
The Use of the Exploratory Sequential Approach in Mixed-Method Research: A Case of Contextual Top Leadership Interventions in Construction H&S


Abstract
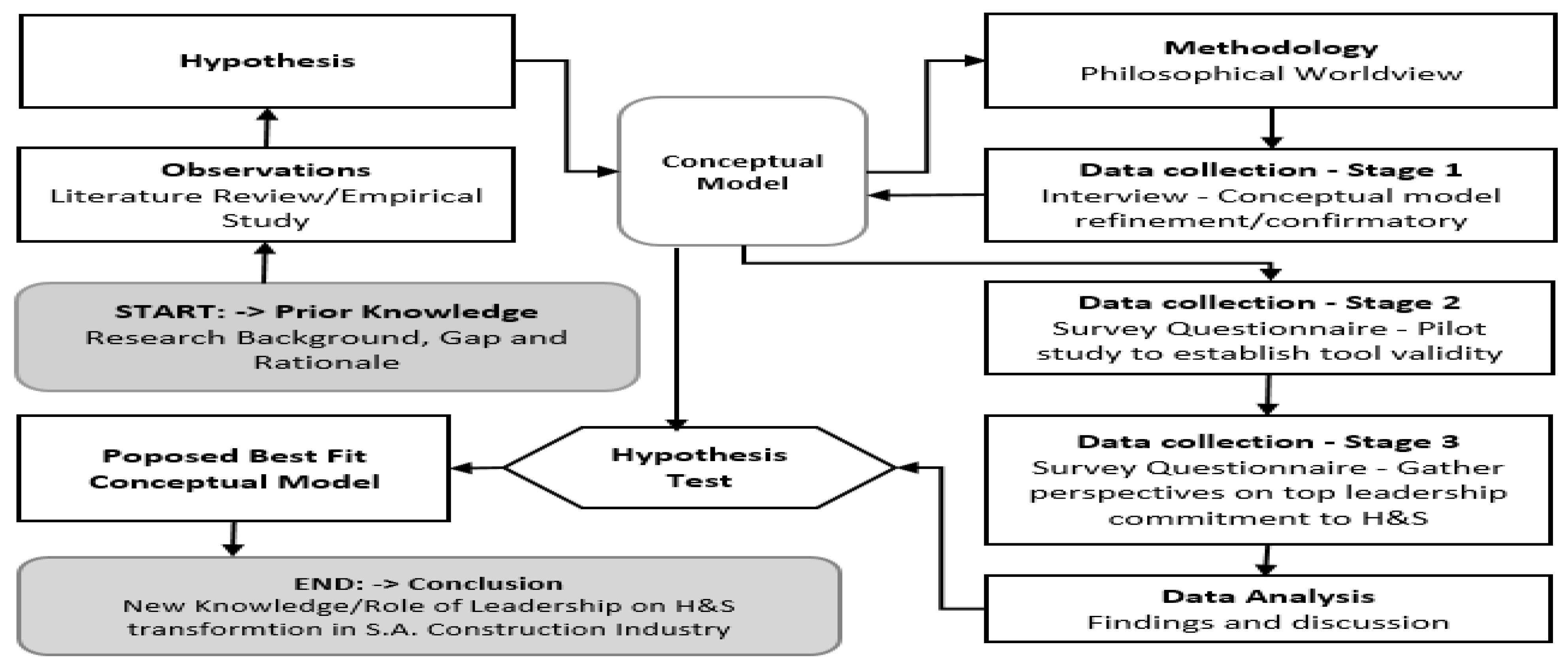
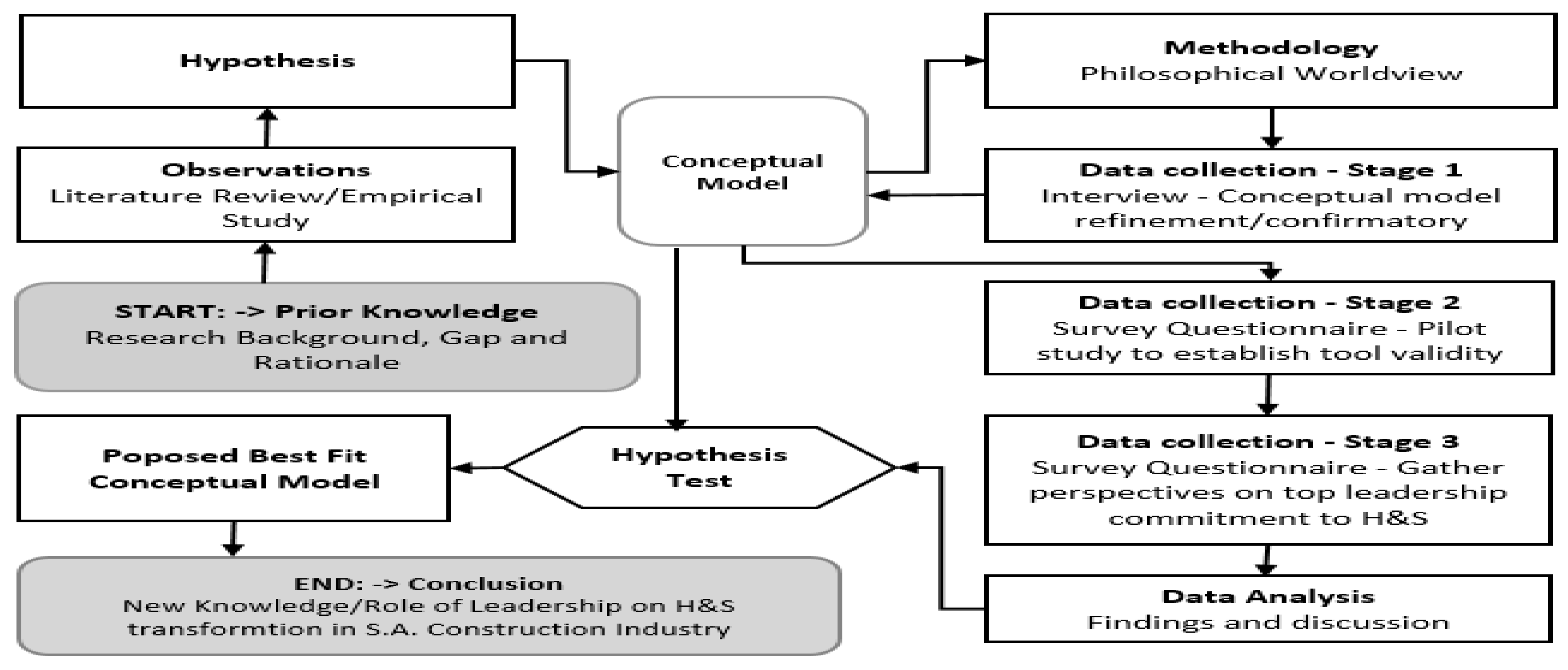
:1. Introduction
2. Theory
2.1. Establishing the Worldview
2.2. Epistemology
2.3. Research Design
2.4. Conceptual Typology
3. Methods
3.1. Data Collection Approaches
3.2. Population and Sampling of the QUAL Study
3.3. Population and Sampling of the QUAN Study
3.4. Interview Data Collection Procedure
3.5. Survey Data Collection Procedure
3.6. Ethical Considerations Regarding Data Collection
- Ethical intent to achieve autonomy—brief instructions were provided in the interview and survey questionnaire forms to ensure that the respondents were as autonomous as possible and that dependence on the interviewer was limited.
- Ethical intent to achieve beneficence—beneficence is how the study will benefit. For this paper, this was demonstrated by the novelty of the mixed method presented and how this method led to the fulfilment of the research objectives.
- Ethical intent to achieve non-maleficence—To ensure just and unbiased participation, demographical information about gender, race, political affiliation, religious beliefs, ethnicity, family orientation, marital status and health conditions of each respondent was not considered or collected. Additionally, ranges of experience rather than discreet numbers were used to provide uniformity among the respondents.
- Ethical intent to achieve justice—The risks for participants were covered by a disclaimer and the voluntary participation of the participants, as well as their anonymity. All human rights defined by state laws to institutional laws were observed. The selection process applied for the respondents ensured that the participation of top organisational leaders was inclusive of all groups, without consideration of any form of segregation or target (blind process).
