
Missing Value Imputation of Time-Series Air-Quality Data via Deep Neural Networks



Abstract
:1. Introduction
2. Materials and Methods
2.1. Datasets
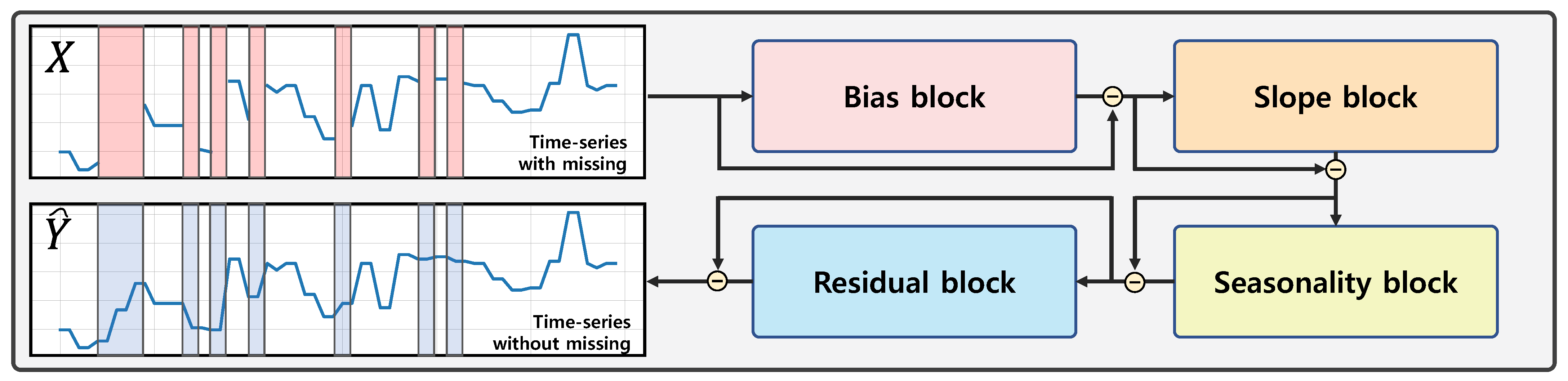
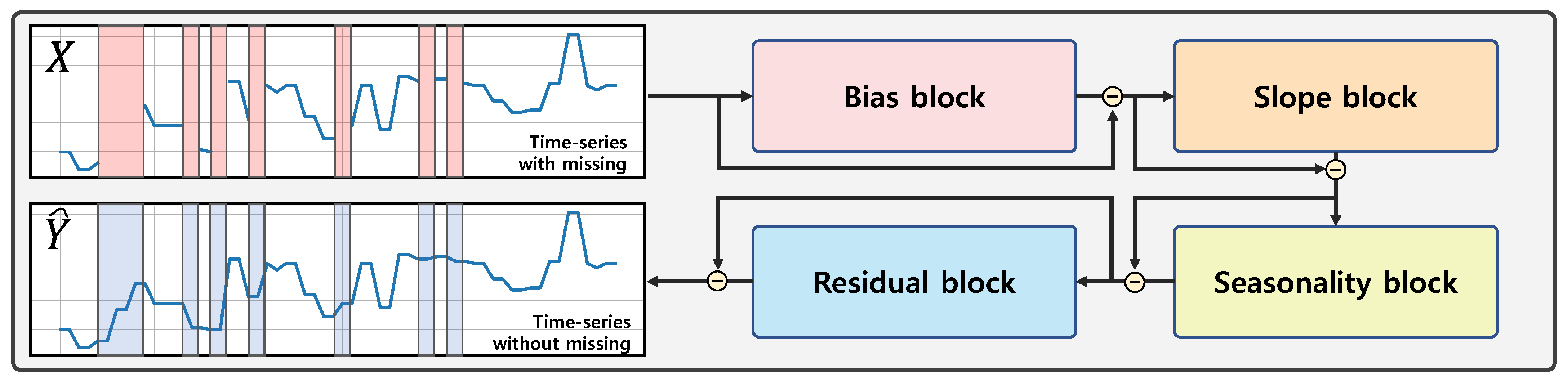
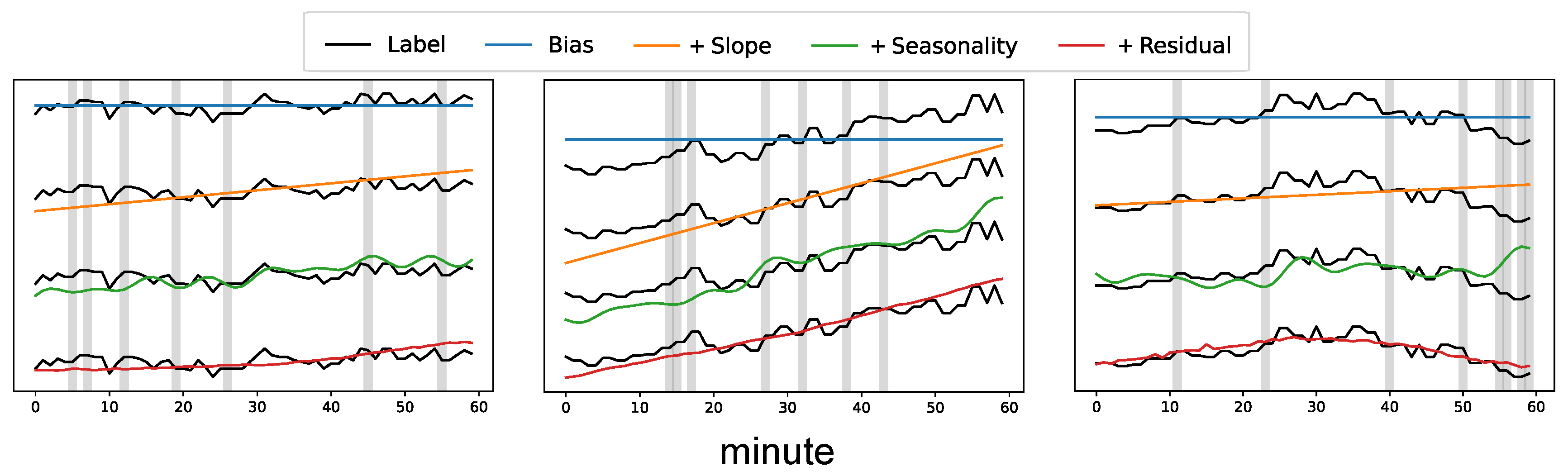
2.2. Imputation Method
2.3. Experimental Details
2.4. Evaluation Metric
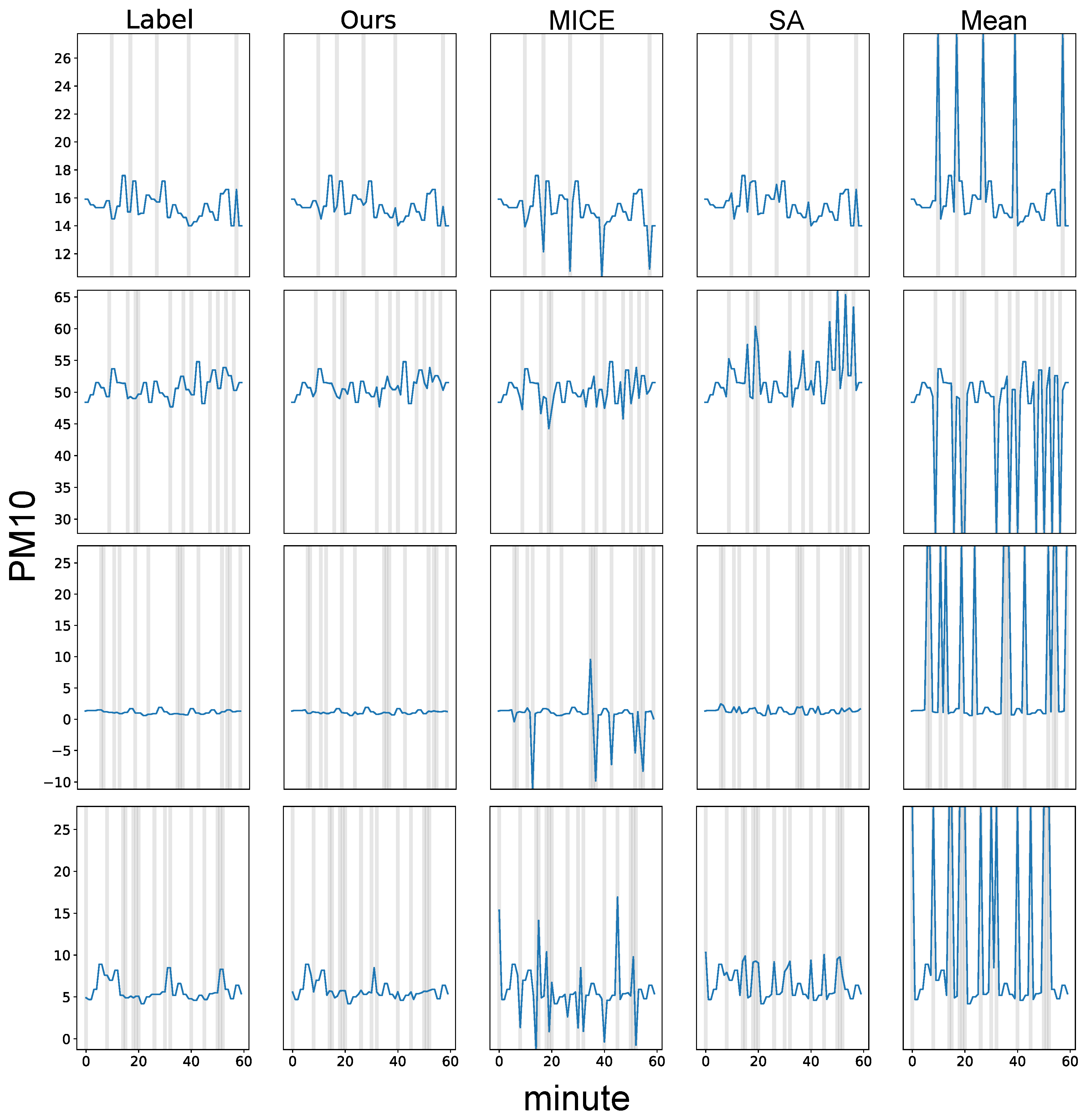
2.5. Baseline Models
- Mean substitution (Mean): The missing values are substituted with the average value of the training dataset.
- Spatial average value substitution (SA): We replace the missing values with the average value of the data collected from different locations. The value is calculated as , where indicates the input data at time step i that is collected at the j-th data collection location.
- Multivariate imputation by chained equations (MICE): We use MICE [3] to impute the missing values. MICE makes multiple imputations using chained equations. MICE is implemented using the FancyImpute library.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MAE | Mean absolute error |
| sMAPE | Symmetric mean absolute percentage error |
References
- Wong, C.M.; Vichit-Vadakan, N.; Kan, H.; Qian, Z. Public Health and Air Pollution in Asia (PAPA): A multicity study of short-term effects of air pollution on mortality. Environ. Health Perspect. 2008, 116, 1195–1202. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Landrigan, P.J. Air pollution and health. Lancet Public Health 2017, 2, e4–e5. [Google Scholar] [CrossRef] [Green Version]
