
Expanding Our Understanding of COVID-19 from Biomedical Literature Using Word Embedding


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data: PubMed Literature
2.1.1. Medical Subject Headings (MeSH)
2.1.2. Substance Name (SN)
2.1.3. Vocabulary Combing MeSH, SN, and OT Terms
2.2. Model: Word Embedding with FastText
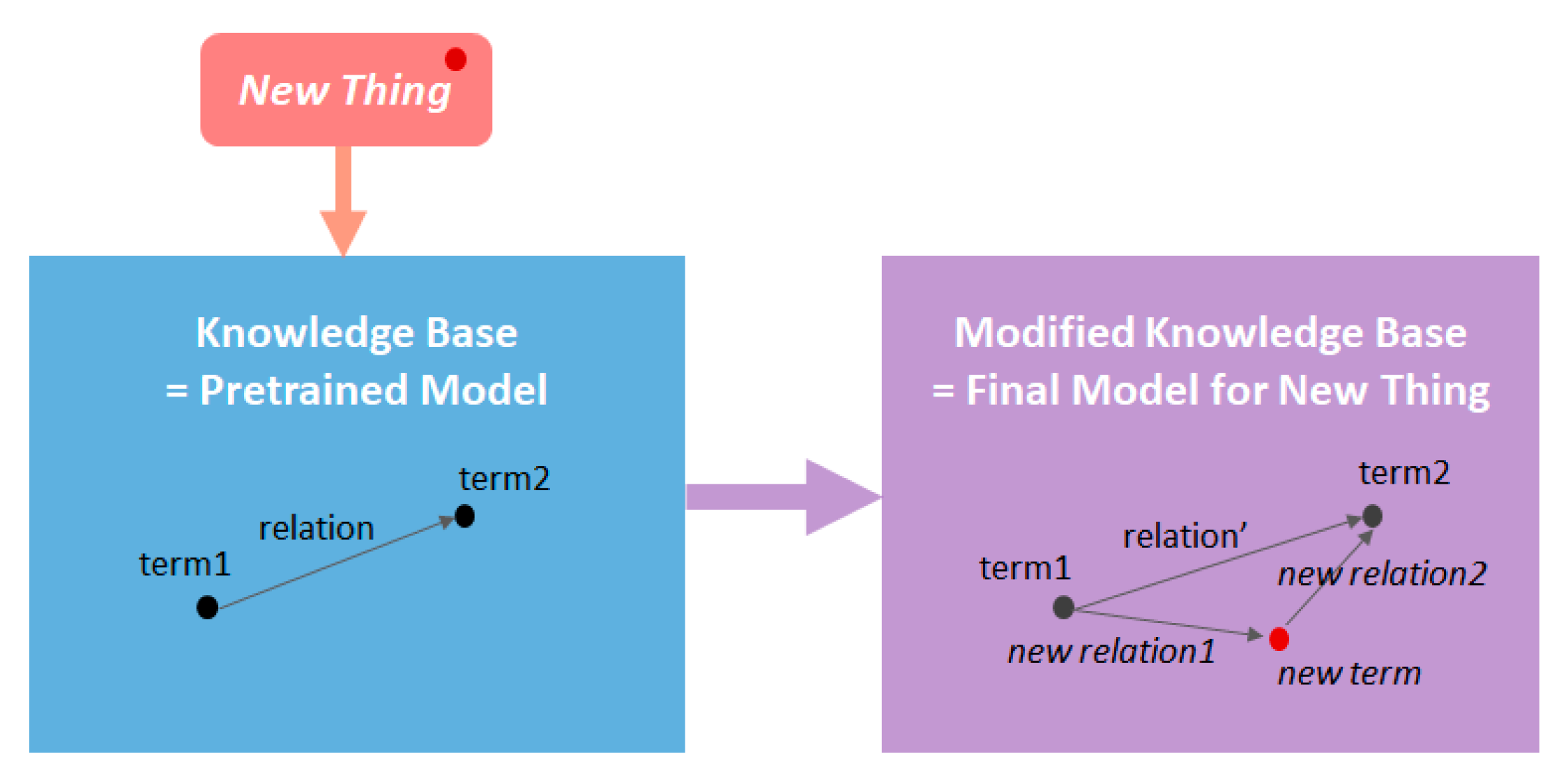
2.2.1. Pretrained Model
2.2.2. Final Model
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Tan, W. A novel coronavirus from patients with pneumonia in China, 2019. N. Engl. J. Med. 2020, 382, 727–733. [Google Scholar] [CrossRef]
- WHO Coronavirus Disease (COVID-19) Dashboard. Available online: https://covid.who.int/ (accessed on 11 March 2021).
