
The New Hyperspectral Analysis Method for Distinguishing the Types of Heavy Metal Copper and Lead Pollution Elements

Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. Materials and Methods
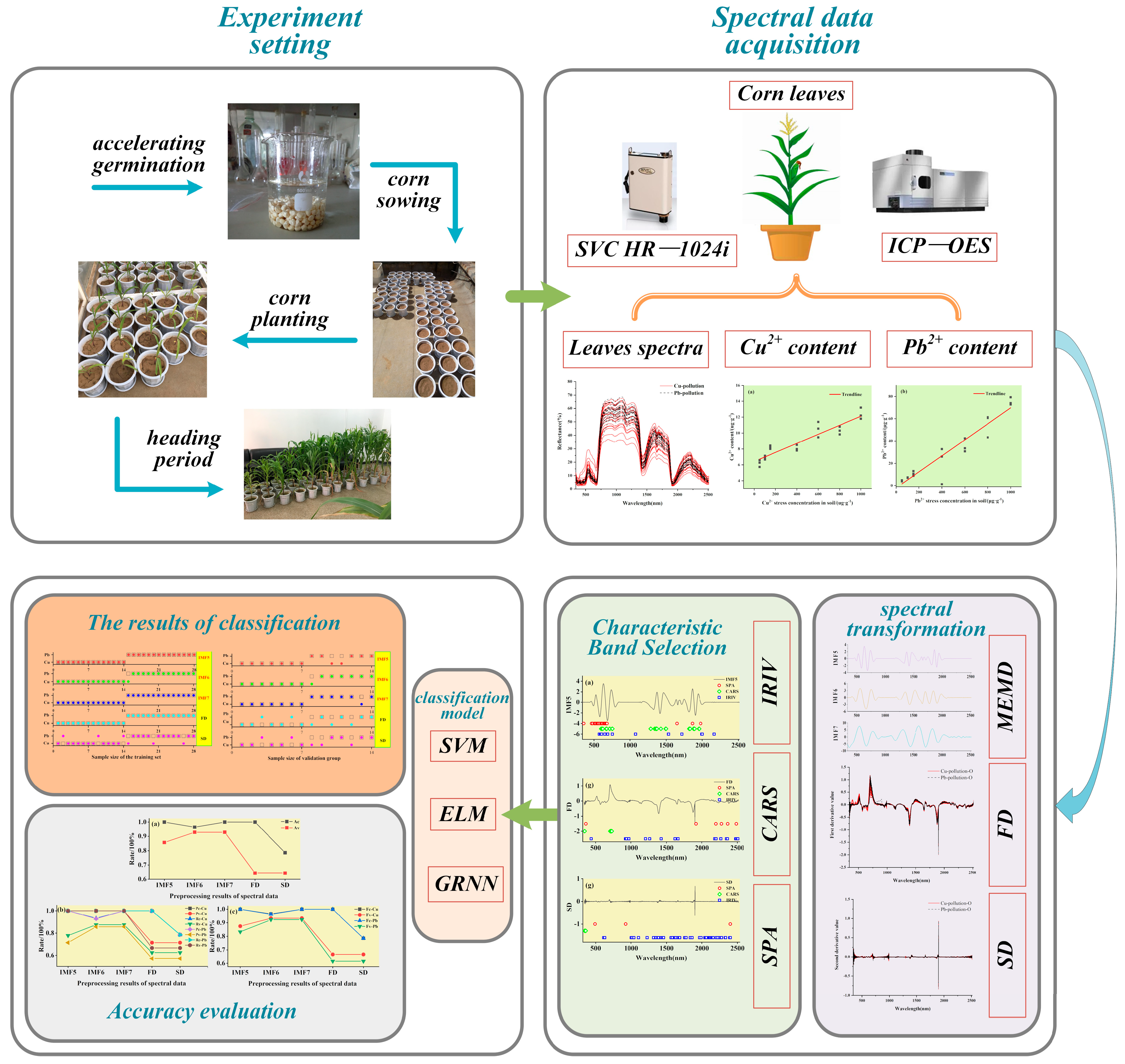
2.1. Experimental Design and Data Acquisition
2.1.1. Experimental Design
2.1.2. Spectral Data Acquisition
2.1.3. Chemical Detection of Heavy Metal Content
2.2. Theory and Method
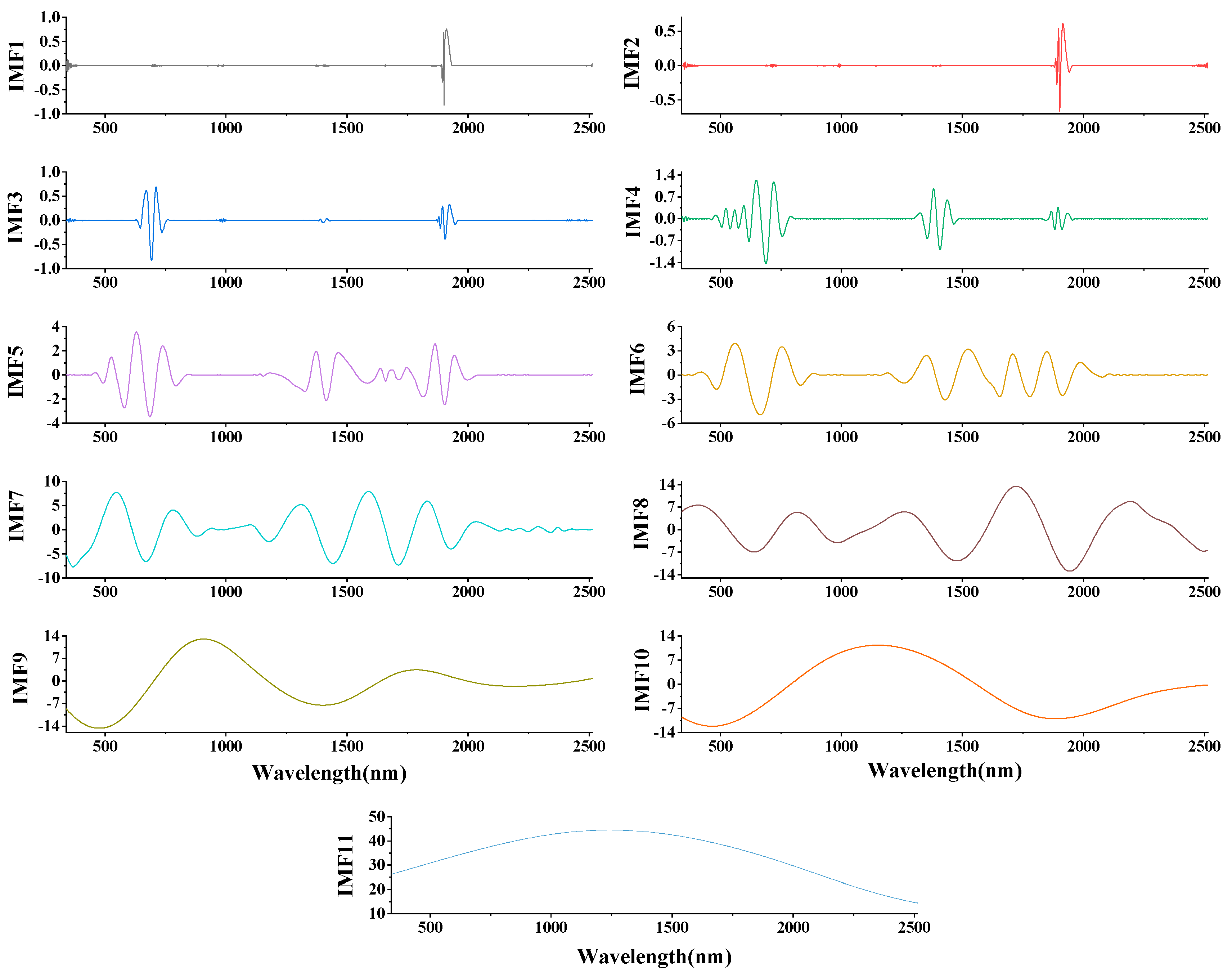
2.2.1. Multivariate Empirical Mode Decomposition (MEMD)
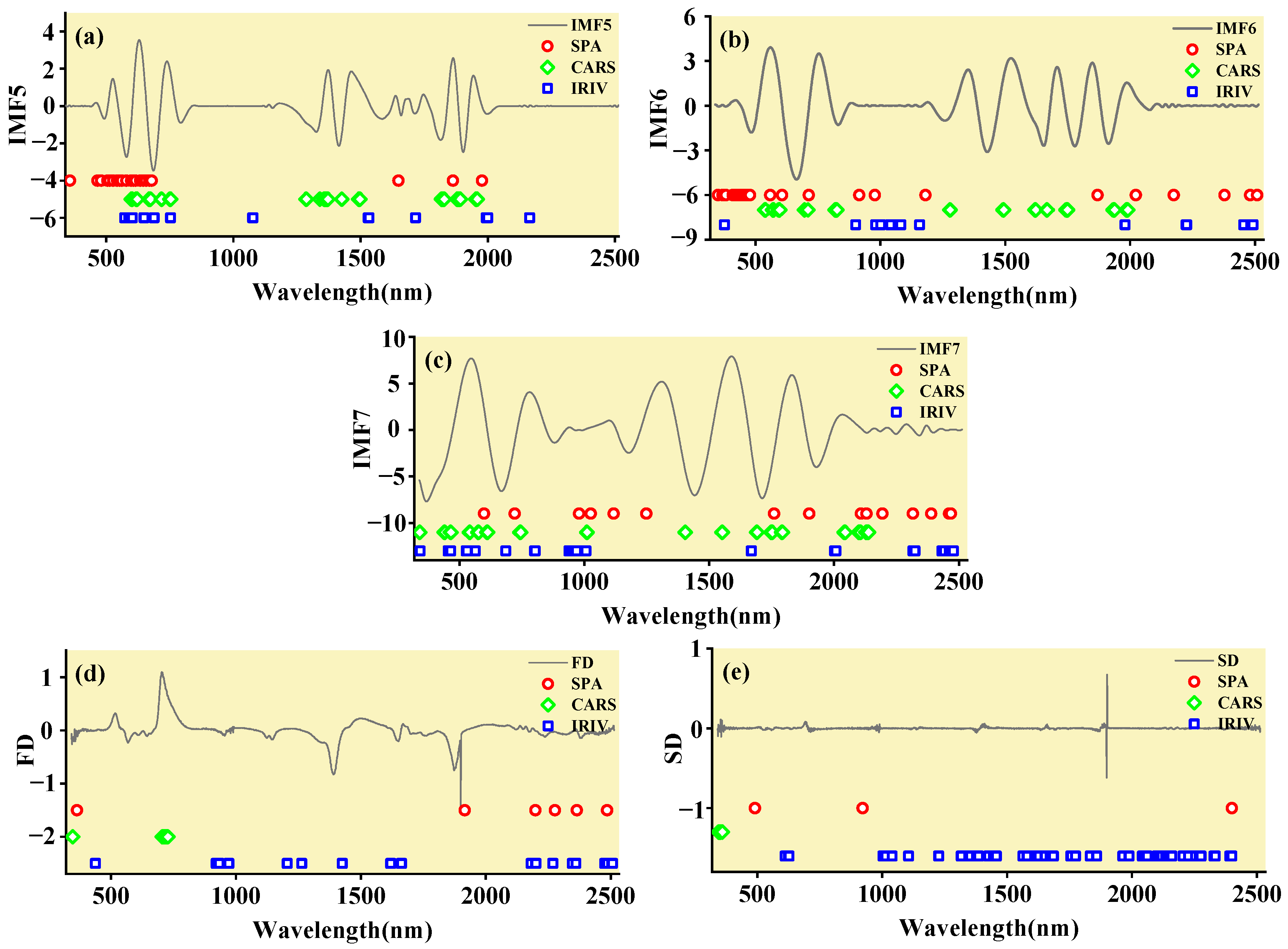
2.2.2. Successive Projections Algorithm (SPA)
2.2.3. Iteratively Retaining Informative Variables (IRIV)
2.2.4. Competitive Adaptive Reweighted Sampling (CARS)
2.2.5. Extreme Learning Machines (ELM)
2.2.6. Support Vector Machines (SVM)
2.2.7. General Regression Neural Network (GRNN)
2.2.8. Accuracy Evaluation Method
2.2.9. Workflow
3. Results and Discussion
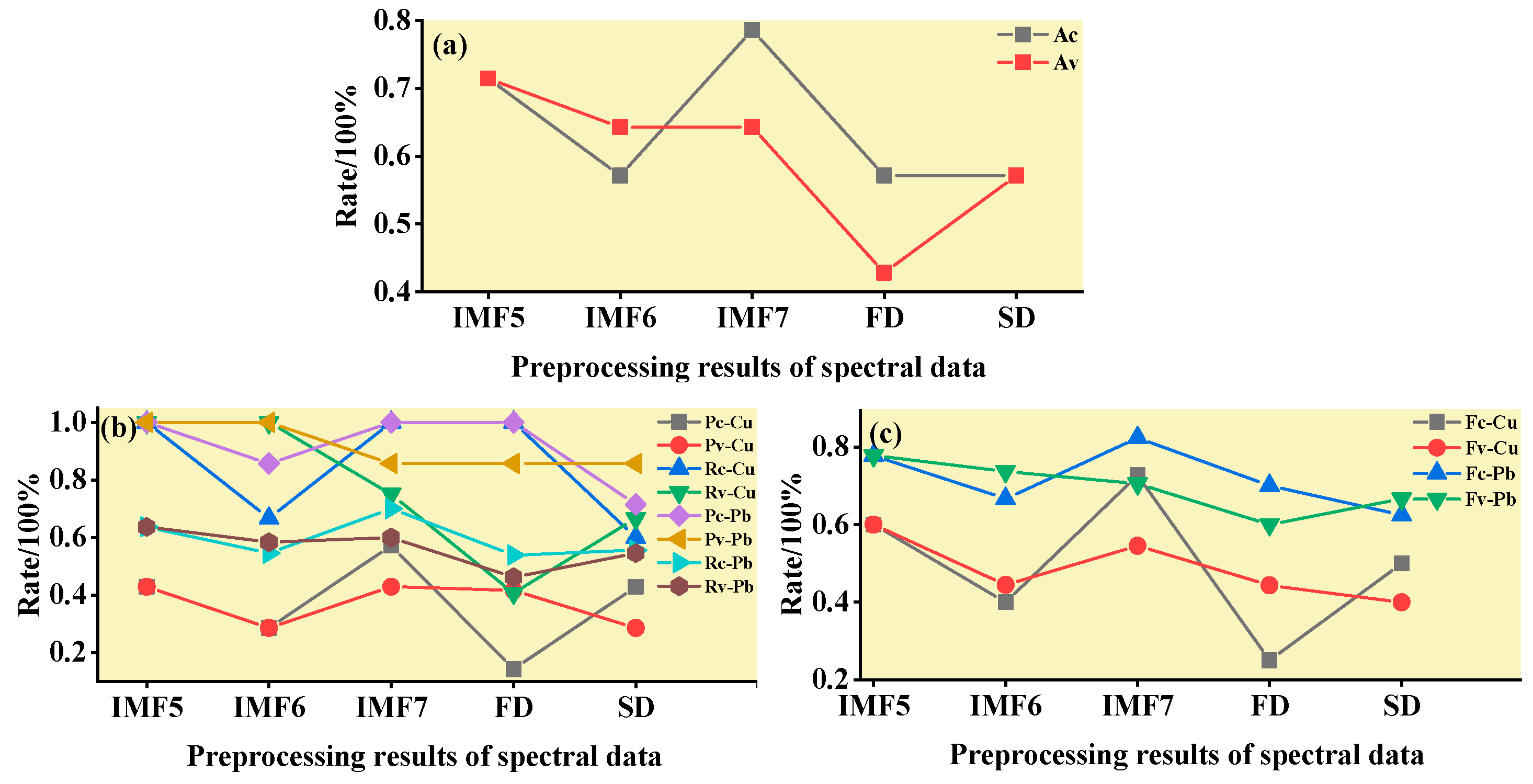
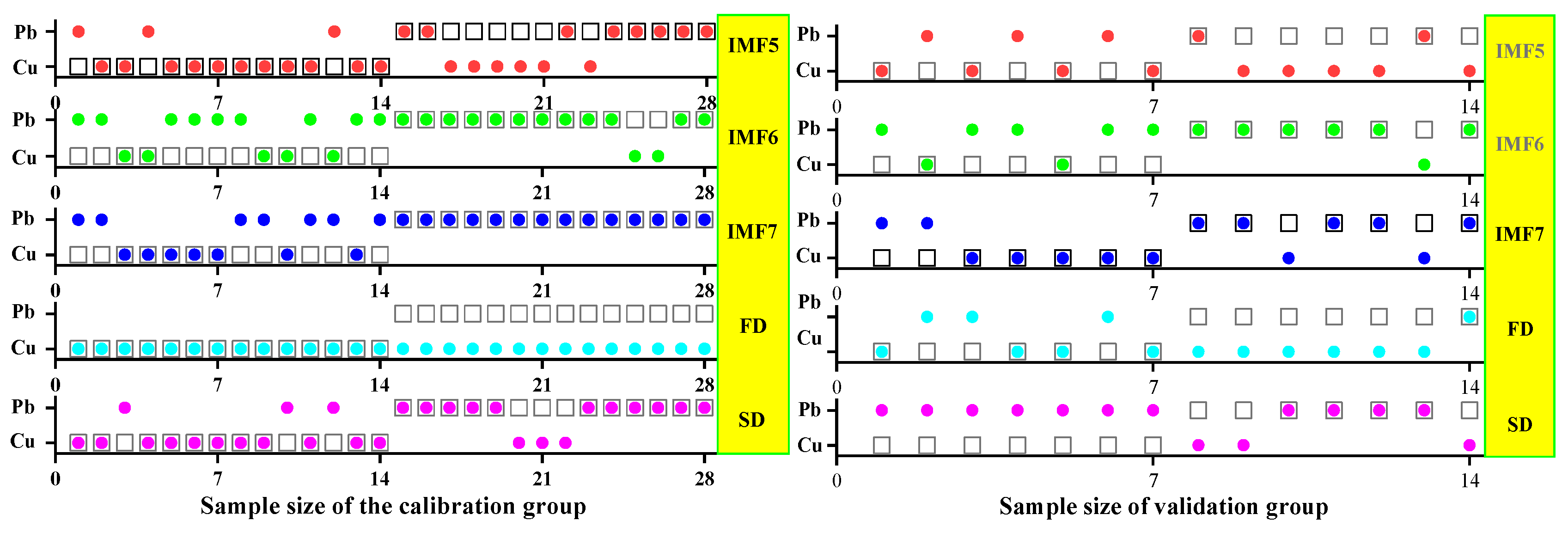
3.1. Data Preprocessing and Analysis
3.1.1. Heavy Metal Content of Corn Leaves
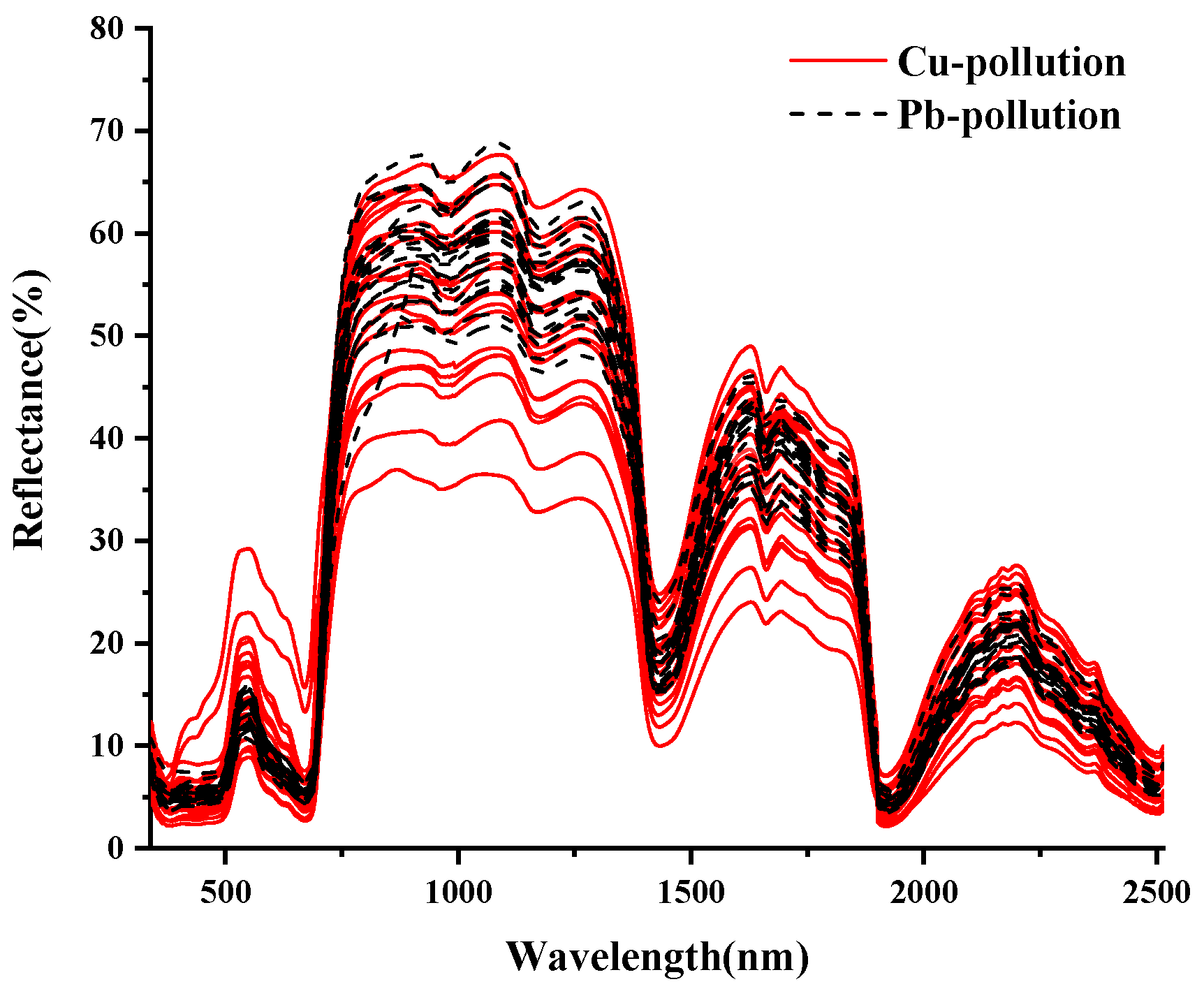
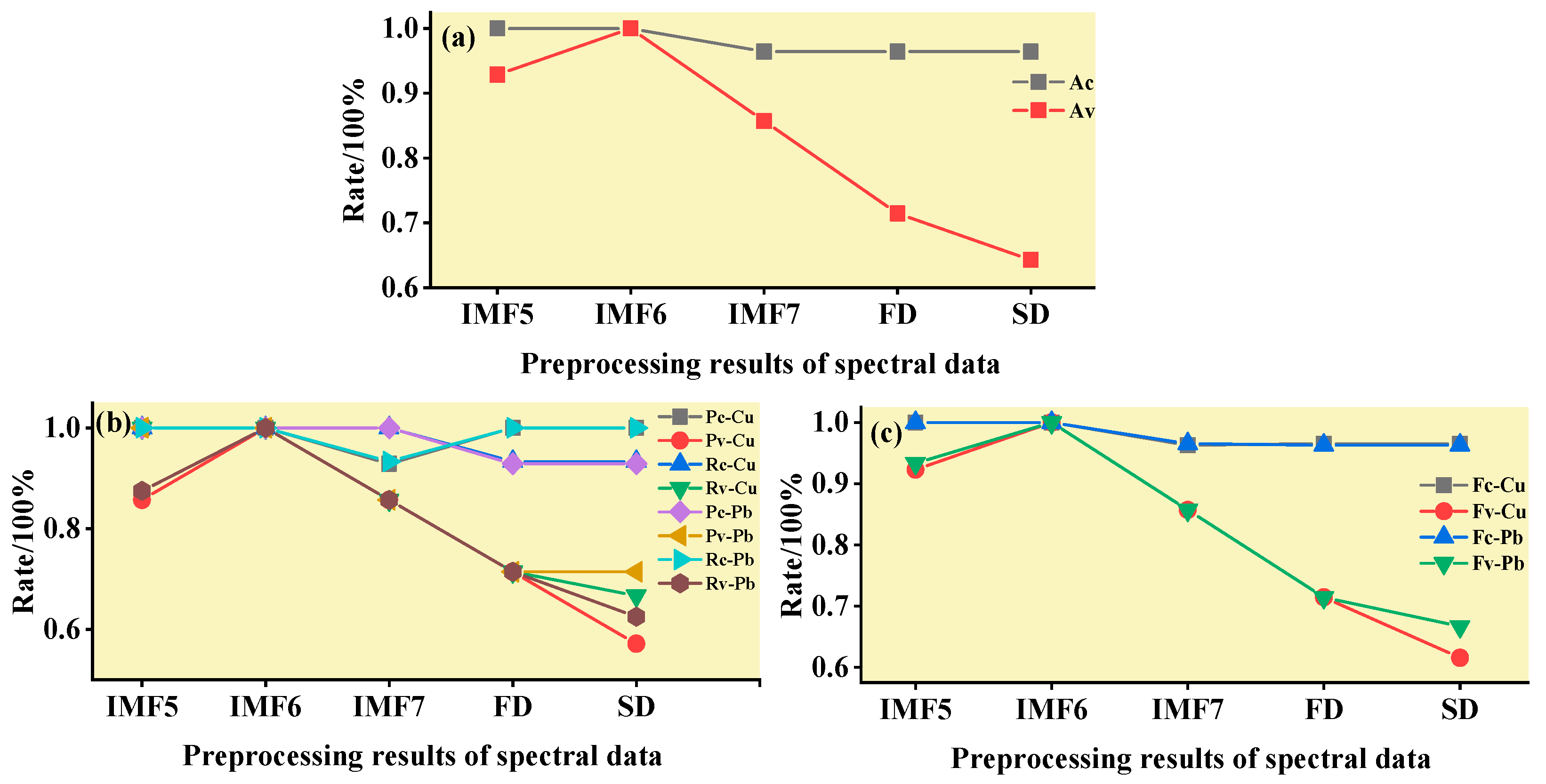
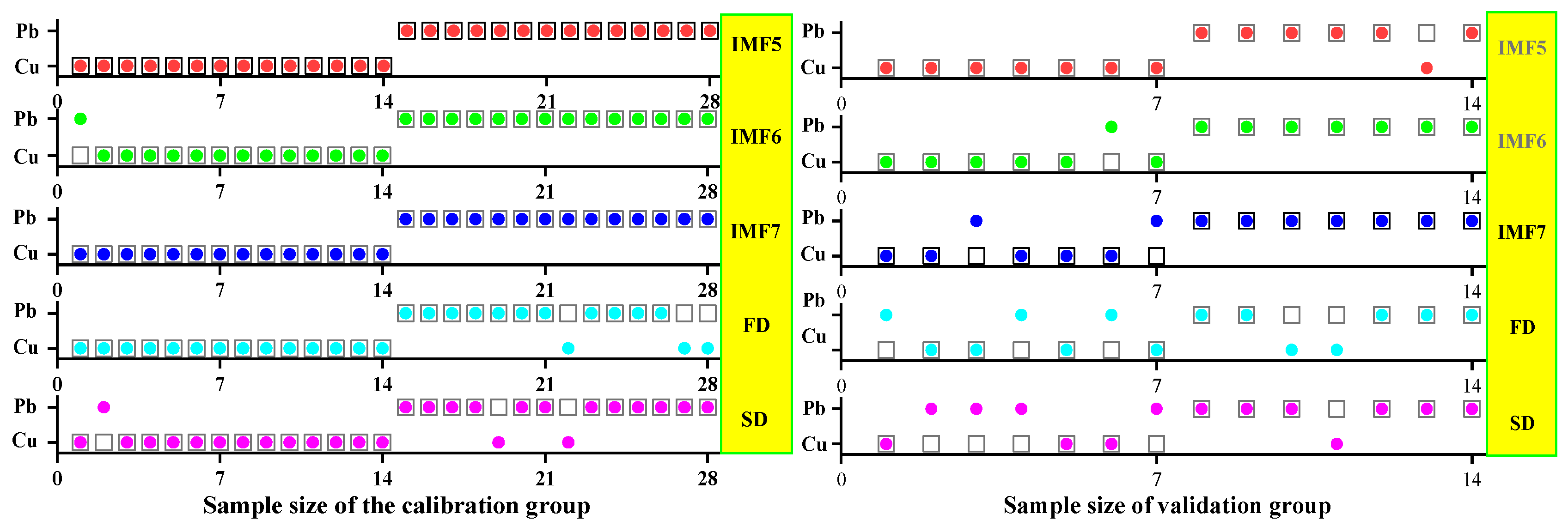
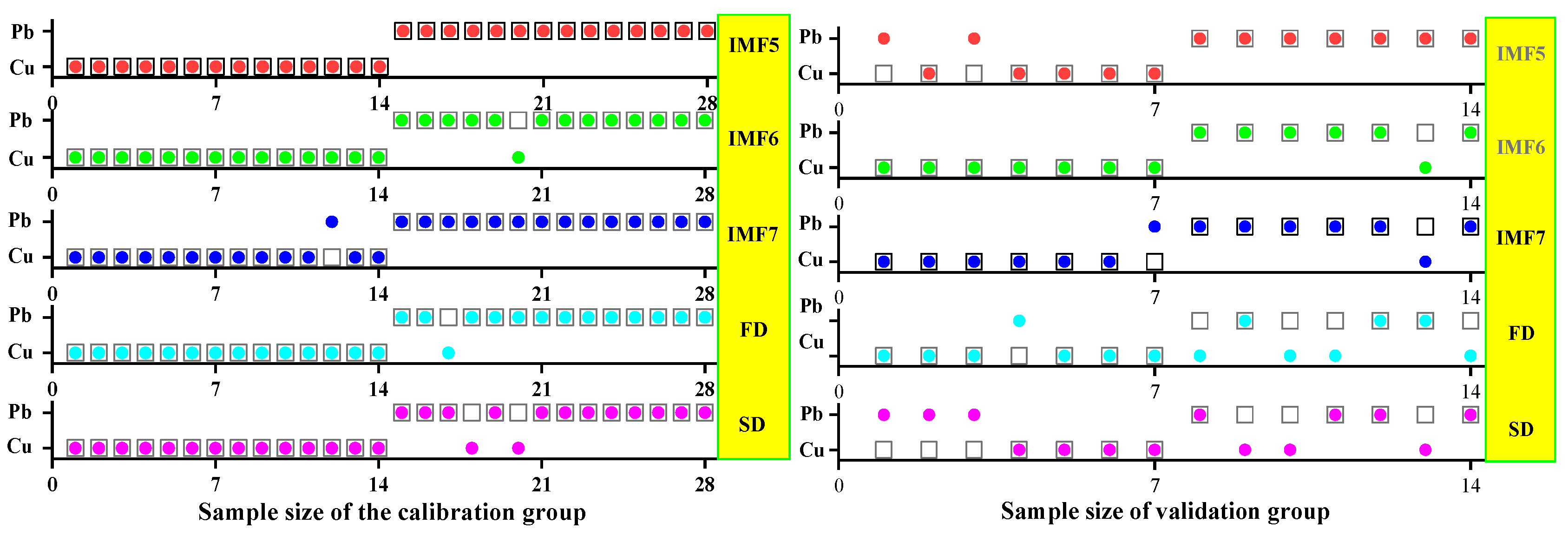
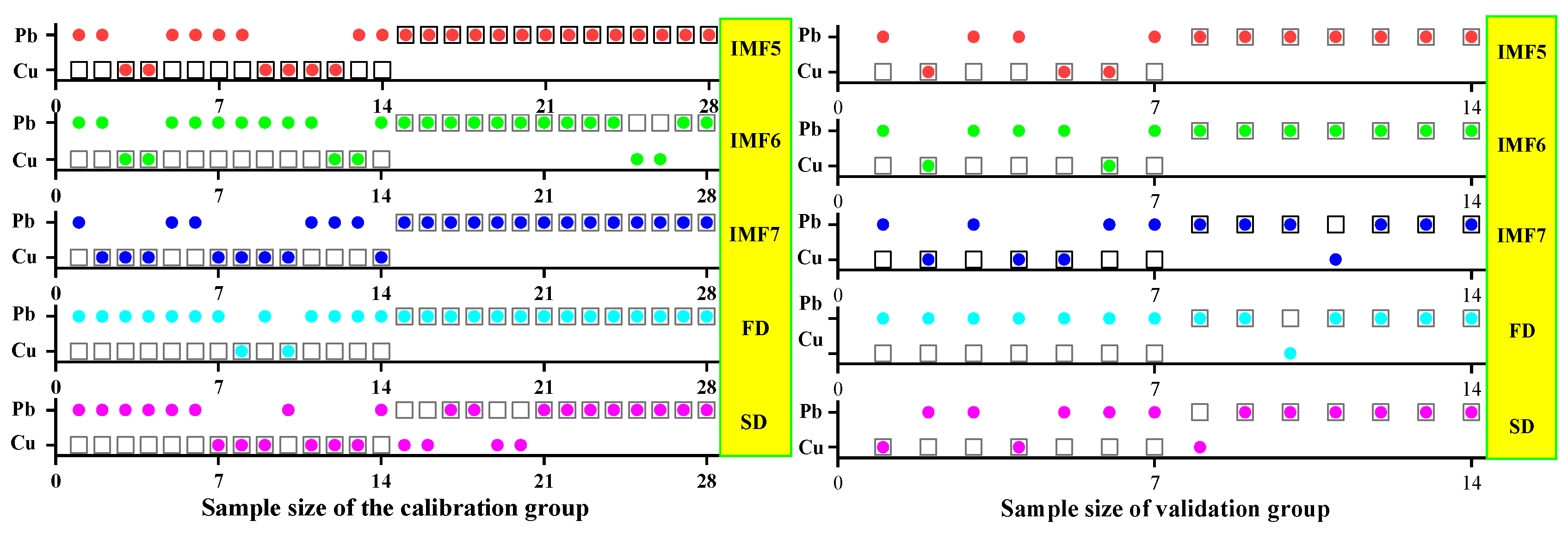
3.1.2. Spectral Data Preprocessing and Analysis
3.2. Characteristic Band Acquisition Using SPA, CARS, and IRIV
3.3. Identification of Copper and Lead Elements
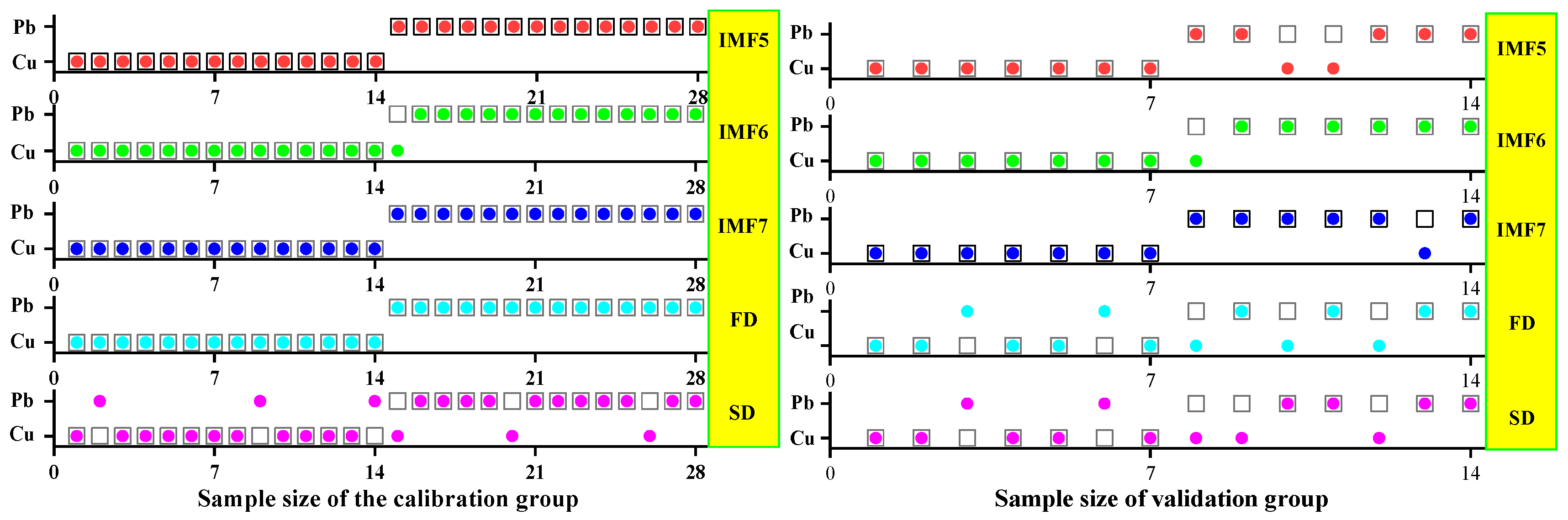
