Nonlinear Time Series Modeling: A Unified Perspective, Algorithm and Application


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- (1)
- Marginal modeling: The identification of the marginal probability law (in particular, the heavy-tailed marginal densities) of a time series plays a vital role in financial econometrics. Notations: common quantile Q, inverse of the distribution function F, respectively denoted and . The mid-distribution is defined as .
- (2)
- Correlation modeling: Covariance function (defined for positive and negative lag h) . , assumed zero in our prediction theory. Correlation function .
- (3)
- Frequency-domain modeling: When covariance is absolutely summable, define spectral density function .
- (4)
- Time-domain modeling: The time domain model is a linear filter relating to white noise , independent random variables. Autoregressive scheme of order m, a predominant linear time series technique for modeling conditional mean, is defined as (assuming ):with the spectral density function given by:To fit an AR model, compute the linear predictor of given by:Verify that the prediction error is white noise. The best fitting AR order is identified by the Akaike criterion (AIC) (or Schwarz’s criterion, BIC) as the value of m minimizes:In what follows, we aim to develop a parallel modeling framework for nonlinear time series.
2. From Linear to Nonlinear Modeling
3. Nonparametric LPTime Analysis
- (a)
- The algorithmic modeling aspect (how it works).
- (b)
- The required theoretical ideas and notions (why it works).
- (c)
- The application to daily S&P 500 return data between 2 January 1963 and 31 December 2009 (empirical proof-of-work).
