
A Study of the Effects of the COVID-19 Pandemic on the Experience of Back Pain Reported on Twitter® in the United States: A Natural Language Processing Approach

 ,
,  ,
,  , ,
, ,  , ,
, ,  ,
,
Abstract
1. Introduction
2. Literature Review
2.1. Back Pain
2.2. Social Media in Public Health
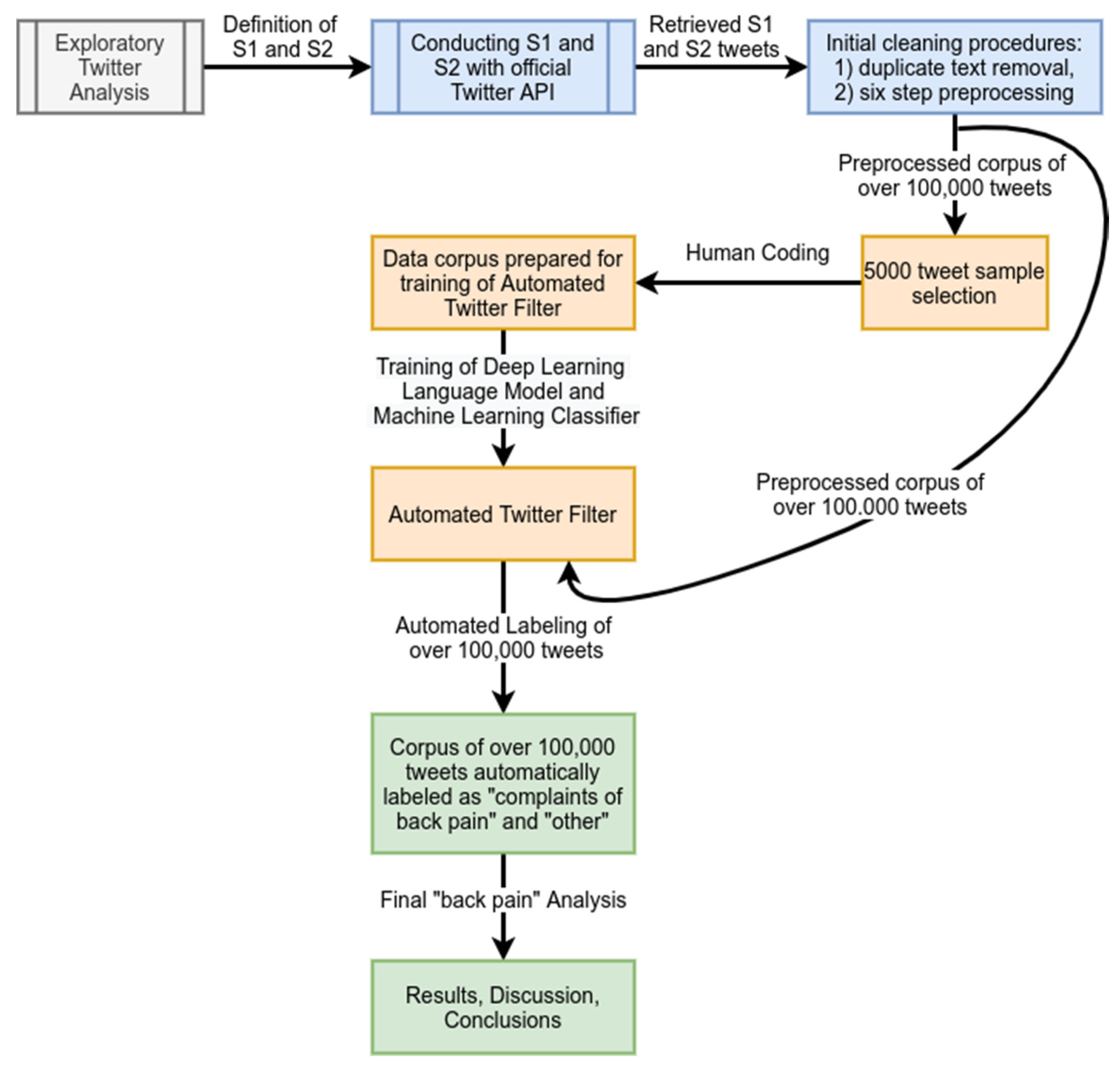
3. Methodology
3.1. Data Acquisition
3.1.1. Exploratory Twitter Data Analysis
3.1.2. Experimental Datasets
3.2. Filtering and Preprocessing of Tweets
- The links to images were replaced with the “_IMAGE” token.
