An Expectation-Maximization Algorithm for Including Oncological COVID-19 Deaths in Survival Analysis


Abstract
1. Introduction
2. Notation and Assumptions on Covid Deaths in the Sample
2.1. Typical Clinical Trial Data and the Kaplan–Meier Estimator
2.2. The Case of Complete Death-Observations
2.3. The Incomplete Case
2.4. Including Covid-Death Events in the Data
3. The EM Mean-Imputation Procedure
3.1. The CoDMI Algorithm
- Initialization step. One starts by setting for , where are arbitrarily chosen initial values. Then one obtains an artificial complete data set , as defined in (5). Examples of initialization are or , where is the life expectancy computed by applying the KM estimator to the standard data z.
- Estimation step. The KM estimator is applied to to produce the survival function estimate . In case of incomplete death-observations, the distribution is completed by posing .
- Expectation step. Using , the m future life expectancy are computed as in (3). The corresponding time points are then replaced by . One then obtains the new artificial complete data set:
- The estimation and the expectation steps are repeated, producing at the k-th stage a new complete data set , provided by the expectations . The iterations stop when a specified convergence criterion is fulfilled. A natural criterion is:for a suitable specified tolerance level (this choice will be left as an option for the user). If condition (6) is not satisfied after a fixed maximum number of iterations (which will also be chosen as a user option), the convergence is considered failed.
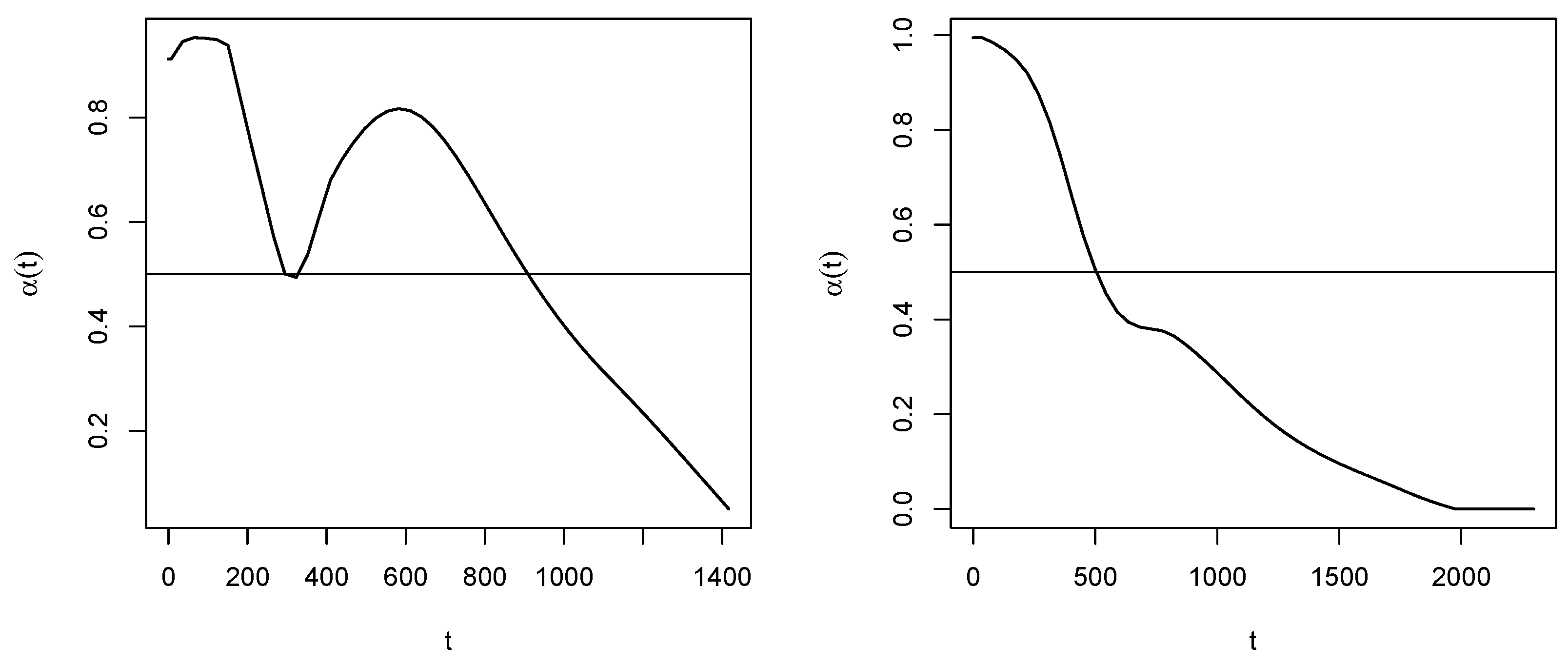
3.2. The Convergence Issue
- (1)
- Finite time convergence. The difference between two successive estimates becomes zero after a finite number of iterations.
