
Leveraging Reddit for Suicidal Ideation Detection: A Review of Machine Learning and Natural Language Processing Techniques


Abstract
:1. Introduction
- We present the state of the art in suicidal ideation detection by reviewing the prevalent methods within these rational aspects:
- How do current studies approach data collection and annotation?
- What techniques are used to extract suicide-indicative features?
- What algorithms are used for detecting suicidal ideations?
- We provide descriptions of several Reddit-based datasets used in the domain;
- We discuss current limitations and future directions of the research in detecting suicidal ideation.
2. Methodology
2.1. Search Strategy
2.2. Eligibility Criteria
2.3. Selection Process
3. Results
3.1. Detection of Suicidal Ideation on Social Media
3.2. Reddit as a Source for Suicidal Ideation Detection
3.3. Machine Learning Approach for Suicidal Ideation Detection
3.4. Data Collection
3.4.1. Extracting Data from Reddit
3.4.2. Using Available Datasets
3.5. Data Annotation
3.5.1. Expert Annotations
3.5.2. Crowdsourced Annotations
3.5.3. Community Affiliation
3.6. Data Preprocessing
3.6.1. Data Cleaning
3.6.2. Tokenization
3.6.3. Lemmatization
3.7. Feature Engineering
3.7.1. Term Frequency–Inverse Document Frequency
3.7.2. Linguistic Inquiry and Word Count
3.7.3. Lexicon-Based Methods
3.7.4. Latent Dirichlet Allocation
3.7.5. Statistical Features
3.7.6. Word Embeddings
3.7.7. Dimensionality Reduction
3.8. Model Development
3.8.1. Support Vector Machine
3.8.2. Logistic Regression
3.8.3. Deep Learning Algorithms
3.9. Model Validation
4. Discussion
4.1. Limitations
4.2. Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional Encoder Representations from Transformers |
| BOW | Bag of Words |
| CNN | Convolutional Neural Network |
| DT | Decision Tree |
| FCNN | Fully Connected Neural Network |
| FFNN | Feedforward Neural Network |
| GRU | Gated Recurrent Units |
| KNN | K-Nearest Neighbors |
| LDA | Latent Dirichlet Allocation |
| LIWC | Linguistic Inquiry and Word Count |
| LR | Logistic Regression |
| LSTM | Long Short-Term Memory |
| MLFFNN | Multilayer Feed Forward Neural Net |
| NB | Naïve Bayes |
| NRC | National Research Council Canada |
| RF | Random Forest |
| RNN | Recurrent Neural Network |
| SVM | Support Vector Machines |
| TF–IDF | Term Frequency–Inverse Document Frequency |
| XGBoost | Extreme Gradient Boosting |
References
- World Health Organization. Suicide Worldwide in 2019: Global Health Estimates; World Health Organization: Geneva, Switzerland, 2021.
- World Health Organization. Preventing Suicide: A Global Imperative; World Health Organization: Geneva, Switzerland, 2014.
- O’Connor, R.C.; Nock, M.K. The Psychology of Suicidal Behaviour. Lancet Psychiatry 2014, 1, 73–85. [Google Scholar] [CrossRef]
- Risk Factors, Protective Factors, and Warning Signs. American Foundation for Suicide Prevention. Available online: https://afsp.org/risk-factors-protective-factors-and-warning-signs/ (accessed on 21 July 2022).