- Calligari, P.; Bobone, S.; Ricci, G.; Bocedi, A. Molecular investigation of SARS–CoV-2 proteins and their interactions with antiviral drugs. Viruses 2020, 12, 445. [Google Scholar] [CrossRef] [Green Version]
- Prajapat, M.; Sarma, P.; Shekhar, N.; Avti, P.; Sinha, S.; Kaur, H.; Medhi, B. Drug targets for corona virus: A systematic review. Indian J. Pharmacol. 2020, 52, 56. [Google Scholar]
- Astuti, I. Severe Acute Respiratory Syndrome Coronavirus 2 (SARS-CoV-2): An overview of viral structure and host response. Diabetes Metab. Syndr. Clin. Res. Rev. 2020, 14, 407–412. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Q.; Guo, D. Emerging coronaviruses: Genome structure, replication, and pathogenesis. J. Med Virol. 2020, 92, 418–423. [Google Scholar] [CrossRef] [PubMed]
- Gordon, D.E.; Jang, G.M.; Bouhaddou, M.; Xu, J.; Obernier, K.; White, K.M.; Krogan, N.J. A SARS-CoV-2 protein interaction map reveals targets for drug repurposing. Nature 2020, 583, 459–468. [Google Scholar] [CrossRef]
- Yang, S.; Fu, C.; Lian, X.; Dong, X.; Zhang, Z. Understanding human-virus protein-protein interactions using a human protein complex-based analysis framework. MSystems 2019, 4. [Google Scholar] [CrossRef] [Green Version]
- Yoshimoto, F.K. The proteins of severe acute respiratory syndrome coronavirus-2 (SARS CoV-2 or n-COV19), the cause of COVID-19. Protein J. 2020, 39, 198–216. [Google Scholar] [CrossRef] [PubMed]
- Tu, Y.F.; Chien, C.S.; Yarmishyn, A.A.; Lin, Y.Y.; Luo, Y.H.; Lin, Y.T.; Chiou, S.H. A review of SARS-CoV-2 and the ongoing clinical trials. Int. J. Mol. Sci. 2020, 21, 2657. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gómez-Ríos, D.; López-Agudelo, V.A.; Ramírez-Malule, H. Repurposing antivirals as potential treatments for SARS-CoV-2: From SARS to COVID-19. J. Appl. Pharm. Sci. 2020, 10, 1–9. [Google Scholar]
- Guy, R.K.; DiPaola, R.S.; Romanelli, F.; Dutch, R.E. Rapid repurposing of drugs for COVID-19. Science 2020, 368, 829–830. [Google Scholar] [CrossRef] [PubMed]
- Serafin, M.B.; Bottega, A.; Foletto, V.S.; da Rosa, T.F.; Hörner, A.; Hörner, R. Drug repositioning is an alternative for the treatment of coronavirus COVID-19. Int. J. Antimicrob. Agents 2020, 55, 105969. [Google Scholar] [CrossRef]
- Liu, S.; Zheng, Q.; Wang, Z. Potential covalent drugs targeting the main protease of the SARS-CoV-2 coronavirus. Bioinformatics 2020, 36, 3295–3298. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Hou, Y.; Shen, J.; Huang, Y.; Martin, W.; Cheng, F. Network-based drug repurposing for novel coronavirus 2019-nCoV/SARS-CoV-2. Cell Discov. 2020, 6, 14. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.; Liu, Y.; Yang, Y.; Zhang, P.; Zhong, W.; Wang, Y.; Li, H. Analysis of therapeutic targets for SARS-CoV-2 and discovery of potential drugs by computational methods. Acta Pharm. Sin. B 2020, 10, 766–788. [Google Scholar] [CrossRef]
- Cernile, G.; Heritage, T.; Sebire, N.J.; Gordon, B.; Schwering, T.; Kazemlou, S.; Borecki, Y. Network graph representation of COVID-19 scientific publications to aid knowledge discovery. BMJ Health Care Inform. 2021, 28, e100254. [Google Scholar] [CrossRef] [PubMed]
- Domingo-Fernández, D.; Baksi, S.; Schultz, B.; Gadiya, Y.; Karki, R.; Raschka, T.; Hofmann-Apitius, M. COVID-19 Knowledge Graph: A computable, multi-modal, cause-and-effect knowledge model of COVID-19 pathophysiology. Bioinformatics 2020. [Google Scholar] [CrossRef]
- Chen, C.; Ebeid, I.A.; Bu, Y.; Ding, Y. Coronavirus knowledge graph: A case study. arXiv 2020, arXiv:2007.10287. [Google Scholar]
- Reese, J.T.; Unni, D.; Callahan, T.J.; Cappelletti, L.; Ravanmehr, V.; Carbon, S.; Mungall, C.J. KG-COVID-19: A framework to produce customized knowledge graphs for COVID-19 response. Patterns 2020, 2, 100155. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Li, M.; Wang, X.; Parulian, N.; Han, G.; Ma, J.; Onyshkevych, B. COVID-19 literature knowledge graph construction and drug repurposing report generation. arXiv 2020, arXiv:2007.00576. [Google Scholar]
- Jurafsky, D. Speech Language Processing; Pearson Education: Tamil Nadu, India, 2000. [Google Scholar]
- Habibi, M.; Weber, L.; Neves, M.; Wiegandt, D.L.; Leser, U. Deep learning with word embeddings improves biomedical named entity recognition. Bioinformatics 2017, 33, i37–i48. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. arXiv 2013, arXiv:1310.4546. [Google Scholar]
- Mikolov, T.; Grave, E.; Bojanowski, P.; Puhrsch, C.; Joulin, A. Advances in pre-training distributed word representations. arXiv 2017, arXiv:1712.09405. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhang, Y.; Chen, Q.; Yang, Z.; Lin, H.; Lu, Z. BioWordVec, improving biomedical word embeddings with subword information and MeSH. Sci. Data 2019, 6, 52. [Google Scholar] [CrossRef] [Green Version]
- Pakhomov, S.; McInnes, B.; Adam, T.; Liu, Y.; Pedersen, T.; Melton, G.B. Semantic similarity and relatedness between clinical terms: An experimental study. In AMIA Annual Symposium Proceedings; American Medical Informatics Association: Bethesda, MD, USA, 2010; Volume 2010, p. 572. [Google Scholar]
- Excelar, COVID-19 Drug Repurposing Database. Available online: https://www.excelra.com/covid-19-drug-repurposing-database/ (accessed on 11 March 2021).