- (2)
- Asymptotic convergence. The difference between two successive estimates tends to zero asymptotically.
- (3)
- Cyclicity. After a certain number of iterations, cycles of the estimated values are established which tend to repeat themselves indefinitely, so that the minimum difference between two successive estimates remains greater than zero. In this case, if this minimal difference is less than the tolerance , the corresponding estimate can be accepted (this is actually referred to by the term “tolerance”). It often happens that small changes in some of the values are sufficient to get out of cyclicity cases. Therefore, some fudging of these data could be used to obtain acceptable solutions when the minimum improvement is out of tolerance.
3.3. Assumptions Underlying CoDMI
3.4. Adjusting for the Assumption
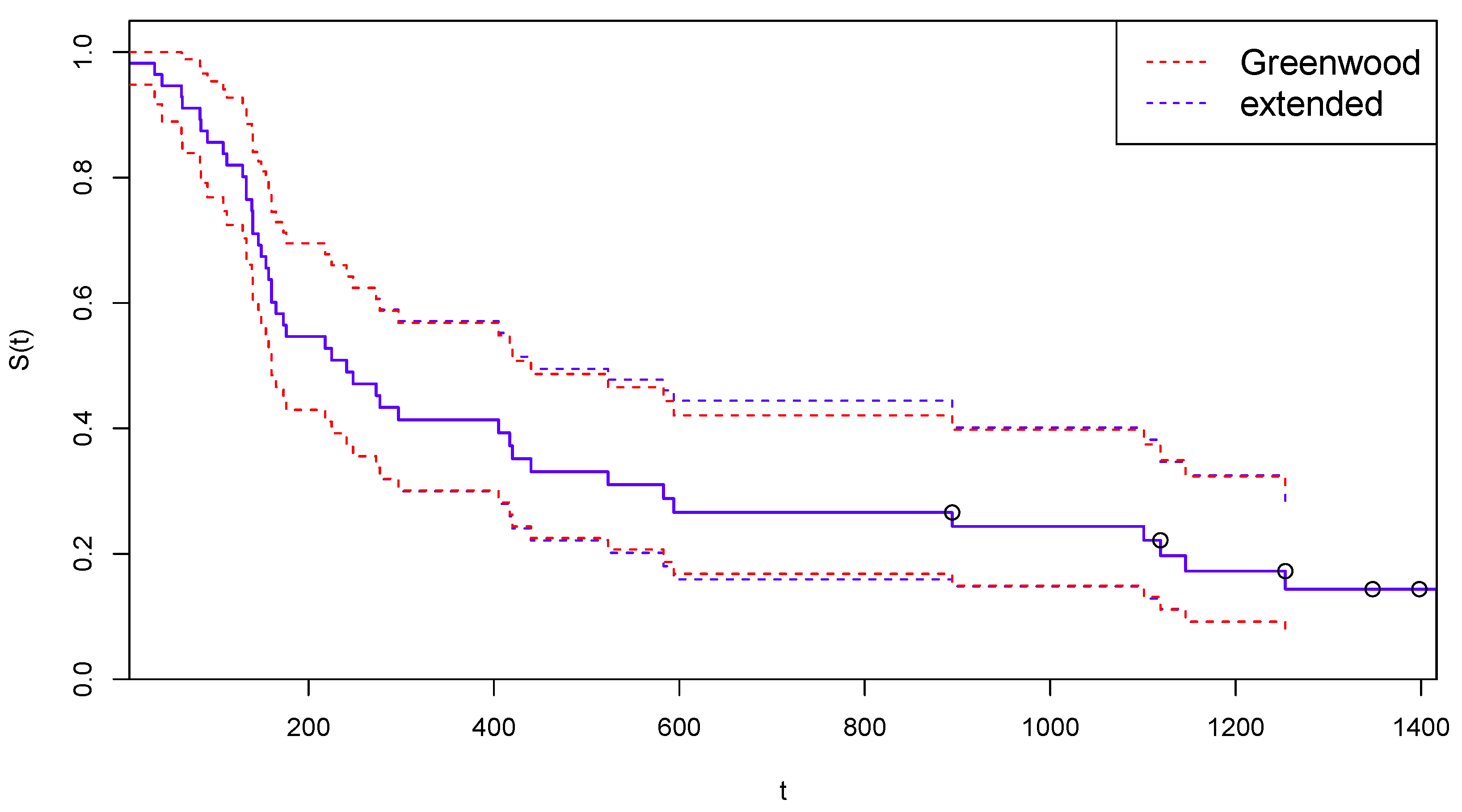
3.5. An Extended Greenwood’s Formula
- or are the observed or estimated survival times ordered by increasing value (the usual conventions on tied values apply);
- if corresponds to a Cen and 1 otherwise;
- if corresponds to a DoC and 0 otherwise.
