Predicting Currency Crises: A Novel Approach Combining Random Forests and Wavelet Transform



Abstract

1. Introduction
2. Methodology and Data
2.1. Discrete Wavelet Transformation
2.2. The EMP Index
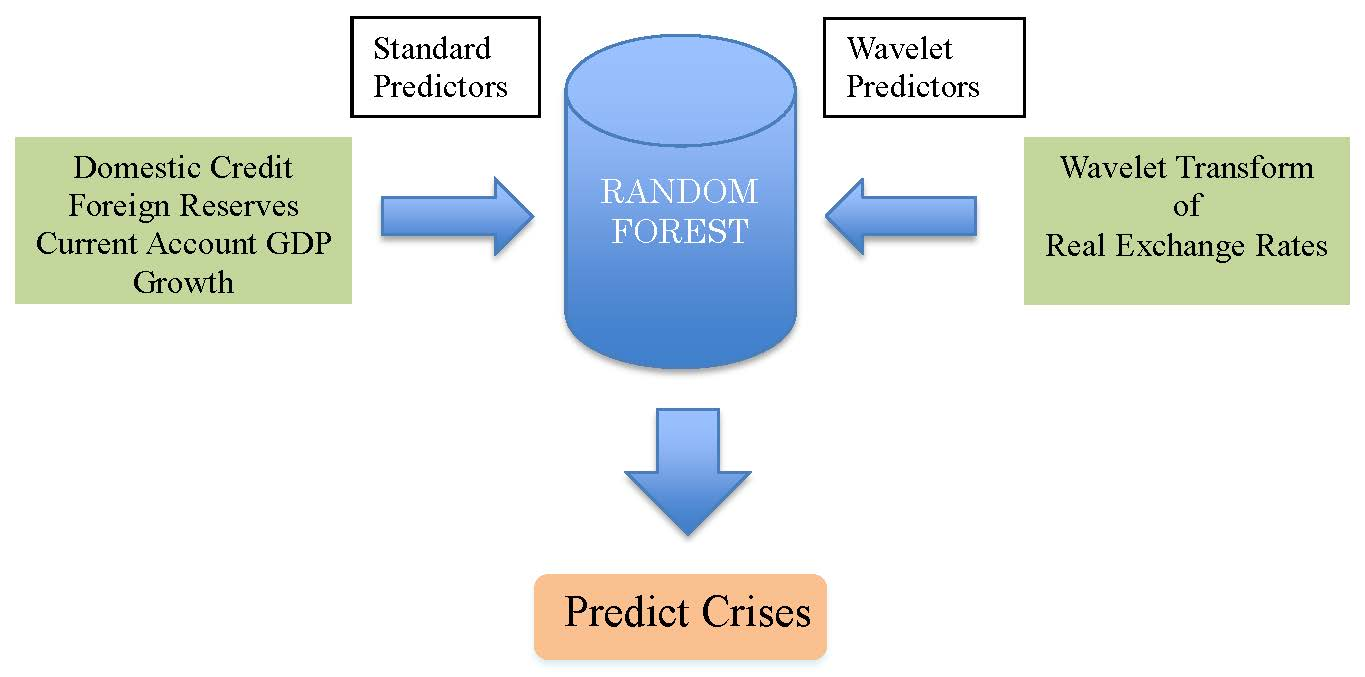
2.3. Classification Model of Random Forests
3. Results
3.1. Wavelet Predictors
3.2. Predictive Accuracy of the Random Forests Classification Model
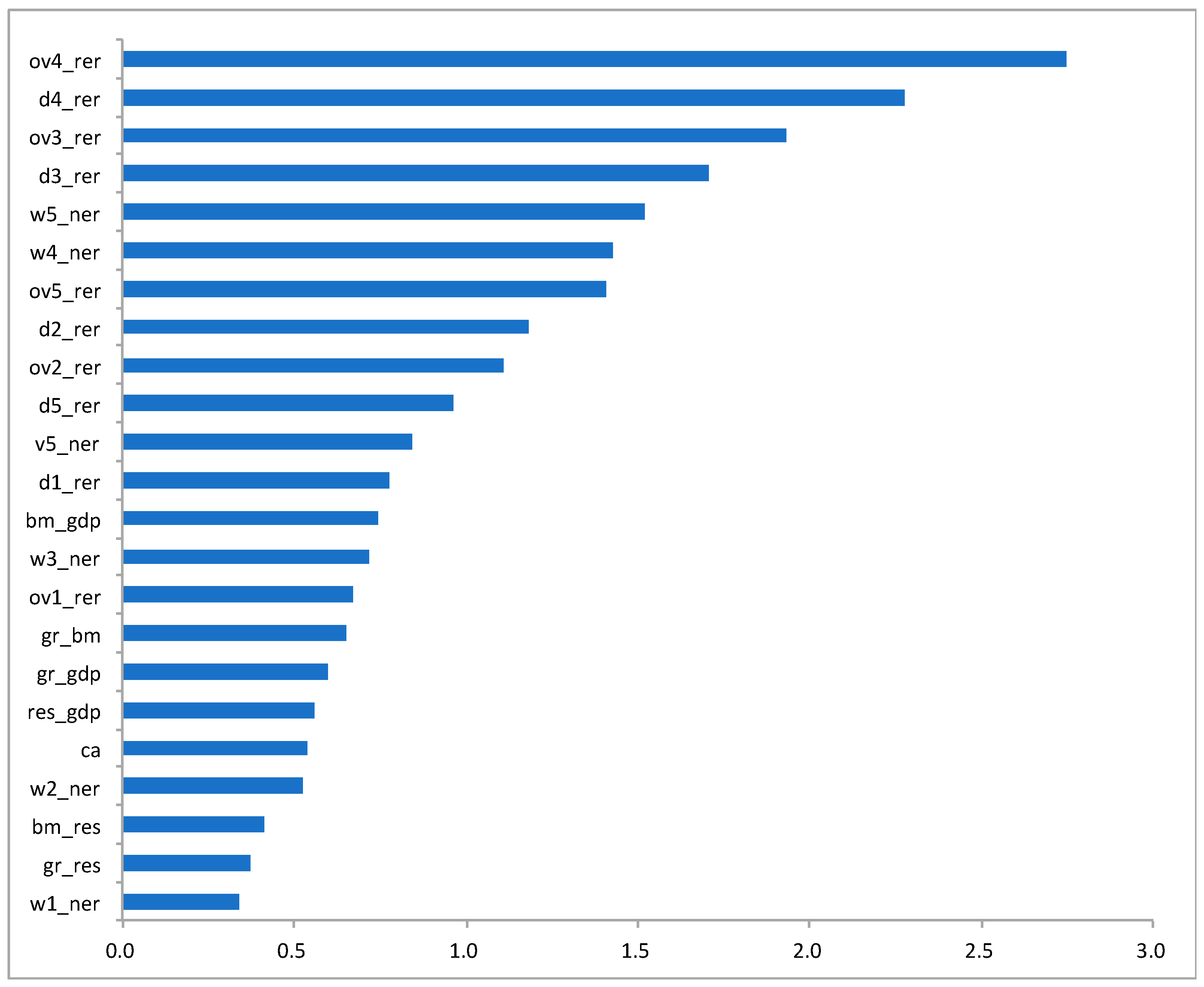
3.3. Variable Importance Measures
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. List of Sample Countries
References
- Abiad, Abdul. 2003. Early Warning Systems: A Survey and a Regime Switching Approach. IMF Working paper No. 03/23. Washington, DC, USA: International Monetary Fund. [Google Scholar]
- Berg, Andrew, and Catherine Pattillo. 1999. Predicting currency crises: The indicator approach and an alternative. Journal of International Money and Finance 18: 561–86. [Google Scholar] [CrossRef]
- Breiman, Leo. 2001. Random forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Bussiere, Matthieu, and Marcel Fratzscher. 2006. Towards a new early warning system of financial crises. Journal of International Money and Finance 25: 953–73. [Google Scholar] [CrossRef]
- Cai, Xiao Jing, Shuairu Tian, Nannan Yuan, and Shigeyuki Hamori. 2017. Interdependence between Oil and East Asian Stock Markets: Evidence from Wavelet Coherence Analysis. Journal of International Financial Markets, Institutions and Money 48: 206–23. [Google Scholar] [CrossRef]
- Eichengreen, Barry, Andrew K. Rose, and Charles Wyplosz. 1995. Exchange market mayhem: The antecedents and aftermath of speculative arracks. Economic Policy 21: 249–312. [Google Scholar] [CrossRef]
- Faria, Gonçalo, and Fabio Verona. 2018. Forecasting stock market returns by summing the frequency decomposed parts. Journal of Empirical Finance 45: 228–42. [Google Scholar] [CrossRef]
- Frankel, Jeffrey A., and Andrew K. Rose. 1996. Currency crashes in emerging markets: An empirical treatment. Journal of International Economics 41: 351–66. [Google Scholar] [CrossRef]
- Frankel, Jeffrey, and George Saravelos. 2012. Can leading indicators assess country vulnerability? Evidence from the 2008–2009 global financial crisis. Journal of International Economics 87: 216–31. [Google Scholar] [CrossRef]