- Franklin, J.C.; Ribeiro, J.D.; Fox, K.R.; Bentley, K.H.; Kleiman, E.M.; Huang, X.; Musacchio, K.M.; Jaroszewski, A.C.; Chang, B.P.; Nock, M.K. Risk Factors for Suicidal Thoughts and Behaviors: A Meta-Analysis of 50 Years of Research. Psychol. Bull. 2017, 143, 187–232. [Google Scholar] [CrossRef] [PubMed]
- Castillo-Sánchez, G.; Marques, G.; Dorronzoro, E.; Rivera-Romero, O.; Franco-Martín, M.; De la Torre-Díez, I. Suicide Risk Assessment Using Machine Learning and Social Networks: A Scoping Review. J. Med. Syst. 2020, 44, 205. [Google Scholar] [CrossRef] [PubMed]
- Aladağ, A.E.; Muderrisoglu, S.; Akbas, N.B.; Zahmacioglu, O.; Bingol, H.O. Detecting Suicidal Ideation on Forums: Proof-of-Concept Study. J. Med. Internet Res. 2018, 20, e215. [Google Scholar] [CrossRef] [PubMed]
- Harmer, B.; Lee, S.; Duong, T.v.H.; Saadabadi, A. Suicidal Ideation. In StatPearls; StatPearls Publishing: Treasure Island, FL, USA, 2022. [Google Scholar]
- Simon, R.I. Passive Suicidal Ideation: Still a High-Risk Clinical Scenario. Curr. Psychiatry 2014, 13, 13–15. [Google Scholar]
- Ji, S.; Pan, S.; Li, X.; Cambria, E.; Long, G.; Huang, Z. Suicidal Ideation Detection: A Review of Machine Learning Methods and Applications. IEEE Trans. Comput. Soc. Syst. 2021, 8, 214–226. [Google Scholar] [CrossRef]
- Gaur, M.; Aribandi, V.; Alambo, A.; Kursuncu, U.; Thirunarayan, K.; Beich, J.; Pathak, J.; Sheth, A. Characterization of Time-Variant and Time-Invariant Assessment of Suicidality on Reddit Using C-SSRS. PLoS ONE 2021, 16, e0250448. [Google Scholar] [CrossRef]
- Grant, R.N.; Kucher, D.; León, A.M.; Gemmell, J.F.; Raicu, D.S.; Fodeh, S.J. Automatic Extraction of Informal Topics from Online Suicidal Ideation. BMC Bioinform. 2018, 19, 211. [Google Scholar] [CrossRef]
- Ji, S.; Yu, C.P.; Fung, S.; Pan, S.; Long, G. Supervised Learning for Suicidal Ideation Detection in Online User Content. Complexity 2018, 2018, 6157249. [Google Scholar] [CrossRef]
- Vioules, M.J.; Moulahi, B.; Aze, J.; Bringay, S. Detection of Suicide-Related Posts in Twitter Data Streams. IBM J. Res. Dev. 2018, 62, 7:1–7:12. [Google Scholar] [CrossRef]
- Matero, M.; Idnani, A.; Son, Y.; Giorgi, S.; Vu, H.; Zamani, M.; Limbachiya, P.; Guntuku, S.C.; Schwartz, H.A. Suicide Risk Assessment with Multi-Level Dual-Context Language and BERT. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 39–44. [Google Scholar] [CrossRef]
- Tadesse, M.M.; Lin, H.; Xu, B.; Yang, L. Detection of Suicide Ideation in Social Media Forums Using Deep Learning. Algorithms 2019, 13, 7. [Google Scholar] [CrossRef]
- Jones, N.; Jaques, N.; Pataranutaporn, P.; Ghandeharioun, A.; Picard, R. Analysis of Online Suicide Risk with Document Embeddings and Latent Dirichlet Allocation. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Cambridge, UK, 3–6 September 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Eichstaedt, J.C.; Smith, R.J.; Merchant, R.M.; Ungar, L.H.; Crutchley, P.; Preoţiuc-Pietro, D.; Asch, D.A.; Schwartz, H.A. Facebook Language Predicts Depression in Medical Records. Proc. Natl. Acad. Sci. USA 2018, 115, 11203–11208. [Google Scholar] [CrossRef]
