
Comparison of Machine Learning Techniques for Mortality Prediction in a Prospective Cohort of Older Adults

 , ,
, ,  , and
, and
Abstract
1. Introduction
2. Methods
2.1. Dataset Description
- Anthropometry: gender, height, weight, hip and waist circumference, body mass index (BMI);
- Medication/Medical history: diabetes, rheumatoid arthritis, secondary osteoporosis, stroke, heart infarction, blood pressure medication, statins, glucocorticoids, previous fracture, previous fall, parent fractured hip;
- Lab analysis: systolic-diastolic blood pressure, plasma glucose, total-HDL-LDL cholesterol, triglycerides, heart rate, manual muscle test (MMT), peak expiratory flow, hand grip strength non-dominant hand, time up and go (TUG);
- Lab tools: GAITRite [44] gait analysis data (i.e., step time, step length, etc.), balance test (sway with full and no vision), bone scans of the non-dominant cortical, trabecular, radius and tibia (via computed tomography-pQCT), total T-score, and analysis of fat and lean mass of various body parts (via X-ray absorptiometry-DXA);
- ActiGraph 1-week accelerometer data (e.g., steps taken, time in light, sedentary, moderate, vigorous activities, energy expenditure, etc.). For the data to be acceptable the minimum wear time per day was 600 min, for at least four days.
2.2. Machine Learning Modelling
2.2.1. Data Pre-Processing
2.2.2. Feature Engineering
2.2.3. Models and Hyper-Parameters Tuning
- Logistic Regression (LR): penalty = [‘l1’, ‘l2’], C = [1e-3, 1e-2.33, 1e-1.66, 1e-1, 1e-0.33, 1e0.33, 1e1, 1e1.66, 1e2.33, 1e3];
- Decision Tree (DT): criterion = [‘entropy’, ‘gini’], max_depth = [1–10], min_samples_leaf = [1–5], min_samples_split = [2–20];
- Random Forest (RF): N_estimators = [10–100], max_features = [‘auto’, ‘sqrt’], min_sample_leaf = [1–4];
- Adaptive Boosting (AdaBoost): N_estimators = [10–100], learning_rate = [1e-4, 1e-3, 1e-2, 1e-1, 2e-1, 3e-1], base estimator = decision tree.
2.2.4. Feature Selection and Outlier Removal
2.2.5. Monte Carlo Data Augmentation
2.2.6. Over/Under-Sampling, Cost-Sensitive Learning, and Probability Calibration
3. Results
3.1. Epidemiological Model
3.2. Base Learners
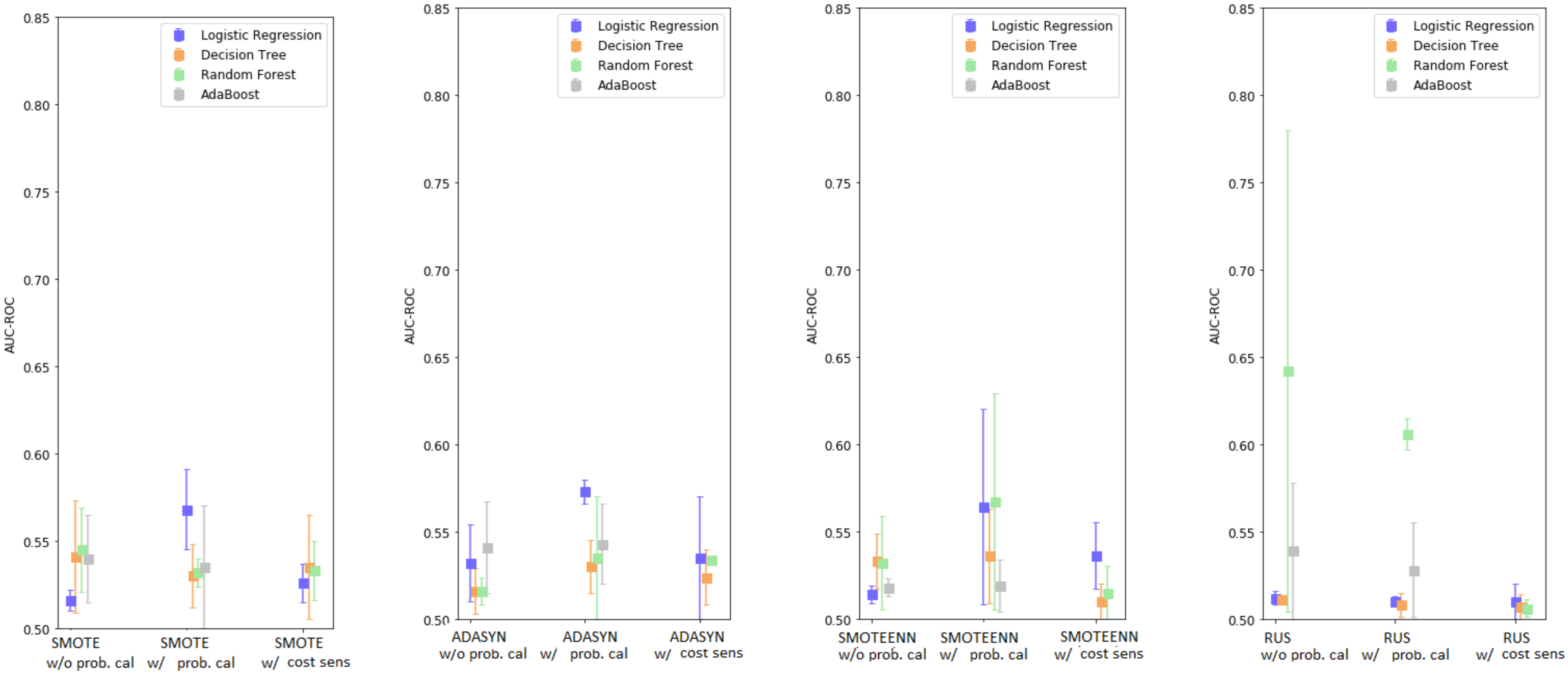
3.3. Enhanced Base Learners
3.4. Enhanced Base Classifiers with Monte Carlo Data Augmentation
- Given the original dataset of 2291 participants, new synthetic data in the same amount have been obtained with the Monte Carlo data augmentation technique and merged into the original dataset
- The labels related to the mortality prediction problem were eliminated for this test from every subject (both original and synthetic)