- ReDO Project, Covid19_DB. Available online: http://www.redo-project.org/covid19db/ (accessed on 11 March 2021).
- DrugBank, Covid-19 Information. Available online: https://www.drugbank.ca/ (accessed on 11 March 2021).
- The Human Protein Atlas. Available online: https://www.proteinatlas.org/ (accessed on 11 March 2021).
- Di Nardo, M.; Madonna, M.; Murino, T.; Castagna, F. Modelling a Safety Management System Using System Dynamics at the Bhopal Incident. Appl. Sci. 2020, 10, 903. [Google Scholar] [CrossRef] [Green Version]
- Galea, S.; Riddle, M.; Kaplan, G.A. Causal thinking and complex system approaches in epidemiology. Int. J. Epidemiol. 2010, 39, 97–106. [Google Scholar] [CrossRef]


{kind=link}
| No. | Hyperparameters | Evaluation_1 | Evaluation_2 | |||||
|---|---|---|---|---|---|---|---|---|
| Vector Size | Window Size | Number of Epochs | Pearson Correlation Similarity | Spearman Correlation Similarity | Q-A Accuracy | |||
| Coefficient | p-Value | Coefficient | p-Value | |||||
| 1 | 100 | 40 | 10 | 0.6774 | 2.13 × 10−20 | 0.6774 | 2.10 × 10−20 | 0.8810 |
| 2 | 100 | 40 | 15 | 0.6708 | 6.71 × 10−20 | 0.6776 | 2.02 × 10−20 | 0.8095 |
| 3 | 100 | 40 | 20 | 0.6687 | 9.62 × 10−20 | 0.6667 | 1.34 × 10−19 | 0.8095 |
| 4 | 100 | 50 | 10 | 0.6718 | 5.61 × 10−20 | 0.6759 | 2.77 × 10−20 | 0.8333 |
| 5 | 100 | 50 | 15 | 0.6634 | 2.34 × 10−19 | 0.6632 | 2.42 × 10−19 | 0.7857 |
| 6 | 100 | 50 | 20 | 0.6688 | 9.43 × 10−20 | 0.6713 | 6.10 × 10−20 | 0.8810 |
| 7 | 100 | 60 | 10 | 0.6747 | 3.41 × 10−20 | 0.6820 | 9.25 × 10−21 | 0.8810 |
| 8 | 100 | 60 | 15 | 0.6715 | 5.89 × 10−20 | 0.6736 | 4.10 × 10−20 | 0.8810 |
| 9 | 100 | 60 | 20 | 0.6745 | 3.51 × 10−20 | 0.6810 | 1.11 × 10−20 | 0.8571 |
| 10 | 150 | 40 | 10 | 0.6711 | 6.38 × 10−20 | 0.6816 | 9.99 × 10−21 | 0.9048 |
| 11 | 150 | 40 | 15 | 0.6749 | 3.29 × 10−20 | 0.6864 | 4.15 × 10−21 | 0.9762 |
| 12 | 150 | 40 | 20 | 0.6718 | 5.65 × 10−20 | 0.6802 | 1.29 × 10−20 | 0.9762 |
| 13 | 150 | 50 | 10 | 0.6775 | 2.07 × 10−20 | 0.6931 | 1.21 × 10−21 | 0.9286 |
| 14 | 150 | 50 | 15 | 0.6781 | 1.88 × 10−20 | 0.6914 | 1.66 × 10−21 | 0.9524 |
| 15 | 150 | 50 | 20 | 0.6772 | 2.19 × 10−20 | 0.6891 | 2.56 × 10−21 | 0.9762 |
| 16 | 150 | 60 | 10 | 0.6708 | 6.70 × 10−20 | 0.6817 | 9.79 × 10−21 | 0.9524 |
| 17 | 150 | 60 | 15 | 0.6780 | 1.89 × 10−20 | 0.6928 | 1.27 × 10−21 | 0.9762 |
| 18 | 150 | 60 | 20 | 0.6695 | 8.39 × 10−20 | 0.6796 | 1.42 × 10−20 | 0.9286 |
| 19 | 200 | 40 | 10 | 0.6714 | 6.05 × 10−20 | 0.6849 | 5.52 × 10−21 | 0.9524 |
| 20 | 200 | 40 | 15 | 0.6718 | 5.66 × 10−20 | 0.6856 | 4.81 × 10−21 | 0.9524 |
| 21 | 200 | 40 | 20 | 0.6700 | 7.66 × 10−20 | 0.6833 | 7.39 × 10−21 | 0.9048 |
| 22 | 200 | 50 | 10 | 0.6783 | 1.81 × 10−20 | 0.6936 | 1.09 × 10−21 | 0.9286 |
| 23 | 200 | 50 | 15 | 0.6761 | 2.64 × 10−20 | 0.6908 | 1.86 × 10−21 | 0.8810 |
| 24 | 200 | 50 | 20 | 0.6716 | 5.86 × 10−20 | 0.6843 | 6.13 × 10−21 | 0.9286 |
| 25 | 200 | 60 | 10 | 0.6708 | 6.65 × 10−20 | 0.6847 | 5.71 × 10−21 | 0.9524 |
| 26 | 200 | 60 | 15 | 0.6755 | 2.96 × 10−20 | 0.6875 | 3.39 × 10−21 | 1.0000 |
| 27 | 200 | 60 | 20 | 0.6669 | 1.30 × 10−19 | 0.6774 | 2.11 × 10−20 | 0.9524 |
| No. | Number of Epochs | Evaluation for Final Model |
|---|---|---|
| COVID-19 with RNA Virus Term Similarity | ||
| 1 | 10 | 0.4112 |
| 2 | 20 | 0.4524 |
| 3 | 30 | 0.4696 |
| 4 | 40 | 0.4779 |
| 5 | 50 | 0.4778 |
| 6 | 60 | 0.4802 |
| 7 | 70 | 0.4822 |
| 8 | 80 | 0.4835 |
| 9 | 90 | 0.4850 |
| 10 | 100 | 0.4862 |
| 11 | 110 | 0.4873 |
| 12 | 120 | 0.4867 |
| 13 | 130 | 0.4851 |
| 14 | 140 | 0.4853 |
| 15 | 150 | 0.4854 |
