
The Dynamic Relationship between Investor Attention and Stock Market Volatility: International Evidence


Abstract
:1. Introduction
2. Literature Review
3. Econometric Models
3.1. The Empirical Similarity Model
3.2. The Heterogeneous Autoregressive (HAR) Model
3.3. The Empirical Similarity Approach with the HAR Components
4. Empirical Analysis
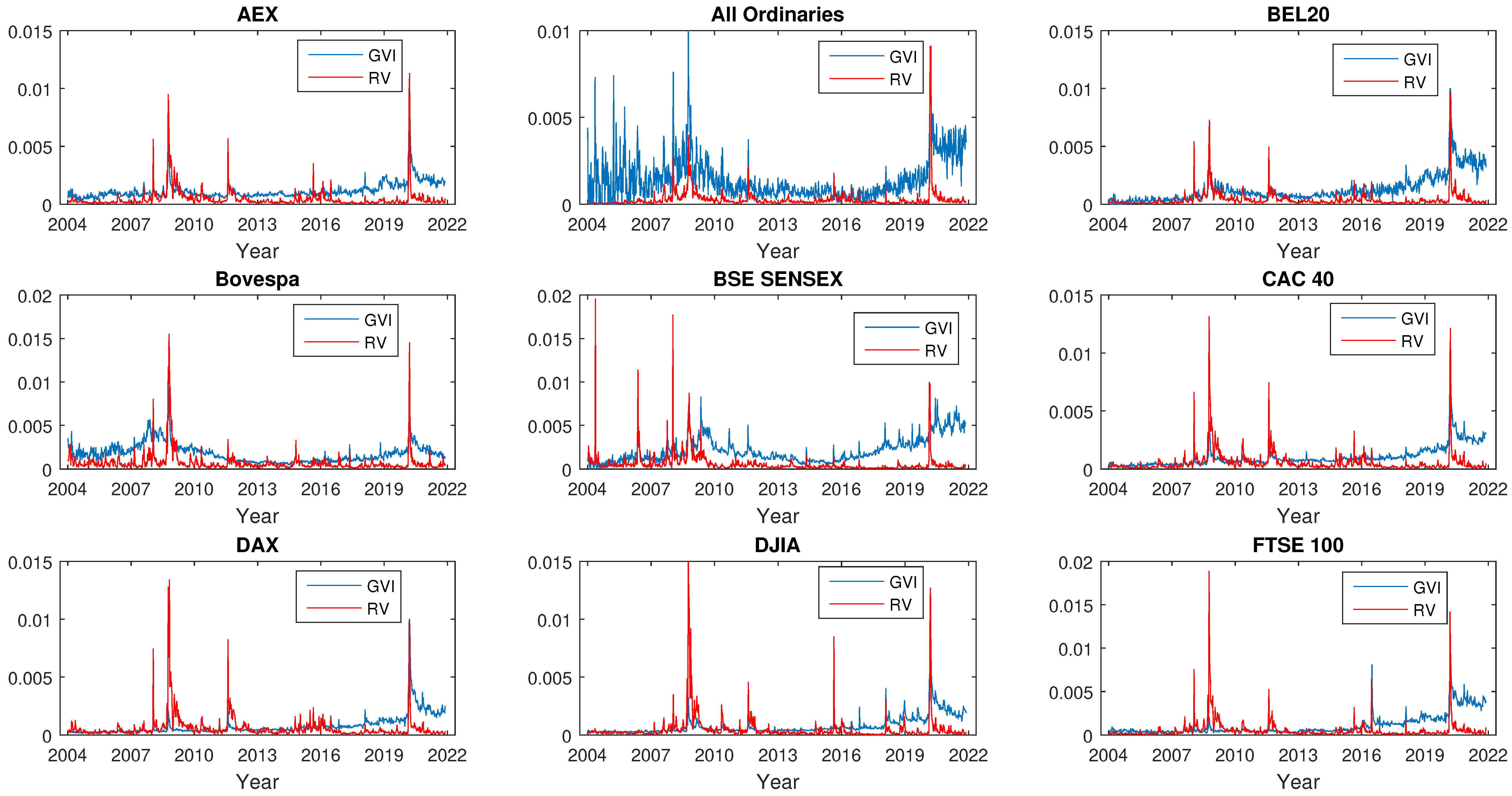
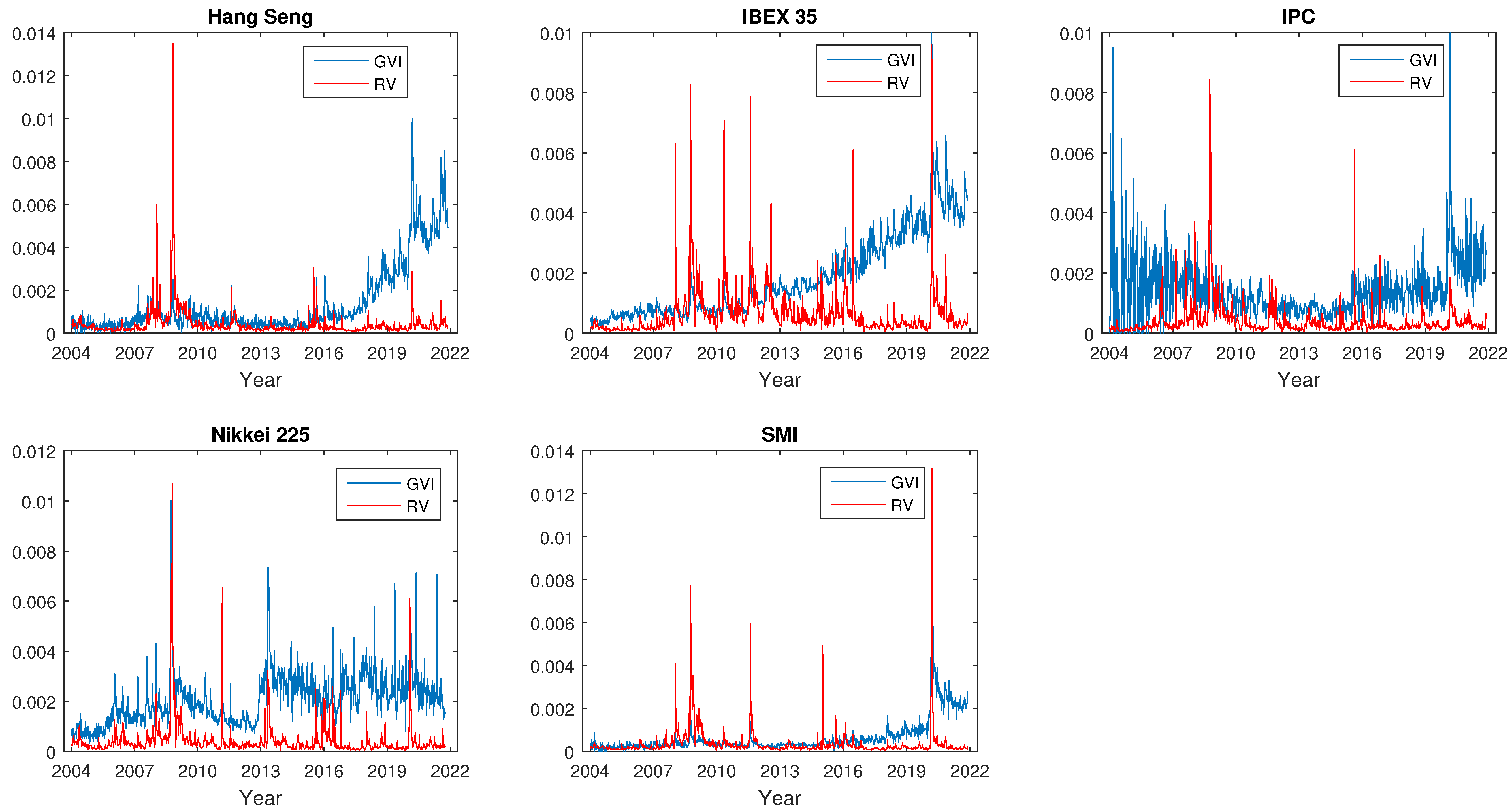
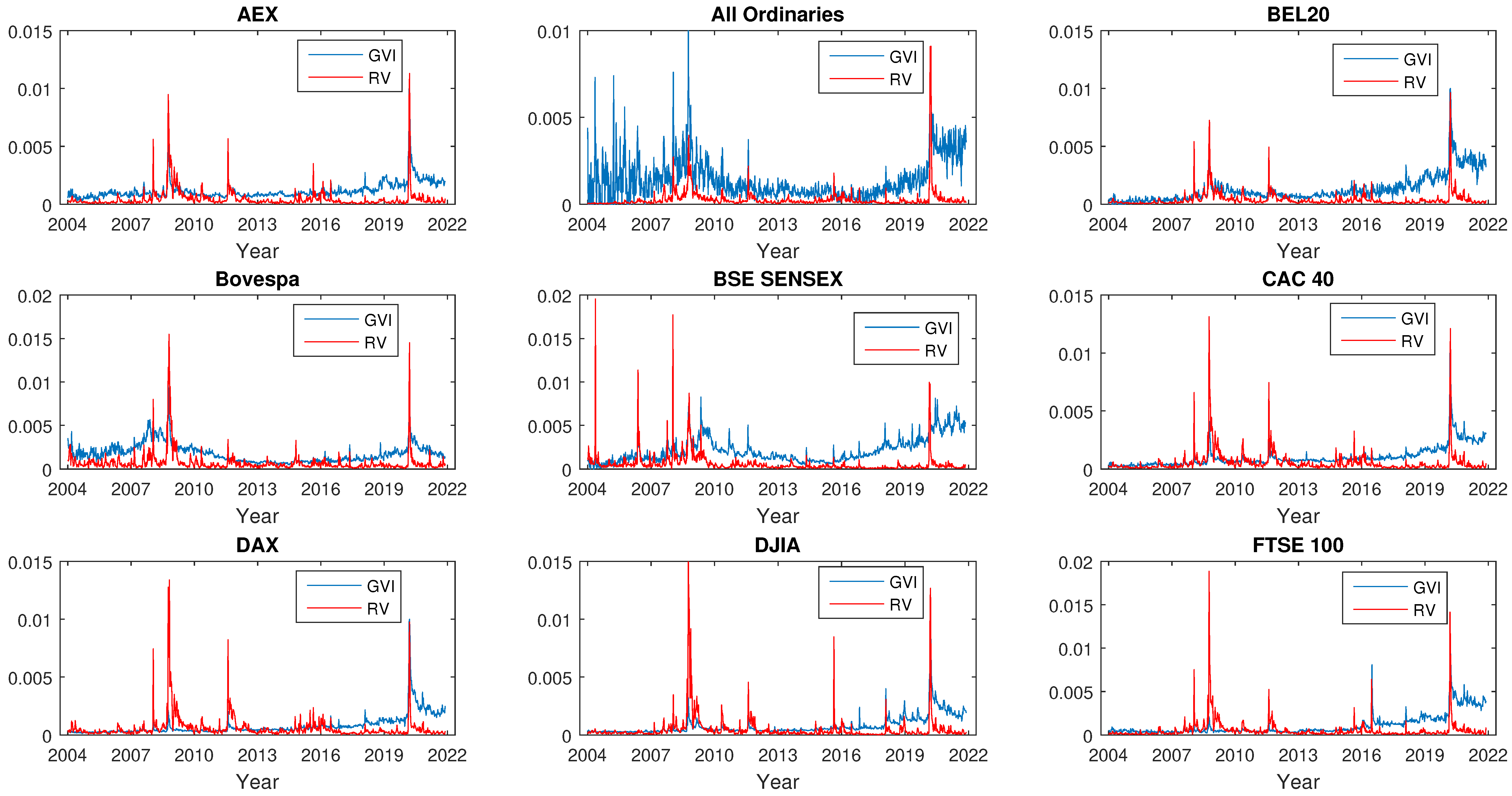
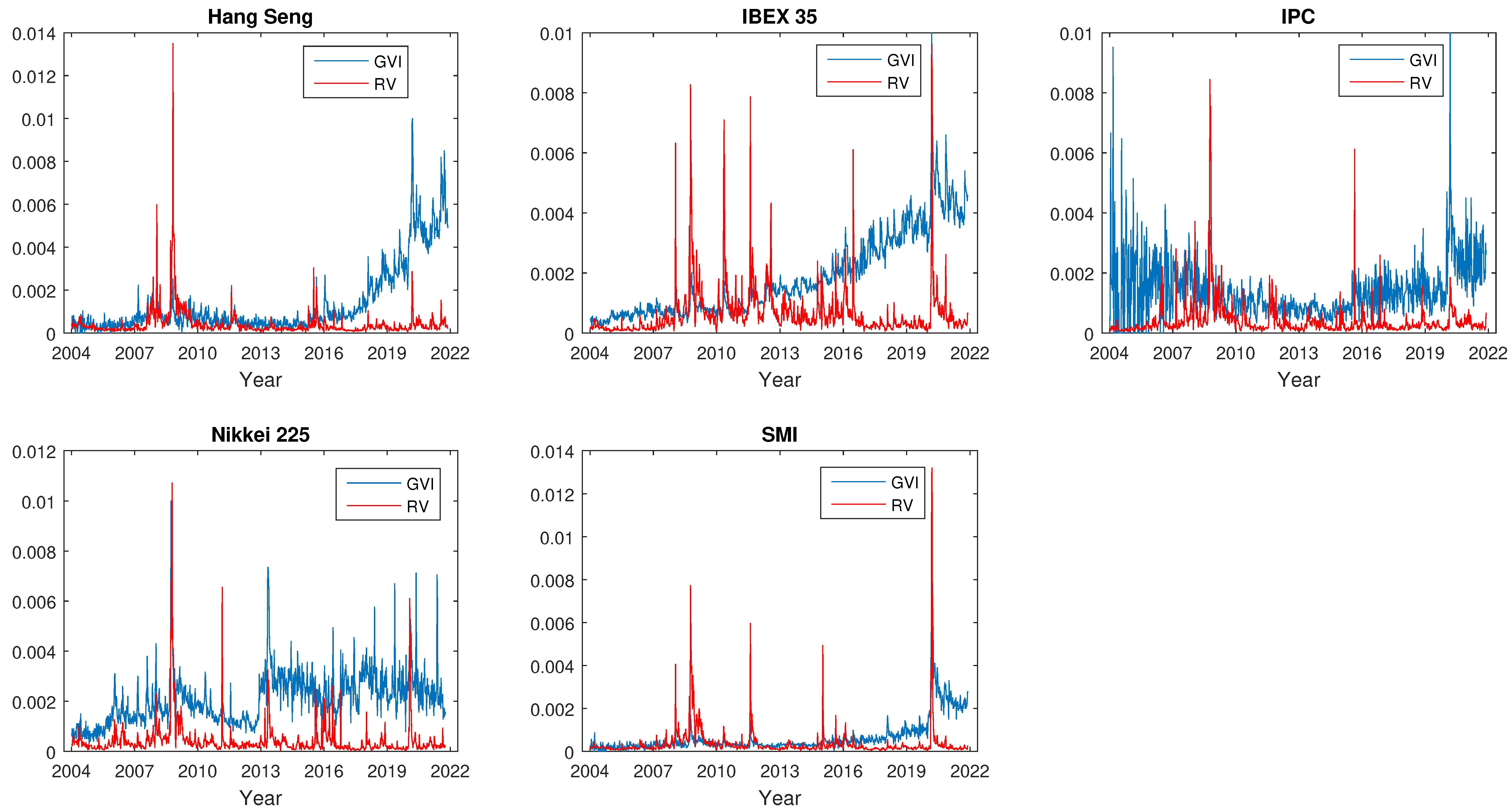