- Van Buuren, S.; Groothuis-Oudshoorn, K. Mice: Multivariate imputation by chained equations in R. J. Stat. Softw. 2011, 45, 1–67. [Google Scholar] [CrossRef] [Green Version]
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A program for missing data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- Che, Z.; Purushotham, S.; Cho, K.; Sontag, D.; Liu, Y. Recurrent neural networks for multivariate time series with missing values. Sci. Rep. 2018, 8, 1–12. [Google Scholar]
- Luo, Y.; Cai, X.; Zhang, Y.; Xu, J.; Yuan, X. Multivariate time series imputation with generative adversarial networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montréal, QC, Canada, 3–8 December 2018; pp. 1603–1614. [Google Scholar]
- Luo, Y.; Zhang, Y.; Cai, X.; Yuan, X. E2gan: End-to-End Generative Adversarial Network for Multivariate Time Series Imputation; AAAI Press: Menlo Park, CA, USA, 2019; pp. 3094–3100. [Google Scholar]
- Oreshkin, B.N.; Carpov, D.; Chapados, N.; Bengio, Y. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. arXiv 2019, arXiv:1905.10437. [Google Scholar]
- Park, J.; Jo, W.; Cho, M.; Lee, J.; Lee, H.; Seo, S.; Lee, C.; Yang, W. Spatial and Temporal Exposure Assessment to PM2.5 in a Community Using Sensor-Based Air Monitoring Instruments and Dynamic Population Distributions. Atmosphere 2020, 11, 1284. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the ICML, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Kim, J.; Kim, T.; Choi, J.H.; Choo, J. End-to-end Multi-task Learning of Missing Value Imputation and Forecasting in Time-Series Data. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8849–8856. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. Adv. Neural Inf. Process. Syst. (NeurIPS) 2019, 32, 8026–8037. [Google Scholar]
- Cao, W.; Wang, D.; Li, J.; Zhou, H.; Li, L.; Li, Y. Brits: Bidirectional recurrent imputation for time series. arXiv 2018, arXiv:1805.10572. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Mean | Stdev. | # Observations | # Locations | Missing Rate (%) |
|---|---|---|---|---|---|
| Guro-gu (PM2.5) | 21.931 | 30.593 | 827,051 | 24 | 26.014 |
| Guro-gu (PM10) | 34.275 | 47.650 | 827,049 | 24 | 26.027 |
| Dangjin-si (PM2.5) | 24.916 | 41.423 | 464,720 | 42 | 28.964 |
| Dangjin-si (PM10) | 43.914 | 190.288 | 464,720 | 42 | 28.963 |
| Target Variable | Metric | Ours | Mean | SA | MICE |
|---|---|---|---|---|---|
| PM2.5 | MAE | 1.170 | 18.634 | 8.972 | 4.825 |
| sMAPE | 7.155 | 75.236 | 36.771 | 28.865 | |
| PM10 | MAE | 2.738 | 30.024 | 17.646 | 9.291 |
| sMAPE | 9.385 | 73.259 | 43.464 | 31.408 |