- All the data belonging to the original dataset were re-labelled as class 1, while all the synthetic data were re-labelled as class 0
- The dataset was divided in 70/30 (as test set), with the 70% again split in 70/30 for training and validation purposes, with stratification being applied
- A standard RF classifier was used to discriminate between the original and the synthetic data. The model was trained on the training set with the hyper-parameters tuned on the validation set. The optimized model was finally evaluated on the test set. RF was adopted, as it was the model which presented the largest difference in performance when using the Monte Carlo technique
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AdaBoost | Adaptive Boosting |
| ADASYN | Adaptive Synthetic |
| APACHE | Acute Physiology and Chronic Health Evaluation |
| AUC-PR | Area Under the Curve–Precision Recall |
| AUC-ROC | Area Under the Curve–Receiver Operating Characteristic |
| AUDIT-C | Alcohol Use Disorders Identification Test |
| BMI | Body Mass Index |
| CI | Confidence Interval |
| CV | Cross-Validation |
| DT | Decision Tree |
| DXA | X-ray Absorptiometry |
| EHR | Electronic Health Records |
| EuroSCORE | European System for Cardiac Operative Risk Evaluation |
| FI | Frailty Index |
| FSCA | Forward Selection Component Analysis |
| GDS | Geriatric Depression Scale |
| HAI | Healthy Ageing Initiative |
| HR | Hazard Ratio |
| ICU | Intensive Care Unit |
| IPAQ | International Physical Activity Questionnaire |
| LR | Logistic Regression |
| MI | Mortality Index |
| ML | Machine Learning |
| MMT | Manual Muscle Test |
| MPM | Mortality Probability Model |
| pQCT | Computed Tomography |
| RF | Random Forest |
| RUS | Random UnderSampling |
| SAPS | Simplified Acute Physiology Score |
| SMOTE | Synthetic Minority Oversampling Technique |
| SMOTEENN | SMOTE and Edited Nearest Neighbours |
| TUG | Time Up and Go |
| VIF | Variance Inflation Factor |
References
- Wittenberg, R.D.; Comas-Herrera, A.; Pickard, L.; Hancock, R. Future Demand for Long-Term Care in the UK: A Summary of Projections of Long-Term Care Finance for Older People to 2051; Joseph Rowntree Foundation: York, UK, 2004. [Google Scholar]
- Eurostat. Ageing Europe—Statistics on Population Developments. Available online: https://ec.europa.eu/eurostat/statistics-explained/index.php?title=Ageing_Europe_-_statistics_on_population_developments#Older_people_.E2.80.94_population_overview (accessed on 27 December 2020).