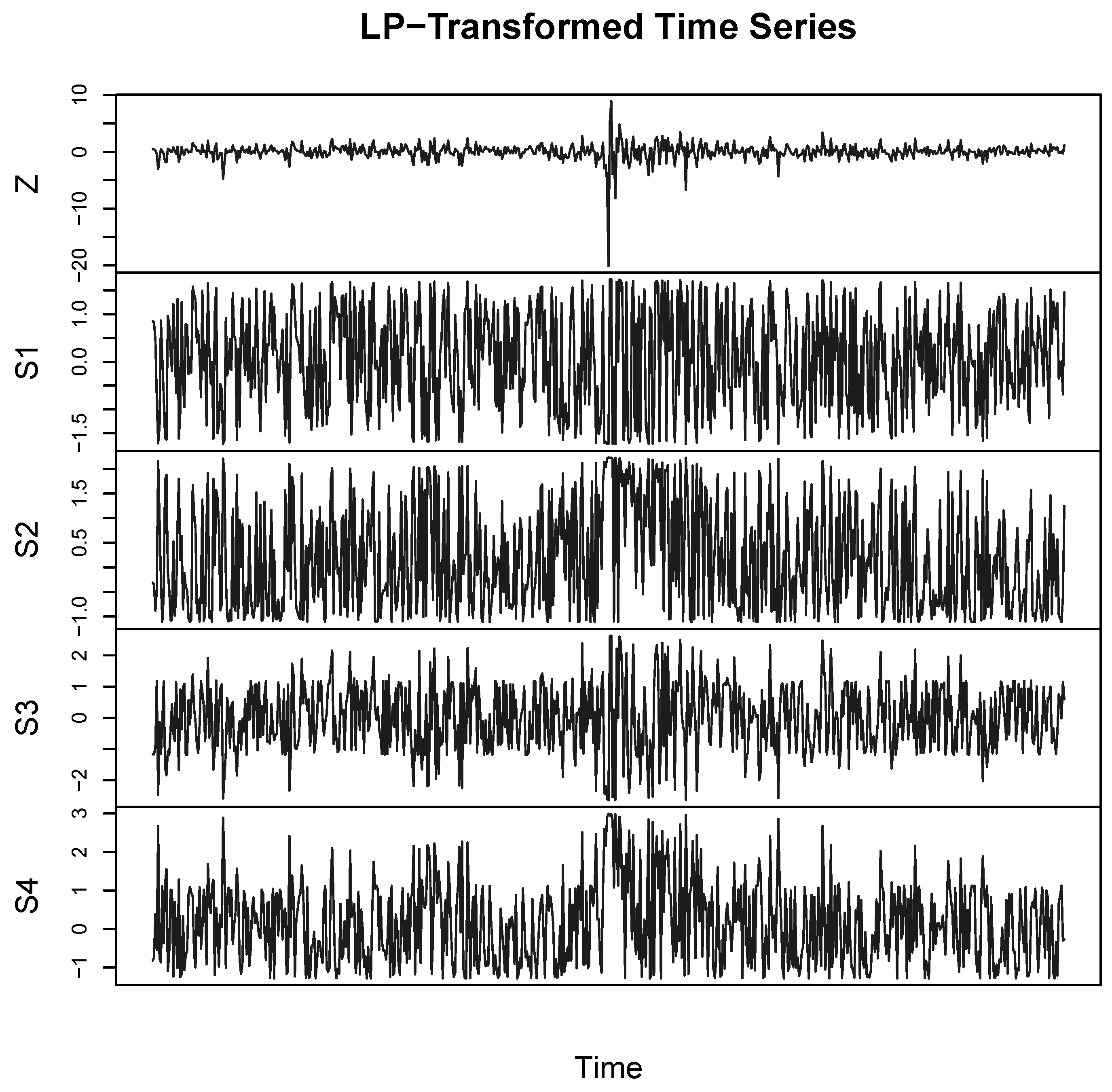
3.1. The Data and LP-Transformation
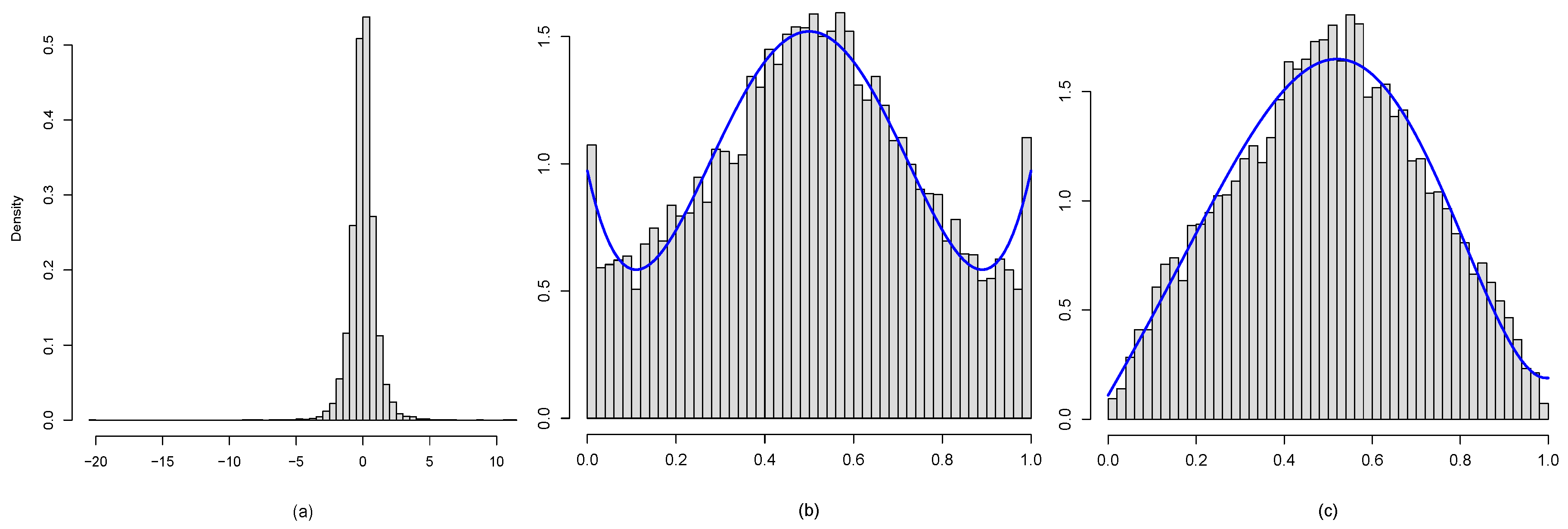
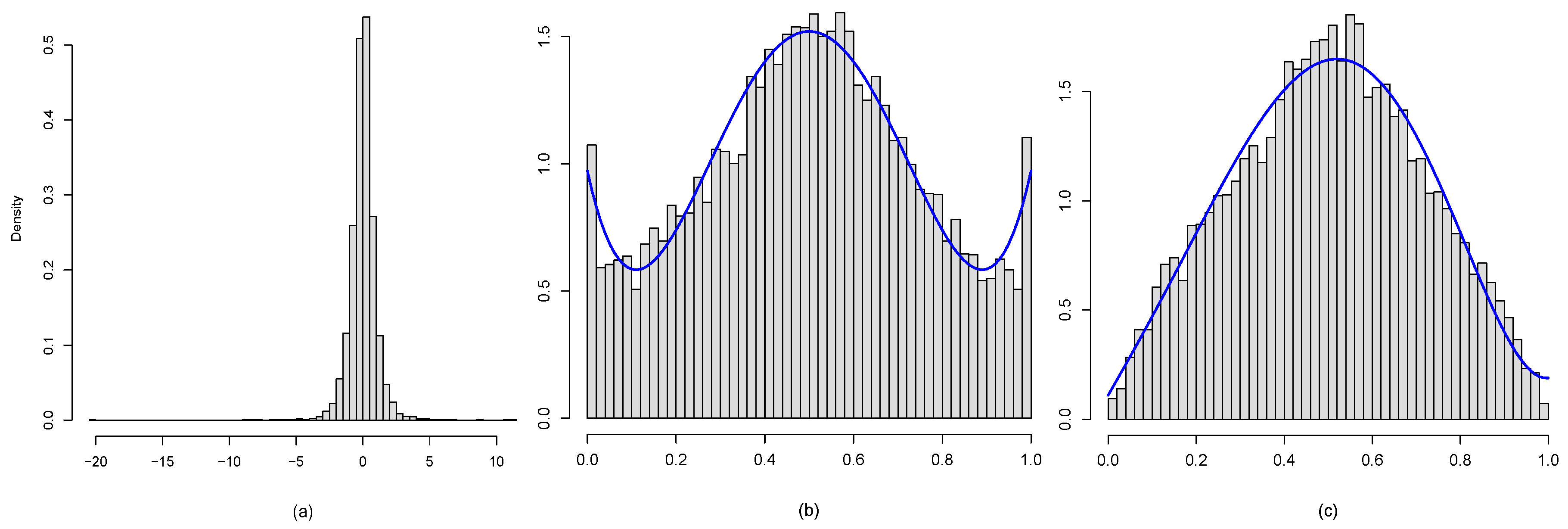
3.2. Marginal Modeling
Non-Normality Diagnosis
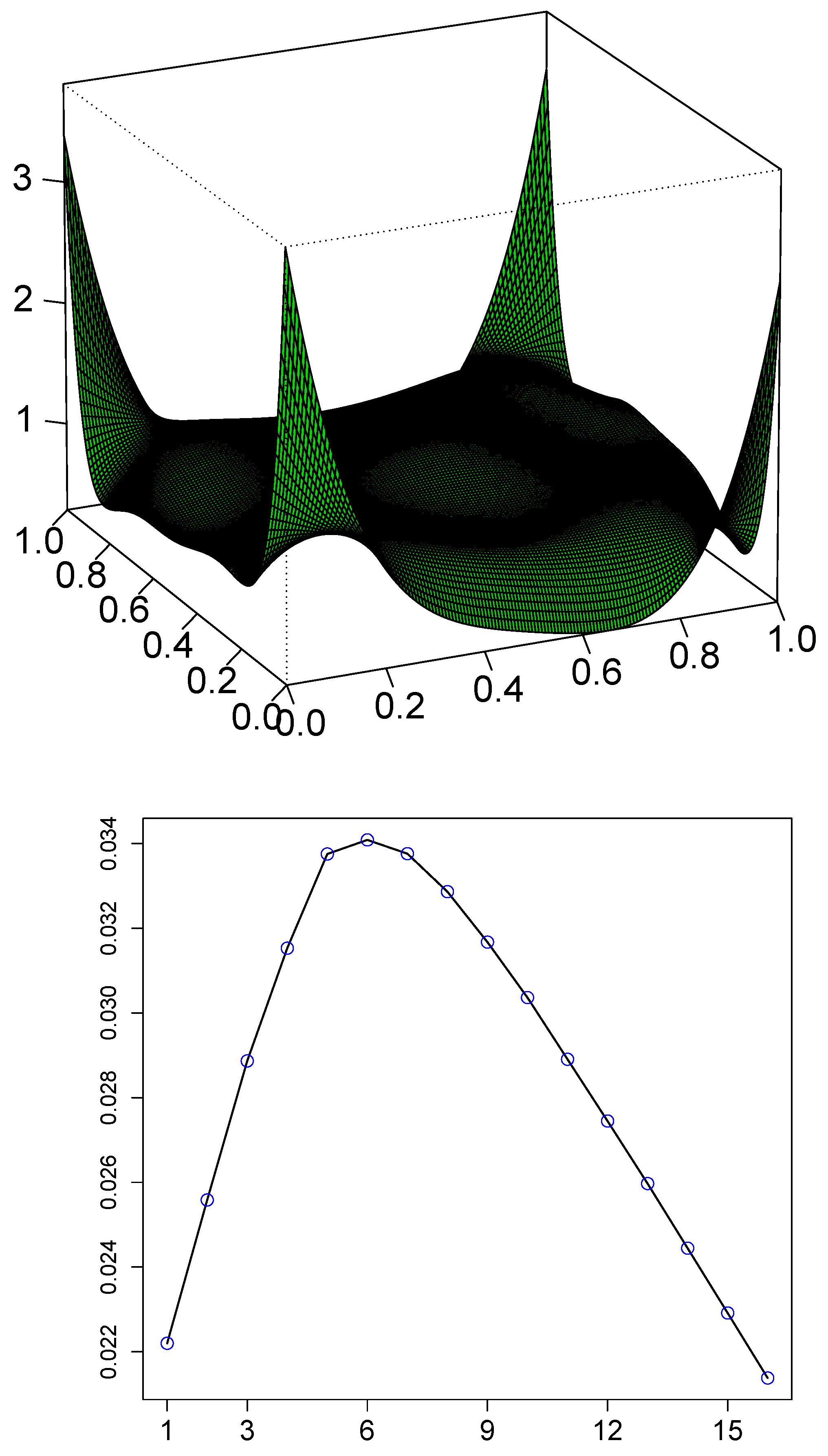
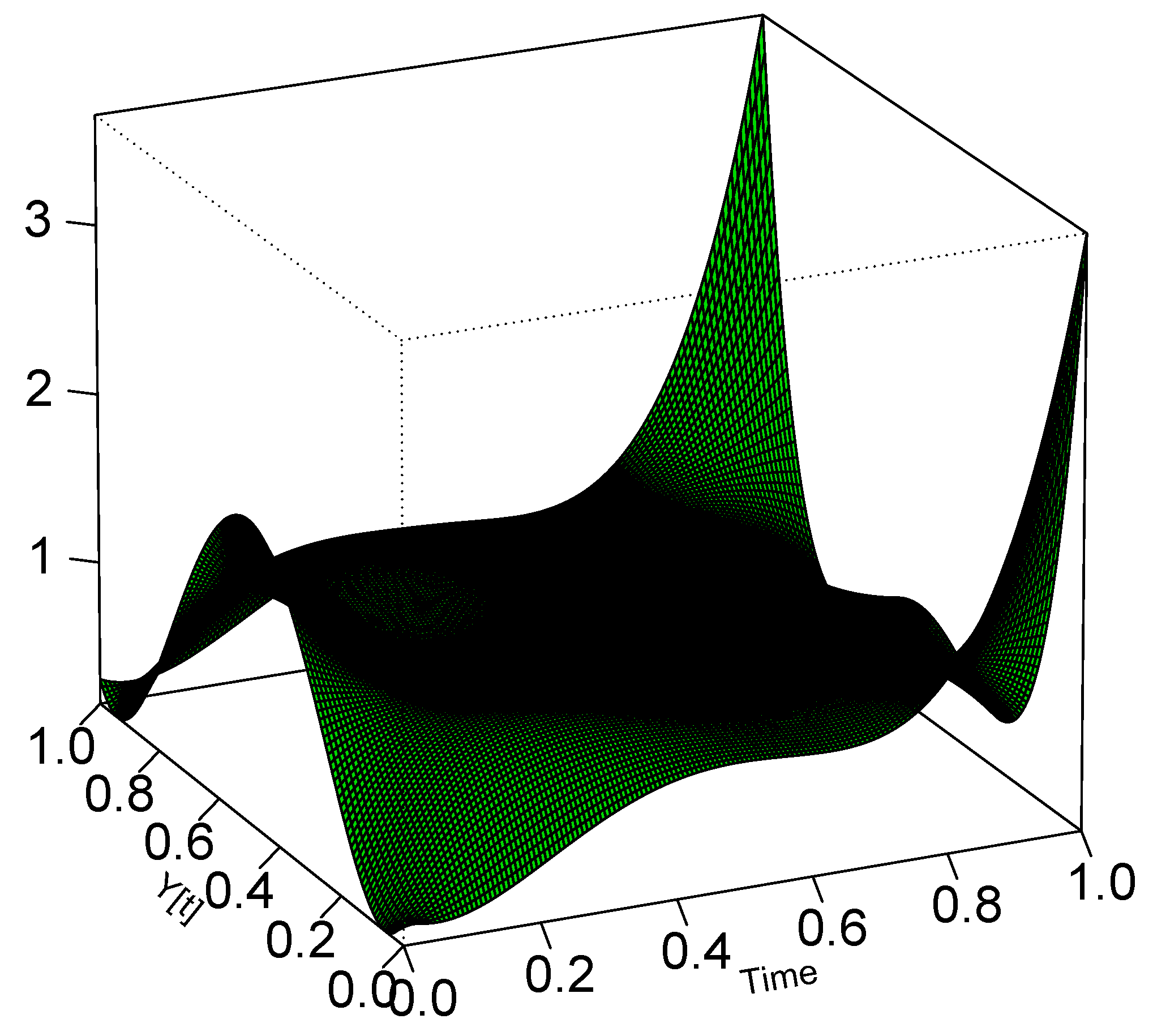
3.3. Copula Dependence Modeling
3.3.1. Nonparametric Serial Copula
3.3.2. LP-Comoment of Lag h
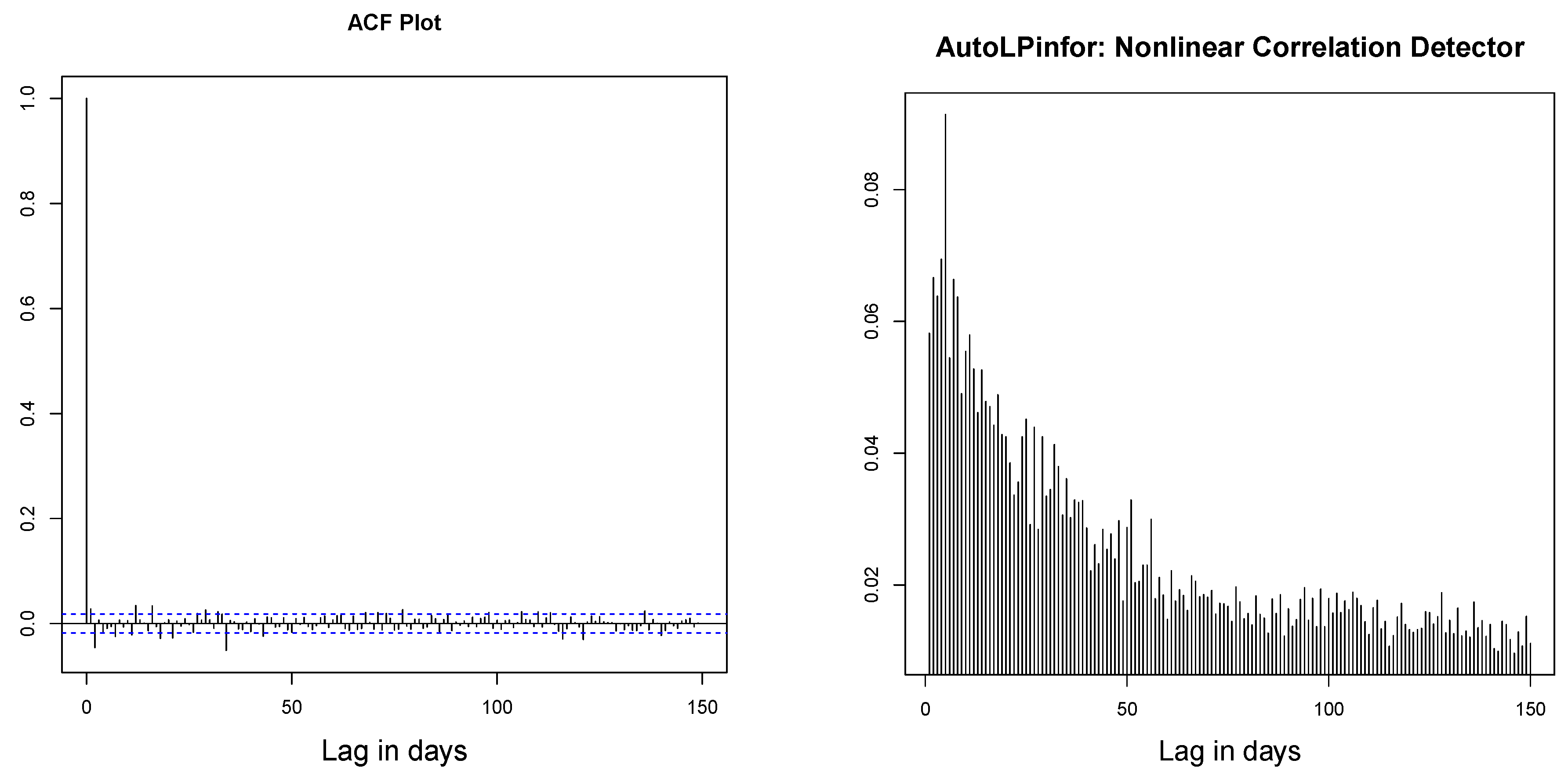
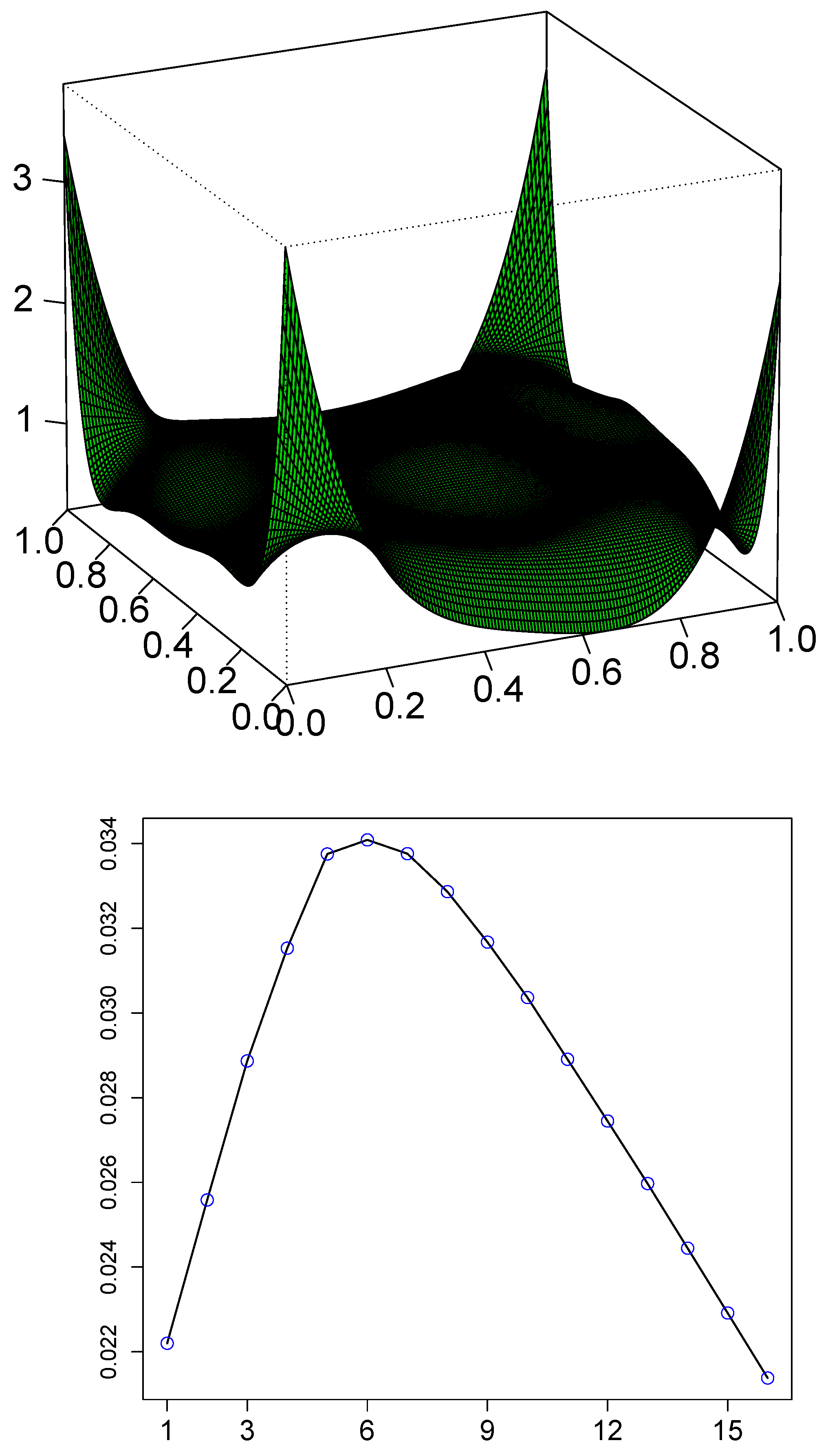
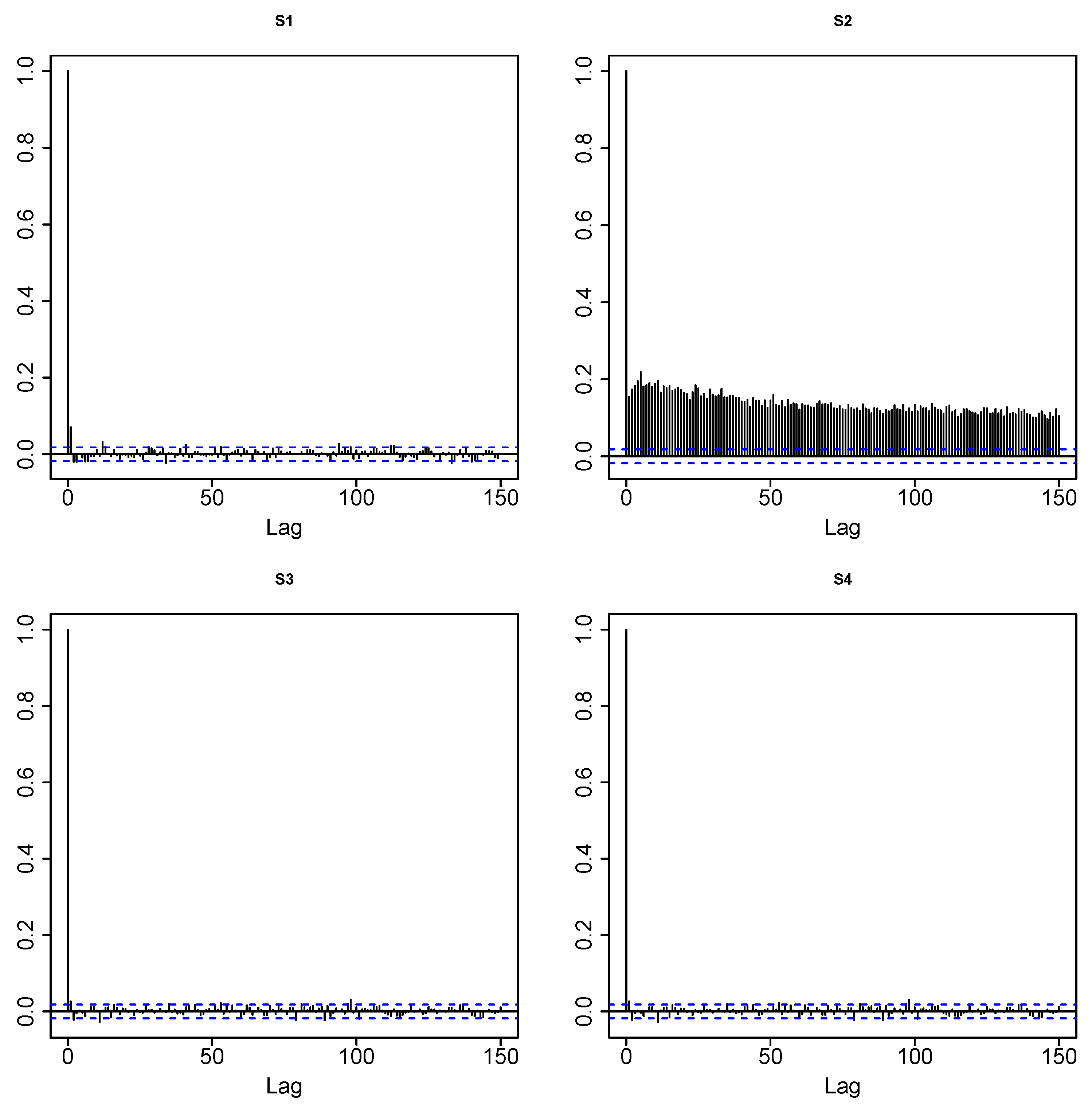
3.3.3. LP-Correlogram, Evidence and Source of Nonlinearity