| Target Variable | Metric | Ours | Mean | SA | MICE |
|---|---|---|---|---|---|
| PM2.5 | MAE | 1.149 | 16.780 | 9.646 | 4.524 |
| sMAPE | 9.710 | 81.604 | 52.389 | 34.859 | |
| PM10 | MAE | 4.664 | 33.521 | 20.465 | 12.279 |
| sMAPE | 13.702 | 86.151 | 56.168 | 44.624 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, T.; Kim, J.; Yang, W.; Lee, H.; Choo, J. Missing Value Imputation of Time-Series Air-Quality Data via Deep Neural Networks. Int. J. Environ. Res. Public Health 2021, 18, 12213. https://doi.org/10.3390/ijerph182212213
Kim T, Kim J, Yang W, Lee H, Choo J. Missing Value Imputation of Time-Series Air-Quality Data via Deep Neural Networks. International Journal of Environmental Research and Public Health. 2021; 18(22):12213. https://doi.org/10.3390/ijerph182212213
Chicago/Turabian StyleKim, Taesung, Jinhee Kim, Wonho Yang, Hunjoo Lee, and Jaegul Choo. 2021. "Missing Value Imputation of Time-Series Air-Quality Data via Deep Neural Networks" International Journal of Environmental Research and Public Health 18, no. 22: 12213. https://doi.org/10.3390/ijerph182212213
APA StyleKim, T., Kim, J., Yang, W., Lee, H., & Choo, J. (2021). Missing Value Imputation of Time-Series Air-Quality Data via Deep Neural Networks. International Journal of Environmental Research and Public Health, 18(22), 12213. https://doi.org/10.3390/ijerph182212213