
Automatic Diagnosis of Mental Healthcare Information Actionability: Developing Binary Classifiers


Abstract
:1. Introduction
2. Methods
2.1. Information Sources, and Search Strategies
2.2. Semantic Feature Labelling Strategy
2.3. Statistics
2.3.1. Readability Assessment
2.3.2. Statistical Differences between Patient and Generic Health Information
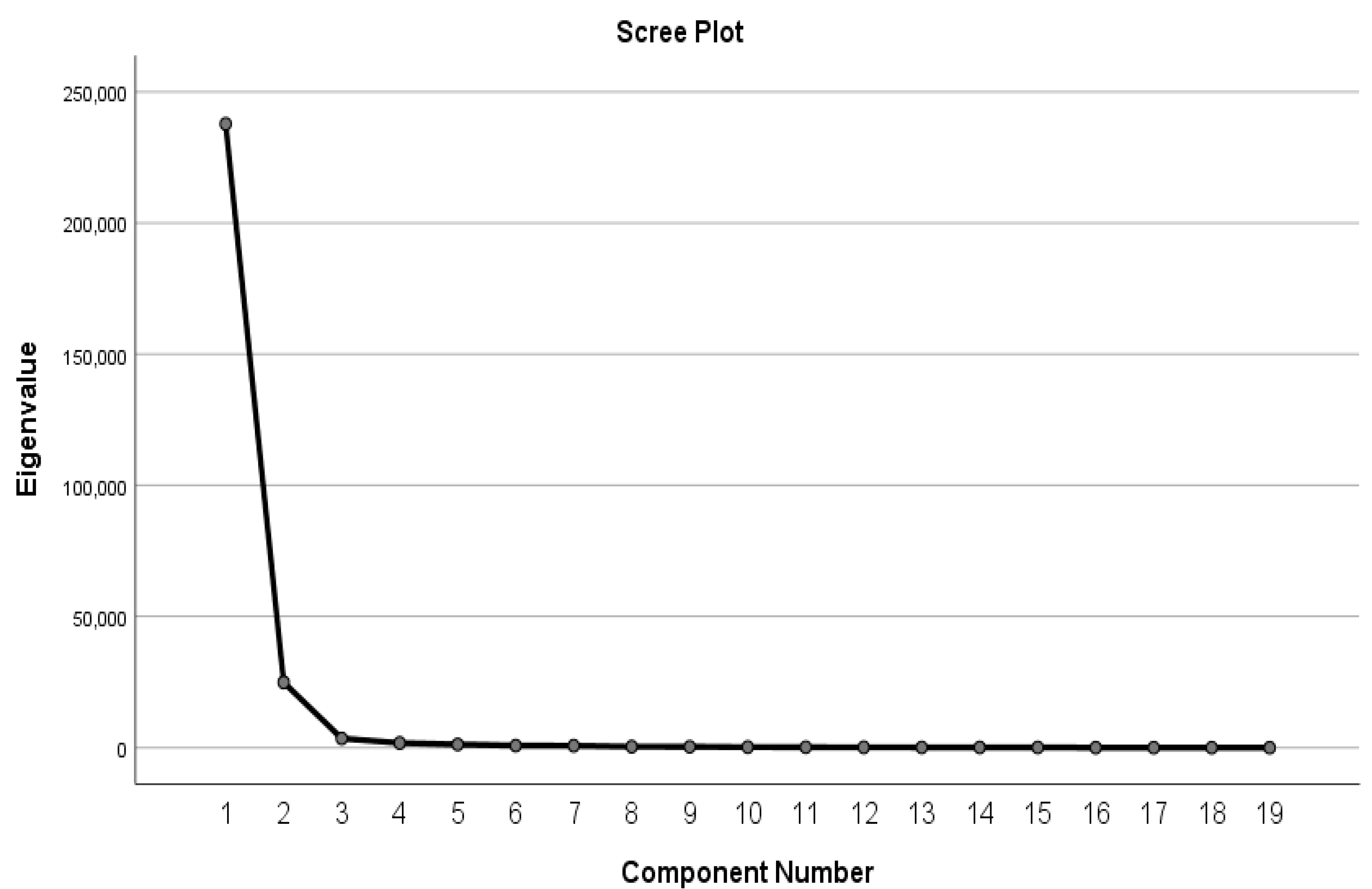
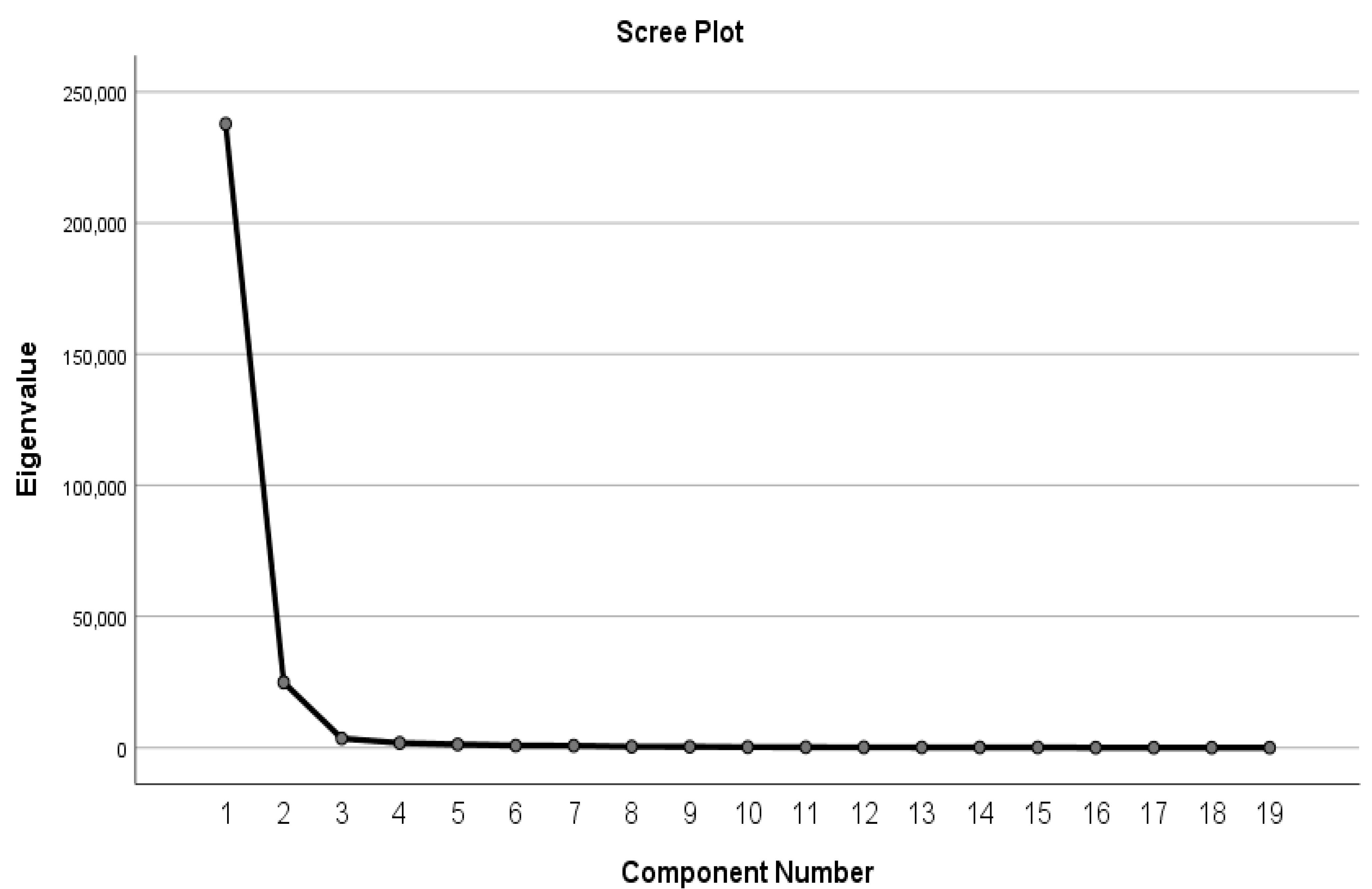
2.3.3. Feature Optimization Using Principal Component Analysis
3. Results
4. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lipari, M.; Berlie, H.; Saleh, Y.; Hang, P.; Moser, L. Understandability, actionability, and readability of online patient education materials about diabetes mellitus. Am. J. Health Syst. Pharm. 2019, 76, 182–186. [Google Scholar] [CrossRef] [PubMed]
- Mac, O.A.; Thayre, A.; Tan, S.; Dodd, R.H. Web-based health information following the renewal of the cervical screening program in Australia: Evaluation of readability, understandability, and credibility. J. Med. Internet Res. 2020, 22, e16701. [Google Scholar] [CrossRef] [PubMed]
- Caballero, A.; Leath, K.; Watson, J. COVID-19 consumer health information needs improvement to be readable and actionable by high-risk populations. Front. Commun. 2020, 5, 56. [Google Scholar] [CrossRef]
- Leung, J.-Y.; Ni Riordain, R.; Porter, S. Readability and quality of online information regarding dental treatment for patients with ischaemic heart disease. Br. Dent. J. 2020, 228, 609–614. [Google Scholar] [CrossRef] [PubMed]
- Murphy, J.; Vaughn, J.; Gelber, K.; Geller, A.; Zakowski, M. Readability, content, quality and accuracy assessment of internet-based patient education materials relating to labor analgesia. Int. J. Obstet. Anesth. 2019, 39, 82–87. [Google Scholar] [CrossRef]
- Mc Laughlin, G.H. SMOG grading-a new readability formula. J. Read. 1969, 12, 639–646. [Google Scholar]
- Coleman, M.; Liau, T.L. A computer readability formula designed for machine scoring. J. Appl. Psychol. 1975, 60, 283–284. [Google Scholar] [CrossRef]
- Klare, G.R.; Rowe, P.P.; John, M.G.S.; Stolurow, L.M. Automation of the Flesch reading ease readability formula, with various options. Read. Res. Q. 1969, 4, 550–559. [Google Scholar] [CrossRef]
- Philip, P.G.; Karen, S. FOGINDEX: A readability formula program for microcomputers. J. Read. 1985, 28, 614–618. [Google Scholar]
- Edward, F. A readability formula that saves time. J. Read. 1968, 11, 513–578. [Google Scholar]
- Martínez, P.; Martínez, J.L.; Segura-Bedmar, I.; Moreno-Schneider, J.; Luna, A.; Revert, R. Turning user generated health-related content into actionable knowledge through text analytics services. Comput. Ind. 2016, 78, 43–56. [Google Scholar] [CrossRef]
- Baur, C. Calling the nation to act: Implementing the national action plan to improve health literacy. Nurs. Outlook 2011, 59, 63–69. [Google Scholar] [CrossRef]