| No | Drug Medical Subject Heading (MeSH) Terms for Anti-Infective PHARMACOLOGICAL Action from the Final Model | Original Indication | Reference |
|---|---|---|---|
| 1 | Cilastatin, Imipenem Drug Combination | Bacterial infection | |
| 2 | Oseltamivir | Influenza virus infection | PMID: 12690091, NCT04345419 et al., 7 cases |
| 3 | Chloroquine | Malaria | PMID: 32074550, NCT04286503 et al., 29 cases |
| 4 | Amoxicillin-Potassium Clavulanate Combination | Bacterial infection | NCT04363060 |
| 5 | Trimethoprim, Sulfamethoxazole Drug Combination | Bacterial infection | NCT04357366, NCT03489629 |
| 6 | Emtricitabine, Rilpivirine, Tenofovir Drug Combination | HIV/AIDS | |
| 7 | Colistin | Bacterial infection | ChiCTR2000032242 (China) |
| 8 | Interferons | Viral infection, Cancer | NCT04379518 et al., 9 cases |
| 9 | Artemether, Lumefantrine Drug Combination | Malaria | |
| 10 | Penicillin | Bacterial infection | |
| 11 | Bacteriocins | Bacterial infection | |
| 12 | Amdinocillin | Bacterial infection | |
| 13 | Tigecycline | Bacterial infection | PMID: 28700943 |
| 14 | Streptogramins | Bacterial infection | |
| 15 | Teicoplanin | Bacterial infection | IRCT20161204031229N3 (Iran) |
| 16 | Palivizumab | Viral infection | |
| 17 | Aztreonam | Bacterial infection | |
| 18 | Meropenem | Bacterial infection | |
| 19 | Azlocillin | Bacterial infection | |
| 20 | Silver Proteins | Antiseptics | |
| 21 | Imipenem | Bacterial infection | |
| 22 | Ribavirin | Viral infection | PMID: 22555152, NCT04392427 |
| 23 | Lincosamides | Bacterial infection | |
| 24 | Piperacillin, Tazobactam Drug Combination | Bacterial infection | NCT02735707 |
| 25 | Polymyxins | Bacterial infection | |
| 26 | Emtricitabine, Tenofovir Disoproxil Fumarate Drug Combination | HIV/AIDS | NCT04329520 |
| 27 | Mefloquine | Malaria | NCT04347031 |
| 28 | Methicillin | Bacterial infection | |
| 29 | Zanamivir | Influenza A virus infection | PMID: 15200845 |
| 30 | Rimantadine | Influenza A virus infection | PMID: 31133031, 15288617 |
| 31 | Valganciclovir | Viral infection | |
| 32 | Amantadine | Dyskinesia associated with parkinsonism, influenza infection | |
| 33 | Cephalosporins | Bacterial infection | |
| 34 | Ampicillin | Bacterial infection | |
| 35 | Doripenem | Bacterial infection | |
| 36 | Simeprevir | HCV infection | |
| 37 | Lopinavir | HIV/AIDS | NCT04372628 et al., 37 cases |
| 38 | Cefamandole | Bacterial infection | |
| 39 | Ceftriaxone | Bacterial infection | NCT02735707 |
| 40 | Thienamycins | Bacterial infection | |
| 41 | Penicillic Acid | Bacterial infection | |
| 42 | Sisomicin | Bacterial infection | |
| 43 | Ganciclovir | Cytomegalovirus retinitis | PMID: 32166607 |
| 44 | Primaquine | Malaria | NCT04349410 |
| 45 | Sulfalene | Bacterial infection | |
| 46 | Azithromycin | Bacterial infection | NCT04332107 et al. 67 cases |
| 47 | Vancomycin | Bacterial infection | NCT02667418 |
| 48 | Spectinomycin | Bacterial infection | |
| 49 | Efavirenz, Emtricitabine, Tenofovir Disoproxil Fumarate Drug Combination | HIV/AIDS | |
| 50 | Minocycline | Bacterial infection | NCT03489629 |
| 51 | Leucomycins | Bacterial infection | |
| 52 | Ticarcillin | Bacterial infection | |
| 53 | Linezolid | Bacterial infection | PMID: 16127068, 16723564, 22094260 |
| 54 | Ertapenem | Bacterial infection | |
| 55 | Clindamycin | Bacterial infection | NCT04349410 |
| 56 | Chloramphenicol | Bacterial infection | PMID: 23148581 |
| 57 | Doxycycline | Bacterial infection | NCT04370782 et al., 6 cases |
| 58 | Hydroxychloroquine | Malaria | NCT04358068 et al., 177 cases |
| 59 | Famciclovir | viral infection | |
| 60 | Tyrocidine | Bacterial infection | |
| 61 | Acyclovir | viral infection | |
