
Spatiotemporal Analysis and Risk Assessment Model Research of Diabetes among People over 45 Years Old in China

Abstract
1. Introduction
1.1. Background
1.2. Research Status
2. Materials and Methods
2.1. Data Source
2.2. Diabetes Definition
2.3. Methods
2.3.1. Spatial Autocorrelation
2.3.2. Spatial Cluster Analysis
2.3.3. Binary Logistic Regression
2.3.4. Geographically Weighted Regression
2.3.5. Random Forest Model
3. Results
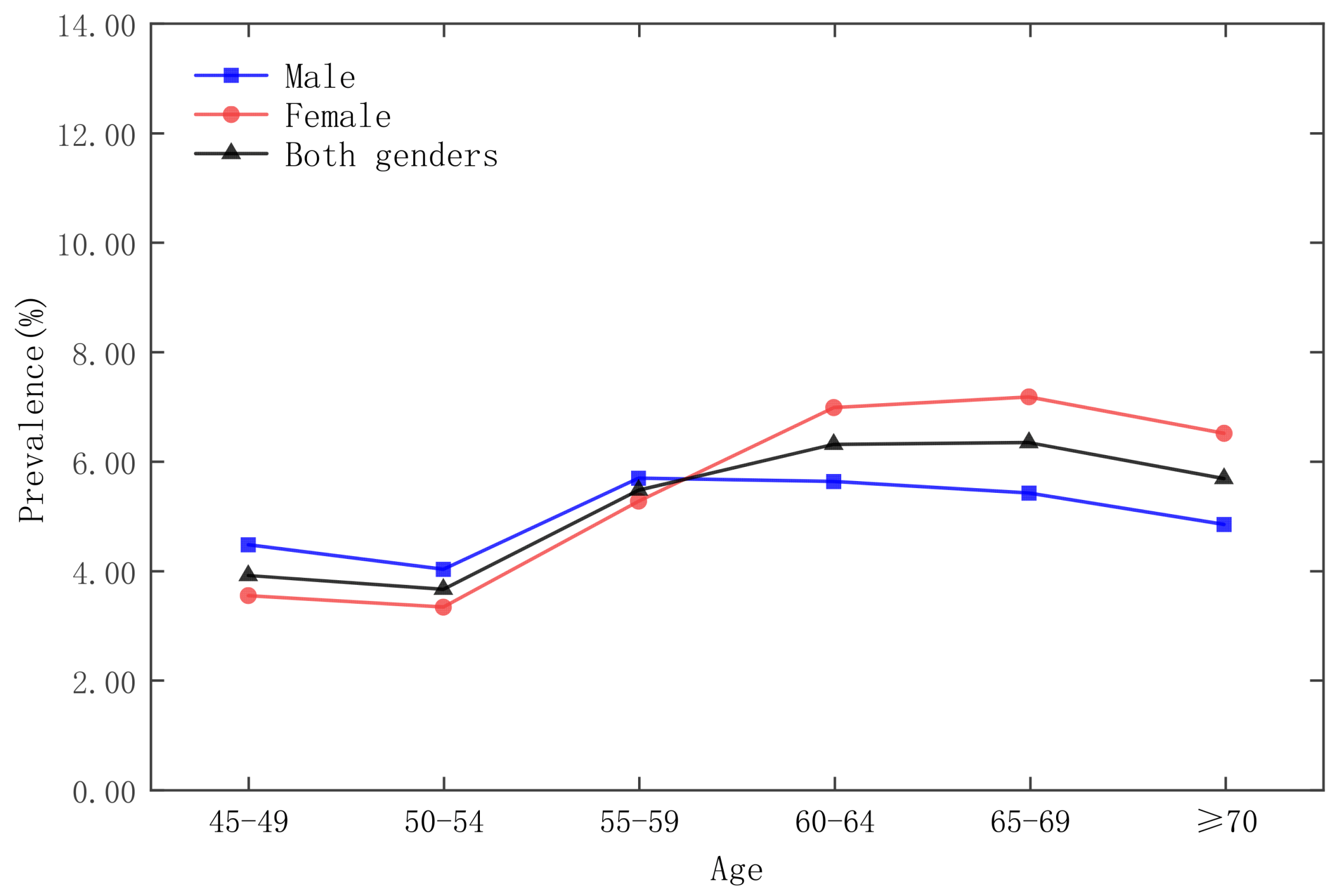
3.1. Statistical Analysis and Spatial Distribution
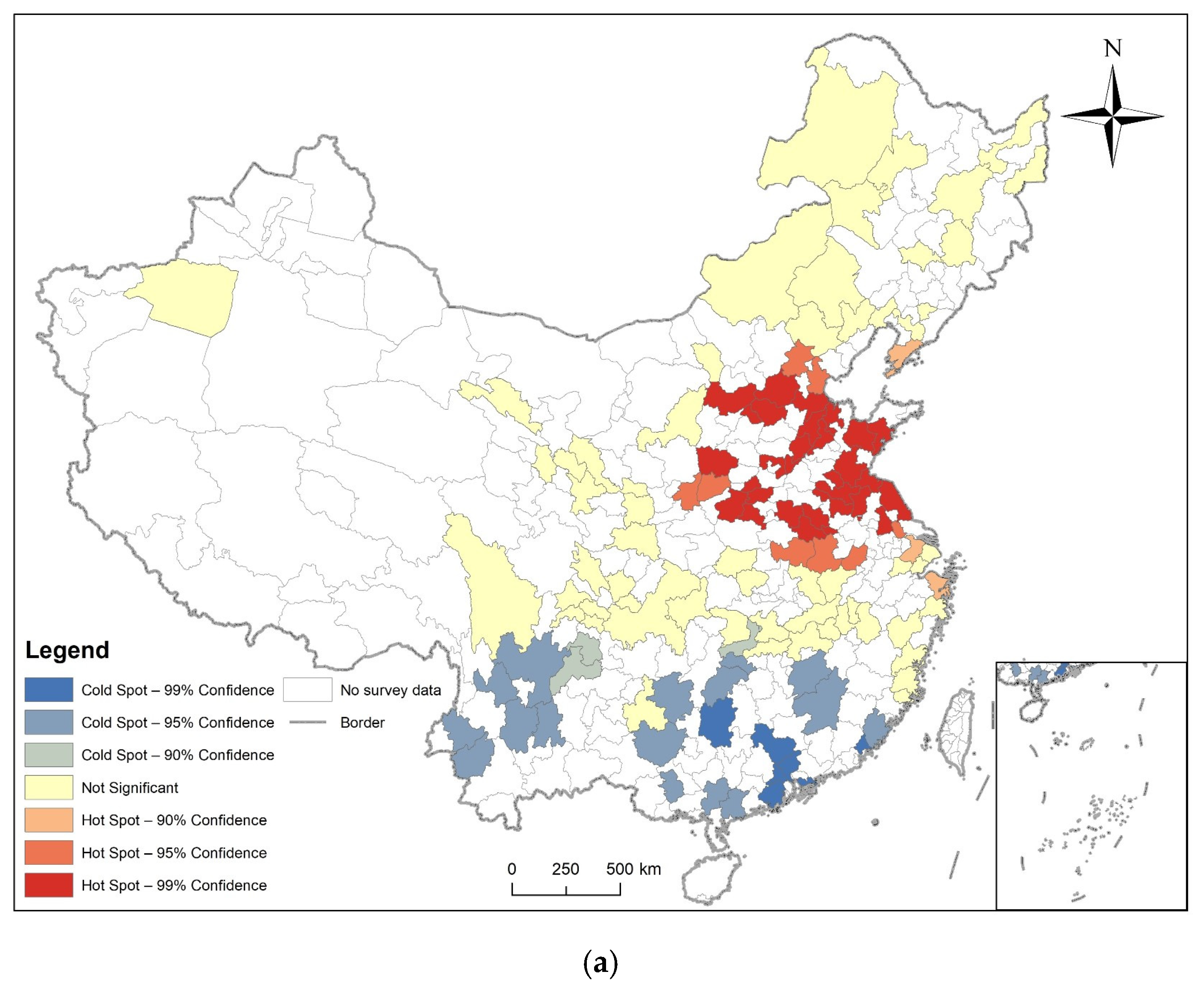
3.2. Spatial Autocorrelation Analysis
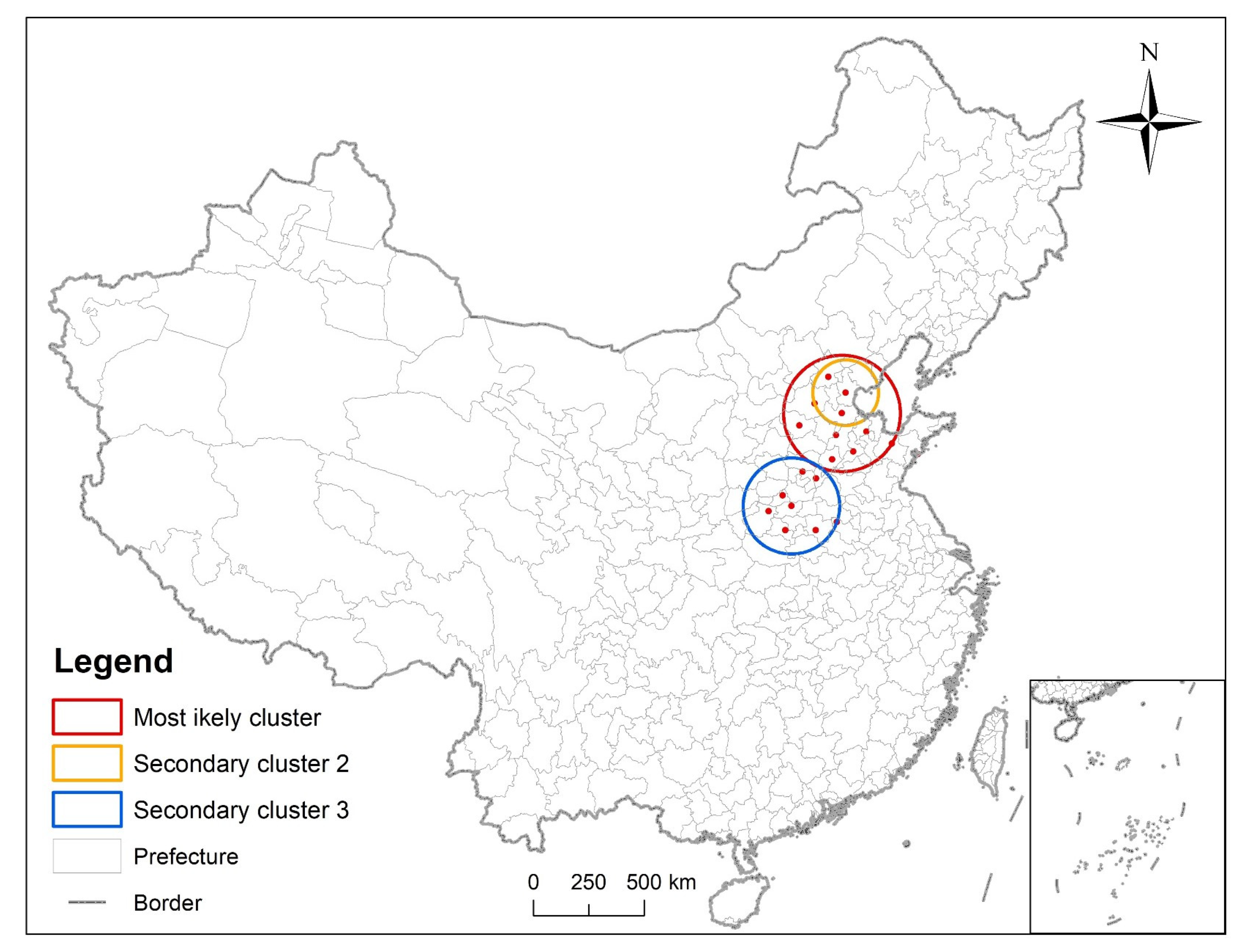
3.3. Analysis of Time and Space
3.4. Binary Logistic Regression
3.5. Geographically Weighted Regression
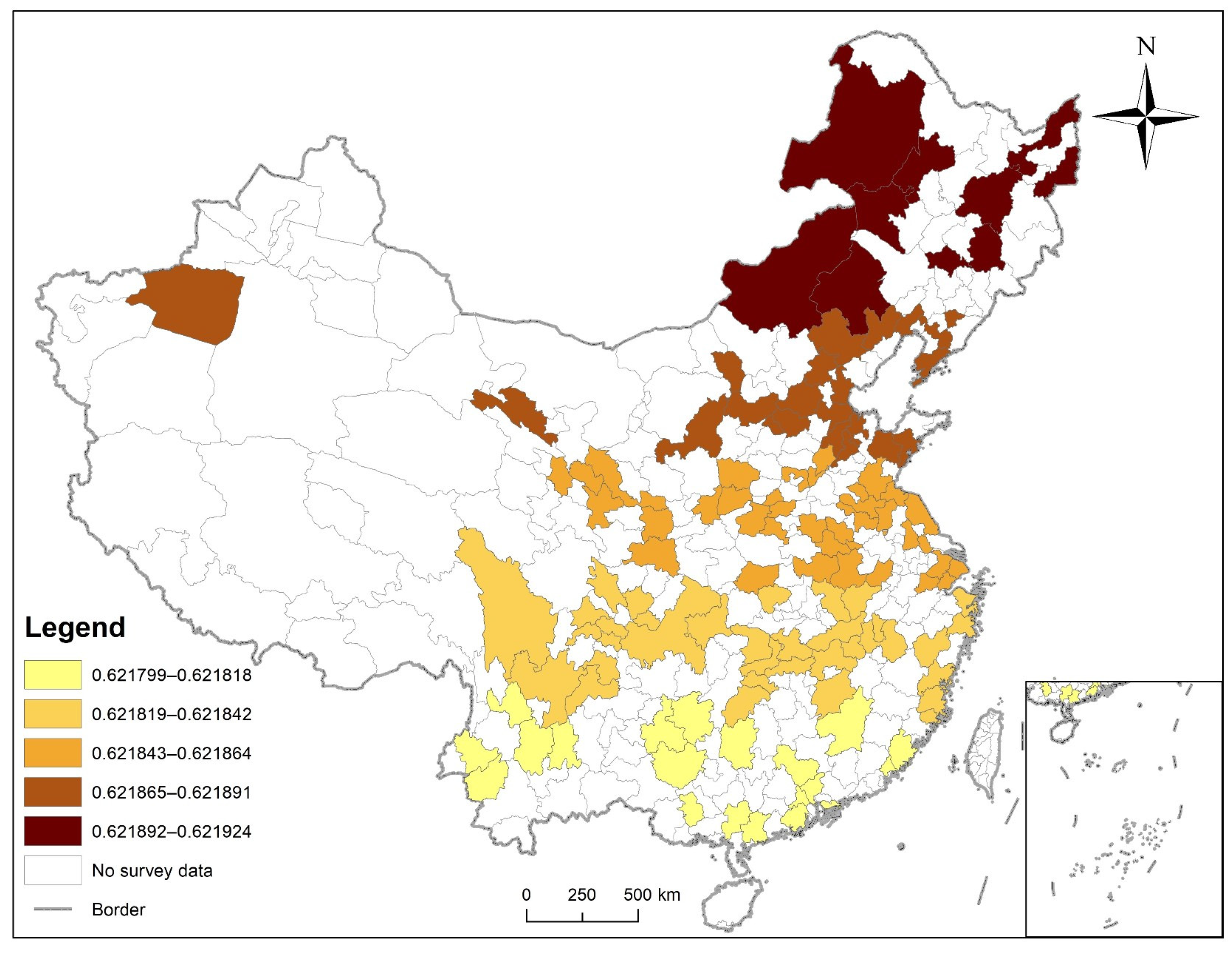
3.6. Disease Risk Assessment
4. Discussion
4.1. Innovation in This Study
4.2. Scale Effect
4.3. Spatiotemporal Characteristic of Diabetes Prevalence
4.4. Diabetes Risk Factors
4.5. Spatial Heterogeneity of Diabetes Risk Factors
4.6. Limitations and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Su, R.; Cai, L.; Cui, W.; He, J.; You, D.; Golden, A. Multilevel Analysis of Socioeconomic Determinants on Diabetes Prevalence, Awareness, Treatment and Self-Management in Ethnic Minorities of Yunnan Province, China. Int. J. Environ. Res. Public Health 2016, 13, 751. [Google Scholar] [CrossRef]
- Su, B.; Wang, Y.; Dong, Y.; Hu, G.; Xu, Y.; Peng, X.; Wang, Q.; Zheng, X. Trends in Diabetes Mortality in Urban and Rural China, 1987–2019: A Joinpoint Regression Analysis. Front. Endocrinol. 2022, 12, 777654. [Google Scholar] [CrossRef]
- Hamat, A.; Jaludin, A.; Mohd-Dom, T.N.; Rani, H.; Jamil, N.A.; Abdul Aziz, A.F. Diabetes in the News: Readability Analysis of Malaysian Diabetes Corpus. Int. J. Environ. Res. Public Health 2022, 19, 6802. [Google Scholar] [CrossRef]