- Robinson, M.; Robertson, S. Health information needs of men. Health Educ. J. 2014, 73, 150–158. [Google Scholar] [CrossRef]
- Schardt, C. Health information literacy meets evidence-based practice. J. Med. Libr. Assoc. 2011, 99, 1–2. [Google Scholar] [CrossRef] [Green Version]
- Ivanitskaya, L.; O’Boyle, I.; Casey, A.M. Health information literacy and competencies of information age students: Results from the interactive online Research Readiness Self-Assessment (RRSA). J. Med. Internet Res. 2006, 8, e6. [Google Scholar] [CrossRef] [PubMed]
- Helitzer, D.; Hollis, C.; Cotner, J.; Oestreicher, N. Health literacy demands of written health information materials: An assessment of cervical cancer prevention materials. Cancer Control 2009, 16, 70–78. [Google Scholar] [CrossRef] [Green Version]
- Giuse, N.B.; Koonce, T.Y.; Storrow, A.B.; Kusnoor, S.V.; Ye, F. Using health literacy and learning style preferences to optimize the delivery of health information. J. Health Commun. 2012, 17 (Suppl. S3), 122–140. [Google Scholar] [CrossRef]
- Kirby, P.L.; Reynolds, K.A.; Walker, J.R.; Furer, P.; Pryor, T.A.M. Evaluating the quality of perinatal anxiety information available online. Arch. Womens Ment. Health 2018, 21, 813–820. [Google Scholar] [CrossRef] [PubMed]
- Ferreira-Lay, P.; Miller, S. The quality of internet information on depression for lay people. Psychiatrist 2008, 32, 170–173. [Google Scholar] [CrossRef] [Green Version]
- Shoemaker, S.J.; Wolf, M.S.; Brach, C. Development of the patient education materials assessment tool (PEMAT): A new measure of understandability and actionability for print and audiovisual patient information. Patient Educ. Couns. 2014, 96, 395–403. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vishnevetsky, J.; Walters, C.B.; Tan, K.S. Interrater reliability of the patient education materials assessment Tool (PEMAT). Patient Educ. Couns. 2018, 101, 490–496. [Google Scholar] [CrossRef]
- Carey, T.A. Beyond patient-centered care: Enhancing the patient experience in mental health services through patient-perspective care. Patient Exp. J. 2016, 3, 8. Available online: https://pxjournal.org/journal/vol3/iss2/8 (accessed on 1 August 2021). [CrossRef]
- Johnston, J.N.; Ridgway, L.; Cary-Barnard, S.; Allen, J.; Sanchez-Lafuente, C.L.; Reive, B.; Kalynchuk, L.E.; Caruncho, H.J. Patient oriented research in mental health: Matching laboratory to life and beyond in Canada. Res. Involv. Engagem. 2021, 7, 21. [Google Scholar] [CrossRef]
- Schünemann, H.J.; Fretheim, A.; Oxman, A.D. Improving the use of research evidence in guideline development: 10. Integrating values and consumer involvement. Health Res. Policy Syst. 2006, 4, 22. Available online: https://pubmed.ncbi.nlm.nih.gov/17147811 (accessed on 1 August 2021). [CrossRef]
