
How Neighborhood Characteristics Influence Neighborhood Crimes: A Bayesian Hierarchical Spatial Analysis



Abstract
1. Introduction
2. Materials and Methods
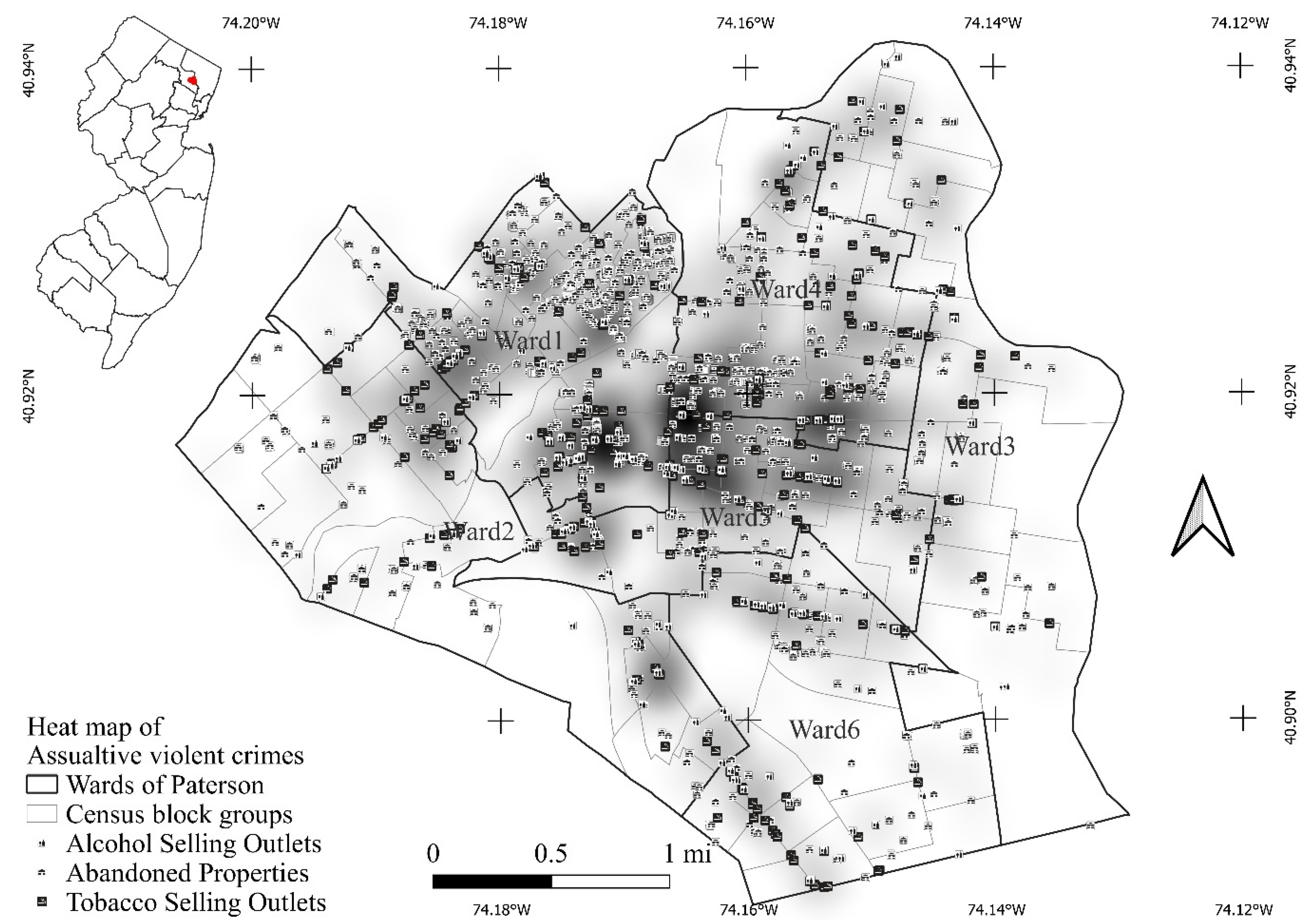
2.1. Paterson, New Jersey
2.2. Violent Crimes, Harmful Products, Urban Prosperity, and Ethnic Landscape
2.3. Bayesian Hierarchical Modeling Approach
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fu, B.; Yu, D.L.; Zhang, Y.J. The livable urban landscape: GIS and remote sensing extracted land use assessment for urban livability in Changchun Proper, China. Land Use Policy 2019, 87, 11. [Google Scholar] [CrossRef]
- Lardier, D.T., Jr.; Reid, R.J.; Yu, D.; Garcia-Reid, P. A Spatial Analysis of Alcohol Outlet Density and Abandoned Properties on Violent Crime in Paterson New Jersey. J. Community Health 2019, 45, 534–541. [Google Scholar] [CrossRef] [PubMed]
- Nazmfar, H.; Alavi, S.; Feizizadeh, B.; Mostafavi, M.A. Analysis of Spatial Distribution of Crimes in Urban Public Spaces. J. Urban. Plan. Dev. 2020, 146, 05020006. [Google Scholar] [CrossRef]
- Feng, J.; Dong, Y.; Song, L.L. A spatio-temporal analysis of urban crime in Beijing: Based on data for property crime. Urban. Stud. 2016, 53, 3223–3245. [Google Scholar] [CrossRef]
- Yu, D.L.; Fang, C.L. The dynamics of public safety in cities: A case study of Shanghai from 2010 to 2025. Habitat Int. 2017, 69, 104–113. [Google Scholar] [CrossRef]
- Liu, L.; Feng, J.X.; Ren, F.; Xiao, L.Z. Examining the relationship between neighborhood environment and residential locations of juvenile and adult migrant burglars in China. Cities 2018, 82, 10–18. [Google Scholar] [CrossRef]
- De Nadai, M.; Xu, Y.Y.; Letouz, E.; Gonzalez, M.C.; Lepri, B. Socio-economic, built environment, and mobility conditions associated with crime: A study of multiple cities. Sci. Rep. 2020, 10, 12. [Google Scholar] [CrossRef]
- Wang, H.J.; Yao, H.X.; Kifer, D.; Graif, C.; Li, Z.H. Non-Stationary Model for Crime Rate Inference Using Modern Urban Data. IEEE Trans. Big Data 2019, 5, 180–194. [Google Scholar] [CrossRef]
- Johansen, R.; Neal, Z.; Gasteyer, S. The view from a broken window: How residents make sense of neighbourhood disorder in Flint. Urban. Stud. 2015, 52, 3054–3069. [Google Scholar] [CrossRef]
- Parkes, A.; Kearns, A.; Atkinson, R. What makes people dissatisfied with their neighbourhoods? Urban. Stud. 2002, 39, 2413–2438. [Google Scholar] [CrossRef]
- He, L.; Paez, A.; Liu, D.S. Built environment and violent crime: An environmental audit approach using Google Street View. Comput. Environ. Urban. Syst. 2017, 66, 83–95. [Google Scholar] [CrossRef]
- Subica, A.M.; Douglas, J.A.; Kepple, N.J.; Villanueva, S.; Grills, C.T. The geography of crime and violence surrounding tobacco shops, medical marijuana dispensaries, and off-sale alcohol outlets in a large, urban low-income community of color. Prev. Med. 2018, 108, 8–16. [Google Scholar] [CrossRef] [PubMed]