4. Examples of Application to Real Survival Data
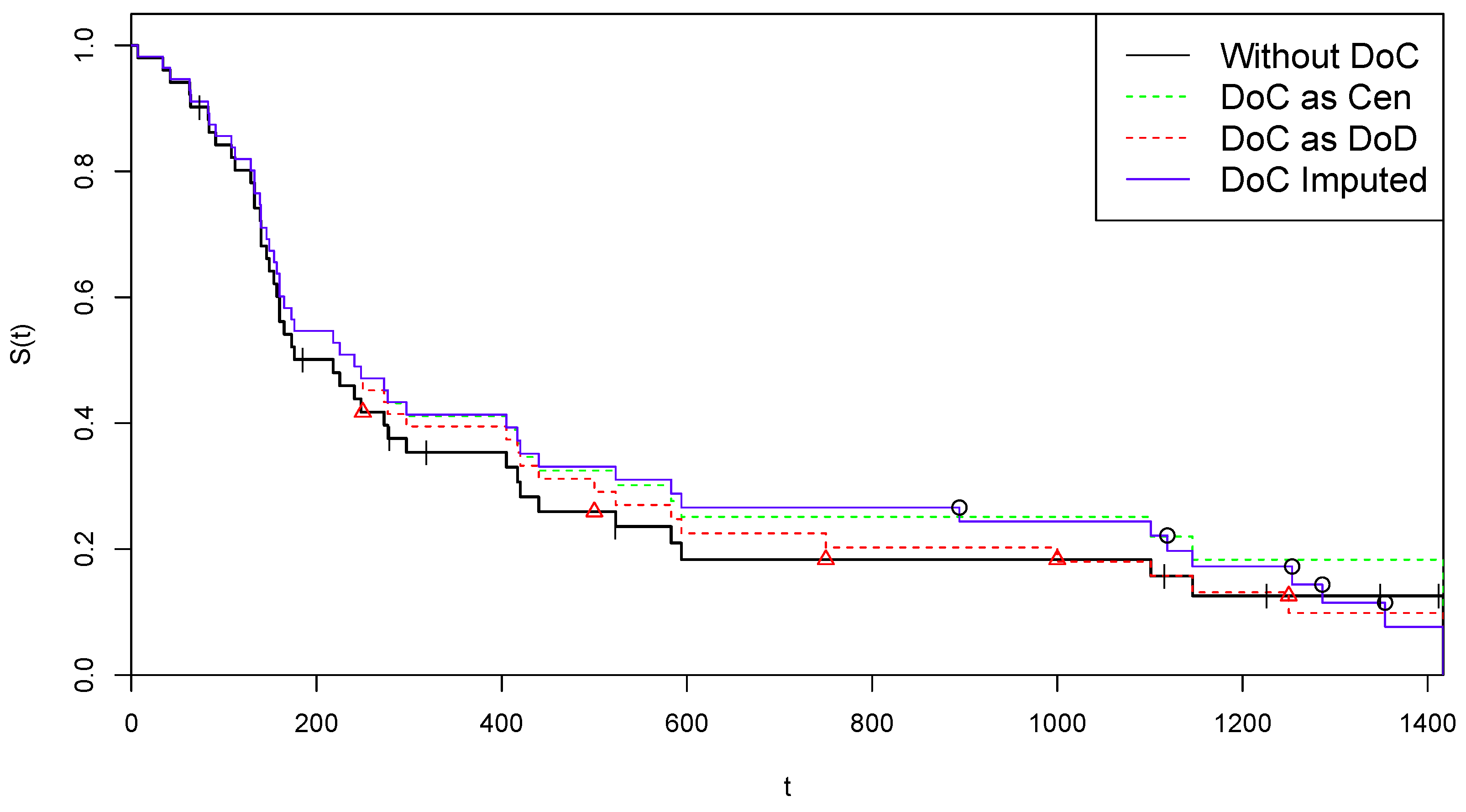
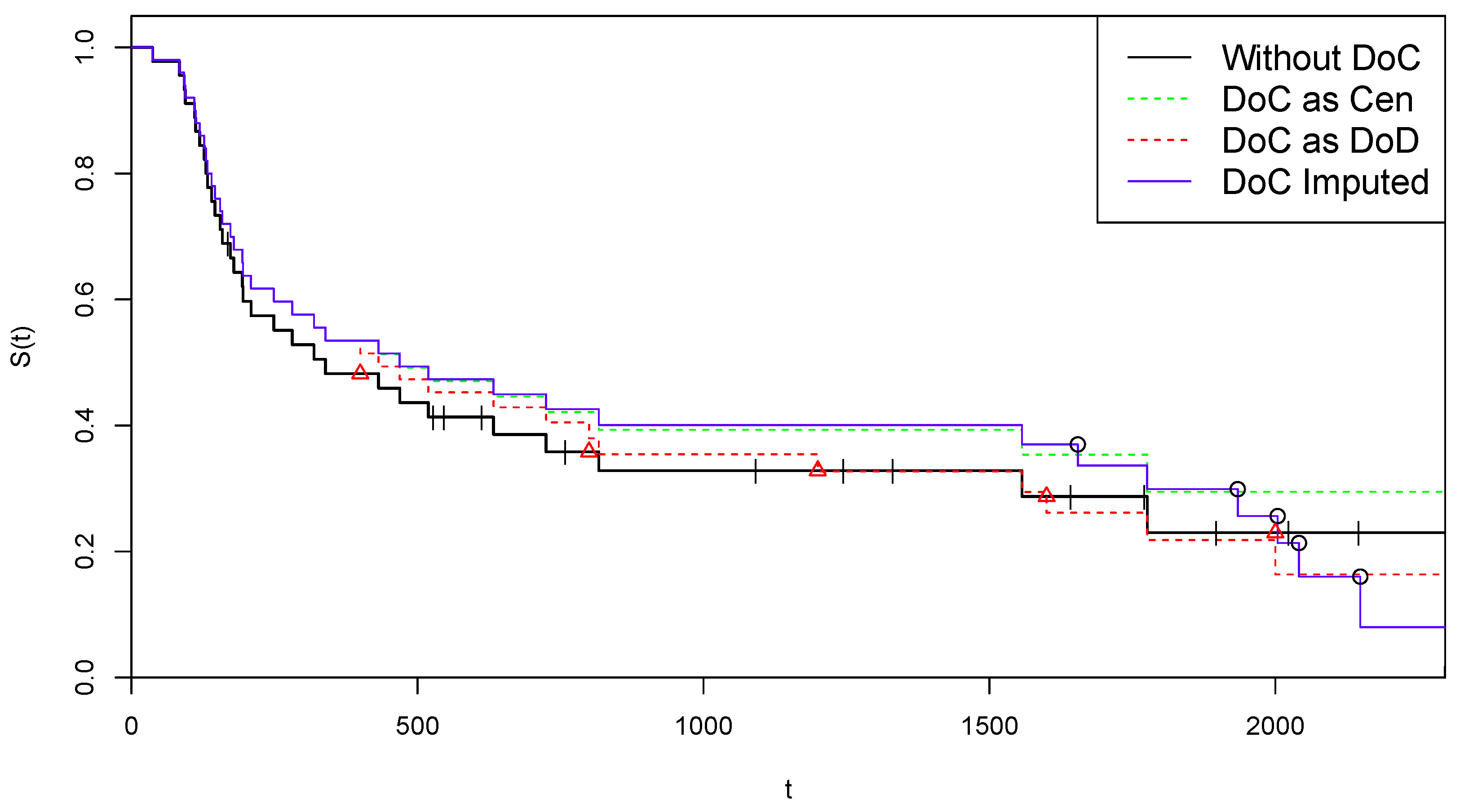
