
Detecting and Analyzing Suicidal Ideation on Social Media Using Deep Learning and Machine Learning Models

 ,
,  ,
,
Abstract
1. Introduction
- For the purpose of identifying suicidal tendencies, the proposal of a hybrid deep learning model that combines convolutional neural networks with bidirectional long-short term memories;
- Evaluation of how well the suggested deep learning model performs in comparison to the XGBoost machine learning model that serves as a baseline.
- Conducting of two different experiments using text and LIWC-based features to test the performance of the proposed models.
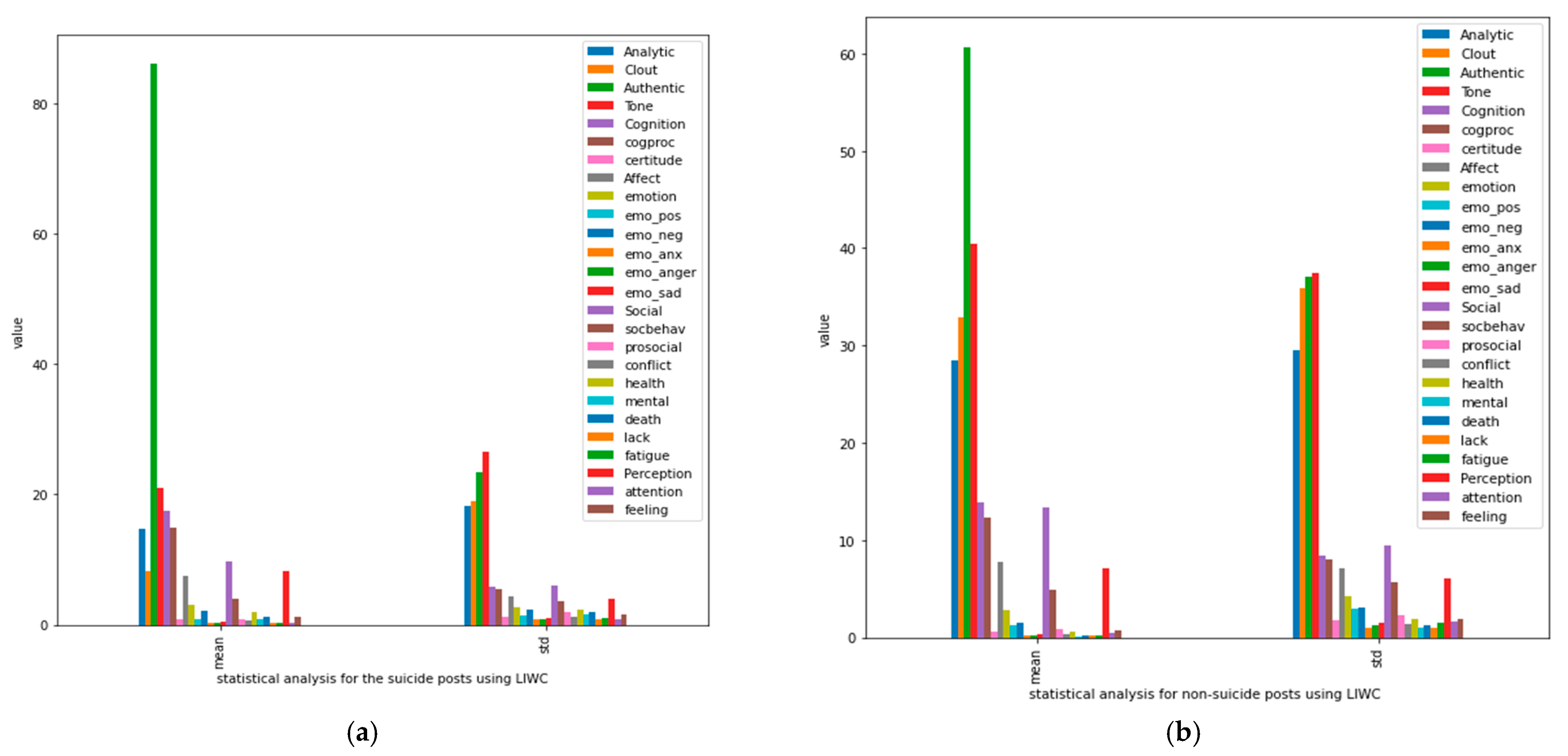
- Analysis of the suicide and non-suicide posts in the dataset and concluding the difference between them using the LIWC tool.
