1. Introduction
A novel coronavirus and accompanying infectious disease were reported to the World Health Organization (WHO) in Wuhan, China in December of 2019 [
1]. The WHO declared this outbreak a Public Health Emergency of International Concern in January of 2020, designating this new coronavirus disease COVID-19 [
1]. Global travel and endogenous spread across hundreds of countries have yielded a worldwide pandemic, with rapidly rising totals of over 752 million confirmed cases and over 6.8 million confirmed deaths through 30 January 2023 [
2].
During the COVID-19 pandemic, ongoing public health order planning and replanning associated with rolling back and reinstituting measures and conducting timely messaging has benefited from the availability of empirical time series—often holding evidence of shifts in epidemiology, availability of acute care resources, and changes in behaviour with regards to risk, testing, vaccination uptake, and clinical presentation. At the same time, decision-making has relied heavily on a variety of types of dynamic models.
Several previous studies [
3,
4,
5,
6,
7] showed success in monitoring, estimating, and predicting the transmission of infectious diseases by stochastic filtering of mathematical epidemiology models using observed datasets via sequential Monte Carlo (SMC) machine learning algorithms. SMC methods were introduced in the early 2000s [
8,
9], and commonly go by the name of particle filtering (PF). Such studies have demonstrated that projections forward from dynamic models in health and health care offer substantial additional value if they can be informed by up-to-date, grounded estimates of the current situation. The particle filtering method—together with several variants—has also been used for COVID-19 [
10,
11,
12,
13,
14,
15] in the last two years since this new infectious disease emerged. Most of these studies used public health surveillance data—such as daily reported cases and daily hospitalized admission patients—to track the transmission dynamics. After the SARS-CoV-2 virus was confirmed detected in untreated wastewater [
16,
17,
18,
19,
20,
21,
22,
23,
24,
25], several researchers [
14] used wastewater surveillance data to ground the mathematical epidemiology models via a partially observed Markov processes (POMP) model. These methods use Markov chain Monte Carlo and sequential Monte Carlo (particle filtering) methods.
This paper presents the use of PF with a model deployed by the health system and used internally for routine provincial-level reporting and decision-making since the fourth month of the pandemic. Such PF incorporated a COVID-19 compartmental transmission model and a wide variety of observed daily datasets from both public health surveillance data and wastewater surveillance data. Within this context, the COVID-19 model provides an integrated characterization of disease transmission, a natural history of infection including both frankly symptomatic and oligo-/pauci-symptomatic pathways, distinct passive and active case-finding systems for the occurrence of travelling cases, basic COVID-19 related acute care flows and occupancy, characterization of two dose-specific vaccination stages, and mortality. Important model outputs include estimates (via sampling) of the effective reproductive number, the count of undiagnosed infectives, and the count of individuals at different stages of the natural history of infection along both pathways. Since July 2020, the model further incorporated a representation of SARS-CoV-2 fecal viral shedding, and when wastewater evidence is available, the PF framework makes use of a likelihood term comparing the empirical viral concentration of SARS-CoV-2 in wastewater with model expectations for that concentration.
The model was built in concert with the Saskatchewan Health Authority and has been in production use for regular health system reporting since June 2020, with some model findings informing understanding of the evolving epidemiological context as early as April 2020. Since that time, and beyond its use for reporting to the Saskatchewan Health Authority and Saskatchewan Ministry of Health, the model has been used to deliver reporting contracts with the Public Health Agency of Canada (for each Canadian province), First Nations and Inuit Health Branch (FNIHB). The resulting reports have proven particularly key in day-to-day instituted health system reporting and informing planning for the Canadian midwestern province of Saskatchewan. In this paper, we characterize the structure of the model and present the results of applying the model to the population of the city of Saskatoon in the province of Saskatchewan, Canada, during the period of wild type SARS-CoV-2 and the alpha variant [
26] from 22 February 2020 to 31 July 2021.
2. Methods
2.1. Deterministic Compartmental Model
We describe here the compartmental model used within this system, which characterizes the total population as divided into different compartments distinguished by different pathways of natural progression, severity of illness, diagnosis, and acute care use. For simplicity, our description of the model omits discussion of the evolution of that model, pausing only to note that the vast majority of the model as described here was in use at the start of regular reporting in June 2020. We also exclude from this section a characterization of variants of that model, differing particularly in the levels of stratification involved. We further exclude discussion of variant-specific adjustment of values of some parameters otherwise treated as constant and the model structure adjusted to accommodate further variants in the application.
The structure of the COVID-19 compartmental model is shown in
Figure 1 and employs a time unit of days. The compartments of the model are introduced as follows. The model contains a largely orthogonal characterization of progression along two possible natural histories of infection (on one hand) and diagnosis status (on the other). Specifically, the model dichotomizes both the infective (compartments denoted by names prefixed by
I or
H) and recovered (compartments prefixed by
R) populations into diagnosed (subscripted by
) and undiagnosed (subscripted by
) status, depending on whether an individual has been diagnosed via lab-confirmed PCR testing. The infective population in the model was further divided into two groups: hospitalized individuals (compartments
and
) and those in the community (subcompartments of the supercompartment
I). Supercompartment
I of infectives in the community is characterized by dividing it into three groups based on the stage of the natural history of infection—presymptomatics (compartments
and
) and those at a later stage along each of the two parallel pathways of infection distinguished by degree of symptomaticity. Specifically, the model treats infected individuals as proceeding from the (infectious) presymptomatic phase to one of two possible natural histories of infection: a frankly symptomatic pathway and an oligosymptomatic route of progression, which accept fractions
and
, respectively, of undiagnosed individuals proceeding from presymptomatic compartment
. The frankly symptomatic pathway starts at an early stage in which individuals have not yet had the opportunity to exhibit complications (compartments
and
) and symptoms are assumed to be mild. The progression of an individual from the first to the second symptomatic stage marks the point where any complications emerge, with a specified fraction (denoted as
) of progressing individuals (regardless of erstwhile diagnosis status) developing severe or critical complications. Such individuals suffering complications are presumed to lead to presentation for care and hospitalization. Frankly symptomatic individuals absent complications proceed on to a stage involving symptomatic individuals beyond the risk of complications (compartments
and
). In contrast to the frankly symptomatic pathway, the oligosymptomatic pathway proceeds from the presymptomatic stage through a natural history of infection in which infected individuals remain infective but never develop symptoms sufficient to motivate care-seeking; compartments along this pathway are denoted by an
subscript. Like their symptomatic counterparts, oligosymptomatic infectives are characterized as proceeding through two subsequent compartments of
, with the timing of progression identical to the frankly symptomatic stages—oligosymptomatic stage 1 (compartments
and
) and oligosymptomatic stage 2 (compartments of
and
). The model also considers the vaccinated population, where only susceptible individuals are assumed to be administered vaccines. Compartment
represents the persons who have only received one dose of a COVID-19 vaccine, and
represents the persons who have received two vaccine doses. As is detailed further below, vaccinated individuals are treated as remaining subject to some vaccine-efficacy-moderated risk of infection (denoted
for only having one dose and
for having two doses).
2.1.1. Diagnosis and Case Finding
In this COVID-19 compartmental model, infected patients can be diagnosed both by passive case finding via presentation for care and (separately) via active case finding, such as through contact tracing, screening, and mass testing [
27]. Passive case finding is treated as diagnosing symptomatic infectives who present for care and is treated as endogenously driven within the model. Such presentation-driven diagnosis is represented by red flows in
Figure 1 and proceeds from compartments of undiagnosed symptomatic infectives that have not yet exhibited complications
to the next stage compartment of diagnosed individuals
. In contrast, reflecting the fact that active case finding can identify individuals not yet exhibiting symptoms, active case finding within the model is represented by flows (the orange arrows in
Figure 1) from a broader set of compartments of undiagnosed exposed and infective individuals to the corresponding next stage diagnosed compartments of the model. It is to be noted that because of the multi-day time lag commonly associated with test results in the province, for both passive and active case finding, we let the flows of undiagnosed infectives proceed to the next stage diagnosed compartments instead of the directly corresponding diagnosed stages; thus, for example, those diagnosed from stage
flow into the next stage compartments of
, rather than into
.
The daily flow of cases being diagnosed by passive testing, but not leading to hospitalization, is mainly governed according to the endogenous model calculations , where is the fraction of undiagnosed symptomatic infected individuals with complications that do not require hospitalization during their course of infection, and is the mean days to develop or avoid complications; this is bounded by the empirical data (denoted as ) of total test volume presenting other than due to hospitalization or international travel. can be calculated by the difference between the daily total test volume (denoted as ) and the three-way sum of daily admitted COVID-19 patients to ICU and non-ICU hospitalizations (denoted as and , respectively) and new likely exogenous cases (denoted as ). This difference reflects the known use of tests for hospitalization and the fact that out-of-province cases were carefully estimated for the opening weeks of the pandemic, and each required tests.
The model characterization of daily diagnosed cases identified specifically by active case finding—conducted via activities such as contact tracing, screening, and drive-through testing—is designed to capture the fact that in such forms of case finding, testing tends to drive the count of individuals diagnosed and identifies infected individuals at all stages of the natural history of infection. To represent the fact that test count drives the count of cases diagnosed with an efficiency limited by the number of infected individuals, we made use of a previously published testing model [
28]. Within this model, the count of infectives identified by testing is characterized as
, where
V is the total test volume,
is the total count of undiagnosed infectives,
is a measure of test efficiency, and
represents an upper limit on the fraction of infectives that could be identified via active case finding. In this test model, the term
characterizes the fraction of all infectives that are diagnosed. Reflecting the fact that active case-finding efforts are incomplete in their reach,
represents the fraction of infectives that would be diagnosed via active-case finding if the total test volumes
V were to be arbitrarily large (i.e., the asymptomatic fraction of infected individuals who would be located as the ratio of test volume to infections approaches infinity); given the broad reach of contact tracing within the province, this work treated
as 1.
is a measure of testing efficiency. When
is 1 (as it is here), for a small active test volume
V, this can be seen roughly corresponding to the product of the test positivity rate and test specificity: For every test performed,
infectives will on average be discovered. The saturating exponential term (
) assumes that as the volume of tests performed for active case finding rises, a greater number of tests is needed to find a given infective. Thus, while more tests will identify additional infectives, doubling the count of tests performed will not double the count of infectives identified. By employing this test model to calculate the cases diagnosed by active case finding in this project and recognizing the priority placed on presentation-driven tests that drive passive case finding, the model assumes that the total volume of tests performed for active finding is given by the difference between the total testing volume (
) and the volume of tests performed for passive case finding
, and thus,
. At any time, the total count of undiagnosed infectives can be calculated by summing all of the undiagnosed compartments, which is
. Thus, the model gives the diagnosed cases found by active testing as
. And the daily count of diagnoses from active case finding for different compartments (e.g.,
,
,
,
,
, and
)—depicted as orange arrows in
Figure 1—is treated as simply being split proportionally according to the count of people in each undiagnosed infective compartment.
2.1.2. Acute Care Utilization
Undiagnosed or diagnosed symptomatic individuals who develop severe or critical COVID-19 complications [
29] at the time of transitioning from the early-stage symptomatic period (leaving
and
) are presumed to present for care and enter into the hospitalization stocks either for acute but non-critical care (compartment
) or for critical care (
)—the purple flows in
Figure 1. The fraction of all individuals progressing from diagnosed early- to diagnosed late-stage symptomatic state who are treated as not developing severe or critical COVID-19 complications is treated as
. The fraction of all individuals progressing from undiagnosed early- to diagnosed late-stage symptomatic state diagnosed by passive testing is
. And the fraction of individuals progressing from undiagnosed early- to undiagnosed late-stage symptomatic state diagnosed by passive testing is
. Of the fraction
of such progressors requiring hospitalization, the fractions that transition to the ICU (
) and non-ICU (
) are given by the parameters
and
, respectively. Individuals in both such hospitalization compartments are further subject to mortality, with deceased individuals transitioning to compartment
D at the time of passing, as indicated by the grey flows in
Figure 1. Given the overall COVID-19 case fatality rate for hospitalized patients requiring ICU care or not in need of such care (denoted by
and
, respectively), the model characterizes the corresponding daily mortality rates as
and
, where
and
are the mean durations of ICU-hospitalized and non-ICU-hospitalized patient stays before death, respectively. As a simplifying assumption and to lower the count of compartments required and the resulting size of the state space, the model does not seek to explicitly model continued hospital residence amongst some patients prior to or following ICU discharge.
2.1.3. Exogenous/Endogenous Infections
The model considers infectives as originating from both endogenous sources (via infection through contact with other infectives in the modeled population) and exogenous sources (where infectives arrive in the population via out-of-province (and particularly international) arrivals), which are flows represented by the magenta arrows in
Figure 1. This exogenous flow is driven by the empirical time series of daily travellers infected outside of the population and was of strong importance for accounting for patterns in the opening two to three months of the pandemic, on account of the importance of international arrivals in driving subsequent endogenous transmission. Endogenous infections are calculated by the transmission system of the model.
2.1.4. Vaccination System
The model considers two levels of vaccination-induced protection for the population [
30]. This characterization reflects the fact that Saskatchewan’s vaccination campaign employed only two-dose vaccines, namely, Pfizer/BioNTech BNT-162b2, Moderna mRNA-1273, and AstraZeneca ChAdOx1. With the BNT-162b2 vaccine being responsible for approximately 74.86% of all vaccines delivered within the province, and conscious of the adverse impact on model state space size and—by extension—machine-learning inference accuracy, we made the simplifying assumption of characterizing vaccinated individuals by two levels of vaccine protection, rather than with further levels and/or via stratification with respect to each vaccine product. Two flows of daily vaccinated cases from the susceptible (compartment
S) to the first level of vaccination-induced protection (compartment
) and from the first-dose vaccinated to a higher level of protection (compartment
) (represented by green arrows in
Figure 1) are driven by the empirical time series of daily receipt of first-dose vaccines and second-dose vaccines. Because of limited evidence concerning the duration of vaccine protection [
30], this model currently assumes the vaccines confer permanent protection. Individuals with both one and two doses of vaccines remain subject to the risk of infection, with the relative risk of infection in each dose-count-specific compartment compared to an unvaccinated symptomatic being given by one minus an estimate of vaccine efficacy against infection with that dose count. The vaccine efficacy against infection of the vaccines used within Saskatchewan is reported based on clinical trial data [
31] that differ from vaccine to vaccine, notably against different COVID-19 variants of concern (VoCs). Reflecting the mixed vaccination regime and the presence of multiple VoCs over the timeframe of the study, the vaccine efficacy against infection considered in this project for a single dose (denoted as
) and two doses (denoted as
) are
and
, respectively, based on the vaccines used in Canada—Pfizer, Moderna, and Astra-Zeneca [
31]. While COVID-19 vaccines routinely offer greater efficacy against hospitalization and mortality than against infection, motivated in part by the desire to avoid the adverse effects on model inference of enlarging the state space of the model and lacking ready empirical data on breakthrough infections at the time of formulation, the model treats breakthrough infection as placing an individual into the same pathways of infection as are used for an infected unvaccinated individual.
2.1.5. Infectious Transmission System
The force of infection parameter
characterizes the hazard rate of infection—the probability density with which a fully susceptible (e.g., a person in the stocks of
S) is subject to infection from an infective and is governed by mass action principles [
32]. The force of infection parameter
is calculated by
, where
c is the contact rate among the population per unit time,
is the probability of transmitting COVID-19 per discordant contact, and
is the effective prevalence of infectives in the mixing community. The construct of the effective prevalence of infectives in the mixing community,
, is designed to take into account the mixing implications of the symptoms, diagnosis, and acute care status of infective individuals; we refer to a relative-mixing-level-adjusted size of a subpopulation as the “effective” size of that subpopulation. The effective prevalence of infectives in the mixing community
is represented by the fraction of the effective infectives among the effective population in the community. We assume that undiagnosed oligosymptomatic individuals (in compartments
,
, and
) have full social contacts and undiagnosed symptomatic individuals (in compartments
and
) exhibit a relative reduction in the level of social mixing, as given by the fraction
, measured relative to full social contacts (themselves as assumed to be associated with a relative mixing rate of 1), and non-hospitalized diagnosed patients (in compartments
,
,
,
, and
) in the community have a similar proportional reduction in mixing, denoted
. Hospitalized patients are treated as not engaging in mixing and thus do not contribute to the size of the effective mixing populations and carry a relative mixing rate of 0. It is important to emphasize that such values represent
relative mixing rate characterizations; secular changes in contact rate across the population (such as those that might be caused by public health orders) are characterized by another element of the formulation detailed below. There are three flows in the model reflecting the force of the infection process—the infection from stocks
S,
, and
, which are associated with rose-coloured flows in
Figure 1.
2.1.6. Municipal Wastewater Surveillance Characterization
Municipal wastewater refers to sewage containing waste from households, workplaces, and other sources served by municipal infrastructure [
33]. In a public health context, wastewater surveillance (WWS) describes the process of sampling and analyzing wastewater to monitor phenomena such as the prevalence of conditions, use of pharmaceuticals, and occurrence of viral outbreaks in communities [
33]. Medema et al. [
34] demonstrated a significant correlation between COVID-19 virus SARS-CoV-2 concentrations in wastewater and the prevalence of COVID-19. This finding suggested that wastewater surveillance of SARS-CoV-2 could offer a tool to monitor the trends of COVID-19 prevalence in cities. Moreover, wastewater surveillance offers a significant advantage, since the concentration of SARS-CoV-2 in the wastewater sampling is representative of the entire population served by the sewage shed, regardless of health status, propensity for care-seeking behaviour, or reported infection status [
33]. Moreover, because of the high shedding levels seen in the early stages of infection by SARS-CoV-2, wastewater assays can often identify presymptomatic or oligosymptomatic populations.
This project involved the design, implementation, deployment, and routinized use of a particle-filtered compartmental model to estimate the epidemiological and health system state using time series including wastewater concentrations of SARS-CoV-2. Due to the dynamics of viral load, fecal shedding in a SARS-CoV-2-infected individual varies across natural histories of infection, such as between symptomatic/asymptomatic, and over stages of progression [
35,
36,
37]. We made use of a weighted shedding model reflecting the fact that individuals in the early stages of infection shed at far higher rates than do those at later stages of infection. Hoffman et al. [
37] estimated that the shedding profile modulates viral concentrations in faecal samples over time.
