




MMDCP: Multi-Modal Dental Caries Prediction for Decision Support System Using Deep Learning




Abstract
:1. Introduction
2. Related Work
3. Proposed Model
3.1. Data Collection
3.2. Data Preprocessing
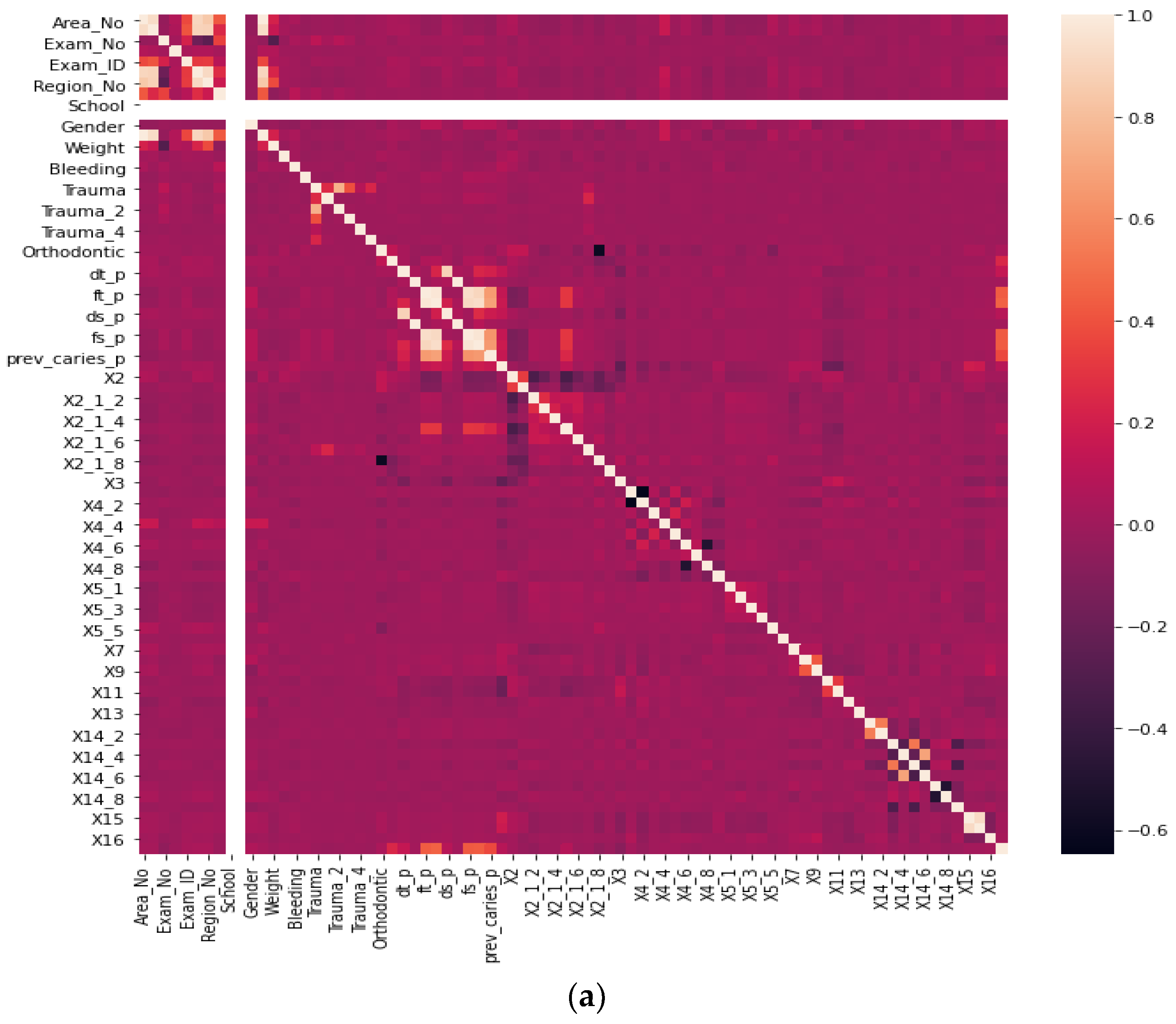
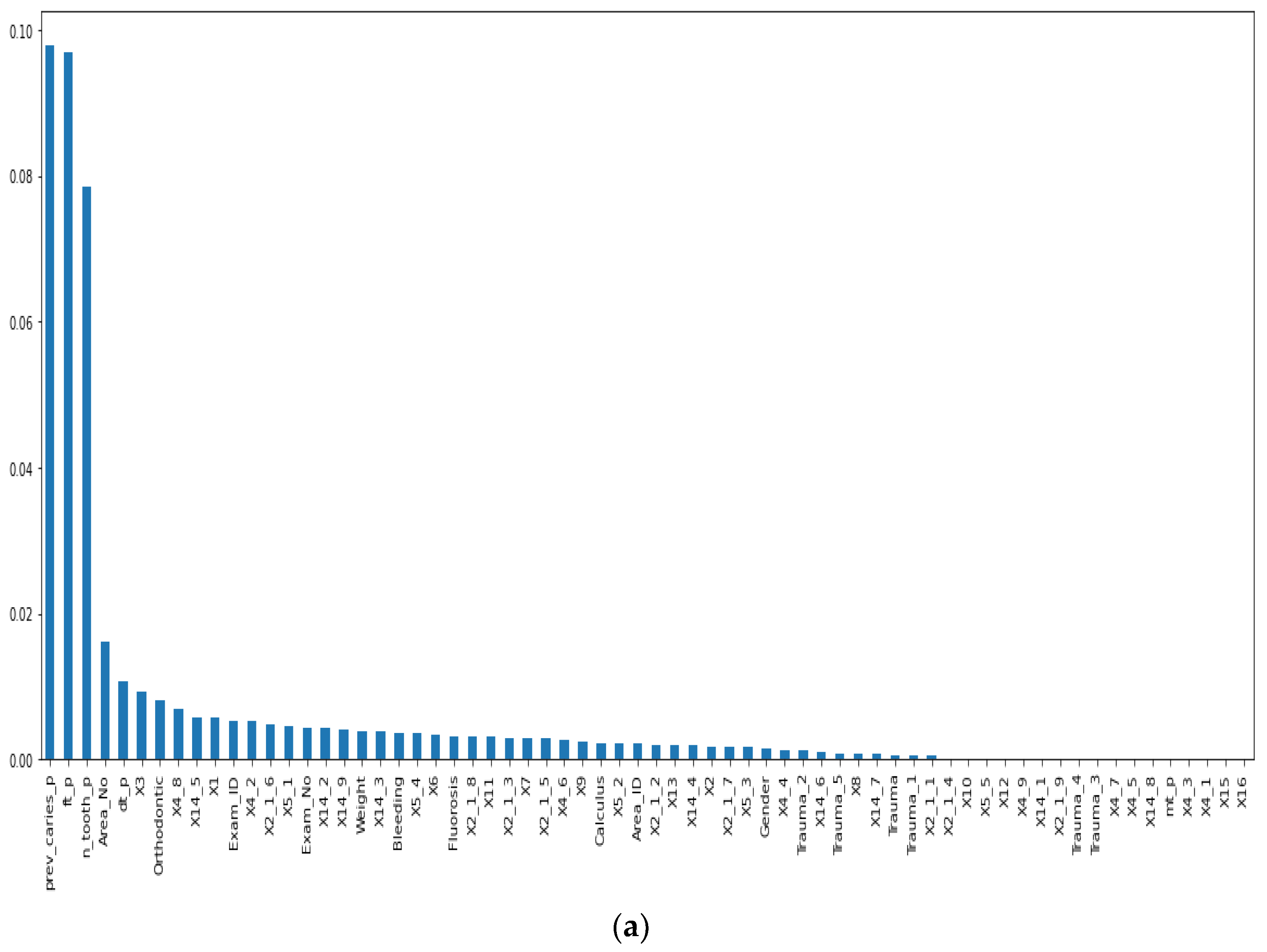
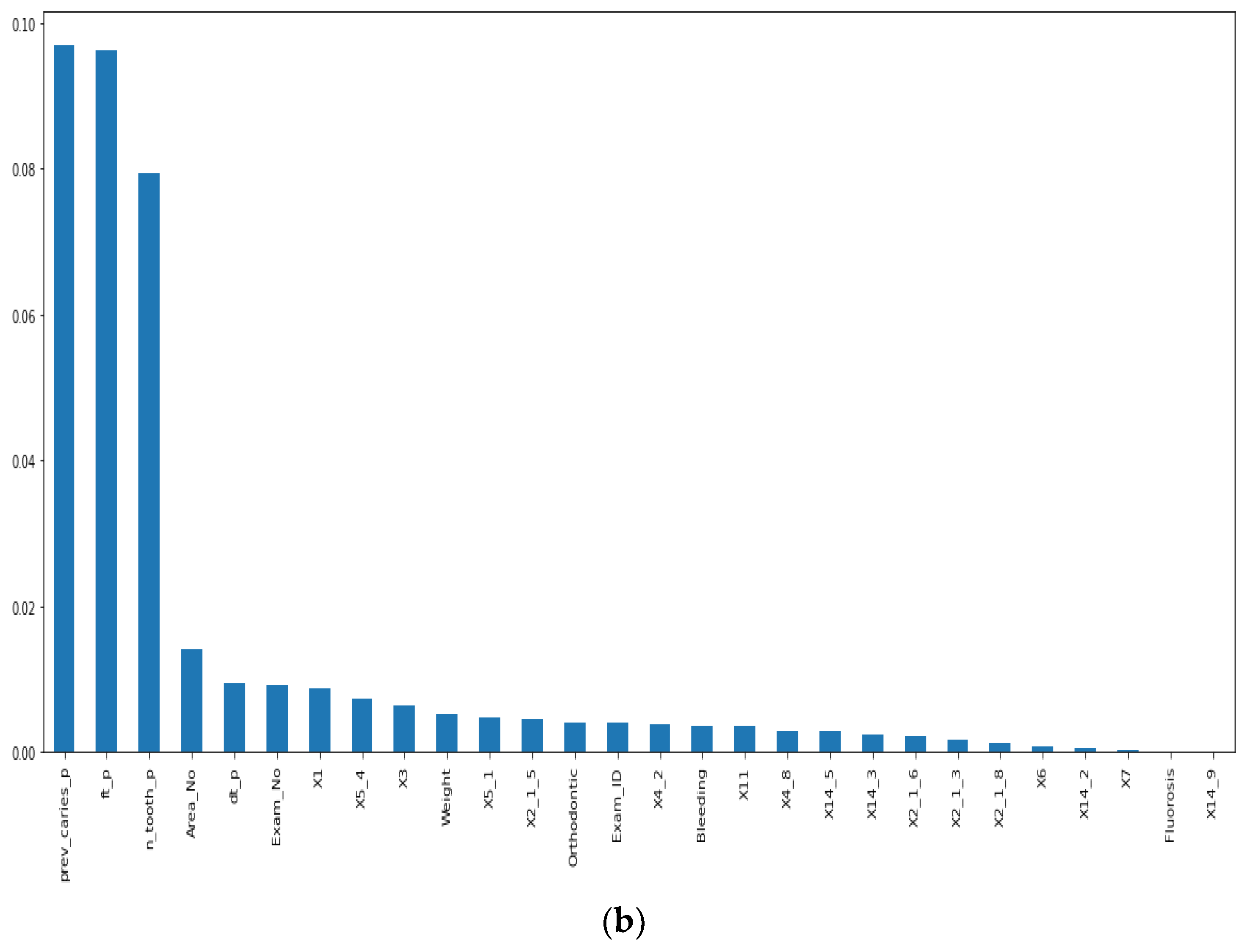
3.2.1. Numerical Dataset Preparation
3.2.2. Image Dataset Preparation
3.3. Prediction Model
3.3.1. Numerical Classifier
3.3.2. Image Classifier
3.3.3. Concatenation Layer
4. Experimentation
4.1. Experimental Setup
4.2. Dataset
4.2.1. Numerical Dataset
4.2.2. Image Dataset
5. Result and Discussion
5.1. Metrics of Evaluation
- TP (True Positive): positive observation predicted as positive;
- TN (True Negative): negative observation that was correctly predicted as being negative;
- FP (False Positive): negative observation wrongly predicted as positive;
- FN (False Negative): positive observation wrongly predicted as negative;
- TPR (True Positive Rate): is the percentage of class labeled as “0” (absence of caries) points incorrectly classified by the model;
- FNR (False Negative Rate): is the percentage of class labeled “1” (presence of caries) points correctly classified by the model.
