1. Introduction
Scientists often wish to learn more about the association between variables they have obtained in their studies. Anthropologists, epidemiologists, public health specialists, and others may undertake field studies and then apply standard statistical procedures to their data and analyze associations such as weight-for-height to find out about the prevalence of obesity, or they are interested in the correlation between body height and household income, or between skinfold thickness and physical activity, or other variables. The true underlying relationship between these variables usually remains unknown and there is no apparent way to investigate causality within such associations, such as: did household income influence height, or do the taller people enjoy more household income, or did more physical activity lead to a reduction in skinfold thickness, or are less obese persons fitter and therefore, undertake more physical activity [
1].
Scientists use various approaches to uncover associations between variables. Apart from looking at isolated pairwise associations between variables using their correlations, linear mixed models may be a way for analyzing data that are non-independent, multilevel/hierarchical, longitudinal, or correlated. There are more sophisticated approaches like Ridge [
2] and Lasso regression [
3], but these are not widely used by researchers because, perhaps, of the need for complex parameter selection and the required data normalization. Other investigators prefer structural equation modeling including path analysis that tests whether measures of a construct are consistent with a researcher’s understanding of the nature of that construct, or to test whether the data fit a hypothesized measurement model. These tools have in common that they are based on the concept of dependent and independent variables. Principal component, factor or cluster analysis are often used for visualizing dependencies among the variables of interest or grouping them. All these approaches usually fail to answer the question: which is the input, and which is the outcome variable. In addition, all of these methods utilize original sets of raw or carefully normalized data.
We propose an alternative approach. Instead of hypothesis-driven approaches to test and, ultimately, confirm particular assertions for sets of variables, we depict networks of associations between extensively correlated variables. This can be done without detailed information about the original set of raw data. This approach creates an initial foundation for making assertions about the nature of causality within the data set, and may then in a later step be part of hypothesis-driven testing. Our method ranks bivariate correlation coefficients in descending order according to magnitude. Doing so creates chains of associations and is independent of any initial concept of underlying data structure.
Let us assume a small correlation matrix with the variables A, B, C, and D. All variables correlate with each other at various magnitudes. We rank these correlations. We start with A. We find that the correlation, r, between A and B (|rAB|) is larger than the correlation between A and C (|rAC|), and that the correlation between A and C again is larger than the correlation between A and D (|rAD|). We rank the three correlation coefficients in a hierarchic order: |rAB| > |rAC| > |rAD|, and get the chain A-B-C-D. We now invert this sequence and start with endpoint D. We get D-C-B-A. Let us assume that also the sequence of correlation coefficients of the inverted chain |rDC|, |rDB|, |rDA| forms a hierarchic order of magnitude with |rDC| > |rDB| > |rDA|. Sequences of correlation coefficients that are characterized by descending order when starting from either end, are named “association chains”. Association chains can be translated into network graphs. At first view, the whole procedure sounds trivial, but it opens the possibility of immediately visualizing extensive interacting variables in an explorative manner.
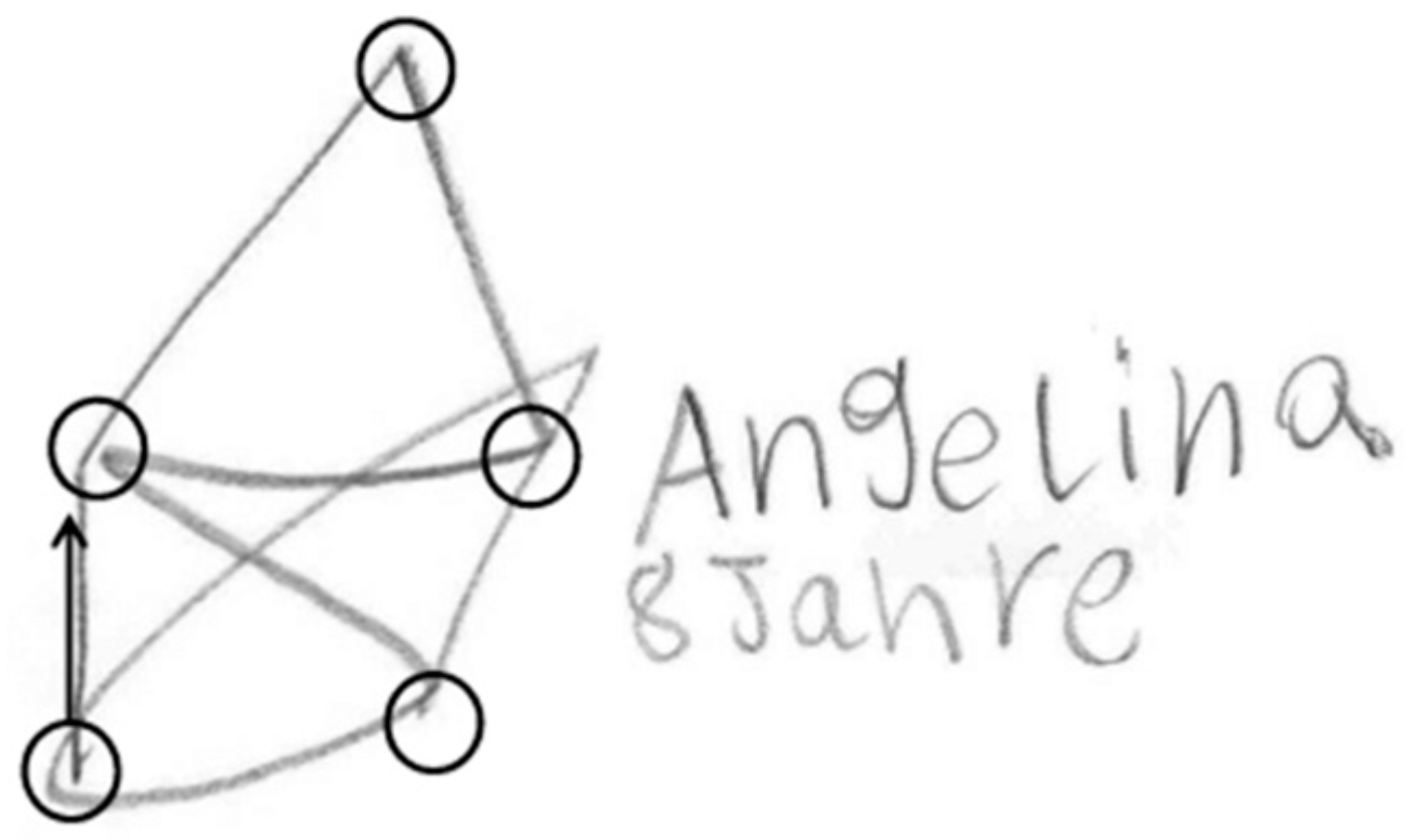
As this method successively connects nodes similar to a popular German child game, we named the method St. Nicolas House Analysis (SNHA). German children like to draw St. Nicolas’ house. It consists of five points that need to be connected by one single line (
Figure 1) without dropping the pencil. Doing so, the children murmur “this-is-the-house-of-Ni-co-laus”. Except for the top of the roof, each point connects with each other point. Essentially, St. Nicolas house is a network, consisting of “nodes” (circles) and “edges” (lines). Edges direct from one node to the next one. St. Nicolas house is a directed graph that has a topological ordering from earlier to later. We use St. Nicolas house as a model for analyzing variables that are linked by multiple correlations [
4].
2. Data
We illustrate the suggested approach with three sets of data. The sets were chosen for reasons of simplicity. They were obtained from different backgrounds to make the approach as easily comprehensible as possible.
Sample 1 (33 Olympic decathletes) consists of performance results of 33 Olympic decathletes at the Olympic Games 1988 [
5]. The research question is: are performances in the different sport disciplines serially related to each other? Is the performance in 100-m running related to the performing in 110-m hurdles which again is related to the performance in long jump, etc., or is discus throw related to the performance in pole vault which is related to the performance of …, etc. Sample 1 may not be considered representative of any defined population of decathletes.
