
Application of Pattern Mining Methods to Assess Exposures to Multiple Airborne Chemical Agents in Two Large Occupational Exposure Databases from France


Abstract
:1. Introduction
2. Materials and Methods
2.1. Description of the Databases
2.2. Data Preparation
2.3. Definitions of Work Situations and Exposures
2.4. Statistical Methods
2.4.1. Frequent Itemset Mining
2.4.2. Association Rules Mining
2.4.3. Application of Frequent Itemset Mining to the Databases
2.5. Subanalyses
2.6. Software
3. Results
3.1. Data Selection
3.2. Application of Frequent Itemset Mining
3.3. Application of Association Rules Mining
3.4. Subanalyses
3.4.1. Carcinogens
3.4.2. Analyses Stratified by Industry and Task
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McKenzie, J.F.; El-Zaemey, S.; Carey, R.N. Prevalence of exposure to multiple occupational carcinogens among exposed workers in Australia. Occup. Environ. Med. 2021, 78, 211–217. [Google Scholar] [CrossRef] [PubMed]
- Scarselli, A.; Corfiati, M.; Di Marzio, D.; Marinaccio, A.; Iavicoli, S. Gender differences in occupational exposure to carcinogens among Italian workers. BMC Public Health 2018, 18, 413. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Labrèche, F.; Duguay, P.; Ostiguy, C.; Boucher, A.; Roberge, B.; Peters, C.E.; Demers, P.A. Estimating occupational exposure to carcinogens in Quebec. Am. J. Ind. Med. 2013, 56, 1040–1050. [Google Scholar] [CrossRef] [PubMed]
- DARES, Comment ont évolué les expositions des salariés du secteur privé aux risques professionnels sur les vingt dernières années ? Premiers résultats de l’enquête Sumer 2017. Dares Anal. 2019, 41, 1–14.
- Lavoué, J.; Friesen, M.C.; Burstyn, I. Workplace Measurements by the US Occupational Safety and Health Administration since 1979: Descriptive Analysis and Potential Uses for Exposure Assessment. Ann. Occup. Hyg. 2012, 57, 77–97. [Google Scholar] [PubMed] [Green Version]
- Stamm, R. MEGA-Database: One Million Data Since 1972. Appl. Occup. Environ. Hyg. 2001, 16, 159–163. [Google Scholar] [CrossRef] [PubMed]
- Scarselli, A.; Montaruli, C.; Marinaccio, A. The Italian Information System on Occupational Exposure to Carcinogens (SIREP): Structure, Contents and Future Perspectives. Ann. Occup. Hyg. 2007, 51, 471–478. [Google Scholar] [CrossRef]
- Mater, G.; Paris, C.; Lavoué, J. Descriptive analysis and comparison of two French occupational exposure databases: COLCHIC and SCOLA. Am. J. Ind. Med. 2016, 59, 379–391. [Google Scholar] [CrossRef] [Green Version]
- Bosson-Rieutort, D.; Sarazin, P.; Bicout, D.J.; Ho, V.; Lavoué, J. Occupational Co-exposures to Multiple Chemical Agents from Workplace Measurements by the US Occupational Safety and Health Administration. Ann. Work Expo. Health 2020, 64, 402–415. [Google Scholar] [CrossRef]
- Clerc, F.; Bertrand, N.J.H.; La Rocca, B. Taking Multiple Exposure Into Account Can Improve Assessment of Chemical Risks. Ann. Work Expo. Health 2017, 62, 53–61. [Google Scholar] [CrossRef]
- Han, J.; Cheng, H.; Xin, D.; Yan, X. Frequent pattern mining: Current status and future directions. Data Min. Knowl. Discov. 2007, 15, 55–86. [Google Scholar] [CrossRef] [Green Version]
- Alves, R.; Rodriguez-Baena, D.S.; Aguilar-Ruiz, J.S. Gene association analysis: A survey of frequent pattern mining from gene expression data. Brief. Bioinform. 2009, 11, 210–224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liao, C.-W.; Perng, Y.-H. Data mining for occupational injuries in the Taiwan construction industry. Saf. Sci. 2008, 46, 1091–1102. [Google Scholar] [CrossRef]
