
Predicting Food Safety Compliance for Informed Food Outlet Inspections: A Machine Learning Approach



Abstract
:1. Introduction
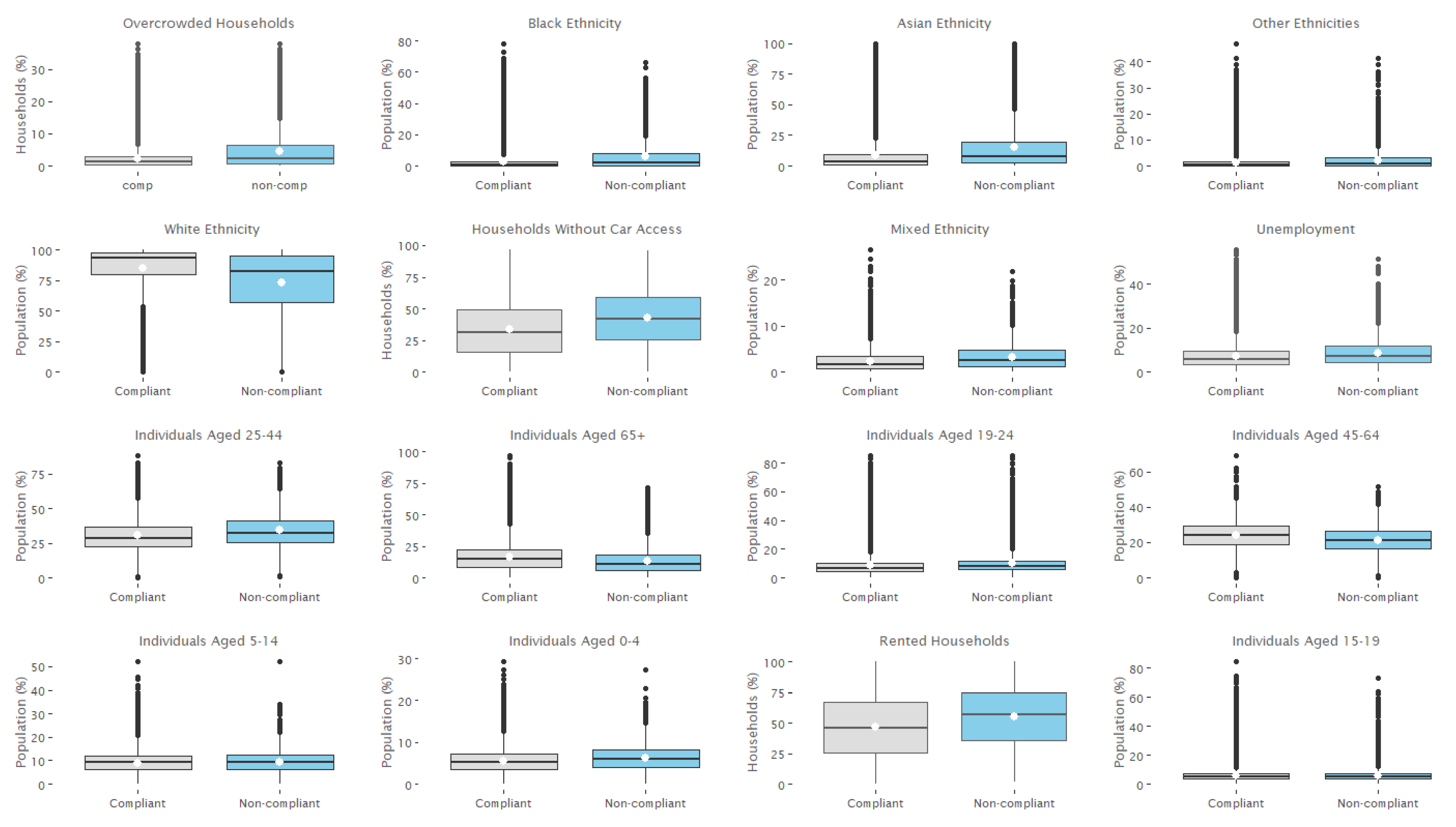
1.1. Neighbourhood Demography and Food Safety
1.2. Machine Learning Approaches for Food Safety
2. Methodology
