Support Vector Machine Methods and Artificial Neural Networks Used for the Development of Bankruptcy Prediction Models and their Comparison




Abstract
1. Introduction
- The dichotomous dependent variable,
- The sampling method,
- Nonstationarity and data instability,
- The use of annual account information,
- The selection of the independent variables,
- The time dimension.
2. Literature Review
3. Materials and Methods
- 10: Manufacture of food products.
- 11: Manufacture of beverages.
- 12: Manufacture of tobacco products.
- 13: Manufacture of textiles.
- 14: Manufacture of wearing apparel.
- 15: Manufacture of leather and related products.
- 16: Manufacture of wood and products of wood and cork, except furniture.
- 17: Manufacture of paper and paper products.
- 18: Printing and reproduction of recorded media.
- 19: Manufacture of coke and refined petroleum products.
- 20: Manufacture of chemicals and chemical products.
- 21: Manufacture of basic pharmaceutical products and pharmaceutical preparations.
- 22: Manufacture of rubber and plastic products.
- 23: Manufacture of other non-metallic mineral products.
- 24: Manufacture of basic metals; foundry.
- 25: Manufacture of fabricated metal products, except machinery and equipment.
- 26: Manufacture of computer, electronic and optical products.
- 27: Manufacture of electrical equipment.
- 28: Manufacture of machinery and equipment.
- 29: Manufacture of motor vehicles (except motorcycles), trailers and semi-trailers.
- 30: Manufacture of other transport equipment.
- 31: Manufacture of furniture.
- 32: Other manufacturing.
- 33: Repairs and installation of machinery and equipment.
- Year 2013: 488 in liquidation, 1464 active,
- Year 2014: 416 in liquidation, 1248 active,
- Year 2015: 354 in liquidation, 1062 active,
- Year 2016: 287 in liquidation, 862 active,
- Year 2017: 163 in liquidation, 489 active.
- Different assets and liabilities balance,
- Negative assets,
- Negative fixed assets,
- Negative tangible fixed assets,
- Negative current assets,
- Negative financial assets,
- Negative inventories.
- AKTIVACELK—Total assets resulting from past economic operations. Thus it means the future economic benefit of the company.
- STALAA—Fixed assets are long-term, fixed and noncurrent. This item includes asset components used for the company business in a long term (more than 1 year) and consumed over time.
- HIM—Intangible fixed assets will depreciate, expressed by the level of depreciation. Intangible fixed assets have a significant impact on the value of the enterprise, they maintain their value for a longer time and are not exposed to the fast operating cycle.
- OBEZNAA—Current assets characterize the operating cycle. They continuously circulate and change their form. They include cash, material, semi-finished products, work in progress, products, or receivables from customers.
- Z—Inventories are current (short-term) assets of the company. They are consumed during operation. In general, inventories include material, inventories for production of its own products and goods
- KP—Short-term receivables are payable in less than 1 year from the date when their arise and represent the creditor’s right to seek fulfilment of a certain obligation from the other party, the receivable is extinguished when the obligation is paid.
- FM—Financial assets including long-term and short-term financial assets. Long-term financial assets hold their value for a longer period of time, they do not change into cash quickly. They include securities, bonds, certificates of deposit, obligations, term deposits or loans granted to companies. Short-term financial assets are used for operation, especially for payment of liabilities. Short-term assets represent high liquidity; the expected holding is less than one year. They mainly include money in bank accounts, treasury, checks, clearing notes, valuables or short-term securities and shares.
- PASIVACELK—Total liabilities—information concerning the source to cover the company’s assets.
- VLASTNIJM—Equity is the internal source of finance for business assets and capital formation. It includes, in particular, contributions of the founders (owners or partners) to the capital stock and components arising from the business management.
- FTZZ—Reserve funds, undistributable reserves and other funds from profit represent the company’s internal sources of finance increasing the company’s equity without changing its capital stock. Reserve funds are used as internal resources to cover future losses of the company. Undistributable reserves are created by cooperatives also to cover the loss.