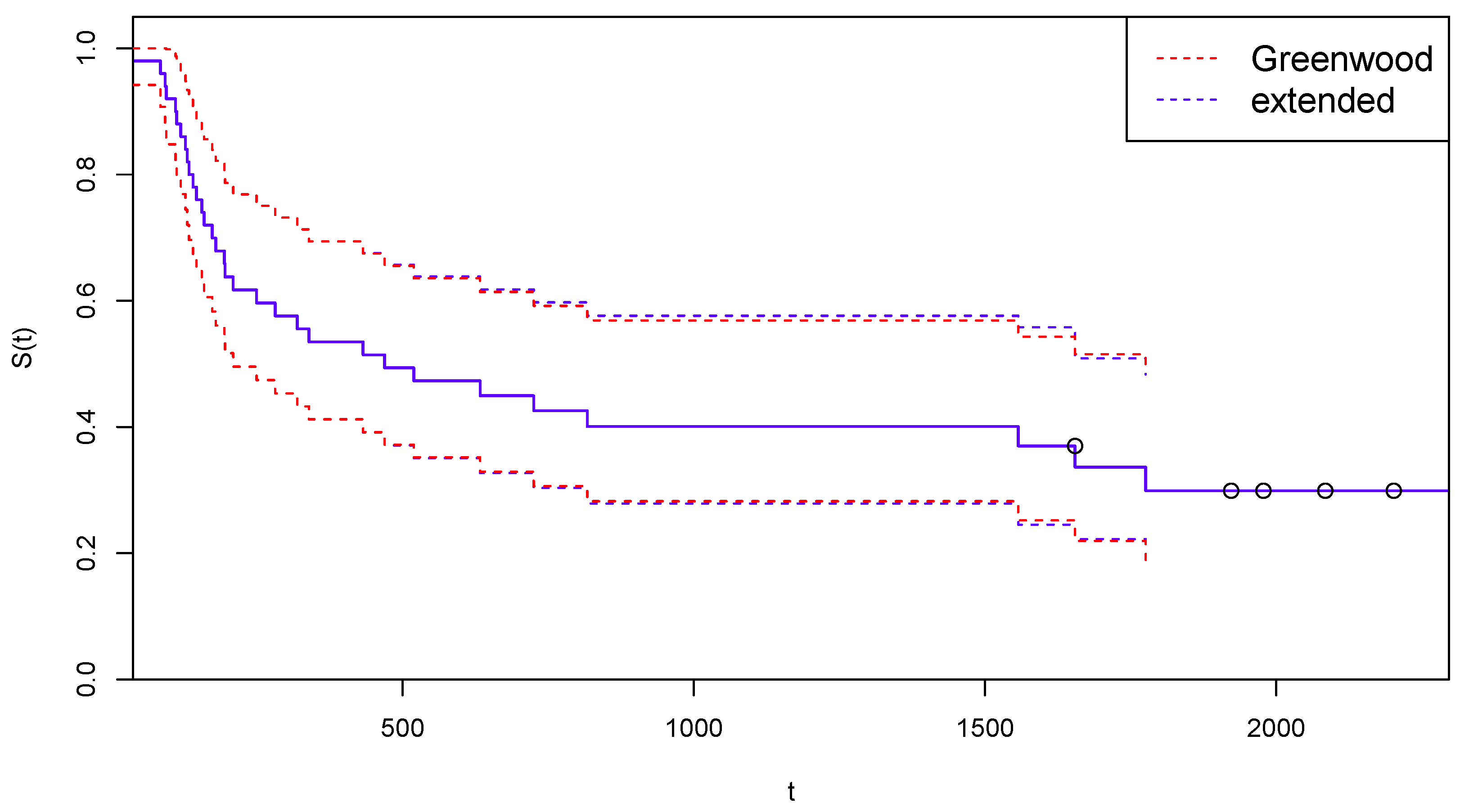
4.1. Application to COVID-19 Extended NCOG Data
4.1.1. Arm A of NCOG Data
4.1.2. Arm B of NCOG Data
5. A Simulation Study
5.1. Details of the Simulation Process
- 1.