3.7. Validity of the Collected Data
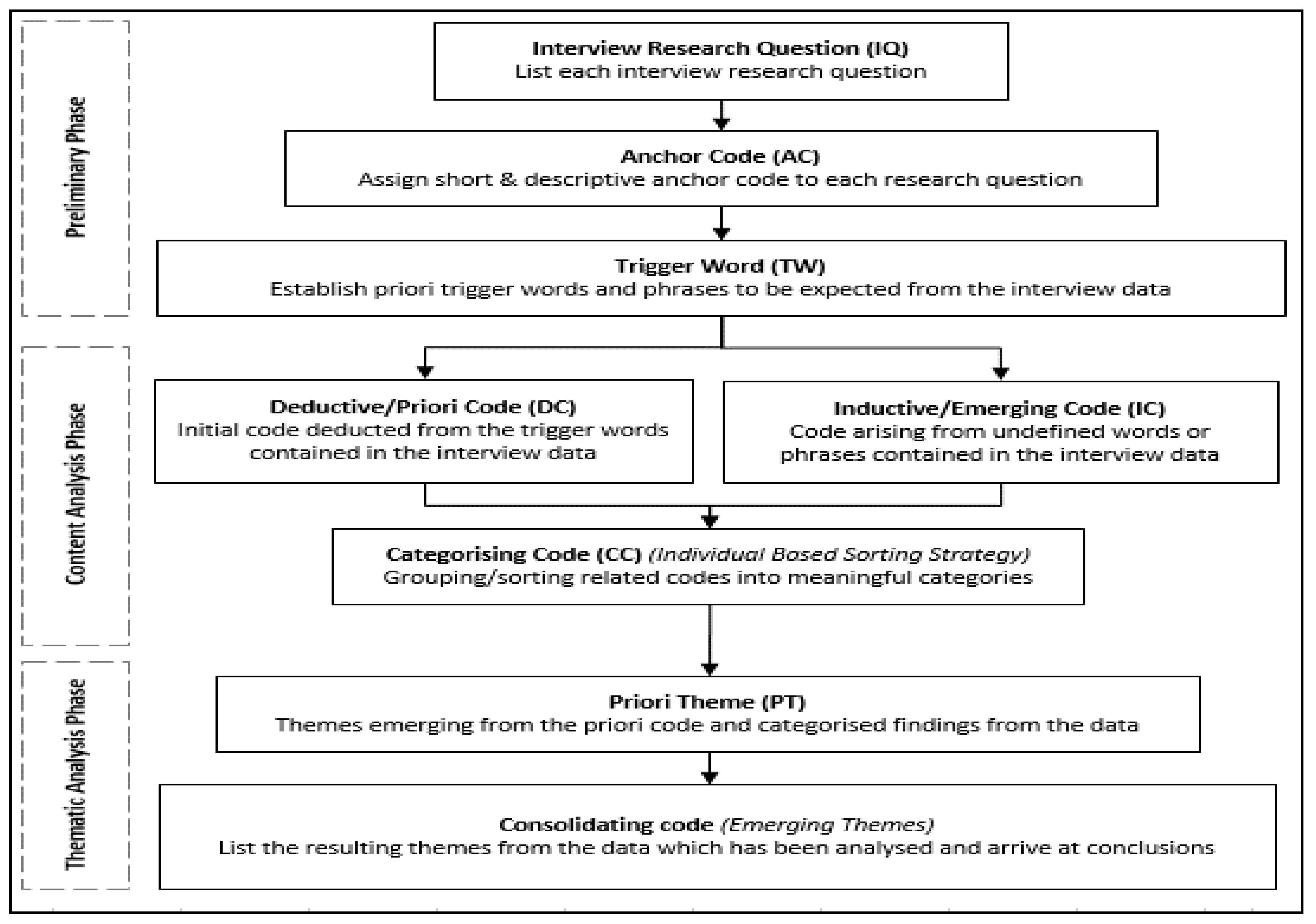
3.8. Reliability of the Collected QUAL Data

{kind=link}
{kind=link}
| Stage | Description | Specifics for This Study |
|---|---|---|
| 1 | Transcription of interview data | The process used to record the interview data during the interviewing phase is interview questionnaires (response spaces). |
| 2 | Familiarisation with the interview transcripts | In this case, understanding the transcripts and typing the information into M.S. Excel for each transcript. |
| 3 | Coding of the interview data | In this case, the coding process followed the process defined by Adu (2019) and is thoroughly described. |
| 4 | Development of a framework for analysis | Intercoder reliability steps as described in the methods and processes, which follow Marying (2014) and Adu (2019). |
| 5 | Application of the framework of the analysis | In this case, an understanding of the tool and its application was developed and applied. The tool of choice was Atlas.ti®. |
| 6 | Data insertion into clusters in the framework | The process for preparing the data for import into Atlas.ti® and then starting the process of coding within this framework. |
| 7 | Interpretation of the interview data | The final output, inclusive of the finalisation of the intercoder, revisits and inclusion of inductive codes that emerged throughout the process. |
- (a)
- Percent agreement
- (b)
- Holsti’s Method
- (c)
- Scott’s Pi (π)
- (d)
- Cohen’s Kappa (κ)
- (e)
- Krippendorff’s Alpha (α)
3.9. Reliability of the Collected QUAN Data
- (a)
- Cronbach’s alpha
- (b)
- Determination of the QUAN data reliability tool
3.10. Interview Data Processing Approach
3.11. Survey Data Processing Approach
- (a)
- Model fit criterion
- (b)
- Further analysis
4. Results
4.1. The Overall Data Collected
4.2. Validity of the QUAL Results
4.3. Coding of the Collected Data
4.4. Results from the Reliability Tests
4.5. Results from the Statistical Analysis
- Spearman rank correlation results: Rho LC to CF = 0.421; ST = 0.101; LC = 1.000; CC = 0.239; NC = 0.317; CO = −0.184
- Ordinal logistic regression: Pseudo R-square (Nagelkerke) index = 0.593; Deviance Sig = 1.000; Chi-square Sig = 0.000
4.6. Hypothesis Testing
4.7. Descriptive Statistics
5. Findings
6. Discussion
6.1. Convergence of the Applied Research Tool
6.2. The Impact of the Tool on Research
6.3. Future Study Focus
6.4. Contribution Made by This Study
7. Conclusions
- In the QUAL phase, the intercoder analysis was marked by a multi-tool approach augmented by a web-based platform. This demonstrated a robust method for approaching the reliability of such data in which the harmonious agreement of various tools provides a higher level of trust in the chosen approach.
- In the QUAN analysis phase, the application of the test of distribution was appropriately placed to enable the selection of the reliability tool early in the analysis process, ensuring correctness in selecting the reliability test tool.
- A significant point of departure from a multitude of methods in the analysis of QUAN data was the qualification of the use of Cronbach’s alpha on the dataset after the distribution test to ensure that its merits for testing such datasets were established and justified.
- The QUAL data coding approach summarised in Figure 2 is novel and anchored on established approaches arising from extensive literature on coding.
