Abstract
Background: The novel coronavirus pneumonia that began to spread in 2019 is still raging and has placed a burden on medical systems and governments in various countries. For policymaking and medical resource decisions, a good prediction model is necessary to monitor and evaluate the trends of the epidemic. We used a long short-term memory (LSTM) model and the improved hybrid model based on ensemble empirical mode decomposition (EEMD) to predict COVID-19 trends; Methods: The data were collected from the Harvard Dataverse. Epidemic data from 21 January 2020 to 25 April 2021 for California, the most severely affected state in the United States, were used to develop an LSTM model and an EEMD-LSTM hybrid model, which is an LSTM model combined with ensemble empirical mode decomposition. In this study, ninety percent of the data were adopted to fit the models as a training set, while the subsequent 10% were used to test the prediction effect of the models. The mean absolute percentage error, mean absolute error, and root mean square error were used to evaluate the prediction performances of the models; Results: The results indicated that the number of confirmed cases in California was increasing as of 25 April 2021, with no obvious evidence of a sharp decline. On 25 April 2021, the LSTM model predicted 3666418 confirmed cases, whereas the EEMD-LSTM predicted 3681150. The mean absolute percentage errors for the LSTM and EEMD-LSTM models were 0.0151 and 0.0051, respectively. The mean absolute and root mean square errors were 5.58 × 104 and 5.63 × 104 for the LSTM model and 1.9 × 104 and 2.43 × 104 for the EEMD-LSTM model, respectively; Conclusions: The results showed the advantage of an EEMD-LSTM model over a single LSTM model, and the established EEMD-LSTM model may be suitable for monitoring and evaluating the epidemic situation and providing quantitative analysis evidence for epidemic prevention and control.
1. Introduction
Coronavirus Disease 2019 (COVID-19) is an acute respiratory viral disease characterized by fever, tiredness, and a dry cough. Acute respiratory distress syndrome, septic shock, multiple organ failure, and even death can occur in severe cases [1]. The first case of COVID-19 was reported from Wuhan, China, in December 2019. Following that, cases were recorded and reported globally. There has been a surge in coronavirus cases globally. Severe acute respiratory syndrome coronavirus 2, in particular, has caused a serious outbreak in the United States. As of 8 April 2022, the number of confirmed cases had surpassed 8 million, and more than 900,000 deaths have been reported [2]. The variants of the novel coronavirus have also contributed to a surge in infections globally, although vaccines have emerged. As a consequence, pandemic containment remains a public health challenge, and the lives of people are in danger, especially those who lack access to medical resources. There is no doubt that epidemic prediction models can improve our understanding of the pandemic and provide evidence for measures to contain it.
Since the outbreak of the epidemic, the traditional dynamics models, including the susceptible-infected-recovered-deaths model and its modifications, have been widely applied to the simulation of the epidemic and related predictions [3,4,5]. It was challenging to use the models because of the difficulty in estimating parameters, underlying nonlinear system of ordinary differential equations, lack of access to some real data, and assumptions related to them [6]. ArunKumar explored the use of autoregressive integrated moving average (ARIMA) models for COVID-19 prediction, which have been used for epidemic predictions for decades and proven to have several advantages related to prediction [7]. However, the ARIMA model was essentially a linear model that was not good at capturing nonlinear trends. To overcome the barriers of these approaches, deep learning algorithms were used to identify the non-linear disease patterns. Regarding nonlinear data, deep learning models have better learning and predictive abilities. Moreover, the COVID-19 is a time series data set and it is highly recommended to use sequential networks to extract the patterns from it. Among deep learning models, the long short-term memory (LSTM) algorithm is appropriate for sequential learning tasks [8]. Based on its excellent capacity, the LSTM algorithm can learn numerous information from data. To make use of sequential data for prediction using deep learning, Yudistira used an LSTM model to learn the correlation on COVID-19 data over time [9]. Some researchers have attempted to develop LSTM models to accurately predict the epidemic trends [10,11,12]. LSTM models have demonstrated some advantages over traditional deep learning algorithms; however, they occasionally show poor performance in predictions, compared with other algorithms [13]. To improve accuracy, several researchers have modified the LSTM algorithm. The W-LSTM model performed better than previously published models, including ARIMA and LSTM, based on model performance evaluation criteria such as the mean square error and mean absolute percentage error (MAPE) [14]. The proposed forecast models, including ARIMA, support vector regression, LSTM, and bidirectional LSTM, have been used for time series predictions of confirmed cases, deaths, and recoveries in ten major countries affected by COVID-19 [13]. Rasjid et al. aimed to predict the COVID-19 death and infection rates in Indonesia using the Savitzky Golay Smoothing and LSTM model [15]. In the present study, we have developed a model that combines LSTM and ensemble empirical mode decomposition (EEMD) to improve accuracy.
