
The t-Distribution in Financial Mathematics and Multivariate Testing Contexts


Abstract
1. Dedication
2. Introduction
2.1. The Multivariate t-Distribution
2.2. Historical Prelude
My own interest up to the appearance of Madan and Seneta (1990) had been in the symmetric VG model. Dilip Madan had moved to the University of Maryland at College Park from the University of Sydney, and I was visiting the University of Virginia when we put the last touches to that paper in 1989. After some years of my own inactivity in this area, I became aware of Chris Heyde’s penetration of yet another probabilistic field, that of financial modelling, and asked him to speak at the University of Sydney on 26 March 1999, on what was soon to be published as Heyde (1999). His opinion of the symmetric VG model was that, although it was heavier tailed than the normal, the tails were not heavy enough to account for what were occasionally relatively extreme values of ; and of course the increments in the VG model had been assumed independent. Although the underlying stochastic process was closed under convolution and analytically convenient, a treatment such as he proposed could effectively reconstruct the process numerically from data. My occasional visits to Canberra allowed me to learn more about the FATGBM ideology, and to obtain advice from Chris on the statistical fitting of the symmetric VG model. The VG model had continued to be of interest. I had had several inquiries as to how to fit it to real data, and I needed to supervise the fourth-year Honours project2 of Annelies Tjetjep in 2002. My focus was Dilip Madan’s post-1990 successful extension and application