- Wuschke, K.; Andresen, M.A.; Brantingham, P.L. Pathways of crime: Measuring crime concentration along urban roadways. Can. Geogr.-Geogr. Can. 2021, 65, 267–280. [Google Scholar] [CrossRef]
- Gulma, U.L. A new geodemographic classification of the influence of neighbourhood characteristics on crime: The case of Leeds, UK. Comput. Environ. Urban. Syst. 2022, 92, 101748. [Google Scholar] [CrossRef]
- Mak, B.K.L.; Jim, C.Y. Contributions of human and environmental factors to concerns of personal safety and crime in urban parks. Secur. J. 2022, 35, 263–293. [Google Scholar] [CrossRef]
- Delmelle, E.C.; Thill, J.C. Mutual relationships in neighborhood socioeconomic change. Urban. Geogr. 2014, 35, 1215–1237. [Google Scholar] [CrossRef]
- Lloyd, D.J.B.; O’Farrell, H. On localised hotspots of an urban crime model. Phys. D-Nonlinear Phenom. 2013, 253, 23–39. [Google Scholar] [CrossRef]
- Schroeder, K.B.; Pepper, G.V.; Nettle, D. Local norms of cheating and the cultural evolution of crime and punishment: A study of two urban neighborhoods. PeerJ 2014, 2, 23. [Google Scholar] [CrossRef]
- Fatehkia, M.; O’Brien, D.; Weber, I. Correlated impulses: Using Facebook interests to improve predictions of crime rates in urban areas. PLoS ONE 2019, 14, e0211350. [Google Scholar] [CrossRef]
- Brown, E. Race, Urban Governance, and Crime Control: Creating Model Cities. Law Soc. Rev. 2010, 44, 769–803. [Google Scholar] [CrossRef]
- Pijper, L.K.; Breetzke, G.D.; Edelstein, I. Building neighbourhood-level resilience to crime: The case of Khayelitsha, South Africa. S. Afr. Geogr. J. 2021, 103, 342–357. [Google Scholar] [CrossRef]
- Wilson, B.; Greenlee, A.J. The geography of opportunity: An exploratory spatial data analysis of U.S. counties. GeoJournal 2016, 81, 625–640. [Google Scholar] [CrossRef]
- McIntyre, S.G. Personal indebtedness, community characteristics and theft crimes. Urban. Stud. 2017, 54, 2395–2419. [Google Scholar] [CrossRef]
- Ganguly, P.; Mukherjee, S. A multifaceted risk assessment approach using statistical learning to evaluate socio-environmental factors associated with regional felony and misdemeanor rates. Phys. A-Stat. Mech. Its Appl. 2021, 574, 125984. [Google Scholar] [CrossRef]
- Masi, C.M.; Hawkley, L.C.; Piotrowski, Z.H.; Pickett, K.E. Neighborhood economic disadvantage, violent crime, group density, and pregnancy outcomes in a diverse, urban population. Soc. Sci. Med. 2007, 65, 2440–2457. [Google Scholar] [CrossRef] [PubMed]
- Hipp, J. What is the ‘Neighbourhood’ in Neighbourhood Satisfaction? Comparing the Effects of Structural Characteristics Measured at the Micro-neighbourhood and Tract Levels. Urban. Stud. 2010, 47, 2517–2536. [Google Scholar] [CrossRef] [PubMed]
- Jennings, J.M.; Milam, A.J.; Greiner, A.; Furr-Holden, C.D.M.; Curriero, F.C.; Thornton, R.J. Neighborhood Alcohol Outlets and the Association with Violent Crime in One Mid-Atlantic City: The Implications for Zoning Policy. J. Urban. Health 2014, 91, 62–71. [Google Scholar] [CrossRef] [PubMed]
