
Vocal Behavior of Teachers Reading with Raised Voice in a Noisy Environment


Abstract
:1. Introduction
2. Materials and Methods
2.1. Participants
2.2. Procedure
2.3. The Text
2.4. Measuring Technique
2.5. Statistics
3. Results
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sala, E.; Rantala, L. Voice Ergonomics: Occupational and Professional Voice Care; Cambridge Scholars Publishing: Cambridge, UK, 2019; ISBN 9781527527591. [Google Scholar]
- Szabo Portela, A.; Hammarberg, B.; Södersten, M. Speaking Fundamental Frequency and Phonation Time during Work and Leisure Time in Vocally Healthy Preschool Teachers Measured with a Voice Accumulator. Folia Phoniatr. Logop. 2013, 65, 84–90. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.H.; Chiang, S.-C.; Chung, Y.-M.; Hsiao, L.-C.; Hsiao, T.-Y. Risk Factors and Effects of Voice Problems for Teachers. J. Voice 2010, 24, 183–192. [Google Scholar] [CrossRef] [PubMed]
- Rossi-Barbosa, L.A.R.; Barbosa, M.R.; Morais, R.M.; de Sousa, K.F.; Silveira, M.F.; Gama, A.C.C.; Caldeira, A.P. Self-Reported Acute and Chronic Voice Disorders in Teachers. J. Voice 2016, 30, 755.e25–755.e33. [Google Scholar] [CrossRef] [PubMed]
- Kooijman, P.G.C.; de Jong, F.I.C.R.S.; Thomas, G.; Huinck, W.; Donders, R.; Graamans, K.; Schutte, H.K. Risk Factors for Voice Problems in Teachers. Folia Phoniatr. Logop. 2006, 58, 159–174. [Google Scholar] [CrossRef]
- Van Houtte, E.; Claeys, S.; Wuyts, F.; Van Lierde, K. The Impact of Voice Disorders Among Teachers: Vocal Complaints, Treatment-Seeking Behavior, Knowledge of Vocal Care, and Voice-Related Absenteeism. J. Voice 2011, 25, 570–575. [Google Scholar] [CrossRef] [Green Version]
- Kristiansen, J.; Lund, S.P.; Persson, R.; Shibuya, H.; Nielsen, P.M.; Scholz, M. A Study of Classroom Acoustics and School Teachers’ Noise Exposure, Voice Load and Speaking Time during Teaching, and the Effects on Vocal and Mental Fatigue Development. Int. Arch. Occup. Environ. Health 2014, 87, 851–860. [Google Scholar] [CrossRef]
- Phyland, D.; Miles, A. Occupational Voice Is a Work in Progress: Active Risk Management, Habilitation and Rehabilitation. Curr. Opin. Otolaryngol. Head Neck Surg. 2019, 27, 439–447. [Google Scholar] [CrossRef]
- Cantor Cutiva, L.C.; Vogel, I.; Burdorf, A. Voice Disorders in Teachers and Their Associations with Work-Related Factors: A Systematic Review. J. Commun. Disord. 2013, 46, 143–155. [Google Scholar] [CrossRef]
- Martins, R.H.G.; Pereira, E.R.B.N.; Hidalgo, C.B.; Tavares, E.L.M. Voice Disorders in Teachers. A Review. J. Voice 2014, 28, 716–724. [Google Scholar] [CrossRef]
