
Exploring Factors That Affected Student Well-Being during the COVID-19 Pandemic: A Comparison of Data-Mining Approaches



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
Measures for Student Well-Being
2.2. Predictive Data-Mining Techniques
2.2.1. Methods Used for Classification
k-NN
Decision Tree
Random Forest
Logistic Regression
Support Vector Machines
Boosting Algorithms
2.2.2. Variable Selection and Importance
2.2.3. Performance Evaluation and Data-Mining Procedure
- Step 1. Data split. Both datasets (DM and DMI) were divided into training and testing at two different proportions (20% and 30%). First, the learners were trained with the training set, and then the classification performance of each learner was tested with the test set.
- Step 2. Variable selection. Firstly, a set was created with all of the variables handled in this study. Then, a two-step procedure was utilized. Variable importance scores and ranks were obtained using three different variable selection methods (the mutual information, the feature importance function, and SHAP). Note that each selection method has its own application ability. For example, the mutual information function only works with the full information; in other words, it cannot handle data with missing values. Therefore, the mutual information method was the only method used for the DM dataset. On the other hand, the feature importance function is performed with a prespecified learner. XGBoost, LightGBM, and CatBoost learners were used for the DM dataset. For the DMI dataset, XGBoost, LightGBM, CatBoost, AdaBoost, GBM, LR, and RF were used. Finally, as the last variable selection method, variable scores were obtained according to the different learners of the SHAP function. XGBoost, LightGBM, and CatBoost algorithms were used for the DM dataset and XGBoost, LightGBM, CatBoost, and GBM algorithms were used for the DMI dataset. The Borda count procedure was then applied in the rank aggregation. Thus, a list of variables from the most influential to the least influential was created. Then, the top 10%, 20%, 30%, 40%, and 100% (all) of the variables were selected as the inputs for the learners.
- Step 3. Classification. After variable selection, the classification step was achieved. Each learner had specific and different numbers of hyperparameters that had to be tuned. According to the predefined hyperparameter configuration search space, the composite procedure based on k-fold CV and GS was applied for each learner. Since the choice of the number of folds depended on different factors such as the training sample size and the number of tuning parameters, there was no strictly defined rule. However, as Jung [64] suggested, we set the fold number k at 5. The learning models were rerun on the testing data using the optimal hyperparameters and the results for their corresponding performance metrics were compared.
3. Results
3.1. The Student Well-Being Score
3.2. Classification
3.2.1. Classification Performed Using the DM Dataset
3.2.2. Classification Performed Using the DMI Dataset
3.3. Important Variables
4. Discussion
Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ellis, W.E.; Dumas, T.M.; Forbes, L.M. Physically isolated but socially connected: Psychological adjustment and stress among adolescents during the initial COVID-19 crisis. Can. J. Behav. Sci. Rev. Can. Sci. Comport. 2020, 52, 177–187. [Google Scholar] [CrossRef]
- Naser, A.Y.; Al-Hadithi, H.T.; Dahmash, E.Z.; Alwafi, H.; Alwan, S.S.; Abdullah, Z.A. The effect of the 2019 coronavirus disease outbreak on social relationships: A cross-sectional study in Jordan. Int. J. Soc. Psychiatry 2021, 67, 664–671. [Google Scholar] [CrossRef] [PubMed]
- Saito, M.; Kikuchi, Y.; Lefor, A.K.; Hoshina, M. Mental health in Japanese children during school closures due to the COVID-19. Pediatrics Int. Off. J. Jpn. Pediatric Soc. 2022, 64, e14718. [Google Scholar] [CrossRef] [PubMed]