- de Munter, L.; Polinder, S.; Lansink, K.W.W.; Cnossen, M.C.; Steyerberg, E.W.; de Jongh, M.A.C. Mortality prediction models in the general trauma population: A systematic review. Injury 2017, 48, 221–229. [Google Scholar] [CrossRef] [PubMed]
- Keuning, B.E.; Kaufmann, T.; Wiersema, R.; Granholm, A.; Pettila, V.; Moller, M.H.; Christiansen, C.F.; Castela Forte, J.; Keus, F.; Pleijhuis, R.G.; et al. Mortality prediction models in the adult critically ill: A scoping review. Acta Anaesthesiol. Scand. 2020, 64, 424–442. [Google Scholar] [CrossRef] [PubMed]
- Xie, J.; Su, B.; Li, C.; Lin, K.; Li, H.; Hu, Y.; Kong, G. A review of modeling methods for predicting in-hospital mortality of patients in intensive care unit. J. Emerg. Crit. Care. Med. 2017, 1, 1–10. [Google Scholar] [CrossRef]
- Tosato, M.; Zamboni, V.; Ferrini, A.; Cesari, M. The aging process and potential interventions to extend life expectancy. Clin. Interv. Aging 2007, 2, 401–412. [Google Scholar] [PubMed]
- National Research Council (US). Panel on a Research Agenda and New Data for an Aging World Preparing for an Aging World: The Case for Cross-National Research; National Academies Press: Washington, DC, USA, 2001.
- Yourman, L.C.; Lee, S.J.; Schonberg, M.A.; Widera, E.W.; Smith, A.K. Prognostic indices for older adults: A systematic review. JAMA 2012, 307, 182–192. [Google Scholar] [CrossRef] [PubMed]
- Knaus, W.A.; Zimmerman, J.E.; Wagner, D.P.; Draper, E.A.; Lawrence, D.E. APACHE-acute physiology and chronic health evaluation: A physiologically based classification system. Crit. Care Med. 1981, 9, 591–597. [Google Scholar] [CrossRef] [PubMed]
- Le Gall, J.R.; Loirat, P.; Alperovitch, A.; Glaser, P.; Granthil, C.; Mathieu, D.; Mercier, P.; Thomas, R.; Villers, D. A simplified acute physiology score for ICU patients. Crit. Care Med. 1984, 12, 975–977. [Google Scholar] [CrossRef] [PubMed]
- Lemeshow, S.; Teres, D.; Avrunin, J.S.; Pastides, H. A comparison of methods to predict mortality of intensive care unit patients. Crit. Care Med. 1987, 15, 715–722. [Google Scholar] [CrossRef] [PubMed]
- Nashef, S.A.; Roques, F.; Michel, P.; Gauducheau, E.; Lemeshow, S.; Salamon, R. European system for cardiac operative risk evaluation (EuroSCORE). Eur. J. Cardiothorac. Surg. 1999, 16, 9–13. [Google Scholar] [CrossRef]
- Spector, W.D.; Takada, H.A. Characteristics of nursing homes that affect resident outcomes. J. Aging Health 1991, 3, 427–454. [Google Scholar] [CrossRef] [PubMed]
- Graf, C. The lawton instrumental activities of daily living scale. AJN 2008, 108, 52–62. [Google Scholar] [CrossRef]
- Walsh, M.; O’Flynn, B.; O’Mathuna, C.; Hickey, A.; Kellett, J. Correlating average cumulative movement and Barthel Index in acute elderly care. In International Joint Conference Ambient Intelligence; Springer: Cham, Switzerland, 2013; pp. 54–63. [Google Scholar]
- Higuchi, S.; Kabeya, Y.; Matsushita, K.; Taguchi, H.; Ishiguro, H.; Kohshoh, H.; Yoshino, H. Barthel index as a predictor of 1-year mortality in very elderly patients who underwent percutaneous coronary intervention for acute coronary syndrome: Better activities of daily living, longer life. Clin. Cardiol. 2016, 39, 83–89. [Google Scholar] [CrossRef]