- Shihadeh, E.S.; Shrum, W. Serious crime in urban neighborhoods: Is there a race effect? Sociol. Spectr. 2004, 24, 507–533. [Google Scholar] [CrossRef]
- Xu, Y.Q.; Fu, C.; Kennedy, E.; Jiang, S.H.; Owusu-Agyemang, S. The impact of street lights on spatial-temporal patterns of crime in Detroit, Michigan. Cities 2018, 79, 45–52. [Google Scholar] [CrossRef]
- Zhang, F.; Fan, Z.Y.; Kang, Y.H.; Hu, Y.J.; Ratti, C. “Perception bias”: Deciphering a mismatch between urban crime and perception of safety. Landsc. Urban. Plan. 2021, 207, 104003. [Google Scholar] [CrossRef]
- Locke, D.H.; Han, S.; Kondo, M.C.; Murphy-Dunningd, C.; Cox, M. Did community greening reduce crime? Evidence from New Haven, CT, 1996-2007. Landsc. Urban. Plan. 2017, 161, 72–79. [Google Scholar] [CrossRef]
- Cuartas, J. Neighborhood crime undermines parenting: Violence in the vicinity of households as a predictor of aggressive discipline. Child. Abus. Negl. 2018, 76, 388–399. [Google Scholar] [CrossRef] [PubMed]
- Ogneva-Himmelberger, Y.; Ross, L.; Caywood, T.; Khananayev, M.; Starr, C. Analyzing the Relationship between Perception of Safety and Reported Crime in an Urban Neighborhood Using GIS and Sketch Maps. ISPRS Int. J. Geo-Inf. 2019, 8, 531. [Google Scholar] [CrossRef]
- Weber, B.S. Uber and urban crime. Transp. Res. Part A-Policy Pract. 2019, 130, 496–506. [Google Scholar] [CrossRef]
- Da Silva, S.; Boivin, R.; Fortin, F. Social media as a predictor of urban crime. Criminologie 2019, 52, 83–109. [Google Scholar] [CrossRef]
- Shiode, S.; Shiode, N. Crime Geosurveillance in Microscale Urban Environments: NetSurveillance. Ann. Am. Assoc. Geogr. 2020, 110, 1386–1406. [Google Scholar] [CrossRef]
- Anselin, L.; Griffith, D.A. Do Spatial Effects Really Matter in Regression-Analysis. Pap. Reg. Sci. Assoc. 1988, 65, 11–34. [Google Scholar] [CrossRef]
- He, Y.; Lv, B.Y.; Yu, D.L. How does spatial proximity to the high-speed railway system affect inter-city market segmentation in China: A spatial panel analysis. Eurasian Geogr. Econ. 2021, 27, 55–81. [Google Scholar] [CrossRef]
- Yu, D.L.; Zhang, Y.J.; Wu, X.W.; Li, D.; Li, G.D. The varying effects of accessing high-speed rail system on China’s county development: A geographically weighted panel regression analysis. Land Use Policy 2021, 100, 11. [Google Scholar] [CrossRef]
- Zhang, Y.Y.; Ma, W.L.; Yang, H.J.; Wang, Q. Impact of high-speed rail on urban residents’ consumption in China-from a spatial perspective. Transp. Policy 2021, 106, 1–10. [Google Scholar] [CrossRef]
- Tu, Y.; Chen, B.; Lang, W.; Chen, T.T.; Li, M.; Zhang, T.; Xu, B. Uncovering the Nature of Urban Land Use Composition Using Multi-Source Open Big Data with Ensemble Learning. Remote Sens. 2021, 13, 4241. [Google Scholar] [CrossRef]