- Lee, J. Mental health effects of school closures during COVID-19. Lancet Child Adolesc. Health 2020, 4, 421. [Google Scholar] [CrossRef]
- Xie, X.; Xue, Q.; Zhou, Y.; Zhu, K.; Liu, Q.; Zhang, J.; Song, R. Mental health status among children in home confinement during the coronavirus disease 2019 outbreak in Hubei Province, China. JAMA Pediatrics 2020, 174, 898–900. [Google Scholar] [CrossRef]
- Porter, C.; Favara, M.; Hittmeyer, A.; Scott, D.; Jiménez, A.S.; Ellanki, R.; Woldehanna, T.; Duc, L.T.; Craske, M.G.; Stein, A. Impact of the COVID-19 pandemic on anxiety and depression symptoms of young people in the global south: Evidence from a four country cohort study. BMJ Open 2021, 11, e049653. [Google Scholar] [CrossRef]
- Lu, M. Dynamic modeling COVID-19 for comparing containment strategies in a pandemic scenario. Ann. Biostat. Biom. Appl. 2020, 4, 1–4. [Google Scholar] [CrossRef]
- Lu, M.; Ishwaran, H. Cure and death play a role in understanding dynamics for COVID-19: Data-driven competing risk compartmental models, with and without vaccination. PLoS ONE 2021, 16, e0254397. [Google Scholar] [CrossRef]
- Pokhrel, S.; Chhetri, R. A literature review on impact of COVID-19 pandemic on teaching and learning. High. Educ. Future 2021, 8, 133–141. [Google Scholar] [CrossRef]
- Colvin, M.K.; Reesman, J.; Glen, T. The impact of COVID-19 related educational disruption on children and adolescents: An interim data summary and commentary on ten considerations for neuropsychological practice. Clin. Neuropsychol. 2022, 36, 45–71. [Google Scholar] [CrossRef]
- Klapproth, F.; Federkeil, L.; Heinschke, F.; Jungmann, T. Teachers’ experiences of stress and their coping strategies during COVID-19 induced distance teaching. J. Pedagog. Res. 2020, 4, 444–452. [Google Scholar] [CrossRef]
- Adams-Prassl, A.; Boneva, T.; Golin, M.; Rauh, C. The Impact of the Coronavirus Lockdown on Mental Health: Evidence from the US. Cambridge Working Papers in Economics 2020–2021. Available online: https://www.repository.cam.ac.uk/bitstream/handle/1810/334492/cwpe2037.pdf?sequence=1 (accessed on 2 April 2022).
- Borgonovi, F.; Pál, J. A Framework for the Analysis of Student Well-Being in the PISA 2015 Study: Being 15 in 2015; OECD Education Working Papers 2016, No. 140; OECD Publishing: Paris, France, 2016. [Google Scholar] [CrossRef]
- Hoyt, L.T.; Chase-Lansdale, P.L.; McDade, T.W.; Adam, E.K. Positive youth, healthy adults: Does positive well-being in adolescence predict better perceived health and fewer risky healthy behaviors in young adulthood? J. Adolesc. Health 2012, 50, 66–73. [Google Scholar] [CrossRef] [PubMed]
- Pollard, E.L.; Lee, P.D. Child well-being: A systematic review of the literature. Soc. Indic. Res. 2002, 61, 59–78. [Google Scholar] [CrossRef]
- Plakhotnik, M.S.; Volkova, N.V.; Jiang, C.; Yahiaoui, D.; Pheiffer, G.; Mckay, K.; Newman, S.; Reißig-Thust, S. The perceived impact of COVID-19 on student well-being and the mediating role of the university support: Evidence from France, Germany, Russia, and the UK. Front. Psychol. 2021, 12, 642689. [Google Scholar] [CrossRef]
- Van de Velde, S.; Buffel, V.; Bracker, P.; Van Hal, G.; Somogyi, N.M.; Willems, B.; Wouters, E. The COVID-19 international well-being study. Scand. J. Public Health 2021, 49, 114–122. [Google Scholar] [CrossRef]
- Defeyter, M.A.; Stretesky, P.B.; Long, M.A.; Furey, S.; Reynolds, C.; Porteous, D.; Dodd, A.; Mann, E.; Kemp, A.; Fox, J.; et al. Mental well-being in UK higher education during COVID-19: Do students trust universities and the government? Front. Public Health 2021, 9, 646916. [Google Scholar] [CrossRef]
- Lukács, A. Mental well-being of university students in social isolation. Eur. J. Health Psychol. 2021, 28, 22–29. [Google Scholar] [CrossRef]