- Guntuku, S.C.; Sherman, G.; Stokes, D.C.; Agarwal, A.K.; Seltzer, E.; Merchant, R.M.; Ungar, L.H. Tracking Mental Health and Symptom Mentions on Twitter During COVID-19. J. Gen. Intern. Med. 2020, 35, 2798–2800. [Google Scholar] [CrossRef] [PubMed]
- Chancellor, S.; De Choudhury, M. Methods in Predictive Techniques for Mental Health Status on Social Media: A Critical Review. NPJ Digit. Med. 2020, 3, 43. [Google Scholar] [CrossRef] [PubMed]
- Skaik, R.; Inkpen, D. Using Social Media for Mental Health Surveillance: A Review. ACM Comput. Surv. 2021, 53, 1–31. [Google Scholar] [CrossRef]
- Beriwal, M.; Agrawal, S. Techniques for Suicidal Ideation Prediction: A Qualitative Systematic Review. In Proceedings of the 2021 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Kocaeli, Turkey, 25–27 August 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 Statement: An Updated Guideline for Reporting Systematic Reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Allen, K.; Bagroy, S.; Davis, A.; Krishnamurti, T. ConvSent at CLPsych 2019 Task A: Using Post-Level Sentiment Features for Suicide Risk Prediction on Reddit. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 182–187. [Google Scholar] [CrossRef]
- Yao, H.; Rashidian, S.; Dong, X.; Duanmu, H.; Rosenthal, R.N.; Wang, F. Detection of Suicidality Among Opioid Users on Reddit: Machine Learning-Based Approach. J. Med. Internet Res. 2020, 22, e15293. [Google Scholar] [CrossRef]
- Gaur, M.; Alambo, A.; Sain, J.P.; Kursuncu, U.; Thirunarayan, K.; Kavuluru, R.; Sheth, A.; Welton, R.; Pathak, J. Knowledge-Aware Assessment of Severity of Suicide Risk for Early Intervention. In Proceedings of the The World Wide Web Conference—WWW ’19, San Francisco, CA, USA, 13–17 May 2019; pp. 514–525. [Google Scholar] [CrossRef]
- Alambo, A.; Gaur, M.; Lokala, U.; Kursuncu, U.; Thirunarayan, K.; Gyrard, A.; Sheth, A.; Welton, R.S.; Pathak, J. Question Answering for Suicide Risk Assessment Using Reddit. In Proceedings of the 2019 IEEE 13th International Conference on Semantic Computing (ICSC), Newport Beach, CA, USA, 30 January–1 February 2019; pp. 468–473. [Google Scholar] [CrossRef]
- McHugh, C.M.; Corderoy, A.; Ryan, C.J.; Hickie, I.B.; Large, M.M. Association between Suicidal Ideation and Suicide: Meta-Analyses of Odds Ratios, Sensitivity, Specificity and Positive Predictive Value. BJPsych Open 2019, 5, e18. [Google Scholar] [CrossRef]
- Iavarone, B.; Monreale, A. From Depression to Suicidal Discourse on Reddit. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 437–445. [Google Scholar] [CrossRef]
- Rabani, S.T.; Khan, Q.R.; Khanday, A. A Novel Approach to Predict the Level of Suicidal Ideation on Social Networks Using Machine and Ensemble Learning. ICTACT J. Soft Comput. 2021, 11, 7. [Google Scholar] [CrossRef]