Figure 1 of [
37] illustrates a generally exponential decrease in the shedding virus load over time, with the exception of the very early stage, when the virus load is relatively lower. Based on this figure, we conducted a rough estimation of the shedding virus load: we posit that the virus load is highest during the presymptomatic stage, and approximated the weight at 0.5; during the exposed and the early symptomatic and cotemporal stages of oligosymptomatic stages, we assume a weight of 0.2; during the symptomatic stages without complications and cotemporal stages of the oligosymptomatic stage, the virus load continues to decrease, and we assumed a weight of 0.1. The estimated weights of viral concentration of different stages based on this research are shown in
Table 1. In light of the weighted shedding profile for individuals and the larger shedding populations of interest, we assume a constant of proportionality
that relates the (weighted) value of the shedding population to the daily concentration of SARS-CoV-2. The value of
is estimated by the PMCMC model, which can be referred to [
38]. Reflecting the fact that the focus of wastewater monitoring within Saskatchewan was on cities exhibiting separated storm-water and wastewater infrastructure marked by short (≤8 h) toilet-to-municipal wastewater treatment plant transit times and the use of autosampling from the primary inflow into the treatment plant, we treated the concentration of COVID-19 wastewater samples for a given city as indicative of the current—rather than the lagged—epidemiology for that city. Finally, this paper primarily provides a concise introduction to the virus-shedding model, as our group is in the planning stages of another paper that will provide a detailed explanation of how wastewater data can be incorporated into COVID-19 models.
2.1.7. Model Parameters
Table 1 gives the value and units for constant parameters of the deterministic COVID-19 model; readers interested in further detail regarding the formulations involving these parameters are referred to
Appendix A.
2.2. Calculation of Variables of Interest from the COVID-19 Model
Figure 1 shows the system of ODEs governing the behaviour of the deterministic COVID-19 model. As detailed in
Section 2.3.1, the stochastic version of this model serves as the state space model for particle filtering. We detail here a set of derived quantities whose formulation is identical for both forms of the model.
A variety of COVID-19 outcomes of interest can be derived from the ODEs shown in Equation (
A1) in
Appendix A, including those relevant for epidemiological and acute care decision-making. From the standpoint of public health planning and epidemiology, important quantities include a dynamic characterization of the effective reproductive number (denoted as
), the count of undiagnosed infectives in the community with time (denoted as
), and the force of infection (
). Each of these quantities provides information important for understanding the evolution of the current pandemic situation and played a central role in the reporting undertaken from the model. Such measures are especially useful in indicating the evolution of the epidemiological situation, anticipating incipient outbreaks, assessing the performance of current intervention strategies, and informing decisions to be made in the near future, such as those involving relaxation or re-imposition of public health orders.
Some of the model-derived values are of foremost value in the sphere of projection, rather than in the historic time horizon. From the standpoint of acute care and surge planning, the model offers particular value by virtue of its capacity to project forward acute care demand, both in the form of new admissions for COVID-19 to the intensive care unit (ICU) and non-ICU hospital needs and, in terms of census counts for both of those levels of acute care services. Particularly when the stochastic version of the model is used with particle filtering, such information can aid in decisions involving the triggering of surge capacity.
2.2.1. Calculation of the Evolving Effective Reproductive Number
The basic reproductive number (denoted as
) and effective reproductive number (denoted here as
) are widely used concepts in mathematical epidemiological models. The basic reproductive number (
) is the average number of secondary infections transmitted by a typical infective individual in a completely susceptible surrounding population [
43]. While an understanding of this quantity is of great value, in the context of an evolving outbreak, with a population of evolving susceptibility, behavioural and public health measure-induced changes in the contact rate, and changing variant ecology, greater day-to-day attention typically rests on the effective reproductive number (
).
is the average number of secondary infections transmitted by a typical infective individual in a population composed of both susceptible and non-susceptible persons and reflective of the current epidemiology, including mixing patterns and public health, institutional and personal protective practices at present, vaccine effectiveness, population turnover, and currently circulating variants. As a general rule, if
, the count of infected individuals will increase over time; if
, the count of infected patients will remain roughly constant; if
, the number of individuals infected will decline over time.
The model detailed here uses two methods to calculate the effective reproductive number (
): a simplified original method and a method that takes into account the differential mixing rates between undiagnosed and diagnosed individuals and the case-finding process that leads individuals to transition from the former to the latter. Both methods played prominent roles in daily reporting using the model throughout different stages of the pandemic. The original method is based on an assumption that all infectives exhibit full—not reduced—mixing with the susceptibles throughout their full duration of infectivity (i.e., until recovery). Recalling that
and
represent the vaccine effectiveness given one or two administered doses, respectively, and that
and
denote the relative rates of mixing amongst symptomatic but undiagnosed individuals and diagnosed individuals, respectively, the original values of
and
in this COVID-19 model are characterized as follows:
However, in real-world scenarios (and in this model), infection spread is governed by other factors besides those captured in the equations above. Specifically, the degree of infection spread from an infective is affected by the relative mixing levels between undiagnosed symptomatics and diagnosed infectives. Whilst the characterization in Equation (
1) considers those factors inasmuch as they affect the fraction of contacts that are made with susceptibles, it fails to consider them in terms of the behaviour of the infective individual over the course of their illness. Considering the effective duration infectives spend in different infected stages leads to a new formulation for each of the basic and effective reproductive numbers, denoted
and
, respectively:
In this contribution, we employ the latter method, which considers the effective time of infectives to estimate and predict the effective reproductive number .
2.2.2. Count of Undiagnosed Infectives in the Community over Time
Given the underlying structure of the model, the count of undiagnosed infectives in the community
can be calculated by summing the count of undiagnosed persons in each infective compartment as follows:
2.2.3. Daily Effective Prevalence of Infectives in the Mixing Community
The point prevalence of COVID-19 is the proportion of individuals in a population who have COVID-19 at a specified point in time [
44]. Thus, the equation of the standard prevalence is as follows:
In the model, we use the effective prevalence instead of the standard prevalence. The effective prevalence considers the weight of contact coefficients of the undiagnosed infectives (
) and the weight of contact coefficients of the diagnosed infectives (
). Thus, the daily effective prevalence of infectives in the mixing community can be calculated by the fraction of the effective infectives in the total effective population in the community. The formulation is as follows:
2.2.4. Force of Infection
Section 2.1.5 introduced the model’s use of the force of infection (
). This quantity can be calculated as the product of what we term the transmission rate—itself the product of the contact rate and probability of transmission per discordant contact—and the fraction of the mixing population that is infectious:
where
is the daily effective prevalence of infectives, as characterized by Equation (
5).
2.2.5. Cumulative Prevalence of Infections
Period prevalence is the proportion of individuals in a population who have had COVID-19 over a specified period of time [
44]. Thus, the cumulative prevalence of COVID-19 infections can be calculated by the fraction of the initial population who have ever been infected by COVID-19. The formulation of the cumulative prevalence of infections at time
T is as follows:
2.2.6. New Hospital Admissions and Census Count for Non-ICU and ICU Needs
A key motivator for the construction of the COVID-19 model characterized in this project is to estimate and predict acute care demand and capacity utilization. This includes considering hospital admissions—including ICU admission and non-ICU admission cases—and the daily number (census) of ICU and non-ICU hospital patients. The daily hospitalized census for ICU and non-ICU at any given time is simply characterized by the values of the compartments
and
, respectively. Recalling that the time unit of the model is days, the per-day rate (daily count) of new admissions of ICU patients is given by the sum of two flows into the
compartment, representing the development of critical symptoms by both previously diagnosed (
) and (separately) previously undiagnosed (
) symptomatic infectives. Similarly, the daily new hospital admissions of patients not requiring ICU care is the sum of two flows into the
compartment, representing the development of severe symptoms by both previously diagnosed (
) and undiagnosed (
) individuals. Thus, the daily new admissions of ICU and non-ICU patients are as follows:
2.3. SMC Algorithm Incorporation of the Stochastic COVID-19 Model
The prominent sequential Monte Carlo (SMC) method of particle filtering is a contemporary state inference and identification methodology that supports filtering of general non-Gaussian and non-linear state space models in light of time series of empirical observations [
3,
5,
8]. This approach estimates, via sampling, the time-evolving internal state of a dynamic system (here, the COVID-19 model) in which random perturbations are present and where information about the state is obtained via noisy measurements made at each observation time. The state space model characterizes the processes governing the time evolution of the internal state of the system with stochastics consisting of random perturbations. The state of the state space model is assumed in general to be latent and unobservable. Information concerning the latent state is obtained periodically via a noisy observation vector. The particle filtering method can be viewed as undertaking a “survival of the fittest” of varying hypotheses as to the current location of the system in state space, with each such hypothesis being represented by a particle, the fitness of which is determined by the consistency between what is observed empirically at each observation time point and what would be expected given the state of the particle (the hypothesized state) at that time point. Interested readers are referred to a more detailed treatment in [
5,
8,
9].
2.3.1. State Space Model
The state space model depicts the processes governing the time evolution of the state—both latent and observable—of a noisy system. In this paper, the state space model consists of a stochastically embellished variant of the deterministic COVID-19 model depicted in
Figure 1 and whose equations are given in Equation (
A1) of
Appendix A. Reflecting the fact that effective use of particle filtering requires an underlying state equation model exhibiting stochastic variability, we characterize here an extension of the deterministic model that incorporates random perturbations in dynamic processes—including several stochastically evolving parameters—so as to reflect stochastic time evolution in the external world. The extended stochastic model introduced in
Figure 2 then serves as the basis for an accompanying particle filter.
The state vector of the particle filtering model is given by:
Dynamic Processes
We consider stochastic processes to characterize the arrival of undiagnosed travel-imported symptomatic cases, contact and care-seeing behaviour, and test positivity rates associated with active screening. Moreover, Poisson processes are used to reflect the stochastics associated with the occurrence of a small number of cases over a small unit of time—denoted as
(carrying the value of 0.001 days in the COVID-19 model) [
3,
5]. The stochastic process characterizing undiagnosed travel-based importation of symptomatic infectives is given by
.
Dynamic Parameters
There are a set of quantities that might commonly be regarded as parameters, but whose values evolved in notable ways over the course of the COVID-19 pandemic, particularly with the evolution of human behaviour and variant ecology, due to changes in active case-finding efforts and the arrival of the pathogen in vulnerable demographics and communities. Such quantities are termed “dynamic parameters” herein. The dynamic parameters of the deterministic COVID-19 model are listed in
Table 2.
2.3.2. Likelihood Function
Our formulation of the overall likelihood function and sub-likelihood functions for this work drew inspiration from our past success in employing negative binomial-based likelihood functions in a diverse set of particle filtering applications in communicable disease [
3,
4,
5,
6] and by others in MCMC-based approaches for H1N1 influenza [
45]. Moreover, for simplicity and in line with formulations used successfully in multiple of our past contributions [
3,
4,
6], the current model characterized the overall likelihood function for the particle filtering model as the product of sub-likelihood functions, each considering a distinct subset of the empirical datasets employed to ground the model:
Each sub-likelihood function is characterized by one of two distinct parametric statistical distributions—a negative binomial distribution or gamma distribution. Such sub-likelihood functions characterize the likelihood of observing the empirical datum, given an underlying model state specified by the particle state. Those two forms of sub-likelihood functions are introduced as follows:
The value of each sub-likelihood function based on a negative binomial distribution is given as follows:
where
y is the observed datum,
x is the model value corresponding to that datum (integer rounded),
r is the dispersion parameter associated with the negative binomial distribution, and
. In this project, the value of the dispersion parameter
r was chosen to be 5.
The value of the sub-likelihood function based on a gamma distribution is given as follows:
where
y is the observed datum,
x is the model value corresponding to that datum,
k is the shape parameter,
, and
. Such likelihood functions within this project assumed a value of
.
It is important to note that while the likelihood function employed here is designed to be used with each of the types of data shown in
Table 3, the likelihood formulation is moreover designed to be robust in the context of missing data for several of those types of data. Data that can be accommodated as missing include hospitalized admission data—ICU and non-ICU, hospitalized census data—ICU and non-ICU, and viral concentration in wastewater data. When a datum is not available for these types of observations, the corresponding sub-likelihood function will be treated as holding a value of unity (1.0). Thus, given missing data of this sort, the overall likelihood function will still carry the value of the product of the sub-likelihood functions for which data are available. Moreover, the model’s form can be readily extended to accommodate the handling of delayed data. Our other work [
4] also demonstrates that even lower-quality data can, at times, contribute significantly to the model’s predictive accuracy.
2.4. Data Sources
Since June 2020 and through early 2022—and with prior episodic use—this model has served in a production capacity for the whole of Saskatchewan, and for varying periods for particular regions, municipalities, and small-area geographies within Saskatchewan. For the period October 2020–October 2021, via a contract with the Public Health Agency of Canada (PHAC), it was further used for reporting and projections multiple times a week for all provinces of Canada. Beyond that, via a contract for reporting to the First Nations and Inuit Health Branch of Health Canada (FNIHB), the model was used in the period November 2020–March 2022 for biweekly reporting and projections for First Nations Reserves in six Canadian provinces. Most such uses have exercised subsets of the likelihood functions considered, with hospital census data and wastewater data being restricted to subsets of jurisdictions.
For a given jurisdiction, empirical datasets are fed into the particle filtering model to estimate and predict the evolution of the epidemiological and acute care state of that jurisdiction. The empirical datasets employed in the model can be divided into two categories: a set incorporated in the likelihood function for training the particle filtering model and another that serves as an exogenous input to the differential equation model.
The following empirical datasets were considered in the likelihood function:
Daily count of new reported incident confirmed or suspected cases.
Cumulative reported incident confirmed or suspected cases from the inception of the pandemic.
Cumulative reported deaths from COVID-19.
Daily count of COVID-19 patients admitted into the ICU.
Daily COVID-19 patients admitted into hospital for non-ICU care.
Daily midnight census (count) of COVID-19 patients in the ICU.
Daily midnight census of COVID-19 patients in the hospital for non-ICU care.
Weekly average virus SARS-CoV-2 concentration in wastewater.
The following empirical datasets were incorporated as exogenous inputs directly into the dynamic model:
Daily new likely exogenous cases, which represent arrivals into the jurisdiction believed to be infected while outside the jurisdiction, with an emphasis on international travel.
Daily count of persons undergoing PCR (nasopharyngeal swab)-based testing.
Daily count of COVID-19 patients admitted into the ICU.
Daily count of COVID-19 patients admitted into hospital for non-ICU care.
Daily count of persons who received their first vaccination dose.
Daily count of persons who received their second vaccinate dose.
It is important to note that the empirical datasets of “Daily count of COVID-19 patients admitted into the ICU” and “Daily COVID-19 patients admitted into hospital for non-ICU care” are used in both the likelihood function and in driving the model directly.
2.5. Characterizing Model Fidelity to Empirical Data
A key driver for the evolution of the particle filtering approach applied here was the ongoing critical assessment of the fidelity between outputs from the particle-filtered model and the above empirical data sources. As a primary metric for assessing such fidelity in this project, we employed a discrepancy function. The discrepancy between the particle filtering model results and each empirical dataset specified here is the mean of the normalized RMSE (root mean square error) across the whole time frame of the model incorporating the empirical data; as such, smaller discrepancies are considered favourable. To accommodate the different scales of multiple empirical datasets, we employ the normalized RMSE to measure the difference between the model-estimated/predicted values and the observed data of each empirical dataset on each day having observed data. The mathematical formulation for the normalized RMSE is specified in
Appendix D.
3. Results
This section characterizes the COVID-19 particle filtering model results and (empirical data availability permitting) associated discrepancies for both day-to-day estimates of the epidemiological state and projection of quantities such as the future daily infected cases, force of infection, and ICU and non-ICU admissions and census.
3.1. Particle Filtering Model Results with Incorporating Empirical Datasets
Although the particle filtering model characterized here at various intervals provided reporting for 17 different jurisdictions, for the sake of simplicity, we focus here on the results for a jurisdiction offering wastewater data and served by one of the longest spans of data—Saskatoon, Saskatchewan. In the application examined here—which is emblematic of simulations conducted on this jurisdiction over long periods of time—the COVID-19 particle filtering model takes in daily incoming empirical data to produce daily reporting. The model runs start on 22 February 2020, when the empirical data became available from the appropriate public health agency (here, the Saskatchewan Health Authority); testing for COVID-19 began on 25 February 2020, and the first reported infected cases occurred on 11 March 2020. The simulation here proceeds to 31 July 2021, prior to the widespread appearance of the Delta variant of concern. Particle filtering was conducted with a particle count of 150,000.
Table 4 presents the mean discrepancy, with five runs of the model. For comparison in scale, the table further provides the 95% confidence interval of each empirical dataset incorporated in the likelihood function to ground the model. As a reminder, the lower the discrepancy, the better the results sampled from the particle filtered model reproduce the empirical dataset.
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7,
Figure 8,
Figure 9 and
Figure 10 show the particle filtering COVID-19 model’s (the results of the minimum discrepancy among those five runs) estimated results compared with empirical data. The comparison between the model results and empirical data indicates that the particle filtering COVID-19 model can estimate the daily COVID-19 transmission and hospitalization status. As an important caveat, for data confidentiality reasons, precise empirical data are only provided here for empirical data publicly available through the Saskatchewan Health Authority COVID-19 dashboard [
46]. For depiction of the two types of data not publicly available (ICU and non-ICU hospital admissions) in those figures, we ensure data confidentiality by showing synthetic data in the figure instead of actual data. Specifically, for each of ICU and (separately) non-ICU hospital admissions, the data shown in the figures for a given day are Poisson-distributed pseudo-empirical data. That is, for day
t with an actual count of
hospital admissions, the synthetic datapoint is drawn from
.
3.2. Estimation of Latent Dynamic Variables
Through ongoing incorporation of the empirical datasets to ground the COVID-19 dynamic model, the particle filtering process estimates the latent states and dynamic variables to inform the COVID-19 transmission.