- HVML—Profit/loss brought forward is part of liabilities, an item of equity. These are resources created after tax in previous years. These are funds which are not transferred to funds or distributed and paid. It consists of three parts - retained earnings, loss carried forward and other profit/loss brought forward.
- HVUO—Profit and loss of the current financial period is the sum of profit and loss from operations and financial activities in the financial period and the profit before tax. For calculation, the income tax for ordinary activities is deducted.
- CIZIZDROJE—External resources are the company’s debts which must be paid within a certain period of time. These are the company’s payables to other entities.
- KZ—Current liabilities are payable within 1 year and used for financing (together with equity) of the normal operation of the company. In particular, they include short-term bank loans, payables to employees and institutions, debts to suppliers or delinquent tax.
- V—Production is goods and services that are used to meet the needs. They result from business activities of the company and characterize the main business activities—production.
- VS—Production consumption mainly includes the costs of consumed material, energy, travel expenses, maintenance and repairs, or low-value assets. It is a sum item which correlates with consumption of materials, services and energy.
- SPMAAEN—Material and energy consumption is an item accounting for inventories - current assets. Energy consumption rises proportionally and positively correlates with the production volume. However, material costs may decrease as the production volume increases. Material consumption is directly dependent on consumption standards and purchase prices.
- SLUZBY—Services are systematic external activities that satisfy human needs, or the business needs in their own course.