- Yuan, Q.; Wang, H.; Gao, P.; Chen, W.; Lv, M.; Bai, S.; Wu, J. Prevalence and Risk Factors of Metabolic-Associated Fatty Liver Disease among 73,566 Individuals in Beijing, China. Int. J. Environ. Res. Public Health 2022, 19, 2096. [Google Scholar] [CrossRef]
- Ali, A.; Alfajjam, S.; Gasana, J. Diabetes Mellitus and Its Risk Factors among Migrant Workers in Kuwait. Int. J. Environ. Res. Public Health 2022, 19, 3943. [Google Scholar] [CrossRef]
- Chung; Kim; Kwock. Dietary Patterns May Be Nonproportional Hazards for the Incidence of Type 2 Diabetes: Evidence from Korean Adult Females. Nutrients 2019, 11, 2522. [Google Scholar] [CrossRef]
- El-Shareif, H. Prevalence, pattern, and attitudes of smoking among libyan diabetic males: A clinic-based study. Ibnosina J. Med. Biomed. Sci. 2022, 11, 171–175. [Google Scholar] [CrossRef]
- Rabieenia, E.; Jalali, R.; Mohammadi, M. Prevalence of nephropathy in patients with type 2 diabetes in Iran: A systematic review and meta-analysis based on geographic information system (GIS). Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 1543–1550. [Google Scholar] [CrossRef]
- Wang, Y.; Liang, X.; Zhou, Z.; Hou, Z.; Yang, J.; Gao, Y.; Yang, C.; Chen, T.; Li, C. Prevalence and Numbers of Diabetes Patients with Elevated BMI in China: Evidence from a Nationally Representative Cross-Sectional Study. Int. J. Environ. Res. Public Health 2022, 19, 2989. [Google Scholar] [CrossRef]
- International Diabetes Federation. Available online: https://idf.org/ (accessed on 28 May 2022).
- Murad, A.; Khashoggi, B.F. Using GIS for Disease Mapping and Clustering in Jeddah, Saudi Arabia. ISPRS Int. J. Geo-Inf. 2020, 9, 328. [Google Scholar] [CrossRef]
- Masimalai, P. Remote sensing and Geographic Information Systems (GIS) as the applied public health and environmental epidemiology. Int. J. Med. Sci. Public Health 2014, 3, 1430. [Google Scholar] [CrossRef]
- Ricketts, T.C. Geographic Information Systems and Public Health. Annu. Rev. Public Health 2003, 24, 1–6. [Google Scholar] [CrossRef][Green Version]
