
Integrating Individual Factors to Construct Recognition Models of Consumer Fraud Victimization


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data and Participants
2.2. Measurements and Feature Processing
2.2.1. Fraud Exposure and Victimhood
2.2.2. Demographic Features
2.2.3. Financial-Related Features
2.2.4. Other Features
2.3. Model Construction and Evaluation
3. Results
3.1. Basic Statistics
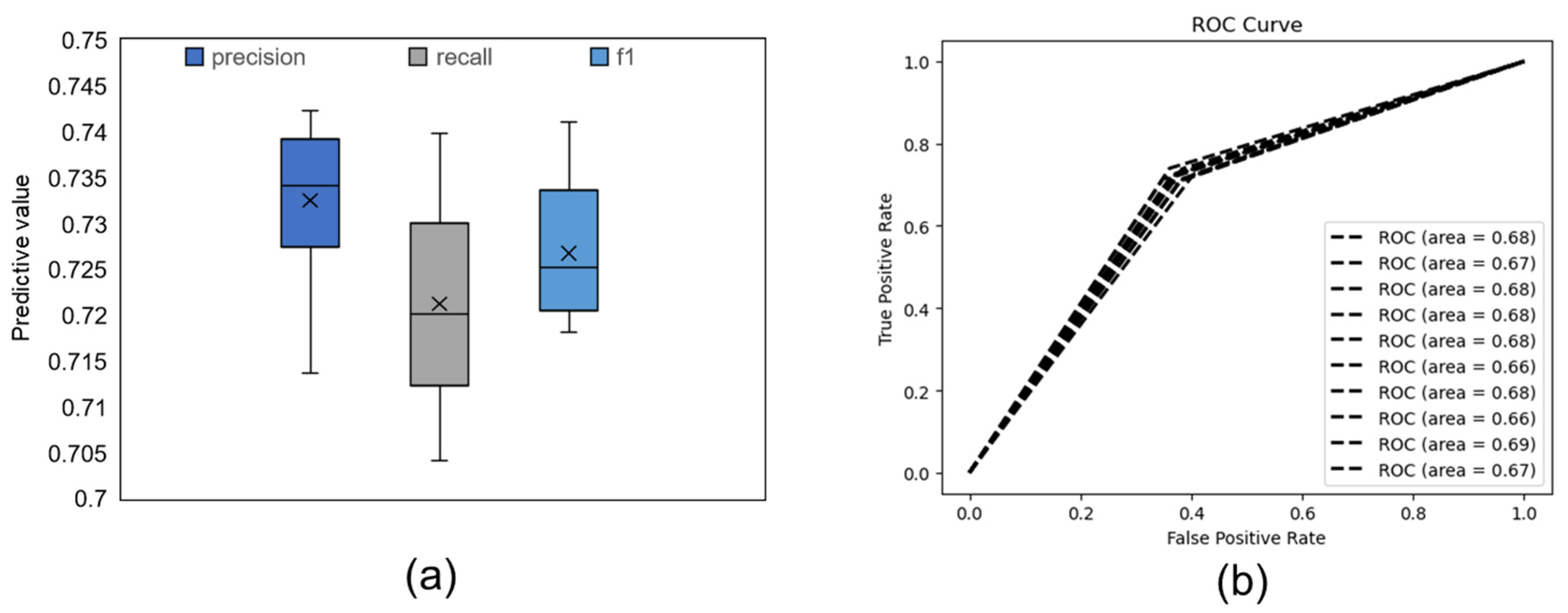
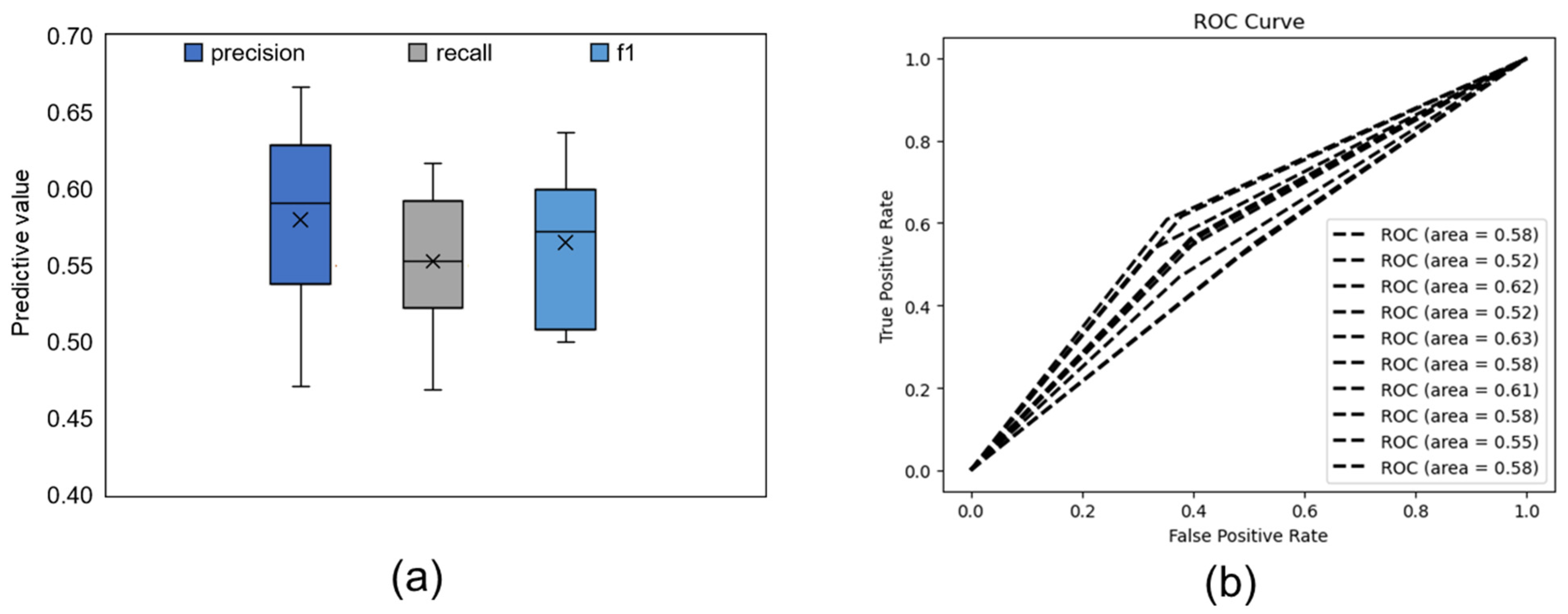
3.2. Model Prediction Results
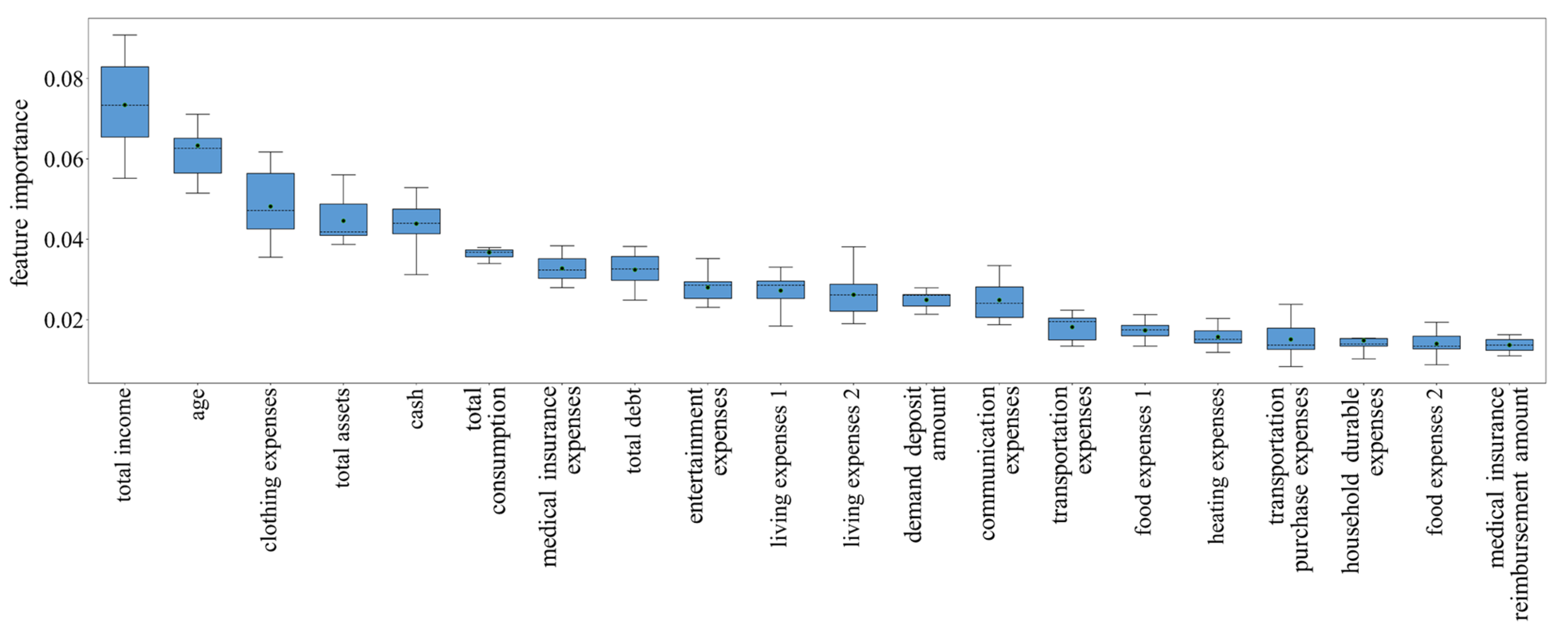
3.3. Model Interpretability
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Williams, E.J.; Beardmore, A.; Joinson, A.N. Individual Differences in Susceptibility to Online Influence: A Theoretical Review. Comput. Hum. Behav. 