
Know Your Clients’ Behaviours: A Cluster Analysis of Financial Transactions



Abstract
1. Introduction
- Objective and subjective KYC data have little influence on trading behaviours.
- The distribution of risk tolerance across each clusters’ trading behavior is found to be similar, showing that trading behaviours may, on occasion, be inconsistent with the KYC-generated risk tolerance.
- KYC criteria appear to concentrate investors within narrow and rigid ‘swim lanes’ and appear to do a poor job of accommodating trading behaviours to the extremes—either highly risk-averse investors or those seeking higher risks.
- Cluster 1—active investors who trade frequently, in large amounts and appear sensitive to market influences,
- Cluster 2—younger savers who make regular, smaller deposits using automated platforms such as preauthorized chequing (PACs) and dollar cost averaging,
- Cluster 3—“just in time” savers who make infrequent trades at seemingly random intervals,
- Cluster 4—older investors who make regular withdrawals and cash out dividends and interest payments, and
- Cluster 5—systematic savers who make larger trades but make use of automation for predictable deposits and re-balancing.
2. Literature Review
2.1. Investment Suitability and Know Your Client
2.2. Trading Behavior
2.3. Machine Learning Algorithms in Finance
3. Data Description and Feature Engineering for Behavioral Finance
3.1. Data Description and Processing
3.2. Feature Engineering
4. Clustering Theory and Methods
4.1. k-Prototypes Clustering
- each client is put into exactly one cluster;
- clients within a cluster have similar attributes; and
- clients in different clusters have dissimilar attributes.
- Initialize the centroid (location) of the clusters by selecting k clients as “prototype” centroids.
- Allocate the clients to the clusters with the closest centroid.
- Compute an overall cost of the allocation by computing total distance of all clients from their assigned centroids.
- Update cluster centroids.
- Re-allocate the clients to the clusters with the closest (updated) centroid.
- Compute the overall cost by computing total distance.
- Iterate steps 4–6 until there is no change in the overall cost and output the clusters.
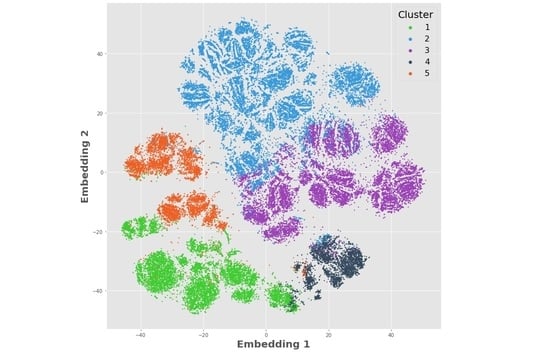
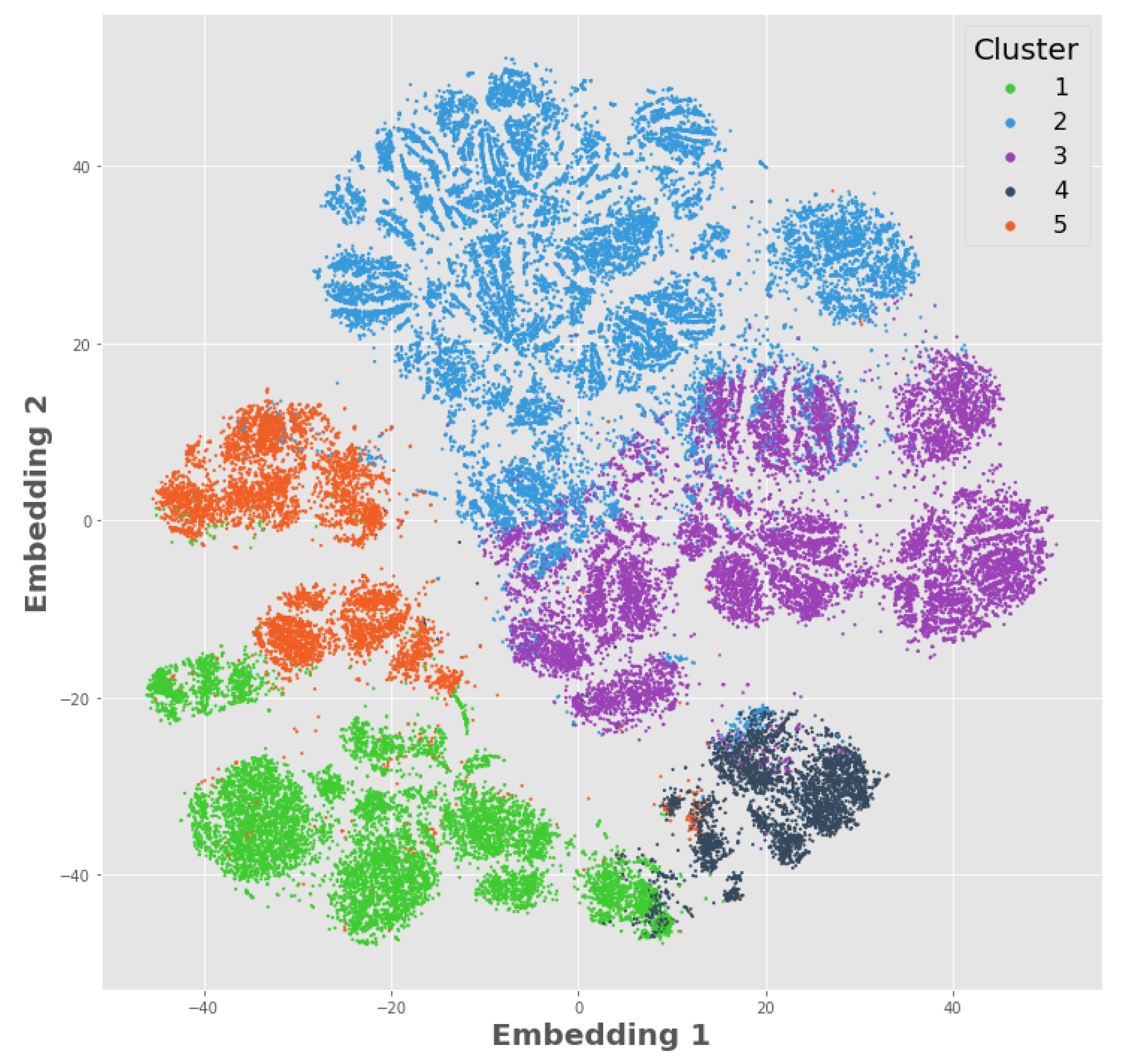
4.2. Visualizing Clusters—t-Distributed Stochastic Neighbor Embeddings
5. Results
5.1. Choosing the Optimal Number of Clusters
5.2. Cluster Visualization Using t-SNE
5.3. Within Cluster Analysis
- Clusters 1 (green) and 5 (orange) are similar in their demographics and trade types, but cluster 5 trades less often with smaller periodic trade sizes.
- Cluster 2 (blue) is distinct from the others where they are largely inactive in their trading.
- Clusters 3 (purple) and 4 (gray) are similar, except that cluster 3 makes larger, less frequent trades and cluster 4 utilizes larger systematic trades.