Empirical mode decomposition (EMD) is an adaptive time-space analysis method suitable for processing series that are non-stationary and non-linear [16]. It decomposes an original dataset into a series of intrinsic mode functions (IMFs) and a residual function, revealing unique features in the data. Mode mixing, on the other hand, is one of the major challenges with empirical mode decomposition, and it is often known as a single IMF with components of several scales or a distinct IMF composed of identical components of other scales. Wu and Huang presented an improved EMD approach, which is EEMD, to overcome the mode mixing in the typical EMD [17]. EEMD is a noise-assisted data analysis method that effectively eliminates the problem of mode mixing by introducing white noise into the original data. According to a report [18], the decomposition strategy also enhances prediction accuracy by supplying explicit signals as model input. A hybrid EEMD-LSTM approach has been used for useful predictions in the fields of precipitation and agricultural product price [19,20]. However, little is known about the value of the EEMD-LSTM in predicting the COVID-19 epidemic trends.
Severe acute respiratory syndrome coronavirus 2 caused a significant outbreak in the United States. California had the most confirmed cases in the United States as of 25 April 2021 [21]. California is a major state in the western (Pacific) area of the United States and has the second-largest metropolis (Los Angeles). It is also the most populous state in the United States and a major global economic hub [22]. As a result, we take the lead in model fitting using California data.
Based on previous studies, the goals of this research were to propose a hybrid EEMD-LSTM model for COVID-19 epidemic prediction and compare a single LSTM model with the proposed hybrid EEMD-LSTM model based on the testing.
2. Materials and Methods
2.1. Study Design and Data
Study design: Public data mining and predictive modeling. This was a forecasting model study to compare the prediction performance of different models and predict the pandemic trends more accurately.
The U.S. state epidemic data (cumulative confirmed cases, deaths) from 21 January 2020, to 25 April 2021, were obtained from the Harvard Dataverse [21].
The cumulatively confirmed cases in America were visualized using R version 4.0.5 (31 March 2021). Ninety percent of the data were used for the training set and the remaining 10% were used as the test set. To make the neural network model converge faster, the min-max normalization was used to normalize the data to the interval of 0 and 1. Assuming that comes from the sequence, , normalization was performed as follows:
2.2. Study Area
Covering an area of 423,970 sq. km, California is a large state in the western (Pacific) region of the United States that is home to one of the most diverse populations globally. It contains the second largest city (Los Angeles), 3 of the largest 10 cities (Los Angeles, San Diego, and San Jose), and the largest county (Los Angeles County) in the United States. In addition, its population was approximately 39,995,077 in 2022. California is the 3rd largest state by area, which places its population density at 251.3 per square mile [22].
2.3. Empirical Mode Decomposition, EMD
Empirical mode decomposition, which was proposed by Huang et al. [16], is suited to nonlinear and non-stationary data through signal decomposition. It is used to decompose complex raw time-series data into a series of IMFs and a residue. The intrinsic mode function captures the repeating behavior of the signal for a given particular time scale and keeps the full non-stationary information of the raw data under consideration. Any non-stationary and non-linear time series is made up of different simple intrinsic modes of oscillation, according to the empirical mode decomposition approach. The essence of the method is to objectively detect these intrinsic oscillatory modes in the data based on their characteristic time scales and deconstruct the data accordingly. Most of the riding waves, such as oscillations with no zero-crossing between extrema, can be avoided using a technique known as sifting. As a result, the empirical mode decomposition method takes signal oscillations into account at a very local level and divides the data into locally non-overlapping time scale components [23]. It decomposes a signal x(t) into its constituent IMFs, each of which meets the following two conditions: (1) in the entire data set, the number of extrema and the number of zero crossings must either be equal or differ at most by one; (2) at any point, the mean value of the envelope defined by the local maximum and minimum is zero.