- Gourinchas, Pierre-Olivier, and Maurice Obstfeld. 2012. Stories of the twentieth century for the twenty-first. American Economic Journal: Macroeconomics 4: 226–65. [Google Scholar] [CrossRef]
- Kaminsky, Graciela, Saul Lizondo, and Carmen M. Reinhart. 1998. The leading indicators of currency crises. IMF Staff Paper 45: 1–48. [Google Scholar] [CrossRef]
- Kuhn, Max, and Kjell Johnson. 2013. Applied Predictive Modeling. New York: Springer. [Google Scholar]
- Percival, Donald B., and Andrew T. Walden. 2000. Wavelet Methods for Time Series Analysis. Cambridge: Cambridge University Press. [Google Scholar]
- Peria, Maria Soledad Martinez. 2002. A regime-switching approach to the study of speculative attacks: A focus on EMS crises. Empirical Economics 27: 299–334. [Google Scholar] [CrossRef]
- Reboredo, Juan C., and Miguel A. Rivera-Castro. 2013. A Wavelet decomposition approach to crude oil price and exchange rate dependence. Economic Modelling 32: 42–57. [Google Scholar] [CrossRef]
- Rose, Andrew K., and Mark M. Spiegel. 2011. Cross-country causes and consequences of the crisis: An update. European Economic Review 55: 309–24. [Google Scholar] [CrossRef]
- Rose, Andrew K., and Mark M. Spiegel. 2012. Cross-country causes and consequences of the 2008 crisis: Early warning. Japan and the World Economy 24: 1–16. [Google Scholar] [CrossRef]
- Sevim, Cuneyt, Asil Oztekin, Ozkan Bali, Serkan Gumus, and Erkam Guresen. 2014. Developing an early warning system to predict currency crises. European Journal of Operational Research 237: 1095–104. [Google Scholar] [CrossRef]
- Shimpalee, Pattama L., and Janice Boucher Breuer. 2006. Currency crises and institutions. Journal of International Money and Finance 25: 125–45. [Google Scholar] [CrossRef]
- Tanaka, Katsuyuki, Takuji Kinkyo, and Shigeyuki Hamori. 2018. Financial hazard map: Financial vulnerability predicted by a random forests classification model. Sustainability 10: 1530. [Google Scholar] [CrossRef]
| 1 | The computation of the MODWT is conducted using the “Wavelets” package in the R software package. |
| 2 | Equation (1) is derived from the energy preserving condition: . |