- PRIDHODN—Value added represents the sales margin, sales, stock level changes of internally produced inventories, or capitalization less production consumption. It includes the sales margin as well as production.
- MZDN—Payroll costs generally comprise of the employee’s gross wages and premiums paid by the employer for each employee’s social security and health insurance.
- NNSOCZAB—Employee’s social security and health insurance costs.
- OHANIM—Depreciation of intangible and tangible fixed assets provides a tool for gradually assigning the value of fixed assets to expenses. Therefore, it means a gradual assignment of the fixed asset cost value to expenses. It represents depreciation of fixed assets.
- STAV—Identifies the situation of the company whether active or in liquidation. There will only be two possible outcomes.
3.1. Support Vector Machines
3.2. Artificial Neural Networks
4. Results
4.1. Support Vector Machines
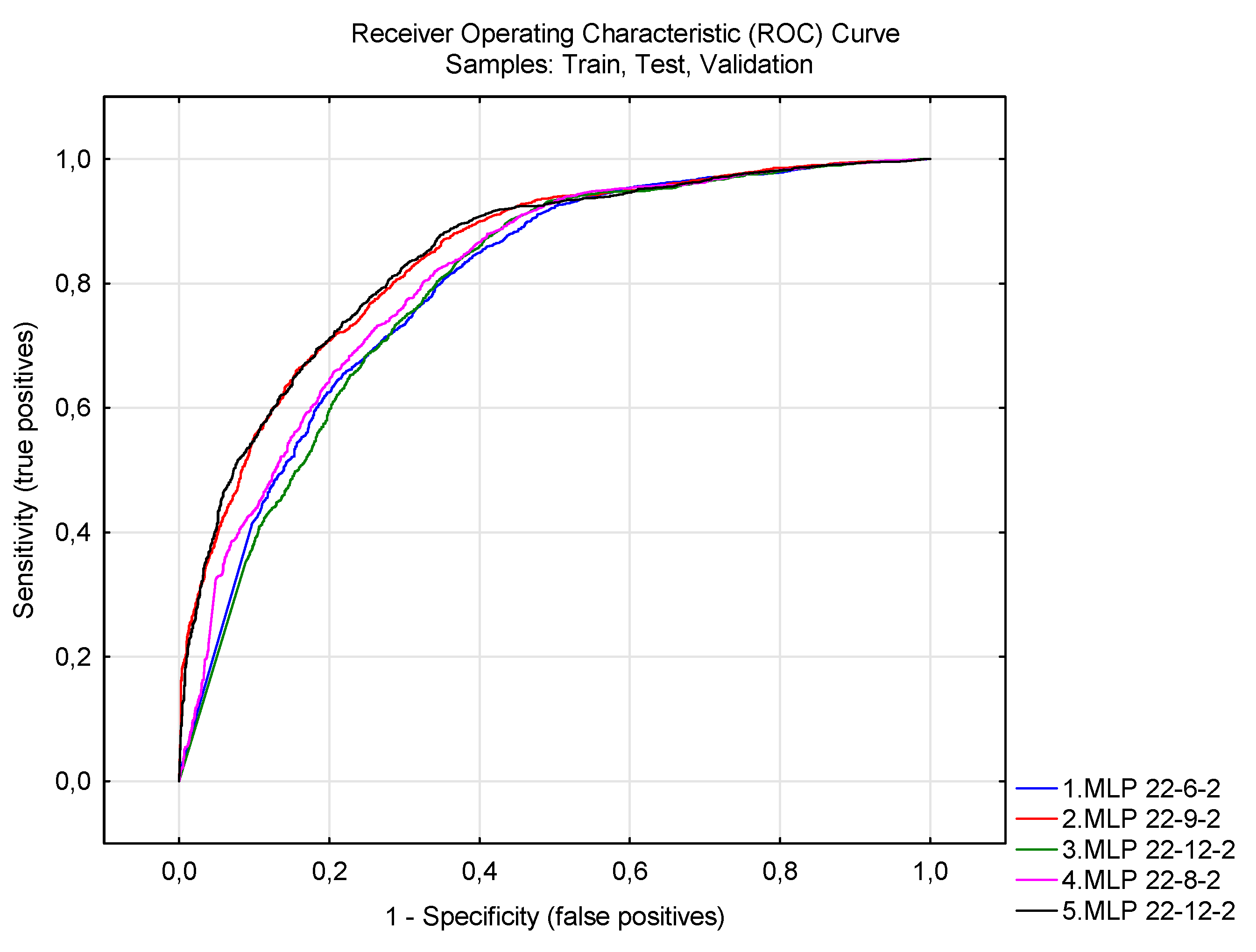
4.2. Artificial Neural Networks
4.3. SVM/NN Comparison
5. Discussion and Conclusions
- Dependent variable dichotomy,
- Sampling method,
- Stationarity and data instability,
- Selection of variables,
- Using information from financial statements, and
- Time dimension.
Author Contributions
Funding
Conflicts of Interest
References
- Altman, Edward I. 1968. Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy. The Journal of Finance 23: 589–609. [Google Scholar] [CrossRef]
- Altman, Edward I. 2000. Predicting Financial Distress of Companies: Revisiting the Z-Score and Zeta Models. Working Paper. New York, NY, USA: New York University. [Google Scholar]
- Altman, Edward I. 2003. The Use of Credit Scoring Models and the Importance of a Credit Culture; Stern School of Business, New York University. Available online: http://pages.stern.nyu.edu/~ealtman/3-%20CopCrScoringModels.pdf (accessed on 25 January 2020).