- Zikirya, B.; He, X.; Li, M.; Zhou, C.S. Urban Food Takeaway Vitality: A New Technique to Assess Urban Vitality. Int. J. Environ. Res. Public Health 2021, 18, 3578. [Google Scholar] [CrossRef] [PubMed]
- Huo, F.; Xu, L.; Li, Y.P.; Famiglietti, J.S.; Li, Z.H.; Kajikawa, Y.; Chen, F. Using big data analytics to synthesize research domains and identify emerging fields in urban climatology. Wiley Interdiscip. Rev.-Clim. Change 2021, 12, e688. [Google Scholar] [CrossRef]
- Zhang, J.W.; Liu, X.T.; Tan, X.Y.; Jia, T.; Senousi, A.M.; Huang, J.W.; Yin, L.; Zhang, F. Nighttime Vitality and Its Relationship to Urban Diversity: An Exploratory Analysis in Shenzhen, China. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 309–322. [Google Scholar] [CrossRef]
- Rekabdarkolaee, H.M.; Krut, C.; Fuentes, M.; Reich, B.J. A Bayesian multivariate functional model with spatially varying coefficient approach for modeling hurricane track data. Spat. Stat. 2019, 29, 351–365. [Google Scholar] [CrossRef]
- Bass, M.R.; Sahu, S.K. Dynamically Updated Spatially Varying Parameterizations of Hierarchical Bayesian Models for Spatial Data. J. Comput. Graph. Stat. 2019, 28, 105–116. [Google Scholar] [CrossRef]
- Franco-Villoria, M.; Ventrucci, M.; Rue, H. A unified view on Bayesian varying coefficient models. Electron. J. Stat. 2019, 13, 5334–5359. [Google Scholar] [CrossRef]
- Rue, H.; Riebler, A.; Sorbye, S.H.; Illian, J.B.; Simpson, D.P.; Lindgren, F.K. Bayesian Computing with INLA: A Review. In Annual Review of Statistics and Its Application; Fienberg, S.E., Ed.; Annual Review of Statistics and Its Application; Annual Reviews: Palo Alto, CA, USA, 2017; Volume 4, pp. 395–421. [Google Scholar]
- Requena-Mullor, J.M.; Maguire, K.C.; Shinneman, D.J.; Caughlin, T.T. Integrating anthropogenic factors into regional-scale species distribution models-A novel application in the imperiled sagebrush biome. Glob. Change Biol. 2019, 25, 3844–3858. [Google Scholar] [CrossRef] [PubMed]
- Koop, G. Bayesian Econometrics; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- LeSage, J.; Pace, R.K. Introduction to Spatial Econometrics; Chapman and Hall/CRC: New York, NY, USA, 2009. [Google Scholar]
- Gilks, W.R.; Roberts, G.O. Strategies for improving MCMC. Markov Chain Monte Carlo Pract. 1996, 6, 89–114. [Google Scholar]
- Casella, G.; George, E.I. Explaining the Gibbs sampler. Am. Stat. 1992, 46, 167–174. [Google Scholar]
- Blangiardo, M.; Cameletti, M.; Baio, G.; Rue, H. Spatial and spatio-temporal models with R-INLA. Spat. Spatio-Temporal. Epidemiol. 2013, 4, 33–49. [Google Scholar] [CrossRef] [PubMed]
- Blangiardo, M.; Cameletti, M. Spatial and Spatio-Temporal Bayesian Models with R-INLA; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Besag, J.; York, J.; Mollié, A. Bayesian image restoration, with two applications in spatial statistics. Ann. Inst. Stat. Math. 1991, 43, 1–20. [Google Scholar] [CrossRef]