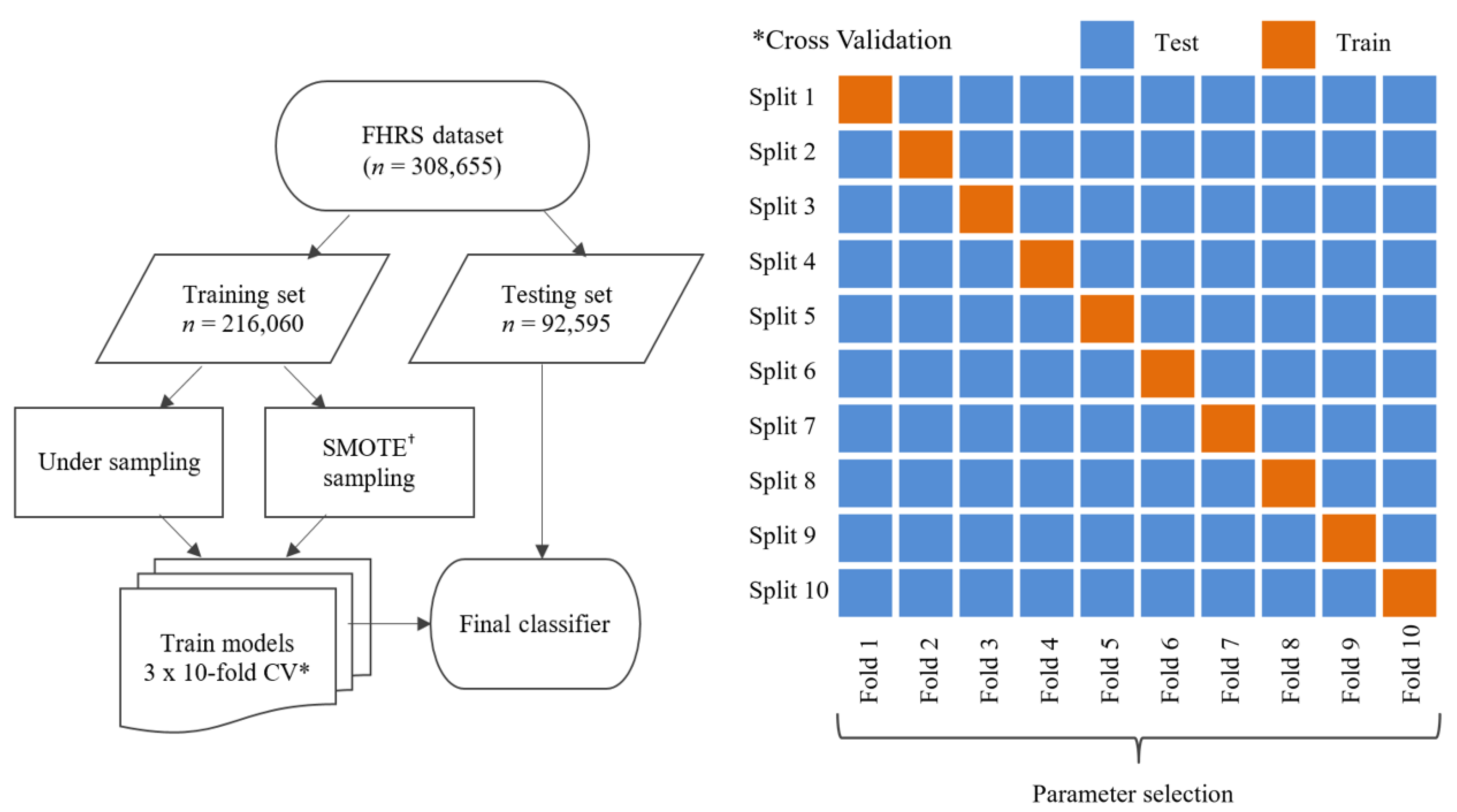
2.1. Data and Data Preparation
2.2. Dataset Partition
2.3. Sampling Strategy
2.3.1. Undersampling
2.3.2. Synthetic Minority Oversampling Technique
2.4. Training Phase
2.5. Model Specifications
2.5.1. Linear Support Vector Machine
2.5.2. Radial Support Vector Machine
