
Evidential Strategies in Financial Statement Analysis: A Corpus Linguistic Text Mining Approach to Bankruptcy Prediction


{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
RQ: How can evidential strategies in financial statements be used for corporate bankruptcy prediction?
2. Theoretical Foundations
2.1. Reviewing the Use of Textual Data in Corporate Bankruptcy Prediction
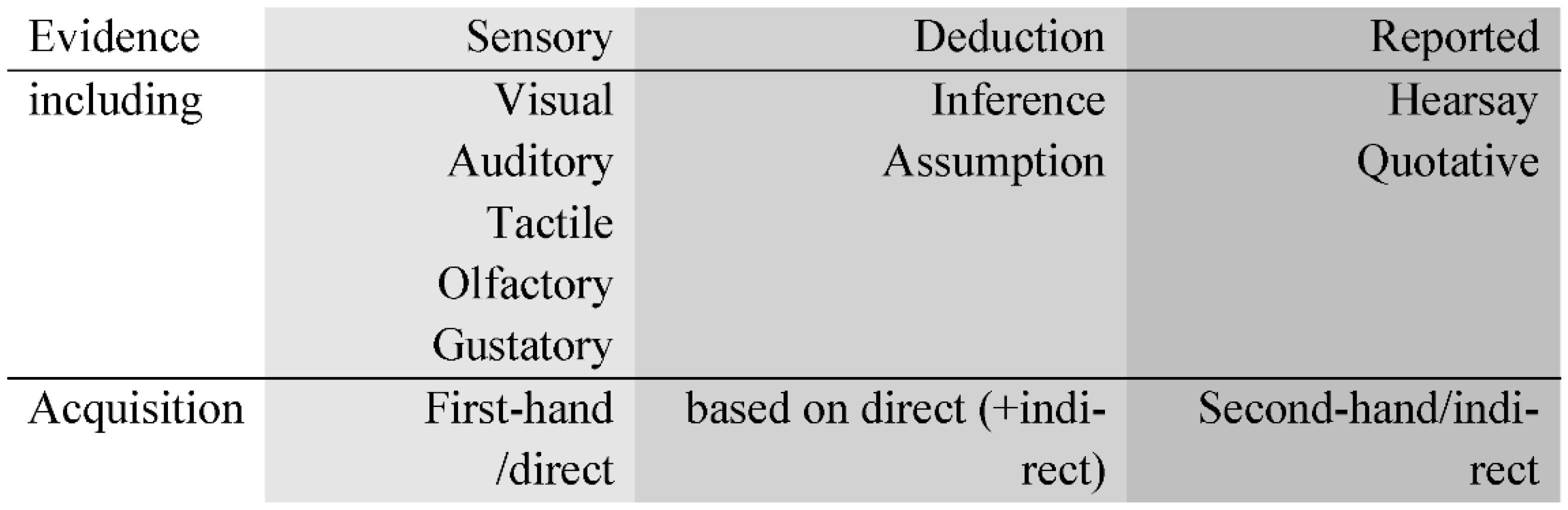
2.2. Reviewing Evidential Strategies
3. Research Methodology and Dataset
4. Data Analysis and Results
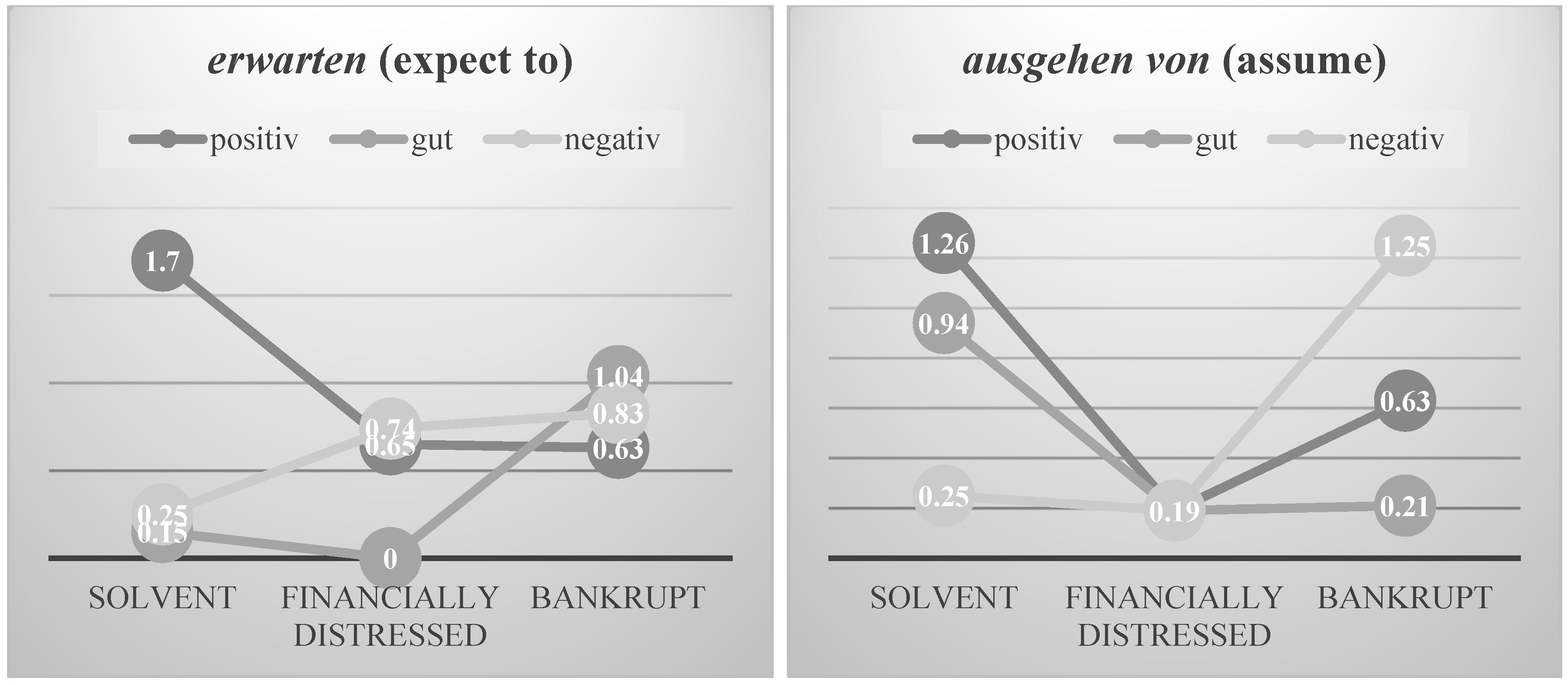
4.1. Corpus of Solvent Companies
- Hierbei wird davon ausgegangen, dass die Marktteilnehmer in ihrem besten wirtschaftlichen Interesse handeln. (Herein, it will be assumed that all market participants act in their best economic self-interest.)
- Insgesamt erwarten wir, dass sich unsere Geschäfte zufriedenstellend entwickeln werden. (Overall, we expect that our business dealings will develop satisfactorily.)
- 3.
- Wir gehen daher davon aus, dass das Schadensereignis keine negativen Auswirkungen auf die weitere Geschäftstätigkeit von Obermeyer Planen + Beraten haben wird. (We thus assume that the damaging event will have no negative impact on the further contractual capability of Obermeyer Planen + Beraten.)
- 4.
- Das Unternehmen geht jedoch davon aus, dass die Rechtsstreitigkeiten ohne nennenswerte negative Auswirkungen auf die Finanz- oder Ertragslage des Unternehmens beigelegt werden können. (The company assumes, however, that the legal disputes will be able to be put aside without any noteworthy negative impact on the financial or profit performance of the company.)
- 5.
- Wir gehen dabei davon aus, dass sich nicht erneut signifikante negative Sondereinflüsse, auch nicht aus den bestehenden Pensionsverpflichtungen, ergeben werden. (Herein, we assume that new significant negative special influences will not ensue, not even from the existing pension obligations.)
- 6.
- Am 31. Dezember 2015 wird nicht erwartet, dass diese Angelegenheit wesentliche negative Auswirkungen auf die Betriebsergebnisse, Liquidität oder finanzielle Situation haben wird. (As of 31 December 2015, it is not expected that this matter will have a crucial negative effect on results of operations, liquidity or financial condition.)
- 7.