2. Background
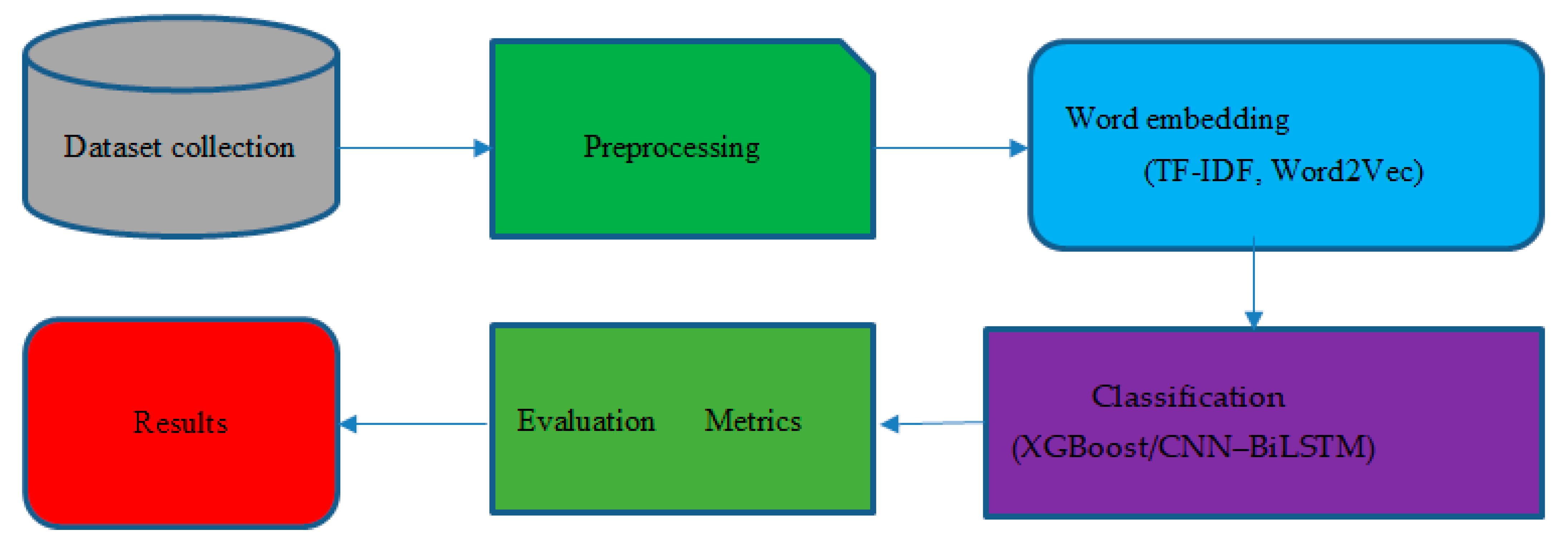
3. Materials and Methods
3.1. Dataset
3.2. Preprocessing
- Punctuation, emoji, and numerical digit removal: this process removes the characters “?, !, :, ;, ’,” and emoji to make the text easily processable.
- Stop word removal: this process removes words such as “the”, “a”, “an”, and “in”, which have no contribution to the operation of the model.
- Lowercasing: this process lowercases all words.
- Tokenization: this process splits each sentence into its basic parts, such as words, phrases, and other pieces of information.
- Lemmatization: this process combines inflected forms of words into their root form.
- To use a DL neural network technique to distinguish between suicidal and non-suicidal posts, all sequences of texts in the dataset must have equal real-value vectors. To accomplish this task, the post-padding sequence method was used.
3.3. Word Embedding
3.3.1. TF-IDF
3.3.2. Word2Vec
3.4. Classification Models
3.4.1. XGBoost Model
3.4.2. CNN–BiLSTM Model
- Embedding layer
- 2.
- Convolutional layer
- 3.
- Max pooling layer
- 4.
- BiLSTM layers
- 5.