Table 1 illustrates the first six measurements. No information was available on how the measurements were obtained, nor on measurement accuracy. The data were chosen to illustrate chains of associations within a complex network of medium to high correlations.
Sample 2 (UN 1998—United Nations Social Indicators Data 1998) was chosen in view of the topic of this Special Issue—what makes children grow—and consists of 12 social indicators relevant for child health, obtained from 207 nations and published by the United Nations in 1998 [
6]. The correlation coefficients tend to be higher than 0.5. The corresponding research question is similar: are the social indicators serially related to each other? The data were chosen to illustrate chains of associations within a complex network of high correlations.
Sample 3 (Birth weight) was also chosen for its relevance to the topic of this Special Issue predicting maternal input variables such as body height, weight, smoking, etc., on the outcome variable birth weight, for investigating risk factors for low birth weight, in 189 children, but in contrast to the samples 1 and 2, is characterized by low correlations, and lacks an a priori assumption regarding input and outcome variables. Sample 3 exemplifies data that are hierarchically structured. The input variables, maternal factors, influence the outcome variable birth weight. The data were collected at Baystate Medical Center, Springfield, Mass during 1986, and may not be considered representative of risk factors for low birth weight. The data were retrieved from the R package MASS [
7]. For this sample the research question differs and reads: which of the explanatory (maternal) variables best predict and forecast the future event (birth weight of the child)?
2.1. Statistical Analysis
Matrices of bivariate correlations can be transformed into networks of agreement. However, the complexity of such networks may depend on thresholds chosen for the transformation. Linear models, principal component analysis, and cluster analysis are appropriate and commonly used techniques for analyzing multivariate data. Yet, it remains to be elucidated whether networks of bivariate correlations indeed reflect truly existing associations, and if so, which of the commonly used techniques best transform correlation matrices into networks. We exemplify our approach using sample 1:
We transformed the correlation matrix reflecting the agreement between the performance results of 33 Olympic decathletes, into a network by
Depicting all pairwise correlations with a threshold at |r| > 0.3 between the sport performances;
Linear models using forward selection for each variable, at two thresholds R2 > 0.01 and R2 > 0.10;
Factor and principal component analysis, and cluster analysis;
St. Nicolas House Analysis.
Different statistical techniques result in different networks. We compared the networks by checking for plausibility. Some of the variables are related to fitness of the lower extremities, such as running and jumping, other variables are related to fitness of the upper extremities, such as throwing. Performance results that are related for anatomical reasons, should be closer associated. Yet, plausibility is not proof that either one of the statistical approaches truly provides the correct solution. We therefore added the antagonistic approach for control, and created networks derived from normally distributed, random generated data from 33 virtual Olympic decathletes with zero correlations between the variables in the following way:
- (1)
We scrambled the truly measured results of running, jumping, throwing and randomly re-assigned the scrambled data to each of the 33 Olympic athletes;
- (2)
We created normally distributed random values for running, jumping, throwing with identical mean values and variances for each of the 33 athletes.
Thereafter, we tested the lack of agreement between the zero correlated variables as indicator of falseness, by counting the number of edges within each of the new random based networks.
All calculations were conducted with the programming language R [
8] version 3.6.3 which is a free software under the terms of the Free Software Foundation’s GNU General Public License in source code form. Further the following additional freely available R packages, not being part of the standard R installation were used for the analysis, openxlsx [
9], asg [
10], dgtools [
11].
2.1.1. Pairwise Correlations
Often the first step in the analysis of multivariate data is to create a correlation matrix and find out which of the variables are relevantly related to each other. This helps in gauging the degree of agreement between the variables.
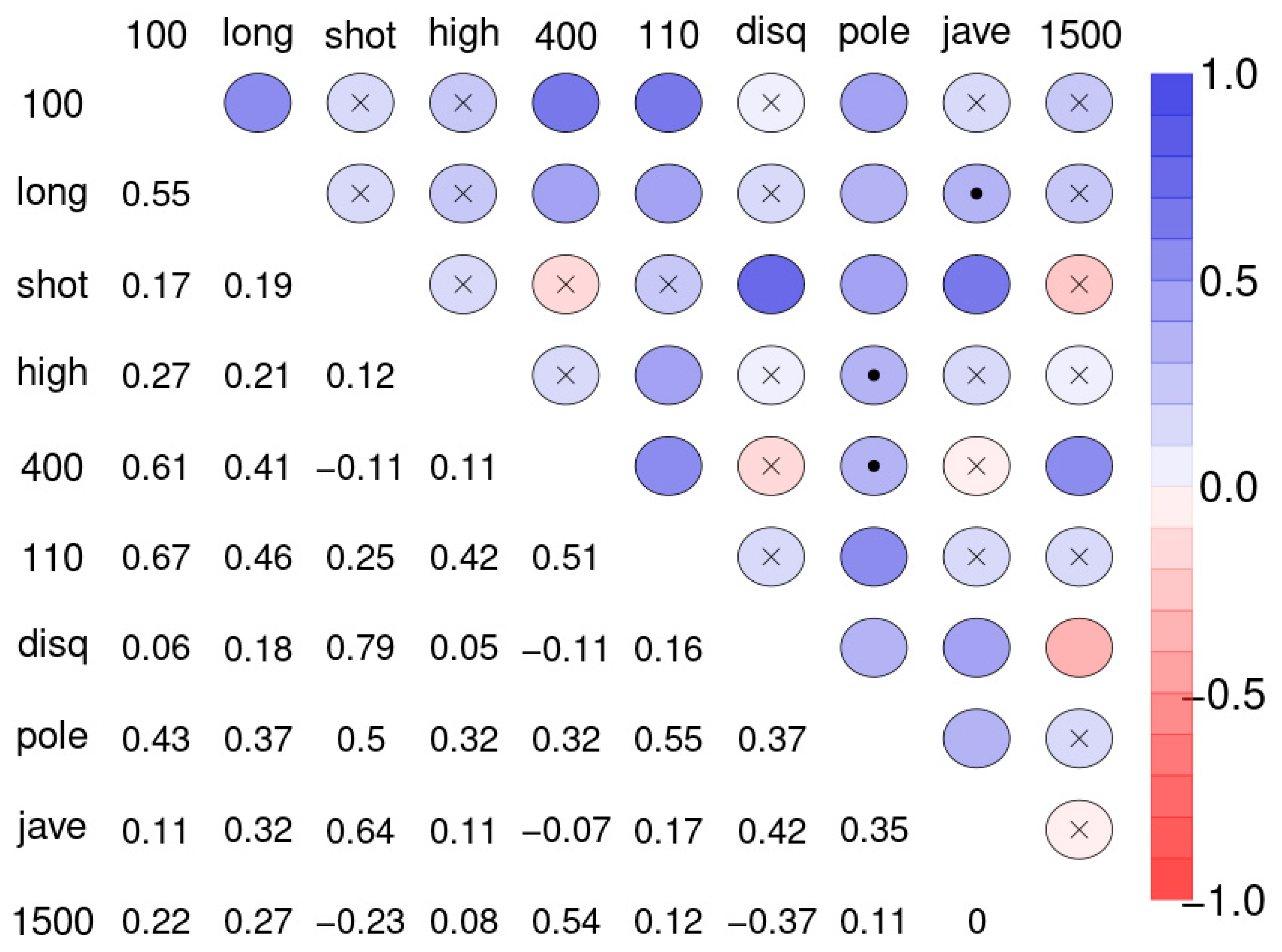
Figure 2 shows the correlation matrix of the ten disciplines of sample 1.
Correlation matrices can be transformed into networks.