- Durch unsere globale Aufstellung gehen wir davon aus, dass sich positive und negative Effekte weitestgehend ausgleichen und damit beherrschbar sind. (Due to our global positioning we assume that the positive and negative effects will largely offset each other and thus remain manageable.)
- 8.
- Wir erwarten, dass wir diese negativen Einflüsse mit neuen innovativen Produkten bzw. Zustellungssystemen ausgleichen können. (We expect that we can offset these negative influences with new innovative products or delivery systems.)
- 9.
- Insbesondere werden die Investitionen die Basis für die Einrichtung der C-SMC-Produktion durch MCHC legen. Daher gehen wir davon aus, dass wir 2017 das negative EBIT deutlich reduzieren können. (In particular, the investment will lay the foundation for the establishment of C-SMC production by MCHC. Therefore we assume that we can reduce the negative EBIT drastically in 2017.)
- 10.
- Es ist zu erwarten, dass das Unternehmen die positive Entwicklung der vergangenen Jahre durch die hoch qualifizierten Mitarbeiter, die sehr gute Ausstattung des Maschinen- und Anlagenparks sowie dem breiten Know-how des Unternehmens weiter fortsetzen kann. (It is to be expected that the company is able to continue the positive progress of the past years due to the highly-qualified employees, the very good equipment of the machine and facility park, as well as the broad know-how of the company.)
- 11.
- Wir erwarten, dass die insgesamt positive Entwicklung der vergangenen Jahre auch in den kommenden Jahren fortgesetzt werden kann. (We expect that the overall positive development of the past years will be able to be continued in the coming years.)
- 12.
- Wir erwarten, dass sich diese Maßnahme 2016 positiv auf das Kapitalanlageergebnis auswirken wird. (We expect that this measure will have a positive effect on the capital investment outcome in 2016.)
- 13.
- Insbesondere ist zu erwarten, dass die gute Marktposition des Unternehmens in Lateinamerika und Afrika weiter ausgebaut werden kann. (Especially, it is to be expected, that the good market position of the company in Latin America and Africa can be expanded further.)
- 14.
- Wir erwarten, dass sich der gute Ausbildungsstand und die hohe Leistungsbereitschaft unserer Mitarbeiter auch künftig positiv auf das Verhältnis unserer Mitglieder und Kunden zu ihrer Bank auswirken werden. (We expect that the high level of training and commitment of our employees will also have a positive impact on the relationship between our members and customers and their bank in the future.)
- 15.
- Zusammenfassend ist daher davon auszugehen, dass die gute Auftragsentwicklung des Berichtsjahres im Jahr 2016 noch einmal übertroffen werden kann. (Summarizing this, it is thus assumed that the good ETO of the 2016 report will be able to be surpassed once again.)
- 16.
- Es ist davon auszugehen, dass sich dieser positive Trend auch in 2016 fortsetzen wird. (It is assumed that this positive trend will also continue in 2016.)
4.2. Corpus of Bankrupt Companies
- 17.
- Die Geschäftsführung schätzt die Risiken als überschaubar ein und geht derzeit davon aus, dass sie keinen nennenswerten negativen Einfluss auf die Entwicklung der Gesellschaft haben werden. (The management evaluates the risk as manageable and currently assumes that they will have no noteworthy negative impact on the development of the company.)
- 18.
- Es ist nicht zu erwarten, dass dieser negative Sondereffekt sich in den Folgejahren wiederholen wird. (It is not to be expected that this negative special effect will repeat in the years to follow.)
- 19.
- Die Gesellschaft geht davon aus, dass diese negativen Einflüsse auf Umsatz und Ergebnis im 2. Halbjahr annähernd ausgeglichen werden können. (The company assumes that the negative influences on sales and earnings can be approximately offset again.)
- 20.
- Mit hoher Wahrscheinlichkeit ist zu erwarten, dass die negativen Folgen für die Bank umso stärker sind, je länger die Pandemie anhält. (It is to be expected with a high degree of certainty that the negative implications for the bank will be the greater the longer the pandemic lasts.)
- 21.
- Es ist zu erwarten, dass die negativen Folgen für die Wirtschaftsleistung unserer Bank umso stärker sind, je länger die Pandemie anhält. (It is to be expected that the negative implications for the economic performance of our bank will be the greater the longer the pandemic lasts.)
- 22.