- Torsney, K.M.; Romero-Ortuno, R. The Clinical Frailty Score predicts inpatient mortality in older hospitalized patients with idiopathic Parkinson’s disease. J. R Coll. Physicians Edinb. 2018, 48, 103–107. [Google Scholar] [CrossRef] [PubMed]
- Moreno, R.P. Outcome prediction in intensive care: Why we need to reinvent the wheel. Curr. Opin. Crit. Care 2008, 14, 483–484. [Google Scholar] [CrossRef] [PubMed]
- Booth, H.; Tickle, L. Mortality modelling and forecasting: A review of methods. Ann. Actuar. Sci. 2008, 3, 3–43. [Google Scholar] [CrossRef]
- Pitacco, E.; Denuit, M.; Haberman, S.; Olivieri, A. Modelling Longevity Dynamics for Pensions and Annuity Business; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Richman, R.; Wuthrich, W. A neural network extension of the Lee-Carter model to multiple populations. Ann. Actuar. Sci. 2018, 15, 346–366. [Google Scholar] [CrossRef]
- Levantesi, S.; Pizzorusso, V. Application of machine learning to mortality modeling and forecasting. Risks 2019, 7, 26. [Google Scholar] [CrossRef]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef] [PubMed]
- Komaris, D.S.; Perez-Valero, E.; Jordan, L.; Barton, J.; Hennessy, L.; O’Flynn, B.; Tedesco, S. Predicting three-dimensional ground reaction forces in running by using artificial neural networks and lower body kinematics. IEEE Access 2019, 7, 156779–156786. [Google Scholar] [CrossRef]
- Tedesco, S.; Crowe, C.; Ryan, A.; Sica, M.; Scheurer, S.; Clifford, A.M.; Brown, K.N.; O’Flynn, B. Motion sensors-based machine learning approach for the identification of anterior cruciate ligament gait patterns in on-the-field activities in rugby players. Sensors 2020, 20, 3029. [Google Scholar] [CrossRef] [PubMed]
- Parikh, R.B.; Manz, C.; Chivers, C.; Harkness Regli, S.; Braun, J.; Draugelis, M.E.; Schuchter, L.M.; Shulman, L.N.; Navathe, A.S.; Patel, M.S.; et al. Machine learning approaches to predict 6-month mortality among patients with cancer. JAMA Netw. Open 2019, 2, e1915997. [Google Scholar] [CrossRef] [PubMed]
- Metsker, O.; Sikorsky, S.; Yakovlev, A.; Kovalchuk, S. Dynamic mortality prediction using machine learning techniques for acute cardiovascular. Procedia Comput. Sci. 2018, 136, 351–358. [Google Scholar] [CrossRef]
- Kang, M.W.; Kim, J.; Kim, D.K.; Oh, K.-H.; Joo, K.W.; Kim, Y.S.; Han, S.S. Machine learning algorithm to predict mortality in patients undergoing continuous renal replacement therapy. Crit. Care 2020, 24, 42. [Google Scholar] [CrossRef]
- Du, X.; Min, J.; Shah, C.P.; Bishnoi, R.; Hogan, W.R.; Lemas, D.J. Predicting in-hospital mortality of patients with febrile neutropenia using machine learning models. Int. J. Med. Inform. 2020, 139, 104140. [Google Scholar] [CrossRef]
- Moll, M.; Qiao, D.; Regan, E.A.; Hunninghake, G.M.; Make, B.J.; Tal-Singer, R.; McGeachie, M.J.; Castaldi, P.J.; San Jose Estepar, R.; Washko, G.R.; et al. Machine learning and prediction of all-cause mortality in COPD. Chest 2020, 158, 952–964. [Google Scholar] [CrossRef]