Figure 3 displays graphically all correlations of
Figure 2, at the thresholds |r| > 0.3 (left) and |r| > 0.5 (right). The disadvantage of such an approach is the arbitrariness when selecting the thresholds. Different thresholds result in different complexity of the network. The essentials of the new method can be summarized as a ranking of bivariate correlation coefficients in descending order according to magnitude (“St. Nicolas House Analysis”, SNHA). SNHA creates hierarchic “association chains” defined by sequences where reversing start and end point does not alter the ordering of elements. In general, correlation matrices, linear mixed model, factor analysis and cluster analysis depict groups of similar variables. Data may share common variance because they may directly influence each other, or there may be common variance due to some unobserved latent source of variation that simultaneously affects the variables within that particular group. All of these methods utilize complete sets of raw data, and essentially focus on dyads of variables that either directly influence each other, or indirectly when unobserved latent variables exist that simultaneously affect clusters of variables thereby suggesting direct effects between variables that in reality, do not exist. In contrast to methods that utilize complete sets of raw data, we are interested in chains of associations that can be derived from correlation matrices. We measure serial effects among variables with extensive interactions. SNHA ranks series of correlation coefficients and thereby creates so-called “association chains”. SNHA does not require original samples of raw data, but only matrices of correlation coefficients. We search for variables that correlate and affect each other serially.
We detect “chains of associations” as follows.
To highlight structural relationships within a set of variables
, on the basis of the corresponding correlation structure
with
, we propose the following procedure to factorize the likelihood function of the variables. Thresholds values in terms of absolute correlation coefficients can be expressed as well as thresholds for the coefficients of determination. For each variable
taken as a starting point, an association chain can be defined via sorting the variables in terms of descending correlation sequences. The first order neighboring element of variable
is defined as
The second order neighboring element of variable
is defined then as
.
This procedure is repeated until or being perceived as insignificant or As a result, we obtain a chain of variables . To qualify as an association chain, we reverse the order and check whether the same sequence of variables is obtained when starting at variable and receiving as the corresponding end point. An association chain is defined by any sequences of correlation coefficients, where reversing the start and end point does not alter the order of elements occurring in that sequences. Note that an ordering of two variables occurring in a sequence starting at variable predetermines the ordering of these two variables in any other sequence.
The validity of the factorizations of the joint density implied by the association chains.
is assessed via Likelihood Ratio tests, where
denotes the set of variables not included in the sequence of variable
. Thereby, the log likelihood of joined unrestricted distribution is compared to the restricted log likelihood implied by the association chain.
Merging all chains discovered within the network forms the final St. Nicolas House graph (
Figure 4). The graph comprises seven association chains detected in sample 1. The chains overlap each other and form the final St. Nicolas House graph. The graph plausibly connects the ten sport disciplines according to upper and lower parts of the body. In order to statistically check the plausibility of each of these chains, we calculated log-likelihoods for all chains.
2.1.2. Log-Likelihood Analysis
Seven association chains were detected in the performance results of 33 Olympic decathletes (
Table 2). We ask, do these seven chains truly summarize the dependencies among the variables? Is the sequence of performances of chain #1 connecting high jump, 110-m hurdles, and pole vault, a likely result? We performed a likelihood based analysis, and summarized the evidence for the seven association chains detected in 33 decathletes. Noting that the chains correspond to a restricted dependence structure captured in a sequence of conditional distribution as indicated in the boxed text 2, we oppose the restricted likelihood with the unrestricted likelihood, and we allow for all mutual dependencies between the variables entailed within this sequence. The likelihood evidence of restricted dependencies (arising from the chains) and the unrestricted dependence structure can be compared by means of a likelihood ratio test.