2017, 72, 412–421. [Google Scholar] [CrossRef]
- Deevy, M.; Lucich, S.; Beals, M. Scams, Schemes & Swindles. Financial Fraud Research Center, Stanford University. Available online: http://longevity.stanford.edu/wp-content/uploads/2017/01/Scams-Schemes-Swindles-FINAL-On-Website.pdf (accessed on 10 December 2021).
- Irvin-Erickson, Y.; Ricks, A. Identity Theft and Fraud Victimization: What We Know about Identity Theft and Fraud Victims from Research-and Practice-Based Evidence. Available online: https://ncvc.dspacedirect.org/handle/20.500.11990/1544 (accessed on 10 December 2021).
- Fan, J.X.; Yu, Z. Understanding Aging and Consumer Fraud Victimization in the Chinese Context: A Two-Stage Conceptual Approach. J. Elder Abus. Negl. 2021, 33, 230–247. [Google Scholar] [CrossRef] [PubMed]
- Anderson, K.B. Consumer fraud in the United States: An FTC Survey. Federal Trade Commission. Available online: https://www.ftc.gov/sites/default/files/documents/reports/consumer-fraud-united-states-ftc-survey/040805confraudrpt.pdf (accessed on 10 December 2021).
- Saunders, L.; Pizor, A.; Twomey, T. Desperate Homeowners: Loan mod Scammers Step in When Loan Services Refuse to Provide Relief. National Consumer Law Center. Available online: https://www.nclc.org/images/pdf/pr-reports/report-loan-mod-scams-2009.pdf (accessed on 10 December 2021).