of the VG models (see items in the references co-authored by Madan, especially Madan et al. (1998)), where fitting from data as well as modelling are integral issues. Madan et al. (1998), in the guise of its Research Report predecessor, was already described in a monograph (Epps, 2000). Dilip Madan, Wake Epps, and Eckhard Platen very kindly supplied me with current materials and information, as of course did Chris Heyde. The next section considers the procedure and effect of fitting the (general) VG by allowing for dependence of increments while retaining their stationarity. We do not address specifically the issue of adequacy of tail structure of the VG distribution. Important new work by Heyde and Kou (2004) suggests, in any case, that the heavy-tail (power-law) structure is not easily distinguishable in practice from the exponential-tail structure.
3. Multivariate Hypothesis Testing Context
3.1. The Step-Down Procedure
3.2. Two-Tail Tests
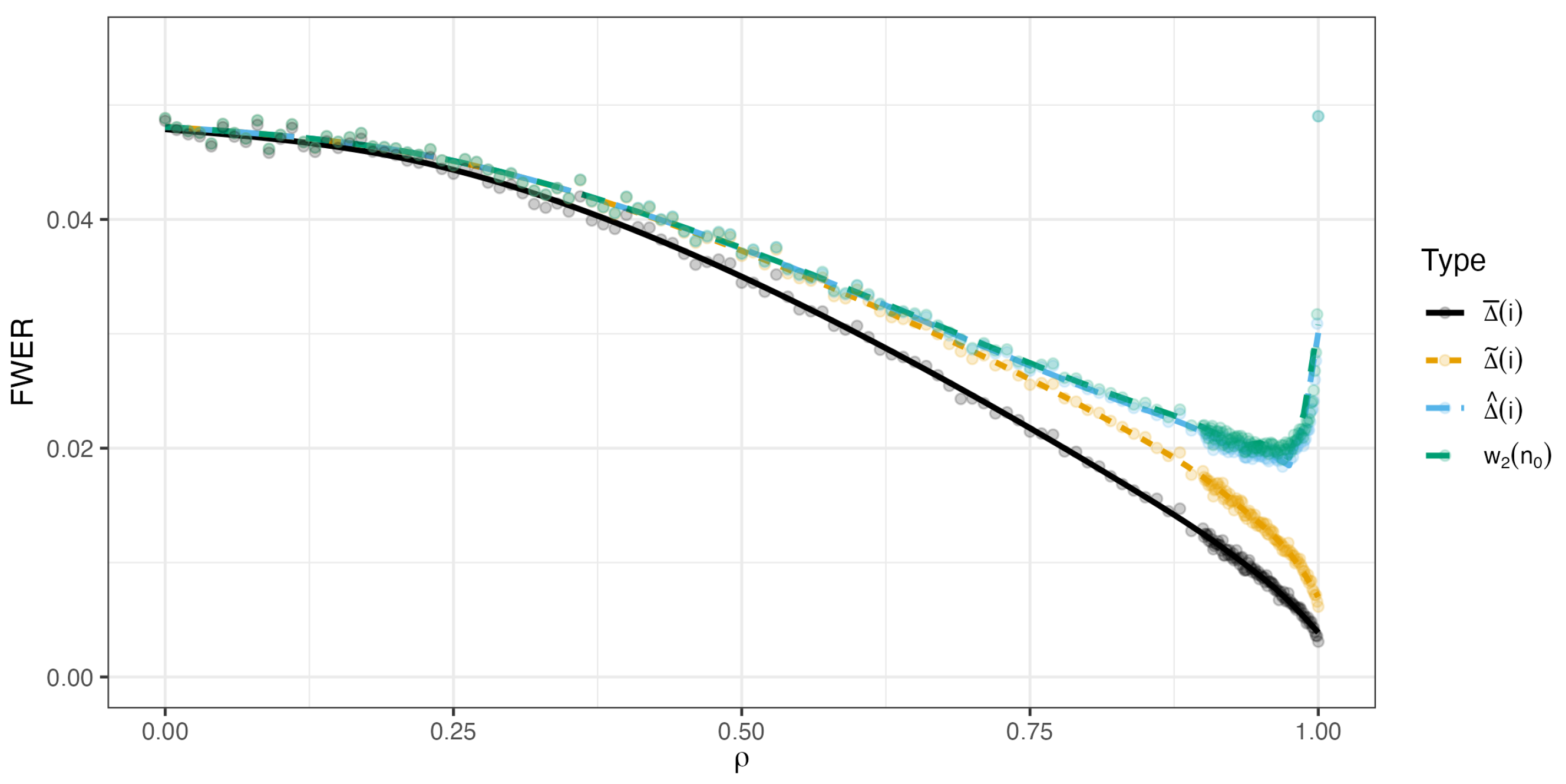
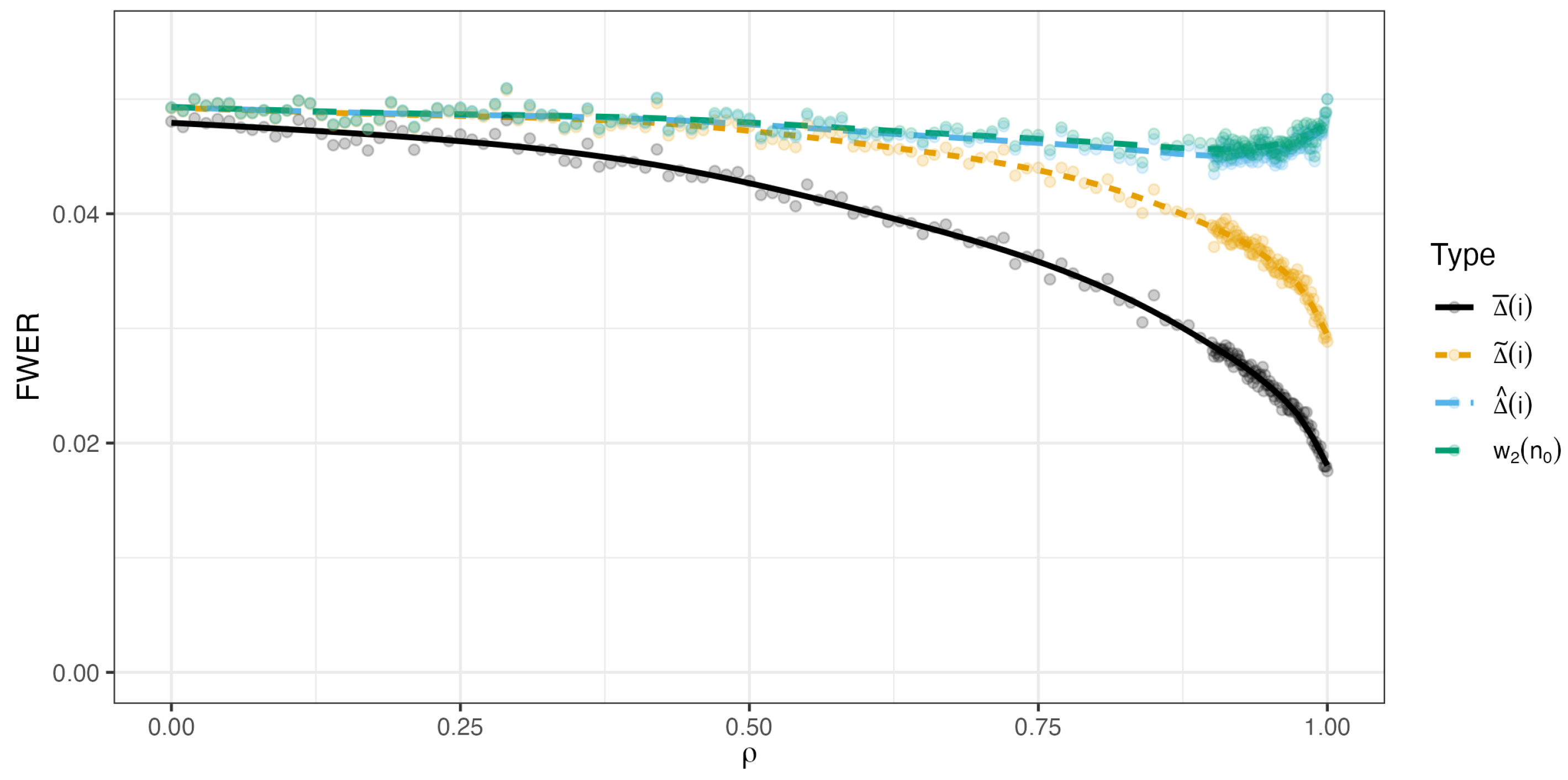
4. Numerical Demonstration. Multivariate t-Distribution
- Setting 1: multivariate t with and .
- Setting 2: multivariate t with and .
5. Some Personal Recollections (ES)
5.1. Joe Gani and Chris Heyde, to September, 1974
Bienaymé
5.2. September 1974–1993
5.3. Chris Heyde, 1993–2008
Chris Heyde, Contact in Final Years
The Variance Gamma and Related Financial Models. A conference in honor of Eugene Seneta. University of Virginia, Charlottesville, Virginia. 22–23 October 2005. Speakers: Chris Heyde (Columbia University and ANU). Dilip Madan (University of Maryland), Eugene Seneta (University of Sydney)., +2 . Organizers: Patrick Dennis (U.Va.), Jeff Holt (U.Va.), Leonard Scott (U.Va.).