- Korp, P. Health on the Internet: Implications for health promotion. Health Educ. Res. 2006, 21, 78–86. [Google Scholar] [CrossRef] [PubMed]
- Prabhu, A.V.; Gupta, R.; Kim, C.; Kashkoush, A.; Hansberry, D.R.; Agarwal, N.; Koch, E. Patient education materials in dermatology: Addressing the health literacy needs of patients. JAMA Dermatol. 2016, 152, 946–947. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kasabwala, K.; Agarwal, N.; Hansberry, D.R.; Baredes, S.; Eloy, J.A. Readability Assessment of Patient Education Materials from the American Academy of Otolaryngology—Head and Neck Surgery Foundation. Otolaryngol.—Head Neck Surg. 2012, 147, 466–471. [Google Scholar] [CrossRef]
- Rayson, P.; Archer, D.; Piao, S.; McEnery, A.M. The UCREL semantic analysis system. In Proceedings of the Beyond Named Entity Recognition Semantic Labeling for NLP Tasks Workshop, Lisbon, Portugal, 25 May 2004. [Google Scholar]
- McIntyre, D.; Archer, D. A corpus-based approach to mind style. J. Lit. Semant. 2010, 39, 167–182. [Google Scholar] [CrossRef]
- Piao, S.S.; Rayson, P.; Archer, D.; McEnery, T. Comparing and combining a semantic tagger and a statistical tool for MWE extraction. Comput. Speech Lang. 2005, 19, 378–397. [Google Scholar] [CrossRef]
- Bolton, K.; Graddol, D.; Mesthrie, R. Tom McArthur’s english today. Engl. Today 2009, 25, 3–8. [Google Scholar] [CrossRef]
- Archer, D.; Rayson, P.; Piao, S.; McEnery, A. Comparing the UCREL semantic annotation scheme with lexicographical taxonomies. In Proceedings of the EURALEX-2004 Conference, Lorient, France, 6–10 July 2004. [Google Scholar]
- Chang, J.J.S.; Chen, J.-N.; Sheng, H.-H.; Ker, S.-J. Combining Machine Readable Lexical Resources and Bilingual Corpora for Broad Word Sense Disambiguation. In Proceedings of the 2nd Conferences of the Association for Machine Translation in the Americas, Montreal, QC, Canada, 2–5 October 1996. [Google Scholar]
- Roccetti, M.; Marfia, G.; Salomoni, P.; Prandi, C.; Zagari, R.M.; Kengni, F.L.G.; Bazzoli, F.; Montagnani, M. Attitudes of Crohn’s disease patients: Infodemiology case study and sentiment analysis of facebook and twitter posts. JMIR Public Health Surveill. 2017, 3, e51. [Google Scholar] [CrossRef] [PubMed]
- D’Souza, R.S.; Hooten, W.M.; Murad, M.H. A Proposed Approach for Conducting Studies that Use Data From Social Media Platforms. Mayo Clin. Proc. 2021, 96, 2218–2229. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
| Structural Language Features (TOF) | PAS | GEN | Mann–Whitney U | dCohen | CLES | ||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | Std. Deviation | Mean | Std. Deviation | Z | P | gHedges | 95% C.I | ||
| Readability Measurements | |||||||||
| Flesch Reading Ease | 66.74 | 12.27 | 46.71 | 11.92 | −27.94 | 0.000 | −1.659 | −1.766, −1.551 | 0.880 |
| FORCAST | 9.94 | 0.93 | 11.30 | 0.82 | −26.705 | 0.000 | 1.562 | 1.456, 1.668 | 0.865 |