- For third-party-initiated trades, cluster 4 has a relatively high trade amount and the largest volatility. Cluster 1 has similarly high trade amounts, but less volatility. Clusters 3 and 5 have very similar trade amounts and volatilities that are smaller than the trade amounts and volatilities of clusters 1 and 4. Cluster 2 has the lowest average trade size and volatility.
- For systematic trades, a similar pattern to third-party-initiated trades is reflected. Clusters 1 and 4 are again similar in the trade amount and volatility, with cluster 4 having slightly larger amounts except in June. Clusters 3 and 5 have almost identical average trade amounts except in August, and cluster 2 has the smallest average trade amount. An interesting aspect of all clusters is the peaks for the average trade amount evident in January and June.
- Cluster 1 dominates the periodic trade amounts, while cluster 2 has almost zero periodic trade amounts on average, with very little volatility. Clusters 3 to 5 have similar trade amounts and volatilities, except in February and March when there is a slight peak before trending down for clusters 3 and 5. Clusters 3 to 5 all have an uptick in the average trade amount in July.
5.4. From Data to People—Personas
- Cluster 1: Active Traders (19% of investors) trade frequently (weekly and monthly) and in large amounts. The pattern of trades is seemingly random and initiated manually. These investors had investments across a spectrum of accounts (mainly registered savings plans (RSPs) and TFSAs), and were of an “average” age distribution and demographic. They had a derived risk tolerance rating that averaged 3.19 with standard deviation 0.63, where 1 is a low or preservative risk tolerance and 5 is high or aggressive.
- Cluster 2: Early Savers (36%) never actively trade and instead rely on systematic transactions (auto-withdrawal, pre-authorized contribution, asset allocations). This group tended to have investments in cash accounts and to be younger. They had a derived risk tolerance rating that averaged 3.18 with standard deviation 0.75.
- Cluster 3: Just-In-Time (27%) initiate trades manually but far less frequently than Cluster 1 and in smaller amounts. These investors had investments across a spectrum of accounts (RSPs, TFSAs, etc.), and were of an “average” age and demographic. They had a derived risk tolerance rating that averaged 3.12 with standard deviation 0.73.
- Cluster 4: Older Investors (7%) trade infrequently and the trades were either initiated systematically or from a third-party (pre-authorized withdrawals, dividends and other disbursements). This cluster had an above average concentration of RIFs, and tended to be older. They had a derived risk tolerance rating that averaged 2.95 with standard deviation 0.71.
- Cluster 5: Systematic Savers (12%) trade recurrently (every 60, 90, or 120 days), in small amounts driven by systematic processes (dollar cost averaging) and periodic trading. These investors had investments across a spectrum of accounts (RSPs, TFSAs etc.), and of an “average” age and demographics. They had a derived risk tolerance rating that averaged 3.19 with standard deviation 0.76.