2.4. Ensemble Empirical Mode Decomposition, EEMD
The EMD is limited by the large length of the time series [23]. More importantly, it has shown mode mixing where the original data appeared at a high frequency [17]. To solve these problems, Huang et al. proposed EEMD. Ensemble empirical mode decomposition first adds Gaussian white noise to the original sequence and uses EMD to decompose the sequence into a series of IMFs. For any sequence, , the EEMD steps are as follows:
- First, the initial parameters, such as the times of the ensembles and the variance of the added white noise, are set, and white noise is added to the sequence, .
- Second, the local extremum of the sequence, , is extracted.
- Third, the upper envelope, , and the lower envelope, , of the sequence, , are determined.
- Fourth, the mean values of the upper and lower envelope are calculated using the following formula: .
- Fifth, the component is extracted as follows .
- Sixth, if the component, , satisfies the conditions for the establishment of the IMF, the first IMF () is obtained; otherwise, the above steps are repeated until the conditions are met and the first IMF is obtained.
- Seventh, a new sequence is calculated using , and the above steps are repeated until all and the residual sequence are obtained.
2.5. Long Short-Term Memory, LSTM
The LSTM developed by Hochreiter and Schmidhuber is a deep learning time series algorithm based on the recurrent neural network (RNN) framework [24]. It consists of memory modules, and their recurrent neural networks can bridge a large number of discrete time steps through the use of memory cells and gate units. In the hidden layers of the neural network, the LSTM has “cells” that have three gates: input, output, and forget gates. These gates regulate the flow of data required by the network to derive an output. The three gates selectively forget the prior memory, receive part of the new information, and selectively output the information when the memory unit is refreshed. The detailed structure of the LSTM is shown in Figure 1.
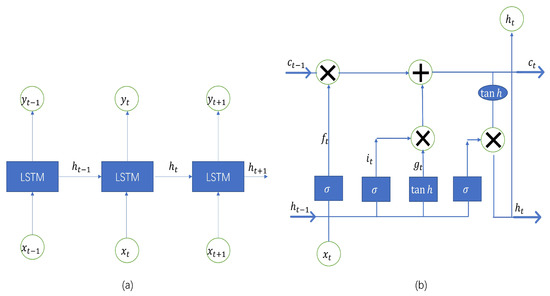
Figure 1.
Architecture of long short-term memory [25]. (a) Architecture of long short-term memory. (b) Architecture of long short-term memory model memory unit.
The functions of each gate are described as follows. The forget gate removes the data that are no longer relevant in the cell state. The gate receives two inputs, (input at the current time) and (prior cell output), which are multiplied with weight matrices before bias is added. The output of the activation function, which receives the outcome, is binary. The input gate is responsible for adding important information to the cell state. To start, the inputs, and , are used to regulate the information using the sigmoid function and filter the values that need to be remembered similar to the forget gate. A vector containing every possible value between and is produced using the tanh function, which produces an output ranging from −1 to +1. To extract useful information, the values of the vector and regulated values are finally multiplied. The role of the output gate is to gather pertinent data from the current cell state and display it as output. The tanh function is first used in the cell to create a vector. The data are subsequently filtered by the values to be remembered using the inputs, and , and the derived information is regulated using the sigmoid function. The values of the vector and regulated values are finally multiplied and supplied as input and output to the following cell, respectively [8]. The equations for an LSTM unit are shown as follows,
where denotes the sigmoid function, denotes the activation vector of the forget gate, denotes the activation vector of the input gate, denotes the activation vector of the input gate, and denotes the output vector of the LSTM unit and the initial values and , the operator denotes the Hadamard product. denote the weights of the input, forget, and output gates and memory unit, respectively. Finally, denote the biases of the input, forget, and output gates and memory unit, respectively [26].
At the same time, the model contains a set of frequently connected subnetworks, allowing the LSTM model to store and access information for a long time, thereby mitigating vanishing or exploding gradients. Therefore, the LSTM model has more advantages over traditional RNN algorithms, which are limited in their ability to deal with long dependencies [8].
2.6. The Hybrid Model—EEMD-LSTM
The EEMD and LSTM have been described previously. The LSTM may have issues with accuracy. The proposed EEMD-LSTM hybrid model leverages the strengths of EEMD and the LSTM to compensate for the shortcomings of a single model. Both EEMD and LSTM were implemented in Matlab R2020a (9.8.0.323502). The flowchart is shown in Figure 2. The proposed model was developed as follows.