- Dudley, T.; Creppage, K.; Shanahan, M.; Proescholdbell, S. Using GIS to Evaluate a Fire Safety Program in North Carolina. J. Community Health 2013, 38, 951–957. [Google Scholar] [CrossRef] [PubMed]
- Dong, W.; Yang, K.; Xu, Q.; Liu, L.; Chen, J. Spatio-temporal pattern analysis for evaluation of the spread of human infections with avian influenza A(H7N9) virus in China, 2013–2014. BMC Infect. Dis. 2017, 17, 704. [Google Scholar] [CrossRef] [PubMed]
- Miranda, M.L.; Casper, M.; Tootoo, J.; Schieb, L. Putting Chronic Disease on the Map: Building GIS Capacity in State and Local Health Departments. Prev. Chronic Dis. 2013, 10, E100. [Google Scholar] [CrossRef]
- Vine, M.F.; Degnan, D.; Hanchette, C. Geographic information systems: Their use in environmental epidemiologic research. Environ. Health Perspect. 1997, 105, 598–605. [Google Scholar] [CrossRef]
- Xu, S.; Ming, J.; Xing, Y.; Gao, B.; Yang, C.; Ji, Q.; Chen, G. Regional differences in diabetes prevalence and awareness between coastal and interior provinces in China: A population-based cross-sectional study. BMC Public Health 2013, 13, 299. [Google Scholar] [CrossRef]
- Li, J.; Wang, S.; Han, X.; Zhang, G.; Zhao, M.; Ma, L. Spatiotemporal trends and influence factors of global diabetes prevalence in recent years. Soc. Sci. Med. 2020, 256, 113062. [Google Scholar] [CrossRef]
- Cao, G.; Cui, Z.; Ma, Q.; Wang, C.; Xu, Y.; Sun, H.; Ma, Y. Changes in health inequalities for patients with diabetes among middle-aged and elderly in China from 2011 to 2015. BMC Health Serv. Res. 2020, 20, 719. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Gong, W. Type 2 diabetes mellitus and neighborhood deprivation index: A spatial analysis in Zhejiang, China. J. Diabetes Investig. 2019, 10, 272–282. [Google Scholar] [CrossRef]
