



Aligning Federated Learning with Existing Trust Structures in Health Care Systems



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Motivation
1.2. Problems and Objectives
2. Materials
2.1. Existing Research Direction
2.2. Federated Learning Technical Definition
| Algorithm 1 FL Algorithm with a central server—FedAvg | ||
| Central Server | Edge devices | |
| : Global model weights : Global model weights at time t : number of edge devices : fraction of participating edge devices m: number of participating edge devices : index of a participating edge device | : batch size : local data on device e : number of training epochs : gradient of the loss with respect to batch b : learning rate | |
| orchestrate function () { initialize wo for (each round t = 1, 2, 3…) { m ← max (C, *, K, 1); St ← (random set of m participating edge devices); for (each device e ∈ St in parallel) { update function ; } ; } } | update function (e, w) { β ← (split Pe into batches of size for each local epoch i from 1 to E) { for (batch b ∈ β) { } } return ω to central server } | |
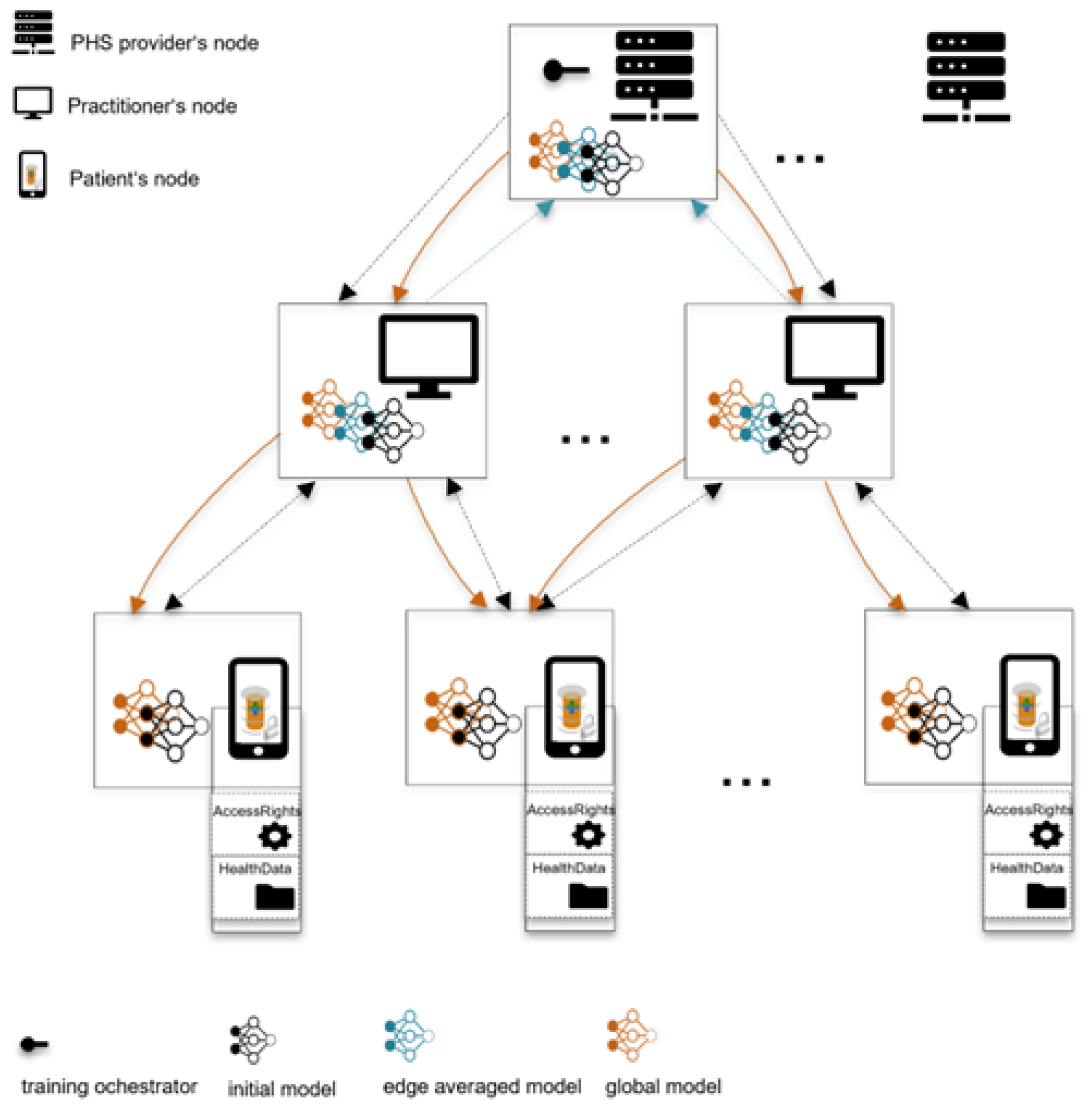
2.3. Envisioned Health Care Systems Paradigm
2.4. Exemplary Learning Case
3. Results—Novel Federated Learning Framework
3.1. Phase 1: Certification and Authorization
3.2. Phase 2: Define Studies
3.3. Phase 3: User Participation Status
3.4. Phase 4: Model Pre-Training
3.5. Phase 5 and 6: User and Model Identification
3.6. Phase 7: User-to-User Association
3.7. Phase 8: User Selector
3.8. Phase 9: Hierarchical Aggregation
3.9. Phase 10: Version Control
3.10. Phase 11: Delete
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yari, I.; Dehling, T.; Kluge, F.; Geck, J.; Sunyaev, A.; Eskofier, B. Security Engineering of Patient-Centered Health Care Information Systems in Peer-to-Peer Environments: Systematic Review. J. Med. Internet Res. 2021, 23, e24460. [Google Scholar] [CrossRef]