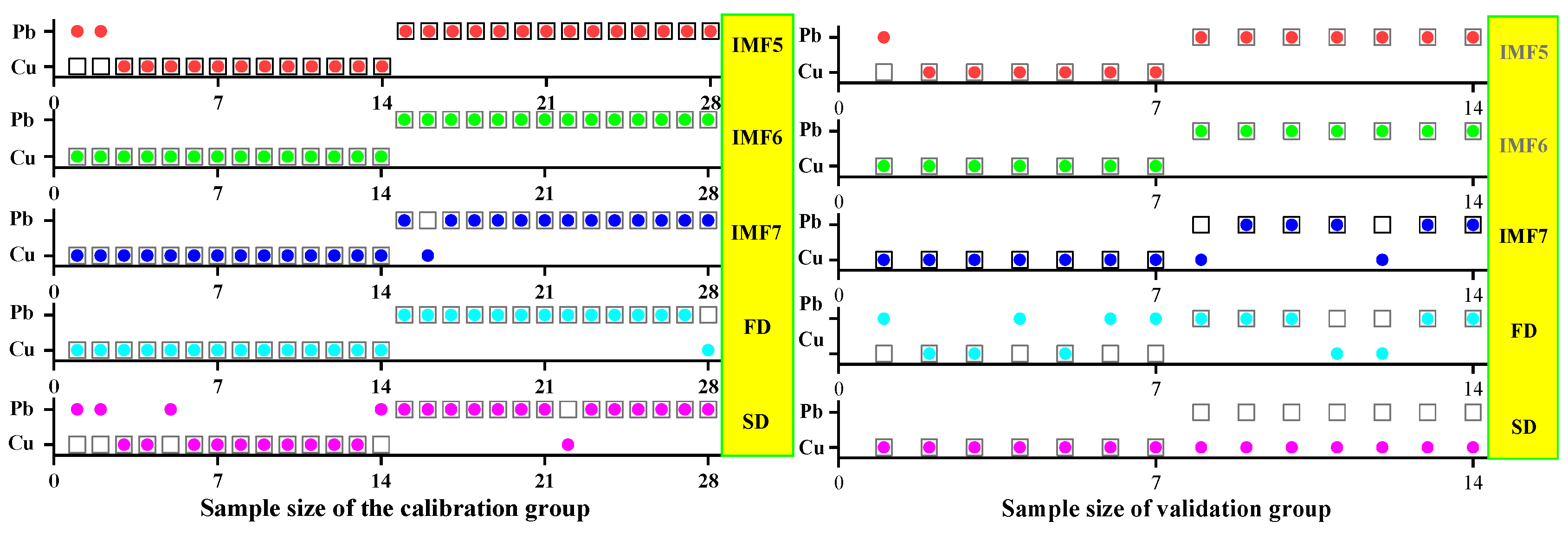
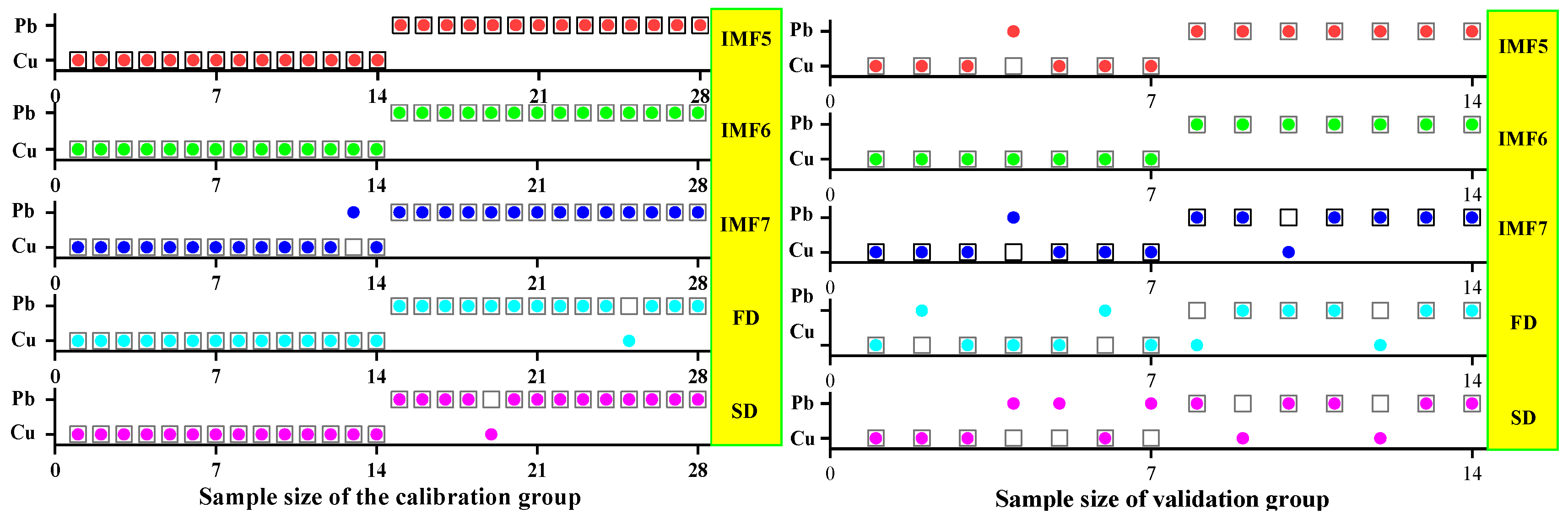
3.3.1. SVM Classification and Discrimination Model Based on the Optimal Wavelength
- (1)
- MEMD-SPA-SVM
- (2)
- MEMD-CARS-SVM
- (3)
- MEMD-IRIV-SVM
3.3.2. ELM Classification and Discrimination Model Based on the Optimal Wavelength
- (1)
- MEMD-SPA-ELM
- (2)
- MEMD-CARS-ELM
- (3)
- MEMD-IRIV-ELM
3.3.3. GRNN Classification and Discrimination Model Based on the Optimal Wavelength
- (1)
- MEMD-SPA-GRNN
- (2)
- MEMD-CARS-GRNN
- (3)
- MEMD-IRIV-GRNN
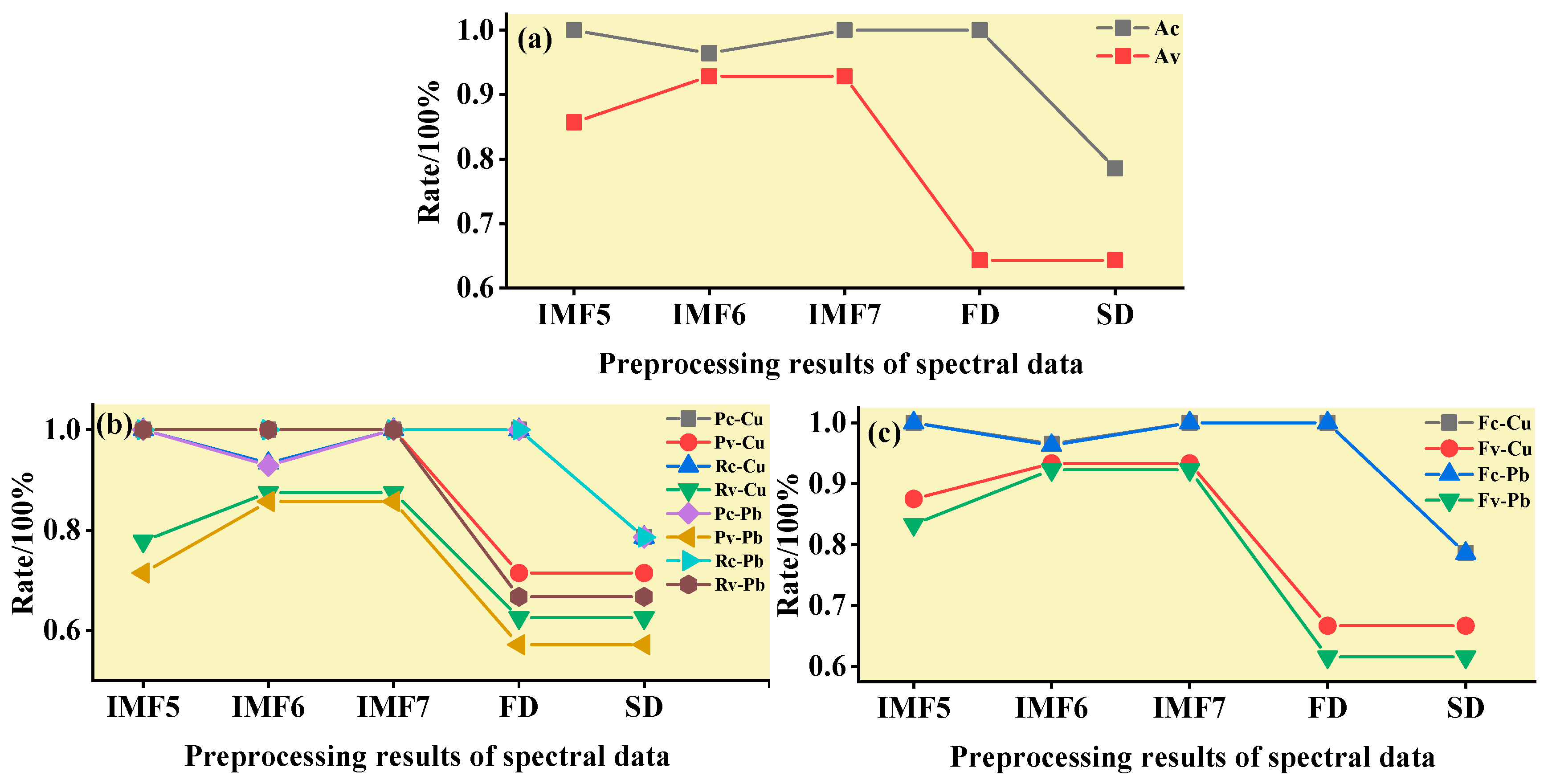
3.3.4. Performance of the Method
3.4. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, L.; Lai, J.; Tan, K.; Wang, X.; Chen, Y.; Ding, J. Development of a soil heavy metal estimation method based on a spectral index: Combining fractional-order derivative pretreatment and the absorption mechanism. Sci. Total Environ. 2022, 813, 151882. [Google Scholar] [CrossRef]
- Caporaso, N.; Whitworth, M.B.; Fisk, I.D. Protein content prediction in single wheat kernels using hyperspectral imaging. Food Chem. 2018, 240, 32–42. [Google Scholar] [CrossRef]
- Ovecka, M.; Takac, T. Managing heavy metal toxicity stress in plants: Biological and biotechnological tools. Biotechnol. Adv. 2014, 32, 73–86. [Google Scholar] [CrossRef]
- Obeng-Gyasi, E.; Armijos, R.X.; Weigel, M.M.; Filippelli, G.M.; Sayegh, M.A. Cardiovascular-Related Outcomes in US Adults Exposed to Lead. Int. J. Environ. Res. Public Health 2018, 15, 759. [Google Scholar] [CrossRef] [Green Version]