Whatever happens, I certainly feel that I have had a fortunate life. I will be happy to have more, but if not, I have had a good innings and can go in peace.
I have fought a good fight, I have finished the race, I have kept the faith.
5.4. ES Contact with Joe Gani
5.4.1. 1983–2016, Varanasi, Mathematical Scientist, Doeblin, ANU
50 Years After Doeblin: Developments in the Theory of Markov Chains, Markov Processes and Sums of Random Variables. Blaubeuren, Germany, 2–7 November 1991.
I would say that although I’ve had a rather broken-up life, looking back I don’t regret it. I consider myself to have been extremely lucky, not least in my marriage and in my children, but also professionally. I’ve had a lot of hurdles to overcome, but fortunately I haven’t been left with a nasty taste.
And you had two very important friends in your life, Ted Hannan and Chris Heyde.
Indeed. Ted was very much like a brother. We used to exchange views, we used to talk about everything – Ted was a person of very wide interests, extremely well read. I still have a copy of the poems of WB Yeats which he gave me on one occasion, and which he used to quote. I can never remember poetry, but he used to be very good at quotation from Yeats and other poets.
‘An elderly man is like a stick with an esophagus’...
That’s right! [laugh] Ted was a wonderful man. I am still very good friends with his widow, whom I visit regularly.
Chris was more like a son (there was a 15-year difference between us) and he was a very clever, very loyal colleague. Now it’s our turn to support Beth Heyde, who has lost her very dear husband.