- Lee, C.S. How Online Fraud Victims are Targeted in China: A Crime Script Analysis of Baidu Tieba C2C Fraud. Crime Delinq. 2021; advance online publication. [Google Scholar] [CrossRef]
- Ganzini, L.; McFarland, B.H.; Cutler, D. Prevalence of Mental Disorders after Catastrophic Financial Loss. J. Nerv. Ment. Dis. 1990, 178, 680–685. [Google Scholar] [CrossRef]
- Spalek, B. Exploring the Impact of Financial Crime: A Study Looking into the Effects of the Maxwell Scandal upon the Maxwell Pensioners. Int. Rev. Vict. 1999, 6, 213–230. [Google Scholar] [CrossRef]
- Deem, D.L. Notes from the Field: Observations in Working with the Forgotten Victims of Personal Financial Crimes. J. Elder Abus. Negl. 2000, 12, 33–48. [Google Scholar] [CrossRef]
- Identity Theft Resource Center. The Aftermath: The Non-Economic Impacts of Identitytheft. Available online: https://www.idtheftcenter.org/wp-content/uploads/2018/09/ITRC_Aftermath-2018_Web_FINAL.pdf (accessed on 10 December 2021).
- Federal Trade Commission. FTC Identity Theft: Planning for the Future Conference. Available online: https://www.ftc.gov/system/files/documents/videos/identity-theft-planning-future-part-1/ftc_identity_theft_planning_for_the_future_transcript_segment_1.pdf (accessed on 25 May 2017).
- Button, M.; Lewis, C.; Tapley, J. Not a victimless crime: The impact of fraud on individual victims and their families. Secur. J. 2014, 27, 36–54. [Google Scholar] [CrossRef]
- Cross, C. ‘They’re very lonely’: Understanding the fraud victimisation of seniors. Int. J. Crime Justice Soc. Democr. 2016, 5, 60. [Google Scholar] [CrossRef] [Green Version]
- Kadoya, Y.; Khan, M.S.R.; Narumoto, J.; Watanabe, S. Who is next? A study on victims of financial fraud in Japan. Front. Psychol. 2021, 12, 649565. [Google Scholar]
- Shadel, D.; Pak, K.B.S. The Psychology of Consumer Fraud. Ph.D. Thesis, Universiteit van Tilburg, Tilburg, The Netherland, 2007. [Google Scholar]
- Grazioli, S. Where Did They Go Wrong? An Analysis of the Failure of Knowledgeable Internet Consumers to Detect Deception over the Internet. Group Decis. Negot. 2004, 13, 149–172. [Google Scholar] [CrossRef]
- Wright, R.; Chakraborty, S.; Basoglu, A.; Marett, K. Where Did They Go Right? Understanding the Deception in Phishing Communications. Group Decis. Negot. 2010, 19, 391–416. [Google Scholar] [CrossRef]
- Kerley, K.R.; Copes, H. Personal Fraud Victims and Their Official Responses to Victimization. J. Police Crim. Psych. 2002, 17, 19–35. [Google Scholar] [CrossRef]
- Schoepfer, A.; Piquero, N.L. Studying the Correlates of Fraud Victimization and Reporting. J. Crim. Justice 2009, 37, 209–215. [Google Scholar] [CrossRef]
- Pratt, T.C.; Holtfreter, K.; Reisig, M.D. Routine online activity and internet fraud targeting: Extending the generality of routine activity theory. J. Res. Crime Delinq. 2010, 47, 267–296. [Google Scholar] [CrossRef]
- Shi, J.; Wu, C.; Qian, X. The Effects of Multiple Factors on Elderly Pedestrians’ Speed Perception and Stopping Distance Estimation of Approaching Vehicles. Sustainability 2020, 12, 5308. [Google Scholar] [CrossRef]
- Shao, J.; Zhang, Q.; Ren, Y.; Li, X.; Lin, T. Why Are Older Adults Victims of Fraud? Current Knowledge and Prospects Regarding Older Adults’ Vulnerability to Fraud. J. Elder Abus. Negl. 2019, 31, 225–243. [Google Scholar] [CrossRef]
- Titus, R.M.; Gover, A.R. Personal fraud: The victims and the scams. Crime Prev. Stud. 2001, 12, 133–152. [Google Scholar]
- Anderson, B.B.; Vance, A.; Kirwan, C.B.; Jenkins, J.L.; Eargle, D. From Warning to Wallpaper: Why the Brain Habituates to Security Warnings and What Can Be Done About It. J. Manag. Inf. Syst. 2016, 33, 713–743. [Google Scholar] [CrossRef]
- AARP. Off the Hook: Reducing Participation in Telemarketing Fraud. Available online: http://www.aarp.org/research/frauds-scams/telemarketing/aresearch-import-179-D17812.html (accessed on 10 December 2021).