6. Discussion and Future Plans
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANOVA | Analysis of variance |
| AUA | Assets under administration |
| CAD | Canadian dollars |
| DB | Davies–Bouldin |
| EFT | Electronic funds transfer |
| FINRA | Financial Industry Regulatory Authority |
| IIROC | Investment Industry Regulatory Organization of Canada |
| KYC | Know your client |
| KYP | Know your product |
| RFM | Recency, frequency, monetary |
| RFMP | RFM profile |
| RSPs | Registered savings plans |
| RT | Risk tolerance |
| SRO | Self-regulatory organization |
| SRR | Security risk ratings |
| t-SNE | t-distributed stochastic neighbour embeddings |
| TFSA | Tax-free savings account |
Appendix A. Trade Type Descriptions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Examples | Description |
|---|---|---|
| Third-party-initiated | Dividend Income Distribution Interest | Third-party transactions are generated by product manufacturers and vary by product type—securities, ETFs, mutual funds, fixed income etc. The generation of these transactions does not require the participation of the advisor or investor and flow from the manufacturer to the dealer and then to the investor’s account. |
| Systematic | Auto Withdrawal Pre-authorized Contribution Asset Allocation Reinvest Dividend | Systematic transactions are created by the advisor or investor to automatically generate on a prescribed timetable (for example monthly or quarterly). When these transactions are set up, they can run for months or years without change, until such time as the advisor or investor determine a revision is required because of new circumstances. |
| Periodic | Buy (securities) Sell (securities) Contribution Exchange Payment Periodic EFT Withdrawal EFT deposit TFSA Spousal contribution Redeem | Periodic transactions are initiated by the advisor or investor without a prescribed transaction amount or time frame. The description for these transactions can vary by product type—for example, “sell” refers to the disposition of a security, while “redeem” refers to the disposition of a mutual fund. |
Appendix B. Imputation
| Variable | Percent Missing | Action |
|---|---|---|
| Age | 2.2% | Imputed with mean |
| Residency | 0.47% | Imputed with mode |
| Risk tolerance | 14.16% | Removed from clustering algorithm |
| Investment objective | 6.7% | Removed clients with missing information |
| Annual income | 0.13% | Imputed with mean |
| Investment knowledge level | 7.8% | Removed clients with missing information |
| Gender | 8.04% | Removed clients with missing information |
Appendix C. Risk Tolerance Score Distribution Analysis
| Df | Sum Sq | Mean Sq | F Value | Pr (>F) | |
|---|---|---|---|---|---|
| Cluster | 4 | 178.83 | 44.71 | 86.11 | <0.0001 |
| Residuals | 47,556 | 24,690.17 | 0.52 |
| Clusters | Difference in Means | Adjusted p-Value |
|---|---|---|
| 1-2 | −0.017 | 0.345 |
| 1-3 | −0.074 | <0.001 |
| 1-4 | −0.247 | <0.001 |
| 1-5 | −0.008 | 0.973 |
| 2-3 | −0.057 | <0.001 |
| 2-4 | −0.229 | <0.001 |
| 2-5 | 0.010 | 0.900 |
| 3-4 | −0.172 | <0.001 |
| 3-5 | 0.067 | <0.001 |
| 4-5 | 0.239 | <0.001 |
| N | H-Statistic | Degrees of Freedom | p-Value | |
|---|---|---|---|---|
| Cluster | 47,561 | 371.93 | 4 | <1 |
| Cluster Pair | Statistic | p-Value | Adjusted p-Value | ||
|---|---|---|---|---|---|
| 1-2 | 8970 | 17,079 | −0.938 | 0.348 | 0.732 |
| 1-3 | 8970 | 12,701 | −7.293 | <0.001 | <0.001 |
| 1-4 | 8970 | 3175 | −16.691 | <0.001 | <0.001 |
| 1-5 | 8970 | 5636 | 0.333 | 0.739 | 0.739 |
| 2-3 | 17,079 | 12,701 | −7.541 | <0.001 | <0.001 |
| 2-4 | 17,079 | 3175 | −17.202 | <0.001 | <0.001 |
| 2-5 | 17,079 | 5636 | 1.165 | 0.244 | 0.732 |
| 3-4 | 12,701 | 3175 | −12.303 | <0.001 | <0.001 |
| 3-5 | 12,701 | 5636 | 6.638 | <0.001 | <0.001 |
| 4-5 | 3175 | 5636 | 15.789 | <0.001 | <0.001 |
| Cluster Pair | Symmetric KL Estimate |
|---|---|
| 1-2 | 0.0238 |
| 1-3 | 0.0220 |
| 1-4 | 0.0980 |
| 1-5 | 0.0276 |
| 2-3 | 0.0102 |
| 2-4 | 0.0689 |
| 2-5 | 0.0052 |
| 3-4 | 0.0445 |
| 3-5 | 0.0102 |
| 4-5 | 0.0773 |
References
- Abbasi, Ameer Ahmed, and Mohamed Younis. 2007. A survey on clustering algorithms for wireless sensor networks. Computer Communications 30: 2826–41. [Google Scholar] [CrossRef]