- Prasath, P.R.; Mather, P.C.; Bhat, C.S.; James, J.K. University student well-being during COVID-19. The role of psychological capital and coping strategies. Prof. Couns. 2021, 11, 46–60. [Google Scholar] [CrossRef]
- Satpathy, B.; Ali, E. A study on psychological well-being of final year management students during COVID-19 pandemic lockdown in India. Int. J. Indian Psychol. 2020, 8, 1–25. [Google Scholar] [CrossRef]
- Villani, L.; Pastorino, R.; Molinari, E.; Anelli, F.; Ricciardi, W.; Graffigna, G.; Boccia, S. Impact of the COVID-19 pandemic on psychological well-being of students in an Italian university: A web-based cross-sectional survey. Glob. Health 2021, 17, 39. [Google Scholar] [CrossRef]
- Schwartz, K.D.; Exner-Cortens, D.; McMorris, C.A.; Makarenko, E.; Arnold, P.; Van Bavel, M.; Williams, S.; Canfield, R. COVID-19 and student well-being: Stress and mental health during return-to-school. Can. J. Sch. Psychol. 2021, 36, 166–185. [Google Scholar] [CrossRef] [PubMed]
- Alsandor, D.J.; Yilmazli Trout, I. Graduate student well-being: Learning and living during the COVID-19 pandemic. Multidiscip. Perspect. High. Educ. 2020, 5, 150–155. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E.; Hall, M.A.; Pal, C.J. Data Mining: Practical Machine Learning Tools and Techniques, 4th ed.; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Romero, C.; Ventura, S. Educational data mining: A review of the state of the art. IEEE Trans. Syst. Man Cybern. Part C 2010, 40, 601–618. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining: A survey from 1995 to 2005. Expert Syst. Appl. 2007, 33, 135–146. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Data mining in education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2013, 3, 12–27. [Google Scholar] [CrossRef]
- Baker, R.S.; Yacef, K. The state of educational data mining in 2009: A review and future visions. J. Educ. Data Min. 2009, 1, 3–17. [Google Scholar] [CrossRef]
- Peña-Ayala, A. Educational data mining: A survey and a data mining-based analysis of recent works. Expert Syst. Appl. 2014, 41, 1432–1462. [Google Scholar] [CrossRef]
- Dutt, A.; Ismail, M.A.; Herawan, T. A systematic review on educational data mining. IEEE Access 2017, 5, 15991–16005. [Google Scholar] [CrossRef]
- Bakhshinategh, B.; Zaiane, O.R.; ElAtia, S.; Ipperciel, D. Educational data mining applications and tasks: A survey of the last 10 years. Educ. Inf. Technol. 2018, 23, 537–553. [Google Scholar] [CrossRef]
- Aldowah, H.; Al-Samarraie, H.; Fauzy, W.M. Educational data mining and learning analytics for 21st century higher education: A review and synthesis. Telemat. Inform. 2019, 37, 13–49. [Google Scholar] [CrossRef]
- Namoun, A.; Alshanqiti, A. Predicting student performance using data mining and learning analytics techniques: A systematic literature review. Appl. Sci. 2021, 11, 237. [Google Scholar] [CrossRef]
- Hernández-Blanco, A.; Herrera-Flores, B.; Tomás, D.; Navarro-Colorado, B. A systematic review of deep learning approaches to educational data mining. Complexity 2019, 2019, 1306039. [Google Scholar] [CrossRef]
- Meinck, S.; Fraillon, J.; Strietholt, R. The Impact of the COVID-19 Pandemic on Education: International Evidence from the Responses to Educational Disruption Survey (REDS) (Revised edition). UNESCO/IEA. 2022. Available online: https://www.iea.nl/sites/default/files/2022-05/UNESCO%20IEA%20REDS%20International%20Report%20Revised%20Edition%2004.05.2022.pdf (accessed on 10 May 2022).
- United Nations Educational, Scientific and Cultural Organization (UNESCO); International Association for the Evaluation of Educational Achievement (IEA). Responses to Educational Disruption Survey: User Guide for the International Database (Revised Edition). 2022. Available online: https://unesdoc.unesco.org/ark:/48223/pf0000380397 (accessed on 31 March 2022).