| Gunning Fog Index | 9.02 | 1.93 | 12.46 | 2.03 | −28.708 | 0.000 | 1.732 | 1.623, 1.841 | 0.890 |
| SMOG Index | 10.12 | 1.60 | 12.50 | 1.50 | −26.710 | 0.000 | 1.540 | 1.435, 1.646 | 0.862 |
| Lexical Complexity | |||||||||
| Medical jargons | 5.14 | 7.84 | 11.25 | 12.12 | −15.490 | 0.000 | 0.585 | 0.49, 0.68 | 0.661 |
| Number of unique words | 329.19 | 148.56 | 426.45 | 171.48 | −13.374 | 0.000 | 0.601 | 0.506, 0.697 | 0.665 |
| Repeated words | 0.02 | 0.16 | 0.02 | 0.14 | −0.342 | 0.732 | 0.000 | −0.093, 0.093 | 0.500 |
| Article mismatches | 0.03 | 0.39 | 0.03 | 0.19 | −2.278 | 0.023 | 0.000 | −0.093, 0.093 | 0.500 |
| Redundant phrases | 0.15 | 0.44 | 0.16 | 0.59 | −0.068 | 0.945 | 0.019 | −0.074, 0.112 | 0.505 |
| Overused words | 9.97 | 11.03 | 16.49 | 12.56 | −15.794 | 0.000 | 0.548 | 0.453, 0.642 | 0.651 |
| Wordy items | 18.41 | 17.82 | 42.24 | 27.64 | −22.941 | 0.000 | 1.002 | 0.903, 1.101 | 0.761 |
| Cliché | 0.12 | 0.42 | 0.12 | 0.40 | −0.405 | 0.685 | 0.000 | −0.093, 0.093 | 0.500 |
| Number of proper nouns | 16.74 | 27.37 | 26.05 | 27.88 | −11.990 | 0.000 | 0.337 | 0.243, 0.43 | 0.594 |
| Number of numerals | 6.05 | 12.22 | 6.70 | 12.07 | −8.593 | 0.000 | 0.054 | −0.039, 0.147 | 0.515 |
| Morphological Complexity | |||||||||
| Average number of characters | 4.64 | 0.35 | 5.16 | 0.32 | −27.139 | 0.000 | 1.558 | 1.452, 1.664 | 0.865 |
| Average number of syllables | 1.50 | 0.14 | 1.73 | 0.14 | −27.329 | 0.000 | 1.643 | 1.536, 1.75 | 0.877 |
| Number of monosyllabic words | 620.35 | 419.24 | 660.40 | 382.71 | −3.852 | 0.000 | 0.100 | 0.007, 0.193 | 0.528 |
| Number of unique monosyllabic words | 157.86 | 56.43 | 162.40 | 58.75 | −1.688 | 0.091 | 0.079 | −0.014, 0.172 | 0.522 |
| Number of complex (3+ syllable) words | 114.68 | 96.87 | 218.95 | 133.45 | −20.794 | 0.000 | 0.879 | 0.782, 0.977 | 0.733 |
| Number of unique 3+ syllable words | 67.81 | 46.31 | 127.20 | 61.92 | −22.513 | 0.000 | 1.070 | 0.97, 1.169 | 0.775 |
| Number of long (6+ characters) words | 283.58 | 210.03 | 434.95 | 251.32 | −16.123 | 0.000 | 0.647 | 0.552, 0.743 | 0.676 |
| Number of unique long words | 157.58 | 90.18 | 245.87 | 111.59 | −18.629 | 0.000 | 0.860 | 0.763, 0.957 | 0.729 |
| Syntactic Complexity | |||||||||
| Average number of sentences per paragraph | 2.58 | 8.09 | 1.54 | 0.36 | −7.647 | 0.000 | −0.193 | −0.286, −0.099 | 0.554 |
| Number of difficult sentences (more than 22 words) | 8.68 | 7.88 | 14.69 | 10.37 | −14.847 | 0.000 | 0.643 | 0.548, 0.738 | 0.675 |
| Average sentence length | 12.73 | 2.82 | 13.80 | 2.93 | −8.281 | 0.000 | 0.371 | 0.278, 0.465 | 0.604 |
| Passive voice | 2.79 | 3.85 | 5.22 | 4.84 | −15.280 | 0.000 | 0.549 | 0.454, 0.644 | 0.651 |
| Sentences that begin with conjunctions | 1.64 | 2.67 | 1.11 | 1.88 | −4.817 | 0.000 | −0.234 | −0.327, −0.141 | 0.566 |
| Number of interrogative sentences (questions) | 4.30 | 4.70 | 2.81 | 4.46 | −10.005 | 0.000 | −0.326 | −0.42, −0.233 | 0.591 |
