
Methodological Issues in Analyzing Real-World Longitudinal Occupational Health Data: A Useful Guide to Approaching the Topic

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
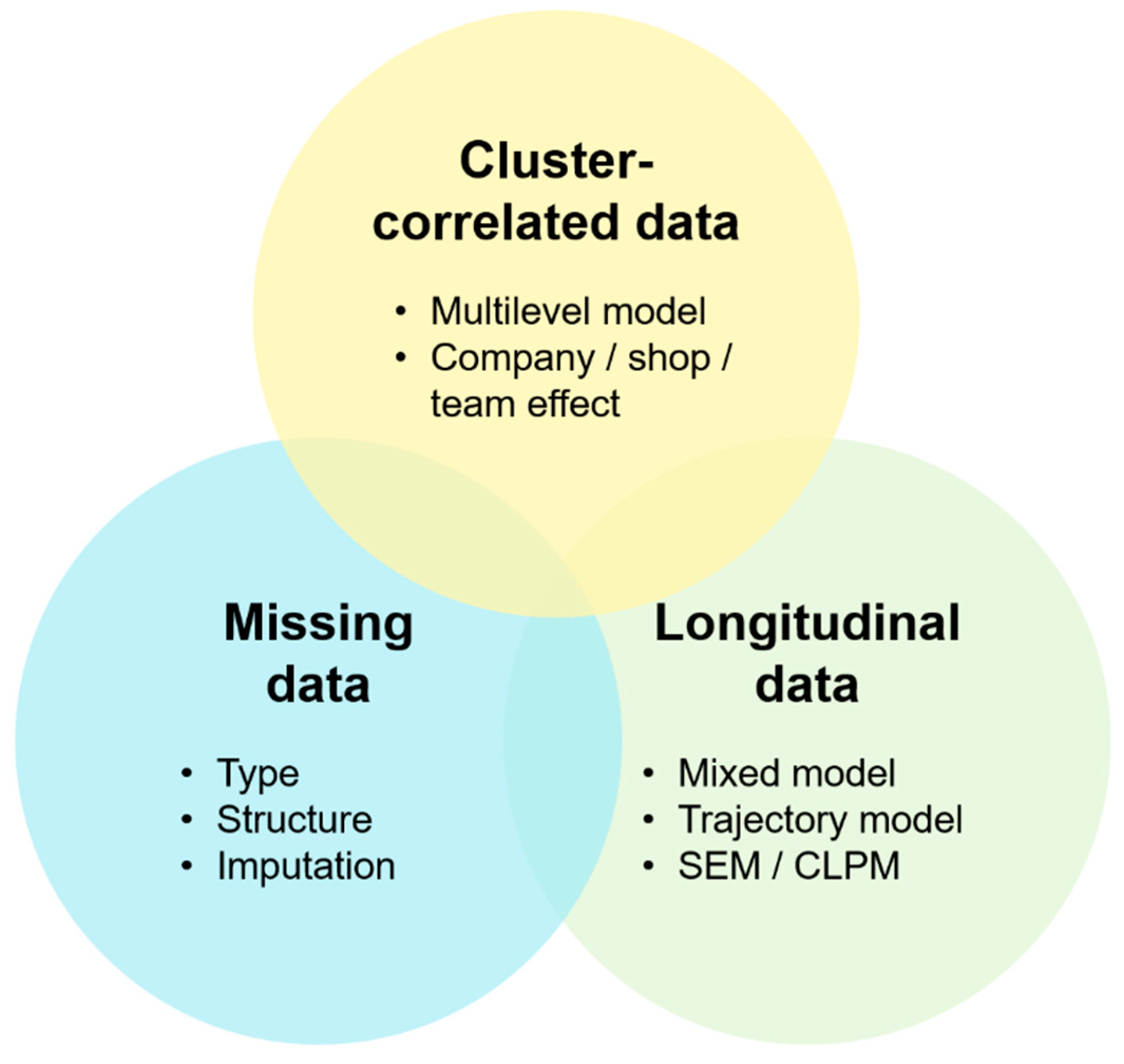
2. Methodological Issues and Methods for the Analysis of Longitudinal Data
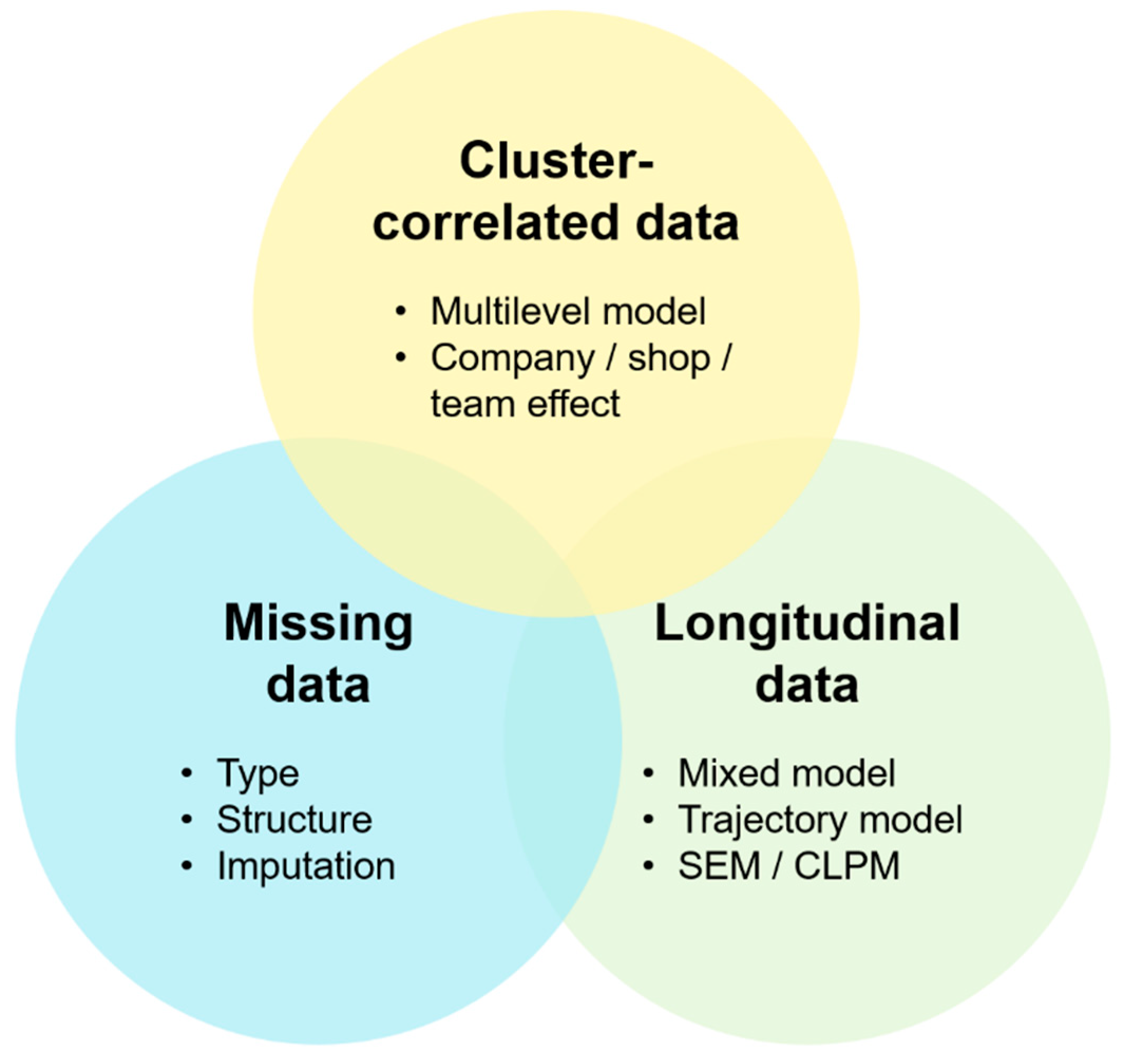
2.1. Cluster-Correlated Data
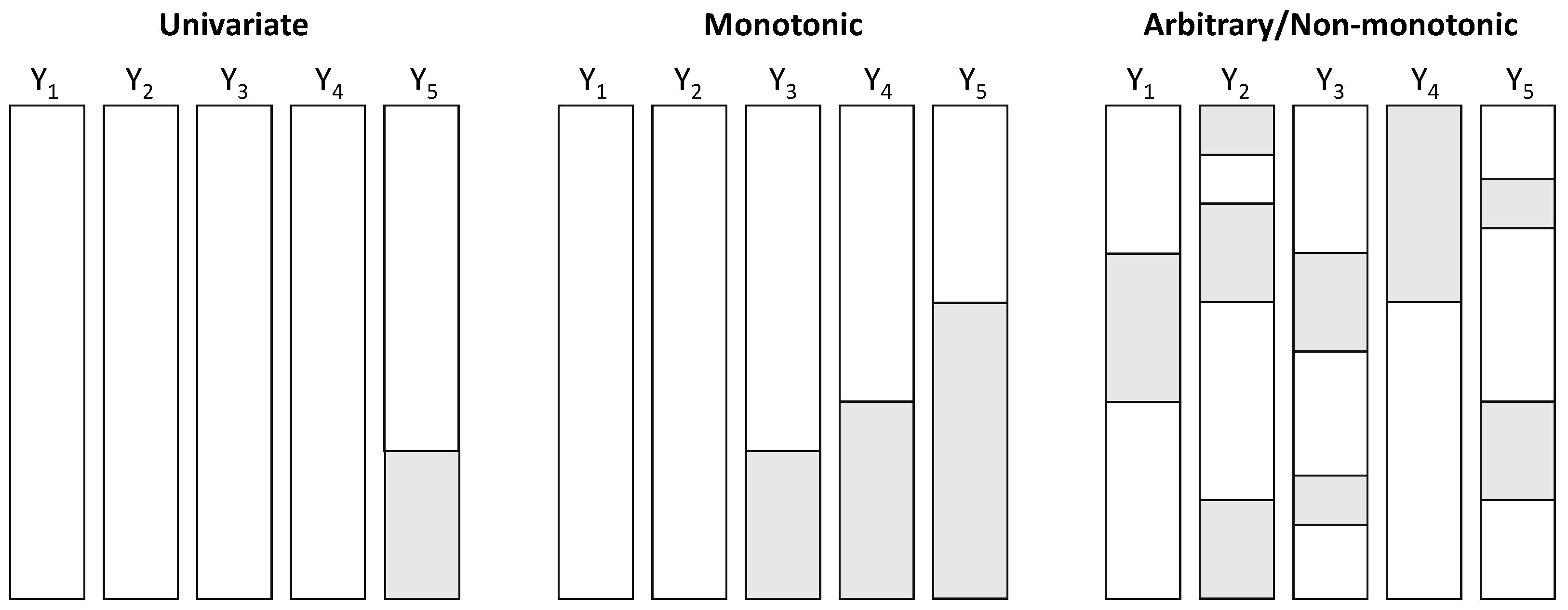
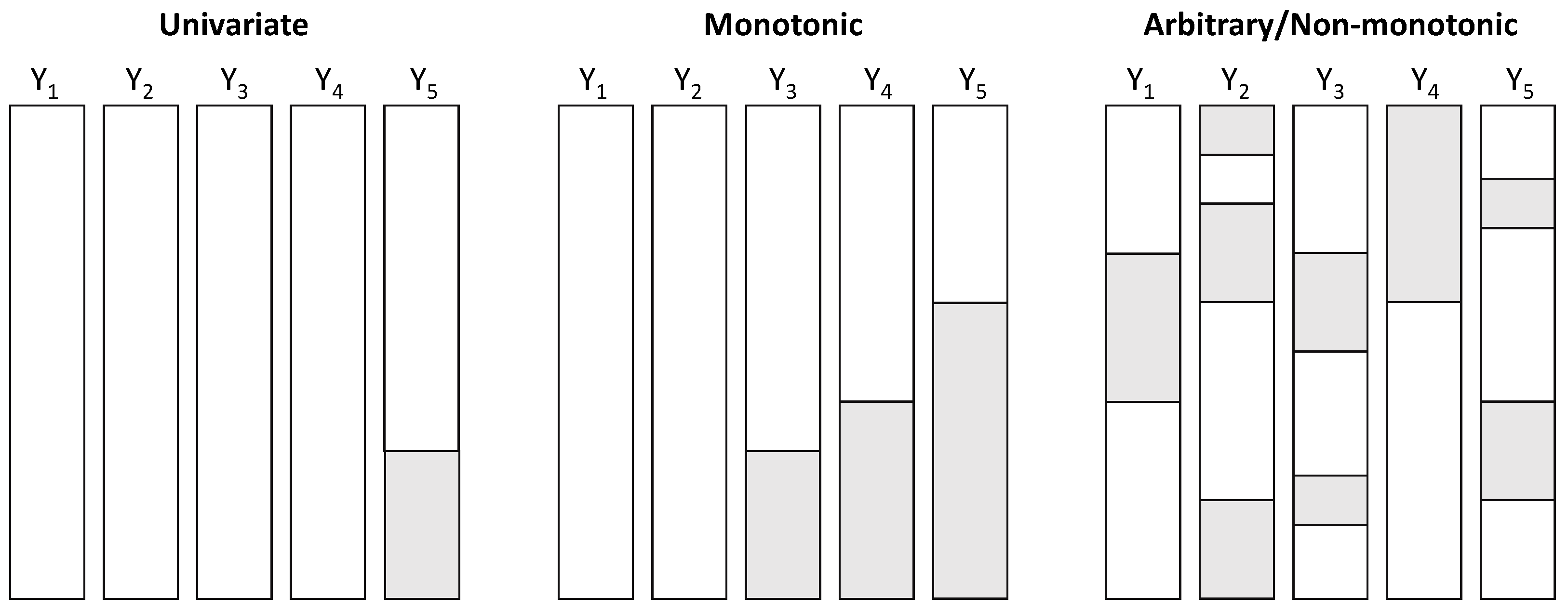
2.2. Missing Data
2.3. Longitudinal Data and Modeling
2.3.1. Analysis of Variance for Repeated Measures
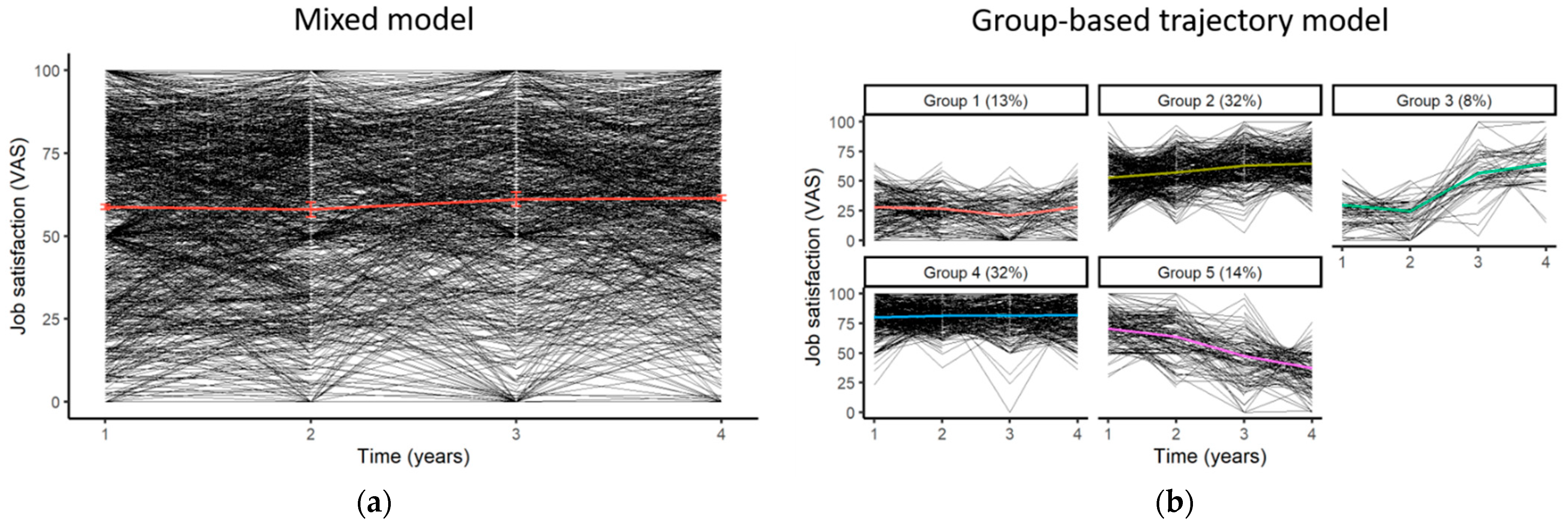
2.3.2. Mixed Models
2.3.3. Generalized Estimating Equations
2.3.4. SEMs and CLPMs, Complementary Approaches to the Mixed Model
2.3.5. Trajectory Models
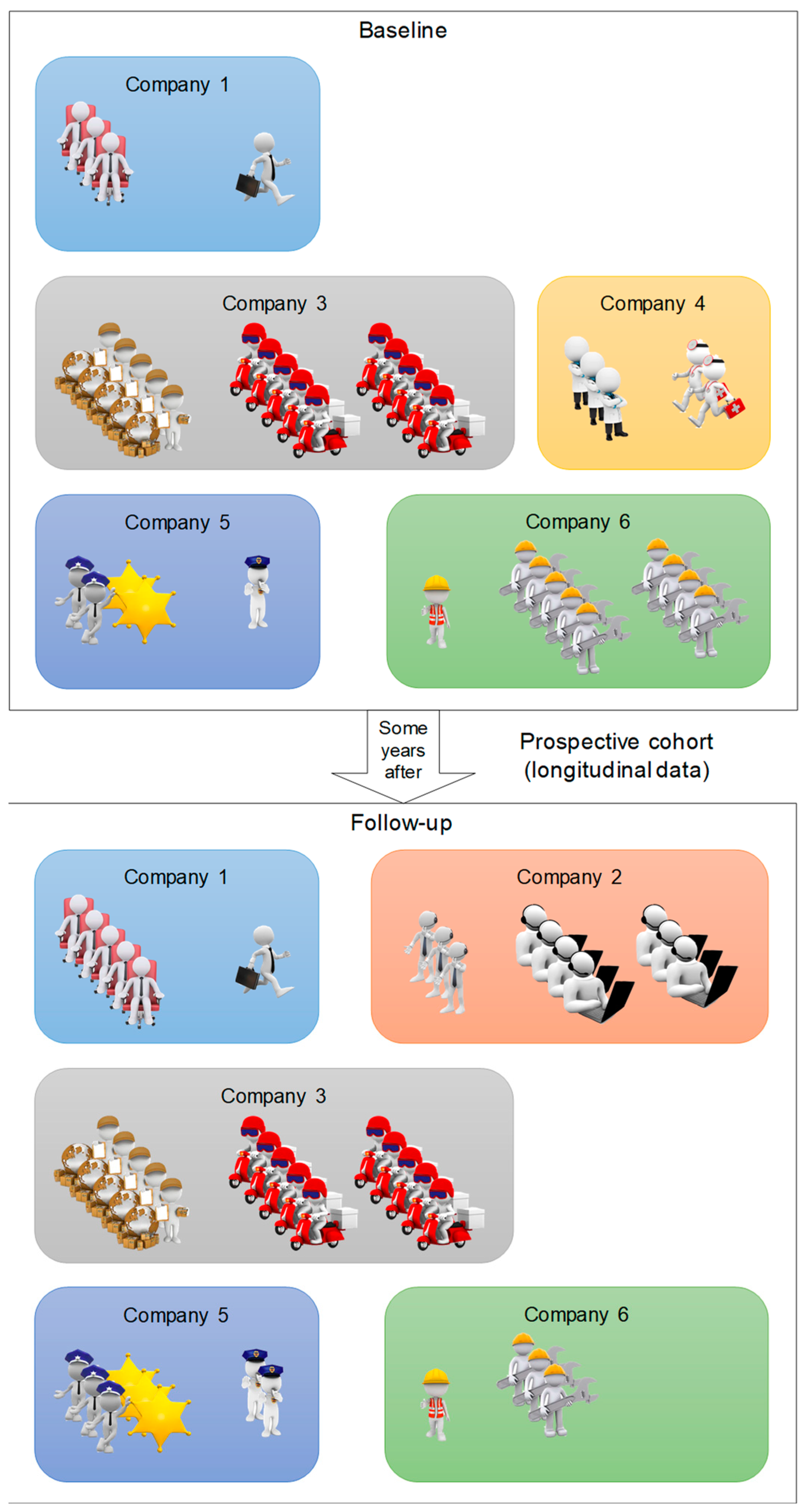
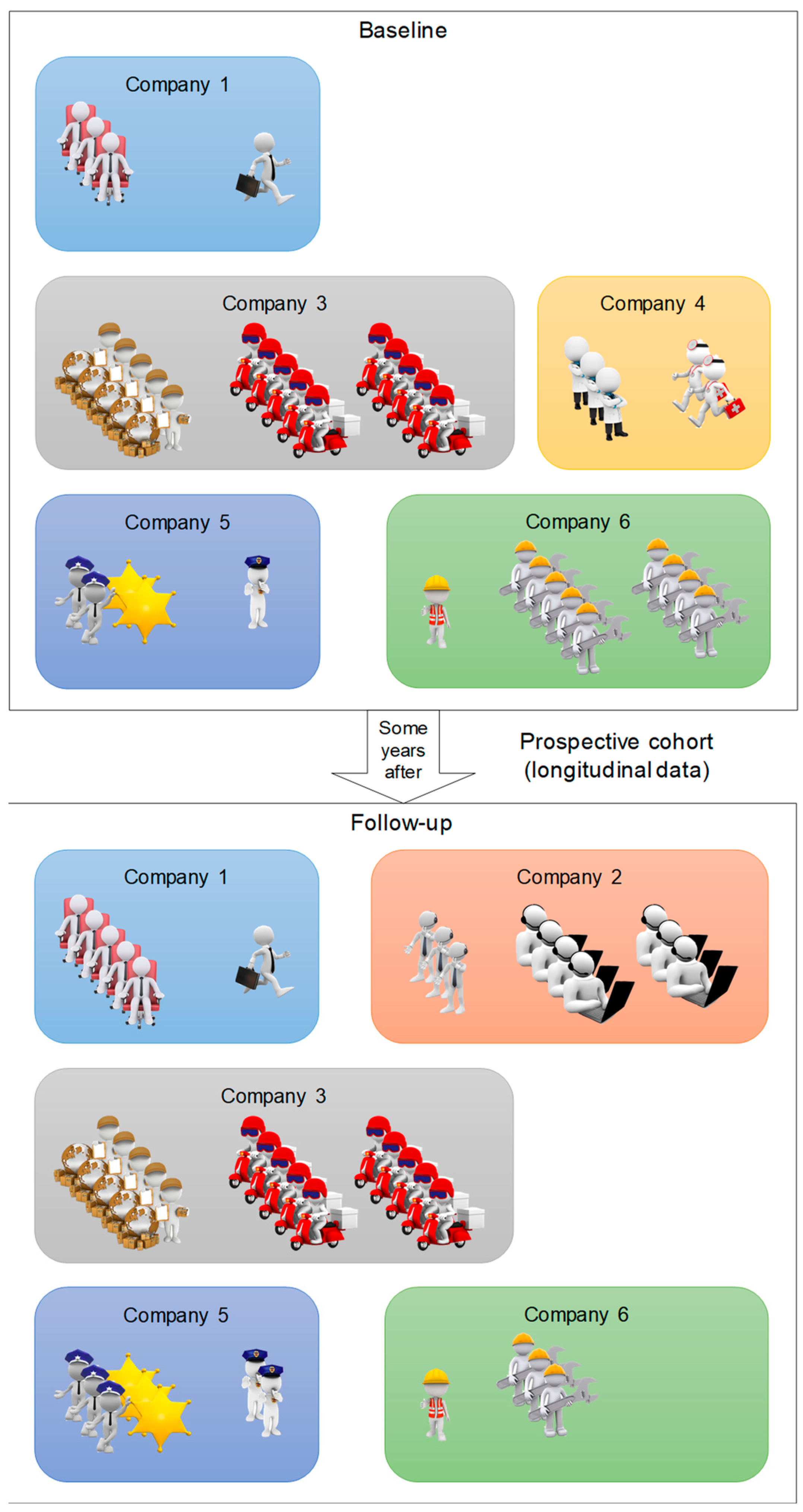
3. Case Report
3.1. Introduction
3.2. Methods
3.2.1. Participants and Exlusion Criteria
3.2.2. Outcomes
3.2.3. Statistics
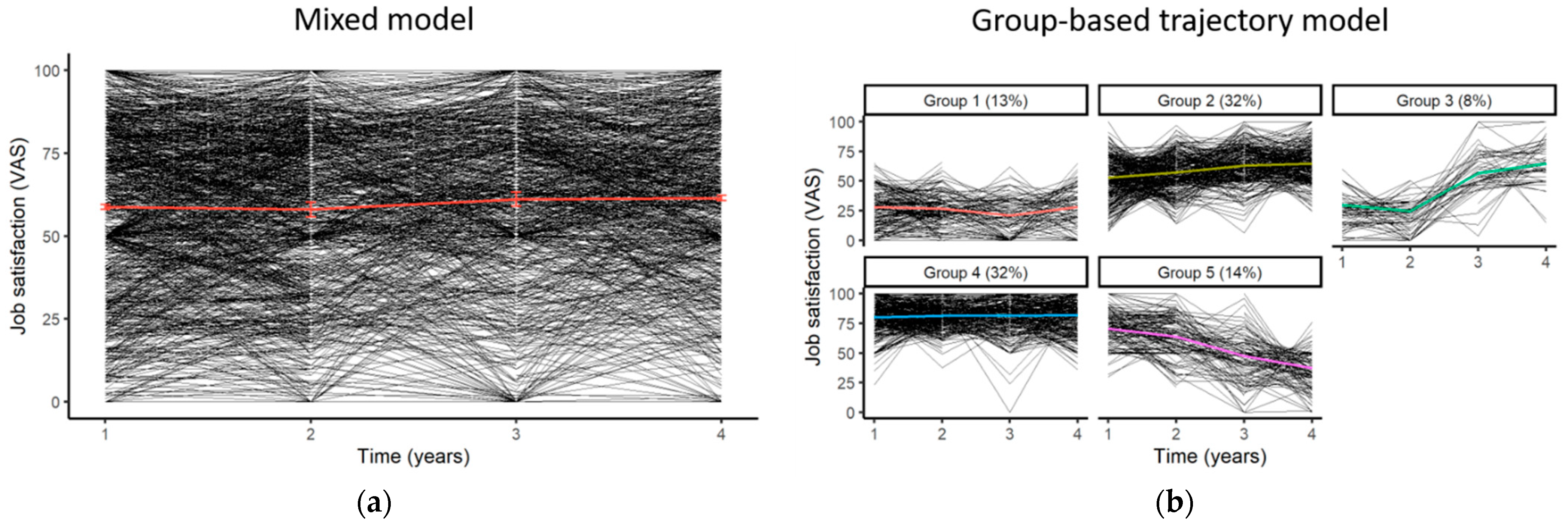
3.3. Data Application
3.4. Conclusions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
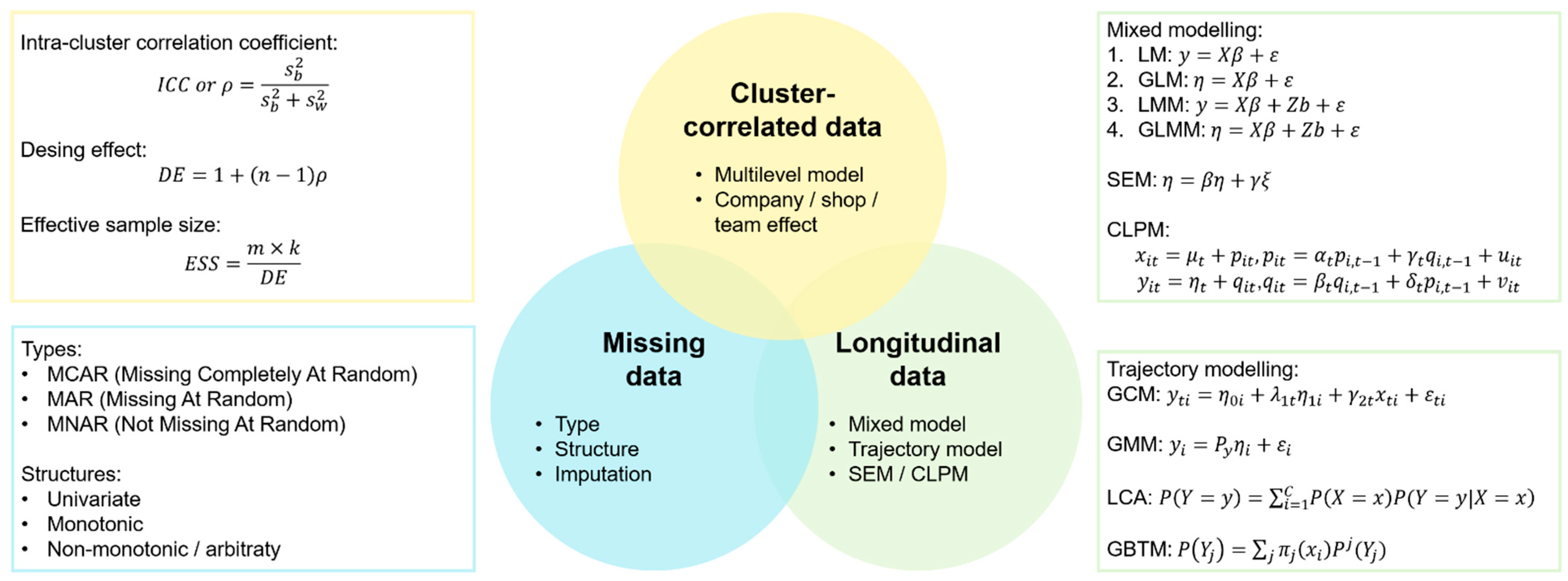
Appendix A. Novelty and Usefulness of Our Approach and Main Formulas Surrounding Cluster-Correlated Data, Missing Data and Longitudinal Data


- Main Formulas Surrounding Cluster-Correlated Data, Missing Data, and Longitudinal Data.
Appendix A.1. Cluster-Correlated Data
Appendix A.2. Longitudinal Data
Appendix A.2.1. Linear Modeling
Appendix A.2.2. Structural Equation Modeling
Appendix A.2.3. Cross-Lagged Panel Modeling
Appendix A.3. Trajectory Modeling
Appendix A.3.1. Growth Curve Modeling
Appendix A.3.2. Growth Mixture Modeling
Appendix A.3.3. Latent Class Analysis
Appendix A.3.4. Group-Based Trajectory Modeling
Appendix A.4. Summary of Models Formula

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Search Strategy | Mathematical Formulation | Missing Data | Advantages | Drawbacks |
|---|---|---|---|---|---|
| MULTILEVEL MODELING | |||||
| MLM | 3585 | a |
|
| |
| FIRST APPROACHES | |||||
| ANOVA for repeated measures | 1547 | a |
|
| |
| Mixed model | 1983 | b * |
|
| |
| TRAJECTORIES | |||||
| GCM | 126 | b |
|
| |
| GMM | 50 | ||||
| LCA | 154 | ||||
| GBTM | 78 | ||||
| COMPLEMENTARY APPROACHES | |||||
| SEM | 380 | a |
|
| |
| CLPM | 105 | b |
|
| |
Appendix B. Details for the Search Strategy Used within Each Database
References
- Basch, E.; Schrag, D. The Evolving Uses of “Real-World” Data. JAMA 2019, 321, 1359–1360. [Google Scholar] [CrossRef] [PubMed]
- Makady, A.; de Boer, A.; Hillege, H.; Klungel, O.; Goettsch, W. What Is Real-World Data? A Review of Definitions Based on Literature and Stakeholder Interviews. Value Health 2017, 20, 858–865. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corrigan-Curay, J.; Sacks, L.; Woodcock, J. Real-world evidence and real-world data for evaluating drug safety and effectiveness. JAMA 2018, 320, 867–868. [Google Scholar] [CrossRef]