Ted and Chris were family. As, I might add, you are too.
Well, thank you for that, Joe. I think this interview will be a fitting tribute to your role.
And thank you very much. I really appreciate it.
5.4.2. Epilogue
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | The paper is available here: https://www.maths.usyd.edu.au/u/eseneta/SenetaChen(1997).pdf, accessed on 1 April 2025. |
| 2 | Eventually incorporated into Tjetjep and Seneta (2006). |
| 3 |
References
- Darroch, J. N., & Seneta, E. (1965). On quasi-stationary distributions in absorbing discrete-time finite markov chains. Journal of Applied Probability, 2(1), 88–100. [Google Scholar] [CrossRef]
- Epps, T. W. (2000). Pricing derivative securities. G–reference, information and interdisciplinary subjects series. World Scientific. [Google Scholar]
- Erdélyi, A., Magnus, W., Oberhettinger, F., & Tricomi, F. G. (1954). Bateman manuscript project: Tables of integral transform (Vol. 2.). McGraw-Hill. [Google Scholar]
- Finlay, R., & Seneta, E. (2006). Stationary-increment student and variance-gamma processes. Journal of Applied Probability, 43(2), 441–453. [Google Scholar] [CrossRef]
- Fung, T., & Seneta, E. (2011). Tail dependence and skew distributions. Quantitative Finance, 11(3), 327–333. [Google Scholar] [CrossRef]
- Fung, T., & Seneta, E. (2023). On familywise error rate cutoffs under pairwise exchangeability. Methodology and Computing in Applied Probability, 25(2), 59. [Google Scholar] [CrossRef]
- Gani, J. (1994). Obituary: Edward James Hannan. Australian Journal of Statistics, 36(1), 1–8. [Google Scholar] [CrossRef]
- Genz, A., Bretz, F., Miwa, T., Mi, X., Leisch, F., Scheipl, F., Bornkamp, B., Maechler, M., & Hothorn, T. (2021). Mvtnorm: Multivariate normal and t distributions. R package version 1.1-3. Available online: https://cran.r-project.org/web/packages/mvtnorm/index.html (accessed on 1 April 2025).
- Heyde, C. C. (1999). A risky asset model with strong dependence through fractal activity time. Journal of Applied Probability, 36(4), 1234–1239. [Google Scholar] [CrossRef]
- Heyde, C. C., & Kou, S. G. (2004). On the controversy over tailweight of distributions. Operations Research Letters, 32(5), 399–408. [Google Scholar] [CrossRef]
- Heyde, C. C., & Leonenko, N. N. (2005). Student processes. Advances in Applied Probability, 37(2), 342–365. [Google Scholar] [CrossRef]
- Heyde, C. C., & Liu, S. (2001). Empirical realities for a minimal description risky asset model. The need for fractal features. Journal of the Korean Mathematical Society, 38, 1047–1059. [Google Scholar]
- Heyde, C. C., & Seneta, E. (1972). Studies in the history of probability and statistics. XXXI. The simple branching process, a turning point test and a fundamental inequality: A historical note on I. J. Bienayme. Biometrika, 59(3), 680–683. [Google Scholar] [CrossRef]
- Heyde, C. C., & Seneta, E. (1977). I. J. Bienaymé: Statistical Theory Anticipated. Springer, New York. [Google Scholar] [CrossRef]
- Heyde, C. C., & Seneta, E. (Eds.). (1988). The bicentennial history issue of the Australian journal of statistics (Vol. 30B). John Wiley & Sons, Ltd. [Google Scholar]
- Holm, S. (1979). A simple sequentially rejective multiple test procedure. Scandinavian Journal of Statistics, 6(2), 65–70. [Google Scholar]
- Madan, D. B., Carr, P. P., & Chang, E. C. (1998). The variance gamma process and option pricing. Review of Finance, 2(1), 79–105. [Google Scholar] [CrossRef]