| Number of exclamatory sentences | 1.35 | 3.35 | 0.08 | 0.40 | −15.709 | 0.000 | −0.564 | −0.658, −0.469 | 0.655 |
| Semantic Language Features (SOF) | PAS | GEN | Mann–Whitney U | dCohen | CLES | ||||
|---|---|---|---|---|---|---|---|---|---|
| Mean | Std. Deviation | Mean | Std. Deviation | Z | P | gHedges | 95% C.I | ||
| A General/abstract terms | 192.704 | 136.215 | 236.460 | 137.767 | −8.986 | 0.000 | 0.319 | 0.226, 0.413 | 0.589 |
| B Medicine/Health | 36.170 | 48.766 | 83.122 | 70.517 | −20.341 | 0.000 | 0.76 | 0.663, 0.856 | 0.704 |
| C Arts and Culture | 1.086 | 2.177 | 0.834 | 1.892 | −2.320 | 0.020 | −0.125 | −0.218, −0.031 | 0.535 |
| E Emotion | 27.789 | 24.826 | 40.559 | 31.436 | −10.517 | 0.000 | 0.445 | 0.351, 0.539 | 0.624 |
| F Food | 6.583 | 17.441 | 8.794 | 22.006 | −2.900 | 0.004 | 0.11 | 0.017, 0.203 | 0.531 |
| G Government | 3.313 | 6.211 | 3.421 | 6.271 | −2.986 | 0.003 | 0.017 | −0.076, 0.11 | 0.505 |
| H Dwelling | 3.071 | 4.797 | 3.479 | 5.305 | −4.073 | 0.000 | 0.08 | −0.013, 0.173 | 0.523 |
| I Employment | 8.121 | 17.709 | 9.363 | 13.094 | −8.108 | 0.000 | 0.081 | −0.012, 0.174 | 0.523 |
| K Sports | 4.176 | 6.593 | 4.900 | 7.616 | −3.112 | 0.002 | 0.101 | 0.008, 0.194 | 0.528 |
| L Living Things | 4.389 | 6.408 | 5.711 | 9.871 | −5.967 | 0.000 | 0.155 | 0.062, 0.248 | 0.544 |
| M Locations | 26.359 | 20.496 | 24.889 | 19.908 | −2.136 | 0.033 | −0.073 | −0.166, 0.02 | 0.521 |
| N Measurements | 44.089 | 33.885 | 62.396 | 41.667 | −12.043 | 0.000 | 0.477 | 0.382, 0.571 | 0.632 |
| O General substances | 13.138 | 12.475 | 16.960 | 17.421 | −5.955 | 0.000 | 0.248 | 0.155, 0.341 | 0.57 |
| P Education | 4.290 | 10.262 | 4.614 | 8.682 | −4.674 | 0.000 | 0.034 | −0.059, 0.127 | 0.51 |
| Q Speech Acts | 28.168 | 25.288 | 24.310 | 18.601 | −2.007 | 0.045 | −0.177 | −0.27, −0.084 | 0.55 |
| S Social Actions | 72.781 | 59.737 | 73.062 | 52.393 | −2.220 | 0.026 | 0.005 | −0.088, 0.098 | 0.501 |
| T Time | 34.453 | 28.926 | 37.985 | 28.055 | −4.312 | 0.000 | 0.124 | 0.031, 0.217 | 0.535 |
| W Environment | 1.268 | 3.327 | 1.879 | 4.366 | −6.058 | 0.000 | 0.155 | 0.062, 0.248 | 0.544 |
| X Psychology | 62.999 | 43.383 | 67.294 | 45.263 | −2.335 | 0.020 | 0.097 | 0.004, 0.19 | 0.527 |
| Y Science/Tech | 2.590 | 6.086 | 2.690 | 4.975 | −3.317 | 0.001 | 0.018 | −0.075, 0.111 | 0.505 |
| Z Names/Grammar | 359.010 | 247.561 | 389.823 | 222.817 | −4.970 | 0.000 | 0.132 | 0.039, 0.225 | 0.537 |
| Z99 Out of Dictionary | 16.810 | 17.383 | 33.909 | 30.551 | −16.818 | 0.000 | 0.669 | 0.574, 0.765 | 0.682 |
| Component | Initial Eigenvalues | Extraction Sums of Squared Loadings | Rotation Sums of Squared Loadings | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Total | % of Variance | Cumulative % | Total | % of Variance | Cumulative % | Total | % of Variance | Cumulative % | |
