
Precise Supervision of Enterprise Environmental Protection Behavior Based on Boolean Matrix Factorization under Low Carbon Background


Abstract
:
1. Introduction
- This paper proposes to predict the probability of each enterprise’s environmental protection behavior compliance before supervision, and based on this, the precise supervision of each enterprise is realized;
- An innovative improvement is achieved on the benchmark method MEBF. On the one hand, an improved stochastic gradient descent (SGD) method is proposed to replace the original optimization scheme. On the other hand, the model bias is introduced and integrated with the former, which further reduces the deviation degree after the algorithm iteration and improves the prediction accuracy;
- Based on the empirical analysis of the experimental results, a precise supervision strategy is proposed, and targeted preventive measures are given, which provides a certain theoretical and practical basis for enterprises to achieve a low-carbon and environmentally friendly economy.
2. Materials and Methods
2.1. Dataset Source
2.2. Proposed Method
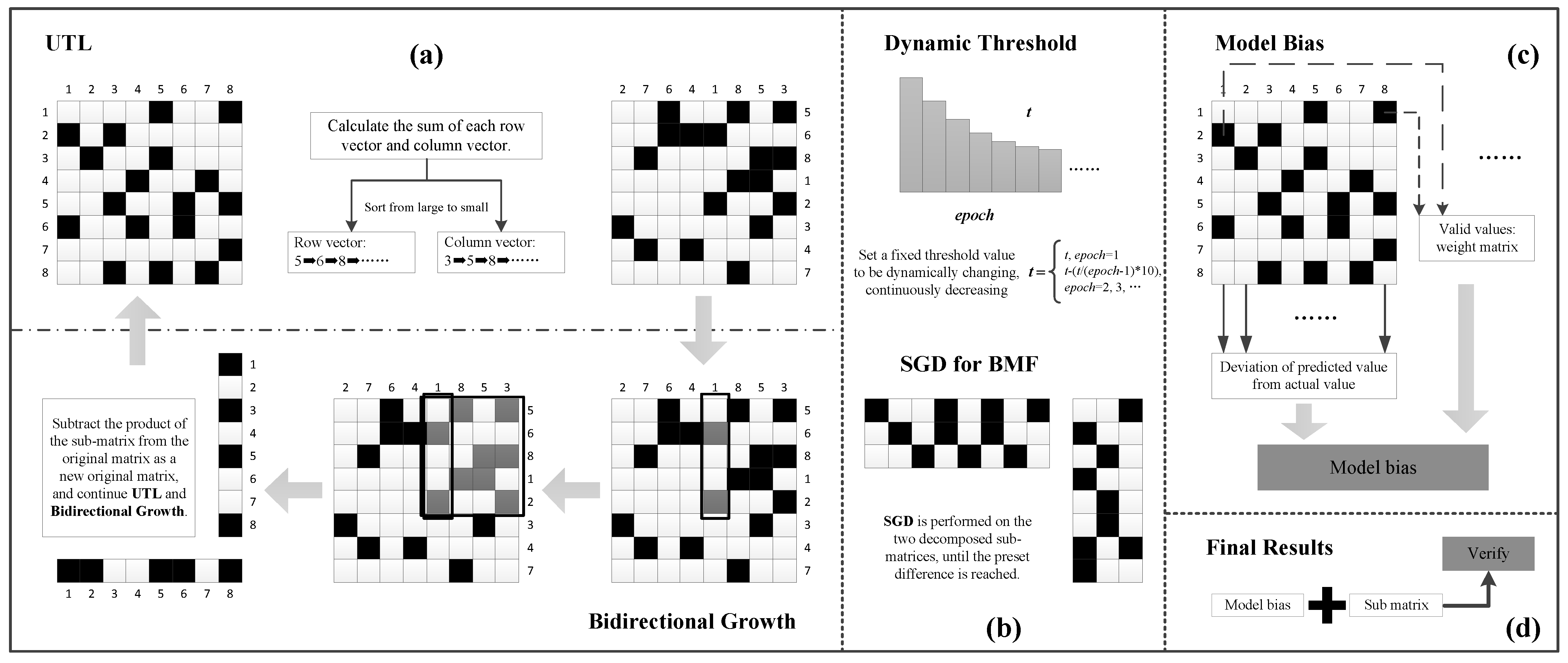
2.2.1. Median Expansion for Boolean Factorization
| Algorithm 1: MEBF | |
| 1: | |
| 2: | UTL matrix : |
| 3: | calculate the sum of each row vector |
| 4: | End for |
| 5: | calculate the sum of each column vector |
| 6: | End for |
| 7: | Sort by |
| 8: | Bidirectional Growth: |
| 9: | Start with column: |
| 10: | Find the middle column, expand the column (coverage ), generate submatrix |
| 11: | If the relative index is overwritten, the corresponding position element becomes 1 |
| 12: | |
| 13: | , cycle steps 10~12 |
| 14: | End if |
| 15: | Start with row: |
| 16: | Find the middle row, expand the row (coverage ), generate submatrix |
| 17: | If the relative index is overwritten, the corresponding position element becomes 1 |
| 18: | |
| 19: | , cycle steps 16~18 |
| 20: | End if |
| 21: | return |
2.2.2. Improvement Measures for MEBF
| Algorithm 2: SGD for BMF | |
| 1: | |
| 2: | do |
| 3: | do |
| 4: | |