Figure 11 shows the model-estimated daily effective reproductive number (the method and underlying mathematical formulation can be found in
Section 2.2.1).
Figure 12 shows the model-estimated daily undiagnosed infectives (with details on formulation found in
Section 2.2.2).
Figure 13 shows the model-estimated force of infection (
) (with details on formulation found in
Section 2.2.4).
Figure 14 shows the model-estimated daily effective prevalence of infectives in the mixing community (with details on formulation found in
Section 2.2.3). And
Figure 15 shows the cumulative prevalence of infections for each day (with details on formulation found in
Section 2.2.5). Readers interested in the estimated latent state of the COVID-19 particle filtering model are referred to
Appendix D.
3.3. Projection Results
While the COVID-19 particle filtering model offers strong performance in monitoring and estimating COVID-19 transmission, throughout its use across jurisdictions, such estimates of current epidemiological state have routinely been accompanied by 14-day projections of COVID-19 transmission and hospitalization.
To assess the predictive capacity of the COVID-19 particle filtering model herein, we employed it to perform 1-day, 7-day and 14-day predictions for each day starting from day 100 in Saskatoon and continuing for the remainder of the time horizon considered here. Within the projection period (e.g., 7 days), no further particle filtering is performed, the model is simply run forward without any incorporation of the observed data. Mirroring the process seen in de facto use of the model, such a projection is performed from each successive day. It is essential to recognize that while the projection itself does not incorporate any new data, between each day on which the projection is launched, new data arrive and are incorporated by the particle filtering. The updated estimate of the latent state of the system afforded by this incorporation of the new data by particle filtering allows the next projection (looking into the “future”, as obtained from the standpoint of that day) to be made on the basis of the refined and updated understanding of the current epidemiological context.
Table 5 shows the predictive discrepancy between the model-predicted results and the empirical data. By comparing the average discrepancy of the three projection runs—1 day, 7 days, and 14 days ahead—we can see that the relative accuracy of the projections decreases with longer prediction timeframes. It bears emphasis that while discrepancies are computed here to compare the model results against empirical data, during the projection timeframes launched from each day, the empirical data are only used for comparison with the model-projected results. However, as noted above, new data are taken into account before undertaking each successive projection.
Figure 16,
Figure 17,
Figure 18,
Figure 19,
Figure 20 and
Figure 21 depict a comparison between the model-predicted results and the empirical datasets (or, for confidentiality of hospital admissions, the empirically inspired synthetic data noted above). To understand the results, it is to be emphasized that for every day, we perform three predictive runs (1-day, 7-day, and 14-day). When shown in boxplots in the figures, the values for (one-)day-ahead predictions of the model will be shown directly in comparison with the corresponding day-ahead empirical data. In contrast, for the 7-day projection results, for each day the figures visually compare the average model-predicted value over that 7-day interval with the corresponding average of the empirical data over that same 7-day interval. As above, it is to be emphasized that within each such projection from a given day, no particle filtering is occurring, and the empirical data are only compared with the model results, not incorporated into the model. As noted above, as would and did occur in day-to-day practice of a deployed system such as this, with the passage of each successive day, new data are incorporated by the particle filtering mechanism to update the estimate of the system state, allowing the next projection to be made on the basis of that updated state estimate.
Those figures show that the preponderance of observed data (blue points in the diagrams) fall within the 50% inter-quartile range of the boxplot, demonstrating relatively accurate model predictions for up to 14 days in advance to inform public health agencies and governments, as in estimates informed by data up to the point of projection. For example, the prediction of daily new reported cases can produce a picture of the trends in future transmission, as informed by the system state estimated by the particle filtering. In a similar manner, the prediction of daily hospitalized ICU, non-ICU admission, and census patients can inform public health agencies’ mobilization of surge capacity, anticipation of capacity utilization, and service demands, and more broadly, support judicious allocation of hospital resources over the multi-week timeframe.
Finally, readers interested in the sensitivity analysis of the model parameters, please refer to a previous study [
47] by our group that evaluated the particle filtering infectious disease models’ prediction accuracy with the influences of the frequent observations of empirical data, the parameters of the negative binomial dispersion parameters, and rates with which the contact rate could evolve.
3.4. Intervention Results
In the previous sections, we showed that the particle filtering algorithm can estimate the state space of the COVID-19 model. Beyond supporting the projection methods examined in the previous session, the capacity to perform such state estimation also confers benefits for conducting simulations of tradeoffs between intervention strategies, despite their counterfactual character. As for projection scenarios discussed in the previous section, during the time horizon of a given intervention run (e.g., 14 days), the particle filtering is disabled, and the dynamic model is run forward with no empirical data being incorporated. But, as for the projection methods above, with each successive day of operation, particle filtering incorporates a new day’s worth of data. The accuracy of the intervention runs conducted forward into the future from a given day following the particle filter update from the previous day benefits from the updated state estimate made possible by particle filtering’s incorporation of a new day’s worth of data.
In this section, we show two intervention experiments to simulate stylized public health intervention policies. The stylized intervention strategies are characterized abstractly for demonstration purposes, but are emblematic of the sort of more textured interventions examined during use of the model and provide a flavour of what could be achieved with other interventions. In each case, the scenarios are run forward for 14 days from each successive day with the intervention mechanisms in place. Such a scenario run undertaken from a given day depicts the posited result of undertaking the associated intervention starting on that day.
For a given such day, a single boxplot for that day depicts, on the basis of the state estimate as of that particular day as updated by particle filtering for that day, the average outcome over the 14-day intervention time horizon. It bears emphasis that, in each case, the intervention scenario is counter-factual—the intervention is not put into effect from day to day; rather, each 14-day intervention scenario projects what the impact of such an intervention would be, were it to be undertaken starting on the current day.
The two interventions considered here are predominantly focused on actions undertaken during two outbreak waves:
The first stylized intervention exhibited here focuses on elevating hygiene-oriented personal protective measures, such as might be exemplified by a regional mask mandate. For simplicity, the examination here characterizes such interventions as multiplying the effective contact rate by a coefficient in the range
.
Figure 22 depicts the results of such a counterfactual scenario occurring, focused on the first outbreak wave in Saskatoon. For simplicity, this scenario posits an aggressive hygiene-enhancing intervention that reduces the contact rate by 50% specifically for the window between day 220 and day 310 (inclusive).
In the second intervention type, we examine the outcomes from a stylized outbreak-response immunization campaign elevating vaccination rates for the 14-day defined period. This effect is achieved by using a coefficient to increase the effective vaccination rate in the model over that timeframe. As an example,
Figure 23 shows the results of elevating the effective vaccination rate by 50% during the third outbreak wave in Saskatoon, with those elevated rates being in place from day 390 to day 510, inclusive.
4. Discussion and Limitations
As demonstrated in its use to support reporting for 17 jurisdictions across Canada for a period of a year or more, the COVID-19 particle filtering model can monitor COVID-19 transmission and hospitalization, estimate the daily latent states and important dynamic variables, and predict future daily transmission and hospitalization status over a multi-week timeframe, all in light of daily updates to the estimated system state. When running the model daily, the daily estimates for COVID-19 transmission, hospitalization status, projections, and intervention results reflect the latest sets of empirical data—including both health system and wastewater data—to provide a current understanding to inform public health and healthcare system decision-making.
This work suffers from a number of limitations. A key one concerns changes in variant ecology. Reflective of the high amounts of transmission experienced globally, the virus SARS-CoV-2 causing COVID-19 has exhibited marked evolution. For most of the period for which data are considered in this paper (early 2020 to the end of July 2021), the wild type of SARS-CoV-2 was the uniform lineage in place in Canada, with the Alpha variant [
26] appearing in Canada in the final week of 2021 (and in Saskatchewan by February 2021), followed by Beta, Gamma, and Delta. With respect to the jurisdictions considered in our example runs here (Saskatoon), the highly distinctive Delta variant [
26] became the dominant variant of SARS-CoV-2 following July 2021 driving the next wave of outbreaks. Our COVID-19 particle filtering model is capable of simulating changes in the virus ecology by adjusting the characteristic parameter values (e.g., to reflect virulence, transmissivity, fraction of cases that are symptomatic, or vaccine effectiveness). For example, to change from simulating the Alpha to the Delta variant, we increased the maximum value of the “transmission contact rate” (denoted
in this paper) and decreased both of the two doses’ vaccine efficacy (denoted
and
). However, the dynamic model assumes the presence of a single variant at a time and is not suitable for characterizing processes requiring representation of multi-variant ecologies, such as those involving competition between multiple lineages. It is also not well-suited for capturing variant cross-reactivity with respect to immunological protection.
Although the structure of the COVID-19 model has demonstrated effectiveness in simulating COVID-19 transmission and hospitalization across diverse jurisdictions from the beginning of the first infected individual occurrence until the end of 2021, there are a number of key shortcomings in the existing structure of the model. Likely the single most important such limitation relates to the failure of the model to adequately characterize the differential impact of vaccination on protection from infection vs. protection from severe disease and death. The model’s existing characterization of COVID-19 vaccination characterizes its impact of vaccination only as mediated by an impact on transmission. While individuals in the model can be infected regardless of vaccination status, once a breakthrough infection of a vaccinated individual occurs, the model lacks existing mechanisms for retaining information on that individual’s vaccination status. As a result, conditional on infection, the model grossly unrealistically characterizes a vaccinated individual as having an identical risk of hospitalization, ICU admission, and death to a non-vaccinated individual. While the model parameters associated with such outcomes can be modified to reflect a high prevalence of vaccination uptake, the model urgently needs a means of characterizing different types of protection conferred by vaccines. Such a representation is particularly urgent in light of the need to capture the evolution of variant ecology emphasized above. However, it is notable that the model presented in this manuscript possesses the capability to capture, to a certain extent, the protective effects of vaccination against severe disease and death. A dynamic variable, denoted the “daily fraction of symptomatic individuals who proceed on to require hospitalization” (represented as ), is defined in the model. This variable undergoes dynamic changes on a daily basis (with the time unit of the model being “day”) and is estimated using the particle filtering algorithm incorporating empirical datasets. Beyond this foundational modification, the model requires the capacity to represent the impact of successive booster vaccines.
Beyond the key change required for the characterization of vaccine-induced protection, the model depicted in this paper exhibits a need to adapt to the updated epidemiological context and evolved understanding of SARS-CoV-2. Most important is the need to take into account the extensively evidenced phenomenon of waning of both natural immunity (acquired from exposure to the disease through infection) and vaccine-induced immunity.
The COVID-19 model structure characterized here is only applied to an aggregate population. Important gains in insight can be secured by the incorporation of key elements of heterogeneity via stratification. Given the marked differences in risk of severe disease and hospitalization, vaccine uptake, assortative mixing, and risk behaviour, stratification by age group is a key priority. Particularly in light of the pronounced rural–urban disparities in vaccination and risk behaviour and opportunities for incorporation of data drawn from SARS-CoV-2 wastewater concentration assays across varying municipalities, stratification by multiple regions could also confer notable benefits.
Most of the needs covered in this section have subsequently been successfully incorporated into newer versions of the particle filtered dynamic model than those presented here, but coverage of this expanded model and particle filtering framework lies outside this presentation. For instance, model structure modifications were made to the vaccination parts, such as adding the third booster vaccination dose and incorporating waning immunity, during simulation of the Omicron variants.
Also left for separate coverage is our refinement and expansion of the model covered here into a particle Markov chain Monte Carlo model offering additional capabilities and sophistication in sampling of static parameters [
38], closer examination and evaluation of the incorporation, and support for drawing insight from wastewater data. Details of the extensive and articulated distributed computation framework used to provide nearly fully automated day-to-day running and reporting of the model results across diverse jurisdictions and data sources at scale are also covered elsewhere.
Last but not least, a notable limitation of the particle filtering model lies in the potential impact of the size of the model’s state space on its results. While extending an aggregated population compartmental model to include multiple stratifications is both insightful and straightforward, it is crucial to recognize that the model’s state space will also significantly expand. Managing a larger-state-space particle filtering model often poses challenges in testing and tuning. Additionally, increased computational resources, such as a larger number of particles, are also a challenge due to a larger state space model. To effectively ground and estimate the state space model, more empirical datasets become necessary. Therefore, multi-dimensional stratified population particle filtering models (for instance, those stratified by multiple age groups or geographical regions, incorporating multiple simulated virus variants in the entire model, or accounting for individuals’ vaccination history during post-infection periods) do not consistently ensure improved results compared to aggregate population models.
5. Conclusions
This study characterizes the design and multi-year deployment of a production-quality particle filter model that played a central role in informing public health decision-making starting in the opening months of the pandemic. By cross-leveraging particle filtering, dynamic (transmission) modeling, and diverse health system and wastewater data sources, the system presented here and close variants offered important initial findings by April 2020 and served to deliver daily updated COVID-19 situational analyses and short-term forecasts for Saskatchewan for the period of June 2020 through December 2021, multiple times a week for each Canadian province for the Public Health Agency of Canada until November 2021. and weekly to First Nations across six Canadian provinces via FNIHB through March 2022.
Particle-filtered dynamic models confer strong benefits by virtue of their ability to incorporate diverse incoming empirical data streams—here including both regularly reported health system data and episodically sampled wastewater data—to perform day-to-day probabilistic estimation and reporting of latent epidemiological and health system quantities of interest. Quantities routinely reported from the model described here include—but are not limited to—COVID-19 cases, testing volumes, hospitalization admissions and census, deaths, force of infection, undiagnosed individuals, and other factors. This further includes a more sophisticated estimate of the effective reproductive number, taking into account incomplete reporting, asymptomatic transmission, diagnosis, isolation, and other considerations. Beyond supporting updated estimation of such quantities and other elements of the system state whenever new data arrive, our extensively deployed particle-filtered framework uses each new system state estimate as the basis for probabilistically projecting forward the evolution of epidemiology and acute-care demand, which can readily support the triggering of surge capacity mobilization, motivate the institution of public health measures, or prepare for higher health capacity utilization. Similar methods can and were used to support the reporting of results from prospective counterfactual intervention scenarios, with each undertaken in light of the latest empirical observations.
As demonstrated by its widespread adoption for continually regrounded reporting and scenario analysis for diverse Canadian jurisdictions, the sequential Monte Carlo approach of particle filtering offers a compelling tool for evidence-based public health decision-making. The capacity of particle filtering to keep transmission models and the resulting probabilistic state estimates and scenario projections continually updated with the latest data offers compelling advantages over earlier generations of techniques such as the extended Kalman filter, and the computational demands of this technique are well-balanced with the velocity of contemporary data streams of relevance. Systems employing particle filtering offer strong advantages well-matched to the urgent need for public health surveillance and decision-making in the coming years.
Author Contributions
Conceptualization, N.D.O., X.L. and J.B.; methodology, N.D.O., X.L. and L.D.; software, N.D.O., X.L., L.D. and V.P.; validation, N.D.O., J.B. and X.L.; formal analysis, N.D.O. and X.L.; investigation, N.D.O., X.L., L.D., V.P. and J.M.; resources, J.B., L.D., N.D.O., V.P. and J.M.; data curation, V.P., X.L., N.D.O., L.D. and J.M.; writing—original draft preparation, X.L.; writing—review and editing, N.D.O., X.L., V.P. and J.M.; visualization, X.L., V.P., J.M. and L.D.; supervision, N.D.O. and J.B.; project administration, N.D.O. and J.B.; funding acquisition, N.D.O. and J.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research benefited foundationally from salary support provided by the Saskatchewan Health Authority and Saskatchewan Ministry of Health. It further received contract funding from the Public Health Agency of Canada (PHAC) and the First Nations and Inuit Health Branch of Indigenous Services Canada. Later evolution of this work was supported by PHAC and NSERC through the Mathematics for Public Health Network via the Emerging Infectious Disease Modeling (EIDM) Initiative. Finally, this study immediately extended work and infrastructure that was supported through the Natural Sciences and Engineering Research Council (NSERC) of Canada Discovery Grants program (RGPIN 2017-04647).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The observed datasets were obtained under confidentiality agreement and within the authors’ secondment to public Saskatchewan Health Authority (SHA). Publication of this data would both violate the confidentiality agreement with the SHA and be contrary to the rules set down by the Saskatchewan Ministry of Health, to which the team also reported. However, noisified versions of all of the observed data are all plotted out (the red dots in the boxplots) in the paper, and the readers may estimate the values of the observed data based on the figures in the paper.