- The consistent application of different tools to the model, comprised of a non-parametric dataset, provided a significant advantage in applying such tools in datasets that are similar to this one in research. This further validated the propositions by Ezie [68] on the approaches to be adopted in such research.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Edmonds, W.A.; Kennedy, T.D. Explanatory-Sequential Approach. In An Applied Guide to Research Designs: Quantitative, Qualitative, and Mixed Methods; Edmonds, W.A., Kennedy, T.D., Eds.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2017; pp. 196–200. [Google Scholar]
- Cooper, D.R.; Schindler, P.S. Business Research Methods, 12th ed.; McGraw-Hill/Irwin: New York, NY, USA, 2013. [Google Scholar]
- Cresswell, J.W. Research Design: Qualitative, Quantitative and Mixed Methods Approaches, 5th ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Palm, W.J., III. System Dynamics, 4th ed.; McGraw-Hill: New York, NY, USA, 2020. [Google Scholar]
- Bairagi, V.; Munot, M.V. Research Methodology: A Practical Scientific Approach, 1st ed.; CRC Press: New York, NY, USA, 2019. [Google Scholar]
- Heesen, R.; Bright, L.K.; Zucker, A. Vindicating methodological triangulation. Synthese 2019, 196, 3067–3081. [Google Scholar] [CrossRef] [Green Version]
- Flick, U. An Introduction to Qualitative Research, 6th ed.; SAGE Publications, Inc.: Berlin, Germany, 2018. [Google Scholar]
- Breitbart, M.M. Participatory research methods. In Key Methods in Geography; Clifford, N., French, S., Valentine, G., Eds.; SAGE Publications, Inc.: London, UK, 2010; pp. 141–156. [Google Scholar]
- Bajpai, N. Business Research Methods; Pearson Education: New Delhi, India, 2016. [Google Scholar]
- Symonds, J.E.; Gorard, S. Death of mixed methods? Or the rebirth of research as a craft. Eval. Res. Educ. 2010, 23, 121–136. [Google Scholar] [CrossRef] [Green Version]
- Neuman, W.L. Social Research Methods, 7th ed.; Pearson Education: Harlow, UK, 2014. [Google Scholar]
- Crotty, M. The Foundations of Social Research—Meaning and Perspective in the Research Process; SAGE Publications, Inc.: London, UK, 1998. [Google Scholar]
- Maliwatu, E. ISO 14001:2015; Understanding Context with Related Risks and Opportunities—A South African Construction Industry Perspective. North-West University Library: Potchefstroom, South Africa, 2018. [Google Scholar]
- Clarke, J.R. Research Models and Methodologies; University of Wollongong: Wollongong, NSW, Australia, 2005. [Google Scholar]
- Askarzai, W.; Unhelkar, B. Research Methodologies: An Extensive Overview. Int. J. Sci. Res. Methodol. 2017, 6, 21–42. [Google Scholar]
- Dumrak, J.; Mostafa, S.; Kamardeen, I.; Rameezdeen, R. Factors associated with the severity of construction accidents: The Case of South Australia. Australas. J. Constr. Econ. Build. 2013, 13, 32–49. [Google Scholar] [CrossRef] [Green Version]
- Marle, F.; Vidal, L. Managing Complex, High-Risk Projects: A Guide to Basic and Advanced Project Management; Springer: London, UK, 2016. [Google Scholar]
- Pepper, S.C. World Hypothesis: A Study in Evidence; University of California Press: Berkeley, CA, USA, 1942. [Google Scholar]
- Zikmund, W.G.; Babin, B.J.; Carr, J.C.; Griffin, M. Business Research Methods, 9th ed.; Cengage Learning: Mason, OH, USA, 2013. [Google Scholar]
- Ichikawa, J.J. The Routledge Handbook of Epistemic Contextualism; Routledge: London, UK, 2017. [Google Scholar]
- Morris, E. Contextualism: The world view of behavior analysis. J. Exp. Child Psychol. 1988, 46, 289–323. [Google Scholar] [CrossRef]
- Kothari, C.R.; Gaurav, G. Research Methodology: Methods & Techniques, 3rd ed.; New Age International Publishers: New Delhi, India, 2015. [Google Scholar]