| 5: | do |
| 6: | |
| 7: | do |
| 8: | |
| 9: | do |
| 10: | |
| 11: | end if |
| 12: | do |
| 13: | do |
| 14: | |
| 15: | do |
| 16: | |
| 17: | end if |
| 18: | |
2.2.3. Model Bias
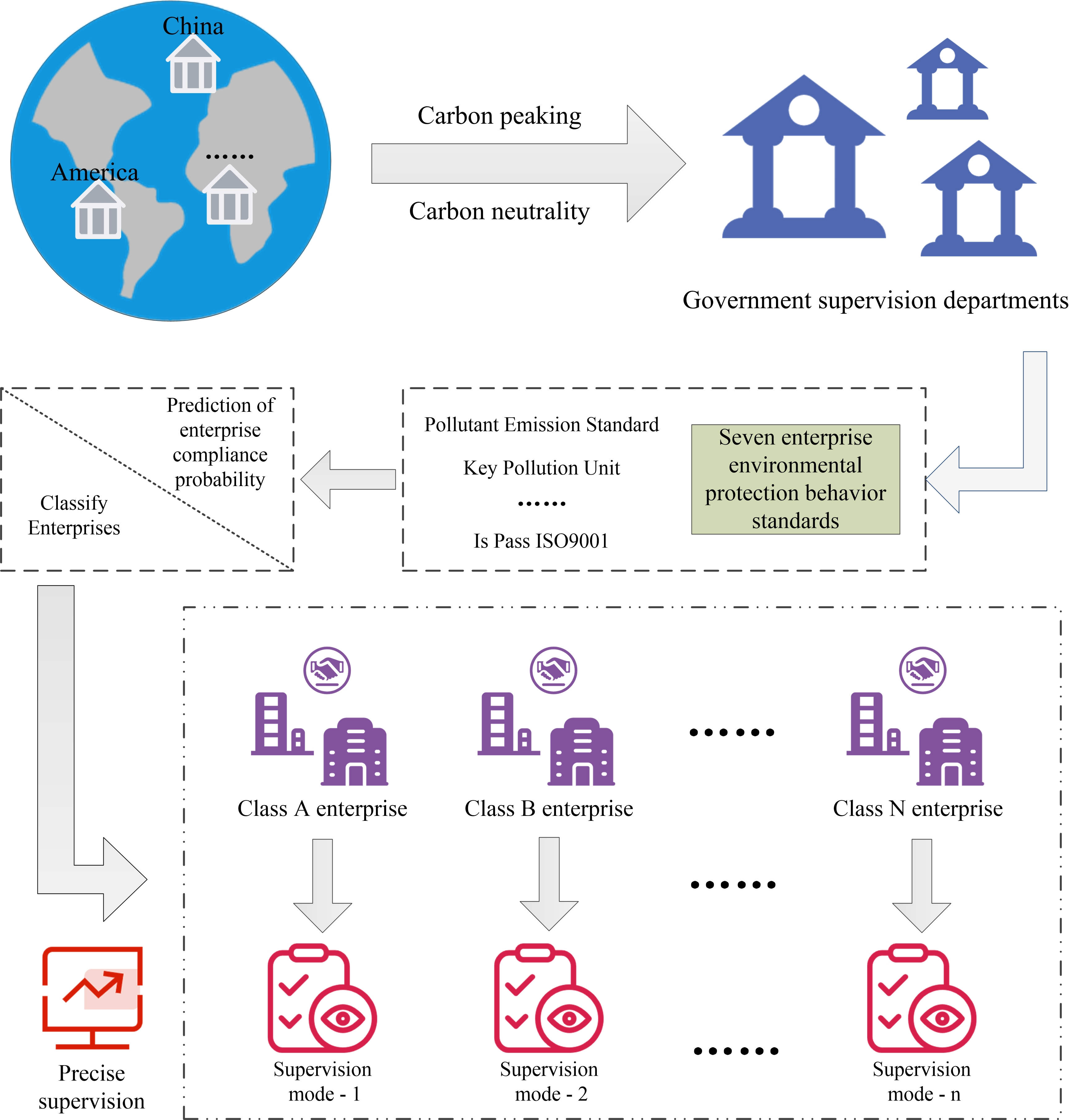
2.2.4. Enterprise Classification
2.3. Evaluating Metrics
3. Results
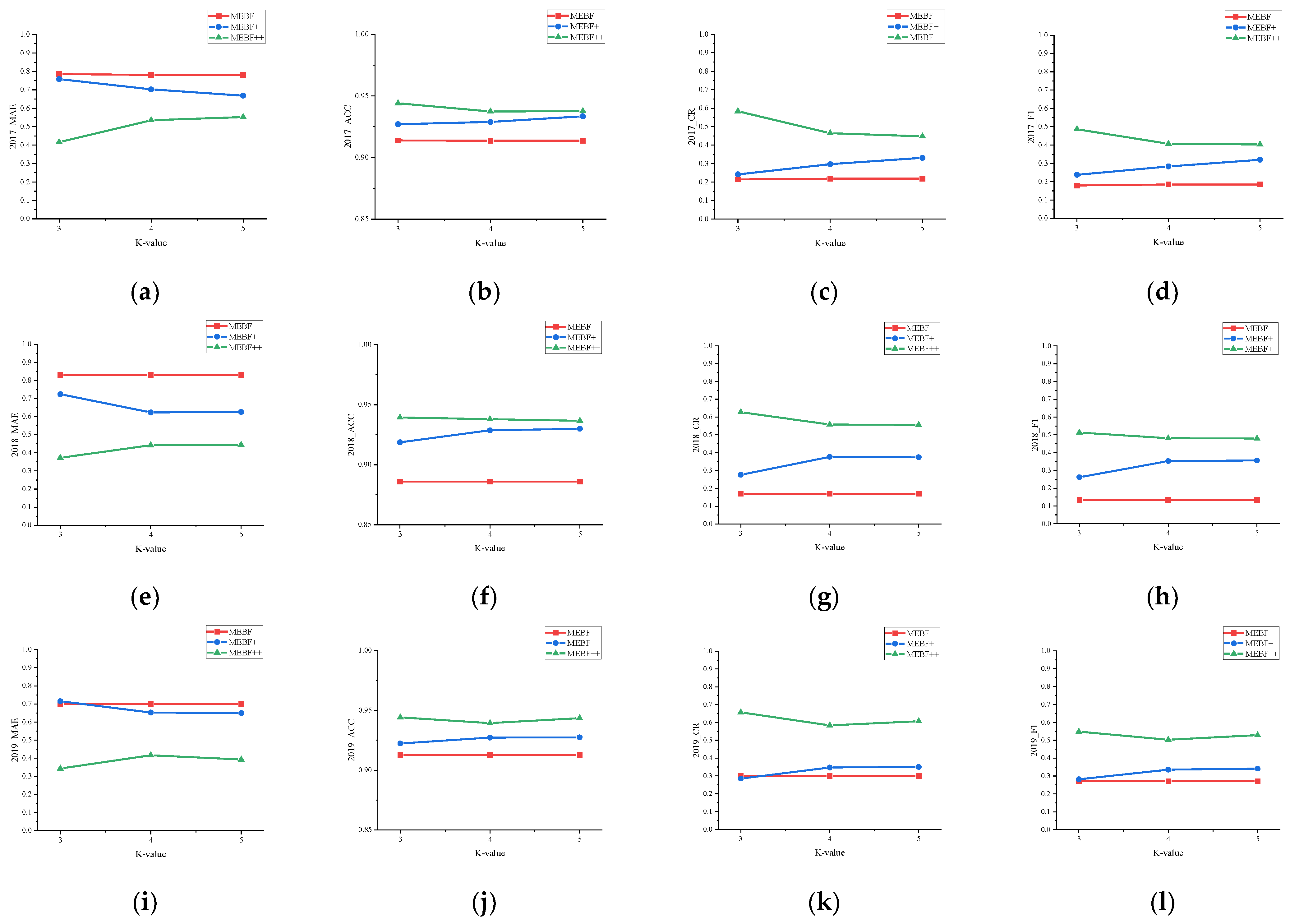
3.1. Superiority Analysis
3.2. Robustness Analysis
4. Discussion
4.1. Effect Analysis
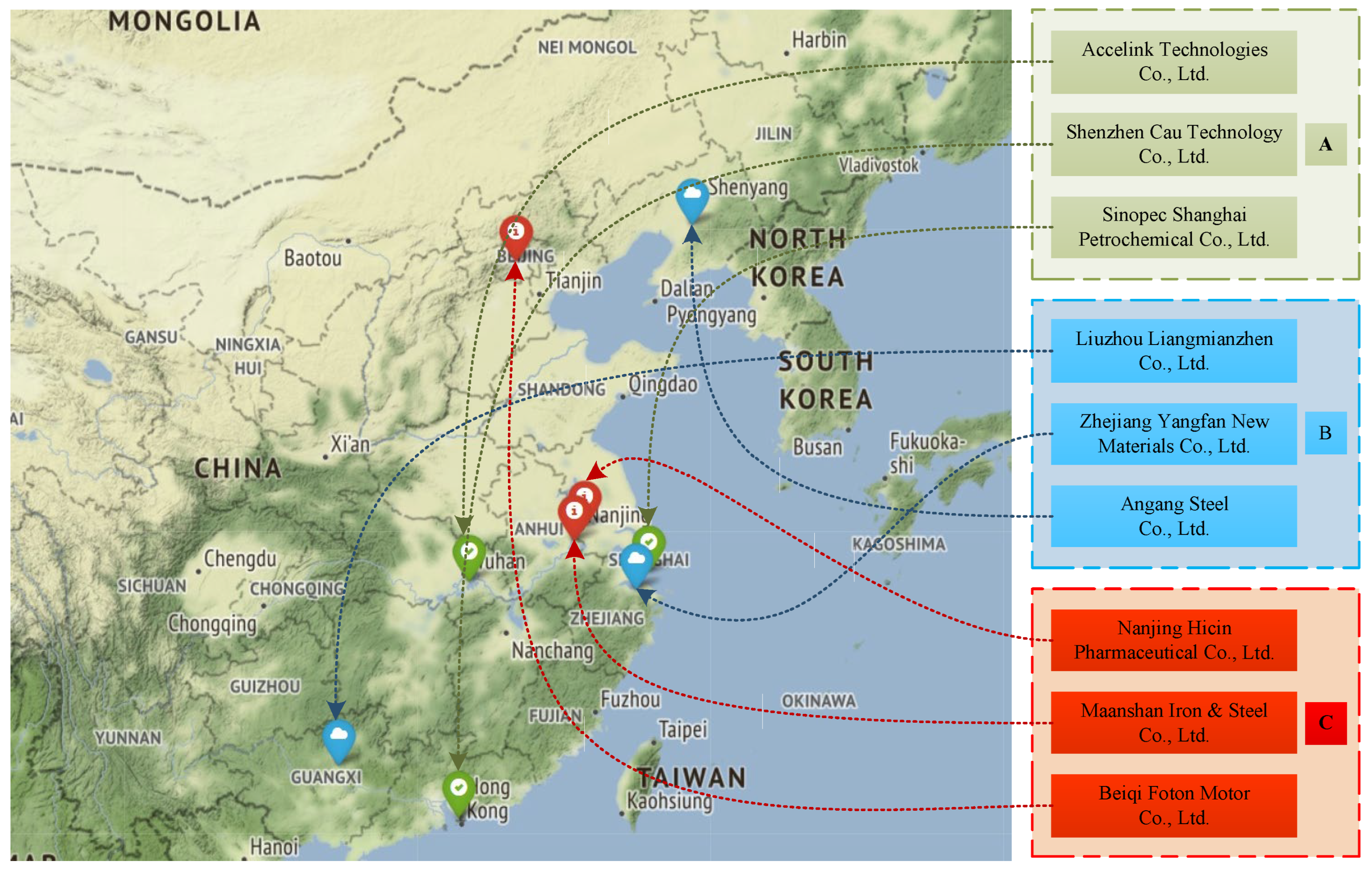
4.2. Precise Supervision
5. Conclusions and Policy Implications
- This paper proposes targeted improvements for the benchmark method MEBF and obtains MEBF+ and MEBF++. The superiority and robustness of the proposed method are verified based on multiple real datasets;
- Based on the analysis of the algorithm results, this paper calculates the score of each enterprise combined with the set of the weight of indicator score. Based on this, the classification threshold is determined, and the classification of the enterprises is completed;
- Comprehensively using the proposed algorithm and analysis results, this paper puts forward narrow precision supervision and broad precision supervision. Based on these strategies, relevant departments can implement a personalized supervision mode for different types of enterprises, realize classified supervision, and improve the supervision mechanism.
- For the narrow precision supervision mode, the emphasis is on the implementation of relevant supervision measures for enterprises according to the type of indicators. The seven indicators mentioned in this paper have been divided into four categories in the previous section. First of all, for key positive indicators, if the enterprise meets the standard, appropriate rewards should be given and the intensity of supervision can be reduced. If it does not meet the standard, the punishment should not be too severe, and more attention should be paid to the guidance of their behavior. Secondly, for key negative indicators, departments must strictly control and increase the punishment to avoid the existence of such