Acknowledgments
The team gratefully acknowledges the support of diverse partners in this work. We wish to extend particular gratitude to the Saskatchewan Health Authority, Saskatchewan Ministry of Health, for provision of health system data, funding the successive development of the particle filtering model and framework, and the supporting infrastructure. We particularly wish to offer special thanks to Jennifer Zerff and Michelle Mula of the SHA, as well as many other university students who helped support this system, especially Eric Redekopp, Aaron Toderash, and Long Pham. We thank PHAC for the wastewater contract that accelerated this work and helped provide trainee support, as well as PHAC and FNIHB for further supporting trainees and the development and maintenance of the particle filtering infrastructure. We further wish to extend our gratitude to John Giesy, Yuwei Xie, Markus Brinkmann, and Kerry McPhedran of the U Saskatchewan Toxicology Centre for providing the wastewater used, key background understanding concerning wastewater analysis, lab processes, wastewater infrastructure, shedding, and related areas; their generosity is so appreciated, and the wastewater side of this model and derivatives will form the basis for a future joint paper. Through his work with the associated PMCMC model, Osgood postdoctoral fellow Jeremy Eng helped estimate a key shedding-related scaling constant to enhance the integration of the wastewater data into the particle filter. We further want to thank Juxin Liu for her esteemed and deep expertise in sequential and PMCMC methods over the years, without which this work would not have been possible. Co-author Osgood further wishes to express his appreciation of support for elements of the work that contributed to the success of these efforts via the NSERC Discovery Grants program, from the Mathematics for Public Health Network, and from SYK and XZO.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SMC | Sequential Monte Carlo |
| PF | Particle Filtering |
| WHO | World Health Organization |
| PMCMC | Particle Markov Chain Monte Carlo |
| PHAC | Public Health Agency of Canada |
| SHA | Saskatchewan Health Authority |
| FNIHB | First Nations and Inuit Health Branch |
| PCR | Polymerase Chain Reaction |
| ICU | Intensive Care Unit |
| WWS | Wastewater Surveillance |
| ODE | Ordinary Differential Equation |
| MCMC | Markov Chain Monte Carlo |
| RMSE | Root Mean Square Error |
| NRMSE | Normalized Root Mean Square Error |
Appendix A. The ODEs of the COVID-19 Mathematical Model
The mathematical equations of the compartmental model are listed as follows:
The meaning of each stock:
S: The number of susceptible individuals
: The number of individuals who have received the first vaccination dose
: The number of individuals who have received two vaccination doses
: The number of undiagnosed susceptible individuals
: The number of undiagnosed temporarily asymptomatic infected individuals
: The number of diagnosed temporarily asymptomatic infected individuals
: The number of undiagnosed persistently asymptomatic infected individuals
: The number of diagnosed persistently asymptomatic infected individuals
: The number of undiagnosed persistently asymptomatic infected individuals with progression from
: The number of diagnosed persistently asymptomatic infected individuals with progression from
: The number of undiagnosed symptomatic infected individuals with complications
: The number of diagnosed symptomatic infected individuals with complications
: The number of undiagnosed symptomatic infected individuals without complications
: The number of diagnosed symptomatic infected individuals without complications
: The number of hospitalized critical infected individuals
: The number of hospitalized acute infected individuals
: The number of undiagnosed recovered individuals
: The number of diagnosed recovered individuals
D: The number of individuals who died of COVID-19
Appendix B. The Mathematical Deduction of the Dynamic Parameters
If parameter
varies over the range
, we characterize the logit of
(transfer from interval
to
) as undergoing Brownian motion according to Stratonovich notation as:
In a more general situation, where
varies in the interval
, we scale
to
, where we have:
Finally, if we substitute Equation (
A3) into (
A2), we can obtain the logit of
(transfer from interval
to
) as undergoing Brownian motion according to Stratonovich notation as:
Appendix C. Boxplots of the COVID-19 Particle Filtering Model Estimated Latent State
Figure A1.
Boxplot of the latent state of stock S.
Figure A1.
Boxplot of the latent state of stock S.
Figure A2.
Boxplot of the latent state of stock .
Figure A2.
Boxplot of the latent state of stock .
Figure A3.
Boxplot of the latent state of stock .
Figure A3.
Boxplot of the latent state of stock .
Figure A4.
Boxplot of the latent state of stock .
Figure A4.
Boxplot of the latent state of stock .
Figure A5.
Boxplot of the latent state of stock .
Figure A5.
Boxplot of the latent state of stock .
Figure A6.
Boxplot of the latent state of stock .
Figure A6.
Boxplot of the latent state of stock .
Figure A7.
Boxplot of the latent state of stock .
Figure A7.
Boxplot of the latent state of stock .
Figure A8.
Boxplot of the latent state of stock .
Figure A8.
Boxplot of the latent state of stock .
Figure A9.
Boxplot of the latent state of stock .
Figure A9.
Boxplot of the latent state of stock .
Figure A10.
Boxplot of the latent state of stock .
Figure A10.
Boxplot of the latent state of stock .
Figure A11.
Boxplot of the latent state of stock .
Figure A11.
Boxplot of the latent state of stock .
Figure A12.
Boxplot of the latent state of stock .
Figure A12.
Boxplot of the latent state of stock .
Figure A13.
Boxplot of the latent state of stock .
Figure A13.
Boxplot of the latent state of stock .
Figure A14.
Boxplot of the latent state of stock .
Figure A14.
Boxplot of the latent state of stock .
Figure A15.
Boxplot of the latent state of stock .
Figure A15.
Boxplot of the latent state of stock .
Figure A16.
Boxplot of the latent state of stock .
Figure A16.
Boxplot of the latent state of stock .
Figure A17.
Boxplot of the latent state of stock .
Figure A17.
Boxplot of the latent state of stock .
Figure A18.
Boxplot of the latent state of stock .
Figure A18.
Boxplot of the latent state of stock .
Figure A19.
Boxplot of the latent state of stock .
Figure A19.
Boxplot of the latent state of stock .
Figure A20.
Boxplot of the latent state of stock .
Figure A20.
Boxplot of the latent state of stock .
Appendix D. Mathematical Equations for Calculating the Normalized RMSE and Discrepancy
The normalized RMSE between the COVID-19 particle filtering model estimated/predicted values and the observed data on each day is calculated as follows:
where
y is the model estimated/predicted value,
is the observed value, and
n is the total number of particles sampled by weight to measure. Then, the discrepancy of each empirical dataset is simply the average of the NRMSE across the whole time frame. The result of the NRMSE lies in the interval [0, 2].
Appendix E. Calculation of Relative Mixing Rate Amongst Undiagnosed Symptomatics and Diagnosed in Community
Ref. [
39] shows “About 35 of the 160 confirmed cases did not minimize social contact. More than a fifth continued to work or carried on with their daily routine despite being sick”. We then assume that 80% of diagnosed mostly isolated themselves by reducing their contacts to 20% of normal and 50% undiagnosed reduce their contacts to 20% of normal. Then we have
References
- World Health Organisation (WHO). Rolling Updates on Coronavirus Disease (COVID-19). 2020. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/events-as-they-happen (accessed on 15 April 2020).
- World Health Organisation (WHO). Coronavirus Disease (COVID-19) Pandemic. 2020. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019 (accessed on 30 January 2023).
- Li, X.; Doroshenko, A.; Osgood, N.D. Applying Particle Filtering in Both Aggregated and Age-structured Population Compartmental Models of Pre-vaccination Measles. PLoS ONE 2018, 13, e0206529. [Google Scholar] [CrossRef]
- Safarishahrbijari, A.; Osgood, N.D. Social media surveillance for outbreak projection via transmission models: Longitudinal observational study. JMIR Public Health Surveill. 2019, 5, e11615. [Google Scholar] [CrossRef] [PubMed]
- Osgood, N.; Liu, J. Towards closed loop modeling: Evaluating the prospects for creating recurrently regrounded aggregate simulation models using particle filtering. In Proceedings of the Winter Simulation Conference 2014, Savannah, GA, USA, 7–10 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 829–841. [Google Scholar]
- Oraji, R.; Hoeppner, V.H.; Safarishahrbijari, A.; Osgood, N.D. Combining Particle Filtering and Transmission Modeling for TB Control. In Proceedings of the 2016 IEEE International Conference on Healthcare Informatics (ICHI), Chicago, IL, USA, 4–7 October 2016; pp. 392–398. [Google Scholar]
- Song, J.; Xie, H.; Gao, B.; Zhong, Y.; Gu, C.; Choi, K.S. Maximum likelihood-based extended Kalman filter for COVID-19 prediction. Chaos Solitons Fractals 2021, 146, 110922. [Google Scholar] [CrossRef] [PubMed]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. Publ. IEEE Signal Process. Soc. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Doucet, A.; Johansen, A.M. A tutorial on particle filtering and smoothing: Fifteen years later. Handb. Nonlinear Filter. 2009, 12, 656–704. [Google Scholar]
- Storvik, G.; Palomares, A.D.L.; Engebretsen, S.; Rø, G.Ø.I.; Engø-Monsen, K.; Kristoffersen, A.B.; de Blasio, B.F.; Frigessi, A. A sequential Monte Carlo approach to estimate a time varying reproduction number in infectious disease models: The COVID-19 case. arXiv 2022, arXiv:2201.07590. [Google Scholar] [CrossRef]
- Sheinson, D.; Meng, Y.; Elsea, D. PIN67 Real-Time Analysis of COVID-19 DATA Using Sequential Monte Carlo Methods. Value Health 2021, 24, S118. [Google Scholar] [CrossRef]
- Peak, C.M.; Kahn, R.; Grad, Y.H.; Childs, L.M.; Li, R.; Lipsitch, M.; Buckee, C.O. Individual quarantine versus active monitoring of contacts for the mitigation of COVID-19: A modelling study. Lancet Infect. Dis. 2020, 20, 1025–1033. [Google Scholar] [CrossRef]
- Koyama, S.; Horie, T.; Shinomoto, S. Estimating the time-varying reproduction number of COVID-19 with a state-space method. PLoS Comput. Biol. 2021, 17, e1008679. [Google Scholar] [CrossRef]
- Jiang, S.; Maggard, K.; Shakeri, H.; Porter, M.D. An Application of the Partially Observed Markov Process in the Analysis of Transmission Dynamics of COVID-19 via Wastewater. In Proceedings of the 2021 Systems and Information Engineering Design Symposium (SIEDS), Charlottesville, VA, USA, 29–30 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Wang, Q.; Zhou, Y.; Chen, X. A vector autoregression prediction model for covid-19 outbreak. arXiv 2021, arXiv:2102.04843. [Google Scholar]
- Ahmed, W.; Angel, N.; Edson, J.; Bibby, K.; Bivins, A.; O’Brien, J.W.; Choi, P.M.; Kitajima, M.; Simpson, S.L.; Li, J.; et al. First confirmed detection of SARS-CoV-2 in untreated wastewater in Australia: A proof of concept for the wastewater surveillance of COVID-19 in the community. Sci. Total Environ. 2020, 728, 138764. [Google Scholar] [CrossRef]
- Lahrich, S.; Laghrib, F.; Farahi, A.; Bakasse, M.; Saqrane, S.; El Mhammedi, M. Review on the contamination of wastewater by COVID-19 virus: Impact and treatment. Sci. Total Environ. 2021, 751, 142325. [Google Scholar] [CrossRef] [PubMed]
- Shah, S.; Gwee, S.X.W.; Ng, J.Q.X.; Lau, N.; Koh, J.; Pang, J. Wastewater surveillance to infer COVID-19 transmission: A systematic review. Sci. Total Environ. 2022, 804, 150060. [Google Scholar] [CrossRef] [PubMed]
- Bogler, A.; Packman, A.; Furman, A.; Gross, A.; Kushmaro, A.; Ronen, A.; Dagot, C.; Hill, C.; Vaizel-Ohayon, D.; Morgenroth, E.; et al. Rethinking wastewater risks and monitoring in light of the COVID-19 pandemic. Nat. Sustain. 2020, 3, 981–990. [Google Scholar] [CrossRef]
- McMahan, C.S.; Self, S.; Rennert, L.; Kalbaugh, C.; Kriebel, D.; Graves, D.; Colby, C.; Deaver, J.A.; Popat, S.C.; Karanfil, T.; et al. COVID-19 wastewater epidemiology: A model to estimate infected populations. Lancet Planet. Health 2021, 5, e874–e881. [Google Scholar] [CrossRef] [PubMed]
- Daughton, C.G. Wastewater surveillance for population-wide COVID-19: The present and future. Sci. Total Environ. 2020, 736, 139631. [Google Scholar] [CrossRef]
- Polo, D.; Quintela-Baluja, M.; Corbishley, A.; Jones, D.L.; Singer, A.C.; Graham, D.W.; Romalde, J.L. Making waves: Wastewater-based epidemiology for COVID-19—Approaches and challenges for surveillance and prediction. Water Res. 2020, 186, 116404. [Google Scholar] [CrossRef]
- Bivins, A.; North, D.; Ahmad, A.; Ahmed, W.; Alm, E.; Been, F.; Bhattacharya, P.; Bijlsma, L.; Boehm, A.B.; Brown, J.; et al. Wastewater-based epidemiology: Global collaborative to maximize contributions in the fight against COVID-19. Environ. Sci. Technol. 2020, 54, 7754–7757. [Google Scholar] [CrossRef]
- Weidhaas, J.; Aanderud, Z.T.; Roper, D.K.; VanDerslice, J.; Gaddis, E.B.; Ostermiller, J.; Hoffman, K.; Jamal, R.; Heck, P.; Zhang, Y.; et al. Correlation of SARS-CoV-2 RNA in wastewater with COVID-19 disease burden in sewersheds. Sci. Total. Environ. 2021, 775, 145790. [Google Scholar] [CrossRef]
- Gonzalez, R.; Curtis, K.; Bivins, A.; Bibby, K.; Weir, M.H.; Yetka, K.; Thompson, H.; Keeling, D.; Mitchell, J.; Gonzalez, D. COVID-19 surveillance in Southeastern Virginia using wastewater-based epidemiology. Water Res. 2020, 186, 116296. [Google Scholar] [CrossRef]
- World Health Organisation (WHO). Tracking SARS-CoV-2 Variants. 2021. Available online: https://www.who.int/en/activities/tracking-SARS-CoV-2-variants/ (accessed on 29 October 2021).
- Centers for Disease Control (CDC). Overview of Testing for SARS-CoV-2 (COVID-19). 2021. Available online: https://www.cdc.gov/coronavirus/2019-ncov/hcp/testing-overview.html (accessed on 14 June 2021).
- Vickers, D.M.; Osgood, N.D. Current crisis or artifact of surveillance: Insights into rebound chlamydia rates from dynamic modelling. BMC Infect. Dis. 2010, 10, 70. [Google Scholar] [CrossRef]
- Shang, Y.; Pan, C.; Yang, X.; Zhong, M.; Shang, X.; Wu, Z.; Yu, Z.; Zhang, W.; Zhong, Q.; Zheng, X.; et al. Management of critically ill patients with COVID-19 in ICU: Statement from front-line intensive care experts in Wuhan, China. Ann. Intensive Care 2020, 10, 73. [Google Scholar] [CrossRef] [PubMed]
- World Health Organisation (WHO). COVID-19 Vaccines. 2021. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019/covid-19-vaccines (accessed on 24 June 2021).
- BC Center for Disease Control. Public Health Statement on Extension of the Interval between First and Second Doses of COVID-19 Vaccines in BC. 2021. Available online: http://www.bccdc.ca/Health-Info-Site/Documents/COVID-19_vaccine/Public_health_statement_deferred_second_dose.pdf (accessed on 24 June 2021).
- Jong, M.; Diekmann, O.; Heesterbeek, H. How does transmission of infection depend on population size? In Epidemic Models: Their Structure and Relation to Data; Publication of the Newton Institute: Cambridge, UK, 1995; pp. 84–94. [Google Scholar]
- Public Health Ontario. Wastewater Surveillance of COVID-19. 2021. Available online: https://www.publichealthontario.ca/-/media/documents/ncov/phm/2021/04/public-health-measures-wastewater-surveillance.pdf?la=en (accessed on 1 April 2021).
- Medema, G.; Heijnen, L.; Elsinga, G.; Italiaander, R.; Brouwer, A. Presence of SARS-Coronavirus-2 RNA in sewage and correlation with reported COVID-19 prevalence in the early stage of the epidemic in the Netherlands. Environ. Sci. Technol. Lett. 2020, 7, 511–516. [Google Scholar] [CrossRef] [PubMed]
- Cevik, M.; Tate, M.; Lloyd, O.; Maraolo, A.E.; Schafers, J.; Ho, A. SARS-CoV-2, SARS-CoV, and MERS-CoV viral load dynamics, duration of viral shedding, and infectiousness: A systematic review and meta-analysis. Lancet Microbe 2020, 2, e13–e22. [Google Scholar] [CrossRef] [PubMed]
- Miura, F.; Kitajima, M.; Omori, R. Duration of SARS-CoV-2 viral shedding in faeces as a parameter for wastewater-based epidemiology: Re-analysis of patient data using a shedding dynamics model. Sci. Total Environ. 2021, 769, 144549. [Google Scholar] [CrossRef] [PubMed]
- Hoffmann, T.; Alsing, J. Faecal shedding models for SARS-CoV-2 RNA amongst hospitalised patients and implications for wastewater-based epidemiology. J. R. Stat. Soc. C Ser. Appl. Stat. 2023, 72, 330–345. [Google Scholar] [CrossRef]
- Osgood, N.; Jeremy, E. Effective Use of PMCMC for Daily Epidemiological Monitoring and Reporting: Methodological Lessons. In Proceedings of the Annual Meeting of Statistical Society of Canada 2022, Virtual, 29 May–5 June 2022. Abstract and Conference Publication. [Google Scholar]
- Zhang, L.M.; Yan, H.G. Coronavirus: Govt Agencies to Suspend Activities for Seniors for 14 Days to Cut Risk of Transmission. 2020. Available online: https://www.straitstimes.com/singapore/health/govt-agencies-to-suspend-activities-for-seniors-for-14-days-starting-march-11-to (accessed on 10 March 2020).
- Tindale, L.; Coombe, M.; Stockdale, J.E.; Garlock, E.; Lau, W.Y.V.; Saraswat, M.; Lee, Y.H.B.; Zhang, L.; Chen, D.; Wallinga, J.; et al. Transmission interval estimates suggest pre-symptomatic spread of COVID-19. eLife 2020, 9, e57149. [Google Scholar] [CrossRef]
- Zhou, F.; Yu, T.; Du, R.; Fan, G.; Liu, Y.; Liu, Z.; Xiang, J.; Wang, Y.; Song, B.; Gu, X.; et al. Clinical course and risk factors for mortality of adult inpatients with COVID-19 in Wuhan, China: A retrospective cohort study. Lancet 2020, 395, 1054–1062. [Google Scholar] [CrossRef]
- Oran, D.P.; Topol, E.J. Prevalence of asymptomatic SARS-CoV-2 infection: A narrative review. Ann. Intern. Med. 2020, 173, 362–367. [Google Scholar] [CrossRef]
- Rothman, K.J.; Greenland, S.; Lash, T.L. Modern Epidemiology; Lippincott Williams & Wilkins: Philadelphia, PA, USA, 2008. [Google Scholar]
- Dicker, R.C.; Coronado, F.; Koo, D.; Parrish, R.G. Principles of Epidemiology in Public Health Practice; An Introduction to Applied Epidemiology and Biostatistics; Centers for Disease Control and Prevention: Atlanta, GA, USA, 2006.