- Tan, K.; Wang, H.M.; Zhang, Q.Q.; Jia, X.P. An improved estimation model for soil heavy metal(loid) concentration retrieval in mining areas using reflectance spectroscopy. J. Soils Sediments 2018, 18, 2008–2022. [Google Scholar] [CrossRef]
- Toth, G.; Hermann, T.; Da Silva, M.R.; Montanarella, L. Heavy metals in agricultural soils of the European Union with implications for food safety. Environ. Int. 2016, 88, 299–309. [Google Scholar] [CrossRef]
- Yeganeh, M.; Afyuni, M.; Khoshgoftarmanesh, A.H.; Khodakarami, L.; Amini, M.; Soffyanian, A.R.; Schulin, R. Mapping of human health risks arising from soil nickel and mercury contamination. J. Hazard. Mater. 2013, 244, 225–239. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Wu, X.; Dai, C.; Li, B. Spectral classification of lettuce cadmium stress based on information fusion and VISSA-GOA-SVM algorithm. J. Food Process Eng. 2019, 42, e13085. [Google Scholar] [CrossRef]
- Shi, T.Z.; Guo, L.; Chen, Y.Y.; Wang, W.X.; Shi, Z.; Li, Q.Q.; Wu, G.F. Proximal and remote sensing techniques for mapping of soil contamination with heavy metals. Appl. Spectrosc. Rev. 2018, 53, 783–805. [Google Scholar] [CrossRef]
- Neinavaz, E.; Darvishzadeh, R.; Skidmore, A.K.; Groen, T.A. Measuring the response of canopy emissivity spectra to leaf area index variation using thermal hyperspectral data. Int. J. Appl. Earth Obs. 2016, 53, 40–47. [Google Scholar] [CrossRef]