- Deb, D.; Dey, R.; Balas, V.E. Engineering Research Methodology: A Practical Insight for Researchers, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Lavrakas, P.L.; Traugott, M.W.; Kennedy, C.; Holbrook, A.L.; de Leeuw, E.D.; West, B.T. Experimental Methods in Survey Research: Techniques That Combine Random Sampling with Random Assignment, 1st ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019. [Google Scholar]
- Elangovan, N.; Rajendran, R. Conceptual Model: A Framework for Institutionalising the Vigor in Business Research; Laser Park Publishing House: New Delhi, India, 2015. [Google Scholar]
- Gogo, S.; Musonda, I. Leading safety culture from the top: A typology for top leadership safety commitment. In Proceedings of the Joint CIB W099 & W123 Annual International Conference 2021: Good Health, Changes & Innovations for Improved Wellbeing in Construction, Glasgow, UK, 9–10 September 2021; pp. 186–193. [Google Scholar]
- Babbie, E. The Practice of Social Research, 14th ed.; Cengage Learning: Boston, MA, USA, 2015. [Google Scholar]
- Patten, M.L.; Newhart, M. Understanding Research Methods: An Overview of the Essentials, 10th ed.; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Barnsbee, L.; Barnett, A.G.; Halton, K.; Nghiem, S. Cost-effectiveness. In Mechanical Circulatory and Respiratory Support; Gregory, S.D., Stevens, M.C., Fraser, J.F., Eds.; Academic Press: Cambridge, MA, USA, 2018; pp. 749–772. [Google Scholar]
- Brisebois, M.; Johnstone, C. System and Method for Managing and Identifying Subject Matter Experts. U.S. Patent 9,317,574, 19 April 2016. [Google Scholar]
- Guest, G.; Bunce, A.; Johnson, L. How many interviews are enough?: An experiment with data saturation and variability. Field Methods 2006, 18, 59–82. [Google Scholar] [CrossRef]
- Galvin, R. How many interviews are enough? Do qualitative interviews in building energy consumption research produce reliable knowledge? J. Build. Eng. 2015, 1, 2–12. [Google Scholar] [CrossRef]
- Rouse, M.J.; Daellenbach, U.S. Rethinking research methods for the resource-based perspective: Isolating sources of sustainable competitive advantage. Strategy Manag. J. 2010, 20, 487–494. [Google Scholar] [CrossRef]
- Bischoping, K. Review of Social Research Methods: Qualitative and Quantitative Approaches, 5th ed.; SAGE Publications, Inc.: London, UK, 2009. [Google Scholar]
- Arksey, H.; Knight, P.T. Interviewing for Social Scientists: An Introductory Resource with Examples; SAGE Publications, Ltd.: London, UK, 1999. [Google Scholar]
- Whiting, L.S. Semi-structured interviews: Guidance for novice researchers. Nurs. Stand. 2008, 22, 35–40. [Google Scholar] [CrossRef]
- Scheele, B.; Groeben, N. Dialog-Konsens-Methoden zur Rekonstruktion Subjektiver Theorien [Dialogue Consensus Methods for the Reconstruction of Subjective Theories]; Francke: Tübingen, Germany, 1988. [Google Scholar]
- Graneheim, U.H.; Lundman, B. Qualitative content analysis in nursing research: Concepts, procedures and measures to achieve trustworthiness. Nurse Educ. Today 2004, 24, 105–112. [Google Scholar] [CrossRef]
- Kim, H.; Sefcik, J.S.; Bradway, C. Characteristics of Qualitative Descriptive Studies: A Systematic Review. Res. Nurs. Health 2017, 40, 23–42. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Van De Walle, D. Development and validation of a work domain goal orientation instrument. Educ. Psychol. Meas. 1997, 57, 995–1015. [Google Scholar] [CrossRef]
- Hayes, A.F.; Krippendorff, K. Answering the call for a standard reliability measure for coding data. Commun. Methods Meas. 2007, 1, 77–89. [Google Scholar] [CrossRef]