4.1. Data Description
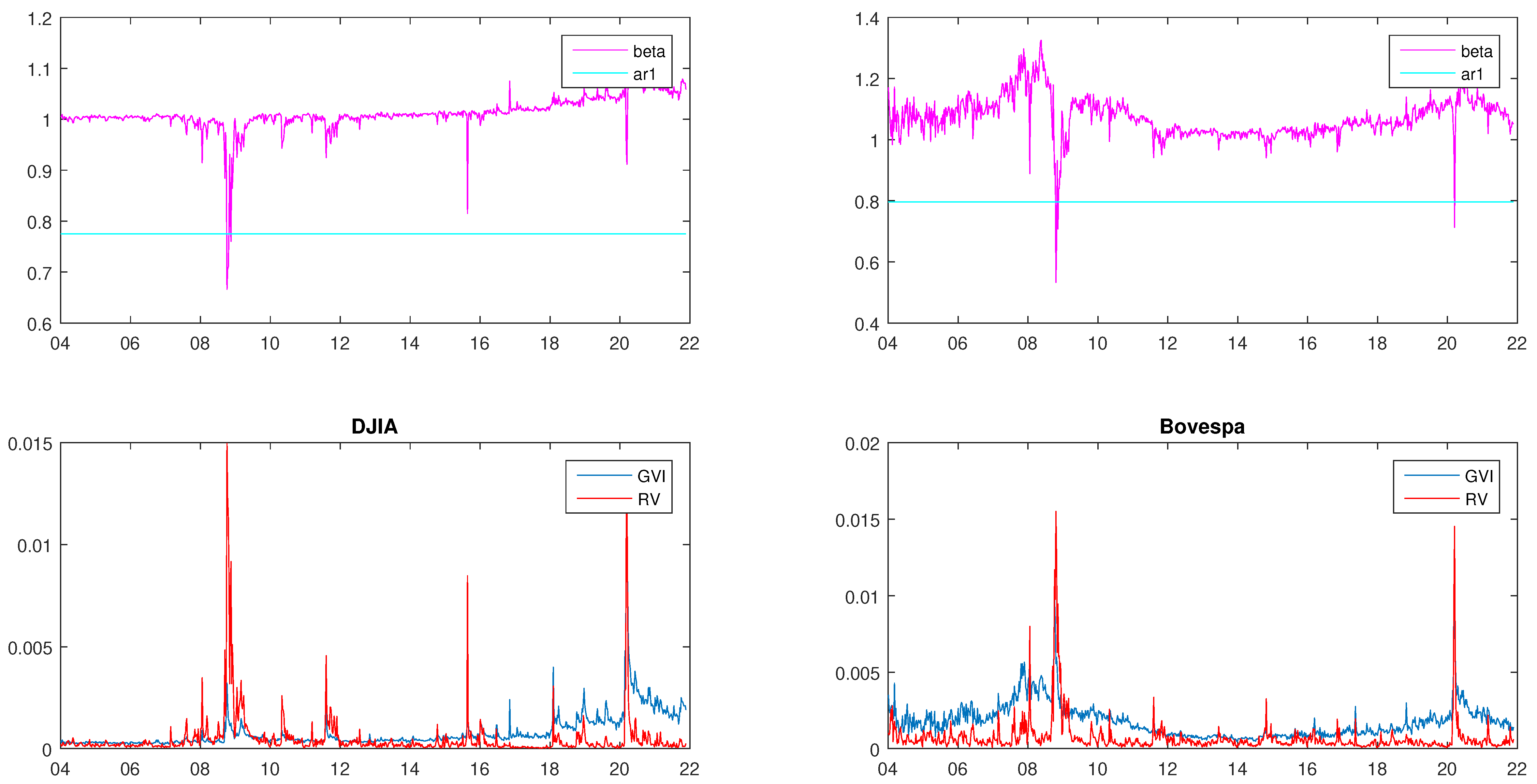
4.2. Lead–Lag Relationship between Volatility and Investor Attention
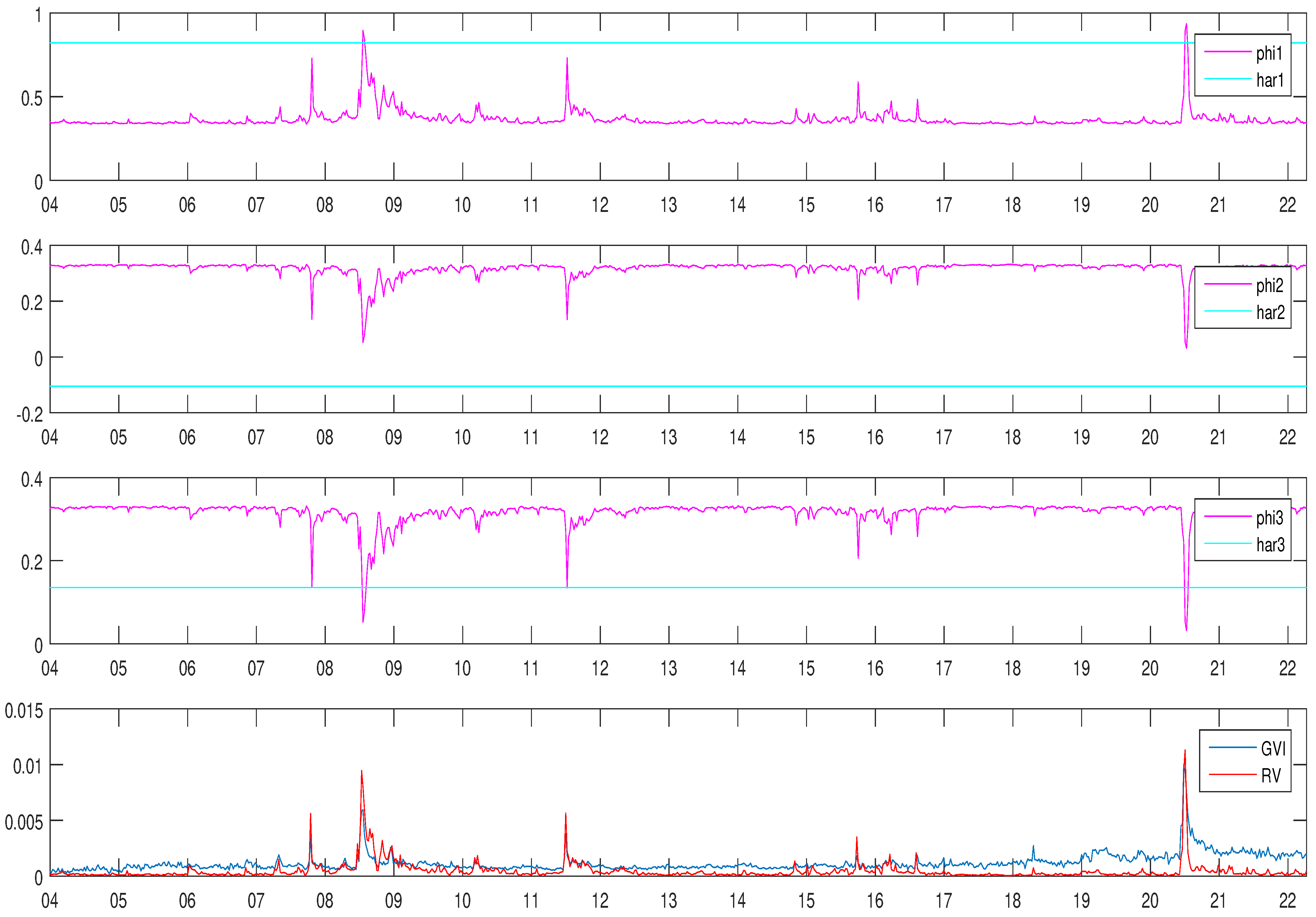
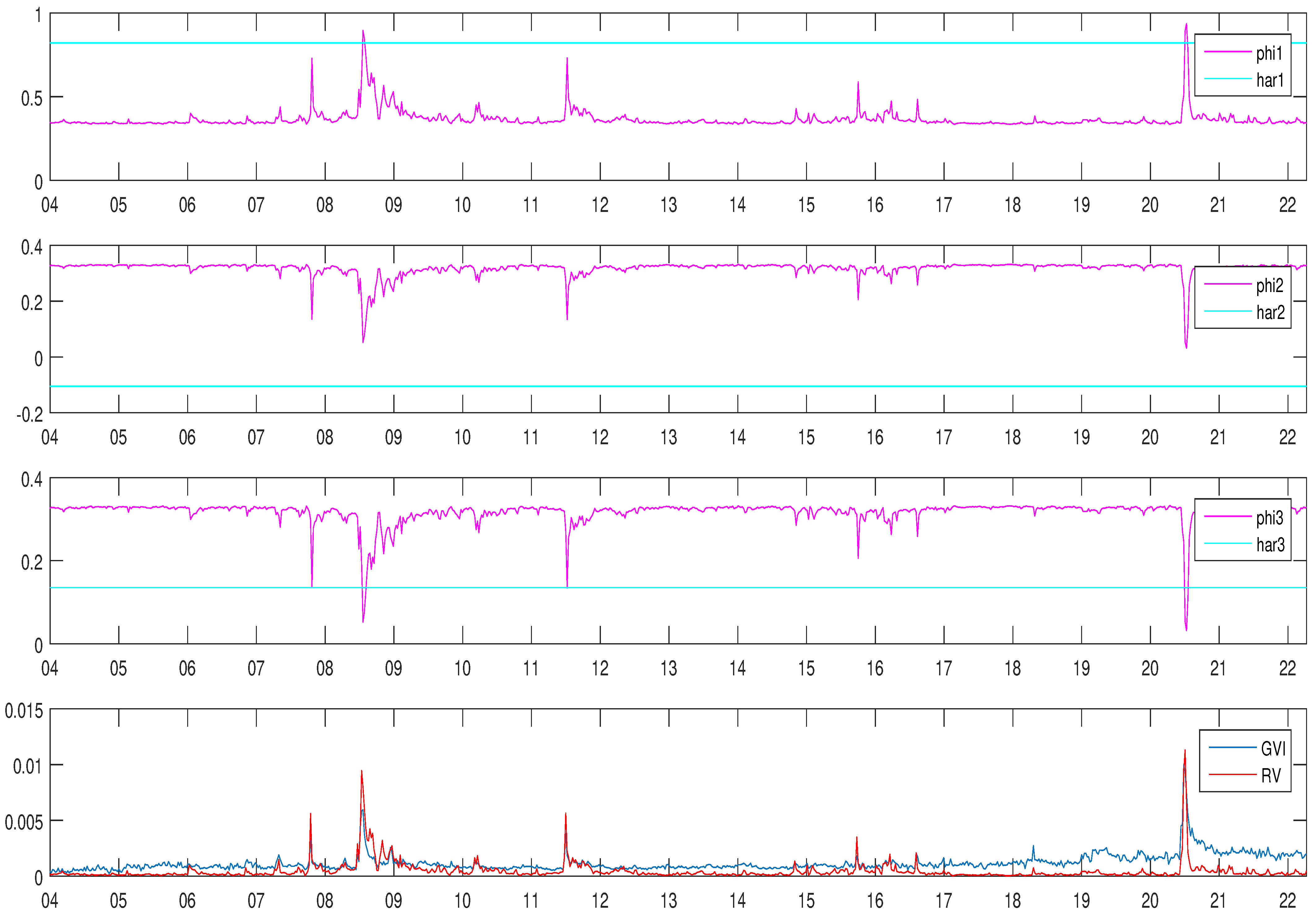
4.3. Estimation Results
4.4. Volatility Forecast Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
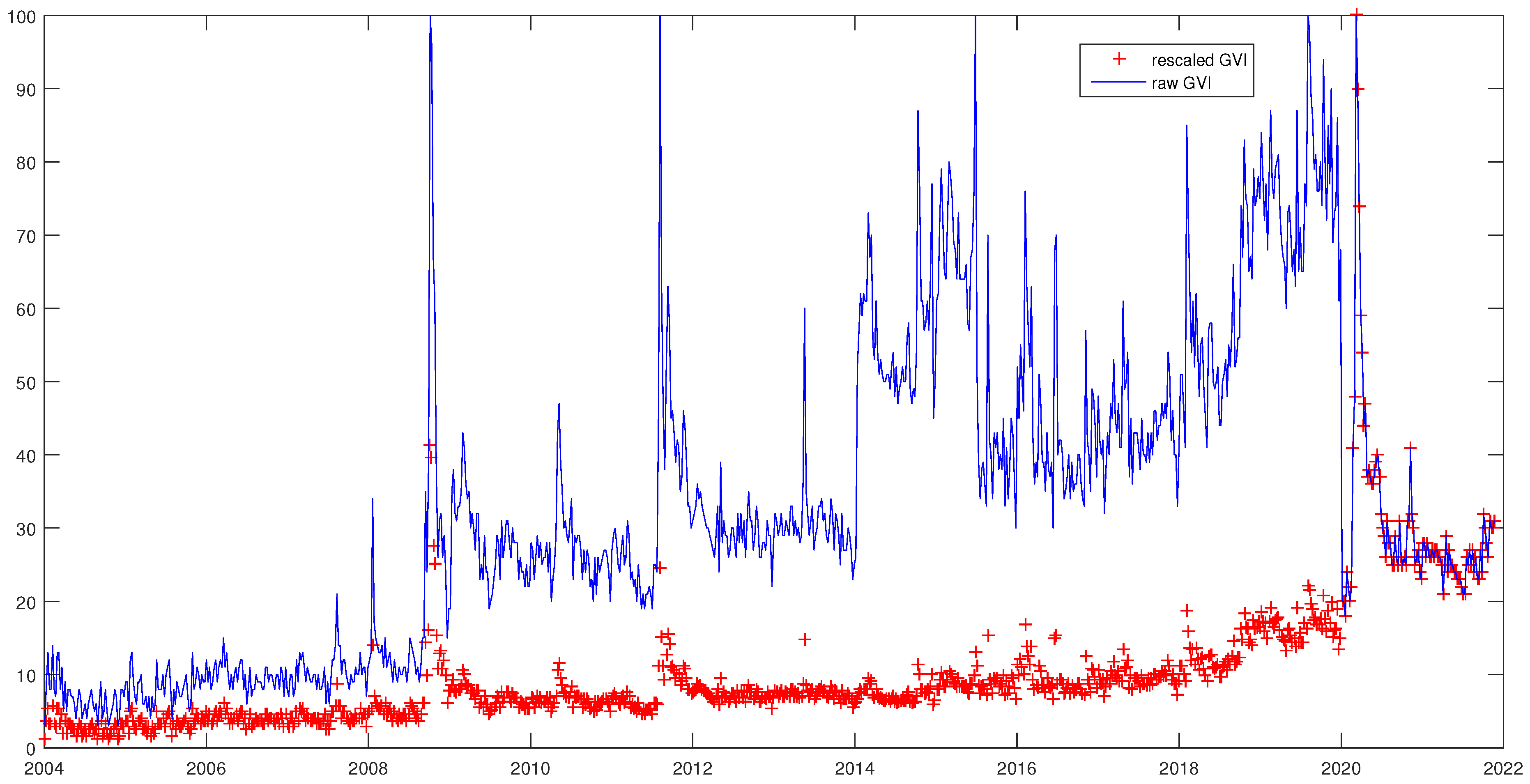
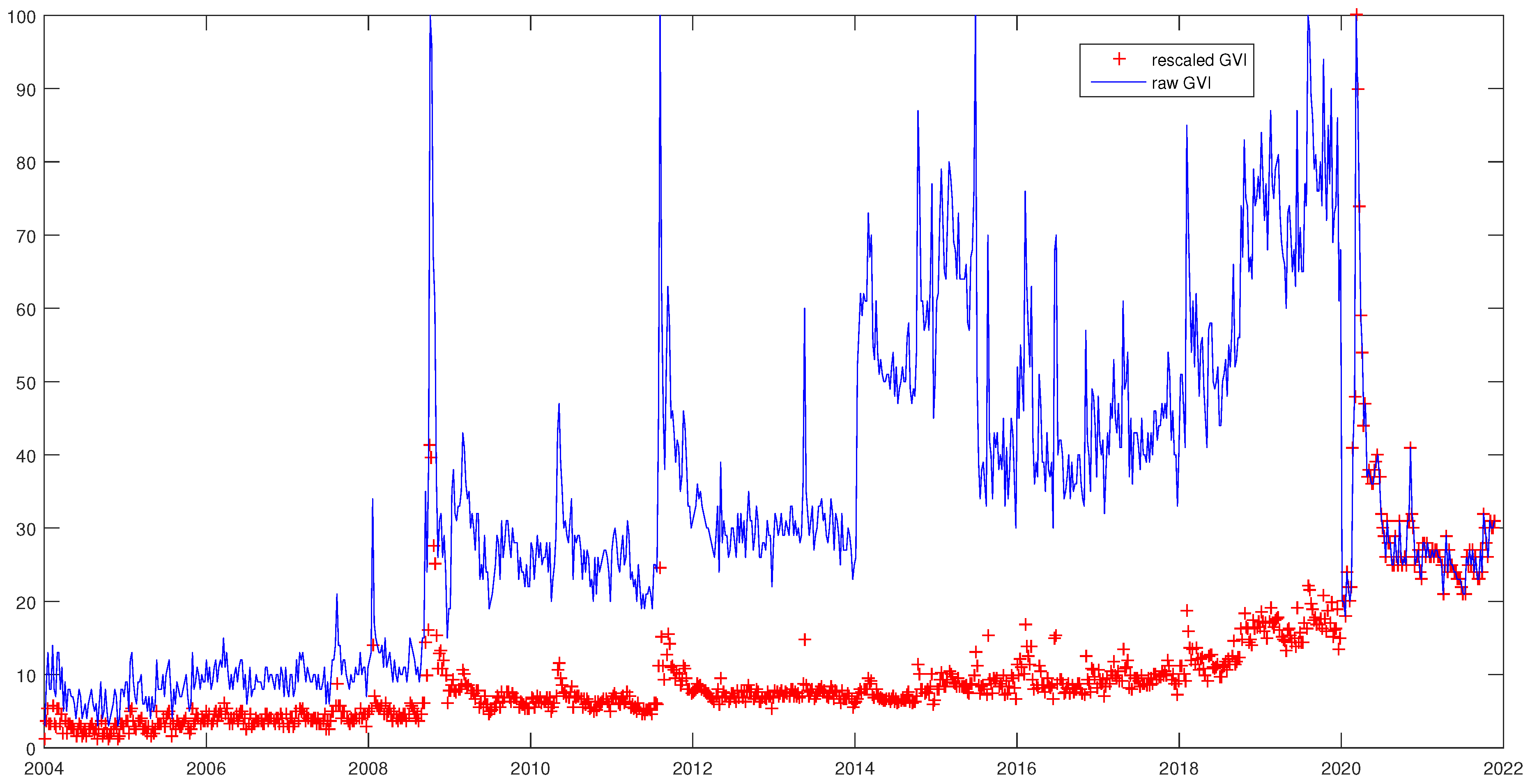
Appendix A. Rescaling Google Data
- Step 1: We downloaded Google search data for query “cac” over period . We obtain the first sample : . Then we downloaded search data for the same search query over period , for , and obtained the second sample : . Note that these two samples may be of different size.
- Step 2: We computed the sum of values, respectively, in samples and :where . We then deduced:We performed the same procedure for sample and deduced .
- Step 3: We divided the last value in by the first value in :Then, we multiplied the resulting value F by :The resulting value will be used in next step.
- Step 4: We determined the effective total search volume over the period (since the GVI at time is duplicated in the dataset):As a result, the total search volume is:
- Step 5: We multiplied values in by and divided by . We then obtained . Then, we multiplied values, , in by and divided by . As a result, we obtained . Then, we merged these samples into one sample E: .
- Step 6: We determined the highest relative search volume in E as:
- Step 7: We divided each value in E by and multiply by 100 to obtain the rescaled data: .