- Xiao, J.; Bulut, O. Evaluating the performances of missing data handling methods in ability estimation from sparse data. Educ. Psychol. Meas. 2020, 80, 932–954. [Google Scholar] [CrossRef] [PubMed]
- Muthén, L.K.; Muthén, B.O. MPlus Version 7: User’s Guide; Muthén & Muthén: Los Angeles, CA, USA, 2012. [Google Scholar]
- Cerrada, M.; Trujillo, L.; Hernández, D.E.; Correa Zevallos, H.A.; Macancela, J.C.; Cabrera, D.; Vinicio Sánchez, R. Auto ML for feature selection and model tuning applied to fault severity diagnosis in spur gearboxes. Math. Comput. Appl. 2022, 27, 6. [Google Scholar] [CrossRef]
- Gorunescu, F. Classification performance evaluation. In Data Mining: Concepts, Models and Techniques; Intelligent Systems Reference Library; Springer: Berlin/Heidelberg, Germany, 2011; Volume 12. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Safavian, S.R.; Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 1991, 21, 660–674. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Walker, S.H.; Duncan, D.B. Estimation of the probability of an event as a function of several independent variables. Biometrika 1967, 54, 167–179. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Dong, X.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar] [CrossRef]
- Schapire, R.; Freund, Y. A decision-theoretic generalization of on-line learning and an application to boosting. In Proceedings of the Second European Conference on Computational Learning Theory, Barcelona, Spain, 13–15 March 1995; pp. 23–37. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A Highly Efficient Gradient Boosting Decision Tree. Advances in Neural Information Processing Systems. 2017. Available online: https://proceedings.neurips.cc/paper/2017/hash/6449f44a102fde848669bdd9eb6b76fa-Abstract.html (accessed on 14 April 2022).
- Zhou, J.; Li, W.; Wang, J.; Ding, S.; Xia, C. Default prediction in P2P lending from high-dimensional data based on machine learning. Phys. A Stat. Mech. Its Appl. 2019, 534, 122370. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the NIPS’18: 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 6639–6649. [Google Scholar]