- Hay, I. Ethical practice in geographical research. In Key Methods in Geography; Clifford, N., French, S., Valentine, G., Eds.; SAGE Publications, Inc.: London, UK, 2010; pp. 35–48. [Google Scholar]
- Miller, D.C.; Salkind, N.J. Handbook of Research Design and Social Measurement, 6th ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2002. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology, 4th ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Strauss, A.; Corbin, J. Basics of Qualitative Research: Techniques and Procedures for Developing Grounded Theory, 2nd ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 1998. [Google Scholar]
- Sarker, S.; Lau, F.; Sahay, S. Using an adapted Grounded Theory approach for inductive theory building about virtual team development. Data Base Adv. Inf. Syst. 2001, 31, 38–56. [Google Scholar] [CrossRef]
- Saunders, M.; Lewis, P.; Thornhill, A. Research Methods for Business Students, 8th ed.; Pearson Education: Harlow, UK, 2019. [Google Scholar]
- Hayashi, P.J.; Abib, G.; Hoppen, N. Validity in Qualitative Research: A Processual Approach. Qual. Rep. 2019, 24, 98–112. [Google Scholar] [CrossRef]
- Adu, P. A Step-by-Step Guide to Qualitative Data Coding; Routledge: London, UK, 2019. [Google Scholar]
- Gale, N.K.; Heath, G.; Cameron, E.; Rashid, S.; Redwood, S. Using the framework method for analysing qualitative data in multi-disciplinary health research. BMC Med. Res. Methodol. 2013, 13, 117. [Google Scholar] [CrossRef] [Green Version]
- Freelon, D.G. ReCal: Intercoder Reliability Calculation as a Web Service. Int. J. Internet Sci. 2010, 5, 20–33. [Google Scholar]
- Neuendorf, K.A. The Content Analysis Guidebook, 2nd ed.; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2012. [Google Scholar]
- Mayring, P. Qualitative Content Analysis: Theoretical Foundation, Basic Procedures and Software Solution; SSOAR: Klagenfurt, Austria, 2014. [Google Scholar]
- Everitt, B.S.; Skrondal, A. The Cambridge Dictionary of Statistics, 4th ed.; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Krippendorff, K. Computing Krippendorff’s Alpha-Reliability; University of Pennsylvania: Philadelphia, PA, USA, 2011. [Google Scholar]
- Bird, T.J.; Bates, A.E.; Lefcheck, J.S.; Hill, N.A.; Thomson, R.J.; Edgar, G.J.; Stuart-Smith, R.D.; Wotherspoon, S.; Krkosek, M.; Stuart-Smith, J.F.; et al. Statistical solutions for error and bias in global citizen science datasets. Biol. Conserv. 2014, 173, 144–154. [Google Scholar] [CrossRef] [Green Version]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Graham, M.; Milanowski, A.; Miller, J. Measuring and Promoting Inter-Rater Agreement of Teacher and Principal Performance Ratings; Westat: Rockville, MD, USA, 2012. [Google Scholar]
- Schreier, M. Qualitative Content Analysis in Practice; SAGE Publications, Ltd.: London, UK, 2012. [Google Scholar]
- Wang, W. A Content Analysis of Reliability in Advertising Content Analysis Studies; East Tennessee State University: Johnson City, TN, USA, 2011. [Google Scholar]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Sim, J.; Wright, C.C. The Kappa Statistic in Reliability Studies: Use, Interpretation, and Sample Size Requirements. Phys. Ther. 2005, 85, 257–268. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mukherjee, S.P.; Sinha, B.K.; Chattopadhyay, A.K. Statistical Methods in Social Science Research, 1st ed.; Springer: Singapore, 2018. [Google Scholar]