- Morawska, J.; Niebudek-Bogusz, E. Risk Factors and Prevalence of Voice Disorders in Different Occupational Groups—A Review of Literature. Otorynolaryngologia-Przegląd Klin. 2017, 16, 94–102. [Google Scholar]
- Pereira, E.R.B.N.; Tavares, E.L.M.; Martins, R.H.G. Voice Disorders in Teachers: Clinical, Videolaryngoscopical, and Vocal Aspects. J. Voice 2015, 29, 564–571. [Google Scholar] [CrossRef] [PubMed]
- Hunter, E.J.; Cantor-Cutiva, L.C.; van Leer, E.; van Mersbergen, M.; Nanjundeswaran, C.D.; Bottalico, P.; Sandage, M.J.; Whitling, S. Toward a Consensus Description of Vocal Effort, Vocal Load, Vocal Loading, and Vocal Fatigue. J. Speech Lang. Hear. Res. 2020, 63, 509–532. [Google Scholar] [CrossRef] [PubMed]
- Byeon, H. The Risk Factors Related to Voice Disorder in Teachers: A Systematic Review and Meta-Analysis. Int. J. Environ. Res. Public Health 2019, 16, 3675. [Google Scholar] [CrossRef] [Green Version]
- de Jong, F.I.C.R.S. An Introduction to the Teacher’s Voice in a Biopsychosocial Perspective. Folia Phoniatr. Logop. 2010, 62, 5–8. [Google Scholar] [CrossRef] [PubMed]
- Marçal, C.C.B.; Peres, M.A. Self-Reported Voice Problems Among Teachers: Prevalence and Associated Factors. Rev. Saúde Pública 2011, 45, 503–511. [Google Scholar] [CrossRef]
- Vertanen-Greis, H.; Löyttyniemi, E.; Uitti, J.; Putus, T. Self-Reported Voice Disorders of Teachers and Indoor Air Quality in Schools: A Cross-Sectional Study in Finland. Logop. Phoniatr. Vocol. 2021, 1–11. [Google Scholar] [CrossRef]
- Imhof, M.; Välikoski, T.-R.; Laukkanen, A.-M.; Orlob, K. Cognition and Interpersonal Communication: The Effect of Voice Quality on Information Processing and Person Perception. Stud. Commun. Sci. 2014, 14, 37–44. [Google Scholar] [CrossRef]
- Morton, V.; Watson, D.R. The Impact of Impaired Vocal Quality on Children’s Ability to Process Spoken Language. Logoped. Phoniatr. Vocol. 2001, 26, 17–25. [Google Scholar] [CrossRef]
- Rogerson, J.; Dodd, B. Is There an Effect of Dysphonic Teachers’ Voices on Children’s Processing of Spoken Language? J. Voice 2005, 19, 47–60. [Google Scholar] [CrossRef]
- Sahlén, B.; Haake, M.; von Lochow, H.; Holm, L.; Kastberg, T.; Brännström, K.J.; Lyberg-Åhlander, V. Is Children’s Listening Effort in Background Noise Influenced by the Speaker’s Voice Quality? Logop. Phoniatr. Vocol. 2018, 43, 47–55. [Google Scholar] [CrossRef]
- Lyberg-Åhlander, V.; Haake, M.; Brännström, J.; Schötz, S.; Sahlén, B. Does the Speaker’s Voice Quality Influence Children’s Performance on a Language Comprehension Test? Int. J. Speech-Lang. Pathol. 2015, 17, 63–73. [Google Scholar] [CrossRef] [PubMed]