- Tan, K.; Wang, H.M.; Chen, L.H.; Du, Q.; Du, P.J.; Pan, C.C. Estimation of the spatial distribution of heavy metal in agricultural soils using airborne hyperspectral imaging and random forest. J. Hazard. Mater. 2020, 382, 120987. [Google Scholar] [CrossRef]
- Zhang, W.; Du, P.J.; Lin, C.; Fu, P.J.; Wang, X.; Bai, X.Y.; Zheng, H.R.; Xia, J.S.; Samat, A. An Improved Feature Set for Hyperspectral Image Classification: Harmonic Analysis Optimized by Multiscale Guided Filter. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3903–3916. [Google Scholar] [CrossRef]
- Milton, N.M.; Ager, C.M.; Eiswerth, B.A.; Power, M.S. Arsenic- and selenium-induced changes in spectral reflectance and morphology of soybean plants. Remote Sens. Environ. 1990, 30, 263–269. [Google Scholar] [CrossRef]
- Horler, D.N.; Dockray, M.; Barber, J. The Red Edge of Plant Leaf Reflectance. Int. J. Remote Sens. 1983, 4, 273–288. [Google Scholar] [CrossRef]
- Liu, M.; Liu, X.; Li, J.; Li, T. Estimating regional heavy metal concentrations in rice by scaling up a field-scale heavy metal assessment model. Int. J. Appl. Earth Obs. 2012, 19, 12–23. [Google Scholar] [CrossRef]
- Lv, J.; Liu, X. Predicting Arsenic Concentration in Rice Plants from Hyperspectral Data Using Random Forests. In Advances in Multimedia, Software Engineering and Computing, Vol 1; Jin, D., Lin, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 128, pp. 601–606. [Google Scholar]