- Tornero-Velez, R.; Isaacs, K.; Dionisio, K.; Prince, S.; Laws, H.; Nye, M.; Price, P.S.; Buckley, T.J. Data Mining Approaches for Assessing Chemical Coexposures Using Consumer Product Purchase Data. Risk Anal. 2021, 41, 1716–1735. [Google Scholar] [CrossRef] [PubMed]
- Stanfield, Z.; Addington, C.K.; Dionisio, K.L.; Lyons, D.; Tornero-Velez, R.; Phillips, K.A.; Buckley, T.J.; Isaacs, K.K. Mining of Consumer Product Ingredient and Purchasing Data to Identify Potential Chemical Coexposures. Environ. Health Perspect. 2021, 129, 067006. [Google Scholar] [CrossRef]
- Tornero-Velez, R.; Egeghy, P.P. Ecological Assembly of Chemical Mixtures. In Chemical Mixtures and Combined Chemical and Nonchemical Stressors: Exposure, Toxicity, Analysis, and Risk, Rider, C.V.; Simmons, J.E., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 151–175. [Google Scholar]
- Bellinger, C.; Mohomed Jabbar, M.S.; Zaïane, O.; Osornio-Vargas, A. A systematic review of data mining and machine learning for air pollution epidemiology. BMC Public Health 2017, 17, 907. [Google Scholar] [CrossRef] [Green Version]
- Vincent, R.; Jeandel, B. COLCHIC—Occupational Exposure to Chemical Agents Database: Current Content and Development Perspectives. Appl. Occup. Environ. Hyg. 2001, 16, 115–121. [Google Scholar] [CrossRef]
- Mater, G.; Sauvé, J.-F.; Sarazin, P.; Lavoué, J. Exposure determinants in the French database COLCHIC (1987–2019)—Statistical modelling across 77 chemicals. Ann. Work Expo. Health (Accept.). 2021. Available online: https://academic.oup.com/annweh/advance-article-abstract/doi/10.1093/annweh/wxab104/6433557?redirectedFrom=fulltext (accessed on 22 February 2022).
- INSEE. French Classification of Activities—NAF Rev. 2, 2008 (Second Edition, 2015); Institut national de la Statistique et des études économiques; INSEE: Paris, France, 2015. [Google Scholar]
- Pôle Emploi. Répertoire Opérationnel des Métiers et Emplois; Pôle Emploi: Paris, France, 2018. [Google Scholar]
- INRS Base de données MétroPol. Available online: https://www.inrs.fr/publications/bdd/metropol.html (accessed on 28 July 2021).
- Lavoue, J.; Burstyn, I. Evidence of Absence: Bayesian Way to Reveal True Zeros Among Occupational Exposures. Ann. Work Expo. Health 2020, 65, 84–95. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference and Prediction; Springer Science & Business Media: New York, NY, USA, 2009. [Google Scholar]
- Borgelt, C. Frequent item set mining. WIREs Data Min. Knowl. Discov. 2012, 2, 437–456. [Google Scholar] [CrossRef]
- Fournier-Viger, P.; Lin, J.C.-W.; Vo, B.; Chi, T.T.; Zhang, J.; Le, H.B. A survey of itemset mining. WIREs Data Min. Knowl. Discov. 2017, 7, e1207. [Google Scholar] [CrossRef]
- Naulaerts, S.; Meysman, P.; Bittremieux, W.; Vu, T.N.; Vanden Berghe, W.; Goethals, B.; Laukens, K. A primer to frequent itemset mining for bioinformatics. Brief. Bioinform. 2013, 16, 216–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geng, L.; Hamilton, H.J. Interestingness measures for data mining: A survey. ACM Comput. Surv. (CSUR) 2006, 38, 9-es. [Google Scholar] [CrossRef]
- Hahsler, M.; Buchta, C.; Gruen, B.; Hornik, K.; Johnson, I.; Borgelt, C. Package ‘arules’: Mining Association Rules and Frequent Itemsets. Version 1.6-7. Available online: https://cran.r-project.org/web/packages/arules (accessed on 22 February 2022).
- IARC Agents classified by the IARC Monographs, Volumes 1–129. Available online: https://monographs.iarc.who.int/list-of-classifications (accessed on 27 July 2021).
- INRS Fluides d'usinage M-282 [Metalworking fluids, Method M-282]. Available online: https://www.inrs.fr/publications/bdd/metropol/fiche.html?refINRS=METROPOL_282 (accessed on 4 November 2021).