- McCormick, J.; Mehta, G.; Olesen, H.V.; Viviani, L.; Macek, M.; Mehta, A. Comparative demographics of the European cystic fibrosis population: A cross-sectional database analysis. Lancet 2010, 375, 1007–1013. [Google Scholar] [CrossRef]
- Dutheil, F.; Duclos, M.; Naughton, G.; Dewavrin, S.; Cornet, T.; Huguet, P.; Chatard, J.-C.; Pereira, B. Wittyfit-live your work differently: Study protocol for a workplace-delivered health promotion. JMIR Res. Protoc. 2017, 6, e6267. [Google Scholar] [CrossRef] [PubMed]
- Platt, R.; Brown, J.S.; Robb, M.; McClellan, M.; Ball, R.; Nguyen, M.D.; Sherman, R.E. The FDA Sentinel Initiative—An Evolving National Resource. N. Engl. J. Med. 2018, 379, 2091–2093. [Google Scholar] [CrossRef] [Green Version]
- Smith, C.A.; Wicks, P.J. PatientsLikeMe: Consumer Health Vocabulary as a Folksonomy. AMIA Annu. Symp. Proc. 2008, 2008, 682–686. [Google Scholar]
- Randhawa, G.S. Building electronic data infrastructure for comparative effectiveness research: Accomplishments, lessons learned and future steps. J. Comp. Eff. Res. 2014, 3, 567–572. [Google Scholar] [CrossRef]
- James, G.; Nyman, E.; Fitz-Randolph, M.; Niklasson, A.; Hedman, K.; Hedberg, J.; Wittbrodt, E.T.; Medin, J.; Moreno Quinn, C.; Allum, A.M.; et al. Characteristics, symptom severity, and experiences of patients reporting chronic kidney disease in the patientslikeme online health community: Retrospective and qualitative study. J. Med. Internet Res. 2020, 22, e18548. [Google Scholar] [CrossRef]
- Benjdir, M.; Audureau, É.; Beresniak, A.; Coll, P.; Epaud, R.; Fiedler, K.; Jacquemin, B.; Niddam, L.; Pandis, S.N.; Pohlmann, G.; et al. Assessing the impact of exposome on the course of chronic obstructive pulmonary disease and cystc fibrosis: The REMEDIA European Project Approach. Environ. Epidemiol. 2021, 5, e165. [Google Scholar] [CrossRef]
- McCaffrey, S.; Black, R.A.; Nagao, M.; Sepassi, M.; Sharma, G.; Thornton, S.; Kim, Y.H.; Braverman, J. Measurement of quality of life in patients with mycosis fungoides/sézary syndrome cutaneous t-cell lymphoma: Development of an electronic instrument. J. Med. Internet Res. 2019, 21, e11302. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maissenhaelter, B.E.; Woolmore, A.L.; Schlag, P.M. Real-world evidence research based on big data. Onkologe 2018, 24 (Suppl. S2), 91–98. [Google Scholar] [CrossRef] [Green Version]