- Lund, J.L.; Kuo, T.-M.; Brookhart, M.A.; Meyer, A.M.; Dalton, A.F.; Kistler, C.E.; Wheeler, S.B.; Lewis, C.L. Development and validation of a 5-year mortality prediction model using regularized regression and Medicare data. Pharmacoepidemiol. Drug Saf. 2019, 28, 584–592. [Google Scholar] [CrossRef] [PubMed]
- Meyer, A.; Zverinski, D.; Pfahringer, B.; Kempfert, J.; Kuehne, T.; Sundermann, S.H.; Stamm, C.; Hofmann, T.; Falk, V.; Eickhoff, C. Machine learning for real-time prediction of complications in critical care: A retrospective study. Lancet Respir. Med. 2018, 6, 905–914. [Google Scholar] [CrossRef]
- Shouval, R.; Labopin, M.; Bondi, O.; Mishan-Shamay, H.; Shimoni, A.; Ciceri, F.; Esteve, J.; Giebel, S.; Gorin, N.C.; Schmid, C.; et al. Prediction of allogeneic hematopoietic stem-cell transplantation mortality 100 days after transplantation using a machine learning algorithm: A European group for blood and marrow transplantation acute leukemia working party retrospective data mining study. J. Clin. Oncol. 2015, 33, 3144–3151. [Google Scholar] [CrossRef]
- Liao, J.; Muniz-Terrera, G.; Scholes, S.; Hao, Y.; Chen, Y.M. Lifestyle index for mortality prediction using multiple ageing cohorts in the USA, UK, and Europe. Sci. Rep. 2018, 8, 6644. [Google Scholar] [CrossRef] [PubMed]
- Weng, S.F.; Vaz, L.; Qureshi, N.; Kai, J. Prediction of premature all-cause mortality: A prospective general population cohort study comparing machine-learning and standard epidemiological approaches. PLoS ONE 2019, 14, e0214365. [Google Scholar] [CrossRef] [PubMed]
- Clift, A.K.; Le Lannou, E.; Tighe, C.P.; Shah, S.S.; Beatty, M.; Hyvarinen, A.; Lane, S.J.; Strauss, T.; Dunn, D.D.; Lu, J.; et al. Development and validation of risk scores for all-cause mortality for the purposes of a smartphone-based “general health score” application: A prospective cohort study using the UK Biobank. JMIR Mhealth Uhealth 2021, 9, e25655. [Google Scholar] [CrossRef]
- Healthy Ageing Initiative. Available online: https://www.healthyageinginitiative.com/ (accessed on 27 December 2020).
- Ballin, M.; Nordstrom, P.; Niklasson, J.; Alamaki, A.; Condell, J.; Tedesco, S.; Nordstrom, A. Daily step count and incident diabetes in community-dwelling 70-years-olds: A prospective cohort study. BMC Public Health 2020, 20, 1830. [Google Scholar] [CrossRef]
- ActiGraph. Available online: https://actigraphcorp.com/ (accessed on 27 December 2020).
- Burke, W.J.; Roccaforte, W.H.; Wengel, S.P. The short form of the geriatric depression scale: A comparison with the 30-item form. J. Geriatr. Psychiatry Neurol. 1991, 4, 173–178. [Google Scholar] [CrossRef] [PubMed]
- AUDIT-C Score. Available online: https://www.mdcalc.com/audit-c-alcohol-use (accessed on 27 December 2020).
- Craig, C.L.; Marshall, A.L.; Sjöström, M.; Bauman, A.E.; Booth, M.L.; Ainsworth, B.E.; Pratt, M.; Ekelund, U.; Yngve, A.; Sallis, J.F.; et al. International physical activity questionnaire: 12-country reliability and validity. Med. Sci. Sports Exerc. 2003, 35, 1381–1395. [Google Scholar] [CrossRef]
- GAITRite. Available online: https://www.gaitrite.com/ (accessed on 27 December 2020).