2.5.3. Random Forest
2.6. Testing Phase
3. Results
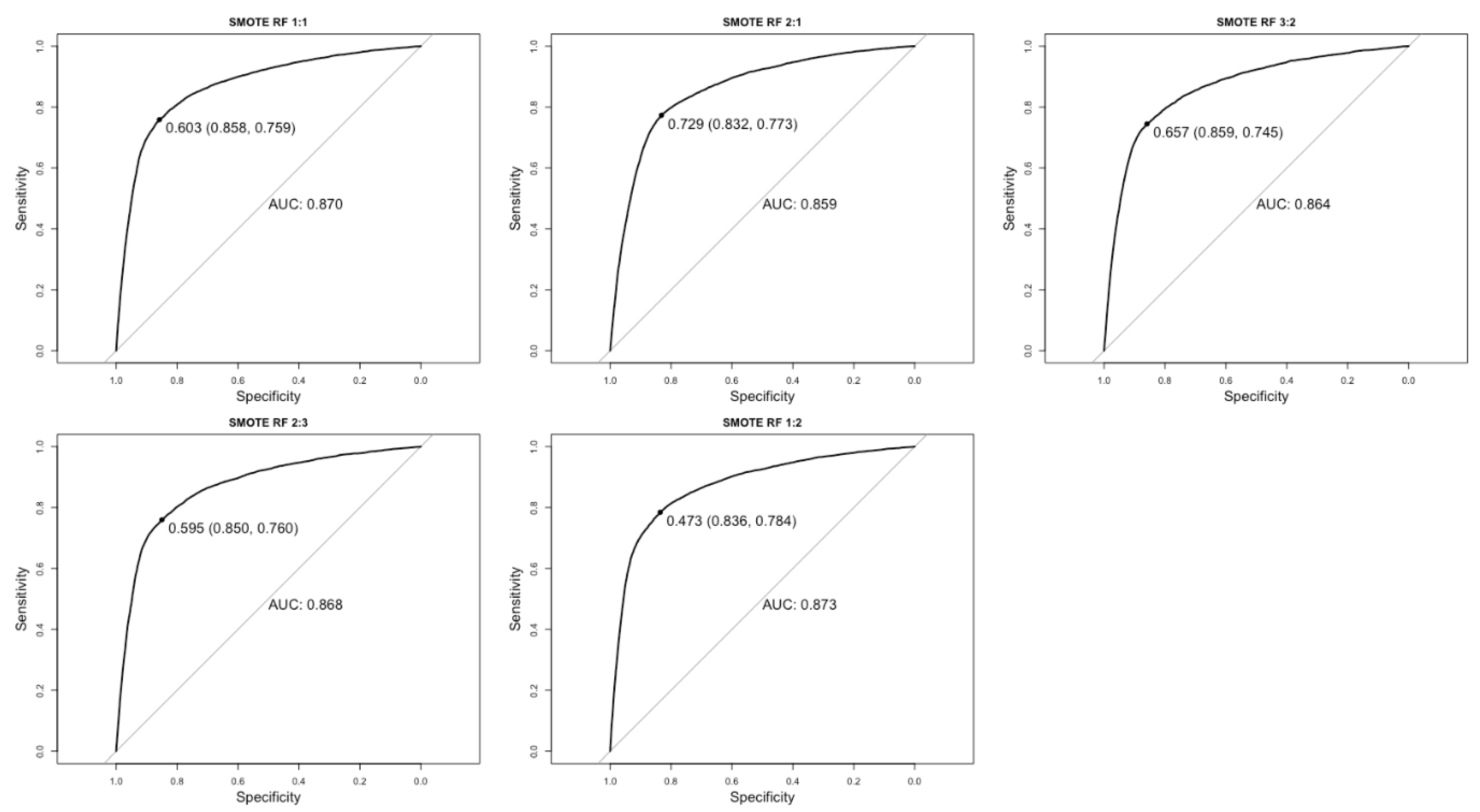
3.1. ROC Curve Analysis
3.2. Application of Cost Penalty
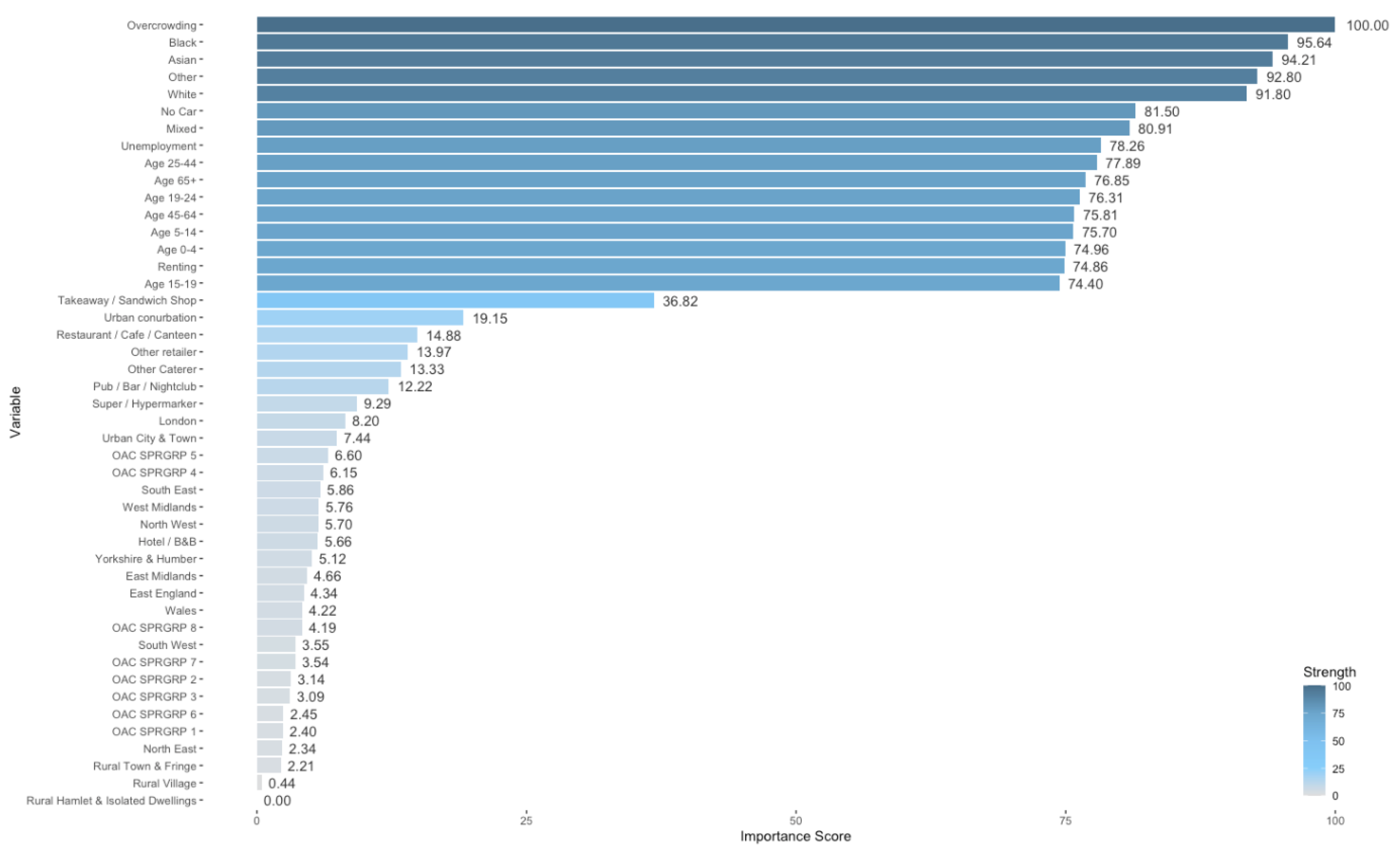
3.3. Variable Importance Scores
4. Discussion
4.1. Strengths and Policy Implications
4.2. Appropriateness of Algorithms and Sampling Strategies
4.3. Variable Importance
4.4. Methodological Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Food Standards Agency. The Food and You Survey. 2019. Available online: http://www.food.gov.uk/science/research-reports/ssresearch/foodandyou (accessed on 20 January 2021).