- Dorigatti, I.; Cauchemez, S.; Pugliese, A.; Ferguson, N.M. A new approach to characterising infectious disease transmission dynamics from sentinel surveillance: Application to the Italian 2009–2010 A/H1N1 influenza pandemic. Epidemics 2012, 4, 9–21. [Google Scholar] [CrossRef]
- Saskatchewan Dashboard. 2015. Available online: https://dashboard.saskatchewan.ca/ (accessed on 31 January 2023).
- Safarishahrbijari, A.; Teyhouee, A.; Waldner, C.; Liu, J.; Osgood, N. Predictive accuracy of particle filtering in dynamic models supporting outbreak projections. BMC Infect. Dis. 2017, 17, 648. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Transmission model structure.
Figure 1.
Transmission model structure.
Figure 2.
The model structure of the stochastic particle filtering model.
Figure 2.
The model structure of the stochastic particle filtering model.
Figure 3.
Daily new reported confirmed or suspected infective cases between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 3.
Daily new reported confirmed or suspected infective cases between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 4.
Cumulative reported infective cases in the community between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 4.
Cumulative reported infective cases in the community between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 5.
Daily count of COVID-19 patients hospitalized in the ICU between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 5.
Daily count of COVID-19 patients hospitalized in the ICU between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 6.
Daily count of COVID-19 patients hospitalized but not in the ICU between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 6.
Daily count of COVID-19 patients hospitalized but not in the ICU between particle filtering model results (boxplot) and empirical data (superimposed red scatterplot).
Figure 7.
Daily count of COVID-19 hospitalized deaths between particle filtering model results (boxplot) and empirical data (red scatter plot).
Figure 7.
Daily count of COVID-19 hospitalized deaths between particle filtering model results (boxplot) and empirical data (red scatter plot).
Figure 8.
Daily wastewater viral concentration of SARS-CoV-2 (N2 copies per 100 mL) between particle filtering model results (boxplot) and empirical data with missing days (red scatter plot).
Figure 8.
Daily wastewater viral concentration of SARS-CoV-2 (N2 copies per 100 mL) between particle filtering model results (boxplot) and empirical data with missing days (red scatter plot).
Figure 9.
Daily count of hospitalized ICU-admitted patients between particle filtering model results (boxplot) and pseudo-empirical synthetic data (superimposed red scatterplot).
Figure 9.
Daily count of hospitalized ICU-admitted patients between particle filtering model results (boxplot) and pseudo-empirical synthetic data (superimposed red scatterplot).
Figure 10.
Daily count of hospitalized non-ICU-admitted patients between particle filtering model results (boxplot) and pseudo-empirical synthetic data (superimposed red scatterplot).
Figure 10.
Daily count of hospitalized non-ICU-admitted patients between particle filtering model results (boxplot) and pseudo-empirical synthetic data (superimposed red scatterplot).
Figure 11.
The daily estimated effective reproductive number.
Figure 11.
The daily estimated effective reproductive number.
Figure 12.
The daily estimated count of undiagnosed infectives.
Figure 12.
The daily estimated count of undiagnosed infectives.
Figure 13.
The daily estimated force of infection.
Figure 13.