- Madan, D. B., & Seneta, E. (1990). The variance gamma (V.G.) Model for share market returns. The Journal of Business, 63(4), 511–524. [Google Scholar] [CrossRef]
- R Core Team. (2023). R: A language and environment for statistical computing. R Foundation for Statistical Computing. [Google Scholar]
- Sarkar, S. K., Fu, Y., & Guo, W. (2016). Improving Holm’s procedure using pairwise dependencies. Biometrika, 103(1), 237–243. [Google Scholar] [CrossRef]
- Seneta, E. (1968). On recent theorems concerning the supercritical galton-watson process. The Annals of Mathematical Statistics, 39(6), 2098–2102. [Google Scholar] [CrossRef]
- Seneta, E. (1974). A note on the balance between random sampling and population size (on the 30th anniversary of G. Malécot’s paper). Genetics, 77(3), 607–610. [Google Scholar] [CrossRef]
- Seneta, E. (1984). The central limit problem and linear least squares in pre-revoluationary Russia: The background. Mathematical Scientist, 9, 37–77. [Google Scholar]
- Seneta, E. (2004). Fitting the variance-gamma model to financial data. Journal of Applied Probability, 41, 177–187. [Google Scholar] [CrossRef]
- Seneta, E. (2008). Interview with Joe Gani. Interviews with Australian scientists. Australian Academy of Science. Available online: https://www.science.org.au/learning/general-audience/history/interviews-australian-scientists/professor-joe-gani-1924-2016 (accessed on 9 March 2024).
- Seneta, E. (2010). Chris heyde on branching processes and population genetics. In R. Maller, I. Basawa, P. Hall, & E. Seneta (Eds.), Selected works of C.C. Heyde (pp. 12–15). Springer. [Google Scholar] [CrossRef]
- Seneta, E. (2019). Joseph Mark Gani 1924–2016. Historical Records of Australian Science, 30(1), 32. [Google Scholar] [CrossRef]
- Seneta, E., & Chen, J. T. (2005). Simple stepwise tests of hypotheses and multiple comparisons. International Statistical Review/Revue Internationale de Statistique, 73(1), 21–34. [Google Scholar] [CrossRef]
- Seneta, E., & Chen, T. (1997). A sequentially rejective test procedure. Theory of Stochastic Processes, 3(19), 393–402. [Google Scholar]
- Seneta, E., & Gani, J. (2009). Christopher Charles Heyde 1939–2008: [Obituary: Professor of statistics.]. Historical Records of Australian Science, 20(1), 67–90. [Google Scholar] [CrossRef]
- Sun, W., Rachev, S., Stoyanov, S. V., & Fabozzi, F. J. (2008). Multivariate skewed student’s t copula in the analysis of nonlinear and asymmetric dependence in the German equity market. Studies in Nonlinear Dynamics & Econometrics, 12(2). [Google Scholar] [CrossRef]
- Tjetjep, A., & Seneta, E. (2006). Skewed normal variance-mean models for asset pricing and the method of moments. International Statistical Review, 74(1), 109–126. [Google Scholar] [CrossRef]
- Wickham, H., Chang, W., Henry, L., Pedersen, T. L., Takahashi, K., Wilke, C., Woo, K., Yutani, H., Dunnington, D., van den Brand, T., Posit & PBC. (2024). Ggplot2: Create elegant data visualisations using the grammar of graphics. Available online: https://cran.r-project.org/web/packages/ggplot2/index.html (accessed on 1 April 2025).
- Wickham, H., & RStudio. (2022). Tidyverse: Easily Install and Load the ‘Tidyverse’. Available online: https://cran.r-project.org/web/packages/tidyverse/index.html (accessed on 1 April 2025).
- Wood, S. (2023). Mgcv: Mixed GAM computation vehicle with automatic smoothness estimation. Available online: https://cran.r-project.org/web/packages/mgcv/index.html (accessed on 1 April 2025).