- Die Geschäftsleitung erwartet, dass sie aufgrund der guten Branchenlage im E-Commerce Umfeld sowie durch zusätzliche Expansion in andere Produktsegmente, im Jahr 2019 ein Umsatzwachstum von 8-10% im Vergleich zum Vorjahr erreichen kann. (The management expects that in 2019 it can achieve a turnover growth of 8–10% in comparison to the previous year due to the good industry position in the e-commerce environment and further expansion in other product segments.)
- 23.
- Wir erwarten, dass sich diese positive Tendenz auch in den folgenden Jahren als stabilisierender Faktor und signifikanter Wettbewerbsvorteil für das Unternehmen erweist. (We expect that this positive tendency will prove to be a stabilizing factor and significant competitive advantage for the company in the years to come.)
- 24.
- Bilanzierung und Bewertung erfolgten trotz bilanzieller Überschuldung der Gesellschaft zu Fortführungswerten, weil die Geschäftsführung davon ausgeht, dass aufgrund der vorliegenden positiven Fortführungsprognose und der damit von der finanzierenden Bank genehmigten neuen Finanzierungsstruktur die Fortführung der Unternehmenstätigkeit überwiegend wahrscheinlich ist. (Despite the company’s sheet over-indebtedness, balancing and appraisal were done at going concern values because the management assumes that the continuation of the company’s operation is predominantly likely due to the positive going concern forecast and the concomitant approval of the new financing structure by the financing bank.)
- 25.
- Nach allen Informationen die uns vorliegen, müssen wir auch für das Jahr 2017 davon ausgehen, dass unsere Branche von den positiven Rahmenbedingungen speziell in Deutschland nicht profitieren konnte und erhebliche Einbrüche im Umsatz mit Gardinen und Dekostoffen (speziell im Mittelpreissegment) zu verzeichnen waren. (Based on all the information available to us, we must also assume for 2017 that our industry could not benefit from the positive underlying conditions, especially in Germany, and that there were significant downturns in sales of curtains and decorative fabrics (especially in the mid-price segment).)
4.3. Corpus of Financially Distressed Companies
- 26.
- Mit hoher Wahrscheinlichkeit lässt sich jedoch bereits jetzt erwarten, dass die negative Folgen für die Bank umso stärker sind, je länger die Pandemie anhält. (However, it is already to be expected with a high degree of certainty that the negative impact will be the greater the longer the pandemic lasts.)
- 27.
- Wir beschreiben diese Sachverhalte in unserem Bestätigungsvermerk, es sei denn, Gesetze oder andere Rechtsvorschriften schließen die öffentliche Angabe des Sachverhalts aus oder wir bestimmen in äußerst seltenen Fällen, dass ein Sachverhalt nicht in unserem Bestätigungsvermerk mitgeteilt werden sollte, weil vernünftigerweise erwartet wird, dass die negativen Folgen einer solchen Mitteilung deren Vorteile für das öffentliche Interesse übersteigen würden. (We describe these matters in our auditor’s report unless law or regulation precludes public disclosure of the matter or, in extremely rare circumstances, we determine that a matter should not be communicated in our auditor’s report because the negative repercussions of such communication would logically be expected to outweigh its public interest benefits.)
- 28.
- Die Geschäftsleitung der flatex Bank AG beobachtet die politischen Entwicklungen kritisch, erwartet jedoch, dass eventuell negative Auswirkungen durch den weiteren Ausbau der Aktivitäten mit den bestehenden Partnern sowie neuen Geschäftspartnern im Mandantengeschäft als auch durch neue Handelsprodukte abgemildert werden können. (The management of flatex Bank AG is keeping a critical eye on political developments, but expects that any negative effects can be mitigated by further expanding activities with existing partners and new business partners in the client business, as well as through new trading products.)
- 29.
- Das Produkt Logistics übertrifft in den ersten acht Monaten die budgetierten Erwartungen und wir erwarten, dass dieser positive Trend bis Ende 2017 anhält. (The Logistics product exceeded budgeted expectations in the first eight months and we expect that this positive trend continues until the end of 2017.)
- 30.
- Es wird erwartet, dass sich die positive gesamtwirtschaftliche Entwicklung insgesamt fortsetzt. (It is expected that the positive macroeconomic development will continue overall.)