| 62 | Nisin | Bacterial infection | |
| 63 | Nebramycin | Bacterial infection | |
| 64 | Penicillanic Acid | Bacterial infection | |
| 65 | Elvitegravir, Cobicistat, Emtricitabine, Tenofovir Disoproxil Fumarate Drug Combination | HIV/AIDS | |
| 66 | Pristinamycin | Bacterial infection | |
| 67 | Nevirapine | HIV/AIDS | |
| 68 | Lamivudine | HIV/AIDS | |
| 69 | Piperacillin | Bacterial infection | NCT04394182 |
| 70 | Valacyclovir | viral infection | |
| 71 | Viomycin | Bacterial infection | |
| 72 | Emtricitabine | HIV/AIDS | NCT04334928 |
| 73 | Ceftazidime | Bacterial infection | |
| 74 | Artemisinins | Malaria | |
| 75 | Josamycin | Bacterial infection | |
| 76 | Telbivudine | viral infection | |
| 77 | Fidaxomicin | Bacterial infection | NCT02667418 |
| 78 | Edeine | Bacterial infection | |
| 79 | Cefoxitin | Bacterial infection | |
| 80 | Proguanil | Malaria | |
| 81 | Fosfomycin | Bacterial infection | |
| 82 | Metha-cycline | Bacterial infection | |
| 83 | Tylosin | Bacterial infection | |
| 84 | Sulbactam | Bacterial infection | |
| 85 | Amikacin | Bacterial infection | |
| 86 | Ritonavir | HIV/AIDS | NCT04372628 et al., 43 cases |
| 87 | Sulfa-doxine | Malaria | |
| 88 | Dihydrostreptomycin Sulfate | Bacterial infection | |
| 89 | Cefotaxime | Bacterial infection | |
| 90 | Cefotetan | Bacterial infection | |
| 91 | Hexetidine | Bacterial infection | |
| 92 | Atovaquone | Pneumocystis pneumonia, toxoplasmosis, malaria | NCT04339426 |
| 93 | Oxacillin | Bacterial infection | |
| 94 | Daptomycin | Bacterial infection | |
| 95 | Rilpivirine | HIV/AIDS | |
| 96 | Sofosbuvir | Hepatitis C virus infection | NCT04443725 |
| 97 | Streptomycin | Bacterial infection | |
| 98 | Artesunate | Malaria | NCT04387240 |
| 99 | Hepcidins | Antimicrobial peptide | |
| 100 | Sparsomycin | Bacterial infection | |
| 108 | Tenofovir | Viral infection | IRCT20200421047155N1 |
| 134 | Mupirocin | Impetigo and secondary skin infection | NCT03489629 |
| 137 | Inosine Pranobex | Viral infection | NCT04360122, NCT04383717 |
| 142 | Cytarabine | Leukemia | NCT02310321 |
| 149 | Clarithromycin | Bacterial infection | NCT04398004 |
| 150 | Itraconazole | Fungal infection | 2020-001243-15 (Begium) |
| 154 | Amoxicillin | Bacterial infection | NCT04363060 |
| 157 | Tazobactam | Bacterial infection | NCT04394182 |
| 160 | Cobicistat | HIV-1 infection | NCT04425382 et al., 3 cases |
| 175 | Quinacrine | Malaria | PMID: 23301007, 31307979, 32194980 |
| 186 | Darunavir | HIV-1 infection | NCT04435587 et al., 4 cases |
| 191 | Iodine | Breast disorders and pain | NCT04344236 |
| 194 | Indinavir | HIV/AIDS | PMID: 15144898 |
| 199 | Clavulanic Acid | Bacterial infection | NCT04363060 |
| 202 | Mycophenolic Acid | Organ rejection | PMID: 5799033 |
| 204 | Maraviroc | HIV infection | NCT04435522, NCT04441385 |
| 220 | Chlorhexidine | Antiseptics | NCT04344236, NCT03489629 |
| 235 | Trimethoprim | Bacterial infection | NCT04357366, NCT03489629 |
| 247 | Sulfamethoxazole | Bacterial infection | NCT04357366, NCT03489629 |
| 253 | Acetylcysteine | Mucolytics | NCT04419025 et al. 4 cases |
| 257 | Dactinomycin | Cancer | PMID: 1335030, 32194980 |
| 269 | Atazanavir Sulfate | HIV-1 infection | NCT02016924 |
| 277 | Idarubicin | Acute Myeloid Leukemia | NCT02310321 |
| 284 | Hydrogen Peroxide | Disinfectant and Sterilizer | NCT04409873 |
| 291 | Povidone-Iodine | Infection | NCT04410159 et al., 7 cases |
| 294 | Sirolimus | Organ rejection | NCT04374903 et al., 3 cases |
| 298 | Methylene Blue | Methemoglobinemia | NCT04376788, NCT04370288 |
| 350 | Pyrazinamide | Tuberculosis | NCT04349241 |