{kind=link}
{kind=link}
{kind=link}
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | 0.99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | 0.00314 | 0.00315 | 0.00317 | 0.00320 | 0.00326 | 0.00335 | 0.00348 | 0.00369 | 0.00400 | 0.00451 | 0.00493 | 0.00554 |
| 15 | 0.00335 | 0.00336 | 0.00338 | 0.00342 | 0.00348 | 0.00357 | 0.00372 | 0.00394 | 0.00427 | 0.00481 | 0.00525 | 0.00590 |
| 14 | 0.00359 | 0.00360 | 0.00362 | 0.00366 | 0.00373 | 0.00383 | 0.00399 | 0.00422 | 0.00458 | 0.00516 | 0.00563 | 0.00631 |
| 13 | 0.00387 | 0.00388 | 0.00390 | 0.00395 | 0.00402 | 0.00413 | 0.00430 | 0.00456 | 0.00494 | 0.00555 | 0.00605 | 0.00678 |
| 12 | 0.00419 | 0.00420 | 0.00423 | 0.00428 | 0.00436 | 0.00448 | 0.00467 | 0.00494 | 0.00535 | 0.00601 | 0.00655 | 0.00733 |
| 11 | 0.00458 | 0.00459 | 0.00462 | 0.00467 | 0.00476 | 0.00490 | 0.00510 | 0.00540 | 0.00584 | 0.00656 | 0.00714 | 0.00797 |
| 10 | 0.00504 | 0.00505 | 0.00508 | 0.00514 | 0.00524 | 0.00539 | 0.00562 | 0.00595 | 0.00643 | 0.00721 | 0.00783 | 0.00874 |
| 9 | 0.00560 | 0.00561 | 0.00565 | 0.00572 | 0.00583 | 0.00600 | 0.00625 | 0.00661 | 0.00715 | 0.00800 | 0.00868 | 0.00967 |
| 8 | 0.00630 | 0.00632 | 0.00636 | 0.00644 | 0.00657 | 0.00677 | 0.00705 | 0.00745 | 0.00804 | 0.00898 | 0.00973 | 0.01081 |
| 7 | 0.00721 | 0.00723 | 0.00728 | 0.00738 | 0.00752 | 0.00775 | 0.00807 | 0.00852 | 0.00919 | 0.01023 | 0.01107 | 0.01226 |
| 6 | 0.00842 | 0.00844 | 0.00850 | 0.00862 | 0.00879 | 0.00905 | 0.00942 | 0.00995 | 0.01070 | 0.01188 | 0.01282 | 0.01416 |
| 5 | 0.01012 | 0.01014 | 0.01022 | 0.01036 | 0.01057 | 0.01088 | 0.01132 | 0.01193 | 0.01280 | 0.01415 | 0.01521 | 0.01673 |
| 4 | 0.01266 | 0.01270 | 0.01280 | 0.01297 | 0.01324 | 0.01361 | 0.01414 | 0.01486 | 0.01589 | 0.01745 | 0.01868 | 0.02042 |
| 3 | 0.01691 | 0.01696 | 0.01709 | 0.01731 | 0.01765 | 0.01812 | 0.01876 | 0.01964 | 0.02086 | 0.02268 | 0.02411 | 0.02611 |
| 2 | 0.02539 | 0.02545 | 0.02562 | 0.02590 | 0.02632 | 0.02688 | 0.02764 | 0.02864 | 0.03001 | 0.03202 | 0.03356 | 0.03571 |
| 1 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 |
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | 0.99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | 0.00314 | 0.00315 | 0.00317 | 0.00320 | 0.00326 | 0.00336 | 0.00353 | 0.00381 | 0.00434 | 0.00561 | 0.00739 | 0.01373 |
| 15 | 0.00335 | 0.00336 | 0.00338 | 0.00342 | 0.00348 | 0.00359 | 0.00377 | 0.00407 | 0.00464 | 0.00599 | 0.00787 | 0.01448 |
| 14 | 0.00359 | 0.00360 | 0.00362 | 0.00366 | 0.00374 | 0.00385 | 0.00405 | 0.00437 | 0.00498 | 0.00642 | 0.00841 | 0.01532 |
| 13 | 0.00387 | 0.00388 | 0.00390 | 0.00395 | 0.00403 | 0.00416 | 0.00436 | 0.00472 | 0.00537 | 0.00691 | 0.00903 | 0.01625 |
| 12 | 0.00419 | 0.00420 | 0.00423 | 0.00428 | 0.00437 | 0.00451 | 0.00474 | 0.00512 | 0.00582 | 0.00748 | 0.00974 | 0.01729 |