- Besag, J.; Green, P.J. Spatial statistics and Bayesian computation. J. R. Stat. Soc. Ser. B 1993, 55, 25–37. [Google Scholar] [CrossRef]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic Publisher: Dordrecht, The Netherland, 1988. [Google Scholar]
- Goodchild, M.; Haining, R.; Wise, S.; Arbia, G.; Anselin, L.; Bossard, E.; Brunsdon, C.; Diggle, P.; Flowerdew, R.; Green, M.; et al. Integrating Gis and Spatial Data-Analysis—Problems And Possibilities. Int. J. Geogr. Inf. Syst. 1992, 6, 407–423. [Google Scholar] [CrossRef]
- Cliff, A.D.; Ord, K. Spatial autocorrelation: A review of existing and new measures with applications. Econ. Geogr. 1970, 46, 269–292. [Google Scholar] [CrossRef]
- Cliff, A.D. Spatial Autocorrelation; Pion: London, UK, 1973. [Google Scholar]
- Anselin, L.; Rey, S. Properties of Tests for Spatial Dependence in Linear-Regression Models. Geogr. Anal. 1991, 23, 112–131. [Google Scholar] [CrossRef]
- Anselin, L.; Bera, A.K.; Florax, R.; Yoon, M.J. Simple diagnostic tests for spatial dependence. Reg. Sci. Urban Econ. 1996, 26, 77–104. [Google Scholar] [CrossRef]
- Griffith, D.A. Spatial Autocorrelation and Spatial Filtering: Gaining Understanding through Theory and Scientific Visualization; Springer Science & Business Media: Berlin, Germany, 2003. [Google Scholar]
- Getis, A.; Griffith, D.A. Comparative spatial filt.tering in regression analysis. Geogr. Anal. 2002, 34, 130–140. [Google Scholar] [CrossRef]
- Anselin, L. Under the hood—Issues in the specification and interpretation of spatial regression models. Agric. Econ. 2002, 27, 247–267. [Google Scholar] [CrossRef]
- Tiefelsdorf, M.; Griffith, D.A. Semiparametric filtering of spatial auto correlation: The eigenvector approach. Environ. Plan. A 2007, 39, 1193–1221. [Google Scholar] [CrossRef]
- Rue, H.; Held, L. Gaussian Markov Random Fields: Theory and Applications; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Jargowsky, P.A.; Park, Y. Cause or Consequence? Suburbanization and Crime in US Metropolitan Areas. Crime Delinq. 2009, 55, 28–50. [Google Scholar] [CrossRef]
- Winkler, R.L.; Johnson, K.M. Moving Toward Integration? Effects of Migration on Ethnoracial Segregation Across the Rural-Urban Continuum. Demography 2016, 53, 1027–1049. [Google Scholar] [CrossRef]
- Kramer, A. The unaffordable city: Housing and transit in North American cities. Cities 2018, 83, 1–10. [Google Scholar] [CrossRef]
- Alves, L.G.A.; Ribeiro, H.V.; Rodrigues, F.A. Crime prediction through urban metrics and statistical learning. Phys. A-Stat. Mech. Its Appl. 2018, 505, 435–443. [Google Scholar] [CrossRef]
- Vogel, B.L.; Meeker, J.W. Perceptions of crime seriousness in eight African-American communities: The influence of individual, environmental, and crime-based factors. Justice Q. 2001, 18, 301–321. [Google Scholar] [CrossRef]