| 1 | According to NetMarketShare (https://netmarketshare.com, accessed on 3 November 2021), Google holds of the market share in 2020. |
| 2 | The data are publicly available from http://www.google.com/trends, accessed on 28 November 2021. |
| 3 | https://gs.statcounter.com, accessed on 3 November 2021. |
References
- Andersen, Torben G., Tim Bollerslev, and Francis X. Diebold. 2007. Roughing it up: Including jump components in the measurement, modeling, and forecasting of return volatility. The Review of Economics and Statistics 89: 701–20. [Google Scholar] [CrossRef]
- Andrei, Daniel, and Michael Hasler. 2014. Investor attention and stock market volatility. The Review of Financial Studies 28: 33–72. [Google Scholar] [CrossRef]
- Bank, Matthias, Martin Larch, and Georg Peter. 2011. Google search volume and its influence on liquidity and returns of german stocks. Financial Markets and Portfolio Management 25: 239. [Google Scholar] [CrossRef]
- Barber, Brad M., and Terrance Odean. 2008. All that glitters: The effect of attention and news on the buying behavior of individual and institutional investors. The Review of Financial Studies 21: 785–818. [Google Scholar] [CrossRef] [Green Version]
- Bollerslev, Tim, Hood Benjamin, Huss John, and Lasse H. Pedersen. 2018. Risk Everywhere: Modeling and Managing Volatility. The Review of Financial Studies 31: 2729–73. [Google Scholar] [CrossRef]
- Carneiro, Herman Anthony, and Eleftherios Mylonakis. 2009. Google trends: A web-based tool for real-time surveillance of disease outbreaks. Clinical Infectious Diseases 49: 1557–64. [Google Scholar] [CrossRef]
- Chen, Tao. 2017. Investor attention and global stock returns. Journal of Behavioral Finance 18: 358–72. [Google Scholar] [CrossRef]
- Choi, Hyunyoung, and Hal Varian. 2012. Predicting the present with google trends. Economic Record 88: 2–9. [Google Scholar] [CrossRef]
- Corsi, Fulvio. 2009. A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics 7: 174–96. [Google Scholar] [CrossRef]
- Corsi, Fulvio, and Roberto Renò. 2012. Discrete-time volatility forecasting with persistent leverage effect and the link with continuous-time volatility modeling. Journal of Business & Economic Statistics 30: 368–80. [Google Scholar]
- Da, Zhi, Joseph Engelberg, and Pengjie Gao. 2011. In search of attention. The Journal of Finance 66: 1461–99. [Google Scholar] [CrossRef]
- Dellavigna, Stefano, and Joshua M. Pollet. 2009. Investor inattention and friday earnings announcements. The Journal of Finance 64: 709–49. [Google Scholar] [CrossRef] [Green Version]
- Diebold, Francis X., and Roberto S. Mariano. 1995. Comparing predictive accuracy. Journal of Business & Economic Statistics 13: 253–63. [Google Scholar]
- Dimpfl, Thomas, and Stephan Jank. 2016. Can internet search queries help to predict stock market volatility? European Financial Management 22: 171–92. [Google Scholar] [CrossRef] [Green Version]
- Ekinci, Cumhur, and Ali Eray Bulut. 2021. Google search and stock returns: A study on bist 100 stocks. Global Finance Journal 47: 100518. [Google Scholar] [CrossRef]
- Ginsberg, Jeremy, Matthew H. Mohebbi, Rajan S. Patel, Lynnette Brammer, Mark S. Smolinski, and Larry Brilliant. 2009. Detecting influenza epidemics using search engine query data. Nature 457: 1012–14. [Google Scholar] [CrossRef]
- Golosnoy, Vasyl, Alain Hamid, and Yarema Okhrin. 2014. The empirical similarity approach for volatility prediction. Journal of Banking & Finance 40: 321–29. [Google Scholar]
- Grullon, Gustavo, Kanatas George, and James P. Weston. 2004. Advertising, breadth of ownership, and liquidity. Review of Financial Studies 17: 439–61. [Google Scholar] [CrossRef]
- Guzman, Giselle. 2011. Internet search behavior as an economic forecasting tool: The case of inflation expectations. Journal of Economic and Social Measurement 36: 119–67. [Google Scholar] [CrossRef]
- Hamid, Alain. 2015. Prediction power of high-frequency based volatility measures: A model based approach. Review of Managerial Science 9: 549–76. [Google Scholar] [CrossRef]
- Hamid, Alain, and Moritz Heiden. 2015. Forecasting volatility with empirical similarity and google trends. Journal of Economic Behavior & Organization 117: 62–81. [Google Scholar]
- Hansen, Peter R., Asger Lunde, and James M. Nason. 2011. The model confidence set. Econometrica 79: 453–97. [Google Scholar] [CrossRef] [Green Version]
- Hasler, Michael, and Chayawat Ornthanalai. 2018. Fluctuating attention and financial contagion. Journal of Monetary Economics 99: 106–23. [Google Scholar] [CrossRef]
- Heber, Gerd, Asger Lunde, Neil Shephard, and Kevin Sheppard. 2009. Oxford-Man Institute’s Realized Library, Version 0.1. Available online: https://realized.oxford-man.ox.ac.uk/ (accessed on 3 November 2021).
- Hirshleifer, David, Sonya Seongyeon Lim, and Siew Hong Teoh. 2009. Driven to distraction: Extraneous events and underreaction to earnings news. The Journal of Finance 64: 2289–325. [Google Scholar] [CrossRef] [Green Version]
- Hou, Kewei, Wei Xiong, and Lin Peng. 2009. A Tale of Two Anomalies: The Implications of Investor Attention for Price and Earnings Momentum. Working Paper. Available online: https://ssrn.com/abstract=976394 (accessed on 3 November 2021).
- Joseph, Kissan, M. Babajide Wintoki, and Zelin Zhang. 2011. Forecasting abnormal stock returns and trading volume using investor sentiment: Evidence from online search. International Journal of Forecasting 27: 1116–27. [Google Scholar] [CrossRef]
- Kahneman, Daniel. 1973. Attention and Effort. Englewood Cliffs: Prentice-Hall, vol. 1063. [Google Scholar]
- Kim, Neri, Katarína Lučivjanská, Peter Molnár, and Roviel Villa. 2019. Google searches and stock market activity: Evidence from norway. Finance Research Letters 28: 208–20. [Google Scholar] [CrossRef]
- Klemola, Antti, Jussi Nikkinen, and Jarkko Peltomäki. 2016. Changes in investors’ market attention and near-term stock market returns. Journal of Behavioral Finance 17: 18–30. [Google Scholar] [CrossRef]
- Lieberman, Offer. 2012. A similarity-based approach to time-varying coefficient non-stationary autoregression. Journal of Time Series Analysis 33: 484–502. [Google Scholar] [CrossRef]
- Liu, Lily Y., Andrew J. Patton, and Kevin Sheppard. 2015. Does anything beat 5-minute rv? A comparison of realized measures across multiple asset classes. Journal of Econometrics 187: 293–311. [Google Scholar] [CrossRef] [Green Version]
- Mondria, Jordi, and Climent Quintana-Domeque. 2013. Financial contagion and attention allocation. The Economic Journal 123: 429–54. [Google Scholar] [CrossRef] [Green Version]
- Padungsaksawasdi, Chaiyuth, Sirim on Treepongkaruna, and Robert Brooks. 2019. Investor attention and stock market activities: New evidence from panel data. International Journal of Financial Studies 7: 30. [Google Scholar] [CrossRef] [Green Version]