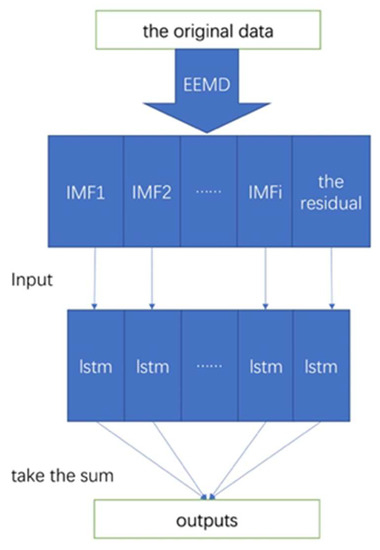
Figure 2.
Flowchart of the proposed EEMD-LSTM hybrid model.
First, ensemble empirical mode decomposition was used to decompose the original epidemic data into several IMFs and a residual.
Second, the LSTM model was trained on the data, and predictions of the IMFs and residuals were individually made.
Third, the final predictions of the EEMD-LSTM model were summed to provide the final output.
2.7. Model Performance Evaluation
The MAPE was mainly used to evaluate the goodness of fit of the model in this study. Other indicators were used to evaluate various aspects of the model more objectively. Assuming that represents the predicted value and represents the true value, we used the following four goodness-of-fit criteria to evaluate the model.
The Mean Absolute Percentage Error is given as:
The values range from zero to infinity: The value 0% represents a perfect model, while values higher than 100% represent an inferior model.
The Mean Absolute Error is given as:
The values range from zero to infinity. Greater values denote larger errors.
The Root Mean Square Error is given as:
3. Results
3.1. The Long Short-Term Memory Model
The California epidemic data (the original sequence) from 21 January 2020, to 25 April 2021, are shown in Figure 3. The number of confirmed cases had been increasing since 21 January 2020; the increase was especially rapid after 300 days.
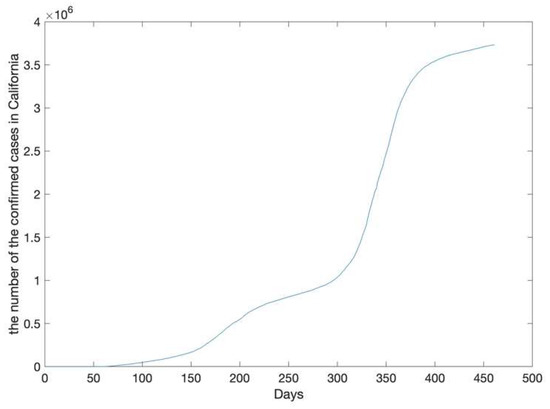
Figure 3.
The number of accumulative confirmed cases in California.
The California epidemic data was recorded from 21 January 2020, to 25 April 2021. The number of confirmed cases was from 0 to 3731677.
The LSTM model training data were collected between 21 January 2020, and 10 March 2021 (90%), while the data for predictions were collected between 11 March 2021, and 25 April 2021 (10%). Two LSTM hidden layers were created in this study, in addition to a dropout layer to minimize overfitting. The model used the Adam optimizer, and the maximum iteration number was set to 400. A time window was established to make better use of data for multi-step prediction, and it needed to be validated for selecting the appropriate parameter. With the test set, this study assessed the performance of models with various lag days (5, 7, 9, 11, 13, 15, 17), as shown in Table 1. The MAPE, MAE, and RMSE were minimal when the number of lag days was set to seven. It proved that the prediction model performed best for seven lag days.

Table 1.
Evaluation of different time windows on the prediction performance.
Considering that the average incubation period for the novel coronavirus is approximately seven days, the lag period had to be seven days according to the actual situation and validation results. In other words, the data accrued over the first seven days affect the forecast for the next day. The predictions of the LSTM model based on the test set are shown in Figure 4. The predictions showed that the number of confirmed cases would continue to increase steadily at a relatively high rate and reach 3,666,418 on 25 April 2021. The reported number of confirmed cases in California was 3,731,677 on 25 April 2021.