| 362 | Camphor | Coughing | PMID: 27823881, 32194980 |
| 367 | Cetylpyridinium | Bacterial infection | NCT04409873 |
| 374 | Daunorubicin | Cancer | PMID: 9647783 |
| No | Protein Substance Name (SN) Terms of Human and Coronavirus from the Final Model | Protein Description | Gene Name | Covid-19 Bait |
|---|---|---|---|---|
| 1 | M protein, Coronavirus | SARS-CoV-2 Viral Protein (M) | ||
| 2 | Nsp1 protein, SARS coronavirus | SARS-CoV-2 Viral Protein (nsp1) | ||
| 3 | nsp14 protein, SARS coronavirus | SARS-CoV-2 Viral Protein (nsp14) | ||
| 4 | 3C-like proteinase, Coronavirus | SARS-CoV-2 Viral Protein (nsp5) | ||
| 5 | dynorphin converting enzyme | |||
| 6 | COG2 protein, human | |||
| 7 | nonstructural protein 3, SARS coronavirus | SARS-CoV-2 Viral Protein (nsp3) | ||
| 8 | angiotensin converting enzyme 2 | SARS-CoV-2 entry receptors | ACE2 | |
| 9 | COX6A1 protein, human | |||
| 10 | poly U polymerase | |||
| 11 | CORIN protein, human | |||
| 12 | COX8C protein, human | |||
| 13 | Nsp16 protein, SARS virus | SARS-CoV-2 Viral Protein (nsp16) | ||
| 14 | COX5A protein, human | |||
| 15 | COQ5 protein, human | |||
| 16 | GBE1 protein, human | |||
| 17 | transmembrane serine protease 2, human | |||
| 18 | sfericase | |||
| 19 | CPVL protein, human | |||
| 20 | COX4I1 protein, human | |||
| 21 | LARS2 protein, human | |||
| 22 | COX5B protein, human | |||
| 23 | NARS2 protein, human | SARS-CoV-2 interacting protein | NARS2 | SARS-CoV-2 nsp8 |
| 24 | UL49A protein, Human herpesvirus 2 | |||
| 25 | COX6B1 protein, human | |||
| 26 | PARS2 protein, human | |||
| 27 | hydrogenase maturating endopeptidase HYBD | |||
| 28 | VARS2 protein, human | |||
| 29 | human airway trypsin-like protease | |||
| 30 | ERI1 protein, human | |||
| 31 | Myxo-bacter alpha-lytic proteinase | |||
| 32 | AARS2 protein, human | |||
| 33 | RARS2 protein, human | |||
| 34 | Tli polymerase | |||
| 35 | ADAM29 protein, human | |||
| 36 | HPN protein, human | |||
| 37 | O-antigen polymerase | |||
| 38 | SPEG protein, human | |||
| 39 | CLPB protein, human | |||
| 40 | FONG protein, human | |||
| 41 | ERManI protein, human | |||
| 42 | PDIK1L protein, human | |||
| 43 | ALG8 protein, human | SARS-CoV-2 interacting protein | ALG8 | SARS-CoV-2 orf9c |
| 44 | NVL protein, human | |||
| 45 | HFM1 protein, human | |||
| 46 | HARS2 protein, human | |||
| 47 | COASY protein, human | |||
| 48 | TMPRSS13 protein, human | |||
| 49 | C1RL protein, human | |||
| 50 | COX20 protein, human | |||
| 51 | ECEL1 protein, human | |||
| 52 | NARFL protein, human | |||
| 53 | GANAB protein, human | |||
| 54 | AFG3L2 protein, human | |||
| 55 | TSEN54 protein, human | |||
| 56 | ERAL1 protein, human | |||
| 57 | m-AAA proteases | |||
| 58 | KY protein, human | |||
| 59 | TMEM129 protein, human | |||
| 60 | KEL protein, human | |||
| 61 | APH1B protein, human | |||
| 62 | MGME1 protein, human | |||
| 63 | ATL3 protein, human | |||
| 64 | oxacillinase | |||
| 65 | COX10 protein, human | |||
| 66 | MYORG protein, human | |||
| 67 | hemagglutinin-protease | |||
| 68 | Tiki1 protein, human | |||
| 69 | FIGN protein, human | |||
| 70 | ATL1 protein, human | |||
| 71 | RLGP protein, human | |||
| 72 | FbxL4 protein, human | |||
| 73 | hemorrhagic metalloproteinase | |||
| 74 | 3C proteases | |||
| 75 | HEXB protein, human | |||
| 76 | GNPTG protein, human | |||
| 77 | ADAM23 protein, human | |||
| 78 | NSF protein, human | |||
| 79 | RNA polymerase SP6 | |||
| 80 | ADAM22 protein, human | |||
| 81 | IntS9 protein, human | |||
| 82 | SERAC1 protein, human | |||
| 83 | RPL41 protein, human | |||
| 84 | pokeweed antiviral protein | |||