- Garrison, L.P.; Neumann, P.J.; Erickson, P.; Marshall, D.; Mullins, C.D. Using Real-World Data for Coverage and Payment Decisions: The ISPOR Real-World Data Task Force Report. Value Health 2007, 10, 326–335. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barrett, J.S.; Heaton, P.M. Real-World Data: An Unrealized Opportunity in Global Health? Clin. Pharmacol. Ther. 2019, 106, 57–59. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques, 3rd ed.; Elsevier: Amsterdam, The Netherlands, 2011; 740p. [Google Scholar]
- Diggle, P.; Heagerty, P.; Liang, K.-Y.; Zeger, S. Analysis of Longitudinal Data, 2nd ed.; OUP: Oxford, UK, 2002; 396p. [Google Scholar]
- Fitzmaurice, G.M.; Laird, N.M.; Ware, J.H. Applied Longitudinal Analysis, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2012; 742p. [Google Scholar]
- Caruana, E.J.; Roman, M.; Hernández-Sánchez, J.; Solli, P. Longitudinal studies. J. Thorac. Dis. 2015, 7, E537–E540. [Google Scholar] [PubMed]
- Van Belle, G.; Fisher, L.D.; Heagerty, P.J.; Lumley, T. Biostatistics: A Methodology for the Health Sciences, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2004; 895p. [Google Scholar]
- Edwards, L.J. Modern statistical techniques for the analysis of longitudinal data in biomedical research. Pediatr. Pulmonol. 2000, 30, 330–344. [Google Scholar] [CrossRef]
- Weiss, R.E. Modeling Longitudinal Data; Springer Science & Business Media: New York, NY, USA, 2005; 445p. [Google Scholar]
- Killip, S.; Mahfoud, Z.; Pearce, K. What Is an Intracluster Correlation Coefficient? Crucial Concepts for Primary Care Researchers. Ann. Fam. Med. 2004, 2, 204–208. [Google Scholar] [CrossRef] [PubMed]
- Song, P.X.-K. Correlated Data Analysis: Modeling, Analytics, and Applications; Springer Science & Business Media: New York, NY, USA, 2007; 356p. [Google Scholar]
- Goldstein, H. Multilevel Statistical Models, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2011; 376p. [Google Scholar]
- Bliese, P.D.; Hanges, P.J. Being Both Too Liberal and Too Conservative: The Perils of Treating Grouped Data as though They Were Independent. Organ. Res. Methods 2004, 7, 400–417. [Google Scholar] [CrossRef]
- Hayes, A.F. A Primer on Multilevel Modeling. Hum. Commun. Res. 2006, 32, 385–410. [Google Scholar] [CrossRef]
- Gibbons, R.D.; Hedeker, D.; DuToit, S. Advances in analysis of longitudinal data. Annu. Rev. Clin. Psychol. 2010, 6, 79–107. [Google Scholar] [CrossRef] [Green Version]
- Murray, D.M. Design and Analysis of Group-Randomized Trials; Oxford University Press: Oxford, UK, 1998; 481p. [Google Scholar]
- Snijders, T.A.B.; Bosker, R.J. Multilevel Analysis: An Introduction to Basic and Advanced Multilevel Modeling, 2nd ed.; SAGE: Thousand Oaks, CA, USA, 2011; 370p. [Google Scholar]
- Begg, M.D.; Parides, M.K. Separation of individual-level and cluster-level covariate effects in regression analysis of correlated data. Stat. Med. 2003, 22, 2591–2602. [Google Scholar] [CrossRef] [PubMed]