- Ariane, P. EHR and PHR: Digital Records in the German Healthcare System; BIOPRO Baden-Württemberg GmbH: Stuttgart, Germany, 2019. [Google Scholar]
- Gematik GmbH. ePA Persönliche Daten, Persönliche Entscheidungen. 2021. Available online: https://www.gematik.de/anwendungen/e-patientenakte/# (accessed on 22 March 2022).
- Dehling, T.; Sunyaev, A. Secure Provision of Patient-Centered Health Information Technology Services in Public Networks—Leveraging Security and Privacy Features Provided by the German Nationwide Health Information Technology Infrastructure. Electron. Mark. 2014, 24, 89–99. [Google Scholar] [CrossRef]
- Tschirsich, M.; Brodowski, C.; Zilch, A. “Hacker Hin Oder Her”: Die Elektronische Patientenakte Kommt! 2019. Available online: https://media.ccc.de/v/36c3-10595-hack-er_hin_oder_her_die_elektronische_patientenakte_kommt (accessed on 12 January 2020).
- Yari, I.A.; Dehling, T.; Kluge, F.; Eskofier, B.; Sunyaev, A. Online at Will: A Novel Protocol for Mutual Authentication in Peer-to-Peer Networks for Patient-Centered Health Care Information Systems, HICSS. In Proceedings of the 54th Hawaii International Conference on System Sciences (HICSS 2021), Kauai, HI, USA, 5–8 January 2021; pp. 3828–3837. [Google Scholar]
- Krist, A.H.; Woolf, S.H. A Vision for Patient-Centered Health Information Systems. JAMA 2011, 305, 300–301. [Google Scholar] [CrossRef] [PubMed]
- Porsche-Consulting. The Digital Revolution of the Healthcare Sector–Ecosystem, Use Cases, Benefits, Challenges and Recommendations for Action. Healthcare of the Future. 2018. Available online: https://www.porsche-consulting.com/fileadmin/docs/Startseite/News/tt1162/Porsche_Consulting_Studie_Healthcare_of_the_Future_EN.pdf (accessed on 14 April 2020).
- Solid. 2020, Solid Project by Tim Berners-Lee. 2020. Available online: https://solidproject.org/ (accessed on 22 December 2020).