- Coppersmith, G.; Leary, R.; Crutchley, P.; Fine, A. Natural Language Processing of Social Media as Screening for Suicide Risk. Biomed. Inform. Insights 2018, 10, 117822261879286. [Google Scholar] [CrossRef]
- Zirikly, A.; Resnik, P.; Uzuner, Ö.; Hollingshead, K. CLPsych 2019 Shared Task: Predicting the Degree of Suicide Risk in Reddit Posts. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 24–33. [Google Scholar] [CrossRef]
- Reddit by the Numbers. Available online: https://www.redditinc.com/press (accessed on 23 July 2022).
- Reddit Privacy Policy. Available online: https://www.reddit.com/policies/privacy-policy (accessed on 23 July 2022).
- Meta Privacy Policy—How Meta Collects and Uses User Data. Available online: https://www.facebook.com/privacy/policy/?entry_point=data_policy_redirect&entry=0 (accessed on 23 July 2022).
- Peer Support for Anyone Struggling with Suicidal Thoughts. Available online: https://www.reddit.com/r/SuicideWatch/ (accessed on 23 July 2022).
- Dutta, R.; Gkotsis, G.; Velupillai, S.; Bakolis, I.; Stewart, R. Temporal and Diurnal Variation in Social Media Posts to a Suicide Support Forum. BMC Psychiatry 2021, 21, 259. [Google Scholar] [CrossRef] [PubMed]
- Shing, H.-C.; Nair, S.; Zirikly, A.; Friedenberg, M.; Daumé III, H.; Resnik, P. Expert, Crowdsourced, and Machine Assessment of Suicide Risk via Online Postings. In Proceedings of the Fifth Workshop on Computational Linguistics and Clinical Psychology: From Keyboard to Clinic, New Orleans, LA, USA, 5 June 2018; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 25–36. [Google Scholar] [CrossRef]
- Nikhileswar, K.; Vishal, D.; Sphoorthi, L.; Fathimabi, S. Suicide Ideation Detection in Social Media Forums. In Proceedings of the 2021 2nd International Conference on Smart Electronics and Communication (ICOSEC), Trichy, India, 7–9 October 2021; pp. 1741–1747. [Google Scholar] [CrossRef]
- Renjith, S.; Abraham, A.; Jyothi, S.B.; Chandran, L.; Thomson, J. An Ensemble Deep Learning Technique for Detecting Suicidal Ideation from Posts in Social Media Platforms. J. King Saud Univ.-Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Shah, F.M.; Haque, F.; Un Nur, R.; Al Jahan, S.; Mamud, Z. A Hybridized Feature Extraction Approach To Suicidal Ideation Detection from Social Media Post. In Proceedings of the 2020 IEEE Region 10 Symposium (TENSYMP), Dhaka, Bangladesh, 5–7 June 2020; pp. 985–988. [Google Scholar] [CrossRef]
- Haque, F.; Nur, R.U.; Jahan, S.A.; Mahmud, Z.; Shah, F.M. A Transformer Based Approach To Detect Suicidal Ideation Using Pre-Trained Language Models. In Proceedings of the 2020 23rd International Conference on Computer and Information Technology (ICCIT), Dhaka, Bangladesh, 19–21 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Kumar, A.; Trueman, T.E.; Abinesh, A.K. Suicidal Risk Identification in Social Media. Procedia Comput. Sci. 2021, 189, 368–373. [Google Scholar] [CrossRef]
