1. Introduction
The stochastic frontier model (SFM) is a standard tool in the estimation of efficiency from observed data. Robustness of SFM has not been examined thoroughly in the literature although many alternative distributional assumptions have been proposed for the error components of the model.
1 Bayesian analysis of SFM is widely used due to the convenience allowed by Markov Chain Monte Carlo in dealing with latent inefficiencies that are present in the model, particularly under alternative distributional assumptions.
Feng et al. (
2019) proposed a semiparametric model for stochastic frontier models, specifically, the one-sided error term is approximated by a log-transformed Rosenblatt-Parzen kernel density estimator. In a Monte Carlo study, they found that that the kernel-based semiparametric model performs better than the commonly-used exponential stochastic frontier model. Their study also indicates that the kernel model shows similar performance to a non-parametric model.
Our motivation in this paper is to take into account the previous literature with an eye towards making the posterior (and, therefore, statistical inferences) more robust to misspecification. For example, standard inference in stochastic frontier models does not take into account not only outliers but, perhaps more importantly, deviations of the assumed distributions of two-sided and one-sided error terms from their actual counterparts. To the extent that the actual distributions are unknown (see, for example,
Feng et al. 2019 for details) misspecification is quite likely so, in practice, statistical inferences are likely to be misleading.
A robust posterior, in the general case, has been proposed by
Miller and Dunson (
2019). Specifically, rather than conditioning on the observed data assumed to be generated by the model, we condition on the event that the model generates data that are
distributionally close to the observed data. This technique allows examining robustness to changes in the distribution of the composed error in SFM. Additionally, coarsening is a form of regularization, reduces overfitting and makes inferences less sensitive to model choice. When we are interested in the estimation of efficiency, returns to scale, productivity growth, etc., this is clearly a desirable goal.
2. Model
Suppose we have observed data and the “ideal”
data is -ideal in the sense that it is a random sample from the true data generating process (DGP). We focus on the case of i.i.d data whose distribution has density , where is a parameter and is the parameter space. The usual posterior may not be robust if there are outliers and/or we are not certain that the density is the true one.
A robust posterior is defined by
Miller and Dunson (
2019) in the i.i.d case as follows:
, where
is the empirical distribution of
and similarly for
, for some discrepancy measure
and a given
. Therefore, we condition on the event that the empirical distribution of actual data is close to the empirical distribution of data generated by the model, using a certain discrepancy function between probability measures.
If
and
for
have densities
and
, respectively, the Kullback–Leibler divergence is defined as:
where
is the Lebesgue measure.
Miller and Dunson (
2019) have derived the following approximation to the posterior under the assumption that
has an exponential distribution with parameter
:
where
and
is the prior. The approximation is accurate when
or
. The main objective of such “coarsened” posteriors is robustness to small changes in the shape of the distribution of the data, i.e., the data generating process. The approximation avoids altogether computation of
or the term
which is independent of
. The interpretation of the coarsened posterior is that it adjusts the sample size from
to
, so effectively we have a smaller sample size.
In this paper we consider the production SFM
2:
where
is a vector of regressors, and
,
. Let
and
and define the parameter vector
. The augmented posterior is:
The marginal density of
is
and is available in closed form:
where
is the standard normal distribution function; see
Kumbhakar and Lovell (
2000, p. 78).
Suppose we have a prior
and
,
denote the data. A coarsened posterior that uses at most
out of
observations is:
Similarly, we can define the coarsened augmented posterior:
where
. For the SFM it becomes:
With a nearly flat prior of the form
3:
the posterior becomes:
Inferences can be implemented using Gibbs sampling with data augmentation based on drawing random numbers from the posterior conditional distributions summarized in
Table 1.
1. Draw regression parameters from
where
.
2. Draw the scale parameter
as follows:
3. Draw the scale parameter
:
4. Draw technical inefficiencies:
where
.
We implement the Gibbs sampler using 15,000 iterations, the first 5000 of which are discarded to mitigate possible start-up effects. In all computations, we set
and
. In the neighborhood of these values, we did not notice the sensitivity of posteriors.