Table 2 provides the corresponding results obtained from the association chains detected as shown in
Figure 4. We assume either joint normality in case of the unrestricted dependence or conditional normality in case of the restricted dependence as implied by the association chains. This implies that the likelihood ratio test statistic follows an asymptotic
distribution.
The
test statistics arise here from the log-likelihood differences. In all of these applications, the aim is to test whether some vector parameter is zero vs. the alternative that it is non-zero and the
statistic is related to the squared size of the observed effect. The required
p-value is the right tail probability for the
value. The number of restrictions provides the corresponding degrees of freedom (df), where
p-values below 0.05 indicate significant differences between the restricted and the unrestricted dependencies among the variables entailed within the considered chain. Small
p-values indicate that the chain is not sufficiently able to capture the dependencies between the variables entailed within the chain. This was not the case. The dependencies within the corresponding sets of variables were found to be sufficiently captured within the chains as all chains detected have
p-values larger than 0.10 (
Table 2).
2.1.3. Model Variance
The correlation between the sport disciplines (
Figure 2, sample 1) varies. The edges of the network differ in strength. The ten variables differ in respect to their integration into the network structure. Whereas some disciplines are highly correlated such as disc and shot with r = 0.79, and 100 and 110 with r = 0.61; others almost completely lack any association. In order to estimate the overall predictive power of the network, we created a linear model and calculated a global average R
2 value.
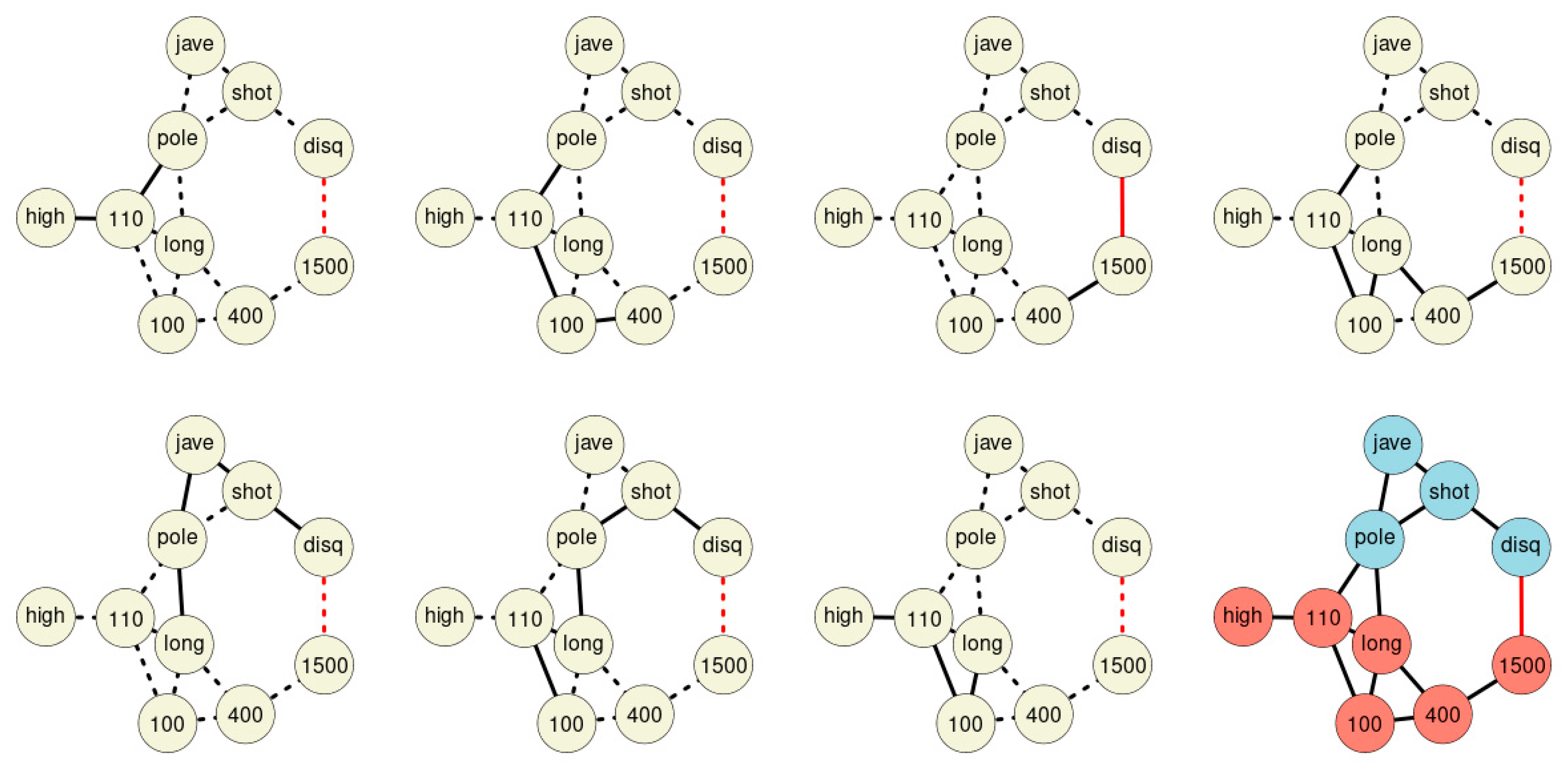
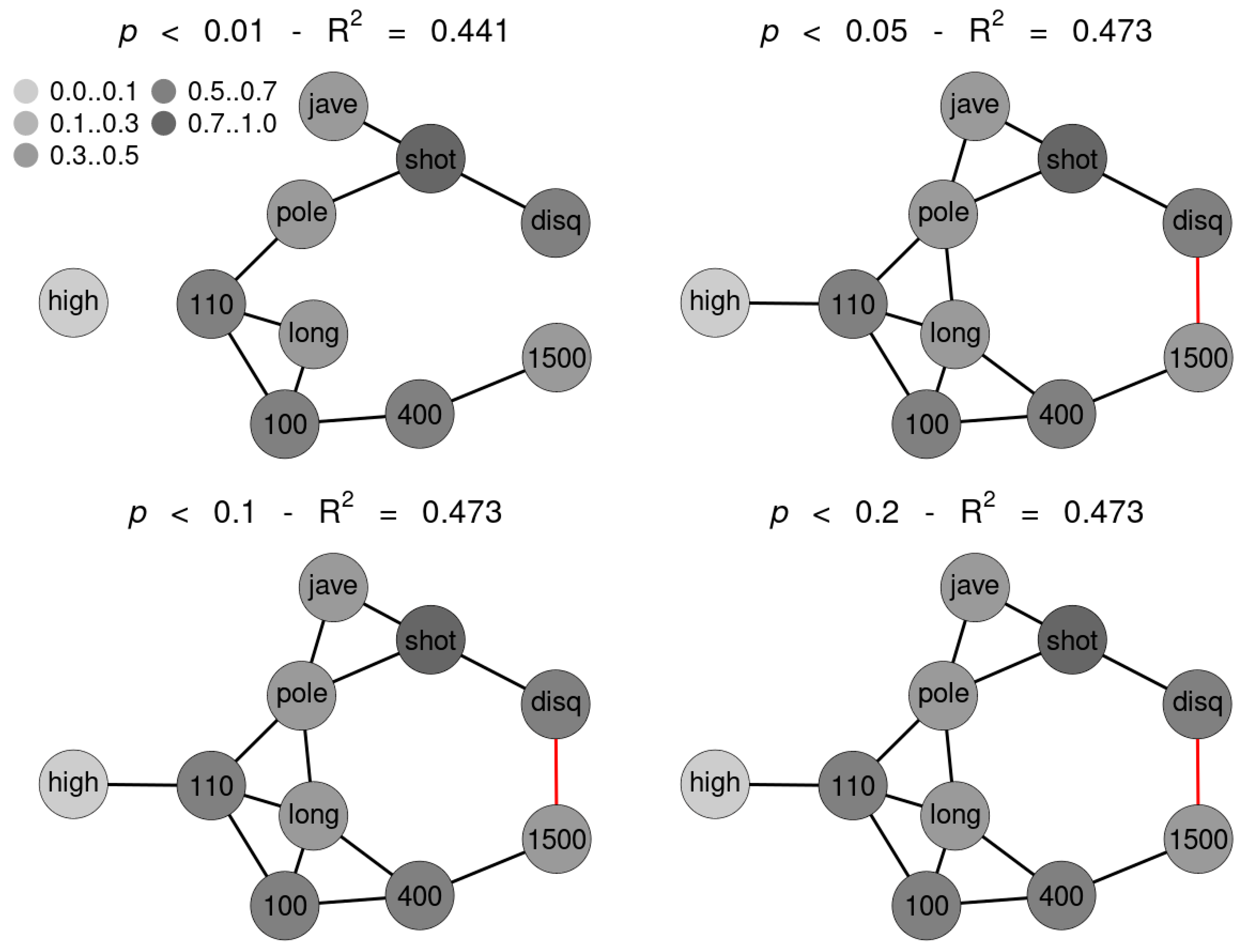
SNHA algorithm creates association chains by ranking absolute correlation coefficients. Ranking correlation coefficients implies deciding up to which threshold a correlation coefficient may be used for the algorithm. We tested to what extent the threshold (alpha
p-value) affects the structure of the St. Nicolas House graph. We set four alpha values (threshold at
p = 0.01 (top left), at
p = 0.05 (top right), at
p = 0.10 (bottom left) and at
p = 0.20 (bottom right). Correlation coefficients below the respective thresholds were not ranked.
Figure 5 exemplifies that the number of edges remains quite resilient except for very restrictive thresholds, suggesting robustness of the SNHA algorithm towards the choice of different alpha values. At alpha values
p = 0.01, SNHA explains 0.441 of the total variance of the sport performances, at alpha values
p = 0.05 to
p = 0.20 the algorithm invariantly explains 0.473 of the total variance.
3. Results
First, we show the network of agreement between the sport disciplines of sample 1 based on simple correlation thresholds with different |r| (
Figure 3). We then analyze the same set of data by statistical methods that are frequently used by scientists when analyzing the association between variables they have obtained in their studies. We apply principal component analysis, cluster analysis and linear modeling. We then compare these methods with SNHA.
In a second step, we apply the same frequently used statistical methods and SNHA to sets of random data that are not correlated. In these data sets, we expect no agreement between the variables, and consider this approach an indicator of falseness whenever spurious correlations are detected.
Finally, we depict the correlation matrices and the SNHA graph of these matrices of the samples 2 and 3 in order to illustrate the dependence structures of interacting variables by SNHA graphs highlighting association chains that may later be subject to subsequent hypothesis testing also in samples that are characterized by low correlations.
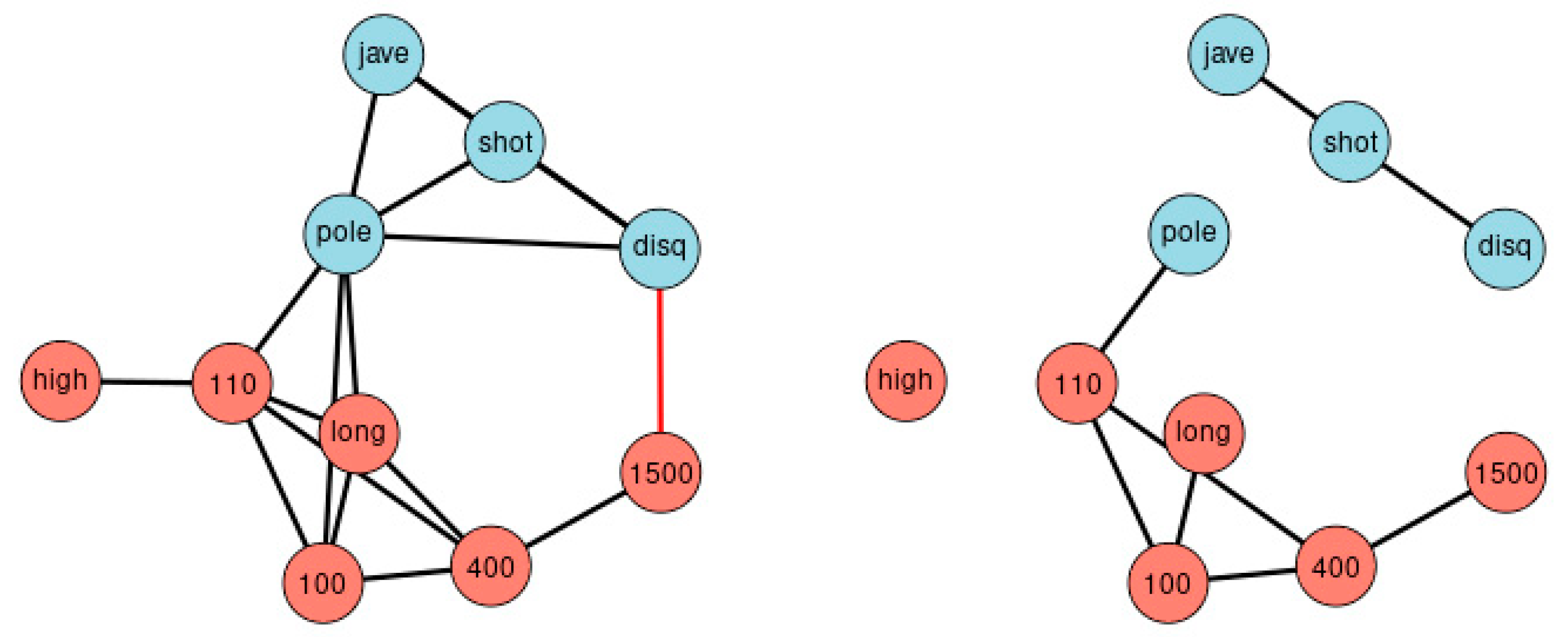
Figure 3 depicts the network of agreement between the sport disciplines of sample 1 based on correlation thresholds with |r| > 0.3 (left) and |r| > 0.5 (right). The choice of threshold influences the complexity of the resulting network. Variables referring to the lower extremities are colored red; variables referring to the upper extremities are colored blue. Performance results of lower and the upper extremities are clearly separated.