- Ji, S.; Li, X.; Huang, Z.; Cambria, E. Suicidal Ideation and Mental Disorder Detection with Attentive Relation Networks. Neural Comput. Appl. 2021, 34, 10309–10319. [Google Scholar] [CrossRef]
- Iserman, M.; Nalabandian, T.; Ireland, M. Dictionaries and Decision Trees for the 2019 CLPsych Shared Task. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 188–194. [Google Scholar] [CrossRef]
- Ríssola, E.; Ramírez-Cifuentes, D.; Freire, A.; Crestani, F. Suicide Risk Assessment on Social Media: USI-UPF at the CLPsych 2019 Shared Task. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 167–171. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Chen, L.; Aldayel, A.; Bogoychev, N.; Gong, T. Similar Minds Post Alike: Assessment of Suicide Risk Using a Hybrid Model. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 152–157. [Google Scholar] [CrossRef]
- González Hevia, A.; Cerezo Menéndez, R.; Gayo-Avello, D. Analyzing the Use of Existing Systems for the CLPsych 2019 Shared Task. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 148–151. [Google Scholar] [CrossRef]
- Ambalavanan, A.K.; Jagtap, P.D.; Adhya, S.; Devarakonda, M. Using Contextual Representations for Suicide Risk Assessment from Internet Forums. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 172–176. [Google Scholar] [CrossRef]
- Gasparetto, A.; Marcuzzo, M.; Zangari, A.; Albarelli, A. A Survey on Text Classification Algorithms: From Text to Predictions. Information 2022, 13, 83. [Google Scholar] [CrossRef]
- Tausczik, Y.R.; Pennebaker, J.W. The Psychological Meaning of Words: LIWC and Computerized Text Analysis Methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Ruiz, V.; Shi, L.; Quan, W.; Ryan, N.; Biernesser, C.; Brent, D.; Tsui, R. CLPsych2019 Shared Task: Predicting Suicide Risk Level from Reddit Posts on Multiple Forums. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 162–166. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Yuan, C.; Feng, X.; Jiang, X.; Li, Y.; Zhao, L. Latent Dirichlet Allocation (LDA) and Topic Modeling: Models, Applications, a Survey. Multimed. Tools Appl. 2019, 78, 15169–15211. [Google Scholar] [CrossRef]
- De Oliveira, N.R.; Pisa, P.S.; Lopez, M.A.; de Medeiros, D.S.V.; Mattos, D.M.F. Identifying Fake News on Social Networks Based on Natural Language Processing: Trends and Challenges. Information 2021, 12, 38. [Google Scholar] [CrossRef]
- Mohammadi, E.; Amini, H.; Kosseim, L. CLaC at CLPsych 2019: Fusion of Neural Features and Predicted Class Probabilities for Suicide Risk Assessment Based on Online Posts. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 34–38. [Google Scholar] [CrossRef]
- Subasi, A. Practical Machine Learning for Data Analysis Using Python; Academic Press: Cambridge, MA, USA, 2020. [Google Scholar]
- Bitew, S.K.; Bekoulis, G.; Deleu, J.; Sterckx, L.; Zaporojets, K.; Demeester, T.; Develder, C. Predicting Suicide Risk from Online Postings in Reddit The UGent-IDLab Submission to the CLPysch 2019 Shared Task A. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 158–161. [Google Scholar] [CrossRef]
