Prices.” Rev. Financ. Stud. 14 (2001): 371–405. [Google Scholar] [CrossRef]
- D Cuoco, H. He, and S. Isaenko. “Optimal Dynamic Trading Strategies with Risk Limits.” Oper. Res. 56.2 (2008): 358–368. [Google Scholar]
- T.A. Pirvu. “Portfolio Optimization under the Value-at-Risk Constraint.” Quantitat. Financ. 7 (2007): 125–136. [Google Scholar] [CrossRef]
- T.A. Pirvu, and G. Zˇitkovic´. “Maximizing Portfolio Growth Rate under Risk Constraints.” Math. Financ. 19 (2009): 423–455. [Google Scholar] [CrossRef]
- S. Moreno-Bromberg, T.A. Pirvu, and A. Reveillac. “CRRA Utility Maximization under Risk Constraints.” Commun. Stoch. Anal. 7 (2013): 203–225. [Google Scholar]
- P. Jorion. “Measuring the Risk in Value at Risk.” Financ. Anal. J. 52 (1996): 47–56. [Google Scholar] [CrossRef]
- P. Artzner, F. Delbaen, and J. Eber. “Coherent Measures of Risk.” Math. Financ. 9 (1999): 203–228. [Google Scholar] [CrossRef]
- T.S. Rachev, V.S. Stoyanov, and J.F. Fabozzi. A Probability Metrics Approach to Financial Risk Measures. West Sussex, UK: Wiley-Blackwell. A John Wiley and Sons Ltd. Publication, 2011, pp. 191–251. [Google Scholar]
- G. Dmitrasˇinovic´-Vidovic´, and A. Ware. “Asymptotic Behaviour of Mean-Quantile Efficient Portfolios.” Financ. Stoch. 10 (2006): 529–551. [Google Scholar] [CrossRef]
- G. Dmitrasˇinovic´-Vidovic´, A. Ware, A. Lari-Lavassani, and X. Li. Dynamic Portfolio Selection under Capital-at-Risk. Calgary, Canada: University of Calgary, 2003. [Google Scholar]
- H. Follmer, and A. Schied. Stochastic Finance: An Introduction in Discrete Time. Chapter 4; Berlin, Germany: Walter de Gruyter, 2004. [Google Scholar]
- T.A. Pirvu, and K. Schulze. “Multi-Stock Portfolio Optimization under Prospect Theory.” Math. Financ. Econ. 6 (2012): 337–362. [Google Scholar] [CrossRef]
- K. Schmedders. “Two-fund separation in Dynamic General Equilibrium.” Discuss. Paper//Centre Math. Stud. Econ. Manag. 1398 (2004). [Google Scholar] [CrossRef]
- R.C. Merton. “An Intertemporal Capital Asset Pricing Model.” Econometrica 41 (1973): 867–887. [Google Scholar]
- J. Tobin. “Liquidity Preferences as Behavior towards Risk.” Rev. Econ. Stud. 25 (1958): 65–86. [Google Scholar] [CrossRef]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gambrah, P.S.N.; Pirvu, T.A. Risk Measures and Portfolio Optimization. J. Risk Financial Manag. 2014, 7, 113-129. https://doi.org/10.3390/jrfm7030113
Gambrah PSN, Pirvu TA. Risk Measures and Portfolio Optimization. Journal of Risk and Financial Management. 2014; 7(3):113-129. https://doi.org/10.3390/jrfm7030113
Chicago/Turabian StyleGambrah, Priscilla Serwaa Nkyira, and Traian Adrian Pirvu. 2014. "Risk Measures and Portfolio Optimization" Journal of Risk and Financial Management 7, no. 3: 113-129. https://doi.org/10.3390/jrfm7030113
APA StyleGambrah, P. S. N., & Pirvu, T. A. (2014). Risk Measures and Portfolio Optimization. Journal of Risk and Financial Management, 7(3), 113-129. https://doi.org/10.3390/jrfm7030113