| 1 | 237,794.144 | 87.165 | 87.165 | 13.060 | 68.736 | 68.736 | 8.049 | 42.361 | 42.361 |
| 2 | 24,898.123 | 9.127 | 96.291 | 1.904 | 10.022 | 78.758 | 6.915 | 36.397 | 78.758 |
| Variables | Component | |
|---|---|---|
| 1 | 2 | |
| Number of complex (3+ syllable) words | 0.922 | 0.331 |
| Number of unique 3+ syllable words | 0.910 | 0.332 |
| Number of long (6+ characters) words | 0.882 | 0.459 |
| Number of unique long words | 0.880 | 0.433 |
| Wordy items | 0.825 | 0.304 |
| Number of unique words | 0.815 | 0.519 |
| Overused words (x sentence) | 0.756 | 0.273 |
| Number of difficult sentences (more than 22 words) | 0.713 | 0.460 |
| B Medicine/Health | 0.686 | 0.250 |
| Passive voice | 0.663 | 0.211 |
| Z Names/Grammar | 0.431 | 0.901 |
| Z99 Out of Dictionary words | 0.465 | 0.884 |
| X Psychology | 0.351 | 0.820 |
| A general/abstract term | 0.524 | 0.816 |
| Q Speech Acts | 0.168 | 0.775 |
| M Locations | 0.192 | 0.756 |
| S Social Actions | 0.374 | 0.748 |
| T Time | 0.363 | 0.674 |
| N measurements | 0.588 | 0.653 |
| Test Result Variable(s) | AUC | Std. Error a | Asymptotic Sig. b | Asymptotic 95% Confidence Interval | |
|---|---|---|---|---|---|
| Lower Bound | Upper Bound | ||||
| Gunning Fog | 0.893 | 0.008 | 0.000 | 0.878 | 0.908 |
| Flesch Reading Ease | 0.882 | 0.008 | 0.000 | 0.866 | 0.898 |
| SMOG | 0.865 | 0.009 | 0.000 | 0.848 | 0.882 |
| FORCAST | 0.865 | 0.009 | 0.000 | 0.848 | 0.882 |
| Structural Variables Only | 0.807 | 0.009 | 0.000 | 0.788 | 0.825 |
| Semantic Variables Only | 0.785 | 0.010 | 0.000 | 0.766 | 0.804 |
| All variables | 0.872 | 0.008 | 0.000 | 0.857 | 0.888 |
| Logistic Regression | 0.863 | 0.008 | 0.000 | 0.847 | 0.879 |
| Pairs | Test Result Pair(s) | Asymptotic | AUC Difference | Std. Error Difference b | Asymptotic 95% Confidence Interval | ||
|---|---|---|---|---|---|---|---|
| z | Sig. (2-Tail) a | Lower Bound | Upper Bound | ||||
| 1 | FORCAST vs. Gunning Fog | −4.331 | 0.00001483 ** | −0.0282 | 0.128 | −0.041 | −0.015 |
| 2 | FORCAST vs. SMOG | −0.021 | 0.98340065 | −0.0001 | 0.132 | −0.014 | 0.014 |
| 3 | FORCAST vs. Structural Variables | 8.320 | 0 | 0.0587 | 0.134 | 0.045 | 0.073 |
| 4 | FORCAST vs. Factor Analysis | −0.865 | 0.386964 | −0.0071 | 0.129 | −0.023 | 0.009 |
| 5 | FORCAST vs. All Variables | 0.214 | 0.83031832 | 0.0019 | 0.130 | −0.016 | 0.020 |
| 6 | FORCAST vs. Flesch Reading Ease | −4.630 | 0.00000365 ** | −0.017 | 0.130 | −0.024 | −0.010 |
| 7 | FORCAST vs. Semantic Variables | 6.994 | 0 ** | 0.0803 | 0.136 | 0.058 | 0.103 |
| 8 | Gunning Fog vs. SMOG | 7.364 | 0 ** | 0.028 | 0.128 | 0.021 | 0.036 |
| 9 | Gunning Fog vs. Structural Variables | 11.619 | 0 ** | 0.0869 | 0.130 | 0.072 | 0.102 |
| 10 | Gunning Fog vs. Factor Analysis | 2.844 | 0.000446202 | 0.0211 | 0.125 | 0.007 | 0.036 |