- Alkomah, F.; Ma, X. A Literature Review of Textual Hate Speech Detection Methods and Datasets. Information 2022, 13, 273. [Google Scholar] [CrossRef]
- Morales, M.; Dey, P.; Theisen, T.; Belitz, D.; Chernova, N. An Investigation of Deep Learning Systems for Suicide Risk Assessment. In Proceedings of the Sixth Workshop on Computational Linguistics and Clinical Psychology, Minneapolis, MN, USA, 6 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 177–181. [Google Scholar] [CrossRef]
- Khan, A.R. Facial Emotion Recognition Using Conventional Machine Learning and Deep Learning Methods: Current Achievements, Analysis and Remaining Challenges. Information 2022, 13, 268. [Google Scholar] [CrossRef]
- Roy, A.; Nikolitch, K.; McGinn, R.; Jinah, S.; Klement, W.; Kaminsky, Z.A. A Machine Learning Approach Predicts Future Risk to Suicidal Ideation from Social Media Data. NPJ Digit. Med. 2020, 3, 78. [Google Scholar] [CrossRef] [PubMed]
- Braithwaite, S.R.; Giraud-Carrier, C.; West, J.; Barnes, M.D.; Hanson, C.L. Validating Machine Learning Algorithms for Twitter Data Against Established Measures of Suicidality. JMIR Ment. Health 2016, 3, e21. [Google Scholar] [CrossRef] [PubMed]
- Reece, A.G.; Danforth, C.M. Instagram Photos Reveal Predictive Markers of Depression. EPJ Data Sci. 2017, 6, 15. [Google Scholar] [CrossRef]
- Mehrpooya, A.; Saberi-Movahed, F.; Azizizadeh, N.; Rezaei-Ravari, M.; Saberi-Movahed, F.; Eftekhari, M.; Tavassoly, I. High Dimensionality Reduction by Matrix Factorization for Systems Pharmacology. Brief. Bioinform. 2022, 23, bbab410. [Google Scholar] [CrossRef] [PubMed]
- Saberi-Movahed, F.; Mohammadifard, M.; Mehrpooya, A.; Rezaei-Ravari, M.; Berahmand, K.; Rostami, M.; Karami, S.; Najafzadeh, M.; Hajinezhad, D.; Jamshidi, M.; et al. Decoding Clinical Biomarker Space of COVID-19: Exploring Matrix Factorization-Based Feature Selection Methods. Comput. Biol. Med. 2022, 146, 105426. [Google Scholar] [CrossRef] [PubMed]
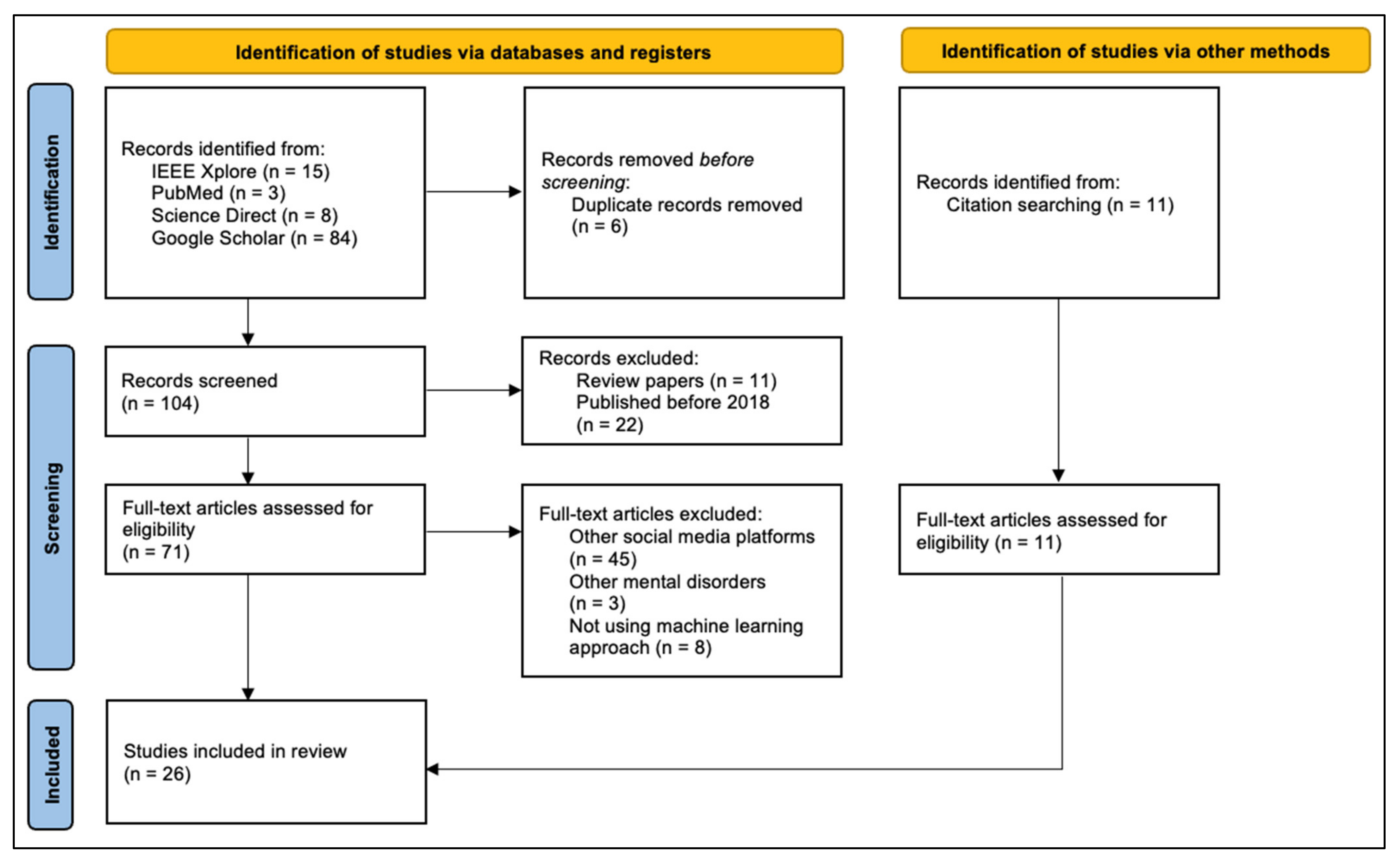

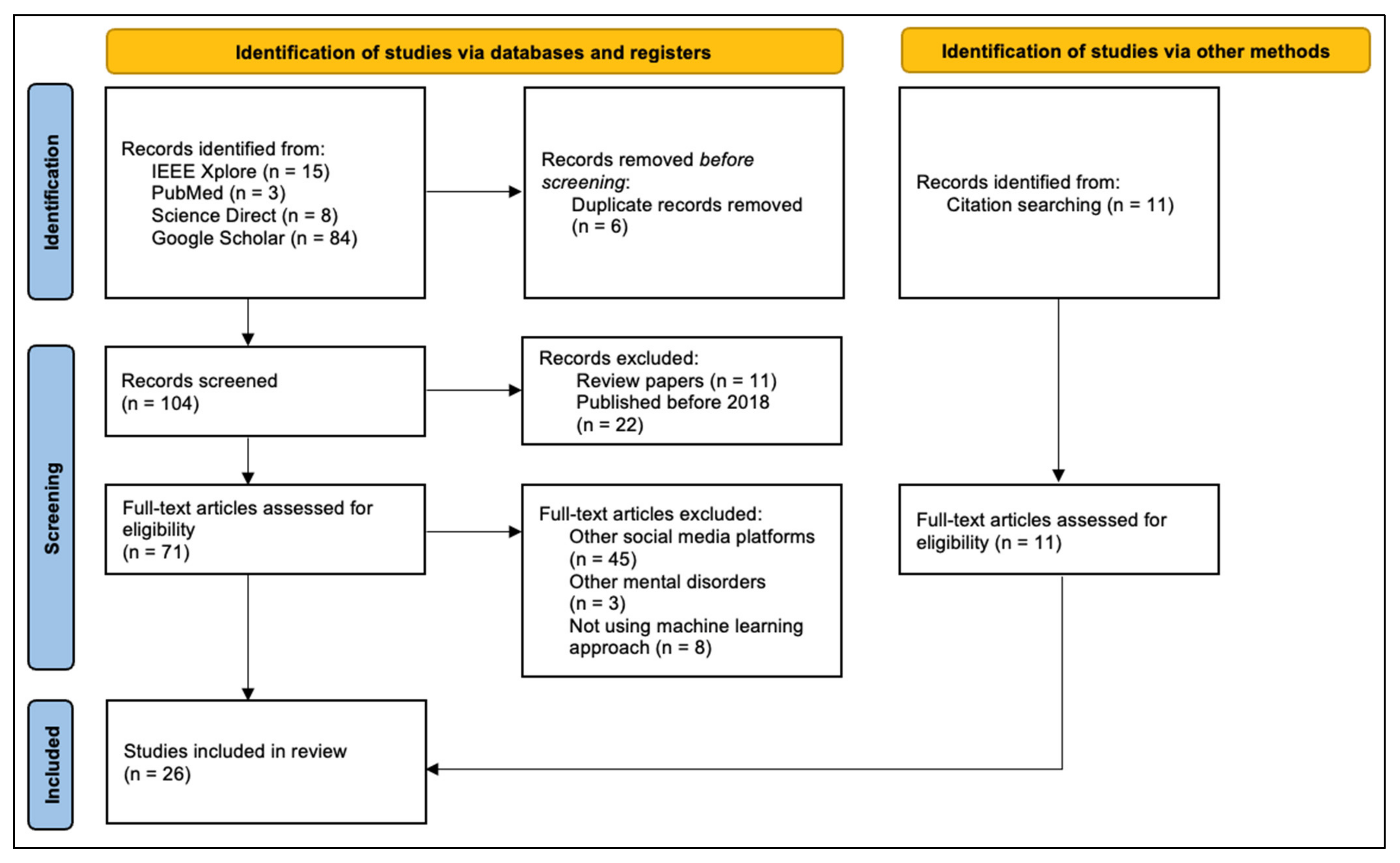{kind=link}
| (a) | ||||
| Dataset | Total Size | Annotated Subset | Annotation Source | Classes |
| Aladağ et al., 2018 [7] | 508,398 posts | 785 posts | Experts | Suicidal, non-suicidal |
| Ji et al., 2018 [13] | 3549 suicidal posts 3652 non-suicidal posts | NA | Community affiliation | Suicidal, non-suicidal |
| Yao et al., 2020 [25] | NA | 500 r/Opiates posts 500 r/SuicideWatch posts | Crowdsourcing | Opioid addiction, no opioid addiction, suicide risk, no suicide risk |
| Reddit SuicideWatch and Mental Health Collection by Ji et al., 2021 [44] | 54,412 posts | NA | Community affiliation | r/Depression, r/SuicideWatch, r/Anxiety, r/Offmychest, r/Bipolar |
| Nikhileswar et al., 2021 [39] | 116,037 suicidal posts 116,037 non-suicidal posts | NA | Community affiliation | Suicidal, non-suicidal |
| (b) | ||||
| Dataset | Total Size | Annotated Subset | Annotation Source | Classes |