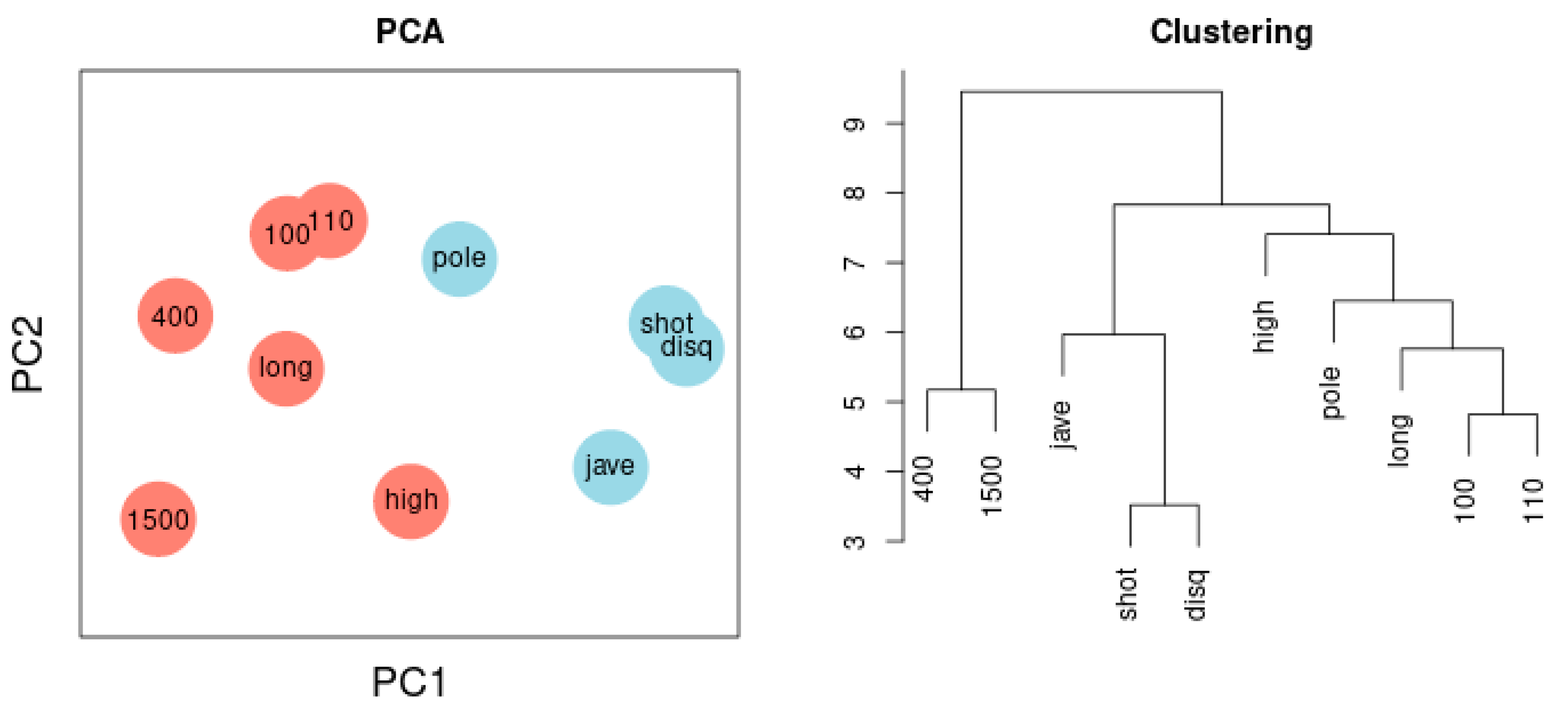
Figure 6 illustrates the Principal Component Analysis of the same sample. The cluster dendrogram similarly separates the ten disciplines and, in addition, highlights the separation of long-distance runs and short-distance sprints.
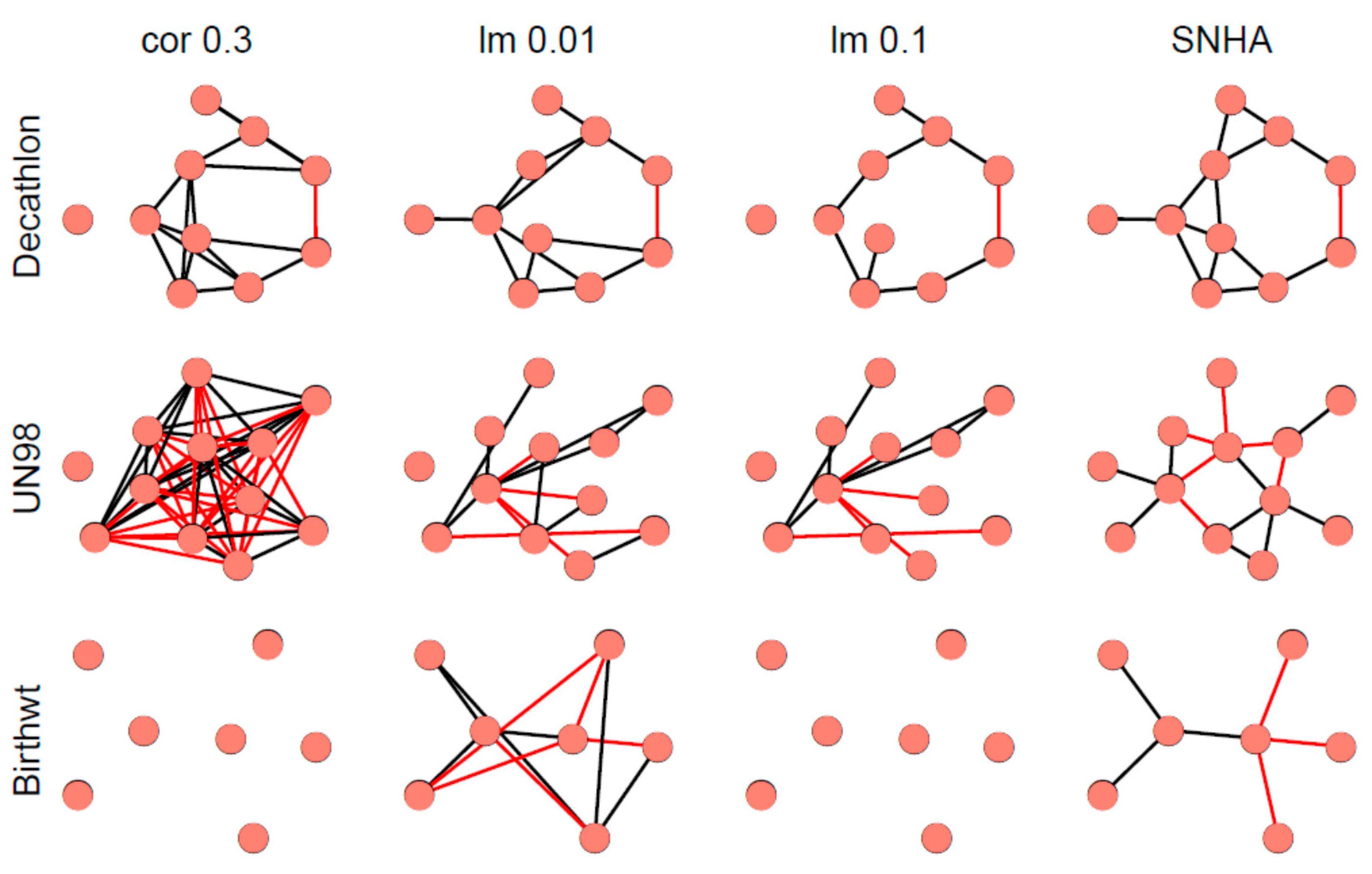
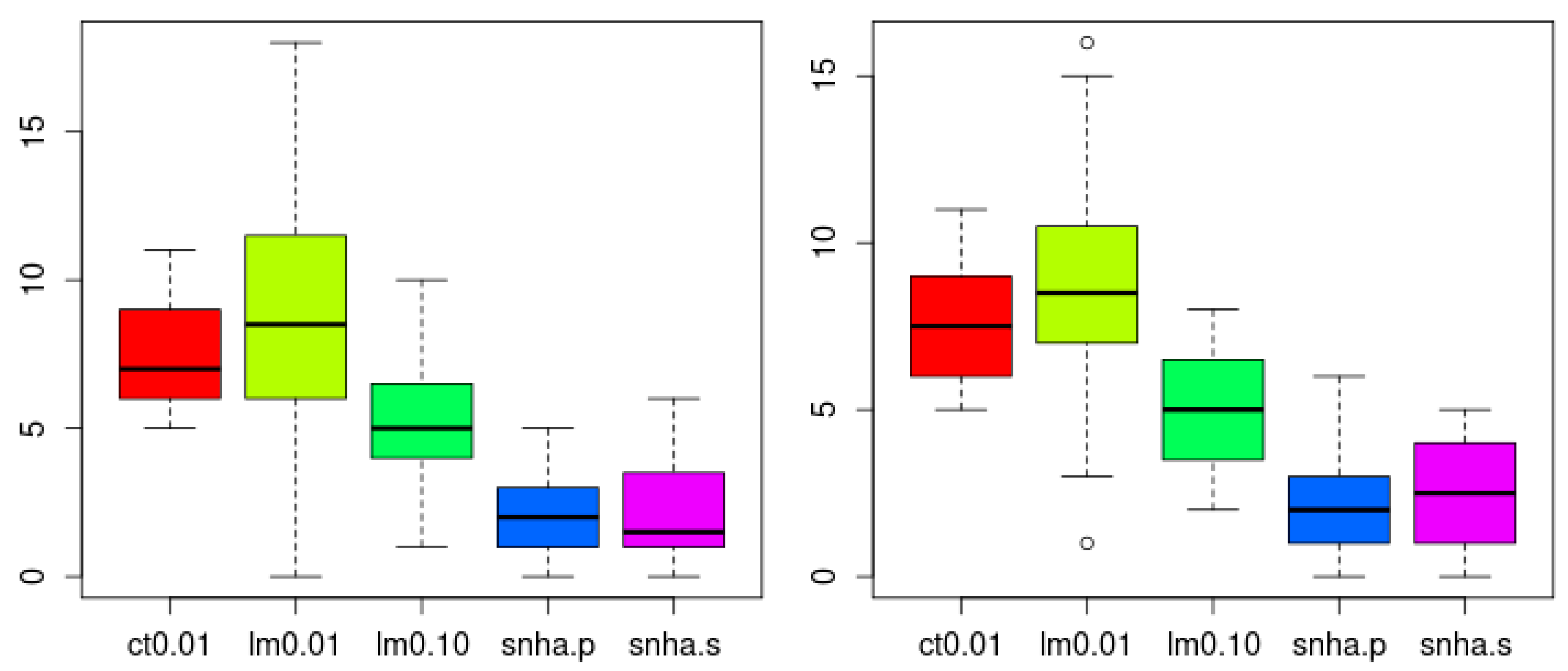
Figure 7 depicts different network graphs derived from sample 1 (Decathlon), sample 2 (UN98), and sample 3 (Birthweight). The networks are created by pairwise correlations at a threshold of |r| > 0.3; by linear models using forward selection for each variable, at two thresholds of R
2 < 0.01 (lm 0.01) and R