- Redundant/repeating characters were removed (for example a ten times repeated “a” was converted to “aa”).
- Textual elements representing retweets were converted to “_RETWEET” token.
- Other textual elements beginning with “http” or “https” or “bit.ly” or “youtu.be” or “facebook.com” or “instagram.com” were converted to “_URL” tokens.
- Language of tweets was assessed with use of langdetect module [35] and all non-English tweets were removed.
- All emoticons were converted to textual representations with use of emoji module [36] (for example “two hearts”).
3.3. Training and Testing
4. Results
4.1. Automatic Filtering Method
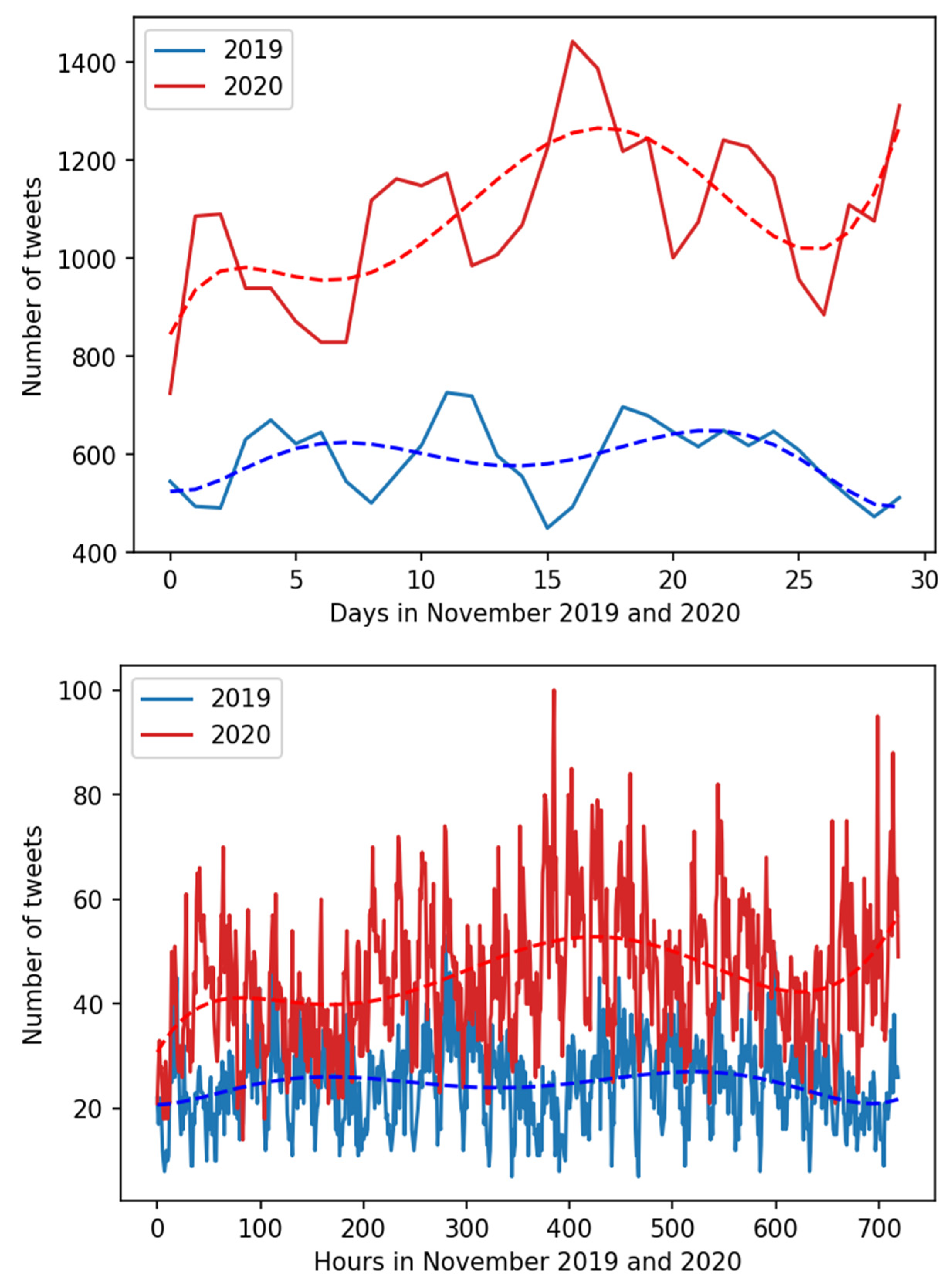
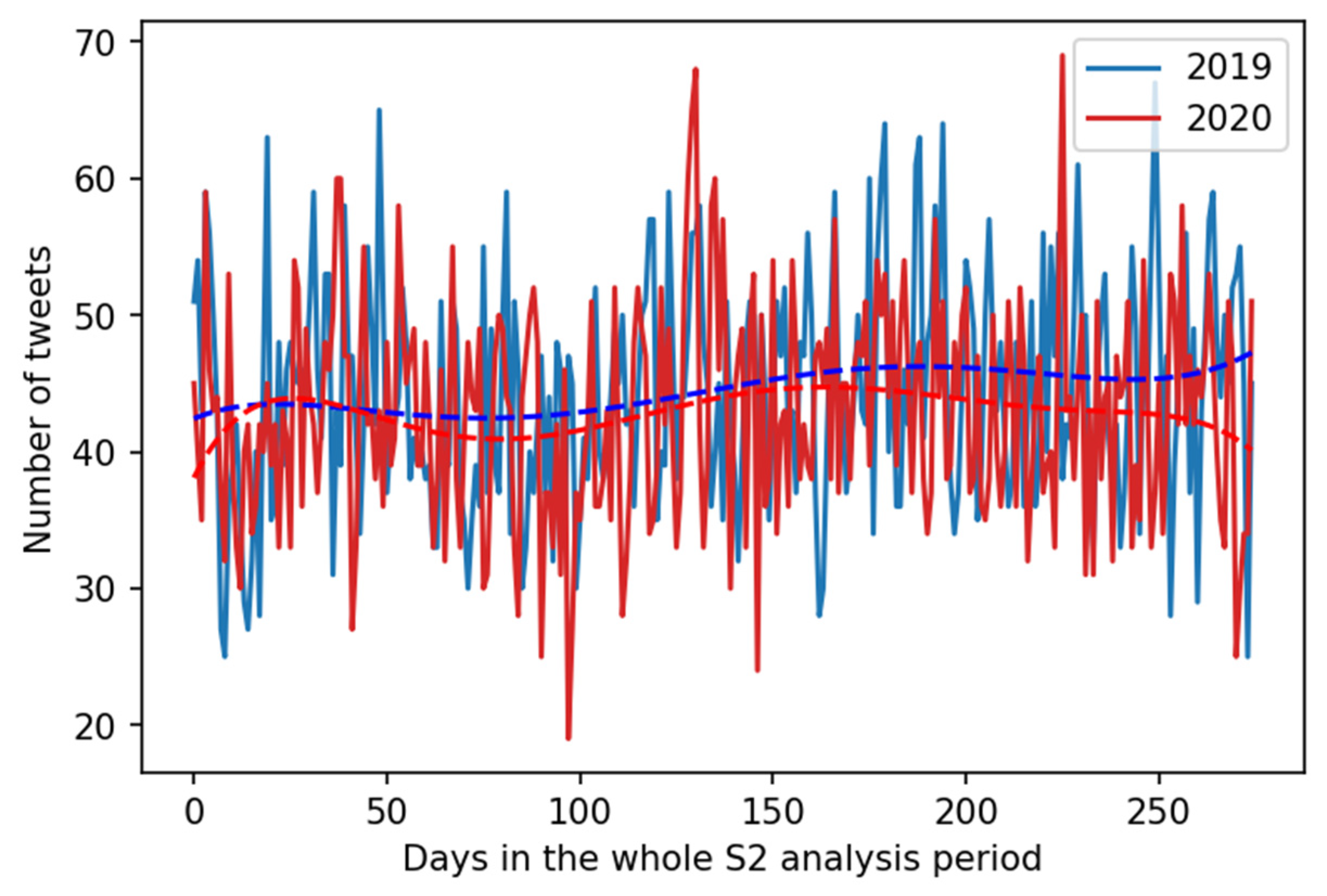
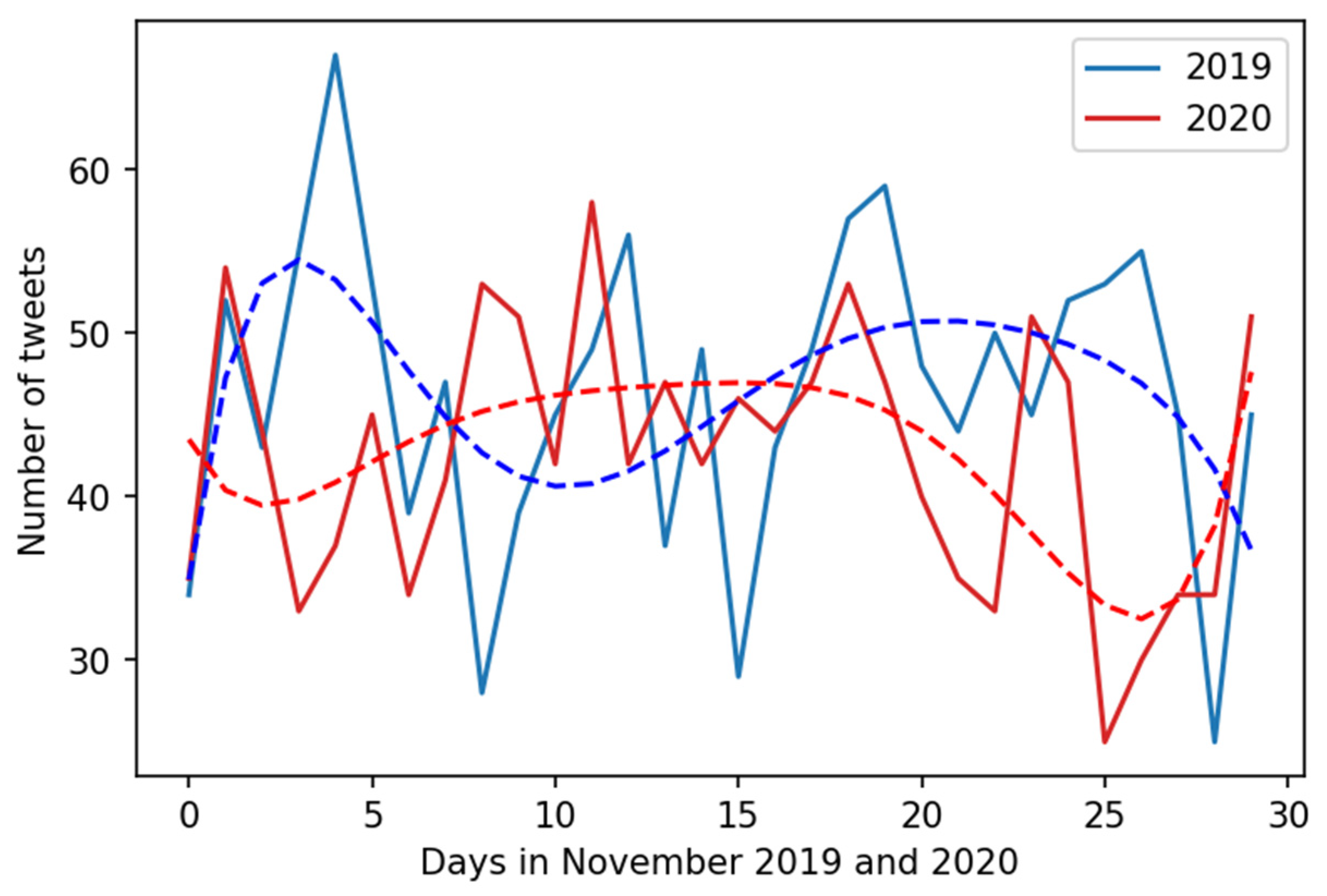
4.2. Hypotheses Testing
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Anjum, S.; Ullah, R.; Rana, M.S.; Ali Khan, H.; Memon, F.S.; Ahmed, Y.; Jabeen, S.; Faryal, R. COVID-19 Pandemic: A Serious Threat for Public Mental Health Globally. Psychiatr. Danub. 2020, 32, 245–250. [Google Scholar] [CrossRef] [PubMed]
- Anderson, R.M.; Heesterbeek, H.; Klinkenberg, D.; Hollingsworth, T.D. How Will Country-Based Mitigation Measures Influence the Course of the COVID-19 Epidemic? Lancet 2020, 395, 931–934. [Google Scholar] [CrossRef]
- Mattioli, A.V.; Ballerini Puviani, M.; Nasi, M.; Farinetti, A. COVID-19 Pandemic: The Effects of Quarantine on Cardiovascular Risk. Eur. J. Clin. Nutr. 2020, 74, 852–855. [Google Scholar] [CrossRef]
- Wilder-Smith, A.; Freedman, D.O. Isolation, Quarantine, Social Distancing and Community Containment: Pivotal Role for Old-Style Public Health Measures in the Novel Coronavirus (2019-NCoV) Outbreak. J. Travel. Med. 2020, 27. [Google Scholar] [CrossRef]
- Šagát, P.; Bartík, P.; Prieto González, P.; Tohănean, D.I.; Knjaz, D. Impact of COVID-19quarantine on Low Back Pain Intensity, Prevalence, and Associated Risk Factors among Adult Citizens Residing in Riyadh (Saudi Arabia): A Cross-Sectional Study. Int. J. Environ. Res. Public. Health 2020, 17, 7302. [Google Scholar] [CrossRef] [PubMed]