behaviors of enterprises. Finally, for general positive indicators and general negative indicators, the department can implement corresponding policies based on the actual production situation of the enterprise and conduct partial fine-tuning of the types of indicators under routine supervision, so as to steadily achieve the goals that are in line with environmental protection policies;
- For the broad precision supervision mode, the emphasis is on the implementation of classified supervision according to the type of enterprise. First of all, according to the classification of enterprises by algorithm, for enterprises with low pollution levels and complying with environmental protection policies, on-site law enforcement inspections should be reduced and spiritual and material awards should be given to boost their social reputation. For enterprises with high environmental risks and weak awareness of abiding by the law, relevant departments should increase their efforts to investigate and deal with environmental violations, increase the frequency of on-site inspections, and urge enterprises to actively improve. For medium-performing enterprises, supervision departments should moderately adjust administrative penalties and reward policies and combine online monitoring with on-site inspections. In addition, the reduction and aggravation in the adjustment process of the supervision system should be moderate to ensure that specific measures are always determined based on the on-site investigation. Additionally, government departments should always reasonably combine law enforcement with law popularization, guide the orderly improvement within enterprises, and jointly achieve low-carbon development.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, W.; Zhang, M.; Wu, S.; Liu, F. A complex path model for low-carbon sustainable development of enterprise based on system dynamics. J. Clean. Prod. 2021, 321, 128934. [Google Scholar] [CrossRef]