- Office for National Statistics. UK Business: Activity, Size and Location; Office for National Statistics: London, UK, 2018. [Google Scholar]
- Fleetwood, J.; Rahmanb, S.; Holland, D.; Millson, D.; Thomson, L.; Poppy, G. As clean as they look? Food hygiene inspection scores. microbiological contamination, and foodborne illness. Food Control 2019, 96, 76–86. [Google Scholar] [CrossRef]
- Holland, D.; Thomson, L.; Mahmoudzadeh, N.; Khaled, A. Estimating deaths from foodborne disease in the UK for 11 key pathogens. BMJ Open Gastroenterol. 2020, 7, e000377. [Google Scholar] [CrossRef] [PubMed]
- National Audit Office. Ensuring Food Safety and Standards; National Audit Office: London, UK, 2019. [Google Scholar]
- Food Standards Agency. Regulating Our Future; Food Standards Agency: London, UK, 2018. [Google Scholar]
- Millstone, E.; Lang, T. Weakening UK food law enforcement: A risky tactic in Brexit. In FRC Food Brexit Policy Briefing; Centre for Food Policy: London, UK, 2018. [Google Scholar]
- Roberts, K.; Kwon, J.; Shanklin, C.; Liu, P.; Yen, W.S. Food safety practices lacking in independent ethnic restaurants. J. Culin. Sci. Technol. 2011, 9, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Harris, K.J.; Murphy, K.S.; DiPietro, R.B.; Rivera, G.L. Food safety inspections results: A comparison of ethnic-operated restaurants to non-ethnic-operated restaurants. Int. J. Hosp. Manag. 2015, 46, 190–199. [Google Scholar] [CrossRef]
- Darcey, V.L.; Quinlan, J.J. Use of geographic information systems technology to track critical health code violations in retail facilities available to populations of different socioeconomic status and demographics. J. Food Prot. 2011, 74, 1524–1530. [Google Scholar] [CrossRef]
- Pothukuchi, K.; Mohamed, R.; Gebben, D. Explaining disparities in food safety compliance by food stores: Does community matter? Agric. Hum. Values 2008, 25, 319–332. [Google Scholar] [CrossRef]
- Wills, W.; Meah, A.; Dickinson, A.; Short, F. Domestic Kitchen Practices: Findings from the ‘Kitchen Life’ Study; Social Science Research Unit Report 24, Prepared for the FSA Social Science Research Committee; University of Hertfordshire Research Archive: Hertford, UK, 2013. [Google Scholar]
- Quinlan, J.J. Foodborne Illness Incidence Rates and Food Safety Risks for Populations of Low Socioeconomic Status and Minority Race/Ethnicity: A Review of the Literature. Int. J. Environ. Res. Public Health 2013, 10, 3634–3652. [Google Scholar] [CrossRef]
- Oldroyd, R.A.; Morris, M.A.; Birkin, M. Food Safety Vulnerability: Neighbourhood determinants of non-compliant establishments in England and Wales. Health Place 2020, 63, 102325. [Google Scholar] [CrossRef] [PubMed]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Oldroyd, R.A.; Morris, M.A.; Birkin, M. Identifying Methods for Monitoring Foodborne Illness: Review of Existing Public Health Surveillance Techniques. JMIR Public Health Surveill. 2018, 4, e57. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arendt, S.; Rajagopal, L.; Strohbehn, C.; Stokes, N.; Meyer, J.; Mandernach, S. Reporting of Foodborne Illness by U.S. Consumers and Healthcare Professionals. Int. J. Environ. Res. Public Health 2013, 10, 3684–3714. [Google Scholar] [CrossRef] [Green Version]
- Sadilek, A.; Brennan, S.; Kautz, H.; Silenzio, V. nEmesis: Which Restaurants Shold You Avoid Today? In First AAAI Conference on Human Computation and Crowdsourcing; AAAI Press: Palm Springs, CA, USA, 2013; pp. 138–146. [Google Scholar]
- Kotsiantis, S.; Kanellopoulos, D.; Pintelas, P. Handling imbalanced datasets: A review. GESTS Int. Trans. Comput. Sci. Eng. 2006, 30, 25–36. [Google Scholar]
- Effland, T.; Lawson, A.; Balter, S.; Devinney, K.; Reddy, V.; Waechter, H.; Gravano, L.; Hsu, D. Discovering foodborne illness in online restaurant reviews. J. Am. Med. Inform. Assoc. 2018, 25, 1586–1592. [Google Scholar] [CrossRef]
- McCarthy, M. Online restaurant reviews identify outbreaks of undetected foodborne illness. BMJ Br. Med. J. 2014, 348, g3560. [Google Scholar] [CrossRef] [PubMed]
- Harrison, C.; Jorder, M.; Stern, H.; Stavinsky, F.; Reddy, V.; Hanson, H.; Waechter, H.; Lowe, L.; Gravano, L.; Balter, S. Using online reviews by restaurant patrons to identify unreported cases of foodborne illness—New York City. 2012–2013. Morb. Mortal. Wkly. Rep. 2014, 63, 441–445. [Google Scholar]
- Food Standards Agency. Food Hygiene Rating Schemes. 2020. Available online: https://www.food.gov.uk/safety-hygiene/food-hygiene-rating-scheme (accessed on 27 February 2020).