- Talevi, D.; Socci, V.; Carai, M.; Carnaghi, G.; Faleri, S.; Trebbi, E.; di Bernardo, A.; Capelli, F.; Pacitti, F. Mental Health Outcomes of the CoViD-19 Pandemic. Riv. Psichiatr. 2020, 55, 137–144. [Google Scholar]
- Belen, H. Self-Blame Regret, Fear of COVID-19 and Mental Health during Post-Peak Pandemic. Res. Square 2020. preprint. [Google Scholar] [CrossRef]
- Rubin, G.J.; Wessely, S. The Psychological Effects of Quarantining a City. BMJ 2020, 368, m313. [Google Scholar] [CrossRef]
- El-Terk, N. Toilet Paper, Canned Food: What Explains Coronavirus Panic Buying. Aljazeera Retrieved May 2020, 26, 2020. [Google Scholar]
- Robinson, E.; Boyland, E.; Chisholm, A.; Harrold, J.; Maloney, N.G.; Marty, L.; Mead, B.R.; Noonan, R.; Hardman, C.A. Obesity, Eating Behavior and Physical Activity during COVID-19 Lockdown: A Study of UK Adults. Appetite 2020, 156, 104853. [Google Scholar] [CrossRef]
- Chen, P.; Mao, L.; Nassis, G.P.; Harmer, P.; Ainsworth, B.E.; Li, F. Coronavirus disease (COVID-19): The need to maintain regular physical activity while taking precautions. J. Sport Health Sci. 2020, 9, 103–104. [Google Scholar] [CrossRef]
- Fan, X.; Straube, S. Reporting on Work-Related Low Back Pain: Data Sources, Discrepancies and the Art of Discovering Truths. Pain Manag. 2016, 6, 553–559. [Google Scholar] [CrossRef]
- Mutubuki, E.N.; Luitjens, M.A.; Maas, E.T.; Huygen, F.J.; Ostelo, R.W.; van Tulder, M.W.; van Dongen, J.M. Predictive Factors of High Societal Costs among Chronic Low Back Pain Patients. Eur. J. Pain 2020, 24, 325–337. [Google Scholar] [CrossRef] [PubMed]
- Tveito, T.H.; Shaw, W.S.; Huang, Y.-H.; Nicholas, M.; Wagner, G. Managing Pain in the Workplace: A Focus Group Study of Challenges, Strategies and What Matters Most to Workers with Low Back Pain. Disabil. Rehabil. 2010, 32, 2035–2045. [Google Scholar] [CrossRef]
- Froud, R.; Patterson, S.; Eldridge, S.; Seale, C.; Pincus, T.; Rajendran, D.; Fossum, C.; Underwood, M. A Systematic Review and Meta-Synthesis of the Impact of Low Back Pain on People’s Lives. BMC Musculoskelet. Disord. 2014, 15, 50. [Google Scholar] [CrossRef]
