




Spatiotemporal Feature Enhancement Aids the Driving Intention Inference of Intelligent Vehicles


Abstract
1. Introduction
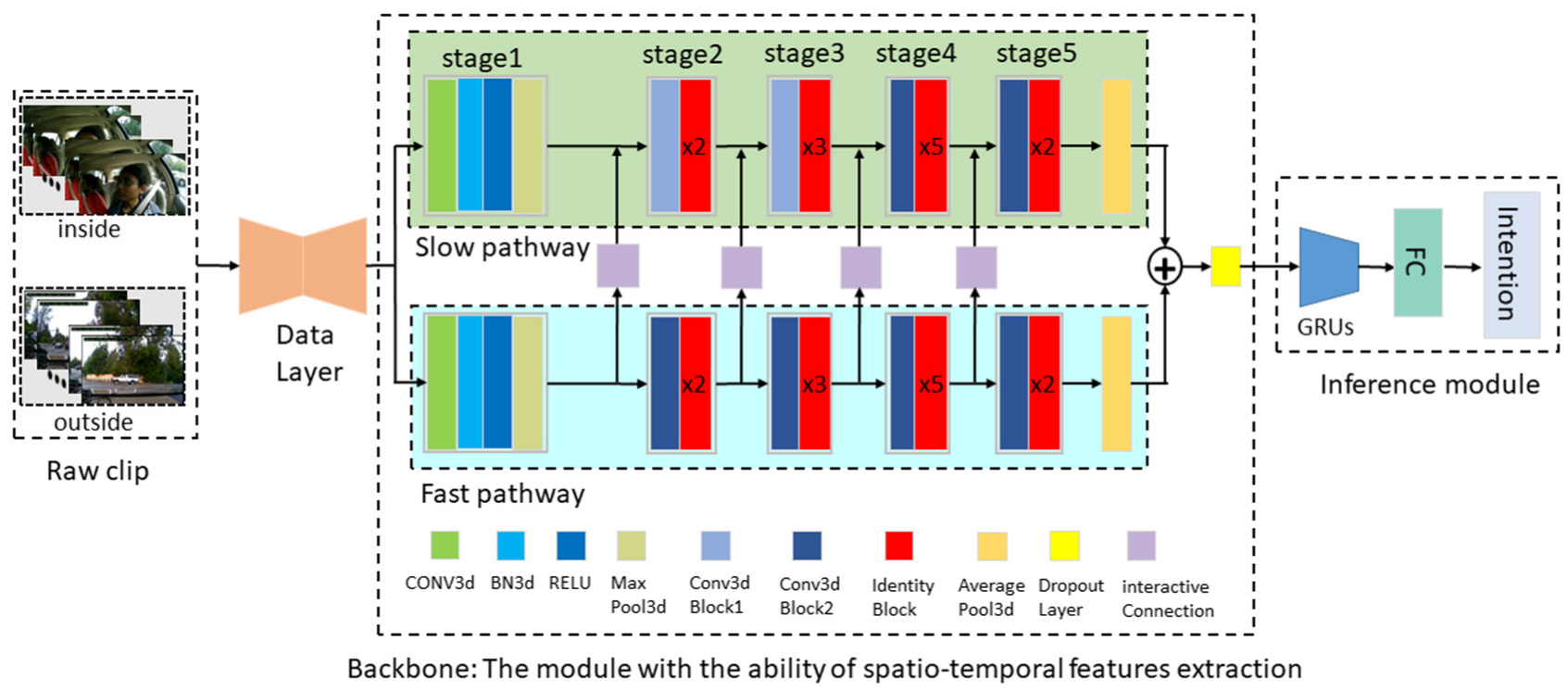
2. Methods
2.1. Data Layer
2.2. Spatiotemporal Feature Extraction, Based on Two-Stream Networks
2.2.1. Slow Pathway
2.2.2. Fast Pathway
- High frame rate. According to the data layer, the number of images allocated to FP is α times that of SP, which also means that FP processes traffic scene video data at a higher speed;
- High temporal resolution. To ensure a high processing speed, the temporal dimension of the convolution kernel is greater than 1 throughout all stages. Therefore, the FP has the ability of detailed motion feature extraction while maintaining temporal fidelity;
- Few-channel capacity. In the study, the number of input channels of FP is 1/8 of SP, denoted as β = 1/8. Therefore, compared with SP, FP focuses more on temporal modeling and weakens the extraction ability of spatial semantic information.