- Ishwaran, H.; Lu, M. Standard errors and confidence intervals for variable importance in random forest regression, classification, and survival. Stat. Med. 2019, 38, 558–582. [Google Scholar] [CrossRef]
- Lu, M.; Parel, J.M.; Miller, D. Interactions between staphylococcal enterotoxins A and D and superantigen-like proteins 1 and 5 for predicting methicillin and multidrug resistance profiles among Staphylococcus aureus ocular isolates. PLoS ONE 2021, 16, e0254519. [Google Scholar] [CrossRef]
- Lu, M.; Ishwaran, H. Discussion on “Nonparametric variable importance assessment using machine learning techniques” by Brian D. Williamson, Peter B. Gilbert, Marco Carone, and Noah Simon. Biometrics 2020, 77, 23–27. [Google Scholar] [CrossRef] [PubMed]
- Wei, G.; Zhao, J.; Feng, Y.; He, A.; Yu, J. A novel hybrid feature selection method based on dynamic feature importance. Appl. Soft Comput. 2020, 93, 106337. [Google Scholar] [CrossRef]
- Lu, M.; Sha, Y.; Silva, T.C.; Colaprico, A.; Sun, X.; Ban, Y.; Wang, L.; Lehmann, B.D.; Chen, X.S. LR hunting: A random forest based cell–cell interaction discovery method for single-cell gene expression data. Front. Genet. 2021, 12, 1431. [Google Scholar] [CrossRef]
- Cadenas, J.M.; Garrido, M.C.; Martínez, R. Feature subset selection filter–wrapper based on low quality data. Expert Syst. Appl. 2013, 40, 6241–6252. [Google Scholar] [CrossRef]
- Emerson, P. The original Borda count and partial voting. Soc. Choice Welf. 2013, 40, 353–358. [Google Scholar] [CrossRef]
- Shahrjooihaghighi, A.; Frigui, H.; Zhang, X.; Wei, X.; Shi, B.; Trabelsi, A. An ensemble feature selection method for biomarker discovery. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Bilbao, Spain, 18–20 December 2017; pp. 416–421. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Müller, A.; Nothman, J.; Louppe, G.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar] [CrossRef]
- Jung, Y. Multiple predicting K-fold cross-validation for model selection. J. Nonparametric Stat. 2018, 30, 197–215. [Google Scholar] [CrossRef]
- Stamatis, C.A.; Broos, H.C.; Hudiburgh, S.E.; Dale, S.K.; Timpano, K.R. A longitudinal investigation of COVID-19 pandemic experiences and mental health among university students. Br. J. Clin. Psychol. 2022, 61, 385–404. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