- Burnham, J.P.; Lu, C.; Yaeger, L.H.; Bailey, T.C.; Kollef, M.H. Using wearable technology to predict health outcomes: A literature review. J. Am. Med. Inform. Assoc. 2018, 25, 1221–1227. [Google Scholar] [CrossRef] [PubMed]
- Haixiang, G.; Yijiang, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Dent, E.; Kowal, P.; Hoogendijk, E.O. Frailty measurement in research and clinical practice: A review. Eur. J. Intern. Med. 2006, 31, 3–10. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.M.; Jylhava, J.; Pedersen, N.L.; Hagg, S. A frailty index for UK biobank participants. J. Gerontol. A Biol. Sci. Med. Sci. 2019, 74, 582–587. [Google Scholar] [CrossRef]
- Kim, N.H.; Cho, H.J.; Kim, S.; Seo, J.H.; Lee, H.J.; Yu, J.H.; Chung, H.S.; Yoo, H.J.; Seo, J.A.; Kim, S.G.; et al. Predictive mortality index for community-dwelling elderly Koreans. Medicine 2016, 95, e2696. [Google Scholar] [CrossRef] [PubMed]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 103375. [Google Scholar] [CrossRef] [PubMed]
- Puggini, L.; McLoone, S. Forward selection component analysis: Algorithms and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2395–2408. [Google Scholar] [CrossRef] [PubMed]
- Puggini, L.; McLoone, S. Feature selection for anomaly detection using optical emission spectroscopy. IFAC PapersOnLine 2016, 49, 132–137. [Google Scholar] [CrossRef][Green Version]
- Ding, Z.; Fei, M. An anomaly detection approach based on isolation forest algorithm for streaming data using sliding window. IFAC Proc. Vol. 2013, 46, 12–17. [Google Scholar] [CrossRef]
- Xiao, C.; Choi, E.; Sun, J. Opportunities and challenges in developing deep learning models using electronic health records data: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1419–1428. [Google Scholar] [CrossRef] [PubMed]
- Parente, A.P.; de Souza, M.B., Jr.; Valdman, A.; Mattos, R.O. Folly data augmentation applied to machine learning-based monitoring of a pulp and paper process. Processes 2019, 7, 958. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority oversampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Hong Kong, 1–8 June 2008. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Thai-Nghe, N.; Gantner, Z.; Schmidt-Thieme, L. Cost-sensitive learning methods for imbalanced data. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Hsu, J.L.; Hung, P.C.; Lin, H.Y.; Hsieh, C.H. Applying under-sampling techniques and cost-sensitive learning methods on risk assessment of breast cancer. J. Med. Syst. 2015, 39, 210. [Google Scholar] [CrossRef] [PubMed]
- Wallace, B.C.; Dahabreh, I.J. Class probability estimates are unreliable for imbalanced data (and how to fix them). In Proceedings of the IEEE 12th International Conference Data Mining, Brussels, Belgium, 10–13 December 2012. [Google Scholar]
- Pozzolo, A.D.; Caelen, O.; Johnson, R.A.; Bontempi, G. Calibrating probability with undersampling for unbalanced classification. In Proceedings of the IEEE Symposium Series Computational Intelligence, Cape Town, South Africa, 7–10 December 2015. [Google Scholar]
- Goncalves, A.; Ray, P.; Soper, B.; Stevens, J.; Coyle, L.; Sales, A.P. Generation and evaluation of synthetic patient data. BMC Med. Res. Methodol. 2020, 20, 108. [Google Scholar] [CrossRef]
- Fowler, E.E.; Berglund, A.; Schell, M.J.; Sellers, T.A.; Eschrich, S.E.; Heine, J. Empirically-derived synthetic populations to mitigate small sample sizes. J. Biomed. Inform. 2020, 105, 103408. [Google Scholar] [CrossRef] [PubMed]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- Kovacs, G. An empirical comparison and evaluation of minority oversampling techniques on a large number of imbalanced datasets. Appl. Soft. Comput. 2019, 83, 105662. [Google Scholar] [CrossRef]