The daily estimated force of infection.
Figure 14.
The daily estimated effective prevalence of infectives in the mixing community.
Figure 14.
The daily estimated effective prevalence of infectives in the mixing community.
Figure 15.
The daily estimated prevalence of cumulative infection.
Figure 15.
The daily estimated prevalence of cumulative infection.
Figure 16.
The projection results (boxplot) of the daily reported cases compared with empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 16.
The projection results (boxplot) of the daily reported cases compared with empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 17.
The projection results (boxplot) of the daily count of patients in the non-ICU compared with the empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 17.
The projection results (boxplot) of the daily count of patients in the non-ICU compared with the empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 18.
The projection results (boxplot) of the daily count of patients hospitalized in the ICU compared with the empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 18.
The projection results (boxplot) of the daily count of patients hospitalized in the ICU compared with the empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 19.
The projection results (boxplot) of the daily count of deaths compared with the empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 19.
The projection results (boxplot) of the daily count of deaths compared with the empirical data (the blue points, not incorporated in the model). (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged empirical data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged empirical data.
Figure 20.
The projection results (boxplot) of the daily count of non-ICU-admitted patients with empirically mimicking synthetic data (the blue points, not incorporated in the model), with the latter being employed to preserve confidentiality. (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data.
Figure 20.
The projection results (boxplot) of the daily count of non-ICU-admitted patients with empirically mimicking synthetic data (the blue points, not incorporated in the model), with the latter being employed to preserve confidentiality. (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data.
Figure 21.
The projection results (boxplot) of the daily count of ICU-admitted patients with the empirically mimicking synthetic data (the blue points, not incorporated in the model), with the latter being employed to preserve confidentiality. (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data.
Figure 21.
The projection results (boxplot) of the daily count of ICU-admitted patients with the empirically mimicking synthetic data (the blue points, not incorporated in the model), with the latter being employed to preserve confidentiality. (a) The next-day projection results. (b) The 7-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data. (c) The 14-day time-window-averaged projection results versus corresponding time-window-averaged synthetic data.
Figure 22.
Model-based projections of the effects, for each successive day, of the average outcome of an intervention reducing the effective contact rate over the next 14 days, starting on that day.
Figure 22.
Model-based projections of the effects, for each successive day, of the average outcome of an intervention reducing the effective contact rate over the next 14 days, starting on that day.
Figure 23.