- Office for National Statistics. 2011 Census Aggregate Data; UK Data Service: London, UK, 2016. [Google Scholar]
- Office for National Statistics. Rural and Urban Classification; UK Data Service: London, UK, 2011. [Google Scholar]
- Office for National Statistics. 2011 OAC Clusters and Name; UK Data Service: London, UK, 2011. [Google Scholar]
- Office for National Statistics. Postcode to Output Area to Lower Layer Super Output Area to Middle Layer Super Output Area to Local Authority District (February 2018) Lookup in the UK; ONS Geography: London, UK, 2018. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 1984, 16, 321–357. [Google Scholar] [CrossRef]
- Altman, A.; Tolosi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Torgo, L. Data Mining Using R: Learning with Case Studies; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Ling, C.X.; Huang, J.; Zhang, H.; Ling, C.X.; Huang, J.; Zhang, H. AUC: A statistically consistent and more discriminating measure than accuracy. Int. Jt. Conf. Artif. Intell. 2003, 3, 519–524. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernal-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Aizerman, M.; Braverman, E.; Rozonoer, L. Theoretical foundations of the potential function method in pattern recognition learning. Autom. Remote Control 1964, 25, 821–837. [Google Scholar]
- Fawagreh, K.; Gaber, M.M.; Elyan, E. Random forests: From early developments to recent advancements. Syst. Sci. Control Eng. 2014, 2, 602–609. [Google Scholar] [CrossRef] [Green Version]
- Bernard, S.; Heutte, L.; Adam, S. A Study of Strength and Correlation in Random Forests; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Youden, J. Index for rating diagnostic tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Robin, X.; Turck, N.; Hainard, A.; Tiberti, N.; Lisacek, F.; Sanchez, J.C.; Müller, M. pROC: An open-source package for R and S+ to analyze and compare ROC curves. BMC Bioinform. 2011, 12, 2–8. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The measurement of observed agreement for categorical data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [Green Version]
- Elkan, C. The Foundations of Cost-Sensitive Learning. In Proceedings of the IJCAI01: Proceedings of the 17th International Joint Conference on Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; Volume 2, pp. 973–978.
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Deng, H.; Runger, G.; Tuv, E. Bias of importance measures for multi-valued attributes and solutions. In Proceedings of the 21st International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 293–300. [Google Scholar]
- Breiman, L.; Friedman, J.; Olshen, R.; Stone, C. Classification and Regression Trees; Chapman and Hall: New York, NY, USA, 1984. [Google Scholar]
- Strobl, C.; Boulesteix, A.; Augustin, T. Unbiased split selection for classification trees based on the Gini index. Comput. Stat. Data Anal. 2007, 52, 483–501. [Google Scholar] [CrossRef] [Green Version]
- Townsend, P.; Phillimore, P.; Beattie, A. Health and Deprivation: Inequalities and the North; Croom Helm: Kent, UK, 1988. [Google Scholar]
- Pham, M.T.; Jones, A.Q.; Sargeant, J.M.; Marshall, B.J.; Dewey, C.E. A qualitative exploration of the perceptions and information needs of public health inspectors responsible for food safety. BMC Public Health 2010, 10, 345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schomberg, J.P.; Haimson, O.L.; Hayes, G.R.; Anton-Culver, H. Supplementing Public Health Inspection via Social Media. PLoS ONE 2016, 11, e0152117. [Google Scholar] [CrossRef] [PubMed]