| 11 | Gunning Fog vs. All Variables | 3.762 | 0.00016845 ** | 0.0301 | 0.126 | 0.014 | 0.046 |
| 12 | Gunning Fog vs. Flesch Reading Ease | 2.581 | 0.00985279 | 0.0112 | 0.126 | 0.003 | 0.020 |
| 13 | Gunning Fog vs. Semantic Variables | 9.640 | 0 ** | 0.1085 | 0.132 | 0.086 | 0.131 |
| 14 | SMOG vs. Structural Variables | 7.736 | 0 ** | 0.0589 | 0.134 | 0.044 | 0.074 |
| 15 | SMOG vs. Factor Analysis | −0.866 | 0.38625534 | −0.0069 | 0.129 | −0.023 | 0.009 |
| 16 | SMOG vs. All Variables | 0.244 | 0.8072572 | 0.0021 | 0.130 | −0.015 | 0.019 |
| 17 | SMOG vs. Flesch Reading Ease | −3.750 | 0.0001769 ** | −0.0168 | 0.130 | −0.026 | −0.008 |
| 18 | SMOG vs. Semantic Variables | 6.867 | 0 ** | 0.0805 | 0.136 | 0.057 | 0.103 |
| 19 | Structural Variables vs. Factor Analysis | −7.964 | 0 ** | −0.0658 | 0.132 | −0.082 | −0.050 |
| 20 | Structural Variables vs. All Variables | −6.408 | 0 ** | −0.0568 | 0.132 | −0.074 | −0.039 |
| 21 | Structural Variables vs. Flesch Reading Ease | −11.563 | 0 ** | −0.0757 | 0.132 | −0.089 | −0.063 |
| 22 | Structural Variables vs. Semantic Variables | 1.831 | 0.06706809 | 0.0216 | 0.138 | −0.002 | 0.045 |
| 23 | Factor Analysis vs. All Variables | 1.202 | 0.22921297 | 0.009 | 0.127 | −0.006 | 0.024 |
| 24 | Factor Analysis vs. Flesch Reading Ease | −1.330 | 0.18366955 | −0.0099 | 0.127 | −0.024 | 0.005 |
| 25 | Factor Analysis vs. Semantic Variables | 7.602 | 0 ** | 0.0874 | 0.133 | 0.065 | 0.110 |
| 26 | All Variables vs. Flesch Reading Ease | −2.239 | 0.02512841 | −0.0189 | 0.128 | −0.035 | −0.002 |
| 27 | All Variables vs. Semantic Variables | 7.342 | 0 ** | 0.0784 | 0.134 | 0.057 | 0.099 |
| 28 | Flesch Reading Ease vs. Semantic Variables | 8.548 | 0 ** | 0.0973 | 0.134 | 0.075 | 0.120 |
| Formula | Thresholds | Sensitivity | Sensitivity | Formula | Thresholds | Sensitivity | Sensitivity |
|---|---|---|---|---|---|---|---|
| Gunning Fog | 9.7500 | 0.919 | 0.685 | Flesch Reading Ease | 37.5000 | 0.906 | 0.690 |
| 9.8500 | 0.908 | 0.705 | 38.5000 | 0.889 | 0.713 | ||
| 9.9500 | 0.897 | 0.720 | 39.5000 | 0.868 | 0.744 | ||
| 10.0500 | 0.893 | 0.739 | 40.5000 | 0.851 | 0.764 | ||
| 10.1500 | 0.882 | 0.755 | 41.5000 | 0.828 | 0.788 | ||
| 10.2500 | 0.874 | 0.771 | 42.5000 | 0.807 | 0.811 | ||
| 10.3500 | 0.862 | 0.785 | 43.5000 | 0.779 | 0.825 | ||
| 10.4500 | 0.844 | 0.799 | 44.5000 | 0.763 | 0.845 | ||
| 10.5500 | 0.831 | 0.804 | 45.5000 | 0.729 | 0.856 | ||
| 10.6500 | 0.821 | 0.815 | 46.5000 | 0.700 | 0.871 | ||
| 10.7500 | 0.807 | 0.829 | 47.5000 | 0.675 | 0.879 | ||
| 10.8500 | 0.792 | 0.839 | 48.5000 | 0.643 | 0.891 | ||
| 10.9500 | 0.769 | 0.851 | 11.9500 | 0.644 | 0.866 | ||
| 11.0500 | 0.753 | 0.863 | 12.0500 | 0.612 | 0.881 |
| Variables | Sensitivity Mean (SD) | Specificity Mean (SD) |
|---|---|---|
| Semantic Variables Only | 0.795 (0.015) | 0.762 (0.029) |
| Structural Features | 0.843 (0.011) | 0.776 (0.027) |