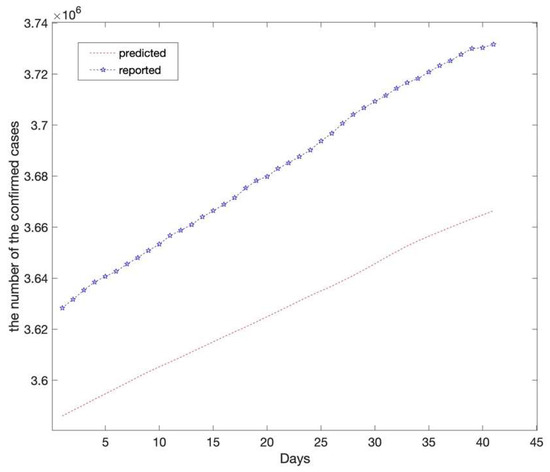
Figure 4.
Compares the reported and predicted data (the long short-term memory model). The red dotted line depicts the long short-term memory model’s prediction results on the test set which reveals that the number of confirmed cases in California will reach 3,666,418 on 25 April 2021. The asterisk line depicts the reported number of confirmed cases in California with 3,731,677 on 25 April 2021.
3.2. The Proposed EEMD-LSTM Hybrid Model
The epidemic data of California were decomposed using EEMD, and the results are shown in Figure 5; the standard deviation of the decomposed white noise was set at 0.01, and the integration was performed 100 times. These decomposed sequences can be added to the original data. These sequences did not show obvious epidemiological information; however, they were easily learned by the deep learning algorithm. The decomposed sequences were used to fit the LSTM model; the results for each sequence are shown in Figure 6. The similarity of the two curves determined the reliability of the prediction. The results of the decomposed sequences were satisfactory. Finally, the predictions for each sequence were summed to obtain the final output (Figure 7). The results showed that the predicted number of cases was greater than the number of reported cases initially. Additionally, the model predicted that the number of cases would continue to increase steadily and reach 3,681,150 on 25 April 2021, which is lower than the reported 3,731,677. The results of the evaluations of the LSTM and EEMD-LSTM models are also shown in Table 2.
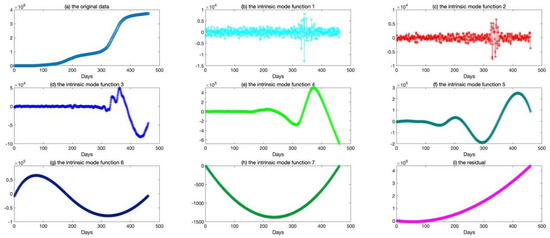
Figure 5.
The results of the original data decomposed by ensemble empirical mode decomposition. (a) The picture depicts the original data (the number of confirmed cases from 21 January 2020, to 25 April 2021). (b–i) The pictures depict the decomposed sequences (IMF1, IMF2, IMF3, IMF4, IMF5, IMF6, IMF7) and the residual by ensemble empirical mode decomposition.
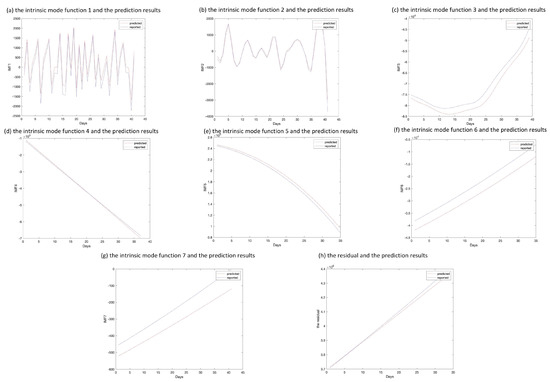
Figure 6.
Comparison of predicted and reported values of intrinsic mode functions and residual sequence. (a–h) The pictures depict the decomposed sequences and the predicted results on the test set through the long short-term memory model.
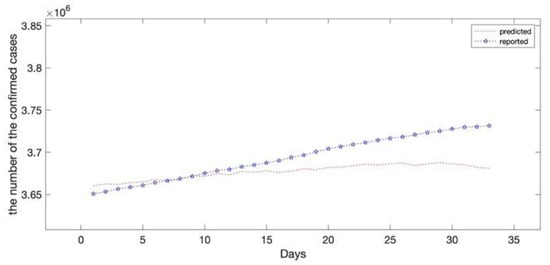
Figure 7.