- Altman, Edward I., and Edith Hotchkiss. 2006. Corporate Financial Distress and Bankruptcy: Predict and Avoid Bankruptcy, Analyze and Invest in Distressed Debt. Hoboken: John Wiley & Sons. 368p. [Google Scholar]
- Balcaen, Sofie, and Hubert Ooghe. 2004. 35 Years of Studies on Business Failure: An Overview of the Classical Statistical Methodologies and their Related Problems. Working paper. Ghent, Belgium: Universiteit Gent. 56p. [Google Scholar]
- Baran, Dušan. 2007. System approach to the stated policy of controlling the company. Ekonomicko-Manažerské Spektrum 1: 2–9. [Google Scholar]
- Becerra, Victor Manuel, Roberto Kawakami Harrop Galvao, and Magda Abou-Seada. 2002. On the utility of input selection and pruning for financial distress prediction models. Paper presented at the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, May 12–17; pp. 1328–33. [Google Scholar] [CrossRef]
- Bishop, Christopher M. 1995. Neural Networks for Pattern Recognition. New York: Oxford University Press. [Google Scholar]
- Boguslauskas, Vytautas, and Ruta Adlyte. 2010. Evaluation of criteria for the classification of enterprises. Inzinerine Ekonomika-Engineering Economics 21: 119–27. [Google Scholar]
- Burges, Christopher J. C. 1998. A tutorial on support vector machines for pattern recognition. Data Mining and Knowledge Discovery 2: 121–67. [Google Scholar] [CrossRef]
- Chen, Bo-Tsuen, and Mu-Yen Chen. 2011. Applying particles swarm optimization for Support Vector Machines on predicting company financial crisis. Paper presented at International Conference on Business and Economics Research, Kuala Lumpur, Malaysia, November 26–28; pp. 301–5. [Google Scholar]
- Dorneanu, Liliana, Mircea Untaru, Doina Darvasi, Vasile Rotarescu, and Cernescu Lavinia. 2011. Using artificial neural networks in financial optimization. Paper presented at International Conference on Business Administration, Puerto Morelos, Mexico, January 29–30; pp. 93–96. [Google Scholar]
- Enke, David, and Suraphan Thawornwong. 2005. The use of data mining and neural networks for forecasting stock market returns. Expert Systems with Applications 29: 927–40. [Google Scholar] [CrossRef]
- Erdogan, Birsen Eygi. 2013. Prediction of bankruptcy using Support Vector Machines: An application to bank bankruptcy. Journal of Statistical Computation and Simulation 83: 1543–55. [Google Scholar] [CrossRef]
- Gestel, Tony Van, Bart Baesens, Johan A. K. Suykens, Dirk Van den Poel, Dirk Emma Baestaens, and Marleen Willekens. 2006. Bayesian Kernel based classification for financial distress detection. European Journal of Operational Research 172: 979–1003. [Google Scholar] [CrossRef]
- Hafiz, Alaka, Oyedele Lukumon, Bilal Muhammad, Akinade Olugbenga, Owolabi Hakeem, and Ajayi Saheed. 2015. Bankruptcy prediction of construction businesses: Towards a big data analytics approach. Paper presented at 2015 IEEE 1st International Conference on Big Data Computing Service and Applications, BigDataService 2015, San Francisco, CA, USA, March 30–April 3; pp. 347–52. [Google Scholar] [CrossRef]
- Härdle, Wolfgang, Yuh-Jye Lee, Dorothea Schäfer, and Yi-Ren Yeh. 2009. Variable selection and oversampling in the use of smooth Support Vector Machines for predicting the default risk of companies. Journal of Forecasting 25: 512–34. [Google Scholar] [CrossRef]