- Softmax layer
3.5. Evaluation Metrics
4. Experimental Results
4.1. Data Splitting
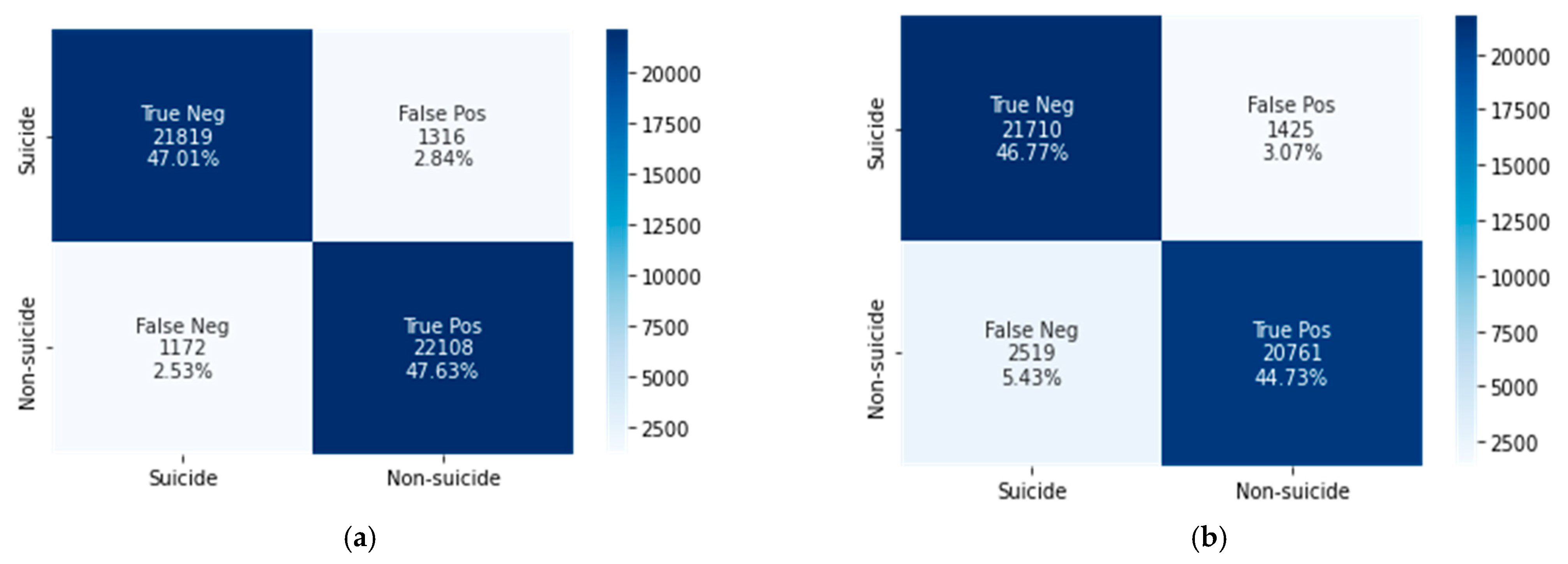
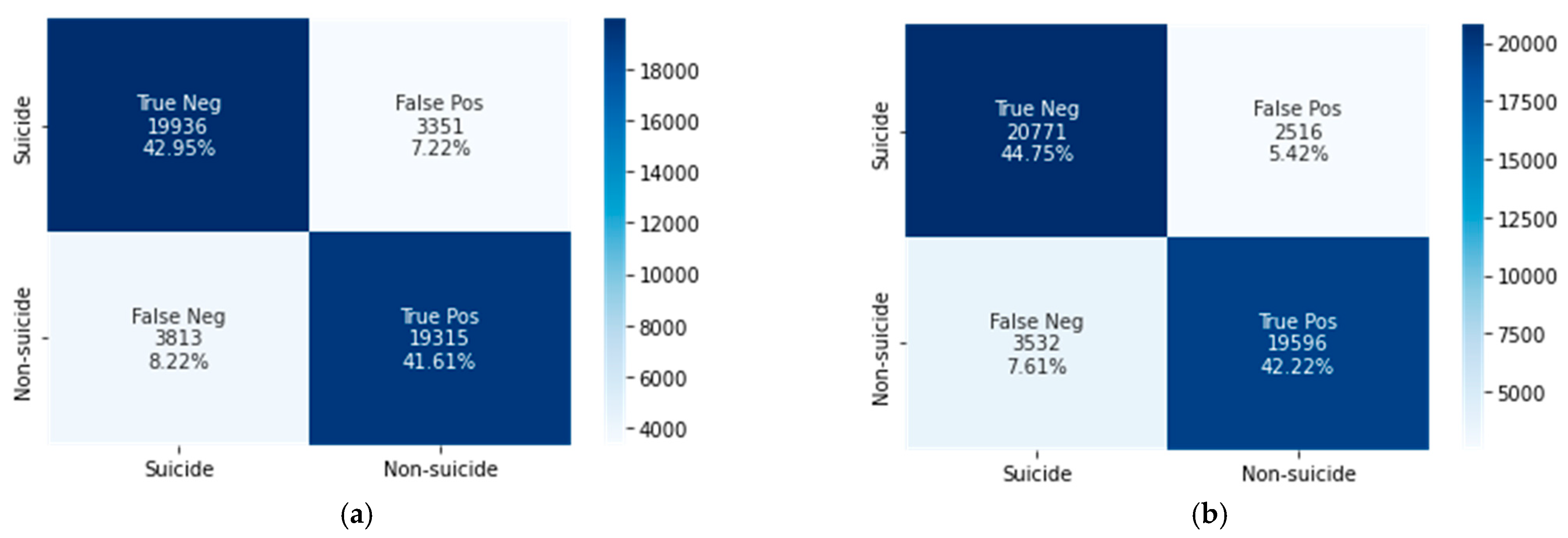
4.2. Classification Results