- Fan, R.; Dong, L.; Yang, W.; Sun, J. Study on the optimal supervision strategy of government low-carbon subsidy and the corresponding efficiency and stability in the small-world network context. J. Clean. Prod. 2017, 168, 536–550. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, J.; Wan, Z.; Yu, M.; Shu, Y.; Tan, Z.; Liu, J. Challenges and countermeasures for international ship waste management: IMO, China, United States, and EU. Ocean. Coast. Manag. 2021, 213, 105836. [Google Scholar] [CrossRef]
- Liu, Y.; He, K.; Qin, F. Remote Sensing Big Data Analysis of the Lower Yellow River Ecological Environment Based on Internet of Things. J. Sens. 2021, 2021, 1059517. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, M.; Wang, G.; Zhao, L.; An, P. Effect of Environmental Regulation on High-quality Economic Development in China—An Empirical Analysis Based on Dynamic Spatial Durbin Model. Environ. Sci. Pollut. R. 2021, 28, 54661–54678. [Google Scholar] [CrossRef]
- Chen, X.; Chen, Z. Can China’s environmental regulations effectively reduce pollution emissions? Int. J. Environ. Res. Public Health 2021, 18, 4658. [Google Scholar] [CrossRef]
- Ministry of Ecology and Environment of China. Guiding Opinions on Coordinating the Control of Epidemics and Ecological and Environmental Protection for Economic and Social Development. 2020. Available online: http://www.gov.cn/zhengce/zhengceku/2020-03/05/content_5487478.htm (accessed on 5 March 2020).
- Zhang, C.; Yu, N.; Tan, D.; Yin, D.; Yin, X.; Randhir, T. Value creation mechanism through carbon asset for the sustainability of the automobile sector. J. Clean. Prod. 2021, 29, 1173–1189. [Google Scholar] [CrossRef]
- Li, T.; Xu, X.; Zhao, K.; Ma, C.; Guirao, J.; Chen, H. Low-carbon strategies in dual-channel supply chain under risk aversion. Math. Biosci. Eng. 2022, 19, 4765–4793. [Google Scholar] [CrossRef]
- Teng, M.; Zhao, M.; Han, C.; Liu, P. Research on mechanisms to incentivize corporate environmental responsibility based on a differential game approach. Environ. Sci. Pollut. R. 2022, 29, 31348–31362. [Google Scholar] [CrossRef]