- Anderson, Anders. 2013. Trading and under-diversification. Review of Finance 17: 1699–741. [Google Scholar] [CrossRef]
- Anitha, Palaksha, and Malini M. Patil. 2019. RFM model for customer purchase behavior using k-means algorithm. Journal of King Saud University-Computer and Information Sciences. [Google Scholar] [CrossRef]
- Arano, Kathleen, Carl Parker, and Rory Terry. 2010. Gender-based risk aversion and retirement asset allocation. Economic Inquiry 48: 147–55. [Google Scholar] [CrossRef]
- Barber, Brad M., and Terrance Odean. 2001. Boys will be boys: Gender, overconfidence, and common stock investment. The Quarterly Journal of Economics 116: 261–92. [Google Scholar] [CrossRef]
- Barber, Brad M., and Terrance Odean. 2008. All that glitters: The effect of attention and news on the buying behavior of individual and institutional investors. The Review of Financial Studies 21: 785–818. [Google Scholar] [CrossRef]
- Barber, Brad M., and Terrance Odean. 2013. The behavior of individual investors. In Handbook of the Economics of Finance. Amsterdam: Elsevier, vol. 2, pp. 1533–70. [Google Scholar]
- Berry, Michael W., and Malu Castellanos. 2004. Survey of text mining. Computing Reviews 45: 548. [Google Scholar]
- Bilali, Genci. 2011. Know your customer—Or not. University of Toledo Law Review 43: 319. [Google Scholar]
- Birant, Derya. 2011. Data mining using RFM analysis. In Knowledge-Oriented Applications in Data Mining. London: IntechOpen. [Google Scholar]
- Brayman, Shawn, Michael Finke, Ellen Bessner, J. E. Grable, Paul Griffin, and Rebecca Clement. 2015. Current practices for risk profiling in Canada and review of global best practices. In Study Prepared for the Investor Advisory Panel of the Ontario Securities Commission. Available online: https://www.osc.gov.on.ca/documents/en/Investors/iap_20151112_risk-profiling-report.pdf (accessed on 20 January 2021).
- Charles, A., and Ramaiah Kasilingam. 2013. Does the investor’s age influence their investment behaviour? Paradigm 17: 11–24. [Google Scholar] [CrossRef]
- Chaturvedi, Anil, Paul E. Green, and J. Douglas Caroll. 2001. k-modes clustering. Journal of Classification 18: 35–55. [Google Scholar] [CrossRef]
- Che, Limei. 2018. Investor types and stock return volatility. Journal of Empirical Finance 47: 139–61. [Google Scholar] [CrossRef]
- Chen, Gongmeng, Kenneth A. Kim, John R. Nofsinger, and Oliver M. Rui. 2007. Trading performance, disposition effect, overconfidence, representativeness bias, and experience of emerging market investors. Journal of Behavioral Decision Making 20: 425–51. [Google Scholar] [CrossRef]
- Cruciani, Caterina. 2017. Investor Decision-Making and the Role of the Financial Advisor: A Behavioural Finance Approach. Cham: Springer. [Google Scholar]
- Davies, David L., and Donald W. Bouldin. 1979. A cluster separation measure. IEEE Transactions on Pattern Analysis and Machine Intelligence, 224–27. [Google Scholar] [CrossRef]
- de Vos, Nico. 2020. Python Implementations of the k-Modes and k-Prototypes Clustering Algorithms, for Clustering Categorical Data. Available online: https://github.com/nicodv/kmodes (accessed on 20 January 2021).
- Donepudi, Praveen Kumar. 2019. Automation and machine learning in transforming the financial industry. Asian Business Review 9: 129–38. [Google Scholar] [CrossRef]
- Drolet, Marie, and René Morissette. 2014. New facts on pension coverage in Canada. Insights on Canadian society. Statistics Canada Catalogue. [Google Scholar]
- Dunn, Olive Jean. 1964. Multiple comparisons using rank sums. Technometrics 6: 241–52. [Google Scholar] [CrossRef]
- D’Urso, Pierpaolo, Carmela Cappelli, Dario Di Lallo, and Riccardo Massari. 2013. Clustering of financial time series. Physica A: Statistical Mechanics and Its Applications 392: 2114–29. [Google Scholar] [CrossRef]
- Emerson, Sophie, Ruairí Kennedy, Luke O’Shea, and John O’Brien. 2019. Trends and applications of machine learning in quantitative finance. Paper presented at 8th International Conference on Economics and Finance Research (ICEFR 2019), Lyon, France, June 18–21. [Google Scholar]
- Financial Industry Regulatory Authority. 2012. Rule 2090. Know Your Client. Available online: https://www.finra.org/rules-guidance/rulebooks/finra-rules/2090 (accessed on 20 January 2021).