4.3. Statistical Analysis of Suicidal and Non-Suicidal Posts
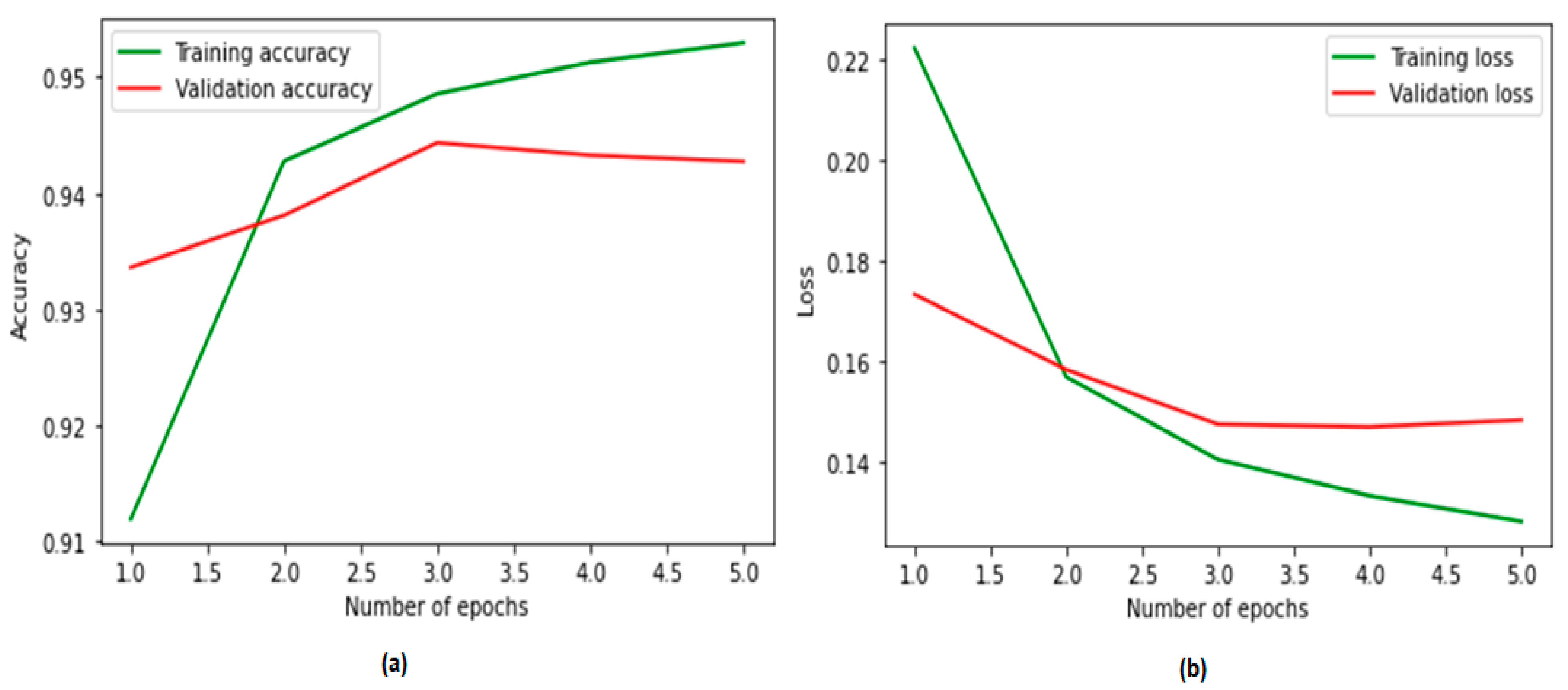
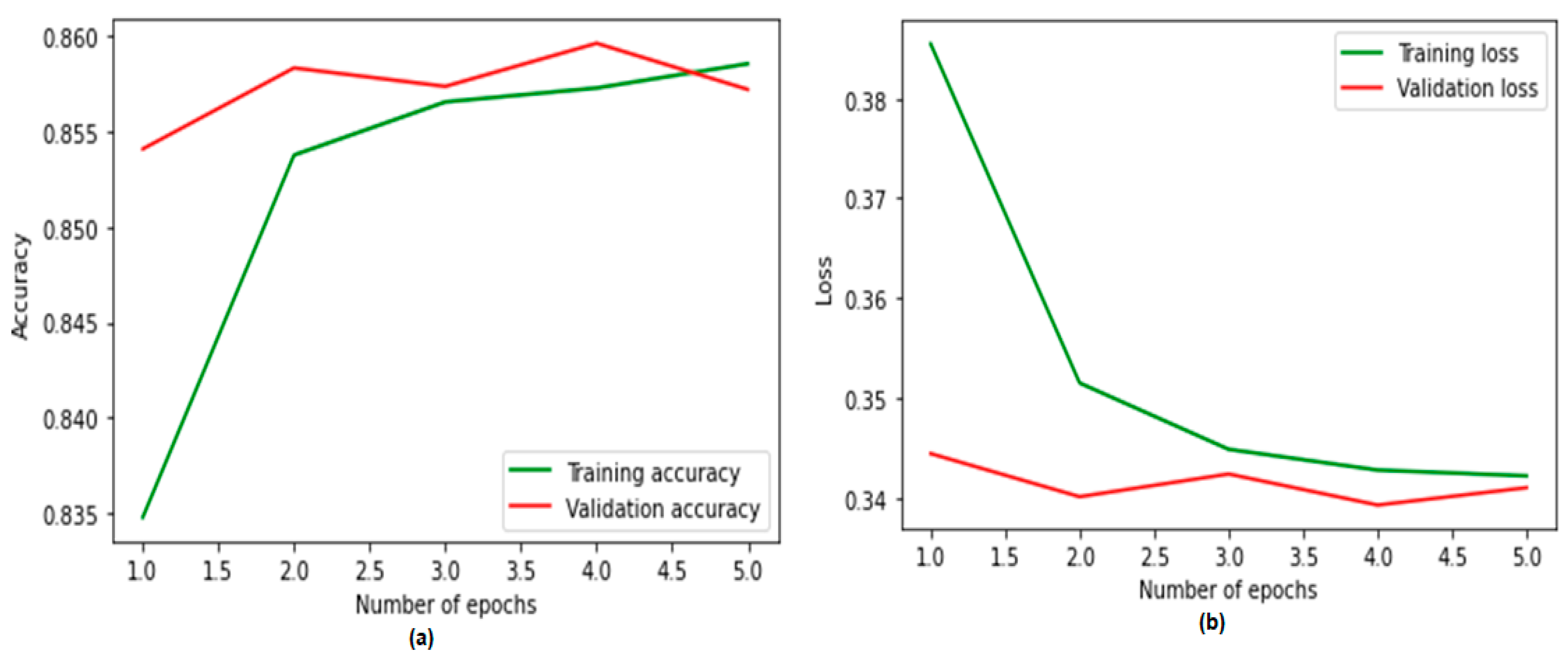
4.4. Performance Plots
4.5. Word Cloud
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Suicide Ideation Detection System. Available online: https://www.who.int/news-room/fact-sheets/detail/suicide (accessed on 12 July 2021).