- Shi, T.; Liu, H.; Wang, J.; Chen, Y.; Fei, T.; Wu, G. Monitoring Arsenic Contamination in Agricultural Soils with Reflectance Spectroscopy of Rice Plants. Environ. Sci. Technol. 2014, 48, 6264–6272. [Google Scholar] [CrossRef]
- Liu, M.L.; Liu, X.N.; Ding, W.C.; Wu, L. Monitoring stress levels on rice with heavy metal pollution from hyperspectral reflectance data using wavelet-fractal analysis. Int. J. Appl. Earth Obs. 2011, 13, 246–255. [Google Scholar] [CrossRef]
- Zhang, J.H.; Yang, K.M.; Han, Q.Q.; Li, Y.R.; Gao, W. Predicting the Copper Pollution Information of Corn Leaves Spectral Based on an IWD-Hankel-SVD Model. Spectrosc. Spectr. Anal. 2021, 41, 1505–1512. [Google Scholar] [CrossRef]
- Slonecker, T.; Haack, B.; Price, S. Spectroscopic Analysis of Arsenic Uptake in Pteris Ferns. Remote Sens. 2009, 1, 644–675. [Google Scholar] [CrossRef] [Green Version]
- Bandaru, V.; Hansen, D.J.; Codling, E.E.; Daughtry, C.S.; White-Hansen, S.; Green, C.E. Quantifying arsenic-induced morphological changes in spinach leaves: Implications for remote sensing. Int. J. Remote Sens. 2010, 31, 4163–4177. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Yao, K.S.; Xu, M. Detection of heavy metal lead in lettuce leaves based on fluorescence hyperspectral technology combined with deep learning algorithm. Spectrochim. Acta A 2022, 266, 8. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Zhou, X.; Wu, X.; Lu, B.; Dai, C.; Shen, J. Research and analysis of cadmium residue in tomato leaves based on WT-LSSVR and Vis-NIR hyperspectral imaging. Spectrochim. Acta A 2019, 212, 215–221. [Google Scholar] [CrossRef]