- Bruckers, L.; Molenberghs, G.; Pulinx, B.; Hellenthal, F.; Schurink, G. Cluster analysis for repeated data with dropout: Sensitivity analysis using a distal event. J. Biopharm. Stat. 2018, 28, 983–1004. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hox, J.J.; Moerbeek, M.; van de Schoot, R. Multilevel Analysis: Techniques and Applications, 3rd ed.; Routledge: Abingdon, UK, 2017; 365p. [Google Scholar]
- Raudenbush, S.W.; Bryk, A.S. Hierarchical Linear Models: Applications and Data Analysis Methods, 2nd ed.; SAGE: Thousand Oaks, CA, USA, 2002; 520p. [Google Scholar]
- Graham, J.W. Missing Data Analysis: Making It Work in the Real World. Annu. Rev. Psychol. 2008, 60, 549–576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Little, T.D.; Lang, K.M.; Wu, W.; Rhemtulla, M. Missing Data. In Developmental Psychopathology; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2016; pp. 1–37. [Google Scholar]
- Hedeker, D.; Gibbons, R.D. Application of random-effects pattern-mixture models for missing data in longitudinal studies. Psychol. Methods 1997, 2, 64–78. [Google Scholar] [CrossRef]
- Kang, H. The prevention and handling of the missing data. Korean J. Anesthesiol. 2013, 64, 402–406. [Google Scholar] [CrossRef]
- Donner, A. The Relative Effectiveness of Procedures Commonly Used in Multiple Regression Analysis for Dealing with Missing Values. Am. Stat. 1982, 36, 378–381. [Google Scholar]
- Newgard, C.D.; Lewis, R.J. Missing Data: How to Best Account for What Is Not Known. JAMA 2015, 314, 940–941. [Google Scholar] [CrossRef]
- Li, P.; Stuart, E.A.; Allison, D.B. Multiple Imputation: A Flexible Tool for Handling Missing Data. JAMA 2015, 314, 1966–1967. [Google Scholar] [CrossRef] [Green Version]
- Little, R.J.A.; Rubin, D.B. Statistical Analysis with Missing Data, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Allison, P.D. Missing Data; Quantitative Applications in the Social Sciences; SAGE Publications: Thousand Oaks, CA, USA, 2001; Volume 136. [Google Scholar]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Kenward, M.G.; Carpenter, J. Multiple imputation: Current perspectives. Stat. Methods Med. Res. 2007, 16, 199–218. [Google Scholar] [CrossRef]
- Diggle, P.; Kenward, M.G. Informative Drop-Out in Longitudinal Data Analysis. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1994, 43, 49–73. [Google Scholar] [CrossRef]
- Little, R.J.A. Modeling the Drop-Out Mechanism in Repeated-Measures Studies. J. Am. Stat. Assoc. 1995, 90, 1112–1121. [Google Scholar] [CrossRef]
- Twisk, J.; de Vente, W. Attrition in longitudinal studies: How to deal with missing data. J. Clin. Epidemiol. 2002, 55, 329–337. [Google Scholar] [CrossRef]