3.3.4. AutoLPinfor: Nonlinear Correlation Measure
3.3.5. Nonparametric Estimation of Blomqvist’s Beta
3.3.6. Nonstationarity Diagnosis, LP-Comoment Approach
3.4. Local Dependence Modeling
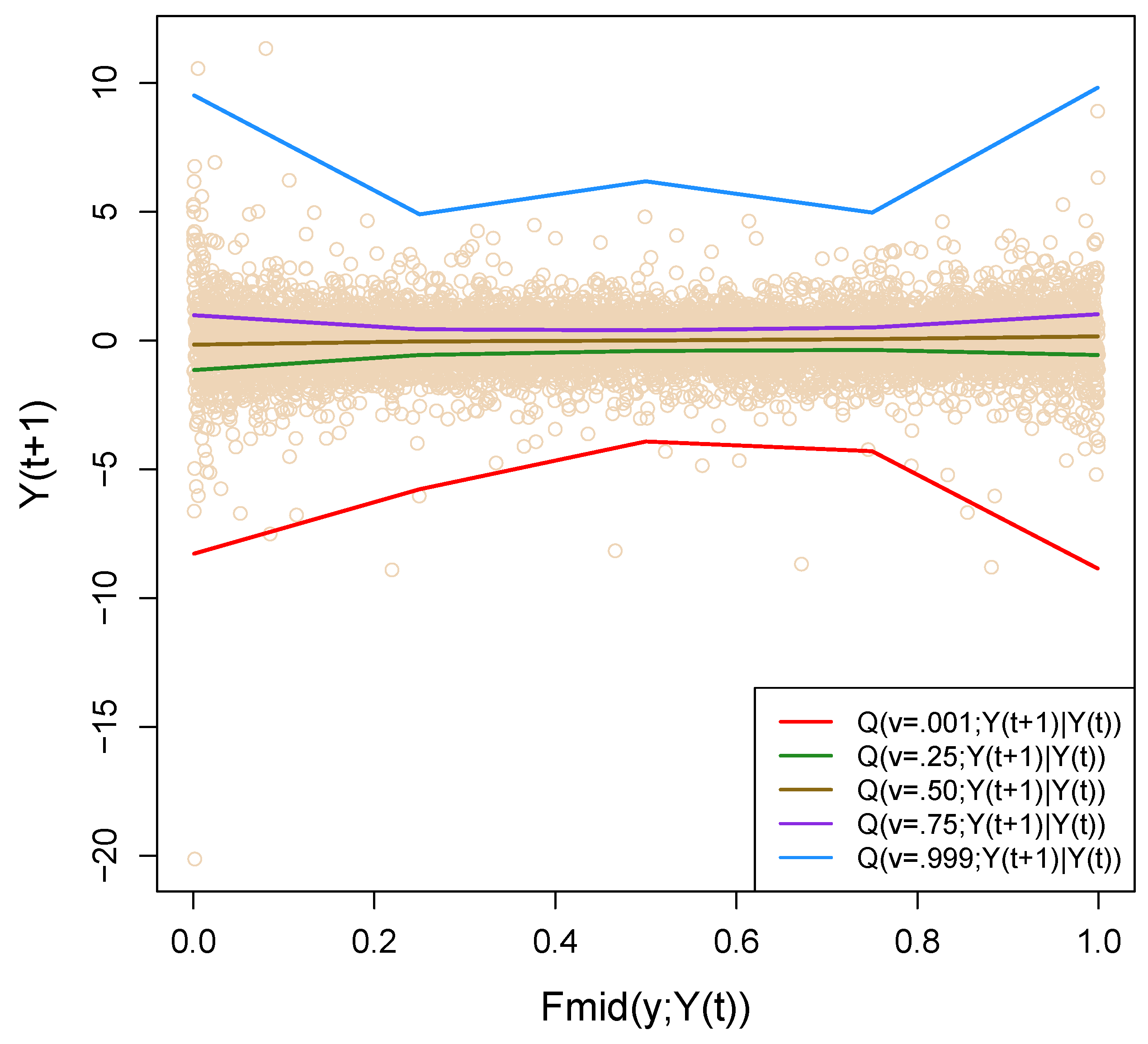
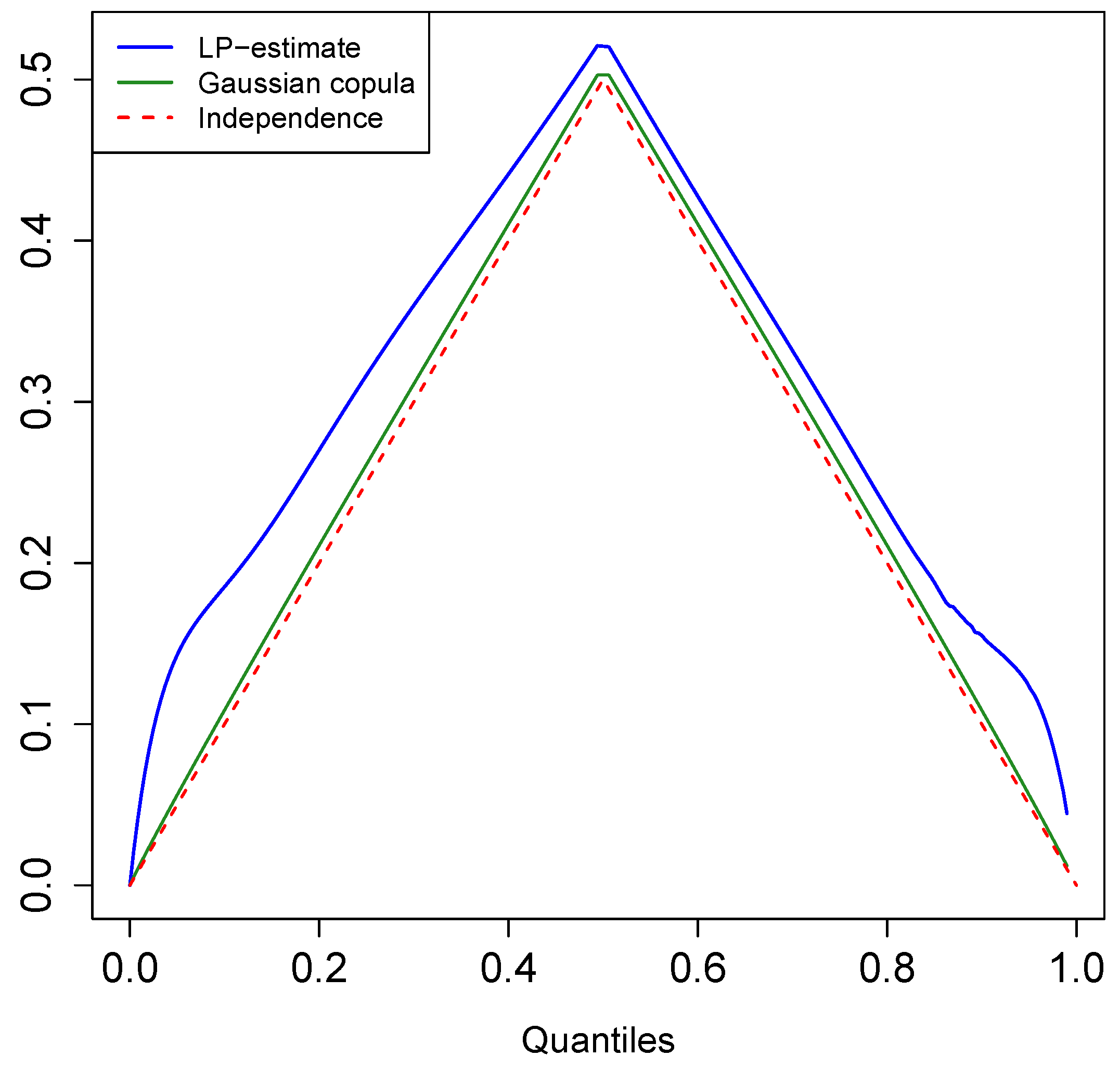
3.4.1. Quantile Correlation Plot and Test for Asymmetry
3.4.2. Conditional LPinfor Dependence Measure
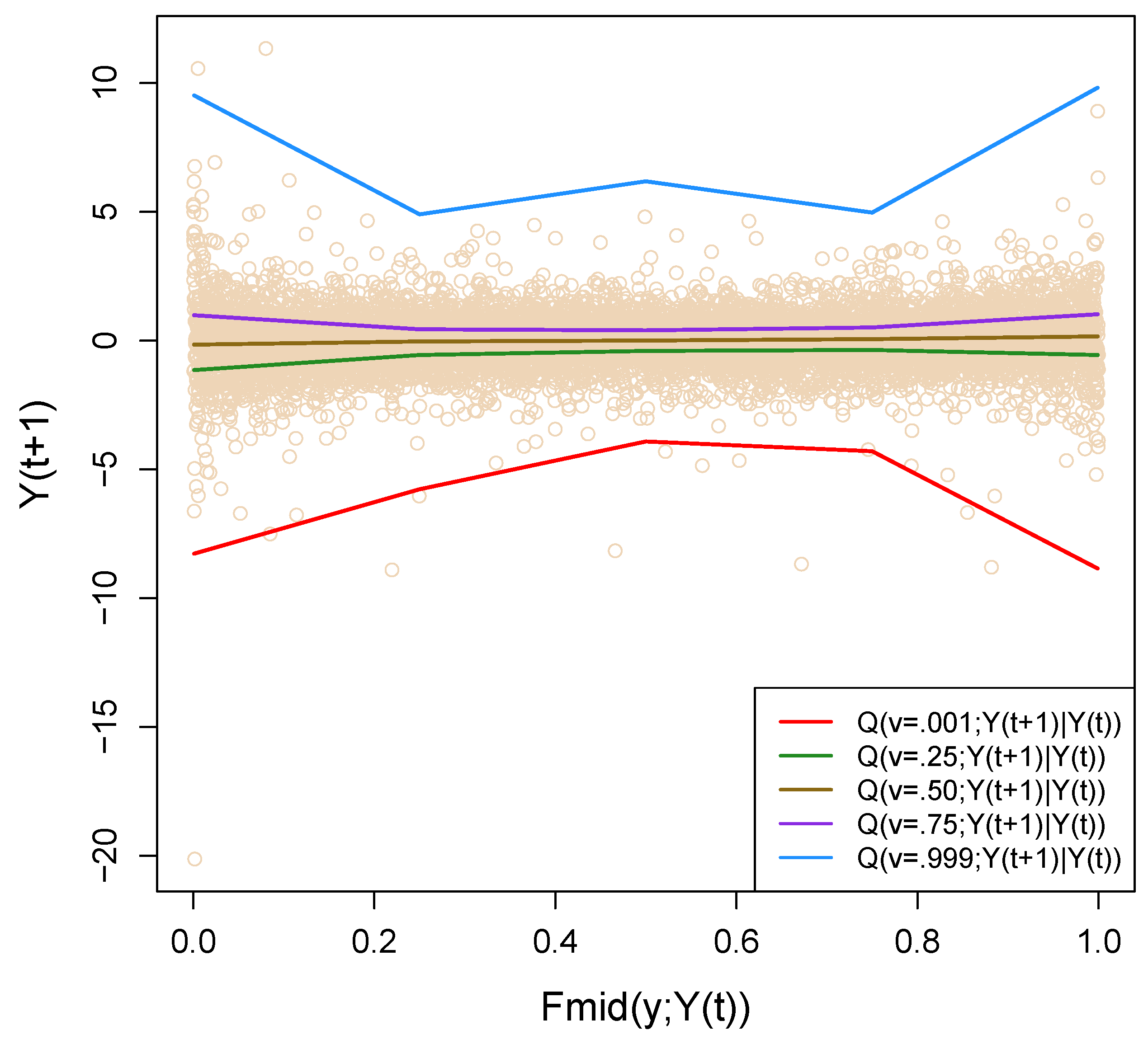
3.5. Non-Crossing Conditional Quantile Modeling
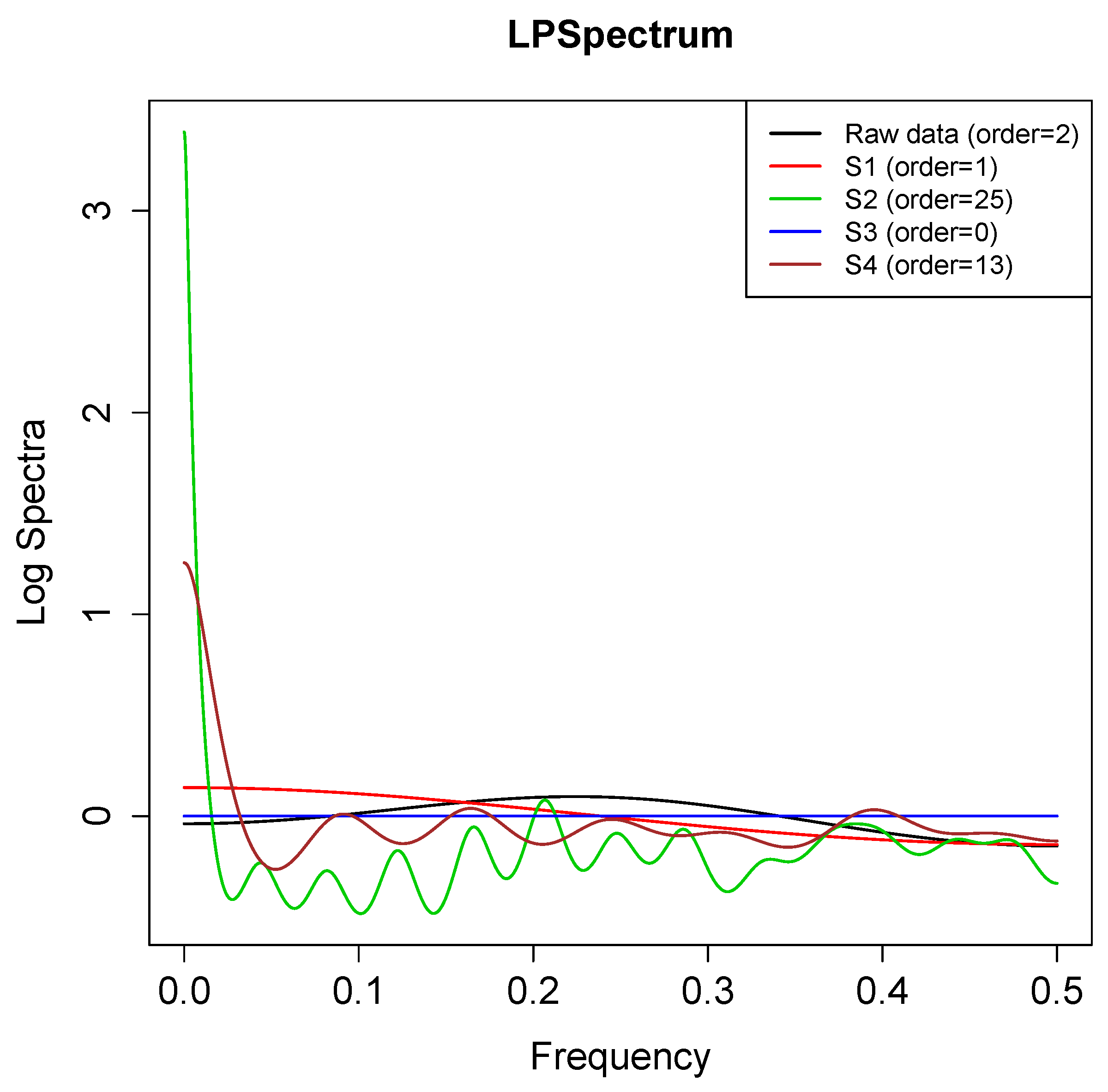
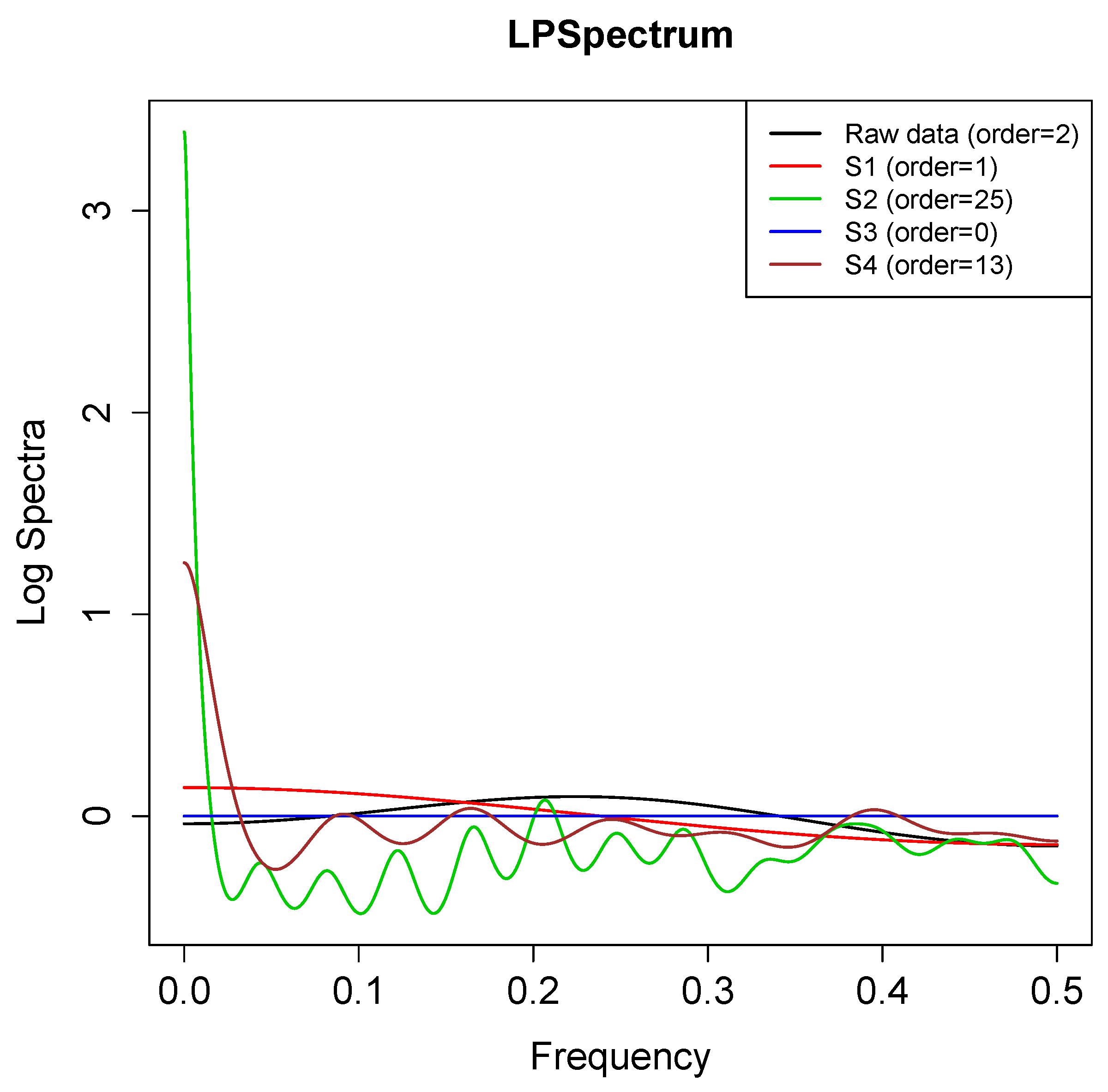
3.6. Nonlinear Spectrum Analysis
3.7. Nonparametric Model Specification
4. Conclusions
- From the theoretical standpoint, the unique aspect of our proposal lies in its ability to simultaneously embrace and employ the spectral domain, time domain, quantile domain and information domain analyses for enhanced insights, which to the best of our knowledge has not appeared in the nonlinear time series literature before.
- From a practical angle, the novelty of our technique is that it permits us to use the techniques from linear Gaussian time series to create non-Gaussian nonlinear time series models with highly interpretable parameters. This aspect makes LPTime computationally extremely attractive for data scientists, as they can now borrow all the standard time series analysis machinery from R libraries for implementation purposes.
- From the pedagogical side, we believe that these concepts and methods can easily be augmented with the standard time series analysis course to modernize the current curriculum so that students can handle complex time series modeling problems (McNeil et al. 2010) using the tools with which they are already familiar.