Model-based projections of COVID-19 for the next 14 days’ average results when simulating an outbreak-response immunization campaign. This is realized by characterizing a stylized elevated vaccine-induced protection level among 50% of the population.
Figure 23.
Model-based projections of COVID-19 for the next 14 days’ average results when simulating an outbreak-response immunization campaign. This is realized by characterizing a stylized elevated vaccine-induced protection level among 50% of the population.
Table 1.
Table of constant parameters.
Table 1.
Table of constant parameters.
| Parameters | Description | Value | Source | Unit |
|---|
| Relative mixing rate amongst undiagnosed symptomatics | 0.6 | [39] | 1 |
| Relative mixing rate amongst diagnosed in community | 0.36 | [39] | 1 |
| Daily travel imported case count of diagnosed | Surveillance data | SHA primary data | Persons/Day |
| Daily count of persons administered the first-dose vaccination | Surveillance data | SHA primary data | Persons/Day |
| Daily count of persons administered the second-dose vaccination | Surveillance data | SHA primary data | Persons/Day |
| Daily count of persons undergoing PCR (nasopharyngeal swab)-based testing | Surveillance data | SHA primary data | Persons/Day |
| Daily count of COVID-19 patients admitted into the ICU | Surveillance data | SHA primary data | Persons/Day |
| Daily count of COVID-19 patients admitted into the non-ICU | Surveillance data | SHA primary data | Persons/Day |
| Fraction of arriving symptomatics identified upon arrival | 1/3 | expert estimation | 1 |
| Fraction of admitting ICU among hospitalized patients | 0.23 | SHA primary data | 1 |
| Mean latent period | 2.9 | PHAC data | Day |
| Mean incubation period following infectivity | 2.72 | [40] | Day |
| Mean time to develop or avoid complications | 6.0 | [41] | Day |
| Mean recovery time following symptoms | 9.5 | PHAC data | Day |
| Mean duration of hospital stay for non-ICU patients before recovery | 12.0 | SHA primary data | Day |
| Mean duration of ICU stay before move to hospital wards, discharge, or death | 6.0 | SHA primary data | Day |
| Mean duration of non-ICU stay before death | 4.57 | SHA primary data | Day |
| Fraction of persistent asymptomatics | 0.4 | [42] | 1 |
| Case fatality rate amongst ICU patients | 0.45 | SHA primary data | 1 |
| Case fatality rate for cases not requiring ICU care | 0.08 | SHA primary data | 1 |
| Vaccine efficacy for dose 1 | 0.8 | [31] | 1 |
| Vaccine efficacy for those completing two-doses primary series | 0.95 | [31] | 1 |
| Ratio of model shedding measure to viral concentration in wastewater | 10.374 | PMCMC model [38] | copies/100 mL/Person |
| Viral shedding weight in exposed stage () | 0.2 | [37] | 1 |
| Viral shedding weight in presymptomatic stage (, ) | 0.5 | [37] | 1 |
| Viral shedding weight in early symptomatic stage with complications and cotemporal stages of oligosymptomatic infection (, , , , , ) | 0.2 | [37] | 1 |
| Viral shedding weight in symptomatic stage (absent complications) and cotemporal stage of oligosymptomatic infectives (, , , ) | 0.1 | [37] | 1 |
| Upper limit on fraction of infectives found by active testing | 1.0 | Reflective of full extent of unit range | 1 |
Table 2.
Table of dynamic parameters.
Table 2.
Table of dynamic parameters.
| Parameters | Meaning | Min (a) | Max (b) | STD | Unit |
|---|
| Transmission contact rate | 0 | 0.4918 | 10.0 | Persons/Day |
| Fraction of symptomatic individuals who proceed on to require hospitalization | 0.04 | 0.06 | 0.1 | 1 |
| Fraction of undiagnosed symptomatics who proceed on to seek care but who are not hospitalized | 0.1 | 0.821 | 0.5 | 1 |