- Fitzmaurice, G. Missing data: Implications for analysis. Nutrition 2008, 24, 200–202. [Google Scholar] [CrossRef] [PubMed]
- Rosenthal, S. Data Imputation. In The International Encyclopedia of Communication Research Methods; American Cancer Society: Atlanta, GA, USA, 2017; pp. 1–12. [Google Scholar]
- Liu, C.; Cripe, T.P.; Kim, M.-O. Statistical Issues in Longitudinal Data Analysis for Treatment Efficacy Studies in the Biomedical Sciences. Mol. Ther. 2010, 18, 1724–1730. [Google Scholar] [CrossRef] [PubMed]
- Verbeke, G. Linear Mixed Models for Longitudinal Data. In Linear Mixed Models in Practice: A SAS-Oriented Approach; Lecture Notes in Statistics; Verbeke, G., Molenberghs, G., Eds.; Springer: New York, NY, USA, 1997; pp. 63–153. [Google Scholar]
- Verbeke, G.; Molenberghs, G. Linear Mixed Models for Longitudinal Data; Springer: New York, NY, USA, 2000. [Google Scholar]
- Laird, N.M.; Ware, J.H. Random-effects models for longitudinal data. Biometrics 1982, 38, 963–974. [Google Scholar] [CrossRef] [PubMed]
- Fahrmeir, L.; Tutz, G. Multivariate Statistical Modelling Based on Generalized Linear Models, 2nd ed.; Springer Science & Business Media: New York, NY, USA, 1994; 537p. [Google Scholar]
- Cnaan, A.; Laird, N.M.; Slasor, P. Using the general linear mixed model to analyse unbalanced repeated measures and longitudinal data. Stat. Med. 1997, 16, 2349–2380. [Google Scholar] [CrossRef]
- McCulloch, C.E.; Neuhaus, J.M. Generalized Linear Mixed Models. In Encyclopedia of Biostatistics; American Cancer Society: Atlanta, GA, USA, 2005. [Google Scholar]
- Ju, K.; Lin, L.; Chu, H.; Cheng, L.-L.; Xu, C. Laplace approximation, penalized quasi-likelihood, and adaptive Gauss–Hermite quadrature for generalized linear mixed models: Towards meta-analysis of binary outcome with sparse data. BMC Med. Res. Methodol. 2020, 20, 152. [Google Scholar] [CrossRef]
- Liang, K.-Y.; Zeger, S.L. Longitudinal data analysis using generalized linear models. Biometrika 1986, 73, 13–22. [Google Scholar] [CrossRef]
- Ballinger, G.A. Using generalized estimating equations for longitudinal data analysis. Organ. Res. Methods 2004, 7, 127–150. [Google Scholar] [CrossRef]
- Zorn, C.J.W. Generalized estimating equation models for correlated data: A review with applications. Am. J. Political Sci. 2001, 45, 470–490. [Google Scholar] [CrossRef]
- Bentler, P.M.; Weeks, D.G. Linear structural equations with latent variables. Psychometrika 1980, 45, 289–308. [Google Scholar] [CrossRef]
- Hoyle, R.H. Structural Equation Modeling: Concepts, Issues, and Applications; SAGE: Thousand Oaks, CA, USA, 1995; 313p. [Google Scholar]
- Ullman, J.B. Structural equation modeling: Reviewing the basics and moving forward. J. Pers. Assess 2006, 87, 35–50. [Google Scholar] [CrossRef] [PubMed]