- Dutmer, A.L.; Preuper, H.R.S.; Soer, R.; Brouwer, S.; Bültmann, U.; Dijkstra, P.U.; Coppes, M.H.; Stegeman, P.; Buskens, E.; van Asselt, A.D. Personal and Societal Impact of Low Back Pain: The Groningen Spine Cohort. Spine 2019, 44, E1443–E1451. [Google Scholar] [CrossRef]
- PEKYAVAŞ, N.Ö.; PEKYAVAS, E. Investigation of The Pain and Disability Situation of The Individuals Working “Home-Office” At Home At The Covid-19 Isolation Process. Int. J. Disabil. Sports Health Sci. 2020, 3, 100–104. [Google Scholar]
- Toprak Celenay, S.; Karaaslan, Y.; Mete, O.; Ozer Kaya, D. Coronaphobia, Musculoskeletal Pain, and Sleep Quality in Stay-at Home and Continued-Working Persons during the 3-Month Covid-19 Pandemic Lockdown in Turkey. Chronobiol. Int. 2020, 37, 1778–1785. [Google Scholar] [CrossRef] [PubMed]
- Puntillo, F.; Giglio, M.; Brienza, N.; Viswanath, O.; Urits, I.; Kaye, A.D.; Pergolizzi, J.; Paladini, A.; Varrassi, G. Impact of COVID-19 Pandemic on Chronic Pain Management: Looking for the Best Way to Deliver Care. Best Pract. Res. Clin. Anaesthesiol. 2020, 34, 529–537. [Google Scholar] [CrossRef] [PubMed]
- Song, X.-J.; Xiong, D.-L.; Wang, Z.-Y.; Yang, D.; Zhou, L.; Li, R.-C. Pain Management during the COVID-19 Pandemic in China: Lessons Learned. Pain Med. 2020, 21, 1319–1323. [Google Scholar] [CrossRef] [PubMed]
- Abdullahi, A.; Candan, S.A.; Abba, M.A.; Bello, A.H.; Alshehri, M.A.; Afamefuna Victor, E.; Umar, N.A.; Kundakci, B. Neurological and Musculoskeletal Features of COVID-19: A Systematic Review and Meta-Analysis. Front. Neurol. 2020, 11, 687. [Google Scholar] [CrossRef] [PubMed]
- Cavazos-Rehg, P.A.; Krauss, M.; Fisher, S.L.; Salyer, P.; Grucza, R.A.; Bierut, L.J. Twitter Chatter About Marijuana. J. Adolesc. Health 2015, 56, 139–145. [Google Scholar] [CrossRef] [PubMed]
- Koh, J.X.; Liew, T.M. How Loneliness Is Talked about in Social Media during COVID-19 Pandemic: Text Mining of 4492 Twitter Feeds. J. Psychiatr. Res. 2020, in press. [Google Scholar] [CrossRef] [PubMed]