- Alcalá-Rmz, V.; Galván-Tejada, C.E.; García-Hernández, A.; Valladares-Salgado, A.; Cruz, M.; Galván-Tejada, J.I.; Celaya-Padilla, J.M.; Luna-Garcia, H.; Gamboa-Rosales, H. Identification of People with Diabetes Treatment through Lipids Profile Using Machine Learning Algorithms. Healthcare 2021, 9, 422. [Google Scholar] [CrossRef] [PubMed]
- Samet, S.; Laouar, M.R.; Bendib, I.; Eom, S. Analysis and Prediction of Diabetes Disease Using Machine Learning Methods. Int. J. Decis. Support Syst. Technol. 2022, 14, 1–19. [Google Scholar] [CrossRef]
- Zhou, M.; Astell-Burt, T.; Bi, Y.; Feng, X.; Jiang, Y.; Li, Y.; Page, A.; Wang, L.; Xu, Y.; Wang, L.; et al. Geographical variation in diabetes prevalence and detection in china: Multilevel spatial analysis of 98,058 adults. Diabetes Care 2015, 38, 72–81. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Ding, H.; Li, Z. Does Internet Use Impact the Health Status of Middle-Aged and Older Populations? Evidence from China Health and Retirement Longitudinal Study (CHARLS). Int. J. Environ. Res. Public Health 2022, 19, 3619. [Google Scholar] [CrossRef]
- Yu, J.; Yi, Q.; Chen, G.; Hou, L.; Liu, Q.; Xu, Y.; Qiu, Y.; Song, P. The visceral adiposity index and risk of type 2 diabetes mellitus in China: A national cohort analysis. Diabetes Metab. Res. Rev. 2022, 38, e3507. [Google Scholar] [CrossRef]
- He, B.; Li, Z.; Xu, L.; Liu, L.; Wang, S.; Zhan, S.; Song, Y. Upper arm length and knee height are associated with diabetes in the middle-aged and elderly: Evidence from the China Health and Retirement Longitudinal Study. Public Health Nutr. 2022, 1–9. [Google Scholar] [CrossRef]
- Liu, X.; Fang, W.; Li, H.; Han, X.; Xiao, H. Is Urbanization Good for the Health of Middle-Aged and Elderly People in China?—Based on CHARLS Data. Sustainability 2021, 13, 4996. [Google Scholar] [CrossRef]
- China Health and Retirement Longitudinal Study. Available online: http://charls.pku.edu.cn/en/ (accessed on 26 July 2022).