- Simulation of standard survival data . The simulated standard (i.e., non-Covid) survival data is generated in each scenario starting from the same set of real data , spanning the time interval . The set is generated by drawing with replacement pairs from the n real-life pairs , maintaining the proportion between DoD and Cen events in z. Let us denote by the largest uncensored time point in .Remark. It should be noted that many tied values can be generated in this step, especially if . Moreover, could result to be censored (a case of incomplete death observations) even if the death observations are complete in the original data. It is easy to guess that generating many scenarios in this way can produce a number of “extreme” pseudo-data . This is useful, however, for testing the algorithm even in unrealistic situations. Most cases of failed convergence correspond to extreme situations.
- 2.
- Simulation of DoC time points . In order to simulate a number of COVID-19 deaths, the time points are generated by drawings with replacement from the points in real data z, satisfying the conditions and . These time points are interpreted as temporary virtual lifetimes and are first used to generate the DoC time points . A number of independent drawings from a uniform (0, 1) distribution are performed, and the corresponding DoC time points are obtained as . Therefore, for all j one has , with taking equally probable values in .Remark. The use of a uniform distribution is obviously questionable, and more “informative” distribution could be suggested. For example, a beta distribution with first parameter greater than 1 and second parameter lower than 1 may be preferable, as it makes more probable values of closer to . However, the form of this distribution is irrelevant to our purposes: we are interested in observing how CoDMI is able to capture the simulated virtual lifetimes, independently of how they are generated.
- 3.
- Simulation of virtual lifetimes . The temporary lifetimes (and the data set ) cannot be directly used to test CoDMI algorithm, since their probabilistic structure is indeterminate and, in any case, we have too few (pseudo-)observations. In order to introduce a probabilistic structure consistent with CoDMI assumptions, we first run the KM estimator on the data set , thus obtaining the corresponding death probability distribution . The virtual lifetimes are then obtained by computing the conditional expectations by this distribution. However, this is not yet fully consistent with CoDMI assumptions, since, as discussed in Section 3.3, the appropriate distribution is the KM best-fitting distribution specified on the extended data, i.e., data including the virtual lifetimes themselves. To obtain this result we should repeat the previous step, i.e., running the product-limit estimator on the new data set , thus producing the new distribution and then simulating new time points by taking the conditional expectation on this distribution. In principle, this step should be iterated similarly to what is completed in the CoDMI algorithm. To avoid convergence problems, however, we prefer to limit the number of iterations to a fixed (low) value , thereby implicitly accepting a certain level of bias in the estimations. After these iterations has been made, the final data set is obtained. Running the KM estimator on these data again, the final distribution is obtained and the definitive time points , with the corresponding , are computed by conditional sampling, given , i.e., simulating from the truncated distribution (after normalization). These sampled values are taken as the true values of virtual lifetimes and life expectancy, respectively, which should be estimated by CoDMI using only the information .
- 4.
- Application of CoDMI and naïve estimators. CoDMI algorithm is applied to the simulated data:with obtained in step 1 and in step 2. Provided that the algorithm converges, we obtain the estimated virtual lifetimes and the estimated life expectancy .To allow comparison, we also derive in this step the predictions of the two naïve “estimators” which are obtained by applying the KM estimator to the simulated data , modified by posing, for all j, and (“DoC as DoD”) or (“DoC as Cen”).
5.2. Valuation of the Predictive Performances
5.3. Results from Simulation Exercises
6. Conclusions and Directions for Future Research
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Derivation of the Extended Greenwood’s Formula
References
- De Felice, F.; Moriconi, F. COVID-19 and Cancer: Implications for Survival Analysis. Ann. Surg. Oncol. 2021, 28, 5446–5447. [Google Scholar] [CrossRef] [PubMed]
- Degtyarev, E.; Rufibach, K.; Shentu, Y.; Yung, G.; Casey, M.; Englert, S.; Liu, F.; Liu, Y.; Sailer, O.; Siegel, J.; et al. Assessing the Impact of COVID-19 on the Clinical Trial Objective and Analysis of Oncology Clinical Trials—Application of the Estimand Framework. Stat. Biopharm. Res. 2020, 12, 427–437. [Google Scholar] [CrossRef] [PubMed]
- European Medicines Agency. ICH E9 (R1) Addendum on Estimands and Sensitivity Analysis in Clinical Trials to the Guideline on Statistical Principles for Clinical Trials. Scientific Guideline. Available online: https://www.ema.europa.eu/en/documents/scientific-guideline (accessed on 17 February 2020).