4 It should be mentioned that the coarsened posterior will have better mixing properties corresponding to
(which already mixes well) as the likelihood is tempered. Convergence was diagnosed successfully using
Geweke’s (
1992) diagnostics.
Suppose
denotes Gibbs draws for technical inefficiencies (i.e., a sample from the posterior), and set
. Then an estimate of firm-specific efficiency is:
Clearly, such measures depend on the amount of coarsening () and, therefore, there is the possibility of sensitive dependence on alternative model specifications.
Sometimes, we may have prior information on the regression parameters,
, summarized in the form:
where the prior mean is
and the prior covariance matrix is given by
where
and
are known. In this case, we have to modify (11) as follows:
where
, and
.
3. Illustration
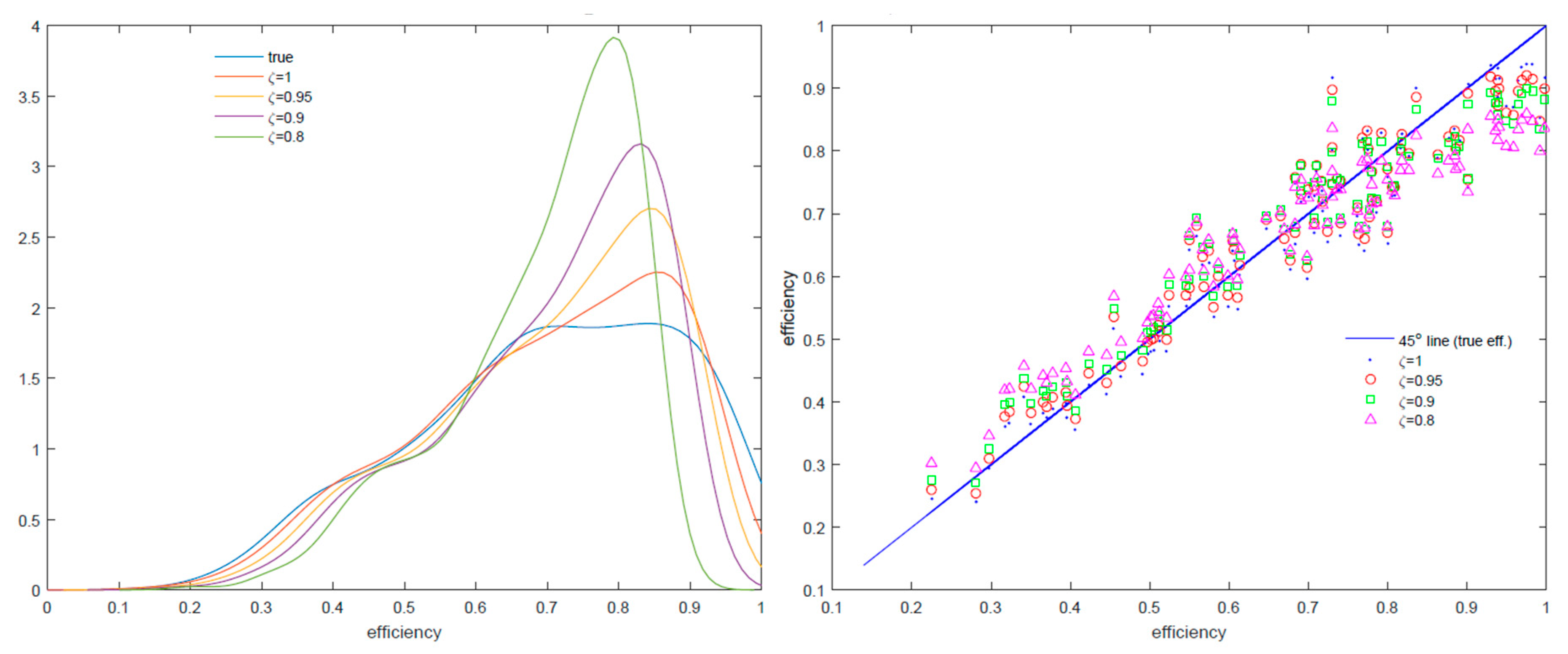
We give an illustration using two models. Model I is: , where , , with observations, when ) and, independently, . Here, and are generated from standard normal distributions. Model II has 900 observations generated from the first model, but the last 100 are generated as , where and . Therefore, in the second model, part of the data is generated from a process without systematic part and lower signal-to-noise ratio.