- Freitas, W.W.L.; de Souza, R.M.C.R.; Amaral, G.J.A.; De Bastiani, F. Exploratory spatial analysis for interval data: A new autocorrelation index with COVID-19 and rent price applications. Expert Syst. Appl. 2022, 195, 116561. [Google Scholar] [CrossRef]
- Cheruiyot, K. Detecting spatial economic clusters using kernel density and global and local Moran’s I analysis in Ekurhuleni metropolitan municipality, South Africa. Reg. Sci. Policy Pract. 2022, 14, 307–327. [Google Scholar] [CrossRef]
- Eccles, K.M.; Bertazzon, S. Applications of geographic information systems in public health: A geospatial approach to analyzing MMR immunization uptake in Alberta. Can. J. Public Health 2015, 106, e355–e361. [Google Scholar] [CrossRef]
- Xue, D.; Yue, L.; Ahmad, F.; Draz, M.U.; Chandio, A.A.; Ahmad, M.; Amin, W. Empirical investigation of urban land use efficiency and influencing factors of the Yellow River basin Chinese cities. Land Use Policy 2022, 117, 106117. [Google Scholar] [CrossRef]
- Ghosh, K.; Dhillon, P.; Agrawal, G. Prevalence and detecting spatial clustering of diabetes at the district level in India. J. Public Health 2019, 28, 535–545. [Google Scholar] [CrossRef]
- Zhang, Y.; Shen, Z.; Ma, C.; Jiang, C.; Feng, C.; Shankar, N.; Yang, P.; Sun, W.; Wang, Q. Cluster of Human Infections with Avian Influenza A (H7N9) Cases: A Temporal and Spatial Analysis. Int. J. Environ. Res. Public Health 2015, 12, 816–828. [Google Scholar] [CrossRef]
- Li, C.; Liu, M.; An, Y.; Tian, Y.; Guan, D.; Wu, H.; Pei, Z. Risk assessment of type 2 diabetes in northern China based on the logistic regression model. Technol. Health Care 2021, 29, 351–358. [Google Scholar] [CrossRef] [PubMed]
- Khodakarami, L.; Pourmanafi, S.; Soffianian, A.R.; Lotfi, A. Modeling Spatial Distribution of Carbon Sequestration, CO2 Absorption, and O2 Production in an Urban Area: Integrating Ground-Based Data, Remote Sensing Technique, and GWR Model. Earth Space Sci. 2022, 9, e2022EA002261. [Google Scholar] [CrossRef]
- Yang, L.; Yu, K.; Ai, J.; Liu, Y.; Yang, W.; Liu, J. Dominant Factors and Spatial Heterogeneity of Land Surface Temperatures in Urban Areas: A Case Study in Fuzhou, China. Remote Sens. 2022, 14, 1266. [Google Scholar] [CrossRef]
- Boateng, E.Y.; Otoo, J.; Abaye, D.A. Basic Tenets of Classification Algorithms K-Nearest-Neighbor, Support Vector Machine, Random Forest and Neural Network: A Review. J. Data Anal. Inf. Processing 2020, 08, 341–357. [Google Scholar] [CrossRef]
- Ren, Z.; Yang, K.; Dong, W. Spatial Analysis and Risk Assessment Model Research of Arthritis Based on Risk Factors: China, 2011, 2013 and 2015. IEEE Access 2020, 8, 206406–206417. [Google Scholar] [CrossRef]
- Daghistani, T.; Alshammari, R. Comparison of Statistical Logistic Regression and RandomForest Machine Learning Techniques in Predicting Diabetes. J. Adv. Inf. Technol. 2020, 11, 78–83. [Google Scholar] [CrossRef]
- DeCesare, N.J.; Hebblewhite, M.; Schmiegelow, F.; Hervieux, D.; McDermid, G.J.; Neufeld, L.; Bradley, M.; Whittington, J.; Smith, K.G.; Morgantini, L.E.; et al. Transcending scale dependence in identifying habitat with resource selection functions. Ecol. Appl. 2012, 22, 1068–1083. [Google Scholar] [CrossRef]
- Sandie, A.B.; Tchatchueng Mbougua, J.B.; Nlend, A.E.N.; Thiam, S.; Nono, B.F.; Fall, N.A.; Senghor, D.B.; Sylla, E.H.M.; Faye, C.M. Hot-spots of HIV infection in Cameroon: A spatial analysis based on Demographic and Health Surveys data. BMC Infect. Dis. 2022, 22, 334. [Google Scholar] [CrossRef] [PubMed]
- Jesri, N.; Saghafipour, A.; Koohpaei, A.; Farzinnia, B.; Jooshin, M.K.; Abolkheirian, S.; Sarvi, M. Mapping and Spatial Pattern Analysis of COVID-19 in Central Iran Using the Local Indicators of Spatial Association (LISA). BMC Public Health 2021, 21, 2227. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Moon, J.; Jung, I. Optimizing the maximum reported cluster size in the spatial scan statistic for survival data. Int. J. Health Geogr. 2021, 20, 33. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Liu, X.; Liu, Y.; Li, X. Meta-analytic evaluation for the spatio-temporal patterns of the associations between common risk factors and type 2 diabetes in mainland China. Medicine 2019, 98, e15581. [Google Scholar] [CrossRef] [PubMed]