- Kiaupaite-Grushniene, Vaiva. 2016. Altman Z-Score model for bankruptcy forecasting of the listed Lithuanian agricultural companies. Paper presented at 5th International Conference on Accounting, Auditing, and Taxation, Tallinn, Estonia, December 8–9; pp. 222–16. [Google Scholar] [CrossRef]
- Kim, Soo Y. 2011. Prediction of hotel bankruptcy using Support Vector Machine, artificial neural network, logistic regression, and multivariate discriminant analysis. Service Industries Journal 31: 441–68. [Google Scholar] [CrossRef]
- Kim, Sungdo, Byeong Min Mun, and Suk Joo Bae. 2018. Data depth based support vector machines for predicting corporate bankruptcy. Applied Intelligence 48: 791–804. [Google Scholar] [CrossRef]
- Klieštik, Tomáš. 2013. Models of Autoregression Conditional Heteroskedasticity Garch and Arch as a tool for modeling the volatility of financial time series. Ekonomicko-Manažerské Spektrum 7: 2–10. [Google Scholar]
- Kralicek, Peter. 1993. Základy Finančního Hospodaření [Basics of Financial Management]. Prague: Linde. 110p. [Google Scholar]
- Krulický, Tomáš. 2019. Using Kohonen networks in the analysis of transport companies in the Czech Republic. Paper presented at SHS Web of Conferences: Innovative Economic Symposium 2018—Milestones and Trends of World Economy, Beijing, China, November 8–9. article number 01010. [Google Scholar]
- López Iturriaga, Félix J., and Iván Pastor Sanz. 2015. Bankruptcy visualization and prediction using neural networks: A study of U.S. commercial banks. Expert Systems with Applications 42: 2857–69. [Google Scholar] [CrossRef]
- Lu, Yang, Nianyin Zeng, Xiaohui Liu, and Shujuan Yi. 2015. A new hybrid algorithm for bankruptcy prediction using switching particle swarm optimization and Support Vector Machines. Discrete Dynamics in Nature and Society 2015: 1–7. [Google Scholar] [CrossRef]
- Machová, Veronika, and Marek Vochozka. 2019. Analysis of business companies based on artificial neural networks. Paper presented at SHS Web of Conferences: Innovative Economic Symposium 2018—Milestones and Trends of World Economy, Beijing, China, November 8–9. article number 01013. [Google Scholar]
- Mousavi, Mohammad M., Jamal Ouenniche, and Bing Xu. 2015. Performance evaluation of bankruptcy prediction models: An orientation-free super-efficiency DEA-based framework. International Review of Financial Analysis 42: 64–75. [Google Scholar] [CrossRef]
- Mulačová, Věra. 2012. The financial and economic crisis and SMEs. Littera Scripta 5: 95–103. [Google Scholar]
- Neumaierová, Inka, and Ivan Neumaier. 2005. Index IN05. In Evropské Finanční Systémy [European Financial Systems]. Edited by Petr Červinek. Brno: Masaryk University, pp. 143–48. [Google Scholar]
- Neumaierová, Inka, and Ivan Neumaier. 2008. Proč se ujal index IN a nikoli pyramidový systém ukazatelů INFA [Why took the IN index and not the pyramid system of INFA indicators]. Ekonomika a management 2: 1–10. [Google Scholar]
- Pao, Hsiao Tien. 2008. A comparison of neural network and multiple regression analysis in modeling capital structure. Expert Systems with Applications 35: 720–27. [Google Scholar] [CrossRef]
- Park, Soo Seon, and Murat Hancer. 2012. A comparative study of logit and artificial neural networks in predicting bankruptcy in the hospitality industry. Tourism Economics 18: 311–38. [Google Scholar] [CrossRef]
- Pollak, Harry. 2003. Jak Obnovit Životaschopnost Upadajících Podniků [How to Restore the Viability of Failure Businesses]. Prague: C. H. Beck. 122p. [Google Scholar]