| 3 | While Fourier transform coefficients are associated with frequencies, wavelet coefficients are associated with a particular scale and set of times. |
| 4 | Using the orthonormality of DWT, the MRA is obtained by pre-multiplying both sides of Equations (2) and (3) by the transposer of and , respectively. |
| 5 | In addition to the Harr filter, we also used LA8 and D4 to derive wavelet predictors and evaluate the predictive accuracy. The reason we have chosen to use the Harr filter is because it is the only filter that produces consistent results. When we used LA8 and D4, the random forests method performed better than the logistic regression based on the balanced accuracy and the F-measure, while the latter performed better than the former based on AUC. By contrast, the random forests method consistently outperformed the logistic regression when the Harr filter was used. |
| 6 | Although the original index also includes interest rate differentials, Kaminsky and Reinhart (1998) removed it from their index because developing countries often adopt interest rate control. Since our sample includes many developing countries, we exclude interest rate differentials from the index. Note also that real exchange rates are used instead of nominal exchange rates to take into account differences in inflation rates across countries. |
| 7 | The computation is conducted using “caret”, “randomForest”, and “pROC” packages in the R software package. |
| 8 | As a result of the truncation, the number of observations in the training set is 53, of which the number of crisis and non-crisis is 19 and 34, respectively. The test set includes all 200 observations, of which the number of crises and non-crisis is 4 and 196, respectively. |
| 9 | We use the set.seed ( ) function in R to reproduce the results. Our results for predictive accuracy and variable importance measures are obtained when the function takes the value of 10. Regarding the choice of key parameters, notably, the number of tress to grow, the minimum size of terminal nodes, and the maximum number of terminal nodes, we use the default values given by “randomForests” package, which are 500, 1, and NULL (which implies that trees are grown to the maximum possible, subject to limits by the minimum size of terminal nodes), respectively. |