- Cui, S. Enterprise Innovation, Executive Experience and Internationalization Strategy: Evidence from High-Carbon Industrial Enterprises Versus Low-Carbon Industrial Enterprises in China. Front. Energy. Res. 2022, 9, 821269. [Google Scholar] [CrossRef]
- Li, M.; Gao, X. Implementation of enterprises’ green technology innovation under market-based environmental regulation: An evolutionary game approach. J. Environ. Manag. 2022, 308, 114570. [Google Scholar] [CrossRef] [PubMed]
- Qu, X.; Sun, X. How to improve the function of government carbon tax in promoting enterprise carbon emission reduction: From the perspective of three-stage dynamic game. Environ. Sci. Pollut. R. 2022, 29, 31348–31362. [Google Scholar] [CrossRef] [PubMed]
- Shen, C.; Wei, M. An Evolutionary Game Model for Online Food Safety Governance Under Two Different Circumstances. IEEE. Access. 2020, 8, 207691–207704. [Google Scholar] [CrossRef]
- Liu, M.; Li, Y. Study on the effect of income perception on cleaner-production fraud. Environ. Sci. Pollut. R. 2022, 29, 44638–44652. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, B.; Fan, J.; Qiao, Q. The multi-player evolutionary game analysis for the protective development of ecotourism. Environ. Sci. Policy 2021, 126, 111–121. [Google Scholar] [CrossRef]
- Luo, M.; Fan, R.; Zhang, Y.; Zhu, C. Environmental Governance Cooperative Behavior among Enterprises with Reputation Effect Based on Complex Networks Evolutionary Game Model. Int. J. Environ. Res. Public Health 2020, 17, 1535. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Li, L. Spatial Heterogeneity of Government Regulation, Spatial Distance and Enterprise Carbon Information Disclosure: An Analysis Based on the Heavy Pollution Industry in China. Int. J. Environ. Res. Public Health 2019, 16, 4777. [Google Scholar] [CrossRef] [Green Version]
- Chang, K.; Wang, D.; Lu, Y.; Chang, W.; Ren, G.; Liu, L.; Zhou, X. Environmental regulation, promotion pressure of officials, and enterprise environmental protection investment. Front. Public Health 2021, 9, 724351. [Google Scholar] [CrossRef]