- Pak, K.; Shadel, D. AARP Foundation national fraud victim study. Available online: https://assets.aarp.org/rgcenter/general/fraud-victims-11.pdf (accessed on 10 December 2021).
- Norris, G.; Brookes, A.; Dowell, D. The Psychology of Internet Fraud Victimisation: A Systematic Review. J. Police Crim. Psych. 2019, 34, 231–245. [Google Scholar] [CrossRef] [Green Version]
- Modic, D.; Anderson, R.; Palomäki, J. We Will Make You like Our Research: The Development of a Susceptibility-to-Persuasion Scale. PLoS ONE 2018, 13, e0194119. [Google Scholar] [CrossRef] [Green Version]
- Modic, D.; Lea, S.E.G. How Neurotic Are Scam Victims, Really? The Big Five and Internet Scams. SSRN J. 2012. [Google Scholar] [CrossRef]
- Purkait, S.; Kumar De, S.; Suar, D. An Empirical Investigation of the Factors That Influence Internet User’s Ability to Correctly Identify a Phishing Website. Inf. Manag. Comput. Secur. 2014, 22, 194–234. [Google Scholar] [CrossRef]
- Holtfreter, K.; Reisig, M.D.; Pratt, T.C. Low Self-Control, Routine Activities, and Fraud Victimization. Criminology 2008, 46, 189–220. [Google Scholar] [CrossRef]
- Whitty, M.T.; Buchanan, T. The Online Dating Romance Scam: The Psychological Impact on Victims—Both Financial and Non-Financial. Criminol. Crim. Justice 2016, 16, 176–194. [Google Scholar] [CrossRef] [Green Version]
- Pattinson, M.R.; Jerram, C.; Parsons, K.; McCormac, A.; Butavicius, M.A. Managing Phishing Emails: A Scenario-Based Experiment. In Human Aspects of Information Security & Assurance, Proceedings of the Fifth International Symposium on Human Aspects of Information Security & Assurance (HAISA), London, UK, 7–8 July 2011; Furnell, S.M., Clarke, N.L., Eds.; University of Plymouth: London, UK, 2011; pp. 74–85. [Google Scholar]
- Vishwanath, A.; Herath, T.; Chen, R.; Wang, J.; Rao, H.R. Why Do People Get Phished? Testing Individual Differences in Phishing Vulnerability within an Integrated, Information Processing Model. Decis. Support Syst. 2011, 51, 576–586. [Google Scholar] [CrossRef]
- Vasilopoulos, N.L.; Cucina, J.M.; McElreath, J.M. Do Warnings of Response Verification Moderate the Relationship Between Personality and Cognitive Ability? J. Appl. Psychol. 2005, 90, 306–322. [Google Scholar] [CrossRef]
- Gottfredson, M.R.; Hirschi, T. A General Theory of Crime; Stanford University Press: Palo Alto, CA, USA, 1990. [Google Scholar]
- van de Weijer, S.G.A.; Leukfeldt, E.R. Big Five Personality Traits of Cybercrime Victims. Cyberpsychology Behav. Soc. Netw. 2017, 20, 407–412. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Hyun Kim, J. Understanding Persuasive Elements in Phishing E-Mails: A Categorical Content and Semantic Network Analysis. Online Inf. Rev. 2013, 37, 835–850. [Google Scholar] [CrossRef]
- Petty, R.E.; Briñol, P. Emotion and Persuasion: Cognitive and Meta-Cognitive Processes Impact Attitudes. Cogn. Emot. 2015, 29, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Fischer, P.; Lea, S.E.; Evans, K.M. Why do individuals respond to fraudulent scam communications and lose money? The psychological determinants of scam compliance. J. Appl. Soc. Psychol. 2013, 43, 2060–2072. [Google Scholar] [CrossRef]
- Button, M.; Nicholls, C.M.; Kerr, J.; Owen, R. Online frauds: Learning from victims why they fall for these scams. Aust. N. Z. J. Criminol. 2014, 47, 391–408. [Google Scholar] [CrossRef]
- Norris, G.; Brookes, A. Personality, Emotion and Individual Differences in Response to Online Fraud. Personal. Individ. Differ. 2021, 169, 109847. [Google Scholar] [CrossRef]