| UMD Reddit Suicidality Dataset v2 by Shing et al., 2018 [38] | 11,129 r/SuicideWatch users 11,129 non-r/SuicideWatch users | 866 r/SuicideWatch users 866 non-r/SuicideWatch users | Crowdsourcing, experts | No risk, low risk, moderate risk, severe risk |
| Reddit C-SSRS Suicide Dataset by Gaur et al., 2019 [26] | NA | 500 users (15,755 posts) | Experts | Indicator, ideation, behavior, attempt, supportive |
| Reddit C-SSRS Suicide Dataset v2 by Gaur et al., 2021 [11] | NA | 448 users (7327 posts) | Experts | Ideation, behavior, attempt, supportive |
| Study | Feature Extraction Techniques | Machine Learning Algorithms | Embedding Techniques | Deep Learning Algorithms | Best Performing Model | Metric and Result |
|---|---|---|---|---|---|---|
| Shing et al., 2018 [38] | BOW, Empath, Readability Index, Syntactic features, LDA, LIWC, NRC Lexicon, mentalDisLex (Mental Disease Lexicon) | SVM, LR, XGBoost | SkipGram | CNN | SVM | Macro F1 = 0.460 |
| Aladağ et al., 2018 [7] | TF–IDF, LIWC, Sentiment | ZeroR, LR, RF, SVM | NA | NA | LR, SVM | Accuracy = 0.920 Accuracy = 0.920 |
| Ji et al., 2018 [13] | Statistics, Part of Speech Tags, LIWC, TF–IDF, LDA | SVM, RF, Gradient Boost Decision Tree, XGBoost, | Word2Vec | MLFFNN, LSTM | XGBoost | Accuracy = 0.957 |
| Allen et al., 2019 [24] | LIWC | NA | GloVe | CNN | CNN used with LIWC | Macro F1 = 0.500 |
| Ambalavanan et al., 2019 [50] | NA | NA | BERT | LSTM | BERT-Softmax | Macro F1 = 0.477 |
| Bitew et al., 2019 [58] | TF–IDF, DeepMoji pre-trained model, | LR, SVM, | NA | NA | LR | Macro F1 = 0.445 |
| Chen et al., 2019 [48] | Sentiments, LIWC, EMPATH, TF–IDF, Statistics | SVM | NA | NA | SVM | Macro F1 = 0.380 |
| Gaur et al., 2019 [26] | Sentiments with AFINN, TF–IDF, Statistics, Syntactic | SVM, RF | ConceptNet | FFNN, CNN | CNN | Graded Recall = 0.600 |
| González Hevia et al., 2019 [49] | TF–IDF, NRC VAD Lexicon | SVM, LR | Multilingual Word Embedding, Doc2Vec | RNN | SVM-LR | Macro F1 = 0.320 |
| Iserman et al., 2019 [45] | Sentiments with AFINN, Hu & Liu, General Inquirer, labMT, LIWC, Lusi, Moral Foundations, Netspeak, NRC Affect Intensity Lexicon, Senticnet, SentimentDictionaries, SentiWordNet, Slangsd, Vader, Whissell, Age&Gender, PERMA | LR, RF, DT | NA | NA | DT | Macro F1 = 0.402 |
| Matero et al., 2019 [15] | Affect & Intensity Lexicon, NRC VAD Lexicon, Age&Gender Lexicon, Big-5 Personality Lexicon, Anxiety, Anger & Depression Lexicon, LDA, Statistics | LR | BERT | LSTM | LSTM-Attention | Macro F1 = 0.500 |
| Mohammadi et al., 2019 [56] | NA | SVM | GloVe, Embeddings from Language Model | CNN, RNN, LSTM, GRU, | Ensemble model consisting of CNN, Bi-RNN, Bi-LSTM, Bi-GRU and SVM | Macro F1 = 0.481 |
| Morales et al., 2019 [60] | BOW, TF–IDF, LDA, POS, Named-Entity Recognition, IBM Watson Personality Insights API, IBM Watson Tone Analyzer | RF, NB, KNN, SVM | SkipGram, FastText | CNN, LSTM, NeuNetS | CNN | Macro F1 = 0.310 |