- Steele, A.J.; Denaxas, S.C.; Shaha, A.D.; Hemingway, H.; Luscombe, N.M. Machine learning models in electronic health records can outperform conventional survival models for predicting patient mortality in coronary artery disease. PLoS ONE 2018, 13, e0202344. [Google Scholar] [CrossRef] [PubMed]
- Davis, J.; Goadrich, M. The relationship between precision-recall and ROC curves. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006. [Google Scholar]
- Rodríguez, A.; Mendoza, D.; Ascuntar, J.; Jaimes, F. Supervised classification techniques for prediction of mortality in adult patients with sepsis. Am. J. Emerg. Med. 2021, 45, 392–397. [Google Scholar] [CrossRef] [PubMed]
- Movahedi, F.; Padman, R.; Antaki, J.F. Limitations of ROC on imbalanced data: Evaluation of LVAD mortality risk scores. arXiv 2020, arXiv:2010.1625. [Google Scholar]
- Stiglic, G.; Kocbek, P.; Fijacko, N.; Zitnik, M.; Verbert, K.; Cilar, L. Interpretability of machine learning based prediction models in healthcare. WIREs Data Min. Knowl. Discov. 2020, 10, e1379. [Google Scholar] [CrossRef]
- Moncada-Torres, A.; van Maaren, M.C.; Hendriks, M.P.; Siesling, S.; Geleijnse, G. Explainable machine learning can outperform Cox regression predictions and provide insights in breast cancer survival. Sci. Rep. 2021, 11, 6968. [Google Scholar] [CrossRef]
- Subudhi, S.; Verma, A.; Patel, A.B.; Hardin, C.C.; Khandekar, M.J.; Lee, H.; McEvoy, D.; Stylianopoulos, T.; Munn, L.L.; Dutta, S.; et al. Comparing machine learning algorithms for predicting ICU admission and mortality in COVID-19. NPJ Digit. Med. 2021, 4. [Google Scholar] [CrossRef] [PubMed]
- Yun, K.; Oh, J.; Hong, T.H.; Kim, E.Y. Prediction of mortality in surgical intensive care unit patient using machine learning algorithms. Front. Med. 2021, 8, 406. [Google Scholar] [CrossRef] [PubMed]
- Servia, L.; Montserrat, N.; Badia, M.; Llompart-Pou, J.A.; Barea-Mendoza, J.A.; Chico-Fernandez, M.; Sanchez-Casado, M.; Jimenez, J.M.; Mayor, D.M.; Trujillano, J. Machine learning techniques for mortality prediction in critical traumatic patients: Anatomic physiologic variables from the RETRAUCI study. BMC Med. Res. Methodol. 2020, 20, 262. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Variables | Hazard Ratio (HR) | HR 95% C.I. | p-Value |
|---|---|---|---|
| Sex | 0.47 | 0.27–0.83 | 0.01 |
| HDL Cholesterol | 0.88 | 0.83–0.93 | <0.005 |
| Rheumatoid arthritis | 0.20 | 0.02–2.43 | 0.21 |
| Total T-score | 0.77 | 0.62–0.96 | 0.02 |
| Secondary osteoporosis | 1.54 | 0.8–2.95 | 0.2 |
| Glucocorticoids | 2.95 | 0.8–10.8 | 0.1 |
| Parent Fractured Hip | 0.68 | 0.31–1.5 | 0.34 |
| Sway trace length (no vision) | 1 | 1.0–1.0 | 0.02 |
| IPAQ MET-min per week | 1 | 1.0–1.0 | 0.01 |
| MODEL | AUC-ROC | AUC-PR | BRIER SCORE | F1 SCORE | ACCURACY | RECALL | PRECISION | |
|---|---|---|---|---|---|---|---|---|
| LR | Test | 0.509 | 0.222 | 0.746 | 0.048 | 0.954 | 0.036 | 0.072 |
| (0.500–0.527) | (0.020–0.520) | (0.741–0.753) | (0.000–0.095) | (0.945–0.959) | (0.000–0.071) | (0.000–0.143) | ||
| Train | 0.568 | 0.280 | 0.543 | 0.079 | 0.957 | 0.536 | 0.043 | |
| (0.534–0.601) | (0.251–0.297) | (0.543–0.544) | (0.072–0.087) | (0.956–0.957) | (0.429–0.679) | (0.038–0.048) | ||
| DT | Test | 0.511 | 0.094 | 0.596 | 0.068 | 0.904 | 0.095 | 0.056 |
| (0.507–0.514) | (0.020–0.148) | (0.566–0.634) | (0.025–0.120) | (0.856–0.930) | (0.000–0.143) | (0.000–0.096) | ||
| Train | 0.522 | 0.104 | 0.587 | 0.079 | 0.913 | 0.093 | 0.076 | |
| (0.518–0.527) | (0.095–0.121) | (0.577–0.593) | (0.069–0.086) | (0.907–0.918) | (0.079–0.112) | (0.059–0.092) | ||