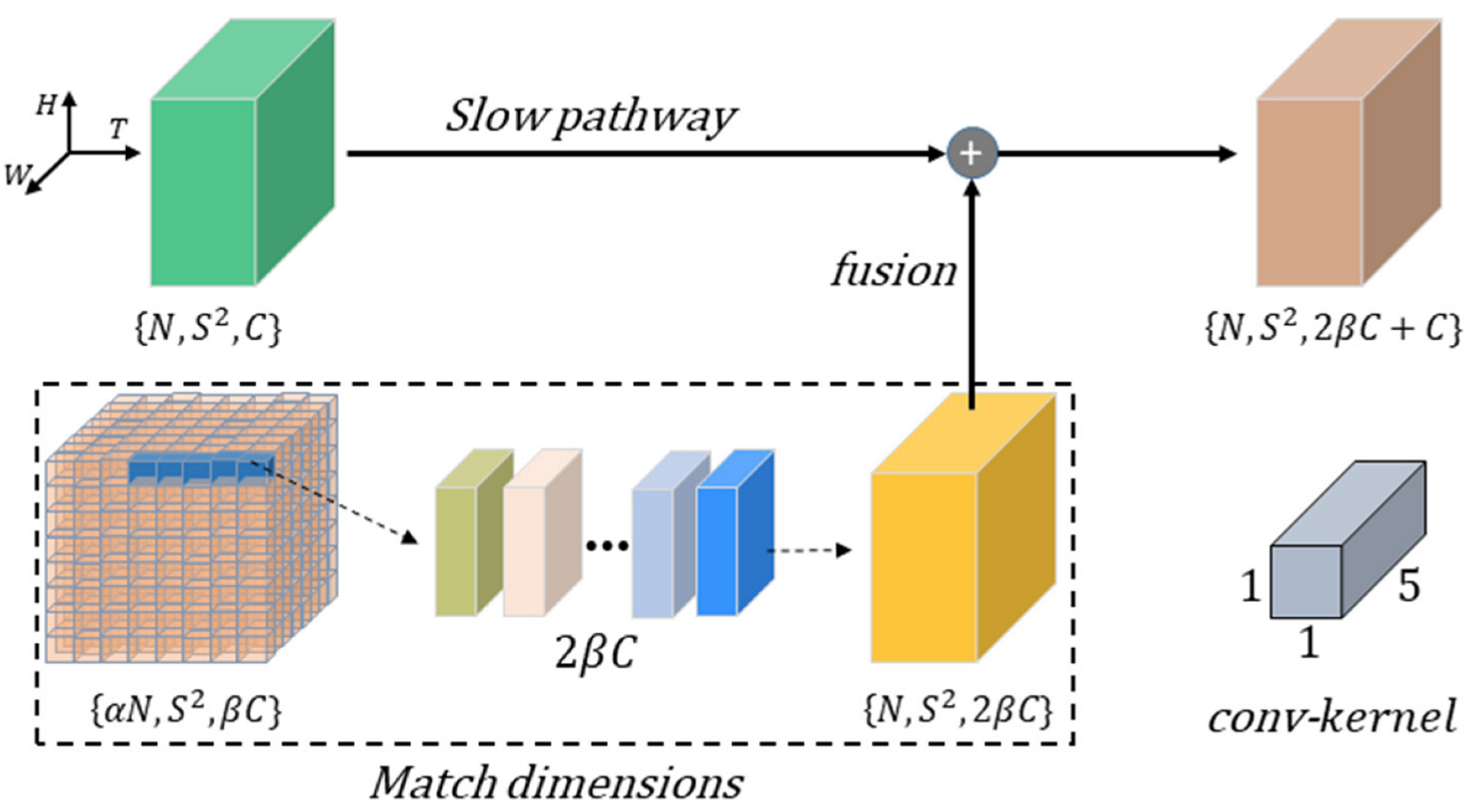
2.2.3. Spatiotemporal Feature Enhancement
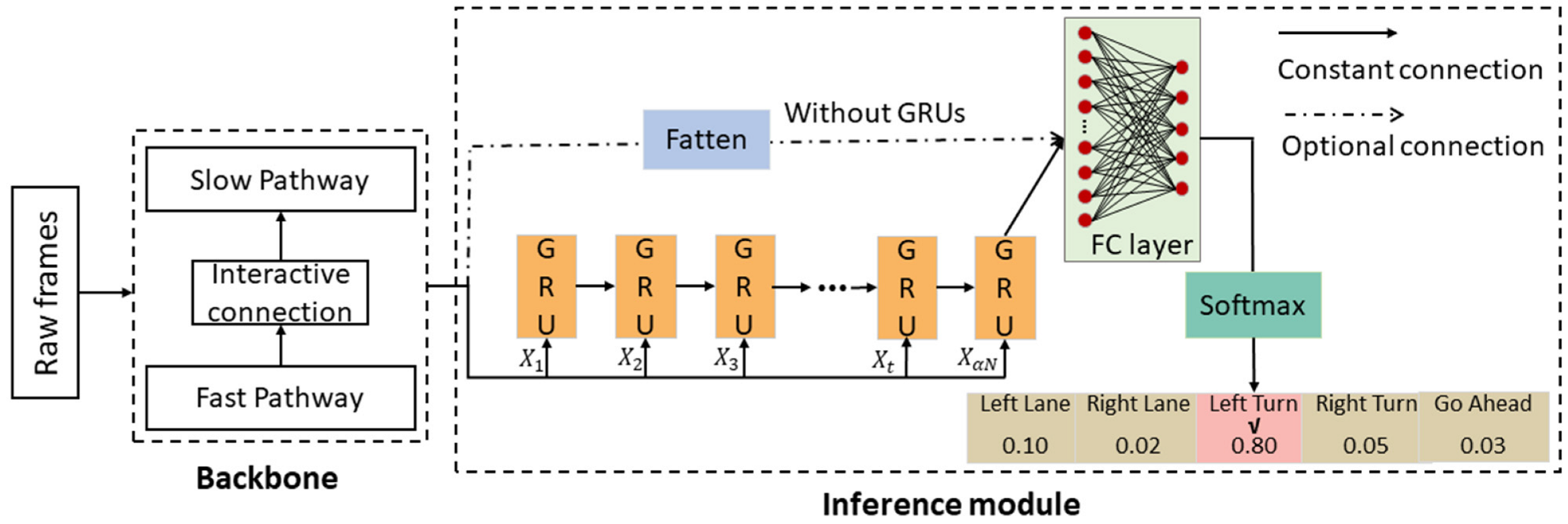
2.3. Driver Intention Inference Module
2.4. Implementation Details and Evaluation Metrics
2.4.1. Implementation Details
2.4.2. Evaluation Metrics
3. Results
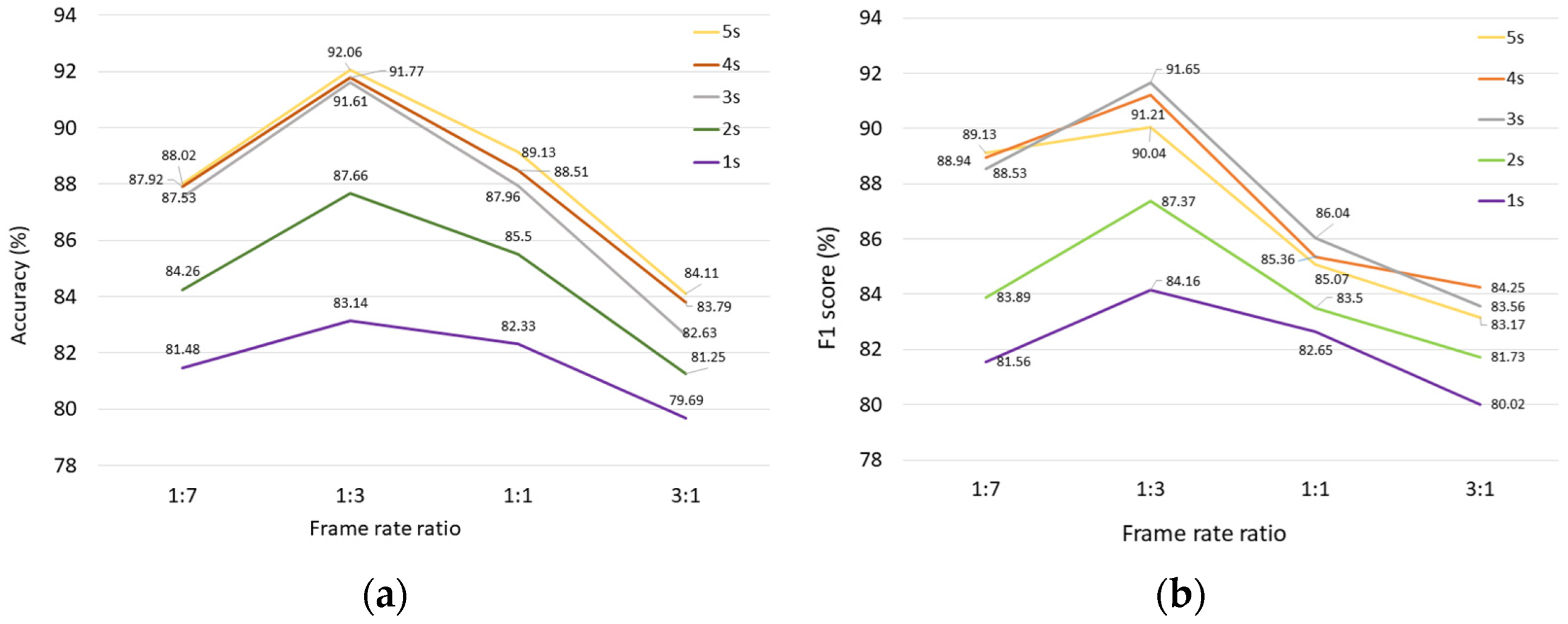
3.1. Comparison of the Performance on Different Frame Rate Ratio
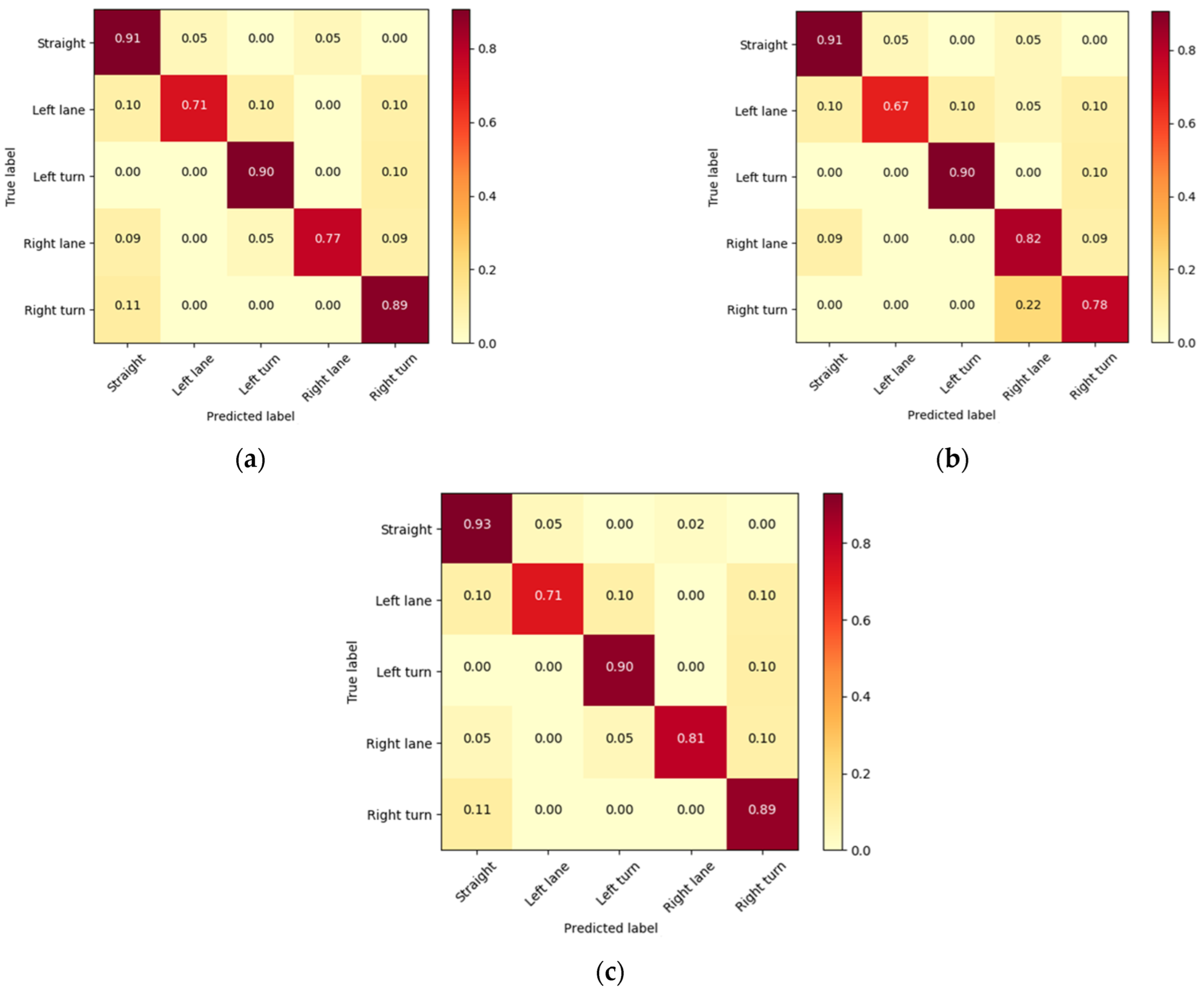
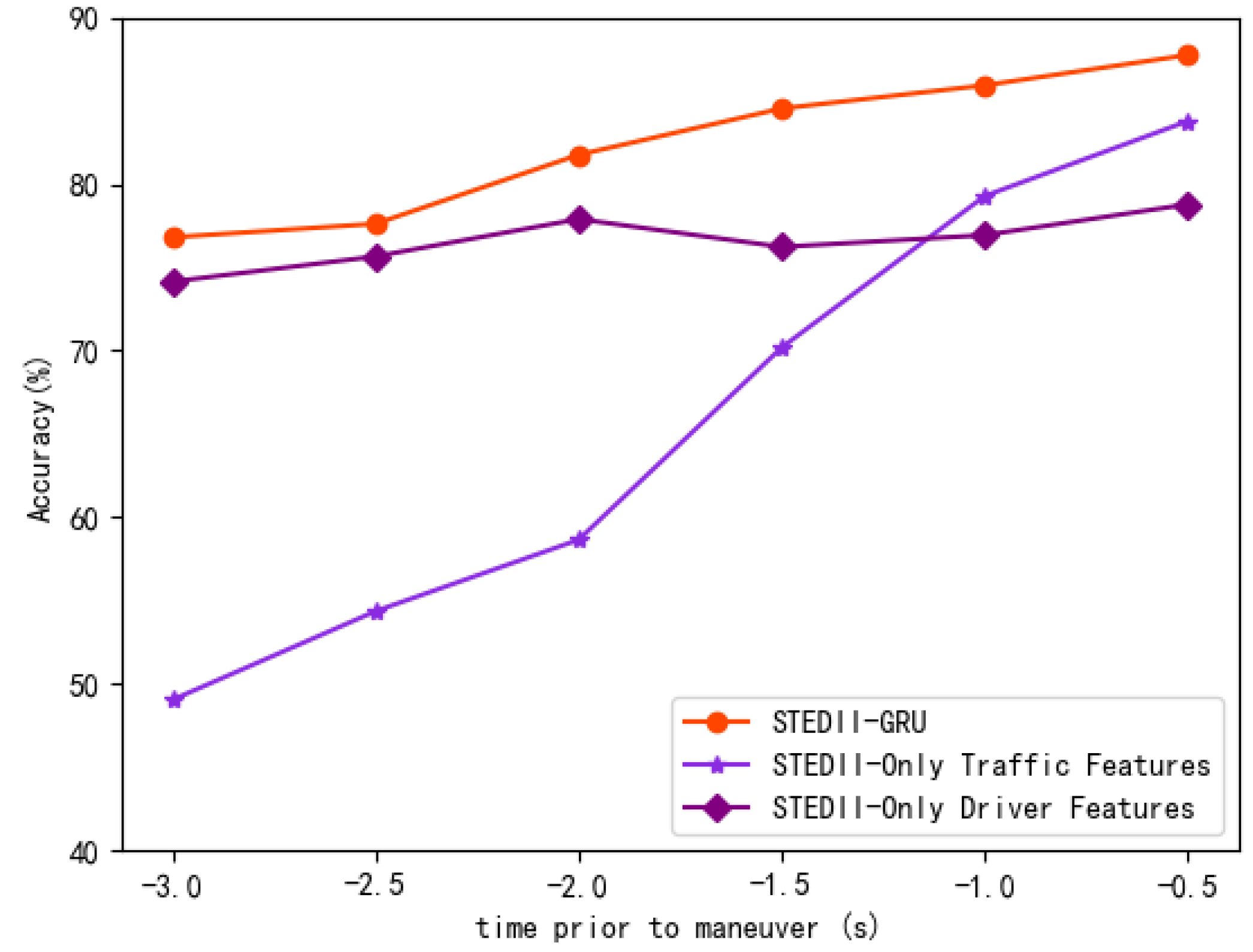
3.2. Driver Intention Inference
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Birrell, S.A.; Wilson, D.; Yang, C.P.; Dhadyalla, G.; Jennings, P. How driver behaviour and parking alignment affects inductive charging systems for electric vehicles. Transp. Res. Part C Emerg. Technol. 2015, 58, 721–731. [Google Scholar] [CrossRef]
- Guo, L.; Manglani, S.; Liu, Y.; Jia, Y. Automatic sensor correction of autonomous vehicles by human-vehicle teaching-and-learning. IEEE Trans. Veh. Technol. 2018, 67, 8085–8099. [Google Scholar] [CrossRef]
- Biondi, F.; Alvarez, I.; Jeong, K.A. Human–vehicle cooperation in automated driving: A multidisciplinary review and appraisal. Int. J. Hum. Comput. Interact. 2019, 35, 932–946. [Google Scholar] [CrossRef]
- Olaverri-Monreal, C. Promoting trust in self-driving vehicles. Nat. Electron. 2020, 3, 292–294. [Google Scholar] [CrossRef]
- Lv, C.; Wang, H.; Cao, D.; Zhao, Y.; Auger, D.J.; Sullman, M.; Matthias, R.; Skrypchuk, L.; Mouzakitis, A. Characterization of Driver Neuromuscular Dynamics for Human–Automation Collaboration Design of Automated Vehicles. IEEE ASME Trans. Mechatron. 2018, 23, 2558–2567. [Google Scholar] [CrossRef]
- Zhang, P.; Qian, Z. Managing traffic with raffles. Transp. Res. Part C Emerg. Technol. 2019, 107, 490–509. [Google Scholar] [CrossRef]
- Hubmann, C.; Schulz, J.; Becker, M.; Althoff, D.; Stiller, C. Automated Driving in Uncertain Environments: Planning with Interaction and Uncertain Maneuver Prediction. IEEE Trans. Intell. Veh. 2018, 3, 5–17. [Google Scholar] [CrossRef]