- Ghosh, P.K.; Chakraborty, A.; Hasan, M.; Rashid, K.; Siddique, A.H. Blockchain Application in Healthcare Systems: A Review. Systems 2023, 11, 38. [Google Scholar] [CrossRef]
- Geissbühler, A.; Spahni, S.; Assimacopoulos, A.; Raetzo, M.; Gobet, G. Design of a Patient-Centered, Multi-Institutional Healthcare Information Network using Peer-to-Peer Communication in a Highly Distributed Architecture. Stud. Health Technol. Inform. 2004, 107, 1048–1052. [Google Scholar]
- Doc.ai. Doc.a–Brands: Passport, Serenity, doc.ai and Genewall. 2020. Available online: https://doc.ai/ (accessed on 22 December 2020).
- RefinioONE. OnePatient. 2019. Available online: https://refinio.net/software.html (accessed on 14 October 2019).
- Cho, H.; Ippolito, D.; Yu, Y.W. Contact Tracing Mobile Apps for COVID-19: Privacy Considerations and Related Trade-Offs. arXiv 2020, arXiv:2003.11511. [Google Scholar]
- Lo, S.K.; Lu, Q.; Zhu, L.; Paik, H.; Xu, X.; Wang, C. Architectural Patterns for the Design of Federated Learning Systems. J. Syst. Softw. 2022, 191, 111357. [Google Scholar] [CrossRef]
- Rabe, L. 2022 Number of Downloads of the Corona-Warn-App via the Apple App Store and the Google Play Store (Cumulative) in Germany from June 2020 to April 2022. 2022. Available online: https://de.statista.com/statistik/daten/studie/1125951/umfrage/downloads-der-corona-warn-app/ (accessed on 14 December 2022).
- Burton, C.; De Boel, L.; Kuner, C.; Pateraki, A.; Cadiot, S.; Hoffman, S.G. The Final European Union General Data Protection Regulation. BNA Priv. Secur. Law Rep. 2016, 15, 153. [Google Scholar]
- Troncoso, C.; Isaakidis, M.; Danezis, G.; Halpin, H. Systematizing Decentralization and Privacy: Lessons from 15 Years of Research and Deployments. Proc. Priv. Enhancing Technol. 2017, 404–426. [Google Scholar] [CrossRef]
- Records Management Code of Practice. 2022, Records Management Code of Practice 2021. Available online: https://transform.england.nhs.uk/information-governance/guidance/records-management-code/ (accessed on 12 April 2022).
- Xu, J.; Glicksberg, B.S.; Su, C.; Walker, P.; Bian, J.; Wang, F. Federated Learning for Healthcare Informatics. J. Healthc. Inform. Res. 2021, 5, 1–19. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečný, J.; Maz-zocchi, S.; McMahan, H.B. Towards Federated Learning at Scale: System Design. arXiv 2019, arXiv:1902.01046. [Google Scholar]
- Ekmefjord, M.; Ait-Mlouk, A.; Alawadi, S.; Åkesson, M.; Stoyanova, D.; Spjuth, O.; Toor, S.; Hellander, A. Scalable Federated Machine Learning with FEDn. arXiv 2021, arXiv:2103.00148. [Google Scholar]
- Deng, Y.; Lyu, F.; Ren, J.; Zhang, Y.; Zhou, Y.; Zhang, Y.; Yang, Y. SHARE: Shaping Data Distribution at Edge for Communication-Efficient Hierarchical Federated Learning. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021; pp. 24–34. [Google Scholar]
- Zhang, H.; Bosch, J.; Olsson, H.H. Federated Learning Systems: Architecture Alternatives. In Proceedings of the 2020 27th Asia-Pacific Software Engineering Conference (APSEC), Singapore, 1–4 December 2020; pp. 385–394. [Google Scholar]
- Wu, J.; Liu, Q.; Huang, Z.; Ning, Y.; Wang, H.; Chen, E.; Yi, J.; Zhou, B. Hierarchical Personalized Federated Learning for User Modeling. Proc. Web Conf. 2021, 2021, 957–968. [Google Scholar]
- Roy, A.G.; Siddiqui, S.; Pölsterl, S.; Navab, N.; Wachinger, C. Braintorrent: A Peer-to-Peer Environment for Decentralized Federated Learning. arXiv 2019, arXiv:1905.06731. [Google Scholar]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K. The Future of Digital Health with Federated Learning. NPJ Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. Artif. Intell. Stat. 2017, 54, 1273–1282. [Google Scholar]