- Financial Industry Regulatory Authority. 2020. Rule 2111. Suitability. Available online: https://www.finra.org/rules-guidance/rulebooks/finra-rules/2111 (accessed on 20 January 2021).
- Foerster, Stephen, Juhani T. Linnainmaa, Brian T. Melzer, and Alessandro Previtero. 2014. The Costs and Benefits of Financial Advice. Working Paper. Available online: https://www.hbs.edu/faculty/Shared%20Documents/conferences/2013-household-behavior-risky-asset-mkts/Costs-and-Benefits-of-Financial-Advice_Foerster-Linnainmaa-Melzer-Previtero.pdf (accessed on 20 January 2021).
- Foerster, Stephen, Juhani T. Linnainmaa, Brian T. Melzer, and Alessandro Previtero. 2017. Retail financial advice: Does one size fit all? The Journal of Finance 72: 1441–82. [Google Scholar] [CrossRef]
- Grace, Chuck. 2014. Practitioner’s Summary: The Costs and Benefits of Financial Advice. Available online: https://restless.co.uk/course/practitioners-guide-to-cost-benefit-analysis-udemy-133053/ (accessed on 20 January 2021).
- Grace, Chuck. 2019. Next-Gen Financial Advice: Digital Innovation and Canada’s Policymakers. Toronto: CD Howe Institute Commentary 538. [Google Scholar]
- Grinblatt, Mark, and Matti Keloharju. 2000. The investment behavior and performance of various investor types: A study of finland’s unique data set. Journal of Financial Economics 55: 43–67. [Google Scholar] [CrossRef]
- Guillemette, Michael, Michael S. Finke, and John Gilliam. 2012. Risk tolerance questions to best determine client portfolio allocation preferences. Journal of Financial Planning 25: 36–44. [Google Scholar]
- Henrique, Bruno Miranda, Vinicius Amorim Sobreiro, and Herbert Kimura. 2019. Literature review: Machine learning techniques applied to financial market prediction. Expert Systems with Applications 124: 226–51. [Google Scholar] [CrossRef]
- Hosseinimotlagh, Seyedmehdi, and Evangelos E. Papalexakis. 2018. Unsupervised content-based identification of fake news articles with tensor decomposition ensembles. Paper presented at Workshop on Misinformation and Misbehavior Mining on the Web (MIS2), Los Angeles, CA, USA, February 9. [Google Scholar]
- Hsu, Yuan-Lin, Hung-Ling Chen, Po-Kai Huang, and Wan-Yu Lin. 2020. Does financial literacy mitigate gender differences in investment behavioral bias? Finance Research Letters, 101789. [Google Scholar] [CrossRef]
- Huang, Yu-Pei, and Meng-Feng Yen. 2019. A new perspective of performance comparison among machine learning algorithms for financial distress prediction. Applied Soft Computing 83: 105663. [Google Scholar] [CrossRef]
- Huang, Zhexue, and Michael K. Ng. 2003. A note on k-modes clustering. Journal of Classification 20: 257. [Google Scholar] [CrossRef]
- Huang, Zhexue. 1997. Clustering large data sets with mixed numeric and categorical values. In Proceedings of the First Pacific Asia Knowledge Discovery and Data Mining Conference. Singapore: World Scientific, pp. 21–34. [Google Scholar]
- Huang, Zhexue. 1998. Extensions to the k-means algorithm for clustering large data sets with categorical values. Data Mining and Knowledge Discovery 2: 283–304. [Google Scholar] [CrossRef]
- Isidore, Renu, and P. Christie. 2019. The relationship between the income and behavioural biases. Journal of Economics, Finance, and Administrative Science 24: 127–44. [Google Scholar] [CrossRef]
- Kim, Kyoung-jae. 2003. Financial time series forecasting using support vector machines. Neurocomputing 55: 307–19. [Google Scholar] [CrossRef]
- Kou, Gang, Yi Peng, and Guoxun Wang. 2014. Evaluation of clustering algorithms for financial risk analysis using MCDM methods. Information Sciences 275: 1–12. [Google Scholar] [CrossRef]
- Kourtidis, Dimitrios, Prodromos Chatzoglou, and Zeljko Sevic. 2017. The role of personality traits in investors trading behaviour: Empirical evidence from greek. International Journal of Social Economics 44: 1402–20. [Google Scholar] [CrossRef]
- Krishna, K., and M. Narasimha Murty. 1999. Genetic k-means algorithm. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics) 29: 433–39. [Google Scholar] [CrossRef]
- Kruskal, William H., and W. Allen Wallis. 1952. Use of ranks in one-criterion variance analysis. Journal of the American Statistical Association 47: 583–621. [Google Scholar] [CrossRef]
- Kullback, Solomon, and Richard A. Leibler. 1951. On information and sufficiency. The Annals of Mathematical Statistics 22: 79–86. [Google Scholar] [CrossRef]
- Lan, Kun, Dan-tong Wang, Simon Fong, Lian-sheng Liu, Kelvin K. L. Wong, and Nilanjan Dey. 2018. A survey of data mining and deep learning in bioinformatics. Journal of Medical Systems 42: 139. [Google Scholar] [CrossRef] [PubMed]
- Le-Khac, Nhien-An, Cai Fan, and Tahar Kechadi. 2012. Clustering approaches for financial data analysis. Paper presented at 8th International Conference on Data Mining, Las Vegas, NA, USA, July 16–19. [Google Scholar]
- Leo, Martin, Suneel Sharma, and Koilakuntla Maddulety. 2019. Machine learning in banking risk management: A literature review. Risks 7: 29. [Google Scholar] [CrossRef]
- Lim, Tristan, and Chin Sin Ong. 2020. Portfolio diversification using shape-based clustering. The Journal of Financial Data Science. [Google Scholar] [CrossRef]
- Lin, Wei-Yang, Ya-Han Hu, and Chih-Fong Tsai. 2011. Machine learning in financial crisis prediction: A survey. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) 42: 421–36. [Google Scholar]
- Linnainmaa, Juhani T., Brian T. Melzer, and Alessandro Previtero. 2018. The Misguided Beliefs of Financial Advisors. Kelley School of Business Research Paper (18-9). Available online: https://ssrn.com/abstract=3101426 (accessed on 25 January 2021).