- Savalei, V.; Bentler, P.M. Structural Equation Modeling. In The Corsini Encyclopedia of Psychology; American Cancer Society: Atlanta, GA, USA, 2010; pp. 1–3. [Google Scholar]
- Ullman, J.B.; Bentler, P.M. Structural Equation Modeling. In Handbook of Psychology, 2nd ed; American Cancer Society: Atlanta, GA, USA, 2012. [Google Scholar]
- Kenny, D.A. Cross-lagged panel correlation: A test for spuriousness. Psychol. Bull. 1975, 82, 887–903. [Google Scholar] [CrossRef]
- Selig, J.P.; Little, T.D. Autoregressive and cross-lagged panel analysis for longitudinal data. In Handbook of Developmental Research Methods; The Guilford Press: New York, NY, USA, 2012; pp. 265–278. [Google Scholar]
- Kenny, D.A.; Harackiewicz, J.M. Cross-lagged panel correlation: Practice and promise. J. Appl. Psychol. 1979, 64, 372–379. [Google Scholar] [CrossRef]
- Hamaker, E.L.; Kuiper, R.M.; Grasman, R.P.P.P. A critique of the cross-lagged panel model. Psychol. Methods 2015, 20, 102–116. [Google Scholar] [CrossRef]
- Curran, P.J.; Willoughby, M.T. Implications of latent trajectory models for the study of developmental psychopathology. Dev. Psychopathol. 2003, 15, 581–612. [Google Scholar] [CrossRef]
- Schumacker, R.; Lomax, R. A Beginner’s Guide to Structural Equation Modeling, 4th ed.; Routledge: Mahwah, NJ, USA, 2016; Volume 288. [Google Scholar]
- Muthén, B.; Muthén, L.K. Integrating Person-Centered and Variable-Centered Analyses: Growth Mixture Modeling with Latent Trajectory Classes. Alcohol. Clin. Exp. Res. 2000, 24, 882–891. [Google Scholar] [CrossRef]
- Herle, M.; Micali, N.; Abdulkadir, M.; Loos, R.; Bryant-Waugh, R.; Hübel, C.; Bulik, C.M.; De Stavola, B.L. Identifying typical trajectories in longitudinal data: Modelling strategies and interpretations. Eur. J. Epidemiol. 2020, 35, 205–222. [Google Scholar] [CrossRef] [Green Version]
- Nguena Nguefack, H.L.; Pagé, M.G.; Katz, J.; Choinière, M.; Vanasse, A.; Dorais, M.; Samb, O.M.; Lacasse, A. Trajectory Modelling Techniques Useful to Epidemiological Research: A Comparative Narrative Review of Approaches. Clin. Epidemiol. 2020, 12, 1205–1222. [Google Scholar] [CrossRef]
- Hox, J.; Stoel, R.D. Multilevel and SEM approaches to growth curve modeling. In Encyclopedia of Statistics in Behavioral Science; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005. [Google Scholar]
- Muthén, B.; Shedden, K. Finite Mixture Modeling with Mixture Outcomes Using the EM Algorithm. Biometrics 1999, 55, 463–469. [Google Scholar] [CrossRef] [PubMed]
- Muthén, B. Second-generation structural equation modeling with a combination of categorical and continuous latent variables: New opportunities for latent class–latent growth modeling. In New Methods for the Analysis of Change; American Psychological Association: Washington, DC, USA, 2001; pp. 291–322. [Google Scholar]