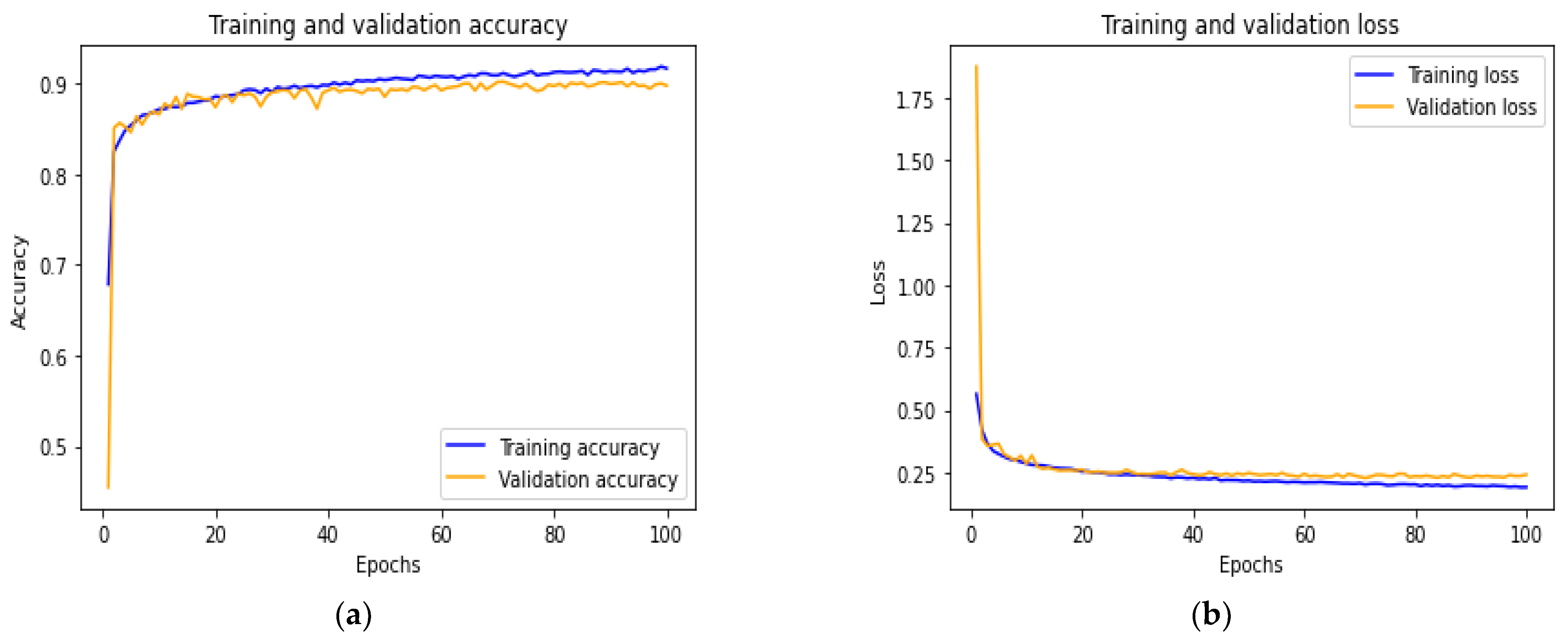
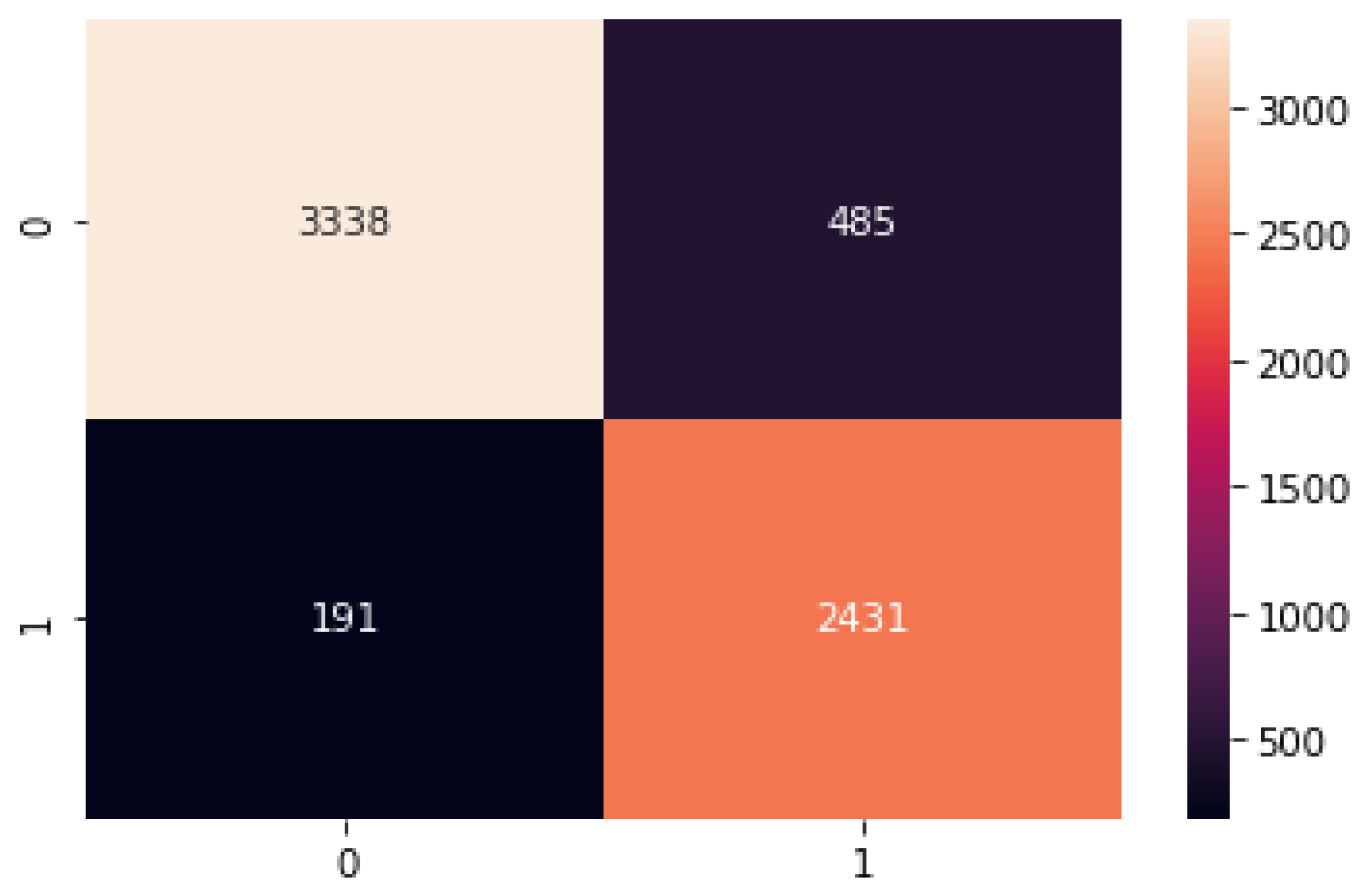
5.2. Proposed Model Results
5.3. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- US Surgeon General Report. Oral health in America: A report of the Surgeon General. J. Calif. Dent. Assoc. 2000, 28, 685–695. [Google Scholar]
- Haworth, S.; Dudding, T.; Waylen, A.; Thomas, S.J.; Timpson, N.J. Ten years on: Is dental general anesthesia in childhood a risk factor for caries and anxiety? Br. Dent. J. 2017, 222, 299–304. [Google Scholar] [CrossRef] [PubMed]
- Foster, T.; Perinpanayagam, H.; Pfaffenbach, A.; Certo, M. Recurrence of early childhood caries after comprehensive treatment with general anesthesia and follow-up. J. Dent. Child 2006, 73, 25–30. [Google Scholar]
- Bowen, W.H.; Birkhed, D.; Granath, L.; McHugh, W.D. Dental caries: Dietary and microbiology factors. In Systemized Prevention of Oral Disease: Theory and Practice; CRC Press: New York, NY, USA, 1986. [Google Scholar]
- Stephan, R.M. Intra-oral hydrogen-ion concentrations associated with dental caries activity. J. Dent. Res. 1944, 23, 257–266. [Google Scholar] [CrossRef]
- Weiss, R.L.; Trithart, A.H. Between-meal eating habits and dental caries experience in preschool children. Am. J. Public Health Nation’s Health 1960, 50, 1097–1104. [Google Scholar] [CrossRef] [PubMed]
- Black, G.V. Mottled teeth: An endemic developmental imperfection of the enamel of the teeth heretofore unknown in the literature of dentistry. Dent. Cosm. 1916, 58, 129–156. [Google Scholar]
- Zero, D.T.; Fontana, M.; Martínez-Mier, E.A.; Ferreira-Zandoná, A.; Ando, M.; González-Cabezas, C.; Bayne, S. The Biology, Prevention, Diagnosis and Treatment of Dental Caries. J. Am. Dent. Assoc. 2009, 140, 25S–34S. [Google Scholar] [CrossRef] [PubMed]