- Lokanan, Mark E. 2018. Securities regulation: Opportunities exist for IIROC to regulate responsively. Administration & Society 50: 402–28. [Google Scholar]
- Lumsden, Shelly-Ann, Srikanth Beldona, and Alastair M. Morrison. 2008. Customer value in an all-inclusive travel vacation club: An application of the RFM framework. Journal of Hospitality & Leisure Marketing 16: 270–85. [Google Scholar]
- van der Maaten, Laurens, and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of Machine Learning Research 9: 2579–605. [Google Scholar]
- McKight, Patrick E., and Julius Najab. 2010. Kruskal-wallis test. In The Corsini Encyclopedia Of Psychology. Hoboken: John Wiley & Sons. [Google Scholar]
- Mondal, Prakash Chandra, Rupam Deb, and Mohammad Nurul Huda. 2016. Transaction authorization from know your customer (KYC) information in online banking. Paper presented at 2016 9th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, December 20–22; pp. 523–26. [Google Scholar]
- Moyano, José Parra, and Omri Ross. 2017. KYC optimization using distributed ledger technology. Business & Information Systems Engineering 59: 411–23. [Google Scholar]
- Ontario Securities Commission, Investor Advisory Panel. 2015. Current Practices for Risk Profiling in Canada and Review of Global Best Practices. Toronto: Ontario Securities Commission. [Google Scholar]
- Nash, Maria. 2021. Investment Industry Association of Canada, Toronto, ON, Canada. Personal Communication, January 11. [Google Scholar]
- Ontario Securities Commission. 2009. National Instruments 31-103. Available online: https://www.osc.gov.on.ca/en/SecuritiesLaw_31-103.htm (accessed on 20 January 2021).
- Ontario Securities Commission. 2014. CSA Staff Notice 31-336—Guidance for Portfolio Managers, Exempt Market Dealers and Other Registrants on the Know-Your-Client, Know-Your-Product and Suitablility Obligations. Available online: https://www.osc.gov.on.ca/documents/en/Securities-Category3/csa_20140109_31-336_kyc-kyp-suitability-obligations.pdf (accessed on 20 January 2021).
- Ontario Securities Commission. 2019. Amendments to National Instrument 31-103 Registration Requirements, Exemptions and Ongoing Registrant. Available online: https://www.osc.gov.on.ca/en/SecuritiesLaw_ni_20191212_31-103_amendments-ongoing-registrant-obligations.htm (accessed on 20 January 2021).