- Ivey-Stephenson, A.Z.; Demissie, Z.; Crosby, A.E.; Stone, D.M.; Gaylor, E.; Wilkins, N.; Lowry, R.; Brown, M. Suicidal Ideation and Behaviors Among High School Students—Youth Risk Behavior Survey, United States, 2019. MMWR Suppl. 2020, 69, 47–55. [Google Scholar] [CrossRef]
- Gliatto, M.F.; Rai, A.K. Evaluation and Treatment of Patients with Suicidal Ideation. Am. Fam. Physician 1999, 59, 1500–1506. [Google Scholar] [PubMed]
- Klonsky, E.D.; May, A.M. Differentiating suicide attempters from suicide ideators: A critical frontier for suicidology research. Suicide Life-Threat. Behav. 2014, 44, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Pompili, M.; Innamorati, M.; Di Vittorio, C.; Sher, L.; Girardi, P.; Amore, M. Sociodemographic and clinical differences between suicide ideators and attempters: A study of mood disordered patients 50 years and older. Suicide Life-Threat. Behav. 2014, 44, 34–45. [Google Scholar] [CrossRef]
- World Health Organization. National Suicide Prevention Strategies: Progress, Examples and Indicators; World Health Organization: Geneva, Switzerland, 2018. [Google Scholar]
- Giachanou, A.; Crestani, F. Like it or not: A survey of Twitter sentiment analysis methods. ACM Comput. Surv. 2016, 49, 1–41. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.-Z.; Lahcen, A.A.; Belfkih, S. ASA: A framework for Arabic sentiment analysis. J. Inf. Sci. 2019, 46, 544–559. [Google Scholar] [CrossRef]
- Pachouly, S.J.; Raut, G.; Bute, K.; Tambe, R.; Bhavsar, S. Depression Detection on Social Media Network (Twitter) using Sentiment Analysis. Int. Res. J. Eng. Technol. 2021, 8, 1834–1839. Available online: www.irjet.net (accessed on 23 April 2022).
- Syed, T.R.; Qamar, R.K.; Akib, M.U. Khanday. Machine Classification for Suicide Ideation Detection on Twitter. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 4154–4160. [Google Scholar]
- Stankevich, M.; Latyshev, A.; Kuminskaya, E.; Smirnov, I.; Grigoriev, O. Depression detection from social media texts. CEUR Workshop Proc. 2019, 6, 2523. [Google Scholar]
- Abdulsalam, A.; Alhothali, A. Suicidal Ideation Detection on Social Media: A Review of Machine Learning Methods. 2022. Available online: http://arxiv.org/abs/2201.10515 (accessed on 7 July 2022).
- De Choudhury, M.; Kiciman, E.; Dredze, M.; Coppersmith, G.; Kumar, M. Discovering shifts to suicidal ideation from mental health content in social media. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San José, CA, USA, 9–12 December 2016; ACM: New York, NY, USA, 2016; pp. 2098–2110. [Google Scholar]
- Coppersmith, G.; Ngo, K.; Leary, R.; Wood, A. Exploratory analysis of social media prior to a suicide attempt. In Proceedings of the Third Workshop on Computational Linguistics and Clinical Psychology, San Diego, CA, USA, 16 June 2016; pp. 106–117. [Google Scholar]
- Lumontod, R.Z., III. Seeing the invisible: Extracting signs of depression and suicidal ideation from college students’ writing using LIWC a computerized text analysis. Int. J. Res. Stud. Educ. 2020, 9, 31–44. [Google Scholar] [CrossRef]
- Masuda, N.; Kurahashi, I.; Onari, H. Suicide Ideation of Individuals in Online Social Networks. PLoS ONE 2013, 8, e62262. [Google Scholar] [CrossRef] [PubMed]
- Pestian, J.; Nasrallah, H.; Matykiewicz, P.; Bennett, A.; Leenaars, A. Suicide Note Classification Using Natural Language Processing: A Content Analysis. Biomed. Inform. Insights 2010, 3, BII.S4706. [Google Scholar] [CrossRef] [PubMed]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of Depression-Related Posts in Reddit Social Media Forum. IEEE Access 2019, 7, 44883–44893. [Google Scholar] [CrossRef]
- Aldhyani, T.H.; Alshebami, A.S.A.; Alzahrani, M.Y. Soft Computing Model to Predict Chronic Diseases. J. Inf. Sci. Eng. 2020, 36, 365–376. [Google Scholar]
- Singh, C.; Imam, T.; Wibowo, S.; Grandhi, S. A Deep Learning Approach for Sentiment Analysis of COVID-19 Reviews. Appl. Sci. 2022, 12, 3709. [Google Scholar] [CrossRef]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of suicide ideation in social media forums using deep learning. Algorithms 2020, 13, 7. [Google Scholar] [CrossRef]