5. Discussion and Implications
5.1. Contributions to Literature
5.2. Feature Engineering Process and Practical Implications
5.3. Limitations and Future Research Opportunities
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aikhenvald, Alexandra Y. 2004. Evidentiality. Oxford: Oxford University Press. [Google Scholar]
- Altman, Edward I. 1968. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. The Journal of Finance 4: 589–609. [Google Scholar] [CrossRef]
- Altman, Edward I., Robert G. Haldemann, and Paul Narayanan. 1977. ZETA™ analysis: A new model to identify bankruptcy risk of corporations. Journal of Banking and Finance 1: 29–54. [Google Scholar] [CrossRef]
- Balasubramanian, Senthil A., G. S. Radhakrishna, Periaiya Sridevi, and Thamaraiselvan Natarajan. 2019. Modeling corporate financial distress using financial and non-financial variables. International Journal of Law and Management 3: 457–84. [Google Scholar] [CrossRef]
- Besnard, Anne-Laure. 2017. BE likely to and BE expected to, epistemic modality or evidentiality? In Evidentiality Revisited. Edited by Juana I. Marín Arrese, Gerda Haßler and Marta Carretero. Amsterdam: John Benjamins Publishing Company, pp. 249–69. [Google Scholar]
- Boas, Franz. 1938. Language in General Anthropology. Edited by F. Boas. Boston: D.C. Heath and Company. [Google Scholar]
- Bureau van Dijk. 2021. Amadeus Database. Available online: https://www.bvdinfo.com/de-de/unsere-losungen/daten/international/amadeus (accessed on 3 November 2021).
- Bushee, Brian J., Ian A. Gow, and Daniel J. Taylor. 2018. Linguistic Complexity in Firm Disclosures: Obfuscation or Information? Journal of Accounting Research 1: 85–121. [Google Scholar] [CrossRef]
- Caserio, Carlo, Delio Panaro, and Sara Trucco. 2020. Management discussion and analysis: A tone analysis on US financial listed companies. Management Decision 3: 510–25. [Google Scholar] [CrossRef]
- Chafe, Wallace L. 1986. Evidentiality: The Linguistic Coding of Epistemology. Norwood: Ablex Publishing Corp. [Google Scholar]
- Chou, Chi-Chun, Janie C. Chang, Chen-Lung Chin, and Wei-Ta Chiang. 2018. Measuring the Consistency of Quantitative and Qualitative Information in Financial Reports: A Design Science Approach. Journal of Emerging Technologies in Accounting 2: 93–109. [Google Scholar] [CrossRef]
- Elsevier. 2022. Scopus. Available online: https://www.scopus.com (accessed on 28 September 2022).
- Fetzer, Anita. 2014. Foregrounding evidentiality in (English) academic discourse: Patterned co-occurrences of the sensory perception verbs seem and appear. Intercultural Pragmatics 3: 333–55. [Google Scholar] [CrossRef]
- Fromm, Hansjörg, Thiemo Wambsganss, and Matthias Söllner. 2019. Towards a Taxonomy of Text Mining Features. Paper presented at the ECIS Proceedings 2019, Stockholm, Sweden, June 8–14. [Google Scholar]
- Hájek, Petr, Vladimir Olej, and Renáta Myšková. 2014. Forecasting corporate financial performance using sentiment in annual reports for stakeholder’s decision-making. Technological and Economic Development of Economy 4: 721–38. [Google Scholar] [CrossRef]
- Hardman, Martha J. 1986. Data-source Marking in the Jaqi Languages. In Evidentiality: The Linguistic Coding of Epistemology. New York: Ablex, p. 136. [Google Scholar]
- HGB. 2021. Handelsgesetzbuch §289—Inhalt des Lageberichts. Available online: https://www.gesetze-im-internet.de/hgb/__289.html (accessed on 15 November 2021).