- Bratman, M. Intention, Plans, and Practical Reason; Harvard University Press: Cambridge, MA, USA, 1987; p. 200. [Google Scholar]
- Jang, Y.; Mallipeddi, R.; Lee, M. Driver’s lane-change intent identification based on pupillary variation. In Proceedings of the 2014 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 10–13 January 2014; pp. 197–198. [Google Scholar]
- Amsalu, S.B.; Homaifar, A. driver behavior modeling near intersections using Hidden Markov Model based on genetic algorithm. In Proceedings of the 2016 IEEE International Conference on Intelligent Transportation Engineering (ICITE), Singapore, 20–22 August 2016; pp. 193–200. [Google Scholar]
- Zheng, Y.; Hansen, J.H.L. Lane-Change Detection from Steering Signal Using Spectral Segmentation and Learning-Based Classification. IEEE Trans. Intell. Veh. 2017, 2, 14–24. [Google Scholar] [CrossRef]
- Mitrovic, D. Machine learning for car navigation. International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems. In Proceedings of the IEA/AIE 2001: Engineering of Intelligent Systems, Berlin, Germany, 8 June 2001; pp. 670–675. [Google Scholar]
- Kim, H.; Bong, J.; Park, J.; Park, S. Prediction of Driver’s Intention of Lane Change by Augmenting Sensor Information Using Machine Learning Techniques. Sensors 2017, 17, 1350. [Google Scholar] [CrossRef]
- Leonhardt, V.; Wanielik, G. Neural network for lane change prediction assessing driving situation, driver behavior and vehicle movement. In Proceedings of the IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Girma, A.; Amsalu, S.; Workineh, A.; Khan, M.; Homaifar, A. Deep Learning with Attention Mechanism for Predicting Driver Intention at Intersection. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1183–1188. [Google Scholar]
- Tang, L.; Wang, H.; Zhang, W.; Mei, Z.; Li, L. Driver Lane Change Intention Recognition of Intelligent Vehicle Based on Long Short-Term Memory Network. IEEE Access 2022, 8, 136898–136905. [Google Scholar] [CrossRef]