- Purvinis, Ojaras, Povilas Šukys, and Ruta Virbickaité. 2005. Research of possibility of bankruptcy diagnostics applying neural network. Inzinerine Ekonomika-Engineering Economics 41: 16–22. [Google Scholar]
- Rybárová, Daniela, Mária Braunová, and Lucia Jantošová. 2016. Analysis of the construction industry in the Slovak Republic by bankruptcy model. Procedia—Social and Behavioral Sciences 230: 298–306. [Google Scholar] [CrossRef]
- Sayadi, Ahmad Reza, Seyyed Mohammad Tavassoli, Masoud Monjezi, and Mohammad Rezaei. 2014. Application of neural networks to predict net present value in mining projects. Arabian Journal of Geosciences 7: 1067–72. [Google Scholar] [CrossRef]
- Shin, Kyung-Shik, Taik Soo Lee, and Hyun-Jung Kim. 2005. An application of Support Vector Machines in bankruptcy prediction model. Expert Systems with Applications 28: 127–35. [Google Scholar] [CrossRef]
- Taffler, Richard J. 1983. The assessment of company solvency and performance using a statistical model—A comparative UK-based study. Accounting and Business Research 13: 295–308. [Google Scholar] [CrossRef]
- Taffler, Richard J., and Howard Tisshaw. 1977. Going, going, gone—Four factors which predict. Accountancy 88: 50–54. [Google Scholar]
- Tian, Yingjie, Yong Shi, and Xiaohui Liu. 2012. Recent advances on support vector machines research. Technological and Economic Development of Economy 18: 5–33. [Google Scholar] [CrossRef]
- Vapnik, Vladimir N. 1995. The Nature of Statistical Learning Theory. New York: Springer. [Google Scholar]
- Vochozka, Marek. 2010. Development of methods for comprehensive evaluation of business performance. Politická Ekonomie 58: 675–88. [Google Scholar] [CrossRef]
- Vochozka, Marek. 2017. Effect of the economic outturn on the cost of debt of an industrial enterprise. Paper presented at SHS Web of Conferences: Innovative Economic Symposium 2017—Strategic Partnership in International Trade, České Budějovice, Czech Republic, October 19. article number 01028. [Google Scholar]
- Vochozka, Marek, and Veronika Machová. 2018. Determination of value drivers for transport companies in the Czech Republic. Nase More 65: 197–201. [Google Scholar] [CrossRef]
- Vochozka, Marek, and Penfei Sheng. 2016. The application of artificial neural networks on the prediction of the future financial development of transport companies. Communications: Scientific Letters of the University of Žilina 18: 62–67. [Google Scholar]
- Vochozka, Marek, Jan Jelínek, Jan Váchal, Jarmila Straková, and Vojtěch Stehel. 2017. Využití Neuronových sítí při Komplexním Hodnocení Podniků [Use of Neural Networks in Complex Business Evaluation]. Prague: C. H. Beck. 234p. [Google Scholar]
- Xu, Xiao-Si, Ying Chen, and Ruo-En Ren. 2006. Studying on forecasting the enterprise bankruptcy based on SVM. Paper presented at the 2006 International Conference on Management Science & Engineering, Lille, France, October 5–7; pp. 1041–45. [Google Scholar]
- Xu, Wei, Hongyong Fu, and Yuchen Pan. 2019. A novel soft ensemble model for financial distress prediction with different sample sized. Mathematical Problems in Engineering 2019: 1–12. [Google Scholar] [CrossRef]
- Zheng, Qin, and Yanhui Jiang. 2007. Financial distress prediction based on decision tree models. Paper presented at the 2007 International Conference on Service Operations and Logistics, and Informatics, Philadelphia, PA, USA, August 27–29; pp. 426–31. [Google Scholar]