- Kim, S. Long-term appreciation of owner-occupied single-family house prices in Milwaukee neighborhoods. Urban. Geogr. 2003, 24, 212–231. [Google Scholar] [CrossRef]
- Wheaton, W.C. Metropolitan fragmentation, law enforcement effort and urban crime. J. Urban. Econ. 2006, 60, 1–14. [Google Scholar] [CrossRef][Green Version]
- Glaeser, E. Cities, Productivity, and Quality of Life. Science 2011, 333, 592–594. [Google Scholar] [CrossRef]
- Yu, D.L.; Fang, C.L.; Xue, D.; Yin, J.Y. Assessing Urban Public Safety via Indicator-Based Evaluating Method: A Systemic View of Shanghai. Soc. Indic. Res. 2014, 117, 89–104. [Google Scholar] [CrossRef]
- Peterson, N.A.; Yu, D.L.; Morton, C.M.; Reid, R.J.; Sheffer, M.A.; Schneider, J.E. Tobacco outlet density and demographics at the tract level of analysis in New Jersey: A statewide analysis. Drug-Educ. Prev. Policy 2011, 18, 47–52. [Google Scholar] [CrossRef]
- Yu, D.L.; Peterson, N.A.; Reid, R.J. Exploring the Impact of Non-normality on Spatial Non-stationarity in Geographically Weighted Regression Analyses: Tobacco Outlet Density in New Jersey. Gisci. Remote Sens. 2009, 46, 329–346. [Google Scholar] [CrossRef]
- Yu, D.L.; Morton, C.M.; Peterson, N.A. Community pharmacies and addictive products: Sociodemographic predictors of accessibility from a mixed GWR perspective. Gisci. Remote Sens. 2014, 51, 99–113. [Google Scholar] [CrossRef]
- Reboussin, B.A.; Ialongo, N.S.; Green, K.M.; Furr-Holden, D.M.; Johnson, R.M.; Milam, A.J. The Impact of the Urban Neighborhood Environment on Marijuana Trajectories During Emerging Adulthood. Prev. Sci. 2019, 20, 270–279. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, D.C.; Waller, L.A. Comparing spatially varying coefficient models: A case study examining violent crime rates and their relationships to alcohol outlets and illegal drug arrests. J. Geogr. Syst. 2009, 11, 1–22. [Google Scholar] [CrossRef]
- Yu, D.; Peterson, N.A.; Sheffer, M.A.; Reid, R.J.; Schnieder, J.E. Tobacco outlet density and demographics: Analysing the relationships with a spatial regression approach. Public Health 2010, 124, 412–416. [Google Scholar] [CrossRef]
- Tobler, W.R. A Computer Movie Simulating Urban Growth in the Detroit Region. Econ. Geogr. 1970, 46, 234–240. [Google Scholar] [CrossRef]
- Besag, J. Spatial interaction and the statistical analysis of lattice systems. J. R. Stat. Soc. Ser. B 1974, 36, 192–225. [Google Scholar] [CrossRef]
- Simpson, D.; Rue, H.; Riebler, A.; Martins, T.G.; Sørbye, S.H. Penalising model component complexity: A principled, practical approach to constructing priors. Stat. Sci. 2017, 32, 1–28. [Google Scholar] [CrossRef]
- Bakka, H.; Rue, H.; Fuglstad, G.A.; Riebler, A.; Bolin, D.; Illian, J.; Krainski, E.; Simpson, D.; Lindgren, F. Spatial modeling with R-INLA: A review. Wiley Interdiscip. Rev.-Comput. Stat. 2018, 10, 24. [Google Scholar] [CrossRef]
- R Core Team R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022.
