
Fast, Ungapped Reads Mapping Using Squid




Abstract
:1. Introduction
2. Materials and Methods
2.1. General Design
2.2. Implementation
2.3. The Pseudo-Hash Function
2.4. Seed Ungapped Extension
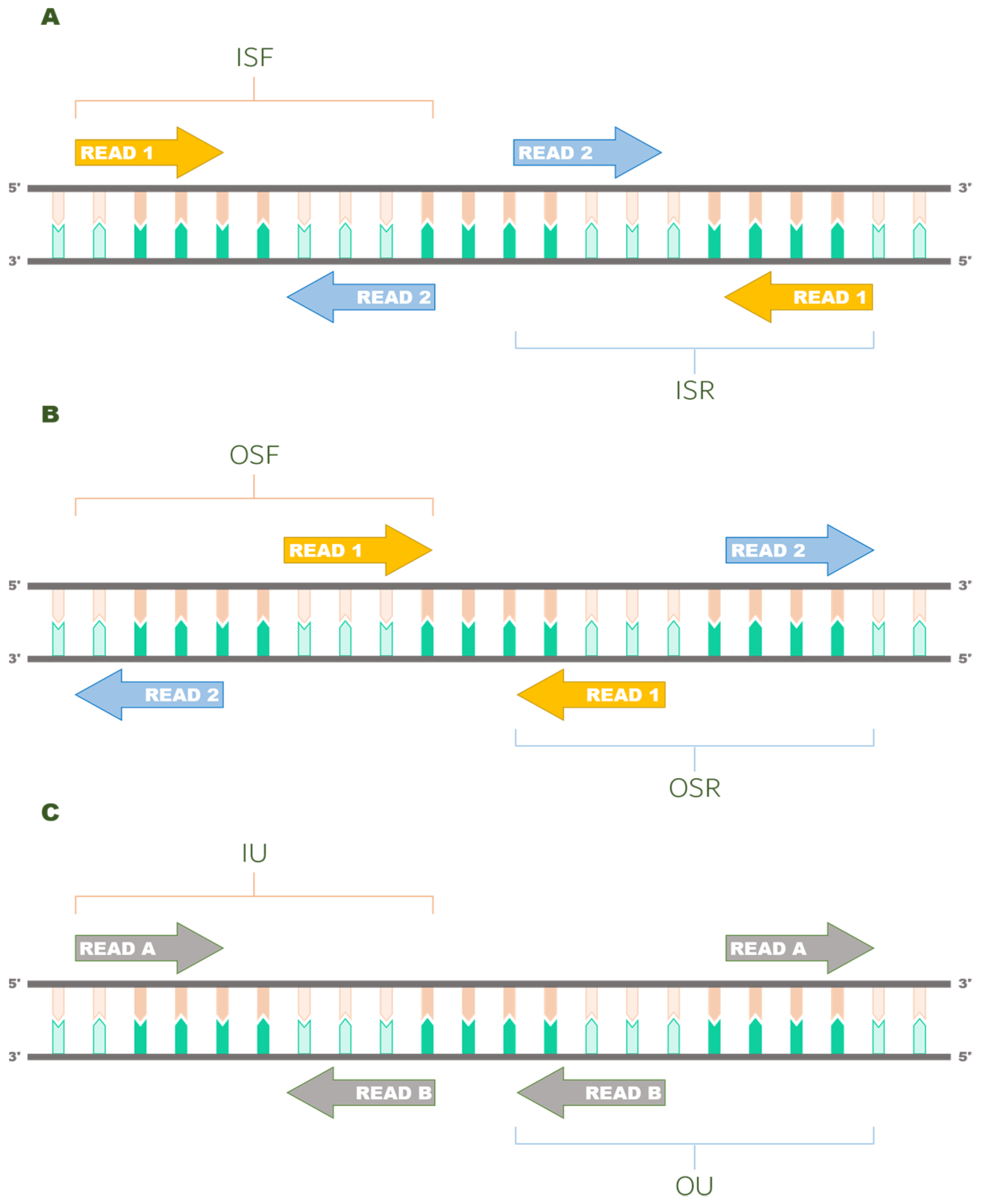
2.5. Reads Orientation Modes
2.6. The Exhaustiveness Parameter
2.7. Simulated Data Preparation
2.8. Real Data Collection
2.9. Benchmarking Software Parameters
3. Results
3.1. Performance Benchmarking
3.2. Accuracy Benchmarking
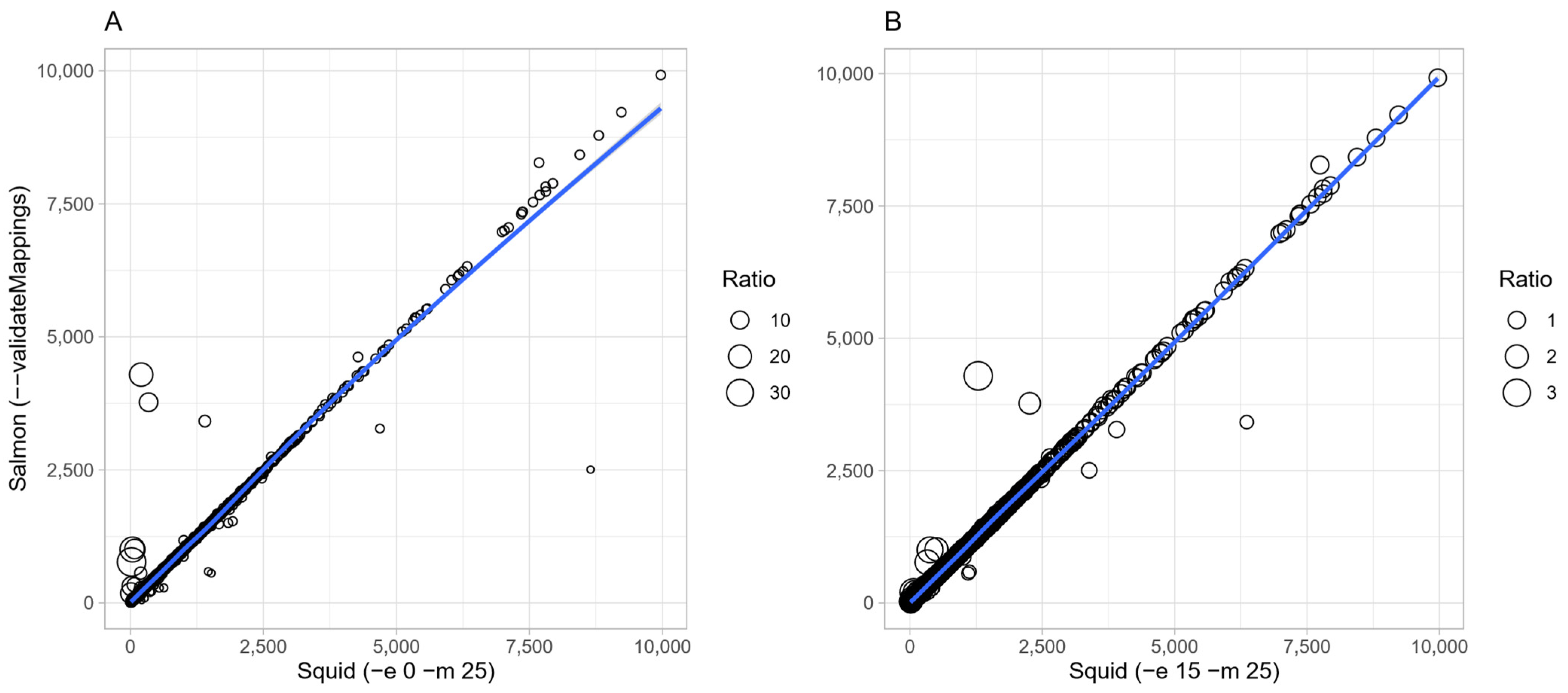
3.3. Study of the Outliers
3.4. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pereira, R.; Oliveira, J.; Sousa, M. Bioinformatics and Computational Tools for Next-Generation Sequencing Analysis in Clinical Genetics. J. Clin. Med. 2020, 9, 132. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lischer, H.E.L.; Shimizu, K.K. Reference-guided de novo assembly approach improves genome reconstruction for related species. BMC Bioinform. 2017, 18, 474. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martin, J.A.; Wang, Z. Next-generation transcriptome assembly. Nat. Rev. Genet. 2011, 12, 671–682. [Google Scholar] [CrossRef] [PubMed]
- Nieuwenhuis, T.; Yang, S.Y.; Verma, R.X.; Pillalamarri, V.; Arking, D.E.; Rosenberg, A.Z.; McCall, M.N.; Halushka, M.K. Consistent RNA sequencing contamination in GTEx and other data sets. Nat. Commun. 2020, 11, 1933. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- GTEx Consortium. The Genotype-Tissue Expression (GTEx) project. Nat. Genet. 2013, 45, 580–585. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Zhou, Y.; Chen, Y.; Gu, J. fastp: An ultra-fast all-in-one FASTQ preprocessor. Bioinformatics 2018, 34, i884–i890. [Google Scholar] [CrossRef] [PubMed]
- Bacci, G.; Bazzicalupo, M.; Benedetti, A.; Mengoni, A. StreamingTrim 1.0: A Java software for dynamic trimming of 16S rRNA sequence data from metagenetic studies. Mol. Ecol. Resour. 2013, 14, 426–434. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R. 1000 Genome Project Data Processing Subgroup. The Sequence Alignment/Map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Langmead, B.; Salzberg, S.L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 2012, 9, 357–359. [Google Scholar] [CrossRef] [Green Version]
- Dobin, A.; Gingeras, T.R. Mapping RNA-seq Reads with STAR. Curr. Protoc. Bioinform. 2015, 51, 11.14.1–11.14.19. [Google Scholar] [CrossRef] [Green Version]
- Boratyn, G.M.; Thierry-Mieg, J.; Thierry-Mieg, D.; Busby, B.; Madden, T.L. Magic-BLAST, an accurate RNA-seq aligner for long and short reads. BMC Bioinform. 2019, 20, 405. [Google Scholar] [CrossRef] [PubMed]
- Squid GitHub Repository. Available online: https://github.com/combogenomics/Squid (accessed on 20 April 2022).