- Hoyt, W.T.; Melby, J.N. Dependability of measurement in counselling psychology: An introduction to generalizability theory. Couns. Psychol. 1999, 27, 325–352. [Google Scholar] [CrossRef]
- Heale, R.; Twycross, A. Validity and reliability in quantitative studies. Evid. Based Nurs. 2015, 18, 66–67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goforth, C. Using and Interpreting Cronbach’s Alpha; University of Virginia Library: Charlottesville, VA, USA, 2015. [Google Scholar]
- Louangrath, P. Reliability and Validity of Survey Scales. Int. J. Res. Methodol. Soc. Sci. 2018, 4, 50–62. [Google Scholar]
- Ezie, O. How to Analyse and Interpret LIKERT-SCALE Questionnaire Using SPSS; Obezip Universal Statisticals: Abuja, Nigeria, 2018. [Google Scholar]
- Razali, N.M.; Wah, Y.B. Power comparisons of Shapiro-Wilk, Kolmogorov-Smirnov, Lilliefors and Anderson-Darling tests. J. Stat. Model. Anal. 2011, 2, 21–33. [Google Scholar]
- Erlingsson, C.; Brysiewicz, P. A hands-on guide to doing content analysis. Afr. J. Emerg. Med. 2017, 7, 93–99. [Google Scholar] [CrossRef]
- Cho, G.; Hwang, H.; Sarstedt, M.; Ringle, C. Cutoff criteria for overall model fit indexes in generalised structured component analysis. J. Mark. Anal. 2020, 8, 189–202. [Google Scholar] [CrossRef]
- Yin, R.K. Analytic Generalization. In Encyclopedia of Case Study Research; Mills, A.J., Eurepos, G., Wiebe, E., Eds.; SAGE Publications, Inc.: Los Angeles, CA, USA, 2009; pp. 20–22. [Google Scholar]
- Popham, W.J. All About Assessment/A Misunderstood Grail. Educ. Leadersh. 2008, 66, 82–83. [Google Scholar]
- Yin, R.K. Case Study Research and Applications, 6th ed.; SAGE Publications, Inc.: Los Angeles, CA, USA, 2018. [Google Scholar]
| Functional Capacity Measure (Variables) | Functional Rules of Engagement |
|---|---|
| Leadership type/style | Leadership type/style influences contextual H&S competence training |
| Contextual H&S competence | Contextual H&S competence training alters Top leadership commitment |
| Top leadership commitment | Contextual H&S competence varies with Top leadership commitment |
| National and industry context/setting | National and industry context/setting influences Top leadership commitment |
| Main (Transformation) element | Critical competency elements resulting from Top leadership commitment alters the Organisational Culture and H&S Culture |
| Virtuous circle (reinforcement element) | Contextual H&S competence training varies with the H&S outcomes resulting from the H&S Culture |
| Probing Technique | Description of the Technique |
|---|---|
| Baiting | The researcher indicates that they are informed of specific facts, encouraging the respondent to elaborate more. |
| Echo | The researcher reinforces the respondent’s argument and helps them effectively enhance it. |
| Leading | The researcher raises a query, asking the respondent to justify their logic. |
| Long question | The researcher requests a fairly lengthy query, which implies that they seek a comprehensive explanation. |
| Silent | The researcher stays still, encouraging the respondent to speak their thoughts aloud. |
| ‘Tell me more.’ | The researcher specifically requests the respondent, despite using repetition, to elaborate on a specific topic or question. |
| Verbal agreement | The researcher shows curiosity in the viewpoints of the respondent through words like ‘uhhuh’ or ‘yeah, all right.’ |
| Stage | Description | Specifics for This Study |
|---|---|---|
| 1 | <0.00 | Poor agreement |
| 2 | 0.00–0.20 | Slight agreement |
| 3 | 0.21–0.40 | Fair agreement |
| 4 | 0.41–0.60 | Moderate agreement |