| RF | Test | 0.509 | 0.187 | 0.044 | 0.040 | 0.956 | 0.030 | 0.052 |
| (0.508–0.509) | (0.020–0.520) | (0.041–0.045) | (0.000–0.080) | (0.955–0.959) | (0.000–0.060) | (0.000–0.104) | ||
| Train | 0.570 | 0.106 | 0.044 | 0.028 | 0.956 | 0.015 | 0.167 | |
| (0.551–0.590) | (0.092–0.117) | (0.043–0.045) | (0.010–0.046) | (0.955–0.957) | (0.000–0.031) | (0.000–0.300) | ||
| ADABOOST | Test | 0.512 | 0.054 | 0.547 | 0.020 | 0.953 | 0.012 | 0.056 |
| (0.510–0.514) | (0.020–0.121) | (0.547–0.548) | (0.000–0.059) | (0.952–0.953) | (0.000–0.036) | (0.000–0.167) | ||
| Train | 0.582 | 0.113 | 0.549 | 0.056 | 0.951 | 0.036 | 0.138 | |
| (0.553–0.611) | (0.068–0.138) | (0.546–0.552) | (0.039–0.074) | (0.949–0.953) | (0.015–0.047) | (0.040–0.196) |
| Model | AUC-ROC | AUC-PR | Precision | Recall |
|---|---|---|---|---|
| LR W/ ADASYN W/ PROB. CAL. | 0.573 (0.566–0.582) | 0.311 (0.288–0.339) | 0.055 (0.054–0.056) | 0.548 (0.500–0.596) |
| DT W/ SMOTE W/O PROB. CAL. | 0.541 (0.509–0.567) | 0.317 (0.123–0.425) | 0.045 (0.033–0.052) | 0.572 (0.179–0.78) |
| RF W/ RUS W/O PROB. CAL. | 0.642 (0.504–0.781) | 0.337 (0.121–0.553) | 0.068 (0.029–0.107) | 0.590 (0.179–1.00) |
| RF W/ RUS W/ PROB. CAL. | 0.606 (0.597–0.615) | 0.467 (0.441–0.493) | 0.053 (0.053–0.054) | 0.875 (0.821–0.929) |
| ADABOOST W/ ADASYN W/ PROB. CAL. | 0.543 (0.520–0.582) | 0.364 (0.300–0.419) | 0.047 (0.044–0.053) | 0.667 (0.536–0.769) |
| LR W/ SMOTE W/O PROB. CAL. W/ D.A. | 0.539 (0.510–0.559) | 0.262 (0.247–0.288) | 0.049 (0.045–0.056) | 0.453 (0.429–0.500) |
| LR W/ ADASYN W/O PROB. CAL. W/ D.A. | 0.539 (0.523–0.555) | 0.273 (0.260–0.288) | 0.049 (0.046–0.055) | 0.476 (0.429–0.500) |
| DT W/ SMOTEENN W/ PROB. CAL. W/ D.A. | 0.530 (0.509–0.560) | 0.448 (0.371–0.503) | 0.044 (0.040–0.047) | 0.845 (0.679–0.964) |
| RF W/ SMOTE W/ PROB. CAL. W D.A. | 0.535 (0.513–0.557) | 0.280 (0.176–0.336) | 0.050 (0.038–0.065) | 0.488 (0.286–0.607) |
| ADABOOST W/ SMOTE W/ PROB. CAL. W/ D.A. | 0.529 (0.505–0.554) | 0.172 (0.074–0.255) | 0.046 (0.039–0.052) | 0.476 (0.286–0.786) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tedesco, S.; Andrulli, M.; Larsson, M.Å.; Kelly, D.; Alamäki, A.; Timmons, S.; Barton, J.; Condell, J.; O’Flynn, B.; Nordström, A. Comparison of Machine Learning Techniques for Mortality Prediction in a Prospective Cohort of Older Adults. Int. J. Environ. Res. Public Health 2021, 18, 12806. https://doi.org/10.3390/ijerph182312806
Tedesco S, Andrulli M, Larsson MÅ, Kelly D, Alamäki A, Timmons S, Barton J, Condell J, O’Flynn B, Nordström A. Comparison of Machine Learning Techniques for Mortality Prediction in a Prospective Cohort of Older Adults. International Journal of Environmental Research and Public Health. 2021; 18(23):12806. https://doi.org/10.3390/ijerph182312806
Chicago/Turabian StyleTedesco, Salvatore, Martina Andrulli, Markus Åkerlund Larsson, Daniel Kelly, Antti Alamäki, Suzanne Timmons, John Barton, Joan Condell, Brendan O’Flynn, and Anna Nordström. 2021. "Comparison of Machine Learning Techniques for Mortality Prediction in a Prospective Cohort of Older Adults" International Journal of Environmental Research and Public Health 18, no. 23: 12806. https://doi.org/10.3390/ijerph182312806
APA StyleTedesco, S., Andrulli, M., Larsson, M. Å., Kelly, D., Alamäki, A., Timmons, S., Barton, J., Condell, J., O’Flynn, B., & Nordström, A. (2021). Comparison of Machine Learning Techniques for Mortality Prediction in a Prospective Cohort of Older Adults. International Journal of Environmental Research and Public Health, 18(23), 12806. https://doi.org/10.3390/ijerph182312806