- Hung, M.; Voss, M.W.; Rosales, M.N.; Li, W.; Su, W.; Xu, J.; Bounsanga, J.; Ruiz-Negrón, B.; Lauren, E.; Licari, F.W. Application of machine learning for diagnostic prediction of root caries. Gerodontology 2019, 36, 395–404. [Google Scholar] [CrossRef] [PubMed]
- Kang, I.-A.; Ngnamsie Njimbouom, S.; Lee, K.-O.; Kim, J.-D. DCP: Prediction of Dental Caries Using Machine Learning in Personalized Medicine. Appl. Sci. 2022, 12, 3043. [Google Scholar] [CrossRef]
- Richens, J.G.; Lee, C.M.; Johri, S. Improving the accuracy of medical diagnosis with causal machine learning. Nat. Commun. 2020, 11, 3923. [Google Scholar] [CrossRef]
- Baiju, R.M.; Peter, E.; Varghese, N.O.; Sivaram, R. Oral Health and Quality of Life: Current Concepts. J. Clin. Diagn. Res. 2017, 11, ZE21–ZE26. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Wu, W.; Zhang, S.-Y.; Zhang, K.-Q.; Li, J.; Liu, Y.; Yin, Z.-H. Dental Caries Prediction Based on a Survey of the Oral Health Epidemiology among the Geriatric Residents of Liaoning, China. BioMed Res. Int. 2020, 2020, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Zaorska, K.; Szczapa, T.; Borysewicz-Lewicka, M.; Nowicki, M.; Gerreth, K. Prediction of Early Childhood Caries Based on Single Nucleotide Polymorphisms Using Neural Networks. Genes 2021, 12, 462. [Google Scholar] [CrossRef] [PubMed]
- Kallenberg, M.; Petersen, K.; Nielsen, M.; Ng, A.Y.; Diao, P.; Igel, C.; Vachon, C.M.; Holland, K.; Winkel, R.R.; Karssemeijer, N.; et al. Unsupervised Deep Learning Applied to Breast Density Segmentation and Mammographic Risk Scoring. IEEE Trans. Med. Imaging 2016, 35, 1322–1331.23. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65–69. [Google Scholar] [CrossRef]
- Nabilla, M.; Brenda, C.; Ichwan, S.J.A.; Arief, C. Deep learning convolutional neural network algorithms for the early detection and diagnosis of dental caries on periapical radiographs: A systematic review. Imag. Sci. Dent. 2021, 51, 237. [Google Scholar] [CrossRef]