- Nguyen, T.-H.-Y.; Bertin, M.; Bodin, J.; Fouquet, N.; Bonvallot, N.; Roquelaure, Y. Multiple Exposures and Coexposures to Occupational Hazards Among Agricultural Workers: A Systematic Review of Observational Studies. Saf Health Work 2018, 9, 239–248. [Google Scholar] [CrossRef] [PubMed]
- Bell, S.M.; Edwards, S.W. Identification and Prioritization of Relationships between Environmental Stressors and Adverse Human Health Impacts. Environ. Health Perspect. 2015, 123, 1193–1199. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kapraun, D.F.; Wambaugh, J.F.; Ring, C.L.; Tornero-Velez, R.; Setzer, R.W. A Method for Identifying Prevalent Chemical Combinations in the U.S. Population. Environ. Health Perspect. 2017, 125, 087017. [Google Scholar] [CrossRef] [Green Version]
- Vyskocil, A.; Drolet, D.; Viau, C.; Lemay, F.; Lapointe, G.; Tardif, R.; Truchon, G.; Baril, M.; Gagnon, N.; Gagnon, F.; et al. A Web Tool for the Identification of Potential Interactive Effects of Chemical Mixtures. J. Occup. Environ. Hyg. 2007, 4, 281–287. [Google Scholar] [CrossRef]
- La Rocca, B.; Sarazin, P. MiXie, an Online Tool for Better Health Assessment of Workers Exposed to Multiple Chemicals. Int. J. Environ. Res. Public Health 2022, 19, 951. [Google Scholar] [CrossRef]

{kind=link}
| Work Situation | Items |
|---|---|
| WS1 | asbestos, lead |
| WS2 | wood dust |
| WS3 | benzene, ethanol, lead |
| WS4 | asbestos, chromium, lead |
| Items | N WS 1 | Support 2 | Sector with Largest Number of WS Exposed |
|---|---|---|---|
| Ethylbenzene, Xylene | 1550 | 14.7% | Manufacture of paints, varnishes and similar coatings, printing ink and mastics (n = 100) 3 |
| Cristobalite, Quartz | 1417 | 13.4% | Quarrying of stone, sand and clay (n = 243) |
| Toluene, Xylene | 1305 | 12.4% | Manufacture of refined petroleum products (n = 115) |
| Ethylbenzene, Toluene | 995 | 9.4% | Manufacture of refined petroleum products (n = 85) |
| Ethylbenzene, Toluene, Xylene | 945 | 9.0% | Manufacture of refined petroleum products (n = 84) |
| Acetone, Toluene | 768 | 7.3% | Waste treatment and disposal (n = 67) |
| Iron, Manganese | 767 | 7.3% | Manufacture of structural metal products (n = 68) |
| Butanone, Toluene | 679 | 6.4% | Manufacture of air and spacecraft and related machinery (n = 58) |
| Acetone, Xylene | 675 | 6.4% | Waste treatment and disposal (n = 59) |