Comparisons of the reported data and the predicted data (EEMD-LSTM model). The predicted results showed that the number of confirmed cases will still increase by 25 April 2021. The red dotted line depicts the hybrid EEMD-LSTM model’s prediction results on the test set which reveals that the number of confirmed cases in California will reach 3,681,150 on 25 April 2021. The asterisk line depicts the reported number of confirmed cases in California with 3,731,677 on 25 April 2021.
Table 2.
Comparison of the prediction performances between EEMD and EEMD-LSTM models.
4. Discussion
COVID-19, which began to spread in 2019, continues to threaten lives, affect economies around the world, and place a burden on government hospitals. Researchers have continued to explore prediction models for COVID-19 because good predictions can provide evidence for epidemic prevention and control policies. This study combined the cutting-edge EEMD technology and an advanced deep learning model—the LSTM—to predict the confirmed cases of COVID-19 in California, the worst-hit state in the United States. Several goodness-of-fit criteria were used to evaluate the prediction model based on the test set for a more objective validation. The proposed EEMD-LSTM model combined the strengths of each model to provide more accurate predictions of the COVID-19 outbreak trends.
Ensemble Empirical Mode Decomposition is a new technology for processing non-stationary and non-linear data, and it has been successfully applied in various fields [19,20,27]. However, it is rarely used for epidemic predictions. Ensemble Empirical Mode Decomposition of data yields sequences that are more regular and suitable for model training. The data on COVID-19 confirmed cases in this work were nonlinear and non-stationary, and EEMD was applied for better predictions by subsequent models.
The SEIR and ARIMA models and other well-known statistical approaches have been widely used for predictions for the COVID-19 epidemic [4,7,11,12]. Various modifications and adaptations have been performed based on these models to boost prediction accuracy. These models were inferior to neural network models, which are more effective for learning nonlinear epidemic data. Furthermore, the LSTM model is regarded as one of the most potent deep learning frameworks for sequential data predictions and provides more benefits than conventional neural network techniques. The LSTM introduced “cells” with three gates, which addressed the limitations associated with processing long dependencies. This allows the LSTM model to store and access information over a long duration. Additionally, LSTM generalizes more effectively, which increases its usage under various conditions [8].
The predictions of the EEMD-LSTM hybrid model were more accurate than those of the standalone LSTM model, according to the results. This indicates that EEMD improved the prediction accuracy of the LSTM model. After 25 April 2021, the number of confirmed cases in California continued to increase. In this study, we present a well-fitted EEMD-LSTM hybrid model for COVID-19 prediction. One of the significant issues in data analysis is data leakage. Models may appear to be accurate due to data leakage, but they quickly turn out to not be as accurate when used for real-world judgments. When training and test data are processed illogically, such as by normalizing the entire dataset and using the test set to validate and assess the performance of the model, data leakage problems arise. In this study, normalization was applied after splitting the data sets, which seemed to undermine the prediction performance.
The number of confirmed cases kept increasing with no clear indication of a decrease on 11 March 2021. This placed a burden on the healthcare system. Furthermore, California’s policy at the time seemed to be failing to control the outbreak. The results from the hybrid model showed that the number of reported infections was higher than the model predicted, which may indicate that more aggressive measures, such as increased testing and reduced social distancing, were required at the time to contain the outbreak.
This study had limitations. The combination of EEMD and LSTM requires various strategies, such as recreating the decomposed sequences for high and low frequencies before they are inputted into the LSTM model for learning or using the decomposed sequences as multiple features to fit a multi-input LSTM model. Future research can compare the performance of these strategies for the EEMD-LSTM model based on prediction accuracy. Additionally, it can be challenging to access data such as global pandemic statistics, weather data, and social distancing. Overall, this investigation showed the usefulness of the EEMD-LSTM model for COVID-19 epidemic predictions, which may help decision-makers and guide the allocation of medical resources. The LSTM model in this study also revealed several potential future paths for more accurate prediction models.
This study has some profound implications. The government, hospitals, and other agencies can utilize this model to guide short-term projections, which will facilitate the development of realistic preventative and control measures and provision of optimal medical care for patients. It is well-known that appropriate prevention and control measures, as well as adequate medical care, can facilitate the rapid management of epidemics [28]. Reasonable preventive and control policies also alleviate the economic burden resulting from long-term lockdowns. Another model was used to predict the COVID-19 lockdowns using the normal distribution [29]. The improved LSTM model may incorporate additional parameters, such as temperature, social distance, and vaccination, which can be used to estimate changes in the environment or guide policy.