- Patton, Andrew J. 2011. Volatility forecast comparison using imperfect volatility proxies. Journal of Econometrics 160: 246–56. [Google Scholar] [CrossRef] [Green Version]
- Patton, Andrew J., and Kevin Sheppard. 2009. Evaluating volatility and correlation forecasts. In Handbook of Financial Time Series. Berlin/Heidelberg: Springer, pp. 801–38. [Google Scholar]
- Peng, Lin, and Wei Xiong. 2006. Investor attention, overconfidence and category learning. Journal of Financial Economics 80: 563–602. [Google Scholar] [CrossRef] [Green Version]
- Politis, Dimitris N., and Joseph P. Romano. 1994. The stationary bootstrap. Journal of the American Statistical Association 89: 1303–13. [Google Scholar] [CrossRef]
- Seasholes, Mark S., and Guojun Wu. 2007. Predictable behavior, profits, and attention. Journal of Empirical Finance 14: 590–610. [Google Scholar] [CrossRef]
- Simon, Herbert A. 1955. A behavioral model of rational choice. The Quarterly Journal of Economics 69: 99–118. [Google Scholar] [CrossRef]
- Vlastakis, Nikolaos, and Raphael N. Markellos. 2012. Information demand and stock market volatility. Journal of Banking & Finance 36: 1808–21. [Google Scholar]
- Vosen, Simeon, and Torsten Schmidt. 2011. Forecasting private consumption: Survey-based indicators vs. google trends. Journal of Forecasting 30: 565–78. [Google Scholar] [CrossRef] [Green Version]
- Vozlyublennaia, Nadia. 2014. Investor attention, index performance, and return predictability. Journal of Banking & Finance 41: 17–35. [Google Scholar]
- Wang, Hua, Liao Xu, and Susan Sunila Sharma. 2021. Does investor attention increase stock market volatility during the COVID-19 pandemic? Pacific-Basin Finance Journal 69: 101638. [Google Scholar] [CrossRef]
- Wen, Fenghua, Longhao Xu, Guangda Ouyang, and Gang Kou. 2019. Retail investor attention and stock price crash risk: Evidence from china. International Review of Financial Analysis 65: 101376. [Google Scholar]
- Yang, Xin, Bing Pan, James A. Evans, and Benfu Lv. 2015. Forecasting chinese tourist volume with search engine data. Tourism Management 46: 386–97. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Country | Search Term |
|---|---|---|
| AEX | Netherlands | “aex” |
| All Ordinaries | Australia | “all ordinaries” |
| BEL 20 | Belgium | “bel 20” |
| Bovespa | Brazil | “bovespa” |
| BSE Sensex | India | “sensex” |
| CAC 40 | France | “cac” |
| DAX | Germany | “dax” |
| DJIA | U.S | “dow” |
| FTSE 100 | U.K | ”ftse” |
| Hang Seng | China | “hang seng index” |
| IBEX 35 | Spain | “ibex” |
| IPC | Mexico | “ipc” |
| Nikkei 225 | Japan | “nikkei 225” |
| SMI | Switzerland | “smi” |
| Index | Realized Volatility | GVI | Corr | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Min | Max | Skew | Kurt | ADF | Mean | Min | Max | Skew | Kurt | ADF | ||||
| AEX | 4.69 × 10 | 1.43 × 10 | 1.13 × 10 | 7.07 | 67.69 | 0.80 | 3.35 × 10 | 1.18 × 10 | 2.38 × 10 | 1.00 × 10 | 4.74 | 40.45 | 0.88 | 8.68 × 10 | 0.66 |
| All Ordinaries | 2.78 × 10 | 6.25 × 10 | 9.10 × 10 | 10.43 | 140.25 | 0.79 | 4.38 × 10 | 1.43 × 10 | 0.00 × 10 | 1.00 × 10 | 1.95 | 8.61 | 0.67 | 7.87 × 10 | 0.50 |
| BEL 20 | 4.05 × 10 | 3.38 × 10 | 9.63 × 10 | 7.35 | 75.34 | 0.76 | 3.74 × 10 | 1.31 × 10 | 0.00 × 10 | 1.00 × 10 | 2.45 | 12.14 | 0.93 | 2.32 × 10 | 0.47 |
| Bovespa | 7.24 × 10 | 5.62 × 10 | 1.55 × 10 | 7.23 | 67.87 | 0.80 | 2.46 × 10 | 1.77 × 10 | 4.68 × 10 | 1.00 × 10 | 2.34 | 12.96 | 0.90 | 2.44 × 10 | 0.61 |
| BSE Sensex | 6.25 × 10 | 1.87 × 10 | 1.96 × 10 | 8.67 | 102.66 | 0.47 | 8.42 × 10 | 2.14 × 10 | 0.00 × 10 | 1.00 × 10 | 1.39 | 4.99 | 0.89 | 1.45 × 10 | 0.34 |
| CAC 40 | 5.61 × 10 | 3.98 × 10 | 1.31 × 10 | 7.21 | 72.50 | 0.75 | 7.52 × 10 | 1.02 × 10 | 1.24 × 10 | 1.00 × 10 | 3.53 | 24.43 | 0.94 | 5.75 × 10 | 0.44 |
| DAX | 5.76 × 10 | 1.41 × 10 | 1.34 × 10 | 7.17 | 70.79 | 0.71 | 1.83 × 10 | 7.82 × 10 | 1.28 × 10 | 1.00 × 10 | 4.74 | 38.82 | 0.94 | 1.75 × 10 | 0.29 |
| DJIA | 4.95 × 10 | 1.70 × 10 | 1.50 × 10 | 7.52 | 70.42 | 0.77 | 7.27 × 10 | 7.95 × 10 | 1.93 × 10 | 1.00 × 10 | 4.49 | 36.96 | 0.93 | 2.46 × 10 | 0.47 |
| FTSE 100 | 5.50 × 10 | 2.75 × 10 | 1.88 × 10 | 8.86 | 108.17 | 0.68 | 6.69 × 10 | 1.11 × 10 | 1.25 × 10 | 1.00 × 10 | 2.55 | 11.43 | 0.95 | 1.00 × 10 | 0.27 |
| Hang Seng | 4.17 × 10 | 2.76 × 10 | 1.35 × 10 | 9.81 | 153.49 | 0.68 | 2.95 × 10 | 1.36 × 10 | 0.00 × 10 | 1.00 × 10 | 2.08 | 7.20 | 0.95 | 5.78 × 10 | 0.11 |
| IBEX 35 | 6.55 × 10 | 3.05 × 10 | 9.59 × 10 | 5.12 | 38.69 | 0.71 | 3.58 × 10 | 1.86 × 10 | 1.41 × 10 | 1.00 × 10 | 1.25 | 4.82 | 0.96 | 5.99 × 10 | 0.16 |
| IPC | 3.95 × 10 | 3.10 × 10 | 8.45 × 10 | 7.52 | 79.83 | 0.65 | 5.08 × 10 | 1.45 × 10 | 0.00 × 10 | 1.00 × 10 | 2.43 | 16.11 | 0.41 | 1.49 × 10 | 0.18 |
| Nikkei 225 | 4.23 × 10 | 2.09 × 10 | 1.07 × 10 | 7.13 | 74.79 | 0.65 | 2.58 × 10 | 2.09 × 10 | 3.00 × 10 | 1.00 × 10 | 1.87 | 10.97 | 0.73 | 1.02 × 10 | 0.50 |
| SMI | 3.69 × 10 | 2.27 × 10 | 1.32 × 10 | 9.78 | 127.28 | 0.73 | 8.91 × 10 | 6.65 × 10 | 0.00 × 10 | 1.00 × 10 | 4.52 | 35.09 | 0.93 | 1.05 × 10 | 0.49 |
| Index | : GVI Does Not Granger Cause RV | : RV Does Not Granger Cause GVI | Results | ||
|---|---|---|---|---|---|
| F-Statisticyy | p-Value | F-Statistic | p-Value | ||
| AEX | 22.371 | 0.000 | 8.258 | 0.000 | |
| All ordinaries | 3.539 | 0.007 | 4.163 | 0.002 | |
| BEL 20 | 14.253 | 0.000 | 13.298 | 0.000 | |
| Bovespa | 17.324 | 0.000 | 17.549 | 0.000 | |
| BSE Sensex | 3.533 | 0.007 | 8.809 | 0.000 | |
| CAC 40 | 29.349 | 0.000 | 13.369 | 0.000 | |
| DAX | 23.101 | 0.000 | 12.466 | 0.000 | |
| DJIA | 14.754 | 0.000 | 8.994 | 0.000 | |
| FTSE 100 | 2.047 | 0.086 | 12.931 | 0.000 | |
| Hang Seng | 0.434 | 0.784 | 4.366 | 0.002 | |
| IBEX 35 | 1.439 | 0.219 | 9.991 | 0.000 | |
| IPC | 1.218 | 0.302 | 1.163 | 0.326 | |
| NIKKEI 225 | 4.350 | 0.002 | 4.988 | 0.001 | |
| SMI | 22.991 | 0.000 | 10.826 | 0.000 | |
| AEX | All Ordinaries | BEL 20 | Bovespa | BSE Sensex | CAC 40 | DAX | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.183 | 0.086 | |||||||||||||
| (0.001) | (0.000) | (0.345) | (0.000) | (0.000) | (0.001) | (0.856) | (0.014) | (0.001) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| 0.026 | −0.015 | |||||||||||||
| (0.000) | (0.465) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.077) | (0.000) | (0.472) | (0.000) | (0.000) | |
| −0.083 | −0.004 | 0.033 | −0.058 | |||||||||||
| (0.137) | (0.000) | (0.000) | (0.007) | (0.000) | (0.000) | (0.927) | (0.000) | (0.012) | (0.172) | (0.221) | (0.000) | (0.000) | (0.005) | |
| −0.003 | 0.004 | 0.07 | −0.005 | −0.019 | 0.048 | |||||||||
| (0.006) | (0.944) | (0.000) | (0.970) | (0.115) | (0.913) | (0.000) | (0.515) | (0.268) | (0.029) | (0.000) | (0.035) | (0.000) | (0.000) | |
| 0.030 | 0.002 | −0.009 | −0.016 | −0.001 | 0.069 | −0.011 | −0.009 | |||||||