- Schiller, I.S.; Remacle, A.; Durieux, N.; Morsomme, D. Effects of Noise and a Speaker’s Impaired Voice Quality on Spoken Language Processing in School-Aged Children: A Systematic Review and Meta-Analysis. J. Speech Lang. Hear. Res. 2022, 65, 169–199. [Google Scholar] [CrossRef] [PubMed]
- Brumm, H.; Zollinger, S.A. The Evolution of the Lombard Effect: 100 Years of Psychoacoustic Research. Behaviour 2011, 148, 1173–1198. [Google Scholar] [CrossRef] [Green Version]
- Uma Maheswari, S.; Shahina, A.; Nayeemulla Khan, A. Understanding Lombard Speech: A Review of Compensation Techniques towards Improving Speech Based Recognition Systems. Artif. Intell. Rev. 2021, 54, 2495–2523. [Google Scholar] [CrossRef]
- Castellanos, A.; Benedí, J.M.; Casacuberta, F. An Analysis of General Acoustic-Phonetic Features for Spanish Speech Produced with the Lombard Effect. Speech Commun. 1996, 20, 23–35. [Google Scholar] [CrossRef]
- Junqua, J.C. The Lombard Reflex and Its Role on Human Listeners and Automatic Speech Recognizers. J. Acoust. Soc. Am. 1993, 93, 510–524. [Google Scholar] [CrossRef]
- Garnier, M.; Henrich, N. Speaking in Noise: How Does the Lombard Effect Improve Acoustic Contrasts between Speech and Ambient Noise? Comput. Speech Lang. 2014, 28, 580–597. [Google Scholar] [CrossRef]
- Bosker, H.R.; Cooke, M. Talkers Produce More Pronounced Amplitude Modulations When Speaking in Noise. J. Acoust. Soc. Am. 2018, 143, EL121–EL126. [Google Scholar] [CrossRef] [Green Version]
- Van Summers, W.; Pisoni, D.B.; Bernacki, R.H.; Pedlow, R.I.; Stokes, M.A. Effects of Noise on Speech Production: Acoustic and Perceptual Analyses. J. Acoust. Soc. Am. 1988, 84, 917–928. [Google Scholar] [CrossRef] [Green Version]
- Pittman, A.L.; Wiley, T.L. Recognition of Speech Produced in Noise. J. Speech Lang. Hear. Res. 2001, 44, 487–496. [Google Scholar] [CrossRef] [Green Version]
- Vlaj, D.; Kacic, Z. The Influence of Lombard Effect on Speech Recognition. In Speech Technologies; Ipsic, I., Ed.; InTech: Rijeka, Croatia, 2011; ISBN 9789533079967. [Google Scholar]
- Vainio, M.; Aalto, D.; Suni, A.; Arnhold, A.; Raitio, T.; Seijo, H.; Järvikivi, J.; Alku, P. Effect of Noise Type and Level on Focus Related Fundamental Frequency Changes. In Proceedings of the INTERSPEECH 2012, 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Patel, R.; Schell, K.W. The Influence of Linguistic Content on the Lombard Effect. J. Speech Lang. Hear. Res. 2008, 51, 209–220. [Google Scholar] [CrossRef]
- Hansen, J.H.L. Analysis and Compensation of Stressed and Noisy Speech with Application to Robust Automatic Recognition. Signal Process. 1989, 17, 282. [Google Scholar] [CrossRef]