- Sutton, J.; Vos, S.C.; Olson, M.K.; Woods, C.; Cohen, E.; Gibson, C.B.; Phillips, N.E.; Studts, J.L.; Eberth, J.M.; Butts, C.T. Lung Cancer Messages on Twitter: Content Analysis and Evaluation. J. Am. Coll. Radiol. 2018, 15, 210–217. [Google Scholar] [CrossRef]
- Lamb, A.; Paul, M.; Dredze, M. Separating Fact from Fear: Tracking Flu Infections on Twitter. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; pp. 789–795. [Google Scholar]
- Heaivilin, N.; Gerbert, B.; Page, J.E.; Gibbs, J.L. Public Health Surveillance of Dental Pain via Twitter. J. Dent. Res. 2011, 90, 1047–1051. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Hu, R.; Chen, C.; Zheng, C.; Su, Y.; Zhu, T. Twitter Discussions and Emotions About the COVID-19 Pandemic: Machine Learning Approach. J. Med. Internet Res. 2020, 22, e20550. [Google Scholar] [CrossRef]
- Abd-Alrazaq, A.; Alhuwail, D.; Househ, M.; Hamdi, M.; Shah, Z. Top Concerns of Tweeters During the COVID-19 Pandemic: Infoveillance Study. J. Med. Internet Res. 2020, 22, e19016. [Google Scholar] [CrossRef]
- Mackey, T.; Purushothaman, V.; Li, J.; Shah, N.; Nali, M.; Bardier, C.; Liang, B.; Cai, M.; Cuomo, R. Machine Learning to Detect Self-Reporting of Symptoms, Testing Access, and Recovery Associated With COVID-19 on Twitter: Retrospective Big Data Infoveillance Study. JMIR Public Health Surveill. 2020, 6, e19509. [Google Scholar] [CrossRef] [PubMed]
- Guntuku, S.C.; Sherman, G.; Stokes, D.C.; Agarwal, A.K.; Seltzer, E.; Merchant, R.M.; Ungar, L.H. Tracking Mental Health and Symptom Mentions on Twitter During COVID-19. J. Gen. Intern. Med. 2020, 35, 2798–2800. [Google Scholar] [CrossRef]
- Fiok, K.; Karwowski, W.; Gutierrez, E.; Reza-Davahli, M. Comparing the Quality and Speed of Sentence Classification with Modern Language Models. Appl. Sci. 2020, 10, 3386. [Google Scholar] [CrossRef]
- Fiok, K.; Karwowski, W.; Gutierrez, E.; Liciaga, T.; Belmonte, A.; Capobianco, R. Automated Classification of Evidence of Respect in the Communication through Twitter. Appl. Sci. 2021, 11, 1294. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Danilak, M.M. Langdetect. 2020. Available online: https://pypi.org/project/langdetect/ (accessed on 20 December 2020).