| (0.000) | (0.390) | (0.000) | (0.985) | (0.002) | (0.015) | (0.829) | (0.525) | (0.003) | (0.961) | (0.105) | (0.586) | (0.000) | (0.557) | |
| (0.000) | (0.000) | (0.009) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | (0.060) | (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | |
| −0.095 | −0.002 | 0.037 | 0.053 | |||||||||||
| (0.216) | (0.000) | (0.913) | (0.000) | (0.022) | (0.000) | (0.586) | (0.000) | (0.524) | (0.000) | (0.003) | (0.001) | (0.000) | (0.030) | |
| 0.015 | −0.005 | 0.072 | ||||||||||||
| (0.000) | (0.049) | (0.322) | (0.003) | (0.000) | (0.903) | (0.012) | (0.004) | (0.390) | (0.000) | (0.000) | (0.008) | (0.00)0 | (0.000) | |
| 0.005 | −0.01 | 0.037 | 0.017 | |||||||||||
| (0.008) | (0.929) | (0.480) | (0.013) | (0.000) | (0.034) | (0.000) | (0.023) | (0.001) | (0.373) | (0.053) | (0.715) | (0.003) | (0.000) | |
| Adj. | 0.671 | 0.785 | 0.666 | 0.528 | 0.611 | 0.886 | 0.664 | 0.826 | 0.256 | 0.831 | 0.618 | 0.903 | 0.587 | 0.906 |
| DJIA | FTSE 100 | Hang Seng | IBEX 35 | IPC | Nikkei 225 | SMI | ||||||||
| (0.001) | (0.100) | (0.000) | (0.001) | (0.000) | (0.001) | (0.000) | (0.000) | (0.002) | (0.000) | (0.061) | (0.000) | (0.000) | (0.000) | |
| 0.039 | 0.046 | 0.048 | 0.035 | |||||||||||
| (0.000) | (0.100) | (0.000) | (0.000) | (0.000) | (0.243) | (0.000) | (0.002) | (0.000) | (0.440) | (0.000) | (0.344) | (0.000) | (0.157) | |
| −0.043 | 0.071 | 0.026 | ||||||||||||
| (0.033) | (0.002) | (0.316) | (0.000) | (0.002) | (0.017) | (0.031) | (0.000) | (0.022) | (0.292) | (0.000) | (0.721) | (0.023) | (0.004) | |
| 0.009 | 0.008 | 0.004 | −0.029 | −0.008 | 0.012 | |||||||||
| (0.000) | (0.046) | (0.000) | (0.647) | (0.000) | (0.819) | (0.074) | (0.877) | (0.015) | (0.663) | (0.001) | (0.892) | (0.001) | (0.663) | |
| 0.028 | 0.005 | −0.003 | −0.038 | −0.05 | −0.003 | −0.084 | ||||||||
| (0.535) | (0.802) | (0.932) | (0.045) | (0.292) | (0.135) | (0.083) | (0.054) | (0.931) | (0.158) | (0.043) | (0.000) | (0.006) | (0.008) | |
| 0.079 | 0.022 | 0.093 | 0.0198 | 0.022 | ||||||||||
| (0.000) | (0.000) | (0.361) | (0.000) | (0.562) | (0.000) | (0.201) | (0.000) | (0.283) | (0.000) | (0.421) | (0.000) | (0.000) | (0.000) | |
| 0.107 | 0.140 | 0.078 | 0.005 | 0.038 | 0.007 | 0.007 | −0.109 | |||||||
| (0.419) | (0.020) | (0.201) | (0.110) | (0.900) | (0.000) | (0.663) | (0.001) | (0.720) | (0.000) | (0.809) | (0.038) | (0.255) | (0.010) | |
| 0.009 | −0.053 | −0.047 | 0.011 | |||||||||||
| (0.000) | (0.006) | (0.021) | (0.846) | (0.228) | (0.062) | (0.589) | (0.054) | (0.542) | (0.000) | (0.004) | (0.000) | (0.000) | (0.073) | |
| −0.139 | 0.021 | 0.016 | 0.02 | −0.101 | 0.056 | |||||||||
| (0.185) | (0.645) | (0.845) | (0.018) | (0.599) | (0.017) | (0.165) | (0.152) | (0.042) | (0.000) | (0.000) | (0.010) | (0.036) | (0.030) | |
| Adj. | 0.627 | 0.862 | 0.475 | 0.910 | 0.504 | 0.920 | 0.505 | 0.941 | 0.436 | 0.265 | 0.482 | 0.570 | 0.583 | 0.884 |
| Index | AR | AR-G | ES | HAR | HAR-G | HAR-ES | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AEX | 0.034 | −0.012 | −0.003 | ||||||||||||||||
| (0.000) | (0.000) | (0.295) | (0.000) | (0.017) | (0.457) | (0.000) | (0.003) | (0.000) | (0.017) | (0.003) | (0.924) | (0.000) | (0.009) | (0.001) | (0.007) | (0.000) | (0.002) | (0.001) | |
| All Ordinaries | 0.009 | −0.015 | 0.009 | 0.044 | −984.755 | ||||||||||||||
| (0.000) | (0.000) | (0.607) | (0.000) | (0.000) | (0.240) | (0.000) | (0.001) | (0.000) | ( 0.002) | (0.047) | (0.636) | (0.000) | (0.001) | (0.358) | (0.000) | (0.000) | (0.000) | (0.234) | |
| BEL 20 | −0.018 | 42,339.759 | 2774.897 | −4383.604 | |||||||||||||||
| (0.000) | (0.000) | (0.005) | (0.000) | (0.005) | (0.208) | (0.000) | (0.001) | (0.000) | (0.072) | (0.003) | (0.096) | (0.000) | (0.045) | (0.009) | (0.013) | (0.119) | (0.101) | (0.167) | |
| Bovespa | −0.049 | −0.013 | −0.001 | −0.061 | −0.033 | ||||||||||||||
| (0.000) | (0.000) | (0.292) | (0.000) | (0.000) | (0.571) | (0.000) | (0.000) | (0.000) | (0.043) | (0.986) | (0.219) | (0.000) | (0.020) | (0.426) | (0.000) | (0.000) | (0.000) | (0.000) | |
| BSE Sensex | 0.032 | −0.046 | 0.015 | −92.085 | |||||||||||||||
| (0.000) | (0.000) | (0.000) | (0.000) | (0.227) | (0.179) | (0.000) | (0.001) | (0.000) | (0.005) | (0.019) | (0.059) | (0.000) | (0.005) | (0.022) | (0.499) | (0.000) | (0.295) | (0.033) | |
| CAC 40 | 0.016 | 0.009 | 0.053 | 0.001 | 42.540 | ||||||||||||||
| (0.000) | (0.000) | (0.002) | (0.000) | (0.050) | (0.417) | (0.000) | (0.002) | (0.000) | (0.853) | (0.025) | (0.151) | (0.000) | (0.977) | (0.019) | (0.053) | (0.222) | (0.003) | (0.006) | |
| DAX | 0.017 | 0.027 | 0.075 | 0.079 | 0.024 | 22.988 | |||||||||||||
| (0.000) | (0.000) | (0.000) | (0.000) | (0.549) | (0.227) | (0.000) | (0.002) | (0.000) | (0.001) | (0.149) | (0.029) | (0.000) | (0.001) | (0.129) | (0.405) | (0.379) | (0.012) | (0.019) | |
| DJIA | 0.032 | 0.023 | 0.049 | 0.066 | 0.049 | 0.030 | −52.484 | ||||||||||||
| (0.000) | (0.000) | (0.007) | (0.000) | (0.328) | (0.342) | (0.000) | (0.006) | (0.000) | (0.160) | (0.286) | (0.082) | (0.000) | (0.161) | (0.290) | (0.364) | (0.000) | (0.206) | (0.021) | |
| FTSE 100 | −0.001 | 0.019 | −0.006 | 49.035 | −68.857 | ||||||||||||||
| (0.000) | (0.000) | (0.000) | (0.000) | (0.965) | (0.479) | (0.000) | (0.003) | (0.000) | (0.088) | (0.046) | (0.007) | (0.000) | (0.086) | (0.046) | (0.793) | (0.005) | (0.379) | (0.192) | |
| Hang Seng | −0.006 | −0.006 | 0.085 | 0.085 | −0.001 | −380.847 | 10,744.545 | ||||||||||||
| (0.000) | (0.000) | (0.000) | (0.000) | (0.588) | (0.684) | (0.000) | (0.003) | (0.000) | (0.000) | (0.108) | (0.012) | (0.000) | (0.000) | (0.111) | (0.931) | (0.123) | (0.046) | (0.047) | |
| IBEX 35 | −0.012 | −0.018 | 0.032 | 0.033 | −0.011 | 22.545 | |||||||||||||
| (0.000) | (0.000) | (0.000) | (0.000) | (0.434) | (0.386) | (0.000) | (0.000) | (0.000) | (0.539) | (0.019) | (0.001) | (0.000) | (0.527) | (0.022) | (0.481) | (0.620) | (0.092) | (0.021) | |
| IPC | 0.015 | −0.013 | 0.070 | 0.077 | 0.019 | 14,116.551 | |||||||||||||
| (0.000) | (0.000) | (0.000) | (0.000) | (0.358) | (0.395) | (0.000) | (0.000) | (0.000) | (0.000) | (0.231) | (0.075) | (0.000) | (0.000) | (0.193) | (0.269) | (0.003) | (0.001) | (0.016) | |
| Nikkei 225 | 0.027 | −0.023 | 0.069 | 0.032 | −626.898 | ||||||||||||||
| (0.000) | (0.000) | (0.012) | (0.000) | (0.161) | (0.262) | (0.002) | (0.001) | (0.000) | (0.000) | (0.230) | (0.466) | (0.000) | (0.000) | (0.213) | (0.108) | (0.000) | (0.001) | (0.262) | |
| SMI | 0.017 | 0.744 | |||||||||||||||||
| (0.000) | (0.000) | (0.001) | (0.000) | (0.082) | (0.353) | (0.000) | (0.001) | (0.000) | (0.050) | (0.033) | (0.019) | (0.000) | (0.036) | (0.047) | (0.090) | (0.000) | (0.000) | (0.005) | |
| Index | MAE | MSE | QLIKE | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AR | AR-G | ES | HAR | HAR-G | HAR-ES | AR | AR-G | ES | HAR | HAR-G | HAR-ES | AR | AR-G | ES | HAR | HAR-G | HAR-ES | |