{kind=link}
| Active Companies | ||||||
| Financial Data | 2013 | 2014 | 2015 | 2016 | 2017 | Total |
| Total assets | 113,590.43 | 112,398.89 | 72,359.06 | 92,463.05 | 102,843.14 | 91,228.91 |
| Fixed assets | 51,794.64 | 48,418.16 | 32,899.65 | 41,244.60 | 49,662.11 | 40,808.34 |
| Current assets | 61,093.99 | 63,352.86 | 38,750.26 | 50,275.42 | 52,550.73 | 49,762.88 |
| Liabilities in total | 113,590.43 | 112,398.89 | 72,359.06 | 92,358.40 | 102,843.14 | 91,228.91 |
| Equity | 51,663.05 | 53,660.95 | 39,599.74 | 42,971.99 | 59,471.72 | 44,077.03 |
| Borrowed capital | 61,076.00 | 58,079.58 | 32,437.83 | 46,616.22 | 42,632.01 | 46,275.94 |
| Operating result | 1574.10 | 14,159.14 | 4604.23 | 7104.33 | 10,576.95 | 6263.25 |
| Economic result for accounting period | 1282.11 | 11,387.14 | 3168.16 | 5231.82 | 9325.24 | 4916.57 |
| Companies in Liquidation | ||||||
| Financial Data | 2013 | 2014 | 2015 | 2016 | 2017 | Total |
| Total assets | 22,033.59 | 21,401.33 | 20,401.53 | 14,201.20 | 10,273.09 | 77,297.73 |
| Fixed assets | 6307.66 | 6768.54 | 5231.99 | 5439.59 | 1481.12 | 33,904.17 |
| Current assets | 15,615.94 | 14,447.03 | 15,116.56 | 8639.67 | 8670.90 | 42,801.79 |
| Liabilities in total | 22,033.23 | 21,390.77 | 20,400.42 | 14,201.20 | 10,273.09 | 77,254.27 |
| Equity | 5454.03 | 5998.58 | 7499.03 | 1768.26 | 2140.76 | 37,917.64 |
| Borrowed capital | 16,453.56 | 15,338.02 | 12,813.47 | 12,382.05 | 8064.87 | 38,566.51 |
| Operating result | −1791.99 | −166.49 | −1219.85 | 214.53 | 284.29 | 7107.70 |
| Economic result for accounting period | −1910.42 | −151.22 | −1492.21 | 116.79 | 141.06 | 5516.93 |
| Function | Definition | Range |
|---|---|---|
| Identity | a | |
| Logistic sigmoid | (0;1) | |
| Hyperbolic tangent | (−1;+1) | |
| Exponential | ||
| Sine | ||
| Softmax | ||
| Gaussian |
| Status—Active Company | Status—In liquidation | Status—All | |
|---|---|---|---|
| Total | 4606 | 1582 | 6188 |
| Correct | 4578 | 130 | 4708 |
| Incorrect | 28 | 1452 | 1480 |
| Correct (%) | 99.39 | 8.22 | 76.08 |
| Incorrect (%) | 0.61 | 91.78 | 23.92 |
| Statistics | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Network name | MLP 22-6-2 | MLP 22-9-2 | MLP 22-12-2 | MLP 22-8-2 | MLP 22-12-2 |
| Training performance | 81.46353 | 83.01016 | 82.2253 | 82.40997 | 83.05633 |
| Testing performance | 80.38793 | 81.89655 | 81.03448 | 81.25 | 81.14224 |
| Validation performance | 81.35776 | 82.65086 | 83.40517 | 82.65086 | 83.40517 |
| Training algorithm | BFGS 170 | BFGS 332 | BFGS 56 | BFGS 110 | BFGS 220 |
| Error function | Entropy | Entropy | SOS | Entropy | Entropy |
| Hidden activation func. | Tanh | Tanh | Identity | Logistic | Tanh |
| Output activation func. | Softmax | Softmax | Logistic | Softmax | Softmax |
| Network | Statistics | Status—Active Company | Status—In liquidation | Status—All |
|---|---|---|---|---|
| 1.MLP 22-6-2 | Total | 4606 | 1582 | 6188 |
| Correct | 4226 | 804 | 5030 | |
| Incorrect | 380 | 778 | 1158 | |
| Correct (%) | 91.75 | 50.82 | 81.29 | |
| Incorrect (%) | 8.25 | 49.18 | 18.71 | |
| 2.MLP 22-9-2 | Total | 4606 | 1582 | 6188 |
| Correct | 4234 | 889 | 5123 | |
| Incorrect | 372 | 693 | 1065 | |
| Correct (%) | 91.92 | 56.20 | 82.79 | |
| Incorrect (%) | 8.08 | 43.81 | 17.21 | |
| 3.MLP 22-12-2 | Total | 4606 | 1582 | 6188 |
| Correct | 4315 | 773 | 5088 | |
| Incorrect | 291 | 809 | 1100 | |