- Taehoon, K.; Wurster, K. Emoji: Emoji for Python. 2021. Available online: https://pypi.org/project/emoji/ (accessed on 20 December 2020).
- Krippendorff, K. Computing Krippendorff’s Alpha-Reliability; Departmental Papers (ASC); University of Pennsylvania: Philadelphia, PA, USA, 2011. [Google Scholar]
- Chicco, D.; Jurman, G. The Advantages of the Matthews Correlation Coefficient (MCC) over F1 Score and Accuracy in Binary Classification Evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Melamed, I.D.; Green, R.; Turian, J. Precision and Recall of Machine Translation. In Companion Volume of the Proceedings of HLT-NAACL 2003-Short Papers; Association for Computational Linguistics: Stroudsburg, PA, USA, 2003; pp. 61–63. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An Analysis of Variance Test for Normality (Complete Samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Abraham, A.; Pedregosa, F.; Eickenberg, M.; Gervais, P.; Mueller, A.; Kossaifi, J.; Gramfort, A.; Thirion, B.; Varoquaux, G. Machine Learning for Neuroimaging with Scikit-Learn. Front. Neuroinform. 2014, 8, 14. [Google Scholar] [CrossRef] [PubMed]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual String Embeddings for Sequence Labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Ari, N.; Ustazhanov, M. Matplotlib in Python. In Proceedings of the 2014 11th International Conference on Electronics, Computer and Computation (ICECCO), Abuja, Nigeria, 29 September–1 October 2014; pp. 1–6. [Google Scholar]
- Nelli, F. Python Data Analytics: With Pandas, NumPy, and Matplotlib; Apress: New York, NY, USA, 2018; ISBN 978-1-4842-3913-1. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Cury, R.M. Oscillation of Tweet Sentiments in the Election of João Doria Jr. for Mayor. J. Big Data 2019, 6, 42. [Google Scholar] [CrossRef]
- Kaushik, R.; Apoorva Chandra, S.; Mallya, D.; Chaitanya, J.N.V.K.; Kamath, S.S. Sociopedia: An Interactive System for Event Detection and Trend Analysis for Twitter Data. In Proceedings of the 3rd International Conference on Advanced Computing, Networking and Informatics, Orissa, India, 23–25 June 2015; pp. 63–70. [Google Scholar]