- Rochet-Capellan, A.; Fuchs, S. Take a Breath and Take the Turn: How Breathing Meets Turns in Spontaneous Dialogue. Philos. Trans. R. Soc. B 2014, 369, 20130399. [Google Scholar] [CrossRef] [PubMed]
- Winkworth, A.L.; Davis, P.J.; Ellis, E.; Adams, R.D. Variability and Consistency in Speech Breathing During Reading: Lung Volumes, Speech Intensity, and Linguistic Factors. J. Speech Lang. Hear. Res. 1994, 37, 535–556. [Google Scholar] [CrossRef]
- Fuchs, S.; Petrone, C.; Krivokapić, J.; Hoole, P. Acoustic and Respiratory Evidence for Utterance Planning in German. J. Phon. 2013, 41, 29–47. [Google Scholar] [CrossRef]
- Cooke, M.; Lu, Y. Spectral and Temporal Changes to Speech Produced in the Presence of Energetic and Informational Maskers. J. Acoust. Soc. Am. 2010, 128, 2059–2069. [Google Scholar] [CrossRef] [Green Version]
- Marcoux, K.; Cooke, M.; Tucker, B.V.; Ernestus, M. The Lombard Intelligibility Benefit of Native and Non-Native Speech for Native and Non-Native Listeners. Speech Commun. 2022, 136, 53–62. [Google Scholar] [CrossRef]
- Lindstrom, F.; Waye, K.P.; Södersten, M.; McAllister, A.; Ternström, S. Observations of the Relationship between Noise Exposure and Preschool Teacher Voice Usage in Day-Care Center Environments. J. Voice Off. J. Voice Found. 2011, 25, 166–172. [Google Scholar] [CrossRef]
- Nusseck, M.; Richter, B.; Spahn, C.; Echternach, M. Analysing the Vocal Behaviour of Teachers during Classroom Teaching Using a Portable Voice Accumulator. Logop. Phoniatr. Vocol. 2018, 43, 1–10. [Google Scholar] [CrossRef]
- Hunter, E.J.; Titze, I.R. Variations in Intensity, Fundamental Frequency, and Voicing for Teachers in Occupational Versus Nonoccupational Settings. J. Speech Lang. Hear. Res. 2010, 53, 862–875. [Google Scholar] [CrossRef]
- Lyberg Åhlander, V.; Pelegrín García, D.; Whitling, S.; Rydell, R.; Löfqvist, A. Teachers’ Voice Use in Teaching Environments: A Field Study Using Ambulatory Phonation Monitor. J. Voice 2014, 28, 841.e5–841.e15. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Remacle, A.; Garnier, M.; Gerber, S.; David, C.; Petillon, C. Vocal Change Patterns During a Teaching Day: Inter- and Intra-Subject Variability. J. Voice 2018, 32, 57–63. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Toki, E.I.; Fakitsa, P.; Plachouras, K.; Vlachopoulos, K.; Kalaitzidis, N.; Pange, J. How Does Noise Pollution Exposure Affect Vocal Behavior? A Systematic Review. AIMS Med. Sci. 2021, 8, 116–137. [Google Scholar] [CrossRef]
- Drugman, T.; Alku, P.; Alwan, A.; Yegnanarayana, B. Glottal Source Processing: From Analysis to Applications. Comput. Speech Lang. 2014, 28, 1117–1138. [Google Scholar] [CrossRef] [Green Version]