- Shen, L.; Chen, Y.; Fan, R.; Wang, Y. Government Supervision on Explosive Enterprises’ Immoral Behaviors in E-Commerce Enterprises: An Evolutionary Game Analysis. Complexity 2021, 2021, 6664544. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, G.; Cao, J.; Wu, A. Evolving strategies of e-commerce and express delivery enterprises with public supervision. Res. Transp. Econ. 2020, 80, 100810. [Google Scholar] [CrossRef]
- Weng, Z.; Luo, P. Supervision of the Default Risk of Online Car-Hailing Platform from an Evolutionary Game Perspective. Sustainability 2021, 13, 555. [Google Scholar] [CrossRef]
- Meng, T.; Li, Q.; Dong, Z.; Zhao, F. Research on the Risk of Social Stability of Enterprise Credit Supervision Mechanism Based on Big Data. J. Organ. End User Comput. 2022, 34, 289223. [Google Scholar] [CrossRef]
- Boutillier, S.; Ryckelynck, P. Sustainable-entrepreneurs: Quantifying opportunities and social networks, case study on sustainable entrepreneurs in a heavy industrial area. Int. J. Entrep. Small Bus. 2017, 31, 85–102. [Google Scholar] [CrossRef]
- China Stock Market & Accounting Research Database. Available online: http://cndata1.csmar.com/ (accessed on 23 March 2022).
- Wan, C.; Chang, W.; Zhao, T.; Li, M.; Cao, S.; Zhang, C. Fast and Efficient Boolean Matrix Factorization by Geometric Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7 February 2020. [Google Scholar] [CrossRef]
- Luo, Z.; Zhu, W.; Wu, W. Beyond Sub-Gaussian Noises: Sharp Concentration Analysis for Stochastic Gradient Descent. J. Mach. Learn. Res. 2022, 23, 1–22. [Google Scholar]
- Zhong, S.; Huang, L.; Wang, C.; Lai, J.; Xie, G.; Li, Y. A Model-Bias Matrix Factorization Approach for Course Score Prediction. Neural. Process. Lett. 2020. [Google Scholar] [CrossRef]
- Cui, Z.; Zhao, P.; Hu, Z.; Cai, X.; Zhang, W.; Chen, J. An improved matrix factorization-based model for many-objective optimization recommendation. Inf. Sci. 2021, 579, 1–14. [Google Scholar] [CrossRef]
- García-Magariño, I.; Medrano, C.; Delgado, J. Estimation of missing prices in real-estate market agent-based simulations with machine learning and dimensionality reduction methods. Neural. Process. Lett. 2020, 32, 2665–2682. [Google Scholar] [CrossRef]