- Patel, Jigar, Sahil Shah, Priyank Thakkar, and Ketan Kotecha. 2015. Predicting stock and stock price index movement using trend deterministic data preparation and machine learning techniques. Expert Systems with Applications 42: 259–68. [Google Scholar] [CrossRef]
- Pedregosa, Fabian, Gael Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, and et al. 2011. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research 12: 2825–30. [Google Scholar]
- Picard, Nathalie, and André de Palma. 2010. Evaluation of MiFID Questionnaires in France. Technical Report. Paris: AMF. [Google Scholar]
- Pompian, Michael M. 2012. Behavioral Finance and Investor Types: Managing Behavior to Make Better Investment Decisions. Hoboken: John Wiley & Sons. [Google Scholar]
- R Core Team. 2020. R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. [Google Scholar]
- Raffinot, Thomas. 2017. Hierarchical clustering-based asset allocation. The Journal of Portfolio Management 44: 89–99. [Google Scholar] [CrossRef]
- Ramírez, Javier, Jaume C. Segura, Carmen Benítez, Angel De La Torre, and Antonio J. Rubio. 2004. A new kullback-leibler vad for speech recognition in noise. IEEE Signal Processing Letters 11: 266–69. [Google Scholar] [CrossRef]
- Rocher, Luc, Julien M. Hendrickx, and Yves-Alexandre De Montjoye. 2019. Estimating the success of re-identifications in incomplete datasets using generative models. Nature Communications 10: 1–9. [Google Scholar] [CrossRef] [PubMed]
- Rousseeuw, Peter J. 1987. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics 20: 53–65. [Google Scholar] [CrossRef]
- Rundo, Francesco, Francesca Trenta, Agatino Luigi di Stallo, and Sebastiano Battiato. 2019. Machine learning for quantitative finance applications: A survey. Applied Sciences 9: 5574. [Google Scholar] [CrossRef]
- Simser, Jeffrey R. 2020. Canada’s financial intelligence unit: FINTRAC. Journal of Money Laundering Control 23: 297–307. [Google Scholar] [CrossRef]
- De Smet, Dieter, and Anne-Laure Mention. 2011. Improving auditor effectiveness in assessing KYC/AML practices: Case study in a luxembourgish context. Managerial Auditing Journal 26: 182–203. [Google Scholar] [CrossRef]
- Steinley, Douglas. 2006. k-means clustering: A half-century synthesis. British Journal of Mathematical and Statistical Psychology 59: 1–34. [Google Scholar] [CrossRef]
- Subrahmanyam, Avanidhar. 2008. Behavioural finance: A review and synthesis. European Financial Management 14: 12–29. [Google Scholar] [CrossRef]
- Talpsepp, Tõnn. 2013. Does gender and age affect investor performance and the disposition effect? Research in Economics and Business: Central and Eastern Europe 2. [Google Scholar]
- Tsai, Chih-Fong. 2014. Combining cluster analysis with classifier ensembles to predict financial distress. Information Fusion 16: 46–58. [Google Scholar] [CrossRef]
- Tukey, John W. 1949. Comparing individual means in the analysis of variance. Biometrics 5: 99–114. [Google Scholar] [CrossRef]
- van der Maaten, Laurens. 2009. Learning a parametric embedding by preserving local structure. Paper presented at Twelfth International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, April 16–18; Volume 5 of Proceedings of Machine Learning Research. Edited by D. van Dyk and M. Welling. pp. 384–91. [Google Scholar]
- Van Liebergen, Bart. 2017. Machine learning: A revolution in risk management and compliance? Journal of Financial Transformation 45: 60–67. [Google Scholar]
- Wang, Qing, Sanjeev R. Kulkarni, and Sergio Verdú. 2005. Divergence estimation of continuous distributions based on data-dependent partitions. IEEE Transactions on Information Theory 51: 3064–74. [Google Scholar] [CrossRef]
- West, David, Scott Dellana, and Jingxia Qian. 2005. Neural network ensemble strategies for financial decision applications. Computers & Operations Research 32: 2543–59. [Google Scholar]
- Xu, Rui, and Don Wunsch. 2008. Clustering. Hoboken: John Wiley & Sons, vol. 10. [Google Scholar]
- Yang, Li. 1999. 3D grand tour for multidimensional data and clusters. In Advances in Intelligent Data Analysis. Edited by D. J. Hand, J. N. Kok and M. R. Berthold. Berlin and Heidelberg: Springer, pp. 173–84. [Google Scholar]
- Zahera, Syed Aliya, and Rohit Bansal. 2018. Do investors exhibit behavioral biases in investment decision making? A systematic review. Qualitative Research in Financial Markets 10: 210–51. [Google Scholar] [CrossRef]
- Zheng, Alice, and Amanda Casari. 2018. Feature Engineering for Machine Learning: Principles and Techniques for Data Scientists, 1st ed. Newton: O’Reilly Media, Inc. [Google Scholar]









| Variable | Summary | Data Type | Example Values |
|---|---|---|---|
| Age | Ages range from 18 to 98 years old, with average at 57.4 years | Continuous | 31 years old |
| Gender | male and female | Indicator | |
| Residency | Province or Country or Region, with from Ontario | Categorical | ON, UK, USA, … |
| Annual income | Gross annual income in CAD | Continuous | Multiples of 100 between $1000 and $220,000 inclusive |