- Gormley, F.J.; Rawal, N.; Little, C.S. Choose your menu wisely: Cuisine-associated food-poisoning risks in restaurants in England and Wales. Epidemiol. Infect. 2011, 140, 997–1007. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Hwang, J.; Mustapha, A. Popular Ethnic Foods in the United States: A Historical and Safety Perspective. Compr. Rev. Food Sci. Food Saf. 2014, 13, 2–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fusco, V.; den Besten, H.M.W.; Logrieco, A.F.; Rodriguez, F.P.; Skandamis, P.N.; Stessl, B.; Teixeira, P. Food safety aspects on ethnic foods: Toxicological and microbial risks. Curr. Opin. Food Sci. 2015, 6, 24–32. [Google Scholar] [CrossRef]
- Hood, N.; Urquhart, R.; Newing, A. Sociodemographic and spatial disaggregation of e-commerce channel use in the grocery market in Great Britain. J. Retail. Consum. Serv. 2020, 55, 102076. [Google Scholar] [CrossRef]
- Yapp, C.; Fairman, R. Factors affecting food safety compliance within small and medium-sized enterprises: Implications for regulatory and enforcement strategies. Food Control 2006, 17, 42–51. [Google Scholar] [CrossRef]
- Wilkins, E.; Radley, D.; Morris, M.A.; Griffiths, C. Examining the validity and utility of two secondary sources of food environment data against street audits in England. Nutr. J. 2017, 16, 82. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Slack, D.; Hilgard, S.; Jia, E.; Singh, S.; Lakkaraju, H. Fooling LIME and SHAP: Adversarial Attacks on Post hoc Explanation Methods. In Proceedings of the AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society (AIES), New York, NY, USA, 7–8 February 2020. [Google Scholar]
- Painsky, A.; Rosset, S. Cross-Validated Variable Selection in Tree-Based Methods Improves Predictive Performance. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2142–2153. [Google Scholar] [CrossRef] [Green Version]
- Openshaw, S.; Taylor, P. A Million or so Correlation Coefficients: Three Experiments on the Modifiable Areal Unit Problem. In Statistical Applicaions in the Spatial Sciences; Pion: London, UK, 1979; pp. 127–144. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Domain and Source | Geography | Variable | Categories/Levels |
|---|---|---|---|
| Food Hygiene Rating Scheme Scores [23] | Reported for individual food outlets | FHRS score (ordinal) | 0 (Improvement necessary), 1, 2, 3, 4, 5 (Very good) |
| Business Type (categorical) | Restaurants, cafés, & canteens; other retailers; super- & hyper-markets; other catering; pubs, bars, & nightclubs; takeaways & sandwich shops; hotels, guesthouses, bed & breakfasts | ||
| Region (categorical) | East Midland, West Midlands, East of England, London, North East, North West, South East, South West, Wales, Yorkshire | ||
| Socio-demographic 2011 census data [24] | Reported at OA level | Age (% of persons) | 0–4; 5–14; 15–19; 20–24; 25–44; 45–64; 65+ |
| Ethnicity (% of persons) | Asian, Black, Mixed, Other, White | ||
| Unemployment (% of persons) | |||
| Overcrowding (% of households) | |||
| No car access (% of households) | |||
| Renting (% of households) | |||
| Rural Urban Classification [25] | Reported at OA level | RUC (categorical): | Urban cities and towns; rural hamlets and isolated dwellings; rural town and fringe; rural village; and urban conurbation |
| Output Area Classification [26] | Reported at OA level | OAC Supergroups (categorical): | (1) Rural residents; (2) cosmopolitans; (3) ethnicity central; (4) multicultural metropolitans; (5) urbanites; (6) suburbanites; (7) constrained city dwellers; (8) hard-pressed living |
| Variable | Level | Mean | SD | Min. | Max. |
|---|---|---|---|---|---|
| Ethnicity (%) | White | 84.06 | 19.64 | 0.00 | 100.00 |
| Mixed | 2.42 | 2.31 | 0.00 | 26.61 | |
| Asian | 8.73 | 13.69 | 0.00 | 99.76 | |
| Black | 3.28 | 6.41 | 0.00 | 78.04 | |
| Other | 1.40 | 2.69 | 0.00 | 48.90 | |