- Hidalgo-Downing, Laura. 2017. Evidential and Epistemic Stance Strategies in Scientific Communication in Evidentiality Revisited. Edited by Juana I. Marín Arrese, Gerda Haßler and Marta Carretero. Amsterdam: John Benjamins Publishing Company, pp. 225–48. [Google Scholar]
- Humpherys, Sean L. 2009. Discriminating Fradulent Financial Statements by Identifying Linguistic Hedging. Paper presented at the AMCIS Proceedings 2009, San Francisco, CA, USA, August 6–9. [Google Scholar]
- Jones, Stewart. 2017. Corporate bankruptcy prediction: A high dimensional analysis. Review of Accounting Studies 3: 1366–422. [Google Scholar] [CrossRef]
- Kirkos, Efstathios. 2015. Assessing methodologies for intelligent bankruptcy prediction. Artificial Intelligence Review 1: 83–123. [Google Scholar] [CrossRef]
- Kloptchenko, Antonia, Camilla Magnusson, Barbro Back, Ari Visa, and Hannu Vanharanta. 2004a. Mining Textual Contents of Financial Reports. The International Journal of Digital Accounting Research 7: 1–29. [Google Scholar] [CrossRef]
- Kloptchenko, Antonina, Tomas Eklund, Jonas Karlsson, Barbro Back, Hannu Vanharanta, and Ari Visa. 2004b. Combining data and text mining techniques for analysing financial reports. Intelligent Systems in Accounting, Finance & Management 1: 29–41. [Google Scholar] [CrossRef]
- Lohmann, Christian, and Thorsten Ohliger. 2020. Bankruptcy prediction and the discriminatory power of annual reports: Empirical evidence from financially distressed German companies. Journal of Business Economics 1: 137–72. [Google Scholar] [CrossRef]
- Loughran, Tim, and Bill McDonald. 2011. When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks. The Journal of Finance 1: 35–65. [Google Scholar] [CrossRef]
- Loughran, Tim, and Bill McDonald. 2016. Textual Analysis in Accounting and Finance: A Survey. Journal of Accounting Research 4: 1187–230. [Google Scholar] [CrossRef]
- Luo, Yan, and Linying Zhou. 2020. Textual tone in corporate financial disclosures: A survey of the literature. International Journal of Disclosure and Governance 17: 101–10. [Google Scholar] [CrossRef]
- Magnusson, Camilla, Antti Arppe, Tomas Eklund, Barbro Back, Hannu Vanharanta, and Ari Visa. 2005. The language of quarterly reports as an indicator of change in the company’s financial status. Information & Management 4: 561–74. [Google Scholar] [CrossRef]
- Marín Arrese, Juana I. 2017. Multifunctionality of Evidential Expressions in Discourse Domains and Genres in Evidentiality Revisited. Edited by Juana I. Marín Arrese, Gerda Haßler and Marta Carretero. Amsterdam: John Benjamins Publishing Company, pp. 195–223. [Google Scholar]
- Mayew, William J., Mani Sethuraman, and Mohan Venkatachalam. 2015. MD&A disclosure and the firm’s ability to continue as a going concern. The Accounting Review 90: 1622–51. [Google Scholar] [CrossRef]
- Myšková, Renáta, and Petr Hájek. 2020. Mining risk-related sentiment in corporate annual reports and its effect on financial performance. Technological and Economic Development of Economy 6: 1422–43. [Google Scholar] [CrossRef]
- Nartey, Mark, and Isaac N. Mwinlaaru. 2019. Towards a decade of synergising corpus linguistics and critical discourse analysis: A meta-analysis. Corpora 2: 203–35. [Google Scholar] [CrossRef]
- Nießner, Tobias, Robert C. Nickerson, and Matthias Schumann. 2021. Towards a taxonomy of AI-based methods in Financial Statement Analysis. Paper presented at the AMCIS Proceedings 2021, Montreal, QC, Canada, August 9–13. [Google Scholar]
- Oswalt, Robert. L. 1986. The Evidential System of Kashaya. In Evidentiality: The Linguistic Coding of Epistemology. Edited by Wallace L. Chafe and Johanna Nichols. Norwood: Ablex Publishing Corp, pp. 20–29. [Google Scholar]
- Pamuk, Mustafa, René O. Grendel, and Matthias Schumann. 2021. Towards ML-based Platforms in Finance Industry—An ML Approach to Generate Corporate Bankruptcy Probabilities based on Annual Financial Statements. Paper presented at the ACIS Proceedings 2021, Sydney, Australia, December 6–10. [Google Scholar]