- Saeedi, P.; Petersohn, I.; Salpea, P.; Malanda, B.; Karuranga, S.; Unwin, N.; Colagiuri, S.; Guariguata, L.; Motala, A.A.; Ogurtsova, K.; et al. Global and regional diabetes prevalence estimates for 2019 and projections for 2030 and 2045: Results from the International Diabetes Federation Diabetes Atlas, 9th edition. Diabetes Res. Clin. Pract. 2019, 157, 107843. [Google Scholar] [CrossRef] [PubMed]
- Oza, A.; Bokhare, A. Diabetes Prediction Using Logistic Regression and K-Nearest Neighbor. In Proceedings of the Congress on Intelligent Systems; Springer: Singapore, 2022; pp. 407–418. [Google Scholar] [CrossRef]
- Sergeev, A.V.; Weckman, G.R. Cardiovascular Disease Treatment Outcomes in Patients with Diabetes: Prediction Models Using Artificial Neural Networks and Logistic Regression. Ann. Epidemiol. 2015, 25, 705. [Google Scholar] [CrossRef]
- Nayak, B.S.; Sobrian, A.; Latiff, K.; Pope, D.; Rampersad, A.; Lourenço, K.; Samuel, N. The association of age, gender, ethnicity, family history, obesity and hypertension with type 2 diabetes mellitus in Trinidad. Diabetes Metab. Syndr. Clin. Res. Rev. 2014, 8, 91–95. [Google Scholar] [CrossRef]
- Aswin, M.; Mohan, V. Diabetes and Hypertension: What Is the Connection? In Hypertension and Cardiovascular Disease in Asia; Ram, C.V.S., Teo, B.W.J., Wander, G.S., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 159–169. [Google Scholar] [CrossRef]
- Asante, D.O.; Walker, A.N.; Seidu, T.A.; Kpogo, S.A.; Zou, J. Hypertension and Diabetes in Akatsi South District, Ghana: Modeling and Forecasting. BioMed Res. Int. 2022, 2022, 9690964. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhou, X.; Lu, J.; Guo, X.; Ji, L. Lipid control in adult Chinese patients with type 2 diabetes: A retrospective analysis of time trends and geographic regional differences. Chin. Med. J. 2022, 135, 356–358. [Google Scholar] [CrossRef]
- Cheng, F.; Li, Y.; Zheng, H.; Tian, L.; Jia, H. Mediating Effect of Body Mass Index and Dyslipidemia on the Relation of Uric Acid and Type 2 Diabetes: Results from China Health and Retirement Longitudinal Study. Front. Public Health 2022, 9, 823739. [Google Scholar] [CrossRef]
- Tomic, D.; Shaw, J.E.; Magliano, D.J. The burden and risks of emerging complications of diabetes mellitus. Nat. Rev. Endocrinol. 2022, 18, 525–539. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Sun, L.; Zhuang, Z.; Hu, X.; Dong, D. Mitochondrial-Derived Peptides in Diabetes and Its Complications. Front. Endocrinol. 2022, 12, 808120. [Google Scholar] [CrossRef] [PubMed]
- Liang, W.; Chikritzhs, T. Alcohol Consumption during Adolescence and Risk of Diabetes in Young Adulthood. BioMed Res. Int. 2014, 2014, 795741. [Google Scholar] [CrossRef] [PubMed]
- Medina-Chávez, J.H.; Vázquez-Parrodi, M.; Santoyo-Gómez, D.L.; Azuela-Antuna, J.; Garnica-Cuellar, J.C.; Herrera-Landero, A.; Balandrán-Duarte, D.A. Integrated Care Protocol: Chronic complications of diabetes mellitus 2. Rev. Med. Del Inst. Mex. Del Seguro Soc. 2022, 60, S19–S33. [Google Scholar]
- Tonstad, S. Cigarette smoking, smoking cessation, and diabetes. Diabetes Res. Clin. Pract. 2009, 85, 4–13. [Google Scholar] [CrossRef]
- Yatsuya, H. Avoid clinical inertia: Importance of asking and advising patients with diabetes who smoke about quitting. J. Diabetes Investig. 2021, 12, 317–319. [Google Scholar] [CrossRef]
- Zhou, Y.H.; Mak, Y.W.; Ho, G.W.K. Effectiveness of Interventions to Reduce Exposure to Parental Secondhand Smoke at Home among Children in China: A Systematic Review. Int. J. Environ. Res. Public Health 2019, 16, 107. [Google Scholar] [CrossRef]
- Xiao, L.; Jiang, Y.; Zhang, J.; Parascandola, M. Secondhand Smoke Exposure among Nonsmokers in China. Asian Pac. J. Cancer Prev. 2020, 21, 17–22. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, Z.; Hu, X.; Yang, G.; Wang, B.; Duan, D.; Fu, Y.; Liang, J.; Zhao, C. Spatial heterogeneity of county-level grain protein content in winter wheat in the Huang-Huai-Hai region of China. Eur. J. Agron. 2022, 134, 126466. [Google Scholar] [CrossRef]