| Age (%) | 0–4 | 5.62 | 2.86 | 0.00 | 29.30 |
| 5–14 | 9.10 | 4.49 | 0.00 | 52.20 | |
| 15–19 | 5.86 | 4.62 | 0.00 | 84.62 | |
| 20–24 | 9.13 | 8.35 | 0.00 | 85.12 | |
| 25–44 | 30.72 | 11.59 | 0.00 | 88.33 | |
| 45–64 | 23.74 | 7.96 | 0.00 | 69.19 | |
| ≥65 | 15.83 | 10.35 | 0.00 | 96.75 | |
| Unemployment (% of individuals) | - | 7.35 | 5.53 | 0.00 | 55.68 |
| Overcrowding (% of households) | - | 2.57 | 3.76 | 0.00 | 38.00 |
| No Car Access (% of households) | - | 34.45 | 21.48 | 0.00 | 96.71 |
| Renting (% of households) | - | 47.53 | 24.77 | 0.00 | 100.00 |
| Sampling Set/Ratio (Non-Comp:Comp) | Model Tuning Parameters | |||||
|---|---|---|---|---|---|---|
| Linear SVM (Cost) | Radial SVM (Cost) | Random Forest (Mtry) | ||||
| SMOTE | Under-Sampled | SMOTE | Under-Sampled | SMOTE | Under-Sampled | |
| Set 1 (1:1) | 1.895 | 0.842 | 32.00 | 32.00 | 5 | 3 |
| Set 2 (2:1) | 0.632 | 0.947 | 64.00 | 0.250 | 5 | 3 |
| Set 3 (3:2) | 0.316 | 0.105 | 64.00 | 2.000 | 6 | 3 |
| Set 4 (2:3) | 2.000 | 2.000 | 16.00 | 16.00 | 5 | 3 |
| Set 5 (1:2) | 1.368 | 2.000 | 16.00 | 0.250 | 5 | 3 |
| Metric | RF Set 1 n = 92,595 | RF Set 2 n = 92,595 | RF Set 3 n = 92,595 | RF Set 4 n = 92,595 | RF Set 5 n = 92,595 | RF Unsampled n = 92,595 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Unweighted | Weighted | Unweighted | Weighted | Unweighted | Weighted | Unweighted | Weighted | Unweighted | Weighted | Unweighted | Weighted | |
| Probability Threshold | 0.603 | 0.481 | 0.729 | 0.645 | 0.657 | 0.515 | 0.595 | 0.459 | 0.473 | 0.367 | 0.067 | 0.021 |
| Area Under Curve | 0.87 | 0.87 | 0.859 | 0.859 | 0.864 | 0.864 | 0.868 | 0.868 | 0.873 | 0.873 | 0.796 | 0.796 |
| Sensitivity | 0.759 | 0.843 | 0.773 | 0.833 | 0.745 | 0.838 | 0.76 | 0.853 | 0.784 | 0.849 | 0.661 | 0.859 |
| Specificity | 0.858 | 0.745 | 0.836 | 0.741 | 0.859 | 0.737 | 0.85 | 0.724 | 0.836 | 0.737 | 0.797 | 0.481 |
| True Positives | 4624 | 5139 | 4712 | 5076 | 4540 | 5107 | 4630 | 5201 | 4781 | 5175 | 4029 | 5903 |
| False Positives | 12,264 | 21,676 | 14,572 | 22,383 | 12,180 | 22,752 | 12,976 | 23,872 | 14,210 | 22,773 | 17,571 | 77,591 |
| True Negatives | 74,235 | 64,823 | 71,924 | 64,116 | 74,319 | 63,747 | 73,523 | 62,627 | 72,289 | 63,726 | 68,928 | 8908 |
| False Negatives | 1472 | 957 | 1384 | 1020 | 1556 | 989 | 1466 | 895 | 1315 | 921 | 2067 | 193 |
| Kappa | 0.338 | 0.230 | 0.301 | 0.218 | 0.334 | 0.216 | 0.325 | 0.210 | 0.313 | 0.220 | 0.210 | 0.010 |
| Precision | 0.274 | 0.192 | 0.244 | 0.185 | 0.272 | 0.183 | 0.263 | 0.179 | 0.252 | 0.185 | 0.187 | 0.071 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oldroyd, R.A.; Morris, M.A.; Birkin, M. Predicting Food Safety Compliance for Informed Food Outlet Inspections: A Machine Learning Approach. Int. J. Environ. Res. Public Health 2021, 18, 12635. https://doi.org/10.3390/ijerph182312635
Oldroyd RA, Morris MA, Birkin M. Predicting Food Safety Compliance for Informed Food Outlet Inspections: A Machine Learning Approach. International Journal of Environmental Research and Public Health. 2021; 18(23):12635. https://doi.org/10.3390/ijerph182312635
Chicago/Turabian StyleOldroyd, Rachel A., Michelle A. Morris, and Mark Birkin. 2021. "Predicting Food Safety Compliance for Informed Food Outlet Inspections: A Machine Learning Approach" International Journal of Environmental Research and Public Health 18, no. 23: 12635. https://doi.org/10.3390/ijerph182312635
APA StyleOldroyd, R. A., Morris, M. A., & Birkin, M. (2021). Predicting Food Safety Compliance for Informed Food Outlet Inspections: A Machine Learning Approach. International Journal of Environmental Research and Public Health, 18(23), 12635. https://doi.org/10.3390/ijerph182312635