- Pai, R.; Dubey, A.; Mangaonkar, N. Real Time Eye Monitoring System Using CNN for Drowsiness and Attentiveness System. In Proceedings of the Asian Conference on Innovation in Technology (ASIANCON), Pune, India, 27–29 August 2021; pp. 1–4. [Google Scholar]
- Leekha, M.; Goswami, M.; Shah, R.R.; Yin, Y.; Zimmermann, R. Are You Paying Attention? Detecting Distracted Driving in Real-Time. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 171–180. [Google Scholar]
- Lin, S.; Runger, G.C. GCRNN: Group-Constrained Convolutional Recurrent Neural Network. IEEE Trans. Neural. Netw. Learn. Syst. 2018, 29, 4709–4718. [Google Scholar] [CrossRef] [PubMed]
- Xing, Y.; Tian, B.; Lv, C.; Cao, D. A Two-Stage Learning Framework for Driver Lane Change Intention Inference. IFAC PapersOnLine 2020, 53, 638–643. [Google Scholar] [CrossRef]
- Hara, K.; Kataoka, H.; Satoh, Y. Can Spatiotemporal 3D CNNs Retrace the History of 2D CNNs and ImageNet? In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6546–6555. [Google Scholar]
- Gebert, P.; Roitberg, A.; Haurilet, M.; Stiefelhagen, R. End-to-end Prediction of Driver Intention using 3D Convolutional Neural Networks. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 969–974. [Google Scholar]
- Huang, H.; Zeng, Z.; Yao, D.; Pei, X.; Zhang, Y. Spatial-Temporal ConvLSTM for Vehicle Driving Intention Prediction. Tsinghua Sci. Technol. 2022, 27, 599–609. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, B. An ensemble deep learning approach for driver lane change intention inference. Transp. Res. Part C Emerg. Technol. 2020, 115, 102615. [Google Scholar] [CrossRef]
- Xing, Y.; Lv, C.; Cao, D.; Velenis, B. Multi-scale driver behavior modeling based on deep spatial-temporal representation for intelligent vehicles. Transp. Res. Part C Emerg. Technol. 2021, 130, 103288. [Google Scholar] [CrossRef]
- Chen, Z.; Huang, X. End-to-end learning for lane keeping of self-driving cars. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1856–1860. [Google Scholar]