- Partington, Alan. 2004. Utterly content in each other’s company. International Journal of Corpus Linguistics 1: 131–56. [Google Scholar] [CrossRef]
- Partington, Alan. 2015. Evaluative prosody. In Corpus Pragmatics. Edited by Karin Aijmer and Christoph Rühlemann. Cambridge: Cambridge University Press, pp. 279–303. [Google Scholar]
- Pasternak-Malicka, Monika, Anna Ostrowska-Dankiewicz, and Robert Dankiewicz. 2021. Bankruptcy—An assessment of the phenomenon in the small and medium-sized enterprise sector-case of poland. Polish Journal of Management Studies 1: 250–67. [Google Scholar] [CrossRef]
- Remus, Robert, Uwe Quasthoff, and Gerhard Heyer. 2010. SentiWS—A Publicly Available German-language Resource for Sentiment Analysis. Paper presented at the LREC Proceedings 2010, Valletta, Malta, May 17–23. [Google Scholar]
- Roumani, Yazan F., Joseph K. Nwankpa, and Mohan Tanniru. 2020. Predicting firm failure in the software industry. Artificial Intelligence Review 6: 4161–82. [Google Scholar] [CrossRef]
- Schmid, Helmut, and Florian Laws. 2008. Estimation of conditional probabilities with decision trees and an application to fine-grained POS tagging. Paper presented at the Coling 2008 Proceedings, Manchester, UK, August 18–22. [Google Scholar]
- Shirata, Cindy Y., Hironori Takeuchi, Shiho Ogino, and Hideo Watanabe. 2011. Extracting Key Phrases as Predictors of Corporate Bankruptcy: Empirical Analysis of Annual Reports by Text Mining. Journal of Emerging Technologies in Accounting 8: 31–44. [Google Scholar] [CrossRef]
- Sinclair, John, ed. 2004. Trust the Text: Language, Corpus and Discourse. London: Routledge. [Google Scholar]
- Smith, Matthew, and Francisco Alvarez. 2021. Predicting Firm-Level Bankruptcy in the Spanish Economy Using Extreme Gradient Boosting. Computational Economics 59: 263–95. [Google Scholar] [CrossRef]
- spaCy v3.2. 2021. spaCy: Industrial-Strength NLP. Available online: https://github.com/explosion/spaCy (accessed on 15 November 2021).
- Tanaka, Katsuyuki, Takuo Higashide, Takuji Kinkyo, and Shigeyuki Hamori. 2019. Analyzing industry-level vulnerability by predicting financial bankruptcy. Economic Inquiry 4: 2017–34. [Google Scholar] [CrossRef]
- Veganzones, David, and Eric Severin. 2021. Corporate failure prediction models in the twenty-first century: A review. European Business Review 2: 204–26. [Google Scholar] [CrossRef]
- Wei, Lu, Guowen Li, Xiaoqian Zhu, and Jianping Li. 2019. Discovering bank risk factors from financial statements based on a new semi-supervised text mining algorithm. Accounting & Finance 3: 1519–52. [Google Scholar] [CrossRef]
- Wodak, Ruth. 2013. Critical Discourse Analysis. Los Angeles: SAGE. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nießner, T.; Gross, D.H.; Schumann, M. Evidential Strategies in Financial Statement Analysis: A Corpus Linguistic Text Mining Approach to Bankruptcy Prediction. J. Risk Financial Manag. 2022, 15, 459. https://doi.org/10.3390/jrfm15100459
Nießner T, Gross DH, Schumann M. Evidential Strategies in Financial Statement Analysis: A Corpus Linguistic Text Mining Approach to Bankruptcy Prediction. Journal of Risk and Financial Management. 2022; 15(10):459. https://doi.org/10.3390/jrfm15100459
Chicago/Turabian StyleNießner, Tobias, Daniel H. Gross, and Matthias Schumann. 2022. "Evidential Strategies in Financial Statement Analysis: A Corpus Linguistic Text Mining Approach to Bankruptcy Prediction" Journal of Risk and Financial Management 15, no. 10: 459. https://doi.org/10.3390/jrfm15100459
APA StyleNießner, T., Gross, D. H., & Schumann, M. (2022). Evidential Strategies in Financial Statement Analysis: A Corpus Linguistic Text Mining Approach to Bankruptcy Prediction. Journal of Risk and Financial Management, 15(10), 459. https://doi.org/10.3390/jrfm15100459