| All variables (49) | 0.907 (0.012) | 0.853 (0.034) |
| Factor Analysis (19) | 0.890 (0.005) | 0.860 (0.007) |
| Pairs | Variables | Mean Difference | S.D. | 95% Confidence Interval of Difference | t | Sig. (2-Tailed) | |
|---|---|---|---|---|---|---|---|
| Lower | Upper | ||||||
| Pair 1 | Semantic Variables vs. Structural Variables | −0.0478 | 0.0153 | −0.0668 | −0.0288 | −6.9770 | 0.0020 ** |
| Pair 2 | Semantic Variables vs. Factor Analysis | −0.0744 | 0.0134 | −0.0911 | −0.0577 | −12.3730 | 0.0000 ** |
| Pair 3 | Semantic Variables vs. All Variables | −0.1116 | 0.0180 | −0.1340 | −0.0892 | −13.8470 | 0.0000 ** |
| Pair 4 | Structural Variables vs. Factor Analysis | −0.0266 | 0.0085 | −0.0372 | −0.0160 | −6.9950 | 0.0020 ** |
| Pair 5 | Structural Variables vs.All Variables | −0.0638 | 0.0182 | −0.0864 | −0.0412 | −7.8450 | 0.0010 ** |
| Pair 6 | Factor Analysis vs. All Variables | −0.0170 | 0.007 | −0.0011 | −0.0329 | −2.6154 | 0.0398 |
| Pairs | Variables | Mean Difference | S.D. | 95% Confidence Interval of Difference | t | Sig. (2-Tailed) | |
|---|---|---|---|---|---|---|---|
| Lower | Upper | ||||||
| Pair 1 | Semantic Variables vs. Structural Variables | −0.014 | 0.047 | −0.073 | 0.045 | −0.664 | 0.543 |
| Pair 2 | Semantic Variables vs. Factor Analysis | −0.098 | 0.028 | −0.132 | −0.063 | −7.890 | 0.001 ** |
| Pair 3 | Semantic Variables vs. All Variables | −0.091 | 0.045 | −0.147 | −0.035 | −4.520 | 0.011 |
| Pair 4 | Structural Variables vs. Factor Analysis | −0.084 | 0.027 | −0.117 | −0.050 | −6.927 | 0.002 ** |
| Pair 5 | Structural Variables vs. All Variables | −0.077 | 0.022 | −0.104 | −0.050 | −7.915 | 0.001 ** |
| Pair 6 | Factor Analysis vs. All Variables | 0.007 | 0.034 | −0.036 | 0.049 | 0.434 | 0.687 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, M.; Xie, W.; Huang, R.; Qian, X. Automatic Diagnosis of Mental Healthcare Information Actionability: Developing Binary Classifiers. Int. J. Environ. Res. Public Health 2021, 18, 10743. https://doi.org/10.3390/ijerph182010743
Ji M, Xie W, Huang R, Qian X. Automatic Diagnosis of Mental Healthcare Information Actionability: Developing Binary Classifiers. International Journal of Environmental Research and Public Health. 2021; 18(20):10743. https://doi.org/10.3390/ijerph182010743
Chicago/Turabian StyleJi, Meng, Wenxiu Xie, Riliu Huang, and Xiaobo Qian. 2021. "Automatic Diagnosis of Mental Healthcare Information Actionability: Developing Binary Classifiers" International Journal of Environmental Research and Public Health 18, no. 20: 10743. https://doi.org/10.3390/ijerph182010743
APA StyleJi, M., Xie, W., Huang, R., & Qian, X. (2021). Automatic Diagnosis of Mental Healthcare Information Actionability: Developing Binary Classifiers. International Journal of Environmental Research and Public Health, 18(20), 10743. https://doi.org/10.3390/ijerph182010743