| Investment knowledge | The self-reported investment knowledge of poor (2%), fair (44%), good (37%), or sophisticated (17%) | Ordinal | 1, 2, 3, or 4 |
| Number of accounts | Clients can have more than one account | Ordinal | 1,2,3,10 |
| Marital status | 67% married, 18% single, 11% unknown and 4% divorced | Categorical | M, D, U, or S |
| Retirement indicator | The client’s retirement status | Indicator | Yes, No |
| Location | ON | BC | AB | MB | NS | Other (CA) | Unknown | USA | UK |
|---|---|---|---|---|---|---|---|---|---|
| Percentage | 65.19 | 14.63 | 12.00 | 3.94 | 2.59 | 0.92 | 0.41 | 0.26 | 0.06 |
| Unique Accounts | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Number of clients | 5475 | 7659 | 6661 | 3051 | 775 | 222 | 79 | 40 | 4 | 4 |
| Feature Type | Description | Variables |
|---|---|---|
| Recency | Number of days since last trade on record | Days between the most recent trade date and 12 August 2019 |
| Frequency | Total number of trades Average number of days between trades | Number of trades between first trade date and 12 August 2019 Number of days divided by number of trades since first trade day |
| Monetary | Buy and sell size totalsBuy and sell size minimum and maximum Trade size by type Variability of trade size by type | Third-party initiated trade type Dividends, income distribution, interest Systematic trade type Auto-withdrawal, pre-authorized contribution, asset allocation, reinvested dividend Periodic trade type Buys, sells, contribution, exchange, payment, electronic funds transfer (EFT), withdrawal, EFT deposit, tax-free savings account (TFSA) contribution, spousal contribution, redeems |
| Profile | KYC information Financial descriptors (e.g., number of accounts) | Age, gender, residency, annual income, investment knowledge level, number of accounts, marital status, retirement indicator |
| Cluster | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Age (years) | 58.7 | 55.5 | 59.6 | 64.5 | 57.9 |
| Annual gross income (CAD) | 72,310.11 | 72,623.69 | 69,397.60 | 62,229.89 | 69,955.47 |
| Investment knowledge level | 2.69 | 2.70 | 2.68 | 2.84 | 2.70 |
| Number of accounts | 3.07 | 3.03 | 3.05 | 2.85 | 2.89 |
| Recency (days) | 57.9 | 179.59 | 179.9 | 153.8 | 61.9 |
| Frequency (trades per day) | 5.77 | 0.006 | 0.0004 | 0.46 | 1.32 |
| Days between trades | 5.15 | 179.46 | 179.9 | 151.93 | 85.18 |
| Mean third-party trade (CAD) | 98.01 | 17.19 | 102.21 | 63.40 | 109.07 |
| SD third-party trade (CAD) | 79.13 | 7.51 | 57.69 | 46.17 | 57.23 |
| Mean systematic trade (CAD) | 350.08 | 22.34 | 292.90 | 946.09 | 251.61 |
| SD Systematic trade (CAD) | 25.53 | 0.13 | 0.11 | 671.11 | 0.35 |
| Mean periodic trade (CAD) | 36,064.08 | 72.09 | 22,071.42 | 11,543.26 | 14,060.87 |
| SD periodic trade (CAD) | 27,685.31 | 0.71 | 12,190.73 | 16,335.76 | 12,828.52 |
| Clusters | |||||
|---|---|---|---|---|---|
| Client Trait | 1—Active Traders | 2—Early Savers | 3—Just-in-Time | 4—Older Investors | 5—Systematic Savers |
| KYC | Average age, income and demographics. Average investment knowledge. Average $ accounts and balances | Slightly younger but average income and demographics. Average investment knowledge. Average $ accounts and balances | Average age, income and demographics. Average investment knowledge. Average $ accounts and balances | Older but average, income and demographics. Average investment knowledge. Average $ accounts and balances | Average age, income and demographics. Average investment knowledge. Average $ accounts and balances |
| Trade behavior | Trade frequently in large amounts and appear sensitive to market influences | Smaller, regular deposits making use of PACs | Infrequent trades at seemingly random intervals | Primarily withdrawals, dividends, and interest payments | Larger, systematic trades and re-balancing |
| Risk tolerance observed average | 3.19/5 | 3.18/5 | 3.12/5 | 2.95/5 | 3.19/5 |
| Risk tolerance anticipated | 5/5 | 4/5 | 3/5 | 1/5 | 2/5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thompson, J.R. .; Feng, L.; Reesor, R.M.; Grace, C. Know Your Clients’ Behaviours: A Cluster Analysis of Financial Transactions. J. Risk Financial Manag. 2021, 14, 50. https://doi.org/10.3390/jrfm14020050
Thompson JR , Feng L, Reesor RM, Grace C. Know Your Clients’ Behaviours: A Cluster Analysis of Financial Transactions. Journal of Risk and Financial Management. 2021; 14(2):50. https://doi.org/10.3390/jrfm14020050
Chicago/Turabian StyleThompson, John R. J., Longlong Feng, R. Mark Reesor, and Chuck Grace. 2021. "Know Your Clients’ Behaviours: A Cluster Analysis of Financial Transactions" Journal of Risk and Financial Management 14, no. 2: 50. https://doi.org/10.3390/jrfm14020050
APA StyleThompson, J. R. ., Feng, L., Reesor, R. M., & Grace, C. (2021). Know Your Clients’ Behaviours: A Cluster Analysis of Financial Transactions. Journal of Risk and Financial Management, 14(2), 50. https://doi.org/10.3390/jrfm14020050