- Vempala, N.N.; Russo, F.A. Modeling Music Emotion Judgments Using Machine Learning Methods. Front. Psychol. 2018, 8, 2239. [Google Scholar] [CrossRef] [Green Version]
- Gan, L.; Yin, Z.; Jia, N.; Xu, S.; Ma, S.; Zheng, L. Data You Need to Know about China; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef]
- Brink, A.G.; Gouldman, A.; Victoravich, L.M. The Effects of Organizational Risk Appetite and Social Pressure on Aggressive Financial Reporting Behavior. Behav. Res. Account. 2018, 30, 23–36. [Google Scholar] [CrossRef]
- Wood, S.; Liu, P.-J.; Hanoch, Y.; Xi, P.M.; Klapatch, L. Call to Claim Your Prize: Perceived Benefits and Risk Drive Intention to Comply in a Mass Marketing Scam. J. Exp. Psychol. Appl. 2018, 24, 196–206. [Google Scholar] [CrossRef] [PubMed]
- Alam, M.S.; Vuong, S.T. Random Forest Classification for Detecting Android Malware. In Proceedings of the 2013 IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013; pp. 663–669. [Google Scholar]
- Arora, N.; Kaur, P.D. A Bolasso Based Consistent Feature Selection Enabled Random Forest Classification Algorithm: An Application to Credit Risk Assessment. Appl. Soft Comput. 2020, 86, 105936. [Google Scholar] [CrossRef]
- Xu, L.; Zheng, Y.; Xu, D.; Xu, L. Predicting the Preference for Sad Music: The Role of Gender, Personality, and Audio Features. IEEE Access 2021, 9, 92952–92963. [Google Scholar] [CrossRef]
- Quiroz, J.C.; Geangu, E.; Yong, M.H. Emotion Recognition Using Smart Watch Sensor Data: Mixed-Design Study. JMIR Ment. Health 2018, 5, e10153. [Google Scholar] [CrossRef] [Green Version]
- Xu, L.; Wen, X.; Shi, J.; Li, S.; Xiao, Y.; Wan, Q.; Qian, X. Effects of Individual Factors on Perceived Emotion and Felt Emotion of Music: Based on Machine Learning Methods. Psychol. Music 2021, 49, 1069–1087. [Google Scholar] [CrossRef]
- Götz, F.M.; Stieger, S.; Gosling, S.D.; Potter, J.; Rentfrow, P.J. Physical Topography Is Associated with Human Personality. Nat. Hum. Behav. 2020, 4, 1135–1144. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Sun, Z.; Wen, X.; Huang, Z.; Chao, C.; Xu, L. Using Machine Learning Analysis to Interpret the Relationship between Music Emotion and Lyric Features. PeerJ Comput. Sci. 2021, 7, e785. [Google Scholar] [CrossRef]
- Sun, Z.; Ji, Z.; Zhang, P.; Chen, C.; Qian, X.; Du, X.; Wan, Q. Automatic Labeling of Mobile Apps by the Type of Psychological Needs They Satisfy. Telemat. Inform. 2017, 34, 767–778. [Google Scholar] [CrossRef]
- Li, J.; Rose, N. Urban Social Exclusion and Mental Health of China’s Rural-Urban Migrants—A Review and Call for Research. Health Place 2017, 48, 20–30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, L.; Sharpe, R.V.; Li, S.; Darity, W.A. Wage Differentials between Urban and Rural-Urban Migrant Workers in China. China Econ. Rev. 2016, 41, 222–233. [Google Scholar] [CrossRef]
- Harrison, B.; Vishwanath, A.; Ng, Y.J.; Rao, R. Examining the Impact of Presence on Individual Phishing Victimization. In Proceedings of the 2015 48th Hawaii International Conference on System Sciences, Kauai, HI, USA, 5–8 January 2015; pp. 3483–3489. [Google Scholar]
- Tencent 110. Online Fraud Governance Report in 2020. Available online: https://download.mouse0232.cn/pdf/0226/%E3%80%90%E8%85%BE%E8%AE%AF110%E3%80%912020%E5%B9%B4%E7%BD%91%E7%BB%9C%E8%AF%88%E9%AA%97%E6%B2%BB%E7%90%86%E6%8A%A5%E5%91%8A.pdf (accessed on 10 December 2021).