- Rathod, P.H.; Brackhage, C.; Van der Meer, F.D.; Muller, I.; Noomen, M.F.; Rossiter, D.G.; Dudel, G.E. Spectral changes in the leaves of barley plant due to phytoremediation of metals—Results from a pot study. Eur. J. Remote Sens. 2015, 48, 283–302. [Google Scholar] [CrossRef]
- Wu, L.; Liu, X.N.; Wang, P.; Zhou, B.T.; Liu, M.L.; Li, X.Q. The assimilation of spectral sensing and the WOFOST model for the dynamic simulation of cadmium accumulation in rice tissues. Int. J. Appl. Earth Obs. 2013, 25, 66–75. [Google Scholar] [CrossRef]
- Gu, Y.W.; Li, S.; Gao, W.; Wei, H. Hyperspectral estimation of the cadmium content in leaves of Brassica rapa chinesis based on the spectral parameters. Acta Ecol. Sin. 2015, 35, 4445–4453. [Google Scholar]
- Zhang, C.Y.; Ren, H.Z.; Qin, Q.M.; Ersoy, O.K. A new narrow band vegetation index for characterizing the degree of vegetation stress due to copper: The copper stress vegetation index (CSVI). Remote Sens. Lett. 2017, 8, 576–585. [Google Scholar] [CrossRef]
- Lv, Y.; Yuan, R.; Song, G.B. Multivariate empirical mode decomposition and its application to fault diagnosis of rolling bearing. Mech. Syst. Signal Processing 2016, 81, 219–234. [Google Scholar] [CrossRef]
- Maheswari, R.U.; Umamaheswari, R. Wind Turbine Drivetrain Expert Fault Detection System: Multivariate Empirical Mode Decomposition based Multi-sensor Fusion with Bayesian Learning Classification. Intell. Autom. Soft. Comput. 2020, 26, 479–488. [Google Scholar] [CrossRef]