5. Conclusions
In conclusion, the goal of this study was to develop and validate an EEMD-LSTM hybrid model for COVID-19 prediction. A model based on LSTM, a novel technique for time series data prediction, and EEMD was used, which allowed more accurate predictions. The forecasting performance on the test set was validated using various model evaluation criteria (MAPE, MAE, and RMSE). Comparisons of the assessment criteria revealed that the proposed EEMD-LSTM hybrid model outperformed the LSTM model. The proposed model may guide epidemic supervision and control and provide a reference for a forecasting approach for future epidemics.
Author Contributions
X.L. and S.L. developed the concept, supervised the project, provided significant academic guidance on manuscript drafting and interpretation, and revised the manuscript critically for intellectual content. S.L. analyzed the data and wrote the manuscript. Y.W., W.Y., A.T. and J.J. conducted the literature review and managed the project. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Chongqing Science and Technology Program (Grant No. cstc2020jcyj-msxmX0279) and the Chongqing Science and Technology Program (Grant No. cstc2020jscx-cylhX0003).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets analyzed during the current study are available in the Dataverse Harvard repository, https://doi.org/10.7910/DVN/HIDLTK (accessed on 14 September 2021).
Conflicts of Interest
The authors declare no competing interests.
Abbreviations
| ARIMA | Autoregressive Integrated Moving Average |
| EEMD | Ensemble Empirical Mode Decomposition |
| EMD | Empirical Mode Decomposition |
| IMFs | Intrinsic Mode Functions |
| LSTM | Long Short-term Memory |
| MAE | Mean Absolute Error |
| MAPE | Mean Absolute Percentage Error |
| RMSE | Root Mean Square Error |
| RNN | Recurrent Neural Network |
References
- WHO. Coronavirus Disease (COVID-19) Outbreak. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019 (accessed on 24 February 2020).
- Johns Hopkins University. Trace U.S. Pandemic Timelines. 2022. Available online: https://coronavirus.jhu.edu/region/united-states (accessed on 8 April 2022).
- Tang, Z.; Li, X.; Li, H. Prediction of new coronavirus infection based on a modified SEIR model. medRxiv 2020. [Google Scholar] [CrossRef]
- Wei, Y.Y.; Lu, Z.Z.; Du, Z.C.; Zhang, Z.J.; Zhao, Y.; Shen, S.P.; Wang, B.; Hao, Y.T.; Chen, F. Fitting and forecasting the trend of COVID-19 by SEIR(+ CAQ) dynamic model. Zhonghua Liu Xing Bing Xue Za Zhi Zhonghua Liuxingbingxue Zazhi 2020, 41, 470–475. [Google Scholar] [PubMed]
- Zhou, X.; Ma, X.; Hong, N.; Su, L.; Ma, Y.; He, J.; Jiang, H.; Liu, C.; Shan, G.; Zhu, W.; et al. Forecasting the worldwide spread of COVID-19 based on logistic model and SEIR model. medRxiv 2020. [Google Scholar] [CrossRef]
- Roda, W.C.; Varughese, M.B.; Han, D.; Li, M.Y. Why is it difficult to accurately predict the COVID-19 epidemic? Infect. Dis. Model. 2020, 5, 271–281. [Google Scholar] [CrossRef] [PubMed]
- ArunKumar, K.; Kalaga, D.V.; Kumar, C.M.S.; Chilkoor, G.; Kawaji, M.; Brenza, T.M. Forecasting the dynamics of cumulative COVID-19 cases (confirmed, recovered and deaths) for top-16 countries using statistical machine learning models: Auto-Regressive Integrated Moving Average (ARIMA) and Seasonal Auto-Regressive Integrated Moving Average (SARIMA). Appl. Soft Comput. 2021, 103, 107161. [Google Scholar] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Yudistira, N. COVID-19 growth prediction using multivariate long short term memory. arXiv 2020, arXiv:2005.04809. [Google Scholar]