- Fernandez, N. Two-stream Convolutional Networks for End-to-end Learning of Self-driving Cars. arXiv 2018, arXiv:1811.05785v2. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal Residual Networks for Video Action Recognition. In Proceedings of the NIPS’16: Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3468–3476. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the CVPR 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the ICML’15: Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 1106–1114. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Liu, F.; Zhang, Z.; Zhou, R. Automatic modulation recognition based on CNN and GRU. Tsinghua Sci. Technol. 2022, 27, 422–431. [Google Scholar] [CrossRef]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Jain, A.; Koppula, H.S.; Raghavan, B.; Soh, S.; Saxena, A. Car that knows before you do: Anticipating maneuvers via learning temporal driving models. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3182–3190. [Google Scholar]
- Wu, Z.; Liang, K.; Liu, D.; Zhao, Z. Driver Lane Change Intention Recognition Based on Attention Enhanced Residual-MBi-LSTM Network. IEEE Access 2022, 10, 58050–58061. [Google Scholar] [CrossRef]
- Yu, B.; Bao, S.; Zhang, Y.; Sullivan, J.; Flannagan, M. Measurement and prediction of driver trust in automated vehicle technologies: An application of hand position transition probability matrix. Transp. Res. Part C Emerg. Technol. 2021, 124, 102957. [Google Scholar] [CrossRef]
- Rong, Y.; Akata, Z.; Kasneci, E. Driver Intention Anticipation Based on In-Cabin and Driving Scene Monitoring. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is Space-Time Attention All You Need for Video Understanding? In Proceedings of the 38th International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; Volume 139, pp. 813–824. [Google Scholar]
- Liu, Z.; Wang, L.; Wu, W.; Qian, C.; Lu, T. TAM: Temporal Adaptive Module for Video Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13688–13698. [Google Scholar]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Lin, J.; Gan, C.; Han, S. TSM: Temporal Shift Module for Efficient Video Understanding. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 7082–7092. [Google Scholar]