In the left panel of
Figure 1, we report the true density of efficiency scores along with estimates of the density for
0.95, 0.98 and 0.9. The densities corresponding to different values of
are sample densities of posterior mean scores across the sample. In the right panel of
Figure 1, we report 100 random efficiency scores corresponding to posteriors with different values of
.
From the right panel of
Figure 1, the differences between efficiency scores are not so marked as in Model II whose results are reported in the upper panels of
Figure 2. In the lower panel, we report marginal posterior densities of the parameters
and
. Efficiency scores are markedly different compared to
and as
decreases to 0.8 the efficiency distributions move to the left. The marginal posteriors of
and
also seem to be different although they are not far from the posterior mean when
.
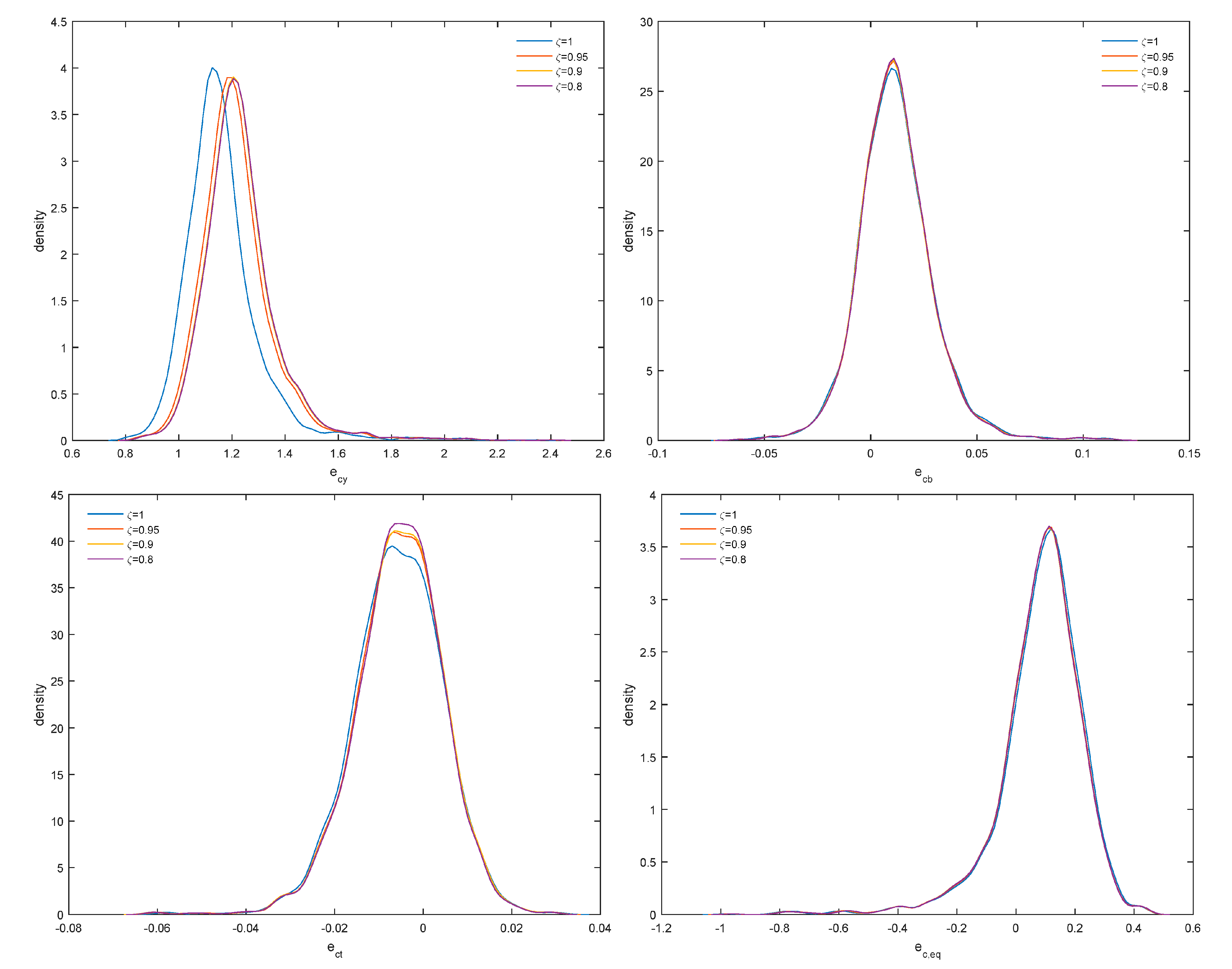
4. Empirical Application
We use the banking data of
Malikov et al. (
2016) to estimate a translog cost frontier with five input prices, five outputs, a bad output (non-performing loans) and equity included as quasi-fixed input. The data is an unbalanced panel with 2397 bank-year observations for 285 large, relatively homogeneous US banks (2001:I–2010:IV). We refer the reader to
Malikov et al. (
2016) for further details on the data. Our results are reported in
Figure 3 and
Figure 4. As
increases, the distribution of efficiency scores shifts to the left, efficiency scores remain, however, highly correlated (upper right panel) and the posterior densities of both
and
shift to the right. Therefore, changes in distributional assumptions are likely to increase the variance of the error term but also the signal-to-noise ratio
from 1.2 to 1.8, on the average. From the results in
Figure 4, posterior densities of output cost elasticity (