- Lee, J.H.; Kim, D.H.; Jeong, S.N.; Choi, S.H. Detection, and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J. Dent. 2018, 77, 106–111. [Google Scholar] [CrossRef]
- Casalegno, F.; Newton, T.; Daher, R.; Abdelaziz, M.; Lodi-Rizzini, A.; Schürmann, F.; Krejci, I.; Markram, H. Caries detection with near-infrared transillumination using deep learning. J. Dent. Res. 2019, 98, 1227–1233. [Google Scholar] [CrossRef]
- Zanella-Calzada, L.A.; Galván-Tejada, C.E.; Chávez-Lamas, N.M.; Rivas-Gutierrez, J.; Magallanes-Quintanar, R.; Celaya-Padilla, J.M.; Galván-Tejada, J.I.; Gamboa-Rosales, H. Deep artificial neural networks for the diagnostic of caries using socioeconomic and nutritional features as determinants: Data from NHANES 2013-2014. Bioengineering 2018, 5, 47. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Oh, S.I.; Jo, J.; Kang, S.; Shin, Y.; Park, J.W. Deep learning for early dental caries detection in bitewing radiographs. Sci. Rep. 2021, 11, 16807. [Google Scholar] [CrossRef]
- Zheng, L.; Wang, H.; Mei, L.; Chen, Q.; Zhang, Y.; Zhang, H. Artificial intelligence in digital cariology: A new tool for the diagnosis of deep caries and pulpitis using convolutional neural networks. Ann. Transl. Med. 2021, 9, 763. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Liang, Y.; Li, W.; Liu, C.; Gu, D.; Sun, W.; Miao, L. Development and evaluation of deep learning for screening dental caries from oral photographs. Oral Dis. 2022, 28, 173–181. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhang, Z.; Song, A. Physiological-signal-based emotion recognition: An odyssey from methodology to philosophy. Measurement 2021, 172, 108747. [Google Scholar] [CrossRef]
- Chakraborty, S.; Aich, S.; Joo, M.; Sain, M.; Kim, H.-C. A Multichannel Convolutional Neural Network Architecture for the Detection of the State of Mind Using Physiological Signals from Wearable Devices. J. Healthc. Eng. 2019, 2019, e5397814. [Google Scholar] [CrossRef] [PubMed]