- Ilg, E.; Mayer, N.; Saikia, T.; Keuper, M.; Dosovitskiy, A.; Brox, T. FlowNet 2.0: Evolution of Optical Flow Estimation with Deep Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1655. [Google Scholar]
- Leonhardt, V.; Pech, T.; Wanielik, G. Data fusion and assessment for maneuver prediction including driving situation and driver behavior. In Proceedings of the 2016 19th International Conference on Information Fusion (FUSION), Heidelberg, Germany, 5–8 July 2016; pp. 1702–1708. [Google Scholar]
- Xing, Y.; Lv, C.; Wang, H.; Cao, D.; Velenis, B. Dynamic integration and online evaluation of vision-based lane detection algorithms. IET Intell. Transp. Syst. 2018, 13, 55–62. [Google Scholar] [CrossRef]
- Khairdoost, N.; Shirpour, M.; Bauer, M.A.; Beauchemin, S.S. Real-Time Driver Maneuver Prediction Using LSTM. IEEE Trans. Intell. Veh. 2020, 5, 714–724. [Google Scholar] [CrossRef]
- Lv, Y.; Liu, Y.; Chen, Y.; Zhu, F. End-to-end Autonomous Driving Vehicle Steering Angle Prediction Based on Spatiotemporal Features. China J. Highw. Transp. 2022, 35, 263–272. [Google Scholar]
- Xing, Y.; Lv, C.; Cao, D.; Wang, H.; Zhao, Y. Driver workload estimation using a novel hybrid method of error reduction ratio causality and support vector machine. Measurement 2018, 114, 390–397. [Google Scholar] [CrossRef]
- Morris, E.A.; Hirsch, J.A. Does rush hour see a rush of emotions? Driver mood in conditions likely to exhibit congestion. Travel Behav. Soc. 2016, 5, 5–13. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Layer | Kernel | Stride | Number of Channels | Output Shape |
|---|---|---|---|---|---|
| data layer | - | - | 3 | 224 × 224 | |
| Stage 1 | Conv3d | (1, 7, 7) | (1, 2, 2) | 64 | 112 × 112 |
| BN3d | - | - | 64 | 112 × 112 | |
| Maxpool3d | (1, 3, 3) | (1, 2, 2) | 64 | 56 × 56 | |
| Stage 2 | conv3d_block1 | (1, 3, 3) | (1, 1, 1) | [64, 64, 256] | 56 × 56 |
| Identity_block × 2 | (1, 3, 3) | - | [64, 64, 256] | 56 × 56 | |
| Stage 3 | conv3d_block1 | (1, 3, 3) | (1, 2, 2) | [128, 128, 512] | 28 × 28 |