), elasticity with respect to non-performing loans (
), technical change (
) and elasticity with respect to quasi-fixed equity (
) remain robust as
changes, although this is less so for output cost elasticity and, therefore, returns to scale.
Finally, to address the question of selecting
,
Miller and Dunson (
2019) propose a measure of fit and a measure of model complexity. A measure of fit is given by the average log-likelihood and the complexity measure is given by the coarsened posterior. Instead, one case uses the log marginal likelihood:
where
is the tempered likelihood. Since this is an identity, we can use
, the posterior mean, and the denominator can be approximated with a multivariate normal distribution:
, where
is the posterior covariance matrix, and
. This is the Laplace approximation to log marginal likelihood (LML), see
DiCiccio et al. (
1997). We report the values of LML for ten values of
in
Figure 5.
Since LML stabilizes at
one would be safe to average efficiency distributions over the different values of
shown in
Figure 3. This is valid as alternative models (corresponding to different values of
) have approximately the same posterior model probability given by:
. Moreover, from the upper right panel of
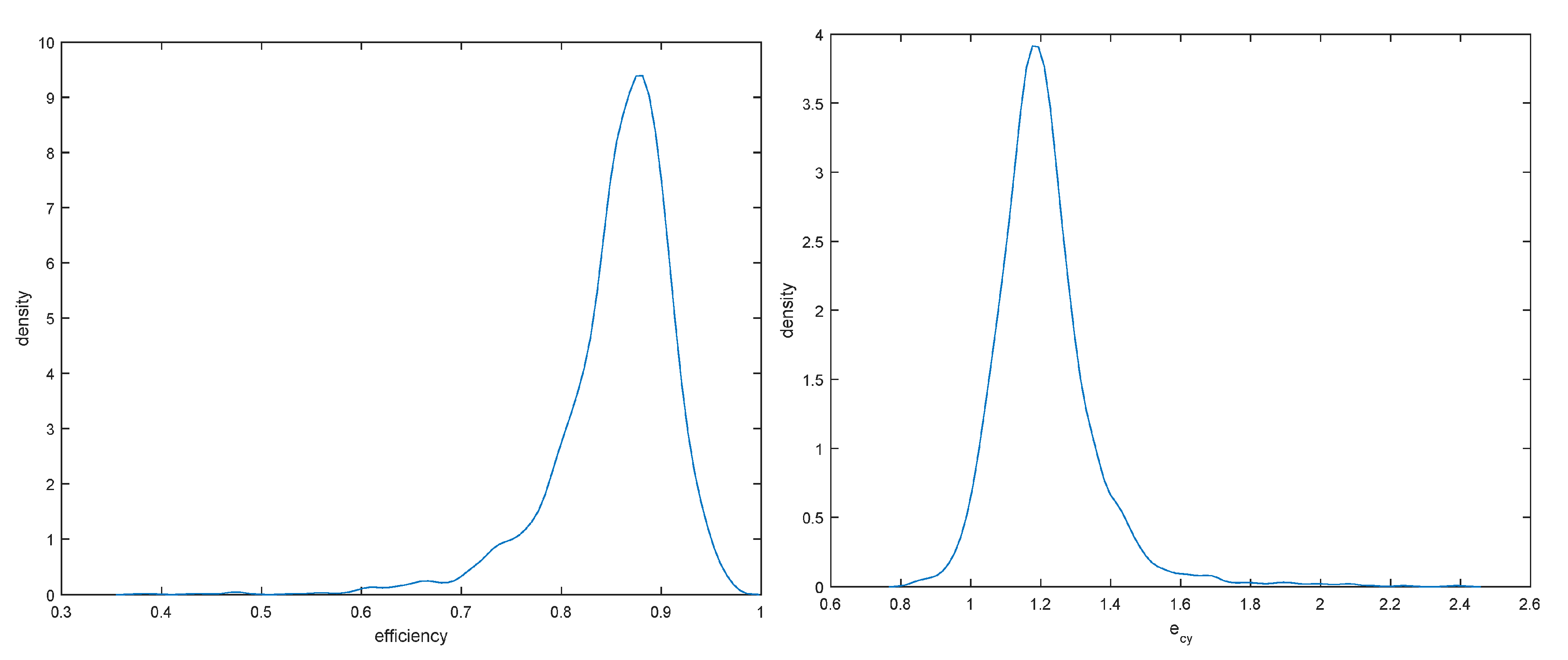
Figure 4, these efficiency scores are highly correlated and slight changes in the data generating process affect only their location. Averaged efficiency densities and densities of output cost elasticity are presented in
Figure 6.
The results indicate that efficiency ranges from 60% to slightly less than 100% with a median near 85%. As output cost elasticity averages 1.2, there seem to exist decreasing returns to scale in U.S large banks (the returns to scale measure is
) with constant returns enjoyed by a sizable number of banks, and increasing returns being only exceptional. Finally, as model uncertainty increases (corresponding to lower values of