- Nagin, D.S. Analyzing developmental trajectories: A semiparametric, group-based approach. Psychol. Methods 1999, 4, 139–157. [Google Scholar] [CrossRef]
- Nagin, D.S. Group-Based Modeling of Development; Harvard University Press: Cambridge, MA, USA, 2005; 226p. [Google Scholar]
- Nagin, D.S.; Odgers, C.L. Group-based trajectory modeling in clinical research. Annu. Rev. Clin. Psychol. 2010, 6, 109–138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nagin, D.S.; Jones, B.L.; Passos, V.L.; Tremblay, R.E. Group-based multi-trajectory modeling. Stat. Methods Med. Res. 2018, 27, 2015–2023. [Google Scholar] [CrossRef] [PubMed]
- Lanza, S.T.; Rhoades, B.L. Latent Class Analysis: An Alternative Perspective on Subgroup Analysis in Prevention and Treatment. Prev. Sci. 2013, 14, 157–168. [Google Scholar] [CrossRef] [Green Version]
- Lanza, S.T.; Cooper, B.R. Latent Class Analysis for Developmental Research. Child Dev. Perspect. 2016, 10, 59–64. [Google Scholar] [CrossRef]
- Dupéré, V.; Lacourse, E.; Vitaro, F.; Tremblay, R.E. Méthodes d’analyse du changement fondées sur les trajectoires de développement individuel. Modèles de régression mixtes paramétriques et non paramétriques. Bull. Méthodol. Sociol. Bull. Sociol. Methodol. 2007, 95, 26–57. [Google Scholar] [CrossRef]
- Rogosa, D.; Brandt, D.; Zimowski, M. A growth curve approach to the measurement of change. Psychol. Bull. 1982, 92, 726–748. [Google Scholar] [CrossRef]
- Martin, D.P.; von Oertzen, T. Growth mixture models outperform simpler clustering algorithms when detecting longitudinal heterogeneity, even with small sample sizes. Struct. Equ. Model. A Multidiscip. J. 2015, 22, 264–275. [Google Scholar] [CrossRef]
- McNeish, D.; Harring, J.R. The effect of model misspecification on growth mixture model class enumeration. J. Classif. 2017, 34, 223–248. [Google Scholar] [CrossRef]
- McNeish, D.; Matta, T. Differentiating between mixed-effects and latent-curve approaches to growth modeling. Behav. Res. 2018, 50, 1398–1414. [Google Scholar] [CrossRef] [PubMed]
- Den Teuling, N.G.P.; Pauws, S.C.; van den Heuvel, E.R. A comparison of methods for clustering longitudinal data with slowly changing trends. Commun. Stat.-Simul. Comput. 2021, 20, 1–28. [Google Scholar] [CrossRef]
- Nelder, J.A.; Wedderburn, R.W.M. Generalized Linear Models. J. R. Stat. Soc. Ser. A (Gen.) 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Booth, J.G.; Hobert, J.P. Maximizing generalized linear mixed model likelihoods with an automated Monte Carlo EM algorithm. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 1999, 61, 265–285. [Google Scholar] [CrossRef]