2 < 0.10 (lm 0.1); and by SNHA. Whereas networks created by pairwise correlations and linear models using a low threshold, appear somewhat messy and less plausible than the network created by SHNA, neither one of the statistical approaches invokes any a priori guarantee of truth. The low correlated birth weight sample failed when processed by pairwise correlations and linear models using high threshold.
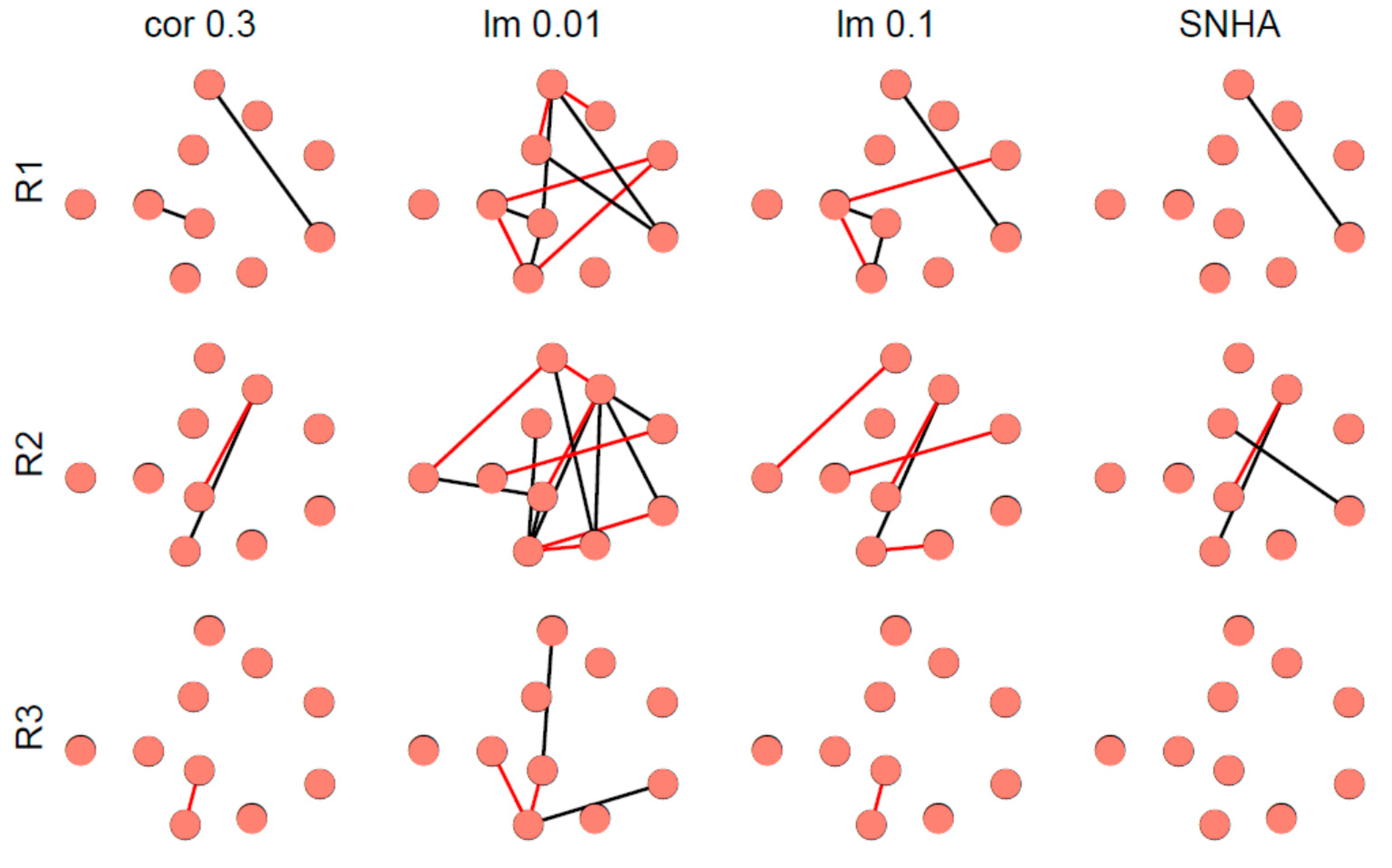
Figure 8 depicts representative examples of virtual networks that lack meaningful correlations between the variables. A few spurious edges within these networks are accidental. The number of edges was used as indicator of falseness.