),
increases slightly and its posterior shifts to the right (upper left panel of
Figure 4).
Finally, in
Table 1 we provide diagnostic measures to ensure that our MCMC draws provide access to the true posterior.
5. Concluding Remarks
We have proposed the concept of coarsened posteriors to robustify inferences from SFM. In an application to U.S banks, we find that economies of scale and technical change can be estimated in a relatively robust way, including elasticities with respect to equity and non-performing loans but efficiency inferences are less robust to the amount of data we use to robustify the posterior. This causes some concern as small changes in the distributional assumptions may change efficiency scores considerably. Fortunately, efficiency scores remain highly correlated across the robustness parameter (
), at least in this application. In terms of future research, it would be interesting to examine the performance of robust posteriors in more complicated SFM and reconcile differences that arise from different approaches to modeling inefficiency. Moreover, an interesting avenue for future research would be based on recent work by
Guo et al. (
2018) who examined whether a parametric production frontier function is suitable in the analysis.
Guo et al. (
2018) developed two test statistics based on local smoothing and an empirical process, respectively and suggested also residual-based wild bootstrap versions of these two test statistics. As coarsening provides more robust results it is likely that the procedures in
Guo et al. (
2018) would tend to be in favor of the parametric specification although one has to resolve the issue of applying the
Guo et al. (
2018) procedures in a Bayesian context.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}