| 85 | COX15 protein, human | |||
| 86 | small cardioactive peptide A | |||
| 87 | DARS2 protein, human | |||
| 88 | AGBL5 protein, human | |||
| 89 | LARGE1 protein, human | |||
| 90 | COX4I2 protein, human | |||
| 91 | NHLH1 protein, human | |||
| 92 | MINDY2 protein, human | |||
| 93 | DHX29 protein, human | |||
| 94 | RNA polymerase Esigma(38) | |||
| 95 | ADAM30 protein, human | |||
| 96 | DLG2 protein, human | |||
| 97 | Ric-8b protein, human | |||
| 98 | UST protein, human | |||
| 99 | Deep Vent DNA polymerase | |||
| 100 | PIGL protein, human | |||
| 143 | EXOSC8 protein, human | SARS-CoV-2 interacting protein | EXOSC8 | SARS-CoV-2 nsp8 |
| 163 | PITRM1 protein, human | SARS-CoV-2 interacting protein | PITRM1 | SARS-CoV-2 M |
| 172 | NGLY1 protein, human | SARS-CoV-2 interacting protein | NGLY1 | SARS-CoV-2 orf8 |
| 177 | ALG11 protein, human | SARS-CoV-2 interacting protein | ALG11 | SARS-CoV-2 nsp4 |
| 281 | TMPRSS2 protein, human | SARS-CoV-2 entry associated proteases | TMPRSS2 | |
| 345 | PCSK6 protein, human | SARS-CoV-2 interacting protein | PCSK6 | SARS-CoV-2 orf8 |
| 352 | MDN1 protein, human | SARS-CoV-2 interacting protein | MDN1 | SARS-CoV-2 orf7a |
| 360 | ERMP1 protein, human | SARS-CoV-2 interacting protein | ERMP1 | SARS-CoV-2 orf9c |
| 384 | QSOX2 protein, human | SARS-CoV-2 interacting protein | QSOX2 | SARS-CoV-2 nsp7 |
| 392 | HectD1 protein, human | SARS-CoV-2 interacting protein | HECTD1 | SARS-CoV-2 nsp8 |
| 497 | USP54 protein, human | SARS-CoV-2 interacting protein | USP54 | SARS-CoV-2 nsp12 |
| 502 | NDUFB9 protein, human | SARS-CoV-2 interacting protein | NDUFB9 | SARS-CoV-2 orf9c |
| 577 | NEU1 protein, human | SARS-CoV-2 interacting protein | NEU1 | SARS-CoV-2 orf8 |
| 664 | PRIM1 protein, human | SARS-CoV-2 interacting protein | PRIM1 | SARS-CoV-2 nsp1 |
| 685 | Cwc27 protein, human | SARS-CoV-2 interacting protein | CWC27 | SARS-CoV-2 E |
| 691 | NDUFAF1 protein, human | SARS-CoV-2 interacting protein | NDUFAF1 | SARS-CoV-2 orf9c |
| 696 | AASS protein, human | SARS-CoV-2 interacting protein | AASS | SARS-CoV-2 M |
| 716 | FKBP10 protein, human | SARS-CoV-2 interacting protein | FKBP10 | SARS-CoV-2 orf8 |
| 740 | ATP6V1A protein, human | SARS-CoV-2 interacting protein | ATP6V1A | SARS-CoV-2 M |
| 756 | Mov10 protein, human | SARS-CoV-2 interacting protein | MOV10 | SARS-CoV-2 N |
| 773 | TCF12 protein, human | SARS-CoV-2 interacting protein | TCF12 | SARS-CoV-2 nsp12 |
| 785 | TBK1 protein, human | SARS-CoV-2 interacting protein | TBK1 | SARS-CoV-2 nsp13 |
| 935 | DDX21 protein, human | SARS-CoV-2 interacting protein | DDX21 | SARS-CoV-2 N |
| 938 | DDX10 protein, human | SARS-CoV-2 interacting protein | DDX10 | SARS-CoV-2 nsp8 |
| 1010 | UPF1 protein, human | SARS-CoV-2 interacting protein | UPF1 | SARS-CoV-2 N |
| 1026 | ACAD9 protein, human | SARS-CoV-2 interacting protein | ACAD9 | SARS-CoV-2 orf9c |
| 1080 | ADAMTS1 protein, human | SARS-CoV-2 interacting protein | ADAMTS1 | SARS-CoV-2 orf8 |
| 1118 | GFER protein, human | SARS-CoV-2 interacting protein | GFER | SARS-CoV-2 nsp10 |
| 1120 | RNF41 protein, human | SARS-CoV-2 interacting protein | RNF41 | SARS-CoV-2 nsp15 |
| 1145 | ADAM9 protein, human | SARS-CoV-2 interacting protein | ADAM9 | SARS-CoV-2 orf8 |
| 1217 | PPT1 protein, human | SARS-CoV-2 interacting protein | PPT1 | SARS-CoV-2 orf10 |
| 1300 | LOX protein, human | SARS-CoV-2 interacting protein | LOX | SARS-CoV-2 orf8 |
| 1450 | MYCBP2 protein, human | SARS-CoV-2 interacting protein | MYCBP2 | SARS-CoV-2 nsp12 |
| 1481 | CTSL protein, human | SARS-CoV-2 entry associated proteases | CTSL | |