- Murad, A.; Faruque, F.; Naji, A.; Tiwari, A.; Helmi, M.; Dahlan, A. Modelling geographical heterogeneity of diabetes prevalence and socio-economic and built environment determinants in Saudi City—Jeddah. Geospat Health 2022, 17. [Google Scholar] [CrossRef]
- Isfandiari, M.A.; Wahyuni, C.U.; Pranoto, A. Tuberculosis Predictive Index for Type 2 Diabetes Mellitus Patients Based on Biological, Social, Housing Environment, and Psychological Well-Being Factors. Healthcare 2022, 10, 872. [Google Scholar] [CrossRef] [PubMed]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | Moran’s Index | p-Value | Z-Score | Spatial Distribution Model |
|---|---|---|---|---|
| 2011 | 0.103458 | <0.001 | 7.139808 | Cluster |
| 2013 | 0.104485 | <0.001 | 7.205062 | Cluster |
| 2015 | 0.067174 | <0.001 | 4.835403 | Cluster |
| 2018 | 0.025585 | <0.007 | 2.652944 | Cluster |
| Cluster Center | Radius (km) | Region | Logarithmic Likelihood Ratio | Relative Risk Level | p-Value |
|---|---|---|---|---|---|
| Cangzhou, Hebei Province | 270.98 | Cangzhou, Tianjin, Dezhou, Baoding, Binzhou, Beijing, Jinan, Shijiazhuang, Liaocheng, Weifang | 52.819422 | 1.54 | <0.001 |
| Tianjin | 153.02 | Tianjin, Cangzhou, Beijing, Baoding | 41.161335 | 1.78 | <0.001 |
| Zhengzhou, Henan Province | 221.64 | Zhengzhou, Jiaozuo, Luoyang, Pingdingshan, Zhoukou, Anyang, Puyang, Bozhou | 39.852687 | 1.54 | <0.001 |
| Cluster Center | Radius (km) | Region | Logarithmic Likelihood Ratio | Relative Risk Level | p-Value |
|---|---|---|---|---|---|
| Dezhou, Shandong Province | 229.44 | Dezhou, Cangzhou, Jinan, Liaocheng, Binzhou, Shijiazhuang, Baoding, Tianjin, Puyang, Anyang | 163.632756 | 4.16 | <0.001 |
| Suqian, Jiangsu Province | 264.81 | Suqian, Xuzhou, Lianyungang, Suzhou, Linyi, Zaozhuang, Yancheng, Huainan, Yangzhou, Taizhou, Bozhou, Fuyang, Hefei | 109.037860 | 3.39 | <0.001 |
| Weinan, Shanxi Province | 377.23 | Weinan, Yuncheng, Baoji, Linfen, Luoyang, Hanzhong, Pingliang, Pingdingshan, Jiaozuo, Xiangfan, Zhengzhou | 94.209061 | 3.20 | <0.001 |
| Variables | Type | Assignments |
|---|---|---|
| Gender | Integer | 0 = Male; 1 = Female |
| Age | Integer | 0 = 45–49; 1 = 50–54; 2 = 55–59; 3 = 60–64; 4 = 65–69; 5 = 70 or more |
| Location of Residential Address | Integer | 0 = Central of City/Town; 1 = Urban-Rural Integration Zone; 2 = Rural; 3 = Special Zone |
| Education | Integer | 0 = Illiterate; 1 = Did not Finish Primary School; 2 = Sishu/Home School; 3 = Elementary School; 4 = Middle School; 5 = High School; 6 = Vocational School; 7 = Two-/Three-Year College/Associate Degree; 8 = Four-Year College/Bachelor’s Degree or more |
| Marital Status | Integer | 0 = Married with Spouse Present; 1 = Married but Not Living with Spouse Temporarily for Reasons Such as Work; 2 = Separated; 3 = Divorced; 4 = Widowed; 5 = Never Married |
| Nation | Integer | 0 = Han Nationality; 1 = Zhuang Nationality; 2 = Manchu; 3 = Hui Nationality; 4 = Miao Nationality; 5 = Uyghur Nationality; 6 = Tujia Nationality; 7 = Yi Nationality; 8 = Other Nationality |
| Hypertension | Integer | 0 = No; 1 = Yes |
| Dyslipidemia | Integer | 0 = No; 1 = Yes |
| Diabetes | Integer | 0 = No; 1 = Yes |
| Cancer | Integer | 0 = No; 1 = Yes |
| Liver Disease | Integer | 0 = No; 1 = Yes |
| Emotional Problems | Integer | 0 = No; 1 = Yes |
| Smoking History | Integer | 0 = No; 1 = Yes |
| Alcohol Use | Integer | 0 = No; 1 = Yes |
| Factors | The Total Number of Samples | Number of Cases | X2 | p-Value | ||
|---|---|---|---|---|---|---|
| Gender | 3.734 | 0.053 | ||||
| Male | 8715 | 463 | 5.31% | |||
| Female | 9459 | 569 | 6.02% | |||
| Age | 37.133 | <0.001 | ||||
| 45–49 | 1307 | 53 | 4.06% | |||
| 50–54 | 3173 | 120 | 3.78% | |||
| 55–59 | 3135 | 181 | 5.77% | |||
| 60–64 | 2856 | 192 | 6.72% | |||
| 65–69 | 3063 | 207 | 6.76% | |||
| ≥70 | 4640 | 279 | 6.01% | |||
| Location of Residential Address | 13.003 | 0.005 | ||||
| Central of City/Town | 3486 | 232 | 6.66% | |||
| Urban-Rural Integration Zone | 1270 | 90 | 7.09% | |||
| Rural | 13346 | 706 | 5.29% | |||
| Special Zone | 72 | 4 | 5.56% | |||