- Bivand, R.; Piras, G. Comparing Implementations of Estimation Methods for Spatial Econometrics. J. Stat. Softw. 2015, 63, 36. [Google Scholar] [CrossRef]
- He, J.Y.; Zheng, H. Prediction of crime rate in urban neighborhoods based on machine learning. Eng. Appl. Artif. Intell. 2021, 106, 104460. [Google Scholar] [CrossRef]
- Jing, F.R.; Liu, L.; Zhou, S.H.; Song, J.Y.; Wang, L.S.; Zhou, H.L.; Wang, Y.W.; Ma, R.F. Assessing the Impact of Street-View Greenery on Fear of Neighborhood Crime in Guangzhou, China. Int. J. Environ. Res. Public Health 2021, 18, 311. [Google Scholar] [CrossRef] [PubMed]
- Kurland, J.; Johnson, S.D. The Influence of Stadia and the Built Environment on the Spatial Distribution of Crime. J. Quant. Criminol. 2021, 37, 573–604. [Google Scholar] [CrossRef]
- Fotheringham, A.S.; Brunsdon, C.; Charlton, M. Geographically Weighted Regression: The Analysis of Spatially Varying Relationship; John Wiley & Sons: West Essex, UK, 2002. [Google Scholar]
- Yu, D.L. Spatially varying development mechanisms in the Greater Beijing Area: A geographically weighted regression investigation. Ann. Reg. Sci. 2006, 40, 173–190. [Google Scholar] [CrossRef]
- Yu, D. Modeling owner-occupied single-family house values in the city of milwaukee: A geographically weighted regression approach. Gisci. Remote Sens. 2007, 44, 267–282. [Google Scholar] [CrossRef]
- Jean, P.K.S. Pockets of Crime: Broken windows, Collective Efficacy, and the Criminal point of View; University of Chicago Press: Chicago, IL, USA, 2008. [Google Scholar]
- Warner, B.D. Robberies with guns: Neighborhood factors and the nature of crime. J. Crim. Justice 2007, 35, 39–50. [Google Scholar] [CrossRef]
- Bones, P.D.C.; Hope, T.L. Broken Neighborhoods: A Hierarchical Spatial Analysis of Assault and Disability Concentration in Washington, DC. J. Quant. Criminol. 2015, 31, 311–329. [Google Scholar] [CrossRef]
- Soltero, E.G.; Hernandez, D.C.; O’Connor, D.P.; Lee, R.E. Does social support mediate the relationship among neighborhood disadvantage, incivilities, crime and physical activity? Prev. Med. 2015, 72, 44–49. [Google Scholar] [CrossRef] [PubMed]
- Ratcliffe, J.H.; McCullagh, M.J. Hotbeds of crime and the search for spatial accuracy. J. Geogr. Syst. 1999, 1, 385–398. [Google Scholar] [CrossRef]
- Schaake, K.; Burgers, J.; Mulder, C.H. Ethnicity, Education and Income, and Residential Mobility Between Neighbourhoods. J. Ethn. Migr. Stud. 2014, 40, 512–527. [Google Scholar] [CrossRef]
- Dickerson, N.T. Black employment, segregation, and the social organization of metropolitan labor markets. Econ. Geogr. 2007, 83, 283–307. [Google Scholar] [CrossRef]
- Reid, R.J.; Lardier, D.T.; Garcia-Reid, P.; Yu, D.L. HIV testing among racial and ethnic minority adolescents living in an urban community. J. HIV-AIDS Soc. Serv. 2017, 16, 228–249. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Variables | Mean | sd | 0.025 Quant | 0.5 Quant | 0.975 Quant |
|---|---|---|---|---|---|