- Li, X.F.; Wu, S.J.; Li, X.Y.; Yuan, H.; Zhao, D. Particle Swarm Optimization-Support Vector Machine Model for Machinery Fault Diagnoses in High-Voltage Circuit Breakers. Chin. J. Mech. Eng. 2020, 33, 10. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.Z.; Xiao, J.; Xiao, H.; Zhang, W.B.; Zhu, W.L.; Li, C.S. Multifault Diagnosis for Rolling Element Bearings Based on Intrinsic Mode Permutation Entropy and Ensemble Optimal Extreme Learning Machine. Adv. Mech. Eng. 2014, 6, 803919. [Google Scholar] [CrossRef]
- Klopfenstein, T.J.; Erickson, G.E.; Berger, L.L. Maize is a critically important source of food, feed, energy and forage in the USA. Field Crops Res. 2013, 153, 5–11. [Google Scholar] [CrossRef]
- Hu, Y.; Burucs, Z.; von Tucher, S.; Schmidhalter, U. Short-term effects of drought and salinity on mineral nutrient distribution along growing leaves of maize seedlings. Environ. Exp. Bot. 2007, 60, 268–275. [Google Scholar] [CrossRef]
- Hediji, H.; Djebali, W.; Cabasson, C.; Maucourt, M.; Baldet, P.; Bertrand, A.; Zoghlami, L.B.; Deborde, C.; Moing, A.; Brouquisse, R.; et al. Effects of long-term cadmium exposure on growth and metabolomic profile of tomato plants. Ecotoxicol. Environ. Saf. 2010, 73, 1965–1974. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.mee.gov.cn/ywgz/fgbz/bz/bzwb/trhj/201807/t20180703_446029.shtml (accessed on 1 August 2018).