- Holmberg, E.B.; Hillman, R.E.; Perkell, J.S. Glottal Airflow and Transglottal Air Pressure Measurements for Male and Female Speakers in Soft, Normal, and Loud Voice. J. Acoust. Soc. Am. 1988, 84, 511–529. [Google Scholar] [CrossRef]
- Titze, I.R. Mechanical Stress in Phonation. J. Voice 1994, 8, 99–105. [Google Scholar] [CrossRef]
- Jiang, J.J.; Titze, I.R. Measurement of Vocal Fold Intraglottal Pressure and Impact Stress. J. Voice 1994, 8, 132–144. [Google Scholar] [CrossRef]
- Szabo Portela, A.; Granqvist, S.; Ternström, S.; Södersten, M. Vocal Behavior in Environmental Noise: Comparisons Between Work and Leisure Conditions in Women With Work-Related Voice Disorders and Matched Controls. J. Voice Off. J. Voice Found. 2018, 32, 126.e23–126.e38. [Google Scholar] [CrossRef] [Green Version]
- Schei, T.B.; Åvitsland, B.S.; Schei, E. Forgetting the Audible Body. Voice Awareness in Teacher Education. Nord. Res. Music. Educ. 2019, 19, 197–215. [Google Scholar]
- Hackworth, R.S. Vocal Health Implications for Music Teachers: A Literature Review. Update Appl. Res. Music. Educ. 2021, 875512332110611. [Google Scholar] [CrossRef]
- López, J.M.; Catena, A.; Montes, A.; Castillo, M.E. Effectiveness of a Short Voice Training Program for Teachers: A Preliminary Study. J. Voice 2017, 31, 697–706. [Google Scholar] [CrossRef] [PubMed]
- Richter, B.; Nusseck, M.; Spahn, C.; Echternach, M. Effectiveness of a Voice Training Program for Student Teachers on Vocal Health. J. Voice 2016, 30, 452–459. [Google Scholar] [CrossRef] [PubMed]
- Gassull, C.; Godall, P.; Polini, E.; Amador, M.; Casanova, C. Effects of a Voice Training Program on Acoustics, Vocal Use, and Perceptual Voice Parameters in Catalan Teachers. Folia Phoniatr. Logop. 2020, 72, 411–418. [Google Scholar] [CrossRef] [PubMed]
- Nallamuthu, A.; Boominathan, P.; Arunachalam, R.; Mariswamy, P. Outcomes of Vocal Hygiene Program in Facilitating Vocal Health in Female School Teachers with Voice Problems. J. Voice 2021, S0892199721000187. [Google Scholar] [CrossRef] [PubMed]
- Nusseck, M.; Immerz, A.; Spahn, C.; Echternach, M.; Richter, B. Long-Term Effects of a Voice Training Program for Teachers on Vocal and Mental Health. J. Voice 2021, 35, 438–446. [Google Scholar] [CrossRef]
- Atará-Piraquive, Á.P.; Cantor-Cutiva, L.C. Gender Differences in Vocal Doses among Occupational Voice Users: A Systematic Review of Literature and Meta-Analysis. Logop. Phoniatr. Vocol. 2021, 47, 63–72. [Google Scholar] [CrossRef]
- Edwards, J.; Beckman, M.E.; Fletcher, J. The Articulatory Kinematics of Final Lengthening. J. Acoust. Soc. Am. 1991, 89, 369–382. [Google Scholar] [CrossRef]