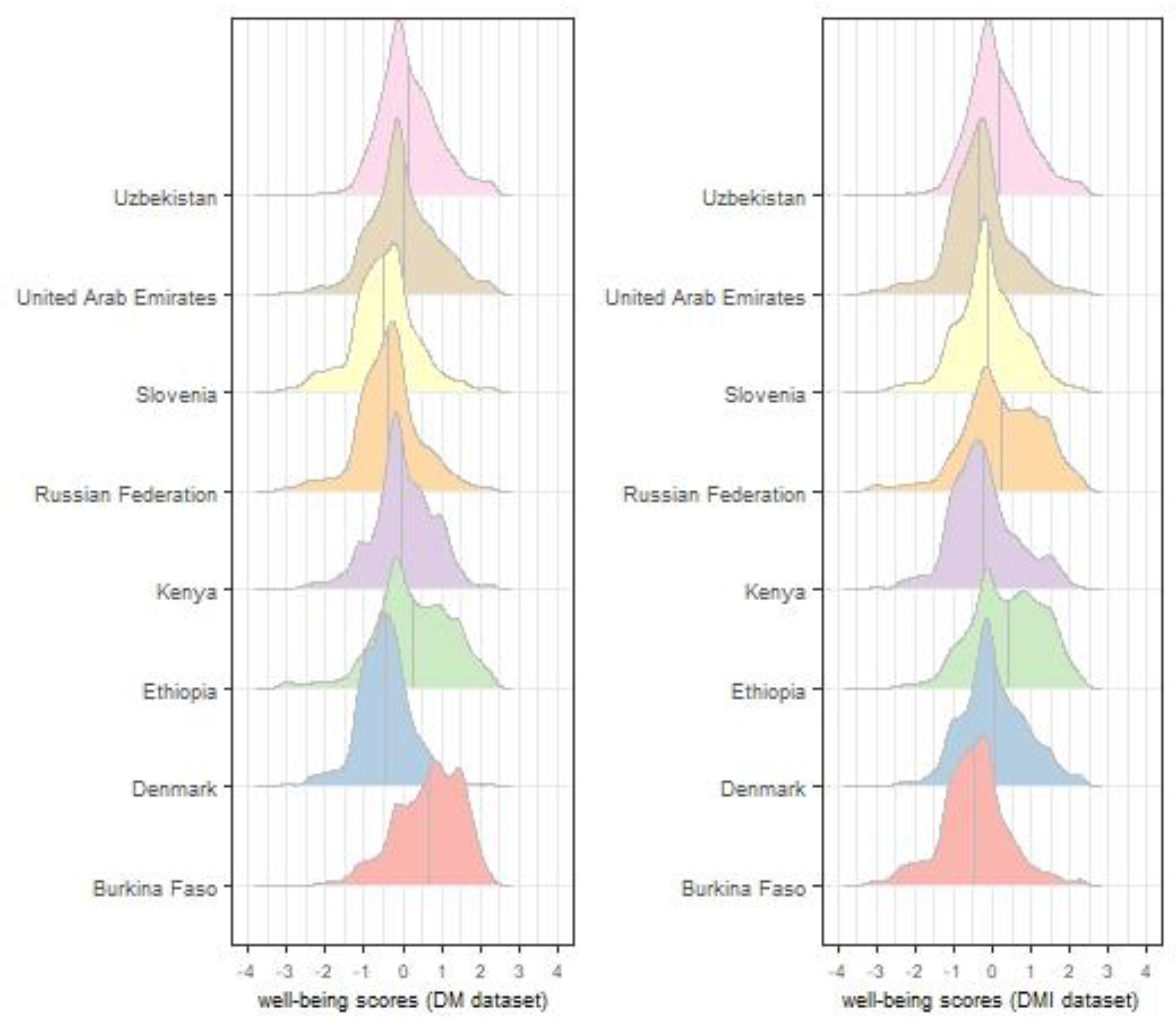
| Country | n (Total) | Well-Being Score | |||
|---|---|---|---|---|---|
| DM | DMI | ||||
| Mean | SD | Mean | SD | ||
| Burkina Faso | 2450 | 0.67 | 0.85 | −0.47 | 0.87 |
| Denmark | 1308 | −0.47 | 0.73 | 0.03 | 0.87 |
| Ethiopia | 3613 | 0.26 | 0.99 | 0.39 | 0.92 |
| Kenya | 1594 | −0.01 | 0.83 | −0.23 | 0.89 |
| Russian Federation | 3502 | −0.36 | 0.82 | 0.24 | 1.01 |
| Slovenia | 2494 | −0.47 | 0.87 | −0.11 | 0.85 |
| United Arab Emirates | 2849 | 0.01 | 0.86 | −0.35 | 0.82 |
| Uzbekistan | 2910 | 0.15 | 0.76 | 0.15 | 0.77 |
| Accuracy (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of Variables (%) | 178 (100%) | 18 (10%) | 36 (20%) | 54 (30%) | 72 (40%) | |||||
| Test Sample Size | 30% | 20% | 30% | 20% | 30% | 20% | 30% | 20% | 30% | 20% |
| CatBoost | 77.06 | 76.81 | 75.92 | 76.23 | 76.27 | 77.39 | 77.32 | 76.91 | 77.69 | 77.58 |
| LightGBM | 76.72 | 77.05 | 75.19 | 76.01 | 76.14 | 77.08 | 76.64 | 76.71 | 76.99 | 77.09 |
| XGBoost | 75.85 | 75.85 | 74.79 | 75.09 | 75.42 | 76.09 | 76.45 | 76.83 | 76.59 | 76.30 |
| Accuracy (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of Variables (%) | 178 (100%) | 18 (10%) | 36 (20%) | 54 (30%) | 72 (40%) | |||||
| Test Sample Size | 30% | 20% | 30% | 20% | 30% | 20% | 30% | 20% | 30% | 20% |
| CatBoost | 77.93 | 77.80 | 75.60 | 75.41 | 76.88 | 76.86 | 77.48 | 76.91 | 77.64 | 77.65 |
| LightGBM | 76.29 | 76.42 | 75.32 | 74.50 | 76.24 | 76.28 | 76.30 | 76.11 | 76.79 | 76.50 |
| XGBoost | 76.51 | 74.83 | 73.83 | 73.46 | 76.24 | 76.23 | 76.63 | 76.09 | 76.42 | 76.86 |
| GBM | 76.32 | 75.70 | 74.90 | 74.57 | 75.77 | 75.53 | 76.05 | 75.70 | 76.19 | 75.53 |
| AdaBoost | 74.97 | 74.35 | 74.36 | 74.25 | 74.61 | 74.74 | 74.89 | 74.71 | 74.53 | 74.57 |
| k-NN | 67.89 | 67.93 | 71.83 | 71.60 | 72.68 | 72.73 | 71.38 | 71.45 | 69.82 | 69.93 |
| DT | 66.80 | 65.30 | 65.75 | 66.07 | 65.93 | 66.77 | 66.94 | 68.10 | 66.44 | 67.35 |
| RF | 76.90 | 76.26 | 74.82 | 74.74 | 76.91 | 75.92 | 77.11 | 76.67 | 77.08 | 76.88 |
| LR | 73.70 | 73.46 | 73.30 | 73.12 | 73.33 | 73.19 | 73.81 | 73.75 | 73.65 | 73.26 |