| 1483 | CYB5R3 protein, human | SARS-CoV-2 interacting protein | CYB5R3 | SARS-CoV-2 nsp7 |
| 1621 | NEK9 protein, human | SARS-CoV-2 interacting protein | NEK9 | SARS-CoV-2 nsp9 |
| 1693 | COMT protein, human | SARS-CoV-2 interacting protein | COMT | SARS-CoV-2 nsp7 |
| 1709 | MARK3 protein, human | SARS-CoV-2 interacting protein | MARK3 | SARS-CoV-2 orf9b |
| 1798 | HS6ST2 protein, human | SARS-CoV-2 interacting protein | HS6ST2 | SARS-CoV-2 orf8 |
| 1816 | MARK2 protein, human | SARS-CoV-2 interacting protein | MARK2 | SARS-CoV-2 orf9b |
| 1840 | Rab14 protein, human | SARS-CoV-2 interacting protein | RAB14 | SARS-CoV-2 nsp7 |
| 1845 | G3BP1 protein, human | SARS-CoV-2 interacting protein | G3BP1 | SARS-CoV-2 N |
| 1871 | Rab10 protein, human | SARS-CoV-2 interacting protein | RAB10 | SARS-CoV-2 nsp7 |
| 1957 | MARK1 protein, human | SARS-CoV-2 interacting protein | MARK1 | SARS-CoV-2 orf9b |
| 2109 | RAB8A protein, human | SARS-CoV-2 interacting protein | RAB8A | SARS-CoV-2 nsp7 |
| 2279 | USP13 protein, human | SARS-CoV-2 interacting protein | USP13 | SARS-CoV-2 nsp13 |
| 2287 | RAB5C protein, human | SARS-CoV-2 interacting protein | RAB5C | SARS-CoV-2 nsp7 |
| 2346 | PRKACA protein, human | SARS-CoV-2 interacting protein | PRKACA | SARS-CoV-2 nsp13 |
| 2369 | PLAT protein, human | SARS-CoV-2 interacting protein | PLAT | SARS-CoV-2 orf8 |
| 2436 | PTGES2 protein, human | SARS-CoV-2 interacting protein | PTGES2 | SARS-CoV-2 nsp7 |
| 2598 | BRD2 protein, human | SARS-CoV-2 interacting protein | BRD2 | SARS-CoV2 E |
| 2722 | PLOD2 protein, human | SARS-CoV-2 interacting protein | PLOD2 | SARS-CoV-2 orf8 |
| 2744 | RALA protein, human | SARS-CoV-2 interacting protein | RALA | SARS-CoV-2 nsp7 |
| 2847 | DPP4 protein, human | SARS-CoV-2 entry receptors | DPP4 | |
| 3039 | NSD2 protein, human | SARS-CoV-2 interacting protein | NSD2 | SARS-CoV-2 nsp8 |
| 3204 | MIB1 ligase, human | SARS-CoV-2 interacting protein | MIB1 | SARS-CoV-2 nsp9 |
| 3456 | CTSB protein, human | SARS-CoV-2 entry associated proteases | CTSB | |
| 4470 | RHOA protein, human | SARS-CoV-2 interacting protein | RHOA | SARS-CoV-2 nsp7 |
| 4471 | SIRT5 protein, human | SARS-CoV-2 interacting protein | SIRT5 | SARS-CoV-2 nsp14 |
| 4540 | DNMT1 protein, human | SARS-CoV-2 interacting protein | DNMT1 | SARS-CoV-2 orf8 |
| 4569 | HMOX1 protein, human | SARS-CoV-2 interacting protein | HMOX1 | SARS-CoV-2 orf3a |
| 4663 | IMPDH2 protein, human | SARS-CoV-2 interacting protein | IMPDH2 | SARS-CoV-2 nsp14 |
| 4780 | RIPK1 protein, human | SARS-CoV-2 interacting protein | RIPK1 | SARS-CoV-2 nsp12 |
| 4929 | HDAC2 protein, human | SARS-CoV-2 interacting protein | HDAC2 | SARS-CoV-2 nsp5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Sohn, E. Expanding Our Understanding of COVID-19 from Biomedical Literature Using Word Embedding. Int. J. Environ. Res. Public Health 2021, 18, 3005. https://doi.org/10.3390/ijerph18063005
Yang H, Sohn E. Expanding Our Understanding of COVID-19 from Biomedical Literature Using Word Embedding. International Journal of Environmental Research and Public Health. 2021; 18(6):3005. https://doi.org/10.3390/ijerph18063005
Chicago/Turabian StyleYang, Heyoung, and Eunsoo Sohn. 2021. "Expanding Our Understanding of COVID-19 from Biomedical Literature Using Word Embedding" International Journal of Environmental Research and Public Health 18, no. 6: 3005. https://doi.org/10.3390/ijerph18063005
APA StyleYang, H., & Sohn, E. (2021). Expanding Our Understanding of COVID-19 from Biomedical Literature Using Word Embedding. International Journal of Environmental Research and Public Health, 18(6), 3005. https://doi.org/10.3390/ijerph18063005