- Mehta, D.D.; Van Stan, J.H.; Zañartu, M.; Ghassemi, M.; Guttag, J.V.; Espinoza, V.M.; Cortés, J.P.; Cheyne, H.A.; Hillman, R.E. Using Ambulatory Voice Monitoring to Investigate Common Voice Disorders: Research Update. Front. Bioeng. Biotechnol. 2015, 3, 155. [Google Scholar] [CrossRef] [Green Version]
- Södersten, M.; Salomão, G.L.; McAllister, A.; Ternström, S. Natural Voice Use in Patients With Voice Disorders and Vocally Healthy Speakers Based on 2 Days Voice Accumulator Information From a Database. J. Voice 2015, 29, 646.e1–646.e9. [Google Scholar] [CrossRef]
- Whittico, T.H.; Ortiz, A.J.; Marks, K.L.; Toles, L.E.; Van Stan, J.H.; Hillman, R.E.; Mehta, D.D. Ambulatory Monitoring of Lombard-Related Vocal Characteristics in Vocally Healthy Female Speakers. J. Acoust. Soc. Am. 2020, 147, EL552–EL558. [Google Scholar] [CrossRef]
- Wang, Y.-T.; Green, J.R.; Nip, I.S.B.; Kent, R.D.; Kent, J.F. Breath Group Analysis for Reading and Spontaneous Speech in Healthy Adults. Folia Phoniatr. Logop. 2010, 62, 297–302. [Google Scholar] [CrossRef] [Green Version]
- DeJonckere, P.H.; Lebacq, J. Vocal Fold Collision Speed in Vivo: The Effect of Loudness. J. Voice 2020. [Google Scholar] [CrossRef] [PubMed]
- Gramming, P.; Sundberg, J.; Ternström, S.; Leanderson, R.; Perkins, W.H. Relationship between Changes in Voice Pitch and Loudness. J. Voice 1988, 2, 118–126. [Google Scholar] [CrossRef]
- Alku, P.; Vintturi, J.; Vilkman, E. Measuring the Effect of Fundamental Frequency Raising as a Strategy for Increasing Vocal Intensity in Soft, Normal and Loud Phonation. Speech Commun. 2002, 38, 321–334. [Google Scholar] [CrossRef]
- Horáček, J.; Laukkanen, A.-M.; Šidlof, P.; Murphy, P.; Švec, J.G. Comparison of Acceleration and Impact Stress as Possible Loading Factors in Phonation: A Computer Modeling Study. Folia Phoniatr. Logop. 2009, 61, 137–145. [Google Scholar] [CrossRef]
- Master, S.; Guzman, M.; Azócar, M.J.; Muñoz, D.; Bortnem, C. How Do Laryngeal and Respiratory Functions Contribute to Differentiate Actors/Actresses and Untrained Voices? J. Voice 2015, 29, 333–345. [Google Scholar] [CrossRef]
- Master, S.; Guzman, M.; Carlos de Miranda, H.; Lloyd, A. Electroglottographic Analysis of Actresses and Nonactresses’ Voices in Different Levels of Intensity. J. Voice 2013, 27, 187–194. [Google Scholar] [CrossRef]
- Titze, I.; Worley, A.S.; Story, B. Source-Vocal Tract Interaction in Female Operatic Singing and Theatre Belting. J. Sing. 2011, 67, 561–572. [Google Scholar]
- Titze, I.R.; Worley, A.S. Modeling Source-Filter Interaction in Belting and High-Pitched Operatic Male Singing. J. Acoust. Soc. Am. 2009, 126, 1530–1540. [Google Scholar] [CrossRef] [Green Version]