| Correct (%) | 93.68 | 48.86 | 82.22 | |
| Incorrect (%) | 6.32 | 51.14 | 17.78 | |
| 4.MLP 22-8-2 | Total | 4606 | 1582 | 6188 |
| Correct | 4320 | 771 | 5091 | |
| Incorrect | 286 | 811 | 1097 | |
| Correct (%) | 93.79 | 48.74 | 82.27 | |
| Incorrect (%) | 6.21 | 51.26 | 17.73 | |
| 5.MLP 22-12-2 | Total | 4606 | 1582 | 6188 |
| Correct | 4252 | 873 | 5125 | |
| Incorrect | 354 | 709 | 1063 | |
| Correct (%) | 92.31 | 55.18 | 82.82 | |
| Incorrect (%) | 7.69 | 44.82 | 17.18 |
| Variables | 1.MLP 22-6-2 | 2.MLP 22-9-2 | 3.MLP 22-12-2 | 4.MLP 22-8-2 | 5.MLP 22-12-2 | Average |
|---|---|---|---|---|---|---|
| OHANIM | 1.307736 | 8.298830 | 1.623772 | 1.197549 | 1.143286 | 2.714235 |
| PRIDHODN | 1.302244 | 4.395480 | 1.584667 | 2.339157 | 2.748509 | 2.474011 |
| VS | 1.319040 | 2.663396 | 1.602347 | 3.742576 | 2.887139 | 2.442900 |
| HVML | 1.269237 | 2.125292 | 1.520003 | 1.517179 | 3.173511 | 1.921044 |
| MZDN | 1.294799 | 2.563237 | 1.561902 | 1.494294 | 2.231695 | 1.829185 |
| OBEZNAA | 1.274424 | 2.737114 | 1.627830 | 1.209418 | 2.123338 | 1.794425 |
| SPMAAEN | 1.324918 | 2.146751 | 1.295759 | 1.266527 | 2.599045 | 1.726600 |
| STALAA | 1.173915 | 2.153740 | 1.231161 | 1.038480 | 2.572654 | 1.633990 |
| Z | 1.289484 | 2.095527 | 1.494067 | 1.115624 | 1.585507 | 1.516042 |
| V | 1.315965 | 2.092471 | 1.608308 | 1.113233 | 1.146686 | 1.455333 |
| FTZZ | 1.278720 | 1.379155 | 1.539660 | 1.668709 | 1.389535 | 1.451156 |
| CIZIZDROJE | 1.527338 | 1.269488 | 1.853573 | 1.073045 | 1.487208 | 1.442131 |
| SLUZBY | 1.422673 | 1.335220 | 2.002430 | 1.127664 | 1.204212 | 1.418440 |
| FM | 1.076257 | 1.418978 | 1.601751 | 1.185785 | 1.525021 | 1.361559 |
| HVUO | 1.298108 | 1.459786 | 1.454034 | 1.219113 | 1.350517 | 1.356312 |
| KZ | 1.258229 | 1.441923 | 1.204971 | 1.326370 | 1.334837 | 1.313266 |
| HIM | 1.095701 | 1.904764 | 1.004551 | 1.328013 | 1.228624 | 1.312330 |
| VLASTNIJM | 1.288897 | 1.338126 | 1.526678 | 1.225678 | 1.160983 | 1.308072 |
| KP | 1.280438 | 1.581155 | 1.337826 | 1.034392 | 1.196151 | 1.285992 |
| NNSOCZAB | 1.016164 | 1.991251 | 1.058640 | 1.060163 | 1.284383 | 1.282120 |
| AKTIVACELK | 1.274310 | 1.452314 | 1.154554 | 1.014583 | 1.388433 | 1.256839 |
| PASIVACELK | 1.274334 | 1.446461 | 1.154320 | 1.014663 | 1.368253 | 1.251606 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horak, J.; Vrbka, J.; Suler, P. Support Vector Machine Methods and Artificial Neural Networks Used for the Development of Bankruptcy Prediction Models and their Comparison. J. Risk Financial Manag. 2020, 13, 60. https://doi.org/10.3390/jrfm13030060
Horak J, Vrbka J, Suler P. Support Vector Machine Methods and Artificial Neural Networks Used for the Development of Bankruptcy Prediction Models and their Comparison. Journal of Risk and Financial Management. 2020; 13(3):60. https://doi.org/10.3390/jrfm13030060
Chicago/Turabian StyleHorak, Jakub, Jaromir Vrbka, and Petr Suler. 2020. "Support Vector Machine Methods and Artificial Neural Networks Used for the Development of Bankruptcy Prediction Models and their Comparison" Journal of Risk and Financial Management 13, no. 3: 60. https://doi.org/10.3390/jrfm13030060
APA StyleHorak, J., Vrbka, J., & Suler, P. (2020). Support Vector Machine Methods and Artificial Neural Networks Used for the Development of Bankruptcy Prediction Models and their Comparison. Journal of Risk and Financial Management, 13(3), 60. https://doi.org/10.3390/jrfm13030060