| 11 | 0.00458 | 0.00459 | 0.00462 | 0.00467 | 0.00477 | 0.00493 | 0.00518 | 0.00559 | 0.00636 | 0.00815 | 0.01057 | 0.01847 |
| 10 | 0.00504 | 0.00505 | 0.00508 | 0.00515 | 0.00526 | 0.00543 | 0.00571 | 0.00617 | 0.00701 | 0.00895 | 0.01154 | 0.01982 |
| 9 | 0.00560 | 0.00561 | 0.00565 | 0.00573 | 0.00585 | 0.00604 | 0.00635 | 0.00686 | 0.00779 | 0.00991 | 0.01270 | 0.02135 |
| 8 | 0.00630 | 0.00632 | 0.00637 | 0.00645 | 0.00659 | 0.00681 | 0.00716 | 0.00774 | 0.00877 | 0.01110 | 0.01411 | 0.02313 |
| 7 | 0.00721 | 0.00723 | 0.00728 | 0.00738 | 0.00755 | 0.00780 | 0.00820 | 0.00885 | 0.01001 | 0.01259 | 0.01585 | 0.02521 |
| 6 | 0.00842 | 0.00844 | 0.00851 | 0.00863 | 0.00882 | 0.00912 | 0.00959 | 0.01033 | 0.01165 | 0.01451 | 0.01804 | 0.02767 |
| 5 | 0.01012 | 0.01014 | 0.01022 | 0.01037 | 0.01061 | 0.01097 | 0.01152 | 0.01239 | 0.01389 | 0.01709 | 0.02090 | 0.03060 |
| 4 | 0.01267 | 0.01270 | 0.01280 | 0.01299 | 0.01328 | 0.01372 | 0.01438 | 0.01541 | 0.01715 | 0.02071 | 0.02473 | 0.03414 |
| 3 | 0.01692 | 0.01696 | 0.01710 | 0.01734 | 0.01771 | 0.01826 | 0.01907 | 0.02028 | 0.02226 | 0.02609 | 0.03010 | 0.03846 |
| 2 | 0.02540 | 0.02546 | 0.02563 | 0.02593 | 0.02639 | 0.02704 | 0.02795 | 0.02926 | 0.03126 | 0.03475 | 0.03801 | 0.04375 |
| 1 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 |
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | 0.99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 16 | 0.00314 | 0.00315 | 0.00317 | 0.00320 | 0.00326 | 0.00337 | 0.00354 | 0.00384 | 0.00440 | 0.00575 | 0.00762 | 0.01422 |
| 15 | 0.00335 | 0.00336 | 0.00338 | 0.00342 | 0.00349 | 0.00360 | 0.00378 | 0.00410 | 0.00470 | 0.00613 | 0.00811 | 0.01499 |
| 14 | 0.00359 | 0.00360 | 0.00362 | 0.00366 | 0.00374 | 0.00386 | 0.00406 | 0.00440 | 0.00504 | 0.00657 | 0.00867 | 0.01585 |
| 13 | 0.00387 | 0.00388 | 0.00390 | 0.00395 | 0.00403 | 0.00416 | 0.00438 | 0.00475 | 0.00544 | 0.00708 | 0.00931 | 0.01680 |
| 12 | 0.00419 | 0.00420 | 0.00423 | 0.00428 | 0.00437 | 0.00452 | 0.00476 | 0.00516 | 0.00590 | 0.00766 | 0.01004 | 0.01787 |
| 11 | 0.00458 | 0.00459 | 0.00462 | 0.00468 | 0.00478 | 0.00494 | 0.00520 | 0.00564 | 0.00645 | 0.00835 | 0.01089 | 0.01907 |
| 10 | 0.00504 | 0.00505 | 0.00508 | 0.00515 | 0.00526 | 0.00544 | 0.00573 | 0.00622 | 0.00711 | 0.00917 | 0.01189 | 0.02044 |
| 9 | 0.00560 | 0.00561 | 0.00565 | 0.00573 | 0.00585 | 0.00606 | 0.00638 | 0.00692 | 0.00790 | 0.01015 | 0.01308 | 0.02200 |
| 8 | 0.00631 | 0.00632 | 0.00637 | 0.00645 | 0.00660 | 0.00683 | 0.00719 | 0.00780 | 0.00889 | 0.01136 | 0.01452 | 0.02380 |
| 7 | 0.00721 | 0.00723 | 0.00728 | 0.00739 | 0.00756 | 0.00782 | 0.00824 | 0.00893 | 0.01015 | 0.01288 | 0.01629 | 0.02589 |