- Lowell, S.Y.; Kelley, R.T.; Colton, R.H.; Smith, P.B.; Portnoy, J.E. Position of the Hyoid and Larynx in People with Muscle Tension Dysphonia. Laryngoscope 2012, 122, 370–377. [Google Scholar] [CrossRef]
- Neil, E.; Worrall, L.; Day, A.; Hickson, L. Voice and Speech Characteristics and Vocal Hygiene in Novice and Professional Broadcast Journalists. Adv. Speech Lang. Pathol. 2003, 5, 1–14. [Google Scholar] [CrossRef]
- Plant, R.L.; Younger, R.M. The Interrelationship of Subglottic Air Pressure, Fundamental Frequency, and Vocal Intensity during Speech. J. Voice 2000, 14, 170–177. [Google Scholar] [CrossRef]
- Sundberg, J. The Science of the Singing Voice; Northern Illinois University Press: DeKalb, IL, USA, 1987; ISBN 9780875801209. [Google Scholar]
- Watson, P.J.; Hixon, T.J.; Maher, M.Z. To Breathe or Not to Breathe—That Is the Question: An Investigation of Speech Breathing Kinematics in World Class Shakespearean Actors. J. Voice 1987, 1, 269–272. [Google Scholar] [CrossRef]
- Gillespie, A.I.; Gartner-Schmidt, J.; Rubinstein, E.N.; Abbott, K.V. Aerodynamic Profiles of Women With Muscle Tension Dysphonia/Aphonia. J. Speech Lang. Hear. Res. 2013, 56, 481–488. [Google Scholar] [CrossRef]
- Sundberg, J.; Leanderson, R.; von Euler, C. Activity Relationship between Diaphragm and Cricothyroid Muscles. J. Voice 1989, 3, 225–232. [Google Scholar] [CrossRef]
- Iwarsson, J.; Sundberg, J. Effects of Lung Volume on Vertical Larynx Position during Phonation. J. Voice 1998, 12, 159–165. [Google Scholar] [CrossRef]
- Iwarsson, J.; Thomasson, M.; Sundberg, J. Effects of Lung Volume on the Glottal Voice Source. J. Voice 1998, 12, 424–433. [Google Scholar] [CrossRef]
- Gelfer, M.P.; Andrews, M.L.; Schmidt, C.P. Effects of Prolonged Loud Reading on Selected Measures of Vocal Function in Trained and Untrained Singers. J. Voice 1991, 5, 158–167. [Google Scholar] [CrossRef]
- Nawka, T.; Anders, L.C.; Cebulla, M.; Zurakowski, D. The Speaker’s Formant in Male Voices. J. Voice 1997, 11, 422–428. [Google Scholar] [CrossRef]
- Guzman, M.; Ortega, A.; Olavarria, C.; Muñoz, D.; Cortés, P.; Azocar, M.J.; Cayuleo, D.; Quintana, F.; Silva, C. Comparison of Supraglottic Activity and Spectral Slope Between Theater Actors and Vocally Untrained Subjects. J. Voice 2016, 30, 767.e1–767.e8. [Google Scholar] [CrossRef]
- Pirilä, S.; Jokitulppo, J.; Niemitalo-Haapola, E.; Yliherva, A.; Rantala, L. Teachers’ and Children’s Experiences after an Acoustic Intervention and a Noise-Controlling Workshop in Two Elementary Classrooms. Folia Phoniatr. Logop. 2020, 72, 454–463. [Google Scholar] [CrossRef] [PubMed] [Green Version]
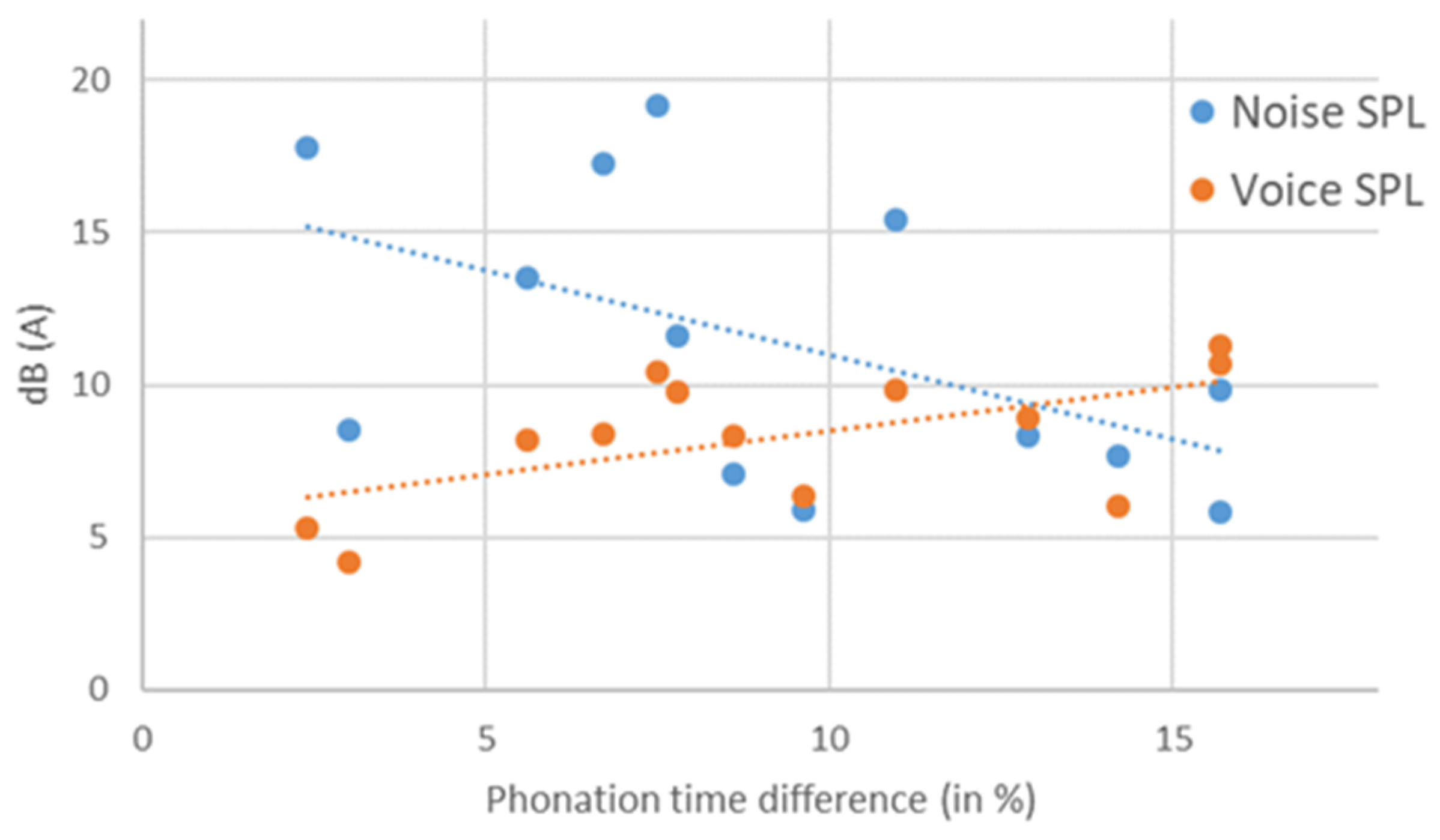

{kind=link}
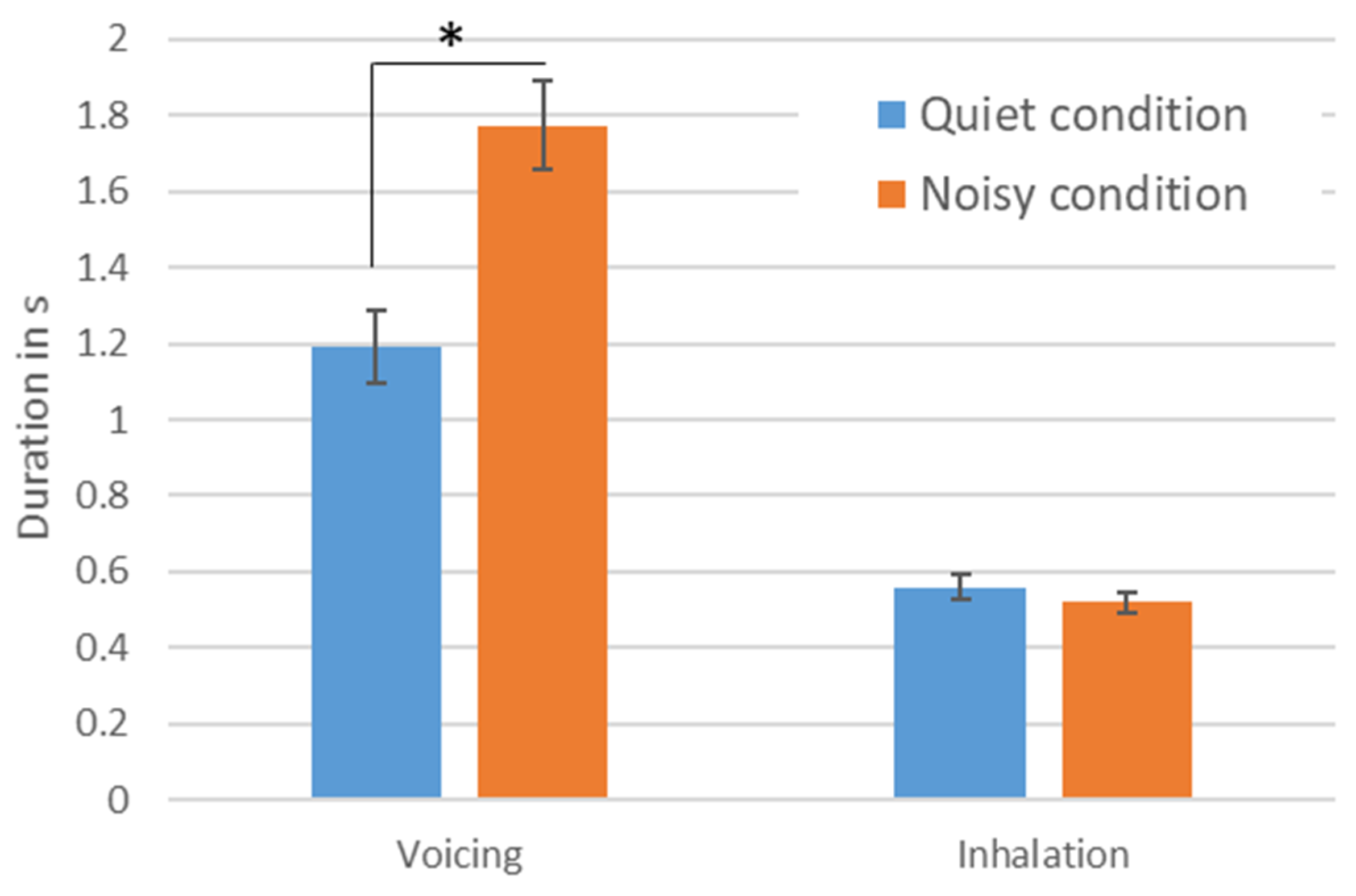