| A measure of test efficiency | 0.01 | 0.25 | 5 | 1 |
Table 3.
Table of sub-likelihood functions.
Table 3.
Table of sub-likelihood functions.
| Likelihood Name | Empirical Dataset | Model Value | Mathematical Form |
|---|
| New reported endogenous COVID-19 cases | | Negative Binomial |
| Cumulative reported endogenous COVID-19 cases | | Negative Binomial |
| Cumulative hospitalized ICU admission patients | | Negative Binomial |
| Cumulative hospitalized non-ICU admission patients | | Negative Binomial |
| Daily hospitalized ICU census patients | | Negative Binomial |
| Daily hospitalized non-ICU census patients | | Negative Binomial |
| Cumulative COVID-19 deaths | D | Negative Binomial |
| Measured concentration of SARS-CoV-2 virus in wastewater | | Gamma Distribution |
Table 4.
Table of discrepancies (normalized root mean square error (NRMSE)) of all empirical datasets compared with model estimated results (with 5 realizations).
Table 4.
Table of discrepancies (normalized root mean square error (NRMSE)) of all empirical datasets compared with model estimated results (with 5 realizations).
| Dataset | Mean | 95% Confidence Interval |
|---|
| Count of daily reported cases | 0.8429 | (0.8343, 0.8515) |
| Cumulative reported cases | 0.2750 | (0.2558, 0.2943) |
| Cumulative death cases | 0.4981 | (0.4842, 0.5121) |
| Daily virus concentration in wastewater | 0.5734 | (0.5511, 0.5957) |
| Cumulative hospitalized non-ICU admissions | 0.1306 | (0.1223, 0.1389) |
| Cumulative hospitalized ICU admissions | 0.5372 | (0.5313, 0.5431) |
| Daily hospitalized non-ICU census | 0.4181 | (0.4117, 0.4245) |
| Daily hospitalized ICU census | 0.6545 | (0.6492, 0.6598) |
| Sum of total | 3.9300 | (3.8980, 3.9617) |
Table 5.
Discrepancies for 1-day, 7-day, and 14-day projection run projected data against empirical datasets.
Table 5.
Discrepancies for 1-day, 7-day, and 14-day projection run projected data against empirical datasets.
| Dataset | Mean Projection Discrepancy |
|---|
| 1-Day | 7-Day | 14-Day |
|---|
| Count of daily reported cases | 0.7051 | 0.8301 | 0.9433 |
| Cumulative reported cases | 0.1591 | 0.1636 | 0.1769 |
| Cumulative death cases | 0.4098 | 0.4164 | 0.4293 |
| Cumulative hospitalized non-ICU admissions | 0.1617 | 0.1582 | 0.1734 |
| Cumulative hospitalized ICU admissions | 0.8705 | 0.8734 | 0.8838 |
| Daily hospitalized non-ICU census | 0.7131 | 0.7506 | 0.8308 |
| Daily hospitalized ICU census | 1.1541 | 1.1846 | 1.2364 |
| Sum of total | 4.1734 | 4.3767 | 4.6738 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




 ,
, 











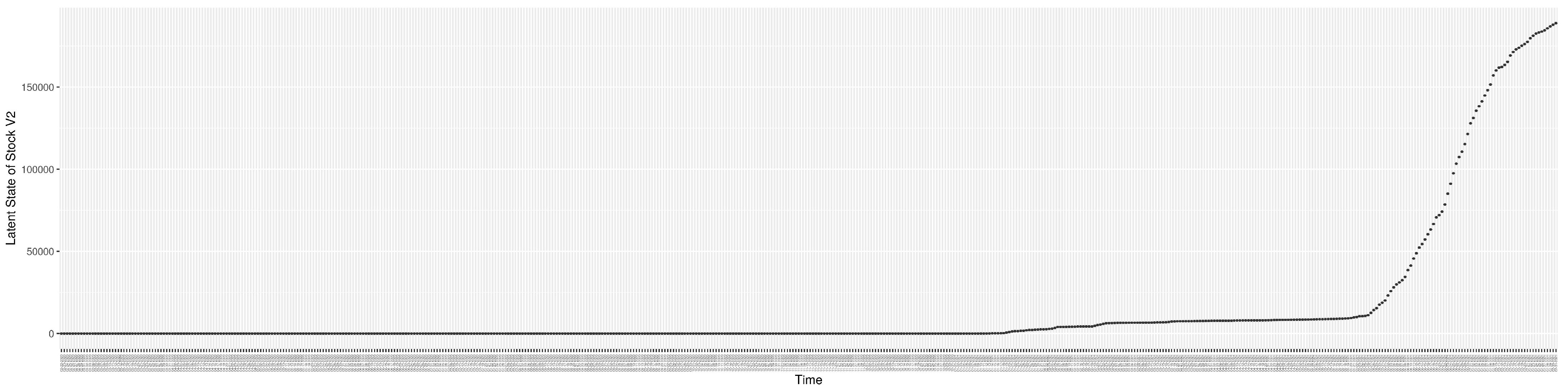
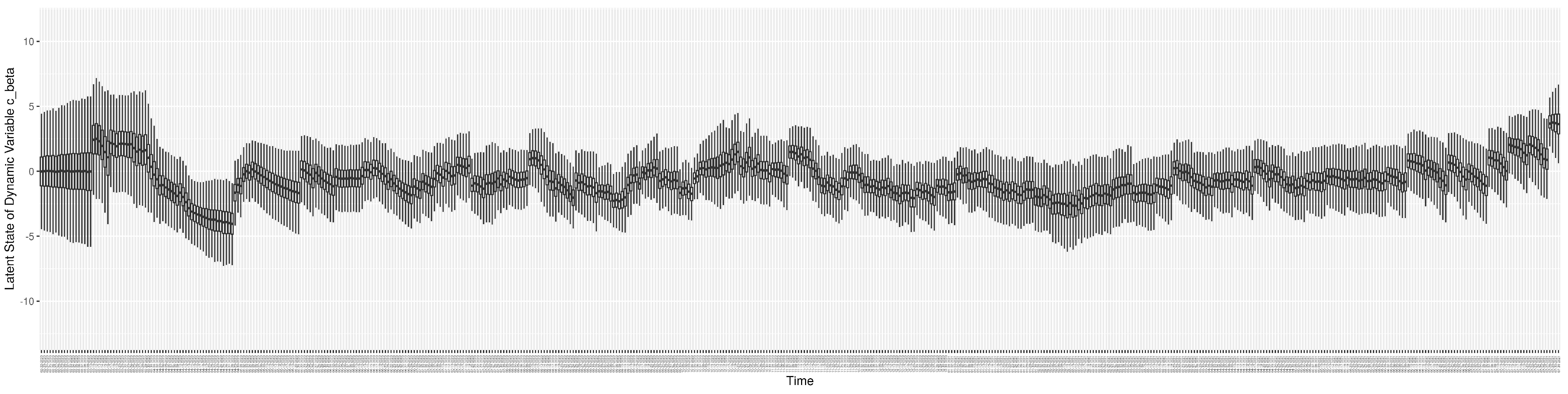
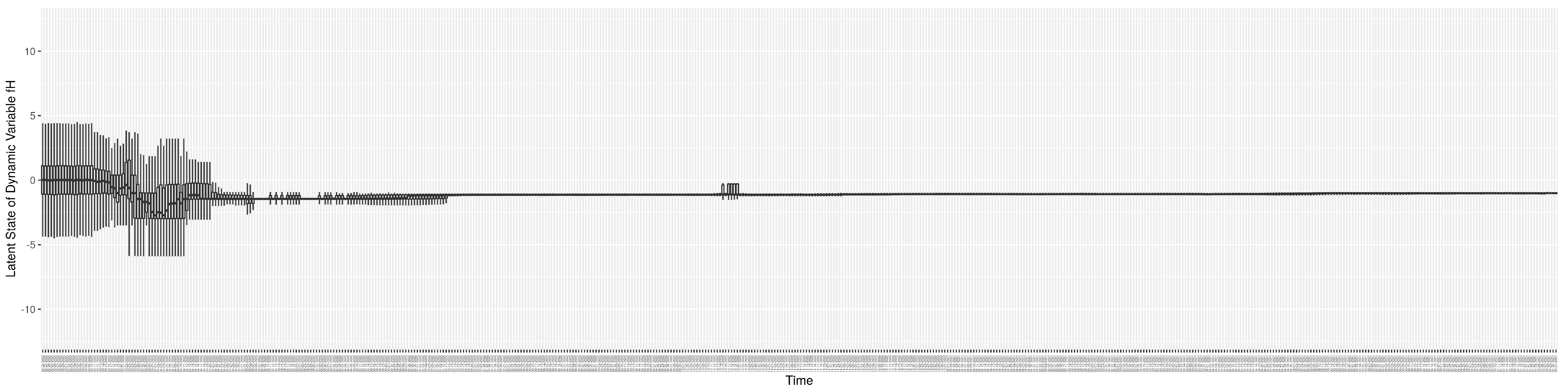
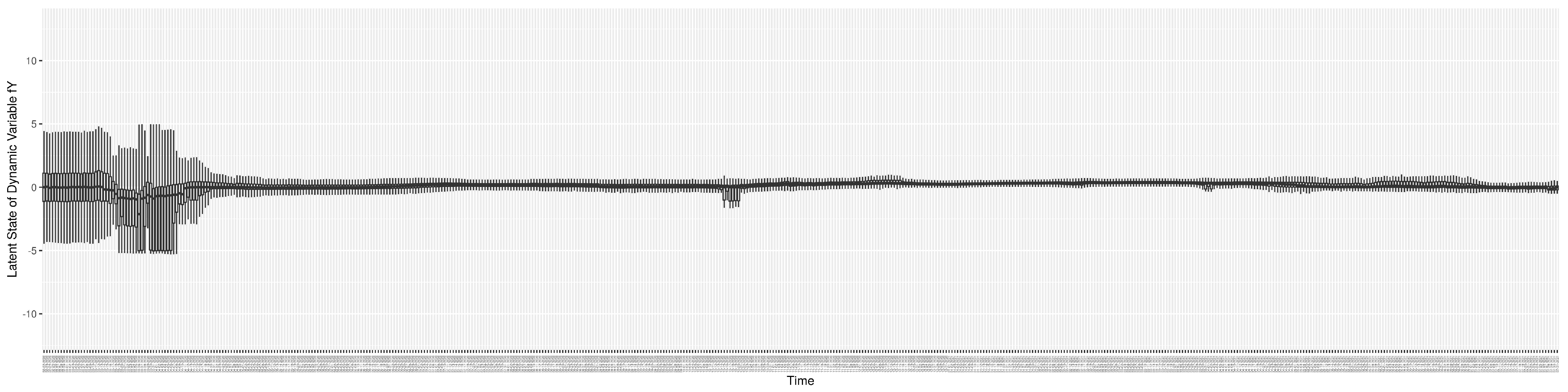

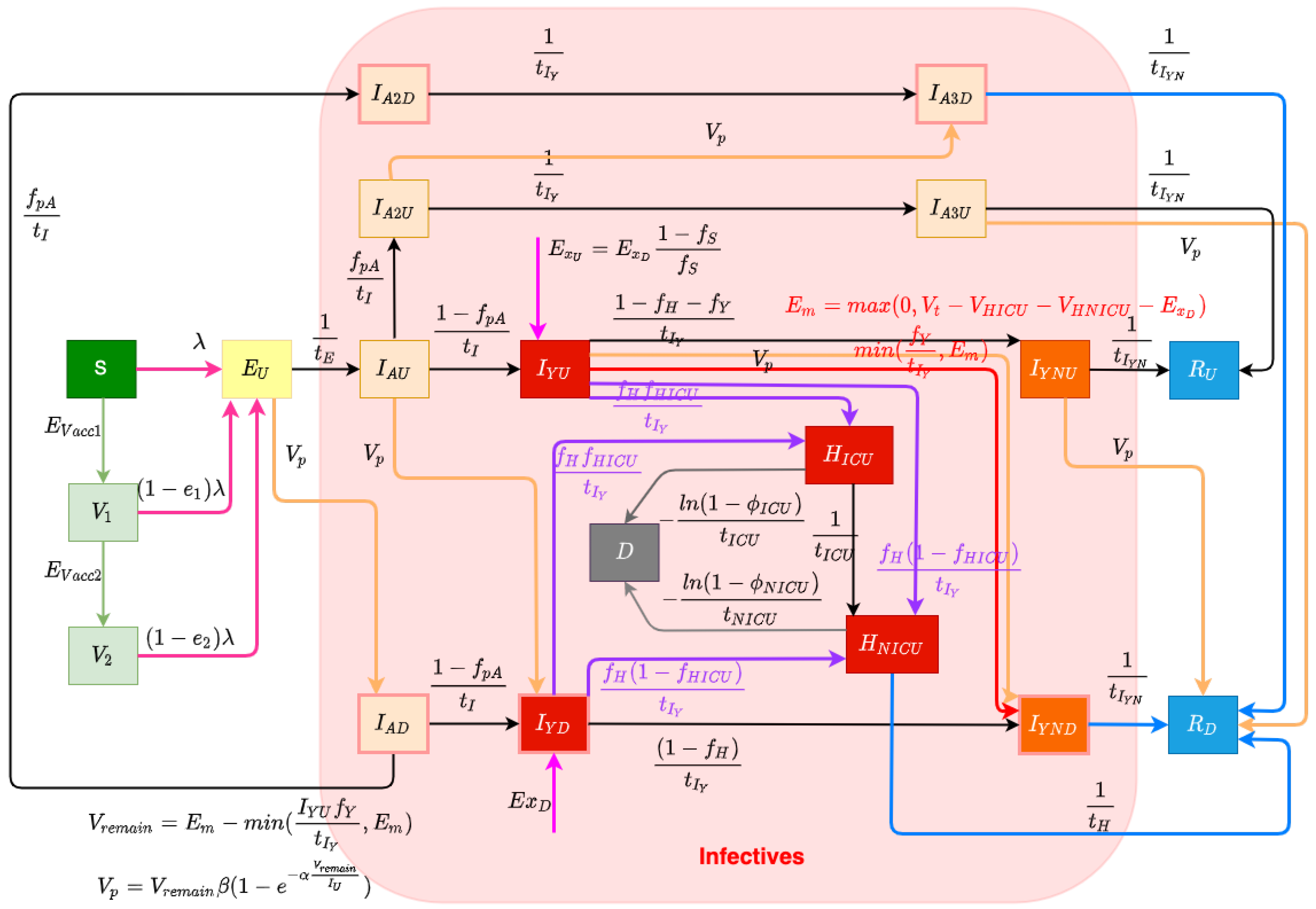

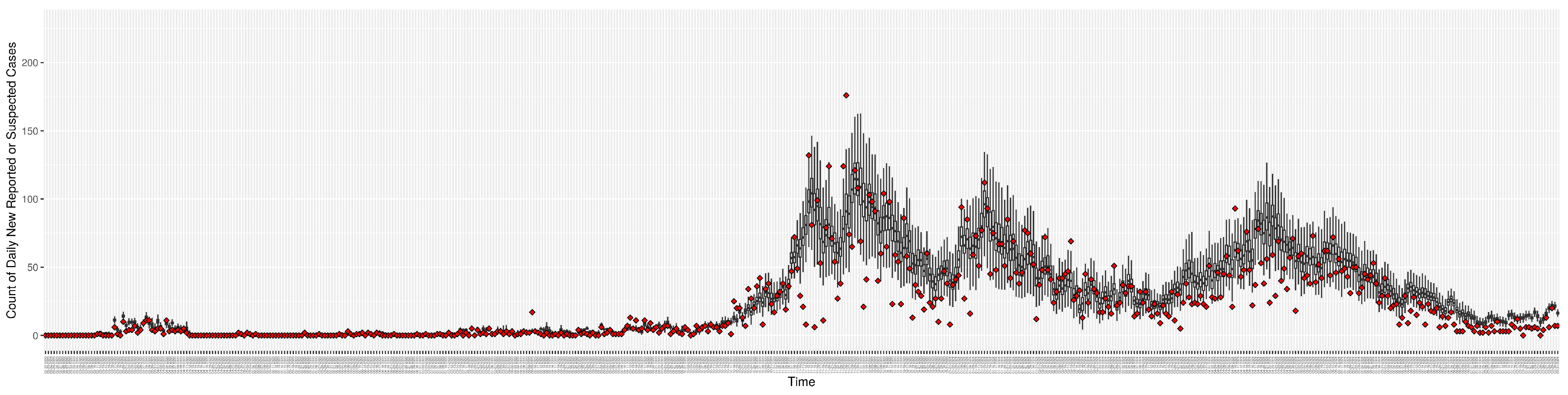
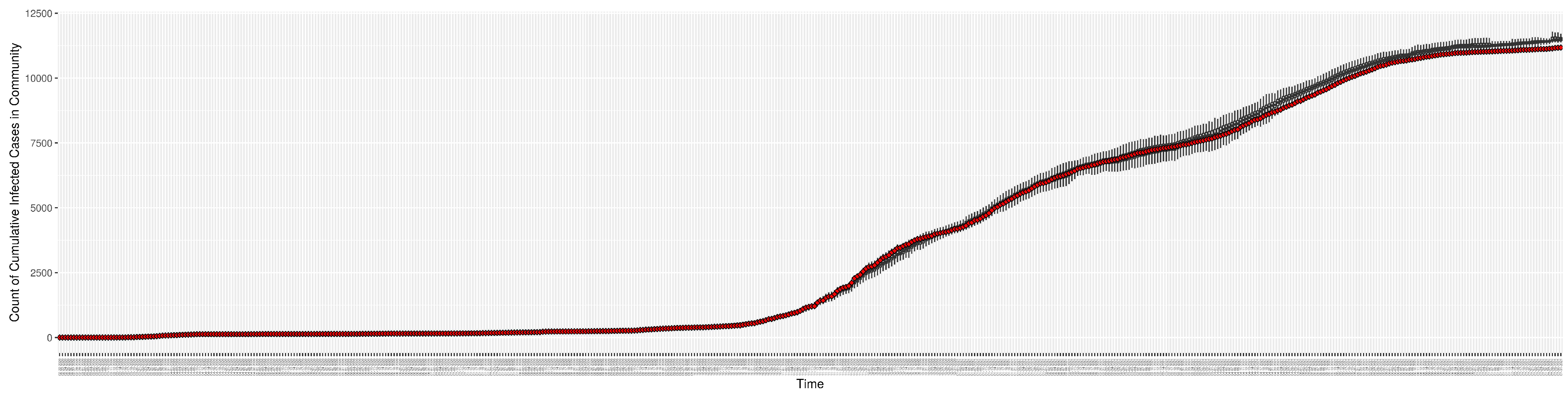

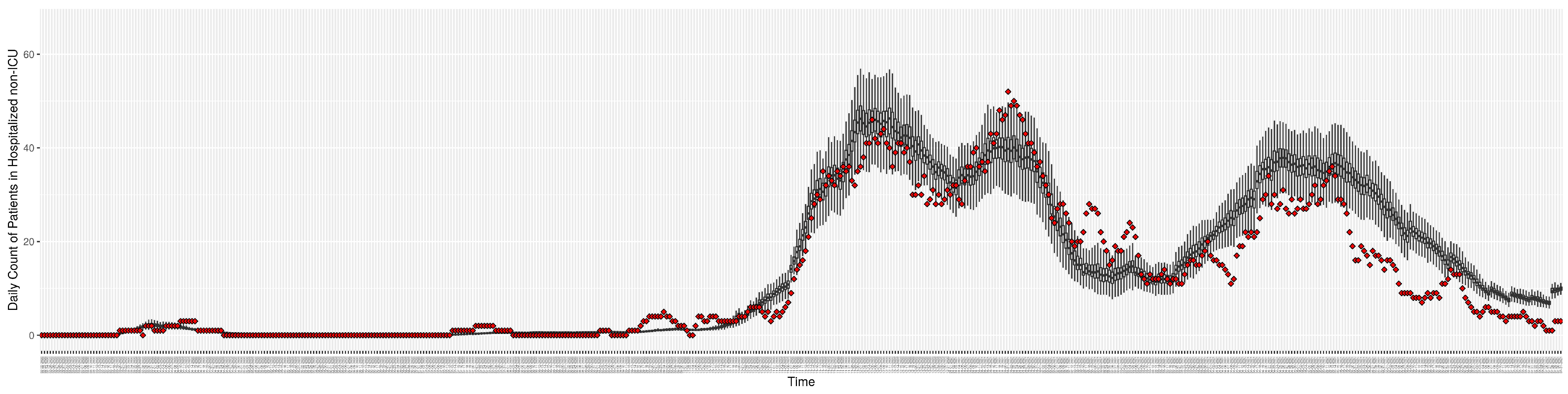

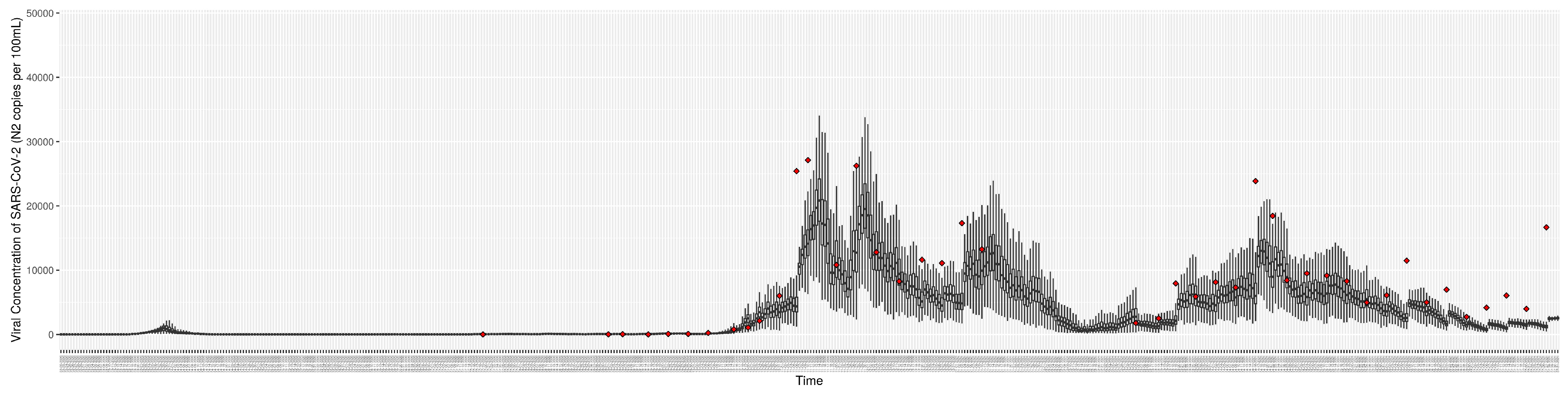

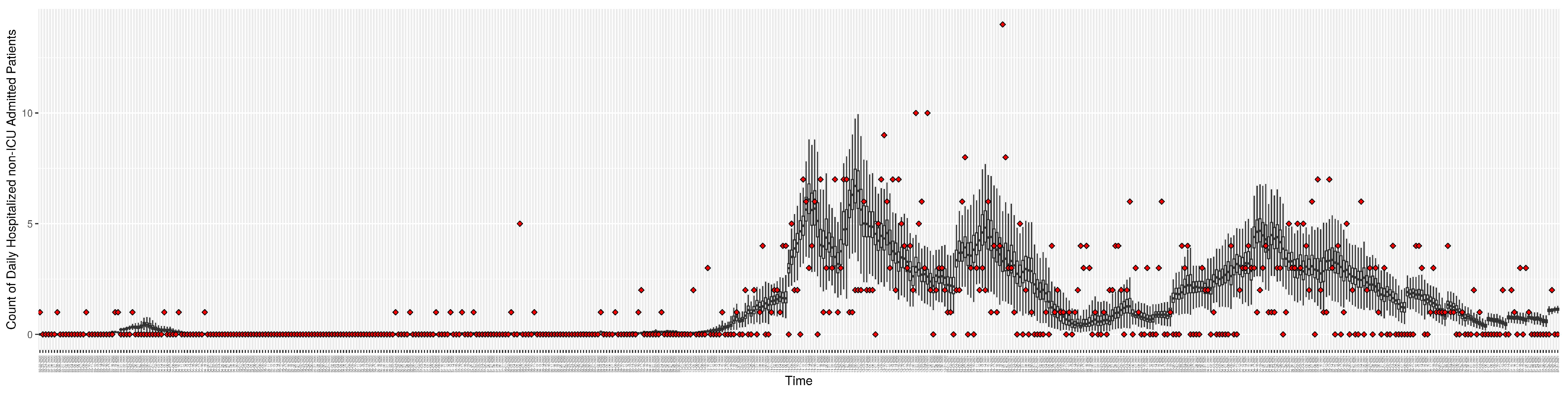
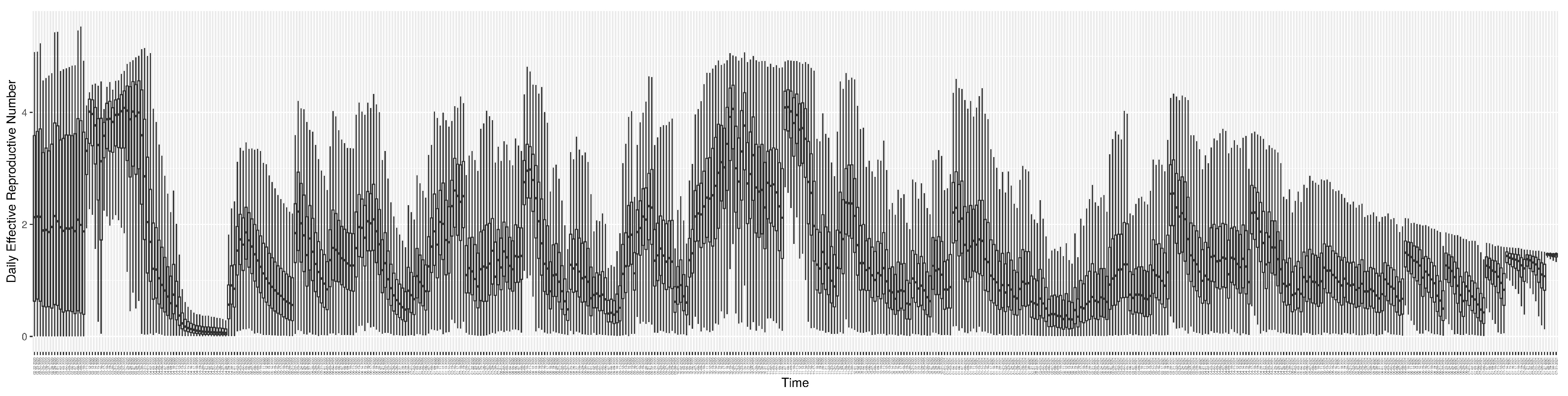
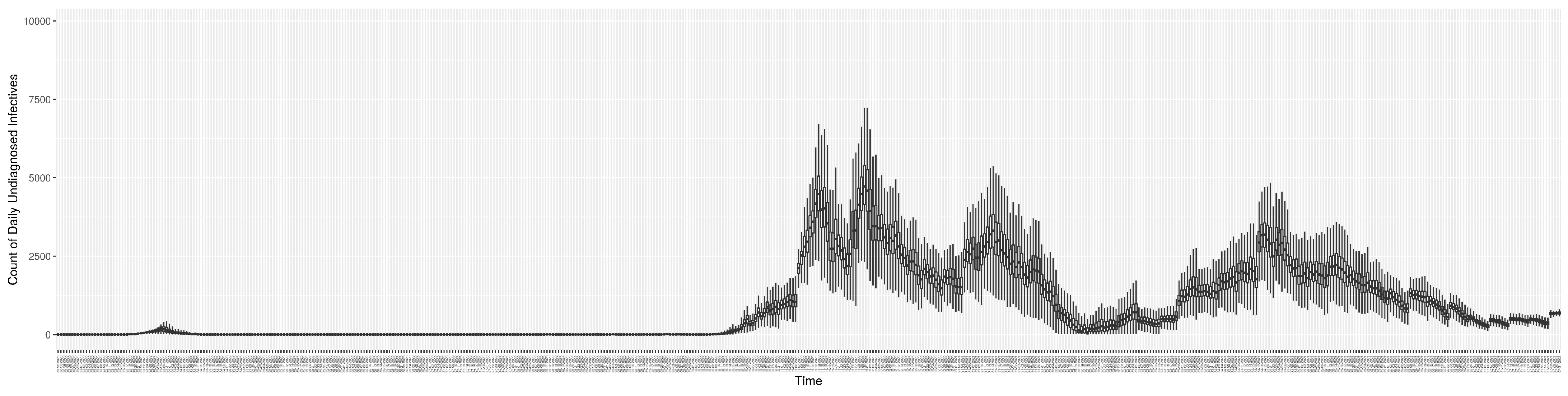
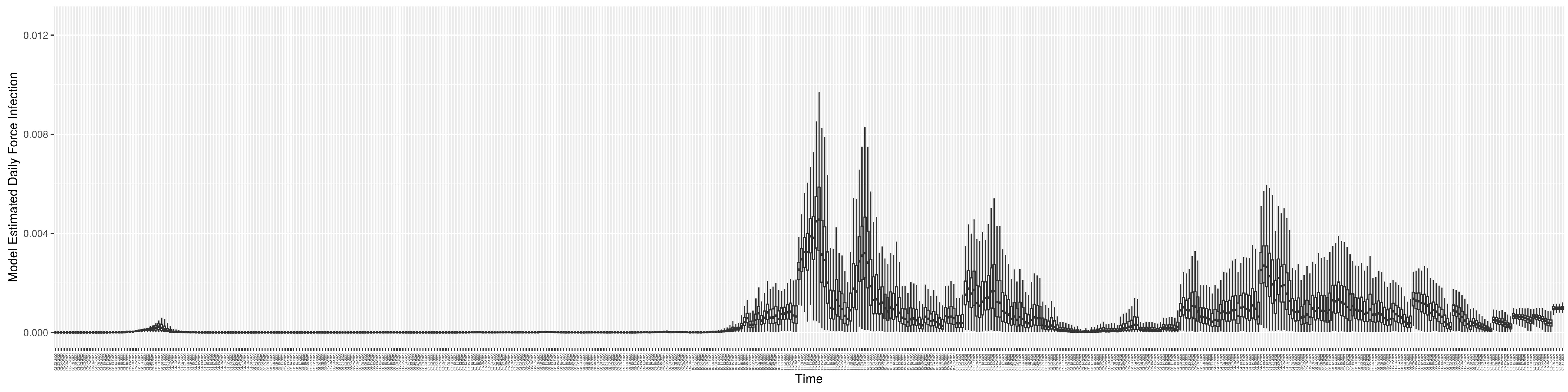
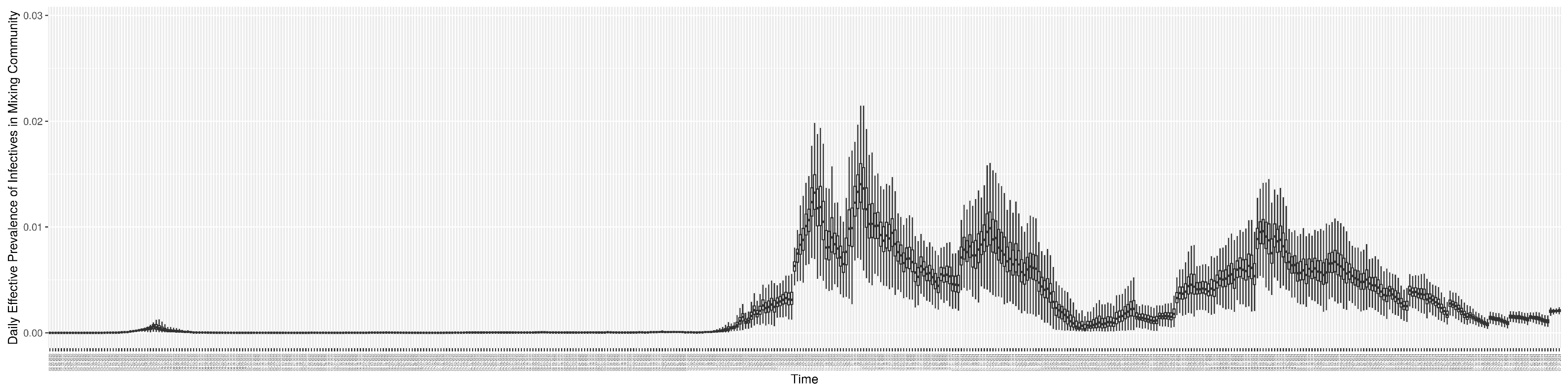
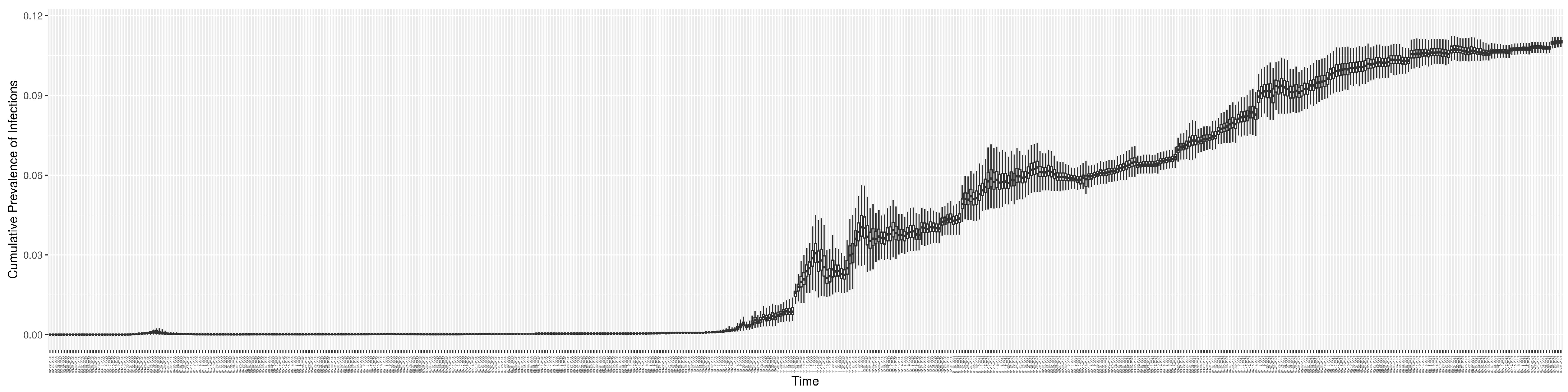
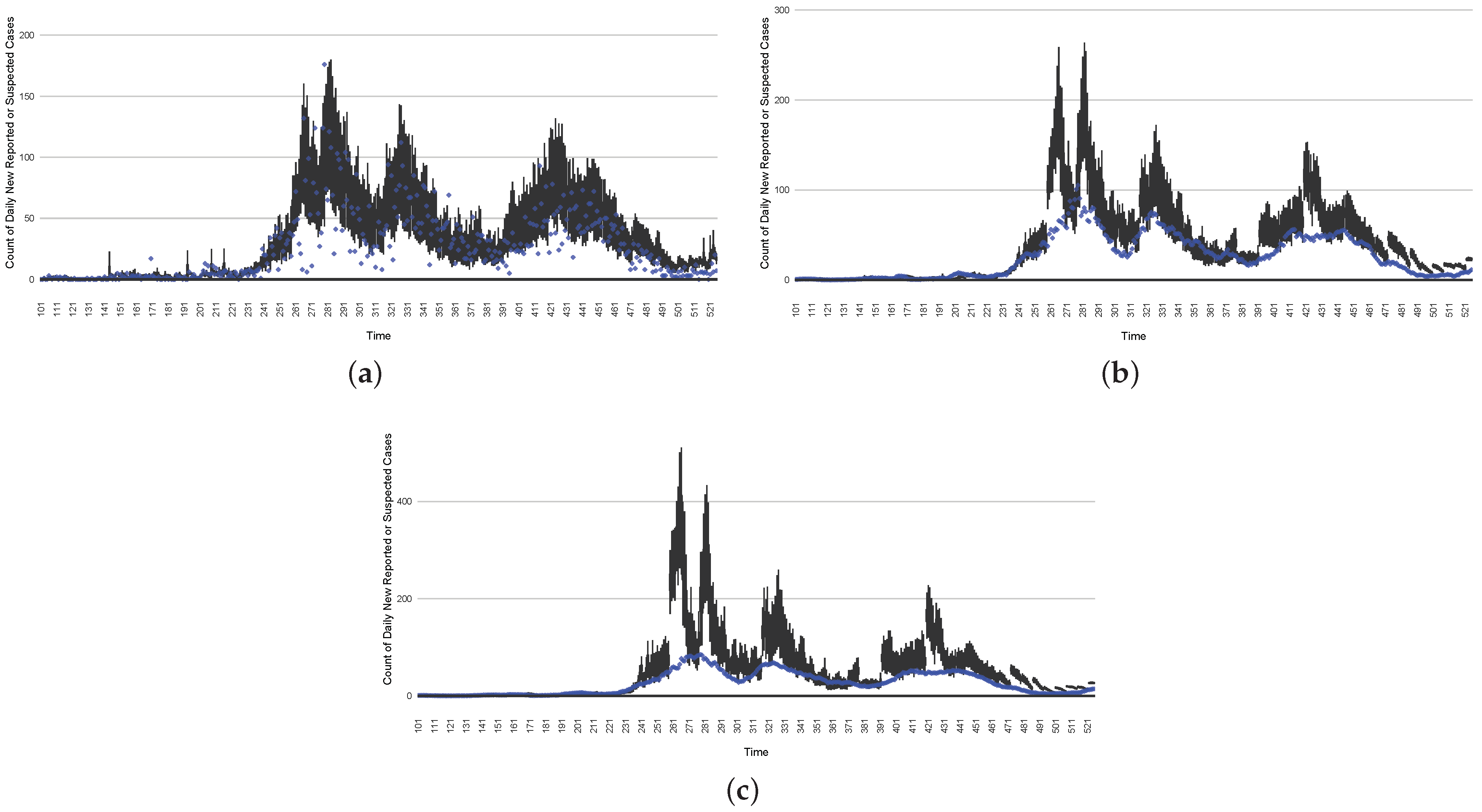
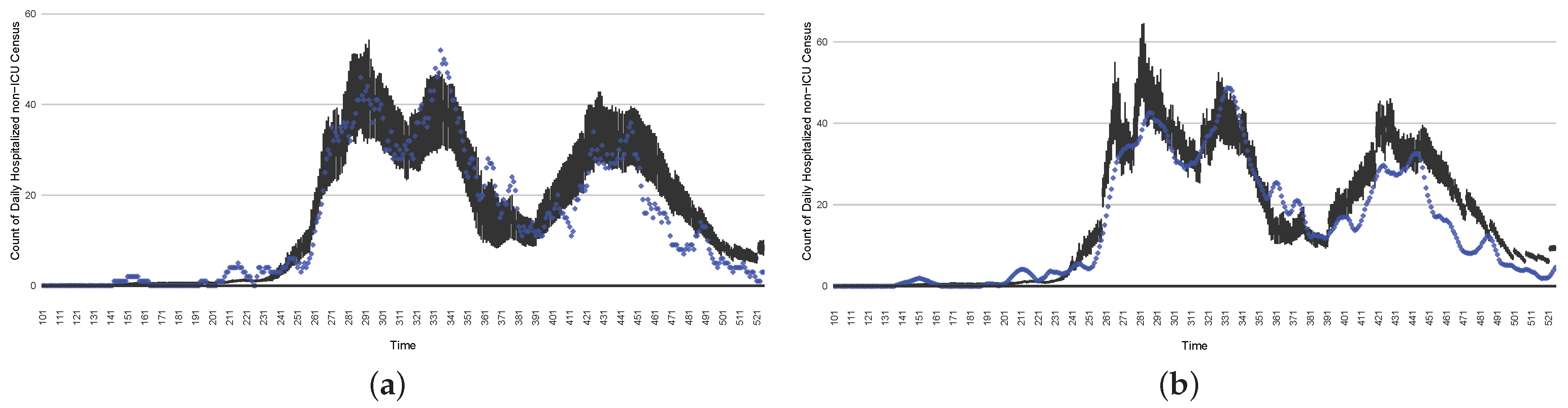
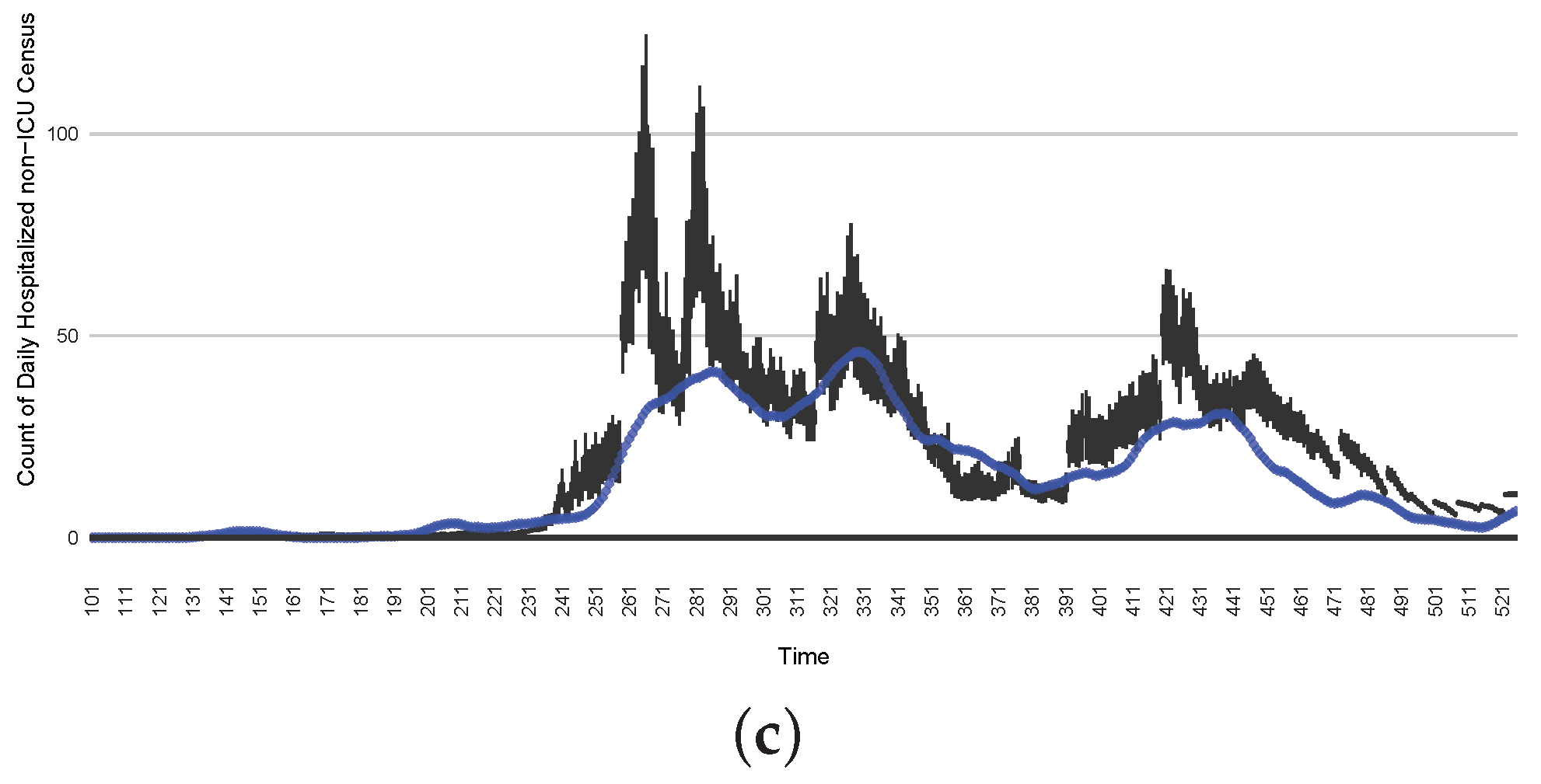
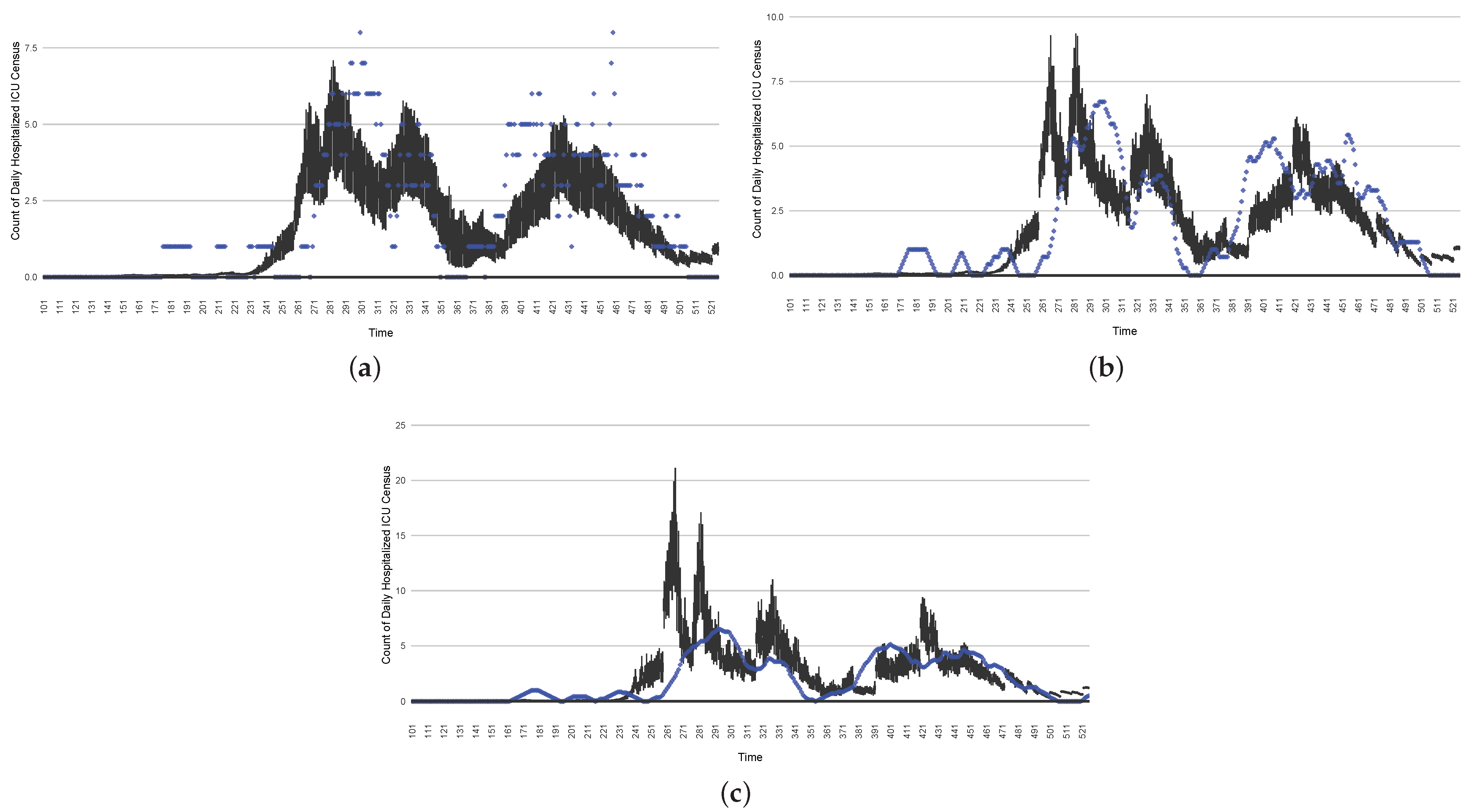
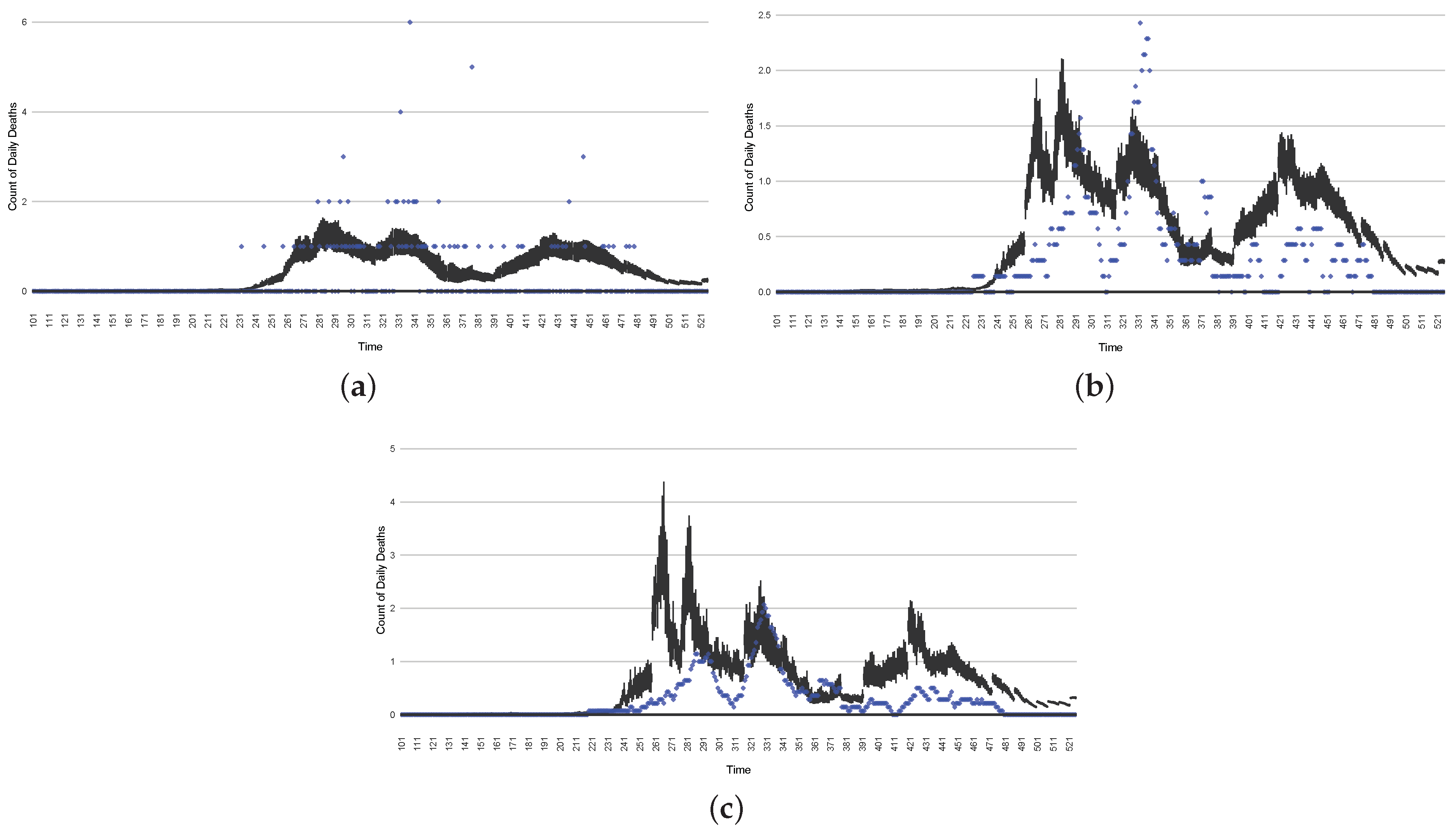
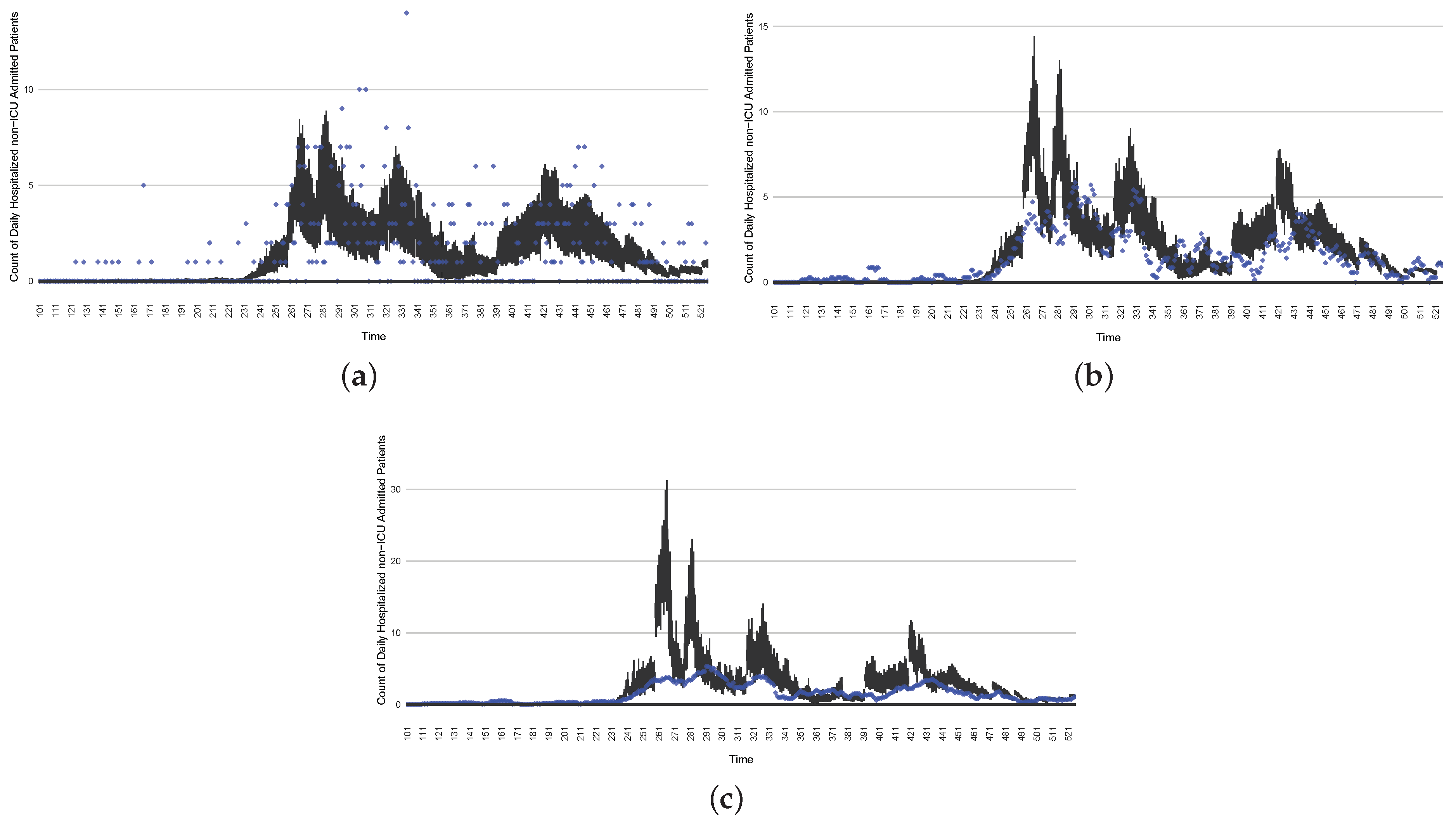

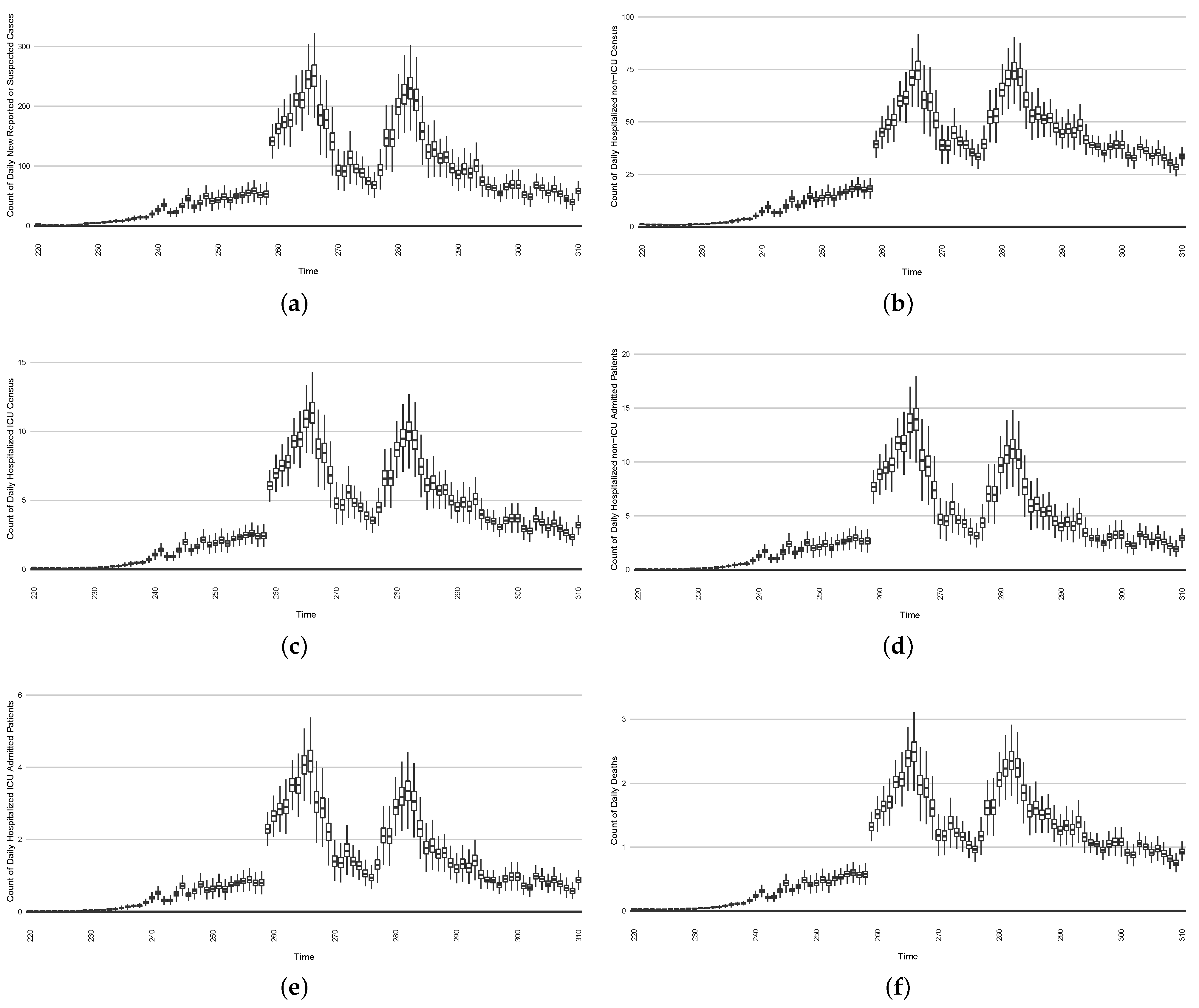
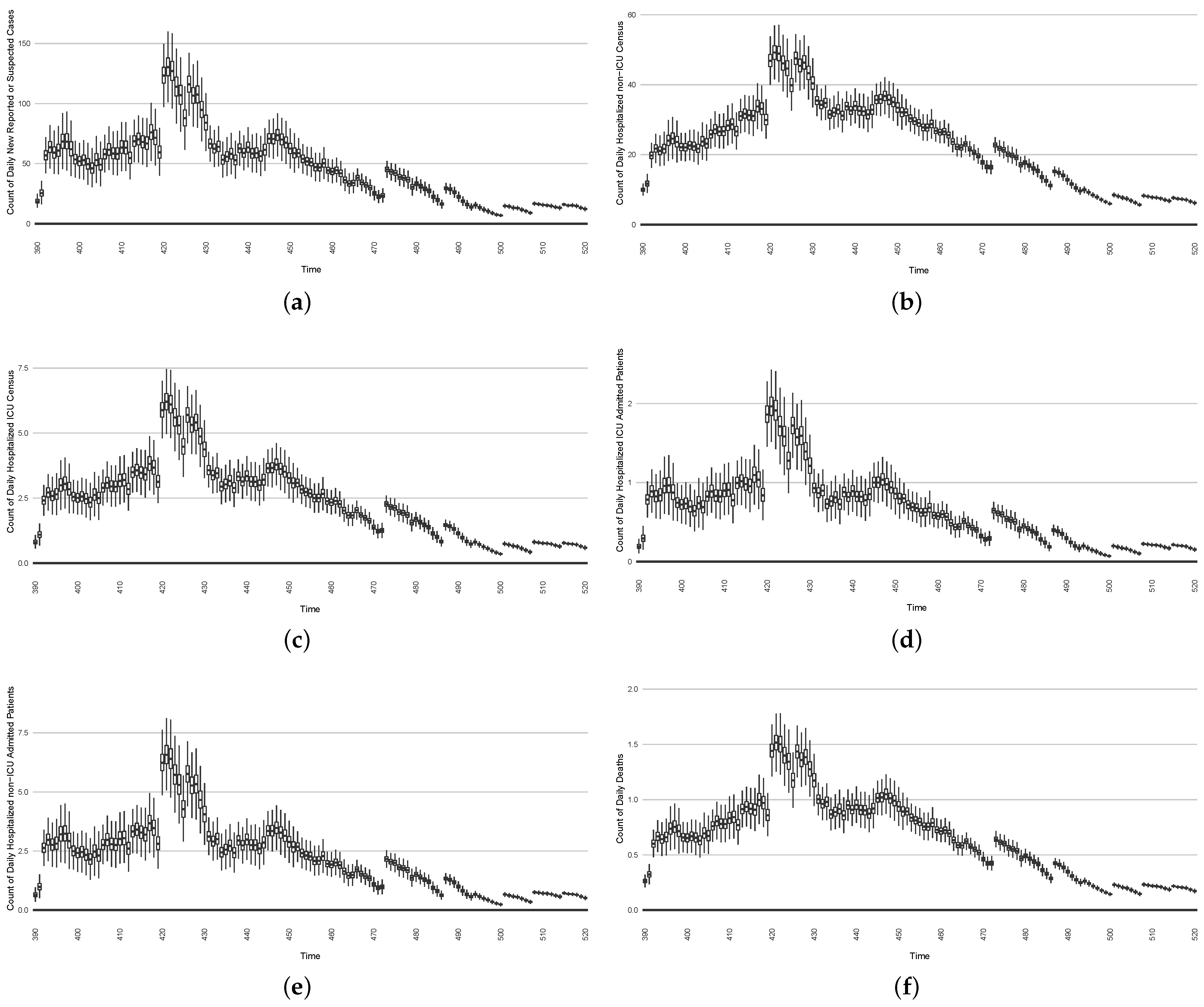

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}