| 6 | 0.00842 | 0.00844 | 0.00851 | 0.00863 | 0.00883 | 0.00915 | 0.00963 | 0.01042 | 0.01181 | 0.01484 | 0.01853 | 0.02834 |
| 5 | 0.01012 | 0.01015 | 0.01023 | 0.01038 | 0.01062 | 0.01100 | 0.01157 | 0.01250 | 0.01409 | 0.01746 | 0.02141 | 0.03125 |
| 4 | 0.01267 | 0.01270 | 0.01281 | 0.01300 | 0.01330 | 0.01376 | 0.01446 | 0.01554 | 0.01738 | 0.02111 | 0.02527 | 0.03473 |
| 3 | 0.01692 | 0.01697 | 0.01711 | 0.01735 | 0.01774 | 0.01831 | 0.01916 | 0.02044 | 0.02252 | 0.02650 | 0.03061 | 0.03893 |
| 2 | 0.02541 | 0.02546 | 0.02564 | 0.02595 | 0.02642 | 0.02709 | 0.02804 | 0.02941 | 0.03148 | 0.03506 | 0.03835 | 0.04400 |
| 1 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 |
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | 0.99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0.01718 | 0.01723 | 0.01738 | 0.01763 | 0.01800 | 0.01850 | 0.01916 | 0.02004 | 0.02124 | 0.02299 | 0.02434 | 0.02622 |
| 2 | 0.02572 | 0.02578 | 0.02595 | 0.02626 | 0.02669 | 0.02728 | 0.02805 | 0.02904 | 0.03038 | 0.03231 | 0.03378 | 0.03582 |
| 1 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 |
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | 0.99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0.01720 | 0.01725 | 0.01741 | 0.01769 | 0.01811 | 0.01872 | 0.01960 | 0.02090 | 0.02296 | 0.02686 | 0.03087 | 0.03904 |
| 2 | 0.02574 | 0.02580 | 0.02599 | 0.02632 | 0.02681 | 0.02751 | 0.02847 | 0.02982 | 0.03185 | 0.03533 | 0.03852 | 0.04406 |
| 1 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 |
| 0 | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 0.95 | 0.99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0.01720 | 0.01726 | 0.01742 | 0.01771 | 0.01815 | 0.01878 | 0.01970 | 0.02105 | 0.02320 | 0.02722 | 0.03130 | 0.03943 |
| 2 | 0.02575 | 0.02581 | 0.02601 | 0.02635 | 0.02686 | 0.02757 | 0.02856 | 0.02997 | 0.03205 | 0.03560 | 0.03881 | 0.04427 |
| 1 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 | 0.05000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seneta, E.; Fung, T. The t-Distribution in Financial Mathematics and Multivariate Testing Contexts. J. Risk Financial Manag. 2025, 18, 224. https://doi.org/10.3390/jrfm18050224
Seneta E, Fung T. The t-Distribution in Financial Mathematics and Multivariate Testing Contexts. Journal of Risk and Financial Management. 2025; 18(5):224. https://doi.org/10.3390/jrfm18050224
Chicago/Turabian StyleSeneta, Eugene, and Thomas Fung. 2025. "The t-Distribution in Financial Mathematics and Multivariate Testing Contexts" Journal of Risk and Financial Management 18, no. 5: 224. https://doi.org/10.3390/jrfm18050224
APA StyleSeneta, E., & Fung, T. (2025). The t-Distribution in Financial Mathematics and Multivariate Testing Contexts. Journal of Risk and Financial Management, 18(5), 224. https://doi.org/10.3390/jrfm18050224