- Xue, J.; Chen, J.; Chen, C.; Zheng, C.; Li, S.; Zhu, T. Public Discourse and Sentiment during the COVID 19 Pandemic: Using Latent Dirichlet Allocation for Topic Modeling on Twitter. PLoS ONE 2020, 15, e0239441. [Google Scholar] [CrossRef]
- Petrovic, S.; Osborne, M.; Lavrenko, V. Rt to Win! Predicting Message Propagation in Twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Catalonia, Spain, 17–21 July 2011. [Google Scholar]
- Jenders, M.; Kasneci, G.; Naumann, F. Analyzing and Predicting Viral Tweets. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–14 May 2013; pp. 657–664. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Search Parameters | Number of Tweets | Frequent Tweet Types | |||||
|---|---|---|---|---|---|---|---|
| Search phrase | Explicit | Localization | XDay19 | XDay20 | Complaints | Other (advertisement, professional discussion, not relevant) | Scam |
| low back pain | No | No | 134 | 183 | No | Yes | No |
| lower back pain | No | No | 164 | 256 | Yes | No | No |
| back pain | No | No | 3331 | 10,726 | Yes | Numerous | Yes |
| back pain | Yes | No | 1303 | 5762 | Yes | Yes | Yes |
| back pain | No | Yes | 54 | 72 | Yes | Yes | Yes |
| Search Number | Time Span | Filtering Duplicated Texts | |
|---|---|---|---|
| Before | After | ||
| 1 | 11 November–1 December 2019 | 53,234 | 28,598 |
| 1 | 11 November–1 December 2020 | 78,559 | 45,544 |
| 2 | 1 March–1 December 2019 | 15,663 | 15,635 |
| 2 | 1 March–1 December 2020 | 14,634 | 14,497 |
| Group | Other | Complaints of Back Pain |
|---|---|---|
| Other | 1895 | 128 |
| Complaints of back pain | 100 | 2877 |
| Metric | Value |
|---|---|
| Accuracy | 0.9544 |
| Balanced accuracy | 0.9516 |
| F1 macro | 0.9526 |
| F1 micro | 0.9544 |
| F1 weighted | 0.9543 |
| MCC | 0.9052 |
| Precision | 0.9536 |
| Recall | 0.9516 |
| Filtering Duplicated Texts | Predicted as Legitimate Complaining Tweets | ||||||
|---|---|---|---|---|---|---|---|