| Ríssola et al., 2019 [46] | TF–IDF, LIWC, Statistics | LR, SVM, RF | GloVe | N/A | LR | Macro F1 = 0.311 |
| Ruiz et al., 2019 [53] | Clinical Text Analysis and Knowledge Extraction System, Social Determinant of Health, NRC Word-Emotion Association Lexicon, Readability Index, Semantic Role Labeling, Sentiments, LDA, Empathy | NB, GB, RF, SVM, | Doc2Vec | CNN, LSTM, | Ensemble model consisting of NB, SVM, GB | Macro F1 = 0.379 |
| Jones et al., 2019 [17] | Suicide Risk Factor Lexicon, LDA | RF, LR, SVM | FLAIR, GloVe | N/A | RF | F1 = 0.920 |
| Tadesse et al., 2019 [16] | Statistics, TF–IDF, BOW, | RF, SVM, NB, XGBoost | Word2Vec | LSTM, CNN | LSTM-CNN | Accuracy = 0.938 |
| Shah et al., 2020 [41] | TF–IDF, N-Gram, LIWC | NB, SVM, KNN, RF | NA | N/A | NB | Accuracy = 0.736 |
| Yao et al., 2020 [25] | TF–IDF | LR, RF, SVM, | GloVe, FastText | RNN, CNN | CNN | F1 = 0.966 |
| Haque et al., 2020 [42] | NA | NA | Glove, BERT | LSTM | BERT with Softmax Layer | Accuracy = 0.952 |
| Kumar et al., 2021 [43] | NA | NB, LR, SVM | GloVe | LSTM, GRU | Bi-GRU with Multiplicative Attention | Micro F1 = 0.300 |
| Rabani et al., 2021 [30] | TF–IDF, BOW, Statistics, LDA, POS | NB, DT, LR, SVM, | NA | N/A | DT | F1 = 0.980 |
| Gaur et al., 2021 [11] | NA | NA | ConceptNet | CNN, LSTM | CNN-LSTM | AUC = 0.640 |
| Ji et al., 2021 [44] | Sentiments, LIWC, LDA | NA | GloVe, FastText | CNN, LSTM, Structured Self-Attentive Sentence Embedding, Relation Network | Relation Network | F1 = 0.545 |
| Nikhileswar et al., 2021 [39] | TF–IDF, BOW | XGBoost, SVM | Universal Sentence Encoder, Word2Vec, | LSTM, CNN, FCNN | FCNN used with Universal Sentence Encoder | Accuracy = 0.942 |
| Renjith et al., 2021 [40] | TF–IDF | SVM | Word2Vec | LSTM, CNN | LSTM-Attention-CNN | Accuracy = 0.903 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yeskuatov, E.; Chua, S.-L.; Foo, L.K. Leveraging Reddit for Suicidal Ideation Detection: A Review of Machine Learning and Natural Language Processing Techniques. Int. J. Environ. Res. Public Health 2022, 19, 10347. https://doi.org/10.3390/ijerph191610347
Yeskuatov E, Chua S-L, Foo LK. Leveraging Reddit for Suicidal Ideation Detection: A Review of Machine Learning and Natural Language Processing Techniques. International Journal of Environmental Research and Public Health. 2022; 19(16):10347. https://doi.org/10.3390/ijerph191610347
Chicago/Turabian StyleYeskuatov, Eldar, Sook-Ling Chua, and Lee Kien Foo. 2022. "Leveraging Reddit for Suicidal Ideation Detection: A Review of Machine Learning and Natural Language Processing Techniques" International Journal of Environmental Research and Public Health 19, no. 16: 10347. https://doi.org/10.3390/ijerph191610347
APA StyleYeskuatov, E., Chua, S.-L., & Foo, L. K. (2022). Leveraging Reddit for Suicidal Ideation Detection: A Review of Machine Learning and Natural Language Processing Techniques. International Journal of Environmental Research and Public Health, 19(16), 10347. https://doi.org/10.3390/ijerph191610347