| Identity_block × 3 | (1, 3, 3) | - | [128, 128, 512] | 28 × 28 | |
| Stage 4 | conv3d_block2 | (3, 3, 3) | (1, 2, 2) | [256, 256, 1024] | 14 × 14 |
| Identity_block × 5 | (3, 3, 3) | - | [256, 256, 1024] | 14 × 14 | |
| Stage 5 | conv3d_block2 | (3, 3, 3) | (1, 2, 2) | [512, 512, 2048] | 7 × 7 |
| Identity_block × 2 | (3, 3, 3) | - | [512, 512, 2048] | 7 × 7 |
| Stage | Layer | Kernel | Stride | Number of Channels | Output Shape |
|---|---|---|---|---|---|
| data layer | - | - | 3 | 224 × 224 | |
| Stage 1 | Conv3d | (5, 7, 7) | (1, 2, 2) | 8 | 112 × 112 |
| BN3d | - | - | 8 | 112 × 112 | |
| Maxpool3d | (1, 3, 3) | (1, 2, 2) | 8 | 56 × 56 | |
| Stage 2 | Conv3d_block2 | (3, 3, 3) | (1, 1, 1) | [8, 8, 32] | 56 × 56 |
| Identity_block × 2 | (3, 3, 3) | - | [8, 8, 32] | 56 × 56 | |
| Stage 3 | Conv3d_block2 | (3, 3, 3) | (1, 2, 2) | [16, 16, 64] | 28 × 28 |
| Identity_block × 3 | (3, 3, 3) | - | [16, 16, 64] | 28 × 28 | |
| Stage 4 | Conv3d_block2 | (3, 3, 3) | (1, 2, 2) | [32, 32, 128] | 14 × 14 |
| Identity_block × 5 | (3, 3, 3) | - | [32, 32, 128] | 14 × 14 | |
| Stage 5 | Conv3d_block2 | (3, 3, 3) | (1, 2, 2) | [64, 64, 256] | 7 × 7 |
| Identity_block × 2 | (3, 3, 3) | - | [64, 64, 256] | 7 × 7 |
| Algorithms | Data Source | Acc ± SD (%) | F1 Score ± SD (%) | Param (M) |
|---|---|---|---|---|
| 3DResNet | I-only | 83.1 ± 2.5 | 81.7 ± 2.6 | 85.26 |
| O-only | 53.2 ± 0.5 | 43.4 ± 0.9 | 85.26 | |
| In and out | 75.5 ± 2.4 | 73.2 ± 2.2 | 170.52 | |
| ConvLSTM+3DResNet | I-only | 77.40 ± 0.02 | 75.49 ± 0.02 | 46.22 |
| O-only | 60.87 ± 0.01 | 66.38 ± 0.03 | 5.41 | |
| In and out | 83.98 ± 0.01 | 84.30 ± 0.01 | 57.92 | |
| TimeSformer | I-only | 81.82 ± 0.48 | 80.51 ± 0.86 | 121.40 |
| O-only | 60.81 ± 0.51 | 50.79 ± 1.38 | 121.40 | |
| In and out | 82.22 ± 0.66 | 78.24 ± 0.95 | 121.40 | |
| TANet | I-only | 83.20 ± 1.91 | 82.84 ± 3.08 | 25.59 |
| O-only | 64.14 ± 0.33 | 55.64 ± 0.42 | 25.59 | |
| In and out | 62.96 ± 0.52 | 55.10 ± 0.67 | 25.59 | |
| STEDII-GRU | I-only | 81.69 ± 0.58 | 80.31 ± 1.86 | 34.82 |