- China Academy of Information and Communications Technology. Research Report on Telecommunication Network Fraud Management under the New Situation. Available online: http://www.caict.ac.cn/kxyj/qwfb/ztbg/202012/P02020121839388994629-5.pdf (accessed on 10 December 2021).
- Găbudeanu, L.; Brici, I.; Mare, C.; Mihai, I.C.; Șcheau, M.C. Privacy Intrusiveness in Financial-Banking Fraud Detection. Risks 2021, 9, 104. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Individual Factors | Fraud Exposure (n = 36,202) | Fraud Victimhood (n = 21,221) | |||
|---|---|---|---|---|---|
| Exposed (n = 21,221) | Not Exposed (n = 14,981) | Fraud Victim (n = 1284) | Fraud Survivor (n = 19,937) | ||
| Age (M ± SD) | 51.52 ± 14.88 | 54.68 ± 14.85 | 53.80 ± 16.44 | 51.37 ± 14.77 | |
| Sex (%) | Male (Female) | 52.20 (47.80) | 53.44 (46.56) | 52.80 (47.20) | 52.15 (47.85) |
| Asset (¥) | M (SD) | 1.15×106 (2.03×106) | 5.80×105 (1.34×106) | 1.04×106 (1.83×106) | 1.16×106 (2.05×106) |
| Debt (¥) | M (SD) | 9.17×104 (2.16×105) | 5.70×104 (1.47×105) | 8.18×104 (2.15×105) | 9.23×104 (2.16×105) |
| Income (¥/year) | M (SD) | 5.67×104 (2.49×105) | 3.42×104 (1.81×105) | 6.39×104 (2.17×105) | 5.62×104 (2.50×105) |
| Consumption (¥/year) | M (SD) | 6.57×104 (7.51×104) | 4.62×104 (6.36×104) | 6.54×104 (7.25×104) | 6.57×104 (7.53×104) |
| Parameters | Models | |
|---|---|---|
| FER | FVR | |
| n_estimators | 127 | 47 |
| max_depth | 20 | 10 |
| min_samples_leaf | 5 | 10 |
| min_samples_split | 35 | 45 |
| max_features | 0.3 | 0.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, L.; Wang, J.; Xu, D.; Xu, L. Integrating Individual Factors to Construct Recognition Models of Consumer Fraud Victimization. Int. J. Environ. Res. Public Health 2022, 19, 461. https://doi.org/10.3390/ijerph19010461
Xu L, Wang J, Xu D, Xu L. Integrating Individual Factors to Construct Recognition Models of Consumer Fraud Victimization. International Journal of Environmental Research and Public Health. 2022; 19(1):461. https://doi.org/10.3390/ijerph19010461
Chicago/Turabian StyleXu, Liuchang, Jie Wang, Dayu Xu, and Liang Xu. 2022. "Integrating Individual Factors to Construct Recognition Models of Consumer Fraud Victimization" International Journal of Environmental Research and Public Health 19, no. 1: 461. https://doi.org/10.3390/ijerph19010461
APA StyleXu, L., Wang, J., Xu, D., & Xu, L. (2022). Integrating Individual Factors to Construct Recognition Models of Consumer Fraud Victimization. International Journal of Environmental Research and Public Health, 19(1), 461. https://doi.org/10.3390/ijerph19010461