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.; Tung, C.C.; Liu, H.H. The Empirical Mode Decompositionand the Hilbert Spectrum for Nonlinear and Non2stationary Time Seriesanalysis; Royal Society: Hong Kong, China, 1998. [Google Scholar]
- Rehman, N.; Mandic, D.P. Multivariate empirical mode decomposition. Proc. R. Soc. A-Math. Phys. Eng. Sci. 2010, 466, 1291–1302. [Google Scholar] [CrossRef]
- Araujo, M.C.U.; Saldanha, T.C.B.; Galvao, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Wu, D.; Nie, P.C.; He, Y.; Wang, Z.P.; Wu, H.X. Spectral Multivariable Selection and Calibration in Visible-Shortwave Near-Infrared Spectroscopy for Non-Destructive Protein Assessment of Spirulina Microalga Powder. Int. J. Food Prop. 2013, 16, 1002–1015. [Google Scholar] [CrossRef]
- Yun, Y.-H.; Wang, W.-T.; Tan, M.-L.; Liang, Y.-Z.; Li, H.-D.; Cao, D.-S.; Lu, H.-M.; Xu, Q.-S. A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration. Anal. Chim. Acta 2014, 807, 36–43. [Google Scholar] [CrossRef]
- Cheng, J.H.; Chen, Z.G. Wavelength Selection Method for Near Infrared Spectroscopy Based on Iteratively Retains Informative Variables and Successive Projections Algorithm. Chin. J. Anal. Chem. 2021, 49, 1402–1409. [Google Scholar] [CrossRef]
- Tang, G.; Huang, Y.; Tian, K.D.; Song, X.Z.; Yan, H.; Hu, J.; Xiong, Y.M.; Min, S.G. A new spectral variable selection pattern using competitive adaptive reweighted sampling combined with successive projections algorithm. Analyst 2014, 139, 4894–4902. [Google Scholar] [CrossRef]
- Yang, Y.; Jin, Y.; Wu, Y.J.; Chen, Y. Application of near infrared spectroscopy combined with competitive adaptive reweighted sampling partial least squares for on-line monitoring of the concentration process of Wangbi tablets. J. Near Infrared Spectrosc. 2016, 24, 171–178. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K.; IEEE. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; IEEE: New York, NY, USA, 2004; pp. 985–990. [Google Scholar]
- Laurin, G.V.; Puletti, N.; Hawthorne, W.; Liesenberg, V.; Corona, P.; Papale, D.; Chen, Q.; Valentini, R. Discrimination of tropical forest types, dominant species, and mapping of functional guilds by hyperspectral and simulated multispectral Sentinel-2 data. Remote Sens. Environ. 2016, 176, 163–176. [Google Scholar] [CrossRef] [Green Version]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [Green Version]
- Hu, M.H.; Zhao, Y.; Zhai, G.T. Active learning algorithm can establish classifier of blueberry damage with very small training dataset using hyperspectral transmittance data. Chemom. Intell. Lab. Syst. 2018, 172, 52–57. [Google Scholar] [CrossRef]
- Boyer, M.; Miller, J.; Belanger, M.; Hare, E.; Wu, J. Senescence and Spectral Reflectance in Leaves of Northern Pin Oak (Quercus Palustris Muenchh); Elsevier: Amsterdam, The Netherlands, 1988; Volume 25. [Google Scholar]
- Strever, A.E.; Young, P.R.; Boshoff, H.; Hunter, J.J. Non-destructive assessment of leaf composition as related to growth of the grapevine (Vitis vinifera L. cv. Shiraz). In Proceedings of the Seventeenth International Giesco Symposium, Asti-Alba (CN), Italy, 29 August–2 September 2011. [Google Scholar]
- Mirzaei, M.; Verrelst, J.; Marofi, S.; Abbasi, M.; Azadi, H. Eco-Friendly Estimation of Heavy Metal Contents in Grapevine Foliage Using In-Field Hyperspectral Data and Multivariate Analysis. Remote Sens. 2019, 11, 2371. [Google Scholar] [CrossRef] [Green Version]
- Jiang, Z.; Yang, Y.; Sha, J. Application of GWR model in hyperspectral prediction of soil heavy metals. Acta Geogr. Sin. 2017, 72, 533–544. [Google Scholar]
- Fu, P.; Zhang, W.; Yang, K.; Meng, F. A novel spectral analysis method for distinguishing heavy metal stress of maize due to copper and lead: RDA and EMD-PSD. Ecotoxicol. Environ. Saf. 2020, 206, 111211. [Google Scholar] [CrossRef]
- Fu, P.J.; Zhang, W.; Yang, K.M.; Meng, F.; Yao, G.B.A.; Liu, P.D. Using the Hilbert-Huang spectrum transformation to estimate soil lead concentration. Remote Sens. Lett. 2021, 12, 768–777. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, W.C.; Cen, Y.; Zhang, L.F.; Wang, N. Predicting cadmium concentration in soils using laboratory and field reflectance spectroscopy. Sci. Total Environ. 2019, 650, 321–334. [Google Scholar] [CrossRef] [PubMed]
- Prospere, K.; McLaren, K.; Wilson, B. Plant Species Discrimination in a Tropical Wetland Using In Situ Hyperspectral Data. Remote Sens. 2014, 6, 8494–8523. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Sun, J.; Mao, H.; Wu, X.; Zhang, X.; Yang, N. Visualization research of moisture content in leaf lettuce leaves based on WT-PLSR and hyperspectral imaging technology. J. Food Process Eng. 2018, 41, e12647. [Google Scholar] [CrossRef]
- Reinart, A.; Kutser, T. Comparison of different satellite sensors in detecting cyanobacterial bloom events in the Baltic Sea. Remote Sens. Environ. 2006, 102, 74–85. [Google Scholar] [CrossRef]
- Allbed, A.; Kumar, L.; Sinha, P. Mapping and Modelling Spatial Variation in Soil Salinity in the Al Hassa Oasis Based on Remote Sensing Indicators and Regression Techniques. Remote Sens. 2014, 6, 1137–1157. [Google Scholar] [CrossRef] [Green Version]
- Kemper, T.; Sommer, S. Estimate of heavy metal contamination in soils after a mining accident using reflectance spectroscopy. Environ. Sci. Technol. 2002, 36, 2742–2747. [Google Scholar] [CrossRef] [PubMed]
- Cheng, H.; Shen, R.; Chen, Y.; Wan, Q.; Shi, T.; Wang, J.; Wan, Y.; Hong, Y.; Li, X. Estimating heavy metal concentrations in suburban soils with reflectance spectroscopy. Geoderma 2019, 336, 59–67. [Google Scholar] [CrossRef]
- Fu, P.J.; Yang, K.M.; Feng, F.S. Study on Heavy Metal in Soil Based on Spectral Second-Order Differential Gabor Transform. J. Indian Soc. Remote 2019, 47, 629–638. [Google Scholar] [CrossRef]
- Zhang, S.; Shen, Q.; Nie, C.; Huang, Y.; Wang, J.; Hu, Q.; Ding, X.; Zhou, Y.; Chen, Y. Hyperspectral inversion of heavy metal content in reclaimed soil from a mining wasteland based on different spectral transformation and modeling methods. Spectrochim. Acta A 2019, 211, 393–400. [Google Scholar] [CrossRef]
- Fang, S.; Yuan, L.E.; Qi, L. Retrieval of Chlorophyll Content Using Continuous Wavelet Analysis across a Range of Vegetation Species. Geomat. Inf. Sci. Wuhan Univ. 2015, 40, 296–302. [Google Scholar]
- Liang, D.; Yang, Q.; Huang, W.; Peng, D.; Song, X. Estimation of leaf area index based on wavelet transform and support vector machine regression in winter wheat. Infrared Laser Eng. 2015, 44, 335–340. [Google Scholar]
- Maruthi Sridhar, B.B.; Han, F.X.; Diehl, S.V.; Monts, D.L.; Su, Y. Spectral reflectance and leaf internal structure changes of barley plants due to phytoextraction of zinc and cadmium. Int. J. Remote Sens. 2007, 28, 1041–1054. [Google Scholar] [CrossRef]











Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Wang, M.; Yang, K.; Li, Y.; Li, Y.; Wu, B.; Han, Q. The New Hyperspectral Analysis Method for Distinguishing the Types of Heavy Metal Copper and Lead Pollution Elements. Int. J. Environ. Res. Public Health 2022, 19, 7755. https://doi.org/10.3390/ijerph19137755
Zhang J, Wang M, Yang K, Li Y, Li Y, Wu B, Han Q. The New Hyperspectral Analysis Method for Distinguishing the Types of Heavy Metal Copper and Lead Pollution Elements. International Journal of Environmental Research and Public Health. 2022; 19(13):7755. https://doi.org/10.3390/ijerph19137755
Chicago/Turabian StyleZhang, Jianhong, Min Wang, Keming Yang, Yanru Li, Yaxing Li, Bing Wu, and Qianqian Han. 2022. "The New Hyperspectral Analysis Method for Distinguishing the Types of Heavy Metal Copper and Lead Pollution Elements" International Journal of Environmental Research and Public Health 19, no. 13: 7755. https://doi.org/10.3390/ijerph19137755
APA StyleZhang, J., Wang, M., Yang, K., Li, Y., Li, Y., Wu, B., & Han, Q. (2022). The New Hyperspectral Analysis Method for Distinguishing the Types of Heavy Metal Copper and Lead Pollution Elements. International Journal of Environmental Research and Public Health, 19(13), 7755. https://doi.org/10.3390/ijerph19137755