| O-only | 84.75 ± 0.59 | 85.30 ± 0.68 | 34.82 | |
| In and out | 92.06 ± 1.89 | 90.04 ± 2.22 | 34.82 |
| Models | Lane-Keeping | Left-Lane Change | Left Turn | Right-Lane Change | Right Turn | Acc (%) | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
(%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | ||
| SVM | 83.43 | 66.93 | 68.24 | 50.37 | 55.32 | 67.69 | 73.54 | 52.48 | 23.45 | 87.31 | 65.85 |
| HMM | 61.70 | 74.35 | 80.00 | 66.67 | 58.33 | 46.66 | 64.00 | 69.56 | 72.72 | 67.34 | 67.74 |
| Bi-LSTM | 85.02 | 70.83 | 75.00 | 78.94 | 44.43 | 66.67 | 78.94 | 75.00 | 66.67 | 75.00 | 74.03 |
| STEDII-FC | 90.69 | 88.63 | 71.42 | 88.23 | 90.00 | 75.00 | 77.27 | 89.47 | 88.89 | 61.53 | 83.81 |
| STEDII -FL | 90.69 | 90.69 | 66.67 | 87.50 | 90.00 | 90.00 | 81.81 | 78.26 | 77.78 | 58.33 | 82.05 |
| STEDII-GRU | 93.02 | 88.89 | 71.42 | 88.23 | 90.00 | 75.00 | 77.27 | 94.45 | 88.89 | 61.53 | 84.92 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Chen, H.; Liu, H.; Feng, X. Spatiotemporal Feature Enhancement Aids the Driving Intention Inference of Intelligent Vehicles. Int. J. Environ. Res. Public Health 2022, 19, 11819. https://doi.org/10.3390/ijerph191811819
Chen H, Chen H, Liu H, Feng X. Spatiotemporal Feature Enhancement Aids the Driving Intention Inference of Intelligent Vehicles. International Journal of Environmental Research and Public Health. 2022; 19(18):11819. https://doi.org/10.3390/ijerph191811819
Chicago/Turabian StyleChen, Huiqin, Hailong Chen, Hao Liu, and Xiexing Feng. 2022. "Spatiotemporal Feature Enhancement Aids the Driving Intention Inference of Intelligent Vehicles" International Journal of Environmental Research and Public Health 19, no. 18: 11819. https://doi.org/10.3390/ijerph191811819
APA StyleChen, H., Chen, H., Liu, H., & Feng, X. (2022). Spatiotemporal Feature Enhancement Aids the Driving Intention Inference of Intelligent Vehicles. International Journal of Environmental Research and Public Health, 19(18), 11819. https://doi.org/10.3390/ijerph191811819