| Search number | Time span | Before | After | % of original tweet number | After | % of original tweet number | % of filtered tweet number |
| 1 | 1 November–1 December 2019 | 53,234 | 28,598 | 53.72 | 17,674 | 33.2 | 61.8 |
| 1 | 1 November–1 December 2020 | 78,559 | 45,544 | 57.97 | 32,530 | 41.41 | 71.43 |
| 2 | 1 March–1 December 2019 | 15,663 | 15,635 | 99.82 | 12,223 | 78.04 | 78.18 |
| 2 | 1 March–1 December 2020 | 14,634 | 14,497 | 99.06 | 11,785 | 80.53 | 81.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiok, K.; Karwowski, W.; Gutierrez, E.; Saeidi, M.; Aljuaid, A.M.; Davahli, M.R.; Taiar, R.; Marek, T.; Sawyer, B.D. A Study of the Effects of the COVID-19 Pandemic on the Experience of Back Pain Reported on Twitter® in the United States: A Natural Language Processing Approach. Int. J. Environ. Res. Public Health 2021, 18, 4543. https://doi.org/10.3390/ijerph18094543
Fiok K, Karwowski W, Gutierrez E, Saeidi M, Aljuaid AM, Davahli MR, Taiar R, Marek T, Sawyer BD. A Study of the Effects of the COVID-19 Pandemic on the Experience of Back Pain Reported on Twitter® in the United States: A Natural Language Processing Approach. International Journal of Environmental Research and Public Health. 2021; 18(9):4543. https://doi.org/10.3390/ijerph18094543
Chicago/Turabian StyleFiok, Krzysztof, Waldemar Karwowski, Edgar Gutierrez, Maham Saeidi, Awad M. Aljuaid, Mohammad Reza Davahli, Redha Taiar, Tadeusz Marek, and Ben D. Sawyer. 2021. "A Study of the Effects of the COVID-19 Pandemic on the Experience of Back Pain Reported on Twitter® in the United States: A Natural Language Processing Approach" International Journal of Environmental Research and Public Health 18, no. 9: 4543. https://doi.org/10.3390/ijerph18094543
APA StyleFiok, K., Karwowski, W., Gutierrez, E., Saeidi, M., Aljuaid, A. M., Davahli, M. R., Taiar, R., Marek, T., & Sawyer, B. D. (2021). A Study of the Effects of the COVID-19 Pandemic on the Experience of Back Pain Reported on Twitter® in the United States: A Natural Language Processing Approach. International Journal of Environmental Research and Public Health, 18(9), 4543. https://doi.org/10.3390/ijerph18094543