- Kumar, R.L.; Khan, F.; Din, S.; Band, S.S.; Mosavi, A.; Ibeke, E. Recurrent neural network and reinforcement learning model for COVID-19 prediction. Front. Public Health 2021, 9, 744100. [Google Scholar] [CrossRef]
- Liu, F.; Wang, J.; Liu, J.; Li, Y.; Liu, D.; Tong, J.; Li, Z.; Yu, D.; Fan, Y.; Bi, X.; et al. Predicting and analyzing the COVID-19 epidemic in China: Based on SEIRD, LSTM and GWR models. PloS ONE 2020, 15, e0238280. [Google Scholar] [CrossRef]
- Yang, Z.; Zeng, Z.; Wang, K.; Wong, S.-S.; Liang, W.; Zanin, M.; Liu, P.; Cao, X.; Gao, Z.; Mai, Z.; et al. Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions. J. Thorac. Dis. 2020, 12, 165. [Google Scholar] [CrossRef]
- Shahid, F.; Zameer, A.; Muneeb, M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals 2020, 140, 110212. [Google Scholar] [CrossRef] [PubMed]
- Tuli, S.; Tuli, S.; Verma, R.; Tuli, R. Modelling for prediction of the spread and severity of COVID-19 and its association with socioeconomic factors and virus types. medRxiv 2020. [Google Scholar] [CrossRef]
- Rasjid, Z.E.; Setiawan, R.; Effendi, A. A comparison: Prediction of death and infected COVID-19 cases in Indonesia using time series smoothing and LSTM neural network. Procedia Comput. Sci. 2021, 179, 982–988. [Google Scholar] [CrossRef] [PubMed]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.-C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. London. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Qiang, X.; Aamir, M.; Naeem, M.; Ali, S.; Aslam, A.; Shao, Z. Analysis and forecasting COVID-19 outbreak in Pakistan using decomposition and ensemble model. Comput. Mater. Contin. 2021, 68, 841–856. [Google Scholar] [CrossRef]
- Yang, Q.; Qing, L.; Gao, P.; Zhang, R. Prediction of annual precipitation in the Northern Slope Economic Belt of Tianshan Mountains based on a EEMD-LSTM model. Arid Zone Res. 2021, 38, 1243–1245. [Google Scholar]
- Fang, X.-Q.; Wu, C.-Y.; Yu, S.-H.; Zhang, D.-B.; Ou Yang, Q. Research on Short-Term Forecast Model of Agricultural Product Price Based on EEMD-LSTM. Chin. J. Manag. Sci. 2021, 29, 68–77. [Google Scholar]
- China Data Lab. US COVID-19 Daily Cases with Basemap. 2020. Available online: https://doi.org/10.7910/DVN/HIDLTK (accessed on 14 September 2021).
- World Population Review. 2022. Available online: https://worldpopulationreview.com/states/california-population (accessed on 18 November 2022).
- Zeiler, A.; Faltermeier, R.; Keck, I.R.; Tomé, A.M.; Puntonet, C.G.; Lang, E.W. Empirical mode decomposition-an introduction. In Proceedings of the 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Gu, J.; Liang, L.; Song, H.; Kong, Y.; Ma, R.; Hou, Y.; Zhao, J.; Liu, J.; He, N.; Zhang, Y. A method for hand-foot-mouth disease prediction using GeoDetector and LSTM model in Guangxi, China. Sci. Rep. 2019, 9, 17928. [Google Scholar] [CrossRef]
- Liu, L.; Han, M.; Zhou, Y.; Wang, Y. Lstm recurrent neural networks for influenza trends prediction. In International Symposium on Bioinformatics Research and Applications; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Wang, T.; Zhang, M.; Yu, Q.; Zhang, H. Comparing the applications of EMD and EEMD on time–frequency analysis of seismic signal. J. Appl. Geophys. 2012, 83, 29–34. [Google Scholar] [CrossRef]
- Tang, B.; Wang, X.; Li, Q.; Bragazzi, N.L.; Tang, S.; Xiao, Y.; Wu, J. Estimation of the transmission risk of 2019-nCov and its implication for public health interventions. J. Clin. Med. 2020, 9, 462. [Google Scholar] [CrossRef] [PubMed]
- Malki, Z.; Atlam, E.-S.; Ewis, A.; Dagnew, G.; Ghoneim, O.A.; Mohamed, A.A.; Abdel-Daim, M.M.; Gad, I. The COVID-19 pandemic: Prediction study based on machine learning models. Environ. Sci. Pollut. Res. 2021, 28, 40496–40506. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).