- Reelfs, J.H.; Hohlfeld, O.; Poese, I. Corona-warn-app: Tracing the start of the official COVID-19 exposure notification app for Germany. In Proceedings of the SIGCOMM’20 Poster and Demo Sessions, Corona-Warn-App: Tracing the Start of the Official COVID-19 Exposure Notification App for Germany, Virtual, 10–14 August 2020; pp. 24–26. [Google Scholar]
- Hardjono, T.; Shrier, D.L.; Pentland, A. Trusted Data: A New Framework for Identity and Data Sharing; MIT Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Hersh, W.R.; Totten, A.M.; Eden, K.B.; Devine, B.; Gorman, P.; Kassakian, S.Z.; Woods, S.S.; Daeges, M.; Pappas, M.; McDonagh, M.S. Outcomes from Health Information Exchange: Systematic Review and Future Research Needs. JMIR Med. Inform. 2015, 3, e5215. [Google Scholar] [CrossRef]
- Vu, Q.H.; Lupu, M.; Ooi, B.C. Architecture of Peer-to-Peer Systems. In Peer-to-Peer Computing; Springer: Berlin/Heidelberg, Germany, 2010; pp. 11–37. [Google Scholar]
- Antunes, R.S.; da Costa, C.A.; Küderle, A.; Yari, I.A.; Eskofier, B. Federated Learning for Healthcare: Systematic Review and Architecture Proposal. ACM Trans. Intell. Syst. Technol. 2022, 13, 1–23. [Google Scholar] [CrossRef]
- Nguyen, J.; Wang, J.; Malik, K.; Sanjabi, M.; Rabbat, M. Where to Begin? On the Impact of Pre-Training and Initialization in Federated Learning. In Proceedings of the Workshop on Federated Learning: Recent Advances and New Challenges (In Conjunction with NeurIPS), New Orleans, LA, USA, 2 December 2022. [Google Scholar]
- Grande, D.; Mitra, N.; Iyengar, R.; Merchant, R.M.; Asch, D.A.; Sharma, M.; Cannuscio, C.C. Consumer Willingness to Share Personal Digital Information for Health-Related Uses. JAMA Netw. Open 2022, 5, e2144787. [Google Scholar] [CrossRef]
- Boenisch, F.; Dziedzic, A.; Schuster, R.; Shamsabadi, A.S.; Shumailov, I.; Papernot, N. When the Curious Abandon Honesty: Federated Learning is Not Private. arXiv 2021, arXiv:2112.02918. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- West, P.; Van Kleek, M.; Giordano, R.; Weal, M.J.; Shadbolt, N. Common Barriers to the use of Patient-Generated Data Across Clinical Settings. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 1 April 2018; pp. 1–13. [Google Scholar]
- Chen, Y.; Qin, X.; Wang, J.; Yu, C.; Gao, W. Fedhealth: A Federated Transfer Learning Framework for Wearable Healthcare. IEEE Intell. Syst. 2020, 35, 83–93. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdullahi, I.Y.; Raab, R.; Küderle, A.; Eskofier, B. Aligning Federated Learning with Existing Trust Structures in Health Care Systems. Int. J. Environ. Res. Public Health 2023, 20, 5378. https://doi.org/10.3390/ijerph20075378
Abdullahi IY, Raab R, Küderle A, Eskofier B. Aligning Federated Learning with Existing Trust Structures in Health Care Systems. International Journal of Environmental Research and Public Health. 2023; 20(7):5378. https://doi.org/10.3390/ijerph20075378
Chicago/Turabian StyleAbdullahi, Imrana Yari, René Raab, Arne Küderle, and Björn Eskofier. 2023. "Aligning Federated Learning with Existing Trust Structures in Health Care Systems" International Journal of Environmental Research and Public Health 20, no. 7: 5378. https://doi.org/10.3390/ijerph20075378
APA StyleAbdullahi, I. Y., Raab, R., Küderle, A., & Eskofier, B. (2023). Aligning Federated Learning with Existing Trust Structures in Health Care Systems. International Journal of Environmental Research and Public Health, 20(7), 5378. https://doi.org/10.3390/ijerph20075378