- Kuderer, N.M.; Choueiri, T.K.; Shah, D.P.; Shyr, Y.; Rubinstein, S.M.; Rivera, D.R.; Shete, S.; Hsu, C.Y.; Desai, A.; de Lima Lopes, G., Jr.; et al. Clinical impact of COVID-19 on patients with cancer (CCC19): A cohort study. Lancet 2020, 395, 1907–1918. [Google Scholar] [CrossRef] [PubMed]
- Guan, W.J.; Ni, Z.Y.; Hu, Y.; Liang, W.H.; Ou, C.Q.; He, J.X.; Liu, L.; Shan, H.; Lei, C.L.; Hui, D.S.; et al. Clinical Characteristics of Coronavirus Disease 2019 in China. N. Engl. J. Med. 2020, 382, 1708–1720. [Google Scholar] [CrossRef] [PubMed]
- Kalbfleisch, J.D.; Prentice, R.L. The Statistical Analysis of Failure Time Data; Wiley: Hoboken, NJ, USA, 2002. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- DeSouza, C.M.; Legedza, A.T.R.; Sankoh, A.J. An Overview of Practical Approaches for Handling Missing Data in Clinical Trials. J. Biopharm. Stat. 2009, 19, 1055–1073. [Google Scholar] [CrossRef] [PubMed]
- Shih, W.J. Problems in dealing with missing data and informative censoring in clinical trials. Curr. Control. Trials Cardiovasc. Med. 2002, 3, 4. [Google Scholar] [PubMed]
- Shen, P.S.; Chen, C.M. Aalen’s linear model for doubly censored data. Statistics 2018, 52, 1328–1343. [Google Scholar] [CrossRef]
- Willems, S.J.V.; Schat, A.; van Noorden, M.S.; Fiocco, M. Correcting for dependent censoring in routine outcome monitoring data by applying the inverse probability censoring weighted estimator. Stat. Methods Med. Res. 2018, 27, 323–335. [Google Scholar] [CrossRef] [PubMed]
- Gray, R.J. A class of K-sample tests for comparing the cumulative incidence of a competing risk. Ann. Stat. 1988, 4, 1141–1154. [Google Scholar]
- Kaplan, E.L.; Meier, P. Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc. 1958, 53, 457–481. [Google Scholar]
- Efron, B. The two sample problem with censored data. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; Volume 4, pp. 831–853. [Google Scholar]
- Efron, B.; Hastie, T. Computer Age Statistical Inference. Algorithms, Evidence, and Data Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Pearl, J.; Glymour, M.; Jewell, N.P. Causal Inference in Statistics. A Primer; Wiley: Hoboken, NJ, USA, 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 7 | 34 | 42 | 63 | 64 | 74+ | 83 | 84 | 91 |
| 108 | 112 | 129 | 133 | 133 | 139 | 140 | 140 | 146 |
| 149 | 154 | 157 | 160 | 160 | 165 | 173 | 176 | 185+ |
| 218 | 225 | 241 | 248 | 273 | 277 | 279+ | 297 | 319+ |
| 405 | 417 | 420 | 440 | 523 | 523+ | 583 | 594 | 1101 |
| 1116+ | 1146 | 1226+ | 1349+ | 1412+ | 1417 |
| 37 | 84 | 92 | 94 | 110 | 112 | 119 | 127 | 130 |
| 133 | 140 | 146 | 155 | 159 | 169+ | 173 | 179 | 194 |
| 195 | 209 | 249 | 281 | 319 | 339 | 432 | 469 | 519 |
| 528+ | 547+ | 613+ | 633 | 725 | 759+ | 817 | 1092+ | 1245+ |
| 1331+ | 1557 | 1642+ | 1771+ | 1776 | 1897+ | 2023+ | 2146+ | 2297+ |
| Summary Statics of | ||||||||
|---|---|---|---|---|---|---|---|---|
| avg. | avg.% | s.e.m. | min | max | ||||