| AEX | 1.130 | 1.158 | 1.084 | 1.296 | 1.291 | 1.000 | 1.405 | 1.411 | 1.112 | 2.638 | 2.226 | 1.000 | 1.227 | 1.329 | 2.029 | 1.106 | 2.008 | 1.000 |
| All Ordinaries | 1.145 | 1.267 | 1.224 | 1.412 | 1.464 | 1.000 | 1.687 | 1.450 | 1.634 | 3.457 | 2.404 | 1.000 | 1.039 | 1.164 | 1.249 | 1.028 | 1.424 | 1.000 |
| BEL 20 | 1.112 | 1.224 | 1.062 | 1.493 | 1.344 | 1.000 | 1.442 | 1.412 | 1.177 | 5.360 | 1.749 | 1.000 | 1.193 | 1.303 | 1.098 | 1.158 | 1.538 | 1.000 |
| Bovespa | 1.036 | 1.069 | 1.035 | 1.368 | 1.124 | 1.000 | 1.278 | 1.238 | 0.857 | 4.026 | 1.349 | 1.000 | 1.278 | 1.238 | 0.857 | 4.026 | 1.349 | 1.000 |
| BSE Sensex | 1.299 | 1.435 | 1.220 | 1.303 | 1.366 | 1.000 | 1.302 | 1.348 | 1.099 | 1.770 | 1.505 | 1.000 | 1.210 | 4.871 | 1.396 | 1.223 | 1.184 | 1.000 |
| CAC 40 | 1.113 | 1.314 | 1.174 | 1.446 | 1.400 | 1.000 | 1.315 | 1.404 | 1.657 | 4.538 | 1.622 | 1.000 | 1.194 | 1.643 | 1.406 | 1.118 | 4.650 | 1.000 |
| DAX | 1.106 | 1.198 | 1.119 | 1.354 | 1.288 | 1.000 | 1.251 | 1.316 | 1.369 | 2.990 | 1.478 | 1.000 | 1.165 | 2.146 | 1.083 | 1.133 | 3.148 | 1.000 |
| DJIA | 1.081 | 1.294 | 1.115 | 1.135 | 1.357 | 1.000 | 1.046 | 1.114 | 1.578 | 1.234 | 1.181 | 1.000 | 1.088 | 1.321 | 0.998 | 1.157 | 5.294 | 1.000 |
| FTSE 100 | 1.074 | 1.143 | 1.070 | 1.190 | 1.309 | 1.000 | 1.008 | 1.065 | 1.084 | 1.768 | 1.819 | 1.000 | 1.153 | 1.395 | 1.097 | 1.023 | 15.871 | 1.000 |
| Hang Seng | 1.104 | 1.134 | 1.161 | 1.123 | 1.150 | 1.000 | 1.189 | 1.281 | 2.287 | 1.185 | 1.271 | 1.000 | 1.154 | 1.152 | 1.356 | 1.052 | 1.081 | 1.000 |
| IBEX 35 | 1.051 | 1.045 | 1.069 | 1.208 | 1.1680 | 1.000 | 1.112 | 1.127 | 1.068 | 2.147 | 1.831 | 1.000 | 1.161 | 1.687 | 1.262 | 1.120 | 1.327 | 1.000 |
| IPC | 1.042 | 1.050 | 1.150 | 1.048 | 1.056 | 1.000 | 0.945 | 0.946 | 1.205 | 0.989 | 0.994 | 1.000 | 1.074 | 1.155 | 1.481 | 1.084 | 1.114 | 1.000 |
| Nikkei 225 | 1.096 | 1.152 | 1.025 | 1.072 | 1.162 | 1.000 | 1.097 | 1.152 | 1.121 | 1.161 | 1.196 | 1.000 | 1.109 | 1.334 | 1.556 | 1.176 | 23.127 | 1.000 |
| SMI | 1.317 | 1.441 | 1.181 | 2.083 | 2.677 | 1.000 | 2.666 | 2.206 | 1.425 | 12.200 | 16.264 | 1.000 | 1.245 | 1.729 | 1.071 | 1.280 | 2.380 | 1.000 |
| Index | HAR | AR | HAR | ES | ES | ES | ES | HAR-ES | HAR-ES | HAR-ES | HAR-ES | HAR-ES |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| vs. | vs. | vs. | vs. | vs. | vs. | vs. | vs. | vs. | vs. | vs. | vs. | |
| AR | AR-G | HAR-G | AR | AR-G | HAR | HAR-G | AR | AR-G | HAR | HAR-G | ES | |
| AEX | −1.481 | 1.290 | 1.120 | 1.482 | 0.024 | |||||||
| All Ordinaries | −0.308 | 1.035 | −1.223 | −0.501 | −0.461 | |||||||
| BEL 20 | −0.823 | −1.555 | −0.943 | −1.644 | ||||||||
| Bovespa | 1.329 | −0.849 | 0.087 | −1.310 | ||||||||
| BSE Sensex | 0.102 | −1.014 | 0.317 | 1.569 | −0.962 | 1.038 | −1.072 | −1.516 | ||||
| CAC 40 | −1.630 | |||||||||||
| DAX | −0.676 | −1.399 | −1.256 | −1.511 | −0.740 | −1.632 | −1.330 | |||||
| DJIA | 0.802 | −1.118 | −1.615 | −1.522 | −1.162 | −1.030 | −1.158 | 0.024 | ||||
| FTSE 100 | −1.155 | −1.286 | −0.516 | −1.274 | 0.861 | −1.280 | −0.452 | −1.289 | −1.365 | |||
| Hang Seng | 0.096 | −1.638 | −1.574 | |||||||||
| IBEX 35 | −0.913 | −1.323 | 0.836 | −1.028 | 1.193 | −0.445 | ||||||
| IPC | 0.344 | −1.624 | −1.373 | 1.422 | 1.130 | 1.385 | 1.282 | |||||
| Nikkei 225 | 0.497 | −1.200 | 1.361 | −1.179 | −1.432 | −1.210 | ||||||
| SMI | 0.602 | −1.016 |
| Index | MAE | MSE | QLIKE | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AR | AR-G | ES | HAR | HAR-G | HAR-ES | AR | AR-G | ES | HAR | HAR-G | HAR-ES | AR | AR-G | ES | HAR | HAR-G | HAR-ES | |
| AEX | 0.065 | 0.065 | 0.065 | 0.065 | 0.065 | 1.000 | 0.346 | 0.346 | 0.437 | 0.346 | 0.346 | 1.000 | 0.007 | 0.007 | 0.007 | 0.014 | 0.007 | 1.000 |
| All Ordinaries | 0.100 | 0.092 | 0.100 | 0.100 | 0.092 | 1.000 | 0.273 | 0.273 | 0.273 | 0.273 | 0.273 | 1.000 | 0.802 | 0.150 | 0.150 | 0.802 | 0.135 | 1.000 |
| BEL 20 | 0.010 | 0.001 | 0.052 | 0.001 | 0.001 | 1.000 | 0.258 | 0.258 | 0.336 | 0.223 | 0.223 | 1.000 | 0.013 | 0.000 | 0.062 | 0.062 | 0.000 | 1.000 |
| Bovespa | 0.234 | 0.176 | 0.323 | 0.036 | 0.036 | 1.000 | 0.446 | 0.446 | 1.000 | 0.237 | 0.237 | 0.446 | 1.000 | 0.073 | 0.073 | 0.073 | 0.073 | 0.917 |
| BSE Sensex | 0.031 | 0.016 | 0.031 | 0.031 | 0.029 | 1.000 | 0.391 | 0.382 | 0.467 | 0.382 | 0.382 | 1.000 | 0.239 | 0.163 | 0.163 | 0.239 | 0.239 | 1.000 |
| CAC 40 | 0.012 | 0.001 | 0.012 | 0.012 | 0.001 | 1.000 | 0.223 | 0.223 | 0.223 | 0.154 | 0.154 | 1.000 | 0.023 | 0.023 | 0.023 | 0.066 | 0.023 | 1.000 |
| DAX | 0.007 | 0.007 | 0.087 | 0.007 | 0.007 | 1.000 | 0.190 | 0.163 | 0.190 | 0.121 | 0.121 | 1.000 | 0.257 | 0.257 | 0.257 | 0.257 | 0.257 | 1.000 |
| DJIA | 0.044 | 0.003 | 0.044 | 0.044 | 0.002 | 1.000 | 0.572 | 0.332 | 0.094 | 0.306 | 0.094 | 1.000 | 0.646 | 0.034 | 1.000 | 0.351 | 0.034 | 0.980 |
| FTSE 100 | 0.109 | 0.071 | 0.073 | 0.073 | 0.063 | 1.000 | 0.866 | 0.326 | 0.326 | 0.326 | 0.326 | 1.000 | 0.067 | 0.067 | 0.283 | 0.647 | 0.067 | 1.000 |
| Hang Seng | 0.064 | 0.064 | 0.064 | 0.064 | 0.052 | 1.000 | 0.267 | 0.267 | 0.267 | 0.267 | 0.267 | 1.000 | 0.076 | 0.089 | 0.025 | 0.184 | 0.139 | 1.000 |
| IBEX 35 | 0.364 | 0.364 | 0.119 | 0.119 | 0.119 | 1.000 | 0.734 | 0.446 | 0.734 | 0.446 | 0.446 | 1.000 | 0.066 | 0.026 | 0.066 | 0.066 | 0.026 | 1.000 |
| IPC | 0.357 | 0.357 | 0.005 | 0.346 | 0.261 | 1.000 | 1.000 | 0.829 | 0.161 | 0.776 | 0.551 | 0.776 | 0.188 | 0.188 | 0.188 | 0.188 | 0.188 | 1.000 |
| Nikkei 225 | 0.027 | 0.013 | 0.373 | 0.086 | 0.018 | 1.000 | 0.374 | 0.374 | 0.374 | 0.374 | 0.374 | 1.000 | 0.189 | 0.098 | 0.086 | 0.189 | 0.086 | 1.000 |
| SMI | 0.070 | 0.070 | 0.070 | 0.070 | 0.070 | 1.000 | 0.300 | 0.300 | 0.300 | 0.300 | 0.300 | 1.000 | 0.008 | 0.008 | 0.366 | 0.008 | 0.008 | 1.000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ben El Hadj Said, I.; Slim, S. The Dynamic Relationship between Investor Attention and Stock Market Volatility: International Evidence. J. Risk Financial Manag. 2022, 15, 66. https://doi.org/10.3390/jrfm15020066
Ben El Hadj Said I, Slim S. The Dynamic Relationship between Investor Attention and Stock Market Volatility: International Evidence. Journal of Risk and Financial Management. 2022; 15(2):66. https://doi.org/10.3390/jrfm15020066
Chicago/Turabian StyleBen El Hadj Said, Imene, and Skander Slim. 2022. "The Dynamic Relationship between Investor Attention and Stock Market Volatility: International Evidence" Journal of Risk and Financial Management 15, no. 2: 66. https://doi.org/10.3390/jrfm15020066
APA StyleBen El Hadj Said, I., & Slim, S. (2022). The Dynamic Relationship between Investor Attention and Stock Market Volatility: International Evidence. Journal of Risk and Financial Management, 15(2), 66. https://doi.org/10.3390/jrfm15020066