SNHA analysis both using Pearson (snha.p) and Spearman (snha.s) correlation resulted in the smallest numbers of false random edges (Holm adjusted
p < 0.05, confirmed by Wilcoxon test), and thus the lowest level of agreement (
Figure 9). There was no significant difference in the number of edges created by snha.p and snha.s.
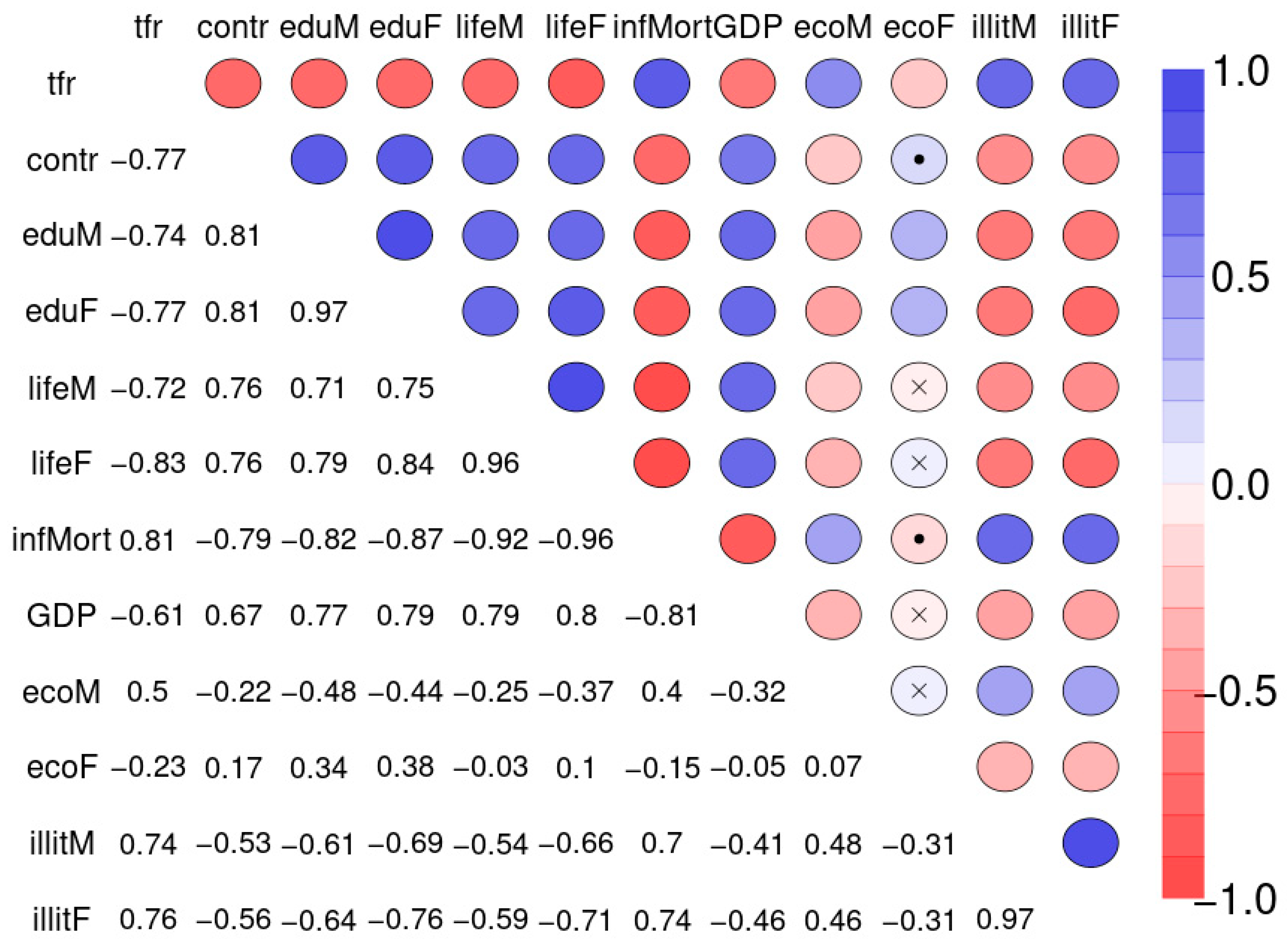
Figure 10 depicts the Spearman correlation matrix for pairwise correlations between the 12 social indicators obtained from 207 nations and published by the United Nations in 1998 (sample 2). The interactions are generally stronger than those of sample 1.
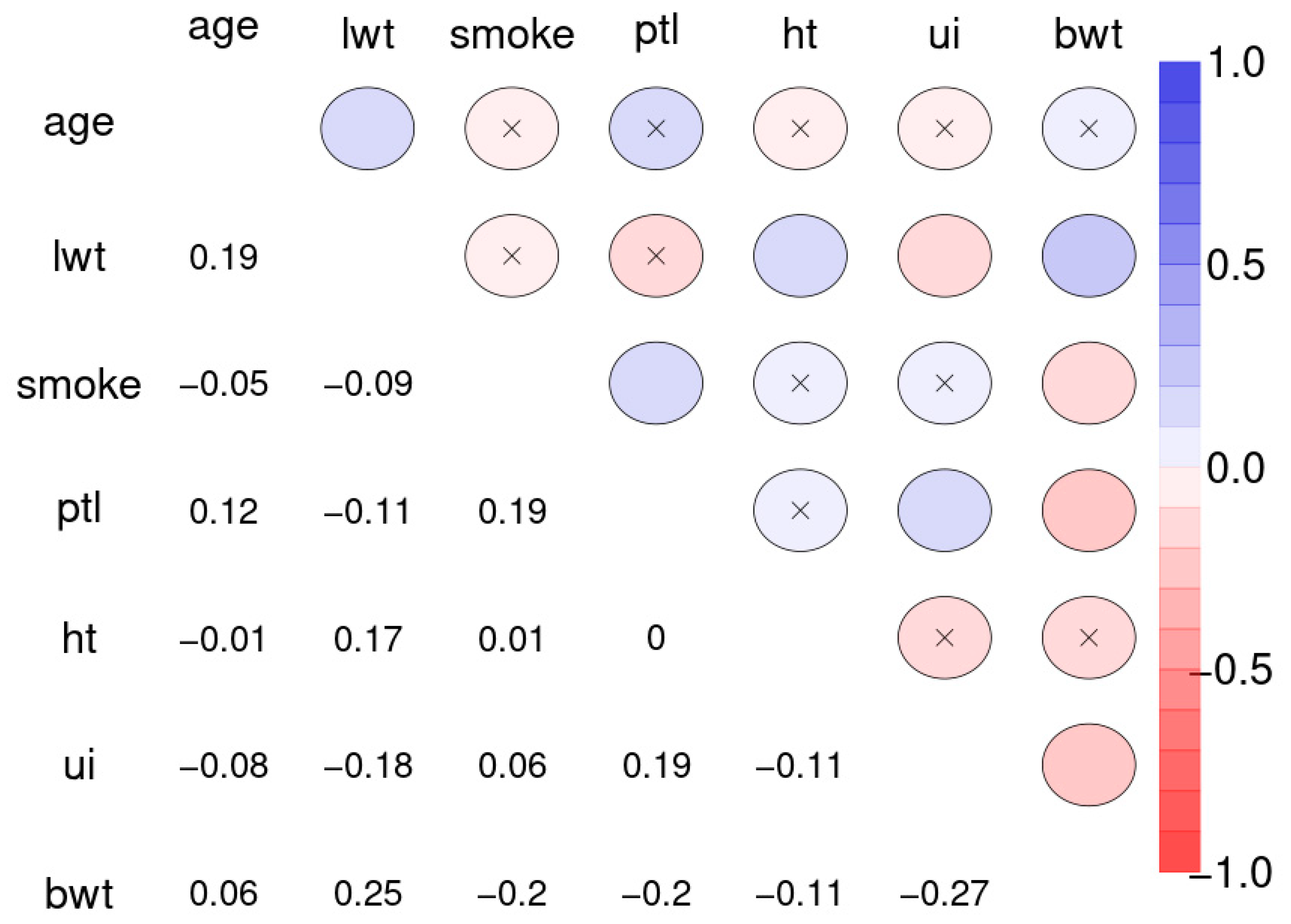
Figure 11 depicts the Spearman correlation matrix for pairwise correlations between the maternal risk factors and birth weight of 189 children (sample 3). These correlations are generally comparably low, several are insignificant.