Author Contributions
Funding
Conflicts of Interest
References
- Adrian, Tobias, and Markus K Brunnermeier. 2011. Covar. Technical Report. Cambridge: National Bureau of Economic Research. [Google Scholar]
- Brillinger, David R. 1977. The identification of a particular nonlinear time series system. Biometrika 64: 509–15. [Google Scholar] [CrossRef]
- Brillinger, David R. 2004. Some data analyses using mutual information. Brazilian Journal of Probability and Statistics 18: 163–83. [Google Scholar]
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica: Journal of the Econometric Society 50: 987–1007. [Google Scholar] [CrossRef]
- Engle, Robert F., and Simone Manganelli. 2004. Caviar: Conditional autoregressive value at risk by regression quantiles. Journal of Business & Economic Statistics 22: 367–81. [Google Scholar]
- Granger, Clive, and Jin-Lung Lin. 1994. Using the mutual information coefficient to identify lags in nonlinear models. Journal of Time Series Analysis 15: 371–84. [Google Scholar] [CrossRef]
- Granger, Clive W. J. 1993. Strategies for modelling nonlinear time-series relationships. Economic Record 69: 233–38. [Google Scholar] [CrossRef]
- Granger, Clive W. J. 1998. Overview of nonlinear time series specification in economics. Paper presented at the NSF Symposium on Nonlinear Time Series Models, University of California, Berkeley, CA, USA, 22 May 1998. [Google Scholar]
- Granger, Clive W. J. 2003. Time series concepts for conditional distributions. Oxford Bulletin of Economics and Statistics 65: 689–701. [Google Scholar] [CrossRef]
- Granger, Clive W. J., and Roselyne Joyeux. 1980. An introduction to long-memory time series models and fractional differencing. Journal of Time Series Analysis 1: 15–29. [Google Scholar] [CrossRef]
- Guo, Xin, Howard Shek, Tze Leung Lai, and Samuel Po-Shing Wong. 2017. Quantitative Trading: Algorithms, Analytics, Data, Models, Optimization. New York: Chapman and Hall/CRC. [Google Scholar]
- Hendry, David F. 2011. Empirical economic model discovery and theory evaluation. Rationality, Markets and Morals 2: 115–45. [Google Scholar]
- McNeil, Alexander J., Rüdiger Frey, and Paul Embrechts. 2010. Quantitative Risk Management: Concepts, Techniques, and Tools. Princeton: Princeton University Press. [Google Scholar]
- Mukhopadhyay, Subhadeep. 2016. Large scale signal detection: A unifying view. Biometrics 72: 325–34. [Google Scholar] [CrossRef] [PubMed]
- Mukhopadhyay, Subhadeep. 2017. Large-scale mode identification and data-driven sciences. Electronic Journal of Statistics 11: 215–40. [Google Scholar] [CrossRef]
- Mukhopadhyay, Subhadeep, and Douglas Fletcher. 2018. Generalized Empirical Bayes Modeling via Frequentist Goodness-of-Fit. Nature Scientific Reports 8: 1–15. [Google Scholar] [CrossRef] [PubMed]
- Mukhopadhyay, Subhadeep, and Shinjini Nandi. 2015. LPTime: LP Nonparametric Approach to Non-Gaussian Non-Linear Time Series Modelling. CRAN, R Package Version 1.0-2. Ithaca: Cornell University Library. [Google Scholar]
- Mukhopadhyay, Subhadeep, and Shinjini Nandi. 2017. LPiTrack: Eye movement pattern recognition algorithm and application to biometric identification. Machine Learning. [Google Scholar] [CrossRef]
- Mukhopadhyay, Subhadeep, and Emanuel Parzen. 2014. LP approach to statistical modeling. arXiv, arXiv:1405.2601. [Google Scholar]
- Parzen, Emanuel. 1967. On empirical multiple time series analysis. In Statistics, Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability. Berkeley: University of California Press, vol. 1, pp. 305–40. [Google Scholar]
- Parzen, Emanuel. 1979. Nonparametric statistical data modeling (with discussion). Journal of the American Statistical Association 74: 105–31. [Google Scholar] [CrossRef]
- Parzen, Emanuel. 1992. Time series, statistics, and information. In New Directions in Time Series Analysis. Edited by Emanuel Parzen, Murad Taqqu, David R. Brillinger, Peter Caines, John Geweke and Murray Rosenblatt. New York: Springer Verlag, pp. 265–86. [Google Scholar]
- Parzen, Emanuel. 1997. Comparison distributions and quantile limit theorems. Paper presented at the International Conference on Asymptotic Methods in Probability and Statistics, Carleton University, Ottawa, ON, Canada, July 8–13. [Google Scholar]
- Parzen, Emanuel, and Subhadeep Mukhopadhyay. 2012. Modeling, Dependence, Classification, United Statistical Science, Many Cultures. arXiv, arXiv:1204.4699. [Google Scholar]
- Parzen, Emanuel, and Subhadeep Mukhopadhyay. 2013a. United Statistical Algorithms, LP comoment, Copula Density, Nonparametric Modeling. Paper presented at the 59th ISI World Statistics Congress (WSC) of the International Statistical Institute, Hong Kong, China, August 25–30. [Google Scholar]
- Parzen, Emanuel, and Subhadeep Mukhopadhyay. 2013b. United Statistical Algorithms, Small and Big Data, Future of Statisticians. arXiv, arXiv:1308.0641. [Google Scholar]
- Salmon, Felix. 2012. The formula that killed wall street. Significance 9: 16–20. [Google Scholar] [CrossRef]
- Terasvirta, Timo, Dag Tjøstheim, and Clive W. J. Granger. 2010. Modelling Nonlinear Economic Time Series. Kettering: OUP Catalogue. [Google Scholar]
- Tsay, Ruey S. 2010. Analysis of Financial Time Series. Hoboken: Wiley. [Google Scholar]
- Tukey, John. 1980. Can we predict where “time series” should go next. In Directions in Times Series. Hayward: IMS, pp. 1–31. [Google Scholar]
- Woodward, Wayne A., Henry L. Gray, and Alan C. Elliott. 2011. Applied Time Series Analysis. Boca Raton: CRC Press. [Google Scholar]
| 1 | The LP nomenclature: In nonparametric statistics, the letter L plays a special role to denote robust methods based on ranks and order statistics such as quantile-domain methods. With the same motivation, we use the letter L. On the other hand, P simply stands for Polynomials. Our custom-constructed basis functions are orthonormal polynomials of mid-rank transform instead of raw y-values; for more details see Mukhopadhyay and Parzen (2014). |



© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhopadhyay, S.; Parzen, E. Nonlinear Time Series Modeling: A Unified Perspective, Algorithm and Application. J. Risk Financial Manag. 2018, 11, 37. https://doi.org/10.3390/jrfm11030037
Mukhopadhyay S, Parzen E. Nonlinear Time Series Modeling: A Unified Perspective, Algorithm and Application. Journal of Risk and Financial Management. 2018; 11(3):37. https://doi.org/10.3390/jrfm11030037
Chicago/Turabian StyleMukhopadhyay, Subhadeep, and Emanuel Parzen. 2018. "Nonlinear Time Series Modeling: A Unified Perspective, Algorithm and Application" Journal of Risk and Financial Management 11, no. 3: 37. https://doi.org/10.3390/jrfm11030037
APA StyleMukhopadhyay, S., & Parzen, E. (2018). Nonlinear Time Series Modeling: A Unified Perspective, Algorithm and Application. Journal of Risk and Financial Management, 11(3), 37. https://doi.org/10.3390/jrfm11030037