- Desmet, B.; Hoste, V. Emotion detection in suicide notes. Expert Syst. Appl. 2013, 40, 6351–6358. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, L.; Chiu, D.; Liu, T.; Li, X.; Zhu, T. Detecting suicidal ideation in Chinese microblogs with psychological lexicons. In Proceedings of the 2014 IEEE 11th International Conference on Ubiquitous Intelligence and Computing and 2014 IEEE 11th International Conference on Autonomic and Trusted Computing and 2014 IEEE 14th International Conference on Scalable Computing and Communications and Its Associated Workshops, Bali, Indonesia, 9–12 December 2014; pp. 844–849. [Google Scholar]
- Braithwaite, S.R.; Giraud-Carrier, C.; West, J.; Barnes, M.D.; Hanson, C.L. Validating machine learning algorithms for Twitter data against established measures of suicidality. JMIR Ment. Health 2016, 3, e21. [Google Scholar] [CrossRef]
- Sueki, H. The association of suicide-related Twitter use with suicidal behaviour: A cross-sectional study of young internet users in Japan. J. Affect. Disord. 2015, 170, 155–160. [Google Scholar] [CrossRef]
- O’Dea, B.; Wan, S.; Batterham, P.J.; Calear, A.L.; Paris, C.; Christensen, H. Detecting suicidality on Twitter. Internet Interv. 2015, 2, 183–188. [Google Scholar] [CrossRef]
- Okhapkina, E.; Okhapkin, V.; Kazarin, O. Adaptation of information retrieval methods for identifying of destructive informational influence in social networks. In Proceedings of the 2017 IEEE 31st International Conference on Advanced Information Networking and Applications Workshops (WAINA), Taipei, Taiwan, 27–29 March 2017; pp. 87–92. [Google Scholar]
- Sawhney, R.; Manchanda, P.; Singh, R.; Aggarwal, S. A computational approach to feature extraction for identification of suicidal ideation in tweets. In Proceedings of the ACL 2018, Student Research Workshop, Melbourne, Australia, 15–20 July 2018; pp. 91–98. [Google Scholar]
- Alkahtani, H.; Aldhyani, T.H.H. Artificial Intelligence Algorithms for Malware Detection in Android-Operated Mobile Devic-es. Sensors 2022, 22, 2268. [Google Scholar] [CrossRef]
- Wang, C.; Jiang, F.; Yang, H. A hybrid framework for text modeling with convolutional rnn. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; ACM: New York, NY, USA, 2017; pp. 2061–2069. [Google Scholar]
- Sawhney, R.; Manchanda, P.; Mathur, P.; Shah, R.; Singh, R. Exploring and learning suicidal ideation connotations on social media with deep learning. In Proceedings of the 9th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Brussels, Belgium, 31 October–1 November 2018; pp. 167–175. [Google Scholar]
- Ji, S.; Yu, C.P.; Fung, S.-F.; Pan, S.; Long, G. Supervised learning for suicidal ideation detection in online user content. Complexity 2018, 2018, 6157249. [Google Scholar] [CrossRef]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the NIPS’13, 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2003; pp. 3111–3119. [Google Scholar]
- Ahmed, H.; Traore, I.; Saad, S. Detecting opinion spams and fake news using text classification. Secur. Priv. 2018, 1, e9. [Google Scholar] [CrossRef]
- Arshi, S.; Zhang, L.; Strachan, R. Prediction using LSTM networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Alsubari, S.N.; Deshmukh, S.N.; Al-Adhaileh, M.H.; Alsaade, F.W.; Aldhyani, T.H. Development of Integrated Neural Network Model for Identification of Fake Reviews in E-Commerce Using Multidomain Datasets. Appl. Bionics Biomech. 2021, 2021, 5522574. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Alzahrani, M.E.; Aldhyani, T.H.H.; Alsubari, S.N.; Althobaiti, M.M.; Fahad, A. Developing an Intelligent System with Deep Learning Algorithms for Sentiment Analysis of E-Commerce Product Reviews. Comput. Intell. Neurosci. 2022, 2022, 3840071. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Roy, A.; Nikolitch, K.; McGinn, R.; Jinah, S.; Klement, W.; Kaminsky, Z.A. A machine learning approach predicts future risk to suicidal ideation from social media data. npj Digit. Med. 2020, 3, 78. [Google Scholar] [CrossRef]