- Patro, R.; Duggal, G.; Love, M.I.; Irizarry, R.A.; Kingsford, C. Salmon provides fast and bias-aware quantification of transcript expression. Nat. Methods 2017, 14, 417–419. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kanehisa, M.; Goto, S. KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Res. 2000, 28, 27–30. [Google Scholar] [CrossRef] [PubMed]
- Jain, C.; Rodriguez-R, L.M.; Phillippy, A.M.; Konstantinidis, K.T.; Aluru, S. High throughput ANI analysis of 90K prokaryotic genomes reveals clear species boundaries. Nat. Commun. 2018, 9, 5114. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, D.; Paggi, J.M.; Park, C.; Bennett, C.; Salzberg, S.L. Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype. Nat. Biotechnol. 2019, 37, 907–915. [Google Scholar] [CrossRef] [PubMed]
- Marçais, G.; Delcher, A.L.; Phillippy, A.M.; Coston, R.; Salzberg, S.L.; Zimin, A. MUMmer4: A fast and versatile genome alignment system. PLoS Comput. Biol. 2018, 14, e1005944. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, D.; Pertea, G.; Trapnell, C.; Pimentel, H.; Kelley, R.; Salzberg, S.L. TopHat2: Accurate alignment of transcriptomes in the presence of insertions, deletions and gene fusions. Genome Biol. 2013, 14, R36. [Google Scholar] [CrossRef] [PubMed] [Green Version]

{kind=link}
{kind=link}
| Reads | Time (s) | Percentage Mapped | Speedup | |||
|---|---|---|---|---|---|---|
| Sample | Squid | Bowtie2 | Squid | Bowtie2 | ||
| S_01 | 294,551 | 18.14 | 98.91 | 100 | 100 | 5.45 |
| S_02 | 428,090 | 25.00 | 149.04 | 100 | 100 | 5.96 |
| S_03 | 433,494 | 24.61 | 156.52 | 100 | 100 | 6.36 |
| S_04 | 477,233 | 24.16 | 163.3 | 100 | 100 | 6.75 |
| S_05 | 568,939 | 33.70 | 216.28 | 100 | 100 | 6.41 |
| S_06 | 822,335 | 50.38 | 280.41 | 100 | 100 | 5.56 |
| S_07 | 1,056,705 | 52.42 | 365.25 | 100 | 100 | 6.96 |
| S_08 | 1,611,954 | 75.84 | 550.62 | 100 | 99.99 | 7.26 |
| S_09 | 1,933,648 | 97.18 | 647.1 | 100 | 100 | 6.65 |
| S_10 | 2,261,861 | 111.65 | 755.5 | 100 | 100 | 6.76 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Riccardi, C.; Innocenti, G.; Fondi, M.; Bacci, G. Fast, Ungapped Reads Mapping Using Squid. Int. J. Environ. Res. Public Health 2022, 19, 5442. https://doi.org/10.3390/ijerph19095442
Riccardi C, Innocenti G, Fondi M, Bacci G. Fast, Ungapped Reads Mapping Using Squid. International Journal of Environmental Research and Public Health. 2022; 19(9):5442. https://doi.org/10.3390/ijerph19095442
Chicago/Turabian StyleRiccardi, Christopher, Gabriel Innocenti, Marco Fondi, and Giovanni Bacci. 2022. "Fast, Ungapped Reads Mapping Using Squid" International Journal of Environmental Research and Public Health 19, no. 9: 5442. https://doi.org/10.3390/ijerph19095442
APA StyleRiccardi, C., Innocenti, G., Fondi, M., & Bacci, G. (2022). Fast, Ungapped Reads Mapping Using Squid. International Journal of Environmental Research and Public Health, 19(9), 5442. https://doi.org/10.3390/ijerph19095442