| SVM | 76.54 | 76.47 | 75.02 | 75.07 | 76.45 | 76.16 | 76.54 | 76.26 | 76.42 | 76.52 |
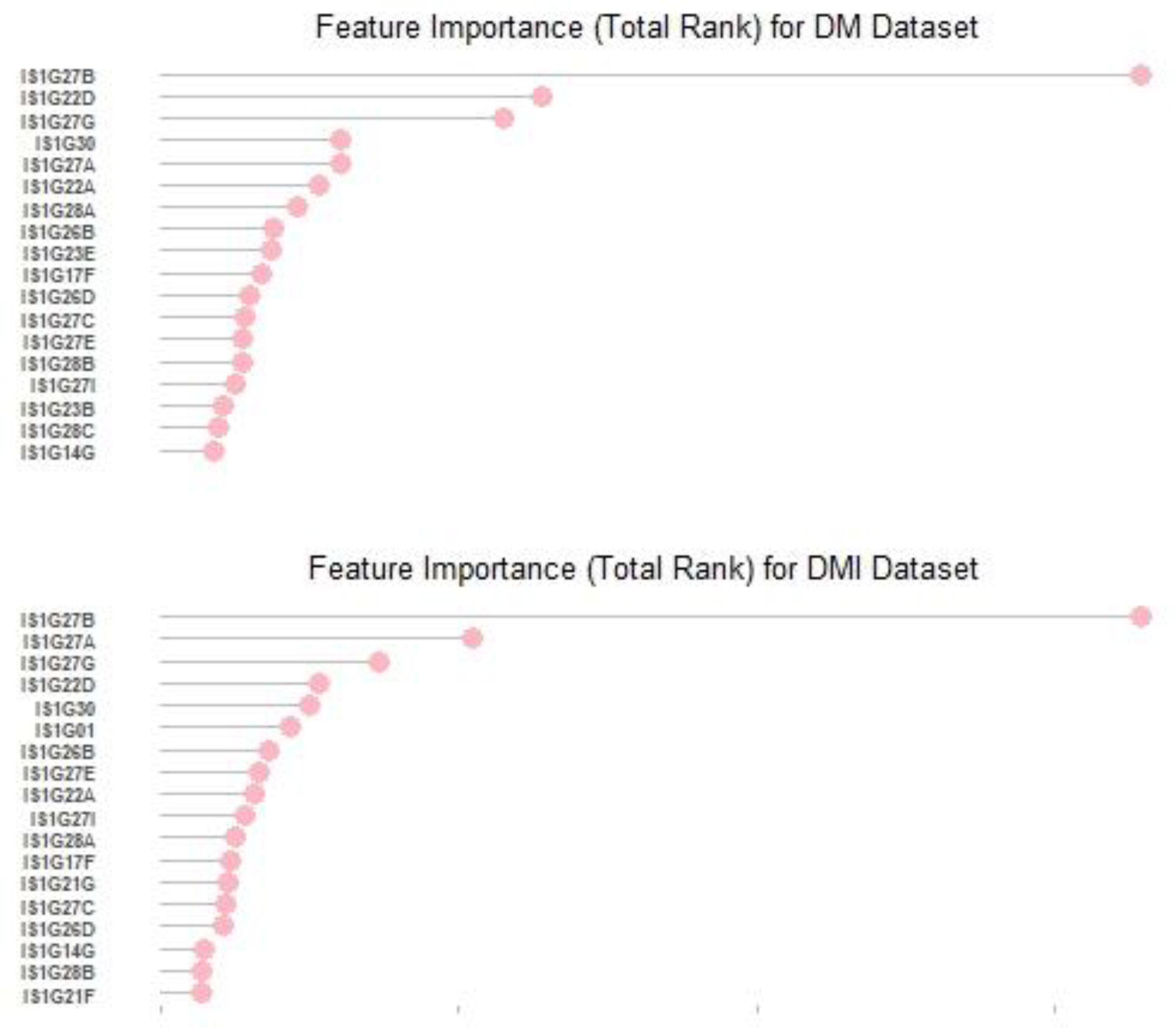
| Rank | Feature | Item |
|---|---|---|
| 1 | IS1G27B | I worried a lot about catching COVID-19 at school. |
| 2 | IS1G22D | It became more difficult to know how well I was progressing. |
| 3 | IS1G27G | I was excited to catch up with friends. |
| 4 | IS1G30 | Overall, how prepared do you feel for learning from home if your school building closed for an extended period in the future? |
| 5 | IS1G27A | I was more motivated to learn when school reopened than at any other time. |
| 6 | IS1G22A | I learned about as much as before the COVID-19 disruption. |
| 7 | IS1G28A | I understood the changed arrangements in my school. |
| 8 | IS1G26B | Our family had to be more careful with money than usual. |
| 9 | IS1G23E | Health advice about COVID-19 |
| 10 | IS1G17F | I was happy to be at home. |
| 11 | IS1G26D | One or both of my parents/guardians were stressed about their job. |
| 12 | IS1G27C | I found it hard to manage the COVID-19 routines at school (e.g., wearing a mask, social distancing) |
| 13 | IS1G27E | I felt that I had fallen behind in my learning compared to other students. |
| 14 | IS1G28B | My teachers went over the work we did during the COVID-19 disruption. |
| 15 | IS1G27I | My teachers seemed more caring towards me than they were before the COVID-19 disruption. |
| 16 | IS1G23B | Looking after my personal safety |
| 17 | IS1G28C | We rushed through a lot of new schoolwork. |
| 18 | IS1G14G | I found it difficult to get extra or different types of work from my teachers. |
| Rank | Feature | Item |
|---|---|---|
| 1 | IS1G27B | I worried a lot about catching COVID-19 at school. |
| 2 | IS1G27A | I was more motivated to learn when school reopened than at any other time. |
| 3 | IS1G27G | I was excited to catch up with friends. |
| 4 | IS1G22D | It became more difficult to know how well I was progressing. |
| 5 | IS1G30 | Overall, how prepared do you feel for learning from home if your school building closed for an extended period in the future? |
| 6 | IS1G01 | Where did you attend school lessons during the COVID-19 disruption? |