- Bota, P.; Wang, C.; Fred, A.; Silva, H. Emotion Assessment Using Feature Fusion and Decision Fusion Classification Based on Physiological Data: Are We There Yet? Sensors 2020, 20, 4723. [Google Scholar] [CrossRef] [PubMed]
- Murugappan, R.; Bosco, J.J.; Eswaran, K.; Vijay, P.; Vijayaraghavan, V. User Independent Human Stress Detection. In Proceedings of the 2020 IEEE 10th International Conference on Intelligent Systems (IS), Varna, Bulgaria, 28–30 August 2020; pp. 490–497. [Google Scholar]
- Uddin, M.T.; Canavan, S. Synthesizing Physiological and Motion Data for Stress and Meditation Detection. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Cambridge, UK, 3–6 September 2019; pp. 244–247. [Google Scholar]
- Venugopalan, J.; Tong, L.; Hassanzadeh, H.R.; Wang, M.D. Multimodal deep learning models for early detection of Alzheimer’s disease stage. Sci. Rep. 2021, 11, 3254. [Google Scholar] [CrossRef]
- Pingali, L. Personal Oral Health Advisor Using Multimodal Sensing and Machine Learning with Smartphones and Cloud Computing. In Proceedings of the 2019 IEEE International Conference on Cloud Computing in Emerging Markets (CCEM), Bengaluru, India, 19–20 September 2019; pp. 17–24. [Google Scholar] [CrossRef]
- Tiulpin, A.; Klein, S.; Bierma-Zeinstra, S.M.A.; Thevenot, J.; Rahtu, E.; Meurs, J.V.; Oei, E.H.G.; Saarakkala, S. Multimodal Machine Learning-based Knee Osteoarthritis Progression Prediction from Plain Radiographs and Clinical Data. Sci. Rep. 2019, 9, 20038. [Google Scholar] [CrossRef]
- Nie, D.; Zhang, H.; Adeli, E.; Liu, L.; Shen, D. 3D Deep Learning for Multi-modal Imaging-Guided Survival Time Prediction of Brain Tumor Patients. Med. Image Comput. Comput. Assist. Interv. 2016, 9901, 212–220. [Google Scholar] [CrossRef]
- Teeth_Dataset|Kaggle. Available online: https://www.kaggle.com/datasets/pushkar34/teeth-dataset (accessed on 9 December 2021).