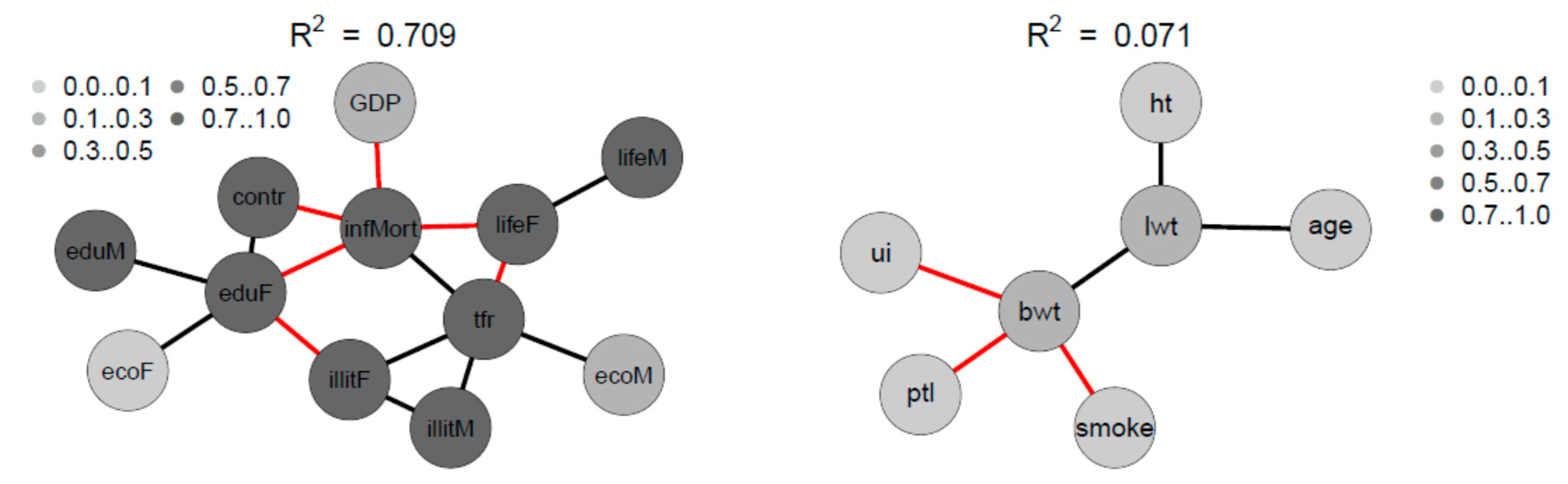
Figure 12 depicts the SNHA graphs of the correlation matrices of the samples 2 and 3.
The four variables infant mortality, total fertility rate, maternal education and illiteracy are highly correlated and take a central position. The gender inequality with extremely opposite positions of male and female economic activity is evident. Male education (eduM) appears of marginal importance when compared with the more central position of female education.
The correlations between maternal risk factors and birth weight are markedly lower with R2 = 0.071. Nevertheless, the SNHA graph appears plausible. Body weight depends on maternal weight, and is negatively related with uterine irritability, smoking of the mother, and premature labor.
4. Discussion
Various statistical approaches exist to uncover associations between variables within large and complicated matrices. Some researchers use linear mixed models, others prefer structural equation modeling, path analysis, principal component, and factor or cluster analysis. Estimating the quality of these models is not trivial and demands advanced techniques such as measuring cluster quality, for instance, using a silhouette index [
12]. Nevertheless, it often remains uncertain whether associations between multiply correlating variables that are detected, represent true associations between these variables. Most statistical models are hypothesis-driven in that they are based on the concept of dependent and independent variables. Typically, the majority of these tools rely on sets of original raw or normalized values and cannot be applied when only secondary material such as correlation matrices, is available.
Therefore, we propose a different approach that we call “St. Nicolas House Analysis” (SNHA). We present a method that is able to also re-analyze processed data of which the original material has been lost. We focused on correlation matrices or other symmetric matrices with values measuring the strength of pairwise associations. We do not need the original set of raw data, instead we rank bivariate correlation coefficients in descending order of magnitude. The present approach is not only independent of the raw material, but also independent of any initial concept of underlying data structure. There is no need for a priori assumption regarding input and outcome variables. The data may be hierarchically structured, or not. We rank and create sequences of correlation coefficients named “association chains”. These sequences of ranked correlation coefficients are then translated into network graphs. The approach is non-parametric, it is robust towards outliers, and independent of the distribution of the data.
The resilience of SNHA towards thresholds and its apparent propensity against detecting unwanted unassociated variables is a major advantage over linear modeling, principal component, and factor or cluster analysis. This property is partially due to the fact that spurious significance is more likely to occur in single pairwise associations than in chains connecting several associations in one.
The resulting St. Nicolas House graphs can further be utilized as input for variable predictions using for instance linear or ordinal logistic regression, with calculated R
2 values for individual nodes, respectively, average R
2 values for all nodes that can serve as a measure of the quality of how well the graph explains the variances. Association chains may even suggest causality in cases when certain elements of a given chain have a temporal order (direction). A particular direction between elements of an association chain can force adjacent elements of that chain to uptake the same direction. SNHA thus immediately visualizes essential associations between extensive interacting variables and hugely complicated matrices. The method was found particularly convenient when dissecting the impact of parental education, various social variables and nutrition on child growth in studies in Indian and Indonesian school children [
4,
13,
14]. The method is able to create initial foundations for later hypotheses that in a second step may then be part of additional hypothesis-driven testing.
In view of combinatorics—consider the 33 decathletes with their 10 × 10 correlation matrix, the 45 coefficients of correlation allowing for 360 combinations of two, 2520 combinations of three, 15,120 combinations of four, etc. serial coefficients of correlation—it is evident that detecting association chains is not a trivial task and may still need improvement. Future studies referring to log likelihood of single association chains appear promising. Within complex networks, alternative association chains of similar significance can exist and can be made visible by more sophisticated techniques, such as the bootstrap method [
15]. The bootstrap method allows for estimating levels of statistical significance for a given St. Nicolas House graph.
5. Conclusions
We propose a robust non-parametric statistical tool for detection and visualization of dependencies between extensive interacting variables. The suggested approach labeled as SNHA is based on sequences of the variables with invariant ordering in terms of the underlying association measure. SNHA can be performed also in case there are no individual measurements, i.e., raw data are available, but aggregate information in form of sample moments, e.g., sample correlations or covariances, is available. It thus enhances secondary and reanalysis of published data. The analysis provides an initial approach for clarifying potential associations between variables that may be subject to subsequent hypothesis testing. A graphical representation of the revealed association chains is possible via network graphs. The corresponding R-code is available on request from the senior author of this paper, Dr. Detlef Groth, University of Potsdam.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}