| 7 | IS1G26B | Our family had to be more careful with money than usual. |
| 8 | IS1G27E | I felt that I had fallen behind in my learning compared to other students. |
| 9 | IS1G22A | I learned about as much as before the COVID-19 disruption. |
| 10 | IS1G27I | My teachers seemed more caring towards me than they were before the COVID-19 disruption. |
| 11 | IS1G28A | I understood the changed arrangements in my school. |
| 12 | IS1G17F | I was happy to be at home. |
| 13 | IS1G21G | My teachers encouraged me to learn. |
| 14 | IS1G27C | I found it hard to manage the COVID-19 routines at school (e.g., wearing a mask, social distancing) |
| 15 | IS1G26D | One or both of my parents/guardians were stressed about their job. |
| 16 | IS1G14G | I found it difficult to get extra or different types of work from my teachers. |
| 17 | IS1G28B | My teachers went over the work we did during the COVID-19 disruption. |
| 18 | IS1G21F | I had a good relationship with my teachers. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yürekli, H.; Yiğit, Ö.E.; Bulut, O.; Lu, M.; Öz, E. Exploring Factors That Affected Student Well-Being during the COVID-19 Pandemic: A Comparison of Data-Mining Approaches. Int. J. Environ. Res. Public Health 2022, 19, 11267. https://doi.org/10.3390/ijerph191811267
Yürekli H, Yiğit ÖE, Bulut O, Lu M, Öz E. Exploring Factors That Affected Student Well-Being during the COVID-19 Pandemic: A Comparison of Data-Mining Approaches. International Journal of Environmental Research and Public Health. 2022; 19(18):11267. https://doi.org/10.3390/ijerph191811267
Chicago/Turabian StyleYürekli, Hülya, Öyküm Esra Yiğit, Okan Bulut, Min Lu, and Ersoy Öz. 2022. "Exploring Factors That Affected Student Well-Being during the COVID-19 Pandemic: A Comparison of Data-Mining Approaches" International Journal of Environmental Research and Public Health 19, no. 18: 11267. https://doi.org/10.3390/ijerph191811267
APA StyleYürekli, H., Yiğit, Ö. E., Bulut, O., Lu, M., & Öz, E. (2022). Exploring Factors That Affected Student Well-Being during the COVID-19 Pandemic: A Comparison of Data-Mining Approaches. International Journal of Environmental Research and Public Health, 19(18), 11267. https://doi.org/10.3390/ijerph191811267