| 1 | 134.14 | 421.94 | 426.14 | 4.21 | 1083.35 | |||
| 2 | 137.64 | 434.06 | 425.96 | 4.31 | 1077.25 | |||
| 3 | 140.10 | 427.67 | 425.51 | 4.26 | 1084.41 | |||
| 4 | 134.01 | 421.72 | 424.59 | 4.31 | 1070.25 | |||
| 5 | 138.20 | 432.20 | 425.59 | 4.33 | 1067.94 | |||
| 6 | 134.54 | 421.22 | 425.62 | 4.23 | 1067.69 | |||
| 7 | 138.66 | 434.07 | 426.54 | 4.32 | 1067.94 | |||
| 8 | 137.66 | 433.16 | 426.60 | 4.31 | 1071.44 | |||
| 9 | 141.41 | 430.15 | 425.71 | 4.29 | 1067.11 | |||
| 10 | 140.08 | 427.10 | 427.14 | 4.29 | 1072.31 | |||
| Summary Statics of | ||||||||
|---|---|---|---|---|---|---|---|---|
| avg. | avg.% | s.e.m. | min | max | ||||
| 1 | 170.39 | 901.20 | 893.29 | 8.20 | 1546.86 | |||
| 2 | 165.77 | 903.10 | 894.93 | 8.17 | 1545.27 | |||
| 3 | 168.02 | 892.31 | 891.88 | 8.16 | 1527.10 | |||
| 4 | 168.50 | 881.61 | 894.61 | 8.17 | 1551.53 | |||
| 5 | 168.56 | 887.58 | 893.39 | 8.13 | 1557.19 | |||
| 6 | 172.76 | 889.36 | 895.64 | 8.11 | 1545.27 | |||
| 7 | 167.56 | 885.83 | 895.42 | 8.13 | 1547.59 | |||
| 8 | 166.83 | 881.27 | 895.01 | 8.13 | 1539.00 | |||
| 9 | 169.95 | 886.48 | 894.43 | 8.18 | 1547.59 | |||
| 10 | 167.30 | 888.51 | 892.08 | 8.20 | 1550.47 | |||
| Global Averages of Prediction Errors | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| DoC Imputed | DoC as DoD | DoC as Cen | |||||||||
| Data | s.e.m. | ||||||||||
| Arm A | 9802 | 137.64 | 428.33 | 425.94 | 1.338 | ||||||
| Arm B | 9472 | 168.56 | 889.72 | 894.07 | 2.557 | ||||||
| Global Averages of Prediction Errors | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DoC Imputed | DoC as DoD | DoC as Cen | ||||||||||
| Data | Adjust. | s.e.m. | ||||||||||
| Arm A | NO | 9804 | 137.55 | 1004.22 | 426.09 | 1.377 | 579.94 | 554.64 | ||||
| YES | 9804 | 137.55 | 1004.22 | 1001.91 | 1.212 | 579.94 | 554.64 | |||||
| Arm B | NO | 9459 | 168.62 | 1394.29 | 894.01 | 2.119 | 488.74 | 437.73 | ||||
| YES | 9459 | 168.62 | 1394.29 | 1396.58 | 1.899 | 488.74 | 437.73 | |||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
De Felice, F.; Mazzoni, L.; Moriconi, F. An Expectation-Maximization Algorithm for Including Oncological COVID-19 Deaths in Survival Analysis. Curr. Oncol. 2023, 30, 2105-2126. https://doi.org/10.3390/curroncol30020163
De Felice F, Mazzoni L, Moriconi F. An Expectation-Maximization Algorithm for Including Oncological COVID-19 Deaths in Survival Analysis. Current Oncology. 2023; 30(2):2105-2126. https://doi.org/10.3390/curroncol30020163
Chicago/Turabian StyleDe Felice, Francesca, Luca Mazzoni, and Franco Moriconi. 2023. "An Expectation-Maximization Algorithm for Including Oncological COVID-19 Deaths in Survival Analysis" Current Oncology 30, no. 2: 2105-2126. https://doi.org/10.3390/curroncol30020163
APA StyleDe Felice, F., Mazzoni, L., & Moriconi, F. (2023). An Expectation-Maximization Algorithm for Including Oncological COVID-19 Deaths in Survival Analysis. Current Oncology, 30(2), 2105-2126. https://doi.org/10.3390/curroncol30020163