- Guo, F.; Wang, Z.; Ji, S.; Lu, Q. Influential Nodes Identification in the Air Pollution Spatial Correlation Weighted Networks and Collaborative Governance: Taking China’s Three Urban Agglomerations as Examples. Int. J. Environ. Res. Public Health 2022, 19, 4461. [Google Scholar] [CrossRef]
- Zhang, N.; Zhang, X.; Yang, Y. The Behavior Mechanism of the Urban Joint Distribution Alliance under Government Supervision from the Perspective of Sustainable Development. Sustainability 2019, 11, 6232. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| End Date | Institution ID | KPU | PES | SEA | EVA | EPC | IPI-14001 | IPI-9001 |
|---|---|---|---|---|---|---|---|---|
| 31 December 2019 | 101881 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
| 10185 | 1 | 0 | 0 | 1 | 0 | 1 | 1 | |
| 106387 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | |
| 101731 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | |
| 101969 | 0 | 1 | 0 | 1 | 0 | 1 | 0 |
| Confusion Matrix | Predictive Value | ||
|---|---|---|---|
| Positive:1 | Negative: 0 | ||
| True value | Positive:1 | Ture Positive (TP) | Ture Negative (FN) |
| Negative: 0 | False Positive (FP) | False Negative (TN) | |
| Year | Method | MAE | ACC | CR | F1 |
|---|---|---|---|---|---|
| 2017 | MEBF | 0.781 | 0.914 | 0.219 | 0.185 |
| MEBF+ | 0.699 | 0.930 | 0.289 | 0.299 | |
| Improve | 10.51% | 1.72% | 24.22% | 38.13% | |
| MEBF++ | 0.509 | 0.939 | 0.491 | 0.424 | |
| Improve | 34.83% | 2.74% | 124.20% | 129.19% | |
| 2018 | MEBF | 0.831 | 0.886 | 0.134 | 0.169 |
| MEBF+ | 0.623 | 0.928 | 0.351 | 0.377 | |
| Improve | 25.03% | 4.74% | 161.94% | 123.08% | |
| MEBF++ | 0.442 | 0.938 | 0.481 | 0.558 | |
| Improve | 46.81% | 5.87% | 258.96% | 230.18% | |
| 2019 | MEBF | 0.700 | 0.913 | 0.271 | 0.300 |
| MEBF+ | 0.651 | 0.929 | 0.341 | 0.349 | |
| Improve | 7.00% | 1.75% | 25.83% | 16.33% | |
| MEBF++ | 0.425 | 0.941 | 0.505 | 0.575 | |
| Improve | 39.29% | 3.07% | 86.35% | 91.67% |
|