| Acetone, Butanone | 664 | 6.3% | Manufacture of plastics products (n = 67) |
| N Items | Items | N WS 1 | Support 2 |
|---|---|---|---|
| 3 | Ethylbenzene, Toluene, Xylene | 945 | 9.0% |
| Acetone, Ethylbenzene, Xylene | 475 | 4.5% | |
| Copper, Iron, Manganese | 463 | 4.4% | |
| Iron, Manganese, Zinc | 462 | 4.4% | |
| Acetone, Toluene, Xylene | 455 | 4.3% | |
| 4 | Acetone, Ethylbenzene, Toluene, Xylene | 360 | 3.4% |
| Copper, Iron, Manganese, Zinc | 337 | 3.2% | |
| Butanone, Ethylbenzene, Toluene, Xylene | 321 | 3.0% | |
| Copper, Iron, Manganese, Nickel | 308 | 2.9% | |
| Iron, Manganese, Nickel, Total chromium | 302 | 2.9% | |
| 5 | Copper, Iron, Manganese, Nickel, Total chromium | 236 | 2.2% |
| Copper, Iron, Manganese, Nickel, Zinc | 233 | 2.2% | |
| Iron, Manganese, Nickel, Total chromium, Zinc | 222 | 2.1% | |
| Copper, Iron, Manganese, Total chromium, Zinc | 221 | 2.1% | |
| Copper, Iron, Nickel, Total chromium, Zinc | 206 | 2.0% |
| Antecedent | Consequent | Confidence | Support |
|---|---|---|---|
| Cristobalite | Quartz | 97.5% | 13.4% |
| Ethylbenzene, Toluene | Xylene | 95.0% | 9.0% |
| Ethylbenzene | Xylene | 94.6% | 14.7% |
| Zinc | Iron | 93.0% | 6.2% |
| Manganese | Iron | 91.5% | 7.3% |
| Copper | Iron | 86.6% | 5.3% |
| Toluene, Xylene | Ethylbenzene | 72.4% | 9.0% |
| Benzene | Toluene | 71.7% | 5.4% |
| Xylene | Ethylbenzene | 68.3% | 14.7% |
| Iron | Manganese | 67.5% | 7.3% |
| Antecedent | Consequent | Lift | Support | Confidence (A → C) 1 | Confidence (C → A) 2 |
|---|---|---|---|---|---|
| Water-soluble metalworking fluids (MWF) | Inhalable metalworking fluids | 62.5 | 1.2% | 93.6% | 82.9% |
| Acetaldehyde | Formaldehyde | 31.1 | 1.2% | 97.8% | 39.5% |
| 1,2,3-Trimethylbenzene | Mesitylene | 23.6 | 1.3% | 69.0% | 44.0% |
| 1,2,3-Trimethylbenzene, Mesitylene | 1,2,4-Trimethylbenzene | 16.2 | 1.3% | 98.5% | 20.8% |
| 1,2,3-Trimethylbenzene | 1,2,4-Trimethylbenzene | 14.7 | 1.7% | 89.8% | 27.5% |
| Nickel, Titanium, Total chromium | Copper | 14.7 | 1.0% | 90.8% | 16.6% |
| Mesitylene | 1,2,4-Trimethylbenzene | 14.4 | 2.6% | 87.7% | 42.1% |
| Aluminum, Nickel, Total chromium | Copper | 14.4 | 1.3% | 88.6% | 21.5% |
| Titanium, Total chromium | Nickel | 14.2 | 1.1% | 81.0% | 19.7% |
| Aluminum, Total chromium | Nickel | 14.0 | 1.5% | 80.2% | 26.2% |
| Items | N WS 1 | Supp 2 | Sector with Largest Number of WS Exposed |