| 5 | 0.61–0.80 | Substantial agreement |
| 6 | 0.81–1.00 | Almost perfect agreement |
| Data Distribution | Normally Distributed Likert-Scale Data | Not-Normally Distributed Likert-Scale Data | |
|---|---|---|---|
| 1 | Method of analysis | Parametric method | Non-parametric method |
| 2 | Reliability tool | Cronbach’s alpha | Generalization |
| 3 | Stability tool | Linear regression | Ordinal logistic regression |
| 4 | Validity tool | Pearson correlation | Spearman rank correlation |
| No | Demographic Item | Interview Study | Survey Study |
|---|---|---|---|
| 1 | Contractor CIDB Grade | 1 × 9 Grades | CIDB grade 9 = 23; 8 = 24; 7 = 20; 6 = 18; 5 = 23; 4 = 17; 3 = 22; 2 = 18; 1 = 17 |
| 2 | Position in company | 3 × CEO; 5 × Executive Director; 1 × Site manager | 20 × CEO; 24 × Executive Director; 34 × Site Director; 42 × Site manager; 29 × Project/GM; 33 × Asst Construction Manager |
| 3 | Experience | 3 × over 10 years; 3 × 6-10 years; 2 × 2–5 years; 1 × less than 1 year. | 84 × over 10 years; 73 × 6–10 years; 22 × 2–5 years; 3 × less than 1 year. |
| 4 | Education | 4 × Diploma; 2 × Postgrad Degree; 2 × Bachelors; 1 × Other (Cert) | 63 × Diploma; 61 × Postgrad Degree; 50 × Bachelors; 7 × Other (Cert); 1 × Matric |
| 5 | Discipline of education and types of projects | 3 × Engineering; 3 × Construction; 2 × Other (H.R./Commerce); 1 × Science | 103 × Public Infrastructure dev.; 37 × Property dev.; 22 × Private property dev.; 16 × Mining Infrastructure dev.; 4 × Other |
| No | Percentage Agreement | Scott’s Pi | Cohen’s Kappa | Krippendorff’s Alpha (Nominal) | n Agreements | n Disagreements |
|---|---|---|---|---|---|---|
| Variable 1 (cols 1 and 2) | 91.9% | 0.725 | 0.725 | 0.726 | 79 | 7 |
| Variable 2 (cols 3 and 4) | 91.9% | 0.738 | 0.738 | 0.739 | 79 | 7 |
| Variable 3 (cols 5 and 6) | 91.9% | 0.738 | 0.738 | 0.739 | 79 | 7 |
| Variable 4 (cols 7 and 8) | 91.9% | 0.738 | 0.738 | 0.739 | 79 | 7 |
| Variable 5 (cols 9 and 10) | 91.9% | 0.725 | 0.725 | 0.726 | 79 | 7 |
| Variable 6 (cols 11 and 12) | 91.9% | 0.725 | 0.725 | 0.726 | 79 | 7 |
| Variable 7 (cols 13 and 14) | 90.7% | 0.707 | 0.707 | 0.708 | 78 | 8 |
| Variable 8 (cols 15 and 16) | 90.7% | 0.707 | 0.707 | 0.708 | 78 | 8 |
| Variable 9 (cols 17 and 18) | 91.9% | 0.725 | 0.725 | 0.726 | 79 | 7 |
| Average | 92% | 0.73 | 0.73 | 0.73 | 79 | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gogo, S.; Musonda, I. The Use of the Exploratory Sequential Approach in Mixed-Method Research: A Case of Contextual Top Leadership Interventions in Construction H&S. Int. J. Environ. Res. Public Health 2022, 19, 7276. https://doi.org/10.3390/ijerph19127276
Gogo S, Musonda I. The Use of the Exploratory Sequential Approach in Mixed-Method Research: A Case of Contextual Top Leadership Interventions in Construction H&S. International Journal of Environmental Research and Public Health. 2022; 19(12):7276. https://doi.org/10.3390/ijerph19127276
Chicago/Turabian StyleGogo, Siphiwe, and Innocent Musonda. 2022. "The Use of the Exploratory Sequential Approach in Mixed-Method Research: A Case of Contextual Top Leadership Interventions in Construction H&S" International Journal of Environmental Research and Public Health 19, no. 12: 7276. https://doi.org/10.3390/ijerph19127276
APA StyleGogo, S., & Musonda, I. (2022). The Use of the Exploratory Sequential Approach in Mixed-Method Research: A Case of Contextual Top Leadership Interventions in Construction H&S. International Journal of Environmental Research and Public Health, 19(12), 7276. https://doi.org/10.3390/ijerph19127276