Weight Label | −1 | 0.5 | −0.5 | −0.5 | −0.5 | 1 | 1 | Total Score | |
|---|---|---|---|---|---|---|---|---|---|
| Institution Name | KPU | PES | SEA | EVA | EPC | IPI-14001 | IPI-9001 | ||
| Shenzhen Cau Technology Co., Ltd. | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1.5 | |
| Maanshan Iron and Steel Co., Ltd. | 1 | 1 | 0 | 1 | 0 | 0 | 0 | −1 | |
| Nanjing Hicin Pharmaceutical Co., Ltd. | 1 | 1 | 0 | 0 | 0 | 0 | 0 | −0.5 | |
| Beiqi Foton Motor Co., Ltd. | 1 | 1 | 0 | 1 | 0 | 0 | 0 | −1 | |
| Liuzhou Liangmianzhen Co., Ltd. | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0.5 | |
| Zhejiang Yangfan New Materials Co., Ltd. | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | |
| Sinopec Shanghai Petrochemical Co., Ltd. | 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | |
| Accelink Technologies Co., Ltd. | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 2.5 | |
| Angang Steel Co., Ltd. | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, W.; Guo, F. Precise Supervision of Enterprise Environmental Protection Behavior Based on Boolean Matrix Factorization under Low Carbon Background. Int. J. Environ. Res. Public Health 2022, 19, 7739. https://doi.org/10.3390/ijerph19137739
Zhou W, Guo F. Precise Supervision of Enterprise Environmental Protection Behavior Based on Boolean Matrix Factorization under Low Carbon Background. International Journal of Environmental Research and Public Health. 2022; 19(13):7739. https://doi.org/10.3390/ijerph19137739
Chicago/Turabian StyleZhou, Wei, and Feipeng Guo. 2022. "Precise Supervision of Enterprise Environmental Protection Behavior Based on Boolean Matrix Factorization under Low Carbon Background" International Journal of Environmental Research and Public Health 19, no. 13: 7739. https://doi.org/10.3390/ijerph19137739
APA StyleZhou, W., & Guo, F. (2022). Precise Supervision of Enterprise Environmental Protection Behavior Based on Boolean Matrix Factorization under Low Carbon Background. International Journal of Environmental Research and Public Health, 19(13), 7739. https://doi.org/10.3390/ijerph19137739