|---|---|---|---|
| Cristobalite, Quartz | 1417 | 32.5% | Quarrying of stone, sand and clay (n = 243) 3 |
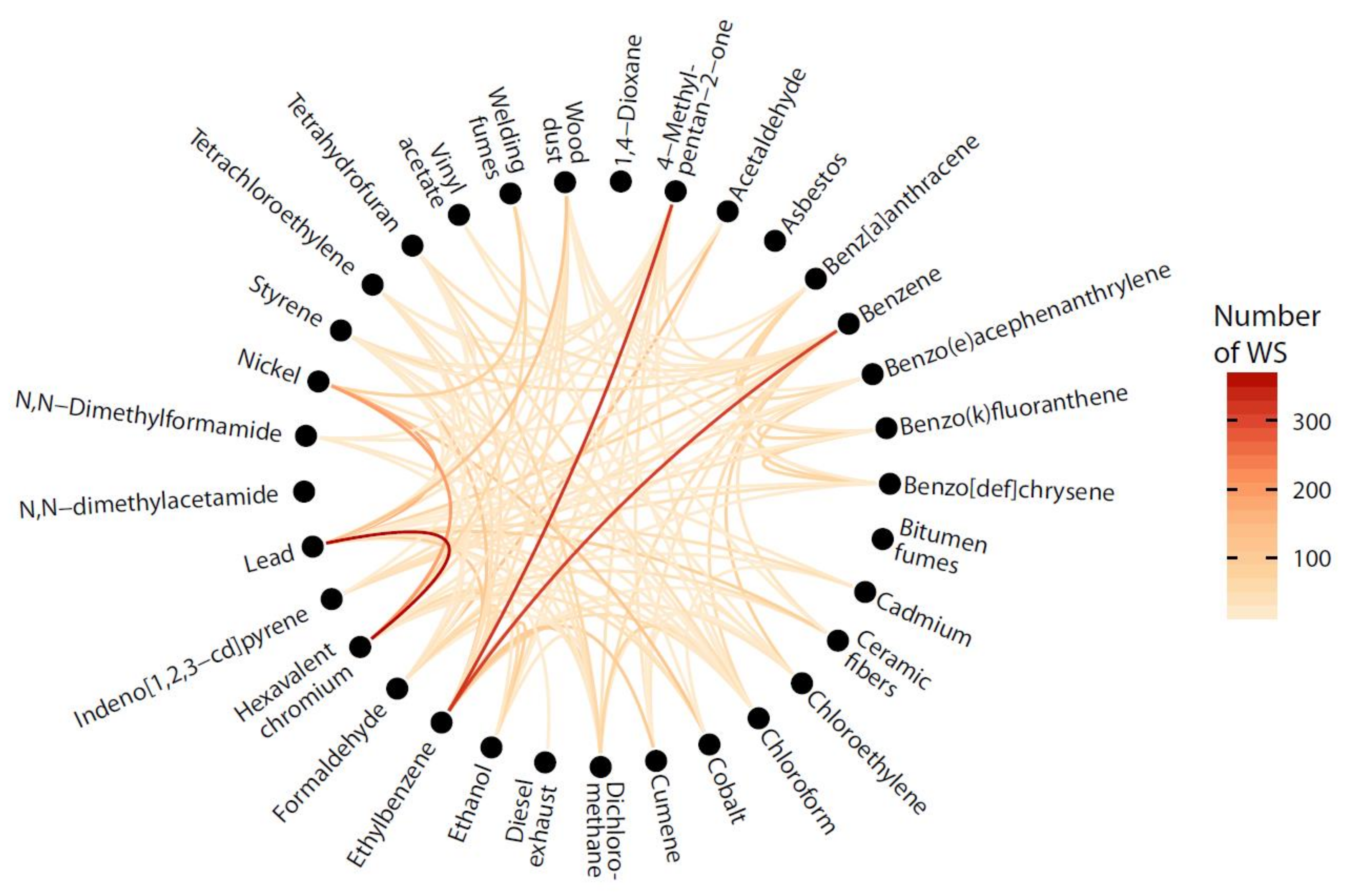
| Hexavalent chromium, Lead | 368 | 8.4% | Waste treatment and disposal (n = 70) |
| Lead, Quartz | 337 | 7.7% | Waste treatment and disposal (n = 47) |
| 4-Methylpentan-2-one (MIBK), Ethylbenzene | 325 | 7.5% | Manufacture of paints, varnishes and similar coatings, printing ink and mastics (n = 39) |
| Benzene, Ethylbenzene | 314 | 7.2% | Manufacture of refined petroleum products (n = 85) |
| Hexavalent chromium, Quartz | 245 | 5.6% | Manufacture of cement, lime and plaster (n = 51) |
| Hexavalent chromium, Nickel | 198 | 4.5% | Treatment and coating of metals: machining (n = 25) |
| Lead, Nickel | 166 | 3.8% | Treatment and coating of metals: machining (n = 19) |
| Quartz, Refractory ceramic fibers (L > 5 μm D < 3 μm) | 139 | 3.2% | Casting of metals (n = 25) |
| Acetaldehyde, Formaldehyde | 131 | 3.0% | Manufacture of plastics products (n = 24) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sauvé, J.-F.; Emili, A.; Mater, G. Application of Pattern Mining Methods to Assess Exposures to Multiple Airborne Chemical Agents in Two Large Occupational Exposure Databases from France. Int. J. Environ. Res. Public Health 2022, 19, 1746. https://doi.org/10.3390/ijerph19031746
Sauvé J-F, Emili A, Mater G. Application of Pattern Mining Methods to Assess Exposures to Multiple Airborne Chemical Agents in Two Large Occupational Exposure Databases from France. International Journal of Environmental Research and Public Health. 2022; 19(3):1746. https://doi.org/10.3390/ijerph19031746
Chicago/Turabian StyleSauvé, Jean-François, Andrea Emili, and Gautier Mater. 2022. "Application of Pattern Mining Methods to Assess Exposures to Multiple Airborne Chemical Agents in Two Large Occupational Exposure Databases from France" International Journal of Environmental Research and Public Health 19, no. 3: 1746. https://doi.org/10.3390/ijerph19031746
APA StyleSauvé, J.-F., Emili, A., & Mater, G. (2022). Application of Pattern Mining Methods to Assess Exposures to Multiple Airborne Chemical Agents in Two Large Occupational Exposure Databases from France. International Journal of Environmental Research and Public Health, 19(3), 1746. https://doi.org/10.3390/ijerph19031746