| Education | 17.018 | 0.03 | ||||
| Illiterate | 4022 | 252 | 6.27% | |||
| Did not Finish Primary School | 3764 | 208 | 5.53% | |||
| Sishu/Home School | 41 | 2 | 4.88% | |||
| Elementary School | 4030 | 221 | 5.48% | |||
| Middle School | 4023 | 201 | 5.00% | |||
| High School | 1503 | 81 | 5.39% | |||
| Vocational School | 420 | 35 | 8.33% | |||
| Two-/Three-Year College/ Associate Degree | 229 | 22 | 9.61% | |||
| Four-Year College/Bachelor’s Degree or more | 142 | 10 | 7.04% | |||
| Marital Status | 3.355 | 0.645 | ||||
| Married with Spouse Present | 14281 | 820 | 5.74% | |||
| Married But Not Living with Spouse Temporarily for Reasons Such as Work | 1214 | 63 | 5.19% | |||
| Separated | 65 | 4 | 6.15% | |||
| Divorced | 226 | 9 | 3.98% | |||
| Widowed | 2280 | 133 | 5.83% | |||
| Never Married | 108 | 3 | 2.78% | |||
| Nation | 10.489 | 0.232 | ||||
| Han Nationality | 17077 | 975 | 5.71% | |||
| Zhuang Nationality | 177 | 8 | 4.52% | |||
| Manchu | 301 | 12 | 3.99% | |||
| Hui Nationality | 107 | 12 | 11.21% | |||
| Miao Nationality | 112 | 3 | 2.68% | |||
| Uyghur Nationality | 81 | 6 | 7.41% | |||
| Tujia Nationality | 25 | 1 | 4.00% | |||
| Yi Nationality | 97 | 3 | 3.09% | |||
| Other Nationality | 197 | 12 | 6.09% | |||
| Hypertension | 161.428 | <0.001 | ||||
| No | 16273 | 792 | 4.87% | |||
| Yes | 1901 | 240 | 12.62% | |||
| Dyslipidemia | 433.646 | <0.001 | ||||
| No | 16601 | 739 | 4.45% | |||
| Yes | 1573 | 293 | 18.63% | |||
| Cancer | 8.651 | 0.003 | ||||
| No | 17946 | 1008 | 5.62% | |||
| Yes | 228 | 24 | 10.53% | |||
| Liver Disease | 12.350 | <0.001 | ||||
| No | 17603 | 979 | 5.56% | |||
| Yes | 571 | 53 | 9.28% | |||
| Emotional Problems | 2.246 | 0.134 | ||||
| No | 17968 | 1015 | 5.65% | |||
| Yes | 206 | 17 | 8.25% | |||
| Smoking History | 19.540 | <0.001 | ||||
| No | 17359 | 955 | 5.50% | |||
| Yes | 815 | 77 | 9.45% | |||
| Alcohol Use | 11.566 | 0.001 | ||||
| No | 11936 | 731 | 6.12% | |||
| Yes | 6238 | 301 | 4.83% |
| Variables | B | SE | Wald | Df | p-Value | OR | 95% CI | |
|---|---|---|---|---|---|---|---|---|
| Lower | Upper | |||||||
| Age (45–49) | 31.808 | 5 | 0.000 | |||||
| 50–54 | −0.062 | 0.170 | 0.134 | 1 | 0.714 | 0.939 | 0.673 | 1.311 |
| 55–59 | 0.348 | 0.162 | 4.629 | 1 | 0.031 | 1.416 | 1.031 | 1.944 |
| 60–64 | 0.488 | 0.161 | 9.193 | 1 | 0.002 | 1.629 | 1.188 | 2.232 |
| 65–69 | 0.475 | 0.160 | 8.843 | 1 | 0.003 | 1.607 | 1.176 | 2.198 |
| ≥70 | 0.389 | 0.155 | 6.291 | 1 | 0.012 | 1.475 | 1.089 | 2.000 |
| Hypertension | 0.703 | 0.081 | 75.339 | 1 | 0.000 | 2.020 | 1.723 | 2.367 |
| Dyslipidemia | 1.302 | 0.076 | 295.059 | 1 | 0.000 | 3.676 | 3.169 | 4.265 |
| Smoking history | 0.373 | 0.128 | 8.446 | 1 | 0.004 | 1.452 | 1.129 | 1.867 |
| Constant | −3.549 | 0.144 | 606.838 | 1 | 0.000 | 0.029 | ||
| Variables | Mean | Max | Min |
|---|---|---|---|
| Age | 0.0571 | 0.057091 | 0.05713 |
| Hypertension | 0.007537 | 0.007361 | 0.00765 |
| Dyslipidemia | 0.265775 | 0.26573 | 0.265843 |
| Smoking History | 0.00879 | 0.008752 | 0.008823 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Dong, W.; Yang, K. Spatiotemporal Analysis and Risk Assessment Model Research of Diabetes among People over 45 Years Old in China. Int. J. Environ. Res. Public Health 2022, 19, 9861. https://doi.org/10.3390/ijerph19169861
Wang Z, Dong W, Yang K. Spatiotemporal Analysis and Risk Assessment Model Research of Diabetes among People over 45 Years Old in China. International Journal of Environmental Research and Public Health. 2022; 19(16):9861. https://doi.org/10.3390/ijerph19169861
Chicago/Turabian StyleWang, Zhenyi, Wen Dong, and Kun Yang. 2022. "Spatiotemporal Analysis and Risk Assessment Model Research of Diabetes among People over 45 Years Old in China" International Journal of Environmental Research and Public Health 19, no. 16: 9861. https://doi.org/10.3390/ijerph19169861
APA StyleWang, Z., Dong, W., & Yang, K. (2022). Spatiotemporal Analysis and Risk Assessment Model Research of Diabetes among People over 45 Years Old in China. International Journal of Environmental Research and Public Health, 19(16), 9861. https://doi.org/10.3390/ijerph19169861