- Shapiro, A.; Browne, M.W. Analysis of covariance structures under elliptical distributions. J. Am. Stat. Assoc. 1987, 82, 1092–1097. [Google Scholar] [CrossRef]
- Browne, M.W. Asymptotically distribution-free methods for the analysis of covariance structures. Br. J. Math. Stat. Psychol. 1984, 37, 62–83. [Google Scholar] [CrossRef] [PubMed]
- Allison, P.D.; Williams, R.; Moral-Benito, E. Maximum likelihood for cross-lagged panel models with fixed effects. Socius 2017, 3, 1–17. [Google Scholar] [CrossRef]
- Zyphur, M.J.; Hamaker, E.L.; Tay, L.; Voelkle, M.; Preacher, K.J.; Zhang, Z.; Allison, P.D.; Pierides, D.C.; Koval, P.; Diener, E.F. From data to causes III: Bayesian priors for general cross-lagged panel models (GCLM). Front. Psychol. 2021, 12, 612251. [Google Scholar] [CrossRef]
| Missing Completely at Random | Missing at Random | Missing Not at Random | |
|---|---|---|---|
| Ad hoc methods Complete case analysis, available-case analysis, weighting methods | Expectation maximization algorithm | “Sensitivity analysis” | |
| Single imputation | |||
| Implicit modeling Hot/cold deck imputation, substitution, composite methods | Explicit modeling Mean/regression/stochastic regression imputation | Multiple imputation | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Colin-Chevalier, R.; Dutheil, F.; Cambier, S.; Dewavrin, S.; Cornet, T.; Baker, J.S.; Pereira, B. Methodological Issues in Analyzing Real-World Longitudinal Occupational Health Data: A Useful Guide to Approaching the Topic. Int. J. Environ. Res. Public Health 2022, 19, 7023. https://doi.org/10.3390/ijerph19127023
Colin-Chevalier R, Dutheil F, Cambier S, Dewavrin S, Cornet T, Baker JS, Pereira B. Methodological Issues in Analyzing Real-World Longitudinal Occupational Health Data: A Useful Guide to Approaching the Topic. International Journal of Environmental Research and Public Health. 2022; 19(12):7023. https://doi.org/10.3390/ijerph19127023
Chicago/Turabian StyleColin-Chevalier, Rémi, Frédéric Dutheil, Sébastien Cambier, Samuel Dewavrin, Thomas Cornet, Julien Steven Baker, and Bruno Pereira. 2022. "Methodological Issues in Analyzing Real-World Longitudinal Occupational Health Data: A Useful Guide to Approaching the Topic" International Journal of Environmental Research and Public Health 19, no. 12: 7023. https://doi.org/10.3390/ijerph19127023
APA StyleColin-Chevalier, R., Dutheil, F., Cambier, S., Dewavrin, S., Cornet, T., Baker, J. S., & Pereira, B. (2022). Methodological Issues in Analyzing Real-World Longitudinal Occupational Health Data: A Useful Guide to Approaching the Topic. International Journal of Environmental Research and Public Health, 19(12), 7023. https://doi.org/10.3390/ijerph19127023