| (Intercept) | 0.602 | 0.435 | −0.255 | 0.604 | 1.453 |
| Pop | 0.220 | 0.098 | 0.030 | 0.218 | 0.416 |
| MHI | −0.021 | 0.004 | −0.028 | −0.021 | −0.014 |
| pcthisp | 1.590 | 0.480 | 0.649 | 1.589 | 2.534 |
| pctaa | 1.995 | 0.415 | 1.183 | 1.994 | 2.813 |
| alc | 0.052 | 0.037 | −0.020 | 0.052 | 0.125 |
| tbc | 0.103 | 0.021 | 0.062 | 0.103 | 0.144 |
| abdp | 0.005 | 0.002 | 0.000 | 0.005 | 0.010 |
| Variables | Mean | sd | 0.025 Quant | 0.5 Quant | 0.975 Quant |
|---|---|---|---|---|---|
| (Intercept) | 0.584 | 0.447 | −0.301 | 0.586 | 1.457 |
| Pop | 0.219 | 0.098 | 0.031 | 0.218 | 0.414 |
| MHI | −0.021 | 0.004 | −0.028 | −0.021 | −0.014 |
| pcthisp | 1.602 | 0.493 | 0.635 | 1.601 | 2.574 |
| pctaa | 2.018 | 0.438 | 1.163 | 2.016 | 2.886 |
| alc | 0.053 | 0.037 | −0.020 | 0.053 | 0.126 |
| tbc | 0.101 | 0.021 | 0.061 | 0.101 | 0.143 |
| abdp | 0.005 | 0.002 | 0.000 | 0.005 | 0.010 |
| Variable | N | Mean | Std. Dev. | Min | Pctl. 25 | Pctl. 75 | Max |
|---|---|---|---|---|---|---|---|
| Pop.b * | 105 | 0.256 | 0.023 | 0.198 | 0.244 | 0.274 | 0.293 |
| Pop.t ** | 105 | 1.912 | 0.252 | 1.243 | 1.793 | 2.09 | 2.324 |
| MHI.b | 105 | −0.019 | 0.004 | −0.033 | −0.021 | −0.017 | −0.01 |
| MHI.t | 105 | −2.427 | 0.446 | −3.331 | −2.776 | −2.123 | −1.28 |
| pcthisp.b | 105 | 1.121 | 0.02 | 1.081 | 1.104 | 1.136 | 1.161 |
| pcthisp.t | 105 | 1.601 | 0.029 | 1.527 | 1.585 | 1.625 | 1.652 |
| pctaa.b | 105 | 1.531 | 0.014 | 1.498 | 1.519 | 1.542 | 1.552 |
| pctaa.t | 105 | 2.252 | 0.029 | 2.187 | 2.231 | 2.271 | 2.317 |
| tbc.b | 105 | 0.083 | 0.009 | 0.059 | 0.078 | 0.09 | 0.105 |
| tbc.t | 105 | 1.973 | 0.405 | 1.048 | 1.68 | 2.214 | 2.993 |
| alc.b | 105 | 0.066 | 0.014 | 0.029 | 0.057 | 0.076 | 0.107 |
| alc.t | 105 | 1.079 | 0.248 | 0.359 | 0.916 | 1.235 | 1.649 |
| abdp.b | 105 | 0.007 | 0.001 | 0.004 | 0.006 | 0.007 | 0.008 |
| abdp.t | 105 | 1.129 | 0.24 | 0.643 | 0.969 | 1.242 | 2.045 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, D.; Fang, C. How Neighborhood Characteristics Influence Neighborhood Crimes: A Bayesian Hierarchical Spatial Analysis. Int. J. Environ. Res. Public Health 2022, 19, 11416. https://doi.org/10.3390/ijerph191811416
Yu D, Fang C. How Neighborhood Characteristics Influence Neighborhood Crimes: A Bayesian Hierarchical Spatial Analysis. International Journal of Environmental Research and Public Health. 2022; 19(18):11416. https://doi.org/10.3390/ijerph191811416
Chicago/Turabian StyleYu, Danlin, and Chuanglin Fang. 2022. "How Neighborhood Characteristics Influence Neighborhood Crimes: A Bayesian Hierarchical Spatial Analysis" International Journal of Environmental Research and Public Health 19, no. 18: 11416. https://doi.org/10.3390/ijerph191811416
APA StyleYu, D., & Fang, C. (2022). How Neighborhood Characteristics Influence Neighborhood Crimes: A Bayesian Hierarchical Spatial Analysis. International Journal of Environmental Research and Public Health, 19(18), 11416. https://doi.org/10.3390/ijerph191811416