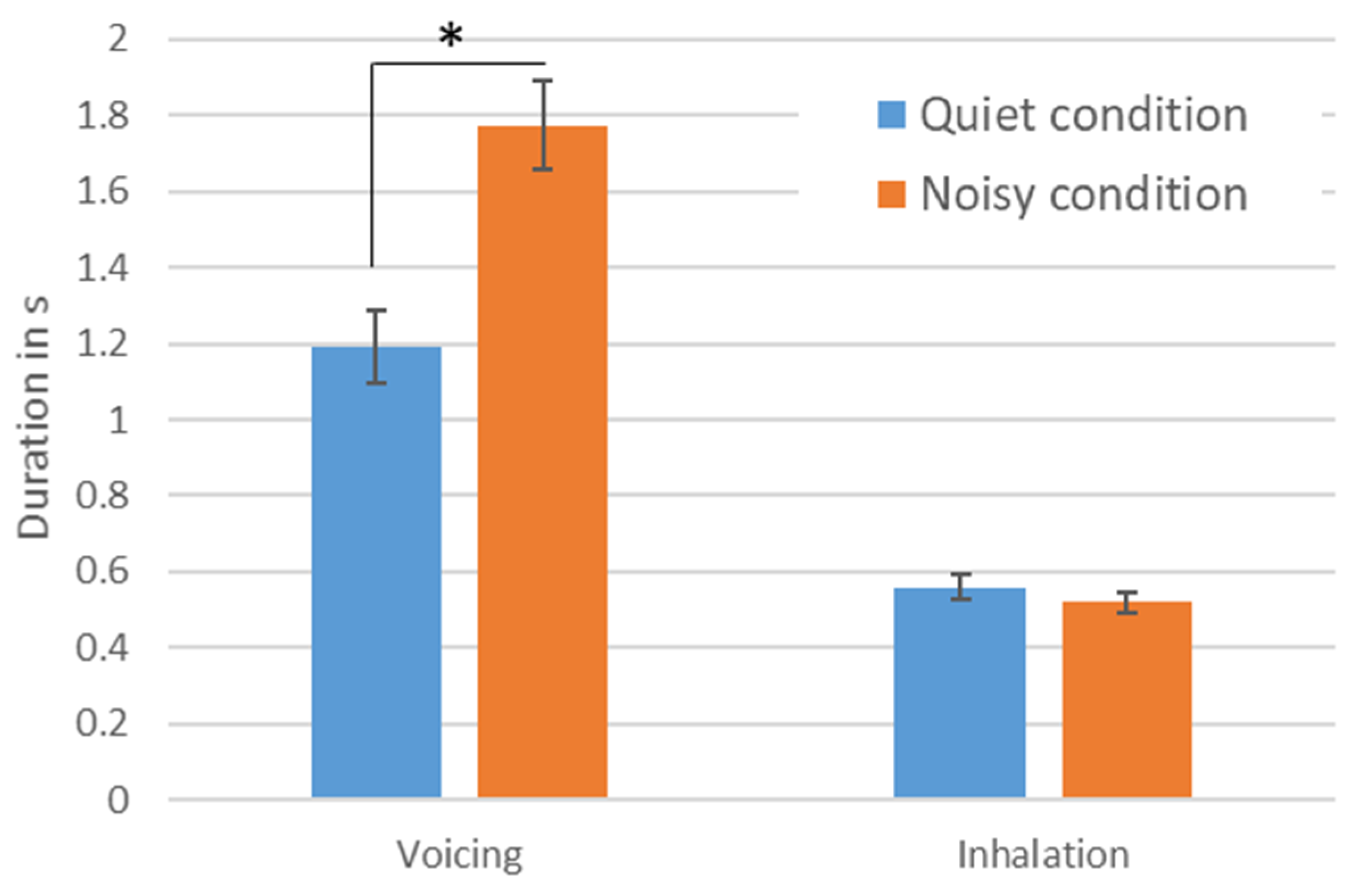{kind=link}
| Quiet Condition | Noisy Condition | Statistics | |
|---|---|---|---|
| Fundamental Frequency (in Hz) | Female: 220.7 (28.1) | Female: 286.4 (50.9) | t = −7.095; p < 0.001 |
| Male: 142.5 (13.8) | Male: 185,4 (29.9) | t = −3.595; p < 0.001 | |
| Voice SPL (in dB(A)) | 76.3 (2.3) | 84.6 (2.2) | t = −13.464; p < 0.001 |
| Noise SPL (in dB(A)) | 57.4 (4.9) | 68.8 (4.8) | t = −9.758; p < 0.001 |
| Phonation time (in percent) | 60.7 (7.4) | 71.6 (5.6) | t = −6.550; p < 0.001 |
| Pause Duration | Quiet Condition | Noisy Condition |
|---|---|---|
| 100 ms | 266 (81.3%) | 167 (74.2%) |
| 200 ms | 61 (18.7%) | 58 (25.8%) |
| Total | 327 (100%) | 225 (100%) |
| Voice Aspect | Response | Vocal Risk | Recommendation |
|---|---|---|---|
| Voice SPL | Increases | Increase in subglottal pressure and | Increase only as high as necessary for maintaining communication and decrease when not necessary |
| Mechanical stress on vocal folds | |||
| ƒo | Increases | increased number vocal fold vibrations, subglottic pressure and mechanical stress on vocal folds | Increase speaking pitch with caution and combine it with supportive resonance strategies |
| Voicing duration | Lengthen | increased number vocal fold vibrations | Use it effectively for sound production |
| Inhalation duration | Remain similar | With increased voicing leads to longer phonation on lower lung volume, related to higher laryngeal position and pressed phonation | Take time to inhale deeper |
| Short pauses | Shortens | Loss of articulation | Maintain clear articulation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nusseck, M.; Immerz, A.; Richter, B.; Traser, L. Vocal Behavior of Teachers Reading with Raised Voice in a Noisy Environment. Int. J. Environ. Res. Public Health 2022, 19, 8929. https://doi.org/10.3390/ijerph19158929
Nusseck M, Immerz A, Richter B, Traser L. Vocal Behavior of Teachers Reading with Raised Voice in a Noisy Environment. International Journal of Environmental Research and Public Health. 2022; 19(15):8929. https://doi.org/10.3390/ijerph19158929
Chicago/Turabian StyleNusseck, Manfred, Anna Immerz, Bernhard Richter, and Louisa Traser. 2022. "Vocal Behavior of Teachers Reading with Raised Voice in a Noisy Environment" International Journal of Environmental Research and Public Health 19, no. 15: 8929. https://doi.org/10.3390/ijerph19158929
APA StyleNusseck, M., Immerz, A., Richter, B., & Traser, L. (2022). Vocal Behavior of Teachers Reading with Raised Voice in a Noisy Environment. International Journal of Environmental Research and Public Health, 19(15), 8929. https://doi.org/10.3390/ijerph19158929