- Teethdecay|Kaggle. Available online: https://www.kaggle.com/datasets/snginh/teethdecay (accessed on 9 December 2021).
- Beraha, M.; Metelli, A.M.; Papini, M.; Tirinzoni, A.; Restelli, M. Feature Selection via Mutual Information: New Theoretical Insights. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–9. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Huang, Z.; Zhu, X.; Ding, M.; Zhang, X. Medical Image Classification Using a Light-Weighted Hybrid Neural Network Based on PCANet and DenseNet. IEEE Access 2020, 8, 24697–24712. [Google Scholar] [CrossRef]
- Hasan, N.; Bao, Y.; Shawon, A.; Huang, Y. DenseNet Convolutional Neural Networks Application for Predicting COVID-19 Using CT Image. SN Comput. Sci. 2021, 2, 389. [Google Scholar] [CrossRef] [PubMed]
- Raitio, M.; Pienihäkkinen, K.; Scheinin, A. Multifactorial modeling for prediction of caries increment in adolescents. Acta Odontol. Scand. 1996, 54, 118–121. [Google Scholar] [CrossRef] [PubMed]
- Pang, L.; Wang, K.; Tao, Y.; Zhi, Q.; Zhang, J.; Lin, H. A New Model for Caries Risk Prediction in Teenagers Using a Machine Learning Algorithm Based on Environmental and Genetic Factors. Front. Genet. 2021, 12, 636867. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Part | Component | Description |
|---|---|---|
| Hardware | OS | Ubuntu 18.0.4 64 bit |
| CPU | Intel Core i7-6850k (3.60 Hz) | |
| GPU | NVIDIA GTX 1080 Ti | |
| RAM | 62.7 GB | |
| Software | TensorFlow | 2.5.0 |
| Python Version | 3.8.0 | |
| CUDA Version | 11.2.0 |
| Metric | Formula | Description |
|---|---|---|
| Precision | Indicates the proportion of positive identifications which were correct. | |
| Recall | Indicates the proportion of actual positives which were correctly classified | |
| F1-score | Combination of precision and recall | |
| Accuracy | Overall performance of the model | |
| AUC-ROC | Comparison of a model’s TPR versus model’s FPR |
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| 0 | 0.95 | 0.87 | 0.91 | 3823 |
| 1 | 0.83 | 0.93 | 0.88 | 2622 |
| Accuracy | 0.90 | 6445 | ||
| Macro average | 0.89 | 0.90 | 0.89 | 6445 |
| Weight average | 0.90 | 0.90 | 0.90 | 6445 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngnamsie Njimbouom, S.; Lee, K.; Kim, J.-D. MMDCP: Multi-Modal Dental Caries Prediction for Decision Support System Using Deep Learning. Int. J. Environ. Res. Public Health 2022, 19, 10928. https://doi.org/10.3390/ijerph191710928
Ngnamsie Njimbouom S, Lee K, Kim J-D. MMDCP: Multi-Modal Dental Caries Prediction for Decision Support System Using Deep Learning. International Journal of Environmental Research and Public Health. 2022; 19(17):10928. https://doi.org/10.3390/ijerph191710928
Chicago/Turabian StyleNgnamsie Njimbouom, Soualihou, Kwonwoo Lee, and Jeong-Dong Kim. 2022. "MMDCP: Multi-Modal Dental Caries Prediction for Decision Support System Using Deep Learning" International Journal of Environmental Research and Public Health 19, no. 17: 10928. https://doi.org/10.3390/ijerph191710928
APA StyleNgnamsie Njimbouom, S., Lee, K., & Kim, J.-D. (2022). MMDCP: Multi-Modal Dental Caries Prediction for Decision Support System Using Deep Learning. International Journal of Environmental Research and Public Health, 19(17), 10928. https://doi.org/10.3390/ijerph191710928