{kind=link}
{kind=link}
| Year | No. of Crises |
|---|---|
| 1992 | 1 |
| 1993 | 2 |
| 1994 | 3 |
| 1997 | 2 |
| 1998 | 1 |
| 1999 | 5 |
| 2002 | 1 |
| 2003 | 3 |
| 2007 | 1 |
| 2015 | 4 |
| Total | 23 |
| EMP_index | res_gdp | gr_res | gr_gdp | ca | gr_bm | |
| Obs. | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 |
| Mean | −0.4671 | −0.0025 | 0.0165 | −0.0009 | 0.0037 | 0.0013 |
| Sd. dev. | 1.5397 | 0.9801 | 0.9856 | 0.9795 | 0.9752 | 0.9773 |
| Min | −7.6276 | −2.4292 | −2.8799 | −4.3650 | −4.2418 | −2.1852 |
| Max | 4.9584 | 2.8716 | 4.6392 | 4.3375 | 2.8742 | 4.5146 |
| bm_gdp | bm_res | d1_rer | d2_rer | d3_rer | d4_rer | |
| Obs. | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 |
| Mean | 0.0044 | 0.0035 | −0.0001 | −0.0001 | −0.0001 | −0.0007 |
| Sd. dev. | 0.9813 | 0.9799 | 0.0088 | 0.0148 | 0.0351 | 0.0837 |
| Min | −3.7706 | −2.1113 | −0.0772 | −0.1122 | −0.2180 | −0.5096 |
| Max | 3.0995 | 4.7506 | 0.0861 | 0.1279 | 0.2288 | 0.5434 |
| d5_rer | ov1_rer | ov2_rer | ov3_rer | ov4_rer | ov5_rer | |
| Obs. | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 |
| Mean | −0.0037 | −0.0001 | −0.0001 | −0.0002 | −0.0009 | −0.0046 |
| Sd. dev. | 0.1417 | 0.0088 | 0.0229 | 0.0554 | 0.1342 | 0.2586 |
| Min | −0.9524 | −0.0772 | −0.1684 | −0.3621 | −0.7815 | −1.7339 |
| Max | 0.9170 | 0.0861 | 0.1924 | 0.4113 | 0.8296 | 1.4932 |
| w1_ner | w2_ner | w3_ner | w4_ner | w5_ner | v5_ner | |
| Obs. | 1000 | 1000 | 1000 | 1000 | 1000 | 1000 |
| Mean | 0.0025 | 0.0047 | 0.0098 | 0.0208 | 0.0445 | 0.8894 |
| Sd. dev. | 0.0120 | 0.0165 | 0.0300 | 0.0604 | 0.1142 | 1.2783 |
| Min | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Max | 0.1614 | 0.2000 | 0.3433 | 0.7592 | 1.0942 | 10.6675 |
| d1_rer | d2_rer | d3_rer | d4_rer | d5_rer | ||||||
| Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | |
| Crisis | −0.0083 | 0.0155 | −0.0164 | 0.0215 | −0.0438 | 0.0405 | −0.1163 | 0.0800 | −0.1775 | 0.1416 |
| Non-crisis | 0.0001 | 0.0085 | 0.0003 | 0.0144 | 0.0010 | 0.0343 | 0.0020 | 0.0818 | 0.0004 | 0.1392 |
| t-test (p-value) | 0.0084 | 0.0006 | 0.0000 | 0.0000 | 0.0000 | |||||
| ov1_rer | ov2_rer | ov3_rer | ov4_rer | ov5_rer | ||||||
| Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | |
| Crisis | −0.0083 | 0.0155 | −0.0246 | 0.0366 | −0.0684 | 0.0759 | −0.1847 | 0.1511 | −0.3622 | 0.2516 |
| Non-crisis | 0.0001 | 0.0085 | 0.0005 | 0.0222 | 0.0014 | 0.0538 | 0.0034 | 0.1308 | 0.0038 | 0.2528 |
| t-test (p-value) | 0.0084 | 0.0017 | 0.0001 | 0.0000 | 0.0000 | |||||
| w1_ner | w2_ner | w3_ner | w4_ner | w5_ner | ||||||
| Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | Mean | Std. dev. | |
| Crisis | 0.0117 | 0.0349 | 0.0180 | 0.0467 | 0.0355 | 0.0860 | 0.0741 | 0.1726 | 0.1613 | 0.2912 |
| Non-crisis | 0.0023 | 0.0108 | 0.0044 | 0.0150 | 0.0092 | 0.0272 | 0.0195 | 0.0547 | 0.0417 | 0.1053 |
| t-test (p-value) | 0.1056 | 0.0888 | 0.0784 | 0.0720 | 0.0309 | |||||
| v5_ner | ||||||||||
| Mean | Std. dev. | |||||||||
| Crisis | 1.1793 | 1.5044 | ||||||||
| Non-crisis | 0.8826 | 1.2719 | ||||||||
| t-test (p-value) | 0.1790 | |||||||||
| 50% | Threshold | 70% | Threshold | |
|---|---|---|---|---|
| Random Forests | Logistic Regression | Random Forests | Logistic Regression | |
| Sensitivity | 0.9565 | 0.8696 | 0.8696 | 0.8696 |
| Specificity | 0.8608 | 0.8270 | 0.9222 | 0.8301 |
| Balanced accuracy | 0.9087 | 0.8483 | 0.8959 | 0.8499 |
| F-measure | 0.9061 | 0.8478 | 0.8951 | 0.8494 |
| Random Forests | Logistic Regression | |||
| AUC | 0.9496 | 0.857 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, L.; Kinkyo, T.; Hamori, S. Predicting Currency Crises: A Novel Approach Combining Random Forests and Wavelet Transform. J. Risk Financial Manag. 2018, 11, 86. https://doi.org/10.3390/jrfm11040086
Xu L, Kinkyo T, Hamori S. Predicting Currency Crises: A Novel Approach Combining Random Forests and Wavelet Transform. Journal of Risk and Financial Management. 2018; 11(4):86. https://doi.org/10.3390/jrfm11040086
Chicago/Turabian StyleXu, Lei, Takuji Kinkyo, and Shigeyuki Hamori. 2018. "Predicting Currency Crises: A Novel Approach Combining Random Forests and Wavelet Transform" Journal of Risk and Financial Management 11, no. 4: 86. https://doi.org/10.3390/jrfm11040086
APA StyleXu, L., Kinkyo, T., & Hamori, S. (2018). Predicting Currency Crises: A Novel Approach Combining Random Forests and Wavelet Transform. Journal of Risk and Financial Management, 11(4), 86. https://doi.org/10.3390/jrfm11040086