- Ryu, S.; Lee, H.; Lee, D.-K.; Park, K. Use of a Machine Learning Algorithm to Predict Individuals with Suicide Ideation in the General Population. Psychiatry Investig. 2018, 15, 1030–1036. [Google Scholar] [CrossRef]
- Ferrag, M.A.; Maglaras, L.; Moschoyiannis, S.; Janicke, H. Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study. J. Inf. Secur. Appl. 2020, 50, 102419. [Google Scholar] [CrossRef]
- Castellanos-Garzón, J.A.; Costa, E.; Jaimes S., J.L.; Corchado Rodríguez, J.M. An evolutionary framework for machine learning applied to medical data. Knowl.-Based Syst. 2019, 185, 104982. [Google Scholar] [CrossRef]
- Al-Adhaileh, M.H.; Aldhyani, T.H.H.; Alghamdi, A.D. Online Troll Reviewer Detection Using Deep Learning Techniques. Appl. Bionics Biomech. 2020, 2022, 4637594. [Google Scholar] [CrossRef] [PubMed]
- Aladağ, A.E.; Muderrisoglu, S.; Akbas, N.B.; Zahmacioglu, O.; Bingol, H.O. Detecting suicidal ideation on forums: Proof-of-concept study. J. Med. Internet Res. 2018, 20, e215. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Input sequence length | 430 |
| Embedding dimension | 32 |
| Vocabulary size | 30,000 |
| Number of filters | 100 |
| LSTM units | 100 |
| Dropout | 0.3 |
| Batch size | 64 |
| Number of epochs | 5 |
| Activation function | ReLU |
| Optimizers | RMSprop (textual features) + Adam (LIWC features) |
| Dataset | Total Samples | Training (70%) | Validation (10%) | Testing (20%) |
|---|---|---|---|---|
| Reddit (SuicideWatch) | 232,074 | 162,452 | 23,207 | 46,415 |
| Algorithm | Precision (%) | Recall (%) | Specificity (%) | F-score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| CNN–BiLSTM | 94.3 | 94.9 | 94.3 | 95 | 95 |
| XGBoost | 93.5 | 89.1 | 93.8 | 91.3 | 91.5 |
| Algorithm | Precision (%) | Recall (%) | Specificity (%) | F-score (%) | Accuracy (%) |
|---|---|---|---|---|---|
| CNN–BiLSTM | 85.2 | 83.5 | 85.6 | 84.3 | 84.5 |
| XGBoost | 88.6 | 84.7 | 89.1 | 86.6 | 86.9 |
| Paper Id | Dataset Distribution | Word Representation Approach | Model | Results |
|---|---|---|---|---|
| Ref [21] | 3549 suicide indicative posts and 3652 non-suicidal | Word2Vec | LSTM-CNN | 93 % accuracy |
| Ref [20] | 3549 suicide posts and 3652 non-suicidal | Word2Vec | LSTM | 92% accuracy |
| Ref [47] | 785 suicide posts and 785 non-suicidal | TF-IDF | SVM | 92% accuracy |
| Proposed model | 116,037 suicide and 116,037 non-suicide posts | Word2Vec | CNN–BiLSTM | 95% accuracy |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aldhyani, T.H.H.; Alsubari, S.N.; Alshebami, A.S.; Alkahtani, H.; Ahmed, Z.A.T. Detecting and Analyzing Suicidal Ideation on Social Media Using Deep Learning and Machine Learning Models. Int. J. Environ. Res. Public Health 2022, 19, 12635. https://doi.org/10.3390/ijerph191912635
Aldhyani THH, Alsubari SN, Alshebami AS, Alkahtani H, Ahmed ZAT. Detecting and Analyzing Suicidal Ideation on Social Media Using Deep Learning and Machine Learning Models. International Journal of Environmental Research and Public Health. 2022; 19(19):12635. https://doi.org/10.3390/ijerph191912635
Chicago/Turabian StyleAldhyani, Theyazn H. H., Saleh Nagi Alsubari, Ali Saleh Alshebami, Hasan Alkahtani, and Zeyad A. T. Ahmed. 2022. "Detecting and Analyzing Suicidal Ideation on Social Media Using Deep Learning and Machine Learning Models" International Journal of Environmental Research and Public Health 19, no. 19: 12635. https://doi.org/10.3390/ijerph191912635
APA StyleAldhyani, T. H. H., Alsubari, S. N., Alshebami, A. S., Alkahtani, H., & Ahmed, Z. A. T. (2022). Detecting and Analyzing Suicidal Ideation on Social Media Using Deep Learning and Machine Learning Models. International Journal of Environmental Research and Public Health, 19(19), 12635. https://doi.org/10.3390/ijerph191912635